1. Introduction
Hyperspectral images (HSI) have gained widespread use due to their ability to provide extensive spectral and spatial information [
1]. With hundreds of bands, HSIs can distinguish surface materials based on their unique spectral characteristics with exceptional spectral resolution. This feature makes them highly valuable for various applications, including vegetation surveys, atmospheric research, military detection, environmental monitoring [
2] and landcover classification [
3]. HSIC is a key research area within the hyperspectral field and involves the classification of individual pixels based on the rich spectral information they contain. As hardware technology continues to improve, the spatial resolution of hyperspectral sensors also increases, allowing for the incorporation of spatial information from surrounding pixels in classification efforts. Currently, the combination of spectral and spatial features is the primary approach in the HSIC field [
4].
The abundance of bands in HSI presents a significant challenge in classification. Processing such large amounts of data directly without reduction would require a network of immense scale and huge computational memory. Furthermore, high spectral resolution creates spectral redundancy, which can be addressed through dimensionality reduction techniques that preserve critical information while reducing data size. Feature extraction is a widely used method for reducing data dimensions in HSI by extracting or sorting effective features for subsequent use. Common methods for feature extraction include principal component analysis (PCA) [
5], independent component analysis (ICA) [
6], linear discriminant analysis (LDA) [
7], multidimensional scaling (MDS) [
8], etc. These algorithms are still widely used as preprocessing methods due to their simplicity and effectiveness. With the increasing maturity of deep learning algorithms, more sophisticated algorithms are being developed to extract features from HSIs. Presently, the prevalent classification method involves using supervised or unsupervised feature extraction algorithms to extract spectral or spatial–spectral features, followed by classifier training using the extracted features.
The earlier developed feature extraction algorithms were based on supervised deep learning. In supervised learning, convolutional neural networks (CNNs) play an crucial role, evolving from one-dimensional CNNs [
9] that only extract spectral features to two-dimensional and three-dimensional CNNs [
10] that extract both spatial and spectral information. Roy et al. proposed the HybridSN network, which combines 2D and 3D convolutions to further enhance classification accuracy [
11]. Zhong et al. introduced the classic residual network into the hyperspectral domain and designed the SSRN network [
12]. Zhong et al. combined attention mechanism and CNNs [
13]. Apart from CNNs, deep recurrent neural networks (DRNN) [
14], deep feed-forward networks (DFFN), and other networks have also achieved promising results in HSIC.
However, supervised learning often heavily relies on labeled data, necessitating a sufficient number of labeled samples to achieve optimal training results. In the case of HSIs, both data collection and labeling involve significant human and time costs. Consequently, in recent years, the focus of feature extraction algorithms has gradually shifted towards unsupervised deep learning. The fundamental difference between unsupervised learning and supervised learning lies in the fact that the training data of unsupervised learning are unlabeled, and samples are classified based on their similarities, reducing the distance between data of the same class and increasing the distance between data of different classes. Without the constraints of labels, unsupervised learning can unleash the potential of models, enabling them to autonomously discover and explore data, learn more latent features, and ultimately result in models with better robustness and generalization. Unsupervised learning can be divided into generative learning and discriminative learning. Generative models learn to model the underlying probability distribution of input data. They are trained on large amounts of data and leverage this information to synthesize new samples that resemble the original data. The most basic generative deep learning algorithms include autoencoders (AE) [
15] and generative adversarial networks (GAN) [
16]. Variants of AEs, such as the adversarial autoencoder (AAE) [
17], variational autoencoder (VAE) [
18], and masked autoencoder (MAE) [
19], have been widely used for feature extraction in hyperspectral image analysis. GANs optimized with algorithms such as deep convolutional GAN (DCGAN) [
20], information maximizing GAN (InfoGAN) [
21], and multitask GAN [
22] have also achieved remarkable results in HSIC.
Discriminative learning models the conditional probability and learns the optimal boundary between different classes. Contrastive learning is a typical discriminative learning algorithm in deep learning, which aims to acquire representations by contrasting positive and negative pairs in the latent space. Positive pairs are spatially close but spectrally similar patches, whereas negative pairs are either spectrally dissimilar or spatially distant patches. By minimizing the distance between positive pairs and maximizing the distance between negative pairs, the model learns to encode both spatial and spectral information in the latent space.
Contrastive learning has made rapid progress in recent years, and many variants such as Moco [
23], SimCLR [
24], BYOL [
25], SwAV [
26], and SimSiam [
27] have been proposed and gradually applied in the field of hyperspectral data analysis [
28]. These methods differ in their choice of contrastive loss, encoder architecture, and training strategy. However, they share a common goal of learning representations that capture the underlying structure of hyperspectral data. Furthermore, the key to contrastive learning is to prevent model collapse, which means that all data converge to the same constant solution after feature representation.
For contrastive learning, we can integrate additional optimization techniques to encourage the model to learn more representative features while ensuring that it does not collapse. In handling the spatial–spectral features of HSIs, spatial and spectral information are often combined into the same sample. Although this approach is simple and compensates for the lack of spectral information, directly inputting the entire sample cube into the model results in a significant amount of redundant information interfering with feature extraction. Some studies have separated spatial and spectral information into different samples and used cross-domain contrastive learning to extract them separately [
28,
29,
30]. This approach can reduce a lot of redundant information but may also lead to the loss of valuable sub-key information. Coordinating the extraction of spatial and spectral information, preserving useful information as much as possible, reducing the interference of useless information, and increasing the model’s attention to key information are essential for improving the efficiency of contrastive learning.
