
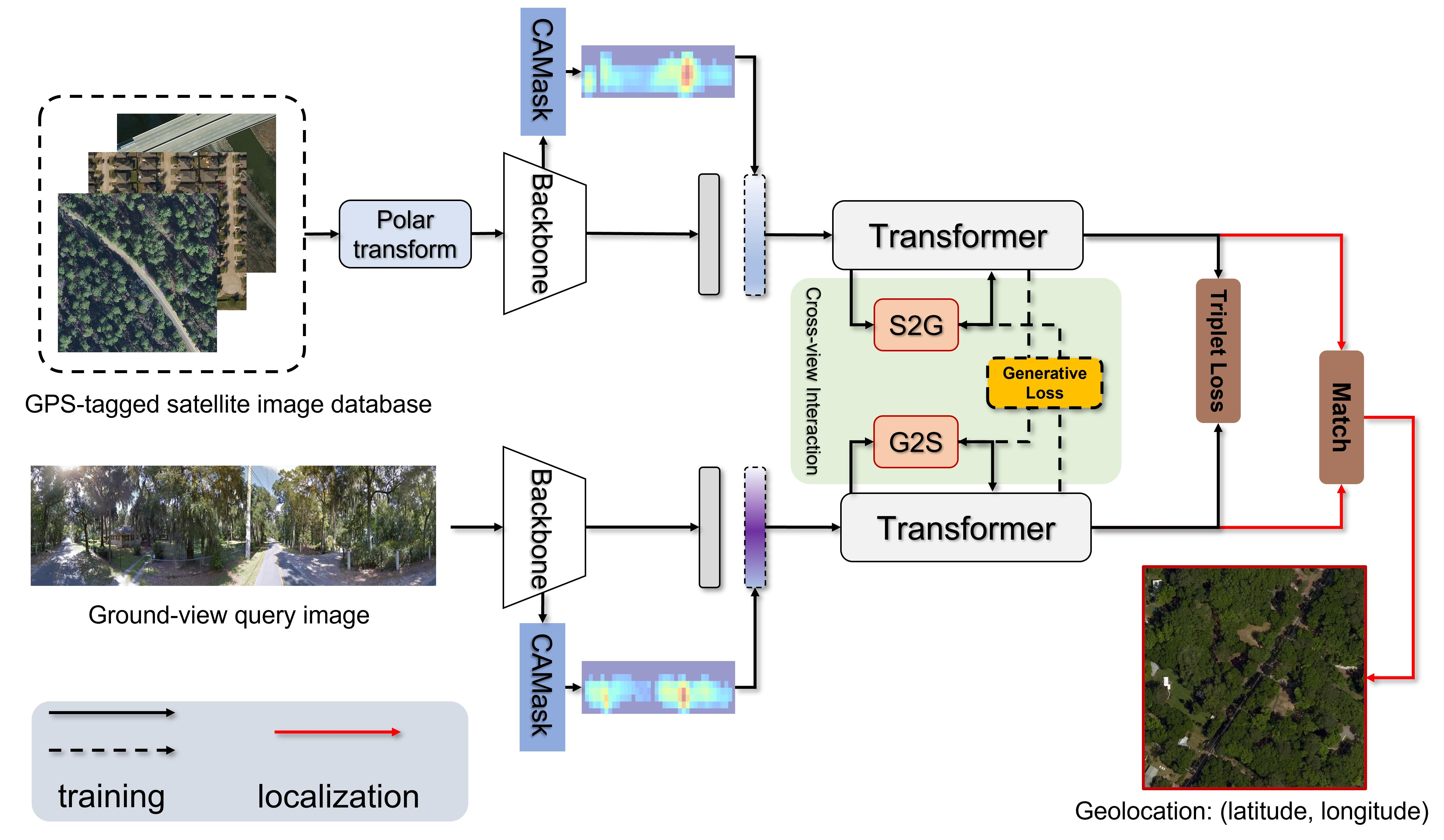
Co-Visual Pattern-Augmented Generative Transformer Learning for Automobile Geo-Localization

Abstract
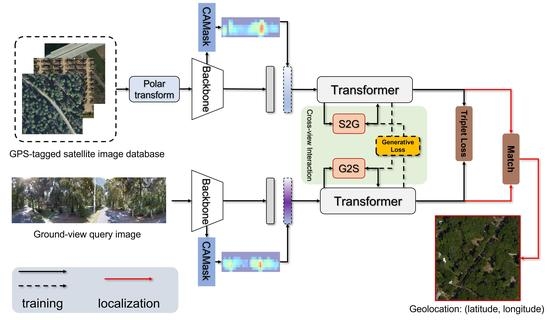
:
1. Introduction
- A novel cross-view knowledge-guided learning approach for CVGL. To the best of our knowledge, the MGTL is the first attempt to build mutual interactions between ground-level and aerial-level patterns in the CVGL community. Unlike existing transformer-based CVGL models that only perform self-attentive reasoning in the respective view, our proposed MGTL produces cross-knowledge information to achieve more representative high-order features.
- Cascaded attention-guided masking to exploit the co-visual patterns. Instead of treating patterns in aerial and ground views equally, we developed an attention-guided exploration algorithm to create network reasoning based on the co-visual patterns, which further improves performance.
