
The Nondestructive Model of Near-Infrared Spectroscopy with Different Pretreatment Transformation for Predicting “Dangshan” Pear Woolliness Disease

Abstract
:1. Introduction
2. Materials and Methods
2.1. Sample Sources
2.2. Experimental Apparatus and Data Acquisition
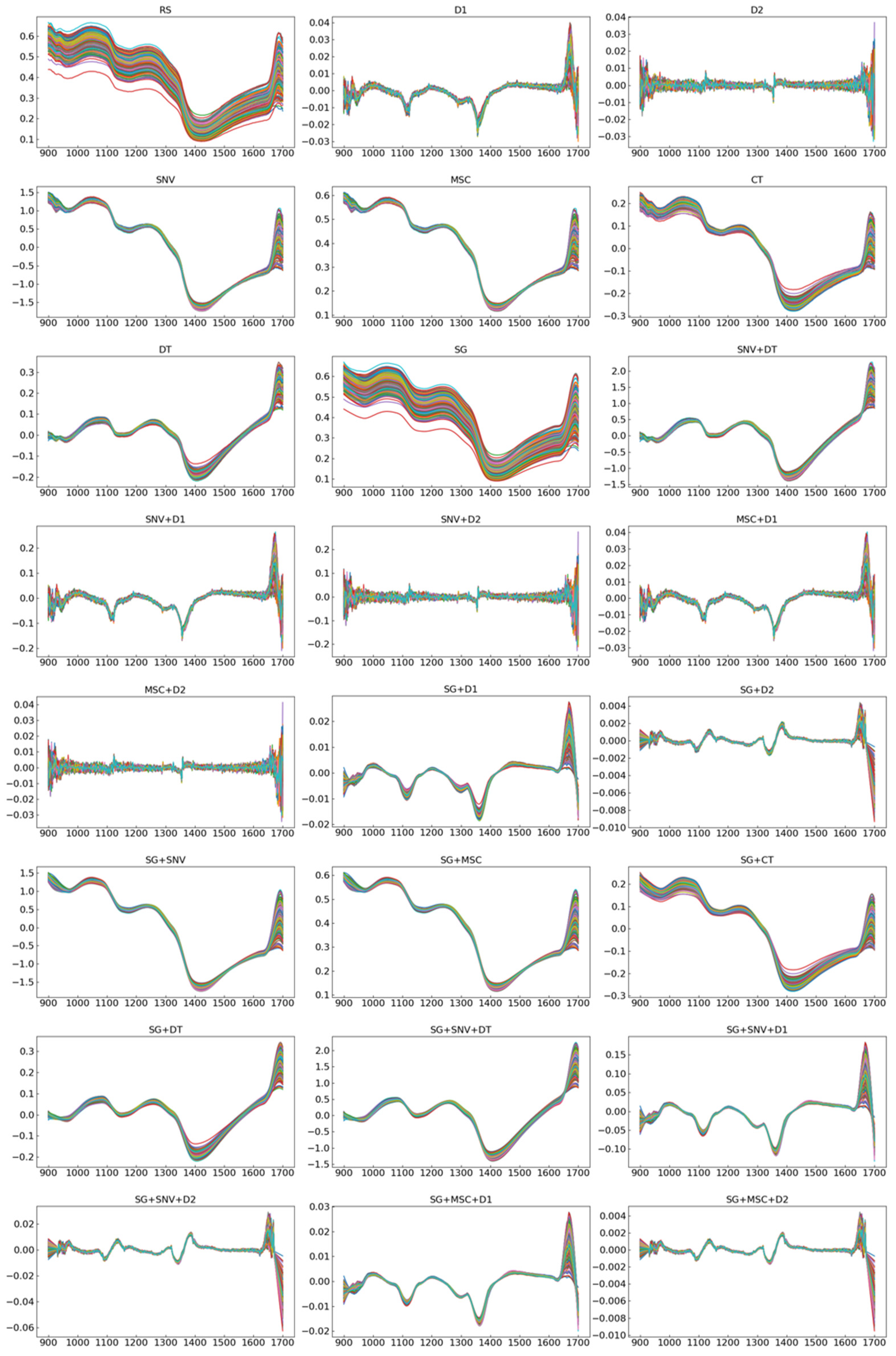
2.3. Pretreatment Transformations
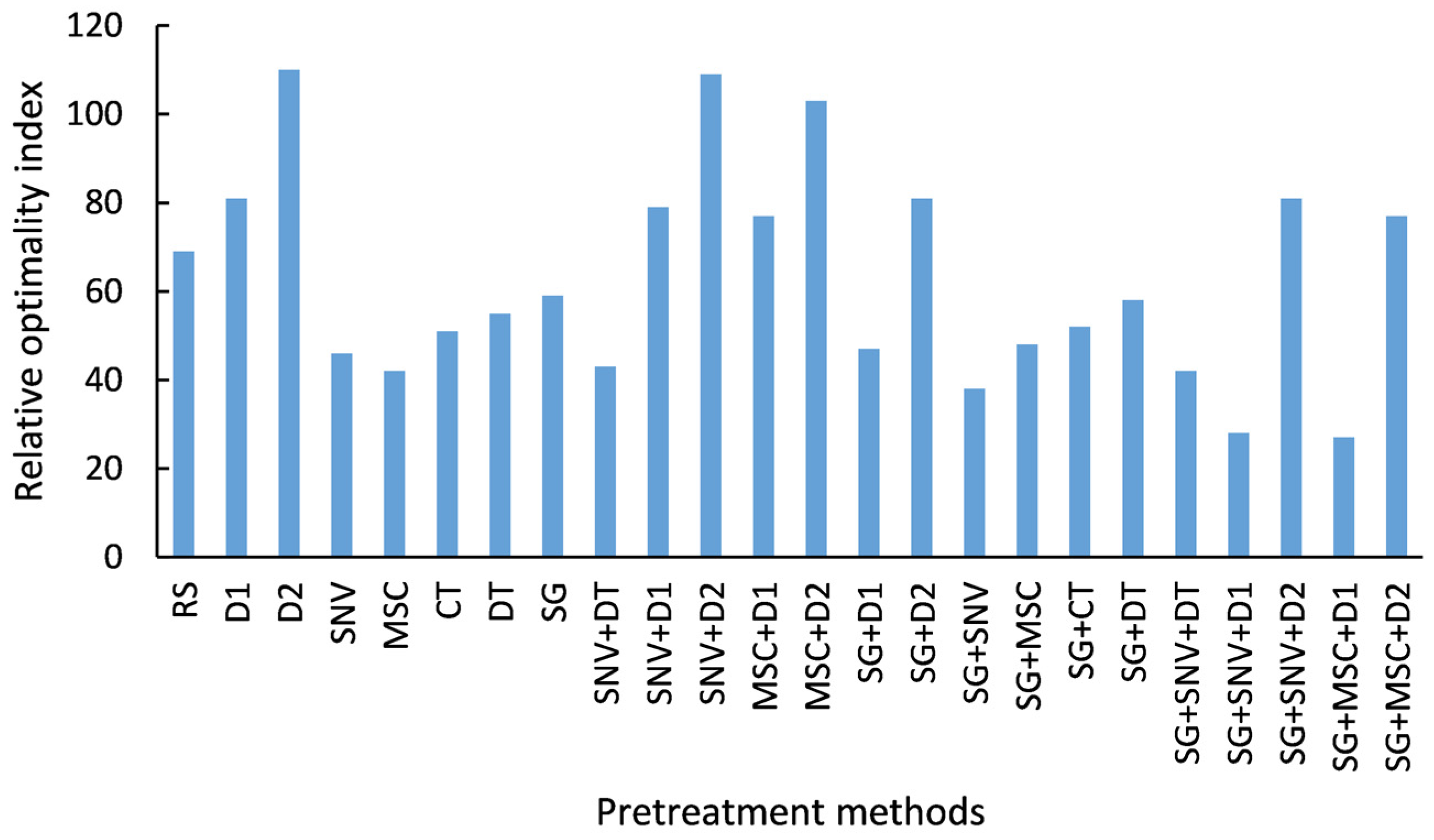
2.4. Ranking Method of Pretreatment Methods
2.5. Classification Algorithms
