4.1. Dataset and Experiment Setup
: For a fair comparison, an indigenously designed dataset of 81 seals was used in the experiments. This dataset contained 16 seal surfaces, and each seal surface had six different product types. All 16 seal surfaces had different character formations, and the six product types of each seal surface corresponded to the fact that each one was produced by different manufacturers (
Figure 8). It is pertinent to mention that all the following factors led to producing six different product types of each seal surface: (i) the seal templates, (ii) the materials and machinery used to produce the seal, (iii) the manufacturing processes. Moreover, the manufacturer, materials, and equipment used to create product types −1, −2, and −3 were from the same company. The seals created with Types −1, −2, and −3 look quite like one another; however, they are different. Contrarily, the types −4, −5, and −6 were assumed to be forged seals. They were produced by different manufacturers by employing various production techniques and materials.
Figure 8 shows the photos of three seal surfaces (numbered 1, 2, and 10) with six different product types.
Table 1 displays the total number of pictures gathered for each seal, which comes to 8616. One of these, 99-b, refers to the background image that was gathered, as seen in
Figure 9. In the experiments, we used background-free photos for training and background-containing images as a test set to assess how robust the approach was to background noise.
The efficacy of our proposed model was examined from various perspectives by dividing the experiment into the following three classification tasks: (i) classifying the seal surface, (ii) the product type, and (iii) the individual seal. The three classification tasks used an identical dataset with different targets of 16 classes, 6 classes, and 81 classes. The first 48 photographs of each seal were used as the training sets, while the remaining images were used as the test sets. According to
Table 2, there were 3888 total training sets. For the classification job of the seal surface, we only used the 72 photos of Product Type −5 for training and compared the classification results to further confirm the method’s generalizability.
