
Efficient Deep Semantic Segmentation for Land Cover Classification Using Sentinel Imagery

Abstract
:1. Introduction
- We create Sentinel-2 and Sentinel-1 composite images at 12 coastal, riparian or lakeside locations in Greece corresponding to specific time ranges within the year 2020. The resulting images, each containing 17 channels, along with associated land cover annotation from the ESA WorldCover product, will be freely provided as an open dataset for training DL models for land cover classification;
- We use this dataset to train a modified U-TAE approach, which uses band attention instead of temporal attention;
- We evaluate the performance obtained by selecting as input different band combinations and;
- We perform a comparative performance evaluation of the proposed approach with two state-of-the-art deep semantic segmentation (U-NET, SegFormer) architectures and one traditional ML algorithm (random forest).
2. Materials and Methods
2.1. Overview
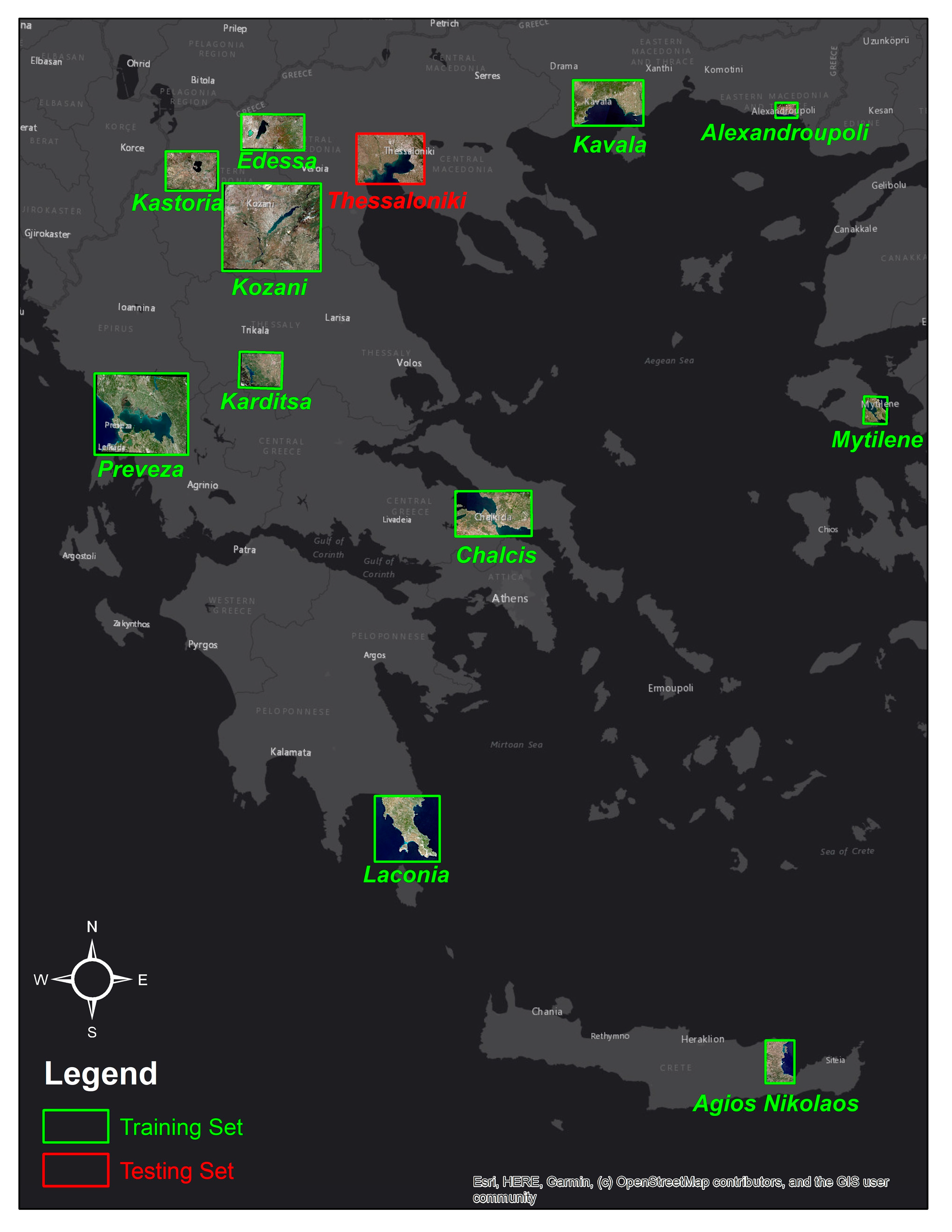
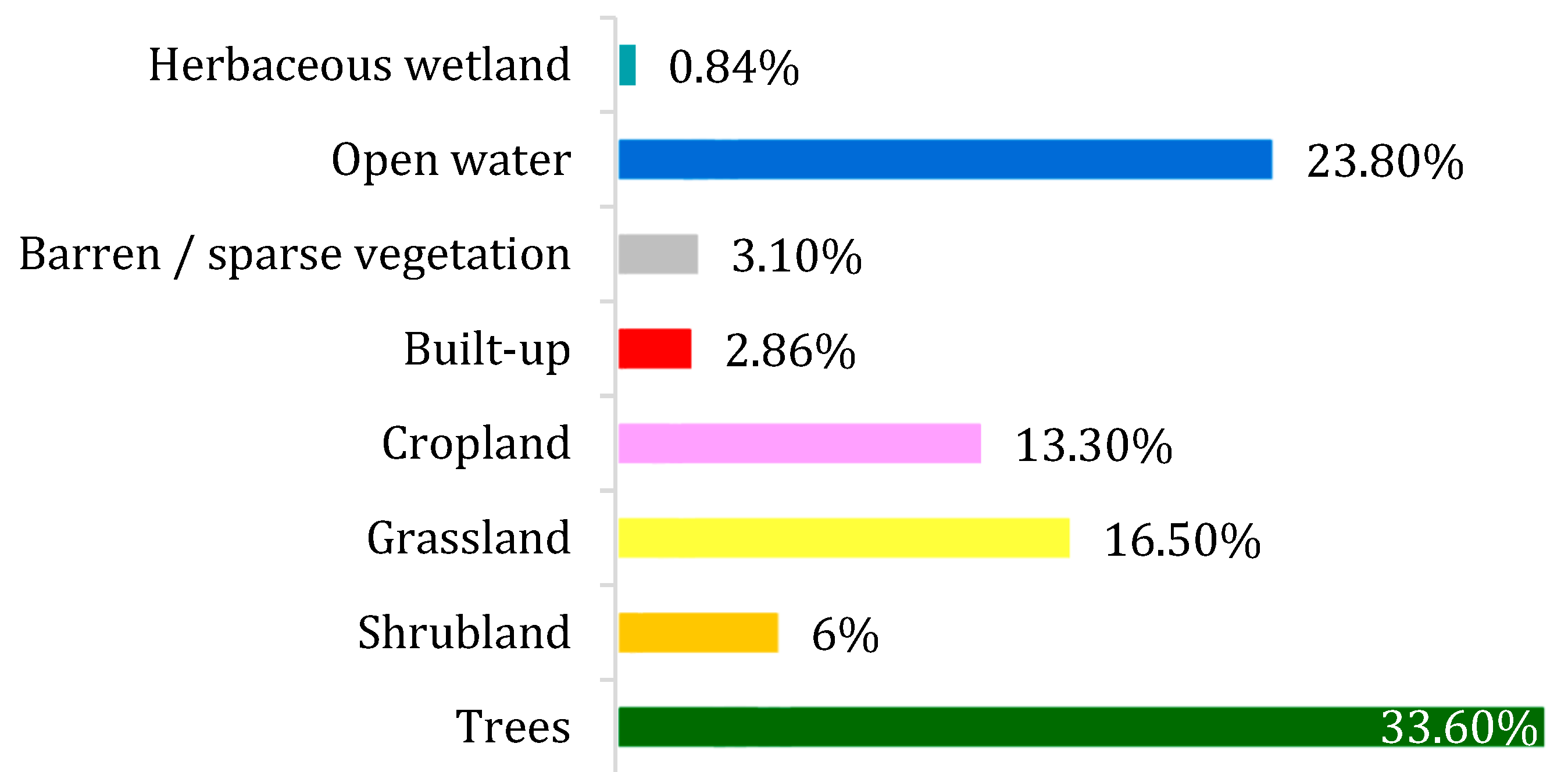
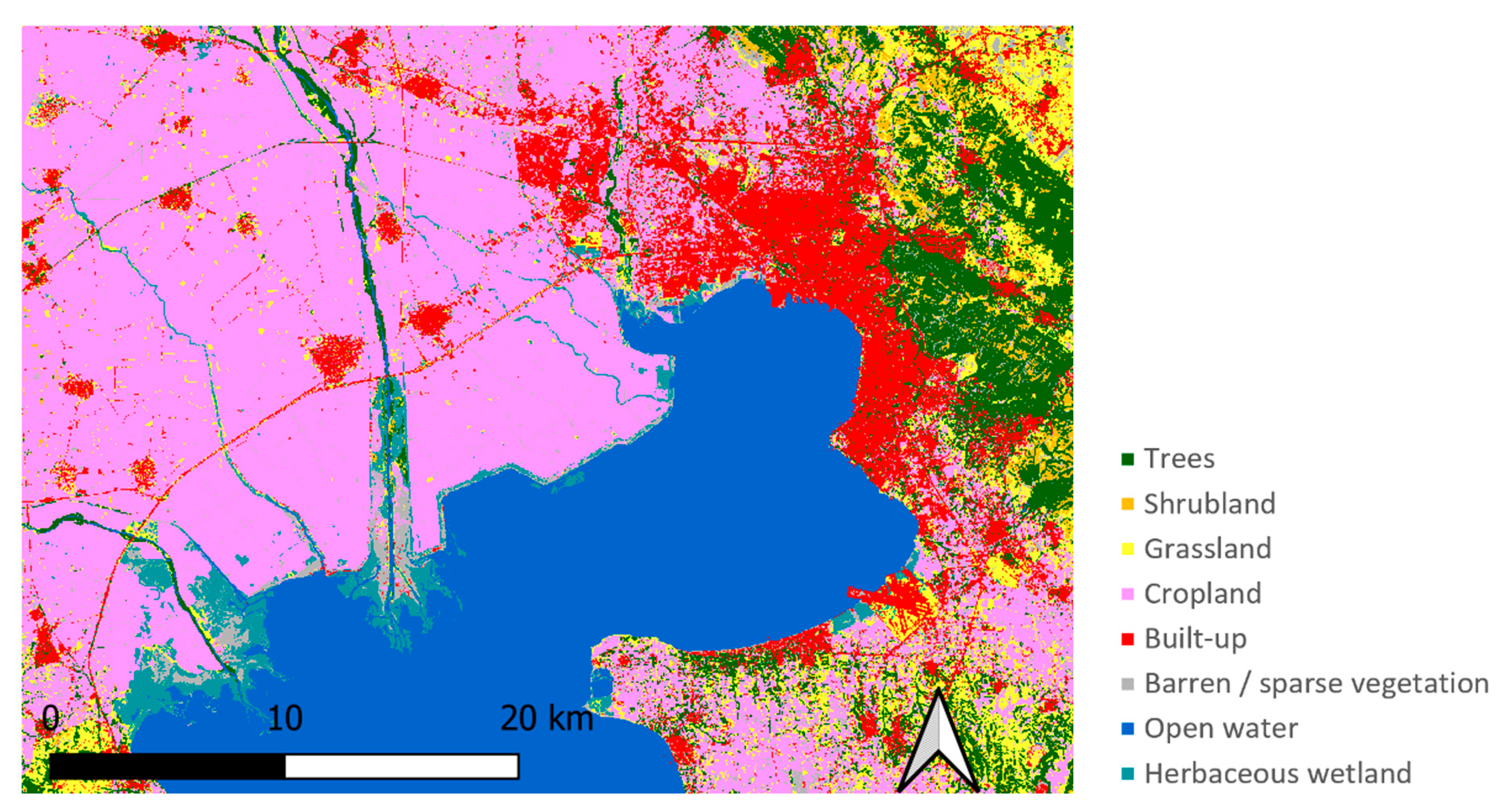
2.2. Regions of Interest
2.3. Remote Sensing Data Selection
2.4. Remote Sensing Preprocessing
2.5. Land Cover Classification Algorithms
- (a)
- U-Net with temporal attention encoder (U-TAE) [40]: This model encodes a multitemporal image sequence in the following steps: (1) a shared multi-level spatial convolutional encoder embeds each image in a simultaneous and independent way, (2) a temporal attention encoder creates a single feature map for every level by stacking the temporal dimensions of the resulting sequence. Specifically, in order to reduce the memory and computational requirements, for every pixel it produces temporal attention masks at the lowest resolution, which are then spatially interpolated at all resolutions. (3) A convolutional decoder calculates features at every resolution level and the final predicted segmentation mask is produced as the output of the highest resolution level;
- (b)
