

Robustness of Sparsely Distributed Representations to Adversarial Attacks in Deep Neural Networks

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Materials and Methods
2.1. Architecture of the Neural Network
2.2. MNIST Dataset
2.3. Training Neural Networks
2.4. Fooling Using Fast Gradient Signed Method
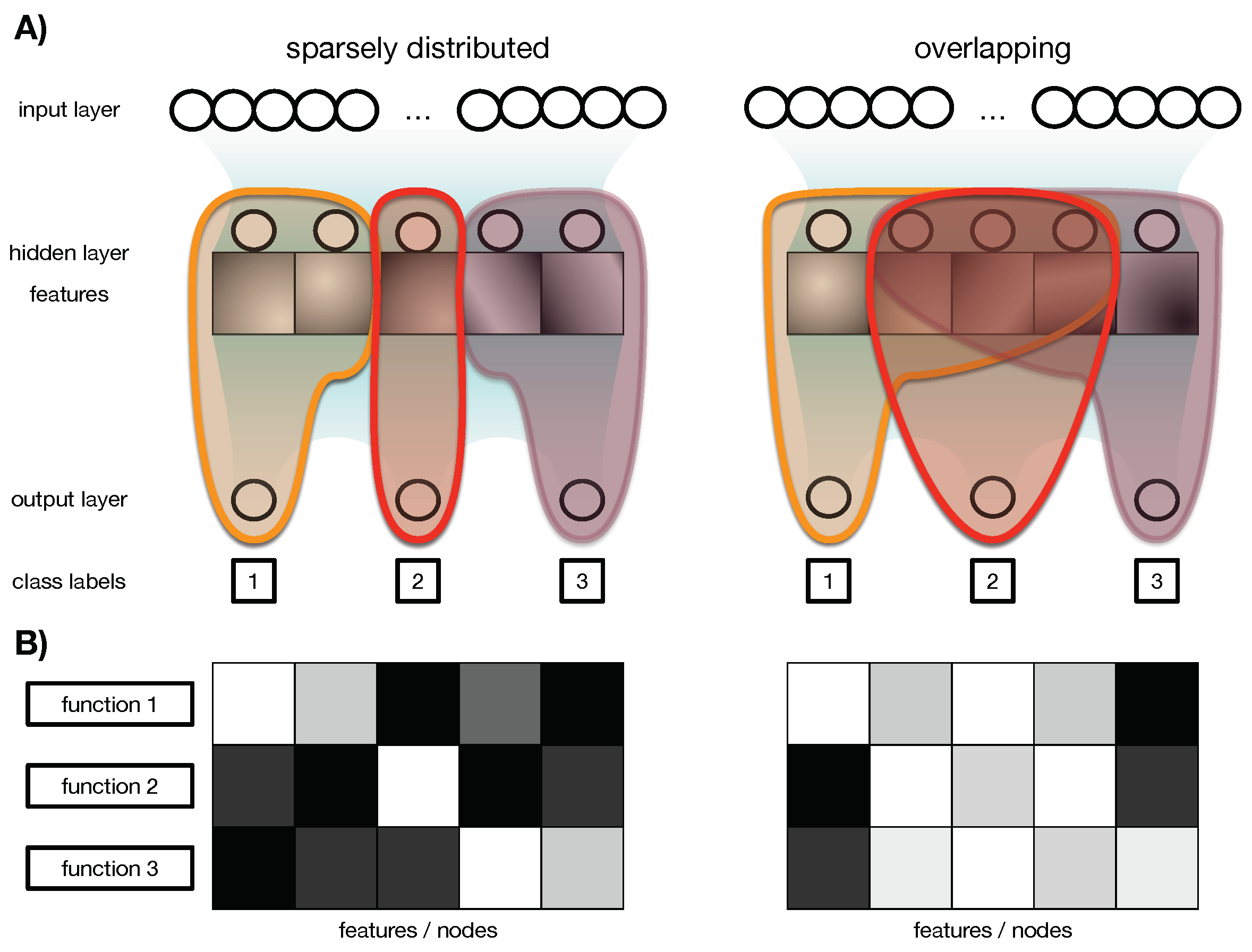
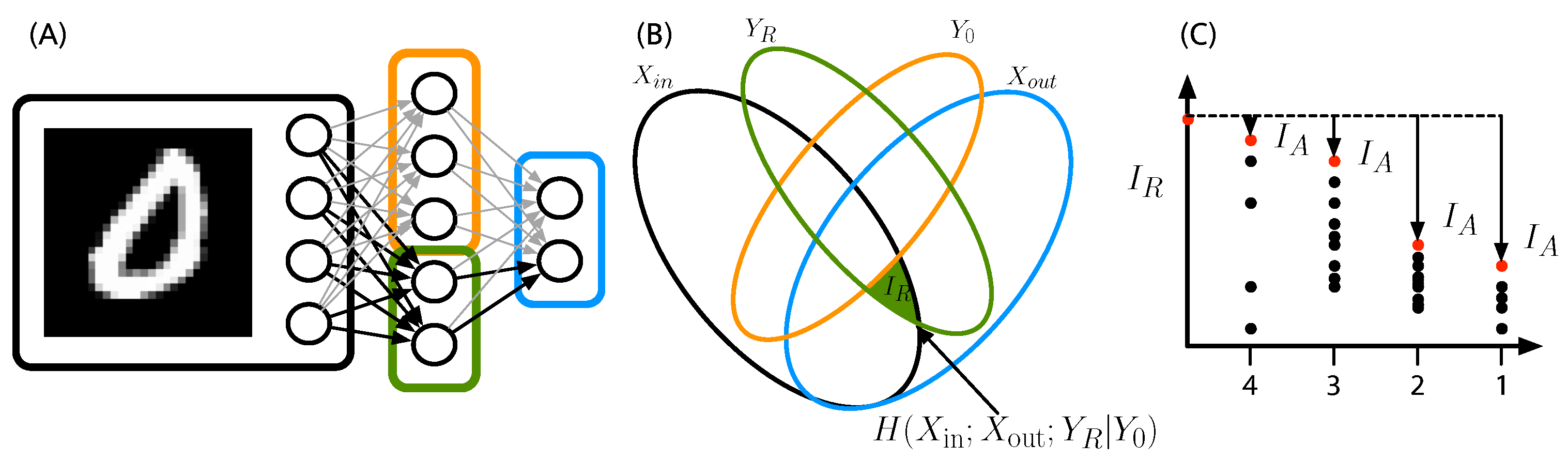
2.5. Relay Information, Greedy Algorithm, and Functional Modules
- —the input classes;
- —the classification results;
- —the hidden states of the subset deemed responsible for relaying the information;
- —the residual set of hidden states not incorporated in .
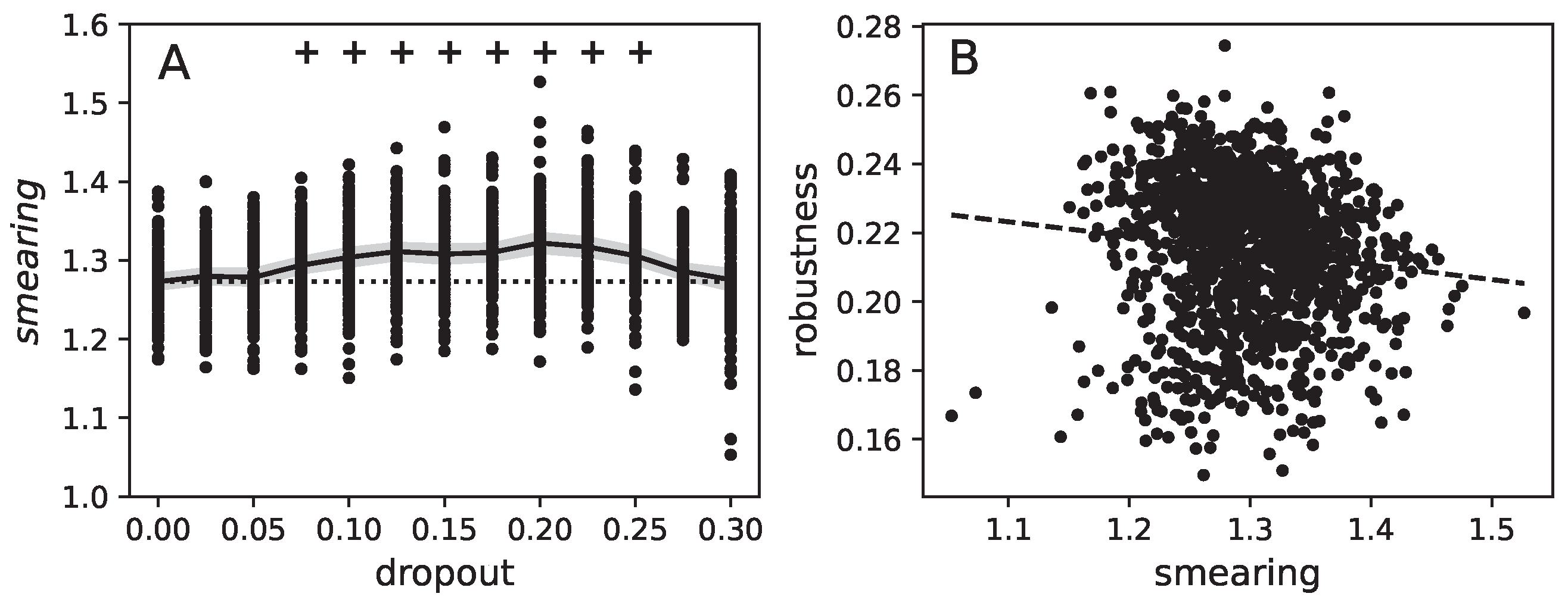
2.6. Smearedness
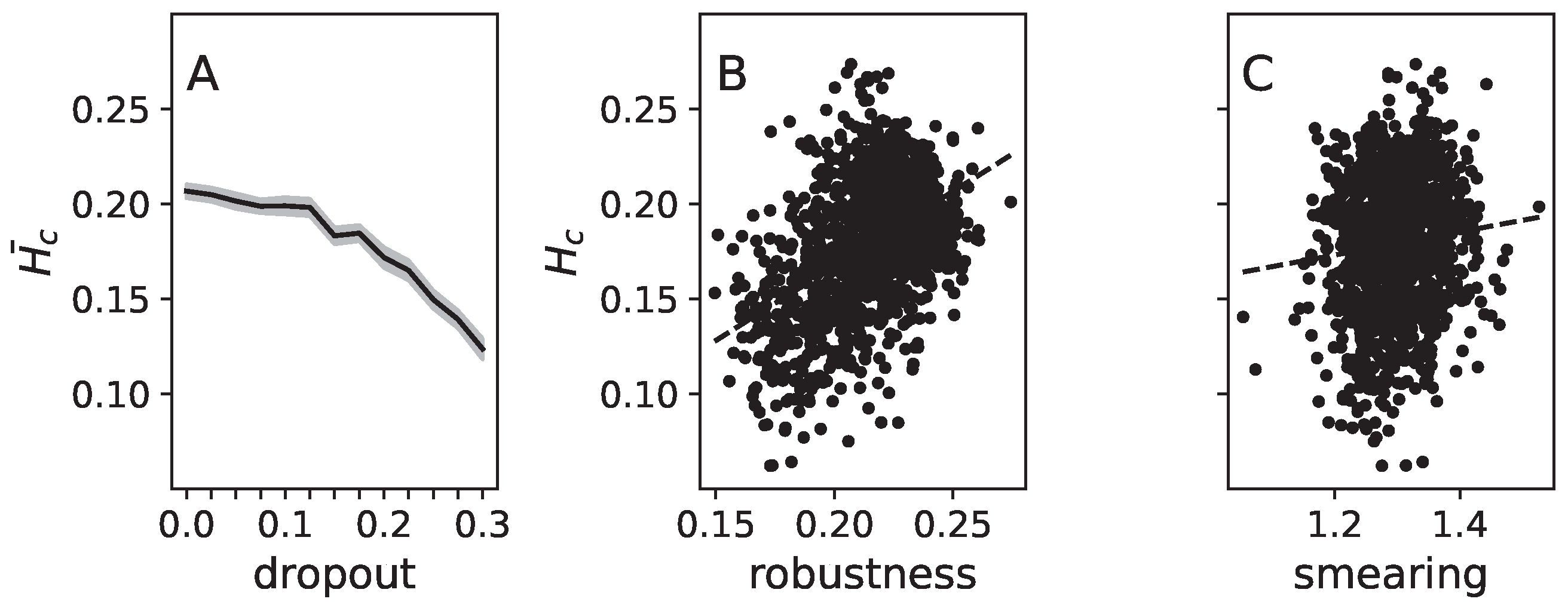
3. Hessian Matrix and Sparsity Induced by Dropout
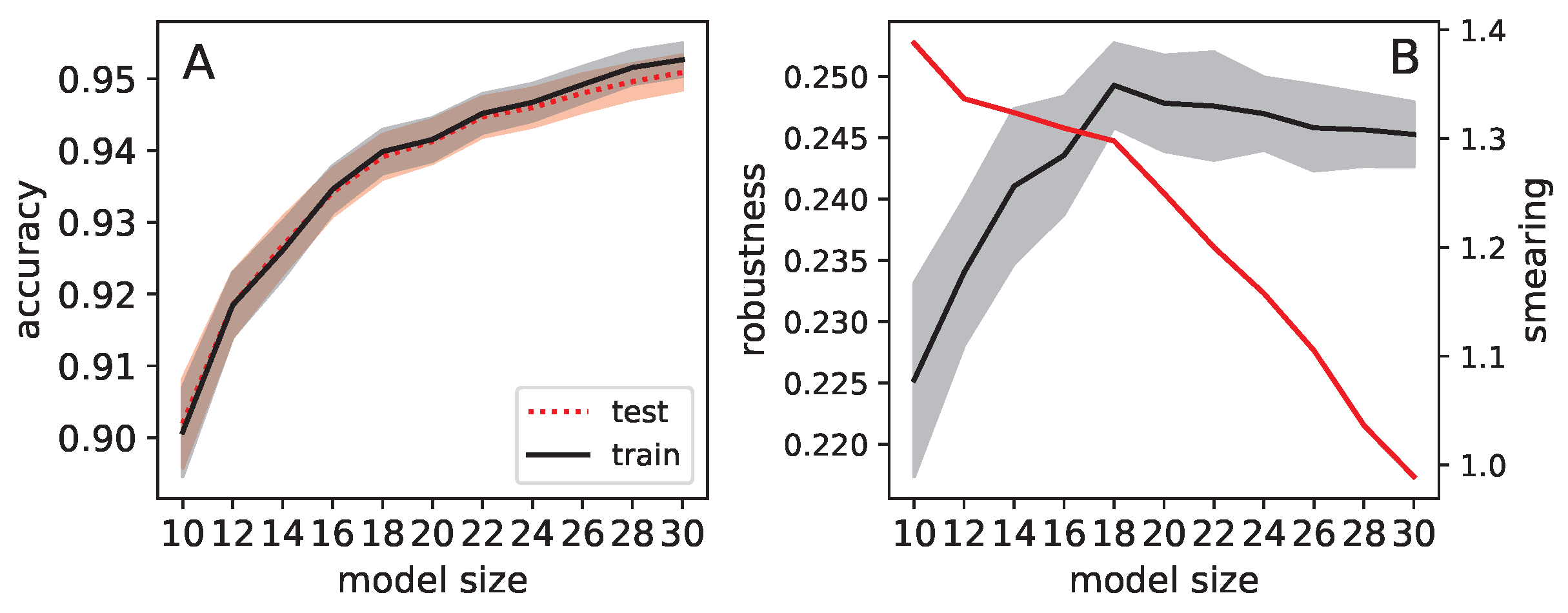
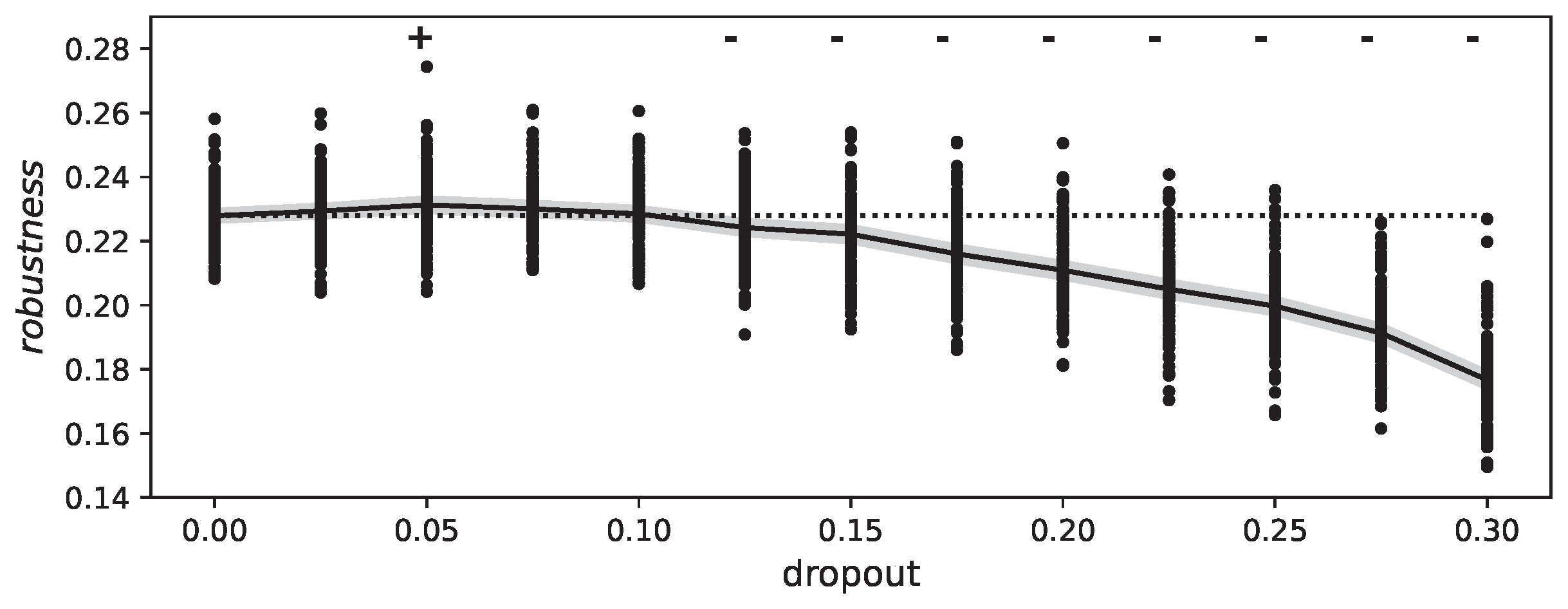
4. Results
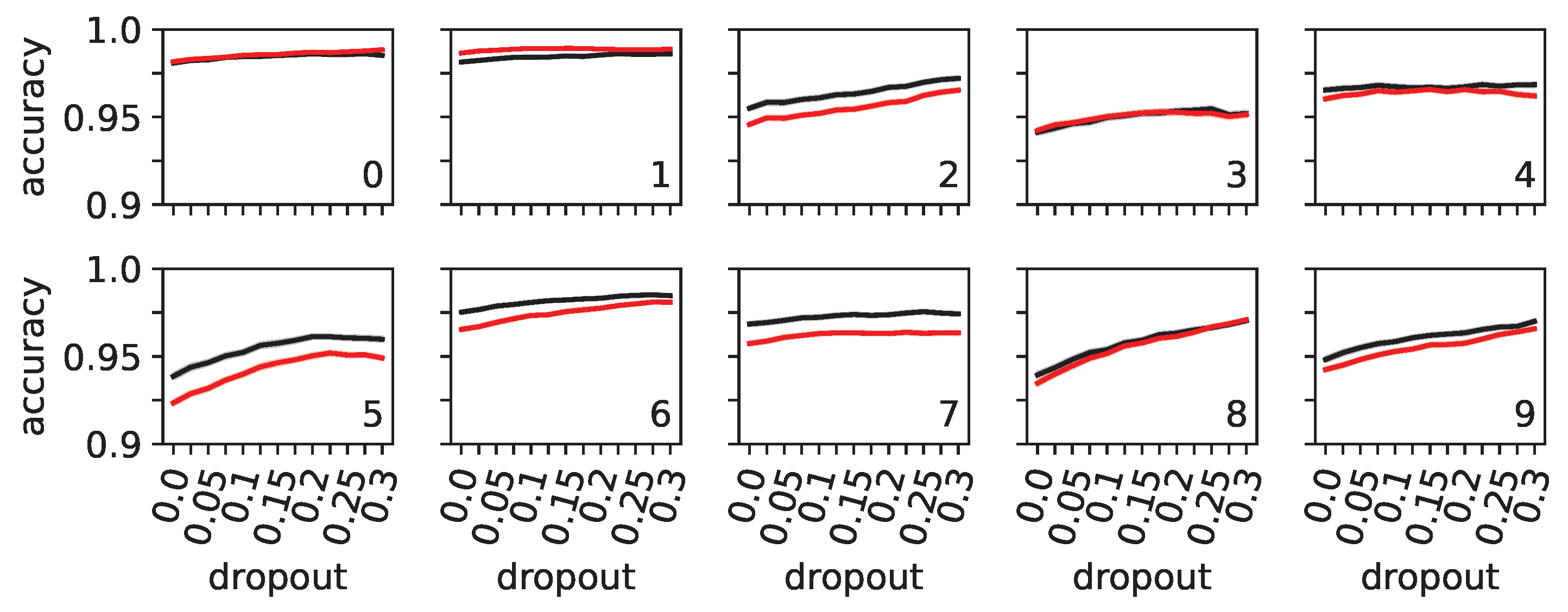
The Effect of Dropout on the Slope of the Loss Function
5. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Shanmuganathan, S. Artificial Neural Network Modelling: An Introduction; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- Fu, J.; Zheng, H.; Mei, T. Look closer to see better: Recurrent attention convolutional neural network for fine-grained image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4438–4446. [Google Scholar]