In this study, we incorporated multiple optimization strategies into contrastive learning to improve feature extraction. These strategies include band erasure (BE), random occlusion (RO) [
31], and gradient mask (GM). The motivation of our study is to greatly improve the feature extraction effect and unlock the potential of the model by adding new data augmentation methods while the model remains unchanged. Experimental results have shown that each of these strategies can significantly improve feature performance and classification accuracy. Furthermore, when combined, they can lead to unexpected improvements.
In the following sections, we will first introduce the relevant algorithms’ background knowledge (
Section 2). Then, we will provide a detailed description of our proposed method’s overall framework and each module (
Section 3). Next, we will describe and analyze our comparative and ablation experiments (
Section 4). Finally, we will present our conclusions (
Section 5). The main contributions of this study are as follows:
- (1)
We propose the band erasure strategy to improve spectral features extracted by contrastive learning.
- (2)
We propose the gradient masking strategy to enhance the model’s attention to key areas, reduce attention to edge positions, and minimize the interference of useless information on features.
- (3)
We propose the Unlocking-the-Potential-of-Data-Augmentation (UPDA) strategy, which involves adding superior data augmentation methods to improve the features extracted by contrastive learning. We used UPDA in the BYOL structure and improved the classification accuracy to a new level.
3. Method
In this section, we provide a detailed introduction to the UPDA method and its application in the BYOL structure. Specifically, we first present the overall framework of the proposed method, followed by a detailed explanation of the newly proposed data augmentation methods, band erasure and gradient mask. Finally, we describe in detail the process of contrastive learning training and training of a classifier using the extracted features.
3.1. Framework of the Method
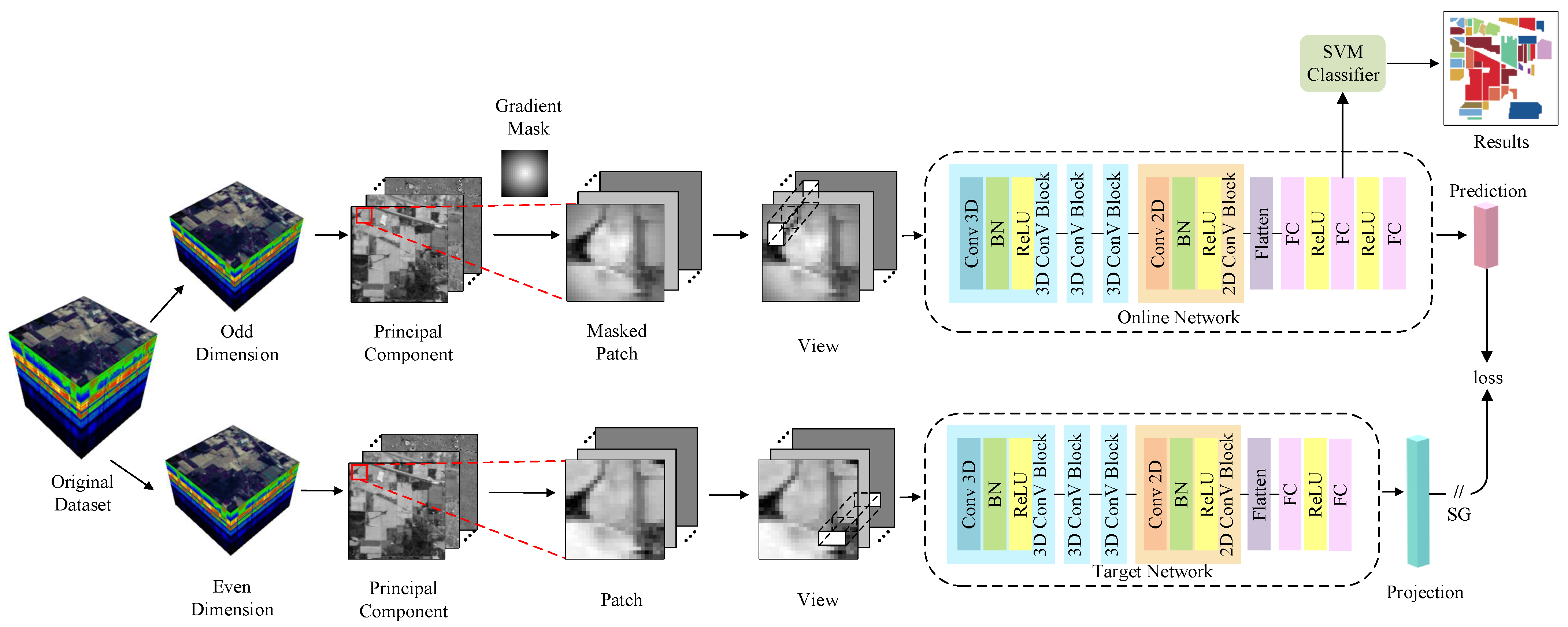
Figure 1 illustrates the framework of the proposed method, which mainly consists of the UPDA process and the contrastive learning feature extraction process, with the former including data preprocessing.
Let be the original input hyperspectral image, where h and w are the height and width of the image, and c is the number of bands. First, the data are subjected to band erasure, where odd and even layers are erased separately to obtain two parts, and , forming two branches.
PCA is then performed on each branch to reduce dimensionality, and the resulting samples are segmented into patches: and . The patches in the upper branch are weighted using a gradient mask, whereas the patches in the lower branch are not processed. Then, both of them are randomly masked to obtain the views and , which are input into the BYOL structure.
The upper branch of the BYOL structure is an online network, while the lower branch is a target network. The former has an additional linear layer, i.e., the predictor. The loss value is calculated based on the outputs of the upper and lower branches and used to update the network parameters.
