1. Introduction
Visual feedback control is an important aspect of many modern applications, ranging from robotics to virtual reality. The ability to perceive and respond to visual information in real time is essential for achieving desired outcomes. The purpose of a visual feedback control architecture is to control a robotic system using information obtained from a visual sensor [
1,
2]. The visual sensor can be placed either on the robot (known as the “eye-in-hand” configuration [
3]) or in another location in the workspace (known as the “eye-to-hand” configuration). This paper will examine the eye-in-hand configuration.
Visual feedback control can be achieved through various methods, such as classical visual servoing, which includes two popular methods, image-based visual servoing (IBVS) and pose-based visual servoing (PBVS) [
3]. In IBVS, the control loop is driven by the error between the desired and current visual features, such as image coordinates, edges, corners, or image moments, while in PBVS, the control loop is driven by the error between the desired and current object pose. Despite their success in many applications, classical visual servoing methods have several limitations. They rely on hand-crafted features, predefined models, and linear control laws, which can result in poor performances under challenging conditions, such as occlusions, lighting changes, and cluttered environments [
3].
Recent advances in deep learning have shown promise in enhancing visual feedback control. Instead of relying on hand-crafted features, deep learning techniques allow the system to learn and extract features directly from raw visual data. Convolutional neural networks (CNNs) have been shown to offer significant benefits when working with images, particularly in their ability to learn relevant features for a specific problem, without requiring predetermined feature extraction methods. To enable fast training, numerous neural architectures were built based on CNNs that were pre-trained for classification tasks, such as AlexNet [
4], VGG-16 [
5], or FlowNet [
6]. In [
7], Saxena et al. used FlowNet to perform the visual servoing task in various environments, without any prior knowledge of the camera parameters or scene geometry. The network predicts the camera’s pose by taking an input array that concatenates the images that specify the current and desired final scenes. The neural architectures presented by Bateux et al. [
8] were derived from AlexNet and VGG16. They are capable of predicting the transformation that occurred in a camera through two images and customized to perform high-precision, robust, and real-time six degrees of freedom (DOF) positioning tasks by using visual feedback. The authors used a synthetic training dataset to support effective learning and improved robustness to illumination changes. In [
9], the authors introduced DeFiNet, designed as a Siamese neural architecture. The features are extracted by two CNNs, which share neural parameters. The resulting features are passed to a regression block to predict the relative pose resulting from the current and target images that are captured by an eye-to-hand camera. Ribeiro et al. [
10] compared three CNN-based architectures for grasping detection, where the neural network should provide a 3D pose, starting from two input images that describe the initial and final layouts of the scene. In the first architecture, a single branch is used, where the two input images are concatenated along the depth dimension to form the input array, and a single regression block generates all six outputs. The second model also uses the same input array but has two separate output branches for position and orientation. In contrast, the last CNN uses a separate feature extractor for each input image, concatenates the extracted features, and then uses a single regression block. Based on experimental results, the first model, which uses a single branch, yields the best performance. Regardless of the neural architectures or design of the learning techniques, some limitations arise from the inherent characteristics of data-driven methods. This includes the fact that the generalization capabilities of the deep model rely on the content of the training dataset, and important modifications of the visual elements captured in the scenes should involve retraining the model.
The technique of early fusion in neural networks involves incorporating additional information that is available to the input of the network. Since the method only extends the depth of the input array, without requesting the use of additional neural layers or connections, the approach does not involve significantly increased computational resources and could remain compatible with real-time scenarios [
11,
12]. This additional information can be obtained through various methods, such as segmentation [
13], feature points [
14], filtering, or utilizing information acquired from multiple sensors or sources to provide a more comprehensive understanding of the environment [
15]. Another approach to data fusion is to integrate the new information into the hidden neural layers, a technique referred to as middle fusion. By integrating the supplementary data into the feature maps at different layers of the feature extractor, the extra information could potentially have a greater impact on global features. However, implementing middle fusion requires significant modifications to the neural architecture and may limit the transfer of learning from pre-trained models. The third possible approach means applying fusion at the decision level, which is the simplest approach and does not require modifications to the neural architecture. With this method, the supplementary data are not used during learning and are only incorporated at the decision-making stage.
The current work is set to evaluate multiple convolutional neural architectures proposed for a visual servoing task. This effectively integrates valuable supplementary knowledge and facilitates the transfer of learning from a CNN pre-trained for the image classification task, this being illustrated by comparing it with classical PBVS (pose-based visual servoing). To achieve this, the CNN architecture utilizes the early fusion method. The proposed template consists of exploiting traditional visual servoing techniques to produce additional useful input data for the deep models. In this regard, the extension of the input neural arrays is discussed for three relevant approaches: region-based segmentation, feature points, and image moments. These three approaches can offer different levels of detail from the initial and final scenes:
The feature points can be considered as providing low-level information, as they give specific points in the image where single or multiple objects of interest are located;
The regions indicated by segmentation can be considered as providing mid-level information, as they give a more general idea of the location and features of an object, by dividing the image into different areas;
The image moments can be considered as providing high-level information, as they compute a summary of the distribution of pixel intensities in the image, which can be used to estimate the pose of the object, but also in decoupling the linear and angular camera velocities.
This paper investigates how traditional techniques could be effectively exploited by deep learning for the visual servoing task. In this regard, we discuss an early fusion approach for CNN-based visual servoing systems, which mixes the initial and final images with maps that illustrate additional information from these scenes. According to our knowledge, this is the first comprehensive analysis of additional ready-to-use information that can improve CNN’s ability to accurately perform the visual servoing task. The relevance of this extra information has been already validated by classic visual servoing techniques, however, the challenge consists of finding proper, simplified descriptions of the initial and final scenes, which could be useful for CNN. The maps should offer ready-to-use information to guide the extraction of features, for an effective computation of the linear and angular camera velocities for a 6 DOF robot. As all necessary information is available in the original images, the extra maps implicitly introduce data redundancy. The extra maps also require expanding the deep model with supplementary learnable parameters. As a consequence, an important aspect to analyze is what level of detail could be more helpful for CNN to make its training easier and more effective.
