
Using Deep Learning and Very-High-Resolution Imagery to Map Smallholder Field Boundaries

 , ,
, ,
Abstract
:
1. Introduction
- (1)
- To compare the efficacy in the detection and delineation of several different imagery types in mapping smallholder field boundaries, including panchromatic, pan-sharpened multi-spectral, and edge-enhanced imagery (all with a spatial resolution of 0.5 m).
- (2)
- To develop an iterative approach to efficiently collect training data, which relied on annotating incorrectly predicted field boundaries from an initial Mask-RCNN model, and assessing how much our model accuracy improved relative to the amount of additional work needed to add additional training data using our iterative approach.
- (3)
- To test the generalizability of our model by applying a model that we trained in Bihar, India, to a site in Uttar Pradesh, India, a neighboring state where we did not use any data for calibrating our model.
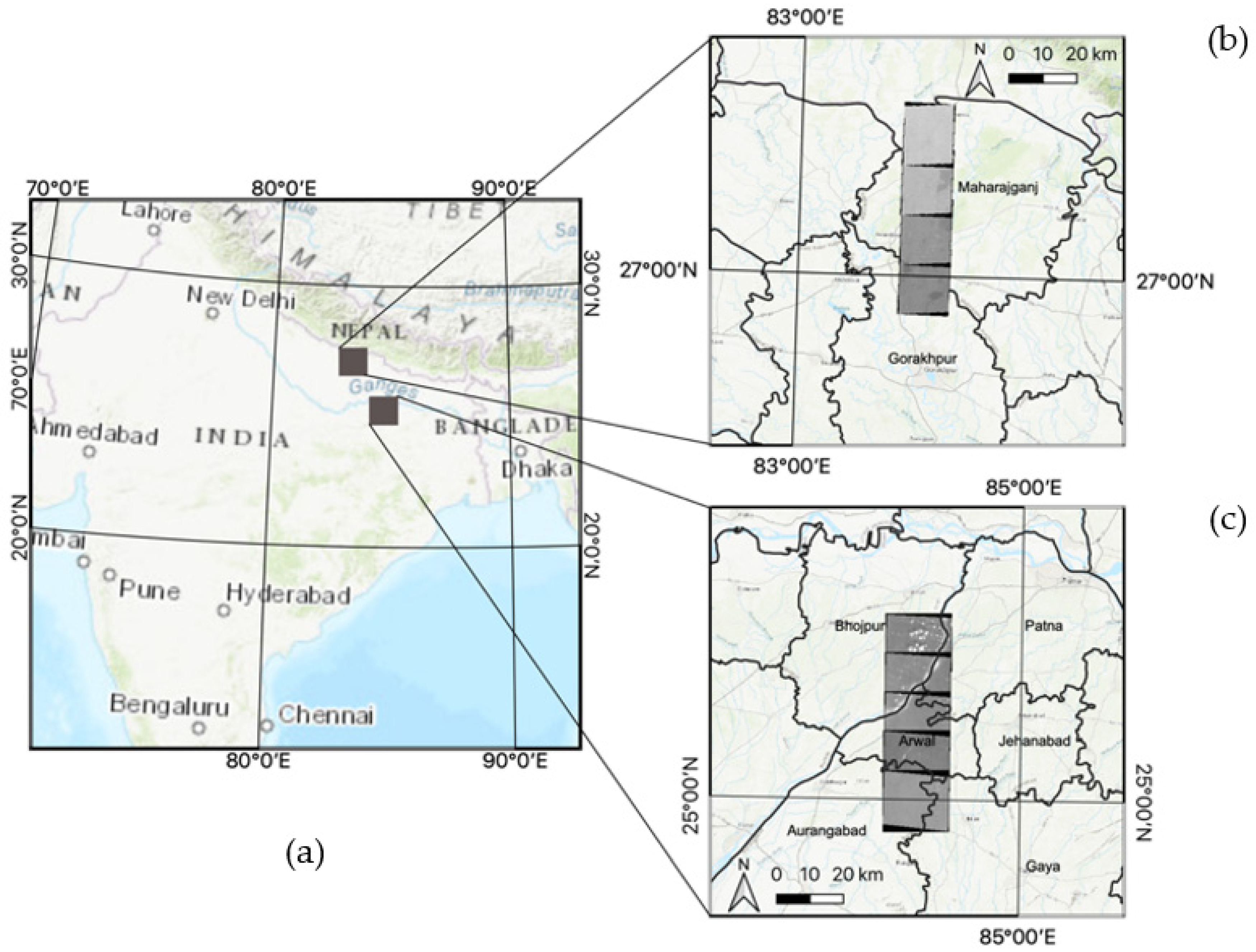
2. Study Area
3. Methods
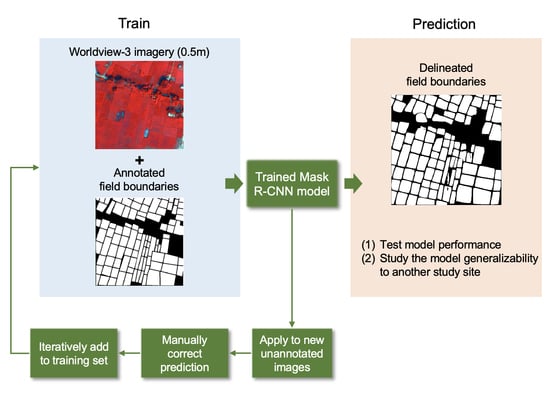
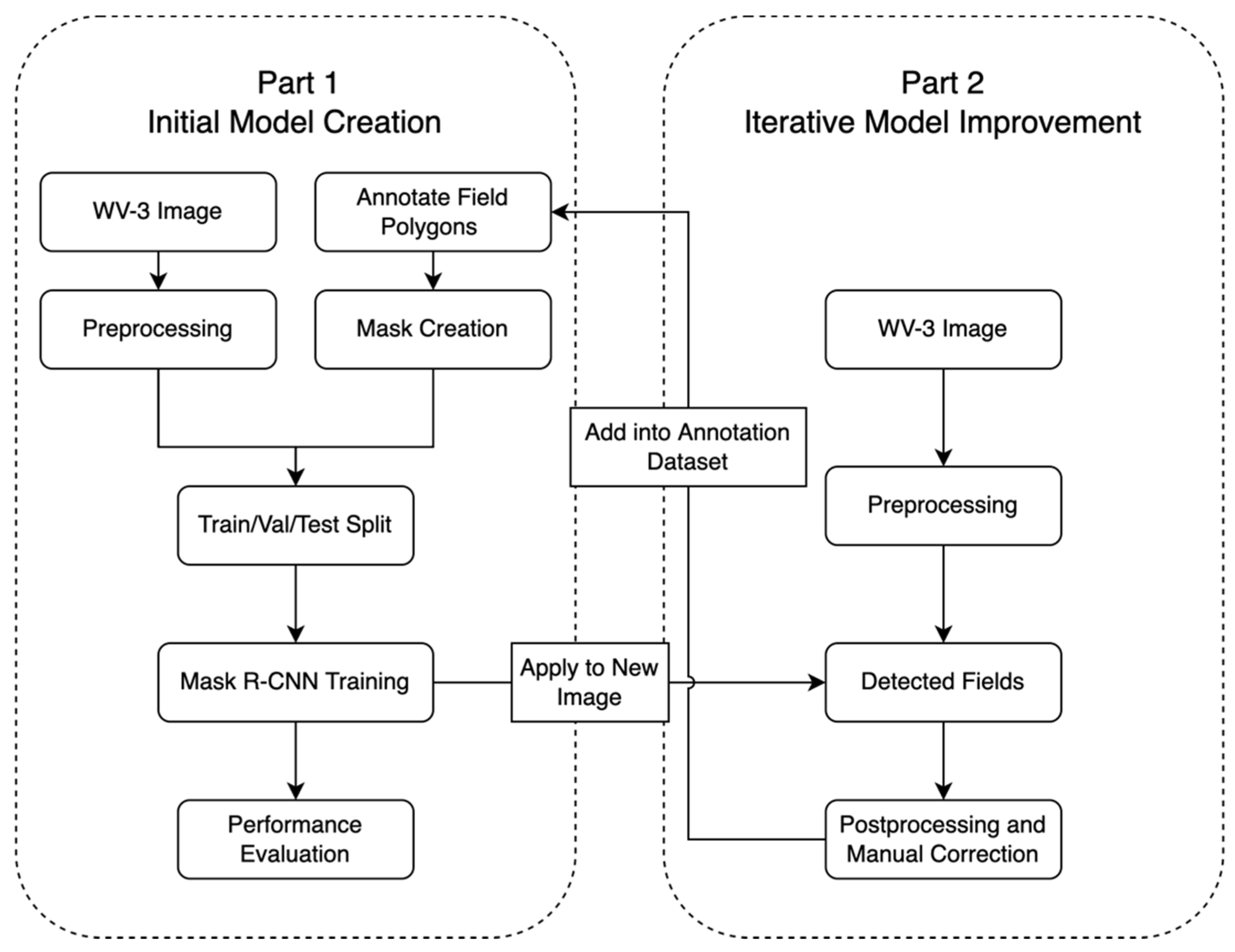
3.1. General Workflow
3.2. Satellite Image Acquisition and Preprocessing
3.3. Field Boundary Annotation and Mask Creation
3.4. Instance Segmentation and Model Implementation
3.5. Performance Evaluation
3.6. Postprocessing and Iterative Data Collection
3.7. Applying Mask R-CNN Model to Second Test Site
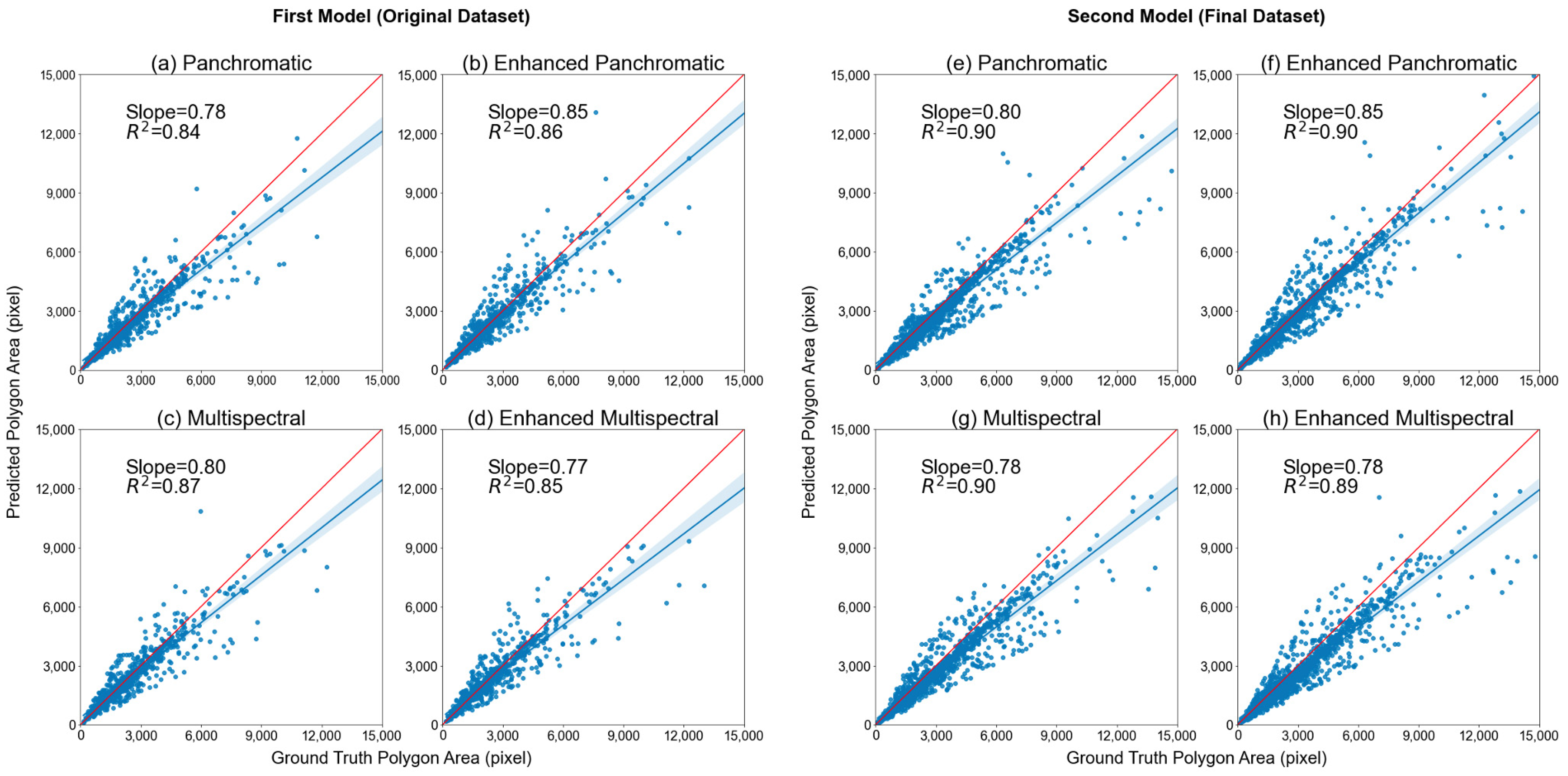
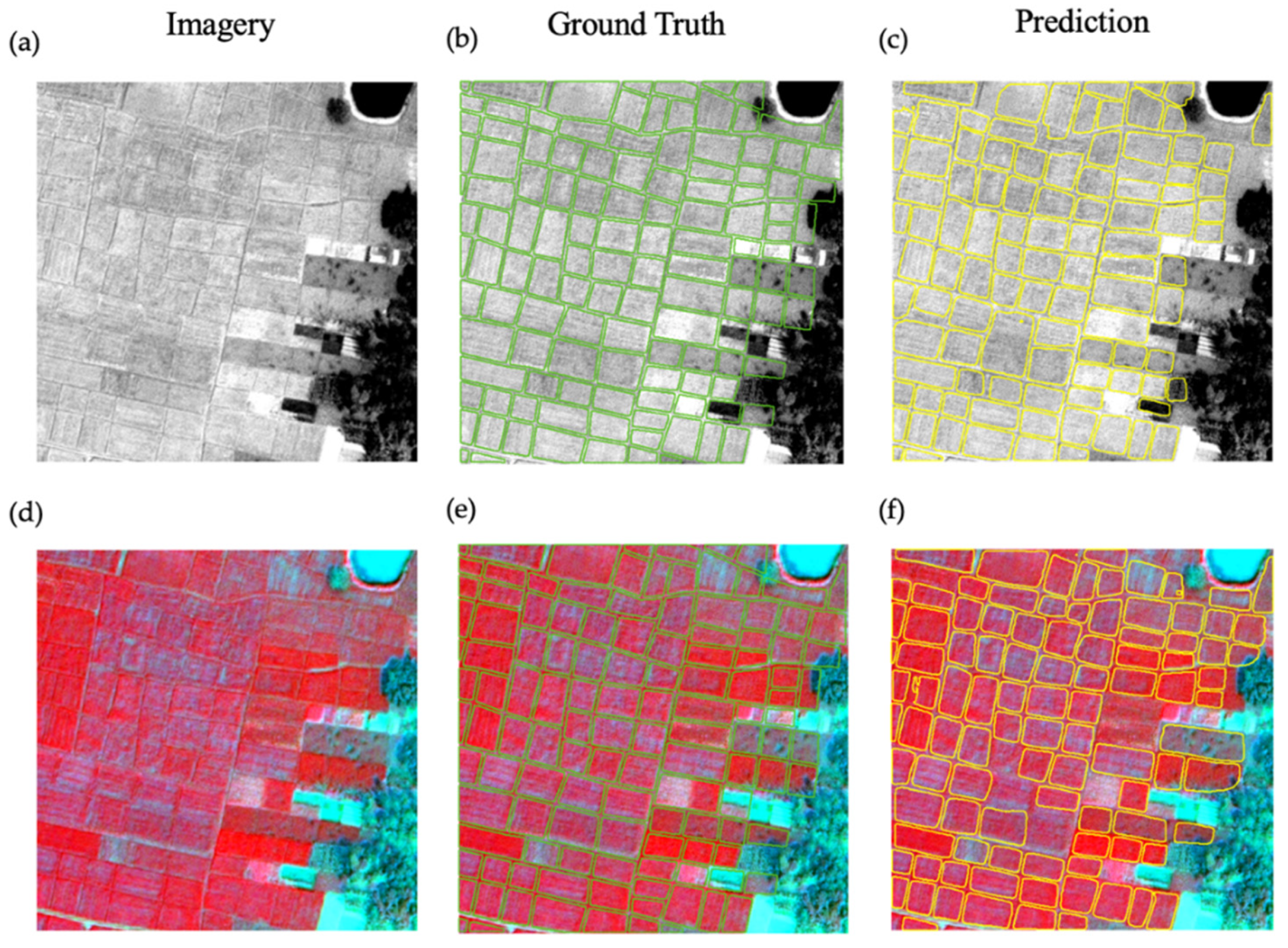
4. Results
4.1. Accuracy of Using WV-3 in Bihar
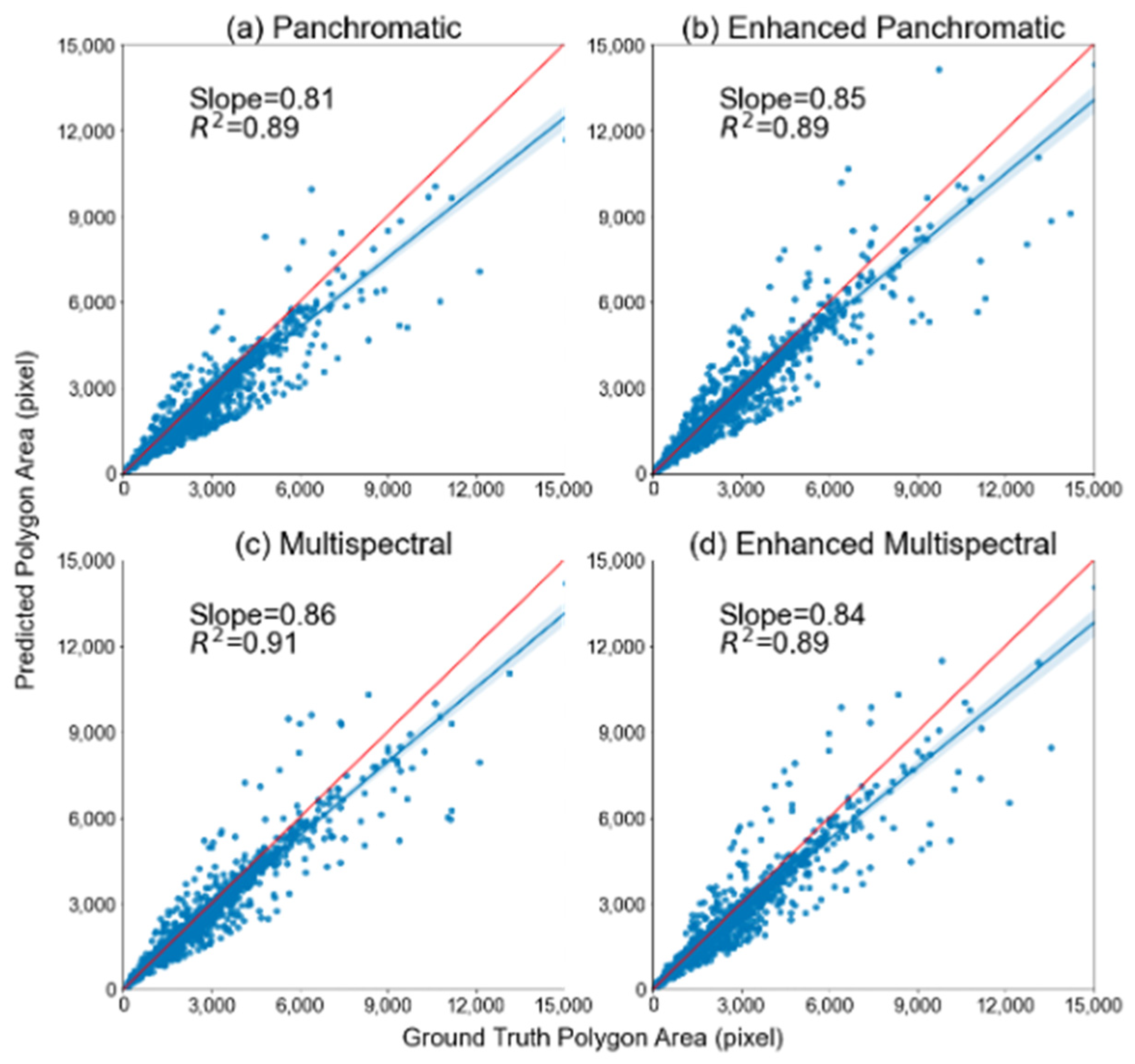
4.2. Generalizability of Models in Uttar Pradesh
5. Discussion
6. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Haworth, B.T.; Biggs, E.; Duncan, J.; Wales, N.; Boruff, B.; Bruce, E. Geographic Information and Communication Technologies for Supporting Smallholder Agriculture and Climate Resilience. Climate 2018, 6, 97. [Google Scholar] [CrossRef] [Green Version]
- Jain, M.; Singh, B.; Srivastava, A.A.K.; Malik, R.K.; McDonald, A.J.; Lobell, D.B. Using Satellite Data to Identify the Causes of and Potential Solutions for Yield Gaps in India’s Wheat Belt. Environ. Res. Lett. 2017, 12, 094011. [Google Scholar] [CrossRef]
- Neumann, K.; Verburg, P.H.; Stehfest, E.; Müller, C. The Yield Gap of Global Grain Production: A Spatial Analysis. Agric. Syst. 2010, 103, 316–326. [Google Scholar] [CrossRef]
- Wagner, M.P.; Oppelt, N. Extracting Agricultural Fields from Remote Sensing Imagery Using Graph-Based Growing Contours. Remote Sens. 2020, 12, 1205. [Google Scholar] [CrossRef] [Green Version]
- Mueller, N.D.; Gerber, J.S.; Johnston, M.; Ray, D.K.; Ramankutty, N.; Foley, J.A. Closing Yield Gaps through Nutrient and Water Management. Nature 2012, 490, 254–257. [Google Scholar] [CrossRef]
- Samberg, L.H.; Gerber, J.S.; Ramankutty, N.; Herrero, M.; West, P.C. Subnational Distribution of Average Farm Size and Smallholder Contributions to Global Food Production. Environ. Res. Lett. 2016, 11, 124010. [Google Scholar] [CrossRef]
- Sylvester, G. Success Stories on Information and Communication Technologies for Agriculture and Rural Development. RAP Publ. 2015, 2, 108. [Google Scholar]
- Garcia-Pedrero, A.; Lillo-Saavedra, M.; Rodriguez-Esparragon, D.; Gonzalo-Martin, C. Deep Learning for Automatic Outlining Agricultural Parcels: Exploiting the Land Parcel Identification System. IEEE Access 2019, 7, 158223–158236. [Google Scholar] [CrossRef]
