
Precise Crop Classification of Hyperspectral Images Using Multi-Branch Feature Fusion and Dilation-Based MLP


Abstract
:1. Introduction
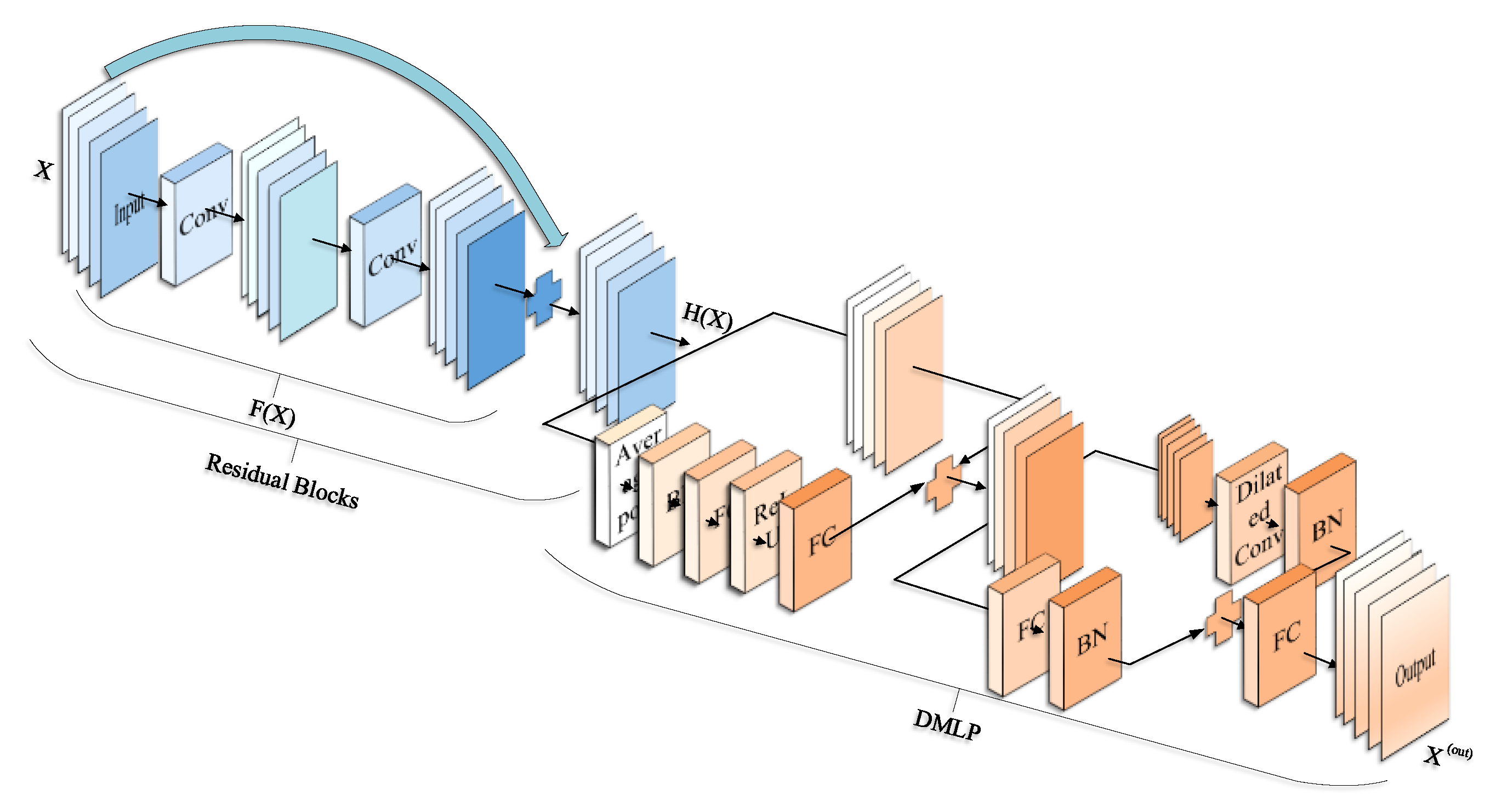
- MLP, as a less constrained network, can eliminate the negative effects of translation invariance and local connectivity. Therefore, this paper modified MLP combined with dilated convolution to fully obtain spectral–spatial features of each sample and improve HSI remote sensing scene classification performance, called DMLP. The dilated convolutional layer replaced the ordinary convolution of MLP, which can enlarge the receptive field without losing resolution and keep the relative spatial position of pixels unchanged.
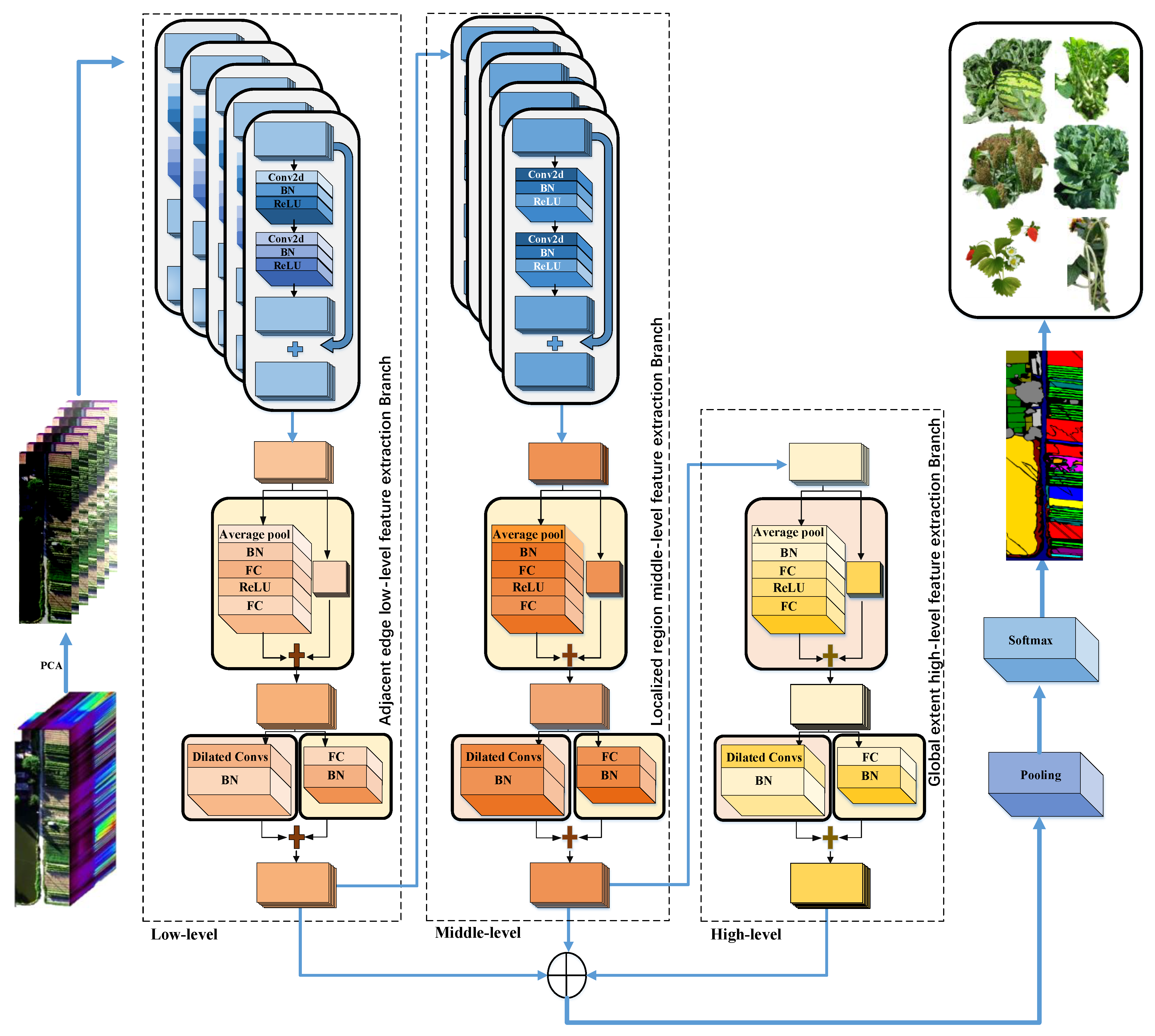
- This paper composes multi-branch residual blocks and DMLP to form a multi-level feature fusion network, called DMLPFFN. Firstly, the residual structure can retain the original characteristics of the HSI data, and avoid the problems of gradient explosion and gradient disappearance in the training process. In addition, DMLP can improve the feature extraction capability of the residual blocks and strengthen the model with essential features while retaining the original features of the hyperspectral data. In DMLPFFN, three branches of features are fused to obtain a feature map with more comprehensive information, which integrates the spectral information, spatial context information, spatial feature information and spatial location information of HSI to improve classification accuracy.
- Comprehensive experiments are designed and executed to prove the effectiveness of DMLPFFN by different hyperspectral datasets. DMLPFFN achieved better classification performance and generalization ability for fine crop classification.