2.6. Evaluation Metrics
3. Results and Discussion
3.1. Dataset Statistics
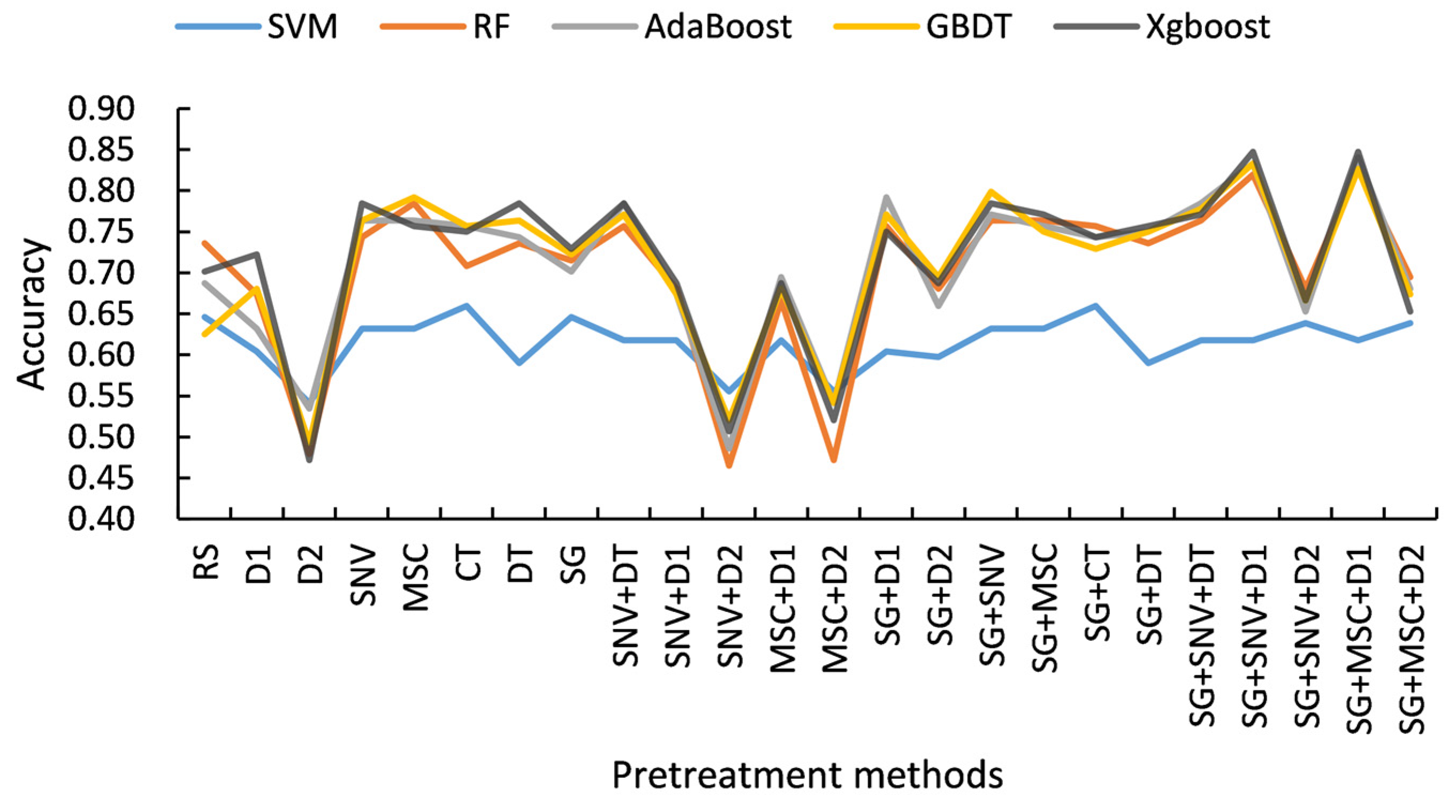
3.2. Analysis and Comparison of Optimal Pretreatment for “Dangshan” Pear Woolliness Disease Identification Modelling
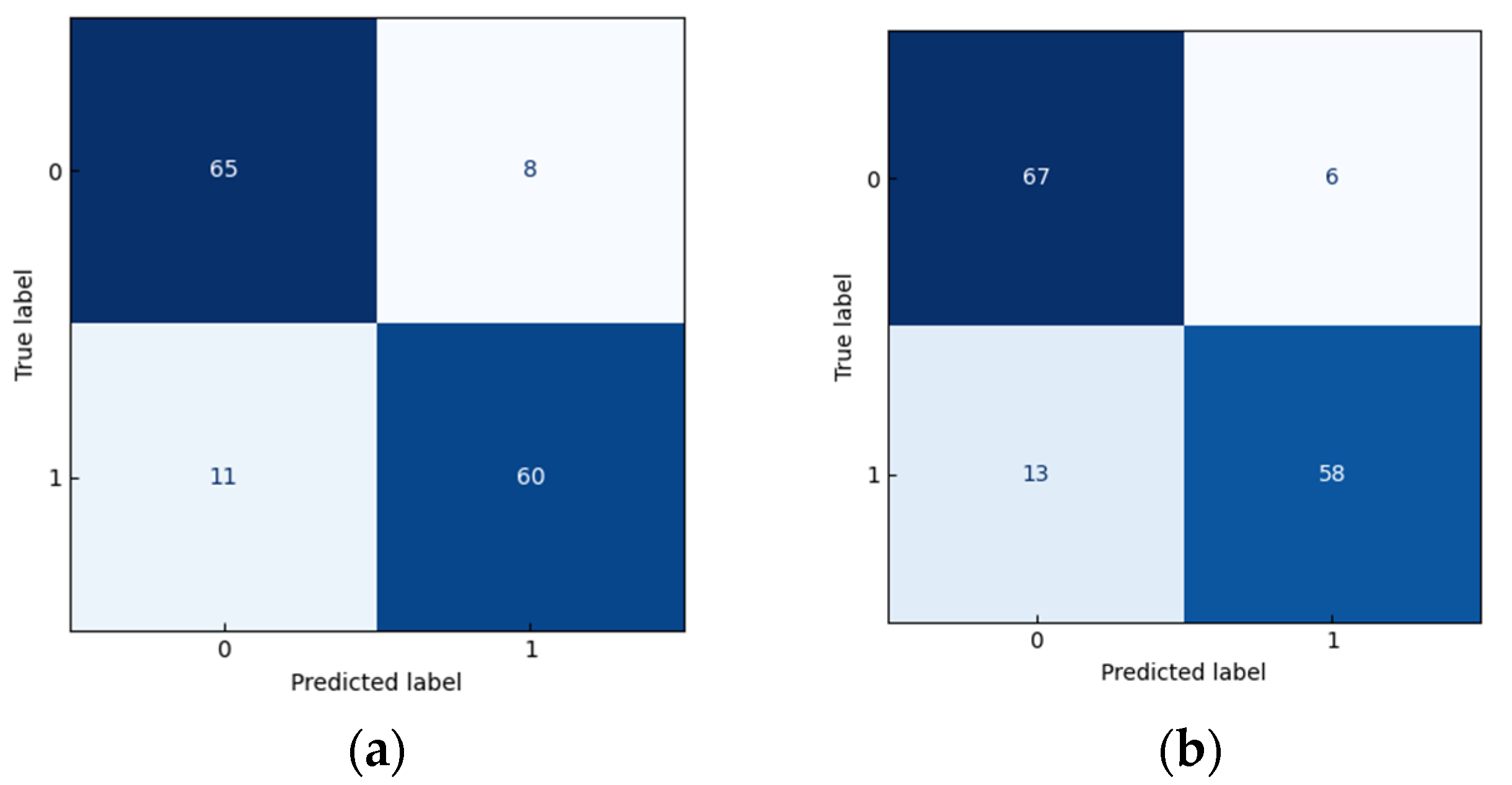
3.3. Optimization of the “Dangshan” Pear Woolliness Model on the Best Optimal Pretreatment Method
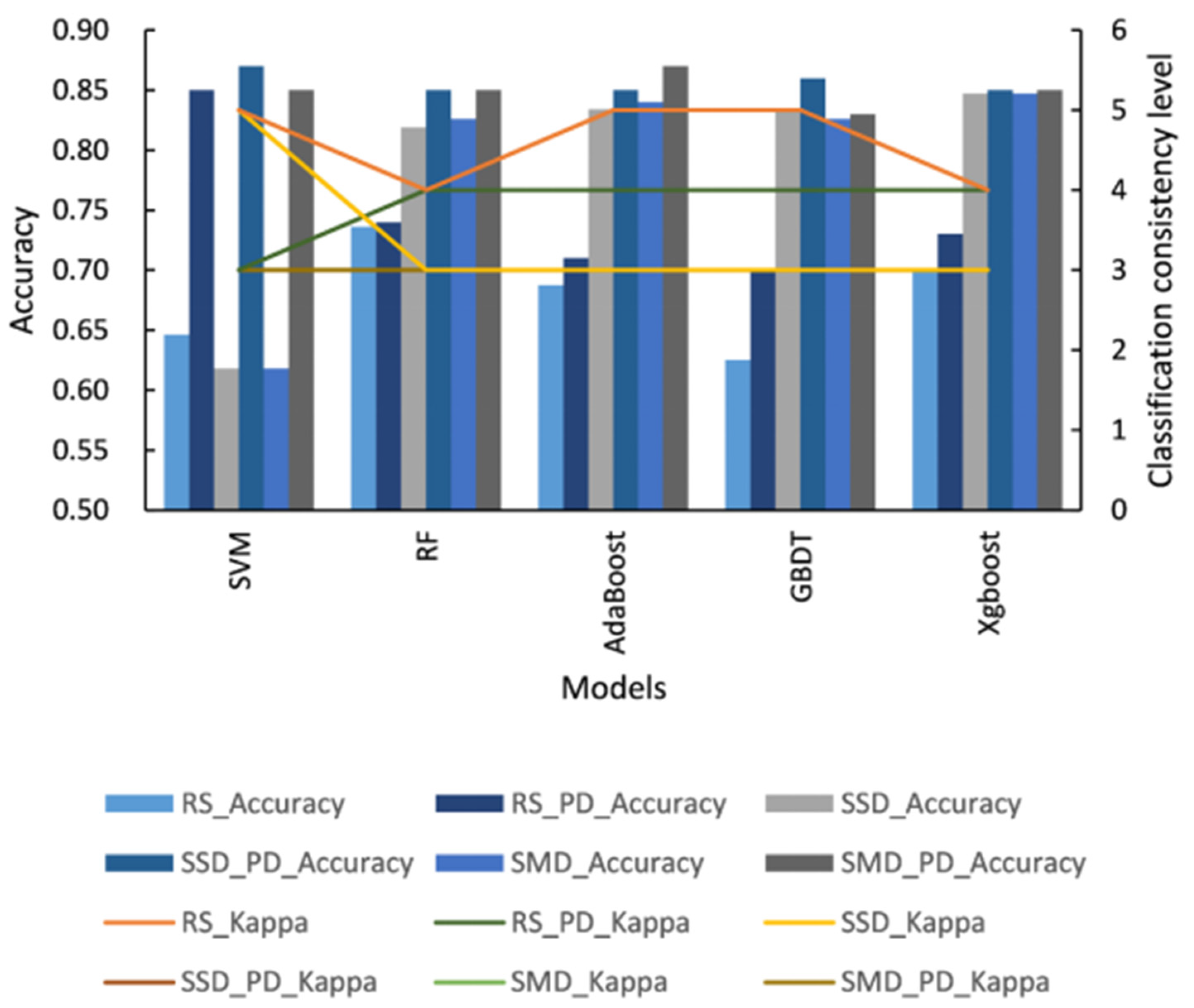
3.4. The Effect of Parameter Debugging and Pretreatment Methods on the Performance of Different Models
4. Conclusions
- After processing the spectral data with suitable pretreatment methods, SVM and AdaBoost based on NIR spectra had excellent performance in terms of accuracy, F1, and Kappa after parameter debugging, which proves the feasibility of near-infrared spectroscopy in identifying the woolliness response disease of “Dangshan” pear.
- The influence of different pretreatment methods on the modelling analysis using near-infrared spectroscopy was different. D2 had a severe influence on the original spectra, and different models showed lower prediction ability in the identification of “Dangshan” pear woolliness response disease with D2 or pretreatment methods including D2. SG+SNV+D1 and SG+MSC+D1 were the two best pretreatment methods in this experiment and played an important role in the identification of woolliness response disease of “Dangshan” pear using near-infrared spectroscopy.
