
A Lightweight Method for Defense Graph Neural Networks Adversarial Attacks

Abstract
:1. Introduction
1.1. Advantages
1.2. Challenges
1.3. Contributions
- The transformation method optimizes the flow of defense against an attack on graph data. Our approach avoids extra training processes and achieves a shorter run time;
- We explore four graph transformations: copying, padding, deleting edges, and nodes compression. We also introduce how to implement these four transformation forms and their complexity is analyzed;
- A series of contrast experiments are designed, which cover both defense effectiveness and run time.
2. Related Work
2.1. Adversarial Attack on Graph
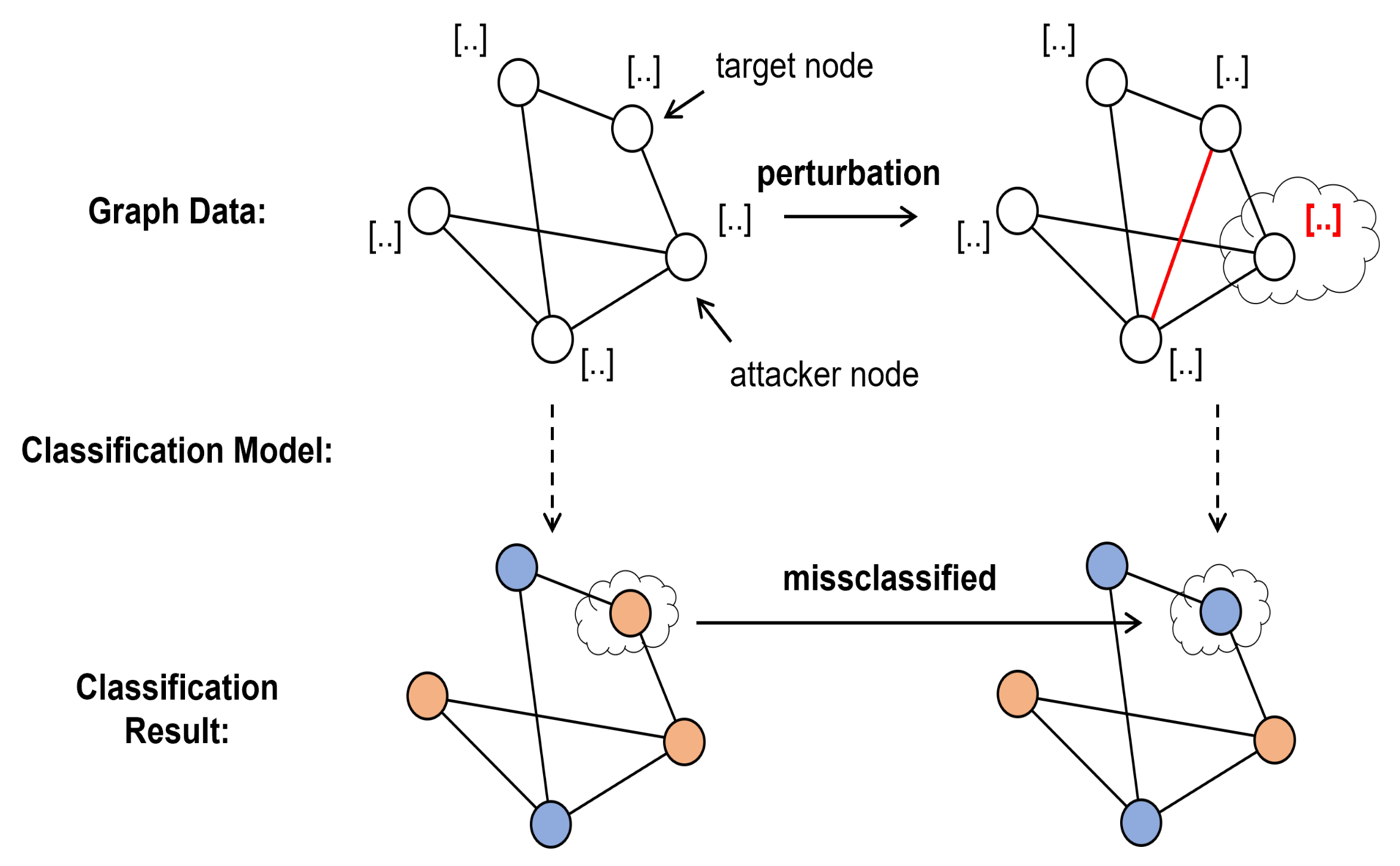
- Classification based on attacker knowledge: If the attacker is familiar with the data and parameters of neural network model utilized by the victim. This is referred to as a white box attack. White box attacks are virtually impossible to execute in the real world, but their influence is the most difficult to eradicate. A grey box attack, is when the attacker can get the data but not details of the model’s contents. NETTACK, mentioned above, is a kind of gray box attack. In a black box attack, an attacker can only obtain query results. A black box attack is the most concealed of the three attacks, so it is more likely to cause serious consequences. RL-S2V is the first time that a black box attack has been implemented in graph data;
- In machine learning, the attack can be classified as Poisoning or Evasion [18]. The poisoning attack happens before training and alters the training data. In general, poisoning attacks induce model failure. Although an evasion attack corrupts the test data and provides adversarial instances, the victim model remains intact.
2.2. The Defense Approach
3. Preliminaries
3.1. Definition
3.2. Target Model
3.3. Producing Adversarial Examples
- Action: means an attacker adds or deletes edges at time t;
- State: It uses a tuple to present the state at time t and represents the changed graph;
- Reward: the attacker’s goal is to interfere with the predicted results of the target classifier, so the reward is always zero except for when time is at the end of the decision process. If the prediction is consistent with the true label, this attack fails and returns as the negative feedback. Otherwise, it returns 1 as the positive feedback.
