
Unsupervised Low-Light Image Enhancement Based on Generative Adversarial Network

Abstract
:1. Introduction
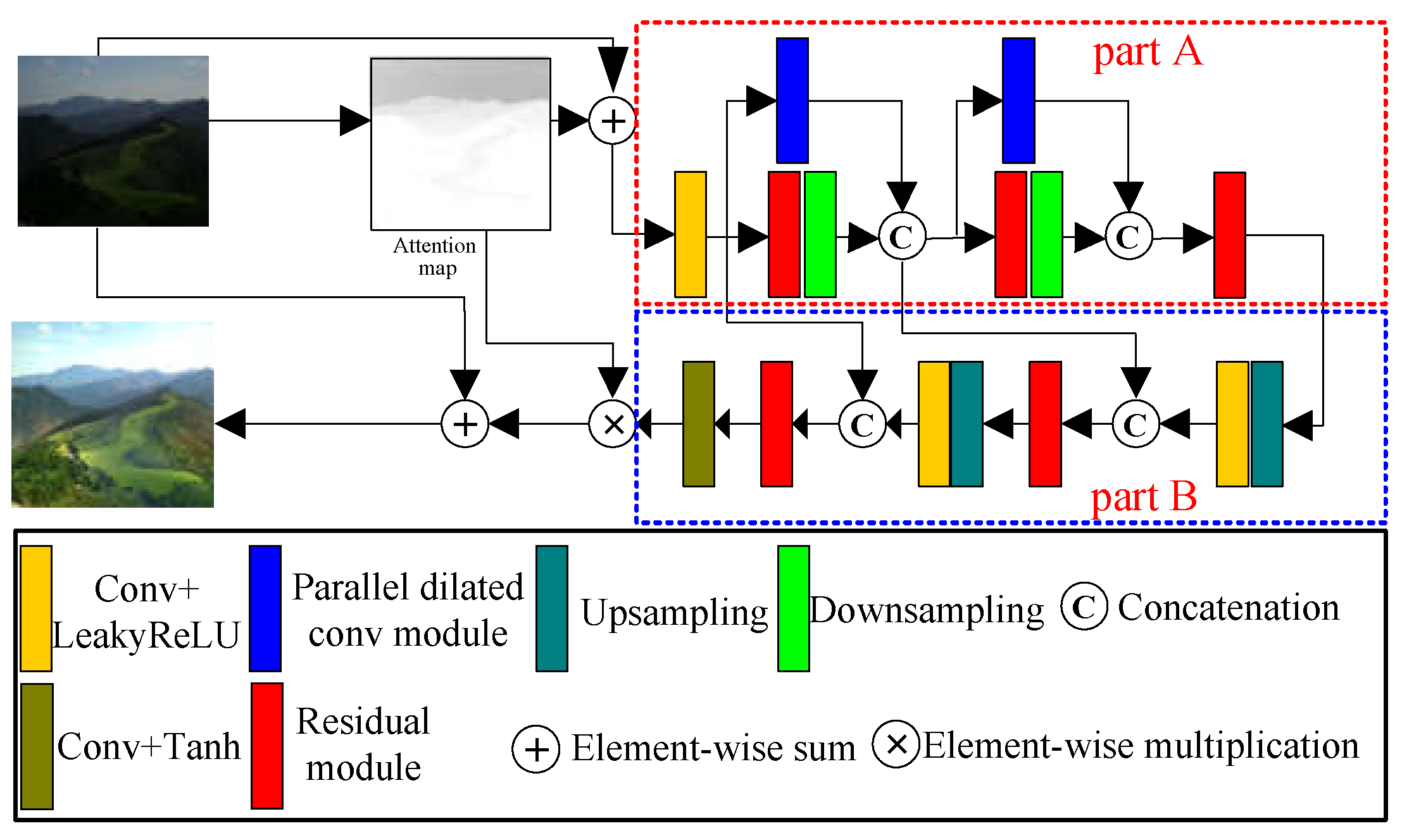
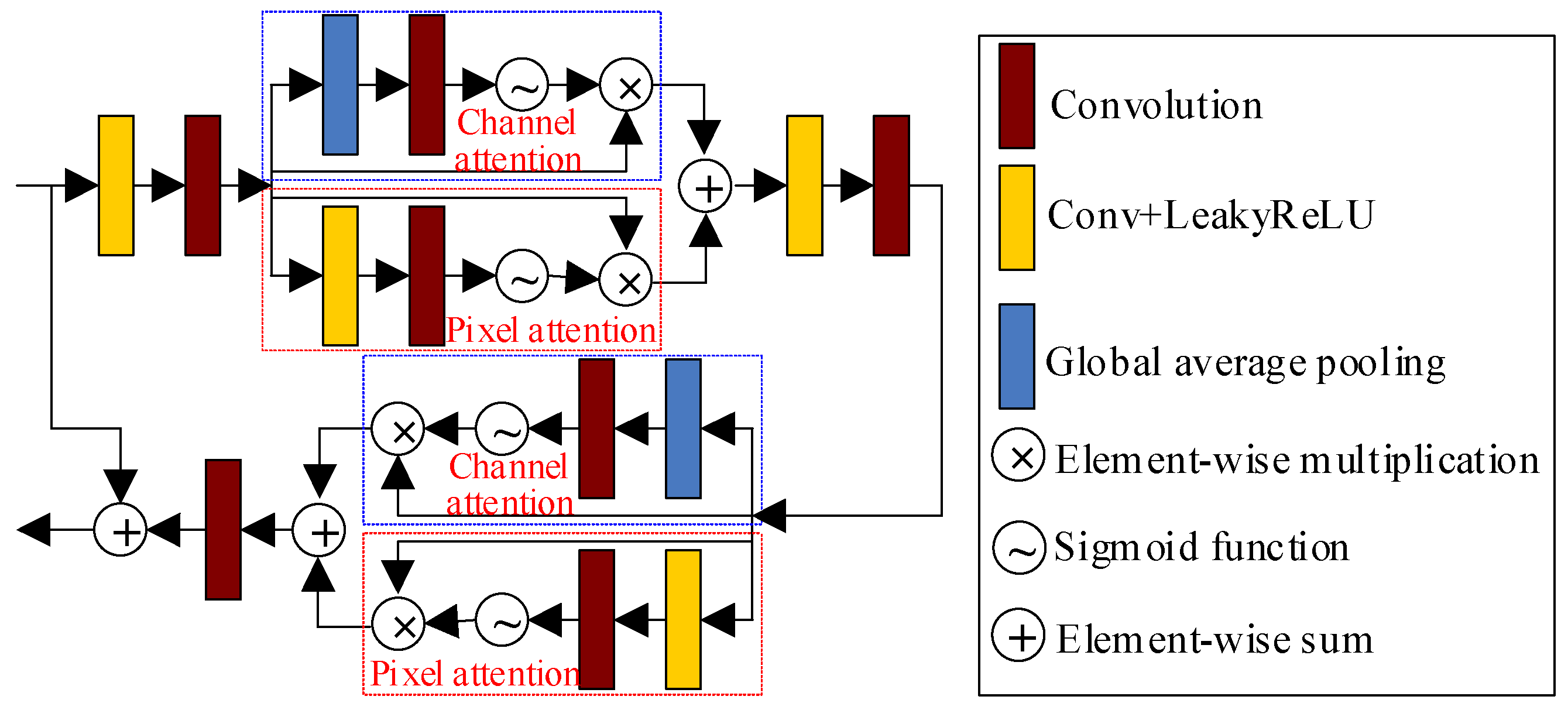
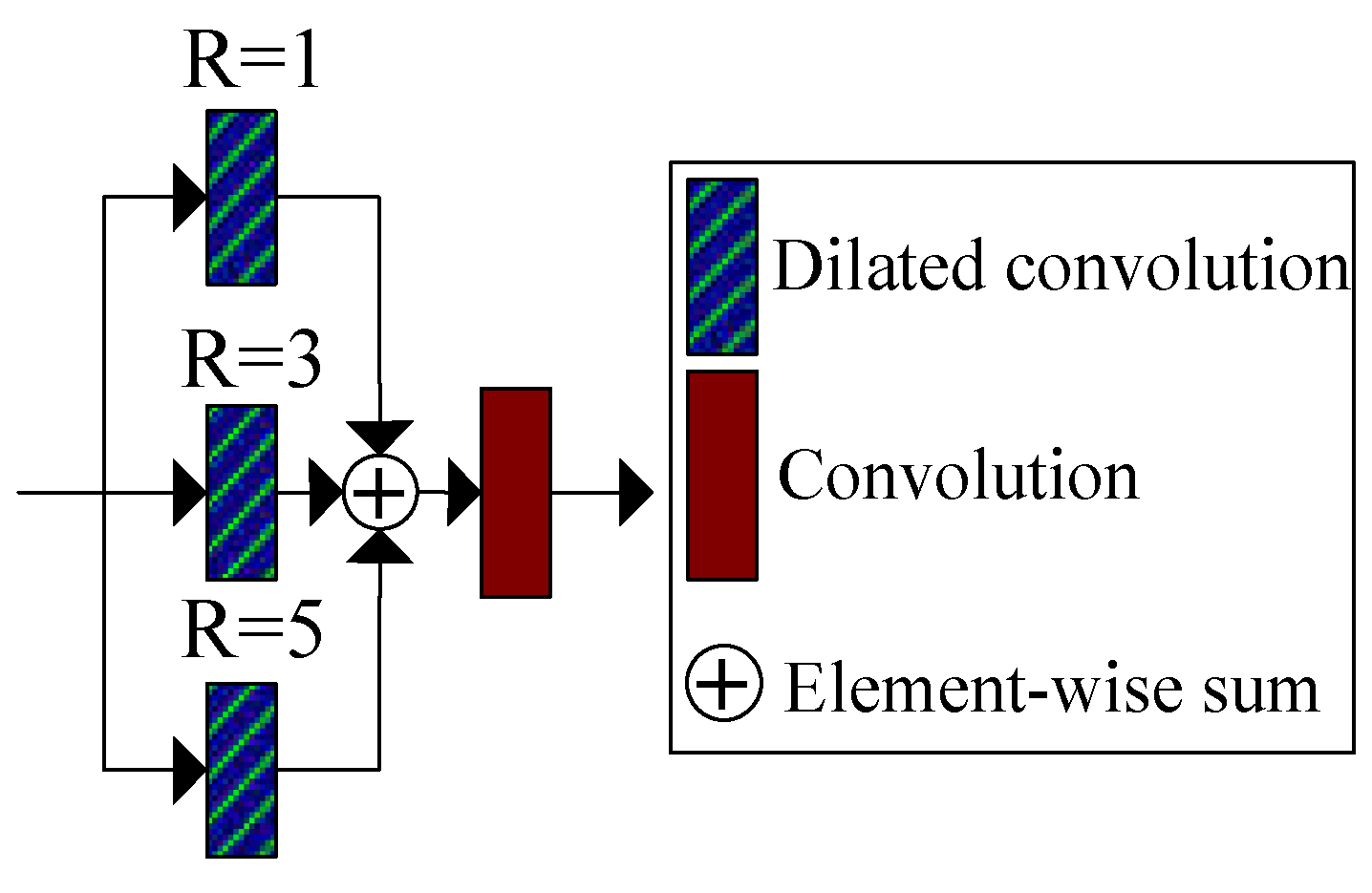
- We designed a novel generator for enhancing low-light images. Firstly, we designed a hybrid attention module consisting of a channel attention module and a pixel attention module. Secondly, we utilized the hybrid attention module as a sub-module within the design of the residual module. Thirdly, we designed a parallel dilated convolution module to capture multiscale information. Lastly, we combined the designed residual module with the hybrid attention module, and parallel dilated convolution module to construct the generative network. Additionally, we employed a skip connection to fuse shallow features with deep features, enhancing the representation of the generative network.
