1. Introduction
Hyperspectral remote sensing can capture subtle changes on the Earth’s surface because of its characteristic of high spectral resolution [
1]. At present, technologies of hyperspectral change detection have been extensively applied in various domains, such as vegetation inspection, urban planning, and disaster monitoring [
2,
3,
4,
5]. Usually, change detection methods need plenty of training samples for effective and stable model results in different application scenes. The more training samples there are, the more stability the model can obtain. However, current change detection approaches are mostly designed for optical or multi-spectral images, which is a domain in which a model can be fed with sufficient training samples. This situation is in sharp contrast with the predicament of inadequate training samples in hyperspectral imaging. Furthermore, the data redundancy in both spectral and spatial information, mixed pixels caused by low spatial resolution, and the expensive change labeling for hyperspectral datasets make it difficult for multi-spectral change detection technologies to be transferred to hyperspectral images’ analysis [
6].
Usually, the procedure of existent hyperspectral change detection methods can be divided into three different steps: the preprocessing of hyperspectral data, the usage of an appropriate change detection method, and the evaluation of the predicted change results:
(1) Data preprocessing: The preprocessing of hyperspectral images is the basic step for later change detection methods and greatly influences the effectiveness of the change detection results. A typical preprocessing includes registering of dual-temporal images and radiation correction to remove the effects of sunlight and the atmosphere.
(2) Change detection methods: An appropriate change detection method plays a critical role in the whole hyperspectral change detection procedure, which can directly influence the final performance indices. The selection or design of change detection methods needs to take the data structure of the preprocessed hyperspectral images into consideration, such as the remaining band number after noisy bands have been removed.
(3) Evaluation of the predicted change results: The prediction evaluation is the last step. Different evaluation indices can describe the performances of change detection methods from different viewpoints, such as the inference ability in the situation of imbalanced change types.
According to the order of appearance of change detection technologies, they can be categorized as traditional change detection methods and deep learning methods. In traditional change detection methods, based on the different procedures of the data processing, they can be further categorized as transformation-based approaches, algebra-based approaches, and independent image classification approaches. Basically, the main idea of transformation-based approaches is transforming temporal variants into another characteristic space to deal with information redundancy, but this makes it difficult for the model to decide on a proper threshold to precisely detect the changes, such as for change vector analysis (CVA) [
7,
8] and the similarity measure [
9]. As for the algebra-based methods, they must handle the great computational cost due to the high-dimensional data structure. Regarding independent image classification, because the detection result is generated by processing two independent classification maps to produce a single change map, the result may be affected by the error propagation of both images’ classification results, which leads to bad performance.
The rapid development of deep learning methods has stimulated the evolution of hyperspectral change detection technologies. Compared to the traditional methods, the successful performance of deep learning models from other domains makes it possible to solve high-dimensional problems and extract extensive information more effectively. From the recent literature, deep learning methods can be roughly categorized into pixel-based methods and spatial–spectral-information-based methods. For pixel-wide scale analysis, researchers have contributed semi-supervised change detection frameworks, which are often composed of an encoder and a decoder to reconstruct the hyperspectral images by pixel spectral mapping. Then, the reconstructed images are distributed to downstream transformation methods and specific threshold segmentation methods, such as PCA and Otsu, to obtain the change map [
10]. In this situation, the current methods consider deep learning as a preprocessing and compression step, but studies have not integrated the end-to-end change detection performance into a complete model, which results in the wasting of time and memory resources. Regarding the literature on feature extractors for both spectral and spatial information, existing methods propose the convolutional neural network to aggregate multi-direction information, by simply applying the conventional 2D spatial convolution on the compressed images or a direct 3D network to aggregate the two kinds of information at the same time [
11,
12,
13]. Although these methods acknowledge that hyperspectral images themselves are equipped with various information, they still encounter bottlenecks that result from ignoring the spectral similarity in spatial areas and due to the insufficiency of hierarchical feature propagation. Furthermore, the local information usually can be distinguished by the relation to the global information, but current deep methods lack the ability to focus on the resemblance of spectral and spatial information simultaneously. The encoder–decoder framework in the literature was typically trained in a semi-supervised manner, which cannot hierarchically pass and fuse the features into deeper weight presentation to benefit change classification. Moreover, random features are distributed in fully connected layers, which are optimized by the later classification loss function and cannot be assigned for class judgment in advance. Therefore, these models’ drawbacks deeply hinder the improvement of current hyperspectral change detection methods’ performance.
To address these drawbacks of existing methods, in this paper, a parallel spectral–spatial attention network with feature redistribution loss in a supervised two-branch encoder–decoder framework is proposed for hyperspectral change detection. The proposed model rectifies the inner structure of the encoder–decoder framework so that it can be adopted in the proposed end-to-end model for transfer its original deep feature performance. Moreover, a weighted-in-parallel spectral–spatial attention module is constructed to focus on the long-range spectral and spatial dependencies within a patch’s input. To ensure that the fluent information flow can be fed into the classification function, an intensive module with multiple skip connections is applied. Furthermore, due to the unclear feature distribution’s influence in classification tasks [
14], the feature redistribution loss function is developed here to provide better fused features for class-oriented loss computation.
