1. Introduction
After decades of rapid development, applications of HSIs have made remarkable progress, especially in the field of satellite hyperspectral remote sensing [
1]. Various satellites, such as Earth Observing 1 (EO-1) [
2], Huanjing-1A (HJ-1A) [
3], Gaofen-5 (GF-5) [
4], DLR Earth Sensing Imaging Spectrometer (DESIS) [
5], preferred reporting items for systematic reviews and meta-analyses (PRISMA) [
6], and Gaofen-14 (GF-14) [
7] have been launched in recent decades, of which the spatial and spectral resolution have experienced significant improvement [
7]. Compared with airborne HSIs, satellite HSIs have obvious advantages in ground applications at large scale, such as mineral exploration [
4], precise agriculture [
8], ecological monitoring [
5], and land cover classification [
9]. HSI classification is one of the core processing techniques for various applications, aiming to assign each pixel of HSI an accurate class label. However, the complex spatial–spectral structure and high-dimensional information of hyperspectral data [
10] make it difficult to obtain optimal classification results by original satellite hyperspectral data without pre-processing.
In the initial stage of the HSI classification, the traditional methods mainly focused on the use of spectral features, such as spectral angle mapper (SAM) [
11] and maximum-likelihood (ML) [
12]. With the improvement of spatial resolution, the intra-class heterogeneity also increases [
13], and it is quite difficult for the algorithms to classify accurately only by spectral features. The spatial characteristics of pixel neighborhoods can provide extra information to fix the problem. Methods such as morphological attribute profiles (MAPs) [
14], extend morphological attribute profiles (EMAPs) [
15], and Markov random field (MRF) [
16] have been used for associative extraction of both spatial and spectral features. However, these methods are highly dependent on professional prior knowledge and the classification performance is greatly affected by hand-crafted spectral–spatial features, making the model generalization ability relatively weak [
17].
With the continuous development of deep learning, it has also received extensive attention in hyperspectral image classification tasks. This is attributed to its obvious advantages in mining feature representations that are conducive to HSI classification from the data itself, and thus, deep learning seldom relies on data prior information or professional knowledge. As a typical data-driven method, deep learning, such as stacked autoencoder (SAE) [
18] and deep belief network (DBN) [
19], usually uses principal component analysis (PCA) to reduce the dimension of HSI data to several bands. Hence, researchers have begun to develop more flexible deep models for HSI classifications. Among them, convolutional neural networks (CNN) have achieved state-of-the-art performance [
20,
21]; the one-dimensional convolutional neural network (1D-CNN) [
22] inputs each pixel as a vector in the spectral domain into the model to extract effective spectral features for hyperspectral image classification, while lacking the full use of spatial information. The classification method based on a two-dimensional convolutional neural network (2D-CNN) [
23] performs better with a smoother visual effect compared with that from the 1D-CNN method. However, there are still defects of 2D-CNN in retaining the spatial–spectral structure information of HSIs, and the ability to capture context information is weak. The classification method based on a three-dimensional convolutional neural network (3D-CNN) [
22] combines 1D-CNN and 2D-CNN to extract the spatial–spectral features of HSIs in a unified framework. Not only is the network structure simpler and more flexible, but also the classification effect is more obvious.
However, the performance of convolutional neural networks is determined by the size of the convolution kernel and the number of convolution channels, which results in a great limitation on the receptive field of the CNN model and the large difficulty in capturing long-range dependencies similar to spectral sequences [
24]. The Transformer [
25], which is developed in the field of natural language processing (NLP), has attracted rising attention due to its superior performance compared with convolutional neural networks [
26]. The application effect of the Transformer in the hyperspectral image classification task is also encouraging. Previously published research used the Transformer module for hyperspectral image classification, and some combined CNN for hyperspectral image classification. He et al. [
27] combined CNN with Transformer and used CNN and Transformer to extract spatial and spectral features, respectively. Qing et al. [
28] designed different Transformers for spatial and spectral features, and captured the long-range dependencies information through a self-attention mechanism. Yang et al. [
29] embedded CNN into the Transformer to extract detailed spectral features and local spatial information using CNN. Zou et al. [
30] proposed a local-enhanced spectral–spatial transformer (LESSFormer), which extracts the underlying features through CNN and forms feature patches, and further extracts local and global spatial-spectral features through Transformer, significantly improving classification performance. Tu et al. [
31] improved the way the original HSI features are embedded, allowing the Transformer module to more efficiently capture long-range dependencies between multi-scale features through local semantic feature aggregation.
