1. Introduction
Partially linear models (PLMs) have gained considerable attention in the field of survival analysis, especially for modeling right-censored data. The flexibility and capability of PLMs to capture both parametric and nonparametric components make them a favored choice for analyzing survival data with complex relationships. The classical PLM is expressed as follows for completely observed data with a sample size
:
where
’s are the completely observed response values (or lifetimes in survival analysis),
are the parametric covariates,
denotes the
dimensional vector of regression coefficients, and
is the univariate unknown smooth function to be estimated based on the values of the nonparametric covariate
’s. Finally,
’s are the random error terms with
. Without censored data, model (1) has been studied by many researchers, and some of the notable studies include [
1,
2], among others. Additionally, ref. [
3] proposed the local linear regression (LLR) estimation for model (1). In the right-censored case, the response variable,
, is incompletely observed and censored from the right by random censoring variable
under the assumption that
and
are completely observed. Accordingly, the censoring mechanism and some new variables can be obtained as follows:
where
denotes the incompletely observed response variable with the censoring indicator
. Thus, instead of
, data pairs
are used in the modeling procedure. There are several important studies on the estimation of model (1) under right-censored data, as given in (2), such as refs. [
4,
5,
6], among others.
While model (1) offers reliable performance for both censored and uncensored data due to its ability to incorporate both parametric and nonparametric components, it encompasses only a singular nonparametric component. This constraint necessitates that researchers select a sole nonparametric covariate from the dataset, a premise that might not align with many real-world situations. Furthermore, adhering to this limitation could result in less dependable estimations unless the dataset genuinely contains only one nonparametric covariate. To improve estimation accuracy and provide a more adaptable model that considers the right-censored response variable,
, this research delves into the partially linear additive model (PLAM), tailored for
nonparametric functions:
Here,
represents the number of nonparametric components, a value determined based on the nature of the relationship between
and
. When this relationship cannot be adequately captured by a linear parametric component, it is treated as a nonparametric covariate, characterized by an unknown smooth function
. As a result, the overall nonparametric component of model (3) is formed by the summation of these functions. The use of PLAMs in survival analysis with right-censored data allows for more realistic modeling of the relationship between covariates and survival outcomes by incorporating both multiple parametric and nonparametric components. By introducing nonparametric components, PLAMs provide a more adaptable framework for capturing potential nonparametric relationships between covariates and survival times. It is crucial to acknowledge that model (3) cannot be estimated unless the censorship problem is suitably addressed. Numerous studies in the literature have concentrated on estimating (3) for data that is fully observed and devoid of any censoring. Ref. [
7] discussed the combination of smoothing splines with semiparametric additive models, while ref. [
8] studied the asymptotic properties of M-estimators for model (3). Additionally, Ref. [
9] presented a comprehensive review of partially linear additive models based on various smoothing techniques.
Distinct from the studies previously mentioned, this paper presents modified LLR estimators for PLAM (3) using three distinct censoring solutions: synthetic data transformation (ST), Kaplan–Meier weights (KMW), and kNN imputation (kNNI). Through the examination of these modified estimators and the exploration of various techniques to tackle censorship, valuable insights can be gained, and the accuracy and effectiveness of modeling right-censored data may be improved. This paper also explains the procedure for obtaining these estimators, encompassing the modified backfitting technique and a non-iterative approach, accompanied by comparative numerical studies. To the best of our knowledge, this research fills a gap in the literature on modeling right-censored data.
The remaining part of the paper is organized as follows: In
Section 2, the fundamentals of right-censored data are presented, and solution approaches are explained.
Section 3 covers the estimation of PLAM using modified LLR estimators based on various censorship solution techniques. In
Section 4, the statistical properties of the estimators are provided.
Section 5 and
Section 6 present simulation and real data studies, respectively. Finally,
Section 7 includes the conclusions of the paper.
2. Right-Censored Data and Solution Methods
In this section, we provide theoretical insights into modeling right-censored data. Let
and
represent the probability distribution functions of the
observed response variable (
) and the censoring variable (
), respectively. Thus, for any arbitrary data point “
”, these functions can be expressed as follows:
It is essential to highlight that the estimation procedure for the model, utilizing the specified distributions (4), critically relies on two “censorship assumptions”. These constrain all variables within model (2). These assumptions, as outlined by ref. [
10] and elaborated by ref. [
11] in the context of right-censored regression models, hold significant significance. In essence, the dataset must meet the subsequent criteria.