The main contributions of this work can be summarized as follows:
The design of an early fusion approach based on image moments, which allows access to high-level descriptions of the initial and final scenes for all the neural layers;
The design of early fusion based on multiple types of maps involving different levels of detail;
An extensive analysis of early fusion approaches integrating maps that provide different levels of detail, extracted by means of feature points, segmentation, and grid-wise image moments; the models with early fusion are derived from two deep architectures and the comparison also includes a traditional visual servoing method;
Evaluation of the proposed designs for experimental layouts with one or multiple objects.
This paper is organized as follows:
Section 2 presents the usage of visual features in visual servoing.
Section 3 unveils the design of the proposed early fusion architectures, while the results are discussed in
Section 4.
Section 5 is dedicated to the conclusions.
2. Visual Features in Visual Servoing
In order to perform the visual feedback control, our work consists of using visual information from cameras to determine the desired motion of a 6 DOF robot. For this, we integrated features that are highly recommended by traditional visual servoing approaches. We reconfigured these visual features to adequately incorporate them as information in the input neural layers. In order to obtain this, the main requirement is the transposition of this visual information into two-dimensional maps of the same sizes as the original RGB images. Thus, by using these types of features, some feature maps have been created to better illustrate the changes between the initial and final scenes and to draw attention to the regions from where CNN’s feature extractor can obtain relevant high-level features.
2.1. Image Segmentation Maps
A first method to extract visual features from images is established by the integration of image segmentation as input information, which has proven to be a valuable approach for enhancing the performances of a visual servoing system. For example, in [
16] the authors are using the luminance of all pixels in an image as visual features instead of relying on geometric features, such as points, lines, or poses. Specifically, they used the grayscale intensity value of each pixel as the luminance feature in order to compute an optimization-based control law that minimizes the difference between the current and a desired image. By using the luminance of all pixels in the image, the authors avoid the need for feature extraction, which can be computationally expensive and error-prone.
Our work proposes the usage of region-based segmentation maps in which each region belonging to the background or objects is labeled with their mean intensity. The location and shape of objects can be implicitly inferred from these maps, as demonstrated in
Figure 1. The resulting segmented map provides a simplified layout of the scene that can guide the feature extractor. As segmentation is region-based, it can be applied to simple or complex scenes, with uniform or non-uniform backgrounds. The usage of the mean intensities of the regions, such as labels, offers several advantages: (i) mean intensity is a relevant feature for a region, despite lighting disturbances; (ii) object matching can be implicitly ensured by the labels when the initial and final layouts have different object poses; (iii) the range of the values obtained in the segmented maps is similar to that of RGB images, making it easy for the CNNs to integrate information from multiple input channels.
Algorithm 1 outlines the main steps of the region-based segmentation algorithm that was used. Since the input images are in RGB format, a conversion to grayscale is required for the image processing steps. As
Figure 1 shows, the background mainly consists of lighter areas. Therefore, computing the image complement is an important step in distinguishing between background and objects. Once a better partition is made, basic segmentation techniques such as Prewitt edge identification and morphological operations can be applied.
| Algorithm 1 Segmentation algorithm. |
| Require: RGB image I (e.g., or ) |
| 1: Convert I to grayscale to obtain . |
| 2: Apply image complement to , in order to obtain . |
| 3: Using a disk of size , apply morphological opening to , to obtain . |
| 4: Subtract from , to obtain . Adjust the intensities of . |
| 5: Compute by extracting the edges of (Prewitt). |
| 6: Improve : perform morphological closing using a disk of size , fill the holes, and erode the image using a disk of size . |
| 7: Obtain A by labeling the objects and background of with the corresponding mean intensity from . |
| Ensure: Segmented map, A (e.g., or ) |
External factors, such as changes in illumination, can affect the accuracy of segmentation results. In response to these challenges, segmented maps can be used in conjunction with RGB images of the initial and final scene layouts to enable a convolutional neural network to recover crucial information from the original images. This additional information can be used to mitigate segmentation errors, refine boundary detection, and eliminate false detections. Moreover, the combined use of segmented maps and RGB images provides a more comprehensive representation of the scene, which can enhance the overall CNN performance.
Other possible solutions that could be considered for creating segmentation maps involve the usage of binary segmented maps, but this method only locates the object, without differentiating between them. Also, in the case of a non-uniform background, segmentation maps could be created by merging adjacent superpixels that share similar color properties.
2.2. Feature Point Maps
The second method that proposes the integration of additional information into the input array of a convolutional neural network in order to obtain more relevant features is based on interest point operators. Interest point operators are used to detect key locations from the image. These operators are specifically chosen to be less sensitive to factors such as scaling, rotation, and image quality disturbances. These features are typically extracted from images captured by a camera and used to compute the error between the current position and the desired position of the robot relative to the object or feature it is tracking. Previous works relied on the analysis of different point detectors in order to extract distinctive characteristics of an image and use them to estimate the motion of a robot. For example, in [
17], the authors propose a visual servoing approach that uses SIFT feature points to track a moving object. The approach is based on a camera mounted on an anthropomorphic manipulator and the goal is to maintain a desired relative pose between the camera and the objects of interest. The papers show that the SIFT points are invariant to scale and rotation and can be used to track the object as the endpoint moves along a trajectory. The remaining robust feature points provide epipolar geometry, which is used to retrieve the motion of the camera and determine the robot’s joint angle vector using inverse kinematics. Another approach is presented in [
18] where the authors propose a method for object tracking based on SURF local feature points. The visual servo controller uses geometrical features computed from the set of interest points, making the method robust against occlusion and changes in viewpoint. The experimental results were demonstrated with a robotic arm and monocular eye-in-hand camera in a cluttered environment.
In this work, we investigate the impact of early fusion on the performance of two different point operators, namely SURF (speed-up robust features) [
19] and BRISK (binary robust invariant scalable key points) [
20]. These two operators are selected due to their proven high performance and robustness to noise and fast computation.
