
AUnet: A Deep Learning Framework for Surface Water Channel Mapping Using Large-Coverage Remote Sensing Images and Sparse Scribble Annotations from OSM Data


 , , , , ,
, , , , ,
Abstract
:1. Introduction
- We present a novel CNN-based architecture termed AUnet to perform semantic segmentation and surface water mapping at multiple scales using very high-resolution (VHR) multispectral imagery. The proposed AUnet architecture is inspired by a well-known encoder–decoder model (U-net [25]), yet it contains critical variations that tailor our model to the intended application, including atrous convolution blocks at each encoder level, evaluation at a large range of scales, and the layer-to-layer connectivity.
- The integrated atrous convolution blocks in the proposed AUnet model enable encoding the geometrical, textural, and spectral properties of water bodies in their global context. These properties aid in distinguishing water from the cloud, ice, snow, and landscape shadows, unlike the need for a local variable threshold in traditional rule-based systems.
- We introduce a novel water channel dataset derived from the Landsat imagery of the Pakistan region, which is used for training and validation purposes of the proposed model. Moreover, the corresponding water channel ground truths are arranged using the OSM mapping tool, which helps generate weakly supervised and scribble annotations (centerlines) of water channels. The newly curated dataset offers a diversified landscape and can serve as a basis for large-scale training, facilitating further works relevant to deep-learning-based water channel segmentation and mapping.
- We introduce a simple yet effective postprocessing mechanism based on median filtering and convolutional blurring to remove the noisy and stray pixels and further improve the AUnet model’s segmentation performance by 2.48%.