The above deep learning methods are all trained in a supervised manner, and the classification performance is determined by the number and quality of labeled samples [
32]. For satellite hyperspectral images, the cost of obtaining large amounts of labeled samples is too high to afford. Moreover, there are usually problems involved in class imbalance in the limited labeled samples, which greatly limits the practical application in satellite hyperspectral image classification. Self-supervised learning [
33,
34] has been widely used in the field of computer vision, with an obvious advantage that the training hardly relies on labeled samples. Therefore, studies on self-supervised learning have been well documented in HSI classification. Wang et al. [
35] conducted concatenate contrastive learning at sub-pixel, pixel, and super-pixel levels based on multi-scale features in the spatial domain. Zhu et al. [
36] also used multi-scale patches in the spatial domain as learning objects and put efficient asymmetric dilated convolution (EADC) into the contrastive learning framework to realize the learning of consistent features in the neighborhood of the target pixel. While ensuring accuracy, the computational efficiency has been improved. Some works constructed multi-views of the same scene through PCA [
37,
38]. After a certain augmented transformation, they used a contrastive learning framework for consistent feature learning. It can be seen that the self-supervised learning strategy based on contrastive learning has achieved good research results in hyperspectral image classification tasks. Guan et al. [
39] considered both spectral and spatial information and found shared information between the spatial domain and spectral domain through a contrastive learning framework to extract high-level semantic information that is helpful for classification. Hu et al. [
40] introduced Transformer into the bootstrap your own latent (BYOL) framework to replace 2D-CNN for feature extraction, but the model reshaped the original data into a one-dimensional sequence, which destroyed the spatial dependence in the two-dimensional space.
The self-supervised learning strategy based on contrastive learning has achieved good research results in hyperspectral image classification tasks. However, under practical application scenarios such as satellite hyperspectral image classification, there are still the following problems to be solved. First of all, although the use of PCA to generate spatial multi-views can reduce the redundant information between various bands [
37], the spatial contrastive learning on the same principal component has difficulty in augmenting the diversity of samples. More importantly, there is an obvious lack of mining of spectral feature similarity of hyperspectral data, which will reduce the robustness of the model [
41]. Secondly, the previous algorithms have shown that classifiers using only spatial features or spectral features will limit the improvement of classification performance. The combination of spatial and spectral features is the mainstream practice of feature extraction in supervised hyperspectral image classification. However, under the self-supervised framework, it is difficult to process cross-domain information. Finally, in satellite hyperspectral images, the distribution of ground objects is often uneven, leading to the widespread problem of class imbalance. Classifiers need to adapt the characteristics of satellite hyperspectral images.