- Models such as RF, AdaBoost, GBDT, and Xgboost were more stringent for the pretreatment methods in identifying the woolliness response disease of “Dangshan” pear, and the performance of the models was significantly improved with a suitable pretreatment method.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Silva, G.J.; Souza, T.M.; Barbieri, R.L.; Costa de Oliveira, A. Origin, Domestication, and Dispersing of Pear (Pyrus Spp.). Adv. Agric. 2014, 2014, 541097. [Google Scholar] [CrossRef]
- Zeng, W.; Qiao, X.; Li, Q.; Liu, C.; Wu, J.; Yin, H.; Zhang, S. Genome-Wide Identification and Comparative Analysis of the ADH Gene Family in Chinese White Pear (Pyrus Bretschneideri) and Other Rosaceae Species. Genomics 2020, 112, 3484–3496. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Zhang, J.; Gao, W.; Wang, H. Study on Chemical Composition, Anti-Inflammatory and Anti-Microbial Activities of Extracts from Chinese Pear Fruit (Pyrus Bretschneideri Rehd.). Food Chem. Toxicol. 2012, 50, 3673–3679. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Wang, T.; Zhou, B.; Gao, W.; Cao, J.; Huang, L. Chemical Composition and Antioxidant and Anti-Inflammatory Potential of Peels and Flesh from 10 Different Pear Varieties (Pyrus Spp.). Food Chem. 2014, 152, 531–538. [Google Scholar] [CrossRef] [PubMed]
- Chen, J.; Wang, Z.; Wu, J.; Wang, Q.; Hu, X. Chemical Compositional Characterization of Eight Pear Cultivars Grown in China. Food Chem. 2007, 104, 268–275. [Google Scholar] [CrossRef]
- Haifa, P.; Yiliu, X.; Yi, Z.; Jinyun, Z.; Zhenghui, G.; Xingkai, Y. Effects of Boron on the Growth and Fruit Quality of Dangshansu Pear(Pyrus Bretshneideri Cv.Dangshansu Pear). Plant Nutr. Fertil. Sci. 2011, 17, 1024–1029. [Google Scholar]
- González-Agüero, M.; Pavez, L.; Ibáñez, F.; Pacheco, I.; Campos-Vargas, R.; Meisel, L.A.; Orellana, A.; Retamales, J.; Silva, H.; González, M.; et al. Identification of Woolliness Response Genes in Peach Fruit after Post-Harvest Treatments. J. Exp. Bot. 2008, 59, 1973–1986. [Google Scholar] [CrossRef]
- Cortés, V.; Blasco, J.; Aleixos, N.; Cubero, S.; Talens, P. Visible and Near-Infrared Diffuse Reflectance Spectroscopy for Fast Qualitative and Quantitative Assessment of Nectarine Quality. Food Bioprocess Technol. 2017, 10, 1755–1766. [Google Scholar] [CrossRef]
- Cocchi, M.; Corbellini, M.; Foca, G.; Lucisano, M.; Pagani, M.A.; Tassi, L.; Ulrici, A. Classification of Bread Wheat Flours in Different Quality Categories by a Wavelet-Based Feature Selection/Classification Algorithm on NIR Spectra. Anal. Chim. Acta 2005, 544, 100–107. [Google Scholar] [CrossRef]
- Miralbés, C. Discrimination of European Wheat Varieties Using near Infrared Reflectance Spectroscopy. Food Chem. 2008, 106, 386–389. [Google Scholar] [CrossRef]
- Jin, X.; Ba, W.; Wang, L.; Zhang, T.; Zhang, X.; Li, S.; Rao, Y.; Liu, L. A Novel Tran_NAS Method for the Identification of Fe- and Mg-Deficient Pear Leaves from N- and P-Deficient Pear Leaf Data. ACS Omega 2022, 7, 39727–39741. [Google Scholar] [CrossRef]
- Jin, X.; Wang, L.; Zheng, W.; Zhang, X.; Liu, L.; Li, S.; Rao, Y.; Xuan, J. Predicting the Nutrition Deficiency of Fresh Pear Leaves with a Miniature Near-Infrared Spectrometer in the Laboratory. Measurement 2022, 188, 110553. [Google Scholar] [CrossRef]
- Ba, W.; Jin, X.; Lu, J.; Rao, Y.; Zhang, T.; Zhang, X.; Zhou, J.; Li, S. Research on Predicting Early Fusarium Head Blight with Asymptomatic Wheat Grains by Micro-near Infrared Spectrometer. Spectrochim. Acta A Mol. Biomol. Spectrosc. 2023, 287, 122047. [Google Scholar] [CrossRef]
- Shao, X.; Ning, Y.; Liu, F.; Li, J.; Cai, W. Application of Near-Infrared Spectroscopy in Micro Inorganic Analysis. Acta Chim. Sin. 2012, 70, 2109. [Google Scholar] [CrossRef]
- Mishra, P.; Biancolillo, A.; Roger, J.M.; Marini, F.; Rutledge, D.N. New Data Preprocessing Trends Based on Ensemble of Multiple Preprocessing Techniques. TrAC Trends Anal. Chem. 2020, 132, 116045. [Google Scholar] [CrossRef]
- Engel, J.; Gerretzen, J.; Szymańska, E.; Jansen, J.J.; Downey, G.; Blanchet, L.; Buydens, L.M.C. Breaking with Trends in Pre-Processing? TrAC Trends Anal. Chem. 2013, 50, 96–106. [Google Scholar] [CrossRef]