2. The Proposed MLP-Based Methods for HSI Classification
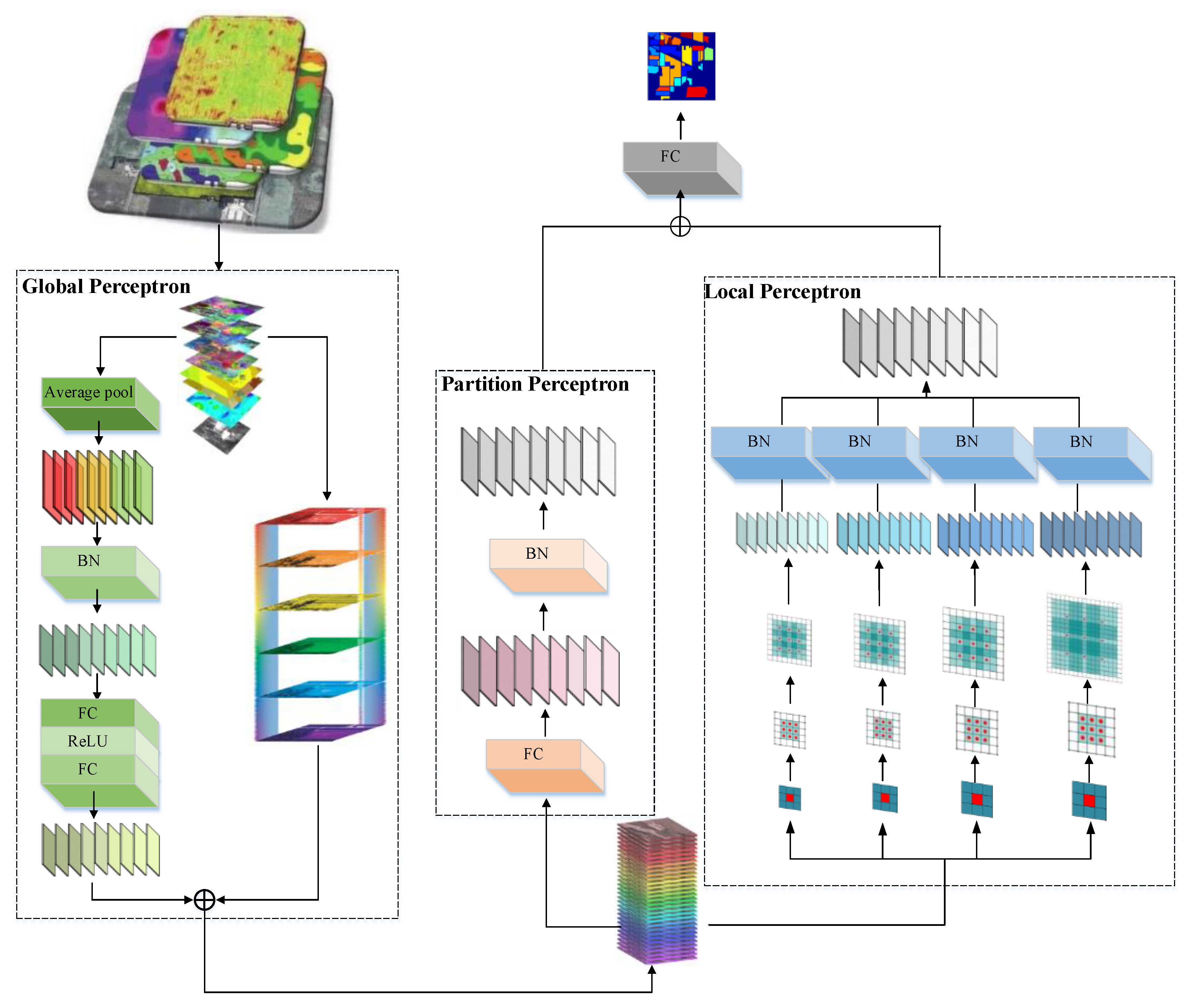
2.1. The Proposed Dilation-Based MLP (DMLP) for HSI Classification
2.1.1. The Global Perceptron Module Block
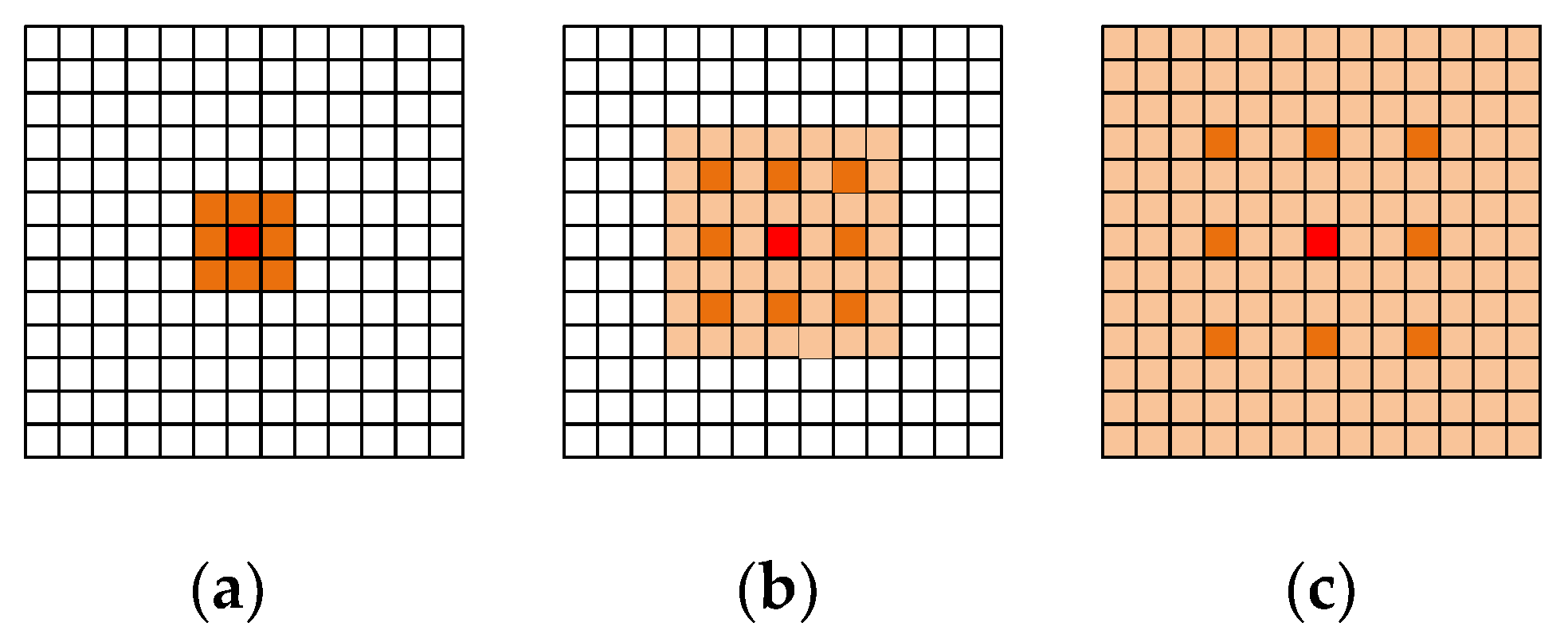
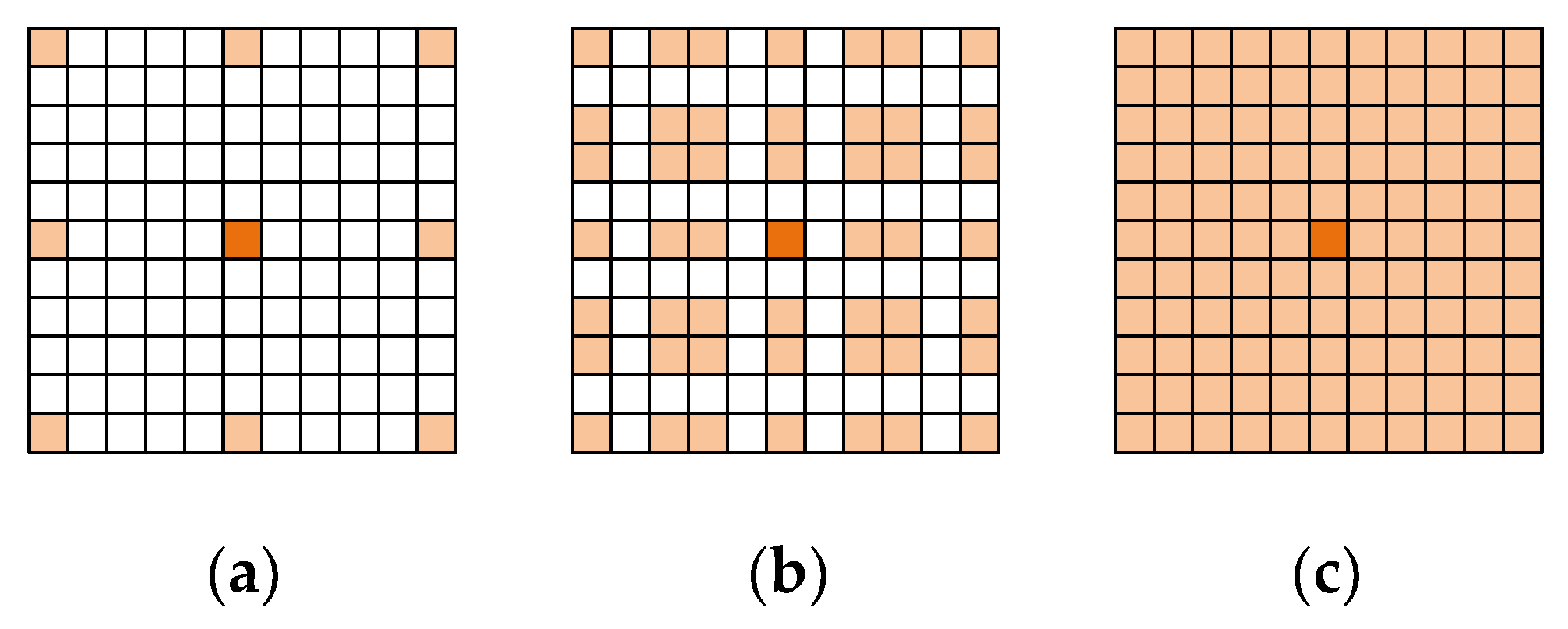
2.1.2. The Partition Perceptron Module Block
2.1.3. The Local Perceptron Module Block
2.2. The Proposed DMLPFFN Model for HSI Classification
2.2.1. Fusion of Multi-Branch Features
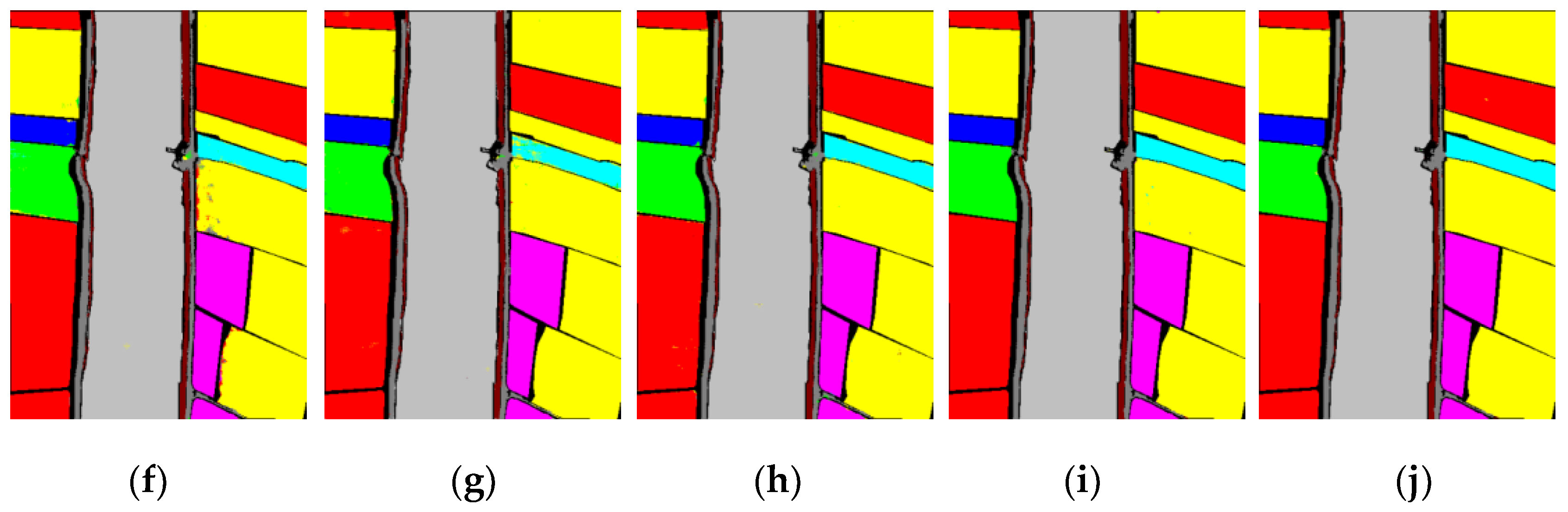
2.2.2. Feature Output Visualization and Analysis
3. Experimental Results
3.1. Public HSI Dataset Description
3.2. Experimental Parameter Setting
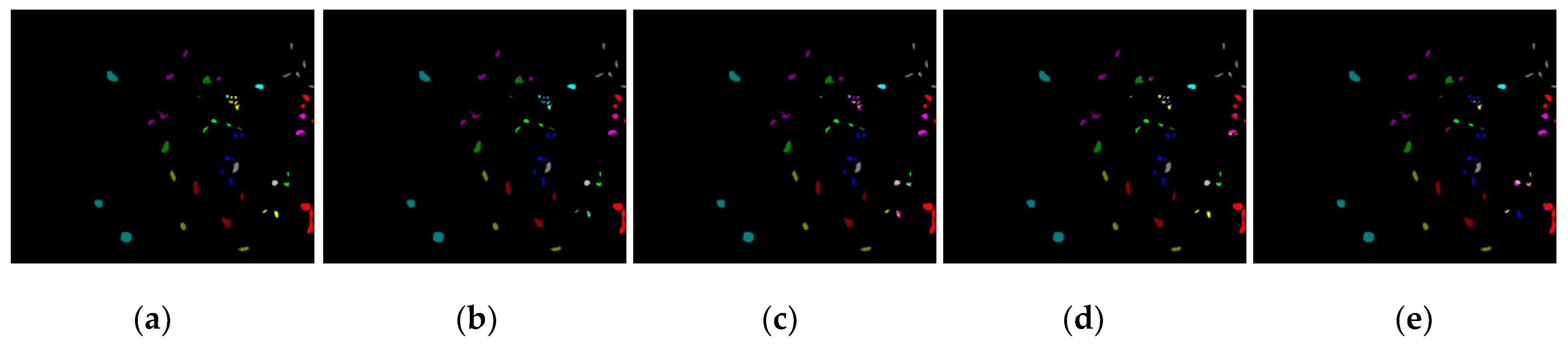
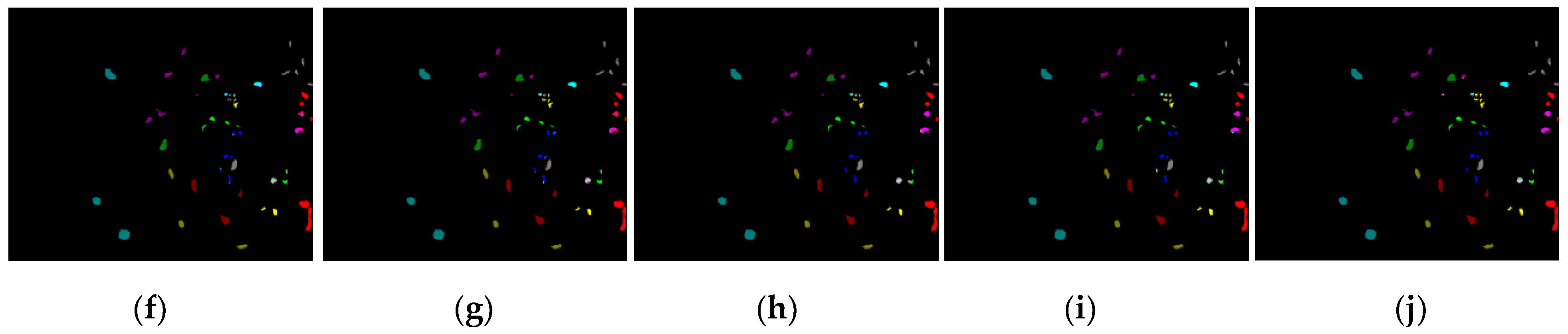
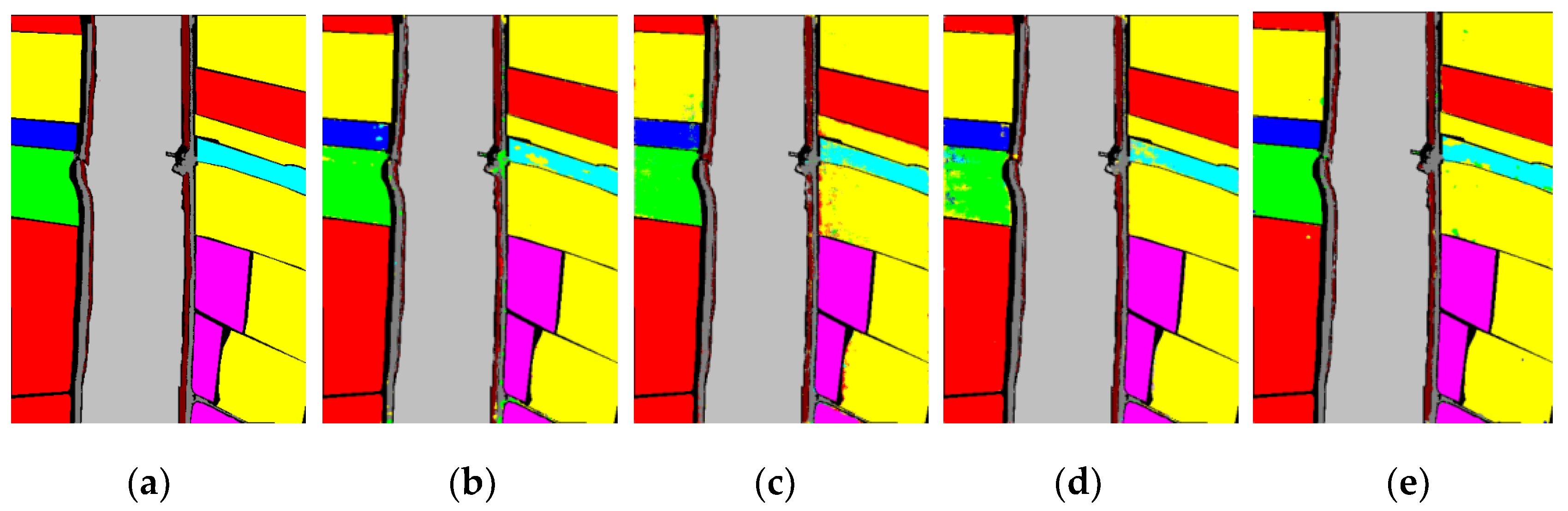
3.3. Comparison of the Proposed Methods with the State-of-the-Art Methods
4. Application in Fine Classification of Crops
5. Discussion
5.1. The Number of Principal Components
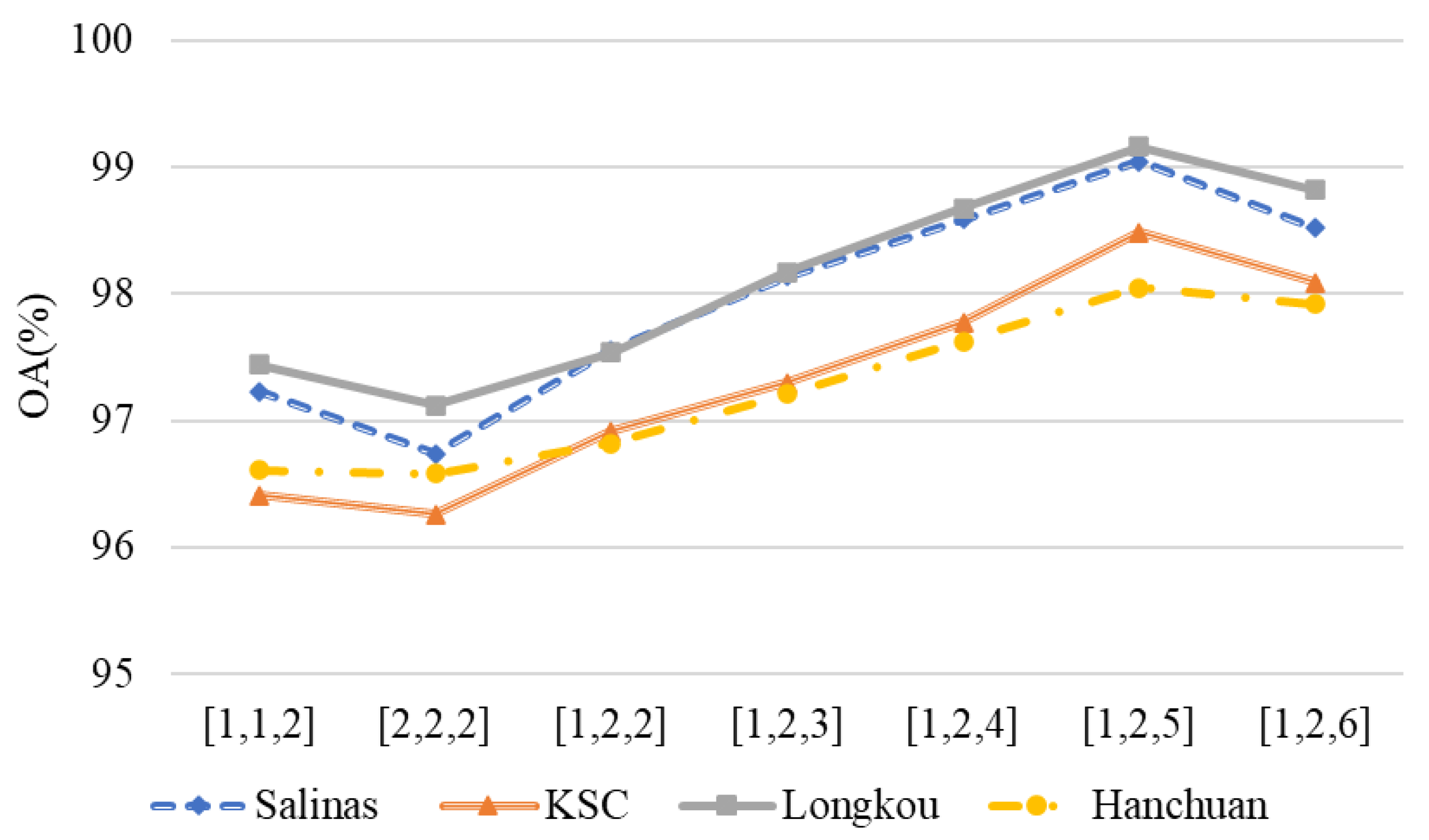
5.2. The Expansion Rate of Dilated Convolution
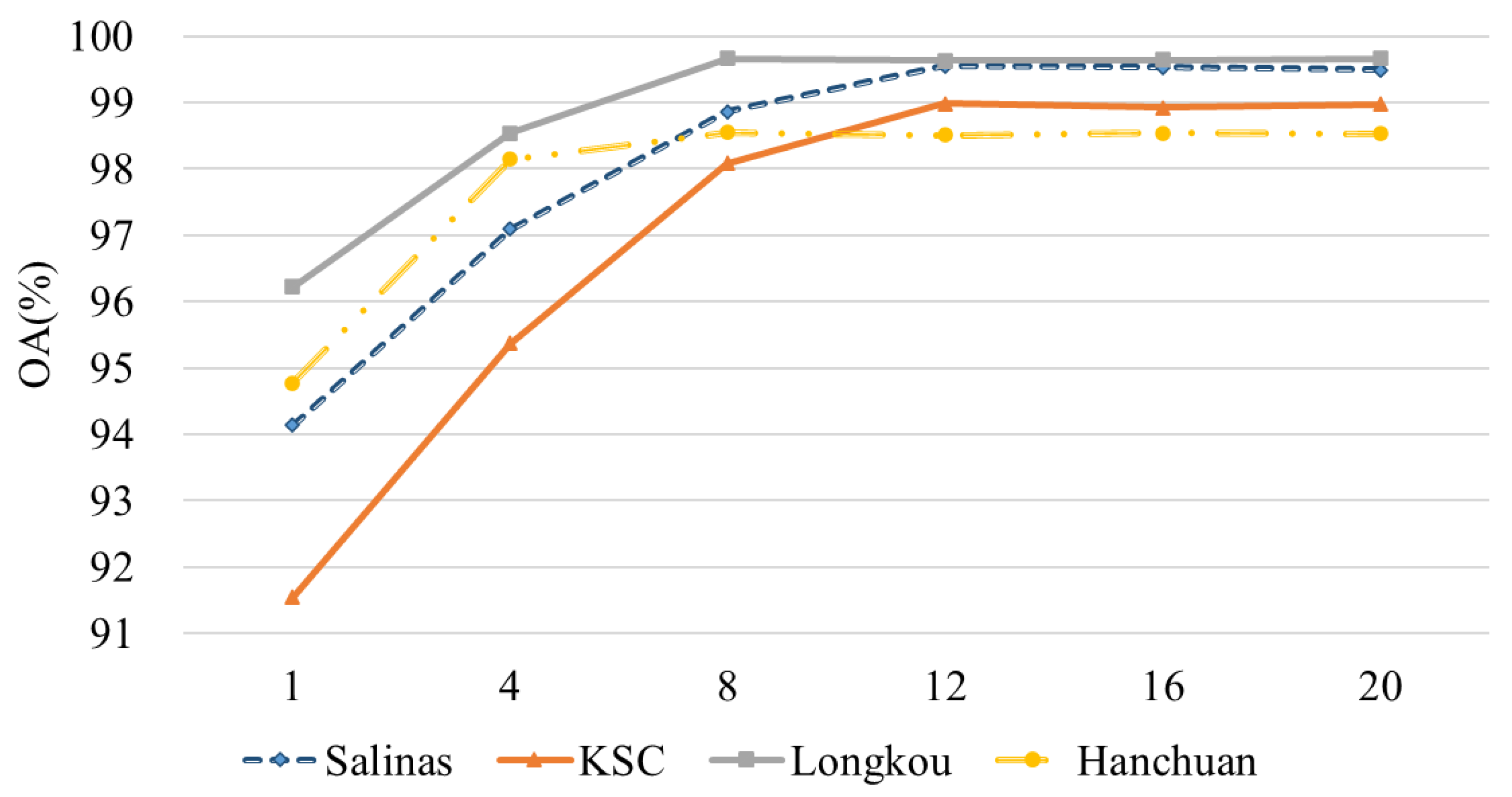
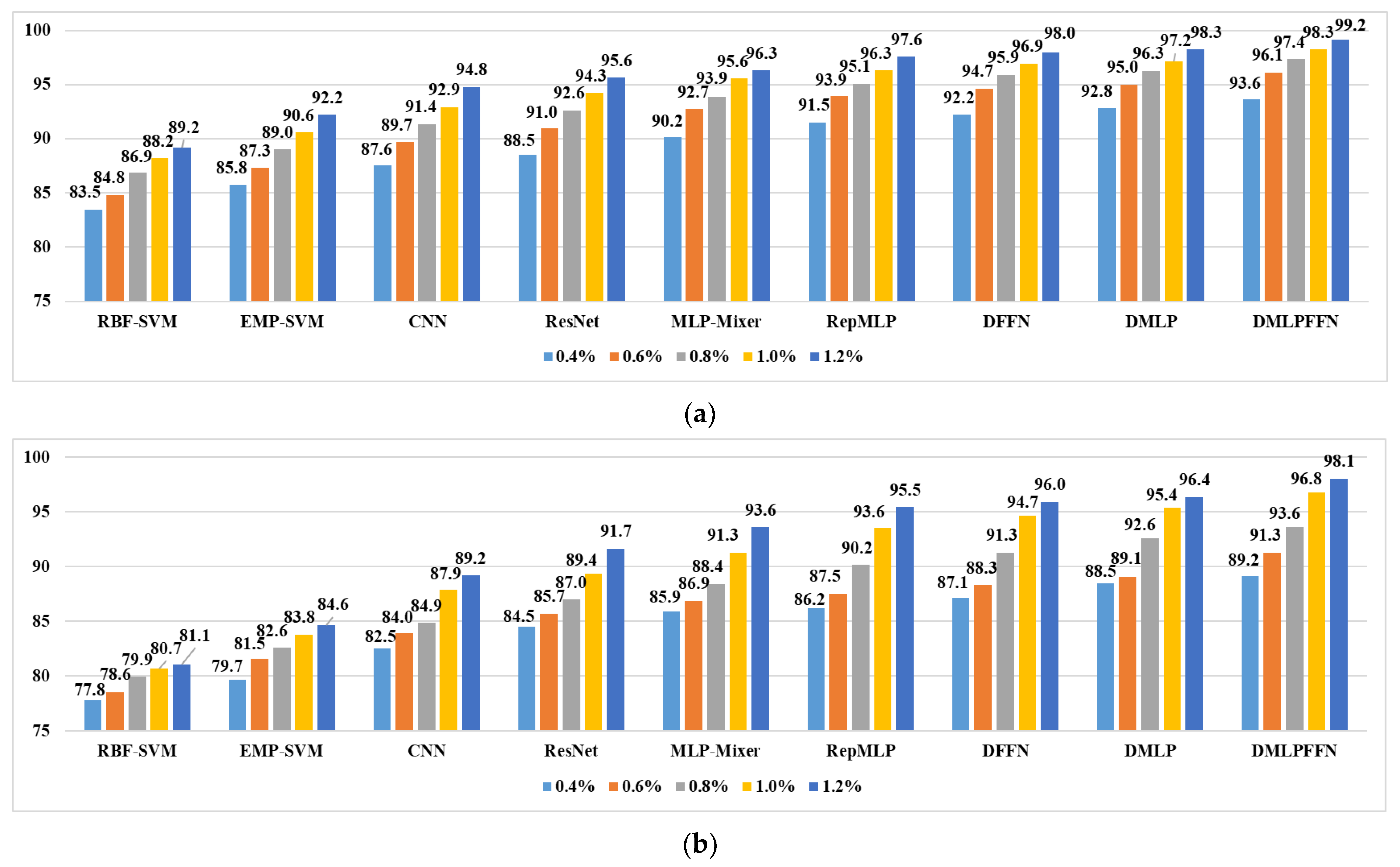
5.3. The Percentage of Training Samples
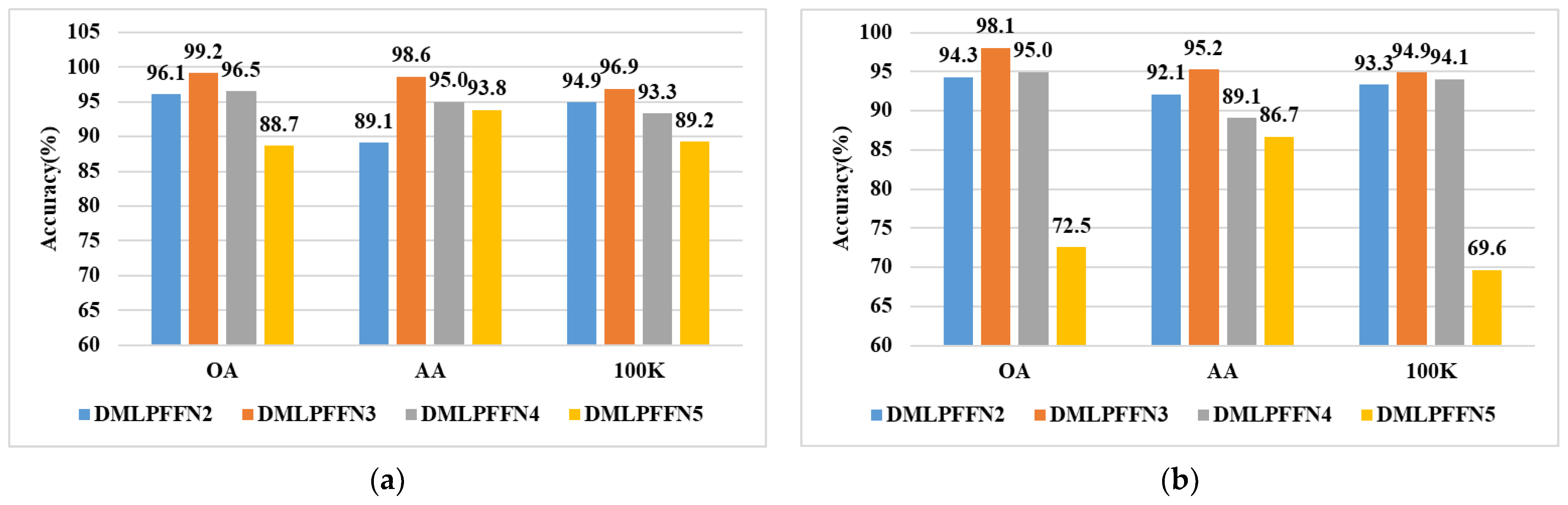
5.4. The Number of Branches in Feature Fusion Strategy
5.5. The Number of Classes for HSI Classification
5.6. Time Consumption and Computational Complexity
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Czaja, W.; Kavalerov, I.; Li, W. Exploring the High Dimensional Geometry of HSI Features. In Proceedings of the 2021 11th Work-Shop on Hyperspectral Imaging and Signal Processing: Evolution in Remote Sensing (WHISPERS), Amsterdam, The Netherlands, 24–26 March 2021; pp. 1–5. [Google Scholar]
- Zhang, Y.; Wang, D.; Zhou, Q. Advances in crop fine classification based on Hyperspectral Remote Sensing. In Proceedings of the 2019 8th International Conference on Agro-Geoinformatics, Istanbul, Turkey, 16–19 July 2019; pp. 1–6. [Google Scholar]
- Kim, Y.; Kim, Y. Hyperspectral Image Classification Based on Spectral Mixture Analysis for Crop Type Determination. In Proceedings of the IGARSS 2018—2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 23–27 July 2018; pp. 5304–5307. [Google Scholar]
- Spiller, D.; Ansalone, L.; Carotenuto, F.; Mathieu, P.P. Crop Type Mapping Using Prisma Hyperspectral Images and One-Dimensional Convolutional Neural Network. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS, Brussels, Belgium, 11–16 July 2021; pp. 8166–8169. [Google Scholar]
- Pignatti, S.; Casa, R.; Harfouche, A.; Huang, W.; Palombo, A.; Pascucci, S. Maize Crop and Weeds Species Detection by Using Uav Vnir Hyperpectral Data. In Proceedings of the IGARSS 2019—2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 7235–7238. [Google Scholar]
- Kefauver, S.C.; Romero, A.G.; Buchaillot, M.L.; Vergara-Díaz, O.; Fernandez-Gallego, J.A.; El-Haddad, G.; Akl, A.; Araus, J.L. Open-Source Software for Crop Physiological Assessments Using High Resolution RGB Images. In Proceedings of the IGARSS 2020—2020 IEEE International Geoscience and Remote Sensing Symposium, Waikoloa, HI, USA, 26 September–2 October 2020; pp. 4359–4362. [Google Scholar]
- Liu, C.; Li, M.; Liu, Y.; Chen, J.; Shen, C. Application of Adaboost based ensemble SVM on IKONOS image Classification. In Proceedings of the 2010 18th International Conference on Geoinformatics, Beijing, China, 18–20 June 2010; pp. 1–5. [Google Scholar]
- Cuozzo, G.; D’Elia, C.; Puzzolo, V. A method based on tree-structured Markov random field for forest area classification. In Proceedings of the IGARSS 2004. 2004 IEEE International Geoscience and Remote Sensing Symposium, Anchorage, AK, USA, 20–24 September 2004; Volume 4, pp. 2352–2354. [Google Scholar]
- Li, Z.; Li, X.; Chen, E.; Li, S. A method integrating GF-1 multi-spectral and modis multitemporal NDVI data for forest land cover classification. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; pp. 3742–3745. [Google Scholar]
