
Adaptable 2D to 3D Stereo Vision Image Conversion Based on a Deep Convolutional Neural Network and Fast Inpaint Algorithm

Abstract
:1. Introduction
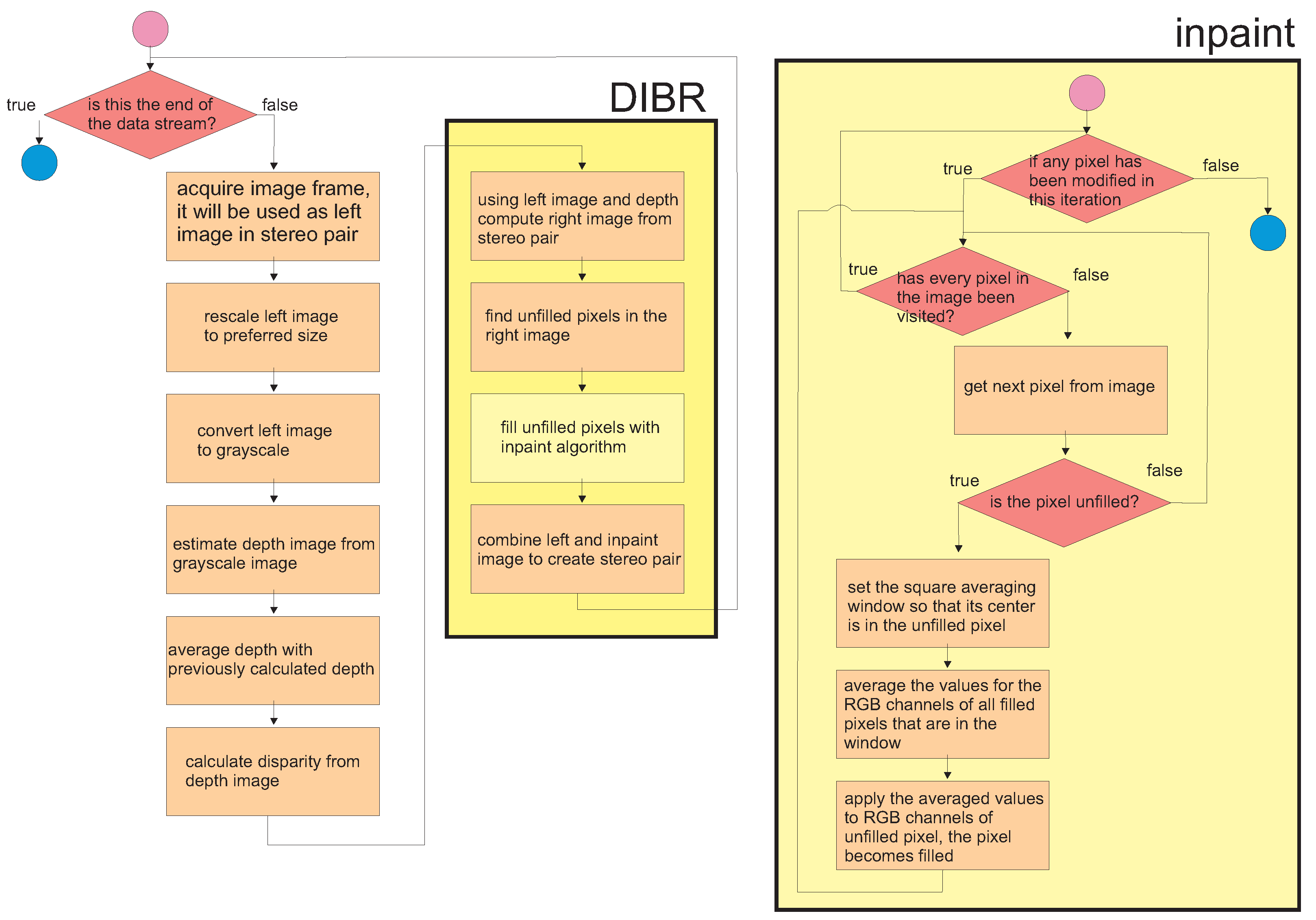
2. Materials and Methods
2.1. Depth Image Estimation
2.2. Depth Image-Based Rendering
| Algorithm 1: Depth image-based rendering (DIBR) algorithm with parameterized maximal disparity | |
| Inputs: | MaxDisp—maximal disparity in output image, θ—averaging coefficient, h, |
| w—height and width of the image, inpaintAlg—inpaint algorithm that fills holes in | |
| the DIBR image, model—DNN (or any other) model to estimate the depth image | |
| from the grayscale image. | |
| Outputs: | Algorithm continuously estimates the right stereo image and stores it in variable |
| rightImgInpaint | |
|
// initialize previous image as empty. depthPrev ← ⌀ // algorithm runs continuously while true do | |
 | |
| Algorithm 2: Fast algorithm for image inpaint (FAST) | |
| Inputs: | Image—input image in which holes will be filled, mask—matrix where 1 |