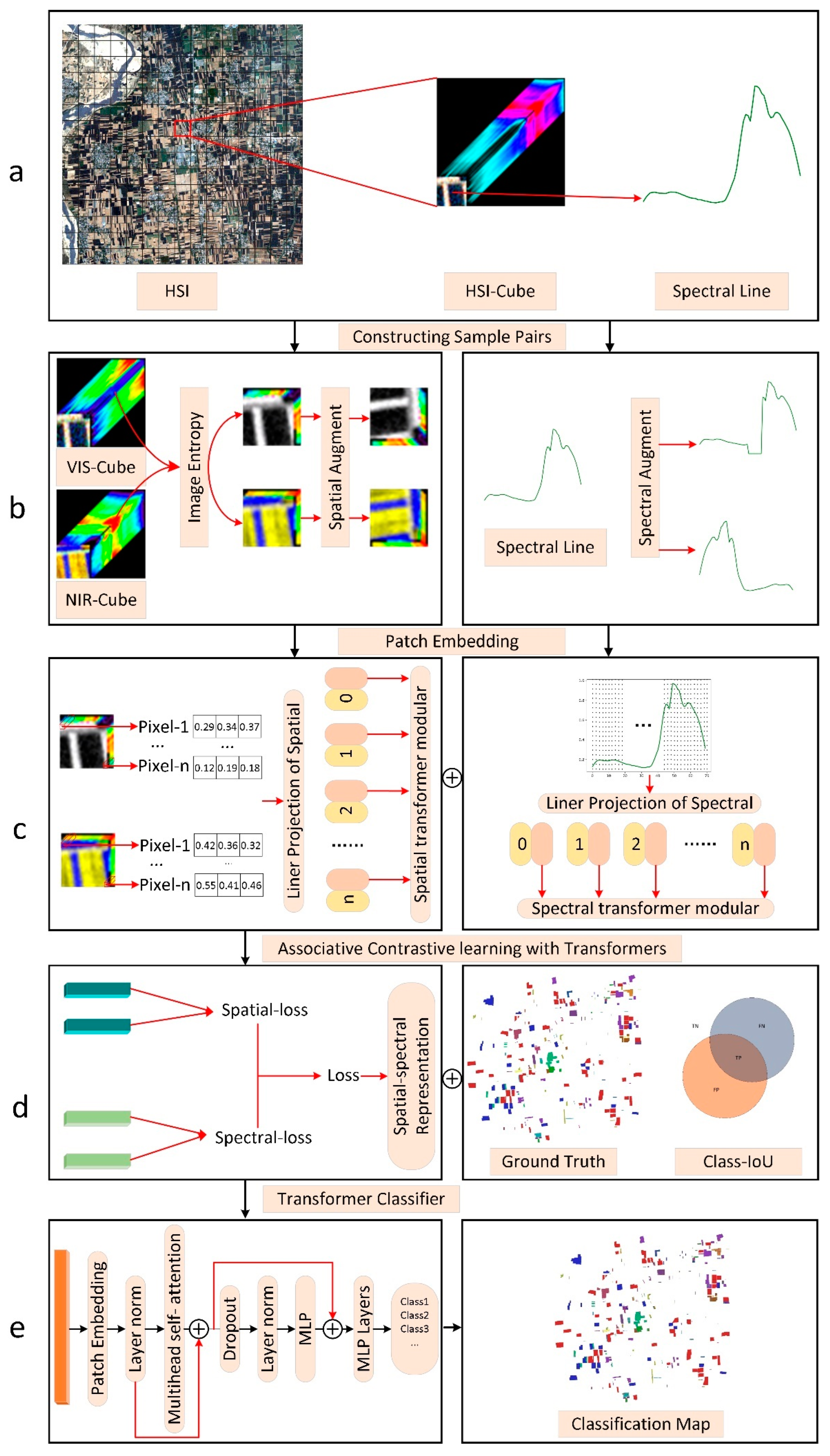
To solve the above problems, we propose a satellite hyperspectral image classification method based on spatial–spectral associative contrastive learning (SSACT), which is completely based on the Transformer network. The biggest highlight of SSACT is that it can capture the long-range dependence of temporal sequence data, which significantly enhances the ability in extracting spectral detail features and spatial dependence of hyperspectral data. SSACT performs both spatial and spectral invariant features of hyperspectral data in a self-supervised manner under a unified contrastive learning framework, and further realizes feature fusion by associative training. SSACT develops a classifier based on the contrastive learning Transformer framework to learn the fusion features and complete the hyperspectral image classification. Our main contributions are as follows:
The study innovatively builds the Transformer-based associative contrastive learning framework for satellite hyperspectral image classification, which helps to learn the unique features of the spatial domain and spectral domain simultaneously, and improves the feature representation ability and classification performance of the model;
