1. Introduction
Because of the rapid advancement of hyperspectral sensors, the resolution and accuracy of hyperspectral images (HSI) have also increased greatly. HSI contains a wealth of spectral information, collecting hundreds of bands of electron spectrum at each pixel. Its rich information allows for excellent performance in classifying HSI, and thus its application has great potential in several fields such as precision agriculture [
1] and Jabir et al. [
2] used machine learning algorithm for weed detection, medical imaging [
3], object detection [
4], urban planning [
5], environment monitoring [
6], mineral exploration [
7], dimensionality reduction [
8] and military detection [
9].
Numerous conventional machine learning methods have been used to the classification of HSI in the past decade or so, such as K-nearest neighbors (KNN) [
10], support vector machines (SVM) [
11,
12,
13,
14], random forests [
15,
16]. Navarro et al. [
17] used neural network for hyperspectral image segmentation. However, as the size and complexity of the training set increases, the fitting ability of traditional methods can show weakness for the task, and the performance often encounters bottlenecks. Song et al. [
18] proposed a HSI classification method based on the sparse representation of KNN, but it cannot effectively apply the spatial information in HSI. Guo et al. [
19] used a fused SVM of spectral and spatial features for HSI classification, but it is still difficult to extract important features from high-dimensional HSI data. Deep learning have developed rapidly in recent years, and their powerful fitting ability can extract features from multivariate data. Inspired by this, the designed deep learning models have proposed in HSI classification tasks, such as recurrent neural network (RNN) [
20,
21,
22], convolutional neural network (CNN) [
23,
24,
25,
26,
27,
28], graph convolutional network (GCN) [
29,
30], capsule network (CapsNet) [
31,
32], long short term memory (LSTM) networks [
33,
34,
35]. Although these deep learning models show good performance in several different domains, they have certain shortcomings in HSI classification tasks.
For CNNs, which are good at natural image tasks, Its benefit is that the image’s spatial information can be extracted during the convolution operation. HSI-CNN [
36] stacks multi-dimensional data from HSI into two-dimensional data and then extracts features efficiently. 2D-CNN [
37] can capture spatial features in HSI data to improve classification accuracy. However, HSI has rich information in the spectral dimension, and if it is not exploited, the performance of the model is bound to be difficult to break through. Although the advent of 3D-CNN [
38,
39,
40,
41] enables the extraction of both spatial and spectral features, the convolution operation is localized, so the extracted features lack the mining and representation of the global Information.
Recently, transformer has evolved rapidly and shown good performance when performing tasks like natural language processing. Based on its self-attention mechanism, it is very good at processing long sequential information and extracting global relations. Vision transformer (ViT) [
42] makes it perform well in several vision domains by dividing images into patches and then inputting them into the model. Swin-transformer [
43] enhances the capability of local feature extraction by dividing the image into windows and performing multi-head self-attention (MSA) separately within the windows, and then enabling the exchange of information between the windows by shifting the windows. It improves the accuracy in natural image processing tasks and effectively reduces the computational effort in the processing of high-resolution images. Due to transformer’s outstanding capabilities for natural image processing, more and more studies are applying it to the classification of HSI [
44,
45,
46,
47,
48,
49,
50]. However, if ViT is applied directly to the HSI classification, there will be some problems that will limit the performance improvement, specifically as follows.
- (1)
The transformer performs well at handling sequence data( spectral dimension information), but lacks the use of spatial dimension information.
- (2)
The multi-head self-attention (MSA) of transformer is adept at resolving the global dependencies of spectral information, but it is usually difficult to capture the relationships for local information.
- (3)
Existing transformer models usually map the image to linear data to be able to input into the transformer model. Such an operation would destroy the spatial structure of HSI.
HSI can be regarded as a sequence in the spectral dimension, and the transform is effective at handling sequence information, so the transformer model is suitable for HSI classification. The research in this paper is based on tranformer and considers the above mentioned shortcomings to design a new model, called spectral-swin transformer (SSWT) with spatial feature extraction enhancement, and apply it in HSI classification. Inspired by swin-transformer and the characteristics of HSI data which contain a great deal of information in the spectral dimension, we design a method of dividing and shifting windows in the spectral dimension. MSA is performed within each window separately, aiming to improve the disadvantage of transformer to extract local features. We also design two modules to enhance model’s spatial feature extraction. In summary, the following are the contributions of this paper.
- (1)
Based on the characteristics of HSI data, a spectral dimensional shifted window multi-head self-attention is designed. It enhances the model’s capacity to capture local information and can achieve multi-scale effect by changing the size of the window.
- (2)
A spatial feature extraction module based on spatial attention mechanism is designed to improve the model’s ability to characterize spatial features.
- (3)
A spatial position encoding is designed before each transformer encoder to deal with the lack of spatial structure of the data after mapping to linear.
- (4)
Three publicly accessible HSI datasets are used to test the proposed model, which is compared with advanced deep learning models. The proposed model is extremely competitive.
The rest of this paper is organized as follows:
Section 2 discusses the related work on HSI classification using deep learning, which includes transformer.
Section 3 describes the proposed model and the design method for each component.