- Delalieux, S.; Somers, B.; Haest, B.; Spanhove, T.; Borre, J.V.; Mücher, C.A. Heathland conservation status mapping through integration of hyperspectral mixture analysis and decision tree classifiers. Remote Sens. Environ. 2012, 126, 222–231. [Google Scholar] [CrossRef]
- Chen, Y.; Lin, Z.; Zhao, X.; Wang, G.; Gu, Y. Deep Learning-Based Classification of Hyperspectral Data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 2094–2107. [Google Scholar] [CrossRef]
- Tao, C.; Pan, H.; Li, Y.; Zou, Z. Unsupervised Spectral–Spatial Feature Learning with Stacked Sparse Autoencoder for Hyperspectral Imagery Classification. IEEE Geosci. Remote Sens. Lett. 2015, 12, 2438–2442. [Google Scholar]
- Sun, Q.; Liu, X.; Fu, M. Classification of hyperspectral image based on principal component analysis and deep learning. In Proceedings of the 2017 7th IEEE International Conference on Electronics Information and Emergency Communication (ICEIEC), Shenzhen, China, 21–23 July 2017; pp. 356–359. [Google Scholar]
- Chen, Y.; Jiang, H.; Li, C.; Jia, X.; Ghamisi, P. Deep Feature Extraction and Classification of Hyperspectral Images Based on Convolutional Neural Networks. IEEE Trans. Geosci. Remote Sens. 2016, 54, 6232–6251. [Google Scholar] [CrossRef] [Green Version]
- Zhang, B.; Qing, C.; Xu, X.; Ren, J. Spatial Residual Blocks Combined Parallel Network for Hyperspectral Image Classification. IEEE Access 2020, 8, 74513–74524. [Google Scholar] [CrossRef]
- Kanthi, M.; Sarma, T.H.; Bindu, C.S. A 3d-Deep CNN Based Feature Extraction and Hyperspectral Image Classification. In Proceedings of the 2020 IEEE India Geoscience and Remote Sensing Symposium (InGARSS), Virtual, 1–4 December 2020; pp. 229–232. [Google Scholar]
- Zhang, H.; Yu, H.; Xu, Z.; Zheng, K.; Gao, L. A Novel Classification Framework for Hyperspectral Image Classification Based on Multi-Scale Dense Network. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS, Brussels, Belgium, 11–16 July 2021; pp. 2238–2241. [Google Scholar]
- Zhu, M.; Fan, J.; Yang, Q.; Chen, T. SC-EADNet: A Self-Supervised Contrastive Efficient Asymmetric Dilated Network for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2020, 60, 1–17. [Google Scholar] [CrossRef]
- Tolstikhin, I.O.; Houlsby, N.; Kolesnikov, A.; Beyer, L.; Zhai, X.; Unterthiner, T.; Yung, J.; Steiner, A.; Keysers, D.; Uszkoreit, J.; et al. Mlp-mixer: An all-mlp architecture for vision. arXiv 2021, arXiv:2105.01601. [Google Scholar]
- Yu, T.; Li, X.; Cai, Y.; Sun, M.; Li, P. S2-MLP: Spatial-Shift MLP Architecture for Vision. In Proceedings of the 2022 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 4–8 January 2022; pp. 3615–3624. [Google Scholar]
- Lian, D.; Yu, Z.; Sun, X.; Gao, S. AS-MLP: An Axial Shifted MLP Architecture for Vision. arXiv 2021, arXiv:2107.08391. [Google Scholar]
- Yu, T.; Li, X.; Cai, Y.; Sun, M.; Li, P. S2-MLPv2: Improved Spatial-Shift MLP Architecture for Vision. arXiv 2021, arXiv:2108.01072. [Google Scholar]
- Chen, S.; Xie, E.; Ge, C.; Liang, D.; Luo, P. CyclNMLP: A MLP-like Architecture for Dense Prediction. arXiv 2021, arXiv:2107.10224. [Google Scholar]
- Potghan, S.; Rajamenakshi, R.; Bhise, A. Multi-Layer Perceptron Based Lung Tumor Classification. In Proceedings of the 2018 Second International Conference on Electronics, Communication and Aerospace Technology (ICECA), Coimbatore, India, 29–31 March 2018; pp. 499–502. [Google Scholar]
- Deng, F.; Bi, Y.; Liu, Y.; Yang, S. Deep-Learning-Based Remaining Useful Life Prediction Based on a Multi-Scale Dilated Convolution Network. Mathematics 2021, 9, 3035. [Google Scholar] [CrossRef]
- Li, Z.; Wang, T.; Li, W.; Du, Q.; Wang, C.; Liu, C.; Shi, X. Deep Multilayer Fusion Dense Network for Hyperspectral Image Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 1258–1270. [Google Scholar] [CrossRef]
