Analytics 2024, 3(2), 194-220; https://doi.org/10.3390/analytics3020011 - 16 Apr 2024
Abstract
Food commodities and energy bills have experienced rapid undulating movements and hikes globally in recent times. This spurred this study to examine the possibility that the shocks that arise from fluctuations of one market spill over to the other and to determine how
[...] Read more.
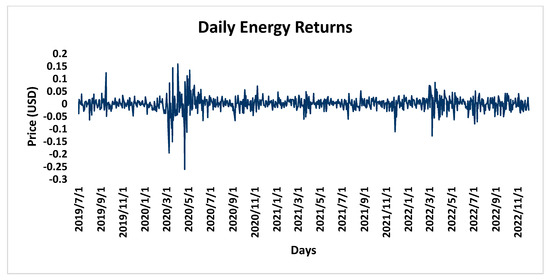
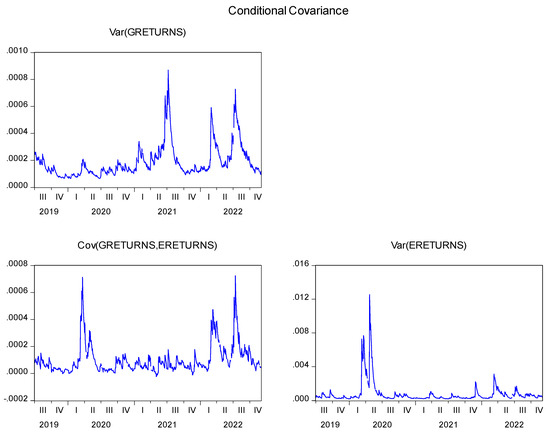
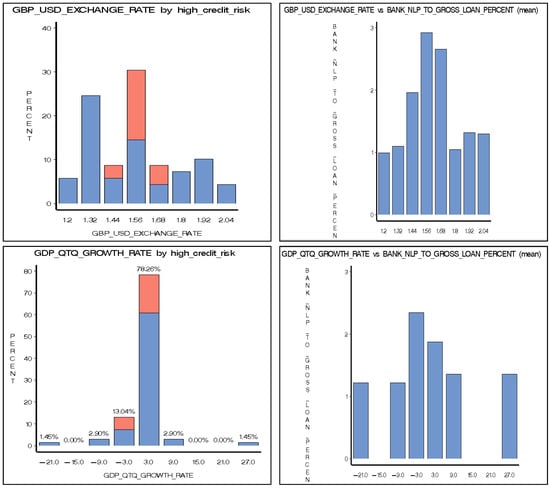
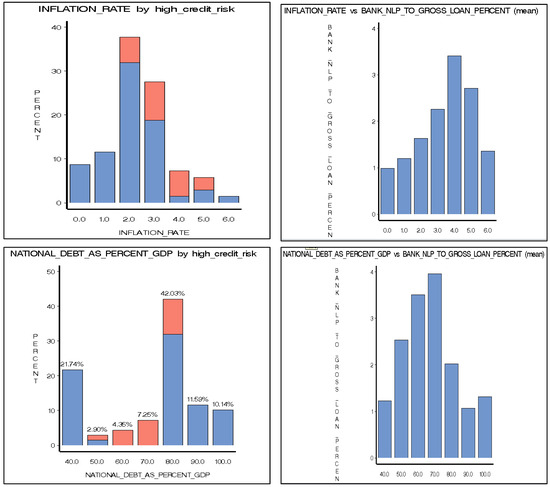
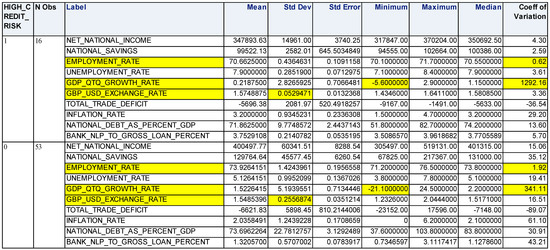
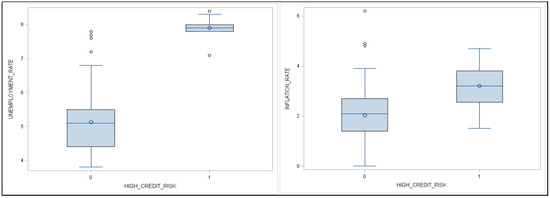
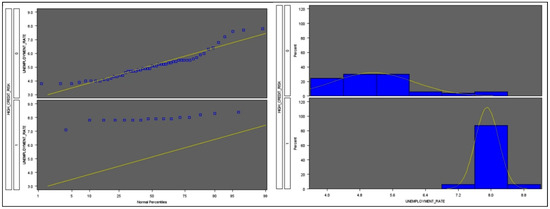
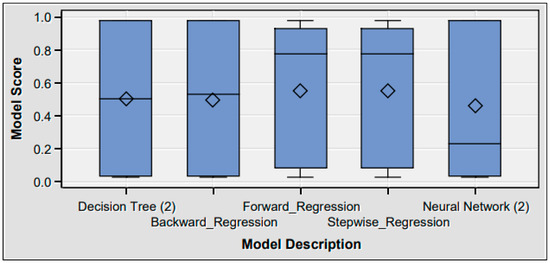
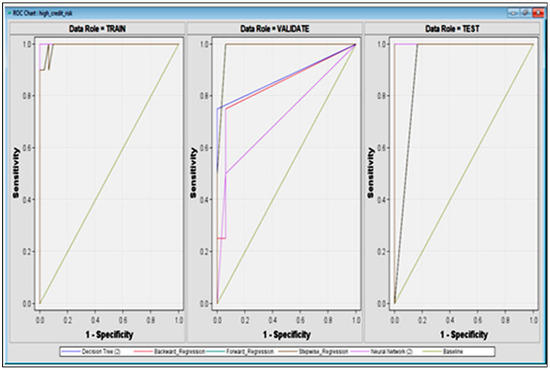
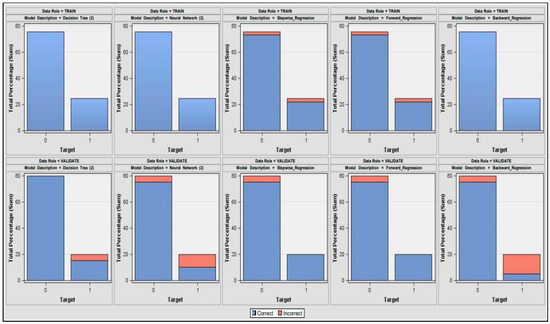
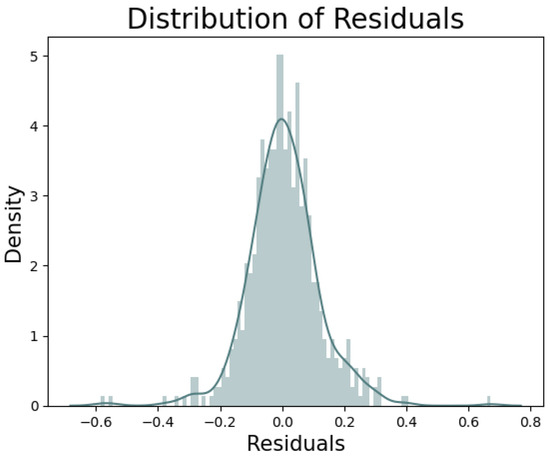
Food commodities and energy bills have experienced rapid undulating movements and hikes globally in recent times. This spurred this study to examine the possibility that the shocks that arise from fluctuations of one market spill over to the other and to determine how time-varying the spillovers were across a time. Data were daily frequency (prices of grains and energy products) from 1 July 2019 to 31 December 2022, as quoted in markets. The choice of the period was to capture the COVID pandemic and the Russian–Ukrainian war as events that could impact volatility. The returns were duly calculated using spreadsheets and subjected to ADF stationarity, co-integration, and the full BEKK-GARCH estimation. The results revealed a prolonged association between returns in the energy markets and food commodity market returns. Both markets were found to have volatility persistence individually, and time-varying bidirectional transmission of volatility across the markets was found. No lagged-effects spillover was found from one market to the other. The findings confirm that shocks that emanate from fluctuations in energy markets are impactful on the volatility of prices in food commodity markets and vice versa, but this impact occurs immediately after the shocks arise or on the same day such variation occurs.