: The top-1 and top-3 accuracy metrics were used to estimate the performance of the proposed model. To balance the number of samples, the sample weight parameter was added to the calculation, then the computational complexity and parameter count of the model were compared concurrently.
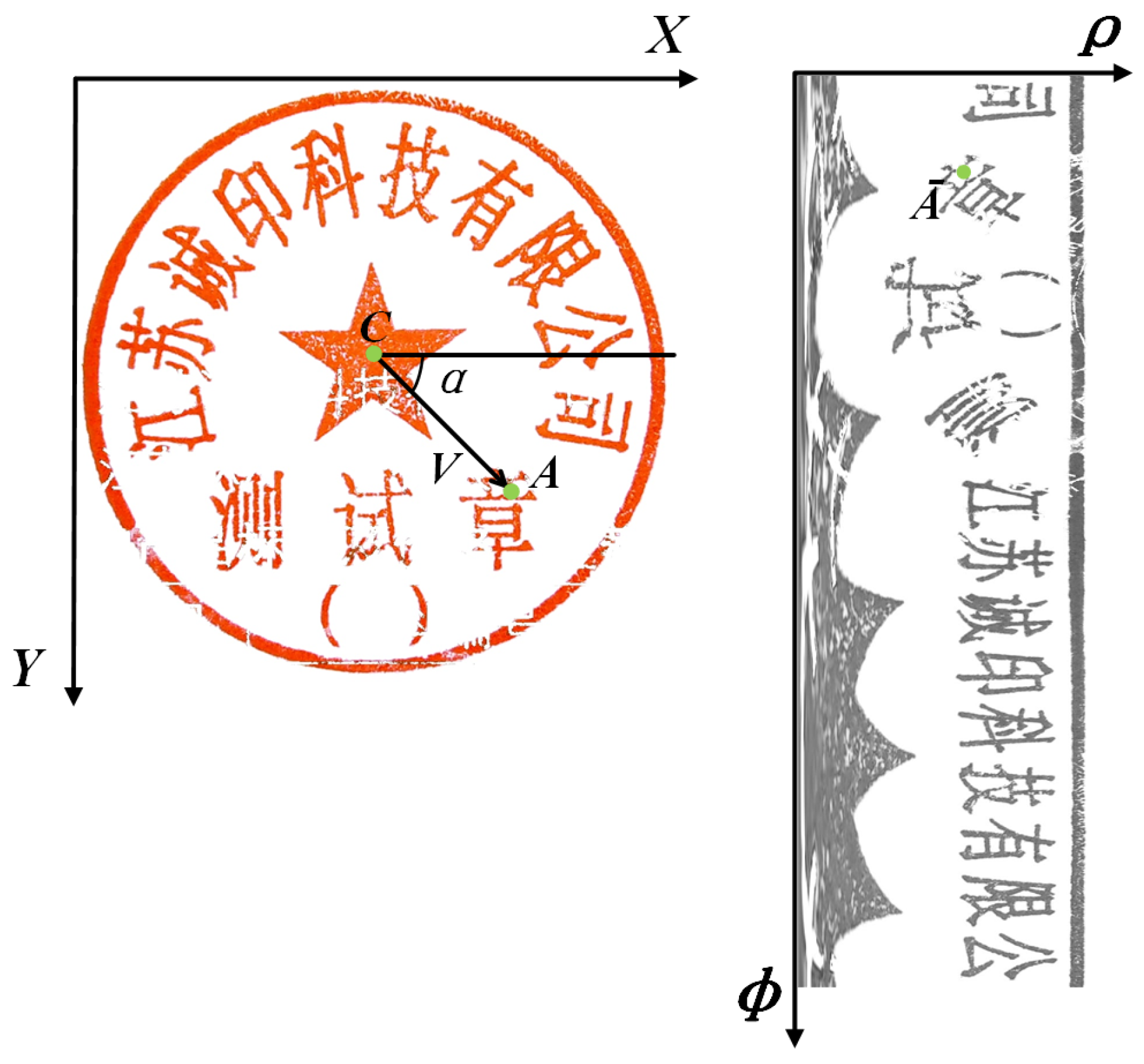
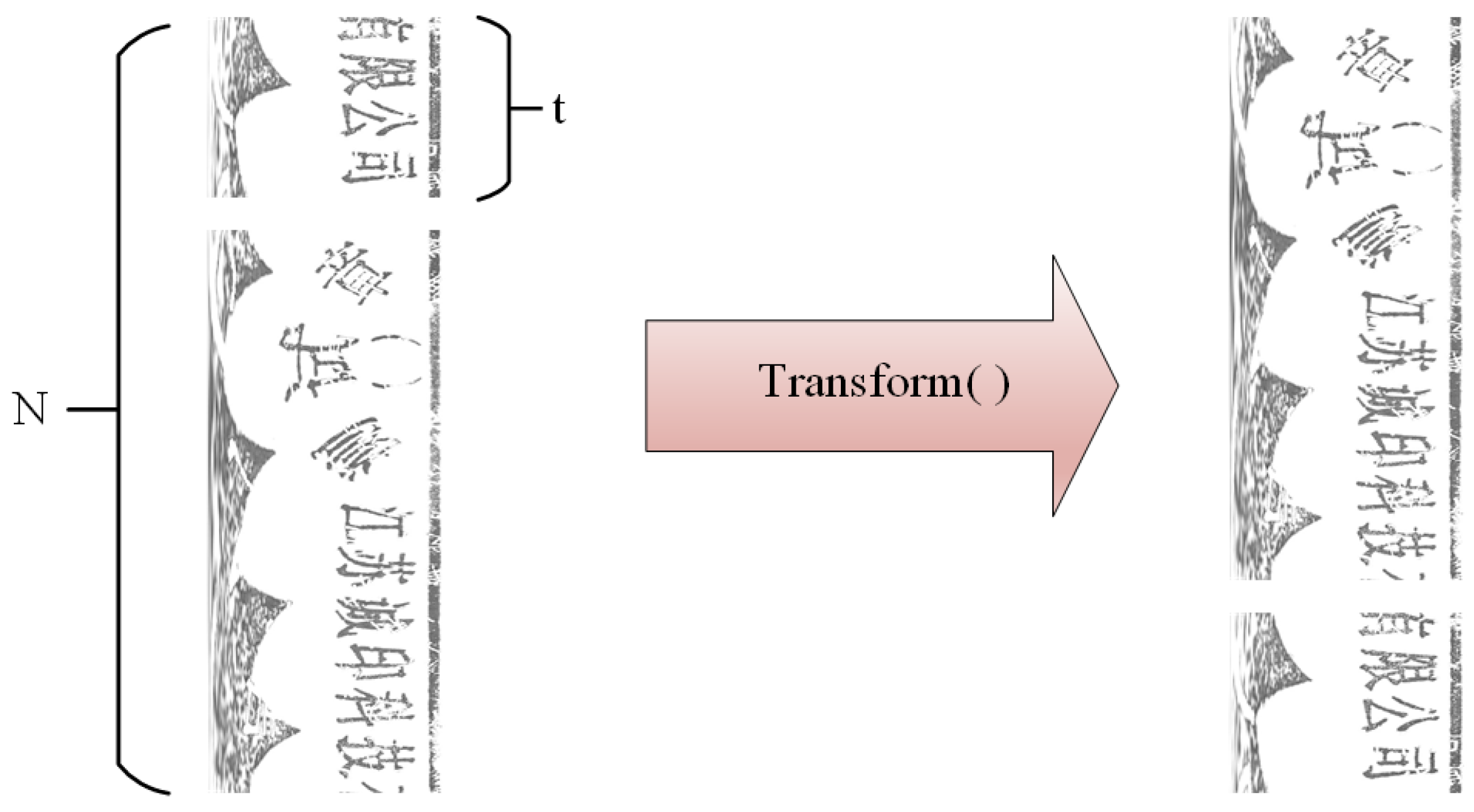
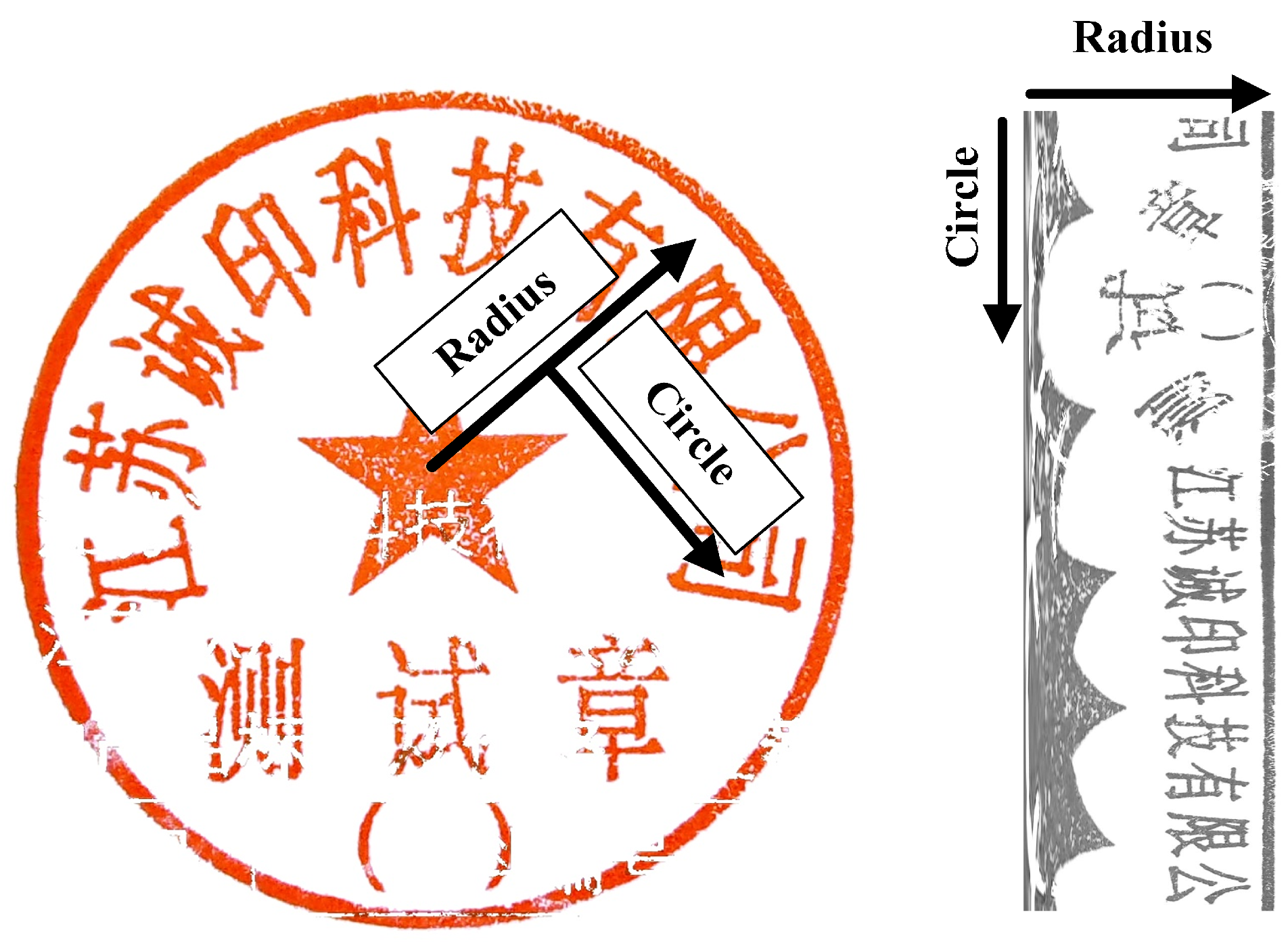
: The 3- and 6-layer Mixer layer models were designed and named StampMLP-3 and StampMLP-6, respectively. The models with a different number of layers helped to explore the impact of the number of layers on the accuracy when compared with MLP-Mixer-3/6, VGG16, and ResNet50. MLP-Mixer and Stamp-MLP have the same hidden layer dimensions (the channel-dim was 128, and the token-dim was 512). However, the input resolutions were different: in Stamp-MLP, the resolution was 798 × 256, while it was 512 × 512 for MLP-Mixer (with a grid resolution of 16 × 16), VGG16, and ResNet50.