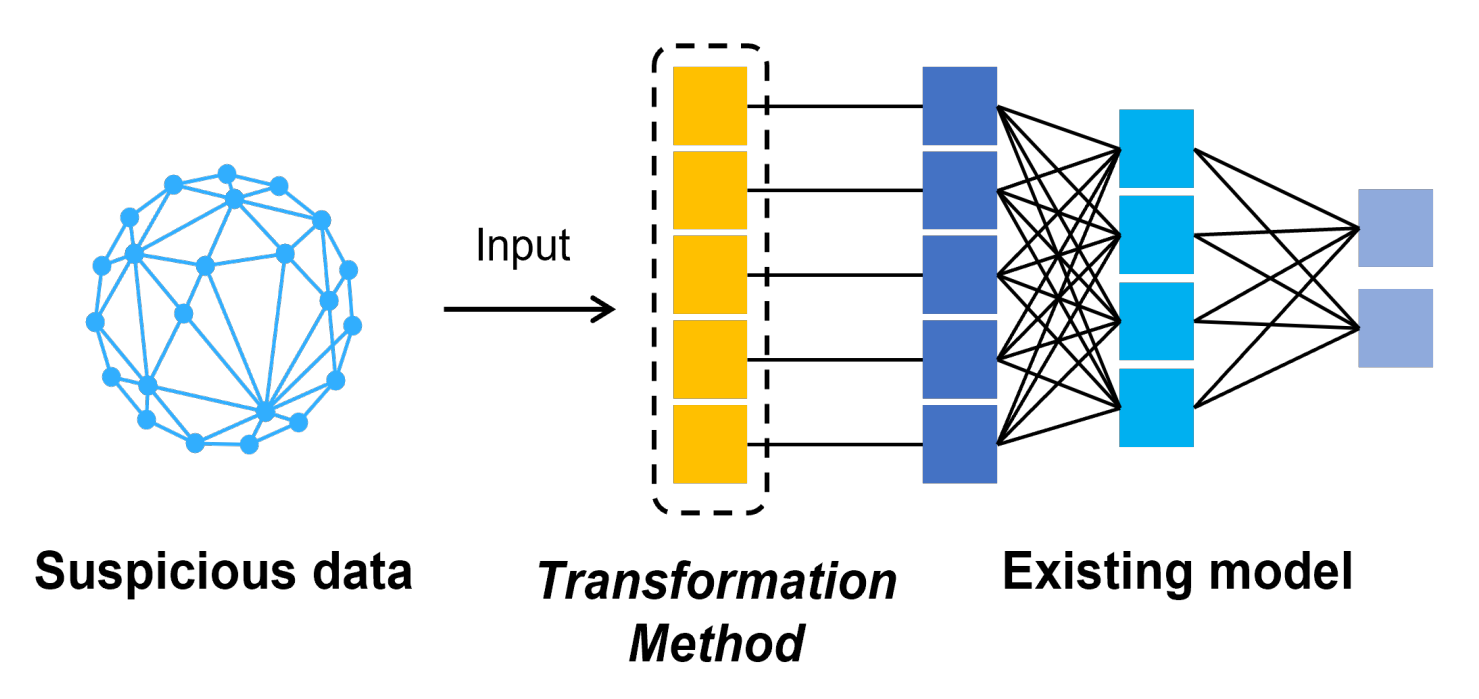
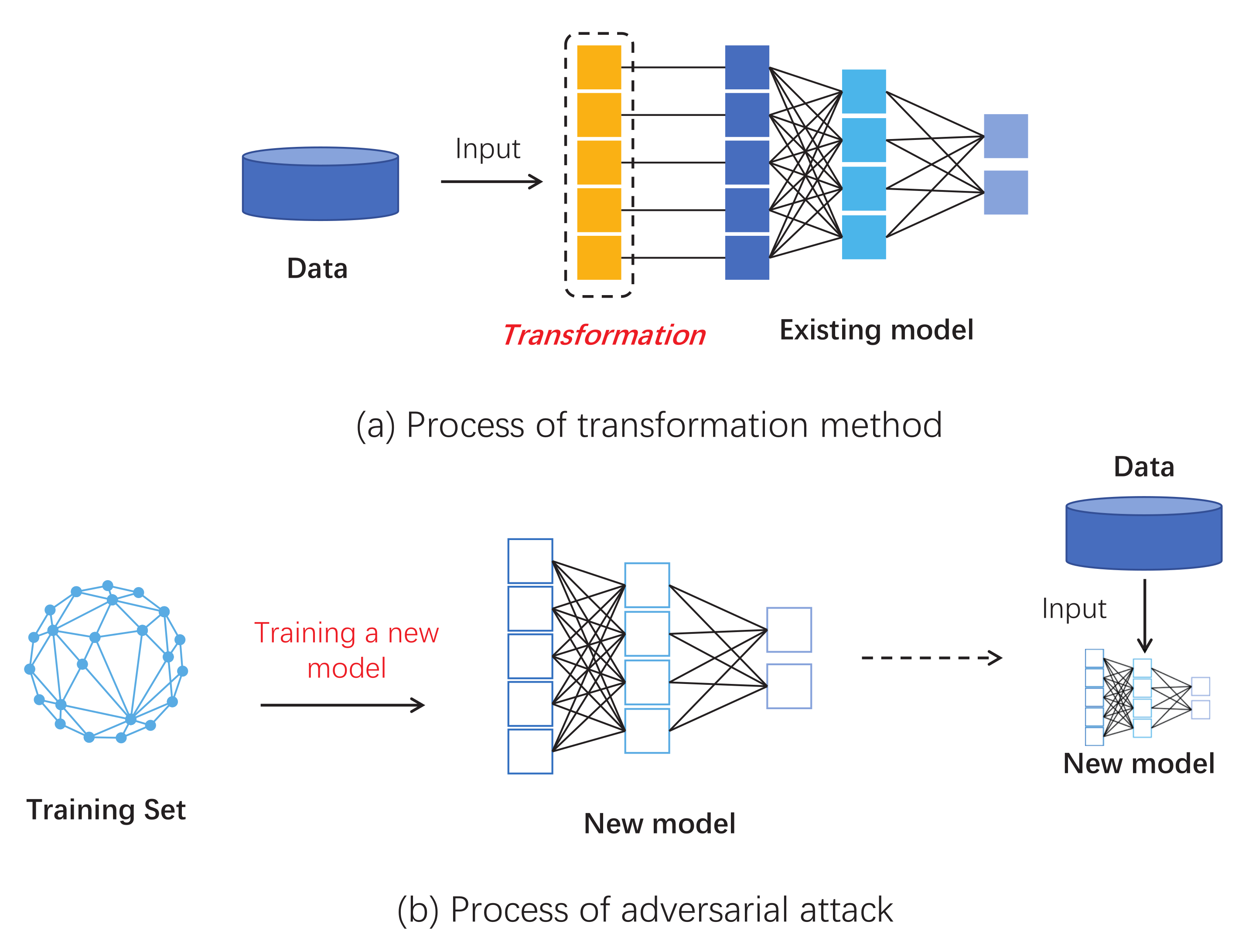
4. Transformation Method
4.1. Execute Solution
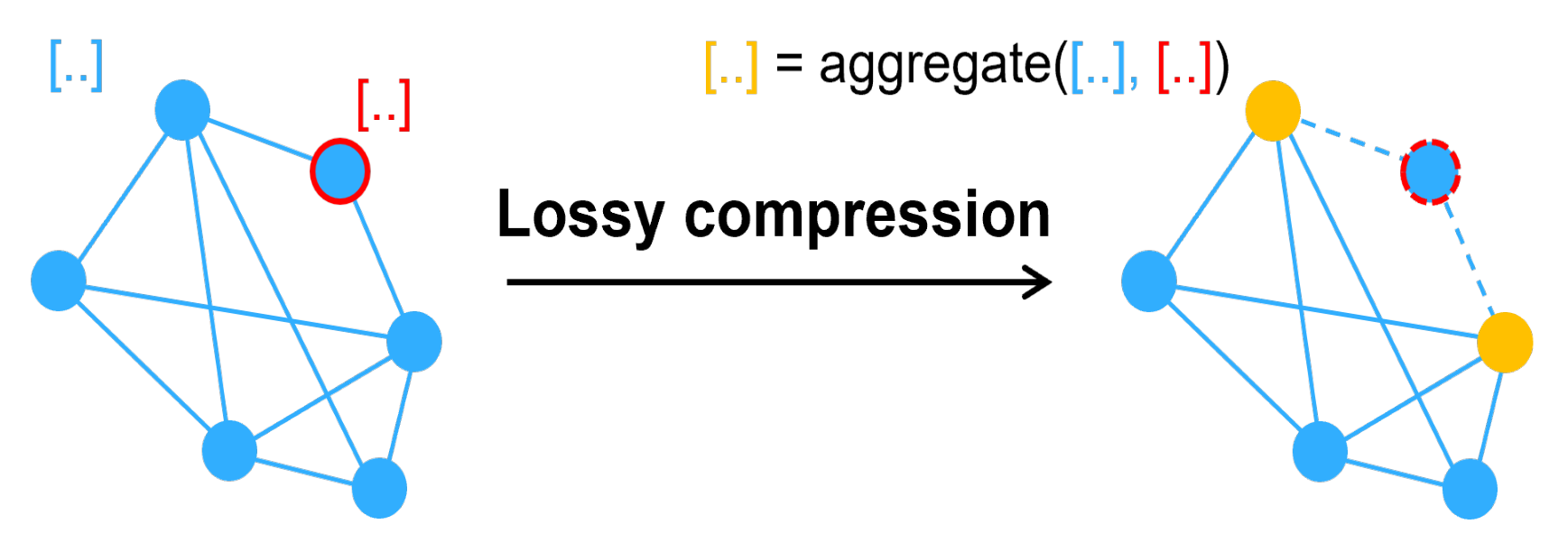
4.1.1. Nodes Compression
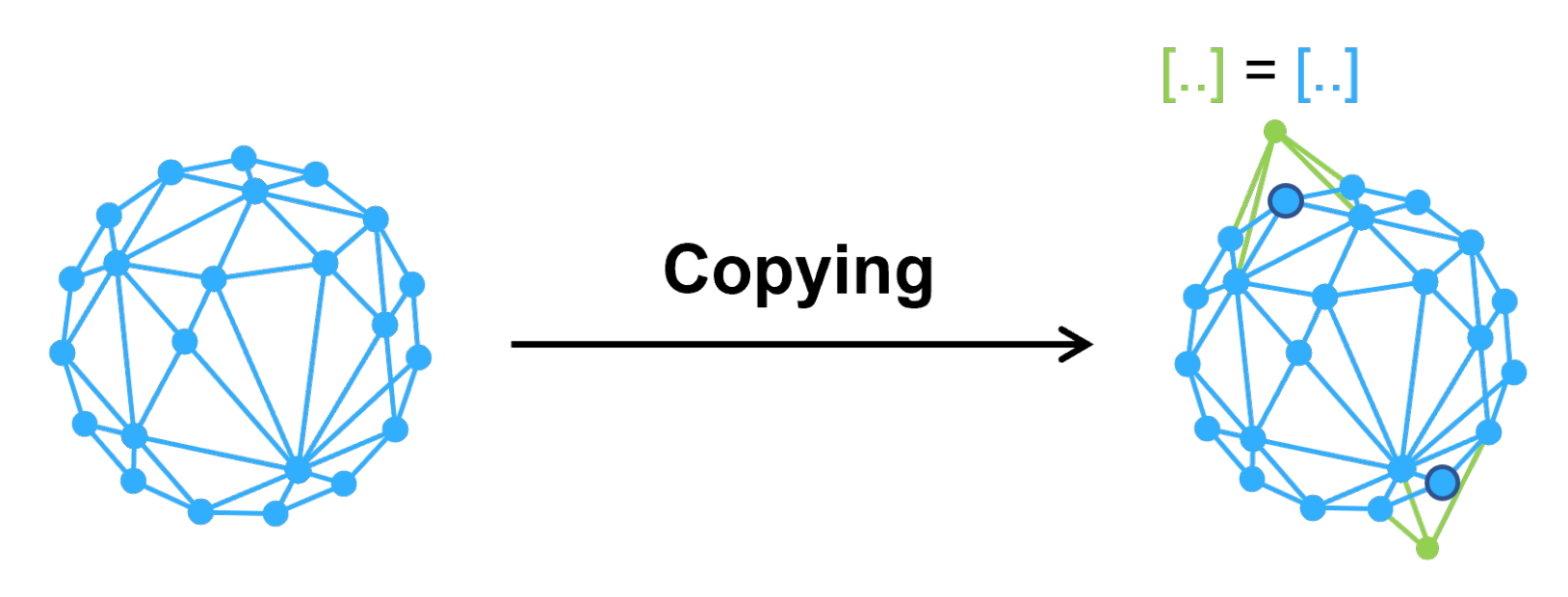
4.1.2. Copy
4.1.3. Pad
4.1.4. Delete Edges
4.2. Analysis
5. Experiment and Discussions
5.1. Dataset
5.2. Baseline Models
- R-GCN uses the attentional mechanism to assign lower attention to suspicious nodes in the process of graph neural network aggregation. According to R-GCN, when the variance of a group of data is large, it means the dispersion degree of this group of data is large, and also means that uncertainty of this group of data is stronger. Hence, a neural network needs to assign less attention to this set of data. In order to achieve such a thought, R-GCN represents the hidden layer in GCN as a Gaussian distribution and calculates the variance from it. When the variance is larger, the weight will be smaller to a node;
