1. Introduction
A tailings pond is a place enclosed by ponds to intercept valley mouths or enclosures. It is used to stack tailings discharged from metal or non-metal mine ores after sorting, wastes from wet smelting, or other industrial wastes [
1]. Tailings ponds’ liquid is toxic, hazardous, or radioactive [
2]. Therefore, tailings ponds become one of the sources of high potential environmental risks. Once an accident occurs, it will cause severe damage to the surrounding residents and environment [
3,
4,
5]. Restricted by factors such as mineral resources and topography, tailings ponds are mostly located in remote mountainous areas. Accurate identification of tailings ponds in a large area is an important part of tailings supervision [
6]. In recent years, the number of accidents and deaths in tailings ponds has increased significantly, which has adversely affected economic development and social stability [
7,
8,
9]. Therefore, it is of great significance to master the number, distribution, and existing status of tailings ponds to prevent accidents and carry out emergency work in tailings ponds.
In the past, the investigation of tailings ponds relied heavily on the manual on-site investigation, which was very inefficient and did not update timely. Remote sensing technology has become one of the effective means of monitoring and risk assessment of tailings ponds and mining areas due to its large spatial coverage and frequent observations. Based on the unique spectral, texture and shape features of tailings ponds, as well as different remote sensing data, some methods for extracting tailings ponds were proposed. Lévesque et al. [
10] investigated the potential of hyperspectral remote sensing for the identification of uranium mine tailings. Ma et al. [
11] used the newly constructed Ultra-low-grade Iron Index (ULIOI) and temperature information to accurately identify tailings information based on Landsat 8 OLI data. Hao et al. [
12] built a tailing extraction model (TEM) to extract mine tailing information by combining the all-band tailing index, the modified normalized difference tailing index (MNTI), and the normalized difference tailings index for Fe-bearing minerals (NDTIFe). Xiao et al. [
6] combined object-oriented target identification technology and manual interpretation to identify tailings ponds. Liu et al. [
13] proposed an identification method for the four main structures of tailings ponds, namely start-up ponds, dykes, sedimentary beaches, and water bodies, using the spatial combination of tailings ponds. Wu et al. [
14] designed a support vector machine method for automatically detecting tailings ponds.
With the growing success of deep learning in image detection tasks, the task of tailings ponds detection using deep learning is emerging. To meet the requirements of fast and accurate extraction of tailings ponds, a target detection method based on Single Shot Multibox Detector (SSD) deep learning was developed [