- Marvaniya, S.; Devi, U.; Hazra, J.; Mujumdar, S.; Gupta, N. Small, Sparse, but Substantial: Techniques for Segmenting Small Agricultural Fields Using Sparse Ground Data. Int. J. Remote Sens. 2021, 42, 1512–1534. [Google Scholar] [CrossRef]
- Masoud, K.M.; Persello, C.; Tolpekin, V.A. Delineation of Agricultural Field Boundaries from Sentinel-2 Images Using a Novel Super-Resolution Contour Detector Based on Fully Convolutional Networks. Remote Sens. 2020, 12, 59. [Google Scholar] [CrossRef] [Green Version]
- Lesiv, M.; Laso Bayas, J.C.; See, L.; Duerauer, M.; Dahlia, D.; Durando, N.; Hazarika, R.; Kumar Sahariah, P.; Vakolyuk, M.; Blyshchyk, V. Estimating the Global Distribution of Field Size Using Crowdsourcing. Glob. Chang. Biol. 2019, 25, 174–186. [Google Scholar] [CrossRef] [PubMed]
- Jain, M.; Srivastava, A.K.; Joon, R.K.; McDonald, A.; Royal, K.; Lisaius, M.C.; Lobell, D.B. Mapping Smallholder Wheat Yields and Sowing Dates Using Micro-Satellite Data. Remote Sens. 2016, 8, 860. [Google Scholar] [CrossRef] [Green Version]
- Mueller, M.; Segl, K.; Kaufmann, H. Edge-and Region-Based Segmentation Technique for the Extraction of Large, Man-Made Objects in High-Resolution Satellite Imagery. Pattern Recognit. 2004, 37, 1619–1628. [Google Scholar] [CrossRef]
- Watkins, B.; van Niekerk, A. A Comparison of Object-Based Image Analysis Approaches for Field Boundary Delineation Using Multi-Temporal Sentinel-2 Imagery. Comput. Electron. Agric. 2019, 158, 294–302. [Google Scholar] [CrossRef]
- Canny, J. A Computational Approach to Edge Detection. IEEE Trans. Pattern Anal. Mach. Intell. 1986, PAMI-8, 679–698. [Google Scholar] [CrossRef]
- Martin, D.R.; Fowlkes, C.C.; Malik, J. Learning to Detect Natural Image Boundaries Using Local Brightness, Color, and Texture Cues. IEEE Trans. Pattern Anal. Mach. Intell. 2004, 26, 530–549. [Google Scholar] [CrossRef]
