1. Introduction
Radiation therapy (RT) is an effective cancer treatment therapy where high-intensity radiation beams are used to kill cancerous tissues and cells, decreasing the size of the malignant tumor. In the RT treatment workflow, radiation oncologists use the images based on a Computed Tomography (CT) or Magnetic Resonance (MR) dataset saved in the Digital Imaging and Communications in Medicine (DICOM) files to delineate or contour the various anatomical regions or structures of the organ of interest in these imaging datasets and provide appropriate structure names. These physician-identified structures are either Organs at Risk (OARs), Planning Target Volume (PTV), Clinical Target Volume (CTV), Gross Tumor Volume (GTV), or ‘Other’ (all the remaining structures). Based on the particular disease site such as prostate or lung cancer, the radiation oncologist contours all neighboring OARs such as bladder, rectum, bowel, femurs, etc., for prostate cases and heart, spinal cord, both lungs, ribs, etc., for the lung cases. While defining these contours and naming them, we observe a high level of variability in the recorded structure names, which makes it hard to consistently gather data for the same structure contour type across a large population of patients. Inconsistencies in the physician-given structure names are primarily due to the personal choice of the physicians coupled with the variation in policies and systems at different RT clinics.
This issue of disparity between the physician-given structure names is addressed by the American Association of Physicists in Medicine (AAPM), and the American Society for Radiation Oncology (ASTRO) [
1,
2,
3]. It mainly addressed the key challenges in the Radiation structure name standardization process and has released a Task Group 263 (TG-263) report where the standard names for the structures are mentioned. With the availability of the standard structure names, there rises the need to automate the standardization of the structure names. It takes huge amounts of time and labour to manually standardize the structure names which presents a challenge in the clinical world that requires rapid decision-making depending upon the criticality of cancer patients. Hence, automatic prediction of standard structure names is a vital problem to solve both from a clinician’s and an informatician’s point of view. However, there have been limited attempts to automate the structure name standardization process using artificial intelligence (AI) and machine learning (ML) related techniques. Extensive experimentation with various data models and networks is required to elevate the current state-of-the-art in this domain.
From a clinical perspective, our framework has the potential to enable the construction of data pooling tools that can reuse retrospective patient imaging and contouring datasets for tracking patient outcomes, building data registries and clinical trials. Standardized structure names help ensure that all members of the radiation oncology team, including physicians, dosimetrists, and therapists, are using consistent and accurate terminology when identifying and contouring anatomical structures. Furthermore, consistent and accurate contouring of anatomical structures is critical for achieving optimal treatment outcomes in radiation oncology. Standardized structure names can help ensure that all team members are working on the same page, which can help improve treatment accuracy and efficacy.
Author Contributions
Conceptualization, P.B. and P.G.; methodology, P.B. and P.R.; software, P.B. and W.C.S.IV; validation, P.B.; formal analysis, P.B., W.C.S.IV, R.K. and P.G.; investigation, P.B.; resources, W.C.S.IV, R.K., J.P. and P.G.; data curation, W.C.S.IV and S.S.; writing—original draft preparation, P.B.; writing—review and editing, P.B., P.G., W.C.S.IV, P.R., S.S. and J.P.; supervision, R.K., J.P. and P.G.; project administration, R.K., J.P. and P.G.; funding acquisition, R.K., P.G. and J.P. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the US Veterans Health Administration-National Radiation Oncology Program (VHA-NROP). The results, discussions, and conclusions reported in this paper are completely those of the authors and are independent from the funding sources.
Institutional Review Board Statement
Ethical review and approval were waived because this study was considered as secondary data analysis and declared as exempt by the US Veteran’s Health Administration IRB.
Informed Consent Statement
Not applicable.
