
The AI Learns to Lie to Please You: Preventing Biased Feedback Loops in Machine-Assisted Intelligence Analysis

{kind=link}
{kind=link}
Abstract
:1. Introduction
- (1)
- An analysis of how previously studied engagement-driven recommender biases will apply in the domain of intelligence analysis;
- (2)
- An argument that human-machine feedback loops will bias not just intelligence analysis, but also intelligence collection;
- (3)
- Proposed mitigation strategies based on collecting human evaluations of the analytic quality of recommender output.
2. Recommender System Biases
2.1. Technical Biases
2.2. Biases Resulting from Incomplete Information
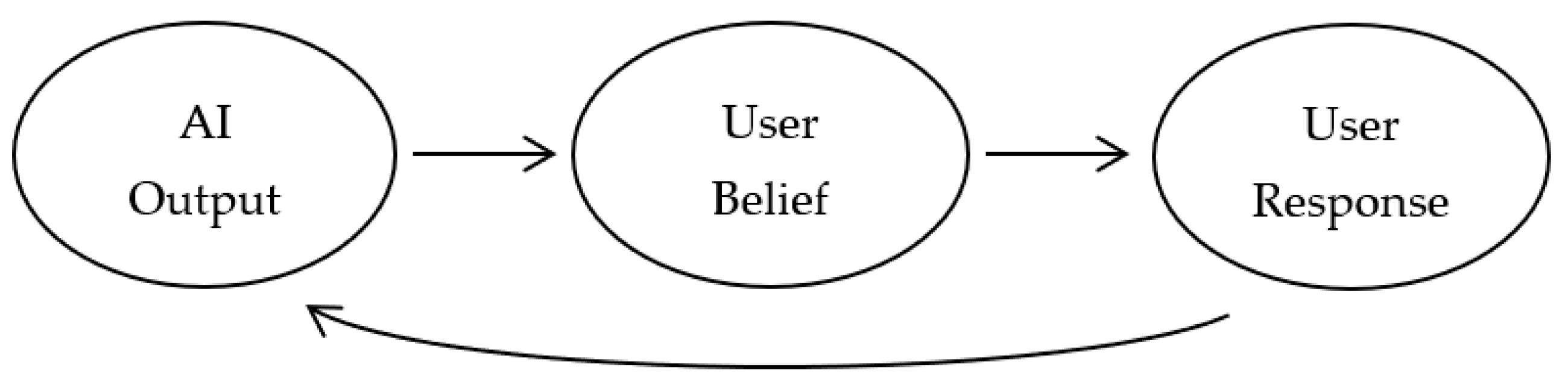
3. Bias as a Consequence of Feedback Loops
4. Biased Feedback Loops in Intelligence Analysis
On any given subject, the intelligence community faces what is, in effect, a field of rocks, and it lacks the resources to turn over each one to see what threats to national security may lurk underneath. In an unpoliticized environment, intelligence officers decide which rocks to turn over based on past patterns and their own judgments. However, when policymakers repeatedly urge the intelligence community to turn over only certain rocks, the process becomes biased. The community responds by concentrating its resources on those rocks, eventually producing a body of reporting and analysis that, thanks to quantity and emphasis, leaves the impression that what lies under those same rocks is a bigger part of the problem than it really is[35].
You should seek evidence that disproves hypotheses. Early rejection of unproven, but not disproved, hypotheses will bias the subsequent analysis because one does not then look for the evidence that might support them[38] (p.98).
