
A Reference-Free Method for the Thematic Accuracy Estimation of Global Land Cover Products Based on the Triple Collocation Approach

Abstract
:1. Introduction
2. Methods
2.1. Mathematical Foundation of TCCA
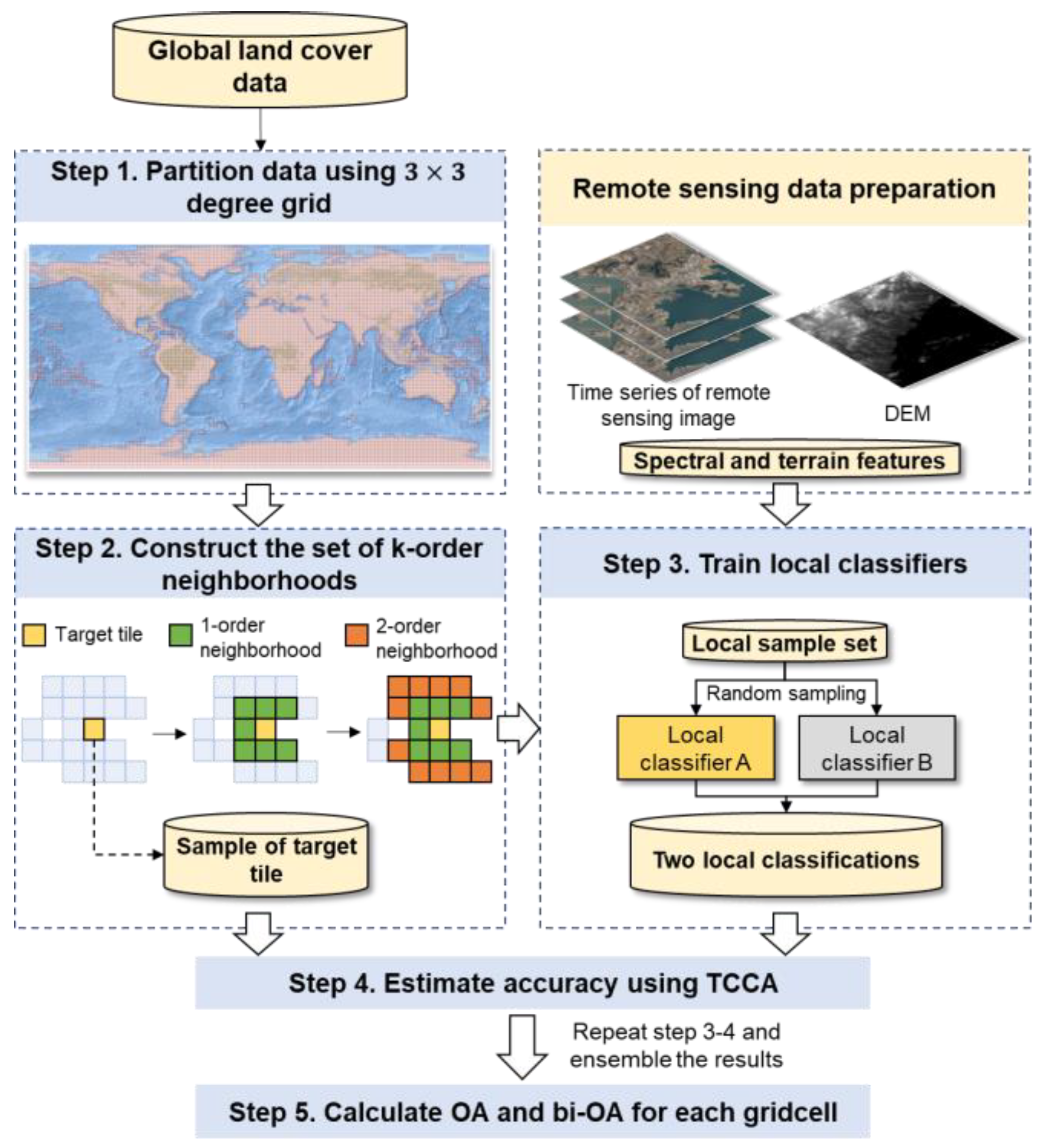
2.2. Solution for TCCA Applied to GLC Assessment
2.2.1. Data Partition
2.2.2. Neighbourhood Construction
2.2.3. Training Two Local Classifiers
2.2.4. Estimating the Accuracy for a Single Class
2.2.5. Estimating the Overall Accuracy
2.3. Testing Conditional Independence
3. Experiments
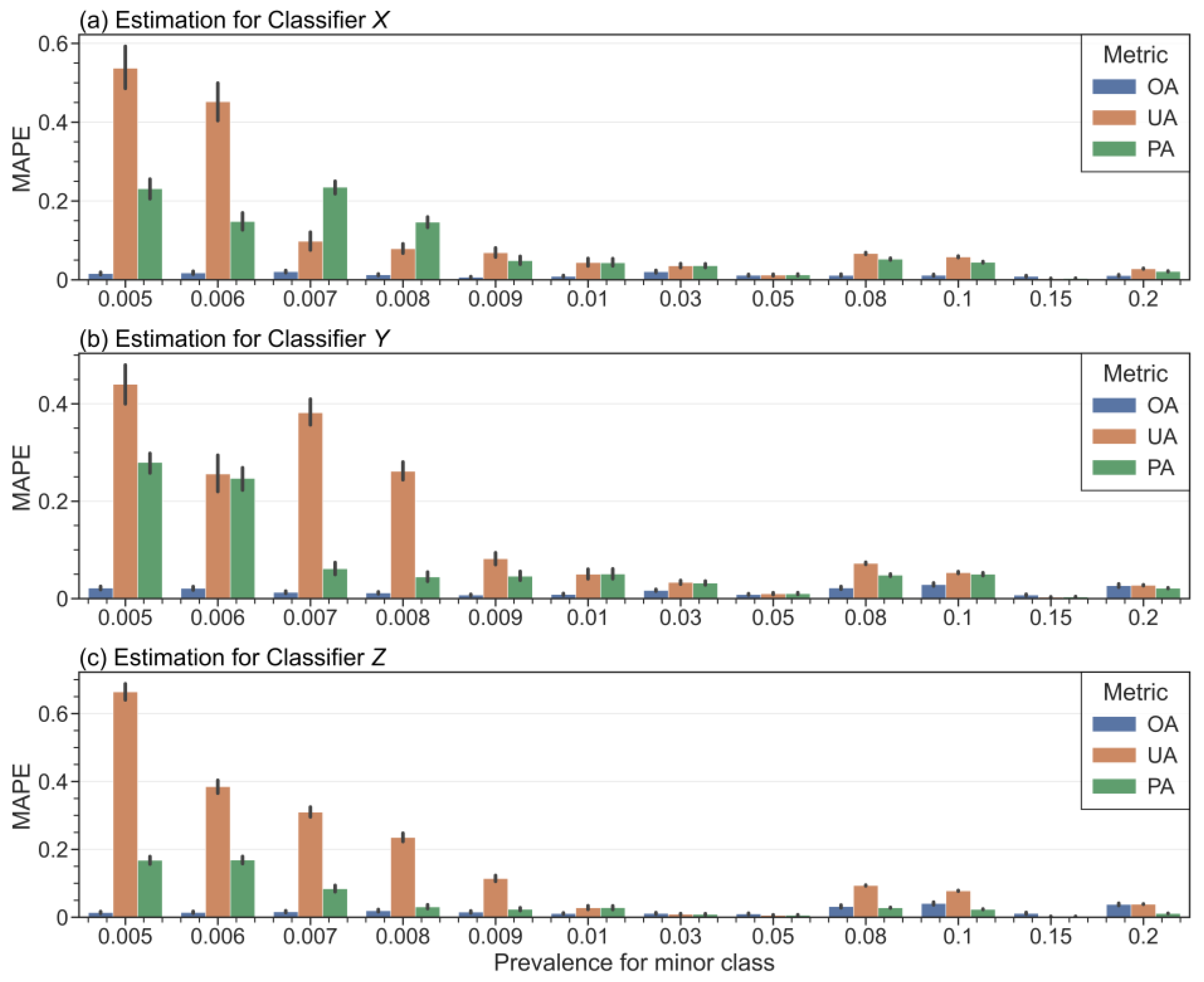
3.1. Sensitivity of TCCA on Extremely Imbalanced Data
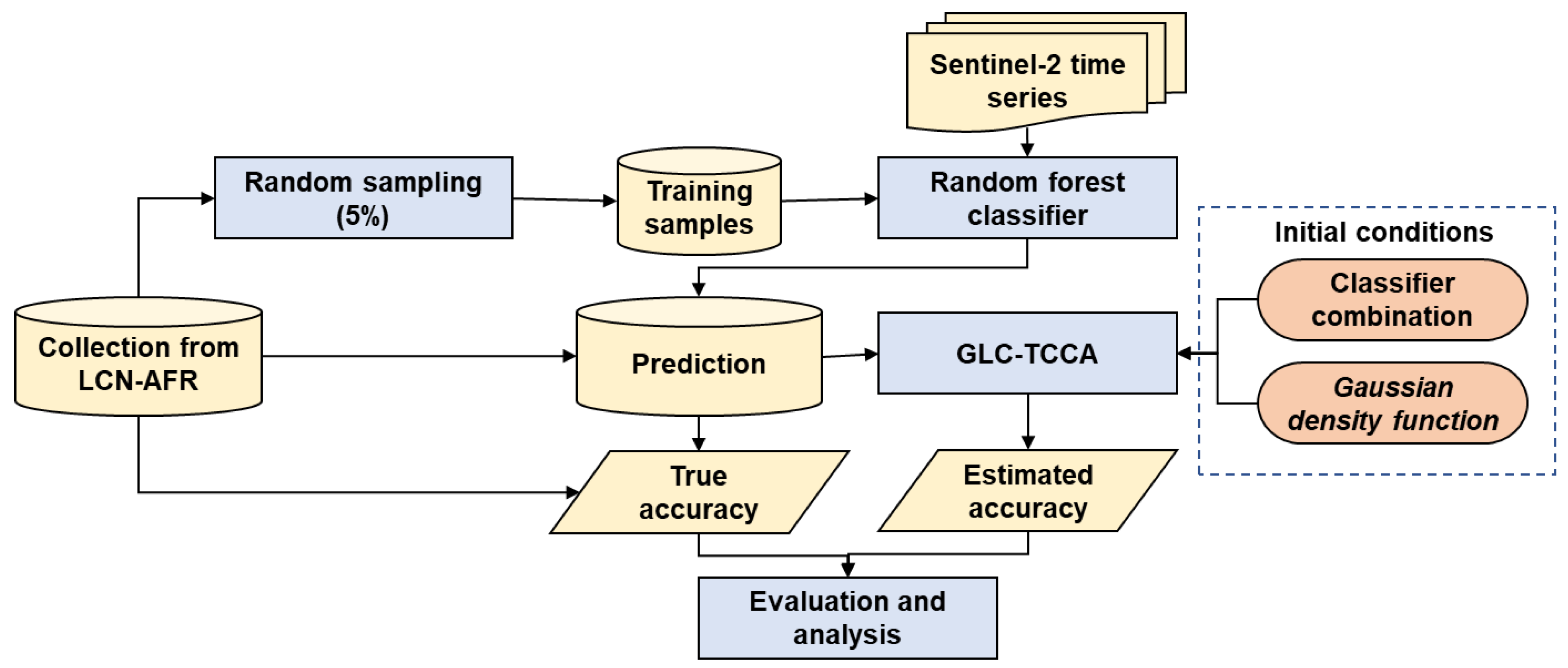
3.2. Tuning GLC-TCCA on a Real-Life Dataset with Known Ground Truth
3.2.1. Experimental Setup
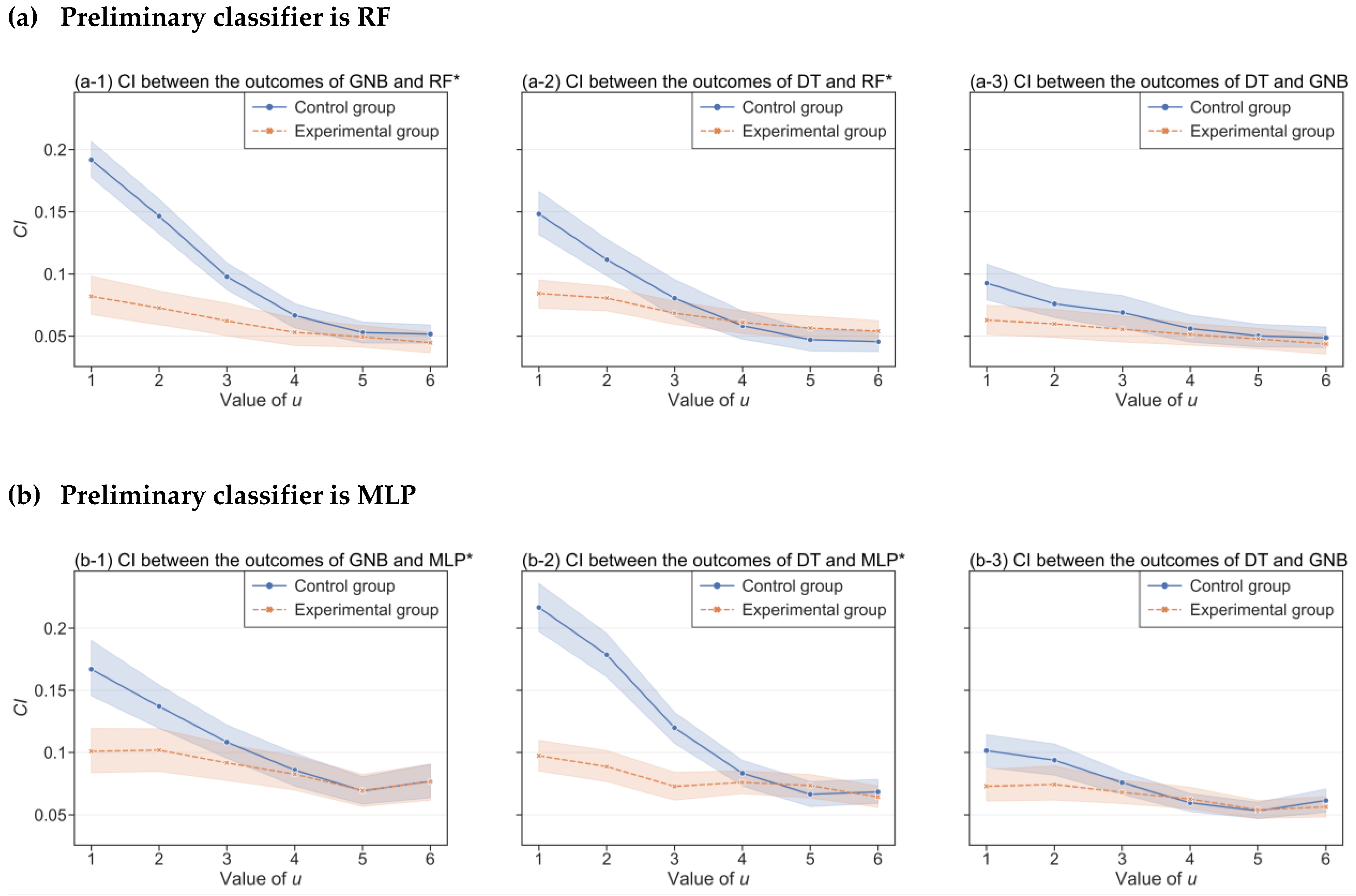
3.2.2. Choice of Classifiers
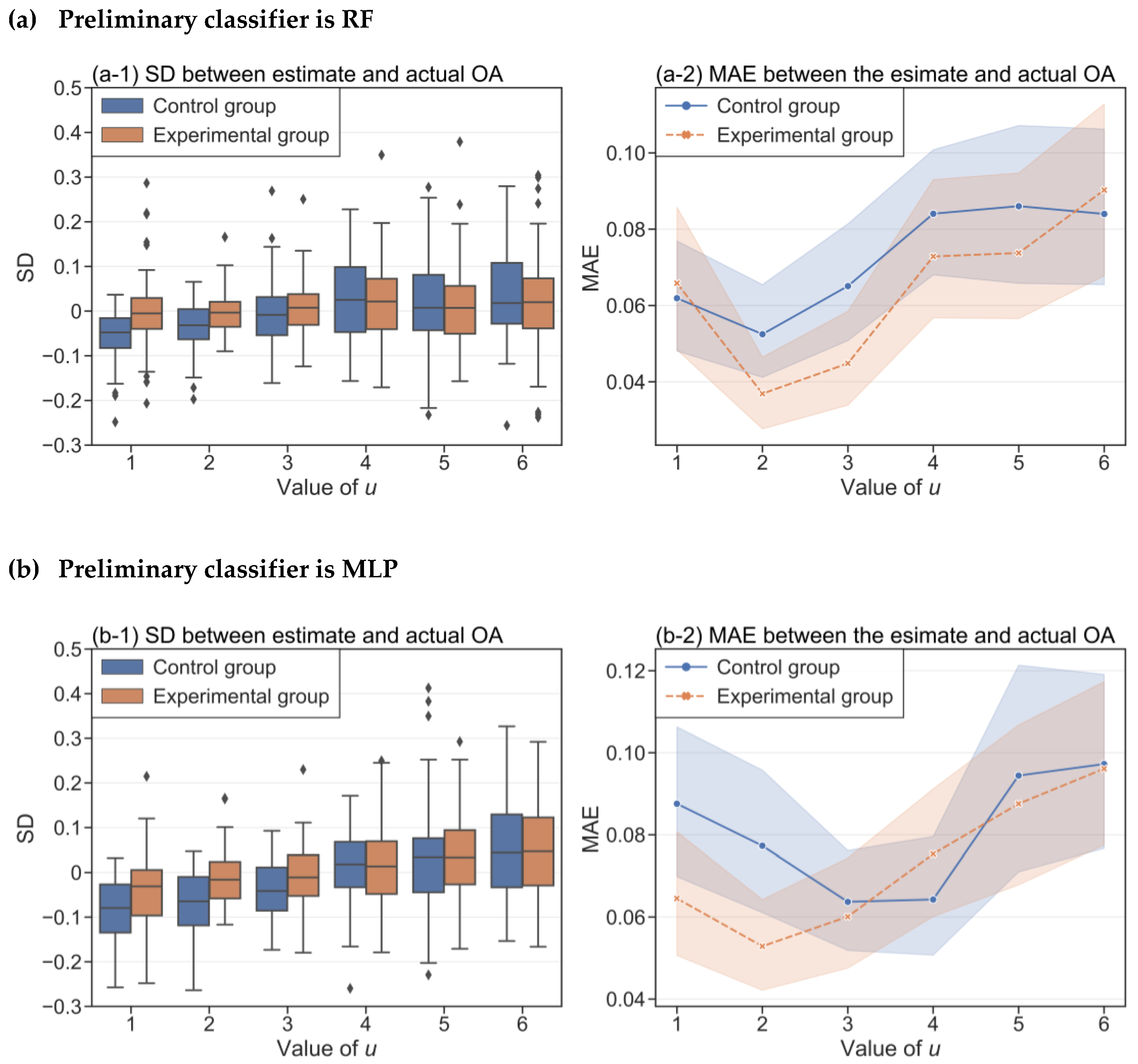
3.2.3. Selection of the Parameter in the Gaussian Density Function
3.3. GLC-TCCA Applied to WorldCover 2020
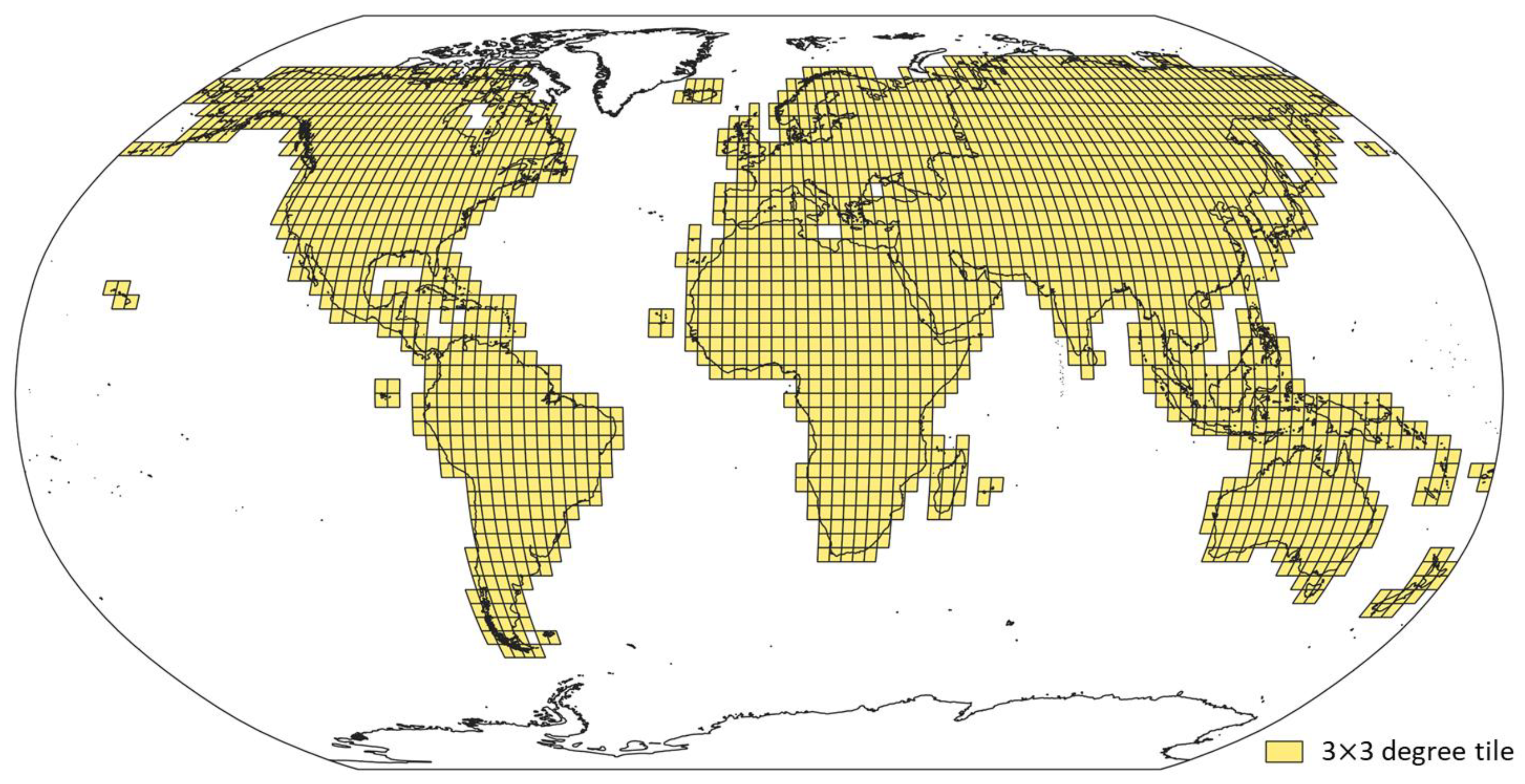
3.3.1. Data Preparation
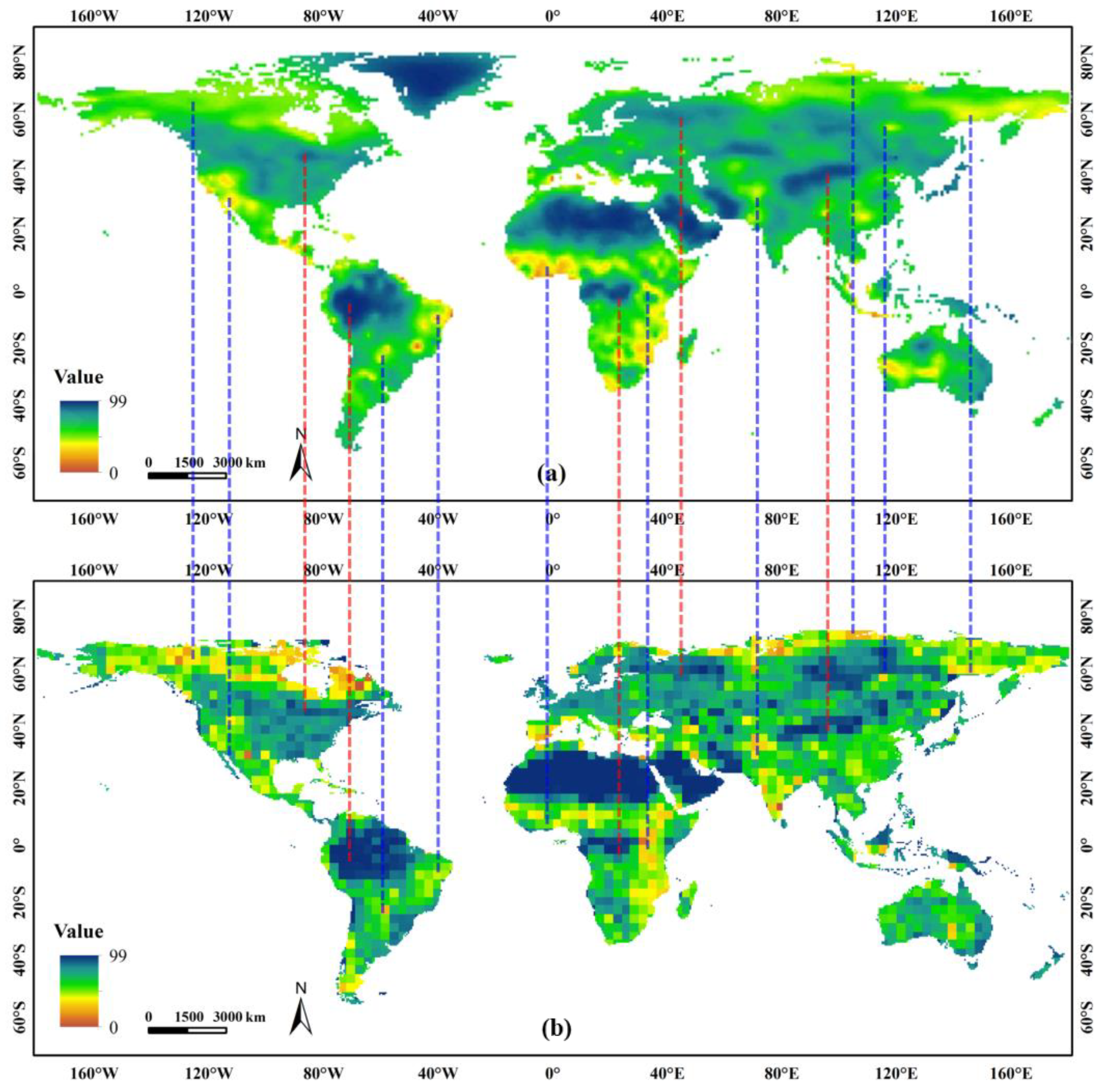
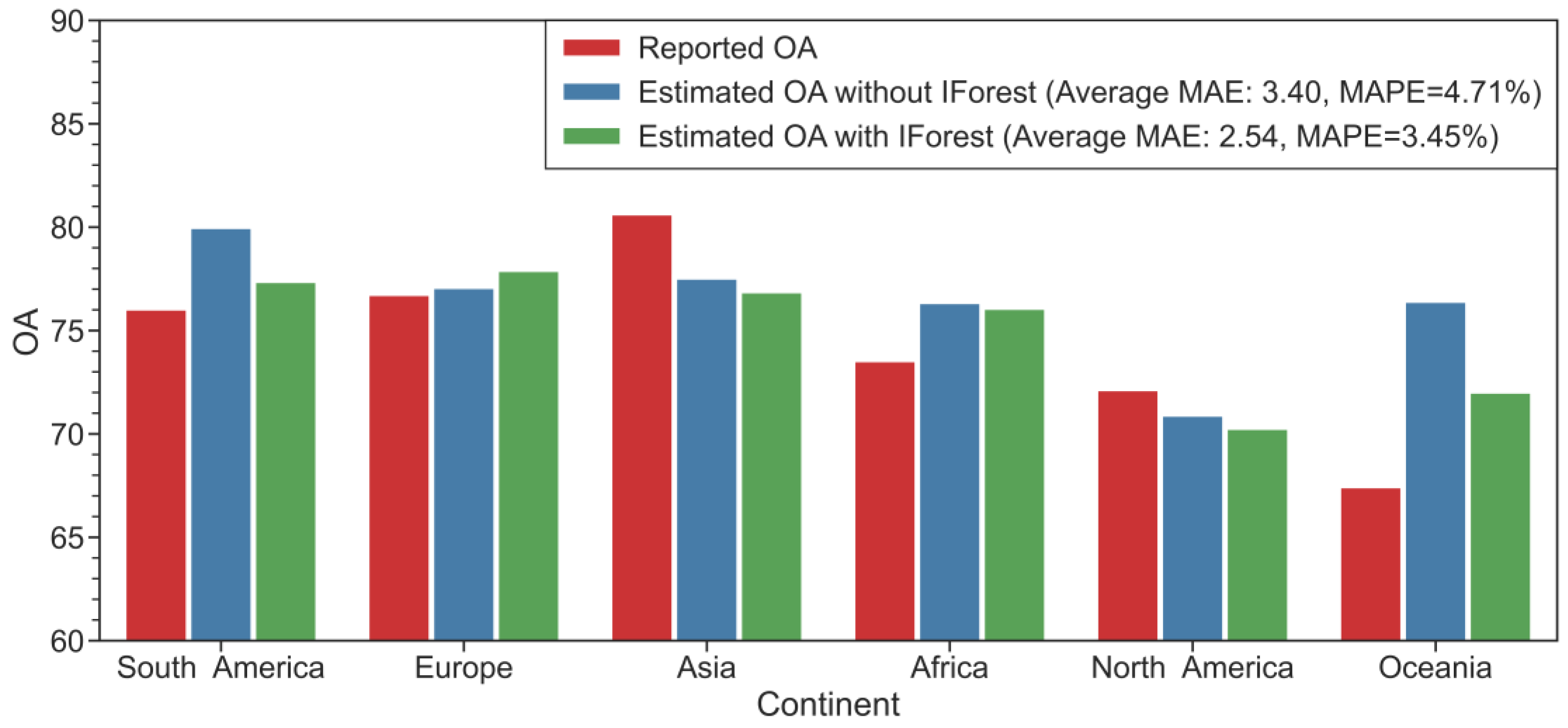
3.3.2. Estimation of WorldCover 2020 at the Continent Level
3.3.3. Improving GLC-TCCA with the Screening of Reliable Sample
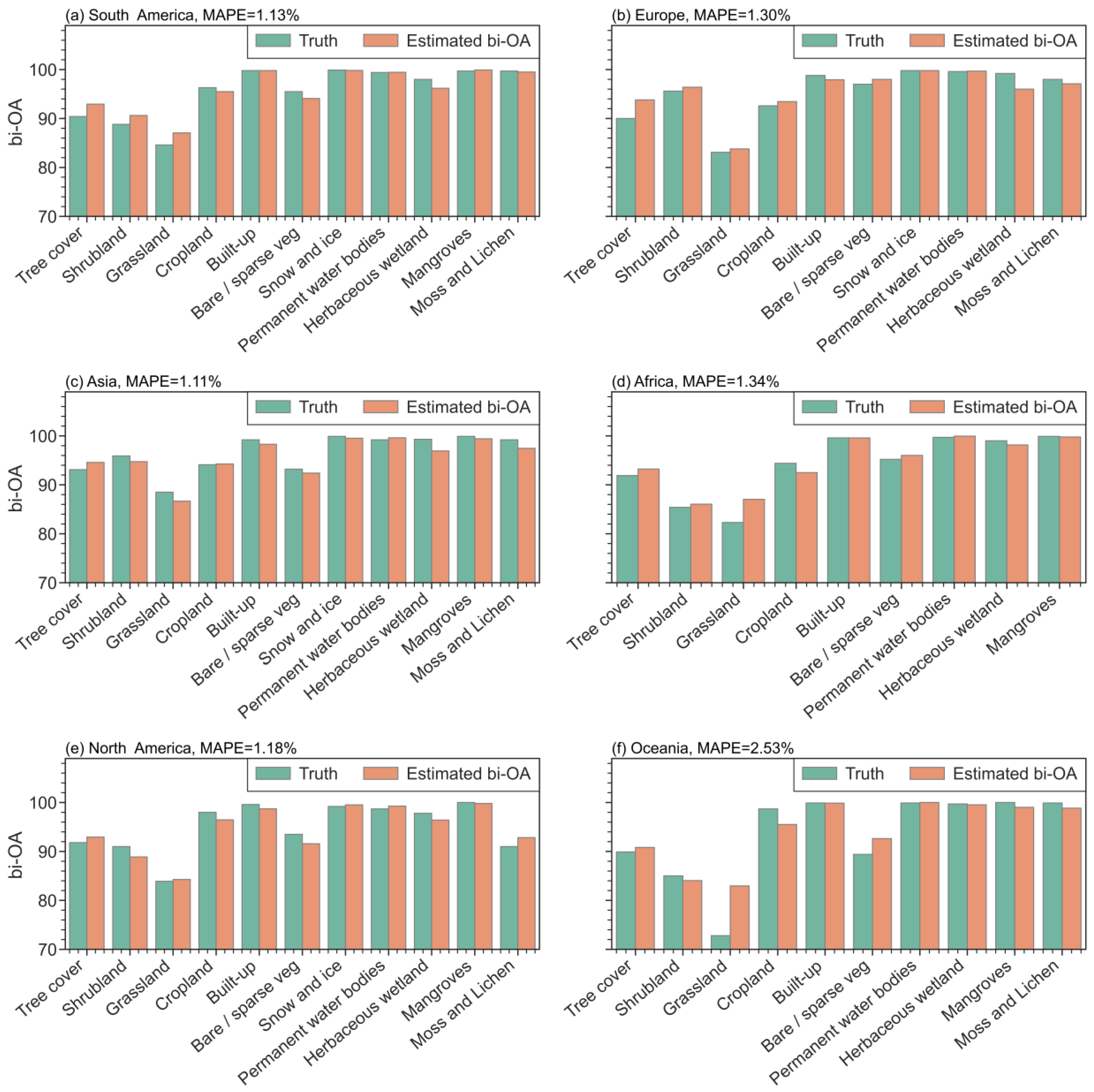
3.3.4. Class-Specific Accuracy Analysis Based on the Estimates of Improved GLC-TCCA
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Conflicts of Interest
References
- Gong, P.; Zhang, W.; Yu, L.; Li, C. New research paradigm for global land cover mapping. J. Remote Sens. 2016, 20, 1002–1016. [Google Scholar] [CrossRef]
- Loveland, T.R.; Reed, B.C.; Brown, J.F.; Ohlen, D.O.; Zhu, Z.; Yang, L.; Merchant, J.W. Development of a global land cover characteristics database and IGBP DISCover from 1 km AVHRR data. Int. J. Remote Sens. 2000, 21, 1303–1330. [Google Scholar] [CrossRef]
- Bossard, M.; Feranec, J.; Otahel, J. CORINE Land Cover Technical Guide: Addendum 2000; European Environment Agency: Copenhagen, Denmark, 2000. [Google Scholar]
- Brown, C.F.; Brumby, S.P.; Guzder-Williams, B.; Birch, T.; Hyde, S.B.; Mazzariello, J.; Czerwinski, W.; Pasquarella, V.J.; Haertel, R.; Ilyushchenko, S.; et al. Dynamic World, Near real-time global 10 m land use land cover mapping. Sci. Data 2022, 9, 251. [Google Scholar] [CrossRef]