The contributions of this paper are as follows:
(i) A parallel spectral–spatial attention module () is proposed, which can provide the long-range dependenciesin the spectral domain and the local spatial region. Moreover, it fuses the separate stages of weighting the input data into a one-stage procedure, which can preserve the original data dependenciesand provide an enhancement in both the spectral and spatial domains at the same time.
(ii) The feature redistribution loss function (FRL) is developed for better feature arrangement. By maximizing the intra-group correlation and minimizing the extra-group correlation, a rectified loss function is developed, which helps the fused features form an enhanced distribution for class-oriented pattern recognition in advance. To ensure that fluent feature information for redistribution can be received, an intensive connected block (ICB) is applied with multiple skip connections between the convolutional submodules.
(iii) The encoder–decoder framework in a two-branch configuration is constructed in the end-to-end supervised change detection task. Although the decoder was not designed for pixel-level alignment, we found it quite effective to reuse its hierarchically transferred featuresfor change class prediction. This can largely contribute to the feature transfer by the skip connection and the fusion with the expanded feature reconstruction at a different scale.
Extensive experiments prove the effective and efficient performance of the presented method. The rest of this article is arranged as follows:
Section 2 presents the related works on hyperspectral change detection methods.
Section 3 introduces the proposed method.
Section 4 gives the comparison result and ablation analysis of the proposed method.
Section 5 is the conclusion of this study.
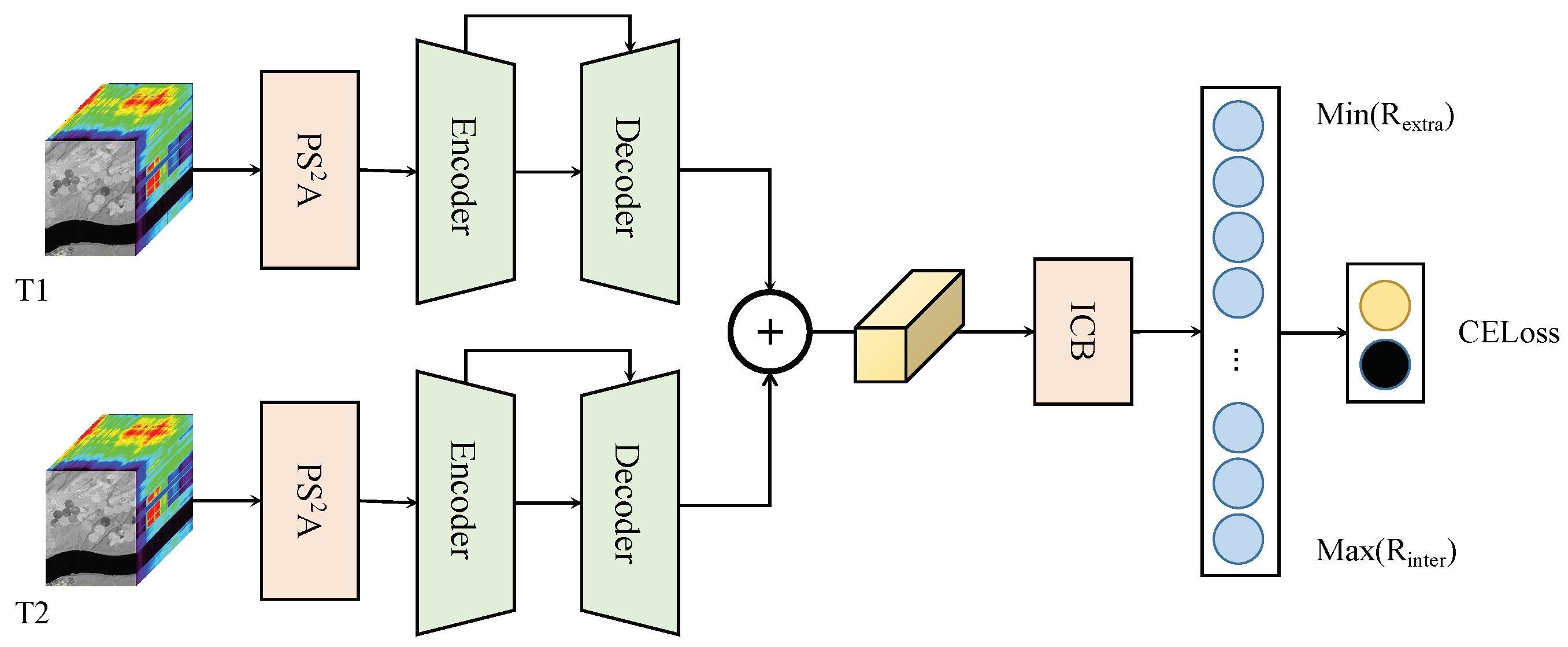
3. Proposed Method
To address these problems and challenges mentioned above and strengthen the robustness and accuracy of model performance, a two-branch feature redistribution network based on the parallel spectral–spatial attention mechanism (TFR-PS
ANet) is proposed. The overall architecture and module designation are shown in
Figure 1.
The hyperspectral image dataset for change detection contains dual-temporal images, which can be described as T1 and T2. First, two parallel spectral–spatial attention modules () are inserted at the start of the whole model to obtain long-range dependencies from both the spectral and spatial domain. Second, weighted feature maps are input into the encoder–decoder framework for a further fused and transformed feature representation. Finally, an intensive connection block is applied to distribute the features into the redistribution loss function and the classification loss function to have a better training procedure.