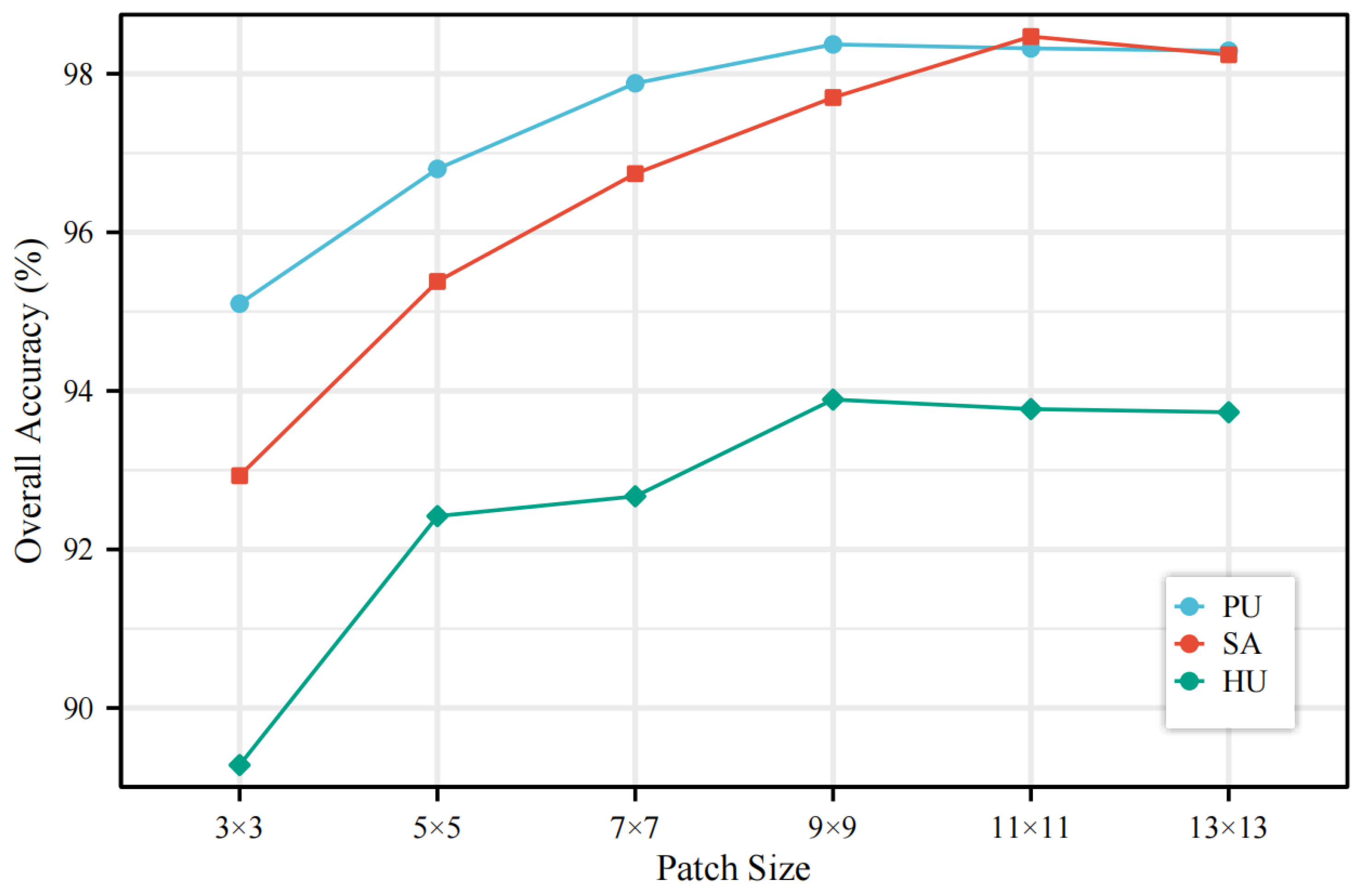
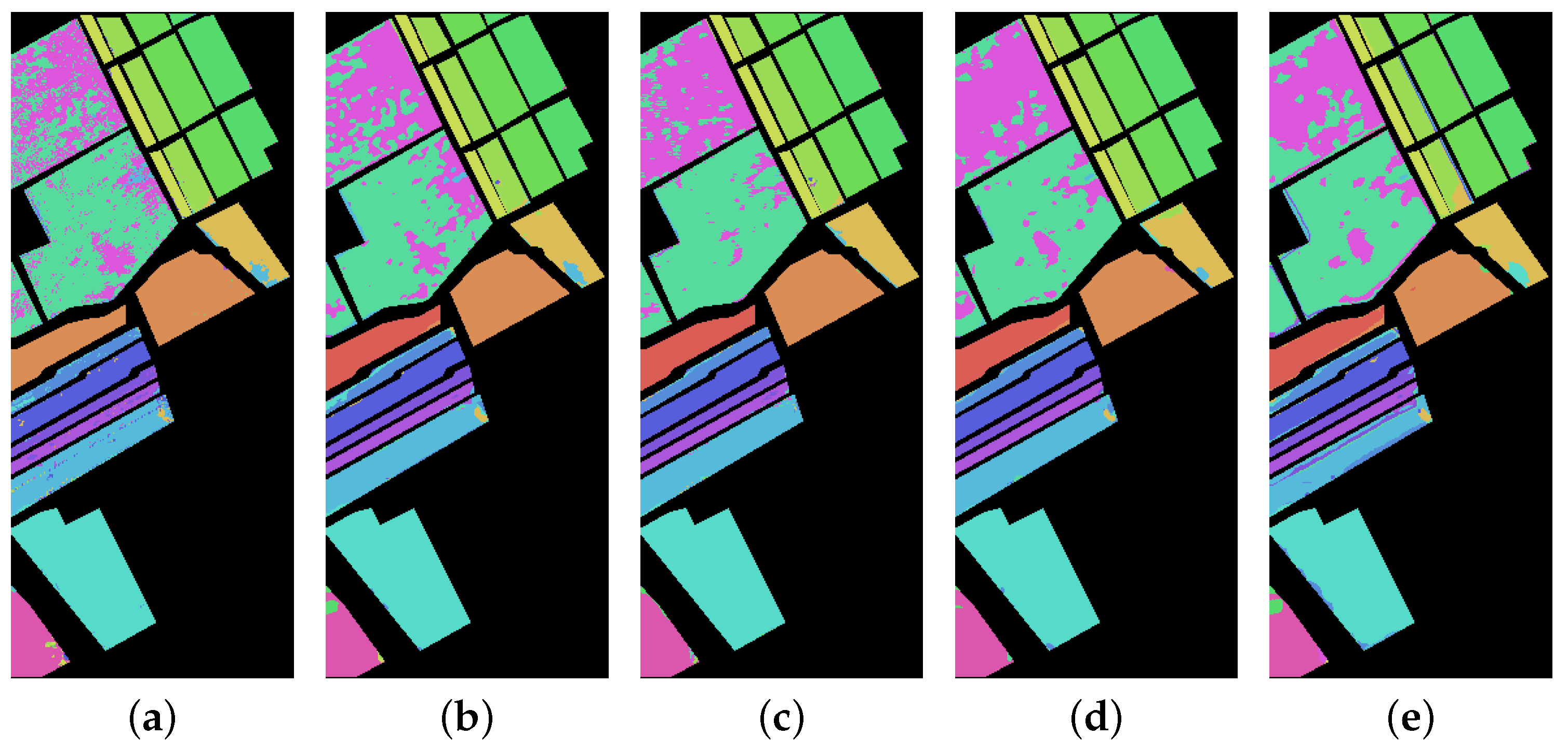
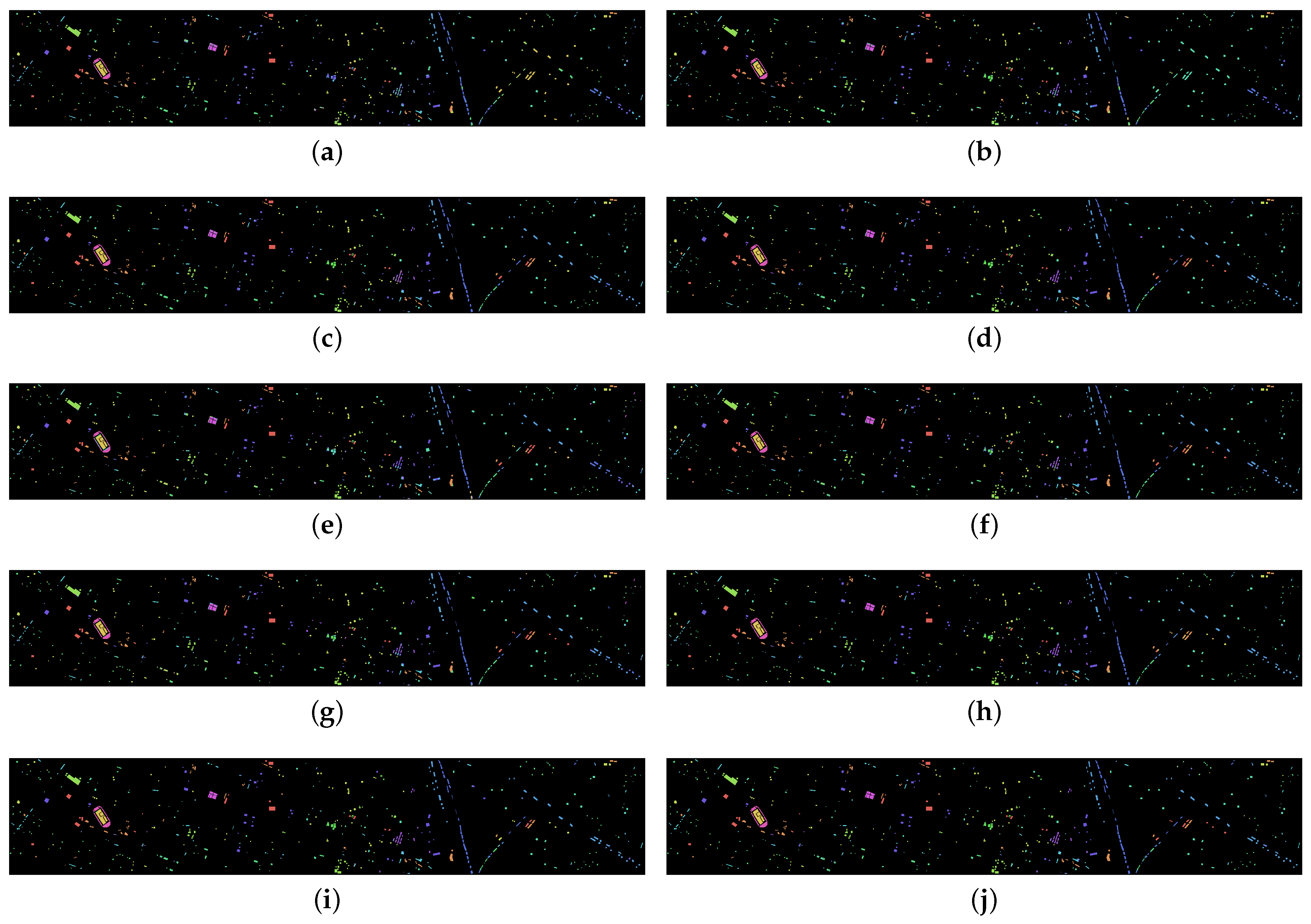
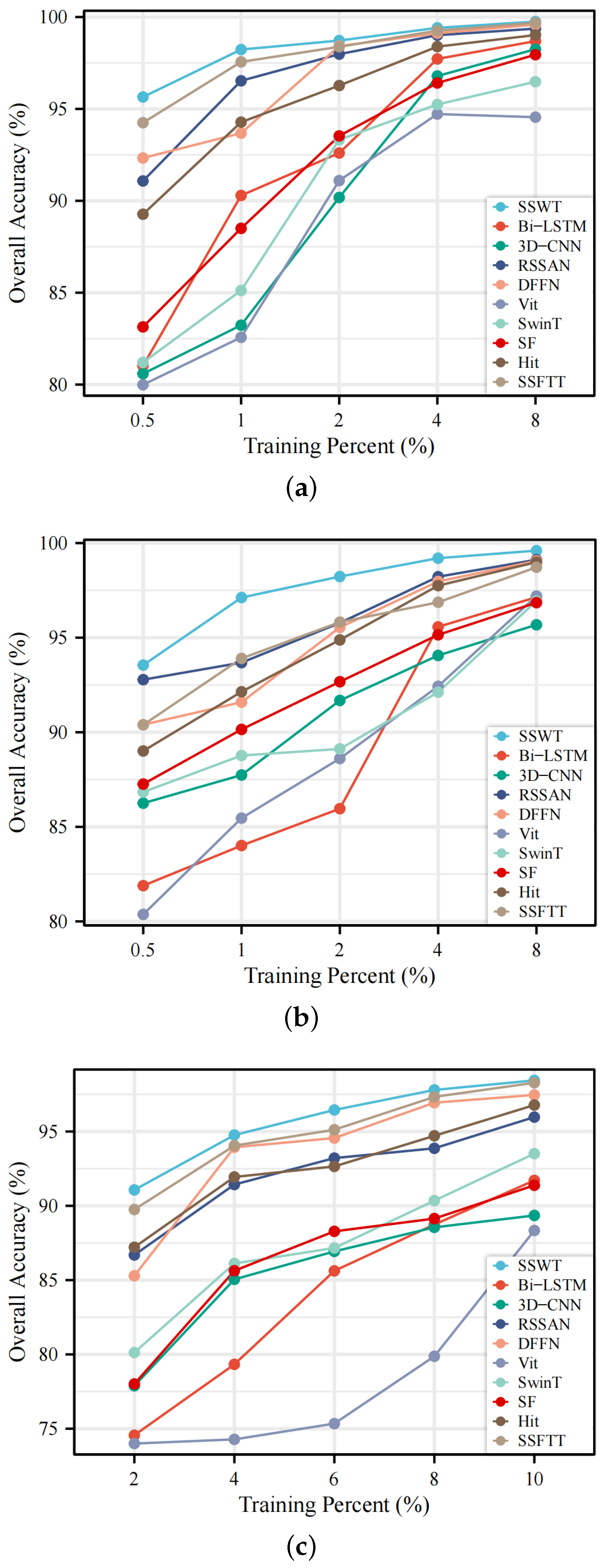
Section 4 presents the three HSI datasets, as well as the experimental setup, results, corresponding analysis.
Section 5 concludes with a summary and outlook of the full paper.
3. Methodology
In this section, we will introduce the proposed spectral-swin transformer (SSWT) with spatial