2. Related Work
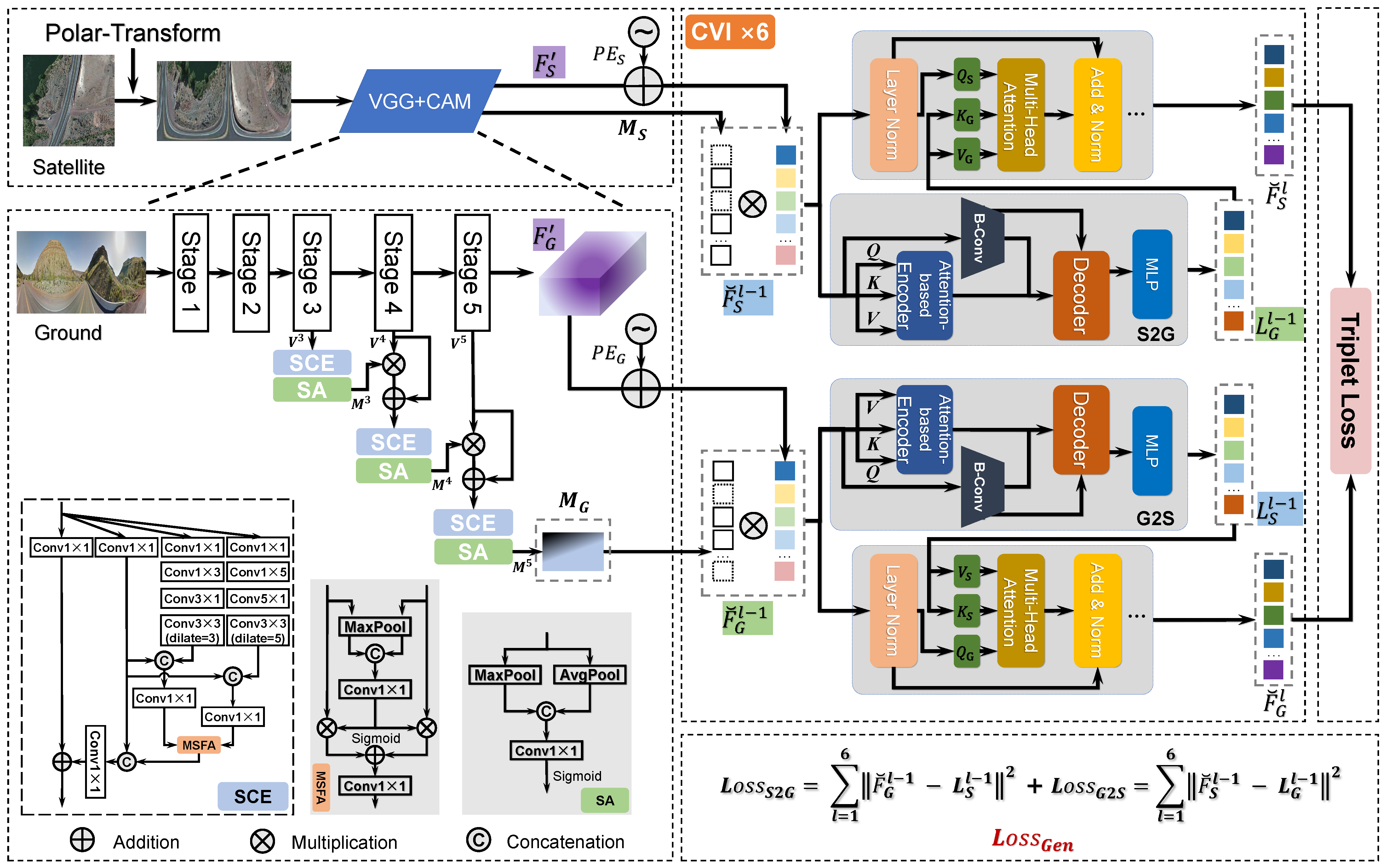
3. Methods
3.1. Problem Formulation
3.2. View-Independent Feature Extractor ()
3.2.1. Overview
3.2.2. Feature Extractor
3.2.3. Cascaded Attention Masking
3.3. Cross-View Synthesis
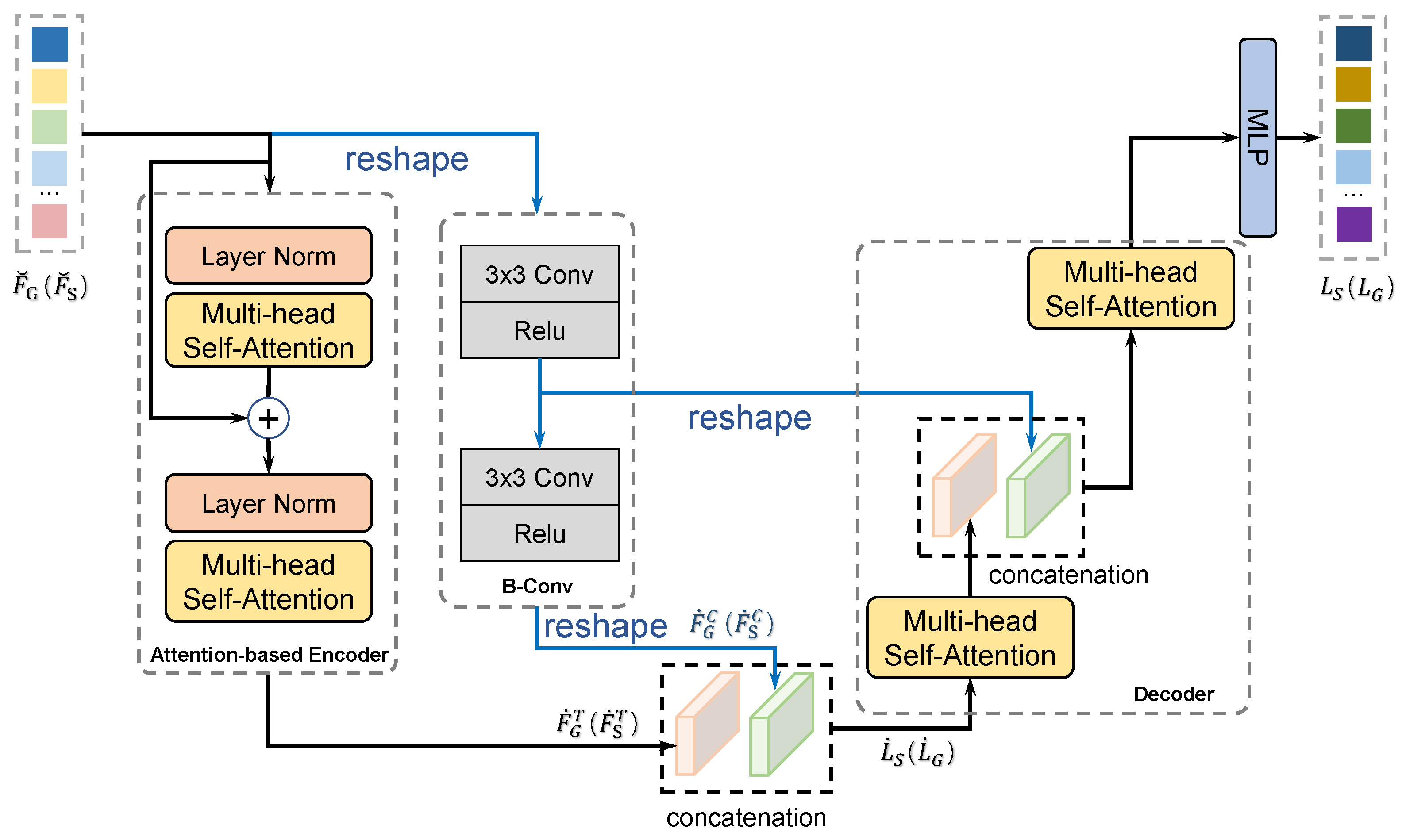
3.4. Generative Knowledge Supported Transformer (GKST)
3.5. Loss Function
4. Experiments
4.1. Experimental Setting
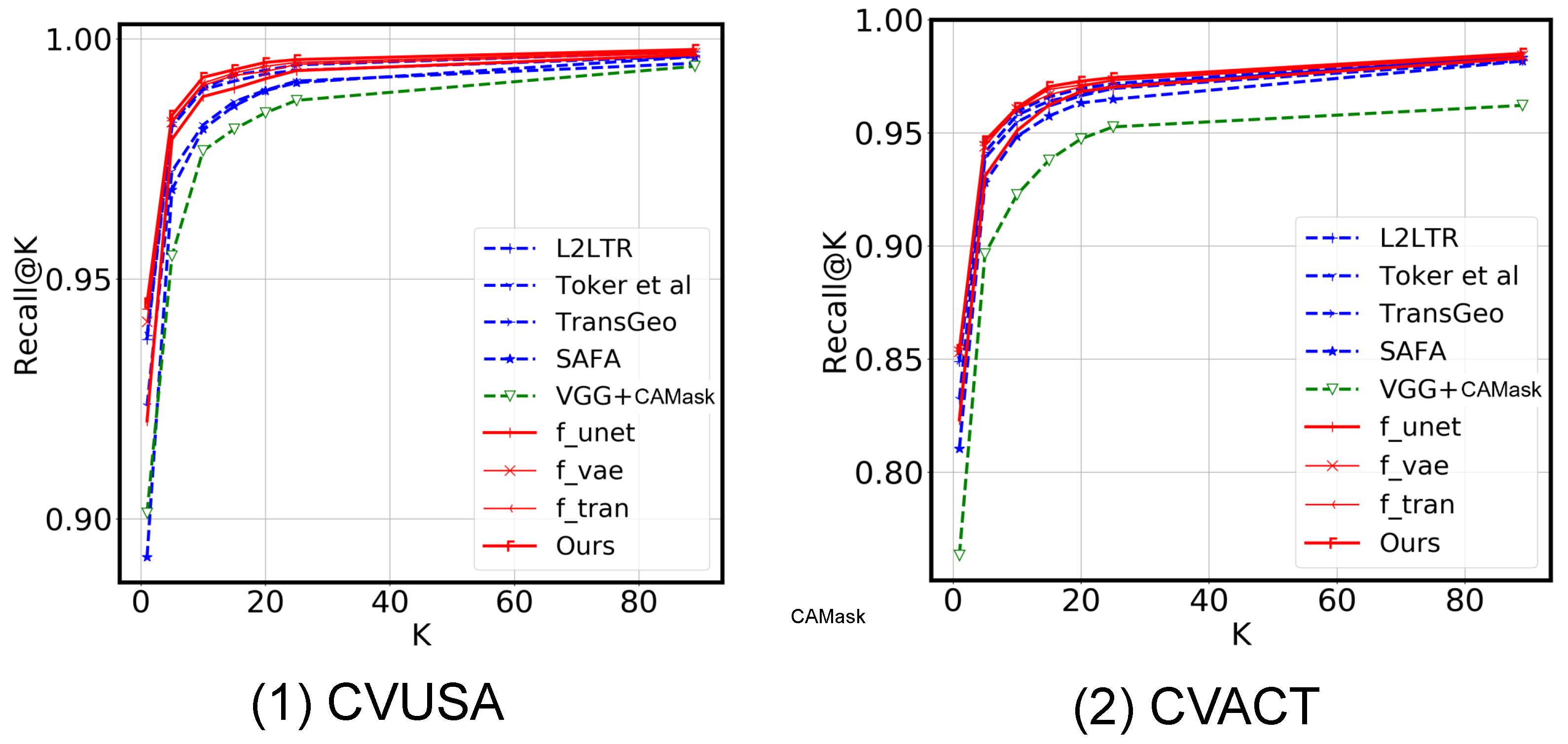
4.2. Main Results
4.3. Ablation Study
4.4. Supplementary Experiment
5. Discussion
6. Future Work
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Saurer, O.; Baatz, G.; Köser, K.; Pollefeys, M.; Ladicky, L.U. Image based geo-localization in the alps. Int. J. Comput. Vis. 2016, 116, 213–225. [Google Scholar] [CrossRef]
- Senlet, T.; Elgammal, A. Satellite image-based precise robot localization on sidewalks. In Proceedings of the IEEE International Conference on Robotics and Automation, St Paul, MN, USA, 14–19 May 2012; pp. 2647–2653. [Google Scholar]
- Xiao, Y.; Codevilla, F.; Gurram, A.; Urfalioglu, O.; López, A.M. Multimodal end-to-end autonomous driving. IEEE Trans. Intell. Transp. Syst. 2020, 23, 537–547. [Google Scholar] [CrossRef]
- Wang, S.; Zhang, Y.; Li, H. Satellite image based cross-view localization for autonomous vehicle. arXiv 2022, arXiv:2207.13506. [Google Scholar]
- Thoma, J.; Paudel, D.P.; Chhatkuli, A.; Probst, T.; Gool, L.V. Mapping, localization and path planning for image-based navigation using visual features and map. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 7383–7391. [Google Scholar]
- Roy, N.; Debarshi, S. Uav-based person re-identification and dynamic image routing using wireless mesh networking. In Proceedings of the 2020 7th International Conference on Signal Processing and Integrated Networks (SPIN) IEEE, Noida, India, 27–28 February 2020; pp. 914–917. [Google Scholar]
- Hu, S.; Lee, G.H. Image-based geo-localization using satellite imagery. IJCV 2020, 128, 1205–1219. [Google Scholar] [CrossRef]
- Arandjelovic, R.; Gronat, P.; Torii, A.; Pajdla, T.; Sivic, J. NetVLAD: CNN architecture for weakly supervised place recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 5297–5307. [Google Scholar]
- Workman, S.; Jacobs, N. On the location dependence of convolutional neural network features. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Boston, MA, USA, 8–10 June 2015; pp. 70–78. [Google Scholar]
- Vo, N.N.; Hays, J. Localizing and orienting street views using overhead imagery. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 494–509. [Google Scholar]
- Hu, S.; Feng, M.; Nguyen, R.M.; Lee, G.H. Cvm-net: Cross-view matching network for image-based ground-to-aerial geo-localization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7258–7267. [Google Scholar]
- Regmi, K.; Shah, M. Bridging the domain gap for ground-to-aerial image matching. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 470–479. [Google Scholar]
- Zhu, S.; Shah, M.; Chen, C. TransGeo: Transformer Is all You Need for Cross-view Image Geo-localization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–23 June 2022; pp. 1162–1171. [Google Scholar]
- Yang, H.; Lu, X.; Zhu, Y. Cross-view Geo-localization with Layer-to-Layer Transformer. Adv. Neural Inf. Process. Syst. 2021, 34, 29009–29020. [Google Scholar]