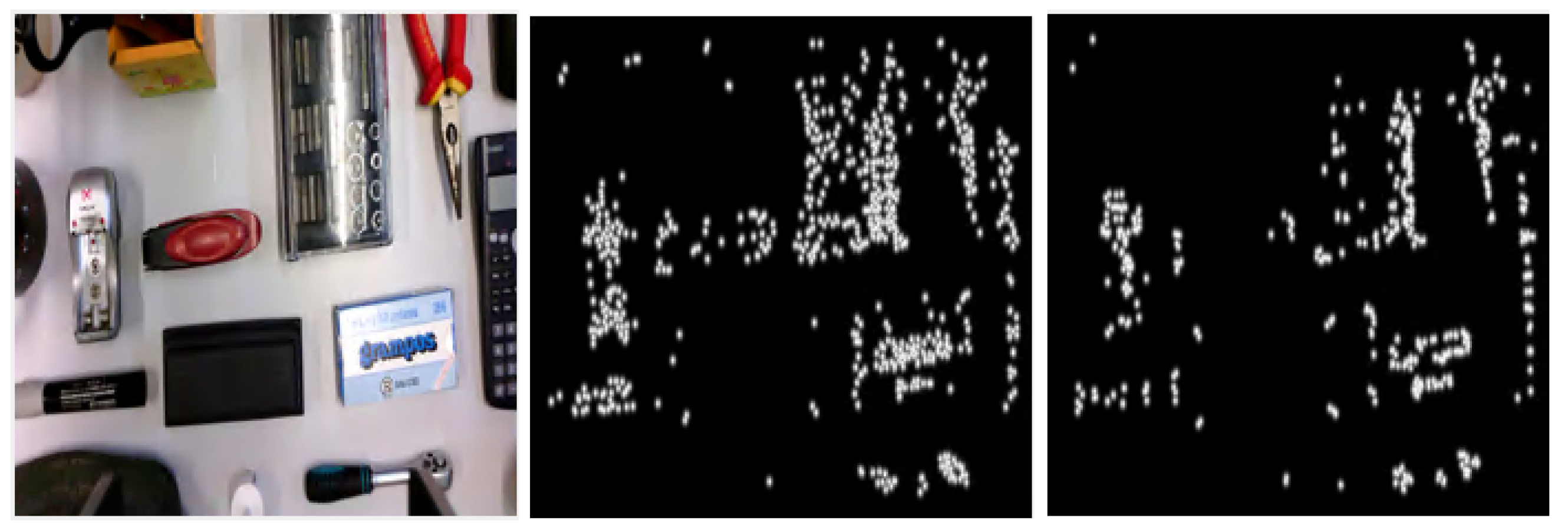
By utilizing a map of the detected SURF or BRISK points, we can extract information about the location of objects in the scene. The SURF algorithm approximates the Hessian matrix by computing integral images, while the BRISK method relies on circular sampling patterns to form a binary descriptor. Both methods provide additional information about the variation of interest points between the initial and final scene layouts, which can improve CNN’s ability to understand the differences between those two point operators.
Algorithm 2 outlines the main steps used to configure the additional maps, where the detected points have higher gray-level intensities than the rest of the pixels. To detect the feature points, the input RGB images are first converted to grayscale and a pre-implemented algorithm for SURF or BRISK point detection is applied. These points are marked into bidimensional maps compatible with the proposed early fusion template, hence their neighborhoods are delimited by a Gaussian filter of size
and standard deviation
. Finally, the resulting map is generated by mixing the neighborhoods marked around all the feature points. Examples of SURF and BRISK detectors for a scene with multiple objects are indicated in
Figure 2. The maps were obtained with a Gaussian filter of size
= 73 (which is about 10% of the minimum dimension of the original images) and a standard deviation of size
= 5. This additional information can guide CNN to better understand the differences between the initial and final layouts and improve the overall accuracy of the regression task.
| Algorithm 2 Mapping using the SURF or BRISK point algorithms. |
| Require: RGB image I (e.g., or ) |
| 1: Convert I to grayscale, resulting in . |
| 2: For , detect the features points, , with . |
| 3: Create a Gaussian kernel, K, of size , with standard deviation . |
| 4: For each point of interest, , create a map having the same size as ; has non-zero elements only around , and the neighborhood of is defined by the kernel K centered in . |
| 5: For each pixel in , create A of the same size by using the maximum value from the previously generated maps: . |
| Ensure: Map of feature points, A (e.g., or ) |
2.3. Image Moment Maps
The third concept that this work uses in order to extract relevant features from the images involves image moments. Image moments are a set of mathematical properties that can be used to describe various characteristics of an image. These properties are computed from the pixel values of the image and can be used to extract features, such as the position, orientation, and shape of an object in the image. Image moments can be computed for any binary or grayscale image. In [
21], the authors address this problem by establishing the analytical form of the interaction matrix for any image moment that can be computed from segmented images. They applied this approach to some basic geometric shapes and selected six combinations of moments to control the six degrees of freedom of an image-based visual servoing system. In comparison, in [
22], the authors build upon the work in [
21] but explore the use of both point-based and region-based image moments for visual servoing of planar objects. The authors use point-based moments to estimate the pose of the object and region-based moments to refine the pose estimate. They propose a control scheme that incorporates both types of moments and use experimental results to demonstrate the effectiveness of the approach.
Assuming that an object in an image is defined by a set of
n points of coordinates
, the image moments
of order
are defined as follows:
while the centered moments
of order
are given by:
The
=
and
=
represent the coordinates of the gravity center, and
is defined as
a, the area of the object. The advantage of the centered moments is the invariance of the translation movements. Many other methods have been developed to find moments that are invariant to scaling and rotation, among the most well-known are Hu moments [
23] and Zernike moments [
24].
Apart from this, another important aspect is to ensure a correct correspondence of visual features between two successive images. For that, two well-known sets of image moments are defined by Chaumette in [
21] and by Tahri and Chaumette in [
22], which were also implemented in this work. The first one, proposed by Chaumette in [
21], states that a feature vector could be defined as
, where
and
are the coordinates of the gravity center and
a is the area of an object in the image, all three considered as linear moments. The last three values of the angular moments are defined as follows:
where,
,
and
, with
and
. The variables
, and
are defined by the centered moments from (2):
,
,
and
. The sixth component,
, is defined as:
Considering the velocity of the camera denoted with = , where are the linear velocities and are the angular velocities, both used to control the movement of the robot from a current configuration to a desired configuration. The linear camera velocities are controlled using the first three components of S, while the angular camera velocities are controlled using the last three components of S.