In this section, the proposed method is presented in four parts to give the detailed information of the design of each, which are the parallel spectral–spatial attention module, the two-branch encoder–decoder framework, the intensive connection block, and the feature redistribution loss function.
3.1. Parallel Spectral–Spatial Attention Module
The parallel spectral–spatial attention module (
) is inserted in the first stage to aggregate the long-range dependencies from the original hyperspectral images as much as possible. As the module name implies,
is composed of spectral attention and spatial attention, but each attention map is computed in parallel. The design details of the proposed
module are shown in
Figure 2.
For a hyperspectral image input patch
in the shape of
, the parallel spectral and spatial attention module is introduced. Regarding the processing of the spectral attention mechanism, the query vector is defined as
, which is used as a reassignment factor for the attention map along with the key vector
. A convolutional layer with a
kernel size is introduced to decrease the spectral channel of the input patch
, followed by two adjacent fully connected layers with the SoftMax activation function to make the query vector
eventually. In reference to the key vector
, it is computed by a convolutional layer with 2 dilation rates, which can expand receptive field, followed by a reshape operation to change the features into a size of
. After
and
are generated, the matrix multiplication operation ⊗ is inserted between them to obtain the attention map
along with a fully connected layer and a SoftMax activation. All the process steps of the spectral attention module can be formulated as follows:
where
denotes the convolution operation with a kernel size of 1 × 1 and
denotes the fully connected layer used to squeeze and expand the middle hidden features. The SoftMax activation function is represented as
. The dilation convolution operation with a kernel size of
is formulated as
, and the reshape operation
is applied in the computation of
and
. Then, the spectral attention map can be obtained by the matrix multiplication operation ⊗ to have
weighted, which is also
here.
With reference to spatial feature extraction, it has a similar process as for spectral feature extraction. The query vector of the spatial domain
is calculated by a convolutional layer with a kernel size of
, followed by an adaptive average pooling operation to compress the spatial size to
pixels. Then, the fully connected layer and the SoftMax activation function are applied to halve the number of features. As for the vector of spatial key vector
, it is calculated by dilation convolution with a kernel size of
and a dilation rate of 2, followed by the reshape operation to change the feature map size to
. Then, the same matrix multiplication operation ⊗ is applied between
and
, followed by the fully connected layer and SoftMax activation function. For the spatial weighting process, the attention map
is reshaped to the same resolution size of
. The detailed calculations are formulated as follows:
With the obtained attention maps of
and
by Equations (3) and (6), the value vector
can be parallelly weighted to achieve the spectral and spatial dependency modeling. The local patch-level perception for hyperspectral images can be defined as:
where ⊙ indicates pointwise production for every band and pixel and
represents the value vector, which here indicates the original patch input
.
is the output feature map after weighting.
3.2. Two-Branch Encoder–Decoder Framework
Different from the traditional classification backbone following the pyramid structure, here, the proposed feature extractor is guided by the encoder–decoder structure, which is common in the semantic segmentation of natural or biomedical images. Due to the fact that the dual-temporal images may have different local spectral and spatial information at the same pixel location, the feature extractor based on the encoder–decoder framework is constructed and assembled in the proposed method in a parallel manner. The two-branch design of the rectified encoder–decoder feature extractor is shown in
Figure 3.
As the left side of
Figure 3 shows, the proposed encoder generates internal feature maps using independent convolutional layers with a kernel size of
. The patch size decreases gradually from
to
. Take the first layer of the encoder network as an example: feature weighted by the attention map in the shape of
is input into a convolutional block with three successive convolutional layers, and then, the output feature map
is calculated and temporarily saved. By a max pooling layer with a kernel size of
, the output features from the last layer are downsampled into the shape of
. Therefore, the components of the encoder are made up of the same and stacked convolutions and max pooling operations. As the right side of
Figure 3 shows, the decoder is responsible for processing and expanding the output features generated from the encoder components. Take the last output layer in the encoder as an example: the spatial resolution of
is expanded by the upsampling operation, while the channel number is enlarged by a convolutional layer. The built feature map is defined as
, which has the same shape as the corresponding encoder
. Both
and
are concatenated, and hence, the channel dimension is doubled as well. Then, the features are processed by a convolutional block with three successive convolutional layers, which have the same definition as that in the encoder.
Given an input patch
, a single convolutional layer
can be defined as follows, which is constructed with a convolution, a batch normalization, and a SELU activation function:
In (8),
indicates batch normalization and
denotes the SELU activation function. The three successive convolutions are represented as
, and
i corresponds to the
i-th block of the encoder. Therefore, the relation between the features from the front and back block can be written as follows:
where
indicates the max pooling operation used to squeeze the spatial resolution in the encoder part. For the decoder part, the input for every decoder block
is processed by the following formula:
The definition of the upsampling with the convolutionis represented in (10), where indicates the upsampling operation using the nearest interpolation and indicates the ReLU activation function. Then, the output features of the upsampling with the convolutionis concatenated along with the corresponding copy from the encoder and computed by sequential convolutional layers .
