1. Introduction
With the development of sensing technology, hyperspectral sensors provide an opportunity to realize the acquisition of hundreds of bands for each pixel, capturing the intensity of the reflectance of high spatial/spectral information and enabling the detection of various objects [
1,
2,
3]. In comparison with red-green-blue (RGB)-based sensing images and multispectral images (MSI), hyperspectral images (HSI) contain hundreds of pieces of spectrum band information because of the increasing band and decreasing bandwidth of each spectral band [
4]. Such abundant band information has a more powerful discriminating ability, especially for similar spectral categories, and thus has been widely applied in high-level earth observation (EO) missions, such as accurate land cover mapping, precision agriculture, target/object detection, urban planning, mineral exploration, and so on [
5,
6,
7].
The land cover mapping problem in high-level Earth observation missions can be transformed as an image classification problem, aiming to identify various objects so that vital information can be obtained by key stakeholders for decision making [
8,
9,
10]. In the early stage, the solution to cope with the HSI classification problem by traditional approaches with feature extraction methods was proposed and applied, including via machine learning methods, such as random forest (RF) [
11], k-nearest neighbors (k-NNs) [
12], support-vector machines (SVMs) [
13], K-means [
14], and so on. However, these conventional classification methods require human experience for feature extraction, thus resulting in a poor performance. In recent years, the appearance of deep learning methods has enhanced the ability to analyze hyperspectral images with an accurate and robust approach, including via convolutional neural networks (CNNs), recurrent neural networks (RNNs), and so on [
5,
15,
16]. Conventional machine learning techniques require careful engineering and considerable domain expertise to design a feature extractor transforming the raw HSI data [
17]. In contrast, deep learning methods can strongly extract the representations of raw data that are needed for HSI classification [
18,
19]. Until now, many novel algorithms have achieved great performance in HSI classification. Swalpa et al. proposed a new end-to-end morphological framework to model nonlinear information during the training process, achieving superior performance in contrast with traditional CNNs on the Indian Pines and Pavia University datasets [
20]. Focusing on multi-modal remote sensing data classification, Wu et al. designed a reconstruction strategy called CCR-Net to learn more compact fusion representations of RS data sources, demonstrating its effectiveness on the Houston 2013 dataset [
21]. Sellami et al. proposed a novel methodology based on multi-view deep neural networks [
22]. In this method, images are initial processed and a specially designed autoencoder and semi-supervised networks are adopted to reach SOTA results on the Indian Pines, Salinas, and Pavia University datasets. Among these deep learning-based methods, CNNs have attracted many scholars to use them on hyperspectral image analysis for spatial and spectral feature extraction due to the strong feature extraction ability of the convolution operation and the strong representation ability brought by their hierarchical structure [
23,
24].
According to the form of input data, CNN-based methods for HSI classification can be divided into spectral CNNs, spatial CNNs, and spectral-spatial CNNs. Spectral CNNs take the pixel vector as input and utilize CNNs to accomplish the classification task only in the spectral dimension. For example, Hu et al. proposed a 1D CNN with five stacked convolutional layers to extract the spectral features of HSI [
25]. Furthermore, Li et al. proposed a novel CNN-based method to encode pixel-pair features and made prediction results via a voting strategy, obtaining excellent classification performance [
26]. To fully exploit the rich spatial information, spatial CNN-based methods were proposed to extract the spatial features of HSI. For example, Haut et al. proposed to use cropped image patches with centered neighboring pixels to train 2D CNNs for HSI classification instead of only a pixel in the previous way [
27]. Xu et al. proposed RPNet to combine both shallow and deep convolutional features, creating a better adaption to the multi-scale object classification of HSI [
28]. Since spectral and spatial information are both crucial for the accurate classification of HSI, spectral-spatial CNN-based methods have been further proposed for jointly exploiting spectral and spatial features in HSI [
29]. For instance, Zhong et al. proposed to use 3D convolutional layers to extract spectral-spatial information with batch normalization regularizing the model [
30]. He et al. proposed a deep 3D CNN to jointly learn both 2D multi-scale spatial features and 1D spectral features from HSI data in an end-to-end approach, achieving state-of-the-art results on the standard HSI datasets [
31].
However, although CNN-based feature extractors have achieved great results in hyperspectral image analysis by employing spatial and spectral information according to the aforementioned reviews, some particular characteristics of CNNs may restrict the network’s performance on the HSI classification problem. The convolution operation in the CNN method is only limited to local feature extraction, whether in the spectral dimension or the spatial dimension; therefore, the receptive field can only be further increased by stacking the number of layers. As a consequence, such a process is often unable to effectively obtain the global receptive field and leads to a huge computation load due to the increase in model parameters. As a result, the CNN-based method is always applied in HSI classification with other strategies to achieve better performance, such as with multiscale dynamic graph and hashing semantic features [
32,
33].
