

An Ensemble Model for Forest Fire Occurrence Mapping in China

 ,
,  ,
, 
Abstract
:1. Introduction
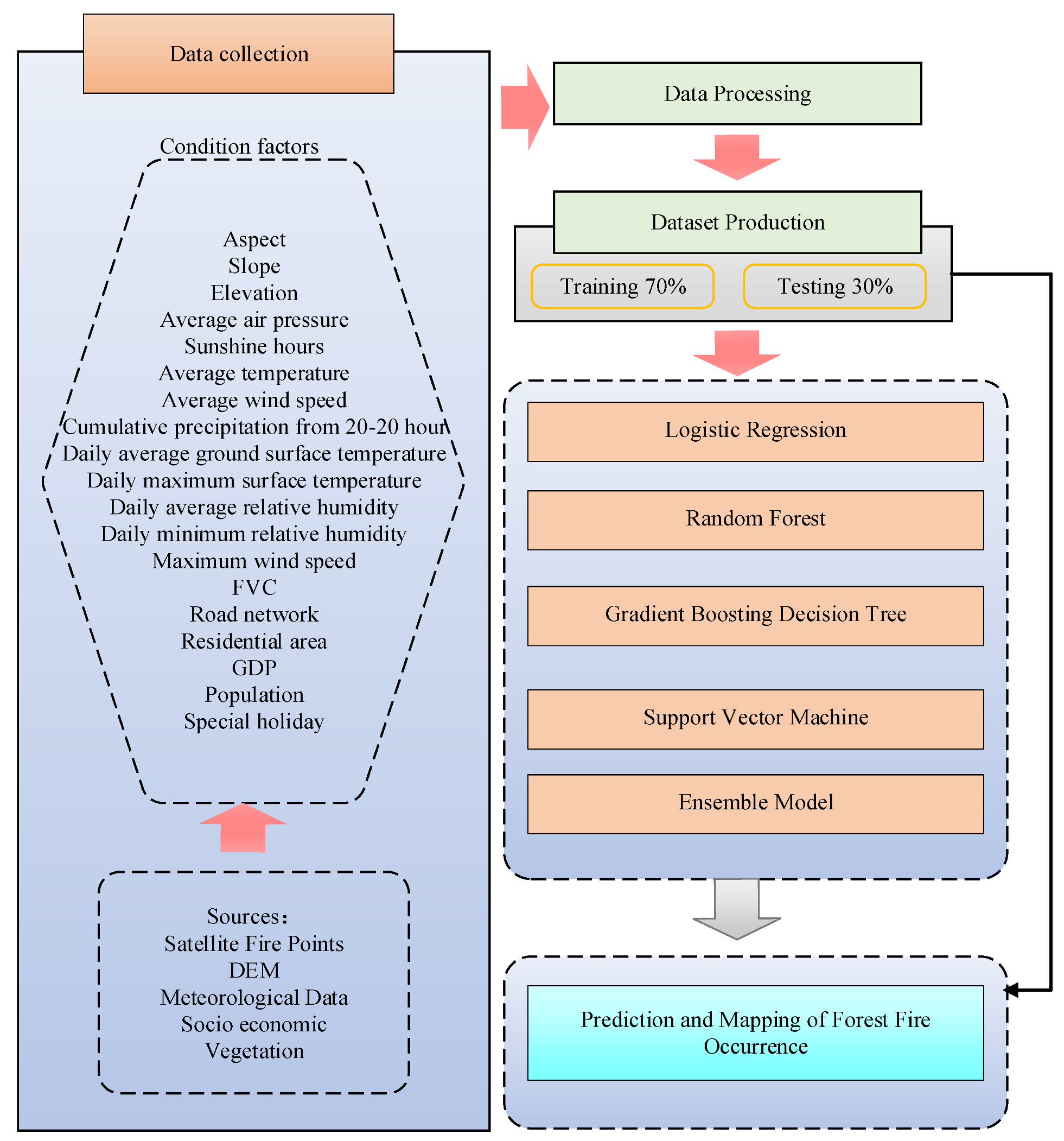
2. Data and Methods
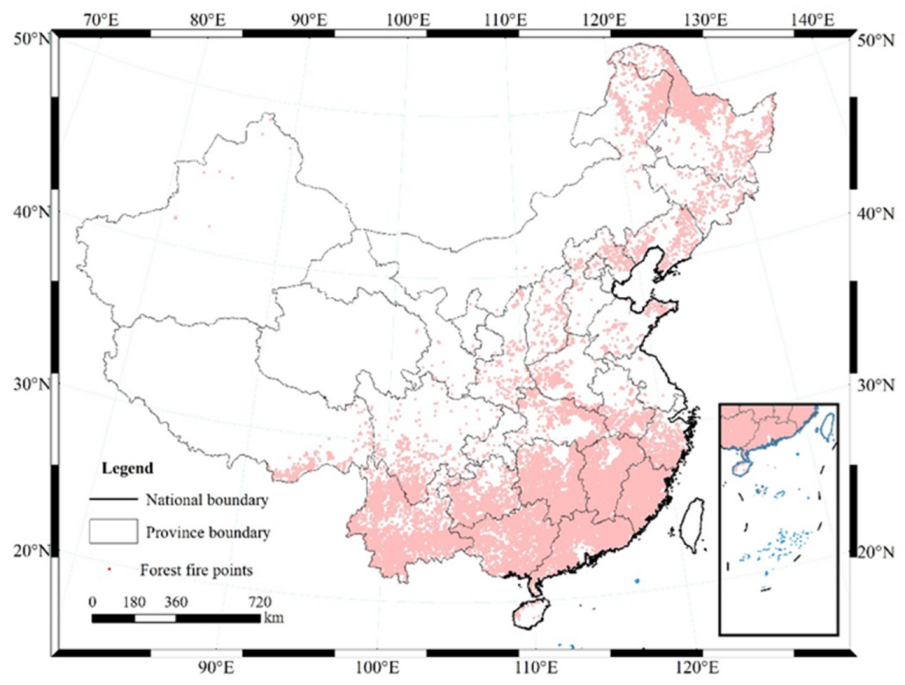
2.1. The Study Area
2.2. Data Sources and Method
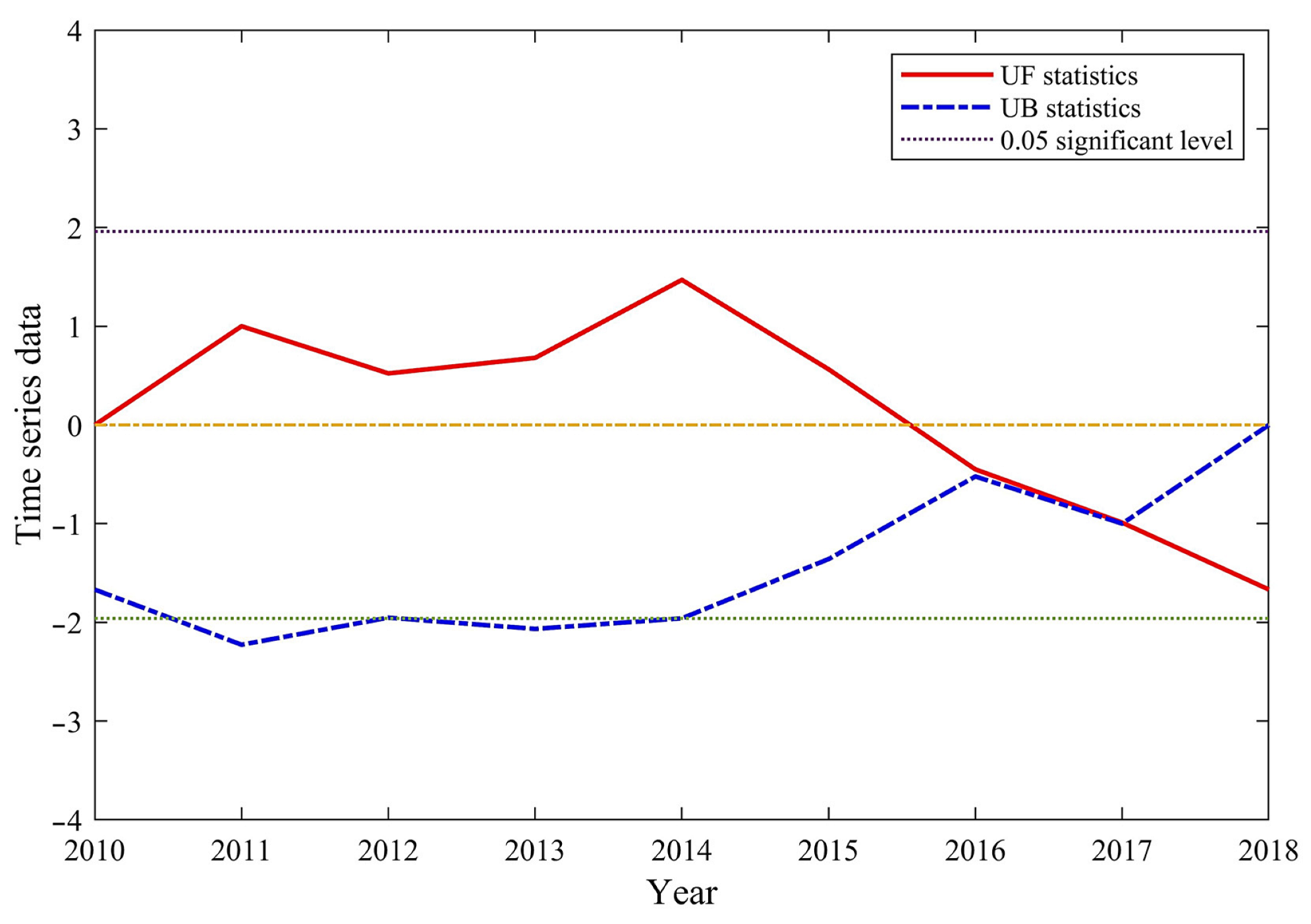
2.2.1. Mann–Kendall Mutation Test
2.2.2. Standard Deviation Ellipse
2.2.3. Logistic Regression
2.2.4. Random Forest
2.2.5. Gradient Boosting Decision Tree
2.2.6. Support Vector Machine
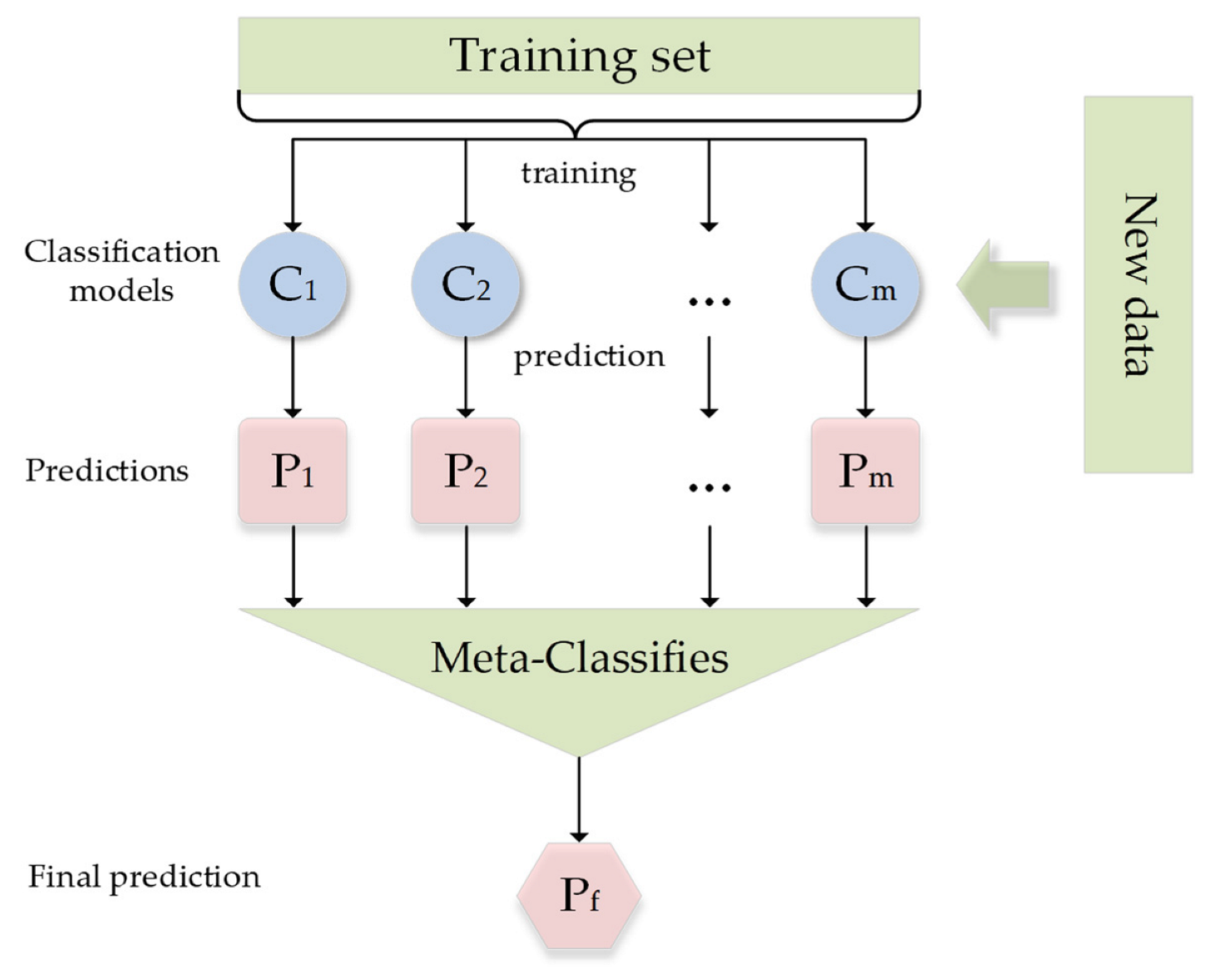
2.2.7. Ensemble Model and Validation
3. Results
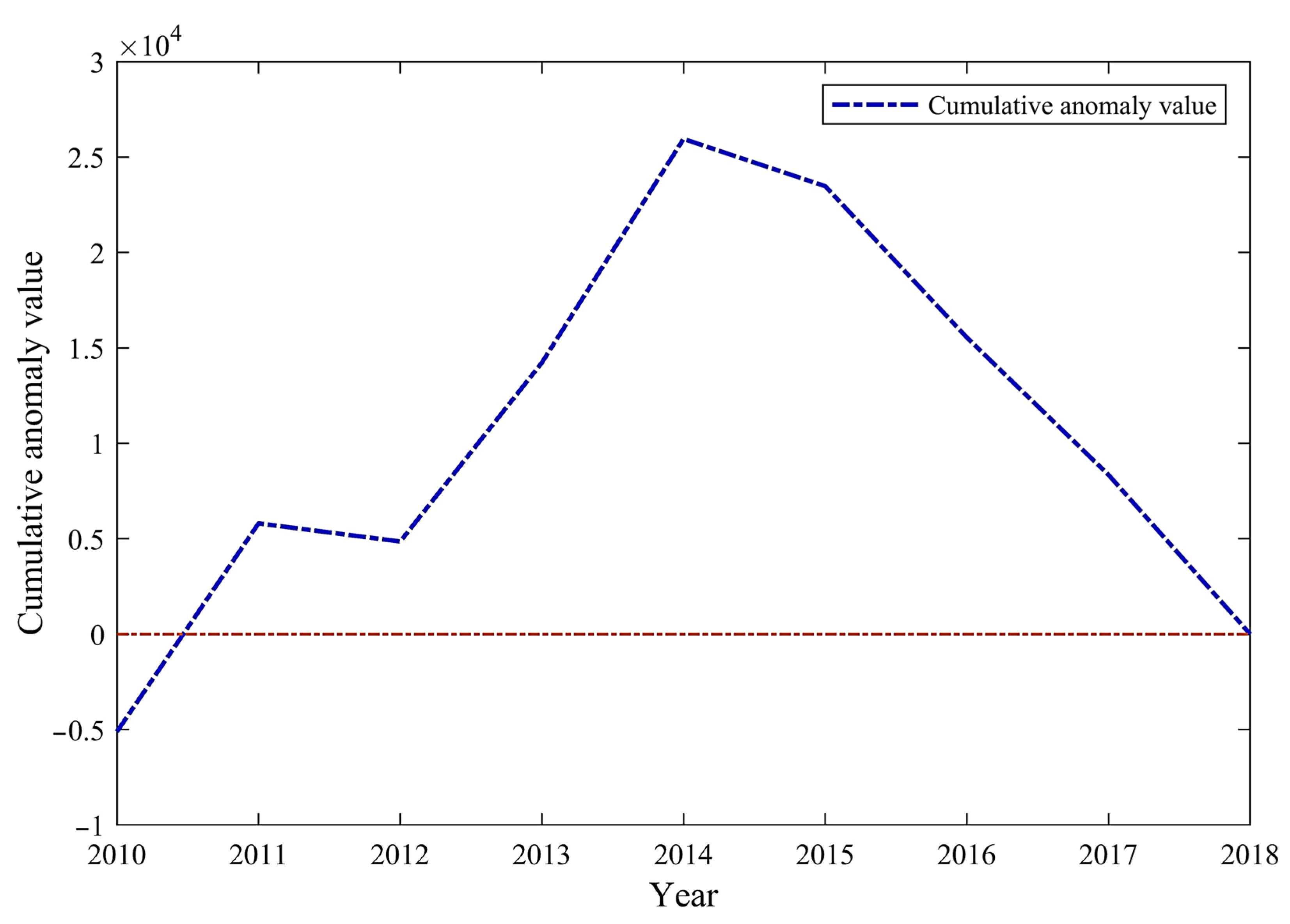
3.1. Changing Trends
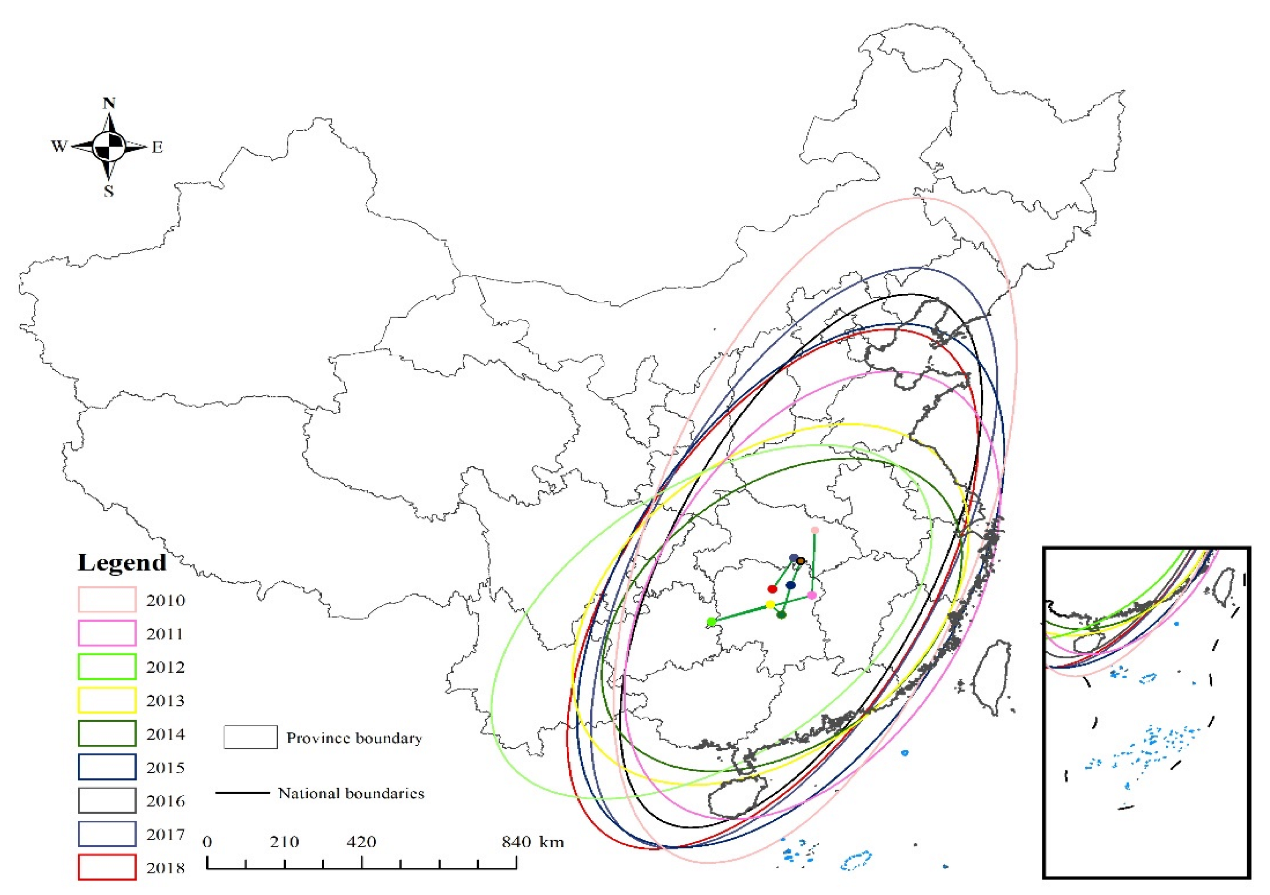
3.2. The Result of Standard Deviation Ellipse Analysis
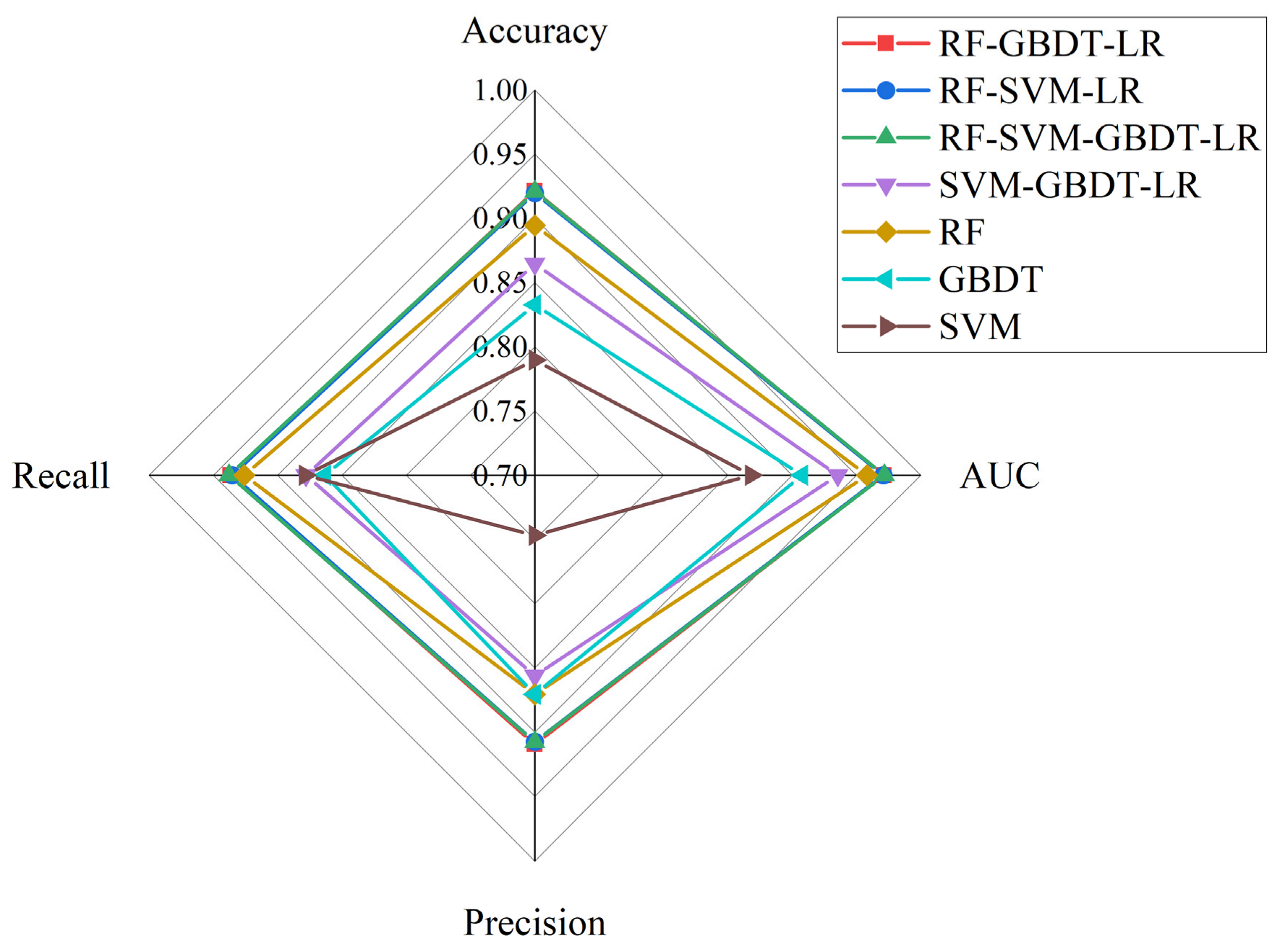
3.3. Accuracy Assessment
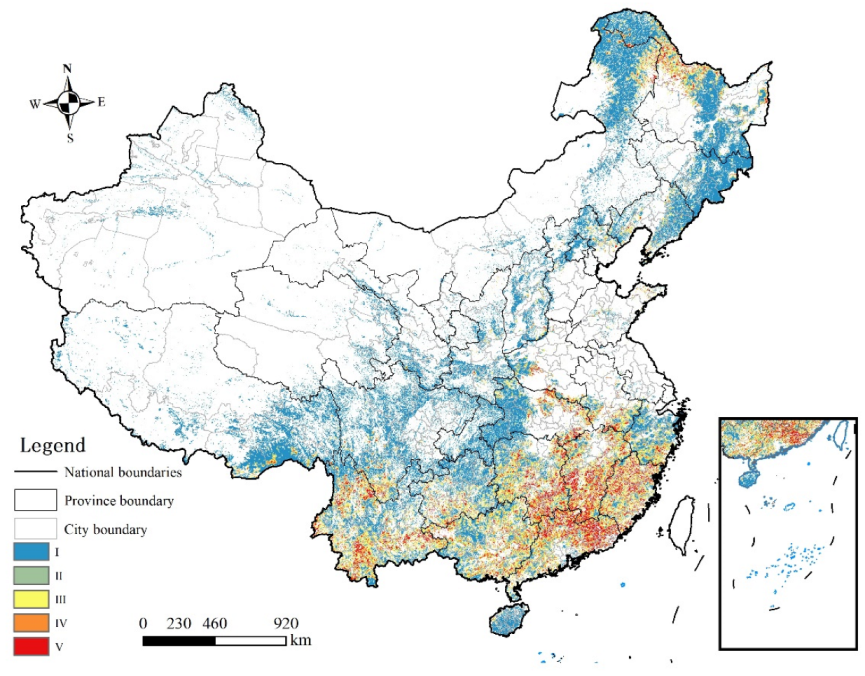
4. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Tinner, W.; Hubschmid, P.; Wehrli, M.; Ammann, B.; Conedera, M. Long-term forest fire ecology and dynamics in southern Switzerland. J. Ecol. 1999, 87, 273–289. [Google Scholar] [CrossRef]
- Johnstone, J.F.; Allen, C.D.; Franklin, J.F.; Frelich, L.E.; Harvey, B.J.; Higuera, P.E.; Mack, M.C.; Meentemeyer, R.K.; Metz, M.R.; Perry, G.L.; et al. Changing disturbance regimes, ecological memory, and forest resilience. Front. Ecol. Environ. 2016, 14, 369–378. [Google Scholar] [CrossRef]
- Jaiswal, R.K.; Mukherjee, S.; Raju, K.D.; Saxena, R. Forest fire risk zone mapping from satellite imagery and GIS. Int. J. Appl. Earth Obs. Geoinf. 2002, 4, 1–10. [Google Scholar] [CrossRef]