- Chen, Z.; Lam, O.; Jacobson, A.; Milford, M. Convolutional neural network-based place recognition. arXiv 2014, arXiv:1411.1509. [Google Scholar]
- Xin, Z.; Cai, Y.; Lu, T.; Xing, X.; Cai, S.; Zhang, J.; Yang, Y.; Wang, Y. Localizing Discriminative Visual Landmarks for Place Recognition. In Proceedings of the IEEE International Conference on Robotics and Automation, Montreal, QC, Canada, 20–24 May 2019; pp. 5979–5985. [Google Scholar]
- Khaliq, A.; Milford, M.; Garg, S. MultiRes-NetVLAD: Augmenting Place Recognition Training with Low-Resolution Imagery. IEEE Robot. Autom. Lett. 2022, 7, 3882–3889. [Google Scholar] [CrossRef]
- Yu, J.; Zhu, C.; Zhang, J.; Huang, Q.; Tao, D. Spatial pyramid-enhanced NetVLAD with weighted triplet loss for place recognition. IEEE Trans. Neural Netw. Learn. Syst. 2019, 31, 661–674. [Google Scholar] [CrossRef]
- Latif, Y.; Garg, R.; Milford, M.; Reid, I. Addressing challenging place recognition tasks using generative adversarial networks. In Proceedings of the International Conference on Robotics and Automation, Brisbane, Australia, 21–26 May 2018; pp. 2349–2355. [Google Scholar]
- Castaldo, F.; Zamir, A.; Angst, R.; Palmieri, F.; Savarese, S. Semantic cross-view matching. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Santiago, Chile, 7–13 December 2015; pp. 9–17. [Google Scholar]
- Mousavian, A.; Kosecka, J. Semantic Image Based Geolocation Given a Map. arXiv 2016, arXiv:1609.00278. [Google Scholar]
- Zhu, S.; Yang, T.; Chen, C. Vigor: Cross-view image geo-localization beyond one-to-one retrieval. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Online, 19–25 June 2021; pp. 3640–3649. [Google Scholar]
- Shi, Y.; Liu, L.; Yu, X.; Li, H. Spatial-aware feature aggregation for image based cross-view geo-localization. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Volume 32. [Google Scholar]
- Shi, Y.; Yu, X.; Liu, L.; Zhang, T.; Li, H. Optimal feature transport for cross-view image geo-localization. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 11990–11997. [Google Scholar]
- Wang, T.; Fan, S.; Liu, D.; Sun, C. Transformer-Guided Convolutional Neural Network for Cross-View Geolocalization. arXiv 2022, arXiv:2204.09967. [Google Scholar]
- Wang, T.; Zheng, Z.; Yan, C.; Zhang, J.; Sun, Y.; Zheng, B.; Yang, Y. Each part matters: Local patterns facilitate cross-view geo-localization. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 867–879. [Google Scholar] [CrossRef]
- Wang, T.; Zheng, Z.; Zhu, Z.; Gao, Y.; Yang, Y.; Yan, C. Learning Cross-view Geo-localization Embeddings via Dynamic Weighted Decorrelation Regularization. arXiv 2022, arXiv:2211.05296. [Google Scholar]
- Zhu, Y.; Yang, H.; Lu, Y.; Huang, Q. Simple, Effective and General: A New Backbone for Cross-view Image Geo-localization. arXiv 2023, arXiv:2302.01572. [Google Scholar]
- Zhang, X.; Li, X.; Sultani, W.; Zhou, Y.; Wshah, S. Cross-view Geo-localization via Learning Disentangled Geometric Layout Correspondence. arXiv 2022, arXiv:2212.04074. [Google Scholar]
- Workman, S.; Souvenir, R.; Jacobs, N. Wide-area image geolocalization with aerial reference imagery. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 8–10 June 2015; pp. 3961–3969. [Google Scholar]