A1. and are independent.
A2. .
The assumption (A1) and (A2) can be explained as follows: (A2) posits that the covariates in the model lack any information about the censorship in
. Assumption (A1) is particularly crucial when implementing censorship solutions. For a more in-depth discussion, one can refer to [
10]’s writings. Drawing from the aforementioned details, this section provides the three censorship solutions. Additionally, towards the section’s close, a figure is showcased to illustrate the practical distinctions between synthetic data transformation and the kNN imputation methods.
Synthetic data transformation: To incorporate the impact of censorship into the modeling procedure, synthetic data transformation is a commonly employed solution method. Consequently, the incomplete response pairs
must be substituted for a synthetic response variable, as proposed by ref. [
12]. Assuming that
is a continuous and known function, it becomes possible to modify the observed lifetimes
in a manner that ensures an unbiased estimation:
where
represents the synthetic response variable with
. Nevertheless, the true distribution of the censoring variable
remains unknown. To address this challenge, ref. [
12] suggested replacing
with its estimated version, known as the Product-Limit estimator (Kaplan–Meier estimator). This estimator calculates the survival probabilities at the arbitrary positive data point “
” as follows:
where
are the sorted values of the right-censored response variable
and
are the corresponding censoring indicators associated to
. Hence, instead of
in (5),
is used and
can be obtained to fit the PLAM.
Kaplan–Meier weights: Kaplan–Meier weights (KMW), as proposed by ref. [
13], are a technique used in survival analysis to address the issue of right-censored data. The Kaplan–Meier estimator is a nonparametric method prevalent nonparametric approach used for estimating survival probabilities amidst censoring. Nonetheless, using standard regression techniques on censored data can lead to biased outcomes. Stute (1993) addressed this by presenting Kaplan–Meier weights, derived from the Kaplan–Meier survival probabilities for each data point. These weights are used to adjust the contribution of each observation in the regression analysis, effectively accounting for the censoring mechanism. By incorporating the Kaplan–Meier weights into the regression model, unbiased estimates of the regression coefficients can be obtained.
Before computing the KMW, let us assume that
denotes the ordered values of the incomplete response values and
and
are the correspondingly ordered values. Then, Kaplan–Meier weight
, associating with the
, is computed based on the Kaplan–Meier estimator
given in (5) as follows:
And KMW is obtained for all possible values of
as a diagonal matrix
. To reach further information about (7) and implanting these weights into the regression models, see refs. [
5,
6].
kNN imputation method: kNN imputation is a prevalent technique for addressing missing data across various domains, as discussed by researchers including [
14]. Additionally, some studies, such as ref. [
15], have adapted the kNN imputation method to manage right-censored data. This method allows for the practical estimation of right-censored data points without the constraints of theoretical limitations. In this context, we provide a succinct overview of the kNN imputation technique and an algorithm tailored for the PLAM dataset. Essentially, the kNN method is a machine learning technique that hinges on the similarity between data points, utilizing distance metrics for predictions. The choice of a suitable similarity measure can greatly impact the results. The Euclidean norm is commonly employed as a measure of distance in numerous studies. The Euclidean norm is a well-known distance and can be computed for the context of censored data points as
where
is the number of censored data points and
and
denote the
and
associated values of a regressor which has a strong correlation between response variable
. Details are provided in Algorithm 1. For imputation, the algorithm introduced by ref. [
15] can be employed. The choice of the appropriate number of neighbors, “
k”, is pivotal, especially given the possibility of some neighbors being right-censored. While ref. [
16] suggests a smaller value for “
k”, such as 1 or 2, an optimal “
k” ranging between 2 to 10 is chosen in this context to minimize the mean squared error (MSE). This approach ensures precision in imputation, taking into account the distinct attributes of the data.
| Algorithm 1 Algorithm for k NN imputation for the right-censored data |
|
|
|
|
|
|
| 1: |
| 2: do |
| 3 |
| 4do |
| 5 |
| 6 |
| 7do |
| 8 |
| 9 |
| 10 |
| 11 |
| 12: |
As previously mentioned,
Figure 1 has been created to illustrate the practical distinctions between the manipulative solution techniques, namely ST and kNNI. This visualization provides insights into how these methods impact the response variable and the changes they bring about. It should be noted that the effect of KMW is not demonstrated in the figure since it is incorporated into the objective function of the right-censored PLAM as weights. However, further explanation regarding KMW will be provided in the next section when obtaining the modified LLR estimators.
