
Boosting Adversarial Transferability with Shallow-Feature Attack on SAR Images
 ,
,
Abstract
:1. Introduction
- This article proposes the SFA attack, which utilizes ghost data packages to extract and fit critical target features that influence model decisions, to enhance the attack effectiveness of adversarial examples under black-box scenarios.
- Unlike existing feature-based adversarial attacks, we focus on more realistic and challenging black-box targeted scenarios and consider the pooling layer that better reflects spatial and semantic information in the image (such as object contours and textures) as the target of feature-level attacks in different networks.
- Extensive single-model and ensemble-model attacks on different classification models show that the adversarial examples generated by our proposed SFA method have stronger attack performance and better transferability.
2. Related Works
2.1. Adversarial Attack in Deep Learning
2.2. White-Box Attack Method
2.3. Black-Box Attack Methods
2.4. Feature-Level ATTACK methods
2.5. Adversarial Attack on SAR Images
3. Methods
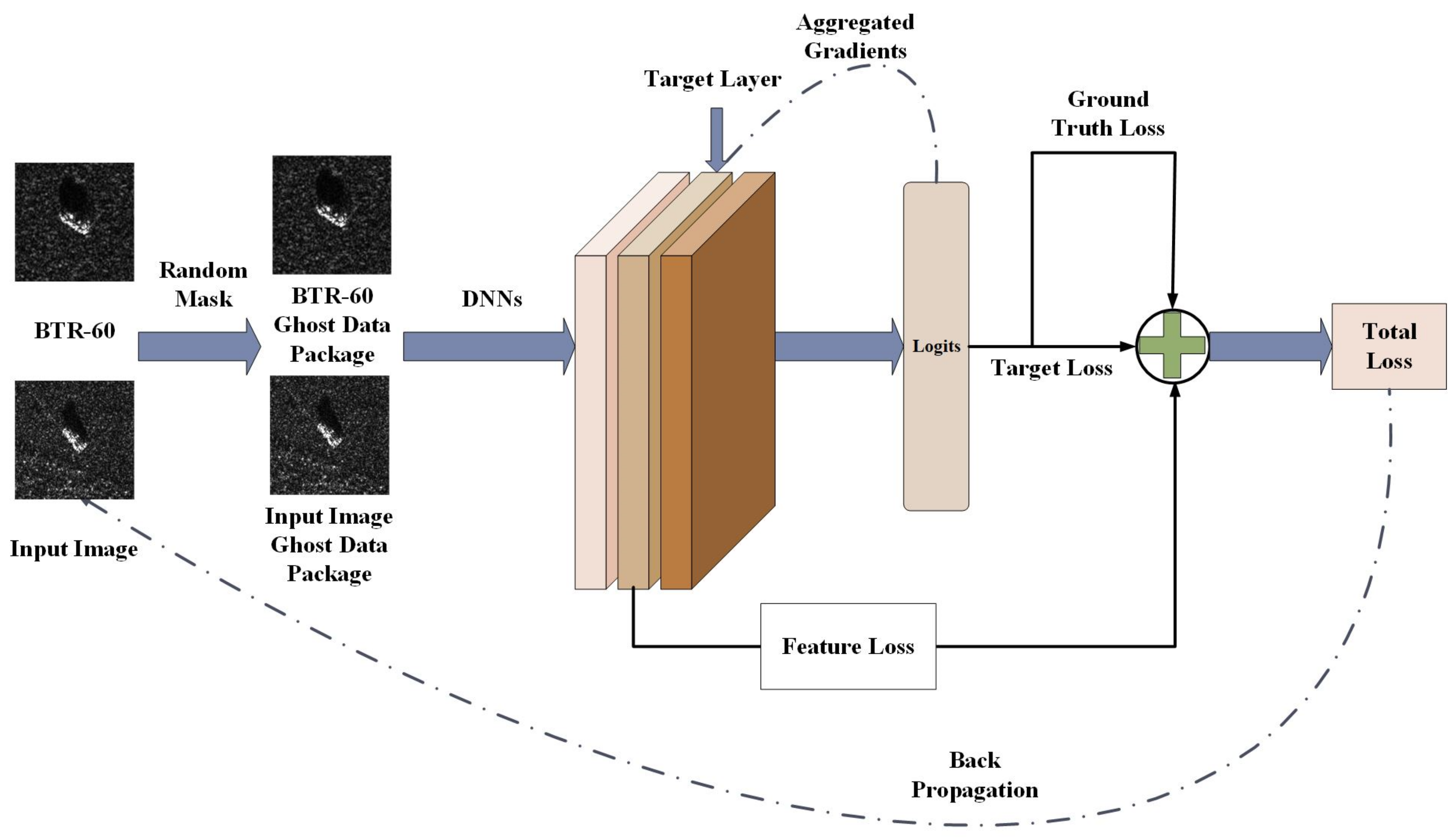
3.1. Overview
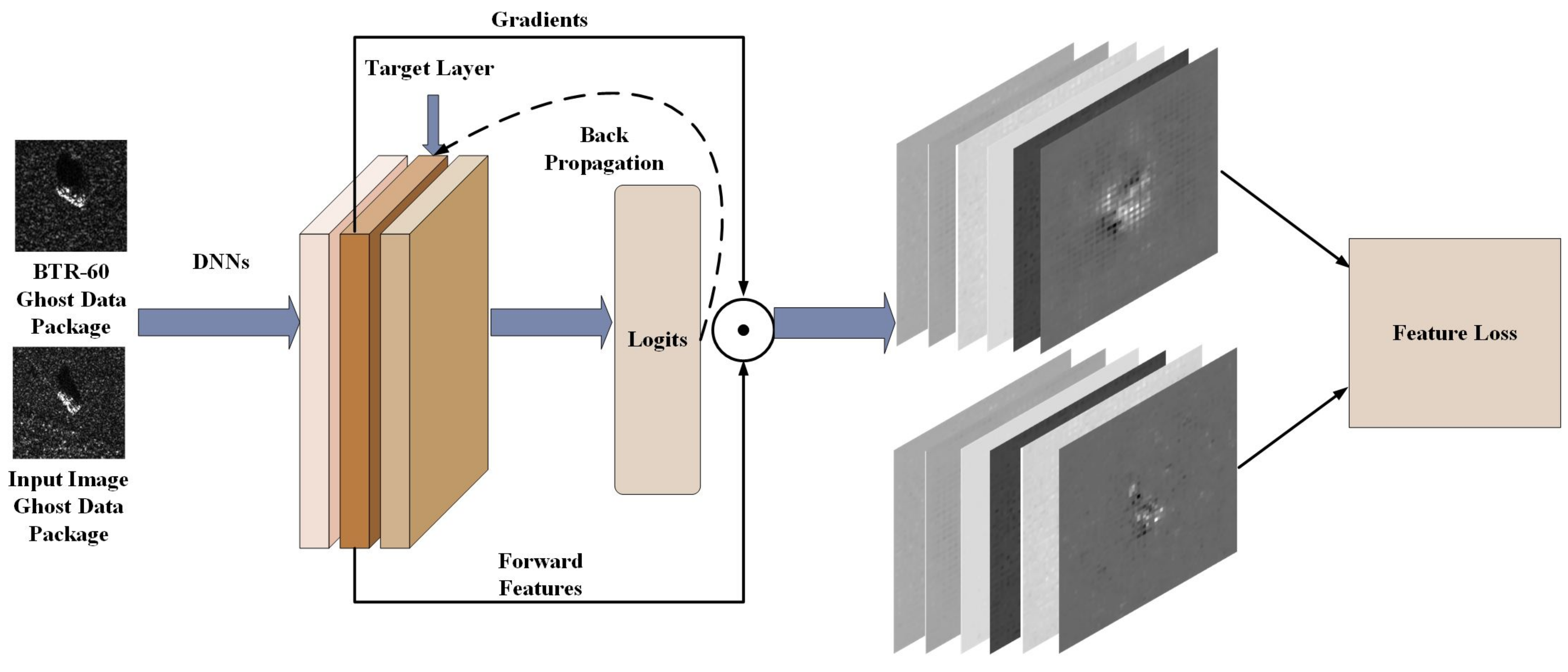
3.2. Loss Function for Feature-Level Attacks
3.3. Loss Function for End-to-End Level Attacks
3.4. Total Loss Function
| Algorithm 1: Ens-I-SFA | |
| Input: | -An Ensemble Model , -A clean image x and its ground-truth label , -An image of target label , -Step size , -Random mask probability p, -Number of iteration N |
| Output: | The adversarial image |
| 1: | for n = 0 to N-1 do |
| 2: | Obtain critical features |
| 3: | Construct feature-level loss: |
| 4: | Construct end-to-end-level loss: |
| 5: | Construct hybrid loss: |
| 6: | Update x by iterative fast gradient sign method: |
| 7: | end for |
| 8: | return |
4. Experiments and Results
4.1. Experimental Preparation
4.2. Experiment Setup
4.3. Single-Model Attack Experiments
4.4. Multi-Model Attack Experiments
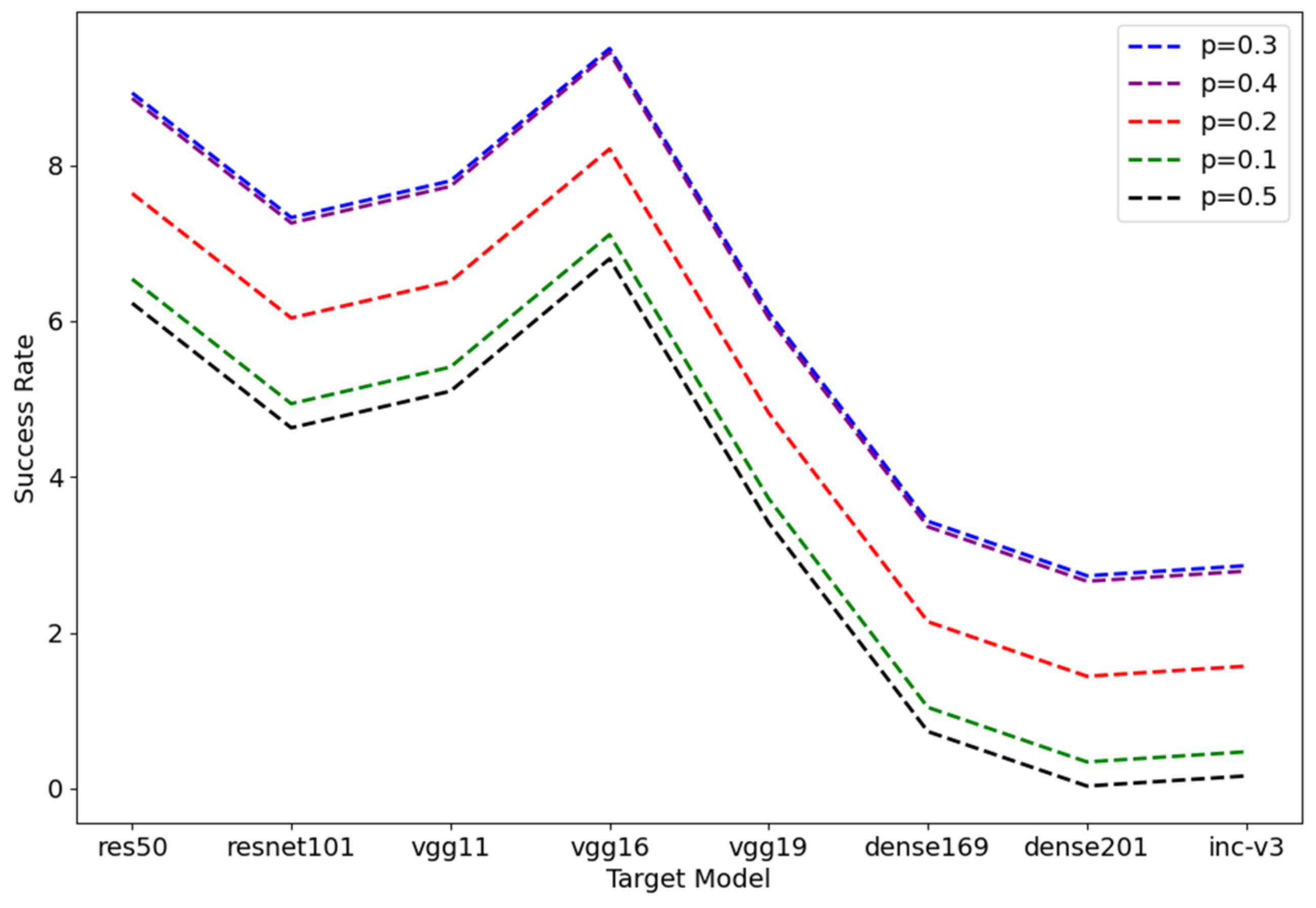
4.5. Hyperparametric Research
5. Discussion
5.1. Discussion on Target Setting for Targeted Attacks
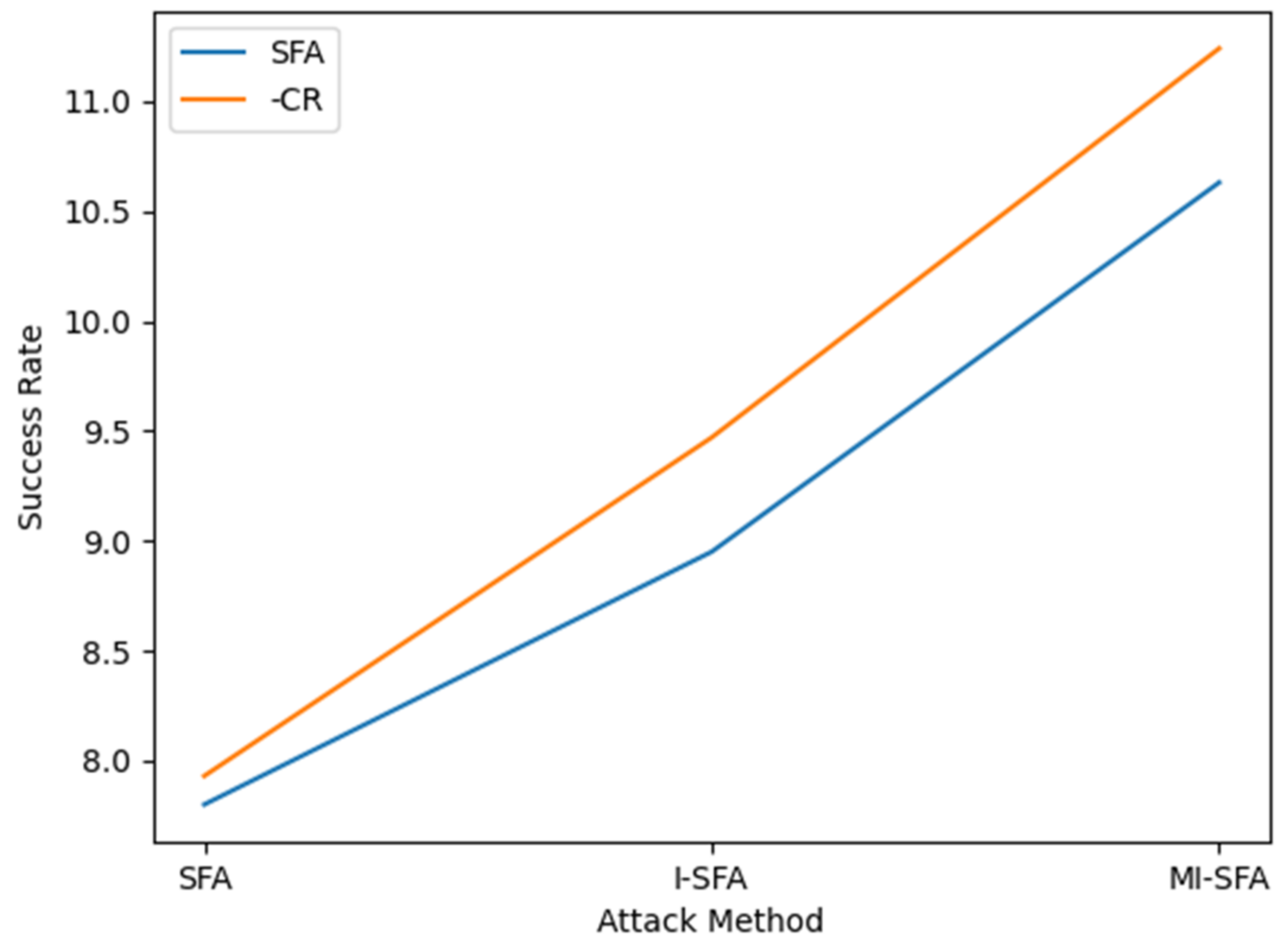
5.2. Discussion on the Consumption of SFA with Its Variants
5.3. Discussion of SFA on Conventional Machine Learning-Based Models
5.4. Discussion of the Impact of Compression and Reconstruction
6. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhang, L.; Leng, X.; Feng, S.; Ma, X.; Ji, K.; Kuang, G.; Liu, L. Domain Knowledge Powered Two-Stream Deep Network for Few-Shot SAR Vehicle Recognition. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5215315. [Google Scholar] [CrossRef]