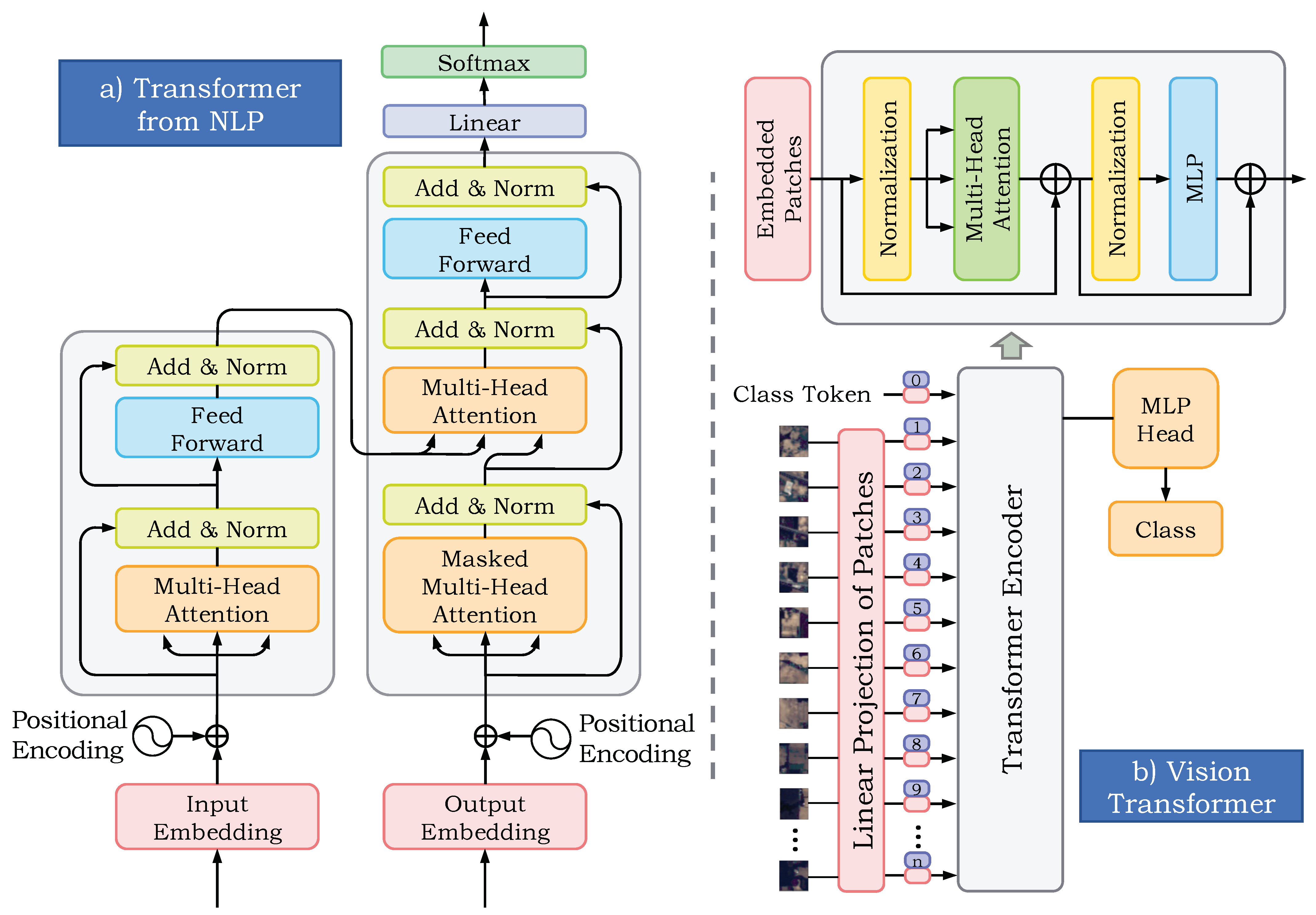
To overcome the drawbacks brought by CNNs, the Transformer structure is designed for processing and analysing sequential data, particularly in image analysis problems. Because of its unique internal multi-head self-attention mechanism, Transformer is capable of capturing long-distance dependencies between tokens from a global perspective. Inspired by related reviews, Transformer has achieved quite good results on multiple downstream tasks in the natural language processing (NLP) and computer vision (CV) domains with the help of large-scale pre-training [
34,
35,
36]. Furthermore, Transformer has also achieved superior results in the field of hyperspectral image classification. For example, to solve the limited receptive field, inflexibility and difficult generalization problems, HSI-BERT was proposed to capture the global dependence among spatial pixels with bidirectional encoder representations from Transformers [
37]. Spatial-spectral Transformer utilized a CNN to extract the spatial features and a modified Transformer to capture global relationships in the spectral dimension, fully exploring the spatial-spectral features [
38]. Moreover, the spatial Transformer network was proposed to obtain the optimal input of HSI classifiers for the first time [
39]. Rethinking hyperspectral image classification with Transformers, SpectralFormer can learn spectral local information from neighboring bands of HS images, achieving a significant improvement in comparison with state-of-the-art backbone networks [
7].
It should be emphasized that although a single Transformer network can pave the way for the HSI classification problem compared to CNN methods by the means of both spatial and spectral information, it still has some problems. First, the Transformer method has a restricted ability to extract local information since it does not possess the strong inductive bias that CNNs do. Second, Transformer needs large-scale pre-training to achieve the same performance as a CNN. Third, the computation load is strongly positive and correlated to the sequence length, so that the Transformer-based method will be unduly computationally intensive when the sequence length is excessively long, and the Transformer’s representational ability will also be limited if the sequence length is too short. Therefore, an adequate approach to combine the benefits of each paradigm (CNN-based and Transformer-based methods) applying spatial and spectral information in the field of the HSI classification task is a challenging problem.