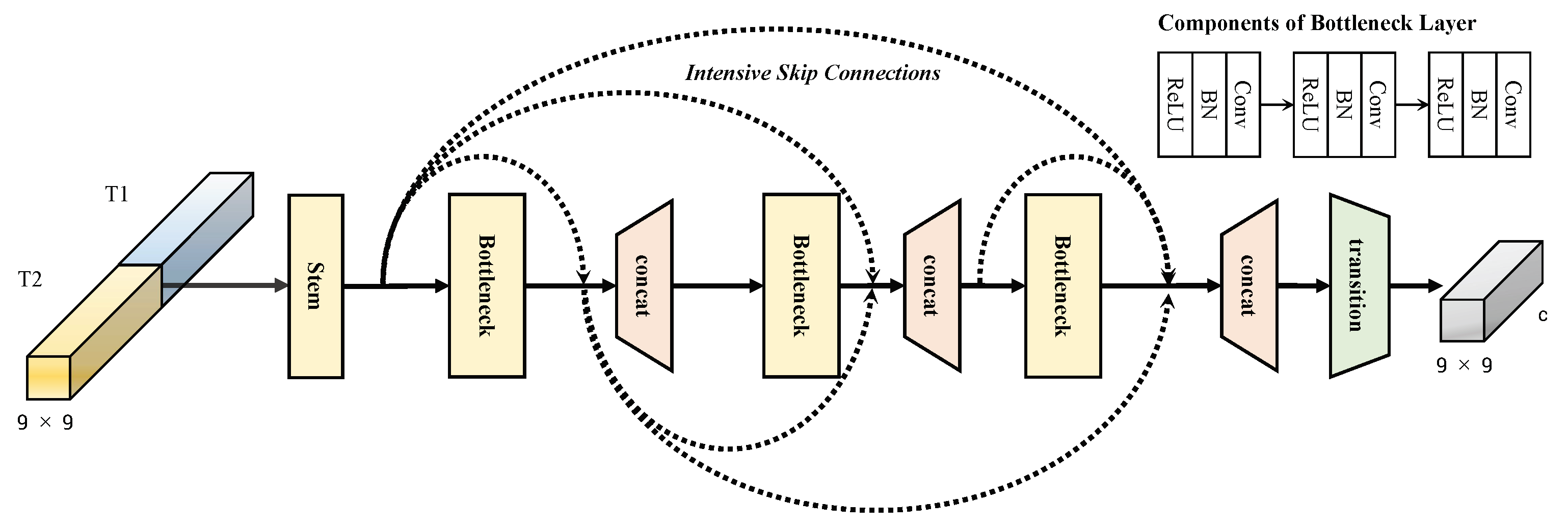
3.3. Intensive Connected Block
To keep the information flow fluent and to pass the hierarchical features, the intensive connected block is constructed. Compared to the residual skip connection, three bottleneck layers with intensive skip connections here were applied to make the model have a low computation cost while keeping a similar time complexity, which was inspired by DenseNet [
33].
The input features
are concatenated by two output feature sets generated from two-branch encoder–decoder framework. Then, it is processed by the stem layer to reduce the channel number to avoid overfittingin the intensive skip connections. When feature maps arrive at the last skip connection, the channel number is expanded by three bottleneck layers. Therefore, a transition layer is introduced to avoid the burden of too many features. The process in the intensive connected block can be formulated as follows:
where
indicates a stem convolutional layer with a
kernel size to decrease feature channel number and
indicates the bottleneck layer shown in
Figure 4.
denotes the transition layer for the computation of the feature output
.
3.4. Feature Redistribution Loss Function
To obtain a better class-oriented feature expression, the feature redistribution loss function (FRL) was developed to distribute the features more properly. The feature redistribution can provide enhanced and fused features for pattern recognition [
14]. Inspired by this work and due to the procedure of the conventional loss computation lacking class distribution information for change detection, the FRL is proposed and can enhance the independence of the feature representation. The structure of the FRL is shown in
Figure 5.
After the process of the ICB, the output features
are convoluted to
, followed by a fully connected layer to change the features to
. Then, the features
are divided into a set of vectors of length
m. Therefore, the defined feature number of vectors is calculated as:
The number of divided groups is the same as the number of land cover change categories
c, and the covariance matrix
corresponding to the variants
n can be calculated as:
where
indicates the mean vector of vector length
m. All defined
n features can be represented as
V and grouped into
c categories
. Every group contains
defined features. With the constructed covariance matrix
, the correlation matrix can be represented as
, where the correlation coefficient between the indices of
i and
j is calculated as:
To maximize the correlation between extra-groups
and minimize the correlation in inter-groups
, both correlations can be defined as follows:
Considering a simple and convenient representation of the formula in (19), the part that represents the correlation for the
k-th group can be defined as:
According to the correlation matrix
and the relation of the indices in
, the interval of
can be calculated and
can be simplified as well:
Therefore, the normalized loss between the extra-groups can be represented as:
Maximizing the internal correlation
is equivalent to minimizing
. The definition is as follows:
Therefore, the normalized loss of the internal correlation can be calculated with:
With the calculated extra-loss and inter-loss, it can be assembled together by the weights’ distribution. The whole loss function can be represented as below:
where
indicate the weight coefficients to adjust the sizeof every loss.
indicates the cross-entropy loss. The effectiveness of the proposed loss function is discussed in the later ablation experiments, and the impacts of the hyperparameters are analyzed as well.