- Li, Y.; Du, L.; Wei, D. Multiscale CNN Based on Component Analysis for SAR ATR. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–12. [Google Scholar] [CrossRef]
- Zhao, Y.; Zhao, L.; Liu, Z.; Hu, D.; Kuang, G.; Liu, L. Attentional Feature Refinement and Alignment Network for Aircraft Detection in SAR Imagery. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5211212. [Google Scholar] [CrossRef]
- Zhou, Y.; Liu, H.; Ma, F.; Pan, Z.; Zhang, F. A Sidelobe-Aware Small Ship Detection Network for Synthetic Aperture Radar Imagery. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5205516. [Google Scholar] [CrossRef]
- Ma, F.; Sun, X.; Zhang, F.; Zhou, Y.; Li, H.-C. What Catch Your Attention in SAR Images: Saliency Detection Based on Soft-Superpixel Lacunarity Cue. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5200817. [Google Scholar] [CrossRef]
- Ali, R.; Reza, S.; Saeid, H. An Unsupervised Saliency-Guided Deep Convolutional Neural Network for Accurate Burn Mapping from Sentinel-1 SAR Data. Remote Sens. 2023, 15, 1184. [Google Scholar]
- Deng, B.; Zhang, D.; Dong, F.; Zhang, J.; Shafiq, M.; Gu, Z. Rust-Style Patch: A Physical and Naturalistic Camouflage Attacks on Object Detector for Remote Sensing Images. Remote Sens. 2023, 15, 885. [Google Scholar] [CrossRef]
- Li, C.; Ye, X.; Xi, J.; Jia, Y. A Texture Feature Removal Network for Sonar Image Classification and Detection. Remote Sens. 2023, 15, 616. [Google Scholar] [CrossRef]
- Xi, Y.; Jia, W.; Miao, Q.; Liu, X.; Fan, X.; Lou, J. DyCC-Net: Dynamic Context Collection Network for Input-Aware Drone-View Object Detection. Remote Sens. 2022, 14, 6313. [Google Scholar] [CrossRef]
- Yang, S.; Peng, T.; Liu, H.; Yang, C.; Feng, Z.; Wang, M. Radar Emitter Identification with Multi-View Adaptive Fusion Network (MAFN). Remote Sens. 2023, 15, 1762. [Google Scholar] [CrossRef]
- Zhao, K.; Gao, Q.; Hao, S.; Sun, J.; Zhou, L. Credible Remote Sensing Scene Classification Using Evidential Fusion on Aerial-Ground Dual-View Images. Remote Sens. 2023, 15, 1546. [Google Scholar] [CrossRef]
- Marjan, S.; Dragi, K.; Sašo, D. Deep Network Architectures as Feature Extractors for Multi-Label Classification of Remote Sensing Images. Remote Sens. 2023, 15, 538. [Google Scholar]
- Wang, B.; Wang, H.; Song, D. A Filtering Method for LiDAR Point Cloud Based on Multi-Scale CNN with Attention Mechanism. Remote Sens. 2022, 14, 6170. [Google Scholar] [CrossRef]
- Jing, L.; Dong, C.; He, C.; Shi, W.; Yin, H. Adaptive Modulation and Coding for Underwater Acoustic Communications Based on Data-Driven Learning Algorithm. Remote Sens. 2022, 14, 5959. [Google Scholar] [CrossRef]