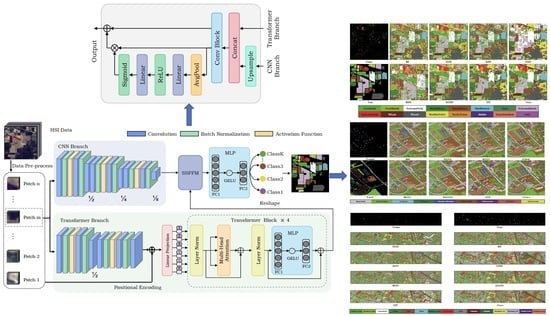
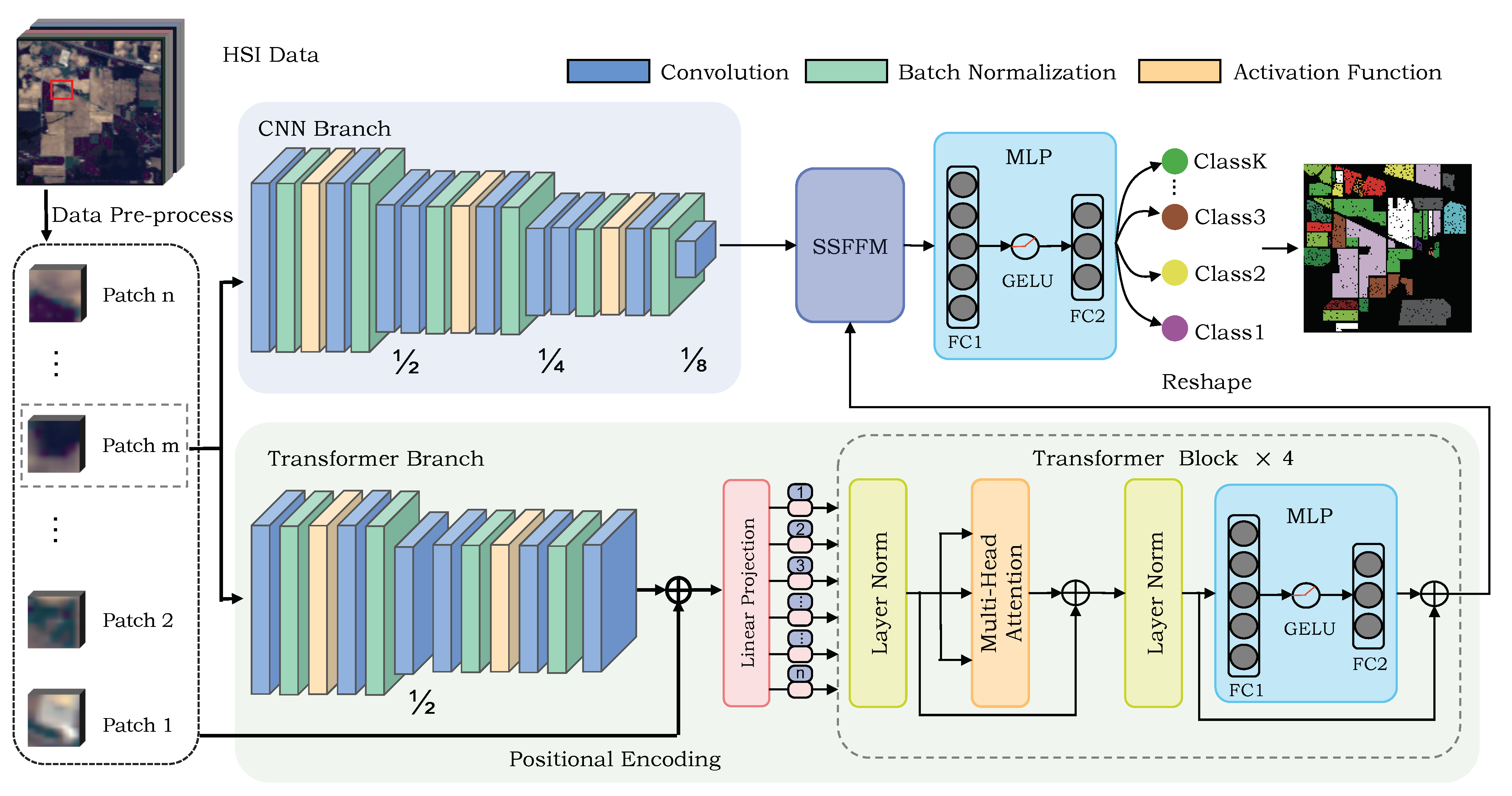
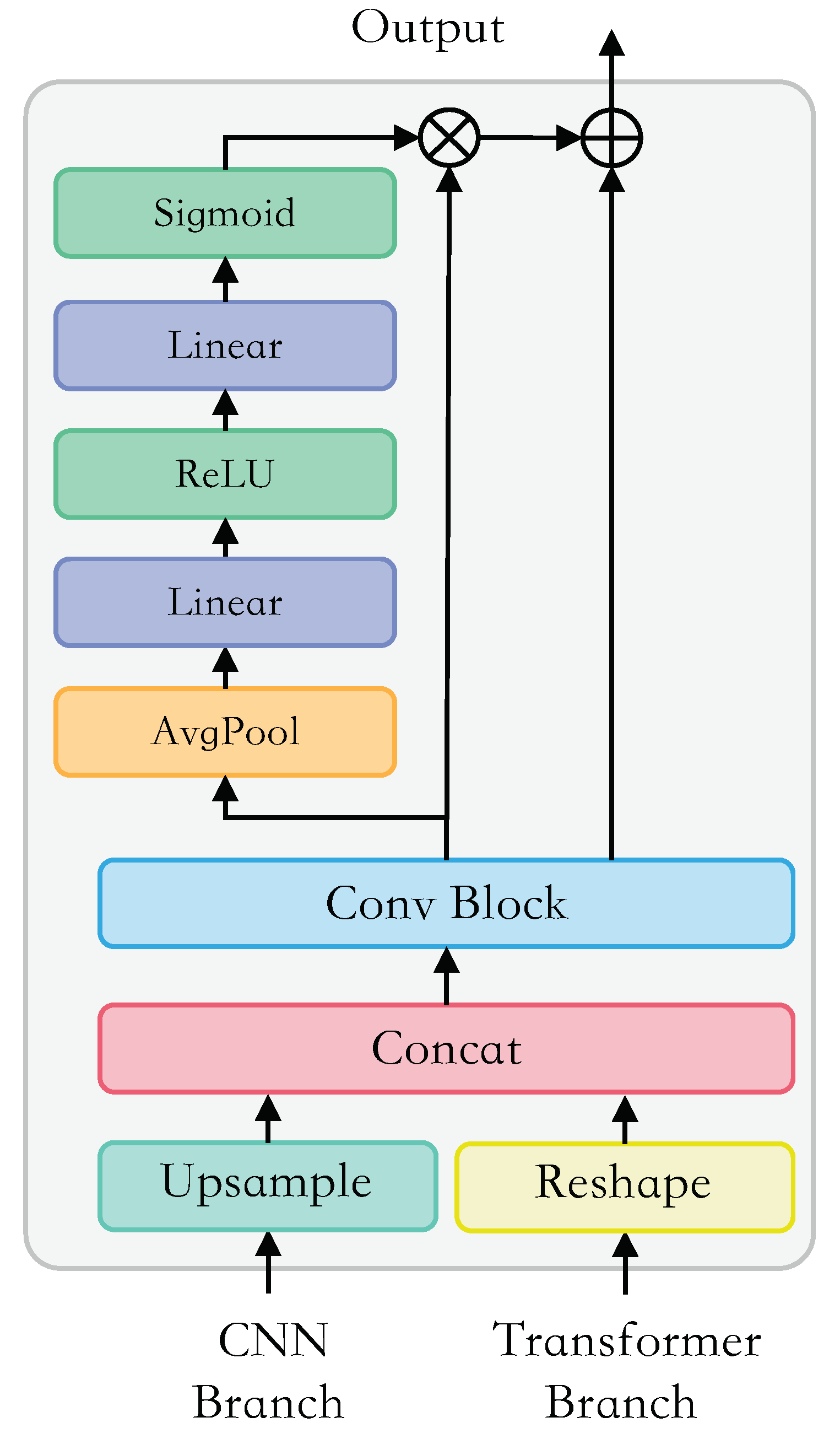
Currently, many scholars attribute their work in the HSI classification problem, including traditional machine learning methods, CNN-based approaches and Transformer-based methods. Although some works integrate CNN and Transformer via a hybrid strategy in a single branch, the spatial and spectral information of HSI are not fully fused and utilized. Local features and global features are not complementary at the receptive field level, and the features of only one branch cannot help the model to discriminate various classes through a feature fusion method, resulting in a less convincing and accurate classification performance [
39]. To address these previous drawbacks introduced by a single CNN and Transformer network, the dual flow framework named Hyper-LGNet aiming to couple local and global features for hyperspectral image classification is proposed, using CNN and Transformer branches to deal with HSI spatial-spectral information. The proposed Spatial-spectral Feature Fusion Module (SSFFM) is applied to integrate spectral and spatial information maximally. The proposed method is validated by using three popular datasets: the Indian Pines, Pavia University and Houston 2013 datasets. The results are compared with traditional machine learning methods and other deep learning architectures, showing that our result achieves the best performance among others even compared with previous SOTA SpectralFormer [
7]. To be more clear, the main contributions are summarized as follows:
- (1)
A dual flow architecture named Hyper-LGNet is proposed, which utilizes CNN and Transformer models from two branches to obtain HSI spatial and spectral information for HSI classification problems on the first attempt.
- (2)
The sensing image feature fusion block, namely the Spatial-spectral Feature Fusion Module, is proposed to maximally fuse spectral information and spatial information from two branches in a dual-flow architecture.