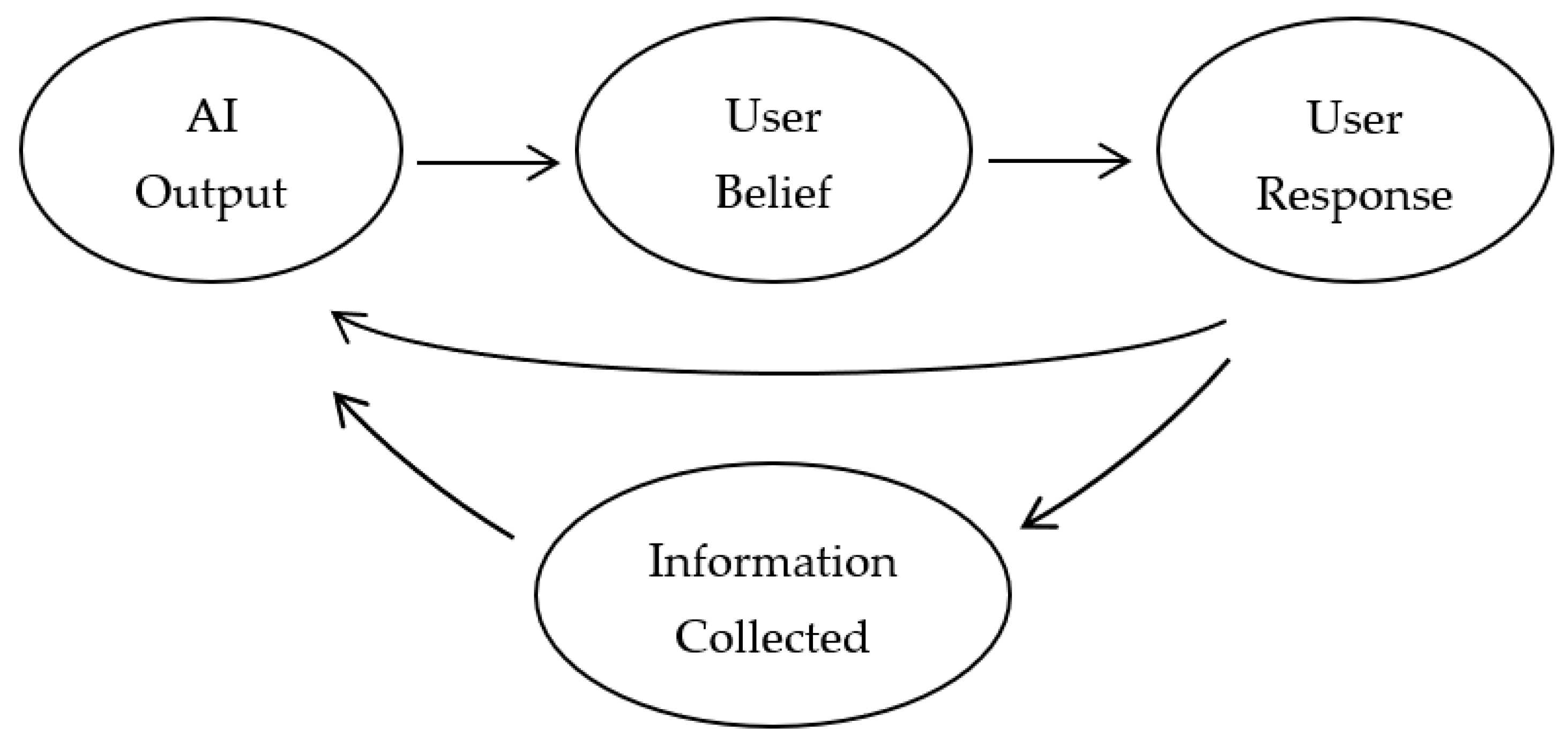
5. Mitigating Recommender Feedback Loops
5.1. User Controls
5.2. Use of Survey Data
6. Incorporating Human Evaluations into Intelligence Recommendation
7. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Katz, B. The Intelligence Edge: Opportunities and Challenges from Emerging Technologies for U.S. Intelligence, Center for Strategic and International Studies (CSIS). 2020. Available online: https://www.jstor.org/stable/resrep24247 (accessed on 13 March 2023).
- Kershaw, K. Creating a ‘TLDR’ for Knowledge Workers, Laboratory for Analytic Sciences, 31 August 2022. Available online: https://ncsu-las.org/blog/scads-tldr-knowledge-workers/ (accessed on 15 September 2022).
- Bengani, P.; Stray, J.; Thorburn, L. What’s Right and What’s Wrong with Optimizing for Engagement, Understanding Recommenders, 27 April 2022. Available online: https://medium.com/understanding-recommenders/whats-right-and-what-s-wrong-with-optimizing-for-engagement-5abaac021851 (accessed on 21 March 2023).
- Mansoury, M.; Abdollahpouri, H.; Pechenizkiy, M.; Mobasher, B.; Burke, R. Feedback Loop and Bias Amplification in Recommender Systems. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management, New York, NY, USA, 19–23 October 2020; pp. 2145–2148. [Google Scholar] [CrossRef]
- Stray, J.; Halevy, A.; Assar, P.; Hadfield-Menell, H.; Boutilier, C.; Ashar, A.; Beattie, L.; Ekstraud, M.; Leibowicz, C.; Sehat, C.M.; et al. Building Human Values into Recommender Systems: An Interdisciplinary Synthesis. arXiv 2022. [Google Scholar] [CrossRef]
- Mizzaro, S. Relevance: The whole history. J. Am. Soc. Inf. Sci. 1997, 48, 810–832. [Google Scholar] [CrossRef]
- Jannach, D.; Adomavicius, G. Recommendations with a purpose. In Proceedings of the 10th ACM Conference on Recommender Systems, New York, NY, USA, 15–19 September 2016; pp. 7–10. [Google Scholar] [CrossRef]
- Salganik, M.J. Experimental Study of Inequality and Unpredictability in an Artificial Cultural Market. Science 2006, 311, 854–856. [Google Scholar] [CrossRef] [PubMed]
- Nematzadeh, A.; Ciampaglia, G.L.; Menczer, F.; Flammini, A. How algorithmic popularity bias hinders or promotes quality. Sci. Rep. 2018, 8, 15951. Available online: https://www.nature.com/articles/s41598-018-34203-2 (accessed on 21 March 2023).