- Jiang, Y.; Li, Y.; Zou, S.; Zhang, H.; Bai, Y. Hyperspectral Image Classification with Spatial Consistence Using Fully Convolutional Spatial Propagation Network. IEEE Trans. Geosci. Remote Sens. 2021, 59, 10425–10437. [Google Scholar] [CrossRef]
- Luo, Y.; Zou, J.; Yao, C.; Zhao, X.; Li, T.; Bai, G. HSI-CNN: A Novel Convolution Neural Network for Hyperspectral Image. In Proceedings of the 2018 International Conference on Audio, Language and Image Processing (ICALIP), Shanghai, China, 16–17 July 2018; pp. 464–469. [Google Scholar]
- He, X.; Chen, Y. Transferring CNN Ensemble for Hyperspectral Image Classification. IEEE Geosci. Remote Sens. Lett. 2021, 18, 876–880. [Google Scholar] [CrossRef]
- Melgani, F.; Bruzzone, L. Support vector machines for classification of hyperspectral remote-sensing images. In 2002 IEEE International Geoscience and Remote Sensing Symposium (IGARSS 2002), Proceedings of the 24th Canadian Symposium on Remote Sensing, Toronto, ON, Canada, 24–28 June 2002; IEEE: Piscataway Township, NJ, USA, 2002; Volume I. [Google Scholar]
- Gu, Y.; Liu, T.; Jia, X.; Benediktsson, J.O.N.A.; Chanussot, J. Nonlinear multiple kernel learning with multiple-structure-element extended morphological profiles for hyperspectral image classification. IEEE Trans. Geosci. Remote 2016, 54, 3235–3247. [Google Scholar] [CrossRef]
- Morchhale, S.; Pauca, V.P.; Plemmons, R.J.; Torgersen, T.C. Classification of pixel-level fused hyperspectral and lidar data using deep convolutional neural networks. In Proceedings of the 2016 8th Workshop on Hyperspectral Image and Signal Processing: Evolution in Remote Sensing (WHISPERS), Los Angeles, CA, USA, 21–24 August 2016; pp. 1–5. [Google Scholar]
- Liu, X.; Meng, Y.; Fu, M. Classification Research Based on Residual Network for Hyperspectral Image. In Proceedings of the 2019 IEEE 4th International Conference on Signal and Image Processing (ICSIP), Wuxi, China, 19–21 July 2019; pp. 911–915. [Google Scholar]
- Ding, X.; Xia, C.; Zhang, X.; Chu, X.; Han, J.; Ding, G. Repmlp: Reparameterizing convolutions into fully-connected layers for image recognition. arXiv 2021, arXiv:2105.01883. [Google Scholar]
- Song, W.; Li, S.; Fang, L.; Lu, T. Hyperspectral Image Classification With Deep Feature Fusion Network. IEEE Trans. Geosci. Remote Sens. 2018, 56, 3173–3184. [Google Scholar] [CrossRef]
- Zhong, Y.; Hu, X.; Luo, C.; Wang, X.; Zhao, J.; Zhang, L. WHU-Hi: UAV-borne hyperspectral with high spatial resolution (H2) benchmark datasets and classifier for precise crop identification based on deep convolutional neural network with CRF. Remote Sens. Environ. 2020, 250, 112012. [Google Scholar] [CrossRef]
- Zhong, Y.; Wang, X.; Xu, Y.; Wang, S.; Jia, T.; Hu, X.; Zhao, J.; Wei, L.; Zhang, L. Mini-UAV-borne hyperspectral remote sensing: From observation and processing to applications. IEEE Geosci. Remote Sens. Mag. 2018, 6, 46–62. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No | Name | Color | Number | False-Color Map | Ground-Truth Map |
|---|---|---|---|---|---|
| 1 | Brocoli_green_weeds_1 |  | 1997 |  |  |
| 2 | Brocoli_green_weeds_2 |  | 3726 | ||
| 3 | Fallow |  | 1976 | ||
| 4 | Fallow_rough_ pow |  | 1394 | ||
| 5 | Fallow_smooth |  | 2678 | ||
| 6 | Stubble |  | 3979 | ||
| 7 | Celery |  | 3579 | ||
| 8 | Grapes_ untrained |  | 11,213 | ||
| 9 | soil_vinyard_develop |  | 6197 | ||
| 10 | Corn_snesced_green_weeds |  | 3249 | ||
| 11 | Lettuce_romaine_4wk |  | 1058 | ||
| 12 | Lettuce_romaine_5wk |  | 1908 | ||
| 13 | Lettuce_romaine_6wk |  | 909 | ||
| 14 | Lettuce_romaine_7wk |  | 1061 | ||
| 15 | Vinyard_untrained |  | 7164 | ||
| 16 | Vinyard_vertical_trellis |  | 1737 | ||
| Total Numbers | 53,785 | ||||
| No | Name | Color | Number | False-Color Map | Ground-Truth Map |
|---|---|---|---|---|---|
| 1 | Scrub | | 1997 |  |  |
| 2 | Willow | | 3726 | ||
| 3 | Palm | | 1976 | ||
| 4 | Pine | | 1394 | ||
| 5 | Broadleaf | | 2678 | ||
| 6 | Hardwood | | 3979 | ||
| 7 | Swap | | 3579 | ||