| indicates pixels that should be filled, h, w—height and width of the image, | |
| windowSize—size of the averaging window. | |
| Outputs: Image with filled holes. // initialize previous image as empty depthPrev ← ⌀ // algorithm runs until all holes are filled change ← True while change do | |
 | |
2.3. Fast Inpaint Algorithm
3. Results
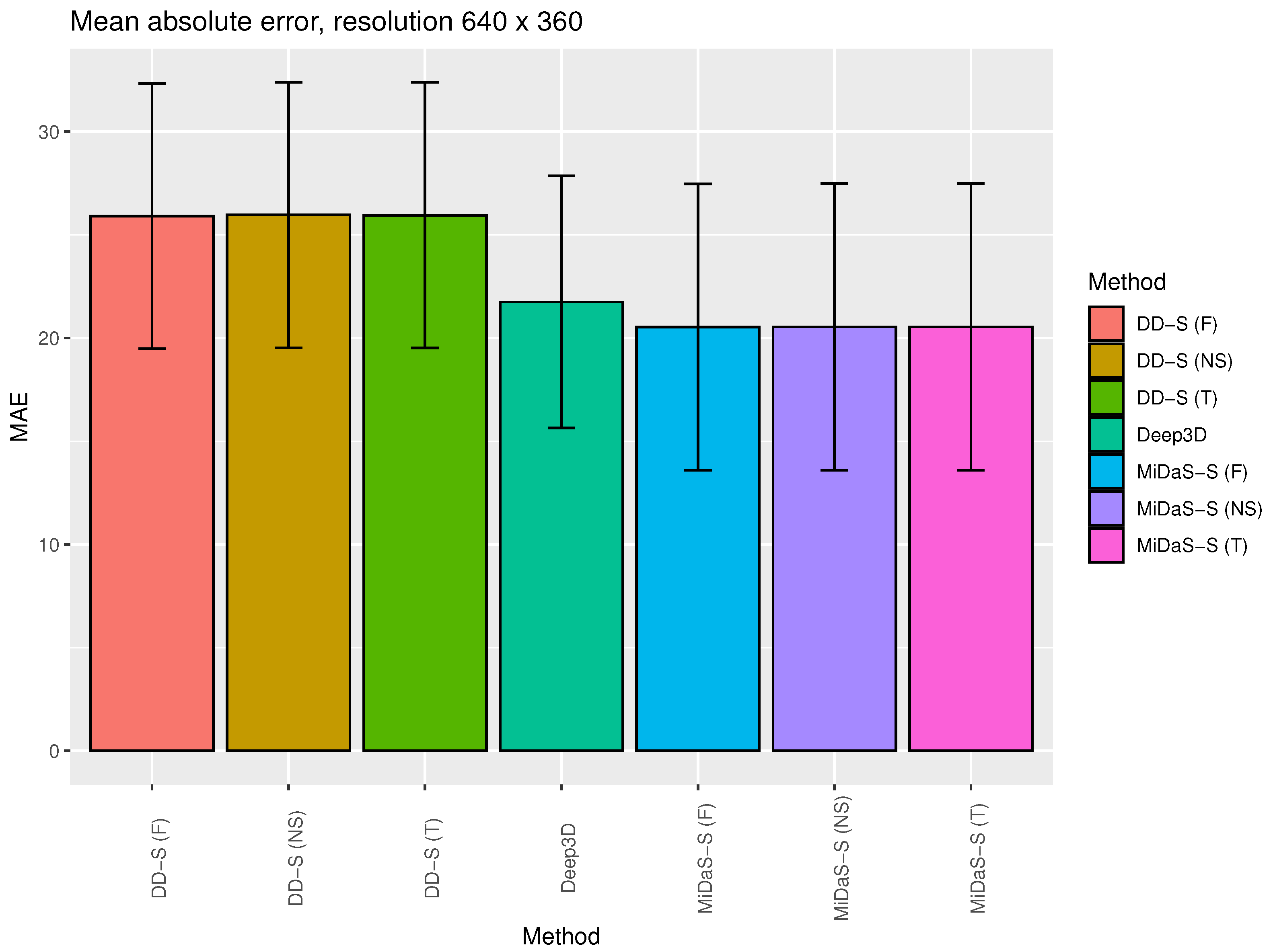
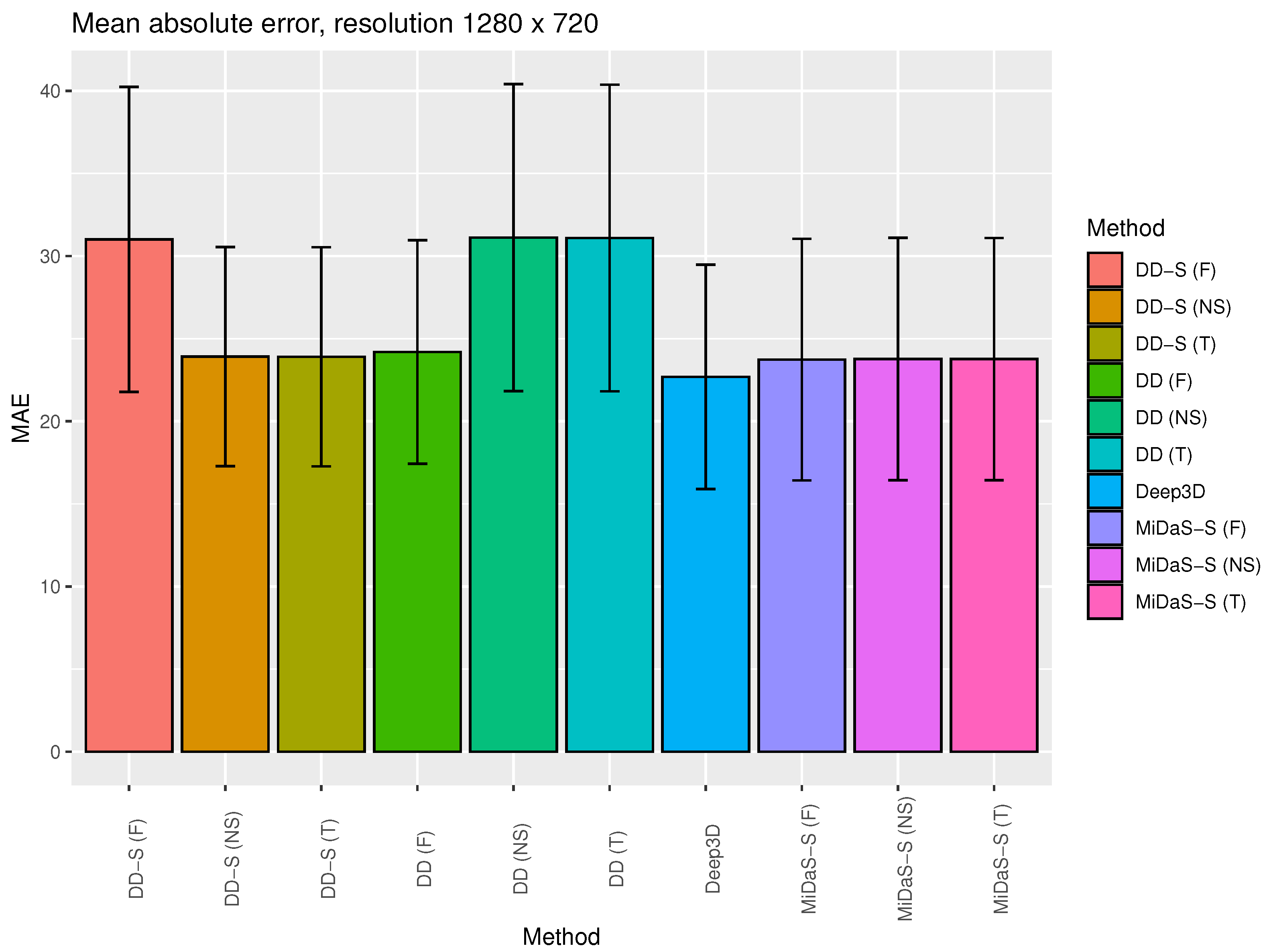
- Quantitative study—using the stereo evaluation set KITTI [47,48]. The KITTI dataset consists of 200 test scenes that were recorded by a moving car via a stereo camera. The images show ordinary traffic involving cars. Static objects are visible, such as trees, road signs, etc. The original resolution of the data is 1242 × 375. The mean absolute error (MAE) was calculated between the right image and the estimation of the right image generated from the left image. We measured the speeds of the various algorithms, defined as the average processing time of the standard deviation of the animation frame, pm, and the number of frames per second (FPS).
- We conducted a qualitative study of the user experiences on the generated stereo videos based on the methodology from [9,49]. From 23 free recordings via Pixabay https://pixabay.com/ (accessed on 10 June 2023), stereo vision videos were generated, and five adults were asked to evaluate the quality of generated videos. Those people were university students, but they were not experts in the computer vision field. They also declared that they had no previous experience with viewing stereo vision videos using virtual reality systems, such as Oculus. Participants in the experiment watched the stereo vision videos using the VR system Oculus Quest 2 via the DeoVR QUEST app. In the DeoVR QUEST app, there is an option to turn off the stereo vision effect (the “Force mono projection on this video” option); test subjects were free to use it to see if the 3D impression was merely a suggestion. Each subject was able to replay a single recording many times.