Full article
(This article belongs to the Special Issue Business Analytics and Applications)
►
Show Figures
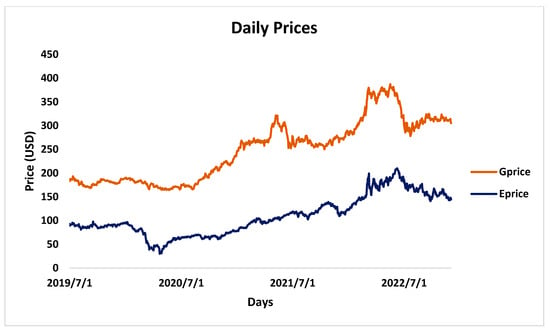
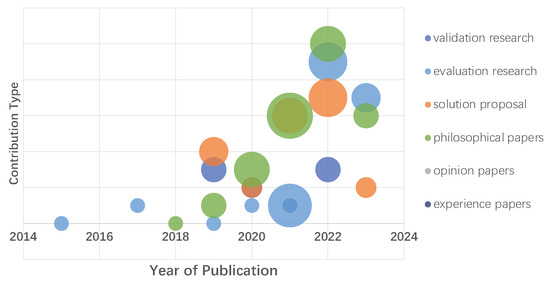
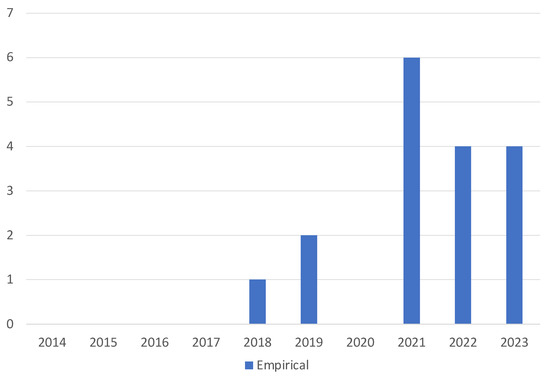
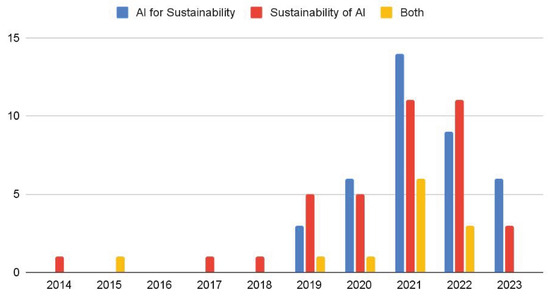
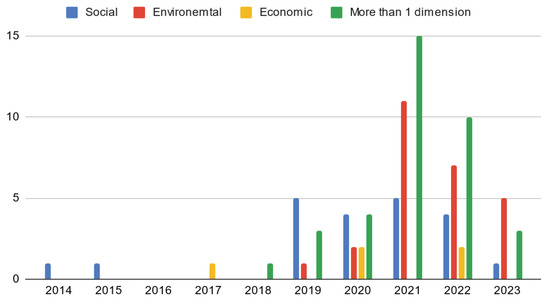
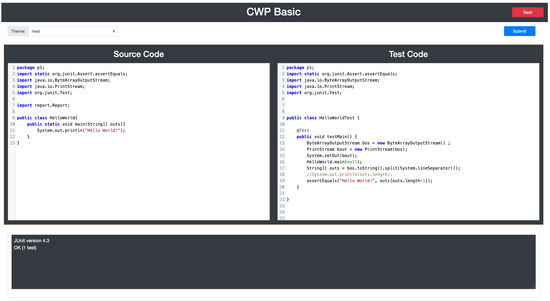
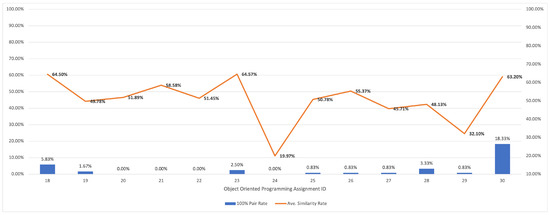