The second set of image moments considered in this work was obtained according to the equations proposed by Tahri and Chaumette in [
22]. The image moments are defined by the feature vector
. The first three components are used to control the linear camera velocities and are defined as follows:
where
and
represent the coordinates of the gravity center,
represents the desired depth between the desired object position and the camera,
is the desired object area, and
a is the area of the object from the current configuration. Given the fact that the area
a represents the number of point features that characterize the object and it cannot be used as a visual feature, Tahri and Chaumette propose in [
22] that it should be replaced with:
The last three components from
are used to control the angular camera velocities. For
and
, the following image moments are proposed:
where
The last component that is used to control the angular velocity
is defined by the orientation angle of an object
in the same manner as in Equation (
5).
Algorithm 3 summarizes the main steps used to configure the additional maps, based on angular image moments. As mentioned earlier, image moments are only some statistical descriptors that capture information about the spatial distribution of intensity values in an image. To produce maps of the same size as the input image, the image is divided into multiple cells. Also, due to the fact that the used dataset does not provide any information about
(the desired depth between the desired object position and the camera), the additional maps were generated solely based on the computation of the angular velocities.
| Algorithm 3 Mapping using the image moment algorithms. |
| Require: RGB images of the desired configuration, , and for the current configuration, |
| Step 1: Convert and to binary, resulting in and . |
| Step 2: Divide and into multiple cells, each of size , resulting in k cells for an image. |
| Step 3: Overlap each cell with 25% pixel information from each neighbor cell. |
| Step 4: Compute angular image moments, with either Tahri or Chaumette equations, for the pair of images (, ), resulting in extra maps (, , , , , and ). |
| Step 5: Compute all minimum and maximum values for all resulting image moment maps from Step 4. |
| Step 6: For all image moments, perform normalization using Equation (10). |
| Ensure: Map of image moments for the desired and current configurations: (, , , , , and )
|
The first step to creating such maps based on image moments consists of the conversion from RGB images to binary, using—by default—the threshold given by Otsu’s algorithm. After that, in order to compute the angular image moments either with the Tahri [
22] or Chaumette [
21] approach, the images were divided into equal cells of size
× , resulting in
k cells for each image. The purpose is to give a more localized and detailed representation of the image moments. This is also helpful for obtaining a representation as a map, which can be integrated into the neural input array to be further processed by all convolutional layers. The next step of the algorithm consists of expanding the resulting cells to overlap with 25% pixels from each neighbor cell. Lastly, using the extended cells, six image moment maps are computed, with the following significance:
and are the maps representing the first angular image moments, either for the desired or the current configuration scene;
and are the maps representing the second angular image moments, either for the desired or the current configuration scene;
and are the maps representing the third angular image moments, either for the desired or the current configuration scene.
The influence of the number of cells and the size of a cell will be discussed in the next section.
After dividing the image into cells and performing the image moments, the values of the maps were negative or larger than 255. This is problematic because images are typically represented as arrays of pixel values that range from 0 to 255. Therefore, if the image moment maps are not in this range, they alter the impact of the transfer of learning. To address this issue, a normalization step was necessary, using the minimum and maximum values of all the computed image moments, with the following equations:
where,
can be exemplified, as stated in Algorithm 3, with one of the following image moment maps: (
,
,
,
,
,
). For example,
is the normalized image moment map,
is the image moment map before the normalization, and
and
are the minimum and maximum values of all
computed for the original training samples, respectively.
Figure 3 exemplifies all the steps described in Algorithm 3 for a pair of desired and current images corresponding to a simple experimental scene with a single object.
3. Early Fusion Architectures for Visual Servoing
In contrast to existing methods that primarily rely on hand-engineered features or geometric calculations, our proposed framework introduces a novel approach to enhancing visual feedback control through early fusion. The novelty of our approach lies in the strategic integration of additional maps alongside RGB images, a departure from the traditional reliance on visual data alone. The innovative combination not only empowers our neural network with a richer contextual understanding of the scene but also ushers in the potential for greater robustness and precision in a certain visual servoing task.
By using the concept of early fusion, we aim to capitalize on the synergy between various forms of contextual information. These additional maps, whether derived from segmentation, feature points, or image moments, are seamlessly combined with the RGB images. This approach goes beyond the typical use of pre-processed information and could empower the model to inherently learn the relationships between visual features and control commands, allowing for a more comprehensive and accurate control mechanism.