3.1. Quantitative Study
3.2. Qualitative (User) Study
4. Discussion
5. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Loop, C.; Zhang, Z. Computing rectifying homographies for stereo vision. In Proceedings of the 999 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (Cat. No PR00149), Ft. Collins, CO, USA, 23–25 June 1999; Volume 1, pp. 125–131. [Google Scholar] [CrossRef]
- Hu, W.; Xia, M.; Fu, C.W.; Wong, T.T. Mononizing Binocular Videos. ACM Trans. Graph. 2020, 39, 7764. [Google Scholar] [CrossRef]
- Chen, W.Y.; Chang, Y.L.; Lin, S.F.; Ding, L.F.; Chen, L.G. Efficient Depth Image Based Rendering with Edge Dependent Depth Filter and Interpolation. In Proceedings of the 2005 IEEE International Conference on Multimedia and Expo, Amsterdam, The Netherlands, 6–8 July 2005; pp. 1314–1317. [Google Scholar] [CrossRef]
- Feng, Z.; Chao, Z.; Huamin, Y.; Yuying, D. Research on Fully Automatic 2D to 3D Method Based on Deep Learning. In Proceedings of the 2019 IEEE 2nd International Conference on Automation, Electronics and Electrical Engineering (AUTEEE), Chicago, IL, USA, 22–24 November 2019; pp. 538–541. [Google Scholar] [CrossRef]
- Po, L.M.; Xu, X.; Zhu, Y.; Zhang, S.; Cheung, K.W.; Ting, C.W. Automatic 2D-to-3D video conversion technique based on depth-from-motion and color segmentation. In Proceedings of the IEEE 10th International Conference on Signal Processing Proceedings, Bangalore, India, 18–21 July 2010; pp. 1000–1003. [Google Scholar] [CrossRef] [Green Version]
- Tsai, S.F.; Cheng, C.C.; Li, C.T.; Chen, L.G. A real-time 1080p 2D-to-3D video conversion system. In Proceedings of the 2011 IEEE International Conference on Consumer Electronics (ICCE), Berlin, Germany, 9–12 January 2011; pp. 803–804. [Google Scholar] [CrossRef]
- Yao, L.; Liu, Z.; Wang, B. 2D-to-3D conversion using optical flow based depth generation and cross-scale hole filling algorithm. Multimed. Tools Appl. 2019, 78, 6583. [Google Scholar] [CrossRef]
- Zhang, Z.; Wang, Y.; Jiang, T.; Gao, W. Visual pertinent 2D-to-3D video conversion by multi-cue fusion. In Proceedings of the 2011 18th IEEE International Conference on Image Processing, Brussels, Belgium, 11–14 September 2011; pp. 909–912. [Google Scholar] [CrossRef]
- Lu, J.; Yang, Y.; Liu, R.; Kang, S.B.; Yu, J. 2D-to-Stereo Panorama Conversion Using GAN and Concentric Mosaics. IEEE Access 2019, 7, 23187–23196. [Google Scholar] [CrossRef]
- Li, Z.; Xie, X.; Liu, X. An efficient 2D to 3D video conversion method based on skeleton line tracking. In Proceedings of the 2009 3DTV Conference: The True Vision—Capture, Transmission and Display of 3D Video, Lisbon, Portugal, 8–10 July 2009; pp. 1–4. [Google Scholar] [CrossRef]
- Cheng, C.C.; Li, C.T.; Chen, L.G. A 2D-to-3D conversion system using edge information. In Proceedings of the 2010 Digest of Technical Papers International Conference on Consumer Electronics (ICCE), London, UK, 9–13 January 2010; pp. 377–378. [Google Scholar] [CrossRef]
- Wu, C.; Er, G.; Xie, X.; Li, T.; Cao, X.; Dai, Q. A Novel Method for Semi-automatic 2D to 3D Video Conversion. In Proceedings of the 2008 3DTV Conference: The True Vision–Capture, Transmission and Display of 3D Video, Budapest, Hungary, 7–9 June 2008; pp. 65–68. [Google Scholar] [CrossRef] [Green Version]
- Feng, Y.; Ren, J.; Jiang, J. Object-Based 2D-to-3D Video Conversion for Effective Stereoscopic Content Generation in 3D-TV Applications. IEEE Trans. Broadcast. 2011, 57, 500–509. [Google Scholar] [CrossRef] [Green Version]