- Liu, L.; Li, H. Lending orientation to neural networks for cross-view geo-localization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 5624–5633. [Google Scholar]
- Zhu, Y.; Sun, B.; Lu, X.; Jia, S. Geographic Semantic Network for Cross-View Image Geo-Localization. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–15. [Google Scholar] [CrossRef]
- Zhu, B.; Yang, C.; Dai, J.; Fan, J.; Ye, Y. R2FD2: Fast and Robust Matching of Multimodal Remote Sensing Image via Repeatable Feature Detector and Rotation-invariant Feature Descriptor. IEEE Trans. Geosci. Remote Sens. 2023. [Google Scholar] [CrossRef]
- Regmi, K.; Borji, A. Cross-view image synthesis using conditional gans. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3501–3510. [Google Scholar]
- Lu, X.; Li, Z.; Cui, Z.; Oswald, M.R.; Pollefeys, M.; Qin, R. Geometry-aware satellite-to-ground image synthesis for urban areas. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 859–867. [Google Scholar]
- Ding, H.; Wu, S.; Tang, H.; Wu, F.; Gao, G.; Jing, X.Y. Cross-view image synthesis with deformable convolution and attention mechanism. In Proceedings of the Chinese Conference on Pattern Recognition and Computer Vision (PRCV), Nanjing, China, 16–18 October 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 386–397. [Google Scholar]
- Lin, T.Y.; Cui, Y.; Belongie, S.; Hays, J. Learning deep representations for ground-to-aerial geolocalization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 8–10 June 2015; pp. 5007–5015. [Google Scholar]
- Sun, B.; Chen, C.; Zhu, Y.; Jiang, J. GeoCapsNet: Aerial to Ground view Image Geo-localization using Capsule Network. arXiv 2019, arXiv:1904.06281. [Google Scholar]
- Cai, S.; Guo, Y.; Khan, S.; Hu, J.; Wen, G. Ground-to-Aerial Image Geo-Localization With a Hard Exemplar Reweighting Triplet Loss. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8391–8400. [Google Scholar]
- Ren, B.; Tang, H.; Sebe, N. Cascaded cross mlp-mixer gans for cross-view image translation. arXiv 2021, arXiv:2110.10183. [Google Scholar]
- Toker, A.; Zhou, Q.; Maximov, M.; Leal-Taixé, L. Coming down to earth: Satellite-to-street view synthesis for geo-localization. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Online, 11–17 October 2021; pp. 6488–6497. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Chen, H.; Wang, Y.; Guo, T.; Xu, C.; Deng, Y.; Liu, Z.; Ma, S.; Xu, C.; Xu, C.; Gao, W. Pre-trained image processing transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Online, 19–25 June 2021; pp. 12299–12310. [Google Scholar]
- Bhojanapalli, S.; Chakrabarti, A.; Glasner, D.; Li, D.; Unterthiner, T.; Veit, A. Understanding robustness of transformers for image classification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Online, 11–17 October 2021; pp. 10231–10241. [Google Scholar]
- Lanchantin, J.; Wang, T.; Ordonez, V.; Qi, Y. General multi-label image classification with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Online, 19–25 June 2021; pp. 16478–16488. [Google Scholar]
- Strudel, R.; Pinel, R.G.; Laptev, I.; Schmid, C. Segmenter: Transformer for Semantic Segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Online, 11–17 October 2021; pp. 7262–7272. [Google Scholar]