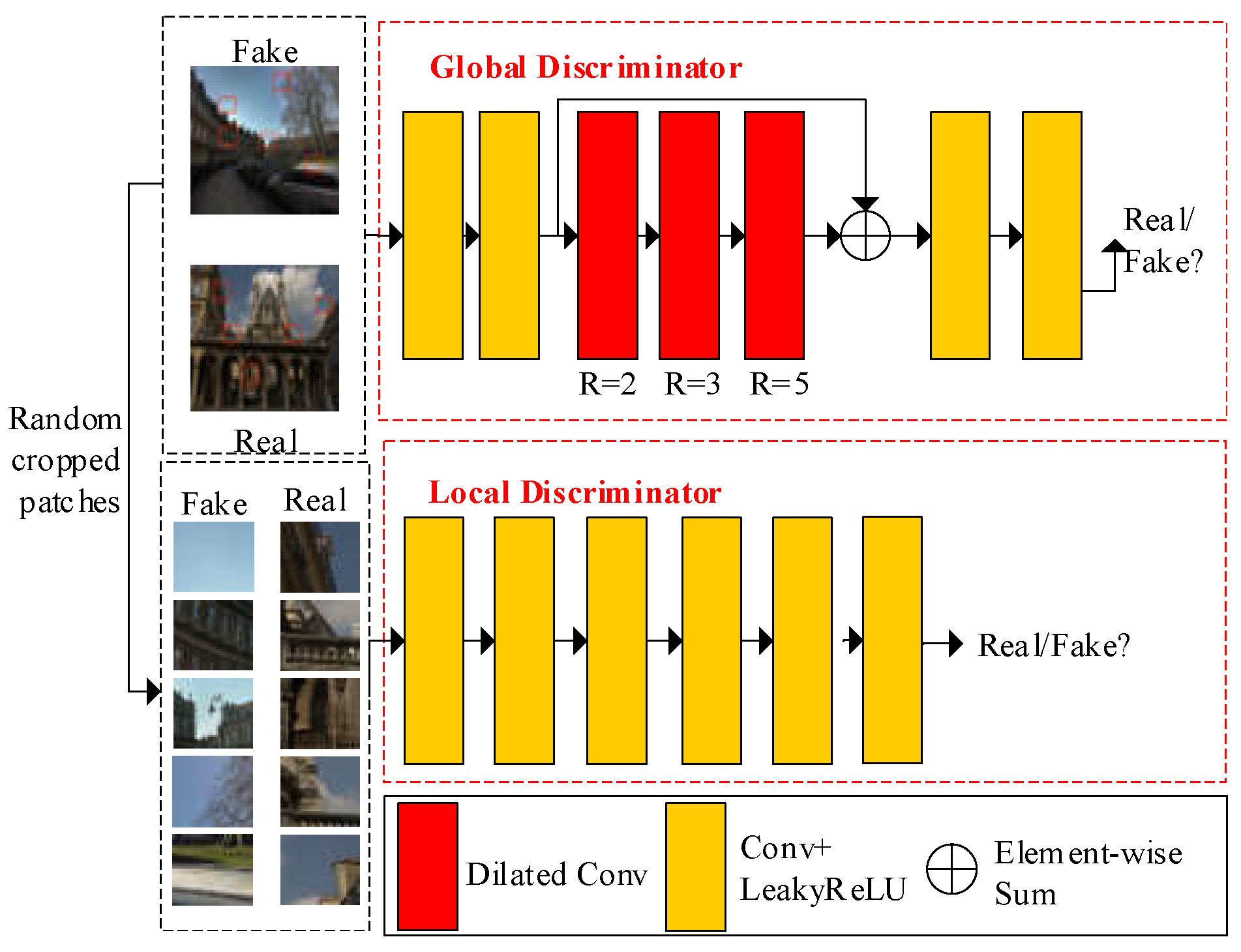
- We propose an adversarial network that includes two discriminators: a global discriminator and a local discriminator. The local discriminator is constructed using six standard convolution layers, while the global discriminator employs three different dilated convolution layers, skip connections, and four standard convolution layers.