- Alemu, M.M. Automated Farm Field Delineation and Crop Row Detection from Satellite Images. Master’s Thesis, University of Twente, Enschede, The Netherlands, 2016. [Google Scholar]
- Belgiu, M.; Csillik, O. Sentinel-2 Cropland Mapping Using Pixel-Based and Object-Based Time-Weighted Dynamic Time Warping Analysis. Remote Sens. Environ. 2018, 204, 509–523. [Google Scholar] [CrossRef]
- Chen, B.; Qiu, F.; Wu, B.; Du, H. Image Segmentation Based on Constrained Spectral Variance Difference and Edge Penalty. Remote Sens. 2015, 7, 5980–6004. [Google Scholar] [CrossRef] [Green Version]
- Crommelinck, S.; Bennett, R.; Gerke, M.; Yang, M.Y.; Vosselman, G. Contour Detection for UAV-Based Cadastral Mapping. Remote Sens. 2017, 9, 171. [Google Scholar] [CrossRef] [Green Version]
- Persello, C.; Tolpekin, V.A.; Bergado, J.R.; de By, R.A. Delineation of Agricultural Fields in Smallholder Farms from Satellite Images Using Fully Convolutional Networks and Combinatorial Grouping. Remote Sens. Environ. 2019, 231, 111253. [Google Scholar] [CrossRef]
- Waldner, F.; Diakogiannis, F.I. Deep Learning on Edge: Extracting Field Boundaries from Satellite Images with a Convolutional Neural Network. Remote Sens. Environ. 2020, 245, 111741. [Google Scholar] [CrossRef]
- Wang, S.; Waldner, F.; Lobell, D.B. Delineating Smallholder Fields Using Transfer Learning and Weak Supervision. In AGU Fall Meeting 2021; AGU: Washington, DC, USA, 2021. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. arXiv 2018, arXiv:1703.06870. [Google Scholar]