- Jin, Y.; Han, D.; Ko, H. Trseg: Transformer for semantic segmentation. Pattern Recognit. Lett. 2021, 148, 29–35. [Google Scholar] [CrossRef]
- Zheng, S.; Lu, J.; Zhao, H.; Zhu, X.; Luo, Z.; Wang, Y.; Fu, Y.; Feng, J.; Xiang, T.; Torr, P.H.; et al. Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 6881–6890. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Online, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 213–229. [Google Scholar]
- Misra, I.; Girdhar, R.; Joulin, A. An end-to-end transformer model for 3d object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Online, 11–17 October 2021; pp. 2906–2917. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable detr: Deformable transformers for end-to-end object detection. arXiv 2020, arXiv:2010.04159. [Google Scholar]
- Liang, Z.; Wang, Y.; Wang, L.; Yang, J.; Zhou, S. Light field image super-resolution with transformers. IEEE Signal Process. Lett. 2022, 29, 563–567. [Google Scholar] [CrossRef]
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.H. Restormer: Efficient transformer for high-resolution image restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–23 June 2022; pp. 5728–5739. [Google Scholar]
- Li, Z.; Liu, X.; Drenkow, N.; Ding, A.; Creighton, F.X.; Taylor, R.H.; Unberath, M. Revisiting stereo depth estimation from a sequence-to-sequence perspective with transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Online, 11–17 October 2021; pp. 6197–6206. [Google Scholar]
- Ding, Y.; Yuan, W.; Zhu, Q.; Zhang, H.; Liu, X.; Wang, Y.; Liu, X. Transmvsnet: Global context-aware multi-view stereo network with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–23 June 2022; pp. 8585–8594. [Google Scholar]
- He, X.; Chen, Y.; Lin, Z. Spatial-spectral transformer for hyperspectral image classification. Remote Sens. 2021, 13, 498. [Google Scholar] [CrossRef]
- Qing, Y.; Liu, W.; Feng, L.; Gao, W. Improved transformer net for hyperspectral image classification. Remote Sens. 2021, 13, 2216. [Google Scholar] [CrossRef]
- Sun, L.; Zhao, G.; Zheng, Y.; Wu, Z. Spectral-spatial feature tokenization transformer for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–14. [Google Scholar] [CrossRef]
- Zhou, H.; Tian, C.; Zhang, Z.; Huo, Q.; Xie, Y.; Li, Z. Multispectral fusion transformer network for RGB-thermal urban scene semantic segmentation. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Chu, X.; Tian, Z.; Zhang, B.; Wang, X.; Wei, X.; Xia, H.; Shen, C. Conditional positional encodings for vision transformers. arXiv 2021, arXiv:2102.10882. [Google Scholar]
- Li, Y.; Zhang, K.; Cao, J.; Timofte, R.; Van Gool, L. Localvit: Bringing locality to vision transformers. arXiv 2021, arXiv:2104.05707. [Google Scholar]
- Chen, C.F.R.; Fan, Q.; Panda, R. Crossvit: Cross-attention multi-scale vision transformer for image classification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Online, 11–17 October 2021; pp. 357–366. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Online, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Yang, F.; Zhai, Q.; Li, X.; Huang, R.; Luo, A.; Cheng, H.; Fan, D.P. Uncertainty-guided transformer reasoning for camouflaged object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Online, 11–17 October 2021; pp. 4146–4155. [Google Scholar]