- U-Net [25]: This is a U-shaped architecture with an encoder and a decoder that extends the fully convolutional networks segmentation for semantic segmentation [47]. Through a step-by-step downsampling operation, high-level features from the encoder are extracted, while the decoder gradually upsamples these features and combines the output with skip connections to return the feature map to the size of the input. The use of skip connections is important to enable feature reusability and stabilise training and convergence;
- (c)
- SegFormer [37]: This is a hierarchical transformer architecture that extends the segmentation transformer (SETR) proposed in [34]. In the encoding stage, efficient transformer modules are used, while in the decoding stage, multilayer perceptrons (MLPs) are applied. Specifically, a transformer encoder that has a hierarchical structure outputs multiple features, each divided by ascending powers of two without positional encoding. This increases performance even if the training and testing resolutions are different. A lightweight MLP decoder aggregates information from different layers, combining both local and global attention to produce powerful representations. Advantages of the proposed algorithm include: (i) the hierarchical transformer structure, which significantly reduces the computational cost without restricting the effective receptive field, (ii) the positional-encoding free encoder, and (iii) a simple, straightforward, and very efficient decoder;
- (d)
- The random forest (RF) algorithm [48] is an ensemble learning algorithm, i.e., combines multiple ML models to obtain the final solution to classification or regression problems. In this case, we used multiple decision trees for land cover classification. Decision tree-based classifiers were widely studied over the past two decades and were used in many practical applications, including remote sensing, due to several advantages: the concept is intuitively appealing, training is relatively simple, and classification is fast. Unlike many machine learning models that function as “black boxes”, a decision tree is an explainable machine learning algorithm and its logic can be fully understood by simply visualising the decision tree. Random forest algorithms for classification use a learning method that builds a set of decision trees during training and outputs the average prediction of the individual trees. Random decision forests are preferred because they avoid the tendency of decision trees to overfit on the training set. Although some degree of explainability is lost as the number of decision trees increases, it is still possible to determine feature importance in a trained RF model.
