1. Introduction
PM
2.5 has a large impact on atmospheric environmental quality and can cause health problems [
1,
2,
3]. Compared with PM10, PM
2.5 has a small particle size, large area, and strong activity; it can remain in the atmosphere for a long time and be transmitted over long distances [
4]. Particles with a diameter of 10 microns usually deposit in the upper respiratory tract, while those below 2 microns can enter the human alveoli, directly affecting the ventilation function of the lungs, causing the body to be in a state of oxygen deprivation [
5]. With the rapid development of the economy, industrial production and human-caused emissions have increased dramatically, resulting in a serious deterioration in air quality in east-central China, with the Beijing–Tianjin–Hebei region being the most significantly affected area [
6,
7].
The conventional monitoring method is to establish ground monitoring stations [
8], and by January 2015, more than 1500 PM
2.5 concentration (unit: µg/m
3) observation stations had been built nationwide to obtain ground-level high-precision PM
2.5 concentrations. However, the ground monitoring stations are restricted by human and material resource conditions, resulting in the uneven distribution of monitoring points, lack of regional representativeness, and lack of continuity of data [
9,
10]. In recent years, many studies have shown that, compared with traditional air pollution monitoring technology, remote sensing [
11] has the advantages of a wide monitoring range, fast and easy to achieve continuous monitoring, and unique ways to acquire environmental information [
12].
Aerosol optical depth (AOD) has been widely and successfully used for PM
2.5 concentration estimation due to its different spatial resolution and its close correlation with particle concentrations [
13,
14,
15]. Many researchers have developed different models establishing a link between satellite AOD and ground PM
2.5 concentrations, including physical models [
16], statistical models, and machine learning models. The physical models, based on the physical relationship between AOD and PM
2.5, use higher quality AOD to assess PM
2.5 concentrations. Tang et al. [
17] used Landsat8 OLI images to develop a physical model of the relationship between AOD and PM
2.5. However, the aerosol patterns need to be determined with long-term ground-based monitoring data, which has an impact on PM
2.5 estimates. Statistical models used to describe the linear relationship between AOD and PM
2.5 have evolved from a single linear model to a linear mixed-effects model [
18] and a geographically and temporally weighted regression (GTWR) model [
19]. He et al. [
20] developed an improved geographically and temporally weighted regression (iGTWR) model that considered the seasonal characteristics of the data to obtain the AOD–PM
2.5 relationship to predict PM
2.5 concentrations in the Beijing–Tianjin–Hebei region, with an R
2 of 0.82 after cross-validation. Chu et al. [
21] proposed to combine geographically and temporally weighted regression (GTWR) and random sample consistency (RANSAC), which resulted in a good fit between AOD and PM
2.5. However, the statistical model could not accurately respond to the complex nonlinear relationship between the variables and PM
2.5, which limited the accuracy of the inversion of PM
2.5.
Compared with statistical models, machine learning models, including random forest, gradient boosting, and deep learning [
22], can better handle nonlinear problems, which can provide a more accurate estimation of PM
2.5 concentrations. Li et al. [
23] combined random forest with AOD to monitor PM
2.5 concentrations in the Beijing–Tianjin–Hebei region, which was advantageous in dealing with the complex nonlinear relationships between a large number of meteorological elements and atmospheric pollutants. Wei et al. [
24] proposed a tree-based spatial–temporal lightweight gradient boosting model with the inclusion of parameters such as meteorological elements, population density, land utilization, and ground elevation for national hourly PM
2.5 concentration prediction. The prediction results achieved an R
2 of 0.85 and an RMSE and MAE of 13.62 and 8.49, respectively, and the proposed method outperformed most traditional statistical regression models and tree-based machine learning models.
However, the above studies were all based on satellite AOD data, which are limited in spatial and temporal coverage due to the low revisit rate of satellites and limitations in the application of the AOD inversion methods [
25,
26], thus affecting the prediction accuracy of PM
2.5. To solve the above problems, Shen et al. [
27] used a deep belief network (DBN) to construct a model in which the top-of-atmosphere reflectance (TOAR) from the MODIS sensor inversion AOD band was used instead of AOD for PM
2.5 prediction. The cross-validation yielded an R
2 of 0.87, which avoided the error in the AOD inversion process and had higher prediction accuracy and spatial coverage. Bai et al. [
28] used four different machine learning algorithms (random forest, extreme gradient boosting, gradient augmented regression, and support vector regression) to construct PM
2.5 prediction models based on TOAR and AOD, respectively, and cross-validation yielded the best performance of the TOAR-based random forest model with an R
2 of 0.75. Yang et al. [
29] integrated variables, such as satellite TOAR, meteorological elements, and land utilization, and used a random forest model to estimate PM
2.5 concentrations in the Yangtze River Delta region with a cross-validated R
2 of 0.92. Yin et al. [
30] used the LightGBM algorithm to predict PM
2.5 concentrations nationwide using TOAR and AOD from Himawari-8, and the LightGBM model had an R
2 of 0.83 in regions where AOD was not available.