After pretraining, the results of the projector are saved as features and input into the SVM classifier for training to complete classification or other downstream tasks. In this way, features are easily migrated between different machines, so that we can extract features on machines with high configuration and complete downstream tasks on any machine. For more detailed information, please refer to the following two subsections.
3.2. Unlocking the Potential of Data Augmentation
3.2.1. Band Erasure
The essence of band erasure is to divide the original HSI into two datasets with non-overlapping bands. In this process, odd and even layers are extracted at intervals, resulting in two datasets that are obtained by erasing half of the bands from the original data and have non-overlapping bands. Band erasure can improve the representativeness of subsequent feature extraction. On the one hand, because hyperspectral data have high spectral resolution and spectral information has a large redundancy, removing half of the bands will not lose critical spectral information and can reduce the interference of redundant information in each branch on feature extraction. On the other hand, the data in the two branches after band erasure are complementary. During the training process of contrastive learning, in order to make the loss function converge, the model tends to focus on shared information and reduce attention to unimportant details. This shared information is often the essential features. We have tried different erasing strategies, such as removing a string of continuous bands or leaving only 1/4 or 1/3 of the total number of bands; however, they are not as effective as the current erasure strategy.
The c spectral bands are divided into and bands, where , resulting in and . PCA is then performed on each branch, and the first d principal component maps are selected. The value of d varies depending on the dataset, with 30 for the IP dataset and 15 for the PU and SA datasets. The principal component maps are then segmented into patches using a sliding window of size with a stride of 1, resulting in cubes. Here, s is set to 25, and the edges are padded with zeros. Two sets of patches, and , are obtained, where N is the number of valid pixels, and the corresponding labels are . The patches contain both spectral and spatial information, with the spectral information compressed by PCA. The class of the center pixel represents the class of the entire patch, so it can be said that the spatial and spectral information closer to the center pixel is more important.
3.2.2. Gradient Mask
The essence of a gradient mask is a weight matrix with the highest value at the center and decreasing values as they move away from the center. The size of the matrix is
, which is the same as the patch size. The label of the patch is determined by the label of the center pixel, so we can infer that the closer to the center of the patch, the more critical the information. The purpose of setting a gradient mask is to reduce the model’s attention to spatial and spectral information at the patch edges and to increase its attention to the key information at the center. It can be said that this is a forced attention transfer method. Specifically, we set the weight of the center to 1 and the weight of the four vertices to 0 and interpolate the other values linearly based on their distance from the center. The weight calculation formula is as Equation (
1).
where
is the location of element in the gradient mask,
is the location of central element, and
.
is the resulting gradient mask.
The resulting mask is displayed as a grayscale image in
Figure 2. The gradient mask is multiplied element-wise with patches
to obtain
, whereas P1 is not processed with the gradient mask. The specific processing process is multiplication of the mask with the corresponding position element of each layer of the patch to obtain a weighted new patch. This ensures that the input samples of the upper and lower branches have small differences at the center and large differences at the edges. During the training process of contrastive learning, in order to achieve the goal of reducing the loss function of the upper and lower branches, the model gradually reduces its attention to the edges of the patch and focuses more on the key information at the center.
3.3. Contrastive Learning
We put into the BYOL structure, where is input to the online network, which is then encoded to obtain the representation . The representation is then obtained through a projector, and the predicted result is obtained through a predictor. On the other hand, is input to the target network, which is then encoded to obtain , and the representation is obtained through a projector. Specifically, the encoder consists of three 3D convolutional layers, a convolutional layer, and a fully connected layer. After convolution, the output is flattened and then input to the fully connected layer. Each layer is followed by batch normalization and a ReLU activation function. The projector consists of a fully connected layer, batch normalization, and a ReLU activation function. The predictor is a narrower fully connected layer, also followed by batch normalization and a ReLU activation function.
The computation process of the online and target networks can be represented by Equations (
2) and (
3). For BYOL, its optimization objective is for the positive examples of the online network to approach the positive examples of the target network in the representation space. Therefore, we update the parameters of the online network using a loss function and update the parameters of the target network using an exponential moving average based on the parameters of the online network, with the update step controlled by the hyperparameter
. The loss
is calculated based on the outputs of the two branches. First, we perform L2 normalization on
and
,
,
and then take the L2-normalization of their difference, as shown in Equation (
4).
As the BYOL structure is asymmetric, in order to fully utilize the data, we exchange the input patches of the two branches, i.e., inputting
to the target network and
to the online network, and calculate the loss function
. It can also greatly increase the efficiency of optimization. The loss function of BYOL is shown as Equation (
5):
is the symmetric loss and we update the parameters according to it. The process of parameter update can be represented as Equations (
6) and (
7):
where
is the parameter of the online network, while
is the parameter of the target network.
is the learning rate and
is the weight of parameter update. ← means assignment.
After reaching the specified number of iterations during training, we save the parameters of the encoder and projector and use the output of the projector as features inputted into the downstream task. In order to evaluate the ability of the contrastive learning model to extract features after introducing UPDA, we use the classical SVM classifier as the downstream task, with classification accuracy as the indicator to evaluate the performance of the features.
We split the sample patches into training and testing sets and use the features of the training set to train the classifier. The features of the test set are input to the trained classifier to obtain the classification result . According to and , we calculate the accuracy of every class, the overall accuracy (OA), and the average accuracy (AA).
4. Experiments and Results
In this section, we report some classification experiments based on our method, and provide a detailed analysis of the experimental results.
