

MSAFNet: Multiscale Successive Attention Fusion Network for Water Body Extraction of Remote Sensing Images

Abstract
:1. Introduction
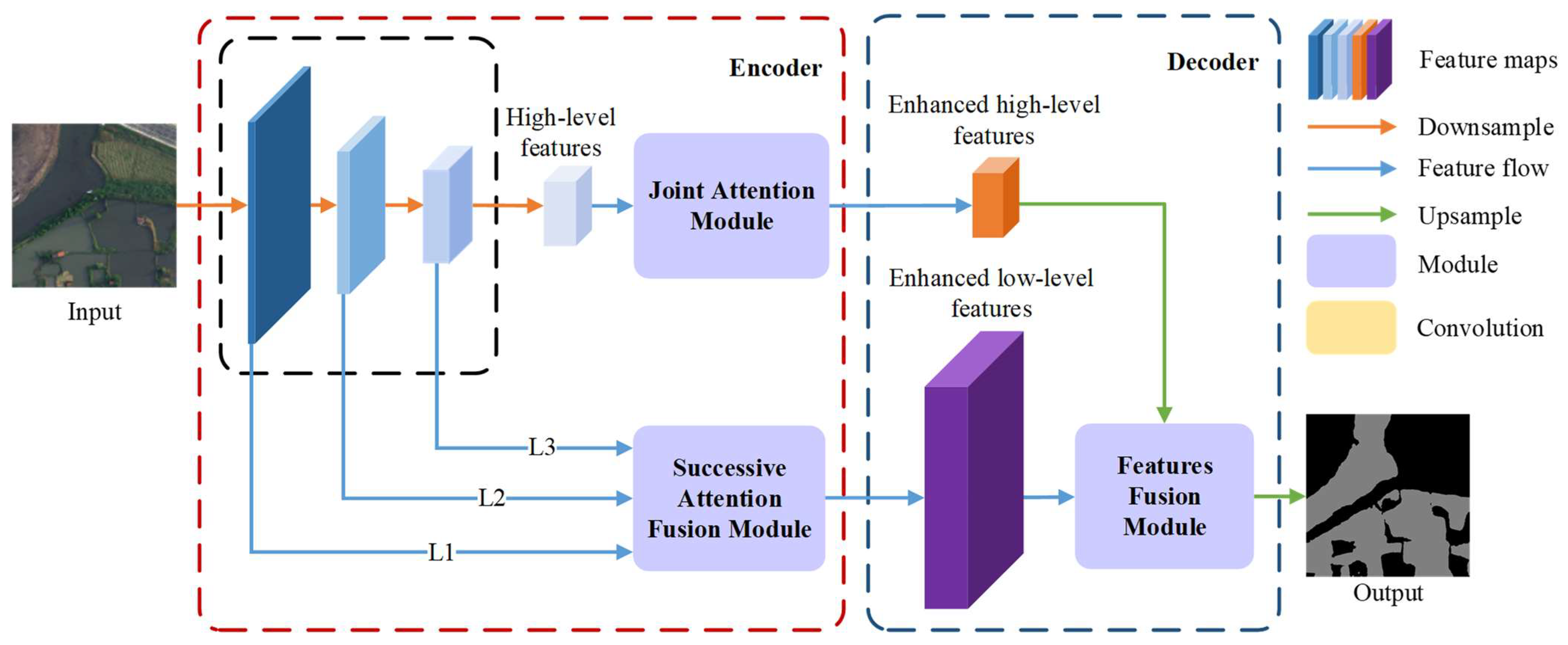
- Based on the encoder–decoder architecture, MSAFNet gradually extracts semantic information and spatial details at multiple scales. In particular, a feature fusion module (FFM) was designed to aggregate and align multi-level features, alleviating the uncertainty in delineating boundaries and making the proposed model more accurate in extracting water bodies.
- A successive attention fusion module (SAFM) is proposed to enhance multi-level features in local regions of the feature map, refining multiscale features parallelly and extracting correlations between hierarchical channels. As a result, the multiscale features are extracted and aggregated adaptively, providing a sufficient contextual representation of various water bodies.