- Quoc, T.T.P.; Linh, T.T.; Minh, T.N.T. Comparing U-Net Convolutional Network with Mask R-CNN in Agricultural Area Segmentation on Satellite Images. In Proceedings of the 2020 7th NAFOSTED Conference on Information and Computer Science (NICS), Ho Chi Minh City, Vietnam, 26–27 November 2020; pp. 124–129. [Google Scholar]
- Marshall, M.; Crommelinck, S.; Kohli, D.; Perger, C.; Yang, M.Y.; Ghosh, A.; Fritz, S.; de Bie, K.; Nelson, A. Crowd-Driven and Automated Mapping of Field Boundaries in Highly Fragmented Agricultural Landscapes of Ethiopia with Very High Spatial Resolution Imagery. Remote Sens. 2019, 11, 2082. [Google Scholar] [CrossRef] [Green Version]
- Elmes, A.; Alemohammad, H.; Avery, R.; Caylor, K.; Eastman, J.R.; Fishgold, L.; Friedl, M.A.; Jain, M.; Kohli, D.; Laso Bayas, J.C. Accounting for Training Data Error in Machine Learning Applied to Earth Observations. Remote Sens. 2020, 12, 1034. [Google Scholar] [CrossRef] [Green Version]
- Tuia, D.; Volpi, M.; Copa, L.; Kanevski, M.; Munoz-Mari, J. A Survey of Active Learning Algorithms for Supervised Remote Sensing Image Classification. IEEE J. Sel. Top. Signal Process. 2011, 5, 606–617. [Google Scholar] [CrossRef]
- Lobell, D.B.; Di Tommaso, S.; Burke, M.; Kilic, T. Twice Is Nice: The Benefits of Two Ground Measures for Evaluating the Accuracy of Satellite-Based Sustainability Estimates. Remote Sens. 2021, 13, 3160. [Google Scholar] [CrossRef]
- Neigh, C.S.; Carroll, M.L.; Wooten, M.R.; McCarty, J.L.; Powell, B.F.; Husak, G.J.; Enenkel, M.; Hain, C.R. Smallholder Crop Area Mapped with Wall-to-Wall WorldView Sub-Meter Panchromatic Image Texture: A Test Case for Tigray, Ethiopia. Remote Sens. Environ. 2018, 212, 8–20. [Google Scholar] [CrossRef]
- Aryal, J.P.; Jat, M.L.; Sapkota, T.B.; Khatri-Chhetri, A.; Kassie, M.; Maharjan, S. Adoption of Multiple Climate-Smart Agricultural Practices in the Gangetic Plains of Bihar, India. Int. J. Clim. Chang. Strateg. Manag. 2018. [Google Scholar] [CrossRef]