Data Availability Statement
No new data were created or analyzed in this study. Data sharing is not applicable to this article.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| DICOM | Digital Imaging and Communications in Medicine |
| OAR | Organ at Risk |
| RT | Radiotherapy |
| PTV | Planning Target Volume |
| VHA | Veterans Health Administration |
| VCU | Virginia Commonwealth University |
| CT | Computed Tomography |
| MR | Magnetic Resonance |
| AAPM | American Association of Physicists in Medicine |
| ASTRO | American Society for Radiation Oncology |
| TG | Task Group |
| NLP | Natural Language Processing |
| ML | Machine Learning |
| AI | Artificial Intelligence |
| IRB | Institutional Review Board |
| TPS | Treatment Planning System |
| ROQS | Radiation Oncology Quality Surveillance Program |
| MRI | Magnetic Resonance Imaging |
| PET | Positron Emission Tomography |
| RT | Radiation Therapy |
| BioBERT | Bidirectional Encoder Representations from Transformers for Biomedical Text Mining |
| DNN | Deep Neural Network |
| CNN | Convolutional Neural Network |
| RNN | Recurrent Neural Network |
| SRU | Simple Recurrent Unit |
| LSTM | Long Short Term Memory |
| ResNet | Residual Network |
| VGG | Vision Geometry Group |
| NROP | National Radiation Oncology Program |
References
- Mayo, C.S.; Moran, J.M.; Bosch, W.; Xiao, Y.; McNutt, T.; Popple, R.; Michalski, J.; Feng, M.; Marks, L.B.; Fuller, C.D.; et al. American Association of Physicists in Medicine Task Group 263: Standardizing nomenclatures in radiation oncology. Int. J. Radiat. Oncol. Biol. Phys. 2018, 100, 1057–1066. [Google Scholar] [CrossRef] [Green Version]
- Wright, J.L.; Yom, S.S.; Awan, M.J.; Dawes, S.; Fischer-Valuck, B.; Kudner, R.; Vega, R.M.; Rodrigues, G. Standardizing normal tissue contouring for radiation therapy treatment planning: An ASTRO consensus paper. Pract. Radiat. Oncol. 2019, 9, 65–72. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Benedict, S.H.; Hoffman, K.; Martel, M.K.; Abernethy, A.P.; Asher, A.L.; Capala, J.; Chen, R.C.; Chera, B.; Couch, J.; Deye, J.; et al. Overview of the American Society for Radiation Oncology–National Institutes of Health–American Association of Physicists in Medicine Workshop 2015: Exploring opportunities for radiation oncology in the era of big data. Int. J. Radiat. Oncol. Biol. Phys. 2016, 95, 873–879. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- El Naqa, I.; Li, R.; Murphy, M.J. Machine Learning in Radiation Oncology: Theory and Applications; Springer: Berlin/Heidelberg, Germany, 2015. [Google Scholar]
- Kang, J.; Schwartz, R.; Flickinger, J.; Beriwal, S. Machine learning approaches for predicting radiation therapy outcomes: A clinician’s perspective. Int. J. Radiat. Oncol. Biol. Phys. 2015, 93, 1127–1135. [Google Scholar] [CrossRef] [PubMed]
- Bose, P.; Sleeman, W.C.; Syed, K.; Hagan, M.; Palta, J.; Kapoor, R.; Ghosh, P. Deep Neural Network Models to Automate Incident Triage in the Radiation Oncology Incident Learning System. In Proceedings of the 12th ACM Conference on Bioinformatics, Computational Biology, and Health Informatics, Online, 1–4 August 2021; Association for Computing Machinery: New York, NY, USA, 2021; p. 51. [Google Scholar] [CrossRef]
- Kreimeyer, K.; Foster, M.; Pandey, A.; Arya, N.; Halford, G.; Jones, S.F.; Forshee, R.; Walderhaug, M.; Botsis, T. Natural language processing systems for capturing and standardizing unstructured clinical information: A systematic review. J. Biomed. Inform. 2017, 73, 14–29. [Google Scholar] [CrossRef]
- Bose, P.; Roy, S.; Ghosh, P. A Comparative NLP-Based Study on the Current Trends and Future Directions in COVID-19 Research. IEEE Access 2021, 9, 78341–78355. [Google Scholar] [CrossRef]
- Mahendran, D.; McInnes, B.T. Extracting Adverse Drug Events from Clinical Notes. arXiv 2021, arXiv:2104.10791. [Google Scholar]
- Bose, P.; Srinivasan, S.; Sleeman, W.C.; Palta, J.; Kapoor, R.; Ghosh, P. A Survey on Recent Named Entity Recognition and Relationship Extraction Techniques on Clinical Texts. Appl. Sci. 2021, 11, 8319. [Google Scholar] [CrossRef]
- Rhee, D.; Nguyen, C.; Netherton, T.; Owens, C.; Court, L.; Cardenas, C. TG263-Net: A deep learning model for organs-at-risk nomenclature standardization. In Medical Physics; Wiley: Hoboken, NJ, USA, 2019; Volume 46, p. E263. [Google Scholar]