- The segmentation performance of AUnet is evaluated both qualitatively and quantitatively, where it produced outstanding water mapping results. The proposed framework outperformed other SOTA solutions with a 0.8791 mean intersection over union score, achieving 3.23% higher water channel segmentation accuracy.
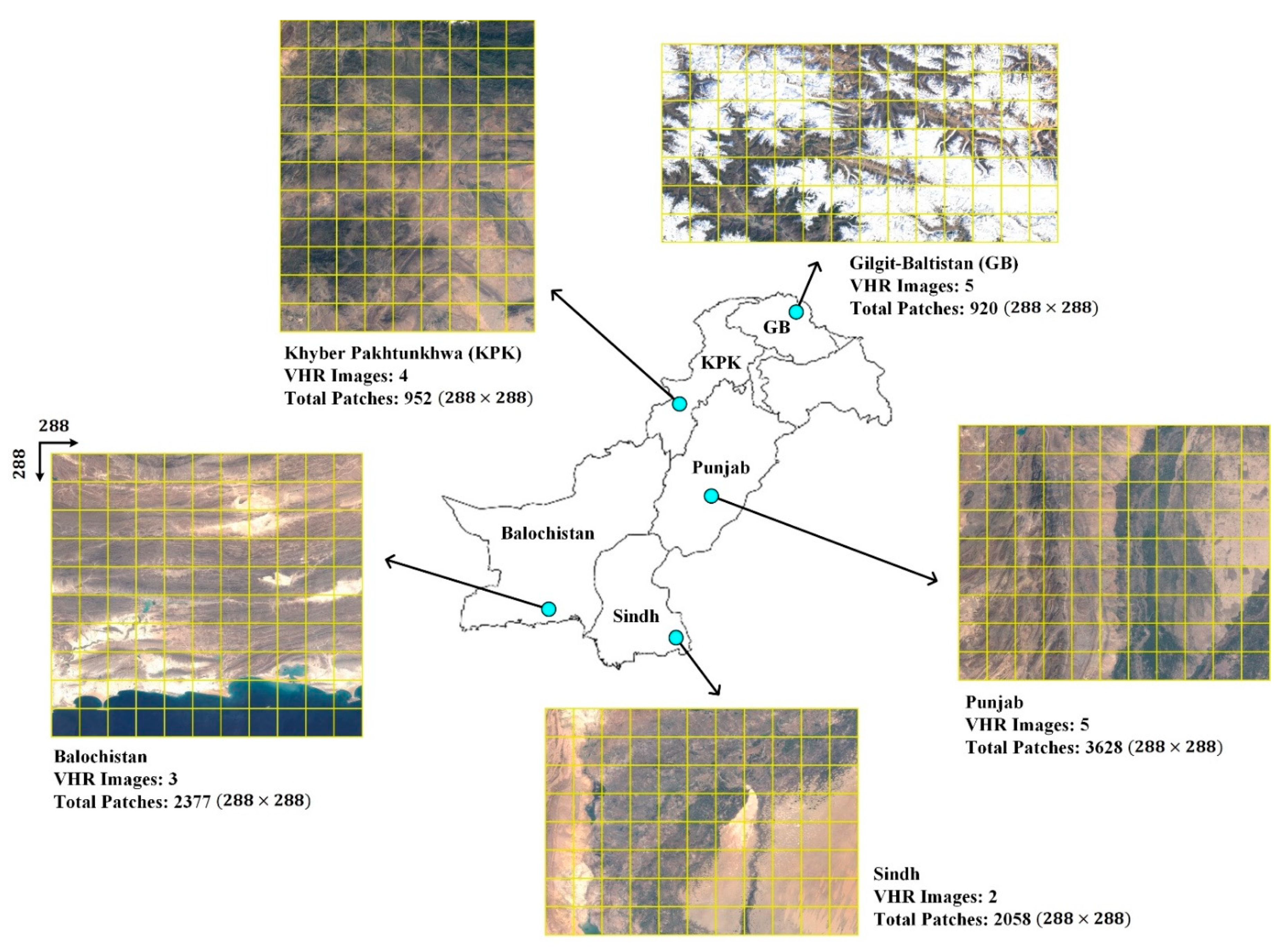
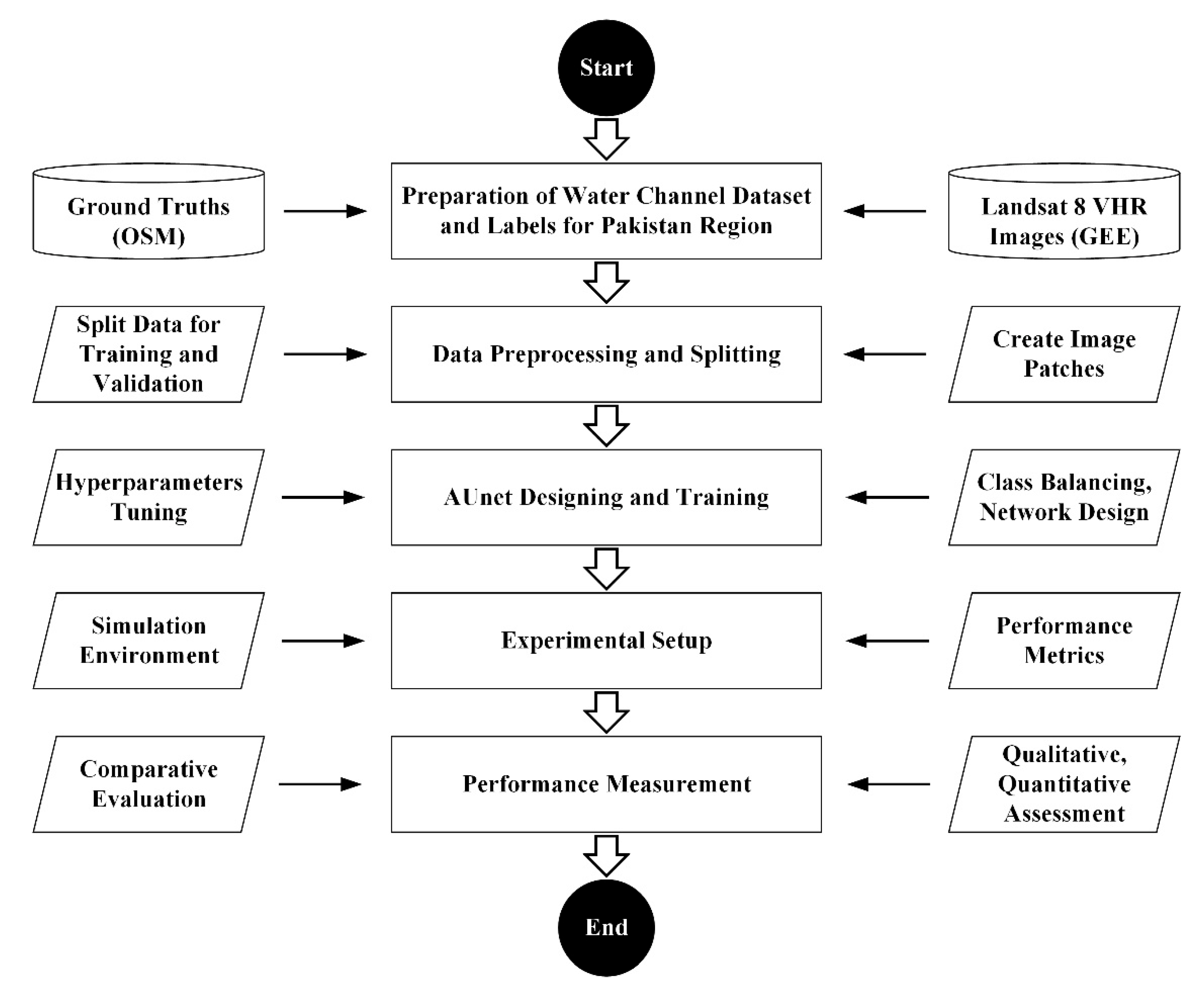
2. Dataset Details
2.1. Dataset Curation and Preprocessing
2.2. Weakly Supervised Technique for Generating Ground-Truth Labels
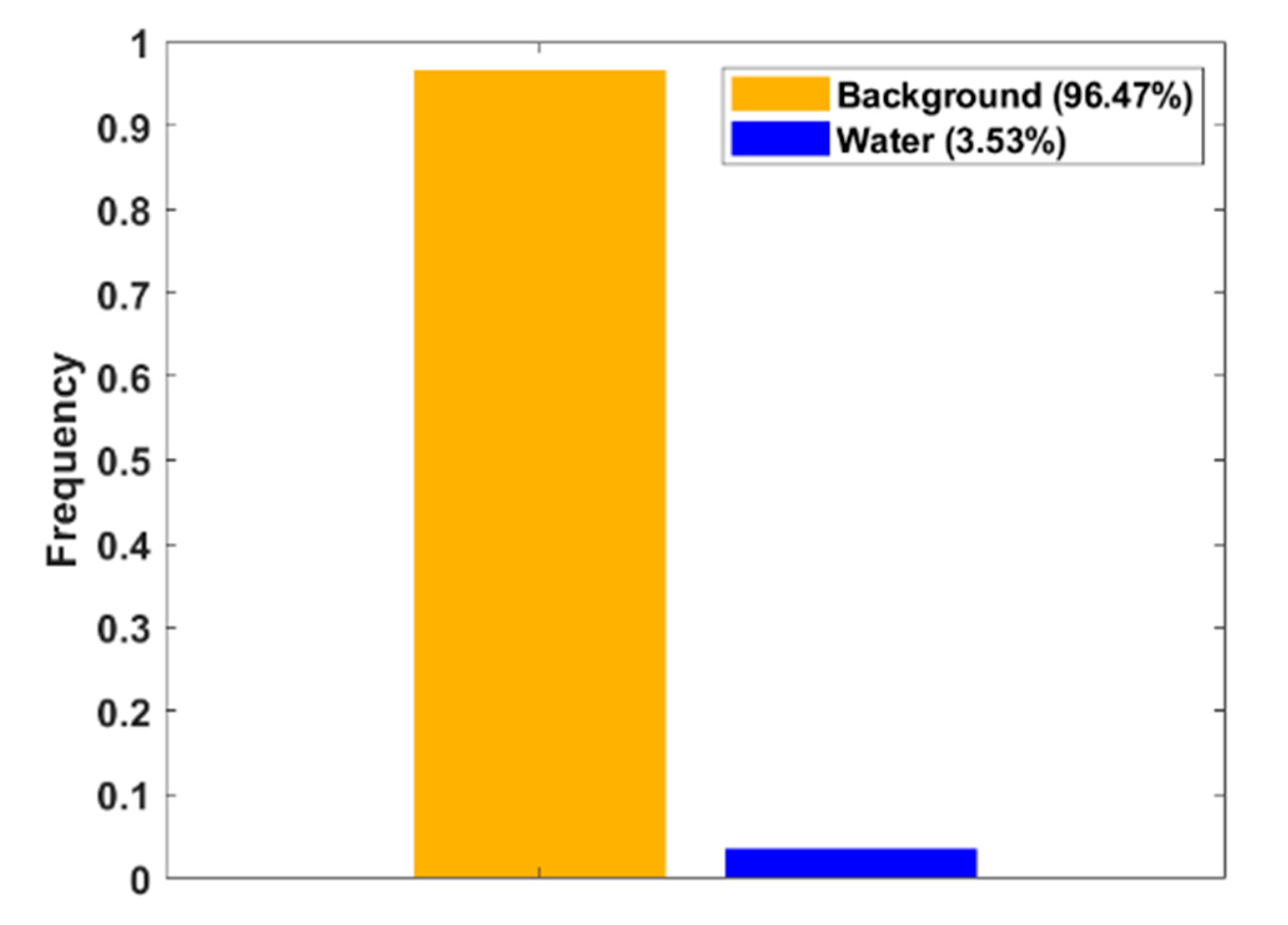
2.3. Pixel Label Balancing
3. Proposed Methodology
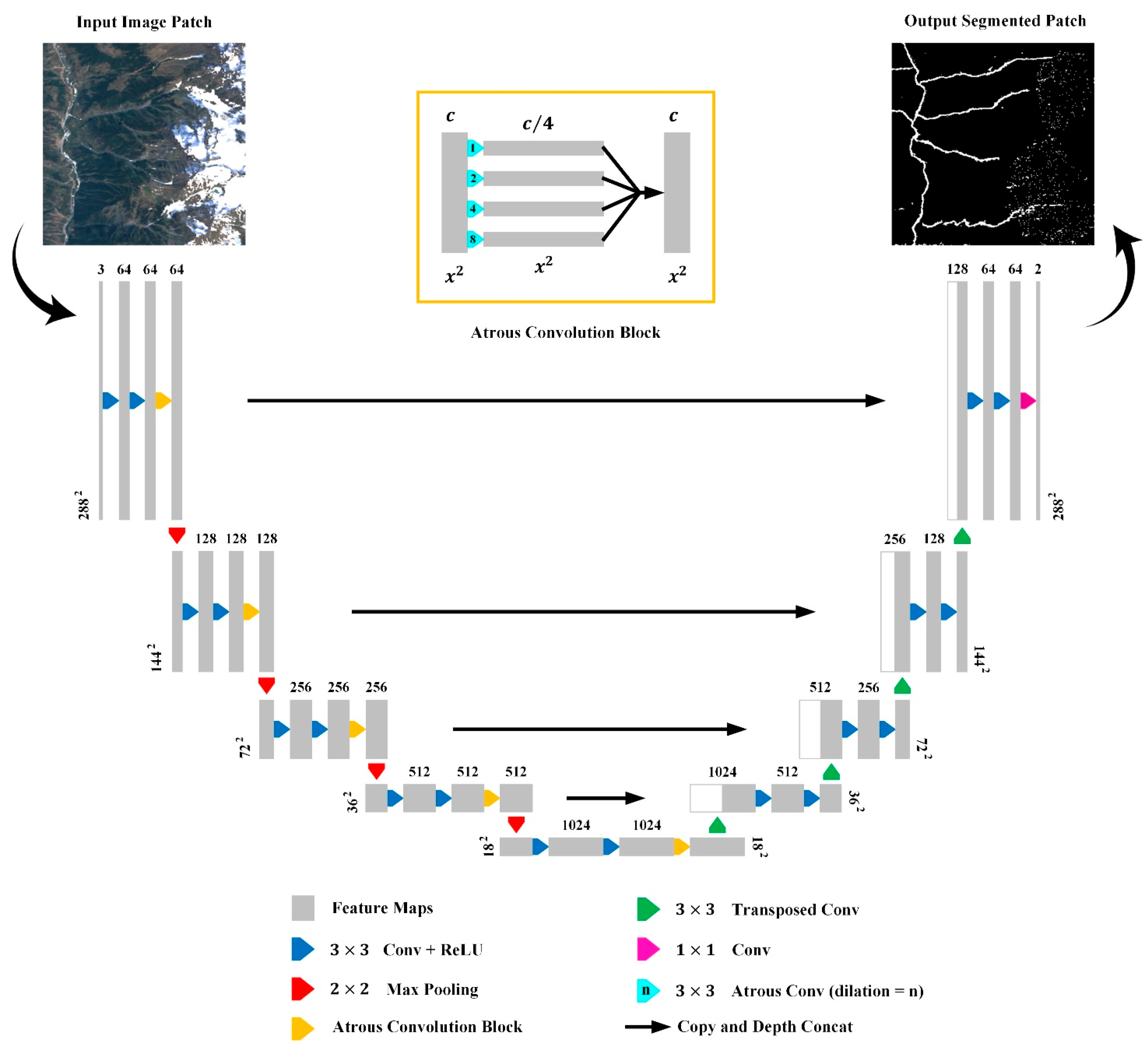
3.1. AUnet Network Architecture
3.1.1. AUnet Encoder
3.1.2. AUnet Decoder
3.2. Postprocessing
4. Experimental Setup
4.1. System Specifications
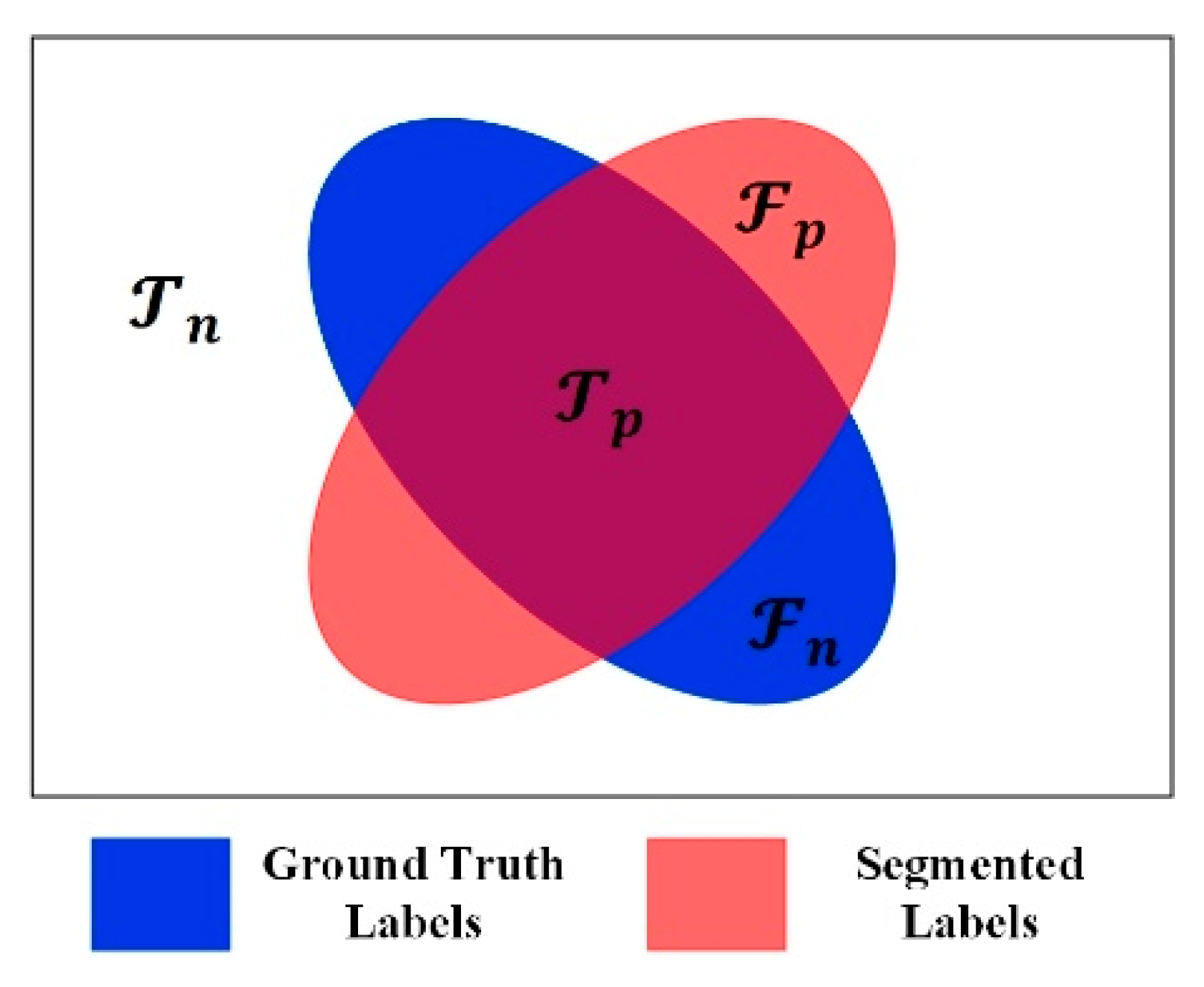
4.2. Evaluation Metrics
4.2.1. Mean Pixel Sensitivity
4.2.2. Mean Pixel Prediction
4.2.3. Mean Intersection over Union
4.2.4. Mean Dice Similarity Coefficient
4.3. AUnet Training Details
4.3.1. Loss Function
4.3.2. Network Training and Hyperparameter Selection
5. Experimental Results
5.1. Qualitative Evaluation
5.2. Quantitative Evaluation
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Xu, Y.; Wu, L.; Xie, Z.; Chen, Z. Building extraction in very high resolution remote sensing imagery using deep learning and guided filters. Remote Sens. 2018, 10, 144. [Google Scholar] [CrossRef] [Green Version]
- Wu, S.; Du, C.; Chen, H.; Xu, Y.; Guo, N.; Jing, N. Road extraction from very high resolution images using weakly labeled OpenStreetMap centerline. ISPRS Int. J. Geo-Inf. 2019, 8, 478. [Google Scholar] [CrossRef] [Green Version]
- Pekel, J.F.; Cottam, A.; Gorelick, N.; Belward, A.S. High-resolution mapping of global surface water and its long-term changes. Nature 2016, 540, 418–422. [Google Scholar] [CrossRef] [PubMed]