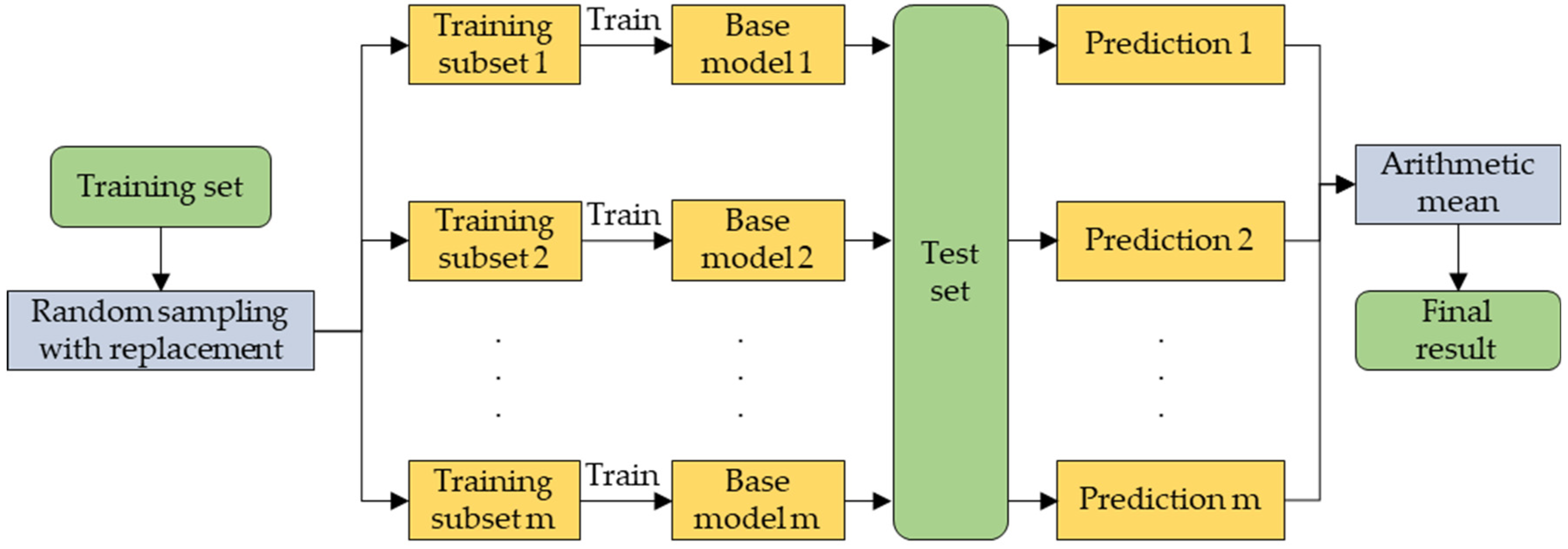
All the above models were single-model predictions, which can lead to poor single-model performance due to various factors such as feature space, model size, and hyperparameter selection, etc. To make up for this deficiency, hybrid models have been created. Hybrid models [
31] refer to models generated by combining signal decomposition techniques with other prediction models. The hybrid model is a further decomposition of the nonlinear original time series into more stable and regular subseries, and the final prediction results are obtained by aggregating the predicted values of all subseries. Ding et al. [
32] performed wavelet decomposition of meteorological variables and PM
