
Multi-Modal Representation via Contrastive Learning with Attention Bottleneck Fusion and Attentive Statistics Features

Abstract
:1. Introduction
- To address the ignorance of context statistics in the existing tensor-based fusion methods in image feature extraction, we propose statistics fusion, which correlates the features of different statistics features of images. Context statistics fusion provides a holistic perspective by integrating standard deviations and features. This enables embedding vectors to capture correlation variations efficiently and accurately.
- Attention bottlenecks are used to fuse statistical modal global features. Our model strategically curtails the cross-modal information flow between latent units via well-defined fusion ‘bottlenecks.’ These bottlenecks compel the model to collate and ‘condense’ the most pertinent inputs from each modality, ensuring that only the necessary information is shared with the other modalities. Multi-headed self-attention may assist in aligning and fusing token-level image and text features, which increases model abstraction capability.
- We aim for representation learning utilizing contrastive learning for multimodal data. The central concept is to compare multimodal anchor tuples with hard negative samples that disrupted modalities with improved positive samples acquired using an optimizable data augmentation procedure. Multiple positive samples are permitted per anchor via a supervised contrastive loss function.
2. Related Work
2.1. Multimodal Fusion
2.2. Contrastive Learning
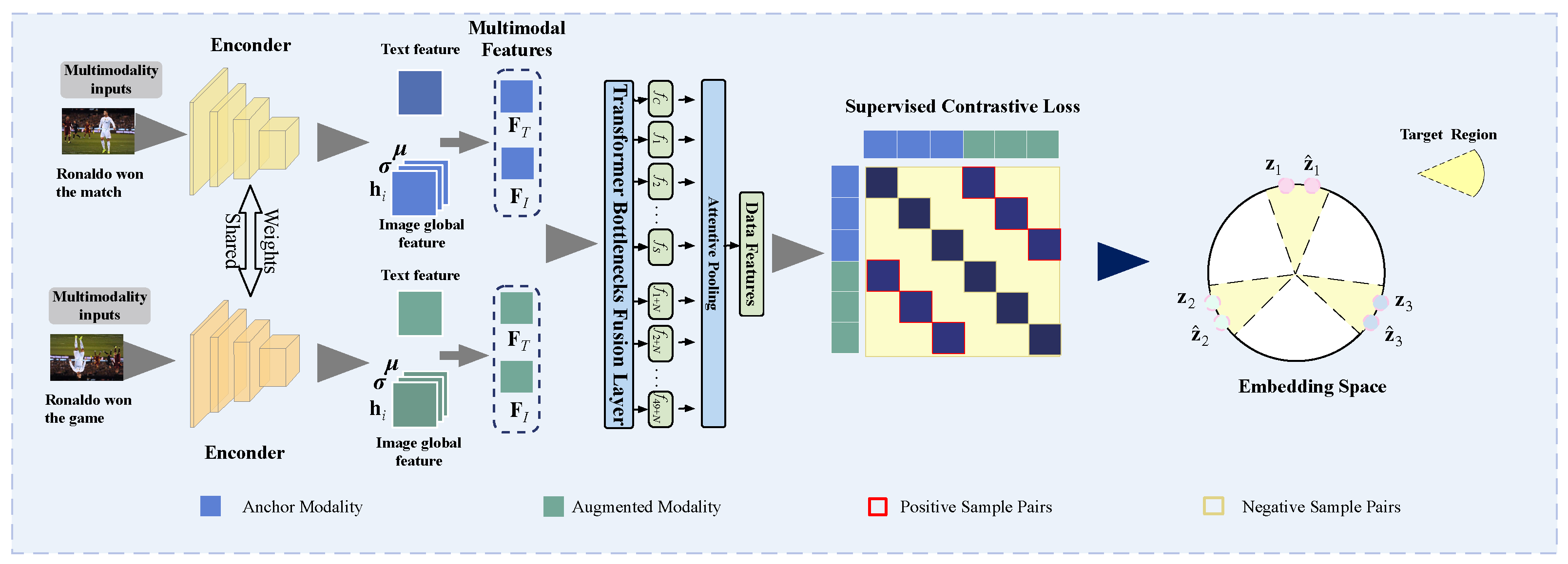
3. Methodology
3.1. Data Augmentation
3.2. Encoder Network
3.3. Channel Attention-Based Global Statistics Image Features
3.4. Multimodal Fusion via Transformer Bottlenecks
3.5. Attentive Pooling
3.6. Supervised Contrastive Losses
4. Experiments and Results
4.1. Datasets
4.2. Implementation Details
4.3. Baselines
4.4. Results and Analysis
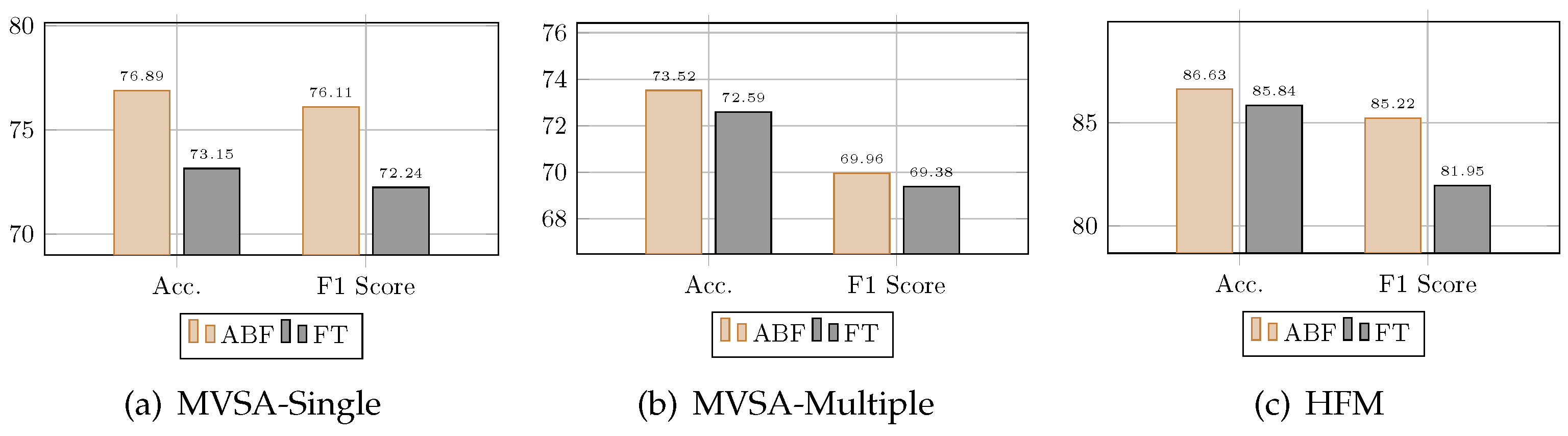
4.5. Ablation Study
4.6. Compared with Funnel Transformer
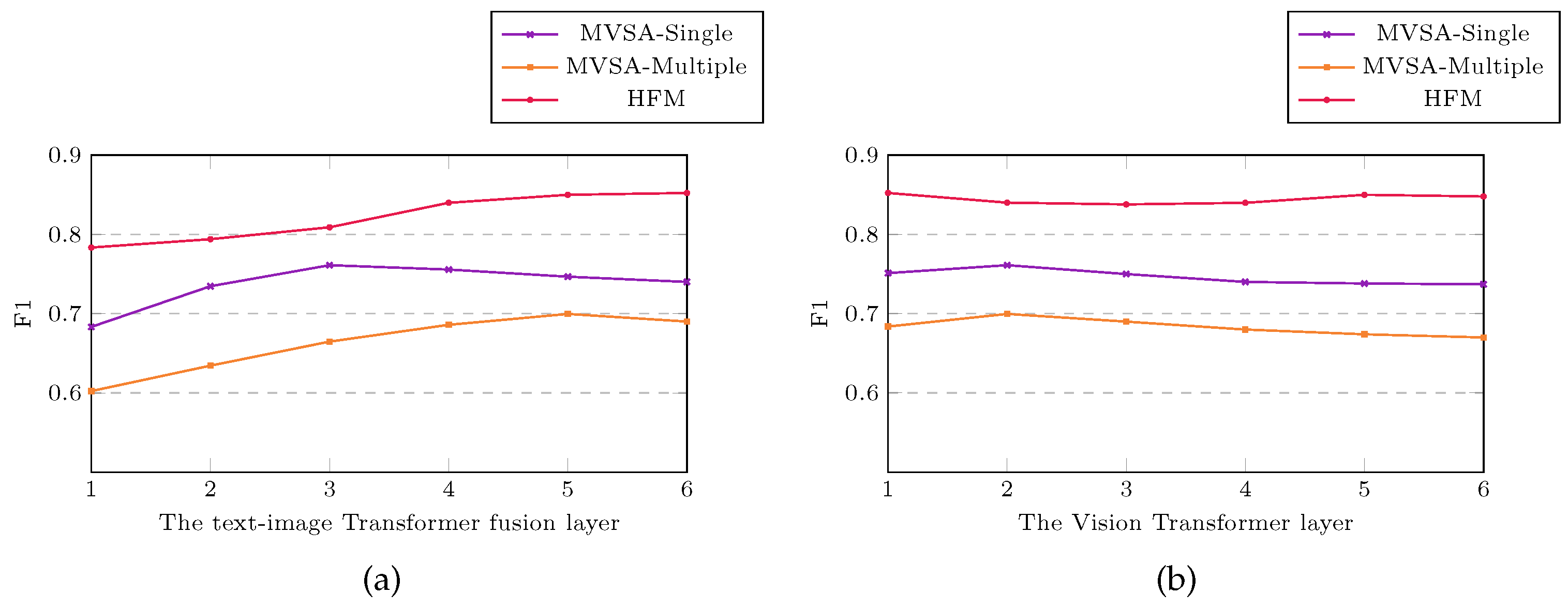
4.7. The Effect of Transformer Layer
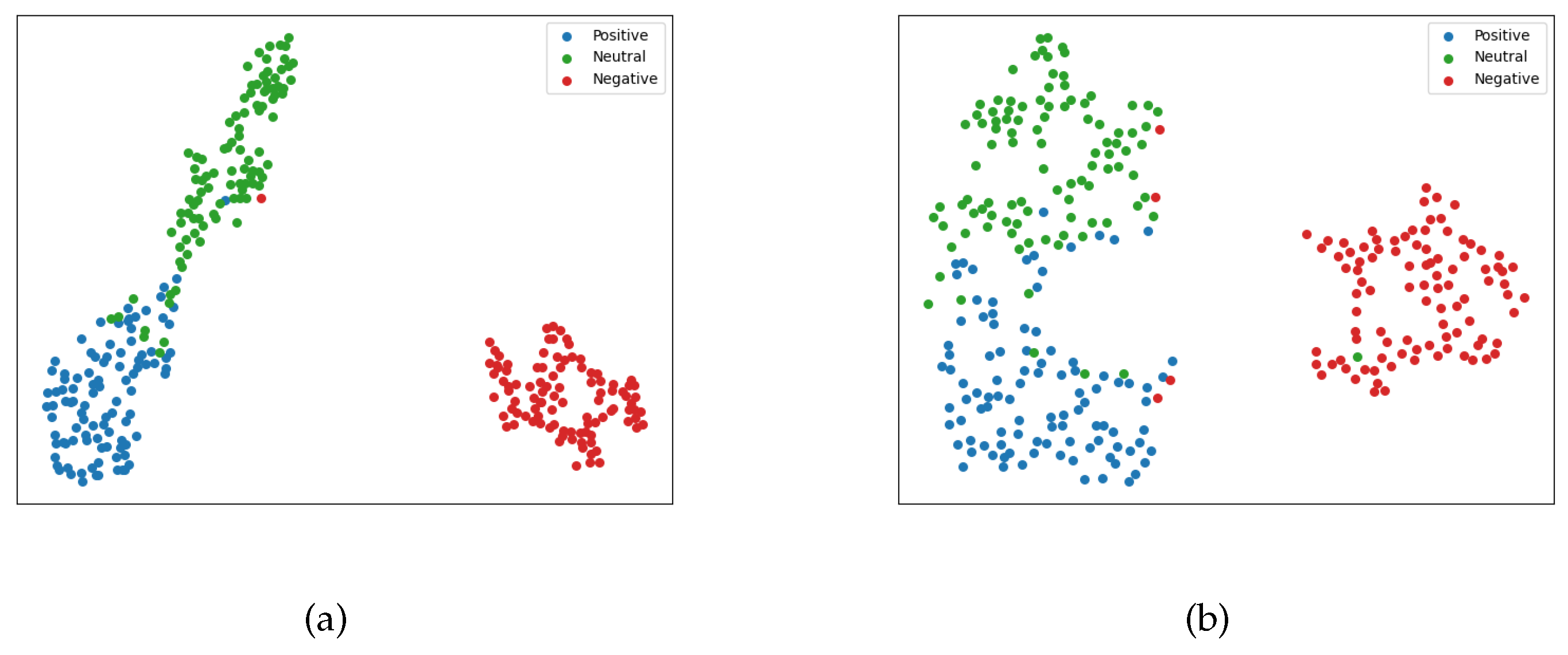
4.8. The Effect of Contrastive Learning
4.9. Case Study