- Feng, M.; Sexton, J.O.; Channan, S.; Townshend, J.R. A global, high-resolution (30-m) inland water body dataset for 2000: First results of a topographic–spectral classification algorithm. Int. J. Digit. Earth 2016, 9, 113–133. [Google Scholar] [CrossRef] [Green Version]
- Yamazaki, D.; Trigg, M.A.; Ikeshima, D. Development of a global~ 90 m water body map using multi-temporal Landsat images. Remote Sens. Environ. 2015, 171, 337–351. [Google Scholar] [CrossRef]
- Bangira, T.; Alfieri, S.M.; Menenti, M.; Van Niekerk, A. Comparing thresholding with machine learning classifiers for mapping complex water. Remote Sens. 2019, 11, 1351. [Google Scholar] [CrossRef] [Green Version]
- Acharya, T.D.; Subedi, A.; Lee, D.H. Evaluation of machine learning algorithms for surface water extraction in a Landsat 8 scene of Nepal. Sensors 2019, 19, 2769. [Google Scholar] [CrossRef] [Green Version]
- Karpatne, A.; Khandelwal, A.; Chen, X.; Mithal, V.; Faghmous, J.; Kumar, V. Global monitoring of inland water dynamics: State-of-the-art, challenges, and opportunities. In Computational Sustainability; Springer: Cham, Switzerland, 2016; pp. 121–147. [Google Scholar]
- Isikdogan, F.; Bovik, A.C.; Passalacqua, P. Surface water mapping by deep learning. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 4909–4918. [Google Scholar] [CrossRef]
- Wang, Y.; Li, Z.; Zeng, C.; Xia, G.S.; Shen, H. An urban water extraction method combining deep learning and Google Earth engine. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 769–782. [Google Scholar] [CrossRef]
- Li, Z.; Wang, R.; Zhang, W.; Hu, F.; Meng, L. Multiscale features supported deeplabv3+ optimization scheme for accurate water semantic segmentation. IEEE Access 2019, 7, 155787–155804. [Google Scholar] [CrossRef]
- Wang, Z.; Gao, X.; Zhang, Y.; Zhao, G. MSLWENet: A novel deep learning network for lake water body extraction of Google remote sensing images. Remote Sens. 2020, 12, 4140. [Google Scholar] [CrossRef]