- Varekamp, C.; Barenbrug, B. Improved depth propagation for 2D to 3D video conversion using key-frames. In Proceedings of the 4th European Conference on Visual Media Production, Lisbon, Portugal, 4–8 July 2007; pp. 1–7. [Google Scholar] [CrossRef]
- Angot, L.J.; Huang, W.J.; Liu, K.C. A 2D to 3D video and image conversion technique based on a bilateral filter. In Proceedings of the Three-Dimensional Image Processing (3DIP) and Applications, Chicago, IL, USA, 22–24 June 2010; Baskurt, A.M., Ed.; International Society for Optics and Photonics, SPIE: Chicago, IL, USA, 2010; Volume 7526, p. 75260D. [Google Scholar] [CrossRef]
- Lie, W.N.; Chen, C.Y.; Chen, W.C. 2D to 3D video conversion with key-frame depth propagation and trilateral filtering. Electron. Lett. 2011, 47, 319–321. [Google Scholar] [CrossRef]
- Rotem, E.; Wolowelsky, K.; Pelz, D. Automatic video to stereoscopic video conversion. In Proceedings of the SPIE—The International Society for Optical Engineering, Colmar, France, 4–7 August 2005. [Google Scholar] [CrossRef]
- Pourazad, M.T.; Nasiopoulos, P.; Ward, R.K. An H.264-based scheme for 2D to 3D video conversion. IEEE Trans. Consum. Electron. 2009, 55, 742–748. [Google Scholar] [CrossRef]
- Ideses, I.; Yaroslavsky, L.; Fishbain, B. Real-time 2D to 3D video conversion. J. Real-Time Image Process. 2007, 2, 3–9. [Google Scholar] [CrossRef] [Green Version]
- Yuan, H.; Wu, S.; An, P.; Tong, C.; Zheng, Y.; Bao, S.; Zhang, Y. Robust Semiautomatic 2D-to-3D Conversion with Welsch M-Estimator for Data Fidelity. Math. Probl. Eng. 2018, 2018, 8746. [Google Scholar] [CrossRef] [Green Version]
- Yuan, H. Robust semi-automatic 2D-to-3D image conversion via residual-driven optimization. EURASIP J. Image Video Process. 2018, 2018, 13640. [Google Scholar] [CrossRef] [Green Version]
- Zhang, L.; Vazquez, C.; Knorr, S. 3D-TV Content Creation: Automatic 2D-to-3D Video Conversion. IEEE Trans. Broadcast. 2011, 57, 372–383. [Google Scholar] [CrossRef]
- Hachaj, T.; Stolińska, A.; Andrzejewska, M.; Czerski, P. Deep convolutional symmetric encoder—Decoder neural networks to predict students’ visual attention. Symmetry 2021, 13, 2246. [Google Scholar] [CrossRef]
- Yang, X.; Zhao, Y.; Feng, Z.; Sang, H.; Zhang, Z.; Zhang, G.; He, L. A light-weight stereo matching network based on multi-scale features fusion and robust disparity refinement. IET Image Process. 2023, 17, 1797–1811. [Google Scholar] [CrossRef]
- Alhashim, I.; Wonka, P. High Quality Monocular Depth Estimation via Transfer Learning. arXiv 2018, arXiv:1812.11941. [Google Scholar]
- Hachaj, T. Potential Obstacle Detection Using RGB to Depth Image Encoder-Decoder Network: Application to Unmanned Aerial Vehicles. Sensors 2022, 22, 6703. [Google Scholar] [CrossRef]
- Ranftl, R.; Lasinger, K.; Hafner, D.; Schindler, K.; Koltun, V. Towards Robust Monocular Depth Estimation: Mixing Datasets for Zero-Shot Cross-Dataset Transfer. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 8261. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, Y.; Zhao, M.; Yu, X. A Regional Regression Network for Monocular Object Distance Estimation. In Proceedings of the 2020 IEEE International Conference on Multimedia & Expo Workshops (ICMEW), Chicago, IL, USA, 22–24 July 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Zhou, T.; Brown, M.; Snavely, N.; Lowe, D.G. Unsupervised Learning of Depth and Ego-Motion from Video. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Amsterdam, The Netherlands, 16–19 July 2017; pp. 6612–6619. [Google Scholar] [CrossRef] [Green Version]
- Chen, S.; Tang, M.; Kan, J. Monocular image depth prediction without depth sensors: An unsupervised learning method. Appl. Soft Comput. 2020, 97, 106804. [Google Scholar] [CrossRef]