After the redistribution loss is applied, the features are sent to the fully connected layer, followed by SoftMax activation function, which links the cross-entropy loss function. This prediction procedure can be formulated as:
4. Experiments
4.1. Description of Dataset
In this paper, three public dual-temporal datasets for hyperspectral change detection were chosen for model testing, which were all captured by the Earth Observing-1 (EO-1) satellite with the Hyperion sensor. It provides a spectral range of 0.4–2.5 μm with 242 spectral bands and a spectral resolution of 10 nm approximately, as well as a spatial resolution of 30 m. In the experiments, spectral bands with a low signal-to-noise ratio (SNR) were removed. To distinguish whether the land cover area had changed or not, the binary ground truth maps were obtained by visually analyzing extensive studies and on-the-spot investigation. The first hyperspectral image dataset is the Irrigated Agriculture Dataset [
34] captured on 1 May 2004 and 8 May 2007, which illustrates an irrigated agricultural area of Hermiston City in Umatilla County, Oregon, USA. It contains
pixels and 156 bands after omitting no-data bands and removing the noise. The training rate followed the original work, which was 9.7% approximately. This dataset is shown in
Figure 6. The second dataset is the Wetland Agriculture Dataset [
34], which contains images captured on 3 May 2006 and 23 April 2007. This dataset illustrates a farmland area of Yuncheng City, Zhejiang Province, China. It contains
pixels and 156 bands after removing noise. Referring to the training rate of the Irrigated Agriculture Dataset, the training samples for the Wetland Agriculture Dataset were further decreased compared to the original work, which was set to about 9.7% as well. The T1 image, T2 image, and ground truth are shown
Figure 7. The last change detection dataset is the River Dataset [
26], which contains images captured on 3 May 2013 and 31 December 2013. This dataset illustrates a river area in Jiangsu Province, China. It contains
pixels and 198 bands after noise removal. The false color image for the River Dataset is shown in
Figure 8. Every dataset was divided into a training set, validation set, and test set. The training samples of the Irrigated Agriculture Dataset and Wetland Agriculture Dataset occupied 9.7% of the total samples approximately using stratified random sampling. For the River Dataset, to consider the problem of class imbalance, the proportion of the unchanged samples to the changed samples was 2:1, which followed the rule of original work. Eventually, the training rate for the River Dataset was 4.03%. For all three public datasets, stratified random sampling was used to generate the random training samples. The details of every dataset are shown in
Table 1.
4.2. Experimental Setup
All experiments were performed on an NVIDIA RTX 3060 with 12G of video memory. Due to the model structure, it can handle different patch input sizes without any spatial resolution restriction. In the training set procedure, the batch size was chosen as 64 patch inputs by default and the learning rate as
with a corresponding
weight decay applied to exhibit better convergence. The Adagrad optimizer was used here to train the proposed TFR-PS
ANet. The united loss function with the cross-entropy loss and the feature redistribution loss were chosen for the model training procedure, and the formula of the cross-entropy loss is shown below:
where
M indicates the number of categories and
is an indicator for which the value is equal to 1 or 0 depending on whether it is the true category of sample
i. The prediction probability belonging to
c of sample
i is expressed as
.
4.3. Evaluation Metrics
For a fair and convenient performance comparison among the three hyperspectral change detection datasets, the accuracy (ACC), kappa coefficient (kappa), F1-score, precision, and recall were selected to evaluate and quantized model’s performance. Every index was calculated based on a confusion matrix, and the larger the value, the better the performance is.