- Wang, F.; Mitch, B. Tree Segmentation and Parameter Measurement from Point Clouds Using Deep and Handcrafted Features. Remote Sens. 2023, 15, 1086. [Google Scholar] [CrossRef]
- Eduardo, A.; Pedro, D.; Ricardo, M.; Maria, P.; Khadijeh, A.; André, V.; Hugo, P. Real-Time Weed Control Application Using a Jetson Nano Edge Device and a Spray Mechanism. Remote Sens. 2022, 14, 4217. [Google Scholar]
- Daniel, H.; José, M.; Juan-Carlos, C.; Carlos, T. Flood Detection Using Real-Time Image Segmentation from Unmanned Aerial Vehicles on Edge-Computing Platform. Remote Sens. 2022, 14, 223. [Google Scholar]
- Zou, Y.; Holger, W.; Barbara, K. Towards Urban Scene Semantic Segmentation with Deep Learning from LiDAR Point Clouds: A Case Study in Baden-Württemberg, Germany. Remote Sens. 2021, 13, 3220. [Google Scholar] [CrossRef]
- Yang, N.; Tang, H. Semantic Segmentation of Satellite Images: A Deep Learning Approach Integrated with Geospatial Hash Codes. Remote Sens. 2021, 13, 2723. [Google Scholar] [CrossRef]
- Wu, B.; Ma, C.; Stefan, P.; David, R. An Adaptive Human Activity-Aided Hand-Held Smartphone-Based Pedestrian Dead Reckoning Positioning System. Remote Sens. 2021, 13, 2137. [Google Scholar] [CrossRef]
- Szegedy, C.; Zaremba, W.; Sutskever, I. Intriguing Properties of Neural Networks. In Proceedings of the International Conference on Learning Representations, Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and Harnessing Adversarial Examples. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Madry, A.; Makelov, A.; Schmidt, L. Towards Deep Learning Models Resistant to Adversarial Attacks. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Xu, Y.; Ghamisi, P. Universal Adversarial Examples in Remote Sensing: Methodology and Benchmark. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5619815. [Google Scholar] [CrossRef]
- Yosinski, J.; Clune, J.; Nguyen, A.; Fuchs, T.; Lipson, H. Understanding Neural Networks through Deep Visualization. arXiv 2015, arXiv:1506.06579. [Google Scholar]
- Wang, Z.; Guo, H.; Zhang, Z.; Liu, W.; Qin, Z.; Ren, K. Feature Importance-aware Transferable Adversarial Attacks. In Proceedings of the International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021. [Google Scholar]
- Meng, D.; Chen, H. MAGNET: A Two-Pronged Defense against Adversarial Examples. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, Dallas, TX, USA, 30 October–3 November 2017. [Google Scholar]