feature extraction enhancement, which will be described in four aspects: the overall architecture, spatial feature extraction module(SFE), spatial position encoding(SPE), and spectral swin-transformer module.
3.1. Overall Architecture
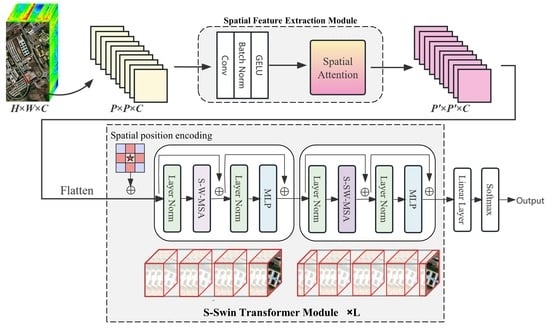
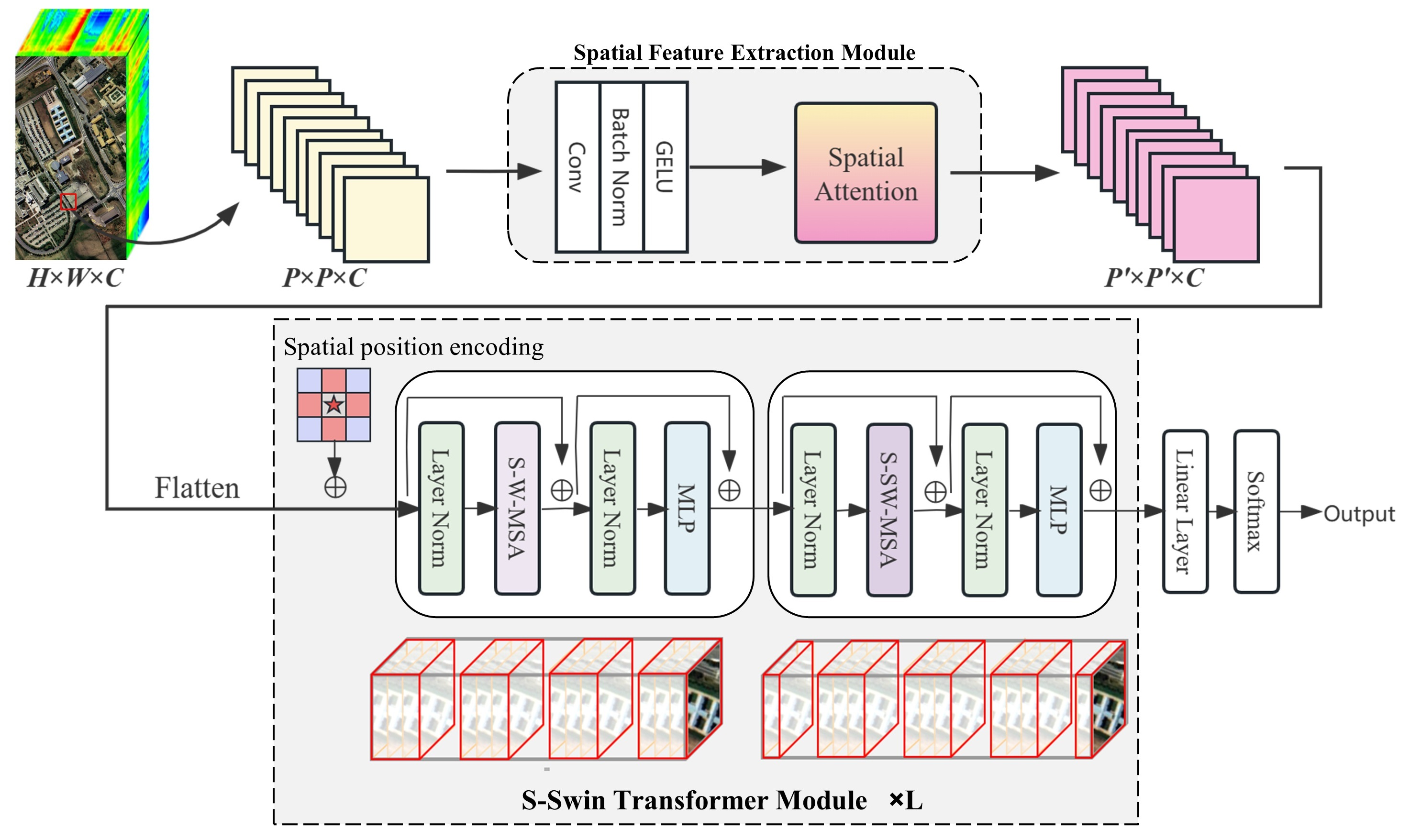
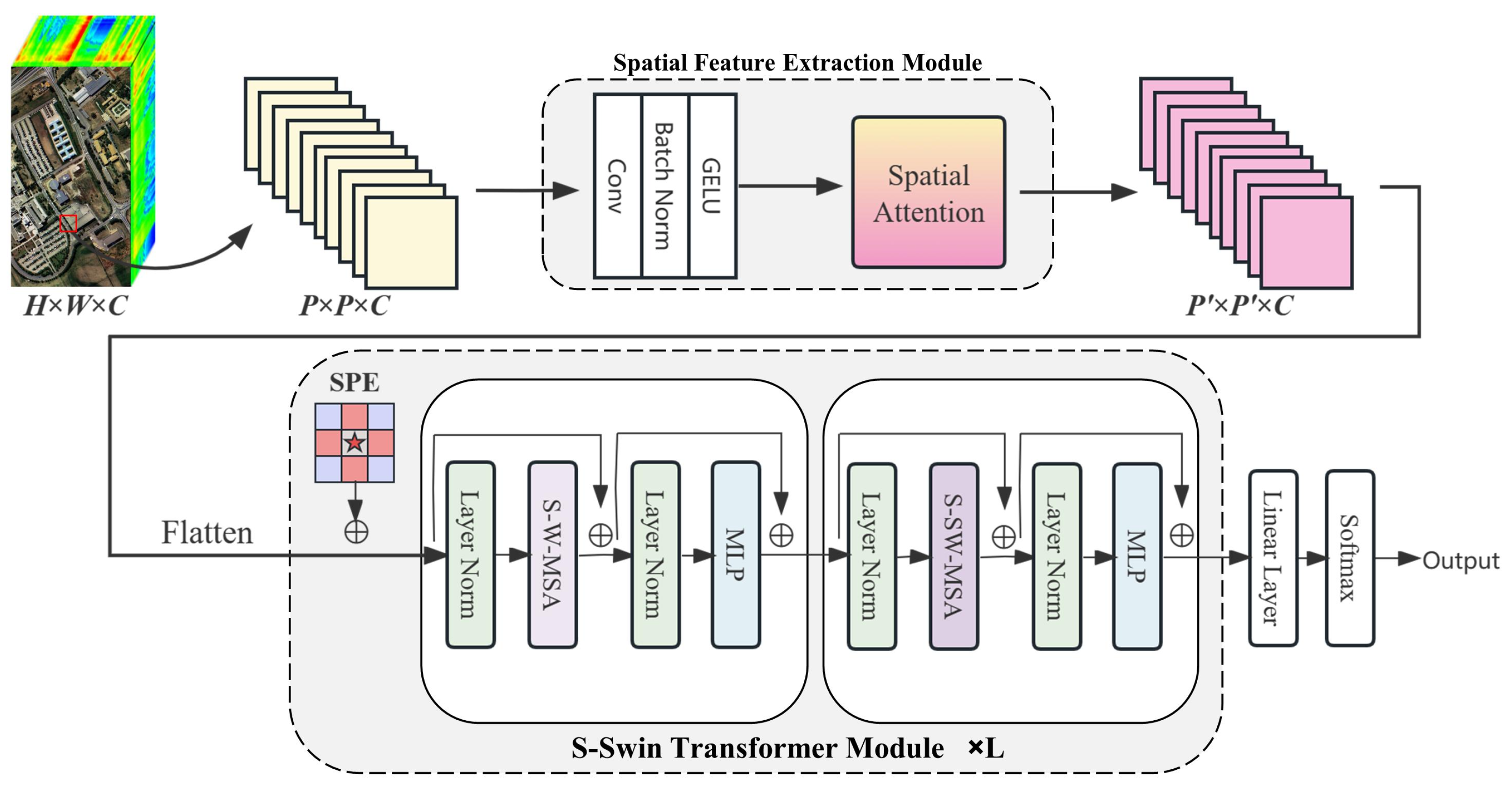
In this paper, we design a new transformer-based method SSWT for the HSI classification. SSWT consists of two major Components for solving the challenges in HSI classification, namely, spatial feature extraction module(SFE) and spectral swin(S-Swin) transformer module. An overview of the proposed SSWT for the HSI classification is shown in
Figure 1. The input to the model is a patch of HSI. the data is first input to SFE to perform initial spatial feature extraction, the module consists of convolution layers and spatial attention. In
Section 3.2, it is explained in further detail. The data is then flattened and entered into the s-swin transformer module. A spatial position encoding is added in front of each s-swin transformer layer to add spatial structure to the data. This part will be described in
Section 3.3. The s-swin transformer module uses the spectral-swin self attention, which will be introduced in
Section 3.4. The final classification results are obtained by linear layers.