We introduce the image entropy module to extract certain bands with rich spatial information and increase the diversity of spatial domain samples, which improves the robustness of spatial contrastive learning;
The pixels in the spatial domain and the blocks in the spectral domain are added as the learning embedding units of the Transformer, respectively. The multi-head attention mechanism of the Transformer is used to extract the spatial dependence and spectral detail features of the target pixel, which is beneficial to the fusion expression of spatial–spectral features;
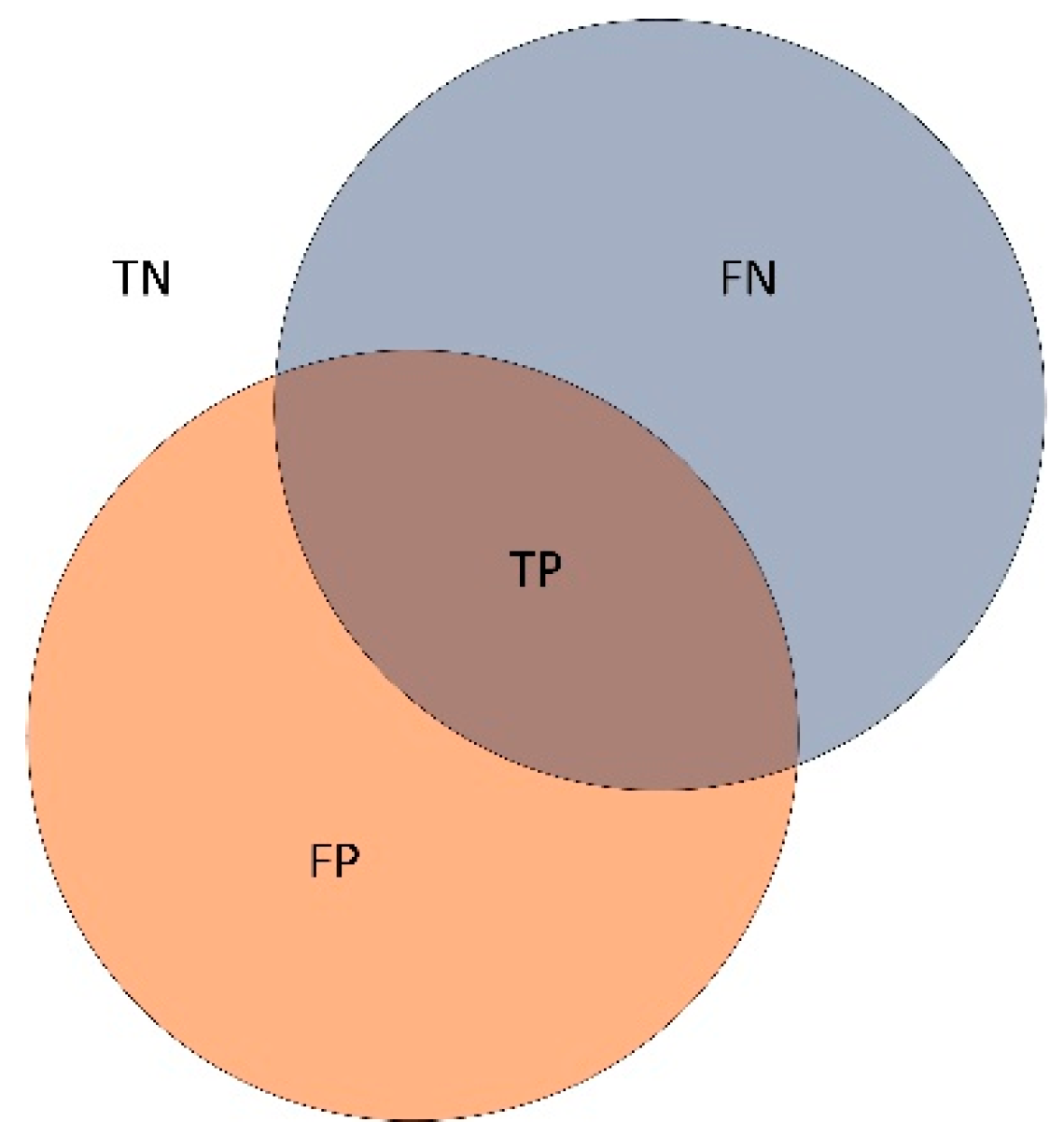
We introduce the class intersection over union into the classification loss function, which effectively diminishes the inter-class classification difference caused by the class imbalance of samples. The effectiveness of the algorithm is proved by the satellite hyperspectral image classification experiments.
The remaining part of the paper proceeds as follows.
Section 2 introduces the experimental datasets, which include two real satellite HSI datasets, and describes the proposed spatial–spectral–associative contrastive learning with Transformers for satellite hyperspectral image classification.