- We propose an improved loss function by introducing pixel loss into the loss function of the generative adversarial network. It is beneficial for recovering detailed image information
2. Related Work
3. Proposed Methods
3.1. Proposed Generator
3.2. Proposed Discriminator
3.3. Proposed Loss Function
4. Simulation and Discussion
| Algorithm 1. Training procedure for our proposed method. |
| 1: For K epochs do 2: For k(k is a hyperparameter, k = 1) steps do 3: Sample minibatch of m low-light image samples {z (1),…, z(m)} from low-light image domain. 4: Sample minibatch of m normal-light image samples {z (1),…, z(m)} from normal-light image domain. 5: Update the discriminator by Adam Optimizer: 7: Sample minibatch of m low-light image samples { z (1),…, z(m)} fromlow-light image domain. 8: Update the generator by Adam Optimizer: |
4.1. Datasets and Metrics
4.2. Ablation Study
4.3. No-Referenced Image Quality Assessment
4.4. Full-Referenced Image Quality Assessment
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Dai, Y.; Liu, W. GL-YOLO-Lite: A Novel Lightweight Fallen Person Detection Model. Entropy 2023, 25, 587. [Google Scholar] [CrossRef] [PubMed]
- Wang, H.; Chen, Y.; Cai, Y.; Chen, L.; Li, Y.; Sotelo, M.A.; Li, Z. SFNet-N: An Improved SFNet Algorithm for Semantic Segmentation of Low-Light Autonomous Driving Road Scenes. IEEE Trans. Intell. Transp. Syst. 2022, 23, 21405–21417. [Google Scholar] [CrossRef]
- Lim, S.; Kim, W. DSLR: Deep Stacked Laplacian Restorer for Low-Light Image Enhancement. IEEE Trans. Multimed. 2021, 23, 4272–4284. [Google Scholar] [CrossRef]
- Veluchamy, M.; Bhandari, A.K.; Subramani, B. Optimized Bezier Curve Based Intensity Mapping Scheme for Low Light Image Enhancement. IEEE Trans. Emerg. Topics Comput. 2021, 6, 602–612. [Google Scholar] [CrossRef]
- Chen, Y.-S.; Wang, Y.-C.; Kao, M.-H.; Chuang, Y.-Y. Deep Photo Enhancer: Unpaired Learning for Image Enhancement from Photographs with GANs. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18-23 June 2018; pp. 6306–6314. [Google Scholar]
- Shi, Y.; Wang, B.; Wu, X.; Zhu, M. Unsupervised Low-Light Image Enhancement by Extracting Structural Similarity and Color Consistency. IEEE Signal Process. Lett. 2022, 29, 997–1001. [Google Scholar] [CrossRef]
- Lin, Y.; Lu, Y. Low-Light Enhancement Using a Plug-and-Play Retinex Model with Shrinkage Mapping for Illumination Estimation. IEEE Trans. Image Process. 2022, 31, 4897–4908. [Google Scholar] [CrossRef] [PubMed]
- Ren, X.; Yang, W.; Cheng, W.-H.; Liu, J. LR3M: Robust Low-Light Enhancement via Low-Rank Regularized Retinex Model. IEEE Trans. Image Process. 2022, 29, 5862–5876. [Google Scholar] [CrossRef]
- Wei, C.; Wang, W.; Yang, W.; Liu, J. Deep Retinex decomposition for low-light enhancement. arXiv 2018, arXiv:1808.04560. [Google Scholar]
- Yang, W.; Wang, S.; Fang, Y.; Wang, Y.; Liu, J. From Fidelity to Perceptual Quality: A Semi-Supervised Approach for Low-Light Image Enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 3060–3069. [Google Scholar]