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Colombo, P.; Chapuis, E.; Labeau, M.; Clavel, C. Improving Multimodal fusion via Mutual Dependency Maximisation. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Virtual, 7–11 November 2021; pp. 231–245. [Google Scholar]
- Han, W.; Chen, H.; Poria, S. Improving Multimodal Fusion with Hierarchical Mutual Information Maximization for Multimodal Sentiment Analysis. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Virtual, 7–11 November 2021; pp. 9180–9192. [Google Scholar]
- Ngiam, J.; Khosla, A.; Kim, M.; Nam, J.; Lee, H.; Ng, A.Y. Multimodal deep learning. In Proceedings of the ICML, Bellevue, WA, USA, 28 June–2 July 2011. [Google Scholar]
- Srivastava, N.; Salakhutdinov, R.R. Multimodal learning with deep boltzmann machines. Adv. Neural Inf. Process. Syst. 2012, 25, 2949–2980. [Google Scholar]
- Shivappa, S.T.; Trivedi, M.M.; Rao, B.D. Audiovisual information fusion in human–computer interfaces and intelligent environments: A survey. Proc. IEEE 2010, 98, 1692–1715. [Google Scholar] [CrossRef]
- Feng, F.; Wang, X.; Li, R. Cross-modal retrieval with correspondence autoencoder. In Proceedings of the 22nd ACM International Conference on Multimedia, Orlando, FL, USA, 7 November 2014; pp. 7–16. [Google Scholar]
- Oord, A.v.d.; Li, Y.; Vinyals, O. Representation learning with contrastive predictive coding. arXiv 2018, arXiv:1807.03748. [Google Scholar]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R. Momentum contrast for unsupervised visual representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9729–9738. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A simple framework for contrastive learning of visual representations. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 13–18 July 2020; pp. 1597–1607. [Google Scholar]
- Tian, Y.; Krishnan, D.; Isola, P. Contrastive multiview coding. In Proceedings of the European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2020; pp. 776–794. [Google Scholar]
- Liu, Y.; Yi, L.; Zhang, S.; Fan, Q.; Funkhouser, T.; Dong, H. P4contrast: Contrastive learning with pairs of point-pixel pairs for rgb-d scene understanding. arXiv 2020, arXiv:2012.13089. [Google Scholar]
- Alayrac, J.B.; Recasens, A.; Schneider, R.; Arandjelović, R.; Ramapuram, J.; De Fauw, J.; Smaira, L.; Dieleman, S.; Zisserman, A. Self-supervised multimodal versatile networks. Adv. Neural Inf. Process. Syst. 2020, 33, 25–37. [Google Scholar]