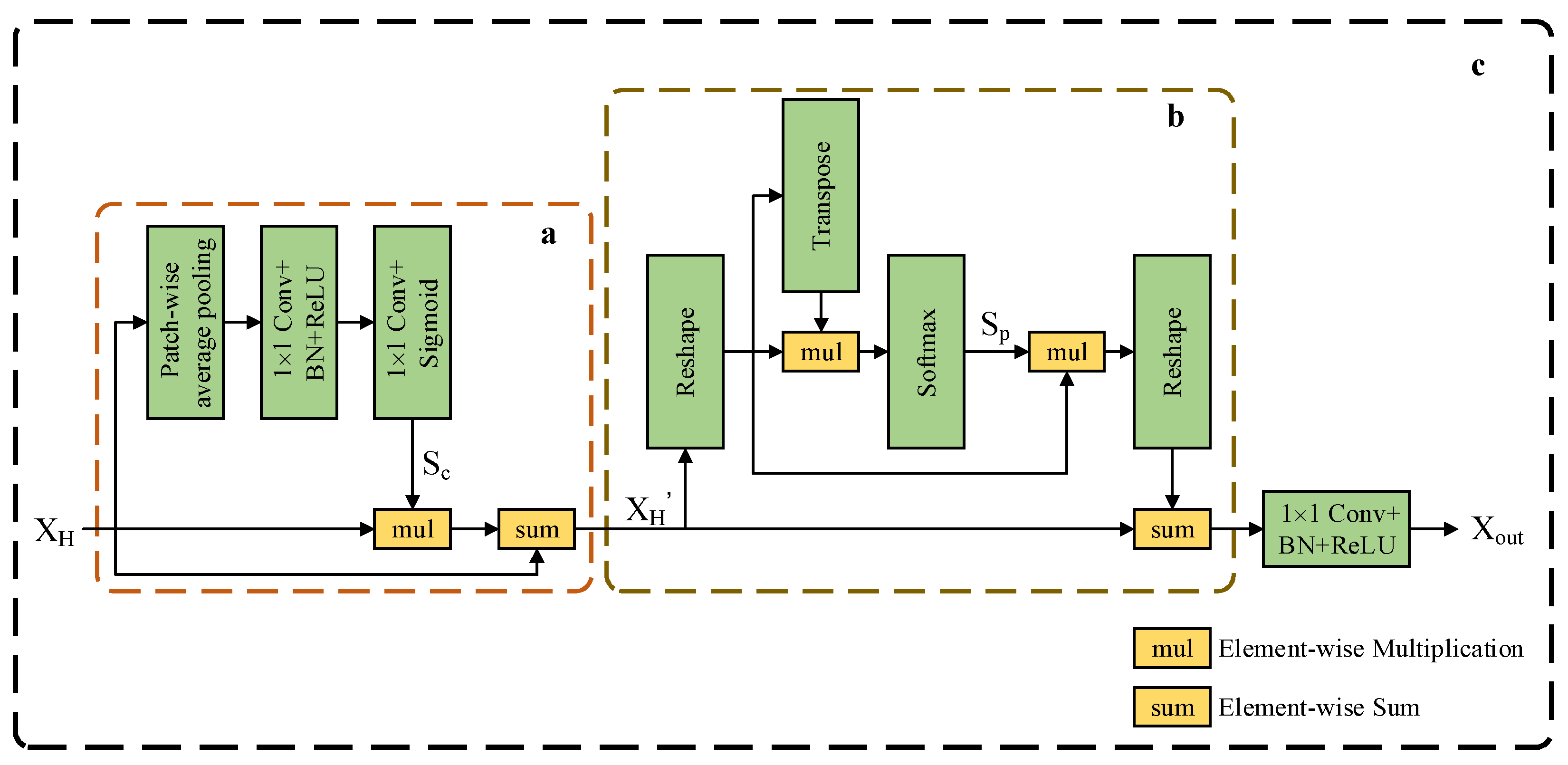
- To enhance the distinguishability of semantic representations, a joint attention module (JAM) was designed. It utilizes position self-attention block (PSAB) to make similar features related to each other regardless of distance to aggregate the features of each position selectively, strengthening the proposed network in resisting noise interference.