2.5 and used the CatBoost algorithm to build a prediction model for PM
2.5, obtaining an R
2 of 0.88. Wang et al. [
33] performed a four-layer wavelet decomposition of the original PM
2.5 and used the XGBoost algorithm to model each layer of PM
2.5 after wavelet decomposition with an R
2 of 0.87. Therefore, this study aims to develop a hybrid learning model that uses MODIS 1B satellite TOAR as the main prediction parameter and adds auxiliary parameters such as meteorological elements and elevation data to estimate daily PM
2.5 concentrations in the Beijing–Tianjin–Hebei region.
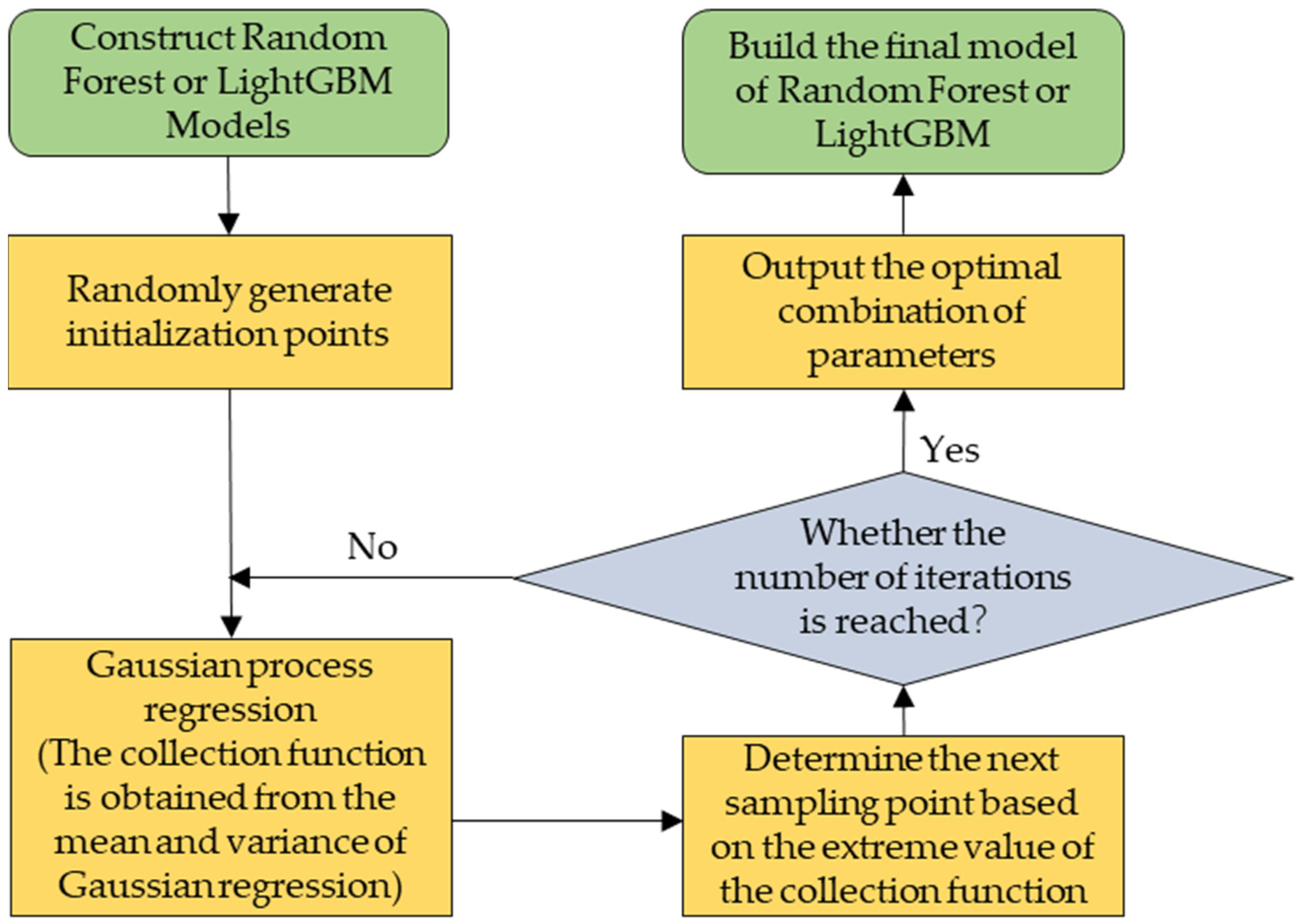
4. Discussion
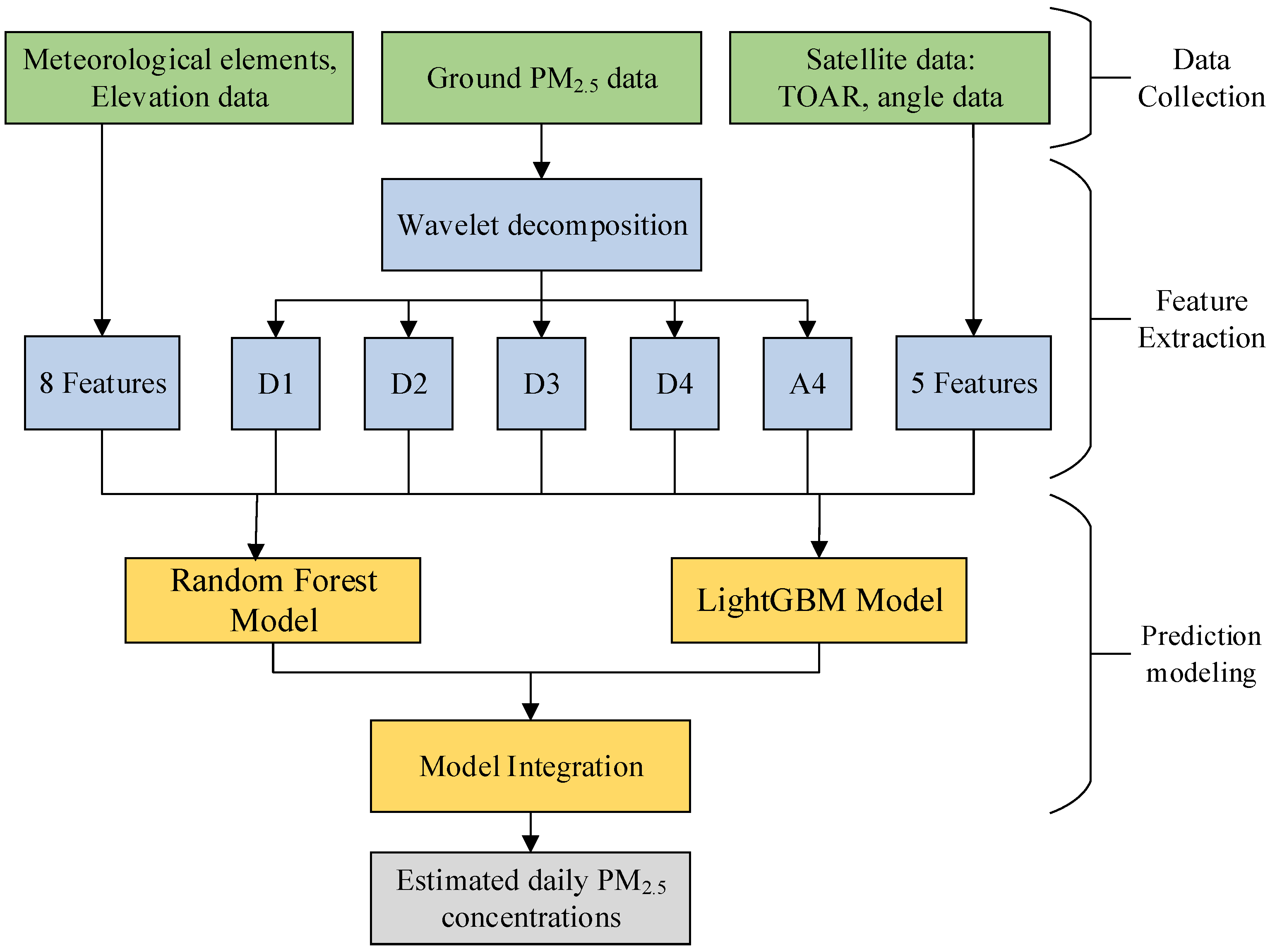