- Wang, W.; Yao, L.; Chen, L.; Cai, D.; He, X.; Liu, W. CrossFormer: A Versatile Vision Transformer Based on Cross-scale Attention. arXiv 2021, arXiv:2108.00154. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Fan, D.P.; Ji, G.P.; Cheng, M.M.; Shao, L. Concealed object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 6024–6042. [Google Scholar] [CrossRef] [PubMed]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the IEEE European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Zhai, M.; Bessinger, Z.; Workman, S.; Jacobs, N. Predicting ground-level scene layout from aerial imagery. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 867–875. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Shi, Y.; Yu, X.; Campbell, D.; Li, H. Where am I looking At? Joint location and orientation estimation by cross-view matching. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 4064–4072. [Google Scholar]
- Lin, J.; Zheng, Z.; Zhong, Z.; Luo, Z.; Li, S.; Yang, Y.; Sebe, N. Joint Representation Learning and Keypoint Detection for Cross-View Geo-Localization. IEEE Trans. Image Process. 2022, 31, 3780–3792. [Google Scholar] [CrossRef] [PubMed]
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Jie, H.; Li, S.; Gang, S. Squeeze-and-Excitation Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Liu, J.J.; Hou, Q.; Cheng, M.M.; Wang, C.; Feng, J. Improving Convolutional Networks With Self-Calibrated Convolutions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 10096–10105. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7794–7803. [Google Scholar]
- Li, X.; Wang, W.; Hu, X.; Yang, J. Selective Kernel Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 510–519. [Google Scholar]
- Liu, S.; Huang, D.; Wang, Y. Receptive field block net for accurate and fast object detection. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 385–400. [Google Scholar]
- Zheng, Z.; Wei, Y.; Yang, Y. University-1652: A multi-view multi-source benchmark for drone-based geo-localization. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 1395–1403. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Abbreviation | Explanation | Abbreviation | Explanation |
|---|---|---|---|
| CVGL | Cross-view geo-localization | MGTL | Mutual generative transformer learning |
| CAMask | Cascaded attention masking | CVI | Cross-view interaction |
| G2S | Ground-to-satellite | VIFE | View-independent feature extractor |
| S2G | Satellite-to-ground | SA | Spatial attention |
| SCE | Spatial context enhancement | MSFA | Multi-scale feature aggregation |
| GKST | Generative knowledge-supported transformer |
| Model | CVUSA | CVACT_val | CVACT_test | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| r@1 | r@5 | r@10 | r@1% | r@1 | r@5 | r@10 | r@1% | r@1 | r@5 | r@10 | r@1% | |
| 2015 Workman et al. [9] | - | - | - | 34.30 | - | - | - | - | - | - | - | - |
| 2016 Vo et al. [10] | - | - | - | 63.70 | - | - | - | - | - | - | - | - |
| 2017 Zhai et al. [71] | - | - | - | 43.20 | - | - | - | - | - | - | - | - |
| 2018 CVM-Net [11] | 22.47 | 49.98 | 63.18 | 93.62 | 20.15 | 45.00 | 56.87 | 87.57 | 5.41 | 14.79 | 25.63 | 54.53 |
| 2019 Liu et al. [31] | 40.79 | 66.82 | 76.36 | 96.12 | 46.96 | 68.28 | 75.48 | 92.04 | 19.9 | 34.82 | 41.23 | 63.79 |