- (3)
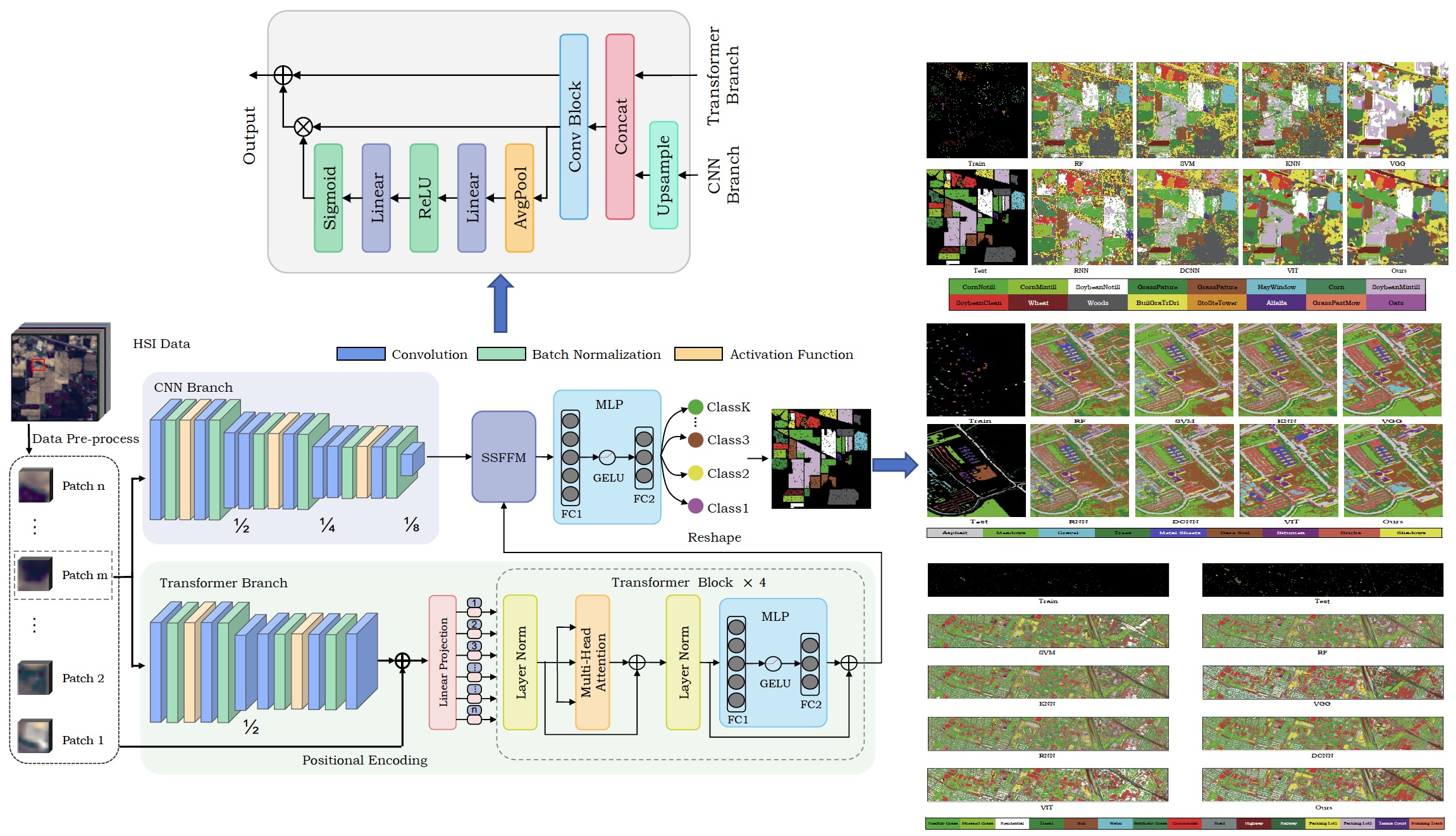
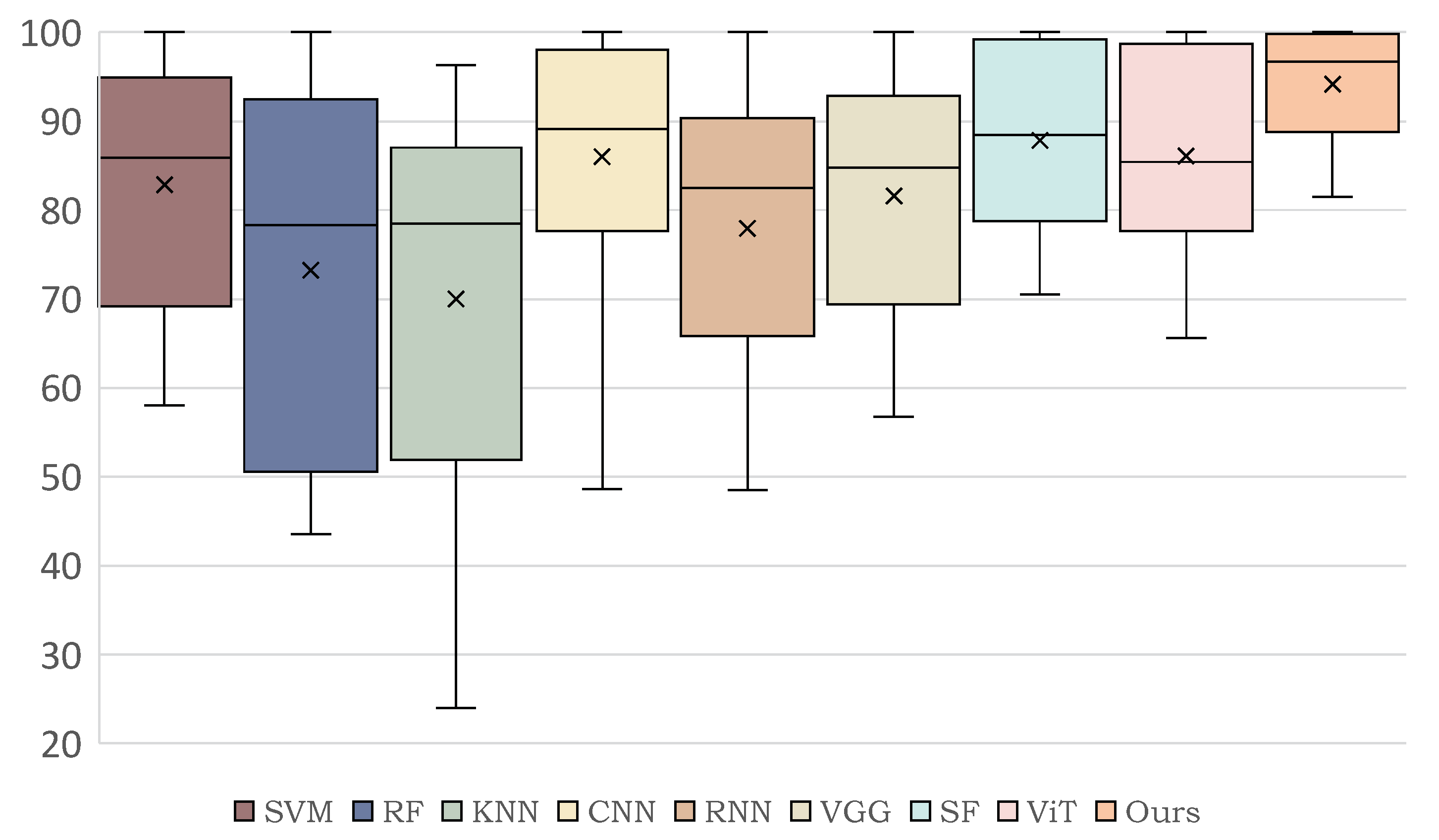
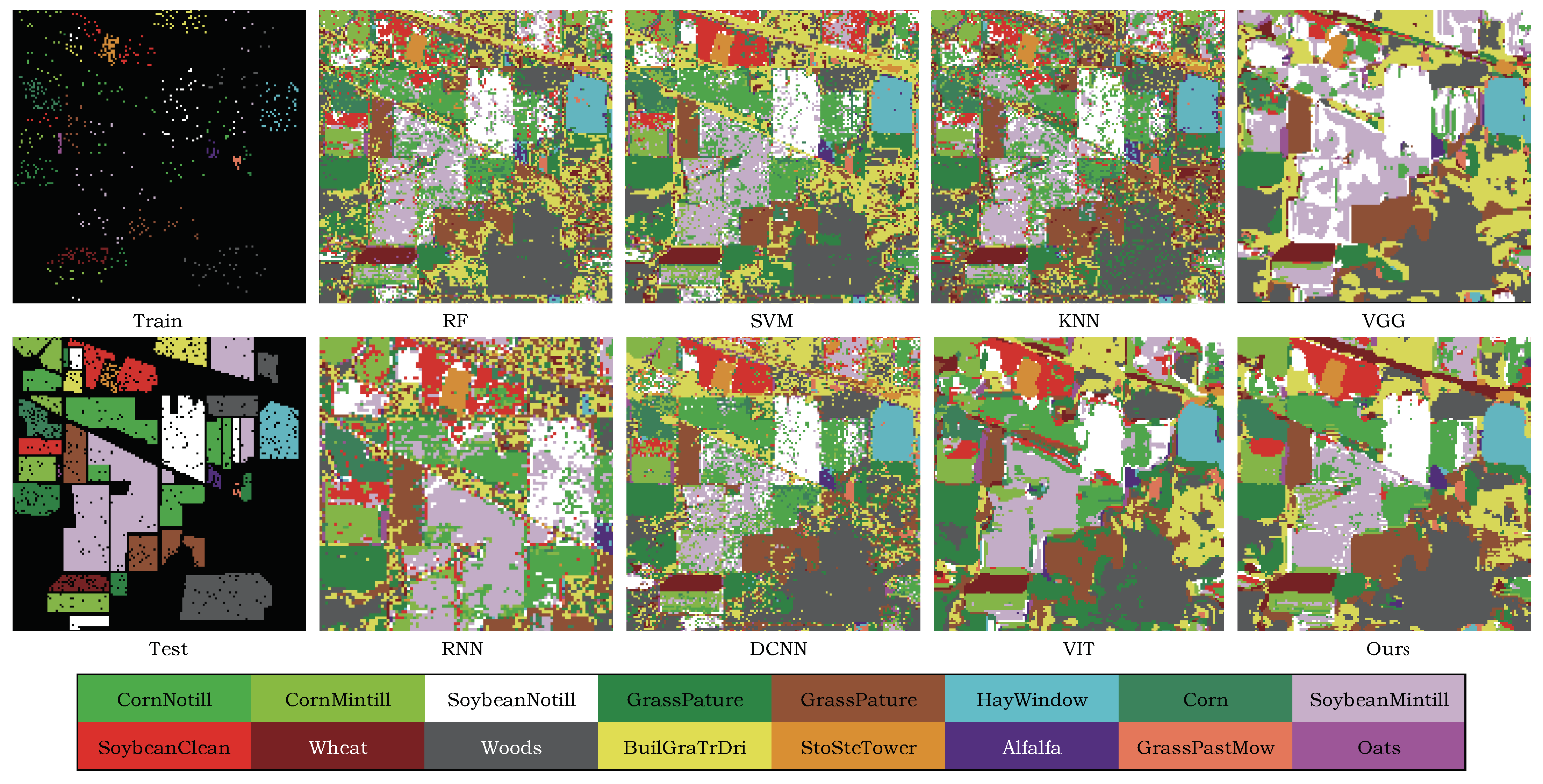
Extensive experiments are conducted on three mainstream datasets, including the Indian Pines, Pavia University and Houston 2013 datasets. In comparison with various methods, a state-of-the-art classification performance is achieved under SpectralFormer data settings.