- Chen, J.; Chen, J.; Liao, A.; Cao, X.; Chen, L.; Chen, X.; He, C.; Han, G.; Peng, S.; Lu, M.; et al. Global land cover mapping at 30 m resolution: A POK-based operational approach. ISPRS J. Photogramm. Remote Sens. 2015, 103, 7–27. [Google Scholar] [CrossRef]
- Gong, P.; Wang, J.; Yu, L.; Zhao, Y.; Zhao, Y.; Liang, L.; Niu, Z.; Huang, X.; Fu, H.; Liu, S.; et al. Finer resolution observation and monitoring of global land cover: First mapping results with Landsat TM and ETM+ data. Int. J. Remote Sens. 2013, 34, 2607–2654. [Google Scholar] [CrossRef]
- Hansen, M.C.; Potapov, P.V.; Pickens, A.H.; Tyukavina, A.; Hernandez-Serna, A.; Zalles, V.; Turubanova, S.; Kommareddy, I.; Stehman, S.V.; Song, X.-P.; et al. Global land use extent and dispersion within natural land cover using Landsat data. Environ. Res. Lett. 2022, 17, 034050. [Google Scholar] [CrossRef]
- Belward, A.S.; Skøien, J.O. Who launched what, when and why; trends in global land-cover observation capacity from civilian earth observation satellites. ISPRS J. Photogramm. Remote Sens. 2015, 103, 115–128. [Google Scholar] [CrossRef]
- Li, X.; Chen, G.; Liu, X.; Liang, X.; Wang, S.; Chen, Y.; Pei, F.; Xu, X. A New Global Land-Use and Land-Cover Change Product at a 1-km Resolution for 2010 to 2100 Based on Human–Environment Interactions. Ann. Assoc. Am. Geogr. 2017, 107, 1040–1059. [Google Scholar] [CrossRef]
- Mantyka-Pringle, C.S.; Visconti, P.; Di Marco, M.; Martin, T.G.; Rondinini, C.; Rhodes, J.R. Climate change modifies risk of global biodiversity loss due to land-cover change. Biol. Conserv. 2015, 187, 103–111. [Google Scholar] [CrossRef]
- Straume, K. The social construction of a land cover map and its implications for Geographical Information Systems (GIS) as a management tool. Land Use Policy 2014, 39, 44–53. [Google Scholar] [CrossRef]
- Congalton, R.G.; Gu, J.; Yadav, K.; Thenkabail, P.; Ozdogan, M. Global Land Cover Mapping: A Review and Uncertainty Analysis. Remote Sens. 2014, 6, 12070–12093. [Google Scholar] [CrossRef]
- Chen, P.; Shi, W.; Kou, R.; Wan, Y. A quantitative investigation of the uncertainty associated with mapping scale in the production of land-cover/land-use data. Int. J. Remote Sens. 2018, 39, 8798–8817. [Google Scholar] [CrossRef]
- Tchuente, A.T.K.; Roujean, J.-L.; Faroux, S. ECOCLIMAP-II: An ecosystem classification and land surface parameters database of Western Africa at 1km resolution for the African Monsoon Multidisciplinary Analysis (AMMA) project. Remote Sens. Environ. 2010, 114, 961–976. [Google Scholar] [CrossRef]
