
Adversarial Defense Method Based on Latent Representation Guidance for Remote Sensing Image Scene Classification

Abstract
:1. Introduction
- We introduce self-supervised representation learning into the study of adversarial defense methods and design an adversarial denoising method. Because only clean data are used in the training phase, the proposed method is label-independent and model-independent, which is beneficial for improving the model’s defense ability against unknown adversarial noise.
- At test time, we use NMI to measure the quality of the reconstructed image and iteratively update its latent representation. Because the adversarial denoising operation is indirectly completed in the latent space, the proposed method has less impact on the quality and spatial information of images.
- We conduct attack and defense tests on various architectures of RSI scene classification datasets. The results show that the proposed method can effectively reduce the impact of adversarial noise on the model and protect the highly vulnerable RSI scene classification models in the real world.
- To test the performance of our method, we chose state-of-the-art adversarial defense methods in the field of computer vision for comparative experiments, and the results show that the proposed method exhibits a competitive defense performance. Furthermore, the proposed method can be combined with other adversarial defense methods as an additional plugin.
2. Related Works
2.1. Adversarial Attacks
2.2. Adversarial Defenses
2.2.1. Adversarial Training
2.2.2. Adversarial Preprocessing
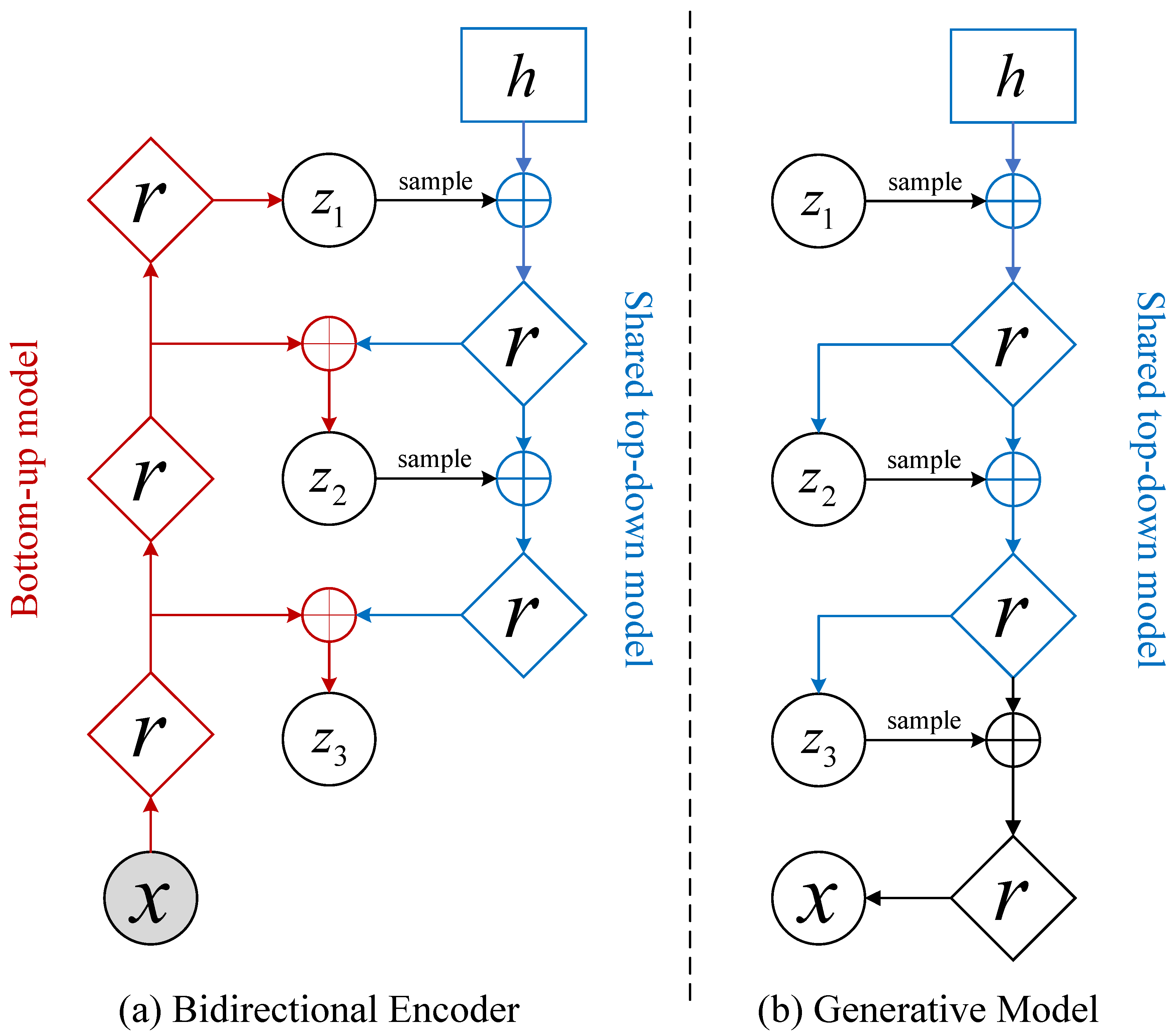
2.3. Variational Autoencoders
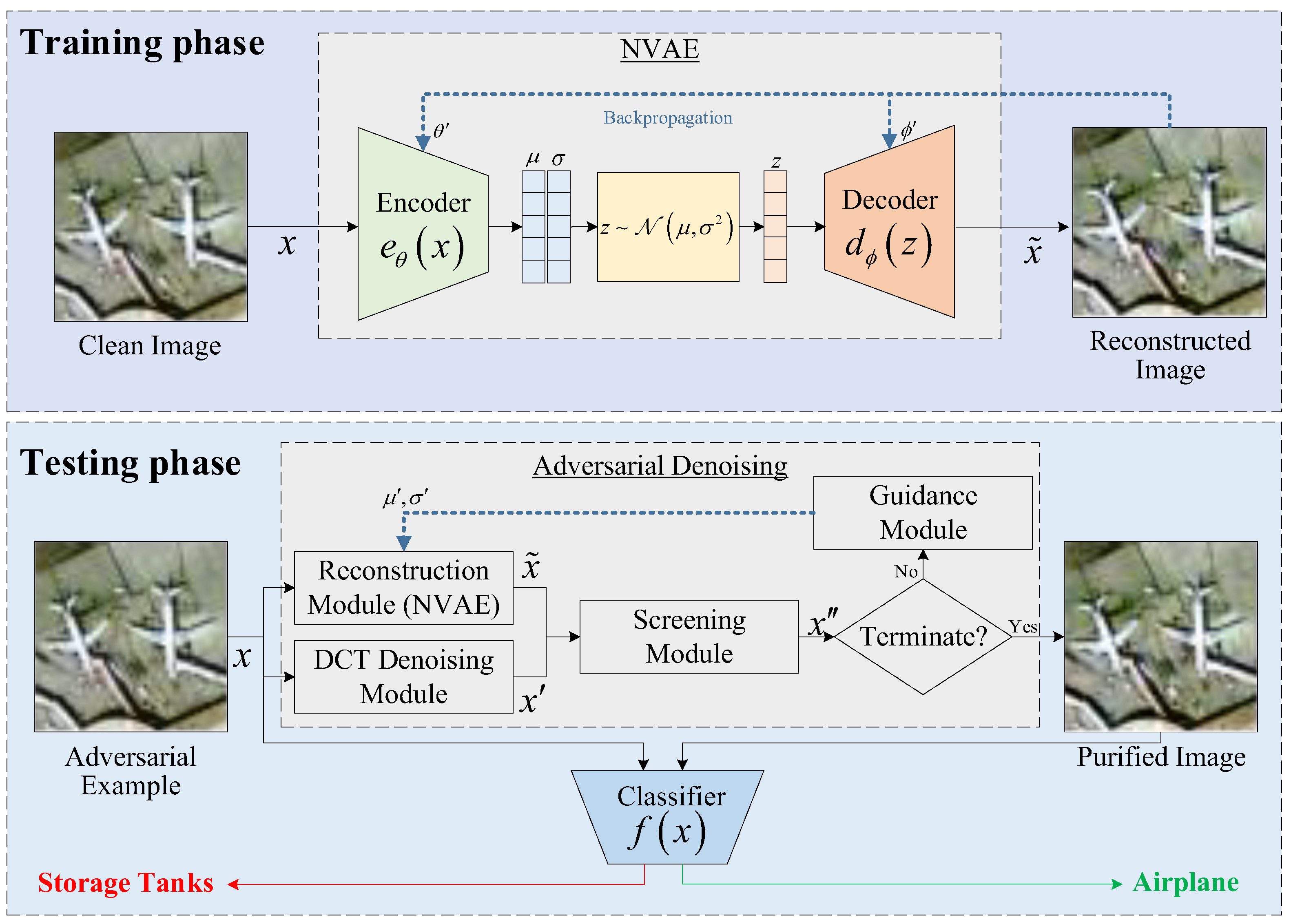
3. Methodology
3.1. Training Phase