- Masoumian, A.; Rashwan, H.A.; Cristiano, J.; Asif, M.S.; Puig, D. Monocular Depth Estimation Using Deep Learning: A Review. Sensors 2022, 22, 5353. [Google Scholar] [CrossRef]
- Ming, Y.; Meng, X.; Fan, C.; Yu, H. Deep learning for monocular depth estimation: A review. Neurocomputing 2021, 438, 14–33. [Google Scholar] [CrossRef]
- Kun Zhou, X.M.; Cheng, B. Review of Stereo Matching Algorithms Based on Deep Learning. Comput. Intell. Neurosci. 2020, 2020, 2323. [Google Scholar] [CrossRef]
- Zhao, C.; Sun, Q.; Zhang, C.; Tang, Y.; Qian, F. Monocular depth estimation based on deep learning: An overview. Sci. China Technol. Sci. 2020, 63, 1582. [Google Scholar] [CrossRef]
- Xiaogang, R.; Wenjing, Y.; Jing, H.; Peiyuan, G.; Wei, G. Monocular Depth Estimation Based on Deep Learning: A Survey. In Proceedings of the 2020 Chinese Automation Congress (CAC), Warsaw, Poland, 16–19 May 2020; pp. 2436–2440. [Google Scholar] [CrossRef]
- Poggi, M.; Tosi, F.; Batsos, K.; Mordohai, P.; Mattoccia, S. On the Synergies Between Machine Learning and Binocular Stereo for Depth Estimation From Images: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 2021, 917. [Google Scholar] [CrossRef] [PubMed]
- Xie, J.; Girshick, R.; Farhadi, A. Deep3D: Fully Automatic 2D-to-3D Video Conversion with Deep Convolutional Neural Networks. In Proceedings of the Computer Vision—ECCV, Berlin, Germany, 20–23 May 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; IEEE: Cham, Switzerland, 2016; pp. 842–857. [Google Scholar]
- Chen, B.; Yuan, J.; Bao, X. Automatic 2D-to-3D Video Conversion using 3D Densely Connected Convolutional Networks. In Proceedings of the 2019 IEEE 31st International Conference on Tools with Artificial Intelligence (ICTAI), Chicago, IL, USA, 22–24 August 2019; pp. 361–367. [Google Scholar] [CrossRef]
- Cannavo, A.; D’Alessandro, A.; Daniele, M.; Giorgia, M.; Congyi, Z.; Lamberti, F. Automatic generation of affective 3D virtual environments from 2D images. In Proceedings of the 15th International Conference on Computer Graphics Theory and Applications (GRAPP 2020), SCITEPRESS, Rome, Italy, 19–24 April 2020; pp. 113–124. [Google Scholar]
- Koido, Y.; Morikawa, H.; Shiraishi, S.; Takeuchi, S.; Maruyama, W.; Nakagori, T.; Hirakata, M.; Shinkai, H.; Kawai, T. Applications of 2D to 3D conversion for educational purposes. In Proceedings of the Stereoscopic Displays and Applications XXIV, Prague, Czech Republic, 29 July–3 August 2013; Woods, A.J., Holliman, N.S., Favalora, G.E., Eds.; International Society for Optics and Photonics, SPIE: Prague, Czech Republic, 2013; Volume 8648, p. 86481X. [Google Scholar] [CrossRef]
- Sisi, L.; Fei, W.; Wei, L. The overview of 2D to 3D conversion system. In Proceedings of the 2010 IEEE 11th International Conference on Computer-Aided Industrial Design & Conceptual Design 1, Amsterdam, The Netherlands, 6–8 June 2010; Volume 2, pp. 1388–1392. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Berlin, Germany, 13–17 July 2016; pp. 770–778. [Google Scholar]
- Fehn, C. Depth-image-based rendering (DIBR), compression, and transmission for a new approach on 3D-TV efficient depth image based rendering with. In Proceedings of the Stereoscopic displays and virtual reality systems XI SPIE, Madrid, Spain, 10–15 August 2004; Volume 5291, pp. 93–104. [Google Scholar]
- Telea, A. An Image Inpainting Technique Based on the Fast Marching Method. J. Graph. Tools 2004, 9, 7596. [Google Scholar] [CrossRef]