- Oliveri, P.; Malegori, C.; Simonetti, R.; Casale, M. The Impact of Signal Pre-Processing on the Final Interpretation of Analytical Outcomes—A Tutorial. Anal. Chim. Acta 2019, 1058, 9–17. Available online: https://www.semanticscholar.org/paper/The-impact-of-signal-pre-processing-on-the-final-of-Oliveri-Malegori/513c8c6936c5e566f0d2f8c378cddb15f54acf26 (accessed on 7 March 2023). [CrossRef] [PubMed]
- Gerretzen, J.; Szymańska, E.; Jansen, J.J.; Bart, J.; van Manen, H.-J.; van den Heuvel, E.R.; Buydens, L.M.C. Simple and Effective Way for Data Preprocessing Selection Based on Design of Experiments. Anal. Chem. 2015, 87, 12096–12103. [Google Scholar] [CrossRef]
- Bian, X.; Wang, K.; Tan, E.; Diwu, P.; Zhang, F.; Guo, Y. A Selective Ensemble Preprocessing Strategy for Near-Infrared Spectral Quantitative Analysis of Complex Samples. Chemom. Intell. Lab. Syst. 2020, 197, 103916. [Google Scholar] [CrossRef]
- Chen, Y.; Liu, L.; Rao, Y.; Zhang, X.; Zhang, W.; Jin, X. Identifying the “Dangshan” Physiological Disease of Pear Woolliness Response via Feature-Level Fusion of Near-Infrared Spectroscopy and Visual RGB Image. Foods 2023, 12, 1178. [Google Scholar] [CrossRef]
- Roger, J.-M.; Biancolillo, A.; Marini, F. Sequential Preprocessing through ORThogonalization (SPORT) and Its Application to near Infrared Spectroscopy. Chemom. Intell. Lab. Syst. 2020, 199, 103975. [Google Scholar] [CrossRef]
- Mishra, P.; Roger, J.M.; Rutledge, D.N.; Woltering, E. SPORT Pre-Processing Can Improve Near-Infrared Quality Prediction Models for Fresh Fruits and Agro-Materials. Postharvest Biol. Technol. 2020, 168, 111271. [Google Scholar] [CrossRef]
- Shi, X.; Yao, L.; Pan, T. Visible and Near-Infrared Spectroscopy with Multi-Parameters Optimization of Savitzky-Golay Smoothing Applied to Rapid Analysis of Soil Cr Content of Pearl River Delta. GEP 2021, 09, 75–83. [Google Scholar] [CrossRef]
- Barnes, R.J.; Dhanoa, M.S.; Lister, S.J. Standard Normal Variate Transformation and De-Trending of Near-Infrared Diffuse Reflectance Spectra. Appl. Spectrosc. 1989, 43, 772–777. [Google Scholar] [CrossRef]
- Isaksson, T.; Næs, T. The Effect of Multiplicative Scatter Correction (MSC) and Linearity Improvement in NIR Spectroscopy. Appl. Spectrosc. 1988, 42, 1273–1284. [Google Scholar] [CrossRef]
- Jin, X.; Li, S.; Zhang, W.; Zhu, J.; Sun, J. Prediction of Soil-Available Potassium Content with Visible Near-Infrared Ray Spectroscopy of Different Pretreatment Transformations by the Boosting Algorithms. Appl. Sci. 2020, 10, 1520. [Google Scholar] [CrossRef]
- Liaw, A.; Wiener, M. Classification and Regression by randomForest. R News 2002, 2, 18–22. [Google Scholar]
- Tien Bui, D.; Pradhan, B.; Lofman, O.; Revhaug, I. Landslide Susceptibility Assessment in Vietnam Using Support Vector Machines, Decision Tree, and Naïve Bayes Models. Math. Probl. Eng. 2012, 2012, 974638. [Google Scholar] [CrossRef]
- Jebur, M.N.; Pradhan, B.; Tehrany, M.S. Optimization of Landslide Conditioning Factors Using Very High-Resolution Airborne Laser Scanning (LiDAR) Data at Catchment Scale. Remote Sens. Environ. 2014, 152, 150–165. [Google Scholar] [CrossRef]
- Song, S.; Zhan, Z.; Long, Z.; Zhang, J.; Yao, L. Comparative Study of SVM Methods Combined with Voxel Selection for Object Category Classification on FMRI Data. PLoS ONE 2011, 6, e17191. [Google Scholar] [CrossRef]
- Schapire, R.E. Explaining AdaBoost; Schölkopf, B., Luo, Z., Vovk, V., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; pp. 37–52. [Google Scholar]
- Wang, L.; Chu, F.; Xie, W. Accurate Cancer Classification Using Expressions of Very Few Genes. IEEE/ACM Trans. Comput. Biol. Bioinf. 2007, 4, 40–53. [Google Scholar] [CrossRef]
- Sokolova, M.; Japkowicz, N.; Szpakowicz, S. Beyond Accuracy, F-Score and ROC: A Family of Discriminant Measures for Performance Evaluation. In Advances in Artificial Intelligence; Springer: Berlin/Heidelberg, Germany, 2006; Available online: https://link.springer.com/chapter/10.1007/11941439_114 (accessed on 16 March 2023).