The remaining sections of this paper are organized as follows:
Section 2 presents the proposed Hyper-LGNet network design;
Section 3 demonstrates the comparative results of different algorithms by various HSI public datasets in a qualitative and quantitative way; and finally, conclusions and directions for future work are drawn in
Section 4.
4. Conclusions
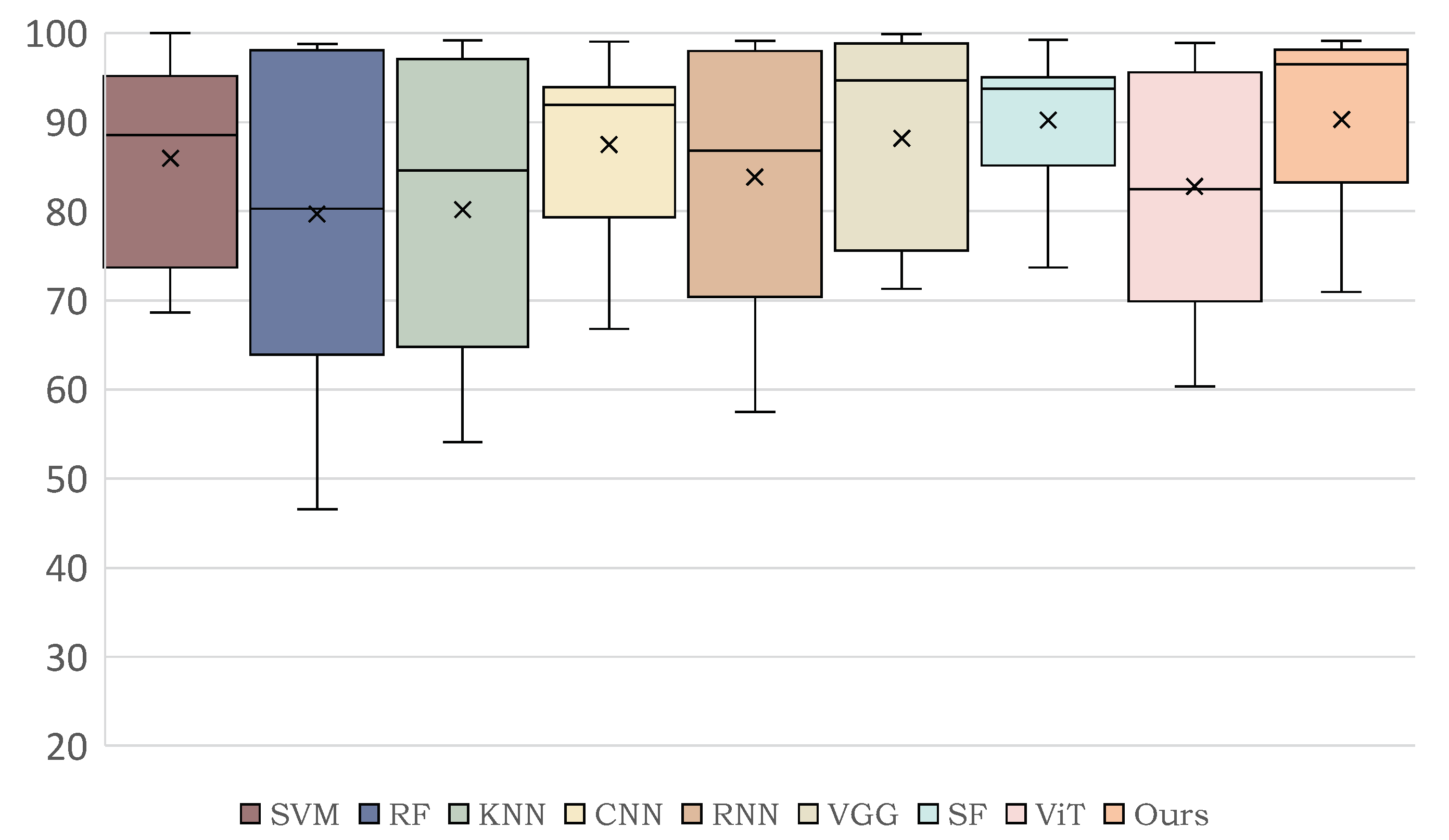
In this study, we aimed at overcoming the respective limitations of CNN-based models and Transformer-based models on HSI classification. Specifically, we proposed a dual-branch architecture to combine the CNN and Transformer models, realizing a full utilization of HSI spatial and spectral information. With the help of a lightweight and hierarchical CNN branch, the crucial local features could be extracted accurately. In addition, the Transformer branch could capture clear long-range dependencies from a global perspective and enhance the local features learned by the CNN branch. The Spatial-spectral Feature Fusion Module (SSFFM) was designed to eliminate the difference between features obtained by two branches for an effective fusion. The proposed Hyper-LGNet, composing of the above methods, achieved the best performance in terms of classification, overall accuracy, average accuracy and kappa on three popular HSI datasets, demonstrating that it has a powerful generalization ability. In particular, compared with the previous SOTA SpectralFormer method and seven other algorithms, our proposed method obtained SOTA performance on these three datasets. Some ablation studies were conducted to discuss the effectiveness of various branches, feature fusion methods and Transformer block numbers.