- Tsendbazar, N.; Herold, M.; Li, L.; Tarko, A.; de Bruin, S.; Masiliunas, D.; Lesiv, M.; Fritz, S.; Buchhorn, M.; Smets, B.; et al. Towards operational validation of annual global land cover maps. Remote Sens. Environ. 2021, 266, 112686. [Google Scholar] [CrossRef]
- Nelson, M.D.; Garner, J.D.; Tavernia, B.G.; Stehman, S.V.; Riemann, R.I.; Lister, A.J.; Perry, C.H. Assessing map accuracy from a suite of site-specific, non-site specific, and spatial distribution approaches. Remote Sens. Environ. 2021, 260, 112442. [Google Scholar] [CrossRef]
- Foody, G.M. Explaining the unsuitability of the kappa coefficient in the assessment and comparison of the accuracy of thematic maps obtained by image classification. Remote Sens. Environ. 2020, 239, 111630. [Google Scholar] [CrossRef]
- Olofsson, P.; Foody, G.M.; Herold, M.; Stehman, S.V.; Woodcock, C.E.; Wulder, M.A. Good practices for estimating area and assessing accuracy of land change. Remote Sens. Environ. 2014, 148, 42–57. [Google Scholar] [CrossRef]
- Zhao, Y.; Gong, P.; Yu, L.; Hu, L.; Li, X.; Li, C.; Zhang, H.; Zheng, Y.; Wang, J.; Zhao, Y.; et al. Towards a common validation sample set for global land-cover mapping. Int. J. Remote Sens. 2014, 35, 4795–4814. [Google Scholar] [CrossRef]
- Stehman, S.V.; Foody, G.M. Key issues in rigorous accuracy assessment of land cover products. Remote Sens. Environ. 2019, 231, 111199. [Google Scholar] [CrossRef]
- Chen, P.; Huang, H.; Shi, W. Reference-free method for investigating classification uncertainty in large-scale land cover datasets. Int. J. Appl. Earth Obs. Geoinf. 2022, 107, 102673. [Google Scholar] [CrossRef]
- Fonte, C.C.; Martinho, N. Assessing the applicability of OpenStreetMap data to assist the validation of land use/land cover maps. Int. J. Geogr. Inf. Sci. 2017, 31, 2382–2400. [Google Scholar] [CrossRef]
- Fritz, S.; See, L.; Perger, C.; McCallum, I.; Schill, C.; Schepaschenko, D.; Duerauer, M.; Karner, M.; Dresel, C.; Laso-Bayas, J.-C.; et al. A global dataset of crowdsourced land cover and land use reference data. Sci. Data 2017, 4, 170075. [Google Scholar] [CrossRef] [PubMed]