4. Properties of the Estimator
The objective of this section is to assess the bias and variance of the modified LLR estimators introduced in the previous section. When evaluating the performance of the parametric component, the variances and biases of the regression coefficients are calculated using the non-iterative solutions given in Equations (14)–(17), owing to its theoretical simplicity.
Empirical studies can be conducted to calculate the bias and variance properties of the estimators. However, when considering LLR as demonstrated in Equations (14)–(17), non-iterative formulations can be employed to compute finite-sample properties for the other two methods. In this matter, conditional bias and variance are obtained based on Equations (14)–(17).
Let us rewrite
as:
where
and
for
. Then
and
can be given by:
And for the KMW solution, Equations (19) and (20) are given by:
where
is the model variance estimated based on LLR and it can be computed using the hat matrix
or
for the KMW solution that are defined after Equation (18). In addition, one can replace
by
or
. Accordingly,
is formulated as follows:
where the degree of freedom (DF), which is given in the denominator of (23), is calculated by
and
is used for the KMW solution. For the further details of
, see ref. [
17]. The modified backfitting algorithm provided in Algorithm 2 requires the estimation of the model variance for each individual nonparametric function in order to calculate the GCV score for bandwidth parameter selection. Consequently, if
is replaced by
or
in (23), then the individual variance estimator
can be easily obtained. The fundamental concept behind computing
lies in selecting the appropriate smoothing and bandwidth parameters using the GCV criterion, as it relies on the estimated model variance. The GCV criterion can be summarized as follows.
criterion: Generalized cross-validation is used to obtain a minimum score based on the optimal tuning parameter for the regression model. In terms of bandwidth selection in additive models with LLR, ref. [
22] presented a detailed work on using GCV and its properties. Accordingly, to choose the optimal
for
function
,
score can be computed based on
given in (18):
where
is the hat matrix obtained for
which is provided at the end of the
Section 3. Notice that calculating the true
in PLAM is asymptotically justifiable if parametric and nonparametric covariates
are independent. If there is multicollinearity, then Equation (24) may be regularized properly due to overestimated
.
4.1. Evaluation of Performance
4.1.1. Metrics for the Parametric Component
In this section, two metrics are presented to assess the performance of the LLR estimator of the parametric component of the model
that are scalar versions of the dispersion error (SMDE) and the relative efficiency (RE), which is computed by ratio of the SMDE values. The formulations are given below:
where
is expressed as a summation of bias square and variance of
and given by:
Then, using (25), s of the methods on estimating can be computed. In this paper, methods are considered for use as censorship solution techniques for s.
Let
and
represent the estimates of parametric components based on two different censorship solutions. Accordingly,
can be formulated as follows:
where
indicates that
is more efficient than
.
4.1.2. Metrics for the Nonparametric Component
To evaluate the quality of the estimated nonparametric component, two measures are presented. The first measure is the root mean squared error (
), which measures the accuracy of each individual estimated function in the model. The second measure is the averaged root mean squared error (
) which is specifically designed to assess the performance of the overall additive component
. The formulations of
and
are written as:
and
where
and
.
5. Simulation Study
The practical performance of the modified LLR estimators in the context of right-censored PLAM with various censorship solution methods is analyzed in this section. To achieve this, different settings for sample size (
), the number of additive nonparametric components (
), and the level of censoring (CL) are considered. Specifically, three sample sizes (
, and
) and three levels of censoring (
, and
) are chosen. A total of eight scenarios are obtained by combining these configurations. Additionally, a total of 24 cases for analysis are formed by using three censorship solution methods. Moreover, accelerated failure time model estimation results are presented as benchmark performance scores. To achieve that existing function, the survival library in R is used. Note that the function written in R for this paper is provided via link:
https://github.com/yilmazersin13/Censored-Partially-linear-additive-models/tree/main, accessed on 9 August 2023. The simulation design and setup used in this study are designed in a manner commonly found in the literature (see ref. [
4]). Small, medium, and large sample sizes are chosen, along with three different censoring levels, in accordance with reference articles. Furthermore, the nonparametric component count has been determined in two distinct ways, introducing a novel approach that differs from most similar studies (see ref. [
9]).