- Chen, Y.; Fan, R.; Yang, X.; Wang, J.; Latif, A. Extraction of urban water bodies from high-resolution remote-sensing imagery using deep learning. Water 2018, 10, 585. [Google Scholar] [CrossRef] [Green Version]
- Mazhar, S.; Sun, G.; Wang, Z.; Liang, H.; Zhang, H.; Li, Y. Flood Mapping and Classification Jointly Using MuWI and Machine Learning Techniques. In Proceedings of the 2021 International Conference on Control, Automation and Information Sciences (ICCAIS), Xi’an, China, 14–17 October 2021; pp. 662–667. [Google Scholar]
- Hassan, B.; Qin, S.; Ahmed, R.; Hassan, T.; Taguri, A.H.; Hashmi, S.; Werghi, N. Deep learning based joint segmentation and characterization of multi-class retinal fluid lesions on OCT scans for clinical use in anti-VEGF therapy. Comput. Biol. Med. 2021, 136, 104727. [Google Scholar] [CrossRef]
- Hassan, B.; Qin, S.; Hassan, T.; Ahmed, R.; Werghi, N. Joint segmentation and quantification of chorioretinal biomarkers in optical coherence tomography scans: A deep learning approach. IEEE Trans. Instrum. Meas. 2021, 70, 2508817. [Google Scholar] [CrossRef]
- Wang, Z.; Liu, J.; Li, J.; Meng, Y.; Pokhrel, Y.; Zhang, H.S. Basin-scale high-resolution extraction of drainage networks using 10-m Sentinel-2 imagery. Remote Sens. Environ. 2021, 255, 112281. [Google Scholar] [CrossRef]
- Ahmed, R.; Chen, Y.; Hassan, B.; Du, L. CR-IoTNet: Machine learning based joint spectrum sensing and allocation for cognitive radio enabled IoT cellular networks. Ad Hoc Networks 2021, 112, 102390. [Google Scholar] [CrossRef]
- Khan, A.; Khan, S.; Hassan, B.; Zheng, Z. CNN-Based Smoker Classification and Detection in Smart City Application. Sensors 2022, 22, 892. [Google Scholar] [CrossRef]
- Ahmed, R.; Chen, Y.; Hassan, B. Deep residual learning-based cognitive model for detection and classification of transmitted signal patterns in 5G smart city networks. Digit. Signal Processing 2022, 120, 103290. [Google Scholar] [CrossRef]