- Murthygowda, M.Y.; Krishnegowda, R.G.; Venkataramu, S.S. An integrated multi-level feature fusion framework for crowd behaviour prediction and analysis. Int. J. Electr. Comput. Eng. (IJECE) 2023, 30. [Google Scholar] [CrossRef]
- Liang, M.; Wei, M.; Li, Y.; Tian, H.; Li, Y. Improvement and Application of Fusion Scheme in Automatic Medical Image Analysis. Asian J. Sci. Technol. 2023. [Google Scholar] [CrossRef]
- Zhang, B.; Cai, H.; Song, Y.; Tao, L.; Li, Y. Computer-aided recognition based on decision-level multimodal fusion for depression. IEEE J. Biomed. Health Inform. 2022, 26, 3466–3477. [Google Scholar] [CrossRef]
- Shi, P.; Qi, H.; Liu, Z.; Yang, A. 3D Vehicle Detection Algorithm Based on Multimodal Decision-Level Fusion. CMES-Comput. Model. Eng. Sci. 2023, 135, 2007–2023. [Google Scholar] [CrossRef]
- Islam, M.M.; Iqbal, T. Mumu: Cooperative multitask learning-based guided multimodal fusion. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 22 February–1 March 2022; Volume 36, pp. 1043–1051. [Google Scholar]
- Shankar, S. Multimodal fusion via cortical network inspired losses. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Dublin, Ireland, 22–27 May 2022; pp. 1167–1178. [Google Scholar]
- Gandhi, A.; Adhvaryu, K.; Poria, S.; Cambria, E.; Hussain, A. Multimodal sentiment analysis: A systematic review of history, datasets, multimodal fusion methods, applications, challenges and future directions. Inf. Fusion 2023, 91, 424–444. [Google Scholar] [CrossRef]
- Li, Z.; Mak, M.-W.; Meng, H.M.-L. Discriminative Speaker Representation Via Contrastive Learning with Class-Aware Attention in Angular Space. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar]
- Sheng, J.; Lam, S.-K.; Li, Z.; Zhang, J.; Teng, X.; Zhang, Y.; Cai, J. Multi-view Contrastive Learning with Additive Margin for Adaptive Nasopharyngeal Carcinoma Radiotherapy Prediction. In Proceedings of the 2023 ACM International Conference on Multimedia Retrieval, Thessaloniki, Greece, 12–15 June 2023; pp. 555–559. [Google Scholar]
- Li, Z.; Mak, M.-W. Speaker representation learning via contrastive loss with maximal speaker separability. In Proceedings of the 2022 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Chiang Mai, Thailand, 7–10 November 2022; pp. 962–967. [Google Scholar]