- Alexey, K.; Ian, J.G.; Samy, B. Adversarial examples in the physical world. In Proceedings of the 5th International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Dong, Y.; Liao, F.; Pang, T.; Su, H.; Zhu, J.; Hu, X.; Li, J. Boosting Adversarial Attacks with Momentum. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Lin, J.; Song, C.; He, K.; Wang, L.; John, E. Nesterov Accelerated Gradient and Scale Invariance for Adversarial Attacks. In Proceedings of the 8th International Conference on Learning Representations, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Xie, C.; Zhang, Z.; Zhou, Y.; Bai, S.; Wang, J.; Ren, Z.; Yuille, A.L. Improving Transferability of Adversarial Examples with Input Diversity. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Dong, Y.; Pang, T.; Su, H.; Zhu, J. Evading Defenses to Transferable Adversarial Examples by Translation-Invariant Attacks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 4307–4316. [Google Scholar] [CrossRef]
- Papernot, N.; McDaniel, P.; Goodfellow, I.; Somesh, J.; Berkay, C.; Ananthram, S. Practical Black-Box Attacks against Machine Learning. In Proceedings of the 2017 ACM on Asia Conference on Computer and Communications Security, Abu Dhabi, United Arab Emirates, 2–6 April 2017. [Google Scholar]
- Zhou, W.; Hou, X.; Chen, Y.; Tang, M.; Huang, X.; Gan, X.; Yang, Y. Transferable Adversarial Perturbations. In Proceedings of the Computer Vision 15th European Conference, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Qian, H.; Isay, K.; Zeqi, G.; Horace, H.; Serge, J.B.; Ser, N. Enhancing adversarial example transferability with an intermediate level attack. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Chen, S.; He, Z.; Sun, C.; Yang, J.; Huang, X. Universal Adversarial Attack on Attention and the Resulting Dataset DAmageNet. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 2188–2197. [Google Scholar] [CrossRef]
- Peng, B.; Peng, B.; Zhou, J.; Xia, J.; Liu, L. Speckle-Variant Attack: Toward Transferable Adversarial Attack to SAR Target Recognition. IEEE Geosci. Remote Sens. Lett. 2022, 19, 4509805. [Google Scholar] [CrossRef]
- Seyed-Mohsen, M.; Alhussein, F.; Pascal, F. DeepFool: A Simple and Accurate Method to Fool Deep Neural Networks. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Liu, Y.; Chen, X.; Liu, C. Delving into Transferable Adversarial Examples and Black-Box Attacks. arXiv 2016, arXiv:1611.02770. [Google Scholar]
- Narodytska, N.; Kasiviswanathan, S.P. Simple Black-Box Adversarial Perturbations for Deep Networks. arXiv 2016, arXiv:1612.06299. [Google Scholar]
- Chen, P.Y.; Zhang, H.; Sharma, Y.; Yi, J.; Cho-jui, H. ZOO: Zeroth Order Optimization based Black-box Attacks to Deep Neural Networks without Training Substitute Models. In Proceedings of the 10th ACM Workshop on Artificial Intelligence and Security, Dallas, TX, USA, 3 November 2017. [Google Scholar]