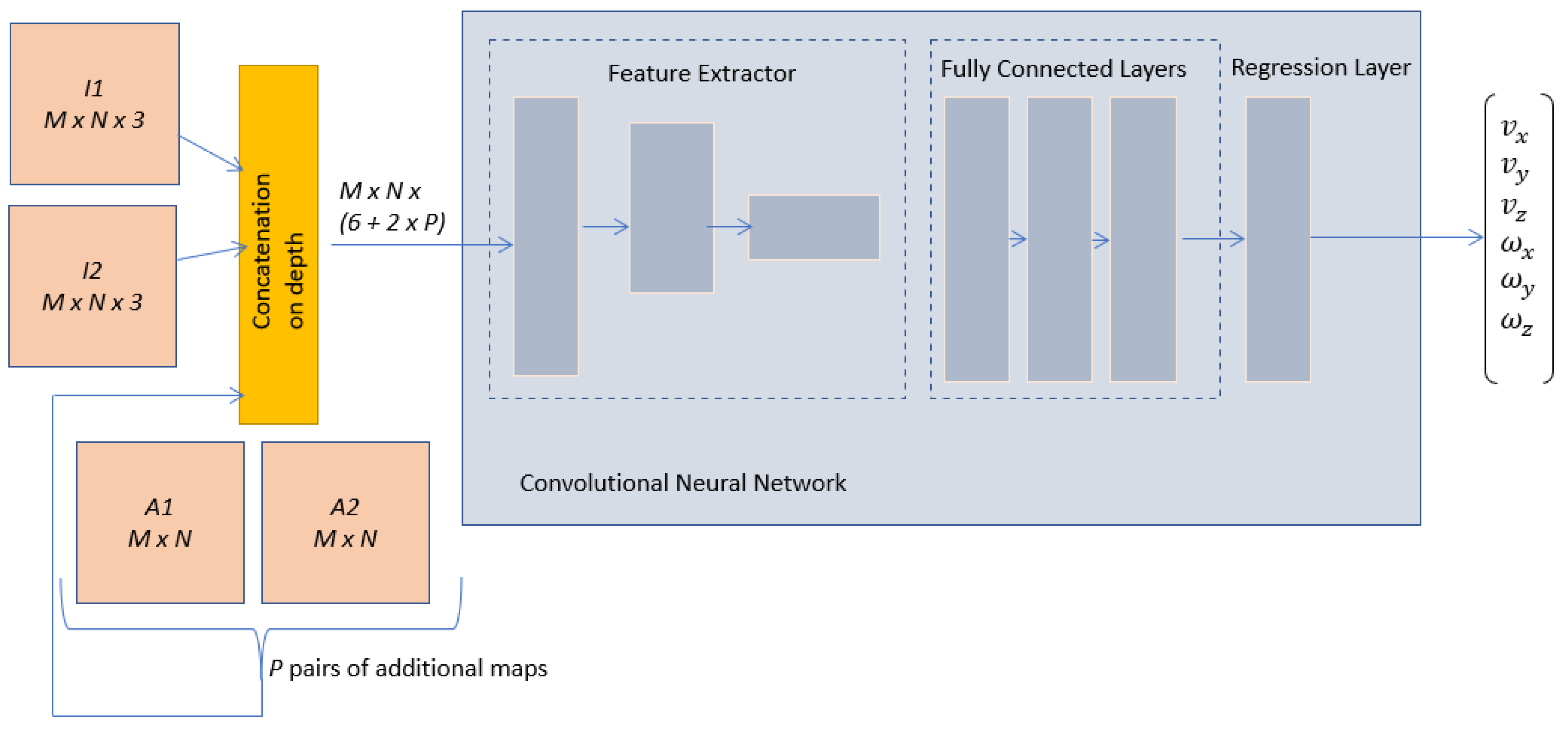
The proposed network architecture is presented in
Figure 4, where the input arrays are generated by concatenating the following arrays:
, of size , is an RGB image representing the initial configuration of the scene;
, of size , is an RGB image that describes the desired configuration of the scene;
and , both of size , are additional maps that can provide supplementary important information for the learning process extracted from and , respectively.
As described in
Section 2, additional maps could be represented by either segmentation maps [
13], points of interest [
14], image moments, or their combinations, in order to improve the performances of a visual servoing neural architecture. The resulting array will be of size
, due to the fact that the concatenation is performed on depth, where
P represents the total depth sizes of all additional maps extracted for the initial or final image.
While it is possible to directly extract feature maps equivalent to and from and using their respective convolutional and pooling layers, including these maps as inputs to the CNN, allows the information to be effectively processed by all the neural layers. This approach also allows CNN to focus on the most significant parts of the scene while extracting deep features. For this early fusion approach, robustness against potential errors—whether from segmentation, feature points, or image moments—is ensured by the inclusion of the original images, and , in the input arrays. This allows the CNN to extract any necessary information directly from them.
The input arrays with increased depth are fed into the feature extraction block, which is made up of convolutional and pooling layers. The purpose of this particular block is to create a concise description of the neural input, thereby enabling easier calculation of the linear and angular velocities. The specific design of the feature extractor and fully connected block is flexible, as long as it is suited to the size of the neural input and output. One common approach is to start with a pre-trained CNN model that has been trained for image classification and modify its architecture for the regression task. In this work, the well-known AlexNet will be such an example and modifications will be made in the last layers to make the architecture compatible with the regression task. Depending on the nature of the additional maps, different modifications must also be made in the first convolutional layer, to adjust the depth of the convolutional filters to an increased number of input channels.
One of the notable promises of our framework lies in its potential for real-time exploitation. The modifications induced by our framework do not involve a significant increase in the complexity of the deep model but rather focus on modifications to the input arrays, which are augmented with relevant information. Improved accuracy performance is expected due to the relevance of additional input data, validated by traditional visual serving techniques. By leveraging the power of a deep model and the efficiency of early fusion, our approach could have the capability to operate seamlessly in real-world environments. The early fusion also facilitates the transfer of learning from deep models devoted to image classification, which permits fast re-training. As specified before, two methods exploit maps relying on feature points or segmentation. For both methods, two additional maps are necessary to describe the initial and final scenes. These additional maps have the same sizes as the RGB images, , and pixel values between [0, 255]. As the concatenation is performed on depth, the resulting input arrays have the size , with the mean updated on each input channel.
The first convolutional layer requires another modification because pre-trained networks, such as AlexNet, are designed for RGB input images; therefore, the first convolutional layer includes filters defined for three input channels,
, where
F is the size of the filters. The filters of the new architecture,
, can be initialized using the filters of the pre-trained CNN, but the initialization procedure should take into account the significance of the extra maps, to allow an effective transfer of learning. The weights of the input channels linked with
and
can be set to
, while for the other two input channels, either obtained by segmentation maps or by feature point maps, their weights can be obtained from
, using the conversion from RGB to grayscale, as the segmented maps and feature point maps are generated in grayscale:
In (11), are the weights for the new filter, obtained by combining the weights from the pre-trained filter , which correspond to the RGB channels, namely , and . During the training phase, these weights will be adjusted to align with the regression task objective.
In the fully connected block, all fully connected layers from the pre-trained model can be reused, except for the last layer, which should have six neurons, one for each desired camera velocity that needs to be approximated by the model. Additionally, the activation function of the last layer should be compatible with the range of outputs, avoiding the use of activation functions, such as a rectified linear unit, which does not permit negative output values. As exemplification, the experimental section will consider the integration of AlexNet neural layers into the architecture proposed in
Figure 4, resulting in three different early fusion neural architectures, based on segmentation maps, SURF feature points, and on BRISK feature points.