- Guo, C.; Li, C.; Guo, J.; Loy, C.C.; Hou, J.; Kwong, S.; Cong, R. Zero-Reference Deep Curve Estimation for Low-Light Image Enhancement. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 1777–1786. [Google Scholar]
- Li, C.; Guo, C.; Chen, C.L. Learning to Enhance Low-Light Image via Zero-Reference Deep Curve Estimation. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 4225–4238. [Google Scholar] [CrossRef]
- Lv, T.; Pan, X.; Zhu, Y.; Li, L. Unsupervised medical images denoising via graph attention dual adversarial network. Appl. Intell. 2021, 51, 4094–4105. [Google Scholar] [CrossRef]
- Li, X.; Wu, Y.; Zhang, W.; Wang, R.; Hou, F. Deep learning methods in real-time image super-resolution: A survey. J. Real Time Image Proc. 2020, 17, 1885–1909. [Google Scholar] [CrossRef]
- Ha, V.K.; Ren, J.; Xu, X.; Liao, W.; Zhao, S.; Ren, J.; Yan, G. Optimized highway deep learning network for fast single image super-resolution reconstruction. J. Real Time Image Proc. 2020, 17, 1961–1970. [Google Scholar] [CrossRef]
- Ren, Z.; Zhang, Y.; Wang, S. A Hybrid Framework for Lung Cancer Classification. Electronics 2022, 11, 1614. [Google Scholar] [CrossRef] [PubMed]
- Hua, W.; Xia, Y. Low-Light Image Enhancement Based on Joint Generative Adversarial Network and Image Quality Assessment. In Proceedings of the 11th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics, Beijing, China, 13–15 October 2018; pp. 1–6. [Google Scholar]
- Kim, G.; Kwon, D.; Kwon, J. Low-Lightgan: Low-Light Enhancement Via Advanced Generative Adversarial Network with Task-Driven Training. In Proceedings of the International Conference on Image Processing, Taipei, Taiwan, 22–25 September 2019; pp. 2811–2815. [Google Scholar]
- Shi, Y.; Wu, X.; Zhu, M. Low-light Image Enhancement Algorithm Based on Retinex and Generative Adversarial Network. arXiv 2019, arXiv:1906.06027. [Google Scholar]
- Guo, L.; Wan, R.; Su, G. Multi-Scale Feature Guided Low-Light Image Enhancement. In Proceedings of the International Conference on Image Processing, Anchorage, AK, USA, 19–22 September 2021; pp. 554–558. [Google Scholar]
- Yang, S.; Zhou, D.; Cao, J.; Guo, Y. Rethinking Low-Light Enhancement via Transformer-GAN. IEEE Signal Process. Lett. 2022, 29, 1082–1086. [Google Scholar] [CrossRef]
- Jiang, Y.; Gong, X.; Liu, D.; Cheng, Y.; Fang, C.; Shen, X.; Yang, J.; Zhou, P.; Wang, Z. EnlightenGAN: Deep Light Enhancement Without Paired Supervision. IEEE Trans. Image Process. 2021, 30, 2340–2349. [Google Scholar] [CrossRef]
- Li, F.; Zheng, J.; Zhang, Y. Generative adversarial network for low-light image enhancement. IET Image Process. 2021, 15, 1542–1552. [Google Scholar] [CrossRef]
- Qu, Y.; Chen, K.; Liu, C.; Ou, Y. UMLE: Unsupervised Multi-discriminator Network for Low Light Enhancement. In Proceedings of the International Conference on Robotics and Automation, Xi’an, China, 30 May–5 June 2021; pp. 4318–4324. [Google Scholar]
- Rao, N.; Lu, T.; Zhou, Q. Seeing in the Dark by Component-GAN. IEEE Signal Process. Lett. 2021, 28, 1250–1254. [Google Scholar] [CrossRef]