2.6. Implementation Details and Metrics
3. Results
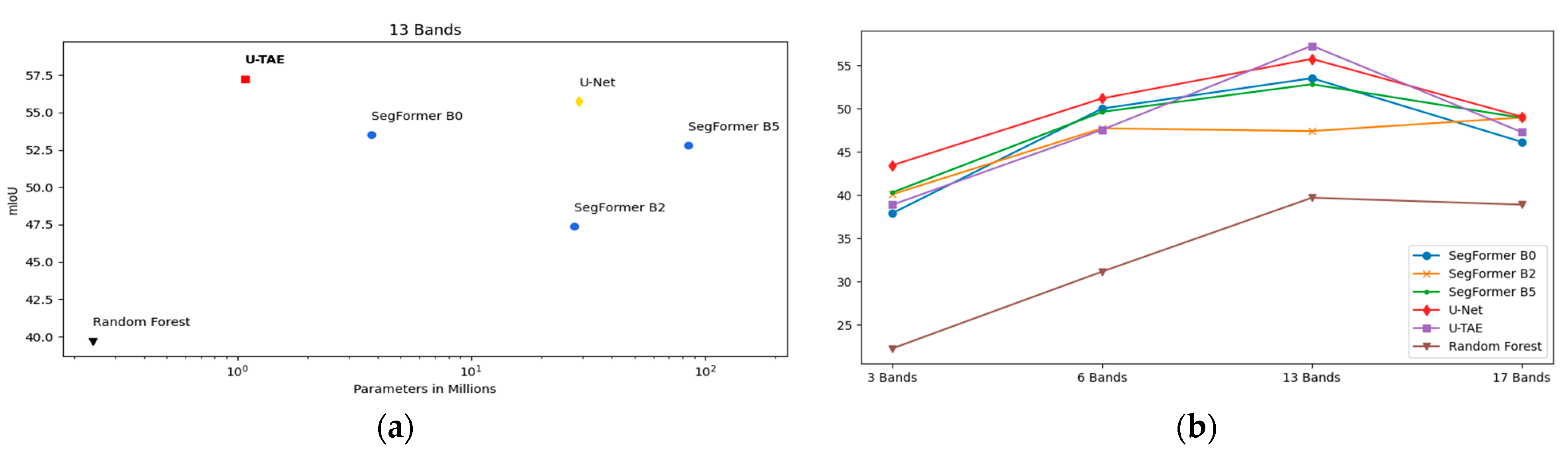
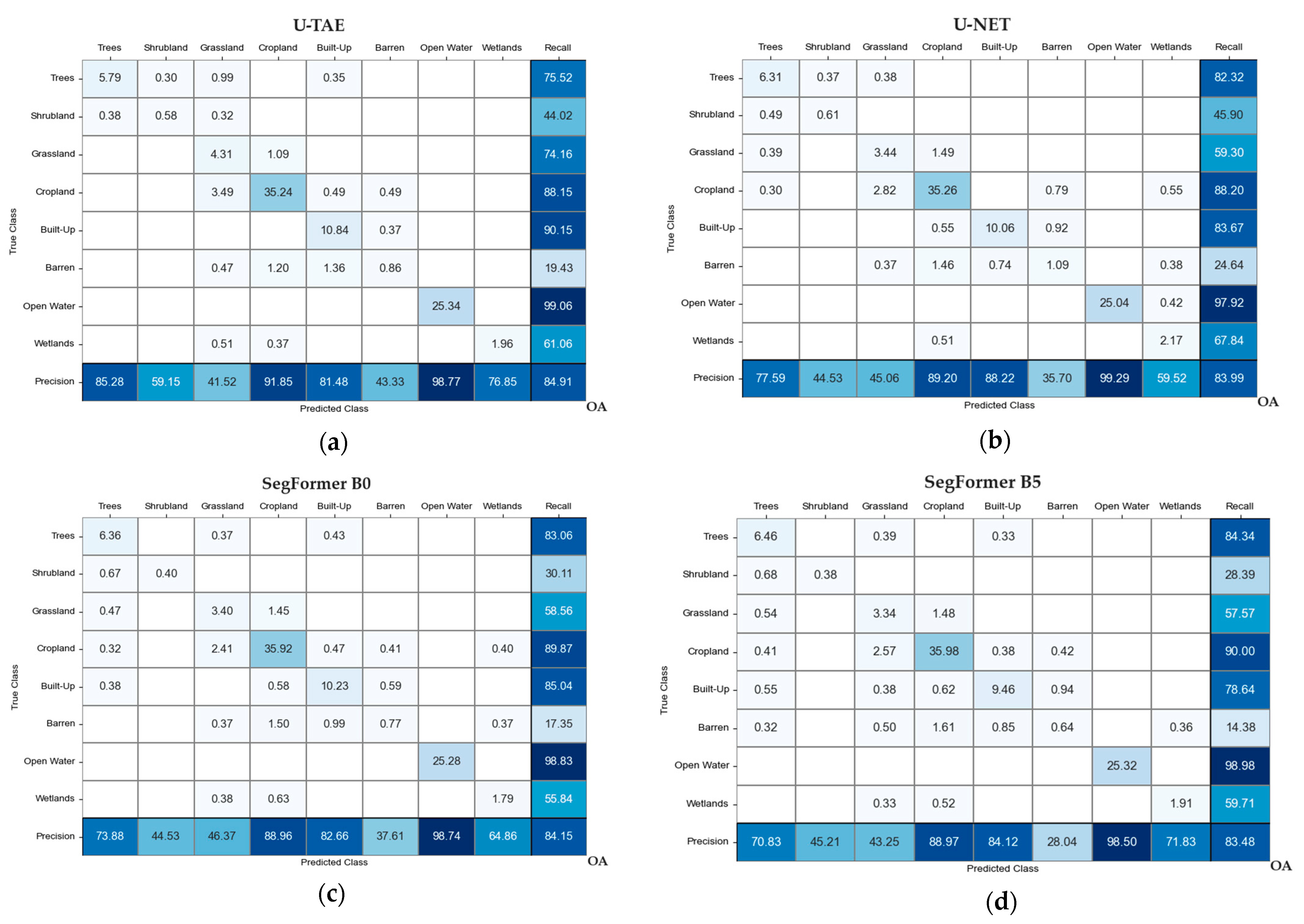
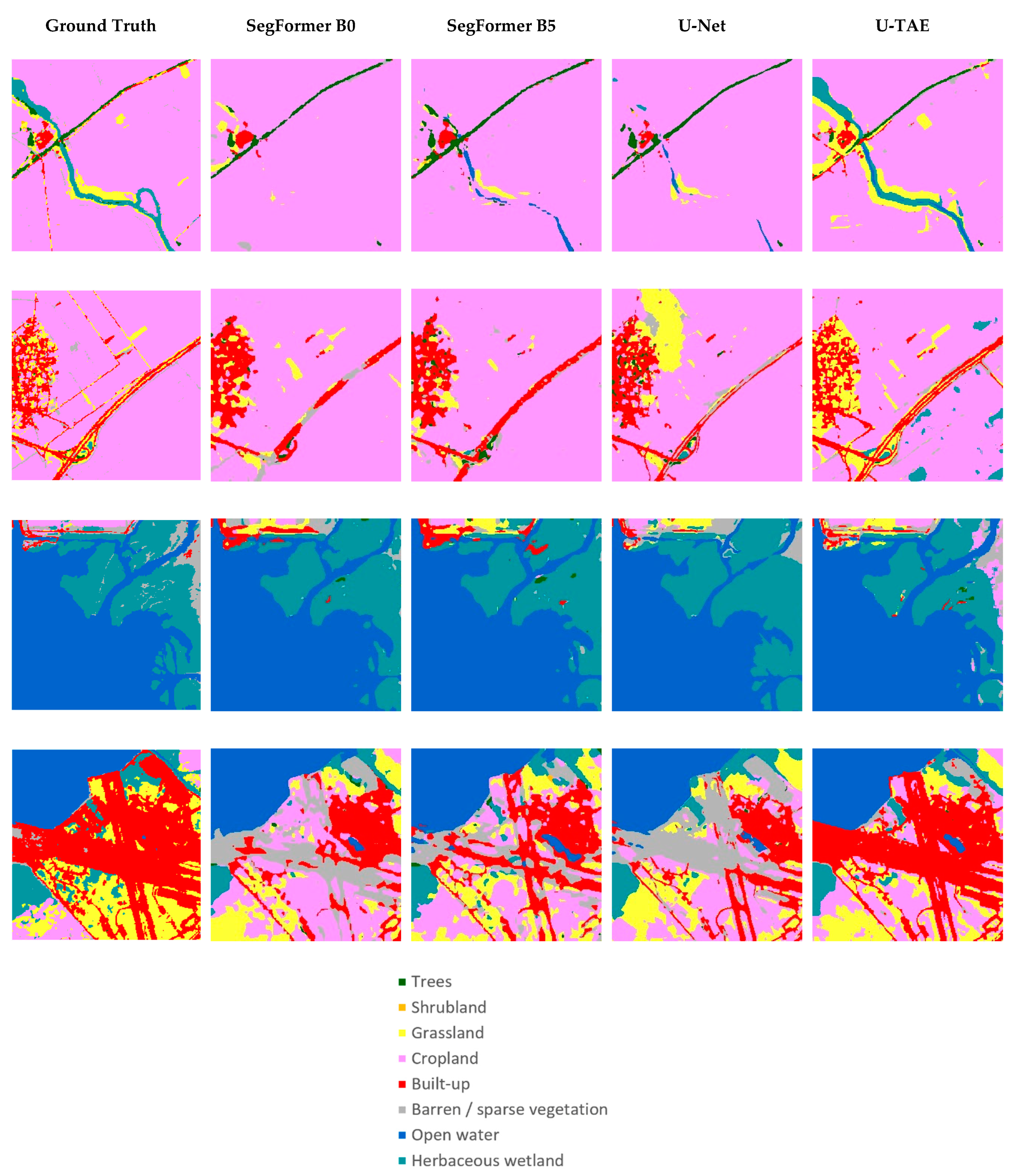
3.1. Experimental Results
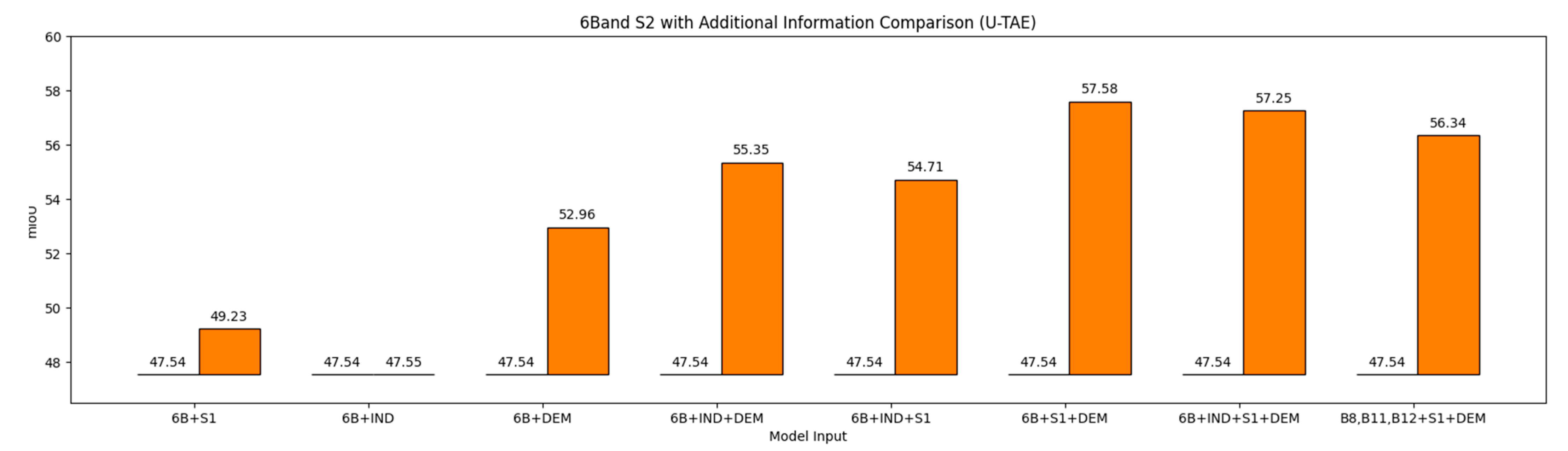
3.2. Band Combination Ablation Study
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Kaplan, G.; Avdan, U. Sentinel-1 and sentinel-2 data fusion for wetlands mapping: Balikdami, turkey. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2018, 42, 729–734. [Google Scholar] [CrossRef] [Green Version]
- Solórzano, J.V.; Mas, J.F.; Gao, Y.; Gallardo-Cruz, J.A. Land Use Land Cover Classification with U-Net: Advantages of Combining Sentinel-1 and Sentinel-2 Imagery. Remote Sens. 2021, 13, 3600. [Google Scholar] [CrossRef]
- Drusch, M.; Del Bello, U.; Carlier, S.; Colin, O.; Fernandez, V.; Gascon, F.; Hoersch, B.; Isola, C.; Laberinti, P.; Martimort, P.; et al. Sentinel-2: ESA’s optical high-resolution mission for GMES operational services. Remote Sens. Environ. 2012, 120, 25–36. [Google Scholar] [CrossRef]
- Torres, R.; Snoeij, P.; Geudtner, D.; Bibby, D.; Davidson, M.; Attema, E.; Potin, P.; Rommen, B.; Floury, N.; Brown, M.; et al. GMES Sentinel-1 mission. Remote Sens. Environ. 2012, 120, 9–24. [Google Scholar] [CrossRef]
- Roy, D.P.; Wulder, M.A.; Loveland, T.R.; Woodcock, C.E.; Allen, R.G.; Anderson, M.C.; Helder, D.; Irons, J.R.; Johnson, D.M.; Kennedy, R.; et al. Landsat-8: Science and product vision for terrestrial global change research. Remote Sens. Environ. 2014, 145, 154–172. [Google Scholar] [CrossRef] [Green Version]
- Cornelia, A.M. Advantages of Identifying Urban Footprint using Sentinel-1. In Proceedings of the FIG Congress 2018 Embracing Our Smart World Where the Continents Connect: Enhancing the Geospatial Maturity of Societies, Istanbul, Turkey, 6–11 May 2018. [Google Scholar]