- Brendel, W.; Rauber, J.; Bethge, M. Decision-Based Adversarial Attacks: Reliable Attacks against Black-Box Machine Learning Models. In Proceedings of the 6th International Conference on Learning Representations, Vancouver, BC, Canada, 30 April 30–3 May 2018. [Google Scholar]
- Ganeshan, A.; Vivek, B.S.; Radhakrishnan, V.B. FDA: Feature Disruptive Attack. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Meng, T.; Zhang, F.; Ma, F. A Target-region-based SAR ATR Adversarial Deception Method. In Proceedings of the 2022 7-th International Conference on Signal and Image Processing, Suzhou, China, 20–22 July 2022. [Google Scholar]
- Zhang, F.; Meng, T.; Ma, F. Adversarial Deception Against SAR Target Recognition Network. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 4507–4520. [Google Scholar] [CrossRef]
- Czaja, W.; Fendley, N.; Pekala, M. Adversarial Examples in Remote Sensing. In Proceedings of the 26th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Seattle, WA, USA, 6–9 November 2018. [Google Scholar]
- Chen, L.; Xu, Z.; Li, Q.; Peng, J.; Wang, S.; Li, H. An Empirical Study of Adversarial Examples on Remote Sensing Image Scene Classification. IEEE Trans. Geosci. Remote Sens. 2021, 59, 7419–7433. [Google Scholar] [CrossRef]
- Xu, Y.; Du, B.; Zhang, L. Self-Attention Context Network: Addressing the Threat of Adversarial Attacks for Hyperspectral Image Classification. IEEE Trans. Image Process. 2021, 30, 8671–8685. [Google Scholar] [CrossRef]
- Li, H.; Huang, H.; Chen, L.; Peng, J.; Huang, H.; Cui, Z.; Mei, X.; Wu, G. Adversarial Examples for CNN-Based SAR Image Classification: An Experience Study. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 1333–1347. [Google Scholar] [CrossRef]
- Wang, Z.; Wang, B.; Zhang, C.; Liu, Y. Defense against Adversarial Patch Attacks for Aerial Image Semantic Segmentation by Robust Feature Extraction. Remote Sens. 2023, 15, 1690. [Google Scholar] [CrossRef]
- Rasol, J.; Xu, Y.; Zhang, Z.; Zhang, F.; Feng, W.; Dong, L.; Hui, T.; Tao, C. An Adaptive Adversarial Patch-Generating Algorithm for Defending against the Intelligent Low, Slow, and Small Target. Remote Sens. 2023, 15, 1439. [Google Scholar] [CrossRef]
- Wang, Z.; Wang, B.; Liu, Y.; Guo, J. Global Feature Attention Network: Addressing the Threat of Adversarial Attack for Aerial Image Semantic Segmentation. Remote Sens. 2023, 15, 1325. [Google Scholar] [CrossRef]
- Carlini, N.; Wagner, D. Towards Evaluating the Robustness of Neural Networks. In Proceedings of the 2017 IEEE Symposium on Security and Privacy, San Jose, CA, USA, 22–26 May 2017. [Google Scholar]