Accuracy (ACC): Regarding pixel-level classification tasks, accuracy is a relatively simple, but effective metric to weigh the model’s performance. The formula for the calculation of the accuracy is:
Kappa coefficient (kappa): The kappa coefficient is another metric usually used for pixel-level classification. According to the formula of the kappa coefficient, it takes the class imbalance into consideration and can measure the model’s performance on different datasets fairly. The formula for the calculation of the kappa coefficient is:
F1-score: The F1-score (also known as the F1-measure) is designed to evaluate the performance of a pixel-level binary classification model. It can be considered as the harmonic mean of the precision and recall. The F1-score is calculated as:
Precision and recall: The precision indicates the true positives in the sum of the true positive and false positive samples. The recall indicates the true positives in the sum of the true positive and false negative samples. The formulae are, respectively:
4.4. Experimental Results
In this section, five methods in the change detection domain were chosen to make comparisons with the proposed TFR-PS
ANet. Two of them are traditional methods based on supervised or unsupervised learning, and the rest are SOTA deep learning methods. CVA is a traditional method using difference maps and unsupervised segmentation, which was Otsu here [
35]. The second traditional method for pattern recognition is SVM, which is extensively used in land cover change detection [
36]. As for the deep learning methods, GETNET [
26] based on the LSConvolution architecture and DSFANet [
27] following the principle of semi-supervised learning were chosen as the comparison methods. For the CNN architecture in two-domain learning, the patch-based WCRN model [
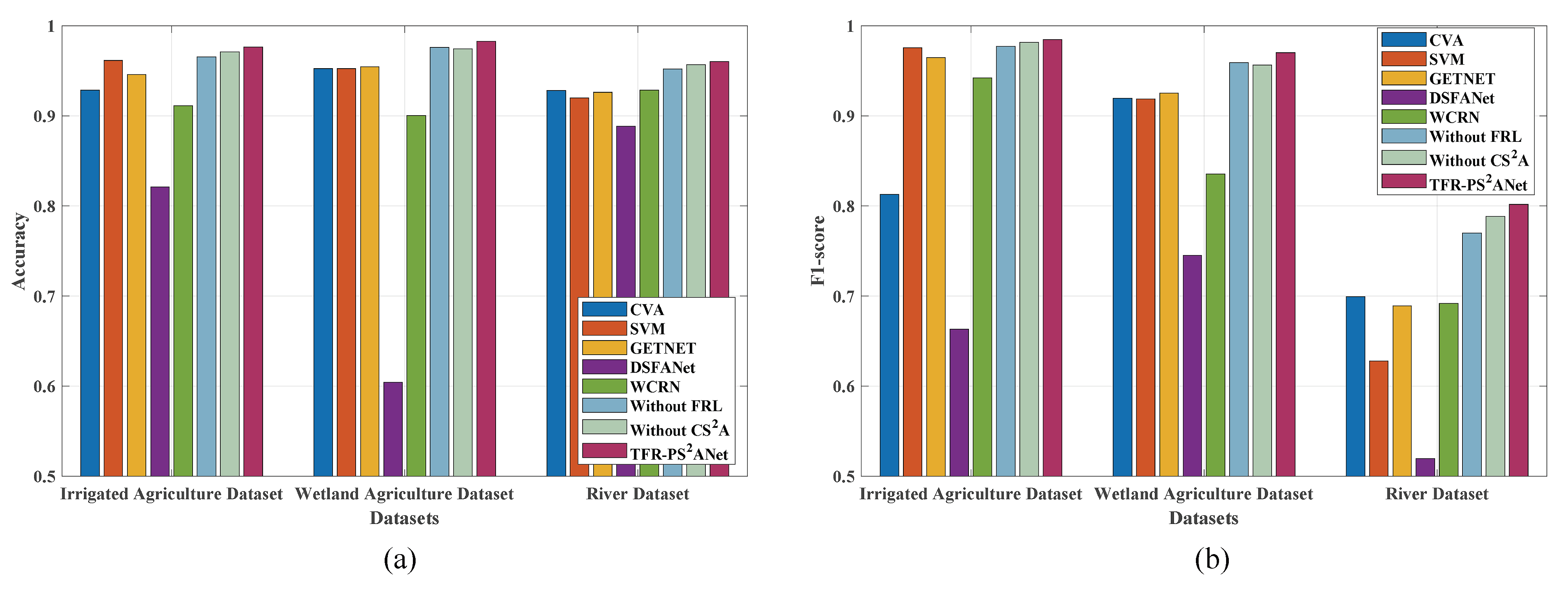
19] was chosen as the comparison model. For the mentioned deep-learning-based methods, the same default parameter settings introduced in the corresponding works were selected. Extensive experiments were conducted on all three hyperspectral change detection datasets. The detailed model comparison results are described below. The overall accuracy and F1-score comparison is shown in
Figure 9, which indicates that the proposed TFR-PS
ANet is superior to most of the other methods.
4.4.1. Experiments on the Irrigated Agriculture Dataset
The model comparison results can be seen in
Table 2. The proposed TFR-PS
ANet was able to achieve the best results on the ACC, kappa coefficient, F1-score, and recall. The best precision was achieved by CVA, while this model had the worst recall result, which is less than about 0.29 compared to that of TFR-PS
ANet. The best competitor was the SVM method. As a traditional method, it outperformed most of the selected deep learning methods. Among them, the unsupervised DSFANet showed the worst change detection results. GETNET showed the best recall in comparison to the other methods, but its precision was lower than that of TFR-PS
ANet, which resulted in an inferior F1-score result. DSFANet is an unsupervised method just like CVA, but it detects too many unchanged pixels wrongly according to its poor precision performance, which may be a result of the complex scenes of the agriculture images.
In the last three rows of
Table 2, the comparisons of TFR-PS
ANet, TFR-PS
ANet without redistribution loss, and TFR-PS
ANet without
are given. The accuracy and kappa coefficient performance of TFR-PS
ANet without redistribution loss showed a clear drop compared to TFR-PS
ANet. TFR-PS
ANet without
showed a slight accuracy decrease, while the kappa coefficient had an obvious disparity. Although the two ablation studies of the models demonstrated weaker results than TFR-PS
ANet, they still outperformed the other competitors, which implies that the encoder–decoder framework can effectively extract the change features. In conclusion, the proposed TFR-PS
ANet had the best performance on most of the metrics compared to the other methods.