- Shapiro, B.I.; Singh, J.P.; Mandal, L.N.; Sinha, S.K.; Mishra, S.N.; Kumari, A.; Kumar, S.; Jha, A.K.; Gebru, G.; Negussie, K.; et al. Bihar Livestock Master Plan 2018–19–2022–23; Government of Bihar: Patna, India, 2018.
- Government of Uttar Pradesh. Integrated Watershed Management Programme in Uttar Pradesh Perspective and Strategic Plan 2009–2027; Government of Uttar Pradesh: Lucknow, India, 2009.
- DigitalGlobe DigitalGlobe Core Imagery Products Guide. Available online: https://www.digitalglobe.com/resources/ (accessed on 20 March 2021).
- Jarvis, A.; Reuter, H.I.; Nelson, A.; Guevara, E. Hole-Filled SRTM for the Globe Version 4, Available from the CGIAR-CSI SRTM 90m Database; CGIAR Consortium for Spatial Information: Montpellier, France, 2008. [Google Scholar]
- Rahman, M.M.; Robson, A.; Bristow, M. Exploring the Potential of High Resolution WorldView-3 Imagery for Estimating Yield of Mango. Remote Sens. 2018, 10, 1866. [Google Scholar] [CrossRef] [Green Version]
- GDAL/OGR Contributors GDAL/OGR Geospatial Data Abstraction Software Library. Available online: https://gdal.org (accessed on 1 June 2020).
- Polesel, A.; Ramponi, G.; Mathews, V.J. Image Enhancement via Adaptive Unsharp Masking. IEEE Trans. Image Process. 2000, 9, 505–510. [Google Scholar] [CrossRef] [Green Version]
- Bradski, G. The OpenCV Library. Dr Dobbs J. Softw. Tools Prof. Program. 2000, 25, 120–123. [Google Scholar]
- van Kemenade, H.; Wiredfool; Murray, A.; Clark, A.; Karpinsky, A.; Gohlke, C.; Dufresne, J.; Nulano; Crowell, B.; Schmidt, D.; et al. Python-Pillow/Pillow 7.1.2 (7.1.2). Available online: https://zenodo.org/record/3766443 (accessed on 1 June 2020).