- Tzouvaras, M.; Kouhartsiouk, D.; Agapiou, A.; Danezis, C.; Hadjimitsis, D.G. The use of Sentinel-1 synthetic aperture radar (SAR) images and open-source software for cultural heritage: An example from Paphos area in Cyprus for mapping landscape changes after a 5.6 magnitude earthquake. Remote Sens. 2019, 11, 1766. [Google Scholar] [CrossRef] [Green Version]
- McCarthy, M.J.; Colna, K.E.; El-Mezayen, M.M.; Laureano-Rosario, A.E.; Méndez-Lázaro, P.; Otis, D.B.; Toro-Farmer, G.; Vega-Rodriguez, M.; Muller-Karger, F.E. Satellite remote sensing for coastal management: A review of successful applications. Environ. Manag. 2017, 60, 323–339. [Google Scholar] [CrossRef]
- Nayak, S. Coastal zone management in India− present status and future needs. Geo-Spat. Inf. Sci. 2017, 20, 174–183. [Google Scholar] [CrossRef]
- Faruque, J.; Vekerdy, Z.; Hasan, Y.; Islam, K.Z.; Young, B.; Ahmed, M.T.; Monir, M.U.; Shovon, S.M.; Kakon, J.F.; Kundu, P. Monitoring of land use and land cover changes by using remote sensing and GIS techniques at human-induced mangrove forests areas in Bangladesh. Remote Sens. Appl. Soc. Environ. 2022, 25, 100699. [Google Scholar] [CrossRef]
- Rakhlin, A.; Davydow, A.; Nikolenko, S. Land cover classification from satellite imagery with u-net and lovász-softmax loss. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 262–266. [Google Scholar]
- Bossard, M.; Feranec, J.; Otahel, J. CORINE Land Cover Technical Guide: Addendum; European Environment Agency: Copenhagen, Denmark, 2000; Volume 40.
- Zanaga, D.; Van De Kerchove, R.; De Keersmaecker, W.; Souverijns, N.; Brockmann, C.; Quast, R.; Wevers, J.; Grosu, A.; Paccini, A.; Vergnaud, S.; et al. ESA WorldCover 10 m 2020 v100; OpenAIRE: Los Angeles, CA, USA, 2021. [Google Scholar] [CrossRef]
- Jordi, I.; Marcela, A.; Benjamin, T.; Olivier, H.; Silvia, V.; David, M.; Gerard, D.; Guada-lupe, S.; Sophie, B.; Pierre, D.; et al. Assessment of an operational system for crop type map production using high temporal and spatial resolution satellite optical imagery. Remote Sens. 2015, 7, 12356–12379. [Google Scholar]
- Pelletier, C.; Valero, S.; Inglada, J.; Champion, N.; Dedieu, G. Assessing the robustness of Random Forests to map land cover with high resolution satellite image time series over large areas. Remote Sens. Environ. 2016, 187, 156–168. [Google Scholar] [CrossRef]