The change detection maps for the Irrigated Agriculture Dataset are shown in
Figure 10. Using the ground truth map as a reference, the proposed TFR-PS
ANet showed the closest visual effects, and the border pixels were visually distinct like the ground truth map, while the change maps detected by CVA, GETNET, and WCRN failed to distinguish the subtle changes in the border pixels. Although SVM showed great visual effects, it detected unrelated subtle changes of the border pixels mistakenly, which led to inferior accuracy and precision. Regarding DSFANet, it showed scattered points in the change result map, which caused a false detection and led to lower accuracy and kappa indices. The reason for this situation could be that the unsupervised DSFANet is not suitable for complex land cover spectral information. Regarding the ablation results of the models TFR-PS
ANet without redistribution loss or
, it can be seen from the visual effects that TFR-PS
ANet without redistribution loss would detect some border pixels mistakenly, while TFR-PS
ANet without
would detect border pixels as a large spot, which would affect the detection result.
4.4.2. Experiments on the Wetland Agriculture Dataset
The comparison results of the models on the Wetland Agriculture Dataset are shown in
Table 3. For this dataset, the proposed method TFR-PS
ANet outperformed the other methods in all indices as well. The best competitor was GETNET, which achieved the highest accuracy in comparison the other models, but it was inferior to TFR-PS
ANet by a slight worse accuracy and kappa coefficient. CVA and SVM were still stable models, achieving very similar accuracy and kappa coefficient performance. DSFANet showed the worst performance and almost could not detect the main farm change region, which can be concluded from the kappa coefficient result. WCRN could achieve an acceptable accuracy result, but the kappa coefficient remained low.
The last three rows of
Table 3 show the comparison among TFR-PS
ANet, TFR-PS
ANet without redistribution loss, and TFR-PS
ANet without
. Compared to TFR-PS
ANet, the ablation results of the model TFR-PS
ANet without redistribution loss were inferior on every metric. The performance of TFR-PS
ANet without
was worse than TFR-PS
ANet without redistribution loss, which may indicate that long-range dependencies are very necessary in areas with much crop spectral information. In conclusion, the proposed TFR-PS
ANet showed the best performance on the Wetland Agriculture Dataset.
The detected change maps of these methods for the Wetland Agriculture Dataset are shown in
Figure 11. The proposed TFR-PS
ANet showed the most similarity to the ground truth map in visual effects, which kept the detailed change information while suppressing unrelated subtle information. The two traditional methods, CVA and SVM, could detect the main agriculture change area, but too many scattered points were also detected mistakenly, which influenced the accuracy and precision indices. GETNET successfully detected most of the change area, but there was a loss of subtle farmland change information as well. DSFANet showed the worst performance, which basically only detected the border of change areas. This may have resulted from its insufficient capacity to process complex scenes. WCRN could detect most of the change area, but the main drawbacks were that it lost the detailed information and farmland edge change information. Furthermore, in the top area of the WCRN change map, it detected some unrelated points, which decreased the accuracy and precision results. Regarding the last three change maps, it can be observed that they basically had similar visual effects except several wrong pixels detected by mistake, and they all showed the best similarity to the ground truth map compared to the other methods.
4.4.3. Experiments on the River Dataset
The comparison results of different methods on the River Dataset are shown in
Table 4. Our proposed TFR-PS
ANet achieved the best ACC, kappa, F1-score, and precision. WCRN was the best competitor, which was designed in the original work on the River Dataset, and showed the best accuracy performance (0.9284) among the compared deep learning methods, followed by the deep leaning GETNET method, having a 0.9260 accuracy. SVM and DSFANet had a 0.9198 and 0.8883 accuracy, respectively. The unsupervised DSFANet did not perform well, which could be a result of its insufficient feature learning under class imbalance.
In the same way, the last three rows give the ablation results of the models. Compared to TFR-PSANet, the model TFR-PSANet without redistribution loss showed a considerable accuracy drop by around 0.01, while the model without showed a slight accuracy decrease. Therefore, it is necessary for change detection to adopt the class-oriented feature redistribution in the second to last layerfor the River Dataset. In conclusion, the proposed TFR-PSANet can perform best among these methods while handling with class imbalance.
The change detection maps for the River Dataset are shown in
Figure 12. It can be observed that TFR-PS
ANet showed the closest similarity to the ground truth map from the visual effects. The first result map generated by the unsupervised CVA showed many unrelated pixels detectedto the left. On the contrary, the second SVM result map showed a failure to detect change pixels to the left. GETNET, as the best competitor, could detect distinct change areas, but they were expanded slightly. DSFANet showed many points and gaps due to it insufficient unsupervised post-processing. For the visual effects, the change map from WCRN showed rough boundaries, which caused a low-precision result. With reference to the change map generated by TFR-PS
ANet without redistribution loss or
, both could detect some noise-like pixels shown ot the top of the change map, which influenced the final accuracy and F1-score, while they still outperformed the other compared methods.
4.4.4. Impact of Hyperparameters
In this section, the influence by both hyperparameters for the redistribution loss and the cross-entropy loss, which are the weights
in Formula (27), were analyzed. The hyperparameter
is responsible for the adjustment for the extra-loss in the redistribution loss function, while
is responsible for the inter-loss. With the hyperparameter
selected, the influence of the distribution of the features can be analyzed. The hyperparameter
was utilized to adjust the influence of redistribution loss, while
worked as the weight for the cross-entropy loss. As
Figure 13 shows, the performance impacts for the accuracy, Kappa, and F1-score were analyzed on all three datasets.