- Yang, Q.; Chao, H.; Nguyen, D.; Jiang, S. A Novel Deep Learning Framework for Standardizing the Label of OARs in CT. In Proceedings of the Artificial Intelligence in Radiation Therapy, Shenzhen, China, 17 October 2019; Nguyen, D., Xing, L., Jiang, S., Eds.; Springer International Publishing: Cham, Swizerland, 2019; pp. 52–60. [Google Scholar]
- Kalman, D. A Singularly Valuable Decomposition: The SVD of a Matrix. Coll. Math. J. 1996, 27, 2–23. [Google Scholar] [CrossRef]
- Sleeman IV, W.C.; Nalluri, J.; Syed, K.; Ghosh, P.; Krawczyk, B.; Hagan, M.; Palta, J.; Kapoor, R. A Machine Learning method for relabeling arbitrary DICOM structure sets to TG-263 defined labels. J. Biomed. Inform. 2020, 109, 103527. [Google Scholar] [CrossRef]
- Syed, K.; Sleeman IV, W.; Ivey, K.; Hagan, M.; Palta, J.; Kapoor, R.; Ghosh, P. Integrated natural language processing and machine learning models for standardizing radiotherapy structure names. Healthcare 2020, 8, 120. [Google Scholar] [CrossRef] [PubMed]
- Syed, K.; Sleeman, W.C.; Hagan, M.; Palta, J.; Kapoor, R.; Ghosh, P. Multi-View Data Integration Methods for Radiotherapy Structure Name Standardization. Cancers 2021, 13, 1796. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Bose, P.; Sleeman, W.; Srinivasan, S.; Palta, J.; Kapoor, R.; Ghosh, P. Integrated Structure Name Mapping with CNN. In Medical Physics; Wiley: Hoboken, NJ, USA, 2021; Volume 48. [Google Scholar]
- Sleeman, W.; Bose, P.; Ghosh, P.; Palta, J.; Kapoor, R. Using CNNs to Extract Standard Structure Names While Learning Radiomic Features. In Medical Physics; Wiley: Hoboken, NJ, USA, 2021; Volume 48. [Google Scholar]
- Hu, B.; Lin, A.; Brinson, C.L. ChemProps: A RESTful API enabled database for composite polymer name standardization. J. Cheminform. 2021, 13, 22. [Google Scholar] [CrossRef]
- Gustafsson, C.T.; Lempart, M.; Swärd, J.; Persson, E.; Nyholm, T.; Karlsson, C.T.; Scherman, J. Deep learning-based classification and structure name standardization for organ at risk and target delineations in prostate cancer radiotherapy. J. Appl. Clin. Med. Phys. 2021, 22, 51–63. [Google Scholar] [CrossRef] [PubMed]
- Lempart, M.; Scherman, J.; Nilsson, M.P.; Gustafsson, C.T. Deep learning-based classification of organs at risk and delineation guideline in pelvic cancer radiation therapy. J. Appl. Clin. Med. Phys. 2023, e14022. [Google Scholar] [CrossRef]
- Haidar, A.; Field, M.; Batumalai, V.; Cloak, K.; Al Mouiee, D.; Chlap, P.; Huang, X.; Chin, V.; Aly, F.; Carolan, M.; et al. Standardising Breast Radiotherapy Structure Naming Conventions: A Machine Learning Approach. Cancers 2023, 155, 564. [Google Scholar] [CrossRef]
- Hagan, M.; Kapoor, R.; Michalski, J.; Sandler, H.; Movsas, B.; Chetty, I.; Lally, B.; Rengan, R.; Robinson, C.; Rimner, A.; et al. VA-Radiation Oncology Quality Surveillance Program. Int. J. Radiat. Oncol. Biol. Phys. 2020, 106, 639–647. [Google Scholar] [CrossRef]
- Srivastava, N.; Salakhutdinov, R. Learning representations for multimodal data with deep belief nets. In Proceedings of the International Conference on Machine Learning Workshop 2012, Edinburgh, UK, 26 June–1 July 2012; Volume 79. [Google Scholar]
- Liu, K.; Li, Y.; Xu, N.; Natarajan, P. Learn to Combine Modalities in Multimodal Deep Learning. arXiv 2018, arXiv:1805.11730. [Google Scholar]
- Shi, J.; Zheng, X.; Li, Y.; Zhang, Q.; Ying, S. Multimodal Neuroimaging Feature Learning With Multimodal Stacked Deep Polynomial Networks for Diagnosis of Alzheimer’s Disease. IEEE J. Biomed. Health Inform. 2018, 22, 173–183. [Google Scholar] [CrossRef]
- Radu, V.; Tong, C.; Bhattacharya, S.; Lane, N.D.; Mascolo, C.; Marina, M.K.; Kawsar, F. Multimodal Deep Learning for Activity and Context Recognition. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2018, 1, 157. [Google Scholar] [CrossRef] [Green Version]
- Yao, J.; Zhu, X.; Zhu, F.; Huang, J. Deep Correlational Learning for Survival Prediction from Multi-modality Data. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2017, Quebec City, QC, Canada, 11–13 September 2017; Descoteaux, M., Maier-Hein, L., Franz, A., Jannin, P., Collins, D.L., Duchesne, S., Eds.; Springer International Publishing: Cham, Swizerland, 2017; pp. 406–414. [Google Scholar]