- QGIS organization. QGIS Geographic Information System; QGIS Association: Online, 2021. [Google Scholar]
- Gorelick, N.; Hancher, M.; Dixon, M.; Ilyushchenko, S.; Thau, D.; Moore, R. Google Earth Engine: Planetary-Scale Geospatial Analysis for Everyone. Remote Sens. Environ. 2017, 202, 18–27. [Google Scholar] [CrossRef]
- Van der Walt, S.; Schönberger, J.L.; Nunez-Iglesias, J.; Boulogne, F.; Warner, J.D.; Yager, N.; Gouillart, E.; Yu, T. Scikit-Image: Image Processing in Python. PeerJ 2014, 2, e453. [Google Scholar] [CrossRef] [PubMed]
- Abdulla, W. Mask R-CNN for Object Detection and Instance Segmentation on Keras and TensorFlow. Available online: https://github.com/matterport/Mask_RCNN (accessed on 1 June 2020).
- Chollet, F. Keras. Available online: https://keras.io (accessed on 1 June 2020).
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems. arXiv 2015, arXiv:1603.04467. [Google Scholar]
- Garcia-Garcia, A.; Orts-Escolano, S.; Oprea, S.; Villena-Martinez, V.; Garcia-Rodriguez, J. A Review on Deep Learning Techniques Applied to Semantic Segmentation. arXiv 2017, arXiv:1704.06857. [Google Scholar]
- Zhang, W.; Liljedahl, A.K.; Kanevskiy, M.; Epstein, H.E.; Jones, B.M.; Jorgenson, M.T.; Kent, K. Transferability of the Deep Learning Mask R-CNN Model for Automated Mapping of Ice-Wedge Polygons in High-Resolution Satellite and UAV Images. Remote Sens. 2020, 12, 1085. [Google Scholar] [CrossRef] [Green Version]
- Bhuiyan, M.A.E.; Witharana, C.; Liljedahl, A.K. Use of Very High Spatial Resolution Commercial Satellite Imagery and Deep Learning to Automatically Map Ice-Wedge Polygons across Tundra Vegetation Types. J. Imaging 2020, 6, 137. [Google Scholar] [CrossRef]
- Braga, J.R.G.; Peripato, V.; Dalagnol, R.; Ferreira, M.P.; Tarabalka, Y.; Aragão, L.E.O.C.; de Campos Velho, H.F.; Shiguemori, E.H.; Wagner, F.H. Tree Crown Delineation Algorithm Based on a Convolutional Neural Network. Remote Sens. 2020, 12, 1288. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.; Xu, W.; Chen, H.; Jiang, J.; Li, X. A Novel Framework Based on Mask R-CNN and Histogram Thresholding for Scalable Segmentation of New and Old Rural Buildings. Remote Sens. 2021, 13, 1070. [Google Scholar] [CrossRef]
- Cheng, T.; Wang, X.; Huang, L.; Liu, W. Boundary-Preserving Mask R-CNN. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 660–676. [Google Scholar]
- Prathap, G.; Afanasyev, I. Deep Learning Approach for Building Detection in Satellite Multispectral Imagery. In Proceedings of the 2018 International Conference on Intelligent Systems (IS), Funchal, Portugal, 25–27 September 2018; pp. 461–465. [Google Scholar]
- Aung, H.L.; Uzkent, B.; Burke, M.; Lobell, D.; Ermon, S. Farm Parcel Delineation Using Spatio-Temporal Convolutional Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 76–77. [Google Scholar]
- Debats, S.R.; Luo, D.; Estes, L.D.; Fuchs, T.J.; Caylor, K.K. A Generalized Computer Vision Approach to Mapping Crop Fields in Heterogeneous Agricultural Landscapes. Remote Sens. Environ. 2016, 179, 210–221. [Google Scholar] [CrossRef] [Green Version]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | The Number of 512 × 512 Image Tiles | The Number of Field Polygons | Location | Source Imagery and Date | |
|---|---|---|---|---|---|
| Original Dataset of First Test Site | Training | 144 | 9664 | Bihar | Worldview-3 29 October 2017 |
| Validation | 18 | 1233 | |||
| Testing | 18 | 1401 | |||
| Final Dataset of First Test Site | Training | 272 | 18,920 | ||
| Validation | 34 | 2276 | |||
| Testing | 34 | 2380 |
| Dataset | The Number of 512 × 512 Image Tiles | The Number of Field Polygons | Location | Source Imagery and Date | |
|---|---|---|---|---|---|
| Dataset of Second Test Site | Testing | 36 | 2266 | Uttar Pradesh | Worldview-3 23 February 2018 |
| TP | FP | FN | Precision | Recall | F1 Score | AP | ||
|---|---|---|---|---|---|---|---|---|
| First Model (Original Dataset) | Panchromatic | 986 | 391 | 415 | 0.72 | 0.70 | 0.71 | 0.63 |