Section 3 analyzes the experimental results of the proposed method and the compared methods. Conclusions are summarized in
Section 4.
3. Results
In this part, firstly, the parameter settings involved in the experiment are described in detail. Secondly, the comparison algorithm and its parameter setting are introduced, and the experimental results under small sample conditions are quantitatively analyzed. Finally, extra experiments were performed on the relevant modules to illustrate the effectiveness of SSACT. During the experiment, the software environment is the following: Pytorch version is 1.12, and the python version is 3.7. The hardware environment is the following: 12th Gen Intel (R) Core (TM) i7-12700K 3.61GHz, 32GB memory, and GPU is RTX 2080Ti.
3.1. Experimental Setup
SSACT includes two stages. In the spatial–spectral associative contrastive learning stage, assuming that the input hyperspectral data is , we slice it with a spatial neighborhood size of 10 grids to obtain a hyperspectral image cube subset . Then, the image entropy of HSI cube subset in different bands is calculated, and the three bands with maximum entropy are selected to construct positive sample pairs. The spatial and spectral data augmentation probability is 0.5. The training epoch of associative contrastive learning is 100, the batch size of the model is 64, the initial learning rate is 0.001, the learning rate is attenuated according to the cosine annealing algorithm, and the temperature coefficient is 0.5, respectively. The output dimensions of the spatial contrastive learning and spectral contrastive learning models are both 128; hence, the feature output after associative contrastive learning is 256 dimensions in total. In the classification stage, the training epoch of hyperspectral image classification is 200, the batch size of the model is 16, the initial learning rate is 0.0001, and the learning rate is attenuated according to the cosine annealing algorithm. All models select the Adam optimizer to update the model parameters. Albeit these models are all constructed based on Transformer, the structural depth varies at different stages. Especially, in the former, the depth of the Transformer is 3 and the heads are set to 12, while in the latter, the depth of the Transformer is 1 and the heads are set to 9.
3.2. Classification Results under Class Imbalance
To verify the classification performance of SSACT, we selected seven classification algorithms with superior performance in spatial feature extraction and spectral feature extraction, including 2D-CNN [
23], 3D-CNN [
22], spectral–spatial residual network (SSRN) [
17], hybrid spectral CNN (HybridSN) [
52], spectral–spatial attention network (SSAN) [
53], vision Transformer (ViT) [
26], and deep multiview learning (DMVL) [
37]. For maintaining a homogeneous experimental condition between different algorithms, we refer to the practice provided by Chen et al. [
54]; the hyperspectral image to be classified is uniformly divided into a subset of hyperspectral images with a patch size of 5, and the training epoch is set to 200. The training and verification ratio is consistent with SSACT, both of which are 0.1. It should be noted that the samples are randomly selected according to the proportion between different classes, and the situation of class imbalance is retained. The classification result graphs are performed on all sample data.
We use overall accuracy (OA), average accuracy (AA), and the Kappa coefficient (Kappa) to quantitatively evaluate the classification performance of various algorithms. Among them, AA is the average of the classification accuracy of the classifier in each class, which is very effective for the evaluation of class imbalance classification tasks. This paper explains the classification accuracy of each class based on AA in detail. For the convenience of statistics, all the evaluation indexes are presented in the range of 0–100 after normalization, and the best result is bold. The classification results of different classification models on two datasets are shown in
Table 3 and
Table 4, and mark the best results in bold.
By analyzing the results of quantitative experiments, we can draw some obvious conclusions:
Compared with other comparison algorithms, SSACT has the best overall performance on OA, Kappa, and especially AA, which is significantly better than the CNN-based supervised deep models;
When the training samples are particularly small, it is difficult for the CNN-based classification model to extract useful features. For example, the training samples of class 5 and class 9 of the GF14 dataset are only 40 and 15, respectively. The CNN-based classification model cannot correctly identify the corresponding classes, thus the classification accuracy rate is very poor, while with the support of Class-IoU, the classification accuracy of SSACT can reach as high as 77.56% and 78.76%, respectively, being a huge progress compared with the traditional model;
A simple combination of spatial–spectral features is difficult to achieve satisfying classification performance, such as 2D-CNN, 3D-CNN, SSRN, HybridSN, and SSAN. However, our models can effectively fuse spatial–spectral features and obtain the best classification performance on the two datasets, which also shows the importance of associative extraction of spatial–spectral features;
The DMVL based on contrastive learning can extract features without labeled samples, while ViT has a certain competitiveness in comprehensive performance, which is inseparable from the excellent performance of the Transformer. SSACT makes full use of the excellent performance of contrastive learning and Transformer in feature extraction without labeled samples, and obtains satisfactory results in the situation of small sample classification.