15]. Balaniuk et al. [
16] explored a combination of free cloud computing, free open-source software, and deep learning methods to automatically identify and classify surface mines and tailings ponds in Brazil. Ferreira et al. [
17] employed different deep learning models for tailings detection based on the construction of a public dataset of tailings ponds. Yan et al. [
18,
19] improved Faser-RCNN by employing an FPN with the attention mechanism and increasing the inputs from three bands to four bands to improve the detection accuracy of tailings ponds. Lyu et al. [
20] proposed a new deep learning-based framework for extracting tailings pond margins from high spatial resolution remote sensing images by combining YOLOv4 and the random forest algorithm.
In summary, the research on tailings ponds detection has been carried out in depth, but there are still some challenges. Traditional methods are designed based on the spectral or texture features of tailings ponds, and it is difficult to obtain good detection results in a large area due to excessive changes in tone, shape and dimension between tailings ponds [
20]. The application of deep learning methods in tailings pond detection has greatly improved the effect of tailings detection. However, due to the lack of a public tailings sample dataset, and the sparse distribution of tailings ponds with various scales, it is still difficult to accurately detect tailings ponds in a large area. More importantly, with the increase of high-resolution remote sensing data and their cost reduction, target detection based on the entire high-resolution remote sensing image will become one of the mainstream directions of research and engineering. To address the aforementioned limitations on extracting tailings ponds, we propose a framework for detecting tailings ponds from the entire remote sensing image based on the improved YOLOv5 model, which can achieve better detection results than the general YOLOv5.
Our contribution can be summarized as follows:
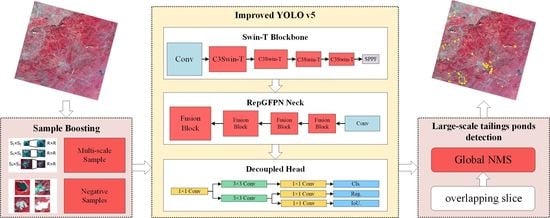
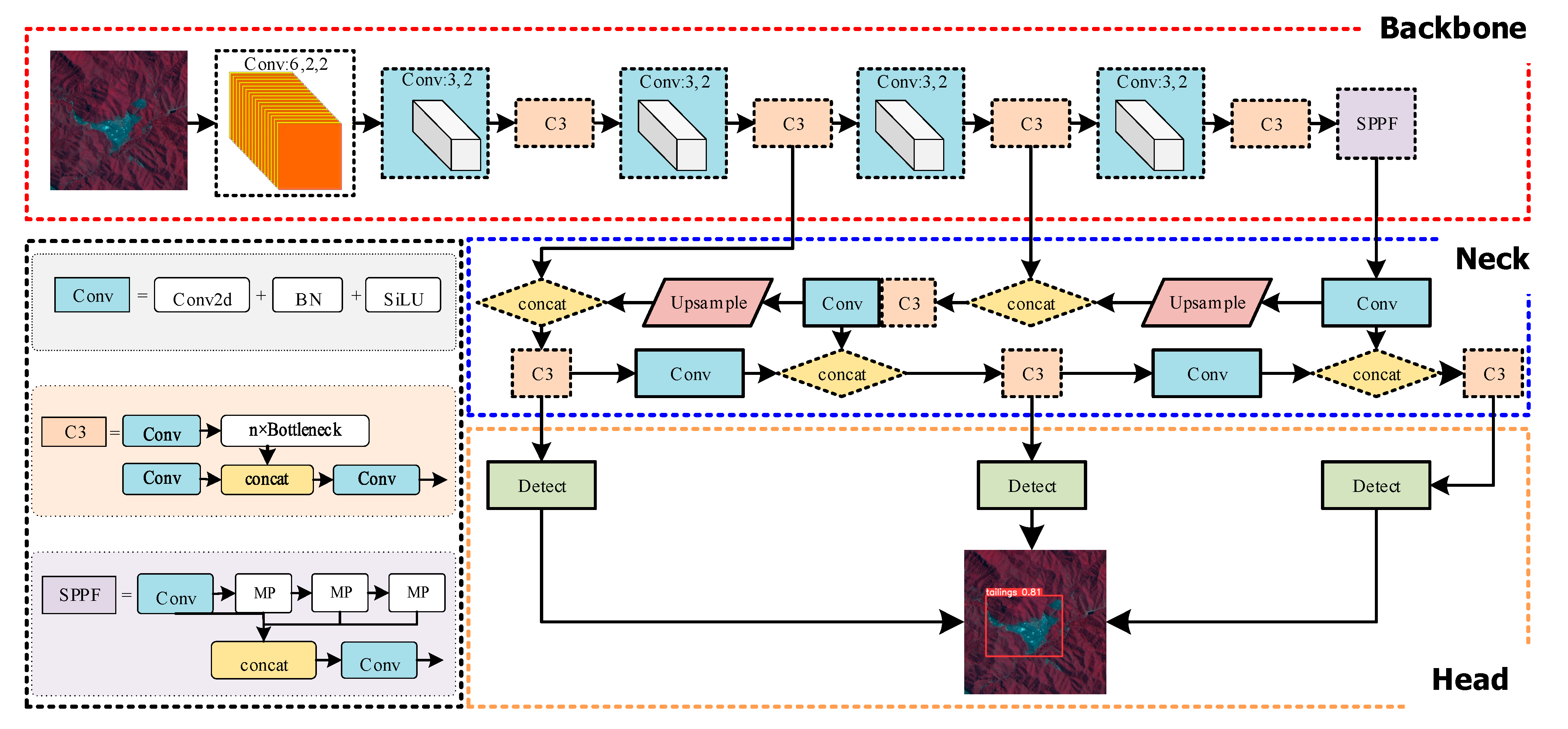
(1) Combine Swin Transformer and C3 to form the new C3Swin-T module, and use the C3Swin-T module to construct Swin-T Blockbone as the backbone of YOLOv5s, which is used to capture sparse tailing pond targets in complex backgrounds.
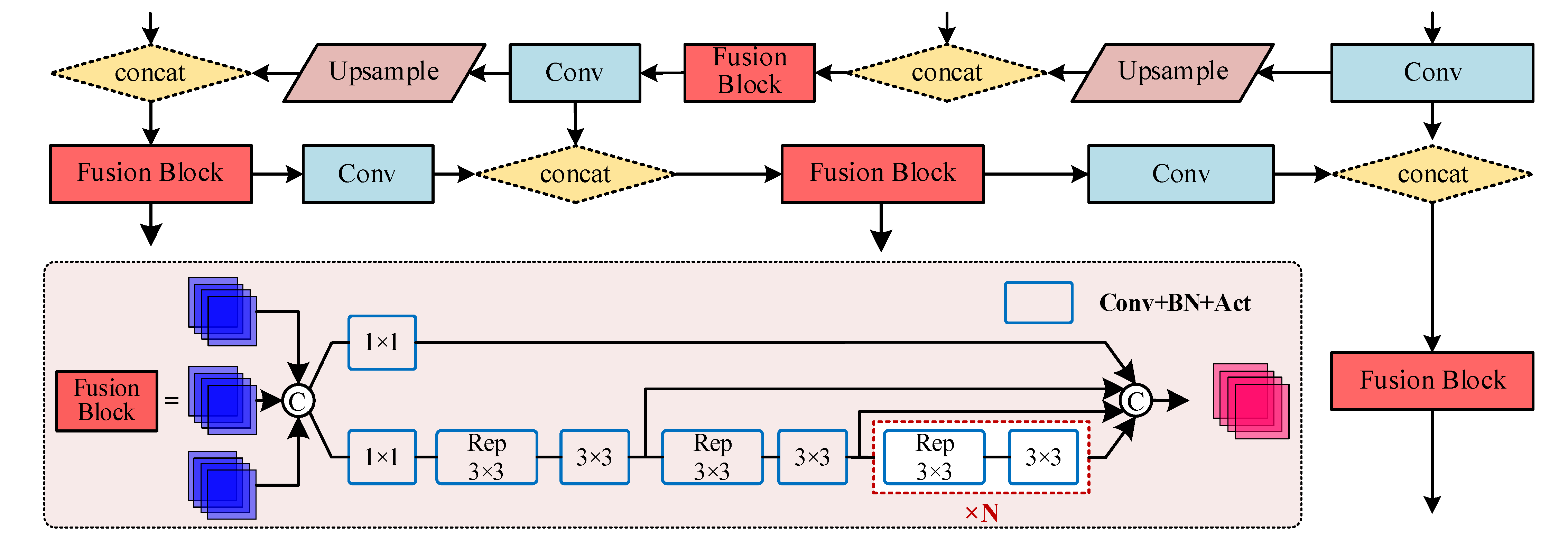
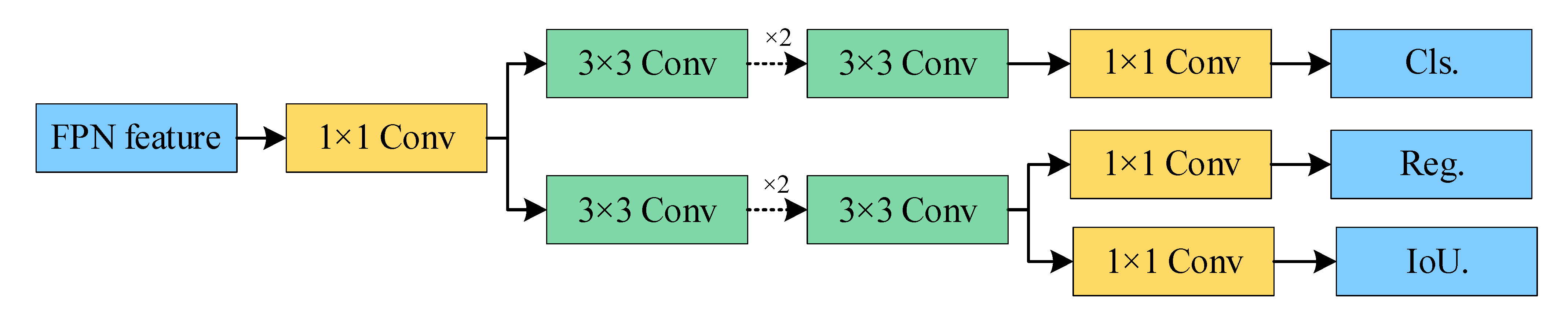
(2) Introduce the Fusion Block in DAMO-YOLO to replace the C3 module of the neck to form RepGFPN Neck, which is used to improve the feature fusion effect of the neck. Replace the original head with Decoupled Head to improve the detection accuracy and model convergence speed.