| 8 | Graminoid | | 11,213 | ||
| 9 | Spartina | | 6197 | ||
| 10 | Cattail | | 3249 | ||
| 11 | Salt | | 1058 | ||
| 12 | Mud | | 1908 | ||
| 13 | Water | | 909 | ||
| Total Numbers | 5211 | ||||
| Method | RBF-SVM | EMP-SVM | CNN | ResNet | MLP-Mixer | RepMLP | DFFN | DMLP | DMLPFFN |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 85.13 ± 0.76 | 93.59 ± 0.26 | 94.57 ± 2.05 | 95.35 ± 1.05 | 96.90 ± 1.87 | 96.95 ± 0.02 | 97.20 ± 2.57 | 98.15 ± 0.79 | 99.26 ± 3.24 |
| 2 | 91.27 ± 1.95 | 96.37 ± 0.15 | 94.59 ± 1.14 | 96.35 ± 1.29 | 96.95 ± 0.31 | 95.09 ± 0.78 | 97.41 ± 0.67 | 97.88 ± 2.13 | 98.13 ± 3.59 |
| 3 | 89.59 ± 2.68 | 81.65 ± 0.78 | 79.38 ± 2.21 | 94.51 ± 0.48 | 95.03 ± 1.28 | 96.21 ± 0.02 | 95.02 ± 1.12 | 96.39 ± 2.47 | 97.08 ± 1.52 |
| 4 | 94.05 ± 3.61 | 95.34 ± 2.03 | 96.07 ± 1.08 | 96.49 ± 1.85 | 97.24 ± 2.05 | 97.39 ± 1.38 | 98.26 ± 0.81 | 98.04 ± 2.76 | 98.86 ± 3.03 |
| 5 | 86.52 ± 2.64 | 92.24 ± 0.35 | 96.48 ± 1.32 | 97.25 ± 2.34 | 97.61 ± 0.54 | 97.78 ± 0.24 | 98.53 ± 2.07 | 98.65 ± 3.51 | 98.87 ± 1.45 |
| 6 | 93.14 ± 2.71 | 95.57 ± 0.29 | 96.86 ± 1.55 | 96.29 ± 0.17 | 98.76 ± 0.62 | 97.98 ± 2.01 | 97.49 ± 3.54 | 98.32 ± 0.94 | 98.69 ± 2.71 |
| 7 | 93.68 ± 0.53 | 95.21 ± 1.65 | 94.09 ± 2.29 | 95.38 ± 1.16 | 96.96 ± 0.35 | 97.39 ± 1.43 | 96.08 ± 3.49 | 97.12 ± 2.54 | 97.78 ± 3.66 |
| 8 | 85.21 ± 2.49 | 86.52 ± 0.46 | 91.39 ± 1.23 | 93.25 ± 0.74 | 94.54 ± 1.82 | 95.61 ± 1.29 | 96.25 ± 3.76 | 97.32 ± 1.54 | 98.15 ± 2.85 |
| 9 | 91.25 ± 0.83 | 92.74 ± 1.26 | 94.25 ± 0.46 | 94.47 ± 0.56 | 95.65 ± 1.47 | 96.97 ± 0.02 | 97.18 ± 5.51 | 97.46 ± 2.34 | 98.06 ± 0.67 |
| 10 | 81.21 ± 2.64 | 90.57 ± 1.37 | 92.52 ± 1.15 | 93.70 ± 0.59 | 94.13 ± 1.56 | 95.72 ± 0.15 | 95.68 ± 1.34 | 96.07 ± 0.51 | 97.92 ± 3.28 |
| 11 | 86.41 ± 2.09 | 91.37 ± 1.23 | 92.36 ± 2.68 | 94.71 ± 2.52 | 95.28 ± 0.92 | 96.23 ± 1.09 | 96.98 ± 4.06 | 97.24 ± 3.49 | 98.64 ± 0.28 |
| 12 | 92.91 ± 1.48 | 93.97 ± 0.15 | 94.57 ± 0.19 | 95.19 ± 0.45 | 95.60 ± 1.01 | 96.34 ± 2.45 | 97.73 ± 1.52 | 98.52 ± 0.67 | 98.97 ± 2.02 |
| 13 | 97.45 ± 2.37 | 98.22 ± 2.65 | 94.07 ± 1.09 | 96.96 ± 0.54 | 97.06 ± 0.37 | 96.63 ± 0.28 | 96.87 ± 4.26 | 97.16 ± 3.69 | 98.21 ± 3.69 |
| 14 | 87.04 ± 1.68 | 94.35 ± 2.04 | 95.13 ± 0.76 | 96.58 ± 1.45 | 96.41 ± 0.24 | 97.33 ± 0.37 | 96.61 ± 1.37 | 96.82 ± 2.58 | 97.22 ± 4.56 |
| 15 | 68.87 ± 2.54 | 66.19 ± 4.23 | 91.57 ± 0.49 | 92.34 ± 0.67 | 93.79 ± 3.17 | 94.58 ± 0.89 | 94.91 ± 0.32 | 95.46 ± 1.49 | 96.08 ± 2.64 |
| 16 | 83.14 ± 0.65 | 80.78 ± 1.32 | 94.53 ± 2.73 | 95.53 ± 1.86 | 96.68 ± 2.33 | 96.92 ± 0.02 | 96.24 ± 3.65 | 97.68 ± 0.34 | 98.34 ± 6.19 |
| OA(%) | 86.04 ± 1.67 | 88.89 ± 0.34 | 92.24 ± 0.67 | 94.57 ± 0.28 | 95.78 ± 0.38 | 96.45 ± 0.13 | 96.98 ± 3.59 | 98.12 ± 2.03 | 99.05 ± 3.29 |
| AA(%) | 87.36 ± 0.54 | 90.35 ± 2.17 | 92.91 ± 0.56 | 93.73 ± 1.84 | 94.93 ± 1.92 | 95.50 ± 0.40 | 96.16 ± 1.49 | 97.24 ± 0.91 | 98.83 ± 2.48 |
| 100 K | 88.54 ± 1.79 | 89.26 ± 4.05 | 92.35 ± 3.67 | 94.84 ± 1.13 | 95.79 ± 2.04 | 96.17 ± 0.23 | 96.95 ± 1.46 | 97.79 ± 2.55 | 99.26 ± 2.86 |
| Method | RBF-SVM | EMP-SVM | CNN | ResNet | MLP-Mixer | RepMLP | DFFN | DMLP | DMLPFFN |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 81.54 ± 0.63 | 89.58 ± 0.61 | 90.68 ± 2.05 | 95.74 ± 1.28 | 93.28 ± 0.42 | 96.35 ± 0.21 | 95.32 ± 2.64 | 96.25 ± 0.35 | 99.20 ± 2.84 |
| 2 | 87.49 ± 1.36 | 92.36 ± 0.23 | 90.35 ± 1.14 | 93.68 ± 1.35 | 92.11 ± 1.93 | 95.17 ± 0.16 | 95.43 ± 0.31 | 96.58 ± 2.86 | 98.63 ± 1.30 |
| 3 | 85.02 ± 2.07 | 74.13 ± 0.35 | 75.27 ± 2.21 | 93.87 ± 0.49 | 92.03 ± 0.57 | 93.89 ± 0.82 | 93.17 ± 1.45 | 94.79 ± 1.43 | 96.09 ± 0.15 |
| 4 | 90.16 ± 3.36 | 90.04 ± 2.02 | 91.64 ± 1.08 | 93.91 ± 1.23 | 94.32 ± 1.04 | 95.76 ± 0.68 | 96.34 ± 0.25 | 96.24 ± 0.68 | 99.31 ± 1.46 |
| 5 | 82.65 ± 1.94 | 88.75 ± 0.57 | 91.96 ± 1.32 | 89.66 ± 1.65 | 94.40 ± 0.63 | 95.62 ± 1.27 | 95.22 ± 2.93 | 97.35 ± 2.30 | 98.82 ± 1.61 |