- Pourtaghi, Z.S.; Pourghasemi, H.R.; Aretano, R.; Semeraro, T. Investigation of general indicators influencing on forest fire and its susceptibility modeling using different data mining techniques. Ecol. Indic. 2016, 64, 72–84. [Google Scholar] [CrossRef]
- Ma, W.; Feng, Z.; Cheng, Z.; Chen, S.; Wang, F. Study on driving factors and distribution pattern of forest fires in Shanxi province. J. Cent. South Univ. For. Technol. 2020, 40, 57–69. [Google Scholar] [CrossRef]
- Shu, L.F.; Zhang, X.L.; Dai, X.A.; Tian, X.R.; Wang, M.Y. Forest Fire Research (Ⅱ): Fire Forecast. World For. Res. 2003, 16, 4. [Google Scholar]
- Tian, X.R.; McRae, D.J.; Shu, L.F.; Zhao, F.J.; Wang, M.Y. Changes of forest fire danger and the evaluation of the fwi system application in the daxing’anling region. Sci. Silvae Sin. 2010, 46, 127–132. [Google Scholar]
- Shao, Y.; Wang, Z.; Feng, Z.; Sun, L.; Yang, X.; Zheng, J.; Ma, T. Assessment of China’s forest fire occurrence with deep learning, geographic information and multisource data. J. For. Res. 2022, 1–14. [Google Scholar] [CrossRef]
- Zhao, F.; Shu, L.F.; Zhou, R.L.; Xiao, X.M.; Wang, M.Y.; Zhao, F.J.; Wang, Q.H. Evaluating fire behavior simulators in southwestern China forest area. Chin. J. Appl. Ecol. 2017, 28, 3144–3154. [Google Scholar] [CrossRef]
- Zhu, Z.; Zhao, F.; Wang, Q.; Deng, X.; Gao, Z. Research Progress in Forest Fire Occurrence Prediction Models. World For. Res. 2022, 35, 26–31. [Google Scholar] [CrossRef]
- Naderpour, M.; Rizeei, H.M.; Ramezani, F. Forest Fire Risk Prediction: A Spatial Deep Neural Network-Based Framework. Remote Sens. 2021, 13, 2513. [Google Scholar] [CrossRef]