3.2. Spatial Feature Extraction Module
Due to transformer’s lack of ability in handling spatial information and local features, we designed a spatial feature extraction (SFE) module to compensate. It consists of two parts, the first one consists of convolutional layers to preliminary extraction of spatial features and batch normalization to prevent overfitting. The second part is a spatial attention mechanism, which aims to enable the model to learn the important spatial locations in the data. The structure of SFE is shown in
Figure 1.
For the input HSI patch cube , where is the spatial size and C is the number of spectral bands. Each pixel space in I consists of C spectral dimensions and forms a one-hot category vector , where n is the number of ground object classes.
Firstly, the spatial features of HSI are initially extracted by CNN layers, and the formula is shown as follows:
where
represents the convolution layer.
represents batch normalization.
denotes the activation function. The formula for the convolution layer is shown below:
where I is the input, J is the number of convolution kernels,
is the
jth convolution kernel with the size of
, and
is the
jth bias.
denotes concatenation, and * is convolution operation.
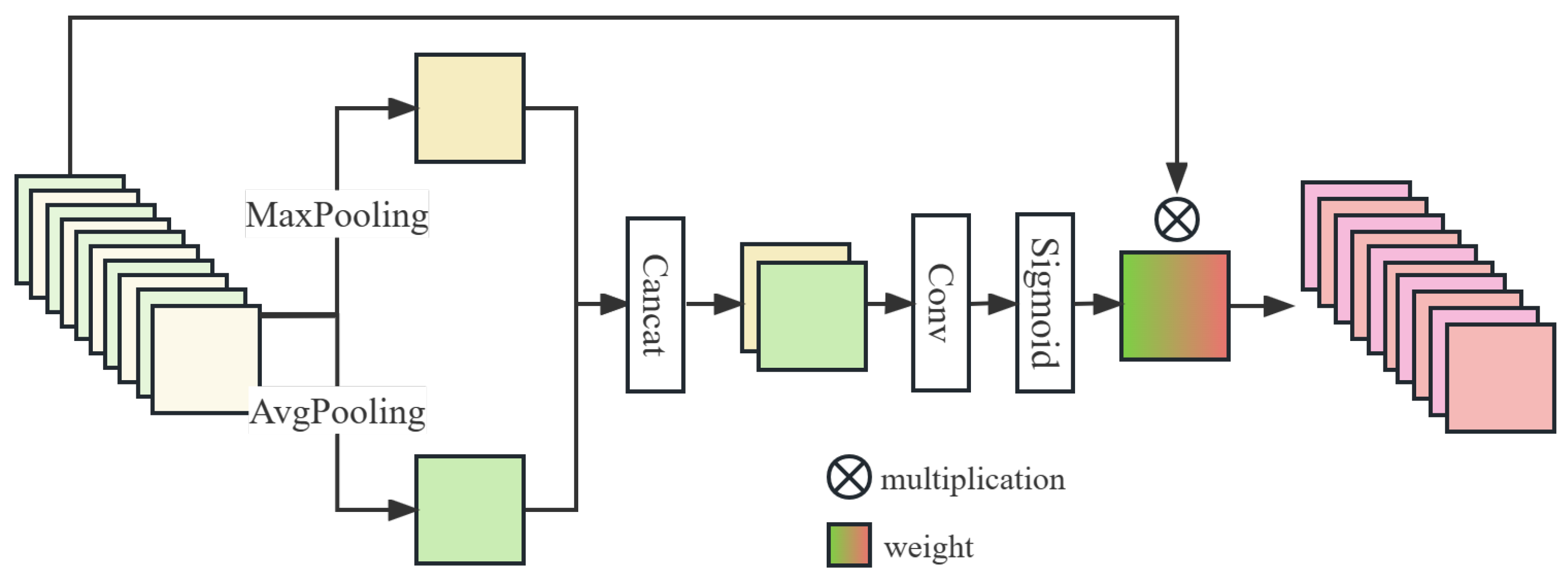
Then, the model may learn important places in the data thanks to a spatial attention mechanism (SA). The structure of SA is shown in
Figure 2. For an intermediate feature map
(
is the spatial size of
X), the process of SA is shown in the following formula:
MaxPooling and AvgPooling are global maximum pooling and global average pooling along the channel direction. Concat denotes concatenation in the channel direction. is activation function. ⊗ denotes the elementwise multiplication.