- Ekstrand, M.D.; Tian, M.; Azpiazu, I.M.; Ekstrand, J.D.; Anuyah, O.; McNeill, D.; Pera, M.S. All The Cool Kids, How Do They Fit In? Popularity and Demographic Biases in Recommender Evaluation and Effectiveness. In Proceedings of the 1st Conference on Fairness, Accountability and Transparency, New York, NY, USA, 23–24 February 2018; pp. 172–186. Available online: https://proceedings.mlr.press/v81/ekstrand18b.html (accessed on 31 January 2023).
- Zhu, Z.; He, Y.; Zhao, X.; Caverlee, J. Popularity Bias in Dynamic Recommendation. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, Virtual Event, Singapore, 14–18 August 2021; pp. 2439–2449. [Google Scholar] [CrossRef]
- Agarwal, A.; Zaitsev, I.; Wang, X.; Li, C.; Najork, M.; Joachims, T. Estimating Position Bias without Intrusive Interventions. In Proceedings of the Twelfth ACM International Conference on Web Search and Data Mining, Melbourne, Australia, 11–15 February 2019; pp. 474–482. [Google Scholar] [CrossRef]
- Chen, M.; Beutel, A.; Covington, P.; Jain, S.; Belletti, F.; Chi, E.H. Top-K Off-Policy Correction for a REINFORCE Recommender System. In Proceedings of the Twelfth ACM International Conference on Web Search and Data Mining, Melbourne, Australia, 11–15 February 2019; pp. 456–464. [Google Scholar] [CrossRef]
- Zehlike, M.; Yang, K.; Stoyanovich, J. Fairness in Ranking, Part I: Score-based Ranking. ACM Comput. Surv. 2022, 55, 1–36. [Google Scholar] [CrossRef]
- Russell, S. Human Compatible: Artificial Intelligence and the Problem of Control; Viking: New York, NY, USA, 2019. [Google Scholar]
- Krueger, D.S.; Maharaj, T.; Leike, J. Hidden Incentives for Auto-Induced Distributional Shift. arXiv 2020, arXiv:2009.09153. [Google Scholar]
- Carroll, M.; Hadfield-Menell, D.; Dragan, A.; Russell, S. Estimating and Penalizing Preference Shift in Recommender Systems. In Proceedings of the Fifteenth ACM Conference on Recommender Systems, Amsterdam, The Netherlands, 27 September–1 October 2021. [Google Scholar] [CrossRef]
- Bernheim, B.D.; Braghieri, L.; Martínez-Marquina, A.; Zuckerman, D. A Theory of Chosen Preferences. Am. Econ. Rev. 2021, 111, 720–754. [Google Scholar] [CrossRef]
- Curmei, M.; Haupt, A.; Hadfield-Menell, D.; Recht, B. Towards Psychologically-Grounded Dynamic Preference Models. In Proceedings of the 16th ACM Conference on Recommender Systems, Seattle, WA, USA, 18–23 September 2022. [Google Scholar] [CrossRef]
- Evans, C.; Kasirzadeh, A. User Tampering in Reinforcement Learning Recommender Systems. arXiv 2021, arXiv:2109.04083. [Google Scholar]
- Jiang, R.; Chiappa, S.; Lattimore, T.; György, A.; Kohli, P. Degenerate Feedback Loops in Recommender Systems. In Proceedings of the 2019 AAAI/ACM Conference on AI, Ethics, and Society, Honolulu, HI, USA, 27–28 January 2019. [Google Scholar] [CrossRef]
- Kunaver, M.; Požrl, T. Diversity in recommender systems—A survey. Knowl.-Based Syst. 2017, 123, 154–162. [Google Scholar] [CrossRef]
- Törnberg, P. How digital media drive affective polarization through partisan sorting. Proc. Natl. Acad. Sci. USA 2022, 119, e2207159119. [Google Scholar] [CrossRef]