- Shao, Y.; Feng, Z.; Sun, L.; Yang, X.; Li, Y.; Xu, B.; Chen, Y. Mapping China’s Forest Fire Risks with Machine Learning. Forests 2022, 13, 856. [Google Scholar] [CrossRef]
- Bazi, I.E.; Laachfoubi, N. A comparative study of Named Entity Recognition for Arabic using ensemble learning approaches. In Proceedings of the 2015 IEEE/ACS 12th International Conference of Computer Systems and Applications (AICCSA), Marrakech, Morocco, 17–20 November 2015; pp. 1–6. [Google Scholar]
- Liu, G.; Shao, Q.; Fan, J.; Ning, J.; Rong, K.; Huang, H.; Liu, S.; Zhang, X.; Niu, L.; Liu, J. Change Trend and Restoration Potential of Vegetation Net Primary Productivity in China over the Past 20 Years. Remote Sens. 2022, 14, 1634–1659. [Google Scholar] [CrossRef]
- Ning, J.; Liu, J.; Kuang, W.; Xu, X.; Zhang, S.; Yan, C.; Li, R.; Wu, S.; Hu, Y.; Du, G.; et al. Spatiotemporal patterns and characteristics of land-use change in China during 2010–2015. J. Geogr. Sci. 2018, 28, 547–562. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.; Feng, Z.; Chen, S.; Zhao, Z.; Wang, F. Application of the Artificial Neural Network and Support Vector Machines in Forest Fire Prediction in the Guangxi Autonomous Region, China. Discret. Dyn. Nat. Soc. 2020, 2020, 5612650. [Google Scholar] [CrossRef] [Green Version]
- Yue, S.; Pilon, P.; Cavadias, G. Corrigendum to “Power of the Mann-Kendall and Spearman’s rho tests for detecting monotonic trends in hydrological series”. J. Hydrol. 2002, 264, 262–263. [Google Scholar] [CrossRef]