The Pytorch library was used to design Stamp-MLP, and the experiments were performed using the Nvidia RTX3090 and the Adam optimizer. It is pertinent to mention that all the experiments were performed with the following default settings: a learning rate of 0.001, a batch size of 128, and a number of training epochs of 48.
4.2. Result
In order to prevent the influence of overfitting, the data in all the results were obtained when the accuracy of the test set and the training set were the closest.
4.2.1. Product Type Classification
The classification accuracy is displayed in
Table 3, where Top-1* denotes the first three product types (i.e., −1, −2, and −3) belonging to the same category because their manufacturing procedures were identical. All the preprocessing operations were applied for all the models in our experiments, except the remap operation, which is one of our novelties and was only applied on our model. It is evident from
Table 3 that Stamp-MLP’s top-1 accuracy was better than VGG16’s, MLP-Mixer’s, and ResNet50’s. Moreover, the proposed strategy slightly was more resistant to the test set with background noise.
Since the disparities between the first three classes (i.e., −1, −2, and −3) were the smallest, the misclassification was mostly centered on these three. However, as Stamp-MLP has a stronger ability to capture pixel-level features, it classified these three classes better than the existing approaches.
4.2.2. Seal Surface Classification
The character information in the seals was used by all the models in surface classification. As shown in
Table 4, VGG16, ResNet50, and Stamp-MLP attained accuracy levels greater than 99%, while MLP-Mixer had an accuracy under 99%. However, on the test set with the background noise, all models had a 100% classification accuracy.
The quantity of the training sets was significantly reduced to evaluate the models under difficult conditions. To evaluate the model’s capacity in handling smaller datasets, we used 72 types −5 print images as the training sets. The experimental findings are shown in
Table 5. While all four models’ accuracy decreased to some degree, VGG16 and ResNet50 were highly affected. The top-1 accuracy decreased by more than 19%, while for Stamp-MLP, the accuracy decreased by only 10%.
4.2.3. Individual Seal Classification
The model must be able to capture the distinctive characteristics that each seal-making technique produces to properly identify each seal. Therefore, assessing how well the model performed in terms of classifying individual seals is of utmost importance.
Table 6 displays the testing results. Especially when compared to MLP-Mixer, Stamp-MLP had better classification accuracy with 91.96% top-1, 97.87% top-3, and 98.5% BG-top-1. The lowest, MLP-Mixer-6, in top-1* also attained an accuracy of 96.93%, which was greater than the top-1 accuracy of 84.25%.
The first three product kinds were very identical and had very small distinguishing traits; therefore, to properly classify, the underlying pixel-level information was needed. The patch linear projection used in MLP-Mixer resulted in the loss of the underlying data. However, Stamp-MLP retained the maximum pixel-level data, therefore giving in an advantage in identifying the variances existing in the various product types. Moreover, Stamp-MLP was more reliable when dealing with the background.
We also compared the number of parameters, FLOPs, throughput (based on RTX3090), MACs (the batch size was 1), and training epochs in addition to the classification accuracy.