3.2. Testing Phase
3.2.1. Reconstruction Module
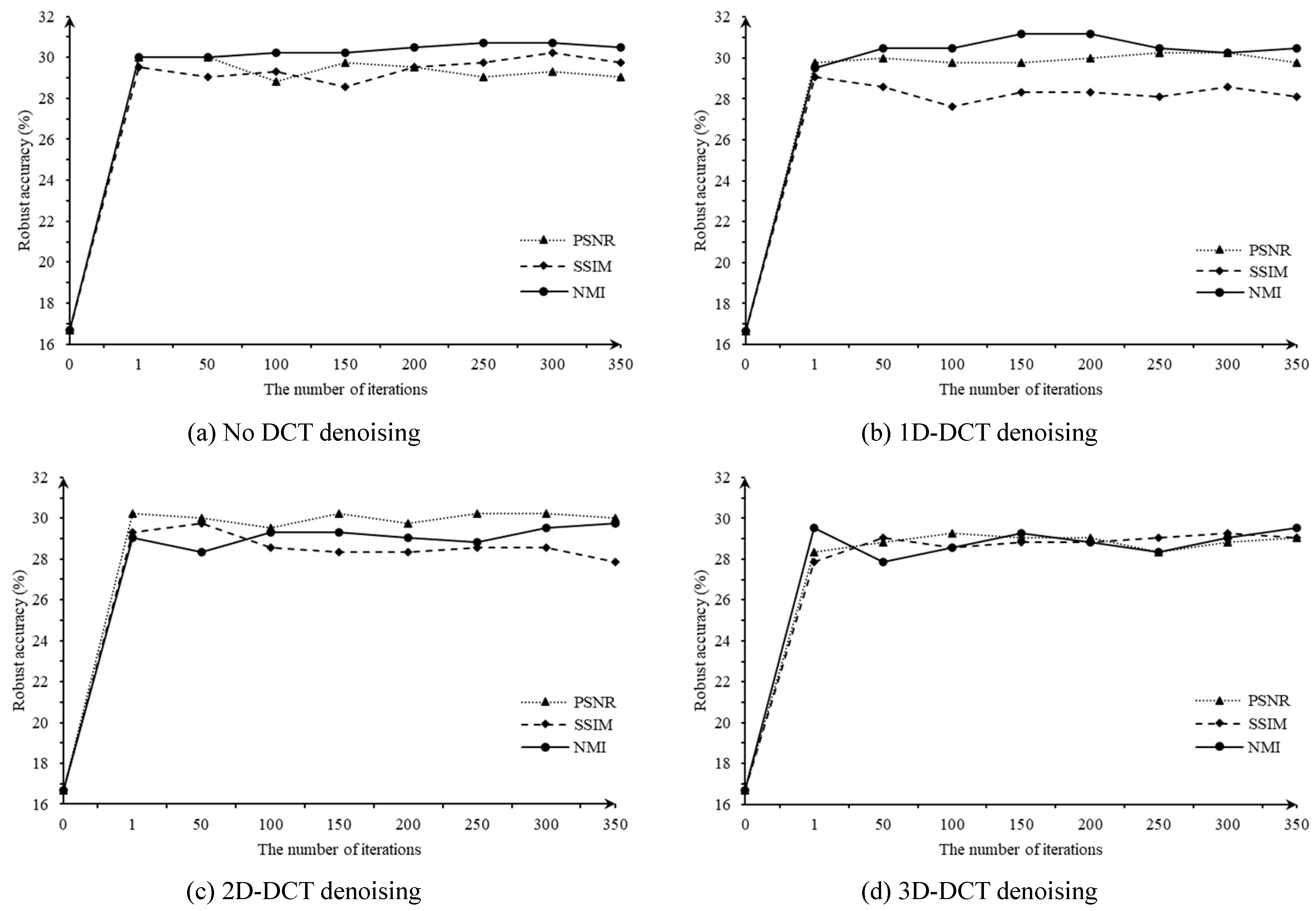
3.2.2. DCT Denoising Module
3.2.3. Screening Module
3.2.4. Latent Representation Guidance Module
4. Experimental Evaluation
4.1. Datasets and Network Architectures
4.2. Experimental Settings
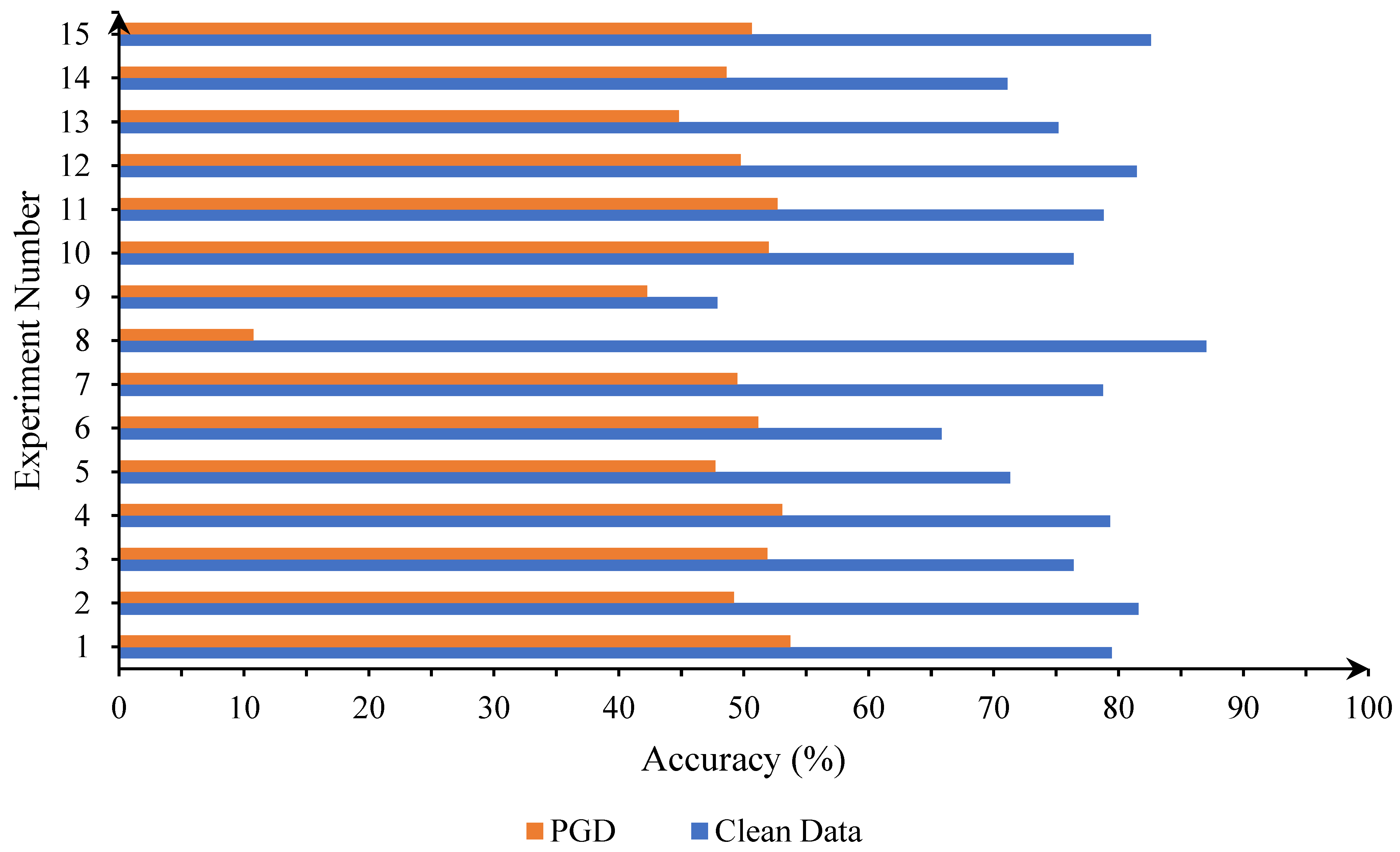
4.3. Effectiveness on Remote Sensing Dataset
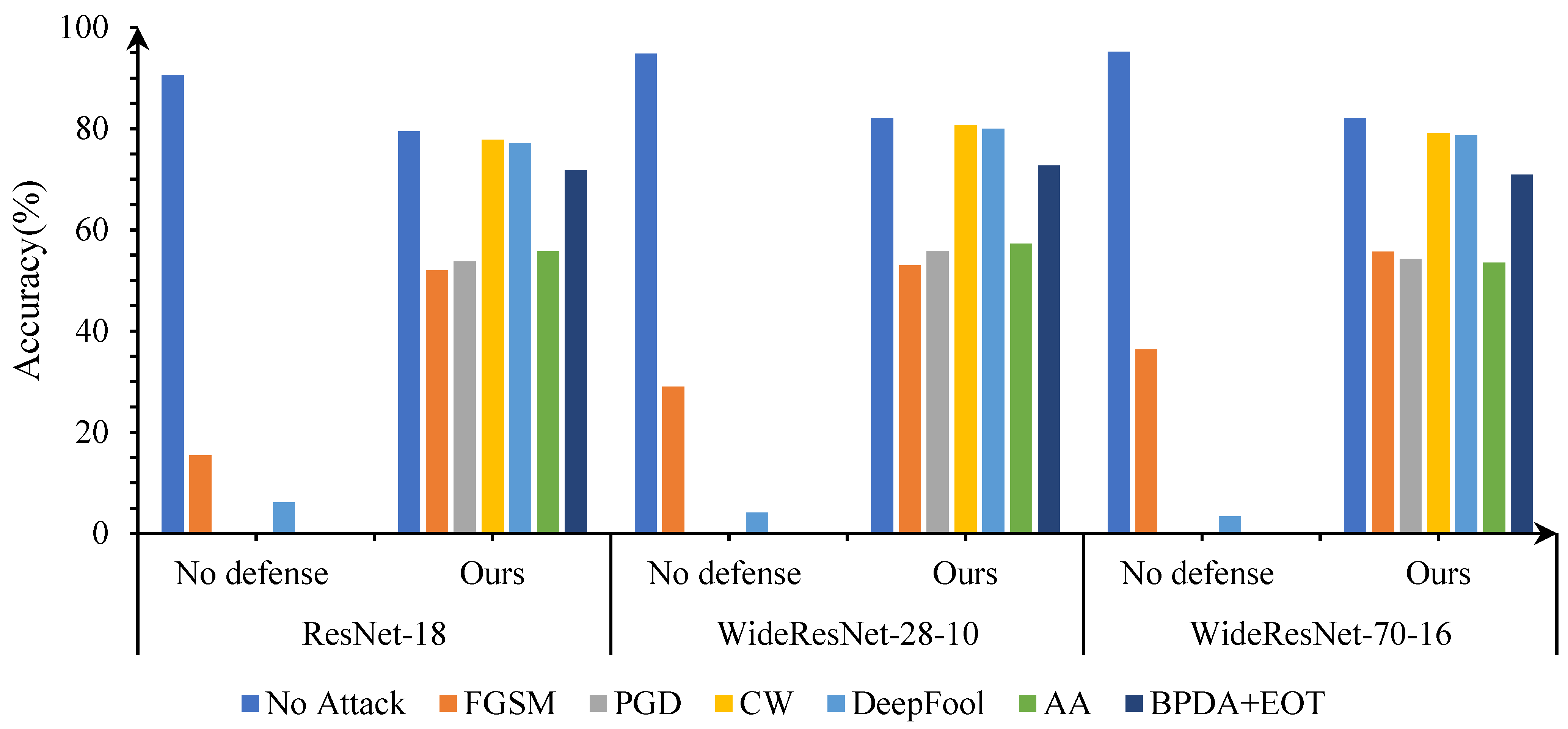
4.3.1. Effectiveness across Different Models on CIFAR-10
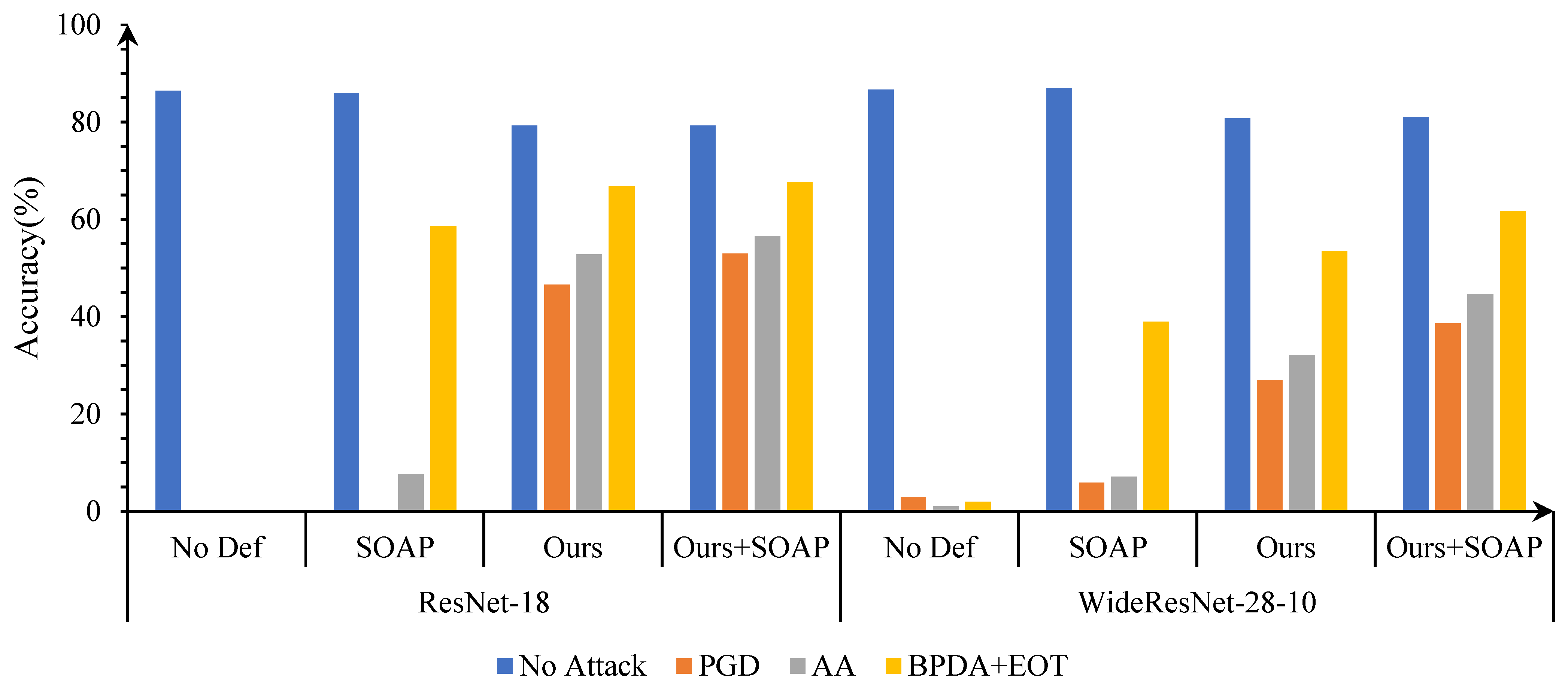
4.3.2. Comparison with Adversarial Purification Methods