- Saah, D.; Johnson, G.; Ashmall, B.; Tondapu, G.; Tenneson, K.; Patterson, M.; Poortinga, A.; Markert, K.; Quyen, N.H.; Aung, K.S.; et al. Collect Earth: An online tool for systematic reference data collection in land cover and use applications. Environ. Model. Softw. 2019, 118, 166–171. [Google Scholar] [CrossRef]
- Stehman, S.V.; Fonte, C.C.; Foody, G.M.; See, L. Using volunteered geographic information (VGI) in design-based statistical inference for area estimation and accuracy assessment of land cover. Remote Sens. Environ. 2018, 212, 47–59. [Google Scholar] [CrossRef]
- Chen, J.; Chen, L.; Chen, F.; Ban, Y.; Li, S.; Han, G.; Tong, X.; Liu, C.; Stamenova, V.; Stamenov, S. Collaborative validation of GlobeLand30: Methodology and practices. Geo-Spat. Inf. Sci. 2021, 24, 134–144. [Google Scholar] [CrossRef]
- Bayas, J.C.L.; See, L.; Bartl, H.; Sturn, T.; Karner, M.; Fraisl, D.; Moorthy, I.; Busch, M.; van der Velde, M.; Fritz, S. Crowdsourcing LUCAS: Citizens Generating Reference Land Cover and Land Use Data with a Mobile App. Land 2020, 9, 446. [Google Scholar] [CrossRef]
- Bayas, J.C.L.; See, L.; Fritz, S.; Sturn, T.; Perger, C.; Dürauer, M.; Karner, M.; Moorthy, I.; Schepaschenko, D.; Domian, D.; et al. Crowdsourcing In-Situ Data on Land Cover and Land Use Using Gamification and Mobile Technology. Remote Sens. 2016, 8, 905. [Google Scholar] [CrossRef]
- Fonte, C.C.; Antoniou, V.; Bastin, L.; Estima, J.; Arsanjani, J.J.; Bayas, J.-C.L.; See, L.; Vatseva, R. Assessing VGI Data Quality. In Mapping and the Citizen Sensor; Foody, G., See, L., Fritz, S., Mooney, P., Olteanu-Raimond, A.-M., Fonte, C.C., Antoniou, V., Eds.; Ubiquity Press: London, UK, 2017; pp. 137–163. [Google Scholar]
- Koukoletsos, T.; Haklay, M.; Ellul, C. Assessing Data Completeness of VGI through an Automated Matching Procedure for Linear Data. Trans. GIS 2012, 16, 477–498. [Google Scholar] [CrossRef]
- Gao, Y.; Liu, L.; Zhang, X.; Chen, X.; Mi, J.; Xie, S. Consistency Analysis and Accuracy Assessment of Three Global 30-m Land-Cover Products over the European Union using the LUCAS Dataset. Remote Sens. 2020, 12, 3479. [Google Scholar] [CrossRef]
- Hua, T.; Zhao, W.; Liu, Y.; Wang, S.; Yang, S. Spatial Consistency Assessments for Global Land-Cover Datasets: A Comparison among GLC2000, CCI LC, MCD12, GLOBCOVER and GLCNMO. Remote Sens. 2018, 10, 1846. [Google Scholar] [CrossRef]