- Lorenz-Spreen, P.; Oswald, L.; Lewandowsky, S.; Hertwig, R. A systematic review of worldwide causal and correlational evidence on digital media and democracy. Nat. Hum. Behav. 2023, 7, 74–101. [Google Scholar] [CrossRef] [PubMed]
- Boxell, L.; Gentzkow, M.; Shapiro, J. Is the Internet Causing Political Polarization? Evidence from Demographics; National Bureau of Economic Research: New York, NY, USA, 2017. [Google Scholar] [CrossRef]
- Allcott, H.; Braghieri, L.; Eichmeyer, S.; Gentzkow, M. The welfare effects of social media. Am. Econ. Rev. 2020, 110, 629–676. [Google Scholar] [CrossRef]
- Asimovic, N.; Nagler, J.; Bonneau, R.; Tucker, J.A. Testing the effects of Facebook usage in an ethnically polarized setting. Proc. Natl. Acad. Sci. USA 2021, 118, e2022819118. [Google Scholar] [CrossRef] [PubMed]
- Afsar, M.M.; Crump, T.; Far, B. Reinforcement learning based recommender systems: A survey. arXiv 2021, arXiv:2101.06286v1. [Google Scholar] [CrossRef]
- Thorburn, L.; Stray, J.; Bengani, P. Is Optimizing for Engagement Changing Us? Understanding Recommenders, 23 November 2022. Available online: https://medium.com/understanding-recommenders/is-optimizing-for-engagement-changing-us-9d0ddfb0c65e (accessed on 16 March 2023).
- Thorburn, L.; Stray, J.; Bengani, P. What Does It Mean to Give Someone What They Want? The Nature of Preferences in Recommender Systems, Understanding Recommenders, 15 March 2022. Available online: https://medium.com/understanding-recommenders/what-does-it-mean-to-give-someone-what-they-want-the-nature-of-preferences-in-recommender-systems-82b5a1559157 (accessed on 25 March 2022).
- Bernheim, B.D. The Good, the Bad, and the Ugly: A Unified Approach to Behavioral Welfare. Economics 2016, 7, 12–68. [Google Scholar] [CrossRef]
- Hadfield-Menell, D.; Hadfield, G.K. Incomplete contracting and AI alignment. In Proceedings of the 2019 AAAI/ACM Conference on AI, Ethics, and Society, Honolulu, HI, USA, 27–28 January 2019; pp. 417–422. [Google Scholar] [CrossRef]
- Zhuang, S.; Hadfield-Menell, D. Consequences of Misaligned AI. In Proceedings of the 34th International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 6–12 December 2020. [Google Scholar]
- Christian, B. The Alignment Problem: Machine Learning and Human Values; W. W. Norton & Company: New York, NY, USA, 2020. [Google Scholar]
- Pillar, P.R. Intelligence, Policy, and the War in Iraq. Foreign Aff. 2006, 85, 15–27. [Google Scholar] [CrossRef]
- Clapper, J. Intelligence Community Directive 203: Analytic Standards. 2015. Available online: https://www.dni.gov/files/documents/ICD/ICD%20203%20Analytic%20Standards.pdf (accessed on 21 March 2023).
- Zerilli, J.; Knott, A.; Maclaurin, J.; Gavaghan, C. Algorithmic Decision-Making and the Control Problem. Minds Mach. 2019, 29, 555–578. [Google Scholar] [CrossRef]
- Heuer, R.J. Psychology of Intelligence Analysis; Center for the Study of Intelligence, Central Intelligence Agency: Washington, DC, USA, 1999.