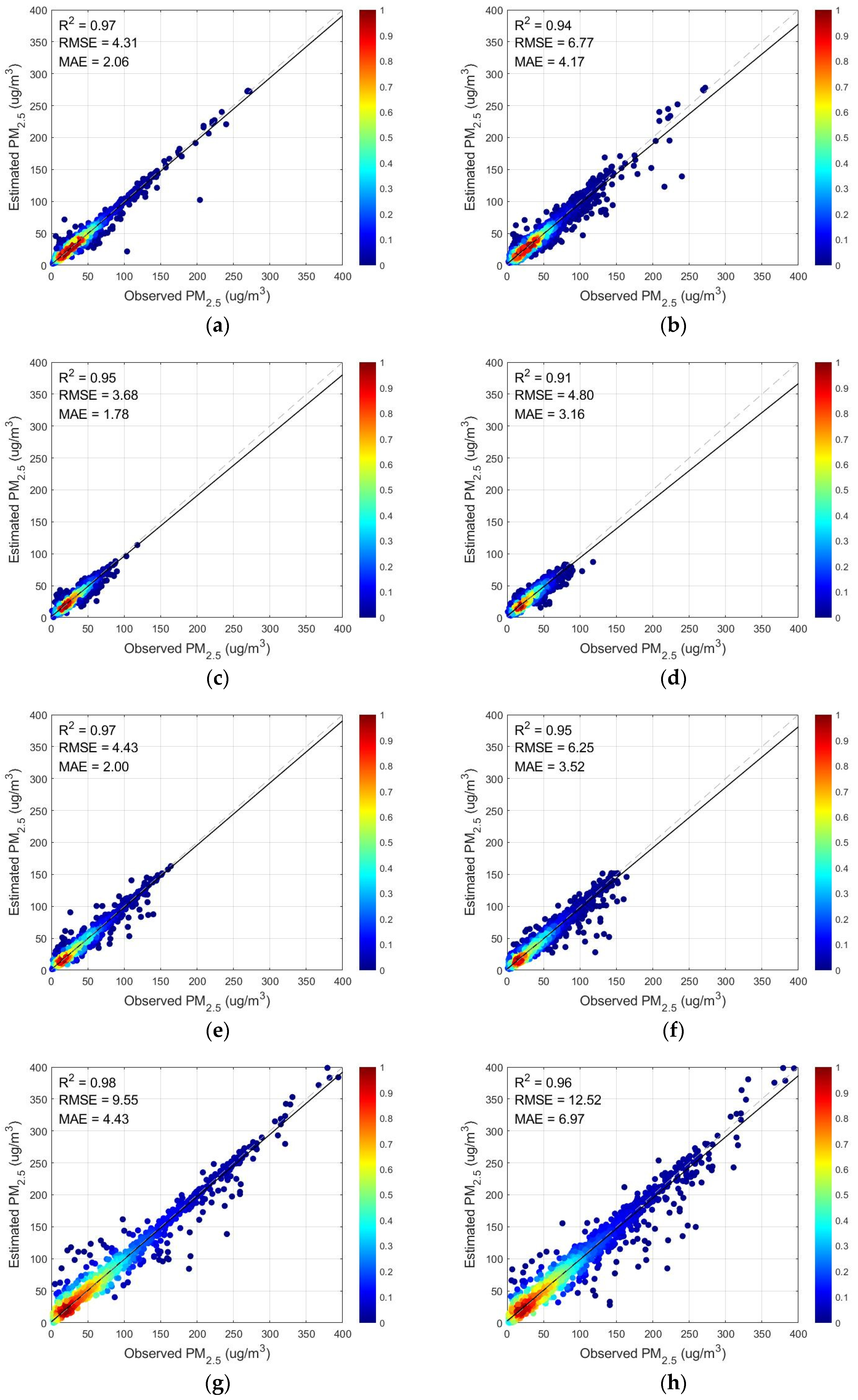
In this study, we proposed a hybrid learning model, which first performed wavelet decomposition of PM
2.5 observations and then constructed an integrated model using Random Forest and LightGBM. The model inputs combined satellite TOAR, meteorological elements, and elevation data and were examined in time and space on daily and seasonal scales for PM
2.5 concentration estimation in the Beijing–Tianjin–Hebei region. The results showed that the estimated and true values were highly consistent, and the time-based cross-validation R
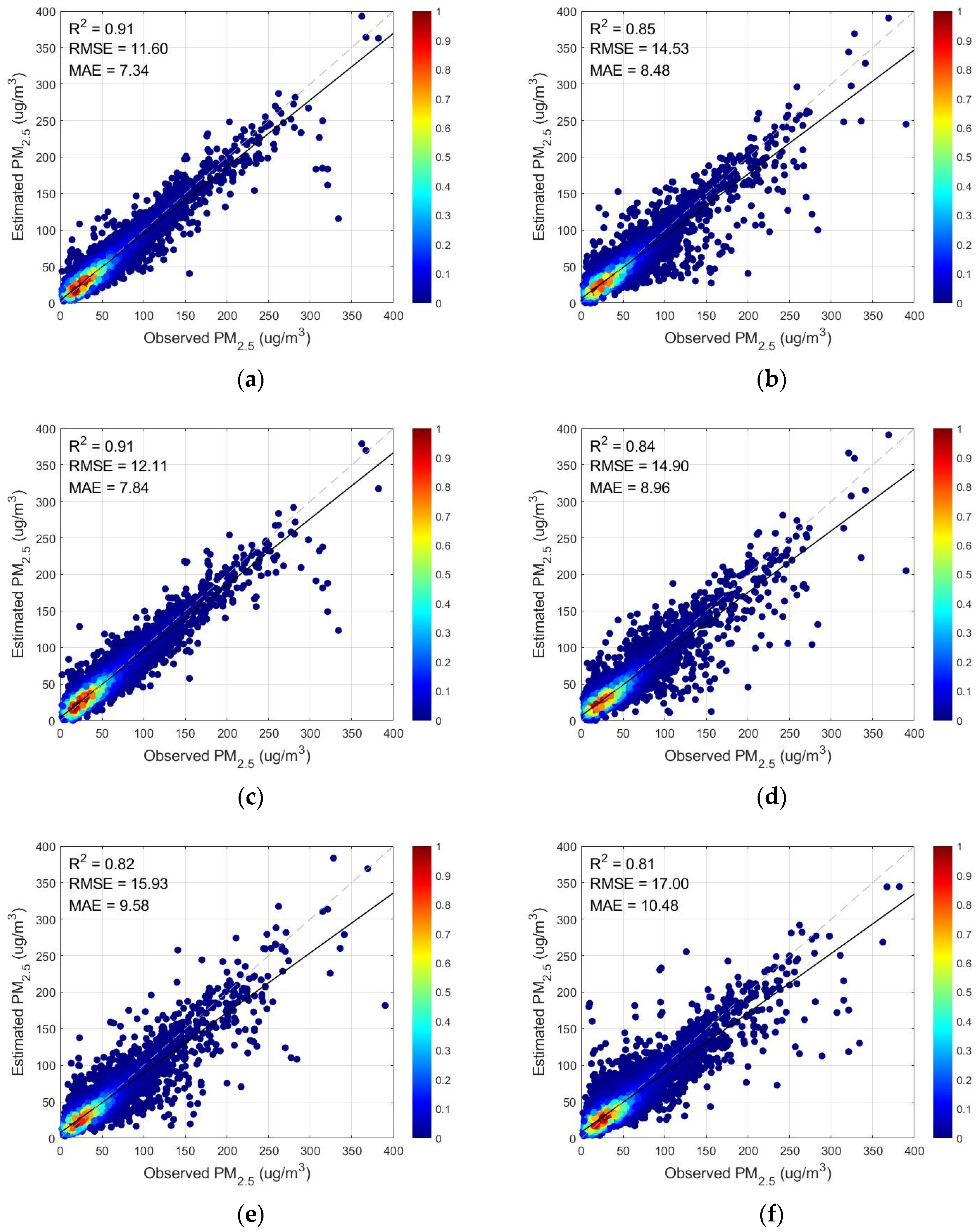
2, RMSE, and MAE were 0.91, 11.60, and 7.34, respectively. It can be concluded from