Table 7 demonstrates that Stamp-MLP used fewer parameters, required fewer training cycles, used less memory, and had fewer FLOPs. Moreover, the detailed specifications of the implemented environment are shown in
Table 8, where “True” indicates we used a GPU.
VGG16’s classification performance in the aforementioned tasks was quite similar to Stamp-MLP; however, Stamp-MLP had the advantage of being more lightweight because it used fewer parameters and fewer optimization epochs, making it better suited for small datasets. Moreover, the performances of the 3-layer model and the 6-layer model were identical, and in practical applications, the 3-layer model can be used to keep the model’s complexity low.
4.3. Discussion
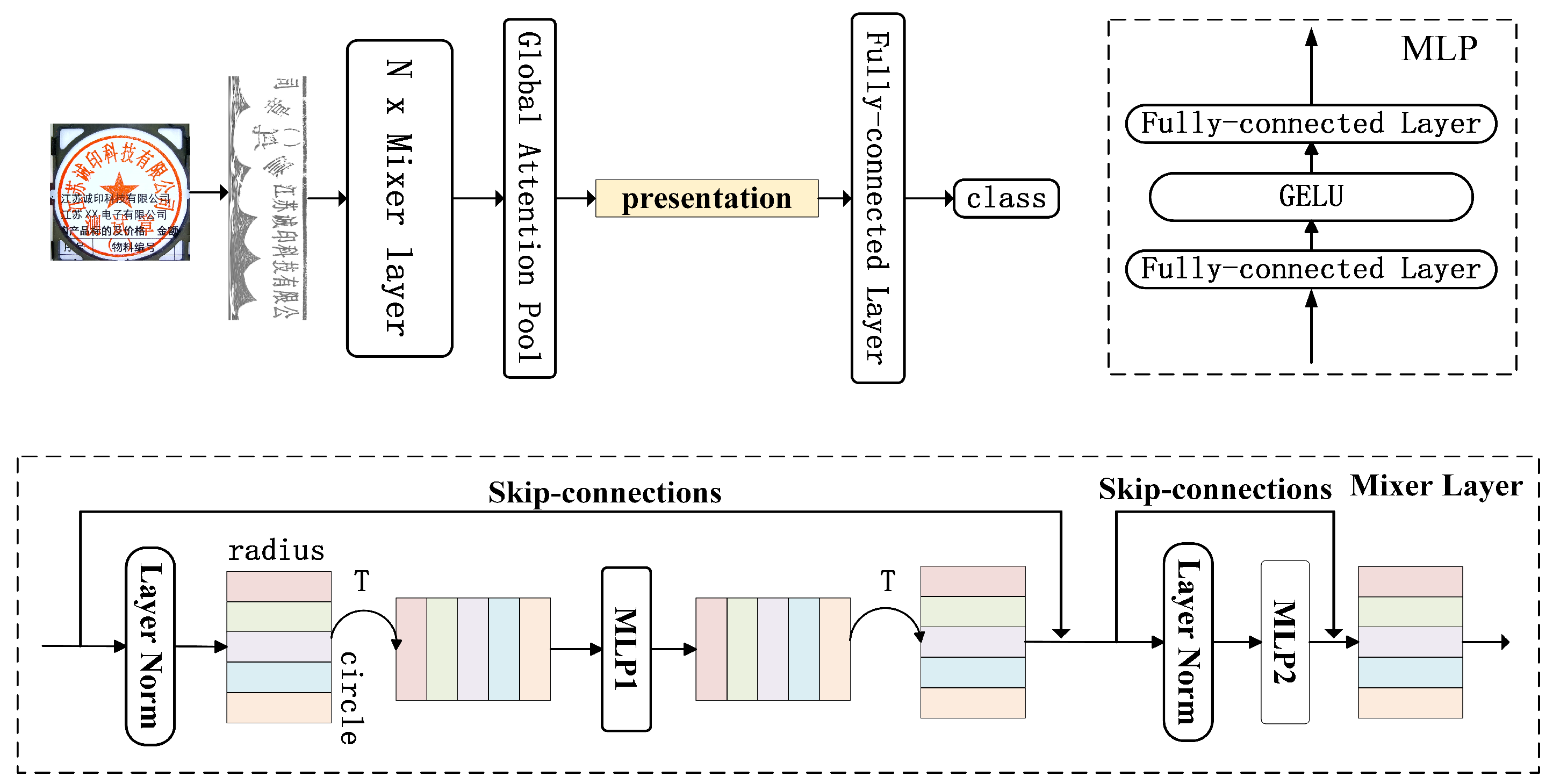
Generally, MLP-Mixer divides the projection grid such that much underlying pixel-level information is lost. It was evident from the experimental results that MLP-Mixer’s product type classification was not encouraging; however, the proposed modified MLP-Mixer remaps the pixel positions such that the circular seal is directly passed to the neural network, preserving the maximum usable information. The model extracts the features of the seal imprint by using the feature aggregation of the two MLPs and global pooling and, then, creates a representation of the seal picture.