- MedianGCN [25] aims to find out why graph convolutional networks are vulnerable to attacks. Based on the breakdown point theory, they point out that the vulnerability of graph convolutional networks mainly comes from the unrobust aggregation functions. The author regards the convolution process of GCN as a mean aggregation and the process of an adversarial attack tends to increase the extreme value and make the mean calculation move away. This makes the aggregation result deviate from the correct result. In this defense, the authors use the median instead of the mean. Compared to the mean, the median only changes when more than half of the values are changed. Therefore, the robustness of using the median calculation is better than that of the mean calculation;
- Adversarial training [19] is a classic defense against an adversarial attack. The basic idea of graph adversarial training is to include adversarial samples into the training stage of the model, expand the training samples, and train the original data and adversarial samples together, so as to improve the robustness of the model.
5.3. Environments
- Training a healthy GCN model as target model and use it to complete the nodes classification task as a benchmark (original results). All the results are evaluated by accuracy;
- Using the target model to complete the nodes classification task under attack and get attacked-results;
- Nodes classification task under attack when the defense methods are involved. We get the third results;
- Analyzing and comparing the three groups of results.
5.4. Experiment and Results
- Experiment 1: Basic defense experiment: We design the experiment with the setup in the previous subsection. The results are averaged over many experiments as shown in Table 3. It should be noted that this experiment was for evasion attacks, so we trained a GCN model as the target, which was restricted from being modified. This also means that we need to keep the number of nodes consistent with the original data, so we compressed the data before adding the extra nodes. When nodes compression is used alone, we modify it as 0 in the adjacency matrix instead of deleting the nodes directly.