- Liu, X.; Zhang, F.; Hou, Z.; Mian, L.; Wang, Z.; Zhang, J.; Tang, J. Self-supervised learning: Generative or contrastive. IEEE Trans. Knowl. Data Eng. 2021, 35, 857–876. [Google Scholar] [CrossRef]
- Jing, L.; Tian, Y. Self-supervised visual feature learning with deep neural networks: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 4037–4058. [Google Scholar] [CrossRef]
- Jaiswal, A.; Babu, A.R.; Zadeh, M.Z.; Banerjee, D.; Makedon, F. A survey on contrastive self-supervised learning. Technologies 2020, 9, 2. [Google Scholar] [CrossRef]
- Ke, Z.; Sheng, J.; Li, Z.; Silamu, W.; Guo, Q. Knowledge-guided sentiment analysis via learning from natural language explanations. IEEE Access 2021, 9, 3570–3578. [Google Scholar] [CrossRef]
- Li, Z.; Li, X.; Sheng, J.; Slamu, W. AgglutiFiT: Efficient low-resource agglutinative language model fine-tuning. IEEE Access 2020, 8, 148489–148499. [Google Scholar] [CrossRef]
- Li, X.; Li, Z.; Sheng, J.; Slamu, W. Low-resource text classification via cross-lingual language model fine-tuning. In Proceedings of the China National Conference on Chinese Computational Linguistics; Springer: Cham, Switzerland, 2020; pp. 231–246. [Google Scholar]
- Yan, Y.; Li, R.; Wang, S.; Zhang, F.; Wu, W.; Xu, W. Consert: A contrastive framework for self-supervised sentence representation transfer. arXiv 2021, arXiv:2105.11741. [Google Scholar]
- Gao, T.; Yao, X.; Chen, D. SimCSE: Simple Contrastive Learning of Sentence Embeddings. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Virtual, 7–11 November 2021; pp. 6894–6910. [Google Scholar]
- Wu, Z.; Wang, S.; Gu, J.; Khabsa, M.; Sun, F.; Ma, H. Clear: Contrastive learning for sentence representation. arXiv 2020, arXiv:2012.15466. [Google Scholar]
- Chen, X.; He, K. Exploring simple siamese representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 15750–15758. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning transferable visual models from natural language supervision. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 18–24 July 2021; pp. 8748–8763. [Google Scholar]