- Hong, D.; Gao, L.; Yokoya, N.; Yao, J.; Chanussot, J.; Du, Q.; Zhang, B. More Diverse Means Better: Multimodal Deep Learning Meets Remote-Sensing Imagery Classification. IEEE Trans. Geosci. Remote Sens. 2021, 59, 4340–4354. [Google Scholar] [CrossRef]
- Yang, X.; Lin, Y.; Wang, Z.; Li, X.; Cheng, K.T. Bi-Modality Medical Image Synthesis Using Semi-Supervised Sequential Generative Adversarial Networks. IEEE J. Biomed. Health Inform. 2020, 24, 855–865. [Google Scholar] [CrossRef] [PubMed]
- Wu, P.; Chang, Q. Brain Tumor Segmentation on Multimodal 3D-MRI using Deep Learning Method. In Proceedings of the 2020 13th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics (CISP-BMEI), Chengdu, China, 17–19 October 2020; pp. 635–639. [Google Scholar] [CrossRef]
- Lu, L.; Wang, H.; Yao, X.; Risacher, S.; Saykin, A.; Shen, L. Predicting progressions of cognitive outcomes via high-order multi-modal multi-task feature learning. In Proceedings of the 2018 IEEE 15th International Symposium on Biomedical Imaging (ISBI 2018), Washington, DC, USA, 4–7 April 2018; pp. 545–548. [Google Scholar] [CrossRef]
- Lee, J.; Yoon, W.; Kim, S.; Kim, D.; Kim, S.; So, C.H.; Kang, J. BioBERT: A pre-trained biomedical language representation model for biomedical text mining. Bioinformatics 2020, 36, 1234–1240. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Voulodimos, A.; Doulamis, N.; Doulamis, A.; Protopapadakis, E. Deep learning for computer vision: A brief review. Comput. Intell. Neurosci. 2018, 2018. [Google Scholar] [CrossRef]
- Wang, S.; Zhang, Y. DenseNet-201-Based Deep Neural Network with Composite Learning Factor and Precomputation for Multiple Sclerosis Classification. ACM Trans. Multimedia Comput. Commun. Appl. 2020, 16, 60. [Google Scholar] [CrossRef]
- Koonce, B. SqueezeNet. In Convolutional Neural Networks with Swift for Tensorflow: Image Recognition and Dataset Categorization; Apress: Berkeley, CA, USA, 2021; pp. 73–85. [Google Scholar] [CrossRef]
- Li, H. Image semantic segmentation method based on GAN network and ENet model. J. Eng. 2021, 2021, 594–604. [Google Scholar] [CrossRef]
- Khan, S.; Naseer, M.; Hayat, M.; Zamir, S.W.; Khan, F.S.; Shah, M. Transformers in Vision: A Survey. ACM Comput. Surv. 2022, 54, 200. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Lakhotia, S.; Bresson, X. An Experimental Comparison of Text Classification Techniques. In Proceedings of the 2018 International Conference on Cyberworlds (CW), Singapore, 3–5 October 2018; pp. 58–65. [Google Scholar]
- Kim, Y. Convolutional Neural Networks for Sentence Classification. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; Association for Computational Linguistics: Doha, Qatar, 2014; pp. 1746–1751. [Google Scholar] [CrossRef] [Green Version]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Tealab, A. Time series forecasting using artificial neural networks methodologies: A systematic review. Future Comput. Inform. J. 2018, 3, 334–340. [Google Scholar] [CrossRef]
- Xu, J.; Li, Z.; Du, B.; Zhang, M.; Liu, J. Reluplex made more practical: Leaky ReLU. In Proceedings of the 2020 IEEE Symposium on Computers and Communications (ISCC), Rennes, France, 7–10 July 2020; pp. 1–7. [Google Scholar] [CrossRef]
- Li, Y.; Yuan, Y. Convergence Analysis of Two-layer Neural Networks with ReLU Activation. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30. [Google Scholar]
- Gold, S.; Rangarajan, A. Softmax to softassign: Neural network algorithms for combinatorial optimization. J. Artif. Neural Netw. 1996, 2, 381–399. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar] [CrossRef]
- Haque, M.F.; Lim, H.Y.; Kang, D.S. Object Detection Based on VGG with ResNet Network. In Proceedings of the 2019 International Conference on Electronics, Information, and Communication (ICEIC), Auckland, New Zealand, 22–25 January 2019; pp. 1–3. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; Pereira, F., Burges, C., Bottou, L., Weinberger, K., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2012; Volume 25. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper With Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
Figure 1.