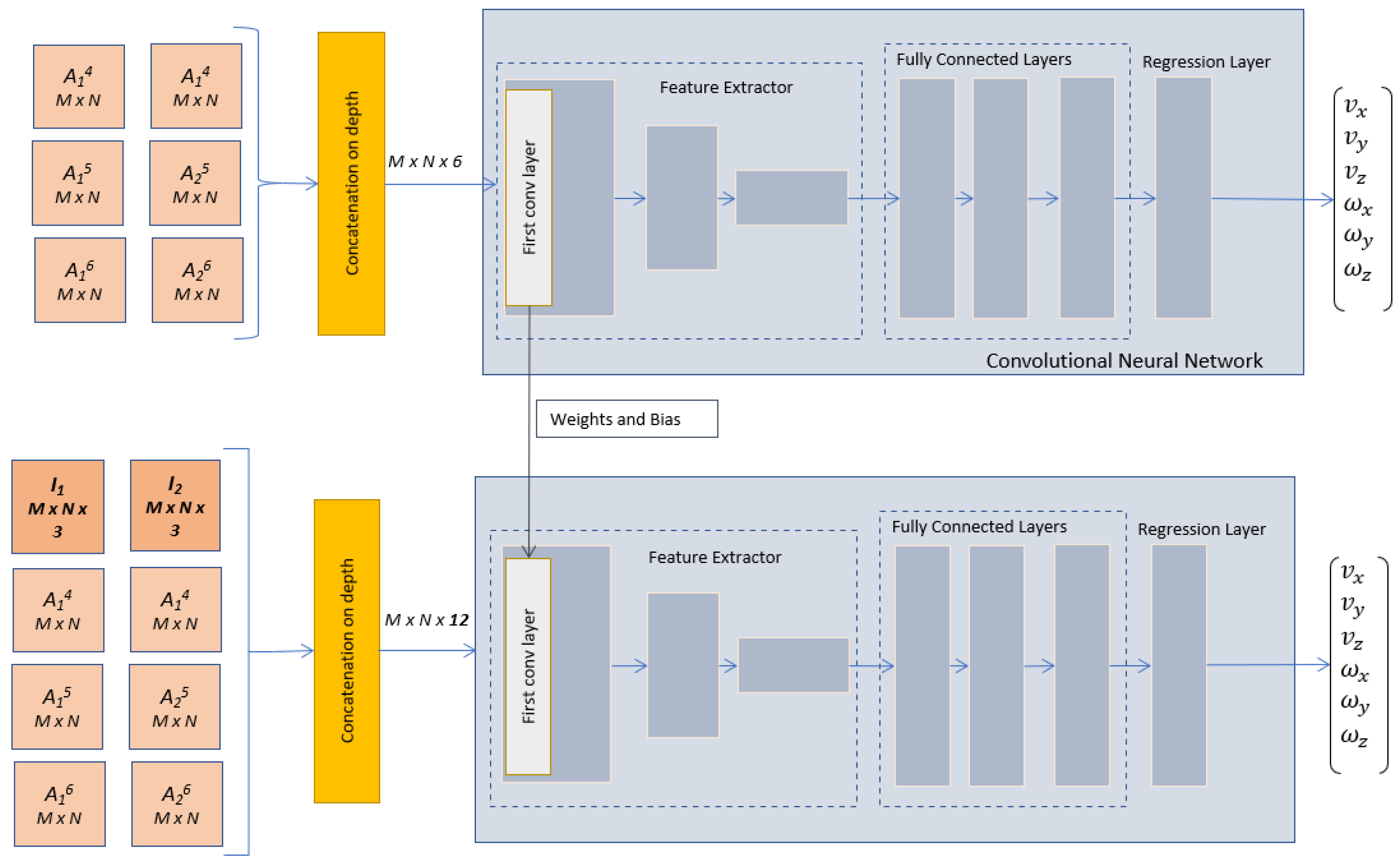
A novel method proposed in this paper is based on the early fusion with image moment maps, which is described in
Figure 5. Firstly, an AlexNet-based architecture is trained using the depth concatenation of the angular image moment maps, as derived from (10), with the mean updated for each input channel. The first convolutional layer includes filters with 6 input channels, one for each image moment map. These filters can be also initialized using the filters of the pre-trained AlexNet. After the training stage, the weights and bias from the first convolutional layer will be transferred to the main early fusion angular image moments-based architecture (
Figure 5, bottom). The maps with the angular image moments and the original RGB images are concatenated on depth, resulting in an array of size
. Therefore, the first convolutional layer will consist of filters with 12 input channels, with the first 6 input channels linked to
and
initialized from the pre-trained AlexNet. The remaining 6 input channels are linked to the image moment maps and initialized from the network trained for the angular image moment maps (
Figure 5, top). Although the training process might appear intricate, the model maintains its simplicity by exclusively operating at the input neural layer. We have refrained from increasing the number of layers or making them more complex. By this, the fusion of contextual information at an early stage not only enhances performance but also holds the promise of reduced computational resources during runtime utilization. This holds particular promise for applications that require rapid and continuous visual feedback control, where computational efficiency is a key factor. As an exemplification, the experimental section will consider the following comparisons regarding the angular image moment maps:
A comparison between the angular image moments computed with the equations from [
21,
22];
A comparison regarding the influence of the cells’ image size, as stated in Algorithm 3;
A comparison regarding the influence of the overlapping cells vs. non-overlapping cells;
A comparison between the performances of a simple early fusion visual servoing architecture (based on segmentation, feature points, or image moment maps) vs. hybrid early fusion, where different types of additional maps are combined.