After establishing the design, the data generation procedure for the right-censored PLAM is outlined here. Firstly, PLAM with completely observed responses is generated as:
where
, is
dimensional parametric covariate matrix with normally distributed and independently
’s that are generated as
. Also, the vector of regression coefficients is determined as
. Regarding the nonparametric component, smooth functions are generated by
with
and
with
when
. Note that, due to how all the variables are scaled in the simulation study, the constant term
is not used throughout the section. Finally, the random error terms
’s are independent and identically distributed with zero mean and constant variance, which can be shown as
.
After generating (30), by applying the censorship procedure given in Algorithm 3, right-censored response variable
is generated based on random censoring variable
and censoring indicator
.
| Algorithm 3 Censoring Procedure |
| Input: Completely observed |
| Output: Right-censored dependent variable |
| 1: For given censoring level (CL), produce from the binomial distribution
|
| 2: for |
| 3: If |
| 4: while |
| 5: generate |
| 6: Else |
| 7: |
| 8: end (for loop in Step 2)
|
| 9: for |
| 10: If |
| 11: |
| 12: Else |
| 13: |
| 14: end (for loop in Step 9) |
Then, right-censored PLAM is obtained with the incomplete response variable . Accordingly, the following figures and tables are provided based on the censorship solution techniques. Algorithms 2 and 3 present the results for the performance of the parametric component estimation, specifically the SMDE and RE values, respectively. In addition, as a benchmark method, the performance of AFT model estimation based on Cox’s semiparametric proportional hazards (CPH) estimator is provided in both simulation and real data examples. The estimates are obtained a using “Survival” package in R.
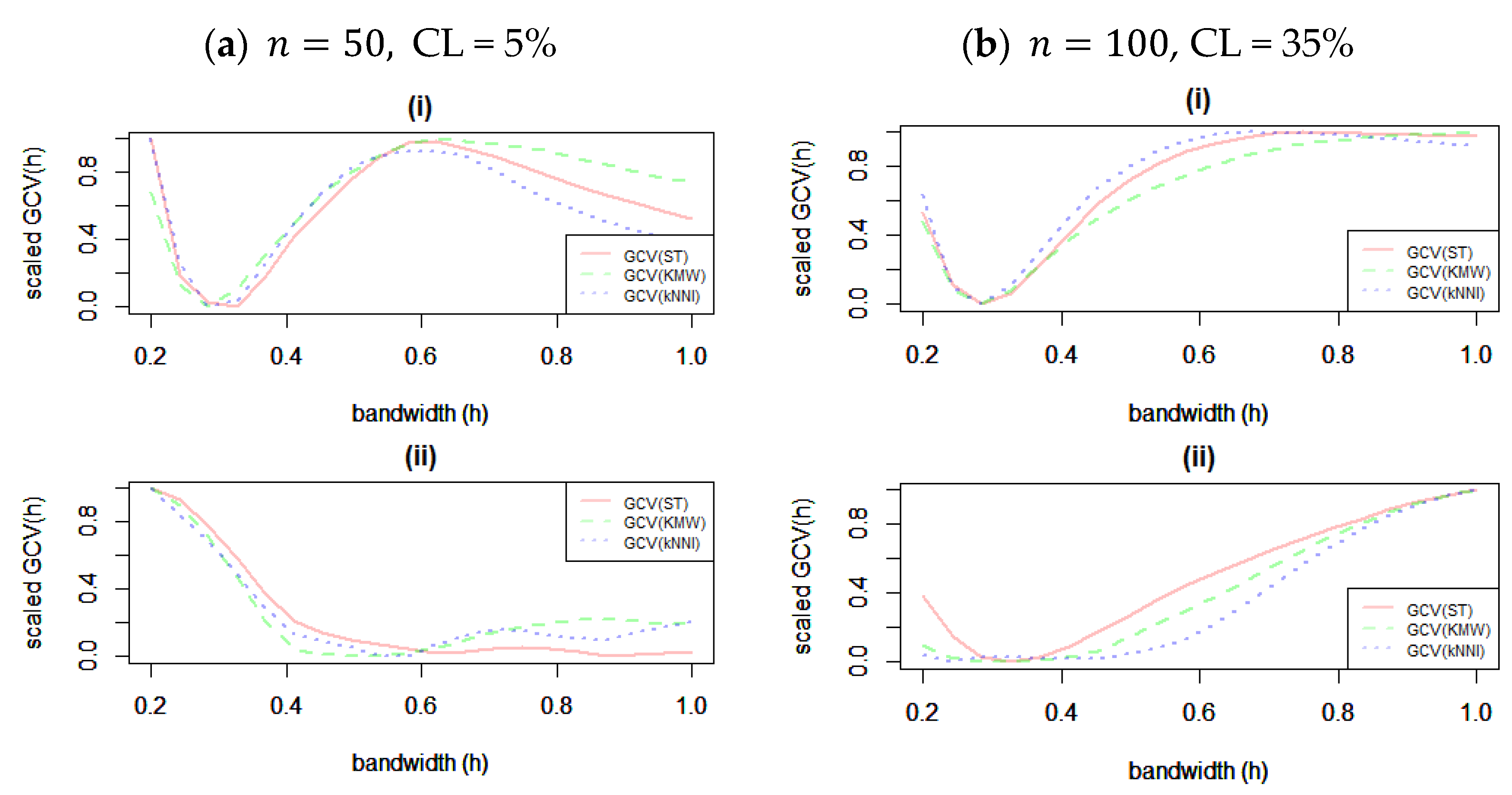
Prior to presenting the findings, we offer a visual representation in
Figure 2 that elucidates the process of bandwidth selection across diverse scenarios. This illustration sheds light on how the choice of bandwidth is intricately intertwined with the extent of censoring and the specific methods employed for addressing censorship. The discerning eye will note that in the context of
, the selection of bandwidth appears to exhibit a lesser degree of sensitivity to variations in the level of censoring and sample size. However, in the case of the
function, it becomes clear that the level of censorship exerts a discernible influence on the chosen bandwidth value. Notably, when confronted with elevated censorship levels across all solution strategies, a preference for smaller bandwidths becomes evident. This outcome is intuitively reasonable since, especially in scenarios involving ST and kNNI, the structural complexity of the data to be fitted takes on a more undulating nature. Therefore, it is evident that we can extrapolate that accounting for the degree of censorship is a pivotal factor when navigating the terrain of bandwidth selection. These findings resonate with prior research in this domain. Ref. [
23] demonstrated similar behavior in a related context, highlighting the sensitivity of bandwidth to censorship levels. In line with the in-depth investigations of ref. [