- Razi, M.A.; Athappilly, K. A comparative predictive analysis of neural networks (NNs), nonlinear regression and classification and regression tree (CART) models. Expert Syst. Appl. 2005, 29, 65–74. [Google Scholar] [CrossRef]
- Nandy, A.; Biswas, M.; Nandy, A.; Biswas, M. Google’s DeepMind and the Future of Reinforcement Learning. In Reinforcement Learning: With Open AI, TensorFlow and Keras Using Python; Apress: Berkeley, CA, USA, 2018; pp. 155–163. [Google Scholar]
- Baker, B.; Gupta, O.; Naik, N.; Raskar, R. Designing neural network architectures using reinforcement learning. arXiv 2016, arXiv:1611.02167. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Nguyen, A.; Yosinski, J.; Clune, J. Deep neural networks are easily fooled: High confidence predictions for unrecognizable images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 427–436. [Google Scholar]
- Heo, J.; Joo, S.; Moon, T. Fooling neural network interpretations via adversarial model manipulation. arXiv 2019, arXiv:1902.02041. [Google Scholar]
- Huang, S.; Papernot, N.; Goodfellow, I.; Duan, Y.; Abbeel, P. Adversarial attacks on neural network policies. arXiv 2017, arXiv:1702.02284. [Google Scholar]