Specifically, we observe the first three classes with the least number of samples in the two datasets. SSACT achieves the best classification performance in five classes, and only lower than ViT in one class. In terms of AA, the performance of SSACT on two datasets is 83.63% and 85.15%, respectively, which is 26.74% and 43.1% higher than other algorithms on average. In addition, the OA values of SSAN are close to SSACT, but it is clear that SSAN has a large gap with SSACT in AA values, which also shows that the Class-IoU plays an important role in solving the problem of class imbalance.
In addition to OA, AA, Kappa, and other indicators, we can also intuitively view the classification performance of the classification model from the classification result graph. The classification results of several algorithms on the two datasets are shown in
Figure 6 and
Figure 7.
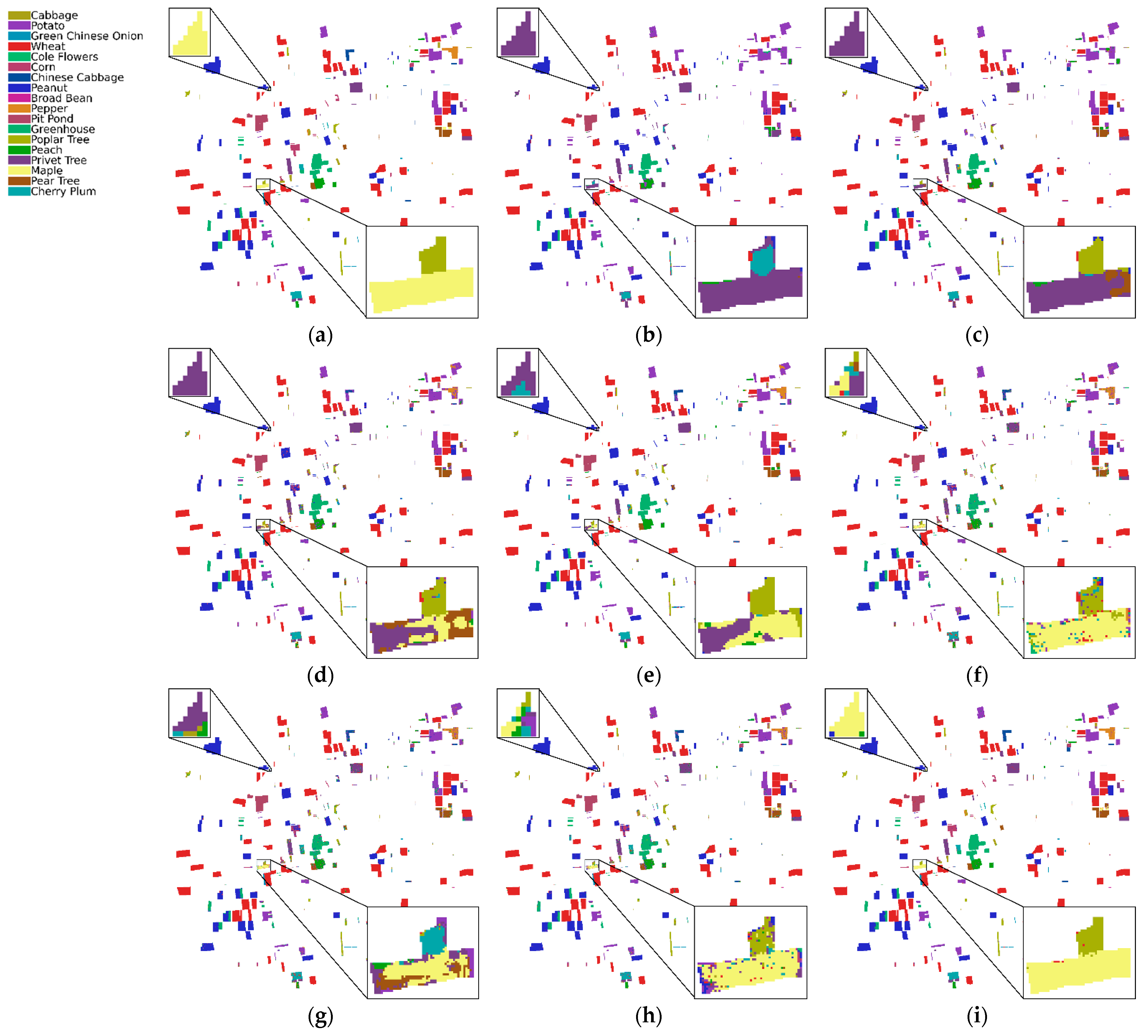
Figure 6 shows that SSACT has relatively few noise points. In order to better illustrate the classification effect, we have enlarged some areas. From the left enlarged region, it can be seen that supervised classification algorithms such as SSRN have poor classification results for class 1 and SSACT and SSAN have better classification results for class 1. From the enlarged area on the right side, it can be seen that SSACT can better classify class 6 and obtain a pleasing ‘Green’, while other algorithms have poor classification results. This is because the number of training samples for class 6 is small, which also shows the role of Class-IoU in solving the problem of class imbalance.