24], our observations underscore the need for cautious bandwidth selection in scenarios characterized by substantial censorship, promoting the accurate modeling of intricate data structures.
The results in
Table 1 demonstrate that the estimation quality of the modified LLR estimators for the parametric component
improves with lower censoring levels and larger sample sizes across all censorship techniques. These tendencies align with the expected theoretical behavior. Specifically, the LLR-KMW estimator exhibits dominant performance in many simulation combinations, closely followed by the LLR-kNNI estimator with competitive SMDE scores. However, the LLR-ST does not yield good performance. Also, as a benchmark method for the model, SMDE scores of the CPH estimator are presented in the table. It is evident that due to the model involving serious complexity with two different nonparametric functions, there is a significant distance between the LLR-based estimators and the CPH estimator, which is expected.
Interestingly, in cases where and or , the LLR-kNNI estimator outperforms the LLR-KMW estimator. As the sample size increases, LLR-KMW takes the lead, in accordance with its theoretical behavior. It is worth noting that due to its fully nonparametric nature, LLR-kNNI may yield better results under different configurations, demonstrating relative independence from specific simulation settings. This characteristic is observed in the combination of and .
Additionally, to assess the impact of censorship on the solution techniques, the increase in SMDE scores between censorship levels is examined. The results indicate that the the LLR-ST estimator is the most affected by censorship, which aligns with the theoretical background of ST presented in
Section 2.
In
Table 2, the calculation of the RE scores follows a decision where the nominators represent the columns, and the denominators represent the rows. Therefore, an RE value of less than 1 in
Table 2 indicates that the method in the column is more effective than the methods in the corresponding row. Please note that, for the sake of saving space, only certain simulation configurations are considered in
Table 2. The results in the table confirm that LLR-KMW is more efficient than LLR-ST in all cases. Simultaneously, LLR-KMW and LLR-kNNI exhibit similar outcomes, indicating that they are not distinctly efficient in any simulation configurations for estimating the parametric component of the PLAM.
Furthermore, when the censoring level is very high (
), the RE scores deviate from 1, making the performance differences among the LLR estimators based on the solution techniques more apparent. Once again, it is evident that, especially for
, ST is the most sensitive technique to censorship compared with the other two methods. Additionally, the results reveal that LLR-kNNI and LLR-KMW display similar RE scores in every combination. In addition, in
Table 2, REs of CPH show that there is a clear dominance of LLR-basis estimators for the estimation of right-censored PLAM. This result also proves that the introduced estimator has important potential to be an alternative estimator for the model of interest that is used in survival analysis.