- Siachalou, S.; Tsakiri-Strati, M. A hidden Markov models approach for crop classification: Linking crop phenology to time series of multi-sensor remote sensing data. Remote Sens. 2015, 7, 3633–3650. [Google Scholar] [CrossRef] [Green Version]
- Giordano, S.; Bailly, S.; Landrieu, L.; Chehata, N. Improved crop classification with rotation knowledge using Sentinel-1 and -2 time series. Photogramm. Eng. Remote Sens. 2020, 86, 431–441. [Google Scholar] [CrossRef]
- Devadas, R.; Denham, R.J.; Pringle, M. Support vector machine classification of object-based data for crop map-ping, using multi-temporal landsat imagery. International archives of the photogrammetry. Remote Sens. Spat. Inf. Sci. 2012, 39, 185–190. [Google Scholar]
- Hu, Q.; Wu, W.-B.; Song, Q.; Lu, M.; Chen, D.; Yu, Q.-Y.; Tang, H.-J. How do temporal and spectral features matter in crop classification in Heilongjiang Province, China? J. Integr. Agric. 2017, 16, 324–336. [Google Scholar] [CrossRef]
- Nguyen, L.H.; Joshi, D.R.; Clay, D.E.; Henebry, G.M. Characterizing land cover/land use from multiple years of Landsat and MODIS time series: A novel approach using land surface phenology modeling and ran-dom forest classifier. Remote Sens. Environ. 2020, 238, 111017. [Google Scholar] [CrossRef]
- Waldrop, M.M. The chips are down for Moore’s law. Nat. News 2016, 530, 144. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Alem, A.; Kumar, S. Deep learning methods for land cover and land use classification in remote sensing: A review. In Proceedings of the 2020 8th International Conference on Reliability, Infocom Technologies and Optimization (Trends and Future Directions)(ICRITO), Noida, India, 4–5 June 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 903–908. [Google Scholar]
- Seydi, S.; Hasanlou, M.; Amani, M. A new end-to-end multi-dimensional CNN framework for land cover/land use change detection in multi-source remote sensing datasets. Remote Sens. 2020, 12, 2010. [Google Scholar] [CrossRef]