The first row shows the accuracy change influenced by hyperparameters and . When , the best accuracy performance on the River Dataset was achieved at , while that on the Irrigated Agriculture Dataset was achieved at . The best accuracy performance on the Wetland Agriculture Dataset was achieved at as well. When , the two best accuracies on Wetland Agriculture and River Datasets were both achieved at , while on the Irrigated Agriculture Dataset, the proposed method achieved the best performance at . Along with the increase of , the proposed TFR-PSANet could achieve the best accuracy on the three datasets at .
The influence on the kappa index is shown in the second row of
Figure 13. It had a similar trend to the accuracy change. From the first figure of the second row, it can be observed that the proposed method could achieve the highest kappa results at
on the Wetland Agriculture Dataset and the River Dataset, while on the Irrigated Agriculture Dataset, it performed best at
. When
, the best results of the kappa index on the Wetland Agriculture and River Datasets were achieved at
as well. However, the highest performance on the Irrigated Agriculture Dataset was achieved at
. According to the last three figures, the proposed TFR-PS
ANet achieved the highest kappa results when
at the same time.
The last row shows the influence on the F1-score index. From the overall visual effects, TFR-PSANet performed stably on both the Irrigated and Wetland Agriculture Datasets. Regarding the analysis of the Irrigated Agriculture Dataset, except the results at , the rest of the figures show that the best F1-score results were achieved at as well. The results on the Wetland Agriculture Dataset showed similar stable trends as those on the Irrigated Agriculture Dataset, which mostly achieved the highest F1-score results at . The trends on the River Dataset increased their fluctuation and stopped at to obtain the best performance.
In other words, from the optimal analysis results of the accuracy, kappa coefficient, and F1-score on all three datasets, the proposed model could obtain the best performance when and . Due to the hyperparameter being able to influence the extra- and inter-loss balance, the model hyperparameters were set as and finally.
4.5. Discussion
The advantage in terms of the accuracy of the proposed TFR-PSANet method over the benchmark methods was due mainly to the application of the module, which contains the parallel spectral–spatial attention mechanism. Moreover, the proposed TFR-PSANet method is assisted by the FRL, which can reassign the features to a class-oriented distribution. According to the extensive experiments conducted above, CVA, as the conventional unsupervised method, performed stably on the three datasets. However, the change detection results largely relied on the determination of a threshold. The inadequate extraction of spectral information led to inferior detection results compared to our proposed method. As a conventional supervised method, SVM needs training samples. Practically, it can be difficult for SVM to handle local spatial information while finding a proper discriminative property for spectral information. On the contrary, the proposed method extracts features from both the spectral and spatial domain, which led to better discriminative abilities of change detection.
For the deep learning methods, GETNET is based on the supervised LSConvolution architecture. It extracts features from the input patch without considering internal spectral and spatial dependencies. Our proposed method can adaptively obtain long-range dependencies using the parallel attention mechanism, while the FRL assists in arranging the features properly. DSFANet is performed in a semi-supervised manner. However, this method showed the worst results on all the change detection datasets, which implies its weakness in dealing with complex spectral information using unsupervised post-processing. In terms of the comparison between WCRN and TFR-PSANet, the proposed method using the attention mechanism showed the better effectiveness of the adaptive two-domain feature learning compared to the CNN-based architecture.
However, there are also some limitations of the proposed method. First, the three change detection datasets have different time intervals. This leads to the problem of the continuous change amount during different periods being hard to compare. The design of the proposed method regarding the dual-temporal images as a pair of independent moments indicates that the change monitoring needs the support of data with the same or higher time resolution. To address this issue, it is worthwhile to extend the current TFR-PSANet to time series analysis. Nevertheless, in most situations, a time series change detection method can only be driven by dual-temporal images from satellites with different spectral and spatial resolutions. Therefore, reliable change monitoring results would largely depend on the accurate match between image pairs with different spatial and spectral resolutions. Furthermore, anthropogenic effects may influence the agriculture change results. However, the proposed supervised method based on the binary change ground truth detects changes in the agricultural area without distinguishing whether these changes are caused by human activities. The performance of the supervised change method is largely influenced by the available ground reference labels. Therefore, to detect changes from one labelto another using the change method, more attention should be paid to constructing multiple change ground truths with more informative on-the-spot investigation.
5. Conclusions
In this article, a general network named TFR-PSANet was proposed to detect land cover changes in dual-temporal hyperspectral images. First, the proposed method, which integrates the module, adaptively extracts spectral and spatial features from input patch pairs. The extracted features enhance the relevant long-range dependencies and suppress the irrelevant information in both the spectral and spatial domain simultaneously. Second, the FRL was added to reassign hidden features to a class-oriented distribution, which can enhance the discriminative ability for changed and unchanged pixels. Moreover, a general two-branch encoder–decoder framework was designed to transform and fuse the high-dimensional information to another characteristic space while keeping the hierarchically transferred features.
We implemented our algorithm and performed experiments on three public hyperspectral change detection datasets. The visual and quantitative results both showed that the proposed method outperformed most of the state-of-the-art methods including conventional and deep network algorithms.
When dealing with different change detection tasks, the proposed TFR-PSANet can be seen as a benchmark method with an adaptive one-stage spectral–spatial feature extraction module. The FRL can provide a reference for various loss functions that accelerate the convergence of the network, as well. In the future, using representation information in self-supervised learning will be considered to improve the performance.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}