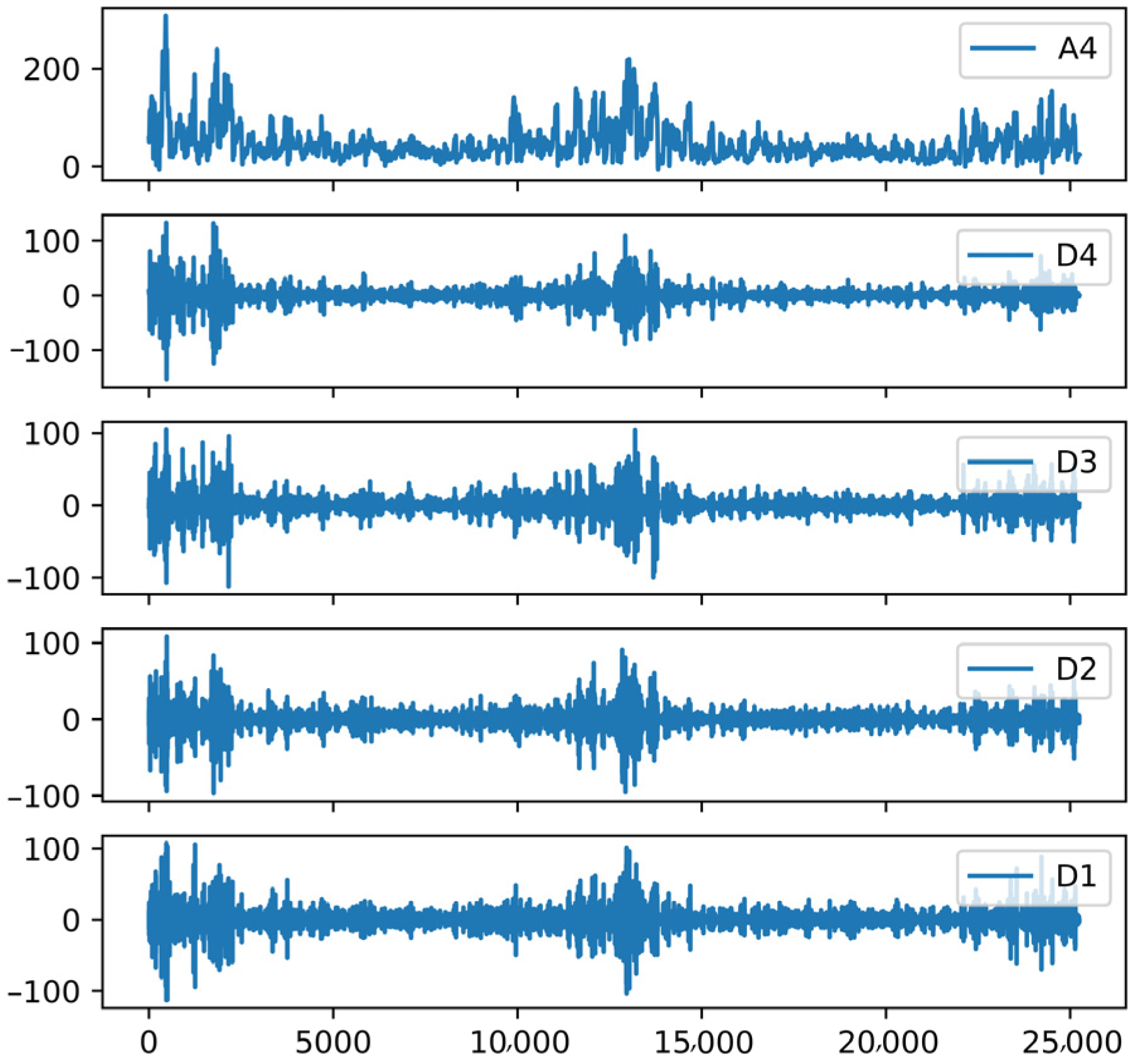
Table 4 that the model effect after adding wavelet decomposition was significantly better than without it, which is due to the fact that adding wavelet decomposition can make full use of the high-frequency and low-frequency components of the PM
2.5 data. We used a total of seven meteorological elements for model training, and the results showed that the boundary layer height was the most important meteorological predictor, followed by surface pressure and temperature. By adding meteorological elements as auxiliary parameters for model construction, it was shown that auxiliary data such as surface pressure and temperature play an important role in PM
2.5 estimations.