- Ahmed, R.; Chen, Y.; Hassan, B. Deep learning-driven opportunistic spectrum access (OSA) framework for cognitive 5G and beyond 5G (B5G) networks. Ad Hoc Netw. 2021, 123, 102632. [Google Scholar] [CrossRef]
- Hassan, T.; Hassan, B.; Akram, M.U.; Hashmi, S.; Taguri, A.H.; Werghi, N. Incremental Cross-Domain Adaptation for Robust Retinopathy Screening via Bayesian Deep Learning. IEEE Trans. Instrum. Meas. 2021, 70, 2516414. [Google Scholar] [CrossRef]
- Hassan, B.; Qin, S.; Hassan, T.; Akram, M.U.; Ahmed, R.; Werghi, N. CDC-Net: Cascaded decoupled convolutional network for lesion-assisted detection and grading of retinopathy using optical coherence tomography (OCT) scans. Biomed. Signal Processing Control. 2021, 70, 103030. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems 25 (NIPS 2012), Lake Tahoe, NV, USA, 3–8 December 2012. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollar, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Hou, Y.; Liu, Z.; Zhang, T.; Li, Y. C-UNet: Complement UNet for remote sensing road extraction. Sensors 2021, 21, 2153. [Google Scholar] [CrossRef]
- Li, M.; Wu, P.; Wang, B.; Park, H.; Yang, H.; Wu, Y. A deep learning method of water body extraction from high resolution remote sensing images with multisensors. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 3120–3132. [Google Scholar] [CrossRef]
- Ma, A.; Wan, Y.; Zhong, Y.; Wang, J.; Zhang, L. SceneNet: Remote sensing scene classification deep learning network using multi-objective neural evolution architecture search. ISPRS J. Photogramm. Remote Sens. 2021, 172, 171–188. [Google Scholar] [CrossRef]
- Prodhan, F.; Zhang, J.; Yao, F.; Shi, L.; Sharma, T.P.; Zhang, D.; Cao, D.; Zheng, M.; Ahmed, N.; Mohana, H. Deep learning for monitoring agricultural drought in South Asia using remote sensing data. Remote Sens. 2021, 13, 1715. [Google Scholar] [CrossRef]