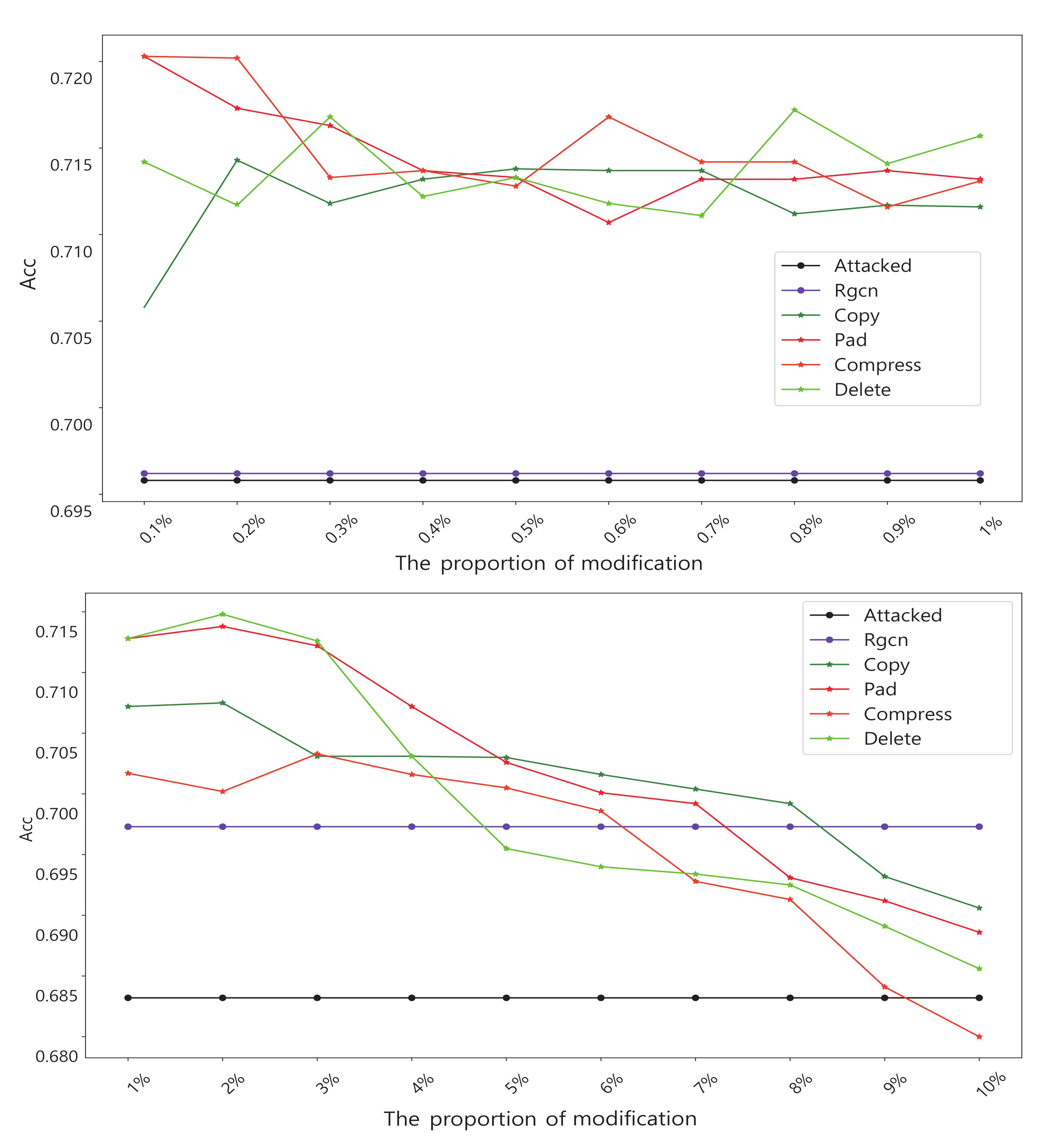
- Experiment 2: Experiments with different transformation scale: In this experiment we focused on the amount of modification. We incrementally increase the number of changes by 1% of the total number of nodes. All experiments in this section will be targeted at NETTACK attacks. We increment the number of nodes by 0.1% in the first stage and 1% in the second stage. The experimental results are shown in Figure 8.
- Experiment 3: Experiments on run time: This set of experiments will intuitively demonstrate that our method has a significant time advantage over existing schemes. We chooses the Pubmed dataset, which is larger and more time-sensitive. Table 4 shows the results.
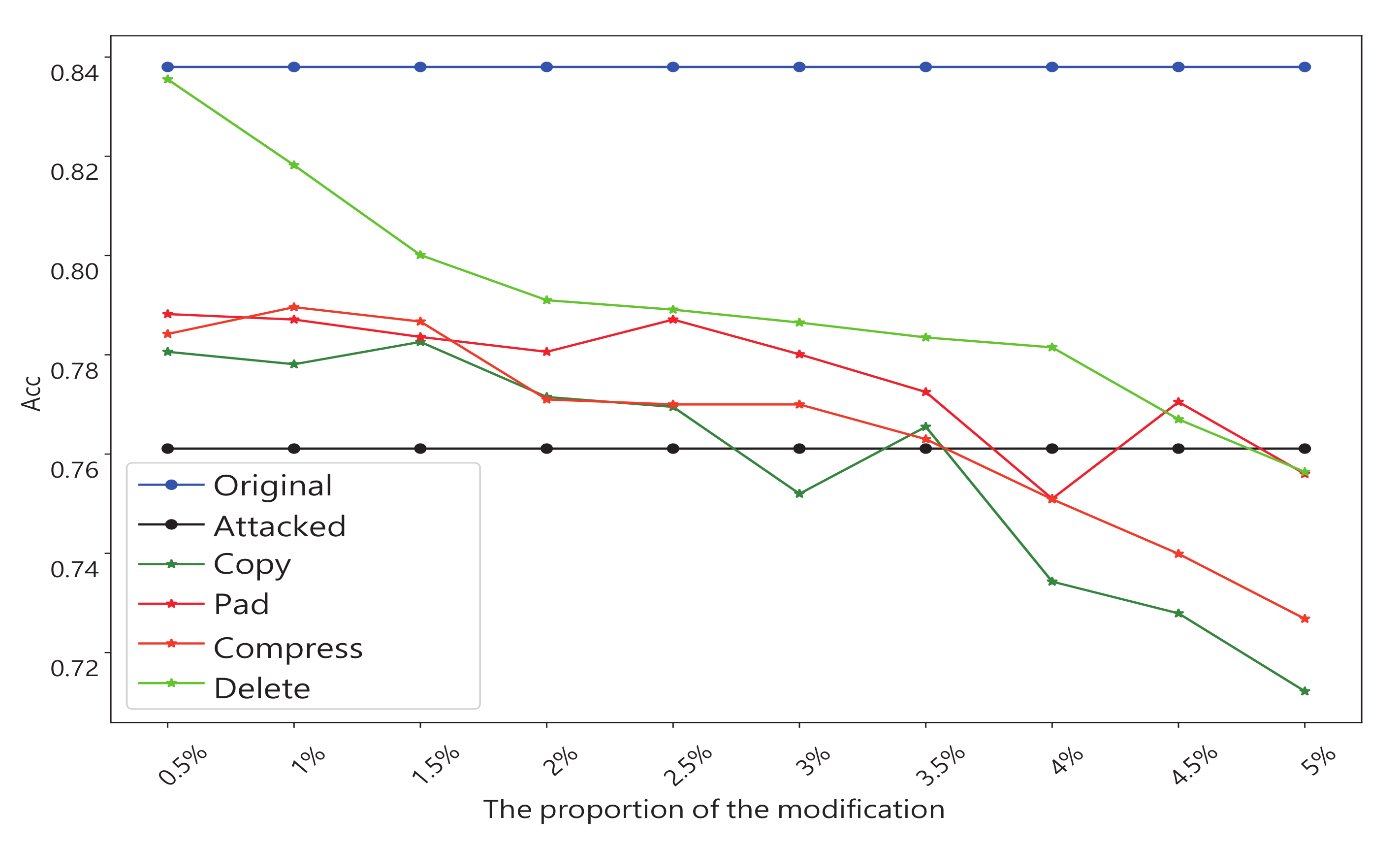
- Experiment 4: Defends against poisoning attacks: Although our method is originally designed to protect against evasion attacks, we also do experiments on poison attacks. The amount of each transformation that we make increases by 0.5% of the total number of nodes. The result is shown in Figure 9.