(3) The SBS and GNMS strategies are proposed to improve the sample quality and suppress repeated detection frames in the whole scene image, respectively, so as to adapt to tailings ponds detection in standard remote sensing images.
4. Results and Discussion
To evaluate the performance of the proposed tailings pond detection framework, we design two sets of comparative experiments based on the GF-6 satellite tailings pond image sample dataset. In the first set of experiments, we mainly highlight the effect of introducing the GNMS strategy. In the second set of experiments, we mainly tested the performance of introducing the SBS (named YOLOv5s+SBS), and the performance of improved YOLOv5s with SBS (named Improved YOLOv5s+SBS), and compared the two models with original YOLOv5s to highlight the contribution of introducing the SBS and improved model.
4.1. Experimental Results of GNMS
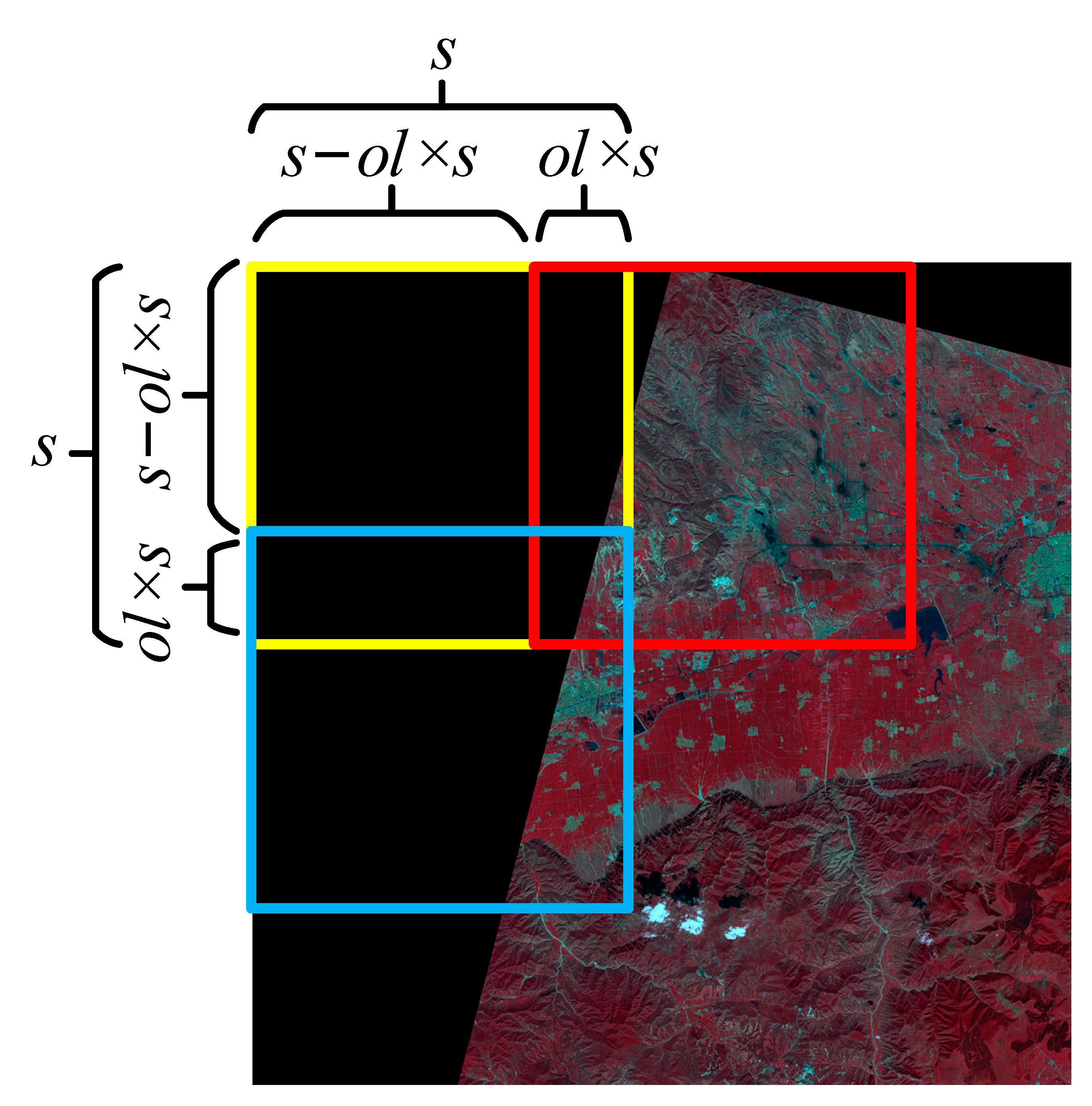
In order to analyze the results of different comparative experiments more objectively, it is necessary to perform GNMS first. In this study,
ol is set to 0.2, and the entire remote sensing image is sliced into 3897 image slices. Taking YOLOv5s+SBS as an example, the results of employing the GNMS strategy on the entire GF-6 image are shown in
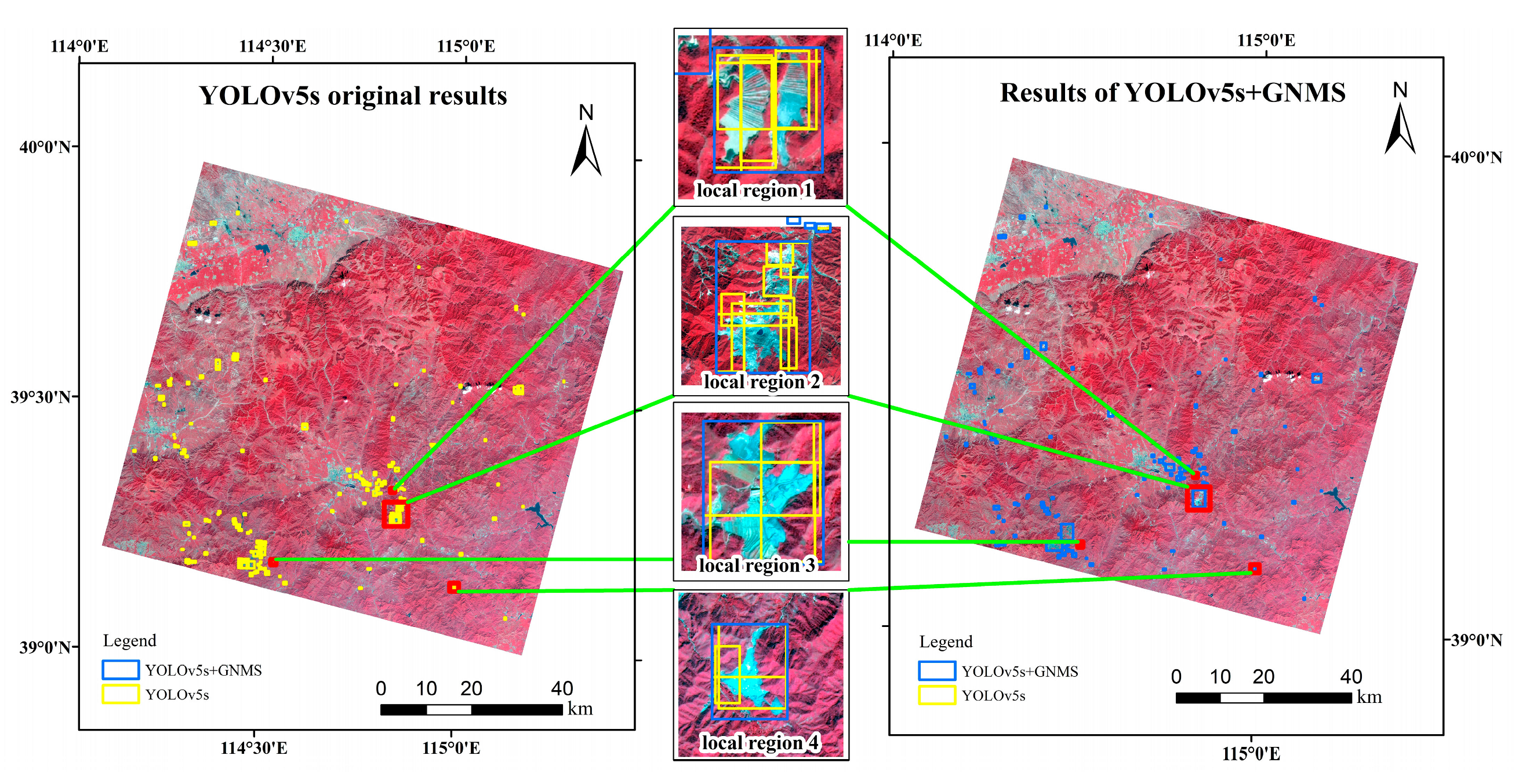
Figure 11. As can be seen from
Figure 11, due to the image slice, the tailing ponds are divided into different image slices, and the training samples that focus on the local area of the tailing ponds are added. Many repeated and partial detection frames are generated. GNMS can effectively eliminate duplicate and partial detection frames. Some of these detection frames even exceed the sample size fed to the YOLOv5s model, which can more accurately count the number of real tailings ponds. Compared with the label frames, the error of the detection frames generated by GNMS on the entire GF-6 image is 9.8%.
In order to further observe the performance of GNMS in detail, four local regions are selected for display. The blue detection frames are the experimental results using the GNMS strategy, and the yellow detection frames are original results. In local region 1, the same tailings pond is repeatedly detected many times due to part of the training samples. Most of the detection frames are suppressed using GNMS, but since the two tailings ponds are too close, they are both represented by the same detection frame. The tailings ponds in region 2 and region 3 are large and may be repeatedly detected in different sub-slices, so the generated detection frames are marked on the image. After being processed by GNMS, the detection frame on the same tailings pond will no longer have partial coverage, but full coverage of the tailings pond. In local region 4, we can see that the same tailings pond is repeatedly detected three times, and after processing by GNMS, only one detection frame remains.