- Camalan, S.; Cui, K.; Pauca, V.P.; Alqahtani, S.; Silman, M.; Chan, R.; Plemmons, R.J.; Dethier, E.N.; Fernandez, L.E.; Lutz, D.A. Change detection of amazonian alluvial gold mining using deep learning and sentinel-2 imagery. Remote Sens. 2022, 14, 1746. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Cham, Germany, 2015; pp. 234–241. [Google Scholar]
- Mohajerani, S.; Saeedi, P. Cloud-Net: An end-to-end cloud detection algorithm for Landsat 8 imagery. In Proceedings of the IGARSS 2019–2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1029–1032. [Google Scholar]
- Ye, H.; Liu, S.; Jin, K.; Cheng, H. CT-UNet: An Improved Neural Network Based on U-Net for Building Segmenta-tion in Remote Sensing Images. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 166–172. [Google Scholar] [CrossRef]
- He, N.; Fang, L.; Plaza, A. Hybrid first and second order attention Unet for building segmentation in re-mote sensing images. Sci. China Inf. Sci. 2020, 63, 140305. [Google Scholar] [CrossRef] [Green Version]
- Jiao, L.; Huo, L.; Hu, C.; Tang, P. Refined UNet: UNet-based refinement network for cloud and shadow precise segmentation. Remote Sens. 2020, 12, 2001. [Google Scholar] [CrossRef]
- Hou, Y.; Liu, Z.; Zhang, T.; Li, Y. C-Unet: Complement UNet for remote sensing road extraction. Sensors 2021, 21, 2153. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. arXiv e-prints 2017, arXiv:1706.03762. [Google Scholar]
- Aleissaee, A.A.; Kumar, A.; Anwer, R.M.; Khan, S.; Cholakkal, H.; Xia, G.-S.; Khan, F.S. Transformers in remote sensing: A survey. Remote Sens. 2022, 15, 1860. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16×16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Zheng, S.; Lu, J.; Zhao, H.; Zhu, X.; Luo, Z.; Wang, Y.; Fu, Y.; Feng, J.; Xiang, T.; Torr, P.H.; et al. Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 6881–6890. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Fan, D.-P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 568–578. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 202; pp. 10012–10022.
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and efficient design for semantic segmentation with transformers. Adv. Neural Inf. Process. Syst. 2021, 34, 12077–12090. [Google Scholar]