- Grigoryan, A.M.; Agaian, S.S. Alpha-rooting and correlation method of image enhancement. Multimodal Image Exploit. Learn. 2022, 12100, 147–156. [Google Scholar]
- Guo, X.; Li, Y.; Ling, H. LIME: Low-Light Image Enhancement via Illumination Map Estimation. IEEE Trans Image Process. 2017, 26, 982–993. [Google Scholar] [CrossRef] [PubMed]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Appina, B. A ‘Complete Blind’ No-Reference Stereoscopic Image Quality Assessment Algorithm. In Proceedings of the 2020 International Conference on Signal Processing and Communications (SPCOM), Bangalore, India, 19–24 July 2020; pp. 1–5. [Google Scholar]
- Alqawasmi, K. Estimation of ARMA Model Order Utilizing Structural Similarity Index Algorithm. In Proceedings of the 8th International Conference on Control, Decision and Information Technologies, Istanbul, Turkey, 17–20 May 2022; pp. 1087–1090. [Google Scholar]
- Javaheri, A.; Brites, C.; Pereira, F.; Ascenso, J. Improving Psnr-Based Quality Metrics Performance for Point Cloud Geometry. In Proceedings of the 27th International Conference on Image Processing (ICIP 2020), Abu Dhabi, United Arab Emirates, 25–28 October 2020; pp. 3438–3442. [Google Scholar]
- Mittal, A.; Moorthy, A.K.; Bovik, A.C. No-Reference Image Quality Assessment in the Spatial Domain. IEEE Trans. Image Process. 2012, 21, 4695–4708. [Google Scholar] [CrossRef] [PubMed]
- Cai, J.; Gu, S.; Zhang, L. Learning a Deep Single Image Contrast Enhancer from Multi-Exposure Images. IEEE Trans Image Process 2018, 27, 2049–2062. [Google Scholar] [CrossRef] [PubMed]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No_Attention | No_Parallel Dilated Conv | No_Cascaded Dilated Conv | No_Pixel Loss | Ours | |
|---|---|---|---|---|---|
| PSNR | 20.5918 | 23.3964 | 25.9701 | 26.1541 | 26.6451 |
| SSIM | 0.7686 | 0.7761 | 0.8667 | 0.8771 | 0.8817 |
| NIQE | 6.7748 | 5.2070 | 4.8803 | 4.9612 | 4.4719 |
| BRISQUE | 25.3088 | 22.2576 | 21.5149 | 40.0626 | 21.2218 |
| Alpha | LIME | CycleGAN | Retinex-Net | EnlightenGAN | Zero-DCE | Zero-DCE++ | Ours | |
|---|---|---|---|---|---|---|---|---|
| 1st image | 6.9561 | 6.6348 | 7.5064 | 12.4557 | 5.2253 | 8.8149 | 7.8973 | 5.1815 |
| 2nd image | 7.1162 | 4.7842 | 5.8236 | 6.7309 | 3.6692 | 5.1637 | 4.5945 | 3.4426 |
| 3rd image | 8.2354 | 8.3674 | 6.5934 | 10.6873 | 5.2263 | 6.3784 | 6.1283 | 5.1637 |
| 4th image | 8.3671 | 6.3724 | 7.6354 | 11.3648 | 4.6992 | 4.4762 | 4.1164 | 3.9651 |
| Average | 7.6687 | 6.5397 | 6.8897 | 10.3097 | 4.7050 | 6.2083 | 5.6841 | 4.4382 |
| Alpha | LIME | CycleGAN | Retinex-Net | EnlightenGAN | Zero-DCE | Zero-DCE++ | Ours | |
|---|---|---|---|---|---|---|---|---|
| 1st image | 42.6327 | 43.6249 | 38.6523 | 44.2361 | 30.4125 | 36.2578 | 33.6245 | 30.5261 |
| 2ndimage | 41.2961 | 40.4375 | 40.1263 | 48.2763 | 29.1547 | 30.1542 | 28.7163 | 20.5238 |
| 3rd image | 36.1284 | 37.9658 | 28.1267 | 38.1476 | 23.6321 | 29.3697 | 24.3698 | 22.9086 |
| 4th image | 39.6183 | 50.5563 | 36.2548 | 53.2174 | 35.2147 | 40.1236 | 29.7211 | 25.4236 |