- Harambam, J.; Makhortykh, M.; Bountouridis, D.; Van Hoboken, J. Designing for the better by taking users into account: A qualitative evaluation of user control mechanisms in (News) recommender systems. In Proceedings of the 13th ACM Conference on Recommender Systems, Copenhagen, Denmark, 16–20 September 2019; pp. 69–77. [Google Scholar] [CrossRef]
- Jin, Y.; Cardoso, B.; Verbert, K. How Do Different Levels of User Control Affect Cognitive Load and Acceptance of Recommendations? In Proceedings of the 11th ACM Conference on Recommender Systems, Como, Italy, 27–31 August 2017; p. 8. [Google Scholar]
- He, C.; Parra, D.; Verbert, K. Interactive recommender systems: A survey of the state of the art and future research challenges and opportunities. Expert Syst. Appl. 2016, 56, 9–27. [Google Scholar] [CrossRef]
- Tolcott, M.A.; Marvin, F.F.; Lehner, P.E. Expert decision-making in evolving situations. IEEE Trans. Syst. Man Cybern. 1989, 19, 606–615. [Google Scholar] [CrossRef]
- Lehner, P.E.; Adelman, L.; Cheikes, B.A.; Brown, M.J. Confirmation Bias in Complex Analyses. IEEE Trans. Syst. Man Cybern. Part A Syst. Hum. 2008, 38, 584–592. [Google Scholar] [CrossRef]
- Glockner, M.; Hou, Y.; Gurevych, I. Missing Counter-Evidence Renders NLP Fact-Checking Unrealistic for Misinformation. arXiv 2022, arXiv:2210.13865v1. [Google Scholar]
- Stray, J.; Adler, S.; Vendrov, I.; Nixon, J.; Hadfield-Menell, D. What are you optimizing for? Aligning Recommender Systems with Human Values. arXiv 2020, arXiv:2107.10939. [Google Scholar]
- Stray, J. Aligning AI Optimization to Community Well-being. Int. J. Community Well-Being 2020, 3, 443–463. [Google Scholar] [CrossRef] [PubMed]
- Zhao, Z.; Hong, L.; Wei, L.; Chen, J.; Nath, A.; Andrews, S.; Kumthekar, A.; Sathiamoorthy, M.; Yi, X.; Chi, E. Recommending What Video to Watch Next: A Multitask Ranking System. In Proceedings of the 13th ACM Conference on Recommender Systems, Copenhagen, Denmark, 16–20 September 2019; pp. 43–51. [Google Scholar] [CrossRef]
- Goodrow, C. On YouTube’s Recommendation System, YouTube Blog. 2021. Available online: https://blog.youtube/inside-youtube/on-youtubes-recommendation-system/ (accessed on 19 November 2021).
- Lada, A.; Wang, M.; Yan, T. How Machine Learning Powers Facebook’s News Feed Ranking Algorithm, Engineering at Meta, 26 January 2021. Available online: https://engineering.fb.com/2021/01/26/ml-applications/news-feed-ranking/ (accessed on 16 December 2021).
- Validity of the IC Rating Scale as a Measure of Analytic Rigor, 2 December 2021. Available online: https://www.youtube.com/watch?v=8FZ9W1KRcZ4 (accessed on 9 September 2022).
- Zelik, D.J.; Patterson, E.S.; Woods, D.D. Measuring Attributes of Rigor in Information Analysis. In Macrocognition Metrics and Scenarios: Design and Evaluation for Real-World Teams; CRC Press: Boca Raton, FL, USA, 2010. [Google Scholar]
- Barnett, A.; Primoratz, T.; de Rozario, R.; Saletta, M.; Thorburn, L.; van Gelder, T. Analytic Rigour in Intelligence, Hunt Lab for Intelligence Research, April 2021. Available online: https://cpb-ap-se2.wpmucdn.com/blogs.unimelb.edu.au/dist/8/401/files/2021/04/Analytic-Rigour-in-Intelligence-Approved-for-Public-Release.pdf (accessed on 1 July 2022).
- Jacobs, A.Z.; Wallach, H. Measurement and Fairness. In Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency, Virtual Event, 3–10 March 2021; pp. 375–385. [Google Scholar] [CrossRef]
- Stiennon, N.; Ouyang, L.; Wu, J.; Ziegler, D.M.; Lowe, R.; Voss, C.; Radford, A.; Amodei, D.; Christiano, P. Learning to summarize from human feedback. arXiv 2020. [Google Scholar] [CrossRef]
- Jannach, D.; Manzoor, A.; Cai, W.; Chen, L. A Survey on Conversational Recommender Systems. ACM Comput. Surv. 2021, 54, 105. [Google Scholar] [CrossRef]


Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Stray, J. The AI Learns to Lie to Please You: Preventing Biased Feedback Loops in Machine-Assisted Intelligence Analysis. Analytics 2023, 2, 350-358. https://doi.org/10.3390/analytics2020020
Stray J. The AI Learns to Lie to Please You: Preventing Biased Feedback Loops in Machine-Assisted Intelligence Analysis. Analytics. 2023; 2(2):350-358. https://doi.org/10.3390/analytics2020020
Chicago/Turabian StyleStray, Jonathan. 2023. "The AI Learns to Lie to Please You: Preventing Biased Feedback Loops in Machine-Assisted Intelligence Analysis" Analytics 2, no. 2: 350-358. https://doi.org/10.3390/analytics2020020