- Papernot, N.; McDaniel, P.; Wu, X.; Jha, S.; Swami, A. Distillation as a defense to adversarial perturbations against deep neural networks. In Proceedings of the 2016 IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 22–26 May 2016; pp. 582–597. [Google Scholar]
- Carlini, N.; Wagner, D. Towards evaluating the robustness of neural networks. In Proceedings of the 2017 IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 22–26 May 2017; pp. 39–57. [Google Scholar]
- Papernot, N.; McDaniel, P. Extending defensive distillation. arXiv 2017, arXiv:1705.05264. [Google Scholar]
- Mao, X.; Chen, Y.; Wang, S.; Su, H.; He, Y.; Xue, H. Composite adversarial attacks. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtually, 2–9 February 2021; Volume 35, pp. 8884–8892. [Google Scholar]
- Khalid, F.; Hanif, M.A.; Rehman, S.; Shafique, M. Security for machine learning-based systems: Attacks and challenges during training and inference. In Proceedings of the 2018 International Conference on Frontiers of Information Technology (FIT), Islamabad, Pakistan, 17–19 December 2018; pp. 327–332. [Google Scholar]
- Bakhti, Y.; Fezza, S.A.; Hamidouche, W.; Déforges, O. DDSA: A defense against adversarial attacks using deep denoising sparse autoencoder. IEEE Access 2019, 7, 160397–160407. [Google Scholar] [CrossRef]