3.3. Spatial Position Encoding
The HSI of the input transformer is mapped to linear data, which can damage the spatial structure of HSI. To describe the relative spatial positions between pixels and to maintain the rotational invariance of samples, a spatial position encoding (SPE) is added before each transformer module.
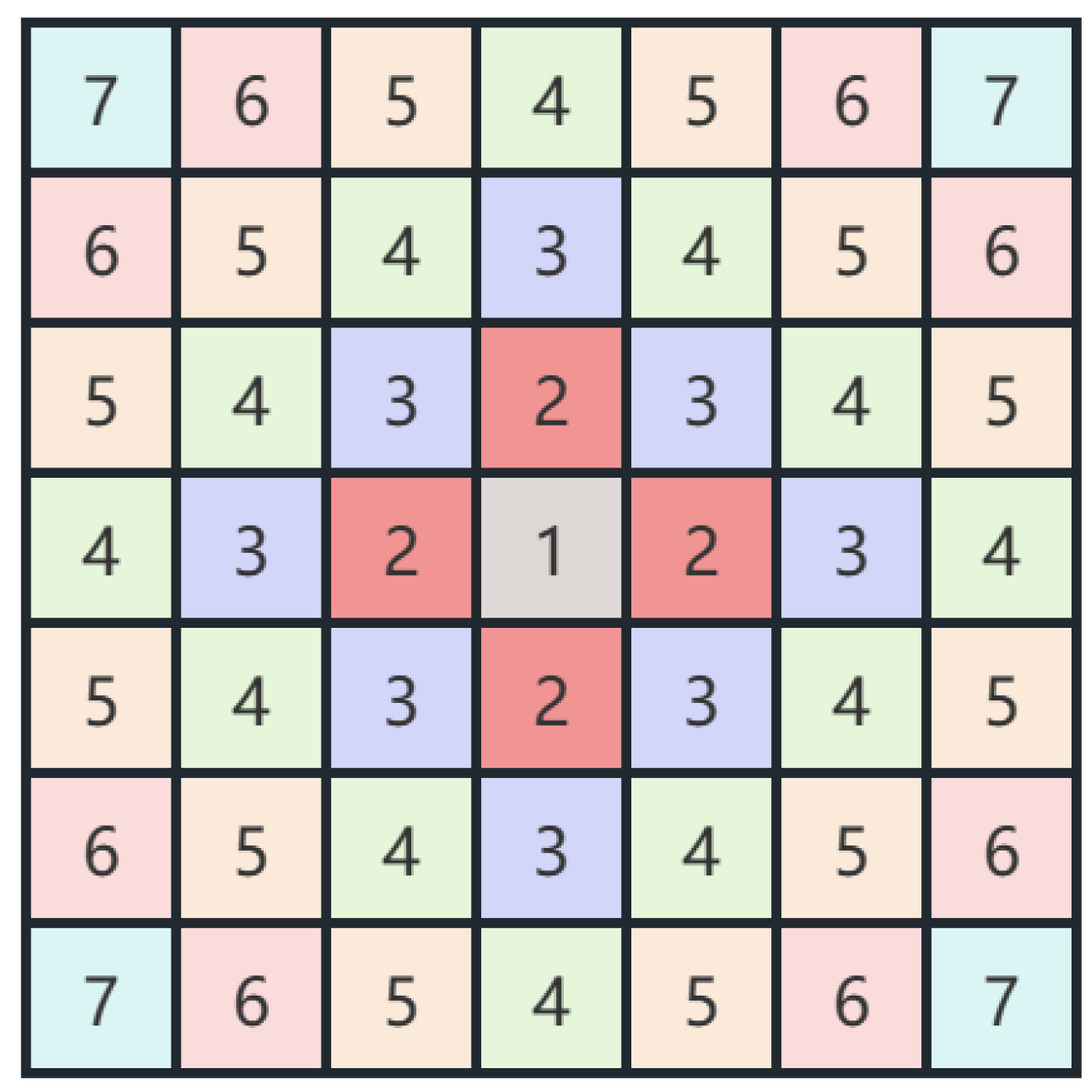
The input to HSI classification is a patch of a region, but only the label of the center pixel is the target of classification. The surrounding pixels can provide spatial information for the classification of center pixel, and their importance tends to decrease with the distance to the center. SPE is to learn such a center-important position encoding. The pixel positions of a patch is defined as follows.
where
denotes the coordinate of central position of the sample, that is the pixel to be classified.
denotes the coordinates of other pixels in the sample. The visualization of SPE when the spatial size of the sample is
can be seen in
Figure 3. The pixel in the central position is unique and most important, and the other pixels are given different position encoding depending on the distance from the center.
To flexibly represent the spatial structure in HSI, the learnable position encoding are embedded in the data:
where
X is the HSI data, and
P represents the position matrix (like
Figure 3) constructed according to Equation (
6).
is a learnable array that takes the position matrix as a subscript to get the final spatial position encoding. Finally, the position encoding is added to the HSI data.