| 6 | 89.31 ± 2.02 | 91.34 ± 0.64 | 91.85 ± 1.55 | 92.29 ± 0.67 | 95.32 ± 1.51 | 95.33 ± 0.51 | 95.17 ± 3.32 | 96.82 ± 0.35 | 98.38 ± 2.83 |
| 7 | 89.15 ± 0.41 | 90.47 ± 1.33 | 90.54 ± 2.29 | 91.38 ± 1.34 | 93.49 ± 0.37 | 95.29 ± 1.48 | 94.72 ± 3.41 | 95.62 ± 1.22 | 96.10 ± 0.59 |
| 8 | 81.22 ± 2.35 | 82.73 ± 0.41 | 87.32 ± 1.23 | 92.45 ± 0.47 | 91.97 ± 0.50 | 92.12 ± 0.75 | 94.81 ± 3.37 | 95.34 ± 1.34 | 98.51 ± 2.61 |
| 9 | 87.25 ± 0.82 | 87.39 ± 1.21 | 90.63 ± 0.46 | 90.84 ± 0.61 | 91.86 ± 0.65 | 93.94 ± 1.53 | 95.57 ± 5.07 | 95.48 ± 0.62 | 97.76 ± 1.62 |
| 10 | 77.95 ± 1.15 | 86.52 ± 1.30 | 88.47 ± 1.15 | 87.91 ± 0.83 | 92.46 ± 1.79 | 92.48 ± 0.62 | 92.69 ± 1.02 | 95.23 ± 0.10 | 97.37 ± 1.10 |
| 11 | 81.19 ± 1.61 | 87.97 ± 1.27 | 88.65 ± 2.68 | 85.68 ± 1.26 | 91.75 ± 1.82 | 93.83 ± 0.14 | 94.05 ± 4.25 | 95.64 ± 2.31 | 98.82 ± 2.23 |
| 12 | 87.34 ± 1.53 | 89.68 ± 0.45 | 90.98 ± 0.19 | 89.19 ± 3.25 | 92.10 ± 0.04 | 93.35 ± 1.16 | 95.92 ± 1.67 | 97.31 ± 0.26 | 98.43 ± 1.68 |
| 13 | 92.57 ± 2.08 | 92.34 ± 2.24 | 90.01 ± 1.09 | 86.56 ± 1.39 | 94.57 ± 0.57 | 93.69 ± 0.28 | 94.38 ± 4.39 | 95.65 ± 3.25 | 97.35 ± 2.46 |
| 14 | 87.08 ± 1.69 | 90.07 ± 2.05 | 90.65 ± 0.76 | 89.33 ± 2.75 | 93.16 ± 1.32 | 95.73 ± 1.20 | 94.25 ± 1.83 | 95.64 ± 1.62 | 97.68 ± 3.65 |
| 15 | 64.38 ± 2.32 | 61.35 ± 2.78 | 87.35 ± 0.49 | 90.93 ± 0.86 | 90.35 ± 2.53 | 91.66 ± 0.82 | 92.73 ± 0.15 | 93.34 ± 1.51 | 98.12 ± 2.83 |
| 16 | 78.67 ± 0.94 | 76.64 ± 1.46 | 90.16 ± 2.73 | 89.68 ± 0.52 | 93.24 ± 1.82 | 93.41 ± 0.97 | 94.21 ± 3.46 | 96.23 ± 0.54 | 97.05 ± 1.25 |
| OA(%) | 81.21 ± 1.42 | 83.90 ± 0.62 | 88.49 ± 0.56 | 91.65 ± 0.32 | 92.47 ± 0.27 | 93.22 ± 0.53 | 94.30 ± 3.34 | 96.32 ± 1.64 | 98.10 ± 1.41 |
| AA(%) | 82.13 ± 0.57 | 86.23 ± 2.13 | 88.46 ± 0.94 | 92.18 ± 0.96 | 91.24 ± 1.83 | 92.91 ± 0.31 | 94.08 ± 1.31 | 95.15 ± 0.48 | 97.23 ± 2.06 |
| 100 K | 84.02 ± 1.62 | 85.46 ± 2.84 | 88.65 ± 2.48 | 90.68 ± 0.84 | 92.82 ± 1.24 | 93.87 ± 0.48 | 94.82 ± 1.02 | 96.34 ± 2.23 | 98.63 ± 1.37 |
| Method | RBF-SVM | EMP-SVM | CNN | ResNet | MLP-Mixer | RepMLP | DFFN | DMLP | DMLPFFN |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 89.59 ± 3.05 | 90.24 ± 1.68 | 91.75 ± 0.21 | 93.68 ± 3.74 | 93.24 ± 0.43 | 94.63 ± 0.65 | 94.98 ± 1.45 | 95.82 ± 3.06 | 97.25 ± 4.20 |
| 2 | 80.25 ± 1.52 | 82.66 ± 0.85 | 86.69 ± 1.28 | 91.24 ± 2.80 | 94.24 ± 0.54 | 94.68 ± 0.49 | 95.81 ± 1.65 | 96.53 ± 3.55 | 96.99 ± 0.42 |
| 3 | 84.73 ± 0.64 | 85.91 ± 1.21 | 83.52 ± 0.98 | 87.67 ± 2.91 | 88.62 ± 3.72 | 89.98 ± 0.76 | 87.71 ± 1.24 | 91.36 ± 0.41 | 92.75 ± 3.28 |
| 4 | 61.82 ± 3.44 | 63.75 ± 0.56 | 72.22 ± 0.52 | 81.08 ± 2.64 | 84.01 ± 1.91 | 86.02 ± 1.64 | 86.71 ± 0.68 | 89.52 ± 2.06 | 91.02 ± 1.56 |
| 5 | 61.56 ± 0.34 | 63.42 ± 4.57 | 71.09 ± 2.90 | 78.50 ± 1.63 | 82.55 ± 2.67 | 84.15 ± 1.53 | 85.53 ± 0.16 | 87.57 ± 0.46 | 89.59 ± 3.46 |
| 6 | 66.38 ± 0.54 | 69.65 ± 3.10 | 70.24 ± 1.24 | 77.43 ± 0.93 | 85.15 ± 2.24 | 90.80 ± 2.35 | 89.62 ± 3.58 | 92.47 ± 3.05 | 94.56 ± 1.48 |
| 7 | 62.29 ± 0.66 | 66.56 ± 3.36 | 69.95 ± 4.02 | 83.88 ± 1.90 | 84.70 ± 0.23 | 85.68 ± 1.85 | 86.06 ± 2.89 | 88.40 ± 3.93 | 90.77 ± 4.51 |
| 8 | 70.25 ± 1.48 | 74.82 ± 0.98 | 79.60 ± 4.22 | 92.10 ± 0.76 | 95.17 ± 0.93 | 96.52 ± 0.19 | 95.25 ± 0.35 | 97.88 ± 4.03 | 98.67 ± 3.51 |
| 9 | 82.64 ± 1.43 | 86.32 ± 2.36 | 89.94 ± 0.48 | 93.93 ± 1.30 | 94.78 ± 0.94 | 95.82 ± 4.24 | 95.94 ± 3.67 | 96.81 ± 0.79 | 97.69 ± 3.04 |
| 10 | 88.78 ± 1.84 | 89.25 ± 1.22 | 91.52 ± 0.98 | 94.77 ± 1.34 | 96.30 ± 0.05 | 97.48 ± 0.38 | 96.24 ± 2.55 | 98.87 ± 1.29 | 99.04 ± 3.46 |
| 11 | 89.65 ± 0.46 | 91.38 ± 2.01 | 95.91 ± 3.55 | 96.51 ± 0.48 | 95.54 ± 3.06 | 96.98 ± 2.91 | 96.41 ± 1.68 | 97.03 ± 3.57 | 98.57 ± 2.11 |
| 12 | 88.35 ± 2.19 | 91.01 ± 0.58 | 93.39 ± 2.20 | 95.09 ± 3.95 | 96.30 ± 1.47 | 94.84 ± 0.91 | 95.62 ± 0.85 | 96.87 ± 0.24 | 97.88 ± 4.62 |
| 13 | 92.26 ± 0.24 | 93.31 ± 0.32 | 95.84 ± 0.04 | 96.65 ± 0.05 | 96.28 ± 0.18 | 97.85 ± 0.33 | 96.81 ± 2.76 | 98.63 ± 3.28 | 99.35 ± 2.16 |