- Guesmi, A.; Alouani, I.; Baklouti, M.; Frikha, T.; Abid, M. Sit: Stochastic input transformation to defend against adversarial attacks on deep neural networks. IEEE Des. Test 2021, 39, 63–72. [Google Scholar] [CrossRef]
- Qiu, H.; Zeng, Y.; Zheng, Q.; Guo, S.; Zhang, T.; Li, H. An efficient preprocessing-based approach to mitigate advanced adversarial attacks. IEEE Trans. Comput. 2021. [Google Scholar] [CrossRef]
- Zeng, Y.; Qiu, H.; Memmi, G.; Qiu, M. A data augmentation-based defense method against adversarial attacks in neural networks. In Proceedings of the Algorithms and Architectures for Parallel Processing: 20th International Conference, ICA3PP 2020, New York City, NY, USA, 2–4 October 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 274–289. [Google Scholar]
- Shan, S.; Wenger, E.; Wang, B.; Li, B.; Zheng, H.; Zhao, B.Y. Gotta catch’em all: Using honeypots to catch adversarial attacks on neural networks. In Proceedings of the 2020 ACM SIGSAC Conference on Computer and Communications Security, Virtual, 9–13 November 2020; pp. 67–83. [Google Scholar]
- Liu, Q.; Wen, W. Model compression hardens deep neural networks: A new perspective to prevent adversarial attacks. IEEE Trans. Neural Netw. Learn. Syst. 2021. [Google Scholar] [CrossRef]
- Kwon, H.; Lee, J. Diversity adversarial training against adversarial attack on deep neural networks. Symmetry 2021, 13, 428. [Google Scholar] [CrossRef]