| 2019 Regmi et al. [12] | 48.75 | - | 81.27 | 95.98 | - | - | - | - | - | - | - | - |
| 2019 SAFA [23] | 89.84 | 96.93 | 98.14 | 99.64 | 81.03 | 92.80 | 94.84 | 98.17 | 55.50 | 79.94 | 85.08 | 94.49 |
| 2020 CVFT [24] | 61.43 | 84.69 | 90.49 | 99.02 | 61.05 | 81.33 | 86.52 | 95.93 | 34.39 | 58.83 | 66.78 | 95.99 |
| 2020 DSM [73] | 91.96 | 97.50 | 98.54 | 99.67 | 82.49 | 92.44 | 93.99 | 97.32 | 35.55 | 60.17 | 67.95 | 86.71 |
| 2021 Toker et al. [41] | 92.56 | 97.55 | 98.33 | 99.57 | 83.28 | 93.57 | 95.42 | 98.22 | 61.29 | 85.13 | 89.14 | 98.32 |
| 2021 L2LTR [14] | 94.05 | 98.27 | 98.99 | 99.67 | 84.89 | 94.59 | 95.96 | 98.37 | 60.72 | 85.85 | 89.88 | 96.12 |
| 2021 LPN [26] | 93.78 | 98.50 | 99.03 | 99.72 | 82.87 | 92.26 | 94.09 | 97.77 | - | - | - | - |
| 2022 SAFA+USAM [74] | 90.16 | - | - | 99.67 | 82.40 | - | - | 98.00 | 56.16 | - | - | 95.22 |
| 2022 LPN+USAM [74] | 91.22 | - | - | 99.67 | 82.02 | - | - | 98.18 | 37.71 | - | - | 87.04 |
| 2022 TransGeo [13] | 94.08 | 98.36 | 99.04 | 99.77 | 84.95 | 94.14 | 95.78 | 98.37 | - | - | - | - |
| 2022 TransGCNN [25] | 94.15 | 98.21 | 98.94 | 99.79 | 84.92 | 94.46 | 95.88 | 98.36 | - | - | - | - |
| 2022 LPN+DWDR [27] | 94.33 | 98.54 | 99.09 | 99.80 | 83.73 | 92.78 | 94.53 | 97.78 | - | - | - | - |
| Ours | 94.50 | 98.41 | 99.20 | 99.78 | 85.42 | 94.64 | 96.11 | 98.51 | 61.55 | 86.61 | 90.74 | 98.46 1 |
| Candidate | Complexity | CVUSA | CVACT_val | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| VGG16 | CAMask | CVI | GFLOPs ↓ | Param. ↓ | r@1 | r@5 | r@10 | r@1% | r@1 | r@5 | r@10 | r@1% |
| ✔ | 28.22 | 29.42 M | 79.94 | 93.66 | 96.25 | 99.31 | 70.67 | 87.73 | 91.13 | 95.78 | ||
| ✔ | ✔ | 59.02 | 91.18 M | 85.15 | 95.13 | 96.89 | 99.43 | 76.32 | 89.64 | 92.26 | 96.21 | |
| ✔ | ✔ | 28.90 | 137.21 M | 90.44 | 96.83 | 97.41 | 99.45 | 81.25 | 92.12 | 94.38 | 97.69 | |
| ✔ | ✔ | ✔ | 59.71 | 171.97 M | 94.50 | 98.41 | 99.20 | 99.78 | 85.42 | 94.64 | 96.11 | 98.51 1 |
| Candidate | Complexity | CVUSA | CVACT_val | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| VGG16 + CVI | w/SA | w/SCE | GFLOPs ↓ | Param. ↓ | r@1 | r@5 | r@10 | r@1% | r@1 | r@5 | r@10 | r@1% |
| ✔ | 28.90 | 137.21 M | 90.44 | 96.83 | 97.41 | 99.45 | 81.25 | 92.12 | 94.38 | 97.69 | ||
| ✔ | ✔ | 28.90 | 137.21 M | 92.29 | 97.65 | 98.67 | 99.72 | 82.37 | 93.35 | 95.17 | 98.23 | |
| ✔ | ✔ | 59.71 | 171.97 M | 93.62 | 98.41 | 99.07 | 99.73 | 84.33 | 94.31 | 95.67 | 98.43 | |
| ✔ | ✔ | ✔ | 59.71 | 171.97 M | 94.50 | 98.41 | 99.20 | 99.78 | 85.42 | 94.64 | 96.11 | 98.51 1 |
| Candidate | Complexity | CVUSA | CVACT_val | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| VGG16 + CAMask | w/o | w/CVI | GFLOPs ↓ | Param. ↓ | r@1 | r@5 | r@10 | r@1% | r@1 | r@5 | r@10 | r@1% |
| ✔ | 59.02 | 91.98 M | 85.15 | 95.13 | 96.89 | 99.43 | 76.32 | 89.64 | 92.26 | 96.21 | ||
| ✔ | ✔ | 59.32 | 113.48 M | 91.42 | 96.21 | 98.04 | 99.62 | 81.99 | 93.16 | 95.04 | 98.23 | |
| ✔ | ✔ | 59.71 | 171.97 M | 94.50 | 98.41 | 99.20 | 99.78 | 85.42 | 94.64 | 96.11 | 98.51 1 | |
| Method | Complexity | CVUSA | CVACT_val | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| GFLOPs ↓ | Param. ↓ | r@1 | r@5 | r@10 | r@1% | r@1 | r@5 | r@10 | r@1% | |
| VAE [75] | 59.89 | 141.84M | 94.11 | 98.27 | 99.03 | 99.71 | 85.32 | 94.42 | 96.04 | 98.41 |