4.1. Datasets
In the classification experiments, three publicly available datasets are used to show the superior performance of our method UPDA, including the Indian Pines (IP), Pavia University (PU), and Salina (SA) datasets.
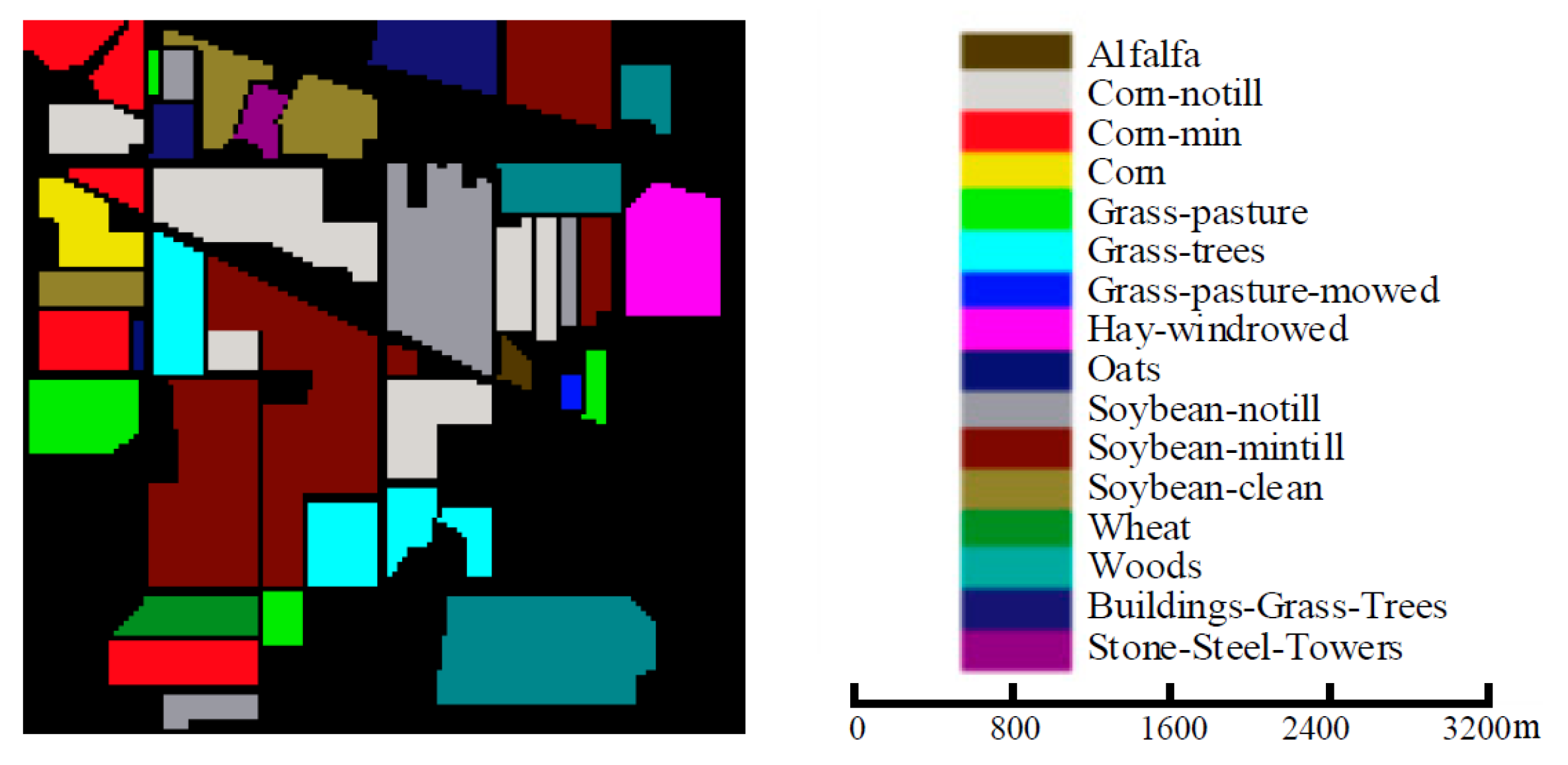
The IP dataset was gathered by the AVIRIS sensor over the Indian Pines test site in northwestern Indiana. It includes 145 × 145 pixels and 224 spectral reflectance bands within the wavelength range of
m. After eliminating bands covering water absorption regions, 200 bands remained, and the ground truth was composed of 16 classes. However, the dataset suffers from an uneven sample size issue, with the largest class having over 2000 samples and the smallest class having only 20 samples. Additionally, the dataset has a relatively low spatial resolution, which poses a challenge for classification. For more information on the IP dataset, please refer to
Figure 3 and
Table 1.