| Average | 39.9189 | 43.1461 | 35.7900 | 45.9694 | 29.6035 | 33.9763 | 29.1079 | 24.8455 |
| Alpha | LIME | CycleGAN | Retinex-Net | EnlightenGAN | Zero-DCE | Zero-DCE++ | Ours | |
|---|---|---|---|---|---|---|---|---|
| NIQE | 8.8655 | 8.9884 | 8.8816 | 7.8564 | 5.2901 | 6.1564 | 5.7911 | 4.8656 |
| BRISQUE | 41.0368 | 40.3652 | 39.6235 | 41.3498 | 30.2563 | 28.6392 | 24.3687 | 23.6987 |
| Alpha | LIME | CycleGAN | Retinex-Net | EnlightenGAN | Zero-DCE | Zero-DCE++ | Ours | ||
|---|---|---|---|---|---|---|---|---|---|
| 1st image | PSNR | 20.1381 | 19.8378 | 23.0964 | 15.9278 | 21.8685 | 15.9880 | 15.4431 | 24.1329 |
| SSIM | 0.8032 | 0.7732 | 0.7944 | 0.7839 | 0.9213 | 0.8529 | 0.6098 | 0.9267 | |
| NIQE | 5.9932 | 6.9635 | 7.2511 | 7.5961 | 4.9968 | 5.0166 | 4.9888 | 4.7602 | |
| BRISQUE | 36.5827 | 34.5062 | 36.7823 | 28.1026 | 23.6384 | 26.8221 | 24.7335 | 23.0285 | |
| 2nd image | PSNR | 19.6382 | 17.9721 | 19.8103 | 13.2096 | 23.2018 | 16.5817 | 16.3813 | 27.3032 |
| SSIM | 0.7886 | 0.7770 | 0.8515 | 0.7312 | 0.9208 | 0.8294 | 0.7320 | 0.9352 | |
| NIQE | 7.6631 | 8.3652 | 8.2236 | 6.2358 | 3.9624 | 4.9968 | 4.6379 | 3.8891 | |
| BRISQUE | 37.8260 | 36.5896 | 31.2014 | 24.1036 | 28.0457 | 28.0211 | 27.4125 | 24.1027 | |
| 3rd image | PSNR | 18.6357 | 17.3886 | 19.0584 | 15.8160 | 17.3886 | 17.2072 | 18.8322 | 20.5577 |
| SSIM | 0.7081 | 0.6572 | 0.6837 | 0.6637 | 0.8802 | 0.7673 | 0.6311 | 0.8695 | |
| NIQE | 9.6635 | 7.6354 | 9.6102 | 5.1632 | 5.1022 | 5.8906 | 5.1063 | 4.9924 | |
| BRISQUE | 31.2569 | 30.1265 | 29.6321 | 29.3678 | 30.9519 | 37.2673 | 36.1859 | 28.6571 | |
| Average | PSNR | 19.3764 | 18.3995 | 22.6550 | 14.9845 | 20.8196 | 16.5923 | 16.8855 | 23.9979 |
| SSIM | 0.7815 | 0.7358 | 0.7765 | 0.7263 | 0.9074 | 0.8165 | 0.6576 | 0.9101 | |
| NIQE | 8.9657 | 7.6547 | 8.3616 | 6.3317 | 4.6871 | 5.3013 | 4.9110 | 4.5472 | |
| BRISQUE | 34.5632 | 33.7408 | 32.5386 | 29.1913 | 27.5453 | 30.7035 | 29.4440 | 25.2628 |
| Alpha | LIME | CycleGAN | Retinex-Net | EnlightenGAN | Zero-DCE | Zero-DCE++ | Ours | |
| PSNR | 17.3354 | 17.8337 | 21.1463 | 17.7947 | 23.9674 | 19.7008 | 18.8698 | 26.6451 |
| SSIM | 0.7022 | 0.6321 | 0.8322 | 0.6257 | 0.8640 | 0.7416 | 0.6463 | 0.8817 |
| NIQE | 8.9621 | 8.9673 | 8.1960 | 6.9928 | 4.8963 | 6.0023 | 5.3725 | 4.4719 |
| BRISQUE | 39.6477 | 40.3188 | 30.3485 | 34.5698 | 23.2056 | 29.4853 | 24.8423 | 21.2218 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, W.; Zhao, L.; Zhong, T. Unsupervised Low-Light Image Enhancement Based on Generative Adversarial Network. Entropy 2023, 25, 932. https://doi.org/10.3390/e25060932
Yu W, Zhao L, Zhong T. Unsupervised Low-Light Image Enhancement Based on Generative Adversarial Network. Entropy. 2023; 25(6):932. https://doi.org/10.3390/e25060932
Chicago/Turabian StyleYu, Wenshuo, Liquan Zhao, and Tie Zhong. 2023. "Unsupervised Low-Light Image Enhancement Based on Generative Adversarial Network" Entropy 25, no. 6: 932. https://doi.org/10.3390/e25060932