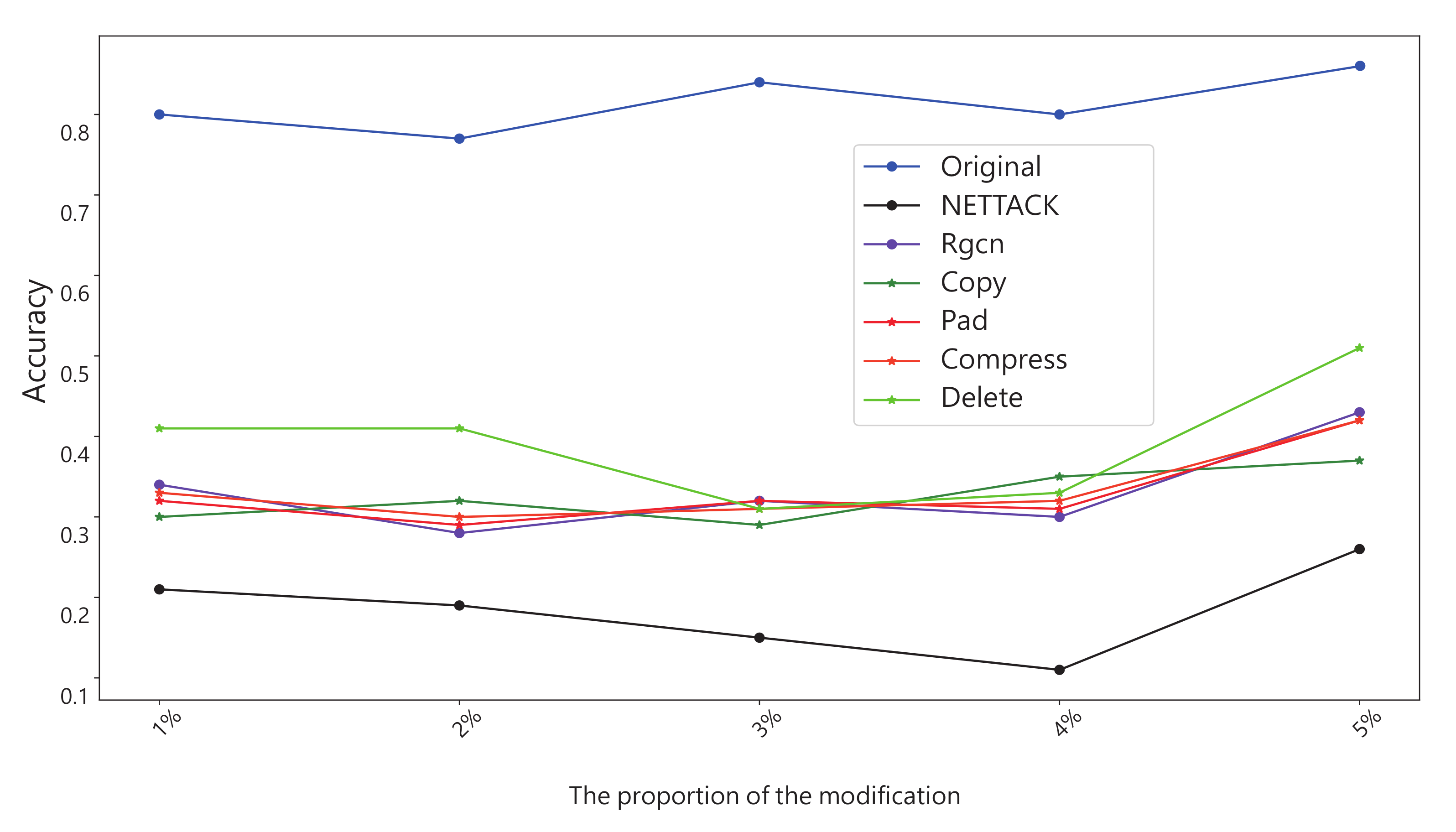
- Experiment 5: The above experiments evaluate the method from a global perspective. The fifth experiment focuses on specific nodes in the dataset before and after the defense. In this experiment, there are randomly selected some nodes as victims. At the same time, in the experiment, we ensure that these nodes will not be deleted in the process of defense. Finally, we looked at how correctly these victims were classified before and after attack and defense. The result is shown in Figure 10.