- Zhang, Y.; Tan, X. Analysis on the variation trend and abrupt change of water level and discharge of Dongping Lake in recent 13 years. Haihe Water Resour. 2022, 1, 77–80. [Google Scholar]
- Zhang, L.; Zhu, Z.; Xi, X.; Wang, H.; Wang, F. Analysis of drought evolution in the Xilin River Basin based on Standardized Precipitation Evapotranspiration Index. Arid Zone Res. 2020, 37, 819–829. [Google Scholar] [CrossRef]
- Feng, X.; Zhong, Y.; Chen, L.; Fu, Y. Evolution of spatial pattern of county regional economy in Yangtze River economic belt. Econ. Geogr. 2016, 36, 18–25. [Google Scholar] [CrossRef]
- Lefever, D.W. Measuring Geographic Concentration by Means of the Standard Deviational Ellipse. Am. J. Sociol. 1926, 32, 88–94. [Google Scholar] [CrossRef]
- Li, J.; Zheng, B.; Wang, J. Spatial-temporal heterogeneity of hand, foot and mouth disease in China from 2008 to 2018. J. Geo-Inf. Sci. 2021, 23, 419–430. [Google Scholar]
- Wu, W.; Zhong, K.; Xu, J. Research on spatiotemporal evolution and influencing factors of county economic differences in Guangdong province. Sci. Surv. Mapp. 2021, 46, 156–163. [Google Scholar] [CrossRef]
- Yuan, J.; Bian, Z.; Yan, Q.; Gu, Z.; Yu, H. An Approach to the Temporal and Spatial Characteristics of Vegetation in the Growing Season in Western China. Remote Sens. 2020, 12, 945–960. [Google Scholar] [CrossRef] [Green Version]
- Feng, Z.; Shi, R. Spatio-temporal features and the association of Ground-level PM2.5 concentration and its emission in China. J. Geo-Inf. Sci. 2021, 23, 1221–1230. [Google Scholar]