Image and structure set data from a single CT slice: (a) Delineation of a bladder (in blue) over the corresponding planning CT image (b) Bitmap representation of the bladder (c) Bony anatomy of the same CT, created with a density-based filter (d) Combination of the structure set and bony anatomy data.
Figure 2.
Pictorial Representation of our Masking Step in the case of (a) images, and (b) doses of Prostate RT Patients.
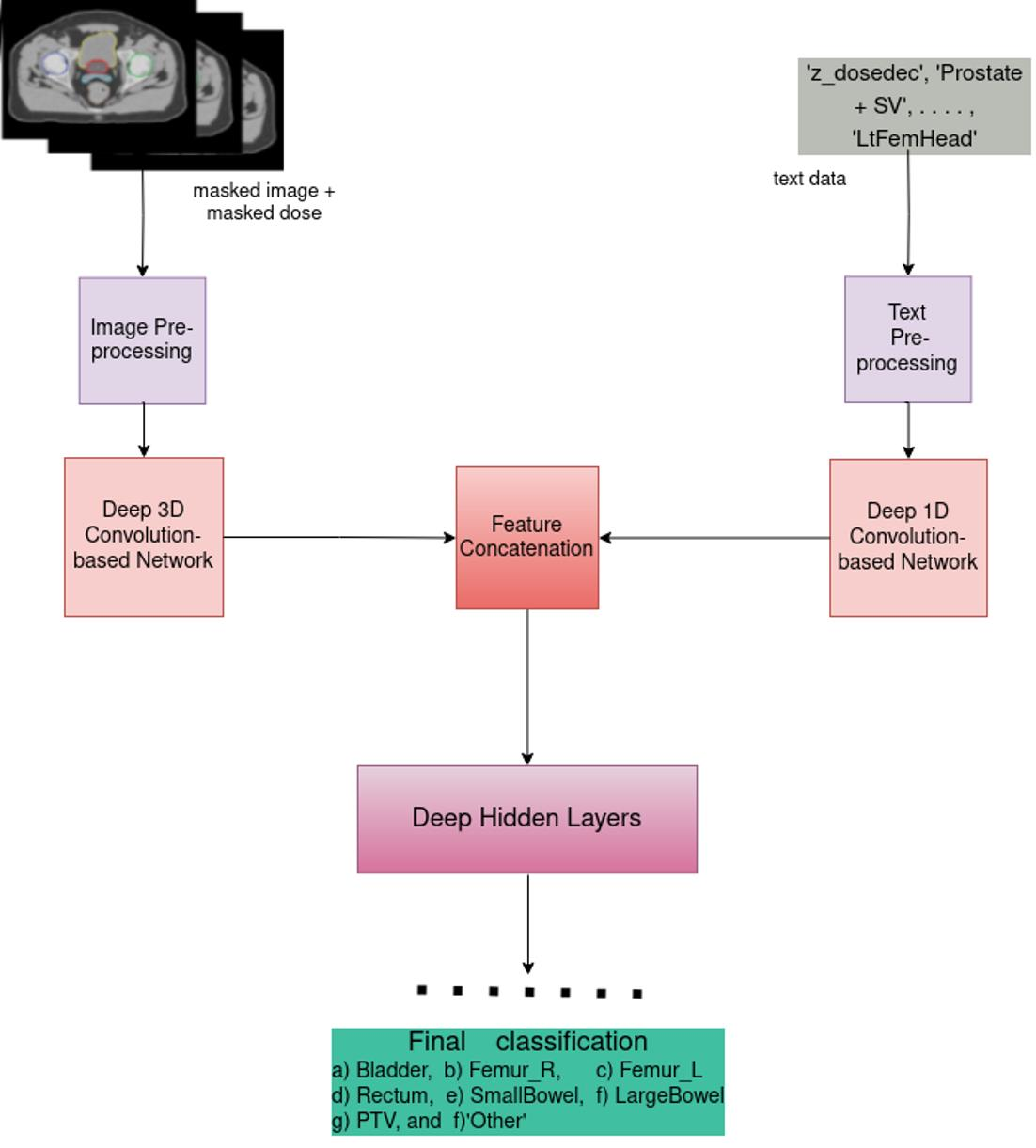
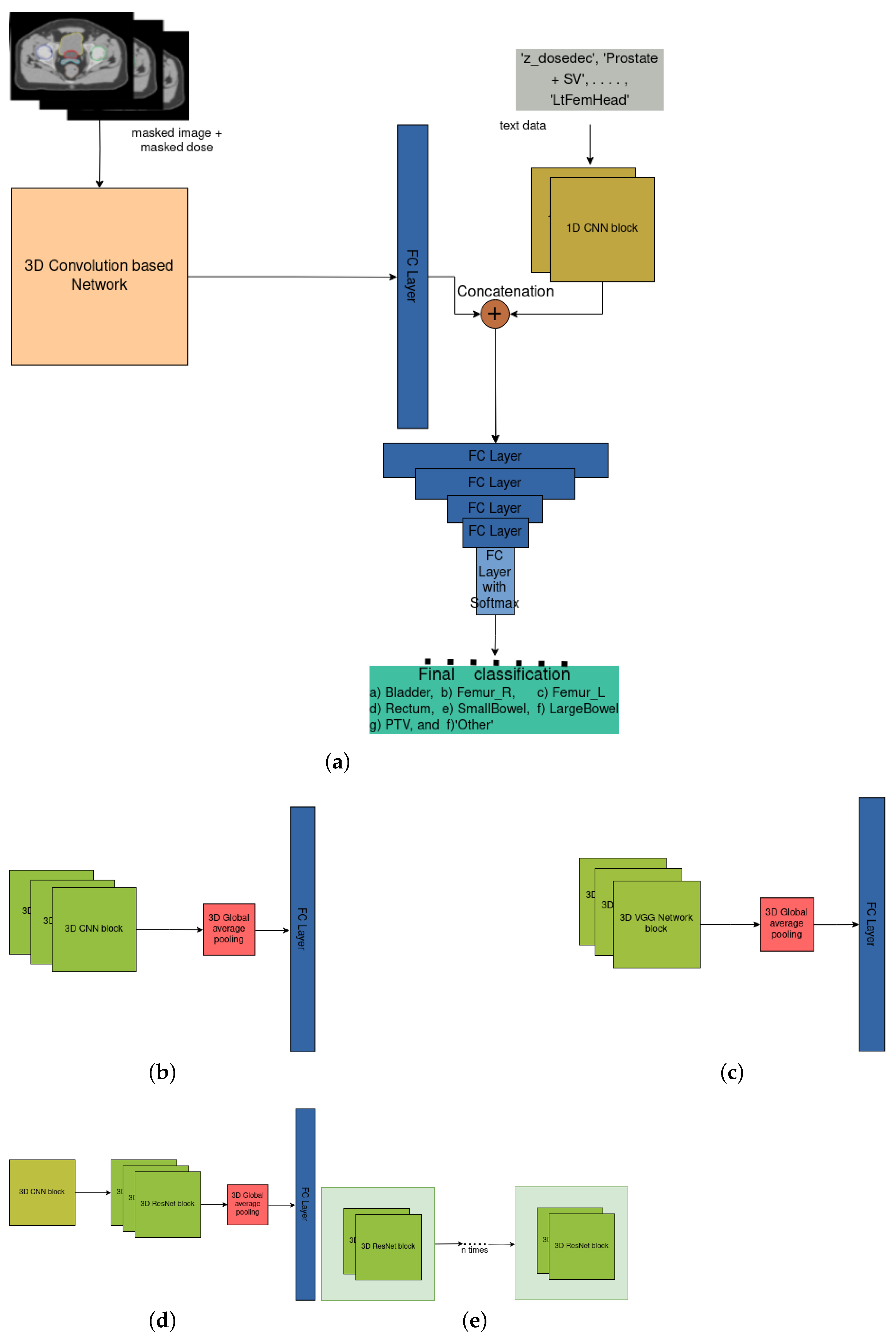
Figure 3.