- Uss, M.; Vozel, B.; Lukin, V.; Chehdi, K. Exhaustive Search of Correspondences between Multimodal Remote Sensing Images Using Convolutional Neural Network. Sensors 2022, 22, 1231. [Google Scholar] [CrossRef]
- Loveland, T.R.; Irons, J.R. Landsat 8: The plans, the reality, and the legacy. Remote Sens. Environ. 2016, 185, 1–6. [Google Scholar] [CrossRef] [Green Version]
- Knight, E.J.; Kvaran, G. Landsat-8 operational land imager design, characterization and performance. Remote Sens. 2014, 6, 10286–10305. [Google Scholar] [CrossRef] [Green Version]
- Roy, D.P.; Wulder, M.A.; Loveland, T.R.; Woodcock, C.E.; Allen, R.G.; Anderson, M.C.; Helder, D.; Irons, J.R.; Johnson, D.M.; Kennedy, R.; et al. Landsat-8: Science and product vision for terrestrial global change research. Remote Sens. Environ. 2014, 145, 154–172. [Google Scholar] [CrossRef] [Green Version]
- Ebel, P.; Meraner, A.; Schmitt, M.; Zhu, X.X. Multisensor data fusion for cloud removal in global and all-season sentinel-2 imagery. IEEE Trans. Geosci. Remote Sens. 2020, 59, 5866–5878. [Google Scholar] [CrossRef]
- Haklay, M.; Weber, P. Openstreetmap: User-generated street maps. IEEE Pervasive Comput. 2008, 7, 12–18. [Google Scholar] [CrossRef] [Green Version]
- Demetriou, D. Uncertainty of OpenStreetMap data for the road network in Cyprus. In Proceedings of the Fourth International Conference on Remote Sensing and Geoinformation of the Environment (RSCy2016), Paphos, Cyprus, 4–8 April 2016; pp. 43–52. [Google Scholar]
- Venkatappa, M.; Sasaki, N.; Shrestha, R.P.; Tripathi, N.K.; Ma, H.O. Determination of vegetation thresholds for assessing land use and land use changes in Cambodia using the Google Earth Engine cloud-computing platform. Remote Sens. 2019, 11, 1514. [Google Scholar] [CrossRef] [Green Version]
- Liaw, A.; Wiener, M. Classification and regression by randomForest. R News 2002, 2, 18–22. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Region | Image | Resolution | Patches | Training | Validation | Testing |