- Deng, O.; Li, Y.; Feng, Z.; Zhang, D. Model and zoning of forest fire risk in Heilongjiang province based on spatial Logistic. Trans. Chin. Soc. Agric. Eng. 2012, 28, 200–205. [Google Scholar]
- Liang, H.; Wang, W.; Guo, F.-T.; Lin, F.; Lin, Y. Comparing the application of logistic and geographically weighted logistic regression models for Fujian forest fire forecasting. Acta Ecol. Sin. 2017, 37, 4128–4141. [Google Scholar]
- Chen, D. Prediction of forest fire occurrence in Daxing’an Mountains based on logistic regression model. For. Resour. Manag. 2019, 2, 116–122. [Google Scholar] [CrossRef]
- Peng, C.-Y.J.; Lee, K.L.; Ingersoll, G.M. An Introduction to Logistic Regression Analysis and Reporting. J. Educ. Res. 2002, 96, 3–14. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Chen, Y.; Zheng, W.; Li, W.; Huang, Y. Large group activity security risk assessment and risk early warning based on random forest algorithm. Pattern Recognit. Lett. 2021, 144, 1–5. [Google Scholar] [CrossRef]
- Zhang, F.; Zhang, Y.; Chen, J.; Zhai, X.; Hu, Q. Performance of multiple machine learning model simulation of process characteristic indicators of different flood types. Prog. Geogr. 2022, 41, 1239–1250. [Google Scholar] [CrossRef]
- Chen, W.; Zhang, S.; Li, R.; Shahabi, H. Performance evaluation of the GIS-based data mining techniques of best-first decision tree, random forest, and naïve Bayes tree for landslide susceptibility modeling. Sci. Total Environ. 2018, 644, 1006–1018. [Google Scholar] [CrossRef]