- Du, C.; Huo, C.; Zhang, L.; Chen, B.; Yuan, Y. Fast C&W: A Fast Adversarial Attack Algorithm to Fool SAR Target Recognition with Deep Convolutional Neural Networks. IEEE Geosci. Remote Sens. Lett. 2021, 19, 4010005. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet Classification with Deep Convolutional Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems 25: 26th Annual Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Radosavovic, I.; Kosaraju, R.P.; Girshick, R.; He, K.; Dollár, P. Designing Network Design Spaces. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the 3rd International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Attack Method | Threat Model | Target | Algorithm |
|---|---|---|---|
| FGSM [22] | white-box | untargeted | gradient-based |
| I-FGSM [28] | white-box | untargeted | gradient-based |
| MI-FGSM [29] | white-box | untargeted | gradient-based |
| Ens-Attack [39] | black-box | / | gradient-based |
| SVA [37] | black-box | untargeted | transfer-based |
| Mixup-Attack [24] | black-box | untargeted | feature-based |
| Deepfool [38] | black-box | / | transfer-based |
| Model | Accuracy |
|---|---|
| AlexNet [55] | 96.3 |
| ResNet18 [56] | 96.8 |
| ResNet50 [56] | 96.4 |
| ResNet101 [56] | 97.5 |
| DenseNet121 [57] | 97.8 |
| DenseNet169 [57] | 97.9 |
| DenseNet201 [57] | 97.9 |
| RegNetX_400MF [58] | 98.3 |
| VGG11 [59] | 98.1 |
| VGG16 [59] | 97.8 |
| VGG19 [59] | 98.0 |
| Inception-v3 [60] | 98.1 |
| Surrogate: AlexNet | Target Model | Total | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Attack | Res-50 | Res-101 | VGG11 | VGG16 | VGG19 | Dense-169 | Dense-201 | Inc-v3 | |
| FGSM | 3.96 | 3.07 | 4.24 | 3.22 | 3.35 | 3.42 | 2.80 | 2.33 | 26.39 |
| SVA | 4.54 | 3.59 | 4.97 | 3.96 | 4.03 | 4.14 | 3.33 | 3.02 | 31.58 |
| SFA | 4.99 | 4.04 | 5.71 | 5.17 | 4.03 | 6.38 | 4.48 | 1.35 | 36.15 |
| I-FGSM | 4.06 | 3.48 | 4.44 | 3.90 | 3.01 | 3.09 | 3.48 | 2.68 | 28.14 |
| I-SVA | 5.21 | 4.75 | 5.02 | 5.22 | 4.60 | 3.95 | 4.04 | 3.51 | 36.30 |
| I- SFA | 9.77 | 7.79 | 10.98 | 7.40 | 9.36 | 6.11 | 7.47 | 4.69 | 63.57 |
| MI-FGSM | 5.12 | 3.54 | 4.51 | 3.89 | 2.94 | 4.02 | 3.54 | 3.06 | 30.62 |
| MI-SVA | 6.58 | 5.23 | 5.91 | 5.26 | 4.41 | 5.34 | 4.86 | 4.14 | 41.73 |
| MI-SFA | 11.12 | 5.44 | 7.85 | 5.37 | 6.53 | 5.70 | 5.08 | 4.00 | 51.09 |
| Deepfool | 1.60 | 1.27 | 1.76 | 1.40 | 1.39 | 1.46 | 1.18 | 1.07 | 11.13 |
| Surrogate: ResNet18 | Target Model | Total | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Attack | Res-50 | Res-101 | VGG11 | VGG16 | VGG19 | Dense-169 | Dense-201 | Inc-v3 | |