Both MLP-Mixer and Stamp-MLP can perform better when classifying seal surfaces. Since the counterfeiting of seals is a significant problem in society, it is crucial to preserve and extract the fundamental characteristics of the seal. These characteristics serve as the foundation for further development of forged seal recognition. Forged seals often share high-level characteristics with genuine seals, such as the same characters, size, layout, etc. The underlying pixels of the image contain the data that may be used to identify a false seal. Therefore, the ability to store and recover such pixel-level information is very crucial.
The experimental results showed that the individual seal categorization was most challenging for the differentiation between the first three product type classes, because all three of these product kinds were produced by the same methods. Although these seals were quite similar to each other, in practical scenarios, they are quite difficult to make by the seal’s creator.
The experimental result showed that the CNNs represented by VGG16 behave similarly in classification; however, they were less resistant to noise in the background. CNNs also require complicated feature computations and large parameters. Moreover, CNNs are difficult to optimize.
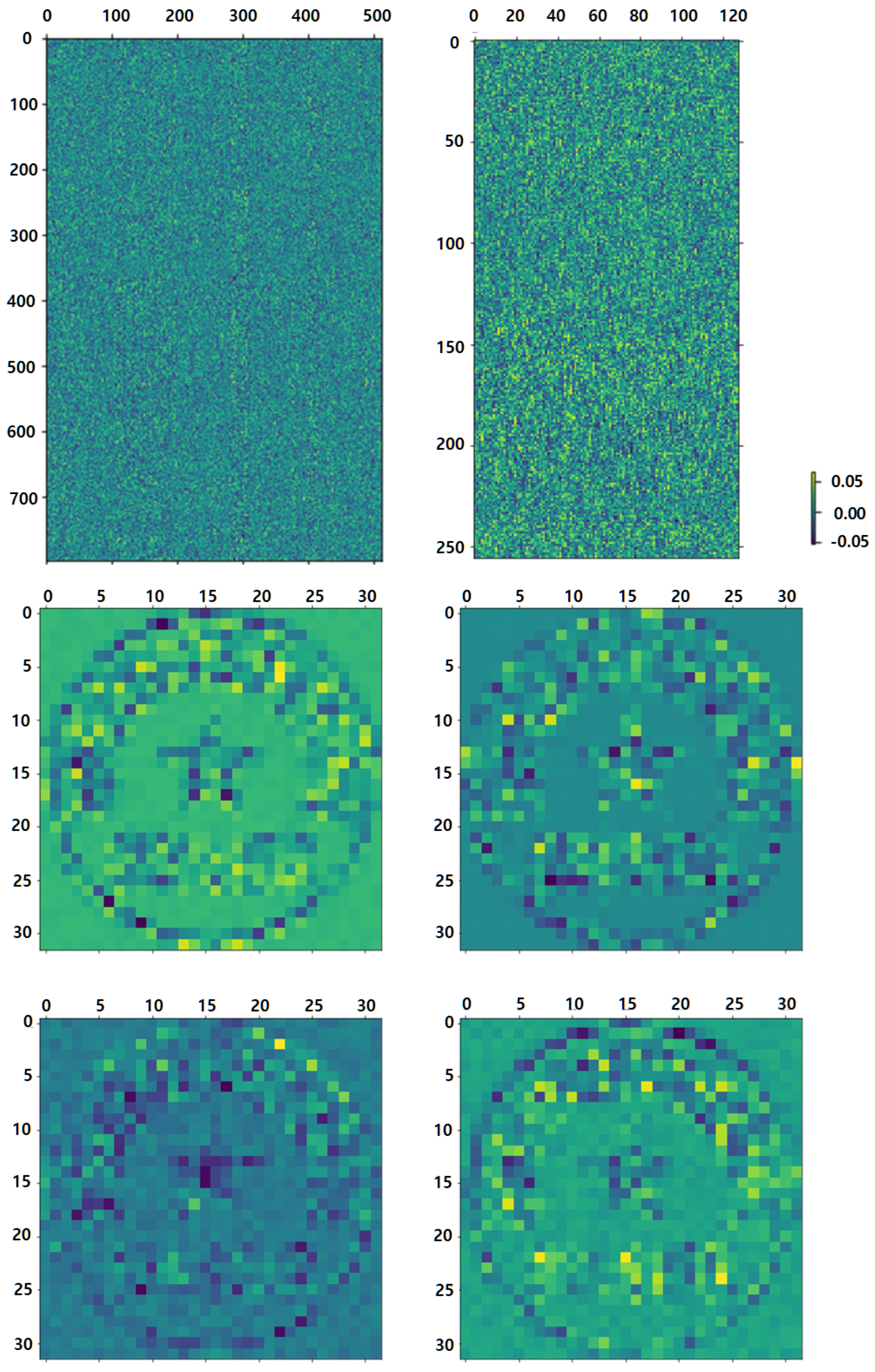
The weights of an MLP’s first layer are shown in
Figure 10. Stamp-MLP’s MLP1 weight of the first layer is shown in the upper left, and the weight in the upper right belongs to MLP2. The first layer of MLP1 in MLP-Mixer had a total of 512 channels, and the weights for 4 of these channels are shown in the lower layer. Stamp-MLP considers the pixel-level details in the overall image as seen by the uniform and erratic weight distribution. The weights of some channels are significantly larger, and the figure shows some light and dark streaks if the model pays more attention to the information in particular locations. The accuracy of Stamp-MLP was higher because the input data fully preserved the pixel-level information and the model uniformly considers all of the input data.
MLP-Mixer also uses the information included in the seal imprint area, the lettering, and the five-pointed star, as shown in
Figure 10. However, the model loses much pixel-level information in the grid (due to the usage of grid split and linear projection), impacting the extraction of grid border information. Finally, this resulted in lower classification accuracy.