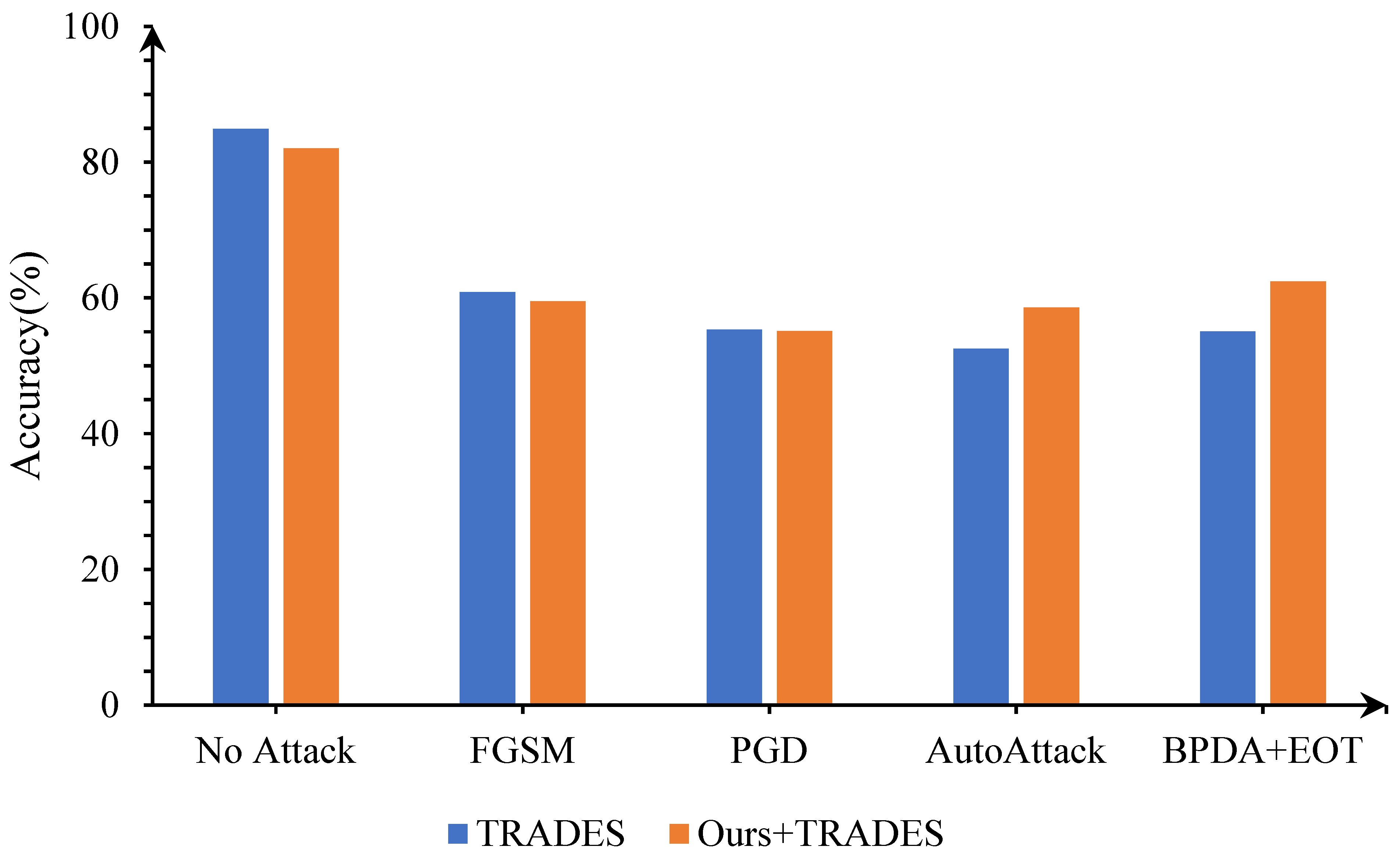
4.3.3. Compatibility with Prior Arts
4.4. Ablation on Experimental Settings
4.4.1. Parameters Involved in NVAE
4.4.2. Parameters Involved in Adversarial Denoising
5. Discussion
- The VAE assumes that the latent space is continuous, which means that samples corresponding to adjacent points in the latent space should also be similar in the data space. This may not be true for data in domains such as natural language or drug molecules.
- The VAE may encounter challenges in sampling and reconstruction when processing high-dimensional data.