5. Conclusions
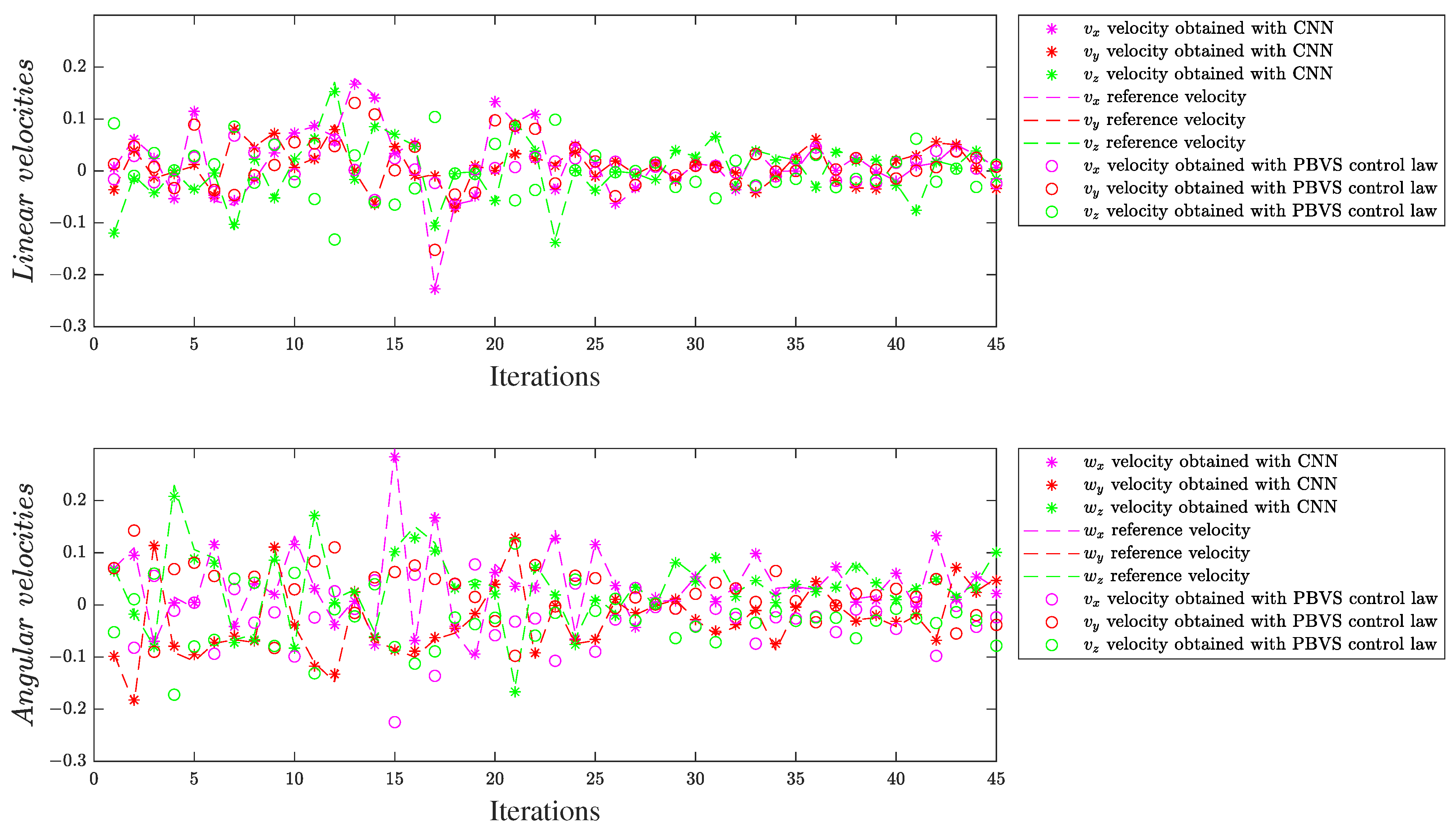
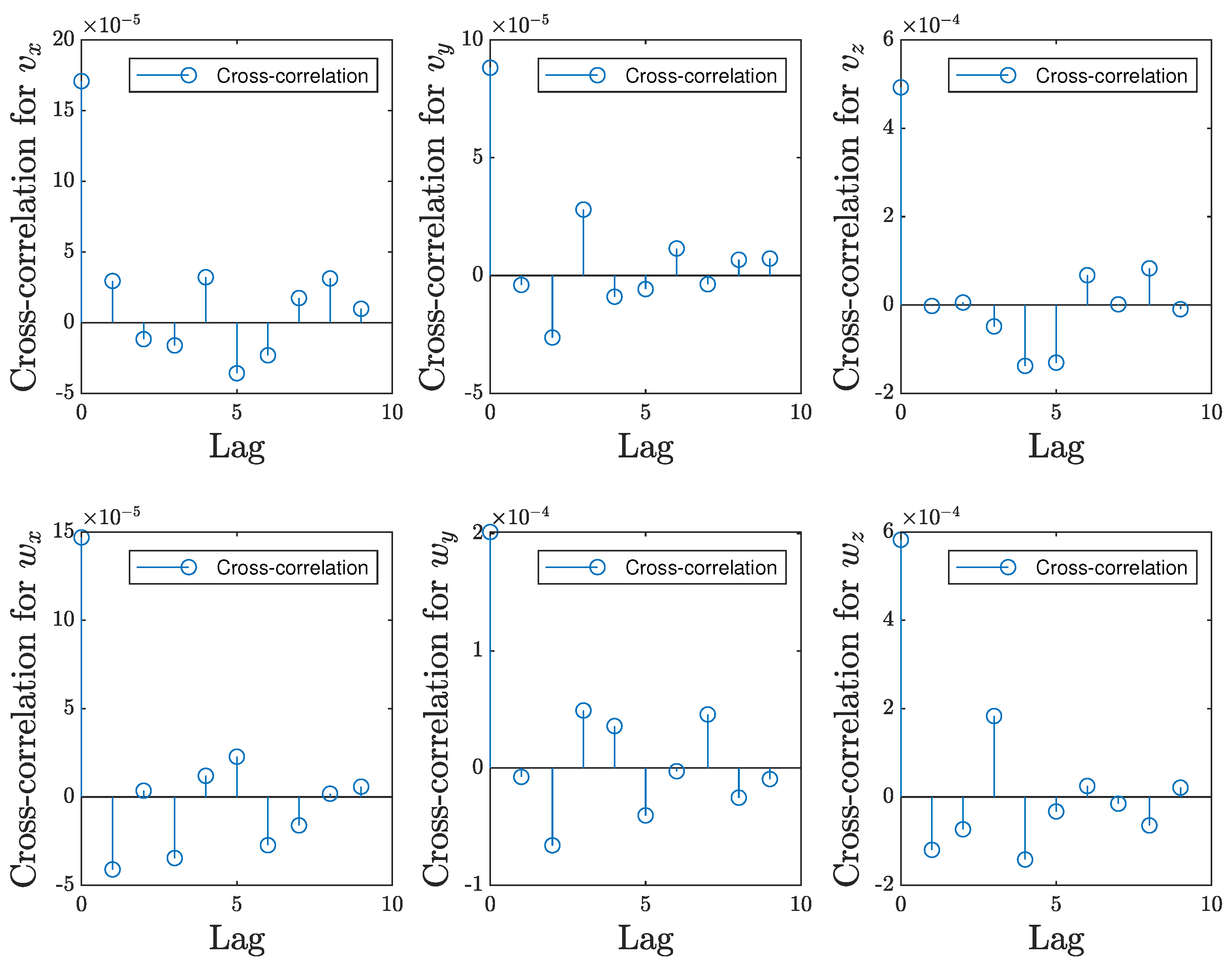
This paper introduces CNN architectures with early fusion for a visual servoing task in the context of the camera positioning on a 6 DOF gripper robot. The neural input array is expanded on depth, by combining the RGB images (corresponding to the initial and final scenes) with some additional maps. The role of these maps is to provide simplified sketches of the initial and final scenes, which can guide CNN in extracting meaningful features.