2. Related Works
2.1. Encoder–Decoder Architecture
2.2. Multi-Level Feature Aggregation
2.3. Attention Mechanism
3. The Proposed Method
3.1. Overview of the MSAFNet
3.2. Successive Attention Fusion Module
3.3. Joint Attention Module
3.4. Features Fusion Module
4. Experiments
4.1. Datasets
4.1.1. The QTPL Dataset
4.1.2. The LoveDA Dataset
4.2. Experimental Details
4.3. Evaluation Metrics
4.4. Experimental Results
4.4.1. Results on the QTPL Dataset
4.4.2. Results on the LoveDA Dataset
4.5. Ablation Study
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Weng, Q. Remote Sensing of Impervious Surfaces in the Urban Areas: Requirements, Methods, and Trends. Remote Sens. Environ. 2012, 117, 34–49. [Google Scholar] [CrossRef]
- Hu, T.; Yang, J.; Li, X.; Gong, P. Mapping Urban Land Use by Using Landsat Images and Open Social Data. Remote Sens. 2016, 8, 151. [Google Scholar] [CrossRef]
- Kuhn, C.; de Matos Valerio, A.; Ward, N.; Loken, L.; Sawakuchi, H.O.; Kampel, M.; Richey, J.; Stadler, P.; Crawford, J.; Striegl, R.; et al. Performance of Landsat-8 and Sentinel-2 Surface Reflectance Products for River Remote Sensing Retrievals of Chlorophyll-a and Turbidity. Remote Sens. Environ. 2019, 224, 104–118. [Google Scholar] [CrossRef] [Green Version]
- Zhang, W.; Li, X.; Yu, J.; Kumar, M.; Mao, Y. Remote Sensing Image Mosaic Technology Based on SURF Algorithm in Agriculture. J. Image Video Proc. 2018, 2018, 85. [Google Scholar] [CrossRef]
- Yang, G.; Li, B.; Ji, S.; Gao, F.; Xu, Q. Ship Detection From Optical Satellite Images Based on Sea Surface Analysis. IEEE Geosci. Remote Sens. Lett. 2014, 11, 641–645. [Google Scholar] [CrossRef]
- Xu, N.; Gong, P. Significant Coastline Changes in China during 1991–2015 Tracked by Landsat Data. Sci. Bull. 2018, 63, 883–886. [Google Scholar] [CrossRef] [Green Version]
- Ma, Y.; Xu, N.; Sun, J.; Wang, X.H.; Yang, F.; Li, S. Estimating Water Levels and Volumes of Lakes Dated Back to the 1980s Using Landsat Imagery and Photon-Counting Lidar Datasets. Remote Sens. Environ. 2019, 232, 111287. [Google Scholar] [CrossRef]
- Xu, N.; Ma, Y.; Zhang, W.; Wang, X.H. Surface-Water-Level Changes During 2003–2019 in Australia Revealed by ICESat/ICESat-2 Altimetry and Landsat Imagery. IEEE Geosci. Remote Sens. Lett. 2021, 18, 1129–1133. [Google Scholar] [CrossRef]
- Rahnemoonfar, M.; Chowdhury, T.; Sarkar, A.; Varshney, D.; Yari, M.; Murphy, R.R. FloodNet: A High Resolution Aerial Imagery Dataset for Post Flood Scene Understanding. IEEE Access 2021, 9, 89644–89654. [Google Scholar] [CrossRef]
- Chen, Z.; Lu, Z.; Gao, H.; Zhang, Y.; Zhao, J.; Hong, D.; Zhang, B. Global to Local: A Hierarchical Detection Algorithm for Hyperspectral Image Target Detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–15. [Google Scholar] [CrossRef]
- Feyisa, G.L.; Meilby, H.; Fensholt, R.; Proud, S.R. Automated Water Extraction Index: A New Technique for Surface Water Mapping Using Landsat Imagery. Remote Sens. Environ. 2014, 140, 23–35. [Google Scholar] [CrossRef]
- Paul, A.; Tripathi, D.; Dutta, D. Application and Comparison of Advanced Supervised Classifiers in Extraction of Water Bodies from Remote Sensing Images. Sustain. Water Resour. Manag. 2018, 4, 905–919. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, L.; Du, B. Deep Learning for Remote Sensing Data: A Technical Tutorial on the State of the Art. IEEE Geosci. Remote Sens. Mag. 2016, 4, 22–40. [Google Scholar] [CrossRef]