- Bertalmio, M.; Bertozzi, A.; Sapiro, G. Navier-stokes, fluid dynamics, and image and video inpainting. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, CVPR 2001, London, UK, 14–19 December 2001; Volume 1, p. I. [Google Scholar] [CrossRef] [Green Version]
- Menze, M.; Heipke, C.; Geiger, A. Object Scene Flow. ISPRS J. Photogramm. Remote. Sens. 2018, 14, 9176. [Google Scholar] [CrossRef]
- Menze, M.; Heipke, C.; Geiger, A. Joint 3D Estimation of Vehicles and Scene Flow. In Proceedings of the ISPRS Workshop on Image Sequence Analysis (ISA), New York, NY, USA, 14–19 July 2015. [Google Scholar]
- Zhang, F.; Liu, F. Casual stereoscopic panorama stitching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Milan, Italy, 10–14 April 2015; pp. 2002–2010. [Google Scholar]
- Sun, W.; Xu, L.; Au, O.C.; Chui, S.H.; Kwok, C.W. An overview of free view-point depth-image-based rendering (DIBR). In Proceedings of the APSIPA Annual Summit and Conference, Berlin, Germany, 9–12 January 2010; pp. 1023–1030. [Google Scholar]
- Xu, S.; Dong, Y.; Wang, H.; Wang, S.; Zhang, Y.; He, B. Bifocal-Binocular Visual SLAM System for Repetitive Large-Scale Environments. IEEE Trans. Instrum. Meas. 2022, 71, 1–15. [Google Scholar] [CrossRef]
- Wang, Y.M.; Li, Y.; Zheng, J.B. A camera calibration technique based on OpenCV. In Proceedings of the The 3rd International Conference on Information Sciences and Interaction Sciences, Amsterdam, The Netherlands, 6–8 July 2010; pp. 403–406. [Google Scholar] [CrossRef]
- Moorthy, A.K.; Su, C.C.; Mittal, A.; Bovik, A.C. Subjective evaluation of stereoscopic image quality. Signal Process. Image Commun. 2013, 28, 870–883. [Google Scholar] [CrossRef]
- McIntire, J.P.; Havig, P.R.; Geiselman, E.E. What is 3D good for? A review of human performance on stereoscopic 3D displays. In Proceedings of the Head-and Helmet-Mounted Displays XVII and Display Technologies and Applications for Defense, Security, and Avionics VI, Prague, Czech Republic, 2–5 July 2012; Volume 8383, pp. 280–292. [Google Scholar]
- Su, C.C.; Moorthy, A.K.; Bovik, A.C. Visual Quality Assessment of Stereoscopic Image and Video: Challenges, Advances, and Future Trends. In Visual Signal Quality Assessment: Quality of Experience (QoE); Deng, C., Ma, L., Lin, W., Ngan, K.N., Eds.; Springer International Publishing: Cham, Switzerland, 2015; pp. 185–212. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Backbone | MaxDisp. | Inpaint | MAE | Time | FPS |
|---|---|---|---|---|---|---|
| DIBR | MiDaS-S [27] | 25 | Fast | ∼45 | ||
| DIBR | MiDaS-S [27] | 50 | Fast | ∼42 | ||
| DIBR | MiDaS-S [27] | 75 | Fast | ∼40 | ||
| DIBR | MiDaS-S [27] | 25 | NS [46] | ∼19 | ||
| DIBR | MiDaS-S [27] | 50 | NS [46] | ∼10 | ||
| DIBR | MiDaS-S [27] | 75 | NS [46] | ∼6 | ||
| DIBR | MiDaS-S [27] | 25 | Telea [45] | ∼12 | ||
| DIBR | MiDaS-S [27] | 50 | Telea [45] | ∼5 | ||
| DIBR | MiDaS-S [27] | 75 | Telea [45] | ∼3 | ||
| DIBR | MiDaS-H [27] | 25 | Fast | ∼7 | ||
| DIBR | MiDaS-H [27] | 50 | Fast | ∼7 | ||
| DIBR | MiDaS-H [27] | 75 | Fast | ∼7 | ||
| DIBR | MiDaS-H [27] | 25 | NS [46] | ∼6 | ||
| DIBR | MiDaS-H [27] | 50 | NS [46] | ∼4 | ||
| DIBR | MiDaS-H [27] | 75 | NS [46] | ∼4 | ||
| DIBR | MiDaS-H [27] | 25 | Telea [45] | ∼4 | ||
| DIBR | MiDaS-H [27] | 50 | Telea [45] | ∼3 | ||
| DIBR | MiDaS-H [27] | 75 | Telea [45] | ∼2 | ||
| DIBR | MiDaS-L [27] | 25 | Fast | ∼4 | ||
| DIBR | MiDaS-L [27] | 50 | Fast | ∼4 | ||
| DIBR | MiDaS-L [27] | 75 | Fast | ∼4 | ||
| DIBR | MiDaS-L [27] | 25 | NS [46] | ∼4 | ||
| DIBR | MiDaS-L [27] | 50 | NS [46] | ∼3 | ||
| DIBR | MiDaS-L [27] | 75 | NS [46] | ∼2 | ||
| DIBR | MiDaS-L [27] | 25 | Telea [45] | ∼3 | ||