- Garnot, V.S.F.; Landrieu, L.; Giordano, S.; Chehata, N. Satellite image time series classification with pixel-set encoders and temporal self-attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 12325–12334. [Google Scholar]
- Garnot, V.S.F.; Landrieu, L. Lightweight temporal self-attention for classifying satellite images time series. In Proceedings of the Advanced Analytics and Learning on Temporal Data: 5th ECML PKDD Workshop, AALTD 2020, Ghent, Belgium, 18 September 2020; Revised Selected Papers 6. Springer International Publishing: Berlin/Heidelberg, Germany, 2020; pp. 171–181. [Google Scholar]
- Garnot, V.S.F.; Landrieu, L. Panoptic segmentation of satellite image time series with convolutional temporal attention networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 4872–4881. [Google Scholar]
- Gorelick, N. Google earth engine. In EGU General Assembly Conference Abstracts; American Geophysical Union: Vienna, Austria, 2013; Volume 15, p. 11997. [Google Scholar]
- Terkenli, T.S. Landscape research in Greece: An overview. Belgeo. Rev. Belg. Géographie 2004, 2–3, 277–288. [Google Scholar] [CrossRef] [Green Version]
- Tzepkenlis, A.; Grammalidis, N.; Kontopoulos, C.; Charalampopoulou, V.; Kitsiou, D.; Pataki, Z.; Patera, A.; Nitis, T. An Integrated Monitoring System for Coastal and Riparian Areas Based on Remote Sensing and Machine Learning. J. Mar. Sci. Eng. 2022, 10, 1322. [Google Scholar] [CrossRef]
- DeFries, R.S.; Townshend, J.R.G. NDVI-derived land cover classifications at a global scale. Int. J. Remote Sens. 1994, 15, 3567–3586. [Google Scholar] [CrossRef]
- Zha, Y.; Gao, J.; Ni, S. Use of normalized difference built-up index in automatically mapping urban areas from TM imagery. Int. J. Remote Sens. 2003, 24, 583–594. [Google Scholar] [CrossRef]
- McFeeters, S.K. The use of the Normalized Difference Water Index (NDWI) in the delineation of open water features. Int. J. Remote Sens. 1996, 17, 1425–1432. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- L Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Contributors, MMSegmentation. OpenMMLab Semantic Segmentation Toolbox and Benchmark. 2020. Available online: https://github.com/open-mmlab/mmsegmentation (accessed on 7 April 2023).