- Shelhamer, E.; Long, J.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–651. [Google Scholar] [CrossRef] [PubMed]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI), Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6230–6239. [Google Scholar]
- Chen, L.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Chen, Y.; Fan, R.; Yang, X.; Wang, J.; Latif, A. Extraction of Urban Water Bodies from High-Resolution Remote-Sensing Imagery Using Deep Learning. Water 2018, 10, 585. [Google Scholar] [CrossRef] [Green Version]
- Isikdogan, F.; Bovik, A.C.; Passalacqua, P. Surface Water Mapping by Deep Learning. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 4909–4918. [Google Scholar] [CrossRef]
- Weng, L.; Xu, Y.; Xia, M.; Zhang, Y.; Liu, J.; Xu, Y. Water Areas Segmentation from Remote Sensing Images Using a Separable Residual SegNet Network. ISPRS Int. J. Geo-Inf. 2020, 9, 256. [Google Scholar] [CrossRef]
- Wang, Z.; Gao, X.; Zhang, Y.; Zhao, G. MSLWENet: A Novel Deep Learning Network for Lake Water Body Extraction of Google Remote Sensing Images. Remote Sens. 2020, 12, 4140. [Google Scholar] [CrossRef]
- Xia, M.; Cui, Y.; Zhang, Y.; Xu, Y.; Liu, J.; Xu, Y. DAU-Net: A Novel Water Areas Segmentation Structure for Remote Sensing Image. Int. J. Remote Sens. 2021, 42, 2594–2621. [Google Scholar] [CrossRef]
- Li, H.; Qiu, K.; Chen, L.; Mei, X.; Hong, L.; Tao, C. SCAttNet: Semantic Segmentation Network with Spatial and Channel Attention Mechanism for High-Resolution Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2021, 18, 905–909. [Google Scholar] [CrossRef]
- Miao, Z.; Fu, K.; Sun, H.; Sun, X.; Yan, M. Automatic Water-Body Segmentation from High-Resolution Satellite Images via Deep Networks. IEEE Geosci. Remote Sens. Lett. 2018, 15, 602–606. [Google Scholar] [CrossRef]
- Xu, Z.; Zhang, W.; Zhang, T.; Li, J. HRCNet: High-Resolution Context Extraction Network for Semantic Segmentation of Remote Sensing Images. Remote Sens. 2021, 13, 71. [Google Scholar] [CrossRef]
- Sun, L.; Cheng, S.; Zheng, Y.; Wu, Z.; Zhang, J. SPANet: Successive Pooling Attention Network for Semantic Segmentation of Remote Sensing Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 4045–4057. [Google Scholar] [CrossRef]
- Li, A.; Jiao, L.; Zhu, H.; Li, L.; Liu, F. Multitask Semantic Boundary Awareness Network for Remote Sensing Image Segmentation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–14. [Google Scholar] [CrossRef]
- Deng, G.; Wu, Z.; Wang, C.; Xu, M.; Zhong, Y. CCANet: Class-Constraint Coarse-to-Fine Attentional Deep Network for Subdecimeter Aerial Image Semantic Segmentation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–20. [Google Scholar] [CrossRef]
- Li, X.; Xu, F.; Lyu, X.; Gao, H.; Tong, Y.; Cai, S.; Li, S.; Liu, D. Dual Attention Deep Fusion Semantic Segmentation Networks of Large-Scale Satellite Remote-Sensing Images. Int. J. Remote Sens. 2021, 42, 3583–3610. [Google Scholar] [CrossRef]
- Liu, R.; Tao, F.; Liu, X.; Na, J.; Leng, H.; Wu, J.; Zhou, T. RAANet: A Residual ASPP with Attention Framework for Semantic Segmentation of High-Resolution Remote Sensing Images. Remote Sens. 2022, 14, 3109. [Google Scholar] [CrossRef]