In
Figure 3, the averaged values of the RE scores are displayed, confirming the interpretations from
Table 2. The figure also shows both the effects of censorship and the sample size. In panel (a), the RE values are very close to each other due to the very low censoring level (
). Panels (b) and (c) demonstrate the change in RE scores as the censoring level increases, with the differences between the estimators becoming more distinct, as mentioned earlier. Consequently, the LLR-kNNI and LLR-KMW estimators are more efficient than the LLR-ST estimator. In panel (c), the performances are once again close to each other, reflecting the large sample size (
).
After analyzing the parametric component, the estimation of the additive nonparametric components is presented in
Table 3 and
Table 4.
Table 3 displays the RMSE values computed for the individual functions, while
Table 4 provides the ARMSE values for all simulation configurations, serving as a measure of the overall performance in estimating the nonparametric component of the right-censored PLAM. Upon initial examination, the LLR-KMW estimator demonstrates a significantly superior performance compared with the other two estimators across all simulation configurations. This dominance is further evidenced by the ARMSE results presented in
Table 4, which contrast the outcomes observed in the parametric component estimation.
An interesting distinction in estimating the nonparametric component is that the performances of the introduced estimators deteriorate as the sample size increases. To explain this phenomenon, it is crucial to note that in the estimation of PLAMs, there exists a balance between the estimation of parametric and nonparametric components, which exhibits an inverse relationship. Furthermore, when data points are scattered widely around the representative smooth curve, the bias of the fitted curve increases. Additionally, the RMSE scores for the three modified LLR estimators are fairly similar to each other, confirming that the modified backfitting algorithm functions effectively with the censorship solution techniques.
Table 4 presents a strong case, confirming the dominant role of the LLR-KMW estimator in estimating nonparametric components within the context of right-censored PLAM. The success of the LLR-KMW estimator lies in its clever use of weighted estimation, which works well for both the parametric and nonparametric aspects of PLAM. Notably, the LLR-KMW estimator does not just improve
β estimates, it also works well together with the LLR-kNNI estimator, forming a powerful estimation duo. When we carefully analyze
Table 4 and take a close look at
Figure 4 and