| OA(%) | 81.65 ± 2.08 | 83.97 ± 0.27 | 86.04 ± 1.62 | 90.75 ± 3.54 | 93.41 ± 1.08 | 94.93 ± 3.83 | 95.82 ± 0.14 | 96.76 ± 1.73 | 98.49 ± 2.64 |
| AA(%) | 79.91 ± 1.63 | 82.57 ± 3.21 | 86.05 ± 2.56 | 89.11 ± 4.06 | 92.35 ± 2.16 | 93.18 ± 1.74 | 94.21 ± 2.03 | 95.24 ± 3.25 | 97.65 ± 4.26 |
| 100 K | 78.39 ± 2.46 | 80.98 ± 1.31 | 84.67 ± 5.78 | 88.86 ± 0.96 | 93.16 ± 2.04 | 94.35 ± 1.98 | 94.05 ± 3.72 | 96.22 ± 1.28 | 97.83 ± 3.29 |
| No | Name | Color | Number | False-Color Map | Ground-Truth Map |
|---|---|---|---|---|---|
| 1 | Corn | | 34,511 |  |  |
| 2 | Cotton | | 8374 | ||
| 3 | Sesamc | | 3031 | ||
| 4 | Broad-leaf soybean | | 63,212 | ||
| 5 | Narrow-leaf soybean | | 4151 | ||
| 6 | Rice | | 11,854 | ||
| 7 | Water | | 67,056 | ||
| 8 | Roads and houses | | 7124 | ||
| 9 | Mixed weed | | 5229 | ||
| Total Numbers | 204,542 | ||||
| No | Name | Color | Number | False-Color Map | Ground-Truth Map |
|---|---|---|---|---|---|
| 1 | Strawberry | | 44,735 |  |  |
| 2 | Cowpea | | 22,753 | ||
| 3 | Soybean | | 10,287 | ||
| 4 | Sorghum | | 5353 | ||
| 5 | Water spinach | | 1200 | ||
| 6 | Watermelon | | 4533 | ||
| 7 | Greens | | 5903 | ||
| 8 | Trees | | 17,978 | ||
| 9 | Grass | | 9469 | ||
| 10 | Red roof | | 10,516 | ||
| 11 | Gray roof | | 16,911 | ||
| 12 | Plastic | | 3679 | ||
| 13 | Bare soil | | 9116 | ||
| Total Numbers | 257,530 | ||||
| Method | RBF-SVM | EMP-SVM | CNN | ResNet | MLP-Mixer | RepMLP | DFFN | DMLP | DMLPFFN |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 88.56 ± 1.28 | 89.24 ± 1.59 | 91.07 ± 1.95 | 93.29 ± 1.82 | 94.71 ± 2.35 | 95.05 ± 3.87 | 95.38 ± 4.75 | 96.25 ± 0.22 | 97.18 ± 4.76 |
| 2 | 91.23 ± 3.54 | 92.36 ± 0.49 | 94.48 ± 1.67 | 95.17 ± 2.79 | 94.53 ± 3.76 | 95.88 ± 1.62 | 94.26 ± 5.31 | 96.17 ± 3.47 | 97.45 ± 1.29 |
| 3 | 90.54 ± 1.59 | 91.57 ± 3.29 | 92.36 ± 0.69 | 93.51 ± 2.93 | 94.58 ± 1.96 | 95.47 ± 3.16 | 96.15 ± 1.67 | 96.20 ± 5.58 | 97.80 ± 2.75 |
| 4 | 89.01 ± 2.68 | 92.15 ± 2.36 | 94.43 ± 3.51 | 95.27 ± 1.59 | 96.73 ± 1.25 | 97.45 ± 2.46 | 96.89 ± 4.14 | 98.22 ± 3.34 | 98.64 ± 0.45 |
| 5 | 85.15 ± 1.34 | 86.20 ± 2.42 | 91.86 ± 0.39 | 92.08 ± 4.07 | 93.37 ± 2.15 | 94.87 ± 3.25 | 95.64 ± 3.59 | 96.56 ± 2.28 | 97.57 ± 0.86 |
| 6 | 84.60 ± 2.36 | 85.71 ± 1.99 | 88.10 ± 3.08 | 90.46 ± 2.54 | 89.78 ± 3.61 | 91.33 ± 5.46 | 92.24 ± 4.02 | 93.37 ± 0.61 | 95.83 ± 1.40 |
| 7 | 91.36 ± 0.74 | 92.01 ± 3.49 | 93.22 ± 5.44 | 92.03 ± 2.65 | 93.76 ± 4.95 | 94.59 ± 2.54 | 94.67 ± 3.09 | 95.68 ± 4.57 | 96.51 ± 2.37 |
| 8 | 80.47 ± 4.16 | 82.28 ± 3.79 | 86.25 ± 2.19 | 88.03 ± 1.43 | 90.27 ± 1.39 | 91.36 ± 5.16 | 92.16 ± 2.14 | 93.59 ± 1.68 | 94.26 ± 3.59 |
| 9 | 79.02 ± 4.39 | 82.13 ± 2.16 | 86.24 ± 4.82 | 89.76 ± 2.65 | 91.33 ± 5.54 | 92.55 ± 4.12 | 93.68 ± 0.56 | 94.03 ± 2.44 | 94.85 ± 1.85 |
| OA(%) | 89.16 ± 3.51 | 92.21 ± 4.03 | 94.78 ± 2.52 | 95.63 ± 4.36 | 96.32 ± 1.93 | 97.58 ± 3.48 | 97.97 ± 4.09 | 98.25 ± 0.77 | 99.16 ± 3.64 |
| AA(%) | 87.31 ± 3.64 | 91.45 ± 1.38 | 95.36 ± 1.04 | 95.88 ± 2.61 | 96.39 ± 3.95 | 97.55 ± 4.32 | 98.06 ± 5.23 | 98.17 ± 4.34 | 98.59 ± 2.65 |
| 100 K | 89.54 ± 4.16 | 90.86 ± 2.05 | 92.02 ± 3.86 | 93.87 ± 4.18 | 94.01 ± 1.95 | 95.17 ± 2.08 | 95.82 ± 4.17 | 96.03 ± 4.09 | 96.88 ± 3.87 |
| Method | RBF-SVM | EMP-SVM | CNN | ResNet | MLP-Mixer | RepMLP | DFFN | DMLP | DMLPFFN |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 80.25 ± 0.12 | 82.62 ± 3.61 | 88.34 ± 3.49 | 90.91 ± 1.96 | 91.67 ± 1.51 | 93.89 ± 0.57 | 92.05 ± 2.06 | 94.25 ± 1.87 | 96.33 ± 1.28 |
| 2 | 64.22 ± 2.02 | 70.86 ± 4.09 | 76.15 ± 2.36 | 83.04 ± 1.49 | 85.26 ± 6.24 | 86.12 ± 2.48 | 88.38 ± 0.74 | 90.02 ± 1.23 | 92.97 ± 2.29 |
| 3 | 73.27 ± 1.28 | 78.15 ± 2.81 | 85.37 ± 3.63 | 91.65 ± 1.91 | 90.95 ± 1.25 | 92.39 ± 2.36 | 92.65 ± 3.28 | 93.37 ± 3.68 | 94.16 ± 1.61 |
| 4 | 88.02 ± 0.88 | 89.34 ± 2.69 | 92.06 ± 1.67 | 94.65 ± 5.66 | 93.38 ± 3.97 | 94.93 ± 4.23 | 95.54 ± 1.08 | 95.37 ± 1.06 | 97.24 ± 0.98 |