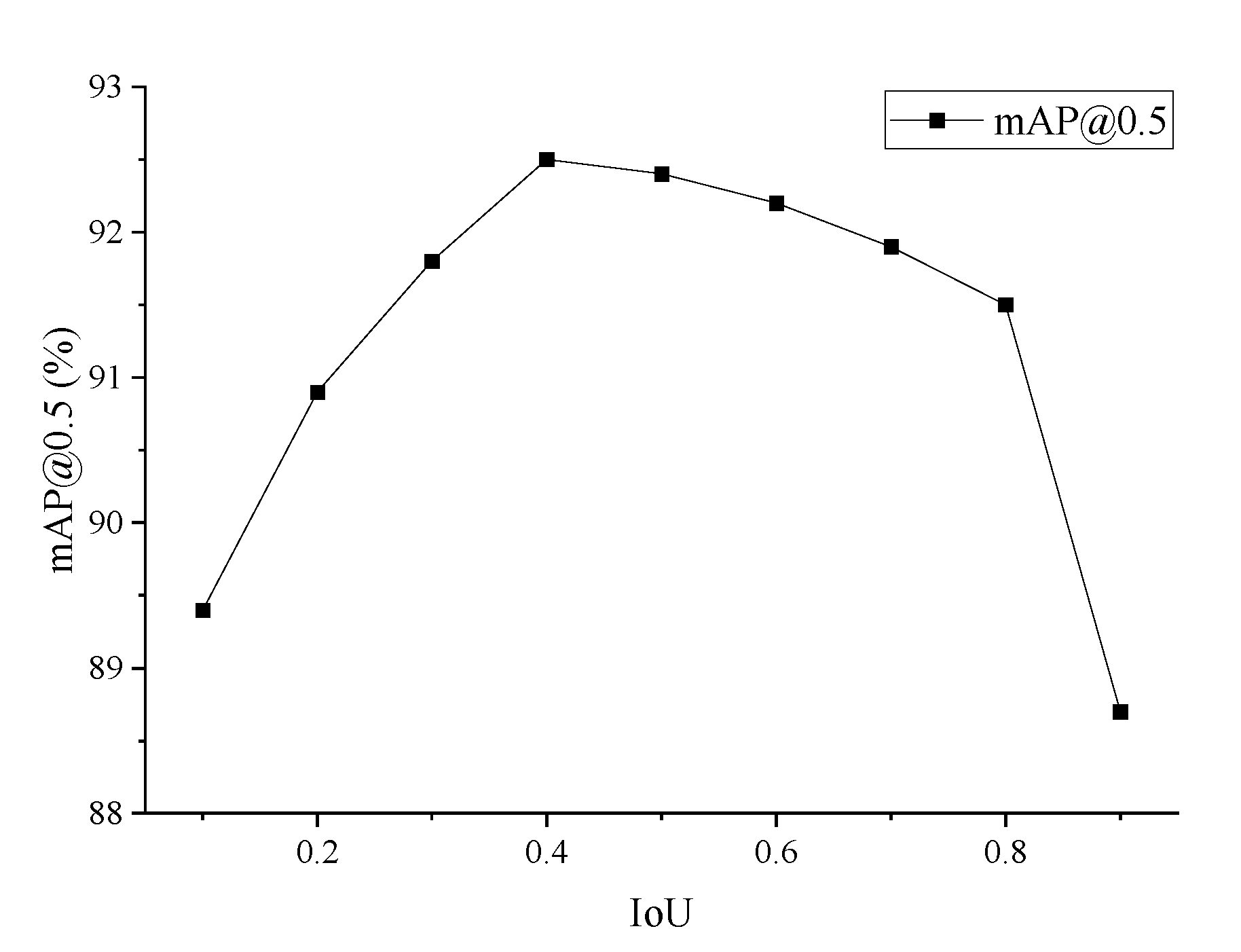
To investigate the effect of the IoU threshold of GNMS on the accuracy of tailings ponds detection, different IoU thresholds are selected to obtain the best mAP@0.5 on the test set. The IoU threshold ranges from (0, 1) with a step size of 0.1, and the results are shown in
Figure 12.
Figure 12 shows that the mAP@0.5 is maximum when the IoU threshold is 0.4.
4.2. Comparative Results of Different Experiments
4.2.1. Qualitative Results
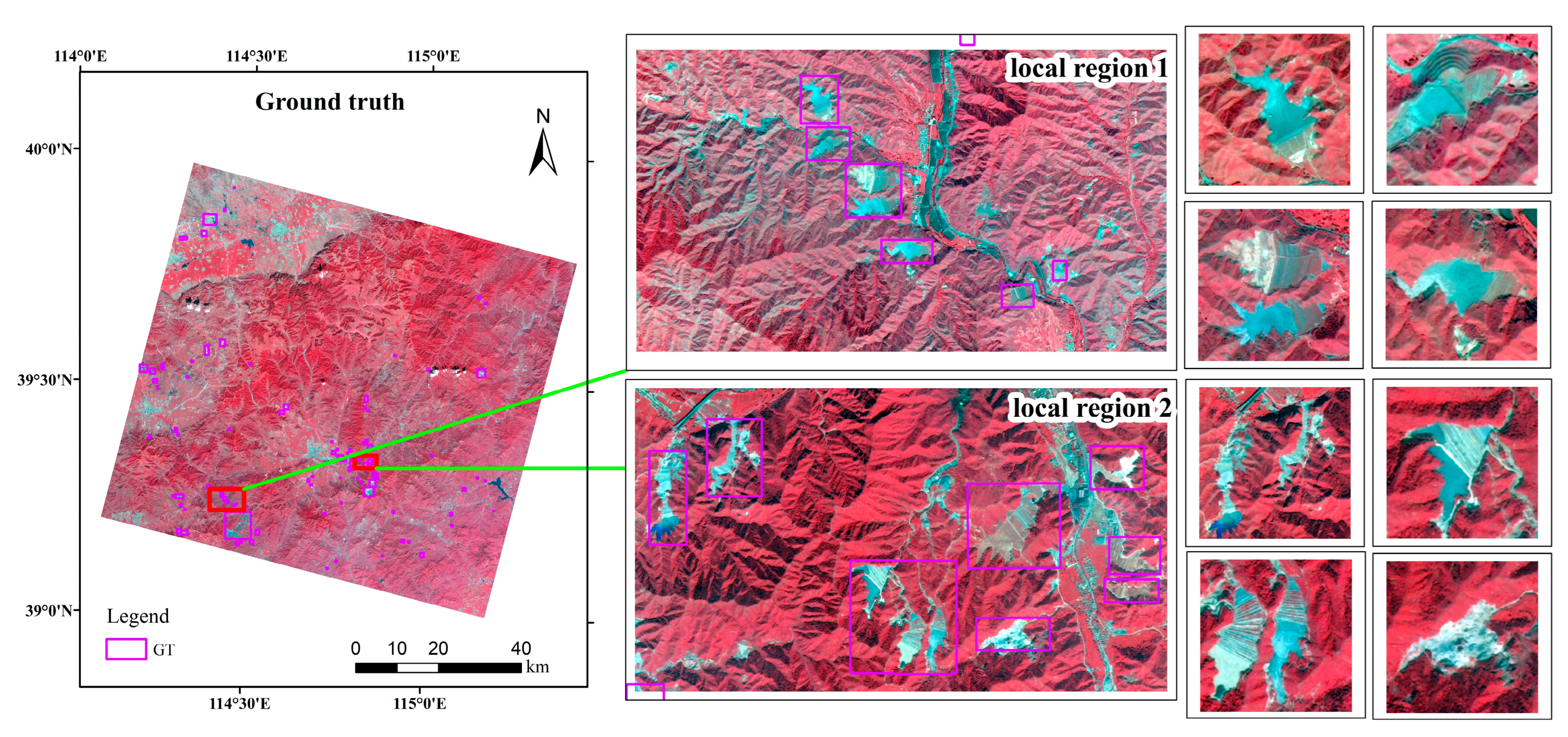
To obtain a more accurate ground truth map, we first marked the location of the tailings ponds on a high-resolution Google Earth map. Based on the precise location information, we marked the label frames of the tailings ponds on the entire GF-6 image. From
Figure 13, these label frames are purple. In order to show the truth map more clearly, we selected two typical local regions, and selected four tailings ponds from each region for display. According to a statistical analysis of the size of the marked tailings ponds, their length and width are typically between 70 m and 3000 m.