- Experiment 6: An experiment on run-time memory usage. In this experiment we used the Cora dataset. We let the experimental program interrupt before it calculates the AUC and gets the memory footprint of the python interpreter at this time. The experimental results are shown in Table 5.
5.5. Analysis and Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Eswaran, D.; Günnemann, S.; Faloutsos, C.; Makhija, D.; Kumar, M. Zoobp: Belief propagation for heterogeneous networks. Proc. VLDB Endow. 2017, 10, 625–636. [Google Scholar] [CrossRef]
- Can, U.; Alatas, B. A new direction in social network analysis: Online social network analysis problems and applications. Phys. A Stat. Mech. Its Appl. 2019, 535, 122372. [Google Scholar] [CrossRef]
- Abbasi, M.; Shahraki, A.; Taherkordi, A. Deep learning for network traffic monitoring and analysis (NTMA): A survey. Comput. Commun. 2021, 170, 19–41. [Google Scholar] [CrossRef]
- Gori, M.; Monfardini, G.; Scarselli, F. A new model for learning in graph domains. In Proceedings of the 2005 IEEE International Joint Conference on Neural Networks, Montreal, QC, Canada, 31 July–4 August 2005; Volume 2, pp. 729–734. [Google Scholar]
- Chapelle, O.; Schölkopf, B.; Zien, A. Semi-Supervised Learning: Adaptive Computation and Machine Learning Series; The MIT Press: Cambridge, MA, USA, 2006. [Google Scholar]
- London, B.; Getoor, L. Collective Classification of Network Data. In Data Classification Algorithms and Applications; Chapman and Hall/CRC: New York, NY, USA, 2014; Volume 399. [Google Scholar]
- Welling, M.; Kipf, T.N. Semi-supervised classification with graph convolutional networks. In Proceedings of the J. International Conference on Learning Representations (ICLR 2017), Toulon, France, 24–26 April 2016. [Google Scholar]
- Wang, H.; Liu, Y.; Yin, P.; Zhang, H.; Xu, X.; Wen, Q. Label specificity attack: Change your label as I want. Int. J. Intell. Syst. 2022, 37, 7767–7786. [Google Scholar] [CrossRef]
- Dai, Q.; Shen, X.; Zhang, L.; Li, Q.; Wang, D. Adversarial training methods for network embedding. In Proceedings of the World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 329–339. [Google Scholar]
- Zhu, D.; Zhang, Z.; Cui, P.; Zhu, W. Robust graph convolutional networks against adversarial attacks. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery &, Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 1399–1407. [Google Scholar]
- Ren, K.; Zheng, T.; Qin, Z.; Liu, X. Adversarial attacks and defenses in deep learning. Engineering 2020, 6, 346–360. [Google Scholar] [CrossRef]
- Xie, C.; Wang, J.; Zhang, Z.; Ren, Z.; Yuille, A. Mitigating Adversarial Effects Through Randomization. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Chen, J.; Wu, Y.; Xu, X.; Chen, Y.; Zheng, H.; Xuan, Q. Fast gradient attack on network embedding. arXiv 2018, arXiv:1809.02797. [Google Scholar]
- Zügner, D.; Akbarnejad, A.; Günnemann, S. Adversarial attacks on neural networks for graph data. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery &, Data Mining, London, UK, 19–23 August 2018; pp. 2847–2856. [Google Scholar]
- Sun, Y.; Wang, S.; Tang, X.; Hsieh, T.Y.; Honavar, V. Adversarial attacks on graph neural networks via node injections: A hierarchical reinforcement learning approach. In Proceedings of the Web Conference 2020, Taipei, Taiwan, 20–24 April 2020; pp. 673–683. [Google Scholar]
- Finkelshtein, B.; Baskin, C.; Zheltonozhskii, E.; Alon, U. Single-Node Attacks for Fooling Graph Neural Networks. Neurocomputing 2022, 513, 1–12. [Google Scholar] [CrossRef]
- Dai, H.; Li, H.; Tian, T.; Huang, X.; Wang, L.; Zhu, J.; Song, L. Adversarial attack on graph structured data. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 1115–1124. [Google Scholar]
- Biggio, B.; Fumera, G.; Roli, F. Security evaluation of pattern classifiers under attack. IEEE Trans. Knowl. Data Eng. 2013, 26, 984–996. [Google Scholar] [CrossRef] [Green Version]
- Feng, F.; He, X.; Tang, J.; Chua, T.S. Graph adversarial training: Dynamically regularizing based on graph structure. IEEE Trans. Knowl. Data Eng. 2019, 33, 2493–2504. [Google Scholar] [CrossRef] [Green Version]
- Zhou, K.; Michalak, T.P.; Vorobeychik, Y. Adversarial robustness of similarity-based link prediction. In Proceedings of the 2019 IEEE International Conference on Data Mining (ICDM), Beijing, China, 8–11 November 2019; pp. 926–935. [Google Scholar]
- Jia, L.; Yao, F.; Sun, Y.; Niu, Y.; Zhu, Y. Bayesian Stackelberg game for antijamming transmission with incomplete information. IEEE Commun. Lett. 2016, 20, 1991–1994. [Google Scholar] [CrossRef]