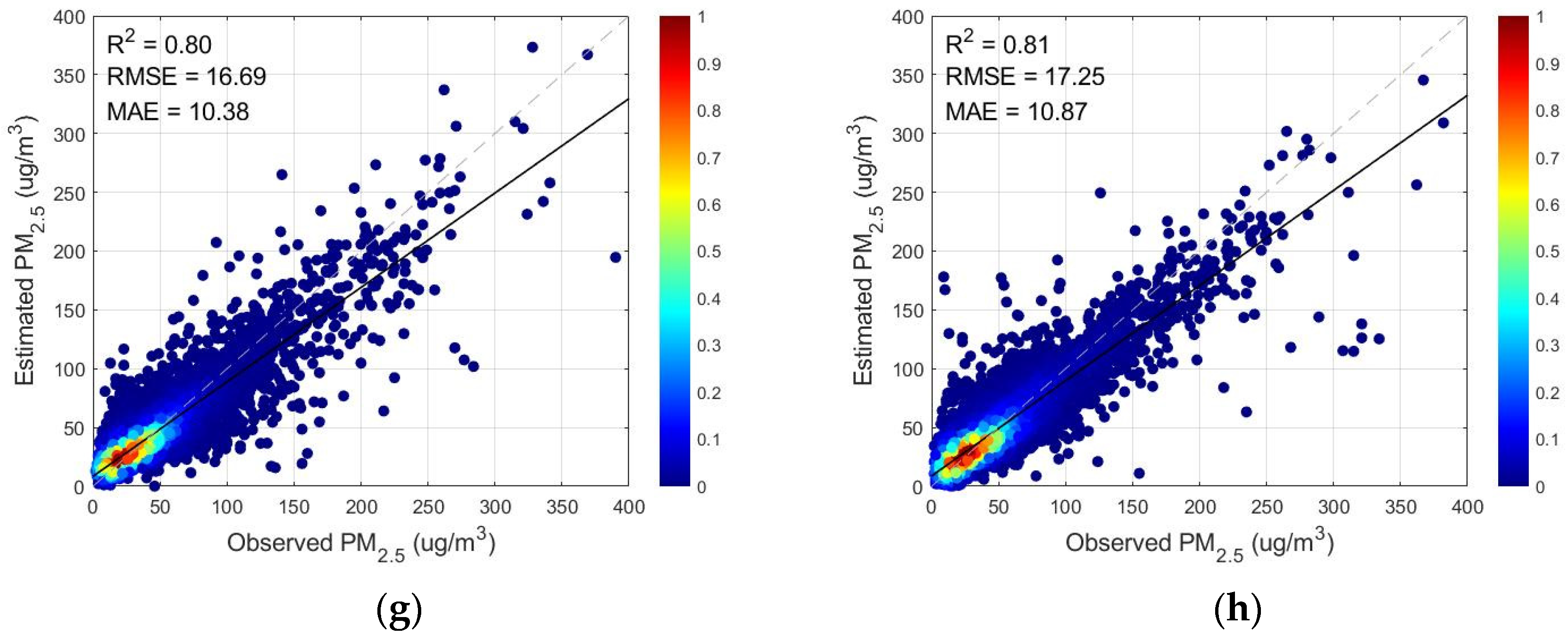
Satellite data have now been widely used to estimate ground-based PM
2.5 concentrations using various models to construct the relationship between satellite data and PM
2.5. However, it can be seen from
Figure 7 that the estimation of PM
2.5 concentrations using AOD and TOAR, respectively, had the most significant error in winter, and it can be seen from
Figure 8 that during the winter period, the R
2 of the prediction performance using TOAR improved by 0.02, and the RMSE and MAE decreased by 2.97 and 2.54, respectively, compared with that using AOD. This is due to the limited coverage of AOD and the vulnerability to external conditions resulting in missing data. The satellite TOAR can effectively compensate for the lack of spatial coverage of AOD and the limitation of the inversion method by replacing AOD for PM
2.5 concentration estimation. Therefore, we selected TOAR as the satellite data for estimating PM
2.5.