- Pérez-Hoyos, A.; García-Haro, F.; San-Miguel-Ayanz, J. Conventional and fuzzy comparisons of large scale land cover products: Application to CORINE, GLC2000, MODIS and GlobCover in Europe. ISPRS J. Photogramm. Remote Sens. 2012, 74, 185–201. [Google Scholar] [CrossRef]
- Liu, L.; Zhang, X.; Gao, Y.; Chen, X.; Shuai, X.; Mi, J. Finer-Resolution Mapping of Global Land Cover: Recent Developments, Consistency Analysis, and Prospects. J. Remote Sens. 2021, 2021, 5289697. [Google Scholar] [CrossRef]
- Foody, G.M. Global and Local Assessment of Image Classification Quality on an Overall and Per-Class Basis without Ground Reference Data. Remote Sens. 2022, 14, 5380. [Google Scholar] [CrossRef]
- Herold, M.; Mayaux, P.; Woodcock, C.; Baccini, A.; Schmullius, C. Some challenges in global land cover mapping: An assessment of agreement and accuracy in existing 1 km datasets. Remote Sens. Environ. 2008, 112, 2538–2556. [Google Scholar] [CrossRef]
- Yang, H.; Li, S.; Chen, J.; Zhang, X.; Xu, S. The Standardization and Harmonization of Land Cover Classification Systems towards Harmonized Datasets: A Review. ISPRS Int. J. Geo-Inf. 2017, 6, 154. [Google Scholar] [CrossRef]
- Radoux, J.; Defourny, P. Automated Image-to-Map Discrepancy Detection using Iterative Trimming. Photogramm. Eng. Remote Sens. 2010, 76, 173–181. [Google Scholar] [CrossRef]
- Radoux, J.; Lamarche, C.; Van Bogaert, E.; Bontemps, S.; Brockmann, C.; Defourny, P. Automated Training Sample Extraction for Global Land Cover Mapping. Remote Sens. 2014, 6, 3965–3987. [Google Scholar] [CrossRef]
- Chen, P.; Shi, W.; Kou, R. Reference-Free Measurement of the Classification Reliability of Vector-Based Land Cover Mapping. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1090–1094. [Google Scholar] [CrossRef]
- Pierdicca, N.; Anniballe, R.; Noto, F.; Bignami, C.; Chini, M.; Martinelli, A.; Mannella, A. Triple Collocation to Assess Classification Accuracy without a Ground Truth in Case of Earthquake Damage Assessment. IEEE Trans. Geosci. Remote Sens. 2017, 56, 485–496. [Google Scholar] [CrossRef]
- Baraldi, A.; Bruzzone, L.; Blonda, P. Quality assessment of classification and cluster maps without ground truth knowledge. IEEE Trans. Geosci. Remote Sens. 2005, 43, 857–873. [Google Scholar] [CrossRef]
- Steele, B.M. Maximum posterior probability estimators of map accuracy. Remote Sens. Environ. 2005, 99, 254–270. [Google Scholar] [CrossRef]