| Enhanced Panchromatic | 897 | 348 | 504 | 0.72 | 0.64 | 0.68 | 0.57 | |
| Multispectral | 953 | 367 | 448 | 0.72 | 0.68 | 0.70 | 0.59 | |
| Enhanced Multispectral | 942 | 354 | 459 | 0.73 | 0.67 | 0.70 | 0.60 | |
| Second Model (Final Dataset) | Panchromatic | 1861 | 903 | 519 | 0.67 | 0.78 | 0.72 | 0.68 |
| Enhanced Panchromatic | 1796 | 656 | 584 | 0.73 | 0.75 | 0.74 | 0.68 | |
| Multispectral | 1829 | 769 | 551 | 0.70 | 0.77 | 0.73 | 0.66 | |
| Enhanced Multispectral | 1831 | 723 | 549 | 0.72 | 0.77 | 0.74 | 0.68 |
| TP | FP | FN | Precision | Recall | F1 Score | AP | ||
|---|---|---|---|---|---|---|---|---|
| First Model (Original Dataset) | Panchromatic | 980 | 398 | 421 | 0.71 | 0.70 | 0.70 | 0.62 |
| Enhanced Panchromatic | 906 | 368 | 495 | 0.71 | 0.65 | 0.68 | 0.57 | |
| Multispectral | 939 | 370 | 462 | 0.71 | 0.67 | 0.69 | 0.58 | |
| Enhanced Multispectral | 933 | 355 | 468 | 0.72 | 0.67 | 0.69 | 0.59 | |
| Second Model (Final Dataset) | Panchromatic | 1844 | 921 | 536 | 0.67 | 0.77 | 0.72 | 0.68 |
| Enhanced Panchromatic | 1782 | 670 | 598 | 0.73 | 0.75 | 0.74 | 0.67 | |
| Multispectral | 1832 | 760 | 548 | 0.71 | 0.77 | 0.74 | 0.67 | |
| Enhanced Multispectral | 1827 | 727 | 553 | 0.72 | 0.77 | 0.74 | 0.68 |
| Mean IoU | Mean Ground Truth Area | Mean Delineated Area | ||||
|---|---|---|---|---|---|---|
| (Pixel) | (m2) | Pixel | (m2) | |||
| First Model (Original Dataset) | Panchromatic | 0.80 | 2348 | 587 | 2220 | 555 |
| Enhanced Panchromatic | 0.80 | 2415 | 604 | 2359 | 590 | |
| Multispectral | 0.80 | 2342 | 586 | 2241 | 560 | |
| Enhanced Multispectral | 0.80 | 2320 | 580 | 2207 | 552 | |
| Second Model (Final Dataset) | Panchromatic | 0.83 | 2457 | 614 | 2260 | 565 |
| Enhanced Panchromatic | 0.84 | 2589 | 647 | 2479 | 620 | |
| Multispectral | 0.83 | 2687 | 672 | 2368 | 592 | |
| Enhanced Multispectral | 0.83 | 2747 | 687 | 2395 | 599 | |
| TP | FP | FN | Precision | Recall | F1 Score | AP | ||
|---|---|---|---|---|---|---|---|---|
| Second Model (Trained with Final WV-3 Dataset in Bihar) | Panchromatic | 1927 | 758 | 739 | 0.72 | 0.72 | 0.72 | 0.64 |
| Enhanced Panchromatic | 1889 | 495 | 777 | 0.79 | 0.71 | 0.75 | 0.64 | |
| Multispectral | 2005 | 485 | 661 | 0.81 | 0.75 | 0.78 | 0.69 | |
| Enhanced Multispectral | 1964 | 538 | 702 | 0.78 | 0.74 | 0.76 | 0.67 |
| TP | FP | FN | Precision | Recall | F1 Score | AP | ||
|---|---|---|---|---|---|---|---|---|
| Second Model (Trained with Final Dataset in Bihar) | Panchromatic | 1920 | 765 | 746 | 0.72 | 0.72 | 0.72 | 0.64 |
| Enhanced Panchromatic | 1896 | 488 | 770 | 0.80 | 0.71 | 0.75 | 0.64 | |
| Multispectral | 1982 | 508 | 684 | 0.80 | 0.74 | 0.77 | 0.68 | |
| Enhanced Multispectral | 1922 | 523 | 744 | 0.79 | 0.72 | 0.75 | 0.65 |
| Mean IoU | Mean Ground Truth Area | Mean Delineated Area | ||||
|---|---|---|---|---|---|---|
| (Pixel) | (m2) | (Pixel) | (m2) | |||
| Second Model (Trained with Final Dataset in Bihar) | Panchromatic | 0.83 | 2236 | 559 | 2033 | 508 |
| Enhanced Panchromatic | 0.84 | 2417 | 604 | 2298 | 575 | |
| Multispectral | 0.85 | 2352 | 588 | 2218 | 555 | |
| Enhanced Multispectral | 0.83 | 2342 | 586 | 2164 | 541 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mei, W.; Wang, H.; Fouhey, D.; Zhou, W.; Hinks, I.; Gray, J.M.; Van Berkel, D.; Jain, M. Using Deep Learning and Very-High-Resolution Imagery to Map Smallholder Field Boundaries. Remote Sens. 2022, 14, 3046. https://doi.org/10.3390/rs14133046
Mei W, Wang H, Fouhey D, Zhou W, Hinks I, Gray JM, Van Berkel D, Jain M. Using Deep Learning and Very-High-Resolution Imagery to Map Smallholder Field Boundaries. Remote Sensing. 2022; 14(13):3046. https://doi.org/10.3390/rs14133046
Chicago/Turabian StyleMei, Weiye, Haoyu Wang, David Fouhey, Weiqi Zhou, Isabella Hinks, Josh M. Gray, Derek Van Berkel, and Meha Jain. 2022. "Using Deep Learning and Very-High-Resolution Imagery to Map Smallholder Field Boundaries" Remote Sensing 14, no. 13: 3046. https://doi.org/10.3390/rs14133046