- Geirhos, R.; Temme, C.R.; Rauber, J.; Schütt, H.H.; Bethge, M.; Wichmann, F.A. Generalisation in humans and deep neural networks. Adv. Neural Inf. Process. Syst. 2018, 31, 7549–7561. [Google Scholar]
- Hintze, A.; Kirkpatrick, D.; Adami, C. The Structure of Evolved Representations across Different Substrates for Artificial Intelligence. arXiv 2018, arXiv:1804.01660. [Google Scholar]
- Hintze, A.; Adami, C. Cryptic information transfer in differently-trained recurrent neural networks. In Proceedings of the 2020 7th International Conference on Soft Computing & Machine Intelligence (ISCMI), Stockholm, Sweden, 14–15 November 2020; pp. 115–120. [Google Scholar]
- Bohm, C.; Kirkpatrick, D.; Hintze, A. Understanding memories of the past in the context of different complex neural network architectures. Neural Comput. 2022, 34, 754–780. [Google Scholar] [CrossRef] [PubMed]
- Hintze, A.; Adami, C. Detecting Information Relays in Deep Neural Networks. arXiv 2023, arXiv:2301.00911. [Google Scholar]
- Kirkpatrick, D.; Hintze, A. The role of ambient noise in the evolution of robust mental representations in cognitive systems. In Proceedings of the ALIFE 2019: The 2019 Conference on Artificial Life, Online, 29 July–2 August 2019; MIT Press: Cambridge, MA, USA, 2019; pp. 432–439. [Google Scholar]