- Friedman, J. Greedy Function Approximation: A Gradient Boosting Machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Wang, S.; Li, J.; Wang, Y.; Li, Y. Radar HRRP Target Recognition Based on Gradient Boosting Decision Tree. In Proceedings of the 2016 9th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics (CISP-BMEI), Datong, China, 15–17 October 2016; pp. 1013–1017. [Google Scholar]
- Zou, Y.; Chen, Y.; Deng, H. Gradient Boosting Decision Tree for Lithology Identification with Well Logs: A Case Study of Zhaoxian Gold Deposit, Shandong Peninsula, China. Nat. Resour. Res. 2021, 30, 3197–3217. [Google Scholar] [CrossRef]
- Vapnik, V. The Nature of Statistical Learning Theory; Springer: New York, NY, USA, 2000. [Google Scholar]
- Yu, H. Support Vector Machine. In Encyclopedia of Database Systems; Liu, L., ÖZsu, M.T., Eds.; Springer US: Boston, MA, USA, 2009; pp. 2890–2892. [Google Scholar] [CrossRef]
- Suthaharan, S. Support Vector Machine. In Machine Learning Models and Algorithms for Big Data Classification: Thinking with Examples for Effective Learning; Suthaharan, S., Ed.; Springer US: Boston, MA, USA, 2016; pp. 207–235. [Google Scholar]
- Huang, Y.; Zhao, L. Review on landslide susceptibility mapping using support vector machines. Catena 2018, 165, 520–529. [Google Scholar] [CrossRef]
- Chen, W.; Pourghasemi, H.R.; Naghibi, S.A. A comparative study of landslide susceptibility maps produced using support vector machine with different kernel functions and entropy data mining models in China. Bull. Eng. Geol. Environ. 2018, 77, 647–664. [Google Scholar] [CrossRef]