- Ding, Y.; Zhang, Z.; Zhao, X.; Hong, D.; Cai, W.; Yang, N.; Wang, B. Multi-Scale Receptive Fields: Graph Attention Neural Network for Hyperspectral Image Classification. Expert Syst. Appl. 2023, 223, 119858. [Google Scholar] [CrossRef]
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.-H.; Shao, L. Multi-Stage Progressive Image Restoration. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Online, 19–25 June 2021; IEEE: Nashville, TN, USA, 2021; pp. 14816–14826. [Google Scholar]
- Zhao, Z.; Xia, C.; Xie, C.; Li, J. Complementary Trilateral Decoder for Fast and Accurate Salient Object Detection. In Proceedings of the 29th ACM International Conference on Multimedia, MM 2021, Online, 20–24 October 2021; Association for Computing Machinery, Inc.: Beijing, China, 2021; pp. 4967–4975. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Ding, L.; Tang, H.; Bruzzone, L. LANet: Local Attention Embedding to Improve the Semantic Segmentation of Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2021, 59, 426–435. [Google Scholar] [CrossRef]
- Feng, W.; Sui, H.; Huang, W.; Xu, C.; An, K. Water Body Extraction from Very High-Resolution Remote Sensing Imagery Using Deep U-Net and a Superpixel-Based Conditional Random Field Model. IEEE Geosci. Remote Sens. Lett. 2019, 16, 618–622. [Google Scholar] [CrossRef]
- Ge, C.; Xie, W.; Meng, L. Extracting Lakes and Reservoirs From GF-1 Satellite Imagery Over China Using Improved U-Net. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Qin, P.; Cai, Y.; Wang, X. Small Waterbody Extraction with Improved U-Net Using Zhuhai-1 Hyperspectral Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Li, X.; Xu, F.; Xia, R.; Li, T.; Chen, Z.; Wang, X.; Xu, Z.; Lyu, X. Encoding Contextual Information by Interlacing Transformer and Convolution for Remote Sensing Imagery Semantic Segmentation. Remote Sens. 2022, 14, 4065. [Google Scholar] [CrossRef]
- Ding, Y.; Zhang, Z.; Zhao, X.; Hong, D.; Cai, W.; Yu, C.; Yang, N.; Cai, W. Multi-Feature Fusion: Graph Neural Network and CNN Combining for Hyperspectral Image Classification. Neurocomputing 2022, 501, 246–257. [Google Scholar] [CrossRef]
- Ding, Y. AF2GNN: Graph Convolution with Adaptive Filters and Aggregator Fusion for Hyperspectral Image Classification. Inf. Sci. 2022, 602, 201–219. [Google Scholar] [CrossRef]
- Yu, F.; Wang, D.; Shelhamer, E.; Darrell, T. Deep Layer Aggregation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 2403–2412. [Google Scholar]
- Liu, R.; Mi, L.; Chen, Z. AFNet: Adaptive Fusion Network for Remote Sensing Image Semantic Segmentation. IEEE Trans. Geosci. Remote Sens. 2021, 59, 7871–7886. [Google Scholar] [CrossRef]
- Qin, X.; Zhang, Z.; Huang, C.; Dehghan, M.; Zaiane, O.R.; Jagersand, M. U$^2$-Net: Going Deeper with Nested U-Structure for Salient Object Detection. Pattern Recognit. 2020, 106, 107404. [Google Scholar] [CrossRef]
- Zhou, Z.; Siddiquee, M.M.R.; Tajbakhsh, N.; Liang, J. UNet++: Redesigning Skip Connections to Exploit Multiscale Features in Image Segmentation. IEEE Trans. Med. Imaging 2020, 39, 1856–1867. [Google Scholar] [CrossRef] [Green Version]
- Peng, C.; Zhang, K.; Ma, Y.; Ma, J. Cross Fusion Net: A Fast Semantic Segmentation Network for Small-Scale Semantic Information Capturing in Aerial Scenes. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–13. [Google Scholar] [CrossRef]