- Hintze, A.; Adami, C. Neuroevolution gives rise to more focused information transfer compared to backpropagation in recurrent neural networks. Neural Comput. Appl. 2022, 1–11. [Google Scholar] [CrossRef]
- Sporns, O.; Betzel, R.F. Modular Brain Networks. Annu. Rev. Psychol. 2016, 67, 613–640. [Google Scholar] [CrossRef] [Green Version]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Wang, S.; Wang, X.; Zhao, P.; Wen, W.; Kaeli, D.; Chin, P.; Lin, X. Defensive dropout for hardening deep neural networks under adversarial attacks. In Proceedings of the 2018 IEEE/ACM International Conference on Computer-Aided Design (ICCAD), San Diego, CA, USA, 5–8 November 2018; pp. 1–8. [Google Scholar]
- Cai, S.; Shu, Y.; Chen, G.; Ooi, B.C.; Wang, W.; Zhang, M. Effective and efficient dropout for deep convolutional neural networks. arXiv 2019, arXiv:1904.03392. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.; Kim, I.J.; Sanes, J.R.; Meister, M. The most numerous ganglion cell type of the mouse retina is a selective feature detector. Proc. Natl. Acad. Sci. USA 2012, 109, E2391–E2398. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- LeCun, Y.; Denker, J.; Solla, S. Optimal brain damage. Adv. Neural Inf. Process. Syst. 1989, 2, 598–605. [Google Scholar]