- This paper is a study on the robustness of deep learning models, which is suitable for slight adversarial noise removal tasks but not for cloud removal [58] and image deblurring tasks. For example, we tested the robustness of the target model to impulsive noise attacks on the CIFAR-10 dataset. The proposed method reduces the prediction accuracy of the model for these blurred images from 50.10% to 27.45%. Of course, such performance is normal among the existing adversarial defense methods.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Li, J.; Pei, Y.; Zhao, S.; Xiao, R.; Sang, X.; Zhang, C. A review of remote sensing for environmental monitoring in China. Remote Sens. 2020, 12, 1130. [Google Scholar] [CrossRef]
- Lv, Z.; Wang, F.; Cui, G.; Benediktsson, J.A.; Lei, T.; Sun, W. Spatial–spectral attention network guided with change magnitude image for land cover change detection using remote sensing images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–12. [Google Scholar] [CrossRef]
- Chen, Y.; Chu, S. Adversarial Defense in Aerial Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 2305–2312. [Google Scholar]
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.; Fergus, R. Intriguing properties of neural networks. arXiv 2013, arXiv:1312.6199. [Google Scholar]
- Vranes, V.; Rajković, N.; Li, X.; Plataniotis, K.N.; Raković, N.T.; Milovanović, J.; Kanjer, K.; Radulovic, M.; Milošević, N.T. Size and shape filtering of malignant cell clusters within breast tumors identifies scattered individual epithelial cells as the most valuable histomorphological clue in the prognosis of distant metastasis risk. Cancers 2019, 11, 1615. [Google Scholar] [CrossRef] [PubMed]
- Czaja, W.; Fendley, N.; Pekala, M.; Ratto, C.; Wang, I.J. Adversarial examples in remote sensing. In Proceedings of the 26th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Seattle, WA, USA, 6–9 November 2018; pp. 408–411. [Google Scholar]
- Xu, Y.; Ghamisi, P. Universal adversarial examples in remote sensing: Methodology and benchmark. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5619815. [Google Scholar] [CrossRef]
- Li, H.; Huang, H.; Chen, L.; Peng, J.; Huang, H.; Cui, Z.; Mei, X.; Wu, G. Adversarial examples for CNN-based SAR image classification: An experience study. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 14, 1333–1347. [Google Scholar] [CrossRef]
- Lu, M.; Li, Q.; Chen, L.; Li, H. Scale-adaptive adversarial patch attack for remote sensing image aircraft detection. Remote Sens. 2021, 13, 4078. [Google Scholar] [CrossRef]
- Lian, J.; Mei, S.; Zhang, S.; Ma, M. Benchmarking adversarial patch against aerial detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–16. [Google Scholar] [CrossRef]
- Sun, H.; Xu, Y.; Kuang, G.; Chen, J. Adversarial robustness evaluation of deep convolutional neural network based SAR ATR algorithm. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium IGARSS, Brussels, Belgium, 11–16 July 2021; pp. 5263–5266. [Google Scholar]
- Lee, S.; Lee, H.; Yoon, S. Adversarial vertex mixup: Toward better adversarially robust generalization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 272–281. [Google Scholar]
- Hou, P.; Zhou, M.; Han, J.; Musilek, P.; Li, X. Adversarial Fine-tune with Dynamically Regulated Adversary. arXiv 2022, arXiv:2204.13232. [Google Scholar]
- Hou, P.; Han, J.; Li, X. Improving Adversarial Robustness with Self-Paced Hard-Class Pair Reweighting. arXiv 2022, arXiv:2210.15068. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and harnessing adversarial examples. arXiv 2014, arXiv:1412.6572. [Google Scholar]
- Madry, A.; Makelov, A.; Schmidt, L.; Tsipras, D.; Vladu, A. Towards deep learning models resistant to adversarial attacks. arXiv 2017, arXiv:1706.06083. [Google Scholar]
- Gu, S.; Rigazio, L. Towards deep neural network architectures robust to adversarial examples. arXiv 2014, arXiv:1412.5068. [Google Scholar]
- Hendrycks, D.; Mazeika, M.; Kadavath, S.; Song, D. Using self-supervised learning can improve model robustness and uncertainty. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar]
- Kim, M.; Tack, J.; Hwang, S.J. Adversarial self-supervised contrastive learning. Adv. Neural Inf. Process. Syst. 2020, 33, 2983–2994. [Google Scholar]
- Wu, H.; Liu, A.T.; Lee, H.Y. Defense for black-box attacks on anti-spoofing models by self-supervised learning. arXiv 2020, arXiv:2006.03214. [Google Scholar]
- He, Z.; Yang, Y.; Chen, P.Y.; Xu, Q.; Ho, T.Y. Be your own neighborhood: Detecting adversarial example by the neighborhood relations built on self-supervised learning. arXiv 2022, arXiv:2209.00005. [Google Scholar]
- Vahdat, A.; Kautz, J. NVAE: A deep hierarchical variational autoencoder. Adv. Neural Inf. Process. Syst. 2020, 33, 19667–19679. [Google Scholar]
- Carlini, N.; Wagner, D. Adversarial examples are not easily detected: Bypassing ten detection methods. In Proceedings of the 10th ACM Workshop on Artificial Intelligence and Security, Dallas, TX, USA, 3 November 2017; pp. 3–14. [Google Scholar]