Overview of our DNN architecture: (a) General architecture of our 3D Convolution-based network on vision-dose data and 1D CNN on text data, (b) Customized 3D CNN on vision-dose, (c) Customized 3D VGG network on vision-dose, (d) Customized 3D ResNet on vision-dose, (e) Stacked customized 3D VGG Network blocks with nested 3D ResNet blocks inside each block on vision-dose data.
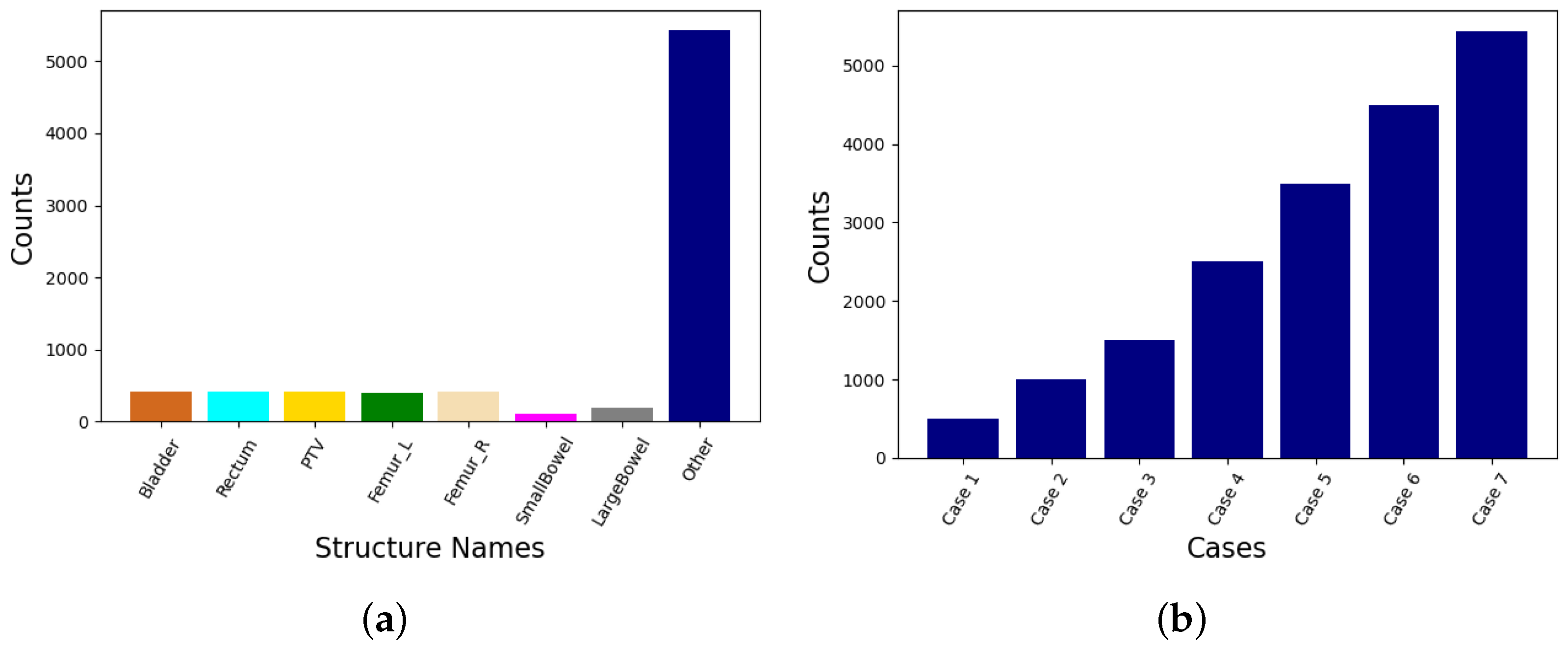
Figure 4.