- Foody, G.M. Latent Class Modeling for Site- and Non-Site-Specific Classification Accuracy Assessment without Ground Data. IEEE Trans. Geosci. Remote Sens. 2011, 50, 2827–2838. [Google Scholar] [CrossRef]
- Stoffelen, A. Toward the true near-surface wind speed: Error modeling and calibration using triple collocation. J. Geophys. Res. Oceans 1998, 103, 7755–7766. [Google Scholar] [CrossRef]
- Gruber, A.; Su, C.-H.; Crow, W.T.; Zwieback, S.; Dorigo, W.A.; Wagner, W. Estimating error cross-correlations in soil moisture data sets using extended collocation analysis. J. Geophys. Res. Atmos. 2016, 121, 1208–1219. [Google Scholar] [CrossRef]
- Hoareau, N.; Portabella, M.; Lin, W.; Ballabrera-Poy, J.; Turiel, A. Error Characterization of Sea Surface Salinity Products Using Triple Collocation Analysis. IEEE Trans. Geosci. Remote Sens. 2018, 56, 5160–5168. [Google Scholar] [CrossRef]
- Li, C.; Tang, G.; Hong, Y. Cross-evaluation of ground-based, multi-satellite and reanalysis precipitation products: Applicability of the Triple Collocation method across Mainland China. J. Hydrol. 2018, 562, 71–83. [Google Scholar] [CrossRef]
- Gong, P.; Li, X.; Wang, J.; Bai, Y.; Chen, B.; Hu, T.; Liu, X.; Xu, B.; Yang, J.; Zhang, W.; et al. Annual maps of global artificial impervious area (GAIA) between 1985 and 2018. Remote Sens. Environ. 2019, 236, 111510. [Google Scholar] [CrossRef]
- Zhang, X.; Liu, L.Y.; Wu, C.S.; Chen, X.D.; Gao, Y.; Xie, S.; Zhang, B. Development of a global 30 m impervious surface map using multisource and multitemporal remote sensing datasets with the Google Earth Engine platform. Earth Syst. Sci. Data 2020, 12, 1625–1648. [Google Scholar] [CrossRef]
- Zhang, X.; Liu, L.; Chen, X.; Gao, Y.; Xie, S.; Mi, J. GLC_FCS30: Global land-cover product with fine classification system at 30 m using time-series Landsat imagery. Earth Syst. Sci. Data 2021, 13, 2753–2776. [Google Scholar] [CrossRef]
- Zhu, Z.; Gallant, A.L.; Woodcock, C.E.; Pengra, B.; Olofsson, P.; Loveland, T.R.; Jin, S.; Dahal, D.; Yang, L.; Auch, R.F. Optimizing selection of training and auxiliary data for operational land cover classification for the LCMAP initiative. ISPRS J. Photogramm. Remote Sens. 2016, 122, 206–221. [Google Scholar] [CrossRef]
- Arsanjani, J.J.; Tayyebi, A.; Vaz, E. GlobeLand30 as an alternative fine-scale global land cover map: Challenges, possibilities, and implications for developing countries. Habitat Int. 2016, 55, 25–31. [Google Scholar] [CrossRef]