|---|---|---|---|---|---|---|
| Balochistan | VHR-1 | 10,600 9080 | 1116 | 670 | 223 | 223 |
| VHR-2 | 10,601 8036 | 972 | 583 | 195 | 194 | |
| VHR-3 | 5056 4909 | 289 | 173 | 58 | 58 | |
| Gilgit–Baltistan | VHR-1 | 2936 1707 | 50 | 30 | 10 | 10 |
| VHR-2 | 7380 3778 | 325 | 195 | 65 | 65 | |
| VHR-3 | 4403 1517 | 75 | 45 | 15 | 15 | |
| VHR-4 | 11,212 2792 | 342 | 205 | 69 | 68 | |
| VHR-5 | 4811 2564 | 128 | 77 | 26 | 25 | |
| Khyber Pakhtunkhwa | VHR-1 | 4261 2757 | 126 | 76 | 25 | 25 |
| VHR-2 | 3568 2228 | 84 | 50 | 17 | 17 | |
| VHR-3 | 7950 3644 | 324 | 194 | 65 | 65 | |
| VHR-4 | 5546 6594 | 418 | 251 | 84 | 83 | |
| Punjab | VHR-1 | 9663 7106 | 792 | 475 | 159 | 158 |
| VHR-2 | 9296 7468 | 800 | 480 | 160 | 160 | |
| VHR-3 | 9459 7469 | 800 | 480 | 160 | 160 | |
| VHR-4 | 11,823 6978 | 984 | 590 | 197 | 197 | |
| VHR-5 | 6116 3573 | 252 | 151 | 51 | 50 | |
| Sindh | VHR-1 | 9459 7097 | 768 | 461 | 154 | 153 |
| VHR-2 | 12,557 8854 | 1290 | 774 | 258 | 258 | |
| Total | 19 VHR | - | 9935 | 5960 | 1991 | 1984 |
| Tuned Parameter | Value |
|---|---|
| Training Patches | 5960 |
| Validation Patches | 1991 |
| Optimizer | Adam |
| Initial Learning Rate | 0.001 [1× 10−4 to 1× 10−1] |
| Weight Decay | 0.0003 [3 × 10−6 to 3 × 10−2] |
| Mini-Batch Size | 128 [16 to 256] |
| Total Epochs | 80 |
| Iterations per Epoch | 46 |
| Total Iterations | 3680 |
| Validation Frequency | 10 |
| Class | Without Postprocessing | With Postprocessing | ||||||
|---|---|---|---|---|---|---|---|---|
| MPS | MPP | MioU | MDSC | MPS | MPP | MioU | MDSC | |
| BG | 0.9865 | 0.9998 | 0.9864 | 0.9932 | 0.9891 | 0.9999 | 0.9891 | 0.9945 |
| WC | 0.9985 | 0.7299 | 0.7291 | 0.8421 | 0.9992 | 0.7697 | 0.7692 | 0.8696 |
| Combined | 0.9925 | 0.8649 | 0.8578 | 0.9177 | 0.9941 | 0.8848 | 0.8791 | 0.9320 |
| Model | Class | Balochistan | Gilgit–Baltistan | Khyber Pakhtunkhwa | Punjab | Sindh | Overall |