- Li, X.; Li, T.; Chen, Z.; Zhang, K.; Xia, R. Attentively Learning Edge Distributions for Semantic Segmentation of Remote Sensing Imagery. Remote Sens. 2022, 14, 102. [Google Scholar] [CrossRef]
- Li, X.; Xu, F.; Xia, R.; Lyu, X.; Gao, H.; Tong, Y. Hybridizing Cross-Level Contextual and Attentive Representations for Remote Sensing Imagery Semantic Segmentation. Remote Sens. 2021, 13, 2986. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-Local Neural Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 7794–7803. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual Attention Network for Scene Segmentation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 3141–3149. [Google Scholar]
- Li, X.; Xu, F.; Liu, F.; Xia, R.; Tong, Y.; Li, L.; Xu, Z.; Lyu, X. Hybridizing Euclidean and Hyperbolic Similarities for Attentively Refining Representations in Semantic Segmentation of Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Li, X.; Xu, F.; Liu, F.; Lyu, X.; Tong, Y.; Xu, Z.; Zhou, J. A Synergistical Attention Model for Semantic Segmentation of Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–16. [Google Scholar] [CrossRef]
- Liu, X.; Liu, R.; Dong, J.; Yi, P.; Zhou, D. DEANet: A Real-Time Image Semantic Segmentation Method Based on Dual Efficient Attention Mechanism. In Proceedings of the 17th International Conference on Wireless Algorithms, Systems, and Applications (WASA), Dalian, China, 24–26 November 2022; pp. 193–205. [Google Scholar]
- Niu, R.; Sun, X.; Tian, Y.; Diao, W.; Chen, K.; Fu, K. Hybrid Multiple Attention Network for Semantic Segmentation in Aerial Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5603018. [Google Scholar] [CrossRef]
- Lyu, X.; Fang, Y.; Tong, B.; Li, X.; Zeng, T. Multiscale Normalization Attention Network for Water Body Extraction from Remote Sensing Imagery. Remote Sens. 2022, 14, 4983. [Google Scholar] [CrossRef]
- Song, H.; Wu, H.; Huang, J.; Zhong, H.; He, M.; Su, M.; Yu, G.; Wang, M.; Zhang, J. HA-Unet: A Modified Unet Based on Hybrid Attention for Urban Water Extraction in SAR Images. Electronics 2022, 11, 3787. [Google Scholar] [CrossRef]
- Nair, V.; Hinton, G.E. Rectified linear units improve Restricted Boltzmann machines. In Proceedings of the 27th International Conference on Machine Learning (ICML), Haifa, Israel, 21–25 June 2010; pp. 807–814. [Google Scholar]
- Wang, J.; Zheng, Z.; Ma, A.; Lu, X.; Zhong, Y. LoveDA: A Remote Sensing Land-Cover Dataset for Domain Adaptive Semantic Segmentation. arXiv 2021, arXiv:2110.08733. [Google Scholar]
- Ruder, S. An Overview of Gradient Descent Optimization Algorithms. arXiv 2017, arXiv:1609.04747. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Index | Description |
|---|---|
| True positive () | The number of correct extraction pixels. |
| False positive () | The number of incorrect extraction pixels. |
| True negative () | The true class of the sample is the negative class, but the number of background pixels that were correctly rejected. |
| False negative () | The number of water pixels not extracted. |
| Method | Kappa | MIoU (%) | FWIoU (%) | F1 (%) | OA (%) |
|---|---|---|---|---|---|
| UNet | 0.9705 | 97.09 | 97.20 | 98.81 | 98.58 |
| PSPNet | 0.9616 | 96.23 | 96.37 | 98.45 | 98.15 |
| DeepLabV3+ | 0.9666 | 96.71 | 96.84 | 98.65 | 98.39 |
| U2-Net | 0.9767 | 97.70 | 97.78 | 99.06 | 98.88 |
| UNet++ | 0.9744 | 97.47 | 97.57 | 98.97 | 98.77 |
| AttentionUNet | 0.9718 | 97.21 | 97.32 | 98.86 | 98.64 |