| DIBR | MiDaS-L [27] | 50 | Telea [45] | ∼2 | ||
| DIBR | MiDaS-L [27] | 75 | Telea [45] | ∼1 | ||
| DIBR | DD-S [26] | 25 | Fast | ∼8 | ||
| DIBR | DD-S [26] | 50 | Fast | ∼7 | ||
| DIBR | DD-S [26] | 75 | Fast | ∼8 | ||
| DIBR | DD-S [26] | 25 | NS [46] | ∼6 | ||
| DIBR | DD-S [26] | 50 | NS [46] | ∼4 | ||
| DIBR | DD-S [26] | 75 | NS [46] | ∼2 | ||
| DIBR | DD-S [26] | 25 | Telea [45] | ∼3 | ||
| DIBR | DD-S [26] | 50 | Telea [45] | ∼9 | ||
| DIBR | DD-S [26] | 75 | Telea [45] | ∼1 | ||
| Deep3D [37] | – | – | – | ∼83 |
| Method | Backbone | MaxDisp. | Inpaint | MAE | Time [S] | FPS |
|---|---|---|---|---|---|---|
| DIBR | MiDaS-S [27] | 25 | Fast | ∼19 | ||
| DIBR | MiDaS-S [27] | 50 | Fast | ∼19 | ||
| DIBR | MiDaS-S [27] | 75 | Fast | ∼18 | ||
| DIBR | MiDaS-S [27] | 25 | NS [46] | ∼5 | ||
| DIBR | MiDaS-S [27] | 50 | NS [46] | ∼2 | ||
| DIBR | MiDaS-S [27] | 75 | NS [46] | ∼1 | ||
| DIBR | MiDaS-S [27] | 25 | Telea [45] | ∼2 | ||
| DIBR | MiDaS-S [27] | 50 | Telea [45] | <1 | ||
| DIBR | MiDaS-S [27] | 75 | Telea [45] | <1 | ||
| DIBR | MiDaS-H [27] | 25 | Fast | ∼6 | ||
| DIBR | MiDaS-H [27] | 50 | Fast | ∼6 | ||
| DIBR | MiDaS-H [27] | 75 | Fast | ∼6 | ||
| DIBR | MiDaS-H [27] | 25 | NS [46] | ∼3 | ||
| DIBR | MiDaS-H [27] | 50 | NS [46] | ∼1 | ||
| DIBR | MiDaS-H [27] | 75 | NS [46] | <1 | ||
| DIBR | MiDaS-H [27] | 25 | Telea [45] | 1 | ||
| DIBR | MiDaS-H [27] | 50 | Telea [45] | <1 | ||
| DIBR | MiDaS-H [27] | 75 | Telea [45] | <1 | ||
| DIBR | MiDaS-L [27] | 25 | Fast | ∼4 | ||
| DIBR | MiDaS-L [27] | 50 | Fast | ∼4 | ||
| DIBR | MiDaS-L [27] | 75 | Fast | ∼4 | ||
| DIBR | MiDaS-L [27] | 25 | NS [46] | ∼2 | ||
| DIBR | MiDaS-L [27] | 50 | NS [46] | <1 | ||
| DIBR | MiDaS-L [27] | 75 | NS [46] | <1 | ||
| DIBR | MiDaS-L [27] | 25 | Telea [45] | <1 | ||
| DIBR | MiDaS-L [27] | 50 | Telea [45] | <1 | ||
| DIBR | MiDaS-L [27] | 75 | Telea [45] | <1 | ||
| DIBR | DD-S [26] | 25 | Fast | ∼3 | ||
| DIBR | DD-S [26] | 50 | Fast | ∼2 | ||
| DIBR | DD-S [26] | 75 | Fast | ∼2 | ||
| DIBR | DD-S [26] | 25 | NS [46] | ∼2 | ||
| DIBR | DD-S [26] | 50 | NS [46] | <1 | ||
| DIBR | DD-S [26] | 75 | NS [46] | <1 | ||
| DIBR | DD-S [26] | 25 | Telea [45] | <1 | ||
| DIBR | DD-S [26] | 50 | Telea [45] | <1 | ||
| DIBR | DD-S [26] | 75 | Telea [45] | <1 | ||
| DIBR | DD [25] | 25 | Fast | ∼1 | ||
| DIBR | DD [25] | 50 | Fast | ∼1 | ||
| DIBR | DD [25] | 75 | Fast | ∼1 | ||
| DIBR | DD [25] | 25 | NS [46] | <1 | ||
| DIBR | DD [25] | 50 | NS [46] | <1 | ||
| DIBR | DD [25] | 75 | NS [46] | <1 | ||
| DIBR | DD [25] | 25 | Telea [45] | <1 | ||
| DIBR | DD [25] | 50 | Telea [45] | <1 | ||
| DIBR | DD [25] | 75 | Telea [45] | <1 | ||
| Deep3D [37] | – | – | – | ∼31 |
| Method | ‘Do You Perceive 3D?’ | ‘Do You Feel Comfortable of Viewing the Stereo Panoramas?’ |
|---|---|---|
| Deep3D [37] | ||
| MiDaS, FAST [27], MaxDisp. = 25 | ||
| MiDaS, FAST [27], MaxDisp. = 50 | ||
| MiDaS, FAST [27], MaxDisp. = 75 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hachaj, T. Adaptable 2D to 3D Stereo Vision Image Conversion Based on a Deep Convolutional Neural Network and Fast Inpaint Algorithm. Entropy 2023, 25, 1212. https://doi.org/10.3390/e25081212
Hachaj T. Adaptable 2D to 3D Stereo Vision Image Conversion Based on a Deep Convolutional Neural Network and Fast Inpaint Algorithm. Entropy. 2023; 25(8):1212. https://doi.org/10.3390/e25081212
Chicago/Turabian StyleHachaj, Tomasz. 2023. "Adaptable 2D to 3D Stereo Vision Image Conversion Based on a Deep Convolutional Neural Network and Fast Inpaint Algorithm" Entropy 25, no. 8: 1212. https://doi.org/10.3390/e25081212