Figure 5, a clear pattern emerges. Both the LLR-KMW and LLR-kNNI estimators perform very similarly when it comes to estimating the nonparametric component. What is even more interesting is that both estimators outperform the LLR-ST estimator, as these enlightening visuals below beautifully demonstrate. In terms of estimating nonparametric components, it is naturally expected that the CPH estimator does not show a good performance due to its theoretical structure. However, its behaviors are similar to LLR-basis estimators in sample size and censoring level changes. In summary, the introduced LLR-basis estimators show better performance than the classical CPH estimator.
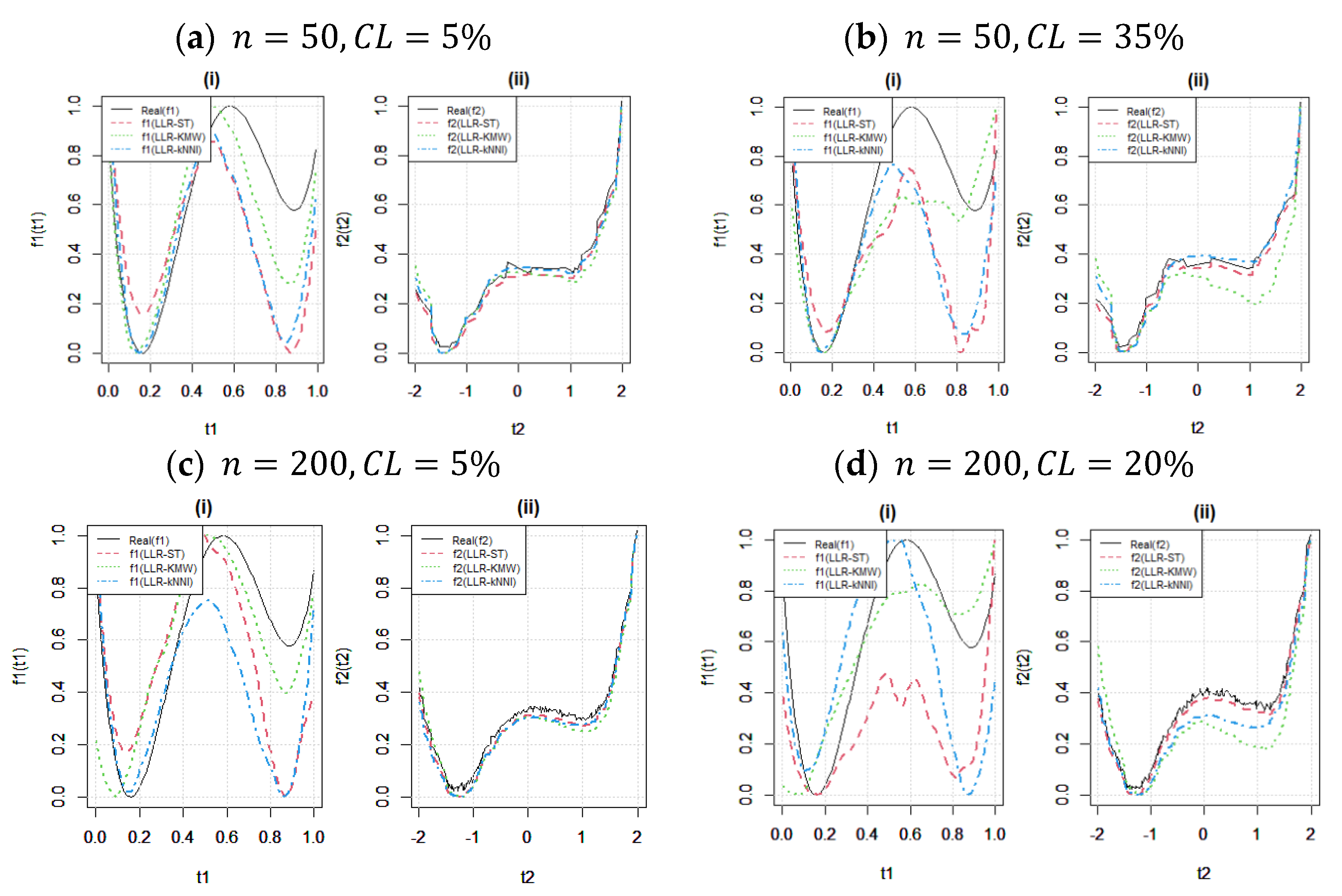
Figure 4 illustrates the behavior of the estimators under different censoring levels with fixed sample sizes. In panels (a)–(b), the effect of the censoring level is investigated when the sample size is small (
). It can be observed that while
is not significantly affected, the estimate of
is heavily influenced by the censored data points. It is important to note that this inference is also related to the initial values
determined in the algorithm and their compatibility with the unknown functions
and
, respectively (see [
9] for further discussions). Furthermore, the results demonstrate that the weakness of the LLR-ST estimator (red dotted line) is clear in all four panels (a), (b), (c), and (d), for both
and
. Additionally, panels (c) and (d) support the findings of
Table 3 and
Table 4, leading to the conclusion that, for larger sample sizes, the fitted curves become more sensitive to the censoring level, resulting in a decrease in their performance.
Figure 5 investigates the effect of sample size (
) for fixed censoring levels in the upper and lower panels, particularly for
in panels (c) and (d), while LLR-KMW and LLR-ST exhibit a slightly more pronounced response to increasing sample size compared with LLR-kNNI. This result is expected due to the nonparametric nature of kNNI. Furthermore, the changes observed in the fitted curves are more noticeable for the estimation of
, as shown in
Figure 4. Additionally, the differences between sample sizes for the lower censoring level (
in panels (a)–(b) indicate that there is minimal variation between the fitted curves for both functions.
These trends are consistent with the findings reported by ref. [
25], where a similar sensitivity of the ST basis estimator to sample size was identified in a related context. The reaction of the kNNI, KMW, and ST estimators to sample size fluctuations aligns with the observations made by ref. [
26] reinforcing the notion that these estimators can exhibit greater flexibility in accommodating varying sample sizes.
To assess the performance of the introduced modified LLR estimators on real-world data and compare them with the simulation results, a real data example is presented in the following section, focusing on the hepatocellular carcinoma dataset.