| FGSM | 3.69 | 2.94 | 3.28 | 3.14 | 3.28 | 3.35 | 1.85 | 0.34 | 21.87 |
| SVA | 5.02 | 4.23 | 4.74 | 4.67 | 4.66 | 4.36 | 2.77 | 1.30 | 31.75 |
| SFA | 8.93 | 7.33 | 7.80 | 9.50 | 6.11 | 3.43 | 2.73 | 2.86 | 48.69 |
| I-FGSM | 3.95 | 3.14 | 3.42 | 3.21 | 3.21 | 3.14 | 1.93 | 1.03 | 23.25 |
| I-SVA | 5.61 | 4.31 | 4.65 | 4.29 | 4.68 | 4.02 | 2.86 | 2.14 | 32.56 |
| I- SFA | 10.62 | 9.85 | 8.95 | 9.27 | 5.58 | 2.40 | 2.31 | 6.09 | 55.07 |
| MI-FGSM | 4.83 | 4.48 | 4.58 | 4.60 | 4.24 | 4.51 | 2.04 | 1.76 | 31.04 |
| MI-SVA | 6.60 | 6.01 | 5.64 | 6.02 | 5.40 | 5.63 | 3.26 | 2.99 | 41.55 |
| MI-SFA | 7.71 | 7.22 | 10.63 | 9.80 | 7.99 | 5.61 | 6.15 | 6.55 | 61.66 |
| Deepfool | 1.77 | 1.49 | 1.67 | 1.65 | 1.65 | 1.54 | 0.98 | 0.46 | 11.21 |
| Surrogate: DenseNet121 | Target Model | Total | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Attack | Res-50 | Res-101 | VGG11 | VGG16 | VGG19 | Dense-169 | Dense-201 | Inc-v3 | |
| FGSM | 3.42 | 2.67 | 3.35 | 3.08 | 3.08 | 2.46 | 1.78 | 0.89 | 17.65 |
| SVA | 4.41 | 4.08 | 5.08 | 4.77 | 4.60 | 3.51 | 2.50 | 1.66 | 30.61 |
| SFA | 4.01 | 3.34 | 5.61 | 5.97 | 4.17 | 6.77 | 4.16 | 2.45 | 36.48 |
| I-FGSM | 1.16 | 0.55 | 3.28 | 3.14 | 3.08 | 2.49 | 2.03 | 1.23 | 16.96 |
| I-SVA | 2.44 | 2.15 | 4.68 | 4.41 | 4.37 | 3.42 | 2.86 | 2.36 | 26.69 |
| I- SFA | 1.12 | 4.44 | 8.52 | 8.04 | 7.51 | 6.37 | 4.09 | 5.41 | 45.50 |
| MI-FGSM | 1.40 | 0.57 | 3.45 | 3.42 | 2.99 | 2.68 | 2.10 | 1.03 | 17.64 |
| MI-SVA | 2.95 | 2.45 | 4.89 | 4.79 | 4.49 | 3.82 | 3.37 | 2.35 | 29.02 |
| MI-SFA | 5.47 | 4.02 | 5.33 | 7.25 | 5.51 | 4.35 | 2.05 | 3.61 | 37.59 |
| Deepfool | 1.56 | 1.44 | 1.79 | 1.68 | 1.62 | 1.24 | 0.88 | 0.59 | 9.18 |
| Surrogate: RegNetX_400MF | Target Model | Total | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Attack | Res-50 | Res-101 | VGG11 | VGG16 | VGG19 | Dense-169 | Dense-201 | Inc-v3 | |
| FGSM | 3.35 | 3.08 | 3.14 | 3.08 | 3.21 | 3.21 | 3.01 | 1.85 | 24.04 |
| SVA | 4.40 | 4.20 | 4.83 | 4.45 | 4.76 | 4.33 | 3.66 | 2.55 | 33.18 |
| SFA | 3.58 | 2.94 | 8.33 | 6.82 | 3.63 | 5.29 | 4.54 | 5.96 | 41.09 |
| I-FGSM | 3.35 | 3.21 | 3.28 | 3.08 | 3.28 | 3.08 | 3.14 | 1.57 | 23.99 |
| I-SVA | 5.07 | 4.54 | 4.37 | 4.75 | 4.70 | 4.02 | 3.82 | 2.33 | 33.60 |
| I- SFA | 5.38 | 5.88 | 7.13 | 5.55 | 4.86 | 2.49 | 2.26 | 2.38 | 35.84 |
| MI-FGSM | 4.43 | 4.35 | 4.65 | 4.26 | 4.31 | 4.27 | 4.03 | 2.78 | 33.08 |
| MI-SVA | 5.93 | 5.78 | 5.71 | 5.64 | 5.34 | 5.24 | 5.16 | 4.21 | 43.01 |
| MI-SFA | 8.74 | 5.51 | 9.06 | 8.56 | 8.65 | 7.44 | 7.46 | 7.56 | 62.98 |
| Deepfool | 1.55 | 1.48 | 1.71 | 1.57 | 1.68 | 1.53 | 1.29 | 0.90 | 11.71 |