- Gu, Q.; Zhu, L.; Cai, Z. Evaluation Measures of the Classification Performance of Imbalanced Data Sets. In Computational Intelligence and Intelligent Systems. ISICA 2009; Springer: Berlin/Heidelberg, Germany, 2009; Available online: https://link.springer.com/chapter/10.1007/978-3-642-04962-0_53 (accessed on 16 March 2023).
- Bekkar, M.; Djemaa, H.; Alitouche, T.A. Evaluation Measures for Models Assessment over Imbalanced Data Sets. J. Inf. Eng. Appl. 2013, 3, 27–38. [Google Scholar]
- Akosa, J. Predictive Accuracy: A Misleading Performance Measure for Highly Imbalanced Data. Proc. SAS Glob. Forum 2017, 12, 1–4. [Google Scholar]
- McHugh, M.L. Interrater Reliability: The Kappa Statistic. Biochem. Med. 2012, 276–282. [Google Scholar] [CrossRef]
- Jolliffe, I.T.; Cadima, J. Principal Component Analysis: A Review and Recent Developments. Phil. Trans. R. Soc. A 2016, 374, 20150202. [Google Scholar] [CrossRef] [PubMed]
- Uddin, P.; Mamun, A.; Hossain, A. PCA-Based Feature Reduction for Hyperspectral Remote Sensing Image Classification. IETE Tech. Rev. 2021, 38, 377–396. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Pretreatment Method | Abbreviations |
|---|---|
| Reflection spectrum without pretreatment method | RS |
| First derivative | D1 |
| Second derivative | D2 |
| Standard normal variate | SNV |
| Multiplicative scatter correction | MSC |
| Mean center | CT |
| Dislodge tendency | DT |
| Savitzky–Golay | SG |
| Dislodge tendency with standard normal variate | SNV + DT |
| First derivative with standard normal variate | SNV + D1 |
| Second derivative with standard normal variate | SNV + D2 |
| First derivative with multiplicative scatter correction | MSC + D1 |
| Second derivative with multiplicative scatter correction | MSC + D2 |
| First derivative with Savitzky–Golay | SG + D1 |
| Second derivative with Savitzky–Golay | SG + D2 |
| Standard normal variate with Savitzky–Golay | SG + SNV |
| Multiplicative scatter correction with Savitzky–Golay | SG + MSC |
| Mean center with Savitzky–Golay | SG + CT |
| Dislodge tendency with Savitzky–Golay | SG + DT |
| Dislodge tendency with standard normal variate and Savitzky–Golay | SG + SNV + DT |
| First derivative with standard normal variate and Savitzky–Golay | SG + SNV + D1 |
| Second derivative with standard normal variate and Savitzky–Golay | SG + SNV + D2 |
| First derivative with multiplicative scatter correction and Savitzky–Golay | SG + MSC + D1 |
| Second derivative with multiplicative scatter correction and Savitzky–Golay | SG + MSC + D2 |
| Numerical Range (Kappa) | Classification Consistency | Classification Consistency Levels |
|---|---|---|
| <0 | Totally Inconsistent | 7 |
| 0.0–0.20 | None | 6 |
| 0.21–0.39 | Minimal | 5 |
| 0.40–0.59 | Weak | 4 |
| 0.60–0.79 | Moderate | 3 |
| 0.80–0.90 | Strong | 2 |
| Above 0.90 | Almost Perfect | 1 |
| Type | Total Number | Number of Diseased | Number of Healthy |
|---|---|---|---|
| Total number of samples | 480 | 240 | 240 |
| Training set | 336 | 169 | 167 |
| Test set | 144 | 71 | 73 |
| Pretreatment Method | SVM | RF | AdaBoost | GBDT | Xgboost | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| RA | RK | RA | RK | RA | RK | RA | RK | RA | RK | |
| RS | 2 | 5 | 7 | 4 | 12 | 5 | 16 | 5 | 9 | 4 |
| D1 | 6 | 6 | 12 | 5 | 17 | 5 | 13 | 5 | 8 | 4 |
| D2 | 10 | 6 | 14 | 7 | 19 | 6 | 19 | 7 | 15 | 7 |
| SNV | 4 | 5 | 6 | 4 | 6 | 4 | 7 | 4 | 2 | 4 |
| MSC | 4 | 5 | 3 | 4 | 6 | 4 | 4 | 4 | 4 | 4 |
| CT | 1 | 5 | 9 | 4 | 7 | 4 | 8 | 4 | 5 | 4 |
| DT | 8 | 6 | 7 | 4 | 9 | 4 | 7 | 4 | 2 | 4 |