- Bahdanau, D.; Cho, K.H.; Bengio, Y. Neural machine translation by jointly learning to align and translate. In Proceedings of the 3rd International Conference on Learning Representations (ICLR 2015), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Gehring, J.; Auli, M.; Grangier, D.; Dauphin, Y. A Convolutional Encoder Model for Neural Machine Translation. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vancouver, BC, Canada, 30 July–4 August 2017; pp. 123–135. [Google Scholar]
- Arghal, R.; Lei, E.; Bidokhti, S.S. Robust graph neural networks via probabilistic lipschitz constraints. In Proceedings of the Learning for Dynamics and Control Conference, Stanford, CA, USA, 27–28 June 2022; pp. 1073–1085. [Google Scholar]
- Chen, L.; Li, J.; Peng, Q.; Liu, Y.; Zheng, Z.; Yang, C. Understanding structural vulnerability in graph convolutional networks. arXiv 2021, arXiv:2108.06280. [Google Scholar]
- Guo, C.; Rana, M.; Cisse, M.; van der Maaten, L. Countering Adversarial Images using Input Transformations. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Das, N.; Shanbhogue, M.; Chen, S.T.; Hohman, F.; Li, S.; Chen, L.; Kounavis, M.E.; Chau, D.H. Shield: Fast, practical defense and vaccination for deep learning using jpeg compression. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery &, Data Mining, London, UK, 19–23 August 2018; pp. 196–204. [Google Scholar]
- Wallace, G.K. The JPEG still picture compression standard. IEEE Trans. Consum. Electron. 1992, 38, xviii–xxxiv. [Google Scholar] [CrossRef]
- Zantedeschi, V.; Nicolae, M.I.; Rawat, A. Efficient defenses against adversarial attacks. In Proceedings of the 10th ACM Workshop on Artificial Intelligence and Security, Dallas, TX, USA, 3 November 2017; pp. 39–49. [Google Scholar]
- Zhao, X.; Liang, J.; Wang, J. A community detection algorithm based on graph compression for large-scale social networks. Inf. Sci. 2021, 551, 358–372. [Google Scholar] [CrossRef]
- Liu, Y.; Safavi, T.; Dighe, A.; Koutra, D. Graph summarization methods and applications: A survey. ACM Comput. Surv. (CSUR) 2018, 51, 1–34. [Google Scholar] [CrossRef]
- Pedreschi, N.; Battaglia, D.; Barrat, A. The temporal rich club phenomenon. Nat. Phys. 2022, 18, 931–938. [Google Scholar] [CrossRef]
- Dernoncourt, F.; Lee, J.Y. PubMed 200k RCT: A Dataset for Sequential Sentence Classification in Medical Abstracts. In Proceedings of the Eighth International Joint Conference on Natural Language Processing (Volume 2: Short Papers), Taipei, Taiwan, 20–23 November 2017; pp. 308–313. [Google Scholar]
- Sen, P.; Namata, G.; Bilgic, M.; Getoor, L.; Galligher, B.; Eliassi-Rad, T. Collective classification in network data. AI Mag. 2008, 29, 93–93. [Google Scholar] [CrossRef]
- Li, Y.; Jin, W.; Xu, H.; Tang, J. Deeprobust: A platform for adversarial attacks and defenses. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtually, 2–9 February 2021; Volume 35, pp. 16078–16080. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Strategy | Need Any Extra Training? | Need to Replace the Existing Model? | Time Complexity |
|---|---|---|---|
| Adversarial training | Yes | Yes | O(n⌃2) (GCN directly adversarial training) |
| Robust neural network | Yes | Yes | O(n⌃2) * O(n) (r-GCN) |
| O(n⌃2) (copy) | |||
| Transformation Method | No | No | O(n) (pad) |
| O(n) (delete) | |||
| O(nlog(n)) (compress) |
| Name | Node | Edge | Attribute | Label |
|---|---|---|---|---|
| Pubmed | 19,717 | 44,338 | 500 | 3 |
| Cora | 2708 | 5429 | 1433 | 8 |
| Item | Original | Attacked | R-GCN | M-GCN 1 | adv_train | Compress | Copy | Pad | Delete_Edge |
|---|---|---|---|---|---|---|---|---|---|
| NETTACK | 0.846 | 0.718 | 0.788 | 0.790 | 0.805 | 0.791 | 0.794 | 0.796 | 0.795 |
| FGA | 0.846 | 0.643 | 0.651 | / | 0.723 | 0.642 | 0.643 | 0.642 | 0.647 |
| RL-S2V | 0.846 | 0.791 | 0.811 | / | 0.830 | 0.815 | 0.809 | 0.805 | 0.815 |
| Item | Original | Attacked | R-GCN | M-GCN | adv_train | Copy | Pad | Delete_Edge | Compress |
|---|---|---|---|---|---|---|---|---|---|
| Acc | 0.842 | 0.761 | 0.783 | 0.785 | 0.815 | 0.783 | 0.777 | 0.785 | 0.774 |
| Time | / | / | 85.701 s | 74.267 s | 74.486 s | 2.563 s | 1.660 s | 0.196 s | 1.471 s |
| Method | Copy | Pad | Delete | Compress | Adversarial Training | r-GCN |
|---|---|---|---|---|---|---|
| Memory | 2444.1 MB | 2446.0 MB | 2437.5 MB | 2443.8 MB | 2523.1 MB | 2525.5 MB |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qiao, Z.; Wu, Z.; Chen, J.; Ren, P.; Yu, Z. A Lightweight Method for Defense Graph Neural Networks Adversarial Attacks. Entropy 2023, 25, 39. https://doi.org/10.3390/e25010039
Qiao Z, Wu Z, Chen J, Ren P, Yu Z. A Lightweight Method for Defense Graph Neural Networks Adversarial Attacks. Entropy. 2023; 25(1):39. https://doi.org/10.3390/e25010039
Chicago/Turabian StyleQiao, Zhi, Zhenqiang Wu, Jiawang Chen, Ping’an Ren, and Zhiliang Yu. 2023. "A Lightweight Method for Defense Graph Neural Networks Adversarial Attacks" Entropy 25, no. 1: 39. https://doi.org/10.3390/e25010039