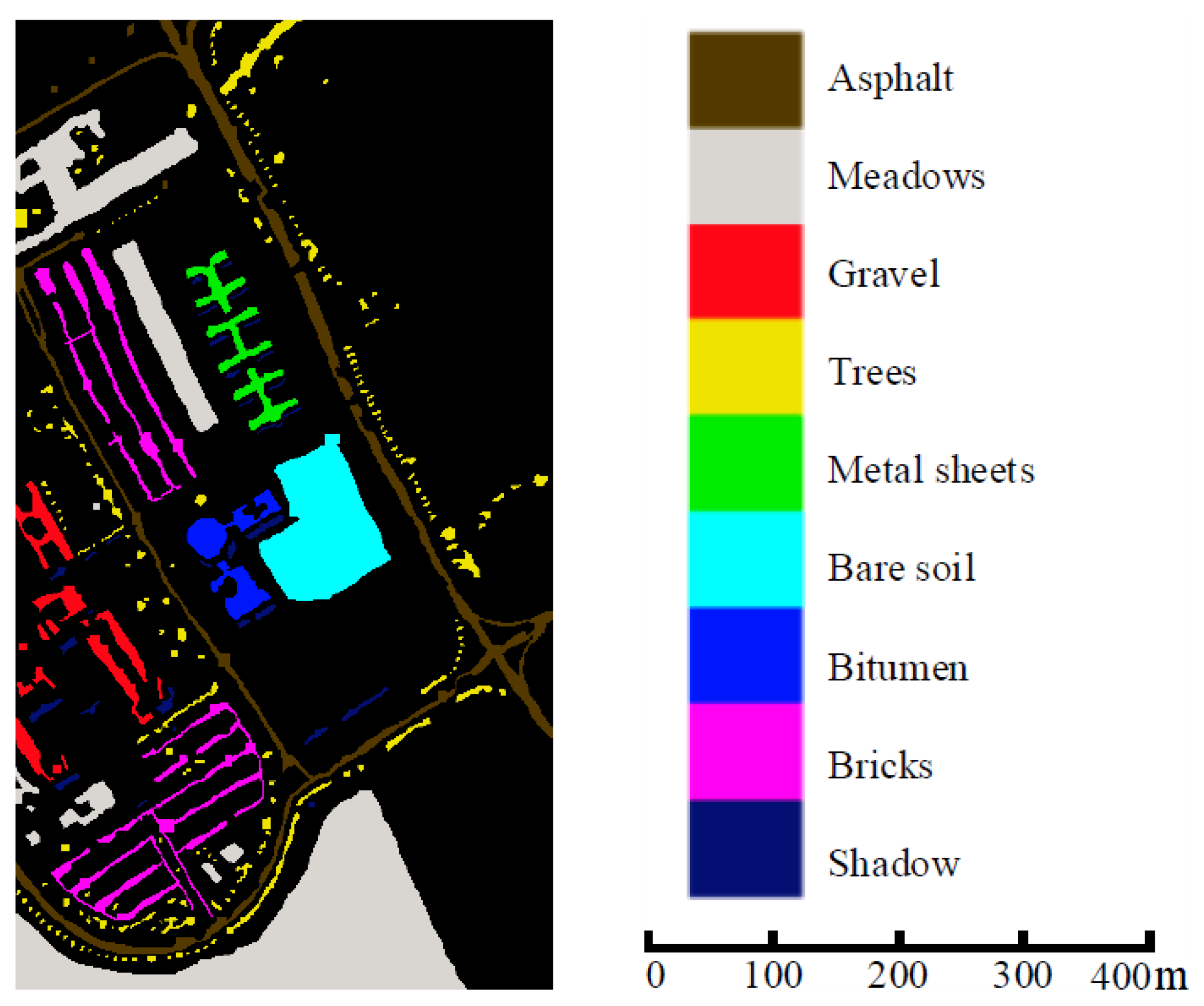
The PU dataset comprises of 610 × 340 pixels and 103 spectral bands within the wavelength range of
m. The ground truth is composed of nine classes. This dataset is characterized by complex background pixels, small connected regions, and numerous discontinuous pixels. Moreover, its wavelength range is smaller than the other two datasets, resulting in less spectral information. For more information on the PU dataset, please refer to
Figure 4 and
Table 2.
The SA dataset is an image with 512 × 217 pixels and 224 spectral bands within the wavelength range of
m. After removing 20 water-absorbing bands, 204 spectral bands remain, and the ground truth is composed of 16 landcover classes. Compared to the other two datasets, the SA dataset is easier to classify due to its fewer obvious flaws such as uneven samples, low resolution, or complex background. For more information on the SA dataset, refer to
Figure 5 and
Table 3.
4.2. Experimental Settings
We designed the backbone network for contrastive learning based on structure of HybridSN, which consists of 3D convolutional layers, and 2D convolutional layers, and the specific network shape of online network and target network are shown in
Table 4.
We set the batch size to 128 and the size of the input patch
s, to
. Considering the low spatial resolution and uneven samples of the IP dataset, the principal component maps were taken as the first 30 for the IP dataset and the first 15 for the PU and SA datasets. In training the classifier, all available labeled pixels were divided into training and testing sets, 10% were randomly selected as training sets for the IP and PU datasets, and 5% for the SA dataset. The number of contrastive learning epochs was set to 50. The coefficient of EMA,
, was set to 0.99. The selection of the above parameters is partly based on [
11,
25] and partly verified by experiments.
In order to verify whether the patch size
s and the number of principal component graphs
d are appropriate, we conducted some verification experiments on the IP and PU dataset. Indeed, when
and
, the features extracted by BYOL make the classifier to achieve the highest classification accuracy on the IP dataset, while
on the PU dataset. The results are shown in
Table 5,
Table 6 and
Table 7.
As for the SVM classifier, we chose “rbf” kernels, the penalty coefficient was set to 10 or 100, and the gamma was set to 0.01 or 0.001. They were obtained through experimental traversal.
The hardware configuration for the experiment was as follows: NVIDIA GeForce GTX 1660 SUPER GPU, Intel Core i7-10700 CPU, and 16 GB DRAM. The software configuration included Windows 10, Python 3.8, Pytorch 1.8.0, and Scikit-learn 0.24.2.
Two well-known metrics were used to evaluate the performance of different methods: accuracy (OA) and average accuracy (AA). All experiments were repeated three times, and the mean values of the results were recorded.