What is more, we used two other popular methods for identifying forged seals—directly applying the CNN to the input seal images without our mapping step and using the CNN with augmentation instead of alignment, to perform a simple experimental comparison with our method. We used VGG16 and rotated our seal images at random angles by using data augmentation.
In the experiment to classify product types (six types), we put 3888 seal images directly into VGG16 without our mapping step and achieved 89.84% accuracy after training. Then, we applied data augmentation to increase the number of seal images from 3888 to 10,000 and achieved 92.71% accuracy after training. The classification accuracy is displayed in
Table 9, where VGG16 refers to directly applying the CNN to the input seal images without our mapping step. VGG16-1 refers to using the CNN with augmentation instead of alignment. VGG16-2 refers to using the method we proposed in the Proposed Methodology Section. Stamp-MLP-3 and Stamp-MLP-6 refer to our proposed models using the data preprocessing method in the Proposed Methodology Section.
In classifying individual seals (81 classes), we put 3888 seal images directly into VGG16, and after training, we had an accuracy of 88.67%. Then, we applied data augmentation to increase the number of seal images from 3888 to 1000, and the accuracy of VGG16 was 91.21%. The concrete data are shown in
Table 10, where VGG16 refers to directly applying the CNN to the input seal images without our mapping step. VGG16-1 refers to using the CNN with augmentation instead of alignment. VGG16-2 refers to using the method we proposed in the Proposed Methodology Section. Stamp-MLP-3 and Stamp-MLP-6 refer to our proposed models using the data preprocessing method in the Proposed Methodology Section.
In the seal surface classification task (16 classes), in order to avoid the accuracy reduction by the difference of the product type, we only chose Product Type −5 for training. Firstly, we put our 1152 seal images directly into VGG16 without the mapping step, and the accuracy was 94.84%. Then, we used data augmentation to increase the number of seal images in the training set from 1152 to 4500 and put them into VGG16. The accuracy was 95.21%. The concrete data are shown in
Table 11, where VGG16 refers to directly applying the CNN to the input seal images without our mapping step. VGG16-1 refers to using the CNN with augmentation instead of alignment. VGG16-2 refers to using the method we proposed in the Proposed Methodology Section. Stamp-MLP-3 and Stamp-MLP-6 refer to our proposed models using the data preprocessing method in the Proposed Methodology Section.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}