- Zhang, H.K.; Roy, D.P. Using the 500 m MODIS land cover product to derive a consistent continental scale 30 m Landsat land cover classification. Remote Sens. Environ. 2017, 197, 15–34. [Google Scholar] [CrossRef]
- Tobler, W.R. A Computer Movie Simulating Urban Growth in the Detroit Region. Econ. Geogr. 1970, 46, 234–240. [Google Scholar] [CrossRef]
- Foody, G.M. Assessing the accuracy of land cover change with imperfect ground reference data. Remote Sens. Environ. 2010, 114, 2271–2285. [Google Scholar] [CrossRef]
- Tateishi, R.; Uriyangqai, B.; Al-Bilbisi, H.; Ghar, M.A.; Tsend-Ayush, J.; Kobayashi, T.; Kasimu, A.; Hoan, N.T.; Shalaby, A.; Alsaaideh, B. Production of Global Land Cover Data–GLCNMO. Int. J. Digit. Earth 2011, 4, 22–49. [Google Scholar] [CrossRef]
- Yu, W.; Li, J.; Liu, Q.; Zeng, Y.; Zhao, J.; Xu, B.; Yin, G. Global Land Cover Heterogeneity Characteristics at Moderate Resolution for Mixed Pixel Modeling and Inversion. Remote Sens. 2018, 10, 856. [Google Scholar] [CrossRef]
- Sahare, M.; Gupta, H. A Review of Multi-Class Classification for Imbalanced Data. Int. J. Adv. Comput. Res. 2012, 2, 160. [Google Scholar]
- Chernoff, E.J. Sample space partitions: An investigative lens. J. Math. Behav. 2009, 28, 19–29. [Google Scholar] [CrossRef]
- Branscum, A.; Gardner, I.; Johnson, W. Estimation of diagnostic-test sensitivity and specificity through Bayesian modeling. Prev. Veter-Med. 2005, 68, 145–163. [Google Scholar] [CrossRef]
- Georgiadis, M.P.; Johnson, W.O.; Gardner, I.A.; Singh, R. Correlation-Adjusted Estimation of Sensitivity and Specificity of Two Diagnostic Tests. J. R. Stat. Soc. Ser. C 2003, 52, 63–76. [Google Scholar] [CrossRef]
- Alemohammad, H.; Booth, K. LandCoverNet: A Global Benchmark Land Cover Classification Training Dataset. arXiv 2020, arXiv:2012.03111. [Google Scholar]
- European Space Agency. Product Validation Report (D12-PVR); WorldCover_PVR_v1.0; European Space Agency: Paris, France, 2021. [Google Scholar]
- Liu, F.T.; Ting, K.M.; Zhou, Z.-H. Isolation Forest. In Proceedings of the 2008 Eighth IEEE International Conference on Data Mining, Pisa, Italy, 15–19 December 2008; IEEE: Pisa, Italy, 2008; pp. 413–422. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Preliminary Classifier | Sampling Parameter | Local Classifier | |||||||