4.3. Classification Performance
To prove the superiority of our method, seven other unsupervised feature extraction methods were adopted as a baseline for comparison: PCA, tensor principal component analysis (TPCA) [
36], stacked sparse autoencoder (SSAE) [
37], unsupervised deep feature extraction (EPLS) [
38], 3D convolutional autoencoder (3DCAE) [
39], ContrastNet [
40], and basic BYOL [
25].
The classification results in the IP dataset are shown in
Table 8. Our method obtains the best OA and AA values, and performs the best in 10 classes, particularly in classes 3, 4, 10, 11, 14, and 15. In classes with very few samples such as Alfalfa, Oats and Stone-Steel-Towers, our method leaves some room for improvement, and in classes with small inter-class gaps, “UPDA + BYOL” is good at distinguishing them, such as class Corn-nottill, Corn-mintill, Corn, Grass-pasture, Grass-trees, Grass-pasture-mowed, Soybean-nottill, Soybean-mintill, and Soybean-clean, which belong to different stages of the same crop. The introduction of UPDA increases the OA of BYOL by 2.29%, and increases the AA by 2.84%, which is a giant leap.
The classification results in the PU dataset are shown in
Table 9. The OA and AA of our method are the highest and it obtains the best accuracy in six of nine classes. Particularly in classes 1, 2, 3, 6, 7, and 8, “UPDA + BYOL” performs much better than the other methods. Regrettably, in the class shadows “UPDA + BYOL” is not as good as the baselines. We guess that the ground cover of the class shadows is not single and our method tends to divide different material in the same class. In addition, our method outperforms the original BYOL in every class, OA, and AA, which demonstrates the effect of introducing UPDA. Furthermore, the introduction of UPDA increases the OA of BYOL by 1.51% and increases the AA by 3.46%.
The classification results in the SA dataset are shown in