6. Hepatocellular Carcinoma Data Example
In this section, the Hepatocellular Carcinoma dataset is modeled using the modified LLR estimators: LLR-ST, LLR-KMW, and LLR-kNNI. Their performances are compared with similar simulation configurations presented in
Section 5. The dataset was originally presented by ref. [
27] to investigate the gene expression of CXCL17 in hepatocellular carcinoma. Ref. [
6] also studied this dataset, comparing parametric and semiparametric models on right-censored data. However, their study focused on a semiparametric model with a univariate nonparametric component using the covariate age. This paper considers a more realistic partially linear additive model (PLAM) that involves two nonparametric covariates.
The dataset consists of 227 data points and five explanatory variables: age, recurrence-free survival (RFS), CXCL17T (CXCT), CXCL17P (CXCP), and CXCL17N (CXCN). It should be noted that the logarithm of the response variable, overall survival time (
), is used in this analysis. The parametric component of the PLAM is determined by the covariates CXCL17T, CXCL17P, and CXCL17N. Additionally,
and
are considered as nonparametric covariates due to their nonlinear structures, as depicted in
Figure 6. The figure also illustrates the censored data points versus the transformed data points using the kNNI and ST solutions. Furthermore, panels (C) and (D) display hypothetical curves that represent the data structure and nonlinearity.
The dataset contains 84 right-censored OS points, indicating a censoring level of
This level of censorship can be classified as heavy censoring. Therefore, we expect that the results from the real data analysis may resemble the corresponding simulation configuration of
and
Based on the information provided above, the partially linear additive model (PLAM) for the right-censored Hepatocellular Carcinoma dataset can be expressed as follows:
where
. While estimating PLAM in (31),
is replaced by its ST version
and kNNI version
. Also, KMW is applied. The outcomes of the Hepatocellular Carcinoma dataset with the modified LLR estimators are provided in
Table 5.
Table 5 largely confirms the findings of the simulation study and demonstrates the superior performance of the LLR-KMW estimator in the estimation of the parametric component. However, in contrast to the simulation study, the LLR-ST estimator also provides results that are closer to the other two estimators, while the performance of LLR-kNNI is less satisfactory than expected. It should be noted that these conditions may be attributed to the relatively large sample size in terms of censored data. Additionally, regarding the bias of β, as anticipated, both ST and KMW yield lower values compared with kNNI, as they theoretically promise less biased estimates. Overall, the performance evaluation in
Table 6 confirms that LLR-KMW exhibits the best results, which are evident from the RE scores.
In both
Table 5 and
Table 6, the performance of benchmark CPH estimators is also provided and, as expected, it does not show a good performance, especially in the estimation of the nonparametric component. On the other hand, in terms of bias,
Table 5 shows that CPH has satisfying bias values but with large variances that cause large SMDE scores. This poor performance is highly related to the lack of the ability of CPH to represent smooth functions. RE scores highly confirm this inference. Summing up the comprehensive assessment presented in
Table 6, we encounter an unequivocal affirmation of the preeminent standing of the LLR-KMW estimator. This affirmation is elegantly illuminated by the notable RE scores, reflecting an ensemble of successful estimation endeavors.
In
Figure 7, bar plots of the calculated relative efficiencies (RE) are presented. Consistent with the findings in
Table 5, LLR-KMW exhibits lower RE scores compared with the other two estimators, which aligns with the results of the simulation study. It is worth noting that while the difference in performance between the estimators may appear significant, numerically they are relatively close to each other, with the RE values scattered around one.
After assessing the estimation of the parametric component,
Figure 8 presents the results of the estimation of the nonparametric components
and
. It is noteworthy that in this dataset, the relative failure of LLR-kNNI and the relative success of LLR-ST can be attributed to the structure of the nonparametric components. Both functions
and
exhibit favorable structures for the properties of LLR-ST, such as magnifying the magnitudes of uncensored data points and assigning zero to censored ones, as clearly observed in panel (ii) of
Figure 8.
To provide a more precise understanding of the solution procedures, the ST points and kNNI points are also included in the plots. These points illustrate why the fitted curves tend to lie below the region where all data points are scattered, especially in panel (ii). This is primarily influenced by the heavy censoring level,
Additionally, in panel (i), one can observe the LLR-ST’s fitted curve being pulled down by the zeros. As expected, LLR-KMW follows a balanced approach between the other two estimators, as shown in
Table 5, yielding the smallest ARMSE scores in the estimation of the nonparametric component of the PLAM.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}