- Moosavi-Dezfooli, S.M.; Fawzi, A.; Frossard, P. Deepfool: A simple and accurate method to fool deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2574–2582. [Google Scholar]
- Croce, F.; Hein, M. Reliable evaluation of adversarial robustness with an ensemble of diverse parameter-free attacks. In Proceedings of the International Conference on Machine Learning, PMLR, Online, 13–18 July 2020; pp. 2206–2216. [Google Scholar]
- Athalye, A.; Carlini, N.; Wagner, D. Obfuscated gradients give a false sense of security: Circumventing defenses to adversarial examples. In Proceedings of the International Conference on Machine Learning, PMLR, Stockholm, Sweden, 10–15 July 2018; pp. 274–283. [Google Scholar]
- Xu, Y.; Du, B.; Zhang, L. Assessing the threat of adversarial examples on deep neural networks for remote sensing scene classification: Attacks and defenses. IEEE Trans. Geosci. Remote Sens. 2020, 59, 1604–1617. [Google Scholar] [CrossRef]
- Li, P.; Hu, X.; Feng, C.; Shi, X.; Guo, Y.; Feng, W. SAR-AD-BagNet: An Interpretable Model for SAR Image Recognition Based on Adversarial Defense. IEEE Geosci. Remote Sens. Lett. 2022, 20, 1–5. [Google Scholar] [CrossRef]
- Zhang, H.; Yu, Y.; Jiao, J.; Xing, E.; El Ghaoui, L.; Jordan, M. Theoretically principled trade-off between robustness and accuracy. In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 7472–7482. [Google Scholar]
- Cheng, G.; Sun, X.; Li, K.; Guo, L.; Han, J. Perturbation-seeking generative adversarial networks: A defense framework for remote sensing image scene classification. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–11. [Google Scholar] [CrossRef]
- Sun, H.; Fu, L.; Li, J.; Guo, Q.; Meng, Z.; Zhang, T.; Lin, Y.; Yu, H. Defense against Adversarial Cloud Attack on Remote Sensing Salient Object Detection. arXiv 2023, arXiv:2306.17431. [Google Scholar]
- Croce, F.; Gowal, S.; Brunner, T.; Shelhamer, E.; Hein, M.; Cemgil, T. Evaluating the Adversarial Robustness of Adaptive Test-time Defenses. arXiv 2022, arXiv:2202.13711. [Google Scholar]
- Yang, J.T.; Jiang, H.; Li, H.; Ye, D.S.; Jiang, W. FAD: Fine-Grained Adversarial Detection by Perturbation Intensity Classification. Entropy 2023, 25, 335. [Google Scholar] [CrossRef]
- Li, W.; Li, Z.; Sun, J.; Wang, Y.; Liu, H.; Yang, J.; Gui, G. Spear and shield: Attack and detection for CNN-based high spatial resolution remote sensing images identification. IEEE Access 2019, 7, 94583–94592. [Google Scholar] [CrossRef]
- Chen, L.; Xiao, J.; Zou, P.; Li, H. Lie to me: A soft threshold defense method for adversarial examples of remote sensing images. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Zhang, Z.; Gao, X.; Liu, S.; Peng, B.; Wang, Y. Energy-Based Adversarial Example Detection for SAR Images. Remote Sens. 2022, 14, 5168. [Google Scholar] [CrossRef]
- Tabacof, P.; Valle, E. Exploring the space of adversarial images. In Proceedings of the 2016 International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016; pp. 426–433. [Google Scholar]
- Raff, E.; Sylvester, J.; Forsyth, S.; McLean, M. Barrage of random transforms for adversarially robust defense. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 6528–6537. [Google Scholar]
- Meng, D.; Chen, H. Magnet: A two-pronged defense against adversarial examples. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, Dallas, TX, USA, 30 October 2017; pp. 135–147. [Google Scholar]
- Liao, F.; Liang, M.; Dong, Y.; Pang, T.; Hu, X.; Zhu, J. Defense against adversarial attacks using high-level representation guided denoiser. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–21 June 2018; pp. 1778–1787. [Google Scholar]
- Xu, Y.; Yu, W.; Ghamisi, P. Task-guided denoising network for adversarial defense of remote sensing scene classification. In Proceedings of the International Joint Conference on Artificial Intelligence Workshop, Vienna, Austria, 23–29 July 2022. [Google Scholar]
- Yang, Y.; Zhang, G.; Katabi, D.; Xu, Z. Me-net: Towards effective adversarial robustness with matrix estimation. arXiv 2019, arXiv:1905.11971. [Google Scholar]
- Shi, C.; Holtz, C.; Mishne, G. Online adversarial purification based on self-supervision. arXiv 2021, arXiv:2101.09387. [Google Scholar]
- Xu, Y.; Sun, H.; Chen, J.; Lei, L.; Kuang, G.; Ji, K. Robust remote sensing scene classification by adversarial self-supervised learning. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS, Brussels, Belgium, 11–16 July 2021; pp. 4936–4939. [Google Scholar]
- Hill, M.; Mitchell, J.; Zhu, S.C. Stochastic security: Adversarial defense using long-run dynamics of energy-based models. arXiv 2020, arXiv:2005.13525. [Google Scholar]
- Yoon, J.; Hwang, S.J.; Lee, J. Adversarial purification with score-based generative models. In Proceedings of the International Conference on Machine Learning, PMLR, Online, 18–24 July 2021; pp. 12062–12072. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Rezende, D.J.; Mohamed, S.; Wierstra, D. Stochastic backpropagation and approximate inference in deep generative models. In Proceedings of the International Conference on Machine Learning, PMLR, Beijing, China, 21–26 June 2014; pp. 1278–1286. [Google Scholar]