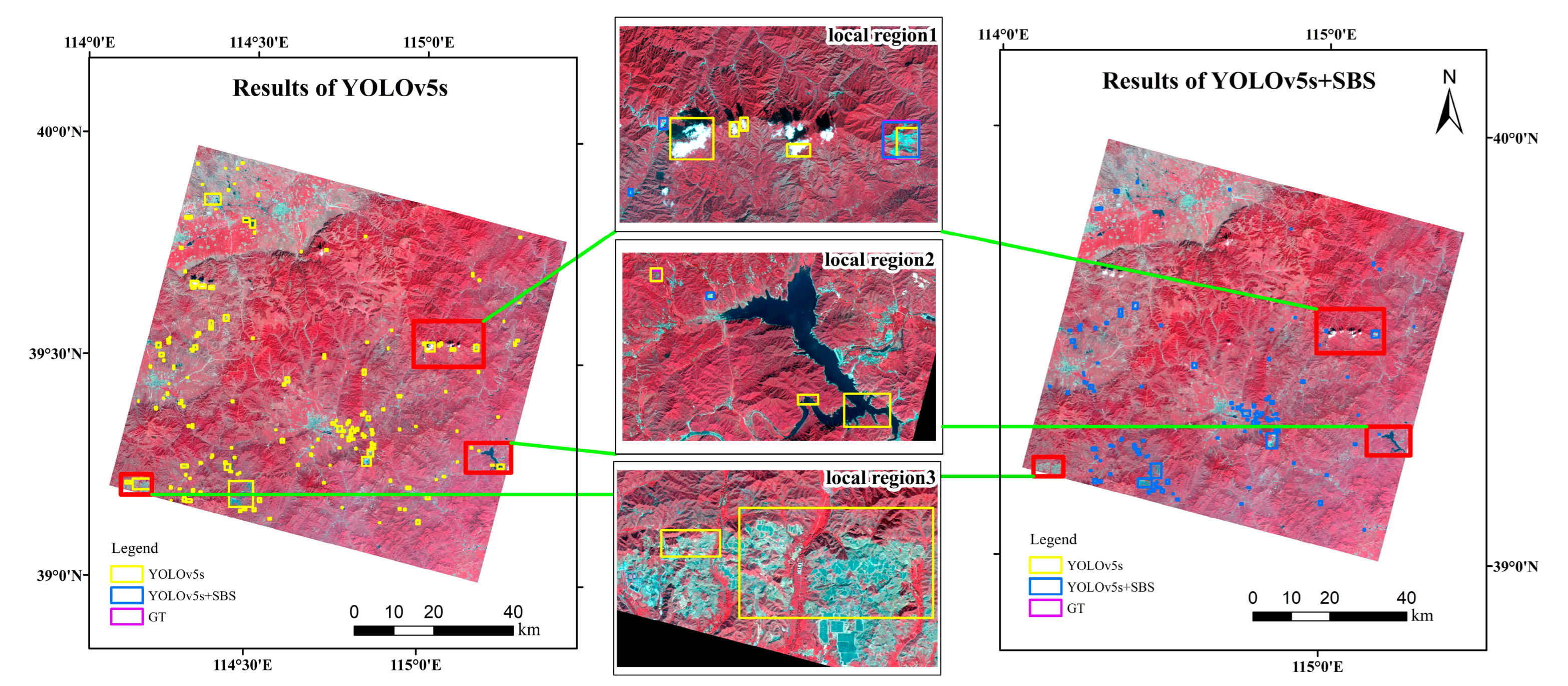
Figure 14 shows the qualitative tailings ponds detection results of YOLOv5s and YOLOv5s+SBS on the entire GF-6 image. Compared with ground truth, the results of the YOLOv5s have more obvious misidentifications. From the results of YOLOv5s, we can see that there are mainly three ground objects that are more misidentified as tailings ponds, namely clouds, reservoirs and bare rocks of mountains. We selected three local regions to display typical errors. Local region 1 is used to show that clouds are misidentified as tailings ponds. Local region 2 is used to show that reservoirs are misidentified as tailings ponds. Local region 3 is used to show that bare rocks are misidentified as tailings ponds. In these three local regions, compared with YOLOv5, the detection results of YOLOv5+SBS can well avoid these obvious errors and obtain better detection results.