| MSNANet | 0.9656 | 96.62 | 96.74 | 98.82 | 98.34 |
| FCN + SE | 0.9714 | 97.18 | 97.28 | 98.84 | 98.62 |
| FCN + CBAM | 0.9722 | 97.26 | 97.36 | 98.88 | 98.66 |
| FCN + DA | 0.9720 | 97.24 | 97.34 | 98.87 | 98.65 |
| LANet | 0.9743 | 97.46 | 97.55 | 98.96 | 98.76 |
| MSAFNet | 0.9786 | 97.88 | 97.96 | 99.14 | 98.97 |
| Method | Kappa | MIoU (%) | FWIoU (%) | F1 (%) | OA (%) |
|---|---|---|---|---|---|
| UNet | 0.6596 | 73.17 | 88.83 | 96.76 | 94.14 |
| PSPNet | 0.6656 | 66.55 | 88.88 | 96.73 | 94.10 |
| DeepLabV3+ | 0.5059 | 64.37 | 84.12 | 94.89 | 90.84 |
| U2-Net | 0.6601 | 73.21 | 88.82 | 96.74 | 94.11 |
| UNet++ | 0.6630 | 73.38 | 88.62 | 96.58 | 93.85 |
| AttentionUNet | 0.6463 | 72.35 | 88.18 | 96.44 | 93.59 |
| MSNANet | 0.6724 | 73.97 | 89.01 | 96.75 | 94.14 |
| FCN + SE | 0.7621 | 79.97 | 91.50 | 97.49 | 95.51 |
| FCN + CBAM | 0.7653 | 80.20 | 91.56 | 97.49 | 95.52 |
| FCN + DA | 0.7710 | 80.61 | 91.75 | 97.55 | 95.63 |
| LANet | 0.7514 | 79.22 | 91.19 | 97.40 | 95.34 |
| MSAFNet | 0.7844 | 81.58 | 92.17 | 97.69 | 95.87 |
| Model | UNet | PSPNet | DeepLabV3+ | UNet++ | U²-Net | MSNANet |
|---|---|---|---|---|---|---|
| Params (Mb) | 31.04 | 46.71 | 54.61 | 47.18 | 44.02 | 72.22 |
| FLOPS (Gbps) | 437.94 | 46.11 | 20.76 | 199.66 | 37.71 | 69.96 |
| Model | FCN + SE | FCN + DA | FCN + CBAM | AttentionUNet | LANet | MSAFNet |
| Params (Mb) | 23.77 | 23.79 | 23.77 | 34.88 | 23.79 | 24.14 |
| FLOPS (Gbps) | 8.24 | 8.25 | 8.24 | 66.64 | 8.31 | 13.31 |
| Dataset | Stages | MIoU (%) | F1 (%) | OA (%) | Params (Mb) | FLOPS (Gbps) |
|---|---|---|---|---|---|---|
| QTPL Dataset | (3) | 97.51 | 98.98 | 98.78 | 23.80 | 8.28 |
| (3, 2) | 97.63 | 99.03 | 98.84 | 23.83 | 8.36 | |
| (3, 2, 1) | 97.68 | 99.06 | 98.87 | 23.84 | 8.44 | |
| LoveDA Dataset | (3) | 78.28 | 97.31 | 95.17 | 23.80 | 8.28 |
| (3, 2) | 78.59 | 97.32 | 95.19 | 23.83 | 8.36 | |
| (3, 2, 1) | 79.35 | 97.36 | 95.29 | 23.84 | 8.44 |
| Module | Indicators | |||||
|---|---|---|---|---|---|---|
| JAM | SAFM | FFM | MIoU (%) | F1 (%) | OA (%) | |
| Ablation Study Model | 97.21 | 98.85 | 98.64 | |||
| √ | 97.30 | 98.89 | 98.68 | |||
| √ | 97.68 | 99.06 | 98.87 | |||
| √ | √ | 97.69 | 99.06 | 98.87 | ||
| MSAFNet | √ | √ | √ | 97.88 | 99.14 | 98.97 |
| Module | Indicators | |||||
|---|---|---|---|---|---|---|
| JAM | SAFM | FFM | MIoU (%) | F1 (%) | OA (%) | |
| Ablation Study model | 78.81 | 97.33 | 95.22 | |||
| √ | 80.76 | 97.52 | 95.58 | |||
| √ | 79.35 | 97.36 | 95.29 | |||
| √ | √ | 79.73 | 97.43 | 95.40 | ||
| MSAFNet | √ | √ | √ | 81.58 | 97.69 | 95.87 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lyu, X.; Jiang, W.; Li, X.; Fang, Y.; Xu, Z.; Wang, X. MSAFNet: Multiscale Successive Attention Fusion Network for Water Body Extraction of Remote Sensing Images. Remote Sens. 2023, 15, 3121. https://doi.org/10.3390/rs15123121
Lyu X, Jiang W, Li X, Fang Y, Xu Z, Wang X. MSAFNet: Multiscale Successive Attention Fusion Network for Water Body Extraction of Remote Sensing Images. Remote Sensing. 2023; 15(12):3121. https://doi.org/10.3390/rs15123121
Chicago/Turabian StyleLyu, Xin, Wenxuan Jiang, Xin Li, Yiwei Fang, Zhennan Xu, and Xinyuan Wang. 2023. "MSAFNet: Multiscale Successive Attention Fusion Network for Water Body Extraction of Remote Sensing Images" Remote Sensing 15, no. 12: 3121. https://doi.org/10.3390/rs15123121