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- Digra, M.; Dhir, R.; Sharma, N. Land use land cover classification of remote sensing images based on the deep learning approaches: A statistical analysis and review. Arab. J. Geosci. 2022, 15, 1003. [Google Scholar] [CrossRef]
- Malenovský, Z.; Rott, H.; Cihlar, J.; Schaepman, M.E.; García-Santos, G.; Fernandes, R.; Berger, M. Sentinels for science: Potential of Sentinel-1, -2, and -3 missions for scientific observations of ocean, cryosphere, and land. Remote Sens. Environ. 2012, 120, 91–101. [Google Scholar] [CrossRef]
- Kussul, N.; Lavreniuk, M.; Skakun, S.; Shelestov, A. Deep learning classification of land cover and crop types using remote sensing data. IEEE Geosci. Remote Sens. Lett. 2017, 14, 778–782. [Google Scholar] [CrossRef]
- Karra, K.; Kontgis, C.; Statman-Weil, Z.; Mazzariello, J.C.; Mathis, M.; Brumby, S.P. Global land use/land cover with Sentinel 2 and deep learning. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS, Brussels, Belgium, 11–16 July 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 4704–4707. [Google Scholar]
- Helber, P.; Bischke, B.; Dengel, A.; Borth, D. Eurosat: A novel dataset and deep learning benchmark for land use and land cover classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 2217–2226. [Google Scholar] [CrossRef] [Green Version]
- Verde, N.; Kokkoris, I.P.; Georgiadis, C.; Kaimaris, D.; Dimopoulos, P.; Mitsopoulos, I.; Mallinis, G. National scale land cover classification for ecosystem services mapping and assessment, using multitemporal copernicus EO data and google earth engine. Remote Sens. 2020, 12, 3303. [Google Scholar] [CrossRef]
- Campos-Taberner, M.; García-Haro, F.J.; Martínez, B.; Izquierdo-Verdiguier, E.; Atzberger, C.; Camps-Valls, G.; Gilabert, M.A. Understanding deep learning in land use classification based on Sentinel-2 time series. Sci. Rep. 2020, 10, 17188. [Google Scholar] [CrossRef]
- Ienco, D.; Interdonato, R.; Gaetano, R.; Minh, D.H.T. Combining Sentinel-1 and Sentinel-2 Satellite Image Time Series for land cover mapping via a multi-source deep learning architecture. ISPRS J. Photogramm. Remote Sens. 2019, 158, 11–22. [Google Scholar] [CrossRef]
- Abdi, A.M. Land cover and land use classification performance of machine learning algorithms in a boreal landscape using Sentinel-2 data. GIScience Remote Sens. 2020, 57, 1–20. [Google Scholar] [CrossRef] [Green Version]
- Rußwurm, M.; Körner, M. Self-attention for raw optical satellite time series classification. ISPRS J. Photogramm. Remote Sens. 2020, 169, 421–435. [Google Scholar] [CrossRef]
- Stergioulas, A.; Dimitropoulos, K.; Grammalidis, N. Crop classification from satellite image sequences using a two-stream network with temporal self-attention. In Proceedings of the 2022 IEEE International Conference on Imaging Systems and Techniques (IST), Kaohsiung, Taiwan, 21–23 June 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1–6. [Google Scholar]
- Yuan, Y.; Lin, L. Self-supervised pretraining of transformers for satellite image time series classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 14, 474–487. [Google Scholar] [CrossRef]
- Martini, M.; Mazzia, V.; Khaliq, A.; Chiaberge, M. Domain-adversarial training of self-attention-based networks for land cover classification using multi-temporal Sentinel-2 satellite imagery. Remote Sens. 2021, 13, 2564. [Google Scholar] [CrossRef]
- Scheibenreif, L.; Hanna, J.; Mommert, M.; Borth, D. Self-supervised vision transformers for land-cover segmentation and classification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 1422–1431. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Code | Input Channels |
|---|---|
| 3B | B2, B3, B4 |
| 4B | B2, B3, B4, B8 |
| 6B | B2, B3, B4, B8, B11, B12 |
| 10B | B2, B3, B4, B5, B6, B7, B8, B8A, B11, B12 |
| IND | NDVI, NDBI, NDWI |
| S1 | VV, VH |
| DEM | ELEVATION, SLOPE |
| 13B | 6B + IND + S1 + DEM |
| 17B | 10B + IND + S1 + DEM |
| 3B | 6B | 13B | 17B | ||||||
|---|---|---|---|---|---|---|---|---|---|
| OA(%) | mIoU(%) | OA(%) | mIoU(%) | OA(%) | mIoU(%) | OA(%) | mIoU(%) | Params (In Millions) | |
| Random Forest | 39 | 22.28 | 60 | 31.16 | 68 | 39.69 | 68 | 38.89 | 0.24 |
| SegFormer B0 | 63.04 | 37.91 | 82.78 | 49.99 | 84.15 | 53.50 | 77.65 | 46.14 | 3.7 |
| SegFormer B2 | 71.29 | 40.09 | 80.28 | 48.96 | 80.28 | 47.39 | 80.96 | 48.96 | 27.5 |
| SegFormer B5 | 75.84 | 40.30 | 82.40 | 49.61 | 83.48 | 52.80 | 80.28 | 48.92 | 84.6 |
| U-NET | 74.02 | 43.44 | 80.90 | 51.17 | 83.99 | 55.73 | 79.85 | 49.05 | 29.0 |
| U-TAE | 71.08 | 38.88 | 76.67 | 47.54 | 84.89 | 57.25 | 80.26 | 47.27 | 1.1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tzepkenlis, A.; Marthoglou, K.; Grammalidis, N. Efficient Deep Semantic Segmentation for Land Cover Classification Using Sentinel Imagery. Remote Sens. 2023, 15, 2027. https://doi.org/10.3390/rs15082027
Tzepkenlis A, Marthoglou K, Grammalidis N. Efficient Deep Semantic Segmentation for Land Cover Classification Using Sentinel Imagery. Remote Sensing. 2023; 15(8):2027. https://doi.org/10.3390/rs15082027
Chicago/Turabian StyleTzepkenlis, Anastasios, Konstantinos Marthoglou, and Nikos Grammalidis. 2023. "Efficient Deep Semantic Segmentation for Land Cover Classification Using Sentinel Imagery" Remote Sensing 15, no. 8: 2027. https://doi.org/10.3390/rs15082027