| SG | 2 | 5 | 8 | 4 | 10 | 4 | 11 | 4 | 7 | 4 |
| SNV+DT | 5 | 5 | 5 | 4 | 4 | 4 | 6 | 4 | 2 | 4 |
| SNV+D1 | 5 | 5 | 11 | 5 | 14 | 5 | 14 | 5 | 10 | 5 |
| SNV+D2 | 9 | 6 | 16 | 7 | 20 | 7 | 18 | 6 | 14 | 6 |
| MSC+D1 | 5 | 5 | 13 | 5 | 11 | 5 | 13 | 5 | 10 | 5 |
| MSC+D2 | 9 | 6 | 15 | 7 | 18 | 6 | 17 | 6 | 13 | 6 |
| SG+D1 | 6 | 6 | 5 | 4 | 3 | 4 | 6 | 4 | 5 | 4 |
| SG+D2 | 7 | 6 | 11 | 5 | 15 | 5 | 12 | 5 | 10 | 5 |
| SG+SNV | 4 | 5 | 4 | 4 | 5 | 4 | 3 | 3 | 2 | 4 |
| SG+MSC | 4 | 5 | 4 | 4 | 7 | 4 | 9 | 4 | 3 | 4 |
| SG+CT | 1 | 5 | 5 | 4 | 9 | 4 | 10 | 4 | 6 | 4 |
| SG+DT | 8 | 6 | 7 | 4 | 8 | 4 | 9 | 4 | 4 | 4 |
| SG+SNV+DT | 5 | 5 | 4 | 4 | 4 | 4 | 5 | 4 | 3 | 4 |
| SG+SNV+D1 | 5 | 5 | 2 | 3 | 2 | 3 | 1 | 3 | 1 | 3 |
| SG+SNV+D2 | 3 | 5 | 11 | 5 | 16 | 5 | 15 | 5 | 11 | 5 |
| SG+MSC+D1 | 5 | 5 | 1 | 3 | 1 | 3 | 2 | 3 | 1 | 3 |
| SG+MSC+D2 | 3 | 5 | 10 | 5 | 13 | 5 | 14 | 5 | 12 | 5 |
| Pretreatment Method | RS | SG+SNV+D1 | SG+MSC+D1 | |||
|---|---|---|---|---|---|---|
| Accuracy | Kappa | Accuracy | Kappa | Accuracy | Kappa | |
| SVM | 0.65 | 0.29 | 0.62 | 0.23 | 0.62 | 0.23 |
| RF | 0.74 | 0.47 | 0.82 | 0.64 | 0.83 | 0.67 |
| AdaBoost | 0.69 | 0.36 | 0.83 | 0.67 | 0.84 | 0.68 |
| GBDT | 0.63 | 0.25 | 0.83 | 0.67 | 0.83 | 0.65 |
| Xgboost | 0.70 | 0.40 | 0.85 | 0.69 | 0.85 | 0.69 |
| Model | Parameters | Value Range and Step Size |
|---|---|---|
| SVM | Kernel | rbf, poly, linear, sigmoid |
| PT | (1, 2000, 50) | |
| Gamma | (0.01, 1, 0.01) | |
| (1, 50, 1) | ||
| (1, 1500, 50) | ||
| RF | Criterion | gini, entropy |
| max_depth | (1, 30, 1) | |
| max_NIO | (1, 1500, 50) | |
| Xgboost | max_depth | (1, 30, 1) |
| max_NIO | (1, 1500, 50) | |
| AdaBoost | max_depth | (1, 30, 1) |
| max_NIO | (1, 1500, 50) | |
| GBDT | max_depth | (1, 30, 1) |
| max_NIO | (1, 1500, 50) |
| Pretreatment Method | SG+SNV+D1 | SG+MSC+D1 | ||||||
|---|---|---|---|---|---|---|---|---|
| Parameter | Accuracy | F1 | Kappa | Parameter | Accuracy | F1 | Kappa | |
| SVM | Kernel = rbf | 0.87 | 0.87 | 0.74 | Kernel = rbf | 0.85 | 0.85 | 0.71 |
| PT = 701 | PT = 701 | |||||||
| Gamma = 32 | Gamma = 701 | |||||||
| RF | Criterion = gini | 0.85 | 0.85 | 0.69 | Criterion = gini | 0.85 | 0.85 | 0.69 |
| max_depth = 12 | max_depth = 12 | |||||||
| max_NIO = 201 | max_NIO = 651 | |||||||
| AdaBoost | max_depth = 2 | 0.85 | 0.85 | 0.71 | max_depth = 3 | 0.87 | 0.87 | 0.74 |
| max_NIO = 251 | max_NIO = 101 | |||||||
| GBDT | max_depth = 3 | 0.86 | 0.86 | 0.72 | max_depth = 3 | 0.83 | 0.83 | 0.65 |
| max_NIO = 601 | max_NIO = 1451 | |||||||
| Xgboost | max_depth = 6 | 0.85 | 0.85 | 0.69 | max_depth = 6 | 0.85 | 0.85 | 0.71 |
| max_NIO = 101 | max_NIO = 501 | |||||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, J.; Liu, L.; Chen, Y.; Rao, Y.; Zhang, X.; Jin, X. The Nondestructive Model of Near-Infrared Spectroscopy with Different Pretreatment Transformation for Predicting “Dangshan” Pear Woolliness Disease. Agronomy 2023, 13, 1420. https://doi.org/10.3390/agronomy13051420
Zhang J, Liu L, Chen Y, Rao Y, Zhang X, Jin X. The Nondestructive Model of Near-Infrared Spectroscopy with Different Pretreatment Transformation for Predicting “Dangshan” Pear Woolliness Disease. Agronomy. 2023; 13(5):1420. https://doi.org/10.3390/agronomy13051420
Chicago/Turabian StyleZhang, Jiahui, Li Liu, Yuanfeng Chen, Yuan Rao, Xiaodan Zhang, and Xiu Jin. 2023. "The Nondestructive Model of Near-Infrared Spectroscopy with Different Pretreatment Transformation for Predicting “Dangshan” Pear Woolliness Disease" Agronomy 13, no. 5: 1420. https://doi.org/10.3390/agronomy13051420