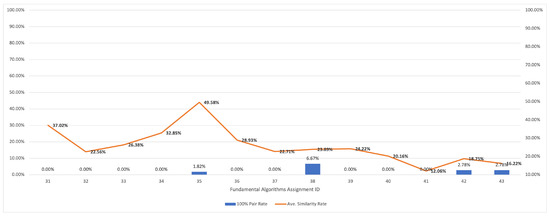
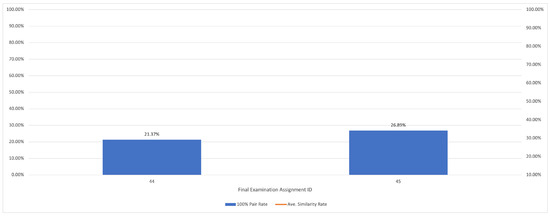
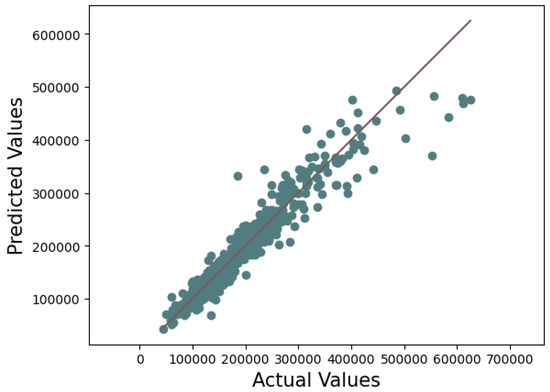
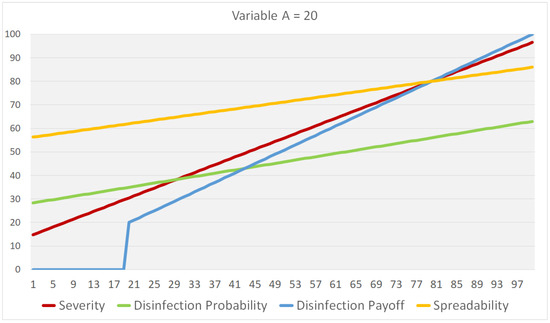
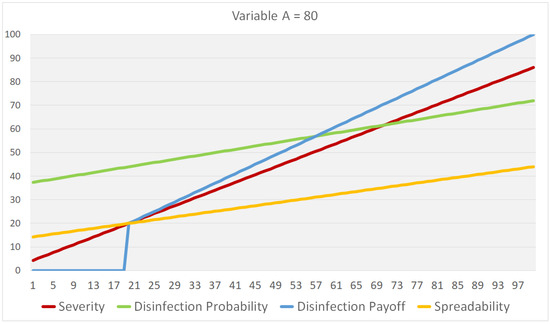
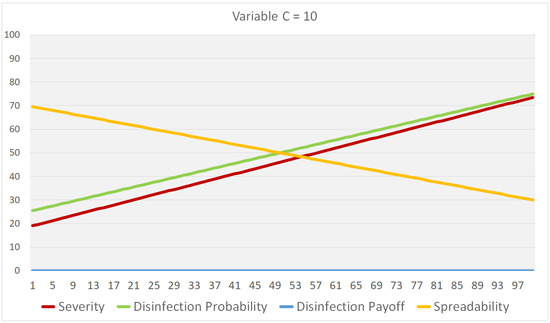
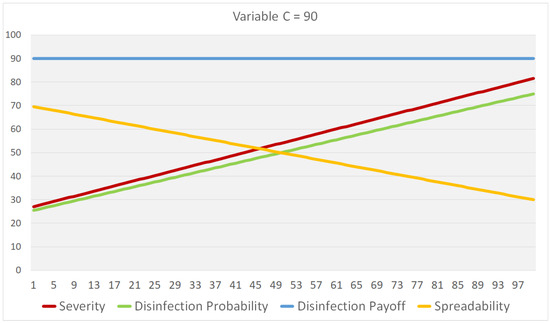
Figure 1






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}