| 5 | 78.22 ± 3.56 | 83.37 ± 1.63 | 89.38 ± 1.06 | 93.98 ± 3.26 | 94.33 ± 4.15 | 95.21 ± 1.89 | 95.48 ± 4.73 | 94.07 ± 1.36 | 95.19 ± 4.11 |
| 6 | 70.52 ± 4.82 | 84.39 ± 2.57 | 86.38 ± 4.39 | 89.32 ± 2.32 | 90.72 ± 3.15 | 91.26 ± 1.37 | 92.22 ± 0.27 | 92.18 ± 3.03 | 93.51 ± 0.88 |
| 7 | 69.22 ± 2.67 | 72.38 ± 0.31 | 86.31 ± 0.98 | 90.70 ± 3.82 | 91.31 ± 10.97 | 92.64 ± 2.06 | 93.46 ± 4.79 | 93.37 ± 0.46 | 95.07 ± 1.54 |
| 8 | 72.02 ± 5.92 | 74.20 ± 1.58 | 77.27 ± 3.18 | 82.08 ± 6.67 | 84.08 ± 4.37 | 86.10 ± 2.70 | 89.22 ± 3.17 | 90.56 ± 2.30 | 92.24 ± 1.85 |
| 9 | 82.20 ± 3.52 | 81.26 ± 4.54 | 88.09 ± 0.95 | 91.73 ± 5.95 | 89.90 ± 1.65 | 92.84 ± 1.19 | 91.34 ± 3.29 | 93.06 ± 3.75 | 94.51 ± 4.18 |
| 10 | 85.22 ± 0.45 | 87.66 ± 3.10 | 89.09 ± 2.16 | 91.33 ± 5.14 | 92.98 ± 7.37 | 93.12 ± 0.58 | 94.05 ± 2.44 | 94.34 ± 2.88 | 95.46 ± 3.56 |
| 11 | 84.27 ± 3.74 | 86.57 ± 1.93 | 91.37 ± 1.06 | 94.36 ± 0.96 | 94.72 ± 2.61 | 93.71 ± 2.82 | 94.54 ± 1.28 | 94.09 ± 3.85 | 95.58 ± 2.60 |
| 12 | 85.02 ± 4.31 | 87.34 ± 0.43 | 89.76 ± 0.41 | 90.17 ± 0.61 | 91.01 ± 0.61 | 92.70 ± 7.52 | 92.09 ± 5.06 | 93.45 ± 0.14 | 94.02 ± 1.03 |
| 13 | 72.22 ± 2.59 | 79.61 ± 0.39 | 86.05 ± 3.28 | 88.39 ± 1.22 | 90.91 ± 2.54 | 91.89 ± 2.93 | 92.16 ± 3.08 | 93.07 ± 4.39 | 94.78 ± 2.37 |
| 14 | 69.52 ± 1.02 | 75.17 ± 2.09 | 84.36 ± 1.02 | 88.03 ± 2.36 | 88.55 ± 1.89 | 90.95 ± 1.70 | 92.81 ± 1.46 | 93.03 ± 2.69 | 94.36 ± 2.09 |
| 15 | 81.22 ± 3.05 | 84.20 ± 1.43 | 95.06 ± 2.47 | 94.84 ± 1.45 | 95.75 ± 3.26 | 94.65 ± 3.16 | 95.89 ± 2.04 | 94.90 ± 1.88 | 95.33 ± 2.76 |
| 16 | 86.63 ± 0.98 | 88.05 ± 3.27 | 93.67 ± 4.09 | 93.87 ± 2.93 | 92.65 ± 2.79 | 94.35 ± 4.59 | 95.73 ± 2.17 | 95.37 ± 2.63 | 97.13 ± 1.58 |
| OA(%) | 81.05 ± 1.43 | 84.64 ± 0.47 | 89.21 ± 1.43 | 91.66 ± 0.60 | 93.61 ± 3.49 | 95.46 ± 3.91 | 95.95 ± 2.27 | 96.38 ± 4.67 | 98.05 ± 4.63 |
| AA(%) | 77.17 ± 2.58 | 81.76 ± 2.14 | 83.65 ± 0.48 | 85.83 ± 3.37 | 88.76 ± 2.35 | 90.27 ± 0.12 | 91.96 ± 0.25 | 93.66 ± 2.23 | 95.24 ± 1.73 |
| 100 K | 79.93 ± 3.86 | 82.59 ± 4.75 | 88.93 ± 1.28 | 89.34 ± 0.69 | 90.61 ± 1.89 | 91.78 ± 1.08 | 92.34 ± 4.87 | 93.92 ± 0.27 | 94.88 ± 1.83 |
| Number of Classes | 10 Classes | 11 Classes | 12 Classes | 13 Classes |
|---|---|---|---|---|
| OA(%) | 92.87 ± 1.63 | 94.26 ± 1.35 | 95.37 ± 1.74 | 98.60 ± 2.26 |
| AA(%) | 92.13 ± 1.82 | 94.38 ± 1.61 | 95.52 ± 1.36 | 98.65 ± 1.57 |
| 100 K | 90.47 ± 0.68 | 93.75 ± 1.87 | 94.94 ± 1.79 | 97.83 ± 1.65 |
| Datasets | Methods | Training Time (s) | Test Time (s) | Parameters (M) | OA(%) |
|---|---|---|---|---|---|
| Long Kou | CNN | 56.37 | 3.82 | 3.29 | 94.78 |
| ResNet | 1150.61 | 215.12 | 22.12 | 95.63 | |
| MLP-Mixer | 421.29 | 61.63 | 5.81 | 96.32 | |
| RepMLP | 418.29 | 66.42 | 7.84 | 97.58 | |
| DFFN | 111.7 | 7.95 | 8.55 | 97.97 | |
| DMLP | 459.71 | 71.24 | 6.36 | 98.25 | |
| DMLPFFN | 83.35 | 5.94 | 9.86 | 99.16 | |
| Han Chuan | CNN | 71.09 | 2.86 | 3.48 | 89.21 |
| ResNet | 1233.39 | 484.61 | 22,15 | 91.66 | |
| MLP-Mixer | 586.49 | 97.87 | 5.14 | 93.61 | |
| RepMLP | 471.27 | 75.79 | 6.83 | 95.46 | |
| DFFN | 201.76 | 15.78 | 7.96 | 95.95 | |
| DMLP | 497.61 | 51.16 | 5.26 | 96.38 | |
| DMLPFFN | 112.26 | 9.51 | 8.31 | 98.05 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, H.; Zhou, H.; Wang, A.; Iwahori, Y. Precise Crop Classification of Hyperspectral Images Using Multi-Branch Feature Fusion and Dilation-Based MLP. Remote Sens. 2022, 14, 2713. https://doi.org/10.3390/rs14112713
Wu H, Zhou H, Wang A, Iwahori Y. Precise Crop Classification of Hyperspectral Images Using Multi-Branch Feature Fusion and Dilation-Based MLP. Remote Sensing. 2022; 14(11):2713. https://doi.org/10.3390/rs14112713
Chicago/Turabian StyleWu, Haibin, Huaming Zhou, Aili Wang, and Yuji Iwahori. 2022. "Precise Crop Classification of Hyperspectral Images Using Multi-Branch Feature Fusion and Dilation-Based MLP" Remote Sensing 14, no. 11: 2713. https://doi.org/10.3390/rs14112713