- Wei, C.; Kakade, S.; Ma, T. The implicit and explicit regularization effects of dropout. In Proceedings of the International Conference on Machine Learning, Virtual, 13–18 July 2020; pp. 10181–10192. [Google Scholar]
- Zhang, Z.; Zhou, H.; Xu, Z.Q.J. Dropout in training neural networks: Flatness of solution and noise structure. arXiv 2021, arXiv:2111.01022. [Google Scholar]
- Zhang, Z.; Zhou, H.; Xu, Z. A Variance Principle Explains Why Dropout Finds Flatter Minima. 2021. Available online: https://openreview.net/forum?id=Ctjb37IOldV (accessed on 1 May 2023).
- Zhang, Z.; Xu, Z.Q.J. Implicit regularization of dropout. arXiv 2022, arXiv:2207.05952. [Google Scholar]
- Kolmogorov, A.N. On the representation of continuous functions of many variables by superposition of continuous functions of one variable and addition. In Proceedings of the Doklady Akademii Nauk; Russian Academy of Sciences: Moscow, Russia, 1957; Volume 114, pp. 953–956. [Google Scholar]
- Hecht-Nielsen, R. Kolmogorov’s mapping neural network existence theorem. In Proceedings of the International Conference on Neural Networks, San Diego, CA, USA, 21–24 June 1987; Volume 3, pp. 11–14. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Bishop, C. Exact calculation of the Hessian matrix for the multilayer perceptron. Neural Comput. 1992, 4, 494–501. [Google Scholar] [CrossRef]