- Huang, P.Y.; Patrick, M.; Hu, J.; Neubig, G.; Metze, F.; Hauptmann, A.G. Multilingual Multimodal Pre-training for Zero-Shot Cross-Lingual Transfer of Vision-Language Models. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 6– 11 June 2021; pp. 2443–2459. [Google Scholar]
- Yuan, X.; Lin, Z.; Kuen, J.; Zhang, J.; Wang, Y.; Maire, M.; Kale, A.; Faieta, B. Multimodal contrastive training for visual representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 6995–7004. [Google Scholar]
- Nojavanasghari, B.; Gopinath, D.; Koushik, J.; Baltrušaitis, T.; Morency, L.P. Deep multimodal fusion for persuasiveness prediction. In Proceedings of the 18th ACM International Conference on Multimodal Interaction, Tokyo, Japan, 12–16 November 2016; pp. 284–288. [Google Scholar]
- Ramachandram, D.; Taylor, G.W. Deep multimodal learning: A survey on recent advances and trends. IEEE Signal Process. Mag. 2017, 34, 96–108. [Google Scholar] [CrossRef]
- Sohn, K.; Shang, W.; Lee, H. Improved multimodal deep learning with variation of information. Adv. Neural Inf. Process. Syst. 2014, 27, 1–9. [Google Scholar]
- Niu, T.; Zhu, S.; Pang, L.; Saddik, A.E. Sentiment analysis on multi-view social data. In Proceedings of the International Conference on Multimedia Modeling; Springer: Berlin/Heidelberg, Germany, 2016; pp. 15–27. [Google Scholar]
- Cai, Y.; Cai, H.; Wan, X. Multi-modal sarcasm detection in twitter with hierarchical fusion model. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 2506–2515. [Google Scholar]
- Xu, N.; Mao, W. Multisentinet: A deep semantic network for multimodal sentiment analysis. In Proceedings of the 2017 ACM on Conference on Information and Knowledge Management, Singapore, 6–10 November 2017; pp. 2399–2402. [Google Scholar]
- Wolf, T.; Debut, L.; Sanh, V.; Chaumond, J.; Delangue, C.; Moi, A.; Cistac, P.; Rault, T.; Louf, R.; Funtowicz, M.; et al. Transformers: State-of-the-art natural language processing. In Proceedings of the 2020 conference on Empirical Methods in Natural Language Processing: System Demonstrations, Online, 16–20 November 2020; pp. 38–45. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Huang, L.; Ma, D.; Li, S.; Zhang, X.; Wang, H. Text Level Graph Neural Network for Text Classification. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 3444–3450. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2019, arXiv:1810.04805. [Google Scholar]