Although this work is an inspiring work utilizing dual-flow architecture in HSI classification, still, several points regarding this work are left for further exploration. Firstly, improvements of the Transformer branch are expected to be made by utilizing more advanced techniques (e.g., self-supervised learning), making it more suitable for HS image classification tasks. Moreover, a more lightweight network could be established to reduce the computation complexity while maintaining the performance. Finally, the fusion module could be further improved for a better effect of fusion.


 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
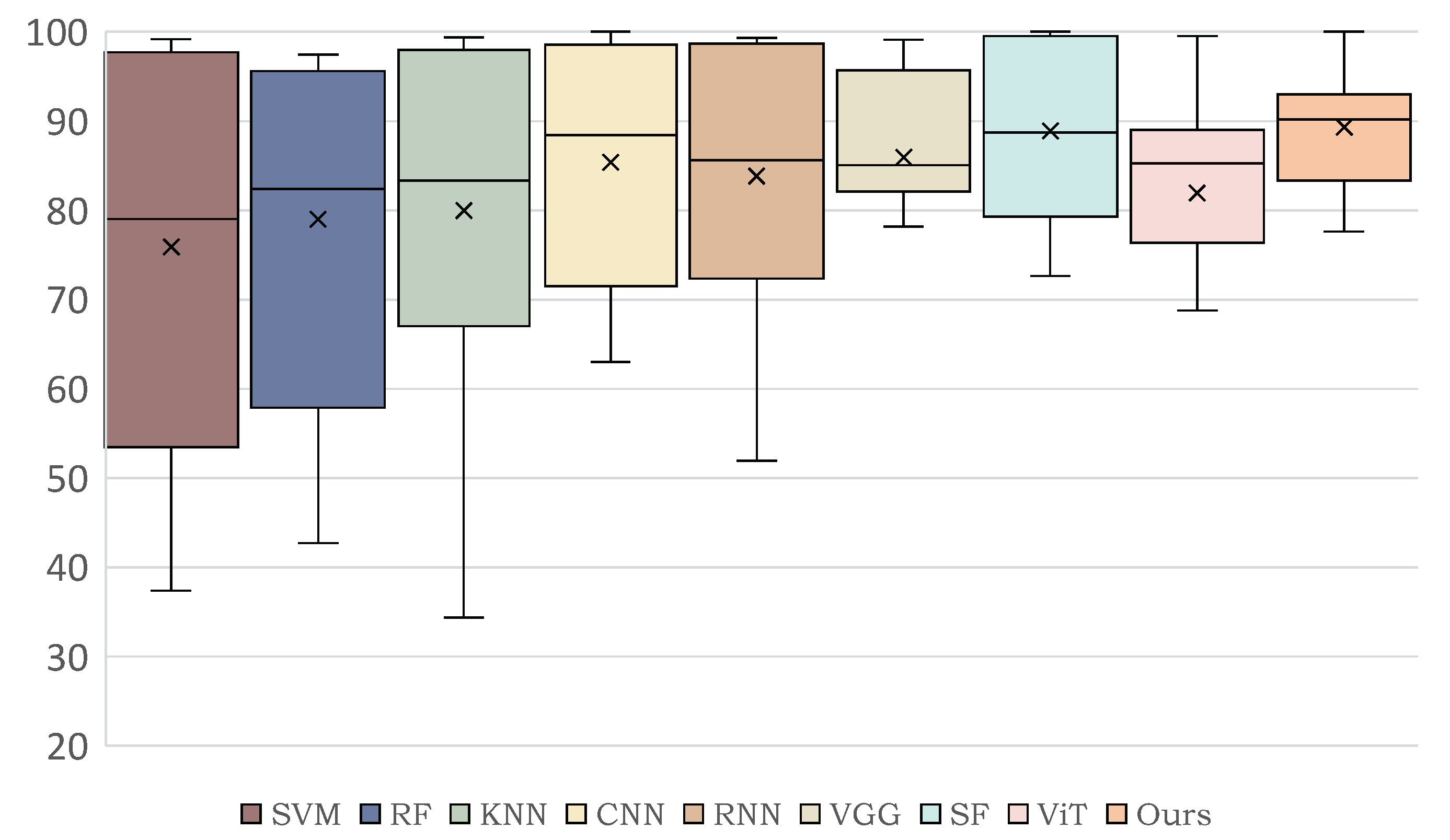{kind=link}
{kind=link}