- Cervantes, J.; Garcia-Lamont, F.; Rodríguez-Mazahua, L.; Lopez, A. A comprehensive survey on support vector machine classification: Applications, challenges and trends. Neurocomputing 2020, 408, 189–215. [Google Scholar] [CrossRef]
- Pang, Y.; Li, Y.; Feng, Z.; Feng, Z.; Zhao, Z.; Chen, S.; Zhang, H. Forest Fire Occurrence Prediction in China Based on Machine Learning Methods. Remote Sens. 2022, 14, 5546–5568. [Google Scholar] [CrossRef]
- Gao, K.; Feng, Z.; Wang, S. Using Multilayer Perceptron to Predict Forest Fires in Jiangxi Province, Southeast China. Discret. Dyn. Nat. Soc. 2022, 2022, 6930812. [Google Scholar] [CrossRef]
- Tariq, A.; Shu, H.; Siddiqui, S.; Munir, I.; Sharifi, A.; Li, Q.; Lu, L. Spatio-temporal analysis of forest fire events in the Margalla Hills, Islamabad, Pakistan using socio-economic and environmental variable data with machine learning methods. J. For. Res. 2022, 33, 183–194. [Google Scholar] [CrossRef]
- Zhou, C.; Yin, K.; Cao, Y.; Li, Y. Landslide susceptibility assessment by applying the coupling method of radial basis neural network and adaboost: A case study from the three gorges reservoir area. Earth Sci. 2020, 45, 1865–1876. [Google Scholar]
- Tuyen, T.T.; Jaafari, A.; Yen, H.P.H.; Nguyen-Thoi, T.; Phong, T.V.; Nguyen, H.D.; Van Le, H.; Phuong, T.T.M.; Nguyen, S.H.; Prakash, I.; et al. Mapping forest fire susceptibility using spatially explicit ensemble models based on the locally weighted learning algorithm. Ecol. Inform. 2021, 63, 101292. [Google Scholar] [CrossRef]
- Gao, C.; Lin, H.; Hu, H.; Song, H. A review of models of forest fire occurrence prediction in China. Chin. J. Appl. Ecol. 2020, 31, 3227–3240. [Google Scholar] [CrossRef]