|---|---|---|---|---|---|---|---|
| FCN-32s [24] | BG | 0.9290 | 0.9770 | 0.9590 | 0.9576 | 0.9609 | 0.7383 |
| WC | 0.4932 | 0.5362 | 0.5218 | 0.4791 | 0.5691 | ||
| FCN-8s [24] | BG | 0.9474 | 0.9818 | 0.9680 | 0.9718 | 0.9698 | 0.7709 |
| WC | 0.5623 | 0.5834 | 0.5633 | 0.5527 | 0.6089 | ||
| U-net [25] | BG | 0.9482 | 0.9800 | 0.9674 | 0.9630 | 0.9730 | 0.8035 |
| WC | 0.6392 | 0.6277 | 0.6359 | 0.5887 | 0.7120 | ||
| SegNet [26] | BG | 0.9496 | 0.9832 | 0.9688 | 0.9741 | 0.9761 | 0.8159 |
| WC | 0.6339 | 0.6605 | 0.6324 | 0.6526 | 0.7277 | ||
| DeepLabv3+ [27] | BG | 0.9561 | 0.9858 | 0.9742 | 0.9775 | 0.9776 | 0.8301 |
| WC | 0.6559 | 0.6908 | 0.6737 | 0.6753 | 0.7340 | ||
| Proposed | BG | 0.9831 | 0.9847 | 0.9891 | 0.9931 | 0.9953 | 0.8791 |
| WC | 0.7809 | 0.6070 | 0.7560 | 0.8540 | 0.8479 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mazhar, S.; Sun, G.; Bilal, A.; Hassan, B.; Li, Y.; Zhang, J.; Lin, Y.; Khan, A.; Ahmed, R.; Hassan, T. AUnet: A Deep Learning Framework for Surface Water Channel Mapping Using Large-Coverage Remote Sensing Images and Sparse Scribble Annotations from OSM Data. Remote Sens. 2022, 14, 3283. https://doi.org/10.3390/rs14143283
Mazhar S, Sun G, Bilal A, Hassan B, Li Y, Zhang J, Lin Y, Khan A, Ahmed R, Hassan T. AUnet: A Deep Learning Framework for Surface Water Channel Mapping Using Large-Coverage Remote Sensing Images and Sparse Scribble Annotations from OSM Data. Remote Sensing. 2022; 14(14):3283. https://doi.org/10.3390/rs14143283
Chicago/Turabian StyleMazhar, Sarah, Guangmin Sun, Anas Bilal, Bilal Hassan, Yu Li, Junjie Zhang, Yinyi Lin, Ali Khan, Ramsha Ahmed, and Taimur Hassan. 2022. "AUnet: A Deep Learning Framework for Surface Water Channel Mapping Using Large-Coverage Remote Sensing Images and Sparse Scribble Annotations from OSM Data" Remote Sensing 14, no. 14: 3283. https://doi.org/10.3390/rs14143283