- Pearlmutter, B.A. Fast exact multiplication by the Hessian. Neural Comput. 1994, 6, 147–160. [Google Scholar] [CrossRef]
- Vivek, B.; Babu, R.V. Single-step adversarial training with dropout scheduling. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 947–956. [Google Scholar]
- Kirkpatrick, J.; Pascanu, R.; Rabinowitz, N.; Veness, J.; Desjardins, G.; Rusu, A.A.; Milan, K.; Quan, J.; Ramalho, T.; Grabska-Barwinska, A.; et al. Overcoming catastrophic forgetting in neural networks. Proc. Natl. Acad. Sci. USA 2017, 114, 3521–3526. [Google Scholar] [CrossRef] [Green Version]








Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sardar, N.; Khan, S.; Hintze, A.; Mehra, P. Robustness of Sparsely Distributed Representations to Adversarial Attacks in Deep Neural Networks. Entropy 2023, 25, 933. https://doi.org/10.3390/e25060933
Sardar N, Khan S, Hintze A, Mehra P. Robustness of Sparsely Distributed Representations to Adversarial Attacks in Deep Neural Networks. Entropy. 2023; 25(6):933. https://doi.org/10.3390/e25060933
Chicago/Turabian StyleSardar, Nida, Sundas Khan, Arend Hintze, and Priyanka Mehra. 2023. "Robustness of Sparsely Distributed Representations to Adversarial Attacks in Deep Neural Networks" Entropy 25, no. 6: 933. https://doi.org/10.3390/e25060933