Table 10. “UPDA + BYOL” performs the best in OA, AA, and all classes except classes 1, 6, 11, and 12. After introducing UPDA, the OA, AA, and accuracy values in each class are all close to 100%, and the introduction of UPDA increases the OA of BYOL by 0.47% and increases the AA by 0.46%, which demonstrates that our method has excellent performance on ideal datasets.
The time consumption of our method and ContrastNet on three datasets are shown in
Table 11. Time consumption of our method is significantly shorter than ContrastNet.
Overall, our method achieves the best results on the three datasets and greatly outperforms other comparative methods.
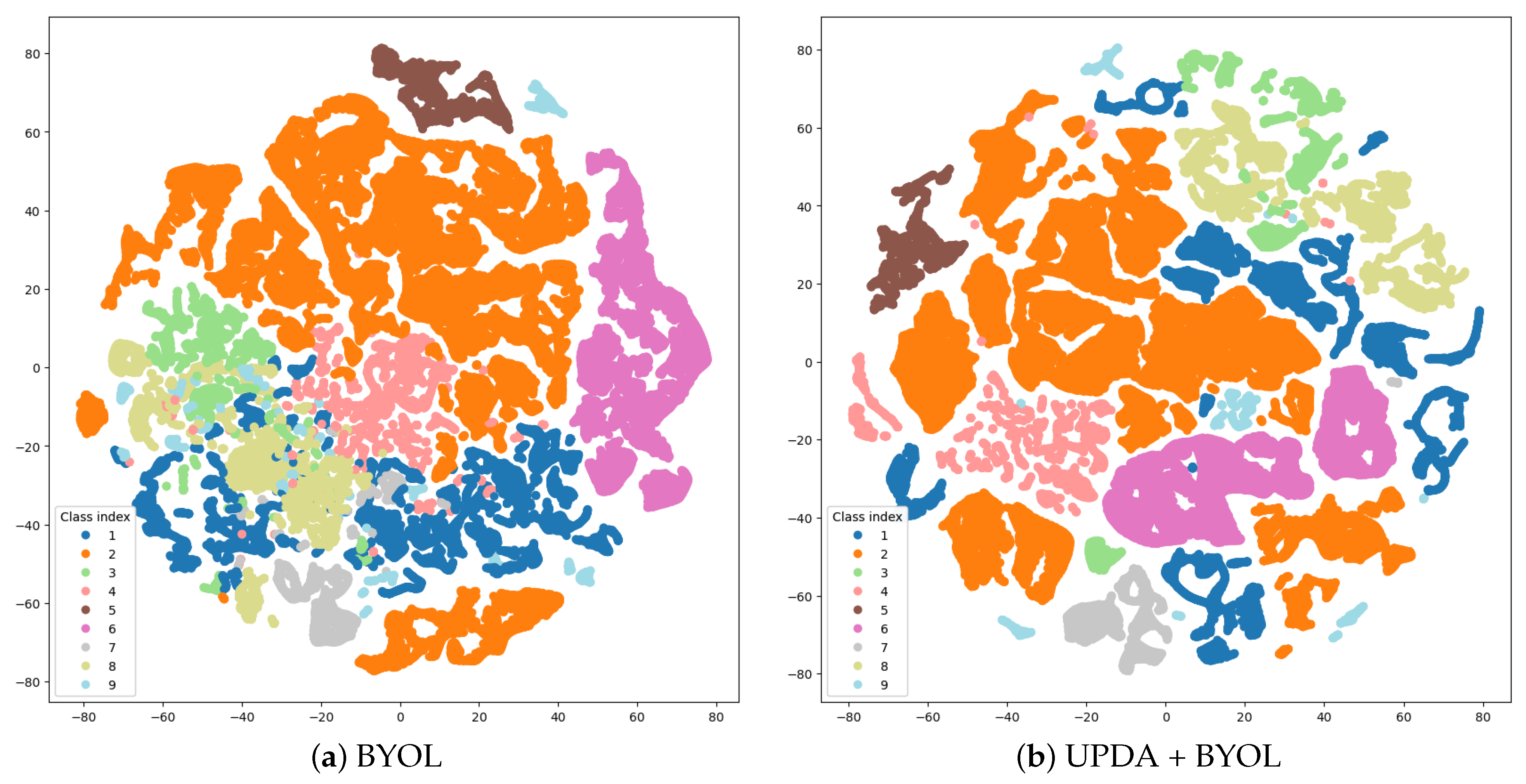
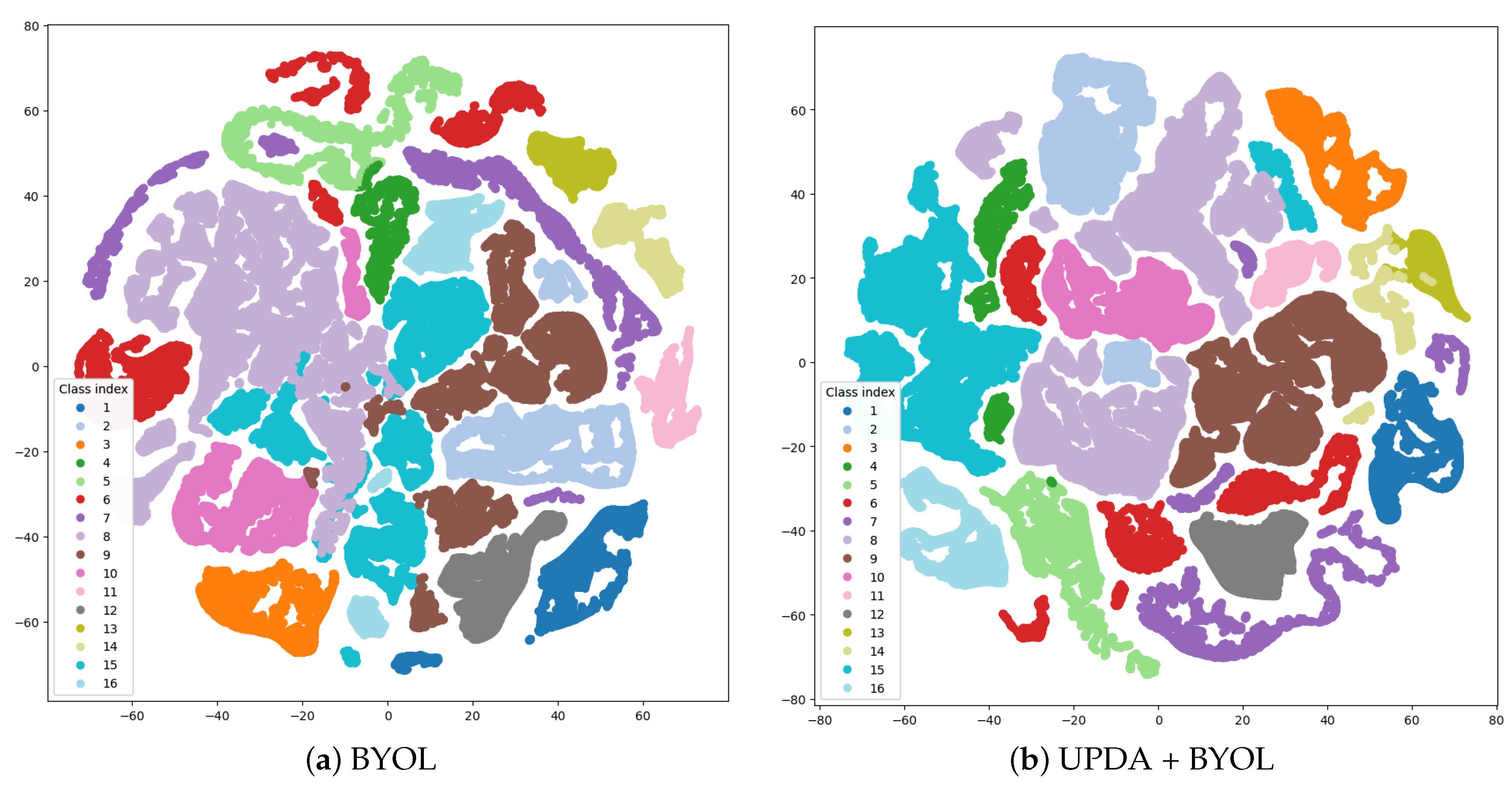
4.4. Feature Visualization
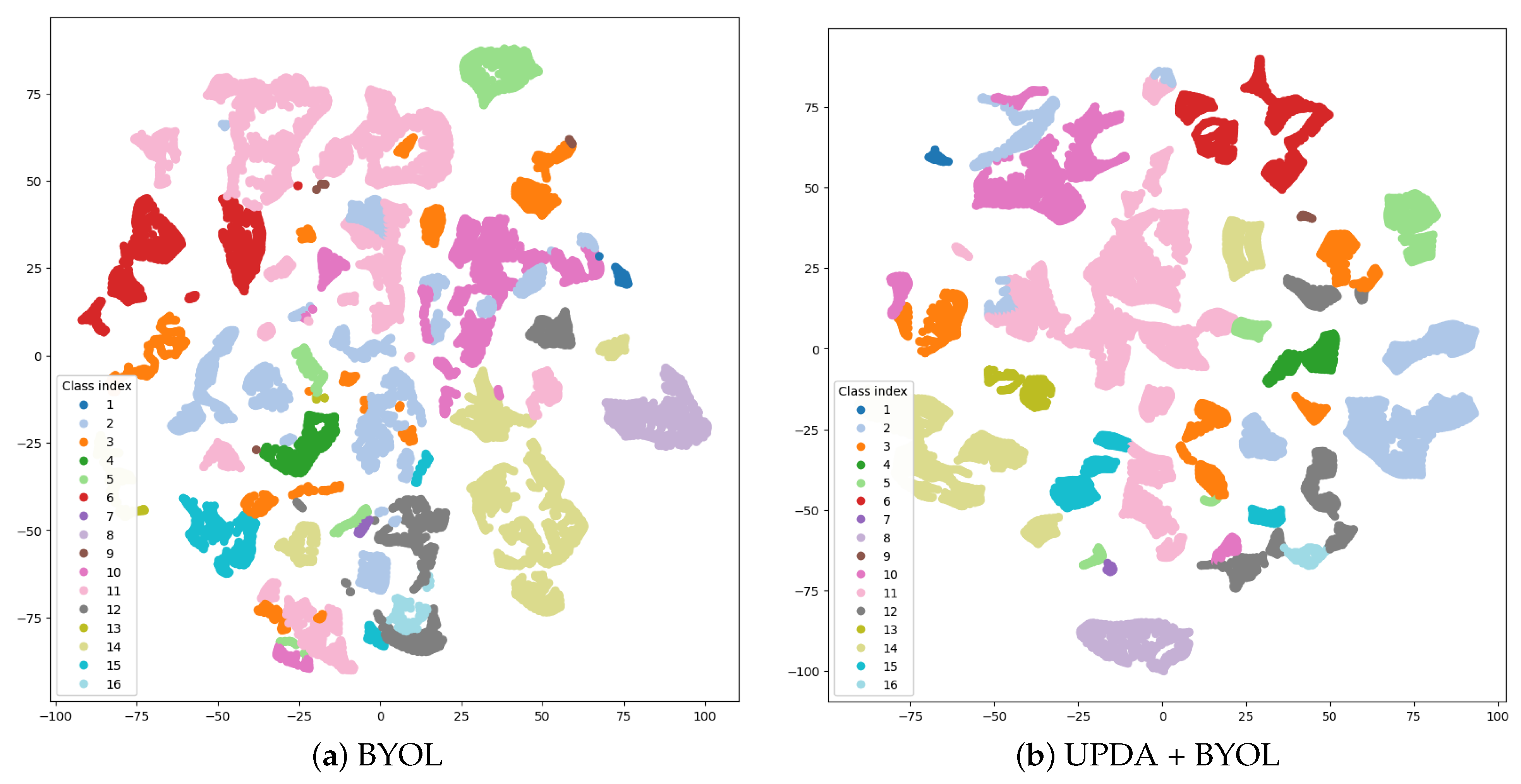
To further assess the effectiveness of UPDA, we utilized the t-distributed stochastic neighbor embedding (t-SNE) [
41] method to visualize the learned representation of spatial–spectral features. For comparison, we also visualized the feature extracted by the BYOL without UPDA. The results are presented in
Figure 6,
Figure 7 and
Figure 8.
In the IP dataset, subfigure (b) displays a more concentrated distribution of color blocks belonging to the same class, with fewer fine points, and the shape is more towards blocks than bars. Classes with few samples such as classes 1, 7, and 9 become easier to separate from other classes.
In the PU dataset, the classes 1, 4, 7, 8, and 9 are partly mixed in subfigure (a), but there are fewer overlapping parts of the color blocks in (b), which means that there exists a larger gap between classes. Furthermore, it is obvious that blocks of class 2 and 6 become more tightly connected after introducing UPDA.
In the SA dataset, the pores in the color block of (b) are smaller, and the fine blocks are almost gone. In addition, the contact points between different color blocks are reduced. After introducing UPDA, the features of classes 13 and 14 are glued together, but the features of classes 1, 10, and 15 are obviously more isolated.