- Zhao, X.; Feng, Z.; Zhou, Y.; Lin, Y. Key Technologies of Forest Resource Examination System Development in China. Engineering 2020, 6, 491–494. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Year | XStdDist (km) | YStdDist (km) | Rotation | Oblateness |
|---|---|---|---|---|
| 2010 | 721.16664 | 1759.22921 | 18.69649 | 2.43942 |
| 2011 | 694.68923 | 1218.07257 | 26.48714 | 1.75341 |
| 2012 | 657.32663 | 1142.30164 | 49.48381 | 1.73780 |
| 2013 | 692.69959 | 1052.93852 | 41.68827 | 1.52005 |
| 2014 | 692.69959 | 930.13757 | 45.00268 | 1.34277 |
| 2015 | 740.76901 | 1444.86086 | 27.73375 | 1.95049 |
| 2016 | 586.31607 | 1451.95680 | 23.84648 | 2.47641 |
| 2017 | 663.13500 | 1585.20545 | 24.58760 | 2.39047 |
| 2018 | 672.25122 | 1446.07839 | 28.09483 | 2.15110 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shao, Y.; Feng, Z.; Cao, M.; Wang, W.; Sun, L.; Yang, X.; Ma, T.; Guo, Z.; Fahad, S.; Liu, X.; et al. An Ensemble Model for Forest Fire Occurrence Mapping in China. Forests 2023, 14, 704. https://doi.org/10.3390/f14040704
Shao Y, Feng Z, Cao M, Wang W, Sun L, Yang X, Ma T, Guo Z, Fahad S, Liu X, et al. An Ensemble Model for Forest Fire Occurrence Mapping in China. Forests. 2023; 14(4):704. https://doi.org/10.3390/f14040704
Chicago/Turabian StyleShao, Yakui, Zhongke Feng, Meng Cao, Wenbiao Wang, Linhao Sun, Xuanhan Yang, Tiantian Ma, Zanquan Guo, Shahzad Fahad, Xiaohan Liu, and et al. 2023. "An Ensemble Model for Forest Fire Occurrence Mapping in China" Forests 14, no. 4: 704. https://doi.org/10.3390/f14040704