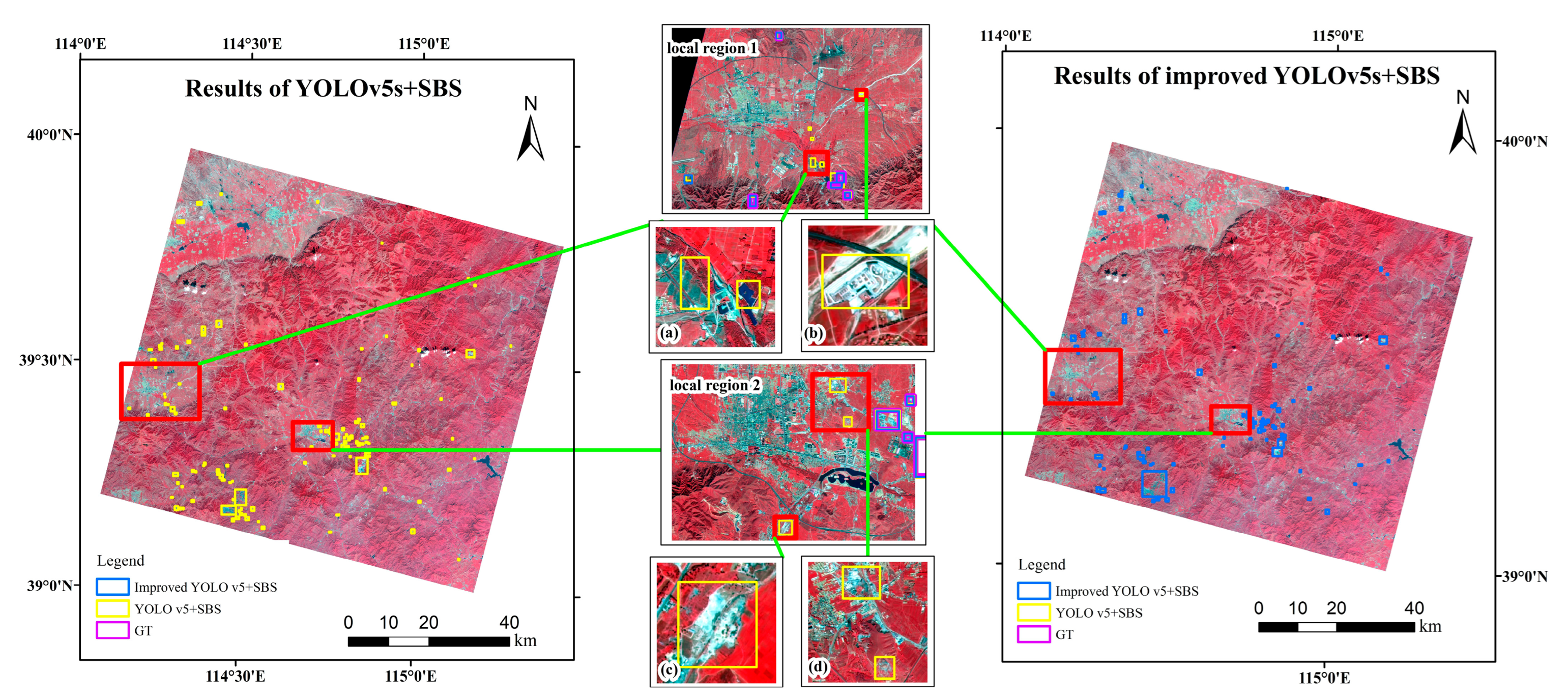
Figure 15 shows the qualitative tailings ponds detection results of YOLOv5s+SBS and improved YOLOv5s+SBS on the entire GF-6 image. Compared with the YOLOv5s model, YOLOv5s+SBS has significantly improved the erroneous extraction of tailings ponds, but there are also several obvious erroneous extractions. Through observation, these misidentified ground objects are mainly concentrated near residential areas, and scattered in other areas, mainly bare land and buildings. We selected two local regions around Lingqiu County and Laiyuan County to show the results. Region 1 is Lingqiu County and region 2 is Laiyuan County. In order to show the detection results more clearly, we selected two sub-areas (a) and (b) in local region 1, and two sub-regions (c) and (d) in local region 2. In sub-region (a), the YOLOv5s+SBS model misidentifies the bare land in the left detection frame and the pond in the right detection frame as tailings ponds. In sub-region (b), the YOLOv5s+SBS model misidentifies a factory in the detection frame as a tailings pond. In both sub-region (c) and (d), the YOLOv5s+SBS model misidentifies the bare land as a tailings pond. Compared with YOLOv5+SBS, the detection results of improved YOLOv5+SBS can obtain better detection results.
In order to overall compare the performance of the three models, we show the results of misrecognition and omissions of different models, respectively, on the entire GF-6 image. Red detection frames represent misrecognition, and green detection frames represent omissions. From
Figure 16, the misrecognition of YOLOv5s is the highest, followed by YOLOv5s+SBS, and our framework has achieved the best performance. YOLOv5s has about the same number of omissions as our framework, while YOLOv5+SBS has relatively more omissions.
4.2.2. Quantitative Results
In this study, a counting method is used for performance evaluation. We use the GF-6 image with label frames as a ground truth map, as shown in
Figure 13. If the detection frame predicted by the models intersects with the label frame, we consider the detection frame predicted by the model to be correctly identified and denote it as TP; if there is no intersection between the detection frame and the labeled frame, and it is identified as other ground objects, it is judged as a misrecognition, which is denoted as FP; if the labeled frames are not detected, they are judged as missing and denoted as FN. We obtain quantitative comparison results of different models using the calculation formula for accuracy evaluation, see
Table 4.
From
Table 4, the accuracy of the proposed framework has been greatly improved by introducing the SBS and improving YOLOv5s. Compared with the original YOLOv5s, the F1 score has increased by 12.22%, and the precision has increased by nearly 25%, but the recall is lower than YOLOv5s. Compared with the YOLOv5s+SBS, the F1 score has increased by about 5%, the precision has increased by 7.66%, and the recall has increased by 2.64%. However, compared to the other two models, the proposed framework increases the detection execution time of tailings ponds on the entire GF-6 image by about three times. It should be pointed out that the final detection result is saved in vector format, not in raster format. It not only improves the detecting efficiency and saves storage space, but also can be easily superimposed on any map with a coordinate system for display.
4.3. Discussion
In this study, YOLOv5s is comprehensively improved, combining the strategies of SBS and GNMS, and innovatively designing a new framework for large-scale tailings ponds extraction from the entire remote sensing image. Our framework achieves the best performance in comparative experiments. Although the execution time is the longest, an entire GF-6 image is about 90 km by 90 km in size, and it takes about 166 s, which is acceptable. In this subsection, it is clarified that all models employ SBS.
4.3.1. Ablation Experiment
There are many improvement measures in our model, including: replacing C3 with C3SwinT module in backbone, replacing C3 with fusion block module in neck, and replacing the coupled head with Decoupled Head. To verify the effect of these measures on the improved YOLOv5s, an ablation experiment is undertaken in this paper. Additionally, the mAP@0.5 and number of parameters are used as evaluation indexes. For fair comparison, default parameters are used for all models. The final results are listed in
Table 5.