| Ensemble Model | Target Model | Total | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Attack | Res-50 | Res-101 | VGG11 | VGG16 | VGG19 | Dense-169 | Dense-201 | Inc-v3 | |
| FGSM | 3.42 | 3.08 | 3.14 | 3.08 | 3.21 | 3.28 | 3.01 | 1.35 | 23.57 |
| SVA | 4.91 | 3.95 | 5.10 | 4.60 | 5.01 | 3.91 | 3.70 | 2.45 | 33.63 |
| SFA | 5.18 | 4.60 | 6.25 | 6.01 | 5.86 | 5.23 | 4.31 | 3.26 | 40.70 |
| I-FGSM | 4.60 | 4.13 | 4.61 | 4.33 | 4.15 | 3.95 | 3.65 | 2.63 | 32.05 |
| I-SVA | 6.77 | 6.03 | 6.50 | 5.88 | 5.26 | 4.92 | 4.20 | 3.79 | 43.35 |
| I- SFA | 6.93 | 6.21 | 9.01 | 8.51 | 7.82 | 7.79 | 6.28 | 5.34 | 57.89 |
| MI-FGSM | 4.95 | 4.23 | 5.30 | 5.04 | 4.62 | 4.87 | 3.93 | 3.16 | 36.10 |
| MI-SVA | 6.60 | 6.08 | 7.23 | 6.88 | 5.83 | 5.39 | 4.47 | 4.06 | 46.54 |
| MI-SFA | 8.82 | 6.60 | 9.60 | 8.69 | 7.76 | 8.69 | 8.01 | 7.32 | 66.49 |
| Deepfool | 1.73 | 1.40 | 1.80 | 1.62 | 1.77 | 1.38 | 1.31 | 0.87 | 11.88 |
| SFA | DenseNet201 | Inception-v3 |
|---|---|---|
| 2.8 | 2.33 | |
| 3.84 | 2.46 | |
| 4.85 | 2.50 | |
| 4.79 | 2.53 | |
| 4.73 | 1.97 | |
| 4.48 | 1.35 |
| Target Label | Success Rate |
|---|---|
| 2S1 | 9.55 |
| BMP2 | 10.19 |
| BRDM_2 | 11.48 |
| BTR_70 | 5.71 |
| D7 | 6.34 |
| T62 | 6.72 |
| T72 | 6.73 |
| ZIL131 | 6.99 |
| ZSU_23_4 | 10.83 |
| Model | AlexNet | ResNet18 | Densenet121 | RegNetX_400MF | |
|---|---|---|---|---|---|
| Attack | |||||
| FGSM | 0.06 | 0.07 | 0.18 | 0.11 | |
| SVA | 0.26 | 0.33 | 0.85 | 0.52 | |
| SFA | 0.78 | 1.62 | 4.24 | 2.87 | |
| I-FGSM | 0.13 | 0.18 | 0.62 | 0.62 | |
| I-SVA | 0.22 | 1.04 | 3.58 | 1.04 | |
| I-SFA | 3.75 | 8.89 | 22.23 | 14.84 | |
| MI-FGSM | 0.12 | 0.17 | 0.62 | 0.55 | |
| MI-SVA | 0.17 | 1.20 | 4.38 | 3.89 | |
| MI-SFA | 3.29 | 6.48 | 20.99 | 13.81 | |
| Model | VGG11 | SVM | |
|---|---|---|---|
| Attack | |||
| SFA | 5.71 | 9.78 | |
| I-SFA | 10.98 | 18.96 | |
| MI-SFA | 7.85 | 13.03 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, G.; Pan, Z.; Zhou, X.; Duan, Y.; Bai, W.; Zhan, D.; Zhu, L.; Zhao, G.; Li, T. Boosting Adversarial Transferability with Shallow-Feature Attack on SAR Images. Remote Sens. 2023, 15, 2699. https://doi.org/10.3390/rs15102699
Lin G, Pan Z, Zhou X, Duan Y, Bai W, Zhan D, Zhu L, Zhao G, Li T. Boosting Adversarial Transferability with Shallow-Feature Attack on SAR Images. Remote Sensing. 2023; 15(10):2699. https://doi.org/10.3390/rs15102699
Chicago/Turabian StyleLin, Gengyou, Zhisong Pan, Xingyu Zhou, Yexin Duan, Wei Bai, Dazhi Zhan, Leqian Zhu, Gaoqiang Zhao, and Tao Li. 2023. "Boosting Adversarial Transferability with Shallow-Feature Attack on SAR Images" Remote Sensing 15, no. 10: 2699. https://doi.org/10.3390/rs15102699