| Unet [70] | 59.53 | 134.74M | 92.04 | 97.91 | 98.80 | 99.67 | 82.31 | 93.08 | 95.09 | 98.30 |
| Transformer [42] | 61.20 | 276.49M | 94.37 | 98.30 | 99.08 | 99.74 | 85.35 | 94.45 | 96.03 | 98.44 |
| Ours | 59.71 | 171.97M | 94.50 | 98.41 | 99.20 | 99.78 | 85.42 | 94.64 | 96.11 | 98.51 1 |
| CVI | CVUSA | CVACT_val | ||||||
|---|---|---|---|---|---|---|---|---|
| r@1 | r@5 | r@10 | r@1% | r@1 | r@5 | r@10 | r@1% | |
| L = 1 | 87.07 | 96.48 | 97.72 | 99.65 | 77.92 | 90.85 | 93.27 | 97.20 |
| L = 3 | 89.67 | 97.15 | 98.26 | 99.70 | 80.40 | 91.63 | 94.18 | 98.17 |
| L = 6 | 94.50 | 98.41 | 99.20 | 99.78 | 85.42 | 94.64 | 96.11 | 98.51 |
| L = 9 | 94.25 | 98.39 | 99.18 | 99.76 | 85.20 | 94.61 | 96.12 | 98.49 1 |
| Module | Complexity | CVUSA | CVACT_val | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| GFLOPs ↓ | Param. ↓ | r@1 | r@5 | r@10 | r@1% | r@1 | r@5 | r@10 | r@1% | |
| Why MSFA in SCE?—Comparison with other aggregation methods. | ||||||||||
| add | 54.62 | 161.30 M | 93.11 | 98.22 | 98.93 | 99.75 | 83.55 | 93.66 | 95.56 | 98.26 |
| concat + conv | 55.75 | 163.71 M | 92.62 | 97.96 | 98.85 | 99.72 | 83.07 | 93.84 | 95.57 | 98.21 |
| SENet [76] | 54.63 | 161.95 M | 93.48 | 98.31 | 98.99 | 99.74 | 85.01 | 94.40 | 96.02 | 98.48 |
| Cbam [69] | 54.63 | 161.96 M | 93.61 | 98.39 | 99.02 | 99.73 | 84.89 | 94.27 | 96.03 | 98.43 |
| SCNet [77] | 56.68 | 166.12 M | 93.82 | 98.38 | 99.08 | 99.74 | 84.67 | 94.28 | 95.97 | 98.35 |
| Non_Local [78] | 65.36 | 163.72 M | 92.84 | 98.01 | 98.86 | 99.67 | 83.48 | 93.99 | 95.68 | 98.29 |
| SKC [79] | 73.84 | 201.91 M | 93.92 | 98.36 | 99.03 | 99.78 | 84.95 | 94.36 | 95.81 | 98.44 |
| MSFA | 59.71 | 171.97 M | 94.50 | 98.41 | 99.20 | 99.78 | 85.42 | 94.64 | 96.03 | 98.51 |
| Why SCE in CAMask?—Comparison with other parallel multi-branch convolutional modules. | ||||||||||
| Conv | 76.38 | 208.51 M | 92.97 | 98.16 | 98.87 | 99.72 | 83.51 | 94.02 | 95.78 | 98.37 |
| TEM [68] | 67.05 | 187.31 M | 94.21 | 98.37 | 99.05 | 99.74 | 85.10 | 94.56 | 95.99 | 98.43 |
| RFB [80] | 67.61 | 188.47 M | 94.13 | 98.33 | 99.07 | 99.72 | 85.08 | 94.48 | 96.01 | 98.40 |
| SCE | 59.71 | 171.97 M | 94.50 | 98.41 | 99.20 | 99.78 | 85.42 | 94.64 | 96.03 | 98.51 |
| Why SA in CAMask?—Comparison with other attention mask generation methods. | ||||||||||
| GAP | 59.71 | 171.97 M | 93.62 | 98.41 | 99.07 | 99.73 | 84.33 | 94.31 | 95.67 | 98.43 |
| GMP | 59.71 | 171.97 M | 93.43 | 98.33 | 99.05 | 99.75 | 84.20 | 94.21 | 95.88 | 98.45 |
| SA | 59.71 | 171.97 M | 94.50 | 98.41 | 99.20 | 99.78 | 85.42 | 94.64 | 96.03 | 98.51 1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, J.; Zhai, Q.; Zhao, P.; Huang, R.; Cheng, H. Co-Visual Pattern-Augmented Generative Transformer Learning for Automobile Geo-Localization. Remote Sens. 2023, 15, 2221. https://doi.org/10.3390/rs15092221
Zhao J, Zhai Q, Zhao P, Huang R, Cheng H. Co-Visual Pattern-Augmented Generative Transformer Learning for Automobile Geo-Localization. Remote Sensing. 2023; 15(9):2221. https://doi.org/10.3390/rs15092221
Chicago/Turabian StyleZhao, Jianwei, Qiang Zhai, Pengbo Zhao, Rui Huang, and Hong Cheng. 2023. "Co-Visual Pattern-Augmented Generative Transformer Learning for Automobile Geo-Localization" Remote Sensing 15, no. 9: 2221. https://doi.org/10.3390/rs15092221