Compared with the baseline network, the improved YOLOv5s boosts mAP@0.5 by 5.95%. Although our model has the highest mAP@0.5 of 92.15%, it has the largest number of parameters. YOLOv5 with Swin-T Backbone achieves 90.20% mAP@0.5, an increase of 4% mAP@0.5 compared with the baseline network, and the number of parameters of the model is slightly increased. YOLOv5 with RepGFPN Neck achieved 89.60% mAP@0.5, mAP@0.5 increased by 3.4%, and the number of parameters increased by 5.22 M. In comparison with the baseline network, YOLOv5 with Decoupled Head improved 2% mAP@0.5, and the number of parameters increased by 7.3 M, second only to our model. It can be seen that the improvement of different parts of YOLOv5 has achieved an increase of mAP@0.5. Swin-T Backbone contributed the most, showing that Swin Transform has a good effect on extracting sparse targets in complex background images. The contribution of RepGFPN Neck is second, indicating that this new feature fusion mode that transfers node stacking calculations to convolutional layer stacking calculations is very effective in target recognition on remote sensing images. Decoupled Head also cannot be ignored, and it is an important means to improve the accuracy of target detection.
4.3.2. Comparison with Other Object Detection Methods
To demonstrate the effectiveness of the improved YOLOv5s in detecting tailings ponds on GF-6 images, this study compares the performance of our method with that of several other state-of-the-art (SOTA) object detection methods, such as YOLOv8s, YOLOv5l, YOLT [
44] and the Swin Transformer [
32], on the GF-6 self-made tailing pond dataset.
Table 6 shows the performance comparison of different methods.
From
Table 6, compared to several other SOTA methods, our improved YOLOv5s obtains the highest mAP@0.5, followed by Swin Transformer and YOLTv5s. For Swin Transformer, the backbone we choose is Swin-T with Lr Schd 3x. YOLTv5 is the fifth version of YOLT, developed based on YOLOv5, and we also chose the size of s. YOLOv8s achieved 88.00% mAP@0.5, which is the latest YOLO released by the community. It adopts the new C2f module and decoupled head, and has a very good performance. Compared with YOLOv5s, YOLOv5l has a larger model depth multiple and layer channel multiple, which can usually achieve better detection results. It should be noted that default hyperparameters were used for all compared models. Although Swin Transformer has achieved sub-optimal performance, it has a large number of parameters. After fusing it with C3, it can maintain a good extraction accuracy and greatly reduce the number of parameters. YOLTv5s can still achieve good detection results while maintaining the same number of parameters as YOLOv5s. YOLOv8s has a small number of parameters and has achieved good detection results. The number of parameters of YOLOv5l is almost the same as that of Swin Transformer, but its improvement of mAP@0.5 is relatively small. In general, our improved YOLOv5 has a great advantage in the task of detecting tailings ponds on GF-6 images.
In order to further analyze the recognition performance of the proposed model for tailings ponds, our model is also compared with the improved YOLOv8s. We replace the C2f modules of the YOLOv8s backbone with C3SwinT modules to form Swin-T Backbone, and replaced the C2f modules of the YOLOv8s neck with fusion block modules to form RepGFPN Neck. From
Table 7, the first row represents YOLOv5s and YOLOv8s with Swin-T Backbone, the second row represents YOLOv5s and YOLOv8s with RepGFPN Neck, and the third row represents improved YOLOv5s and YOLOv8s with Swin-T Backbone, RepGFPN Neck and Decoupled Head. It should be pointed out that YOLOv8s has Decoupled Head, and the improved YOLOv8s only employs Swin-T Backbone and RepGFPN Neck. Compared with different improved YOLOv8s models, different improved YOLOv5s models have higher mAP@0.5, and the parameters of the models also have certain advantages.
4.3.3. Limitations and Future Works
Although our framework obtained the best accuracy for tailings ponds identification, there are still misidentifications, and the detection of tailings ponds in a large area still faces challenges.
Figure 17 shows some typical cases misidentified by our framework, such as bare soil, factories, residential areas, and highway service areas, which are morphologically and spectrally similar to tailings ponds. In addition, the phenomenon of missing extraction of the framework cannot be ignored, and the typicality of these undetected tailings ponds is often not prominent enough, which is also worthy of attention and research in the future.
Furthermore, we generated a dataset of tailings ponds based on standard false-color images of the GF-6 high-resolution camera, which is still small-scale and not particularly general compared to other public datasets of ground objects. In the future, it is necessary to establish large-scale tailings pond dataset based on GF-6 standard false-color images and explore specific data enhancement methods. Apart from some misidentifications and omissions, our framework lacks competition in the number of model parameters and detection time. We hope to carry out model pruning and knowledge distillation in the future to improve model efficiency and meet more application scenarios. In addition, tailings ponds have strong spatial heterogeneity, and the characteristics of tailings ponds in different regions are quite different. Therefore, the fusion of multi-source data, such as hyperspectral data, are used to more finely detect tailings ponds in larger areas.
5. Conclusions
This study proposes an improved YOLOv5s framework for tailings ponds extraction from the entire GF-6 high spatial resolution remote sensing image. The proposed SBS technique improves the quality of the tailings ponds image sample dataset by adding multi-scale samples and negative samples. The improved YOLOv5s consists of Swin-T Backbone, RepGFPN Neck and Decoupled Head. The C3Swin-T module formed by Swin Transformer and C3 can well-capture the features of sparse tailing pond targets in complex backgrounds. Fusion Block can achieve better feature fusion effects by introducing strategies such as CSPNet, reparameterization mechanism, and multi-layer aggregation. Decoupled Head replacing a coupled head also achieved better results. In addition, the designed GNMS can effectively suppress the repeated detection frames on the entire remote sensing image and improve the detection effect. The results show that the precision and F1 score of tailings ponds detection using the improved framework are significantly improved, which are 24.98% and 12.22%, respectively, compared with the original YOLOv5s, and 7.66% and 4.99%, respectively, compared with YOLOv5s+SBS, reaching 86.00% and 81.90%, respectively. Our framework can provide an effective method for government departments to conduct a tailings ponds inventory, and provide a useful reference for mine safety and environmental monitoring.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}