The GF14 satellite hyperspectral image dataset is the closest to the practical application. The distribution of different objects is obtained by field mapping. The cost of obtaining labeled samples is very high, but it gives us an important reference for satellite hyperspectral image classification research. From the overall classification effect, the noise and misclassification of SSACT are less than other algorithms, reflecting better classification performance. We have enlarged some of the classification results for class 16. From the left enlarged region, it can be seen that the classification effect of the seven comparison algorithms on class 16 is not ideal. It is common to misclassify class 16 into category 15, indicating that there are similar features between class 16 and class 15, and the classifier is difficult to distinguish. Note that SSACT can better distinguish between class 16 and class 15, which fully shows that the spatial–spectral–associative contrastive learning framework proposed in this paper can better extract diagnostic features, thereby enhancing the classification performance of the classifier.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
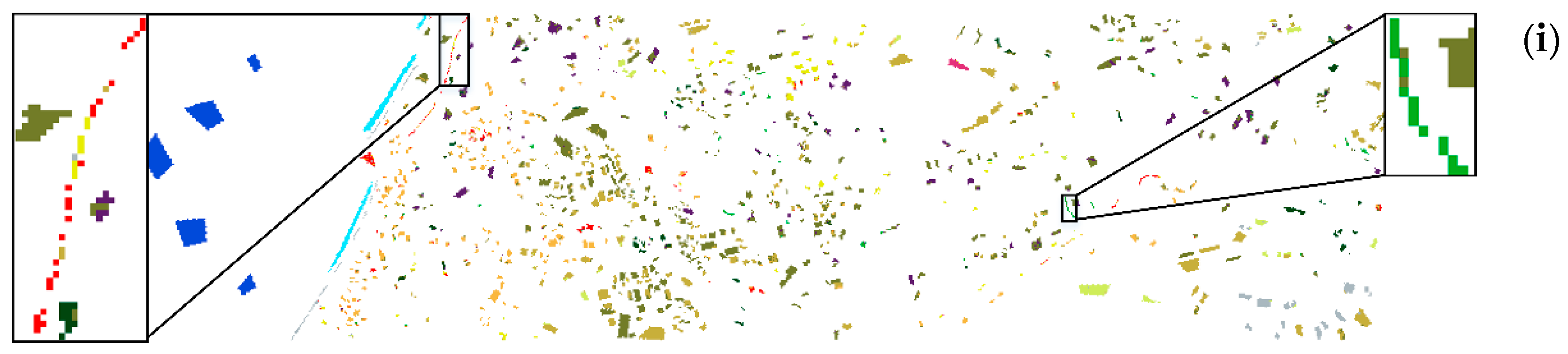{kind=link}
{kind=link}