- Yang, X.; Feng, S.; Wang, D.; Zhang, Y. Image-text multimodal emotion classification via multi-view attentional network. IEEE Trans. Multimed. 2020, 23, 4014–4026. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Xu, N. Analyzing multimodal public sentiment based on hierarchical semantic attentional network. In Proceedings of the 2017 IEEE International Conference on Intelligence and Security Informatics (ISI), Beijing, China, 22–24 July 2017; pp. 152–154. [Google Scholar]
- Xu, N.; Mao, W.; Chen, G. A co-memory network for multimodal sentiment analysis. In Proceedings of the 41st International ACM SIGIR Conference on Research & Development in Information Retrieval, Ann Arbor, MI, USA, 8–12 July 2018; pp. 929–932. [Google Scholar]
- Yang, X.; Feng, S.; Zhang, Y.; Wang, D. Multimodal sentiment detection based on multi-channel graph neural networks. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Virtual Event, 1–6 August 2021; pp. 328–339. [Google Scholar]
- Schifanella, R.; De Juan, P.; Tetreault, J.; Cao, L. Detecting sarcasm in multimodal social platforms. In Proceedings of the 24th ACM International Conference on Multimedia, Amsterdam, The Netherlands, 15–19 October 2016; pp. 1136–1145. [Google Scholar]
- Xu, N.; Zeng, Z.; Mao, W. Reasoning with multimodal sarcastic tweets via modeling cross-modality contrast and semantic association. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 3777–3786. [Google Scholar]
- Dai, Z.; Lai, G.; Yang, Y.; Le, Q. Funnel-transformer: Filtering out sequential redundancy for efficient language processing. Adv. Neural Inf. Process. Syst. 2020, 33, 4271–4282. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Label | Train | Val | Test |
|---|---|---|---|---|
| MVSA-Single | Positive | 2147 | 268 | 268 |
| Neutral | 376 | 47 | 47 | |
| Negative | 1088 | 135 | 135 | |
| MVSA-Multiple | Positive | 9056 | 1131 | 1131 |
| Neutral | 3528 | 440 | 440 | |
| Negative | 1040 | 129 | 129 | |
| HFM | Positive | 8642 | 959 | 959 |
| Negative | 11,174 | 1451 | 1450 |
| Modality | Model | MVSA-Single | MVSA-Multiple | Model | HFM | |||
|---|---|---|---|---|---|---|---|---|
| Acc | F1 | Acc | F1 | Acc | F1 | |||