- Ma, S.; Liu, C.; Li, Z.; Yang, W. Integrating adversarial generative network with variational autoencoders towards cross-modal alignment for zero-shot remote sensing image scene classification. Remote Sens. 2022, 14, 4533. [Google Scholar] [CrossRef]
- Zhang, L.; Liu, Y. Image generation based on texture guided vae-agan for regions of interest detection in remote sensing images. In Proceedings of the ICASSP 2021–2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 2310–2314. [Google Scholar]
- Heydari, A.A.; Mehmood, A. SRVAE: Super resolution using variational autoencoders. In Proceedings of the Pattern Recognition and Tracking XXXI, Online, 27 April–8 May 2020; Volume 11400, pp. 87–100. [Google Scholar]
- Cardenas, B.; Arya, D.; Gupta, D.K. Generating Annotated High-Fidelity Images Containing Multiple Coherent Objects. In Proceedings of the 2021 IEEE International Conference on Image Processing (ICIP), Anchorage, AK, USA, 19–22 September 2021; pp. 834–838. [Google Scholar]
- Du, C.; Xie, P.; Zhang, L.; Ma, Y.; Tian, L. Conditional prior probabilistic generative model with similarity measurement for ISAR imaging. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Im Im, D.; Ahn, S.; Memisevic, R.; Bengio, Y. Denoising criterion for variational auto-encoding framework. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Volume 31. [Google Scholar]
- Yang, Y.; Newsam, S. Bag-of-Visual-Words and Spatial Extensions for Land-Use Classification. In Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems, New San Jose, CA, USA, 2–5 November 2010; pp. 270–279. [Google Scholar]
- Krizhevsky, A.; Hinton, G. Learning Multiple Layers of Features from Tiny Images; Technical Report; University of Toronto: Toronto, ON, Canada, 2009. [Google Scholar]
- Nie, W.; Guo, B.; Huang, Y.; Xiao, C.; Vahdat, A.; Anandkumar, A. Diffusion Models for Adversarial Purification. arXiv 2022, arXiv:2205.07460. [Google Scholar]
- Singh, D.; Kaur, M.; Jabarulla, M.Y.; Kumar, V.; Lee, H.N. Evolving fusion-based visibility restoration model for hazy remote sensing images using dynamic differential evolution. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–14. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameter | Value |
|---|---|
| Epoch | 200 |
| Batch size | 200 |
| Normalizing flows | 0 |
| Latent variable scales | 1 |
| Groups in each scale | 10 |
| Residual cells per group | 1 |
| Channels in | 20 |
| Initial channels in enc./dec. | 32 |
| Preprocessing/postprocessing blocks | 2 |
| Cells per block | 3 |
| Mixture components in dec. | 10 |
| Model | Method | No Attack | FGSM | PGD | C&W | DeepFool | AutoAttack |
|---|---|---|---|---|---|---|---|
| LeNet | No Def | 70.00 | 19.52 | 10.24 | 0.00 | 0.00 | 8.57 |
| Ours | 69.76 | 35.72 | 31.67 | 64.05 | 61.19 | 39.52 | |
| VGG16 | No Def | 77.14 | 20.95 | 6.19 | 0.00 | 0.00 | 4.29 |
| Ours | 76.19 | 24.05 | 15.48 | 52.29 | 52.38 | 18.33 | |
| AlexNet | No Def | 77.86 | 23.57 | 10.71 | 0.00 | 0.00 | 3.81 |
| Ours | 76.19 | 43.33 | 42.38 | 72.14 | 72.62 | 46.19 | |
| ResNet-18 | No Def | 85.95 | 28.33 | 19.76 | 0.00 | 0.00 | 16.67 |
| Ours | 83.33 | 33.57 | 26.67 | 57.38 | 55.00 | 31.19 |
| Method | Standard Acc | Robust Acc | |
|---|---|---|---|
| BPDA+EOT | AutoAttack | ||
| No Defence | 90.62 | 0.00 | 0.00 |
| Me-net | 87.20 | 15.00 | 26.30 |
| EBM+LD | 84.12 | 54.90 | - |
| DSM+LD | 86.14 | 70.01 | - |
| SOAP | 87.00 | 38.97 | 7.10 |
| Ours | 79.44 | 72.68 | 57.31 |
| No | Change | Standard Acc | Robust Acc |
|---|---|---|---|
| 1 | No changes | 79.44 | 53.73 |
| 2 | Channels in | 81.57 | 49.21 |
| 3 | Channels in = 30 | 76.38 | 51.88 |
| 4 | Groups in each scale = 5 | 79.30 | 53.08 |
| 5 | Groups in each scale = 15 | 71.32 | 47.72 |
| 6 | Channels in enc./dec. = 16 | 65.83 | 51.17 |
| 7 | Channels in enc./dec. = 48 | 78.76 | 49.47 |
| 8 | Preprocessing/postprocessing blocks = 1 | 87.03 | 10.75 |
| 9 | Preprocessing/postprocessing blocks = 3 | 47.88 | 42.26 |
| 10 | Cells per block = 2 | 76.4 | 52.00 |
| 11 | Cells per block = 4 | 78.82 | 52.70 |
| 12 | Epoch = 100 | 81.45 | 49.74 |
| 13 | Epoch = 300 | 75.17 | 44.79 |
| 14 | Epoch = 100 | 71.10 | 48.61 |
| 15 | Epoch = 300 | 82.58 | 50.65 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Da, Q.; Zhang, G.; Wang, W.; Zhao, Y.; Lu, D.; Li, S.; Lang, D. Adversarial Defense Method Based on Latent Representation Guidance for Remote Sensing Image Scene Classification. Entropy 2023, 25, 1306. https://doi.org/10.3390/e25091306
Da Q, Zhang G, Wang W, Zhao Y, Lu D, Li S, Lang D. Adversarial Defense Method Based on Latent Representation Guidance for Remote Sensing Image Scene Classification. Entropy. 2023; 25(9):1306. https://doi.org/10.3390/e25091306
Chicago/Turabian StyleDa, Qingan, Guoyin Zhang, Wenshan Wang, Yingnan Zhao, Dan Lu, Sizhao Li, and Dapeng Lang. 2023. "Adversarial Defense Method Based on Latent Representation Guidance for Remote Sensing Image Scene Classification" Entropy 25, no. 9: 1306. https://doi.org/10.3390/e25091306