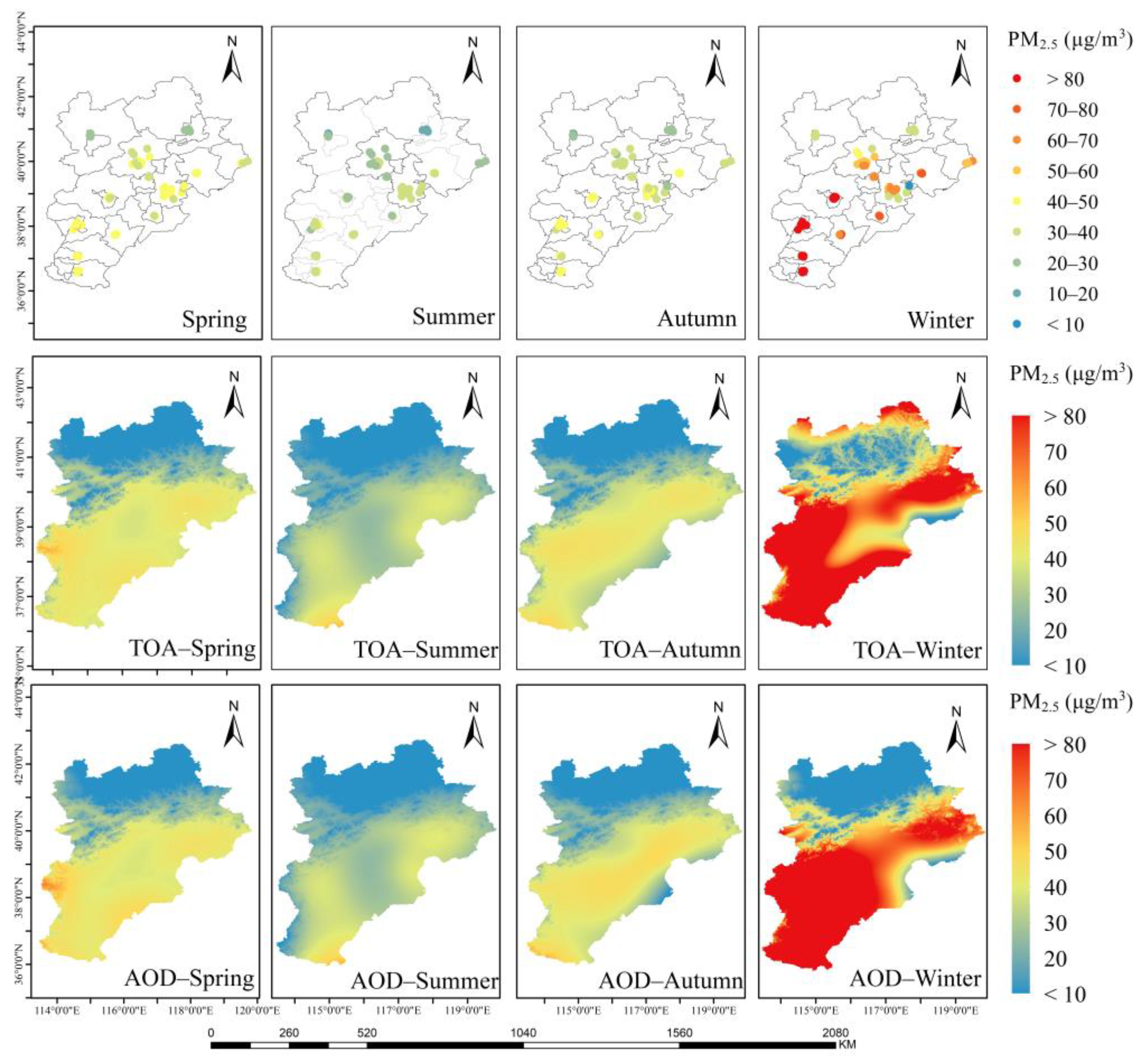
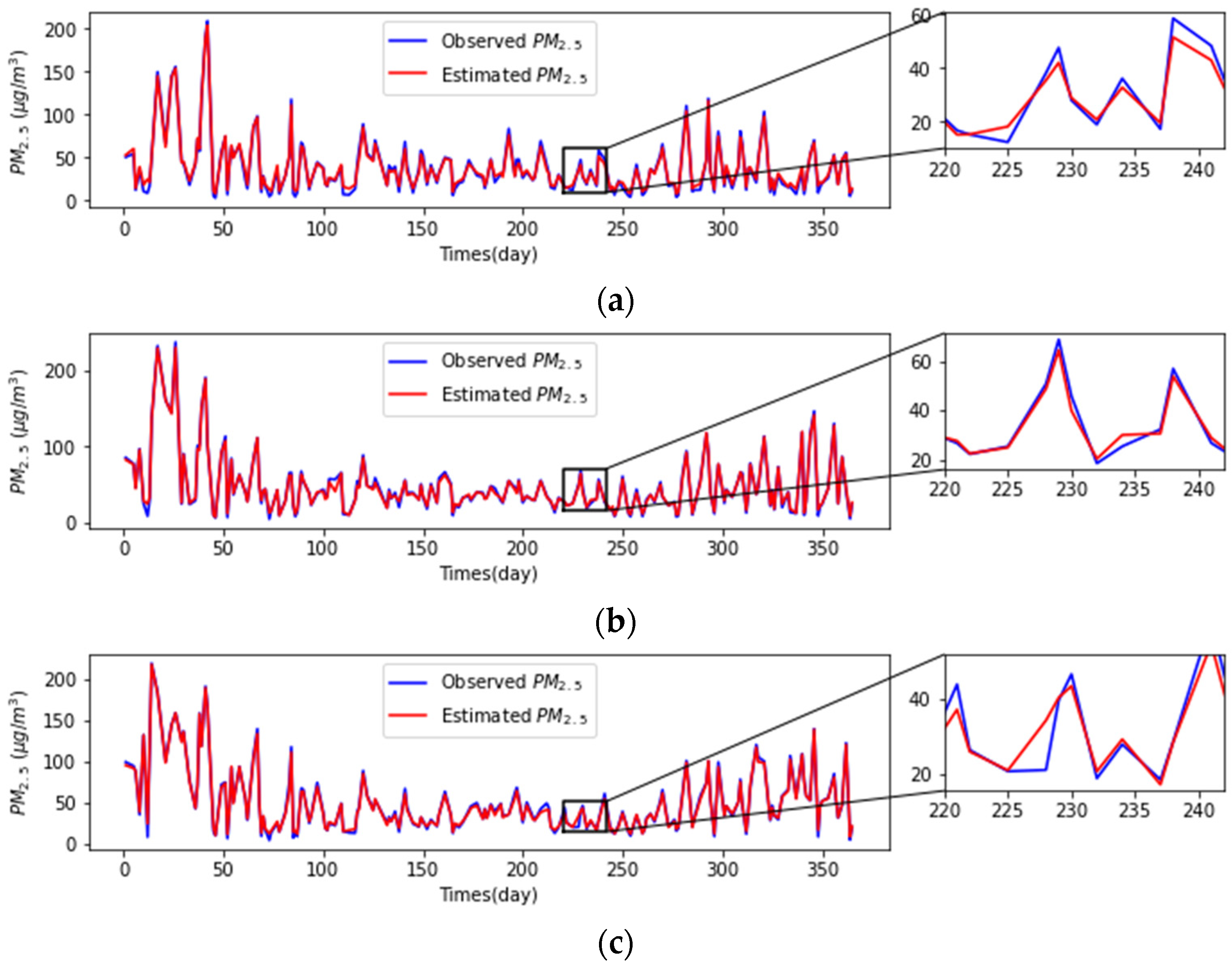
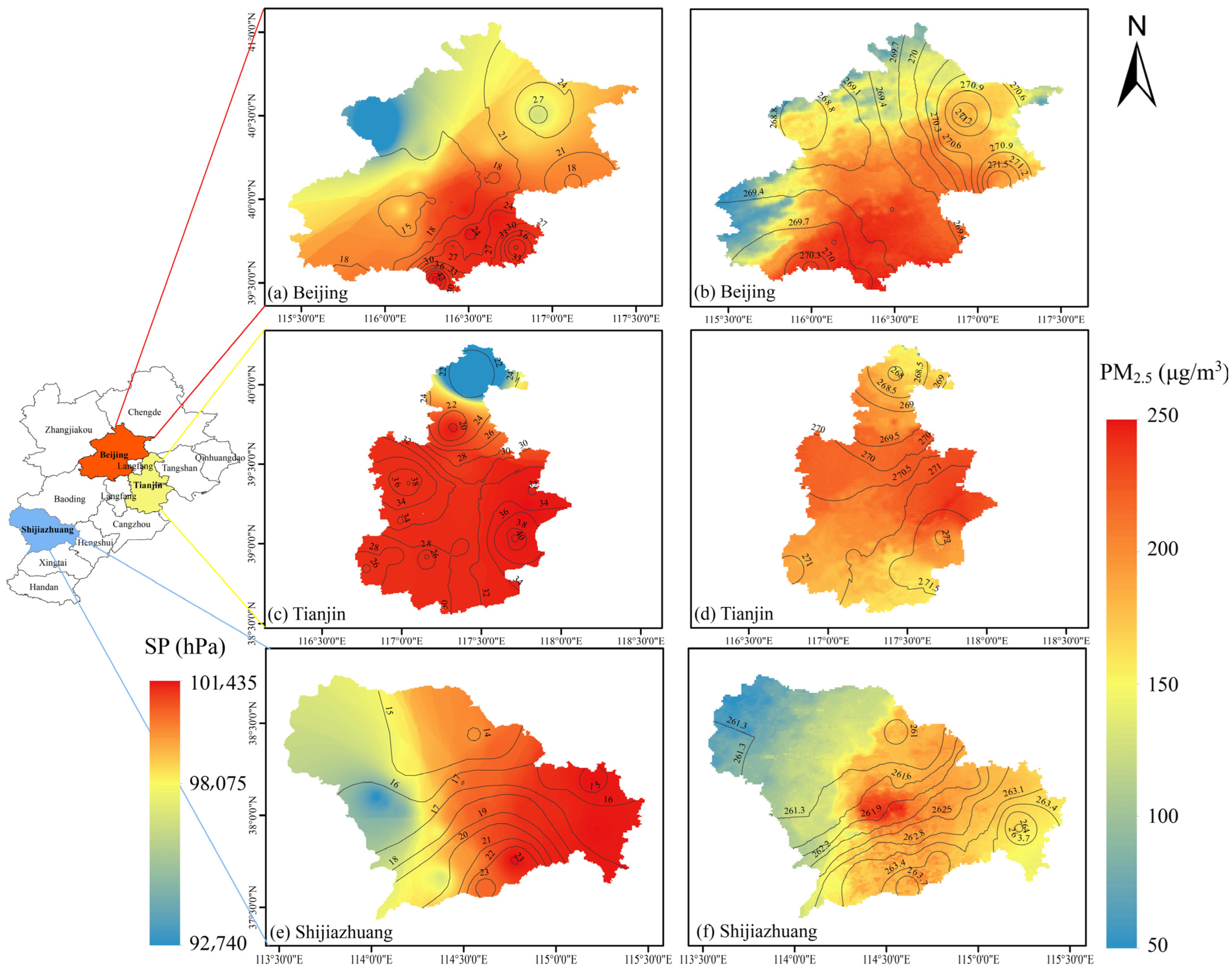
Based on the results of the model, we analyzed the spatial and temporal characteristics of PM2.5 concentrations in the Beijing–Tianjin–Hebei region by season, with the lightest pollution in summer, the most serious pollution in winter, and spring and autumn in between; meanwhile, three more seriously polluted areas (Beijing, Tianjin, and Shijiazhuang) were selected to analyze the trends of daily PM2.5 concentrations over one year, and they were further studied to conclude that PM2.5 concentrations and meteorological elements are highly correlated. Compared with previous studies, the proposed hybrid learning model outperformed most advanced statistical models and machine learning models in terms of prediction performance, running speed, and memory consumption. Therefore, the hybrid learning model using TOAR and correlation variables can be a good alternative to AOD for PM2.5 high-precision predictions, which is useful for pollution prevention and control in the Beijing–Tianjin–Hebei region.
At the same time, this study also had certain limitations: (a) the research used the data of state-controlled sites, which are mainly distributed in the central areas of the city or in the more polluted areas; so, the model validation was also based on city center sites. In future research, the provincial-controlled sites and national-controlled sites will be used as research data to improve the regional representativeness of the sample and the generalization ability of the model; (b) PM2.5 concentrations are affected by many factors, such as population density, traffic flow, and Normalized Difference Vegetation Index (NDVI), etc.; these influencing factors were lacking in this study. In future research on PM2.5 concentration estimation, data from more sources will be collected, and various factors will be comprehensively considered.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}