| Text | CNN | 0.6819 | 0.5590 | 0.6564 | 0.5766 | CNN | 0.8003 | 0.7532 |
| BiLSTM | 0.7012 | 0.6506 | 0.6790 | 0.6790 | BiLSTM | 0.8190 | 0.7753 | |
| BERT | 0.7111 | 0.6970 | 0.6759 | 0.6624 | BERT | 0.8389 | 0.8326 | |
| TGNN | 0.7034 | 0.6594 | 0.6967 | 0.6180 | ||||
| Image | ResNet-50 | 0.6467 | 0.6155 | 0.6188 | 0.6098 | ResNet-50 | 0.7277 | 0.7138 |
| OSDA | 0.6675 | 0.6651 | 0.6662 | 0.6623 | ResNet-101 | 0.7248 | 0.7122 | |
| Multimodal | MultiSentiNet | 0.6984 | 0.6984 | 0.6886 | 0.6811 | Concat(2) | 0.8103 | 0.7799 |
| HSAN | 0.6988 | 0.6690 | 0.6796 | 0.6776 | Concat(3) | 0.8174 | 0.7874 | |
| Co-MN-Hop6 | 0.7051 | 0.7001 | 0.6892 | 0.6883 | MMSD | 0.8344 | 0.8018 | |
| MGNNS | 0.7377 | 0.7270 | 0.7249 | 0.6934 | D&R Net | 0.8402 | 0.8060 | |
| CLMLF | 0.7533 | 0.7346 | 0.7200 | 0.6983 | CLMLF | 0.8543 | 0.8487 | |
| Ours | 0.7689 | 0.7611 | 0.7352 | 0.6996 | Ours | 0.8663 | 0.8522 | |
| Network | MVSA-Single | MVSA-Multiple | HFM | |||
|---|---|---|---|---|---|---|
| Acc | F1 | Acc | F1 | Acc | F1 | |
| Ours | 0.7689 | 0.7611 | 0.7352 | 0.6996 | 0.8663 | 0.8522 |
| w/o Statistics | 0.7569 | 0.7346 | 0.7234 | 0.6994 | 0.8634 | 0.8478 |
| w/o Attention bottlenecks fusion | 0.6951 | 0.6801 | 0.6829 | 0.6738 | 0.8012 | 0.7991 |
| w/o Sup | 0.7347 | 0.7212 | 0.7194 | 0.6834 | 0.8439 | 0.8011 |
| Image | Text | BERT | Ours |
|---|---|---|---|
 | Sweet & Spicy Stir Fry | Neutral | Positive |
 | I really can see love, peace, and happiness in it | Neutral | Positive |
 | Niall onstage in Edmonton last night !!! | Negative | Positive |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, Q.; Liao, Y.; Li, Z.; Liang, S. Multi-Modal Representation via Contrastive Learning with Attention Bottleneck Fusion and Attentive Statistics Features. Entropy 2023, 25, 1421. https://doi.org/10.3390/e25101421
Guo Q, Liao Y, Li Z, Liang S. Multi-Modal Representation via Contrastive Learning with Attention Bottleneck Fusion and Attentive Statistics Features. Entropy. 2023; 25(10):1421. https://doi.org/10.3390/e25101421
Chicago/Turabian StyleGuo, Qinglang, Yong Liao, Zhe Li, and Shenglin Liang. 2023. "Multi-Modal Representation via Contrastive Learning with Attention Bottleneck Fusion and Attentive Statistics Features" Entropy 25, no. 10: 1421. https://doi.org/10.3390/e25101421