3.4. Spectral Swin-Transformer Module
The structure of the spectral swin-transformer (S-SwinT) module is shown in
Figure 1. Transformer is good at processing long dependencies and lacks the ability to extract local features. Inspired by swin-transformer [
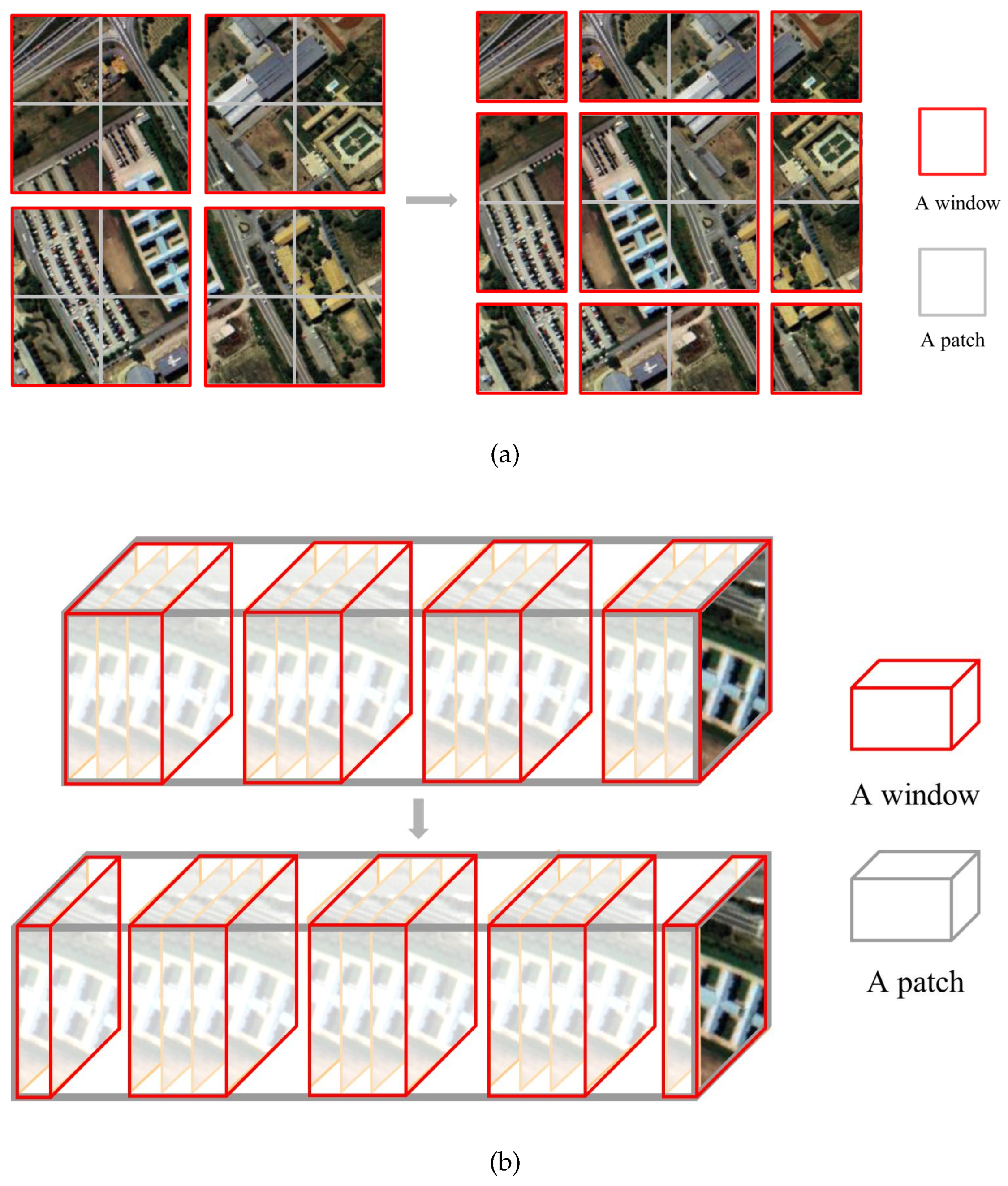
43], window-based multi-head self-attention (MSA) is used in our model. Because the input of HSI is a patch which is usually small in spatial size, it cannot divide the window in space as Swin-T does. Considering the rich data of HSI in the spectral dimension, a window of spectral shift was designed for MSA, called spectral window multi-head self-attention (S-W-MSA) and spectral shifted window multi-head self-attention (S-SW-MSA). MSA within windows can effectively improve local feature capturing, and window shifting allows information to be exchanged in the neighboring windows. MSA can be expressed by the following formula:
Q, K, V are matrices mapped from the input matrices called queries, keys and values. is the dimension of K. The attention scores are calculated from Q and K. h is the head number of MSA, W denotes the output mapping matrix., and represents the output of MSA.
As shown in
Figure 4, the size of input is assumed to be
, where
is the space size and
C is the number of spectral bands. Given that all windows’ size is set to
, the window is divided uniformly for the spectral dimension. The size of each window after division is
. Then MSA is performed in each window. Next the window is moved half a window in the spectral direction, The size of each window at this point is
. MSA is again performed in each window. Wherefore, the process of S-W-MSA with m windows is:
where ⊕ means concat,
is the data of the
i-th window.
Compared to SwinT, the other components of the S-SwinT module remain the same except for the design of the window, such as MLP, layer normalization (LN) and residual connections.
Figure 1 describes two nearby S-SwinT modules in each stage, which can be represented by the following formula.
where S-W-MSA and S-SW-MSA denote the spectral window based and spectral shifted window based MSA,
and
are the outputs of S-(S)W-MSA and MLP in block
l.
5. Conclusions
In this paper, we summarize the shortcomings of the existing ViT for HSI classification tasks. For the lack of ability to capture local contextual features, we use the self-attentive mechanism of shifted windows. The corresponding design is made for the characteristics of HSI, i.e., the spectral shifted window self-attention, which effectively improves the local feature extraction capability. For the insensitivity of ViT to spatial features and structure, we designed the spatial feature extraction module and spatial position encoding to compensate. The superiority of the proposed model has been verified by experimental results across three public HSI datasets.
In future work, we will improve the calculation of S-SW-MSA to reduce its time complexity. In addition, we will continue our research based on the transformer and try to achieve higher performance with a model of pure transformer structure.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}