By comparing the visualization of features, we can conclude that UPDA can help BYOL to reduce the intra-class gap, increase the inter-class gap, and improve the representation of features.
4.5. Analysis of Different Strategies
In order to investigate the impact of different data augmentation methods in UPDA on classification performance, we conducted ablation experiments. In addition to the blank group and the complete group, we created the “BE”, “RO”, “GM”, “BE + RO”, “BE + GM”, and “RO + GM” groups, and conducted experiments on three datasets. We repeated each experiment three times and recorded the average OA.
Table 12 shows the results. The “BE + GM + RO” group achieved the best OA in all three datasets, which shows that the combination of the three strategies is most effective.
The “BE + GM” group achieved second place in the IP and SA dataset and third place in the PU dataset. The “GM + RO” group achieved second place in the PU dataset and third place in the SA dataset. In general, when the strategies are grouped in pairs, the effect varies according to different datasets.
When each strategy is joined individually, RO performs better than GM and BE, and BE performs the worst overall. There is no doubt that the introduction of each strategy improves the results, and they achieve the best classification performance when working together.
When considering the characteristics of the dataset, we can also analyze the strengths and weaknesses of each strategy. For the PU datasets with a small wavelength range and complex background, the effect of RO is the most significant and the effect of BE is the weakest when compared with other datasets. We can infer that RO can help to more effectively extract spatial features from environments where spatial features are not obvious, and BE can work better in datasets rich in spectral information. The performances of GM in different datasets are quite varied, and it is less pronounced when combined with other strategies.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}