Some of the most effective traditional visual servoing techniques were explored to generate extra maps with different levels of detail, relevant to the approximation of the linear and angular camera velocities required by the visual controller. This analysis focuses on the design of early fusion approaches using the following types of maps (stand-alone or in combination): angular moment maps, region-based segmented maps, and feature point maps. Each type of map offers a different level of information extracted from initial and final images. To allow simple training, the transfer of learning from a CNN pre-trained for image classification is adopted. The transfer of learning is adjusted to also manage the supplementary neural parameters from the first convolutional layer, which were introduced due to the use of early fusion.
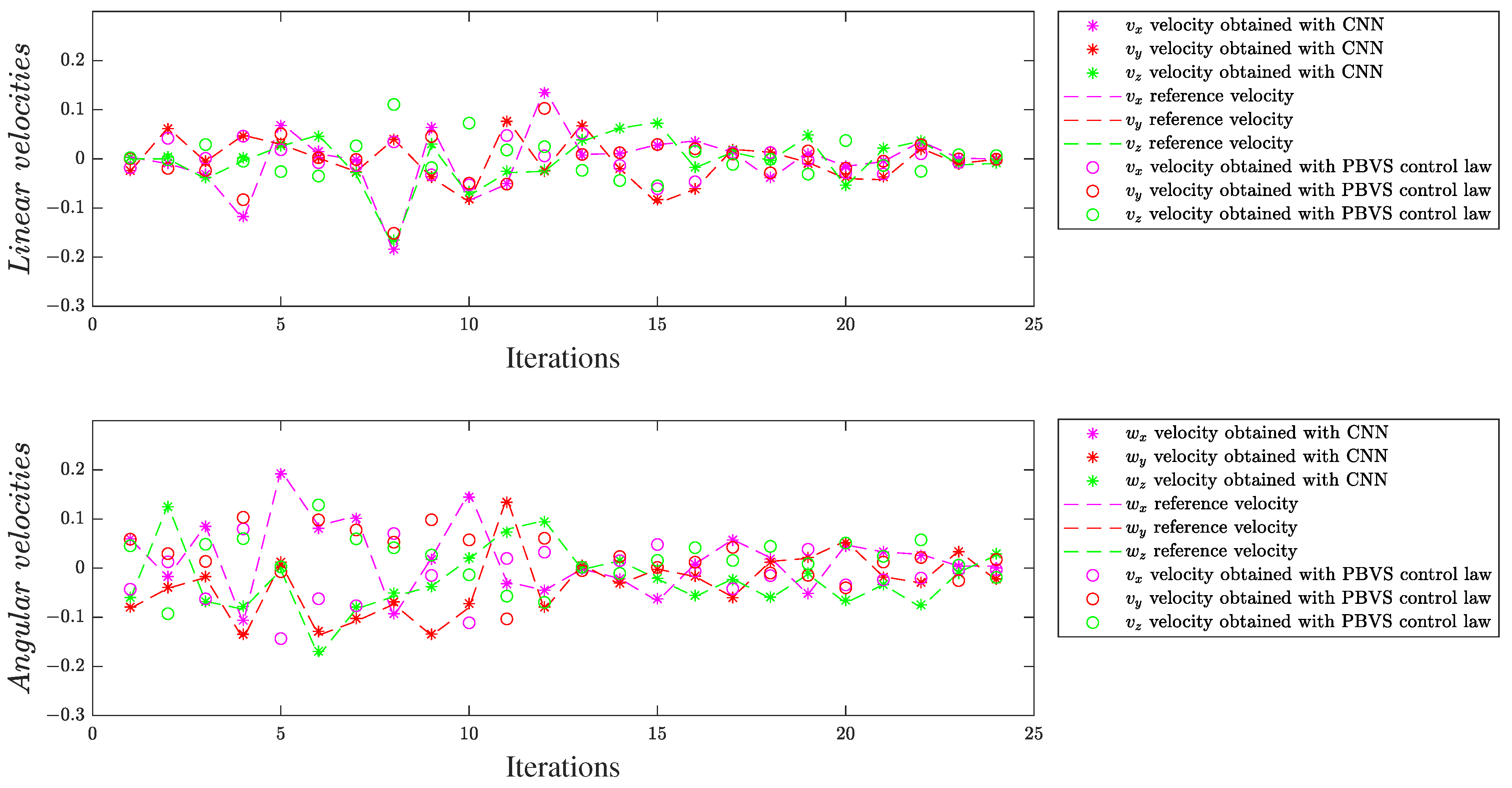
We evaluated the deep models on two different scenes, with a single object and multiple objects, respectively. These experimental scenarios allowed investigating what level of detail is helpful for the CNN design and the limitations resulting from early fusion. Mainly, each extra map increases the level of input data redundancy and requires the use of additional neural parameters in the deep model. In this context, we concluded that low-level (SURF feature points) and mid-level information (segmentation maps) are more helpful than high-level information, such as image moments. A feature point technique and region-segmentation technique were configured to produce a single supplementary map for each image, to highlight the important areas, such that the differences between the initial and final scenes can be easily found by CNN.
Future work will focus on evaluating the performances of the proposed early fusion-based CNN architectures in applications for eye-in-hand and eye-to-hand configurations. An envisaged step involves the acquisition of images combined with dense disparity maps to allow the integration of additional maps with linear image moments. The potential for improved precision and robustness offered by the combined input information holds promise for advancing the field of visual servoing and facilitating practical applications in domains requiring precise camera positioning and control.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}