|---|---|---|---|---|---|---|---|---|---|
| DT | RF | SVM | GNB | ||||||
| Mean | Std | Mean | Std | Mean | Std | Mean | Std | ||
| RF | 0.084 | 0.042 | 0.411 | 0.117 | 0.387 | 0.114 | 0.082 | 0.057 | |
| 0.081 | 0.037 | 0.408 | 0.112 | 0.375 | 0.112 | 0.073 | 0.050 | ||
| 0.068 | 0.036 | 0.391 | 0.108 | 0.361 | 0.108 | 0.062 | 0.047 | ||
| 0.061 | 0.035 | 0.349 | 0.103 | 0.326 | 0.116 | 0.053 | 0.040 | ||
| 0.056 | 0.033 | 0.327 | 0.123 | 0.298 | 0.115 | 0.050 | 0.032 | ||
| 0.054 | 0.031 | 0.311 | 0.125 | 0.284 | 0.123 | 0.045 | 0.030 | ||
| MLP | 0.097 | 0.047 | 0.459 | 0.118 | 0.530 | 0.116 | 0.010 | 0.065 | |
| 0.088 | 0.044 | 0.466 | 0.113 | 0.523 | 0.121 | 0.010 | 0.062 | ||
| 0.073 | 0.041 | 0.441 | 0.105 | 0.493 | 0.124 | 0.092 | 0.052 | ||
| 0.076 | 0.032 | 0.404 | 0.122 | 0.451 | 0.119 | 0.082 | 0.050 | ||
| 0.073 | 0.035 | 0.362 | 0.147 | 0.406 | 0.151 | 0.070 | 0.046 | ||
| 0.064 | 0.031 | 0.344 | 0.155 | 0.386 | 0.146 | 0.076 | 0.052 | ||
| Continent | Reported OA (Official) | Estimated OA | Absolute Error | Absolute Percentage Error |
|---|---|---|---|---|
| South America | 76.10 | 80.04 | 3.94 | 5.18% |
| Europe | 76.80 | 77.14 | 0.34 | 0.44% |
| Asia | 80.70 | 77.59 | 5.11 | 3.85% |
| Africa | 73.60 | 76.41 | 2.81 | 3.82% |
| North America | 72.20 | 70.96 | 1.24 | 1.71% |
| Oceania | 67.50 | 76.47 | 8.97 | 13.29% |
| Average | 3.40 | 4.71% |
| Continent | Average Number of Neighbouring Tiles |
|---|---|
| South America | 172 |
| Europe | 245 |
| Asia | 255 |
| Africa | 237 |
| North America | 196 |
| Oceania | 146 |
| Global | 223 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, P.; Huang, H.; Shi, W.; Chen, R. A Reference-Free Method for the Thematic Accuracy Estimation of Global Land Cover Products Based on the Triple Collocation Approach. Remote Sens. 2023, 15, 2255. https://doi.org/10.3390/rs15092255
Chen P, Huang H, Shi W, Chen R. A Reference-Free Method for the Thematic Accuracy Estimation of Global Land Cover Products Based on the Triple Collocation Approach. Remote Sensing. 2023; 15(9):2255. https://doi.org/10.3390/rs15092255
Chicago/Turabian StyleChen, Pengfei, Huabing Huang, Wenzhong Shi, and Rui Chen. 2023. "A Reference-Free Method for the Thematic Accuracy Estimation of Global Land Cover Products Based on the Triple Collocation Approach" Remote Sensing 15, no. 9: 2255. https://doi.org/10.3390/rs15092255