Bar plots showing (a) the distribution of various data classes in the RT Prostate Structure Naming Dataset, and (b) the variation in the number of samples from the ‘Other’ class in different cases of consideration.
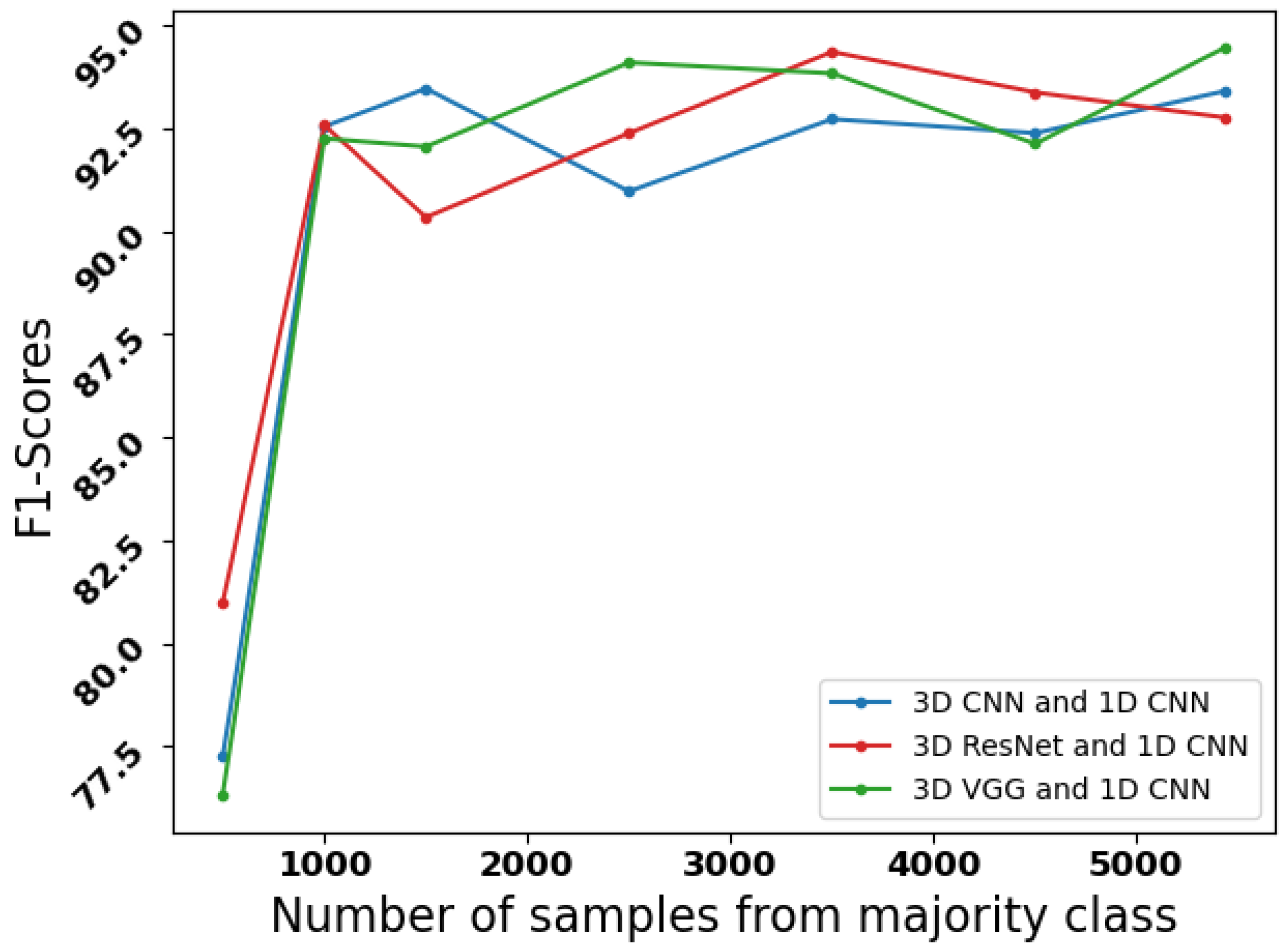
Figure 5.
Line curve showing the variation in F1-Scores of the model with variation in the number of samples from the majority ‘Other’ class.
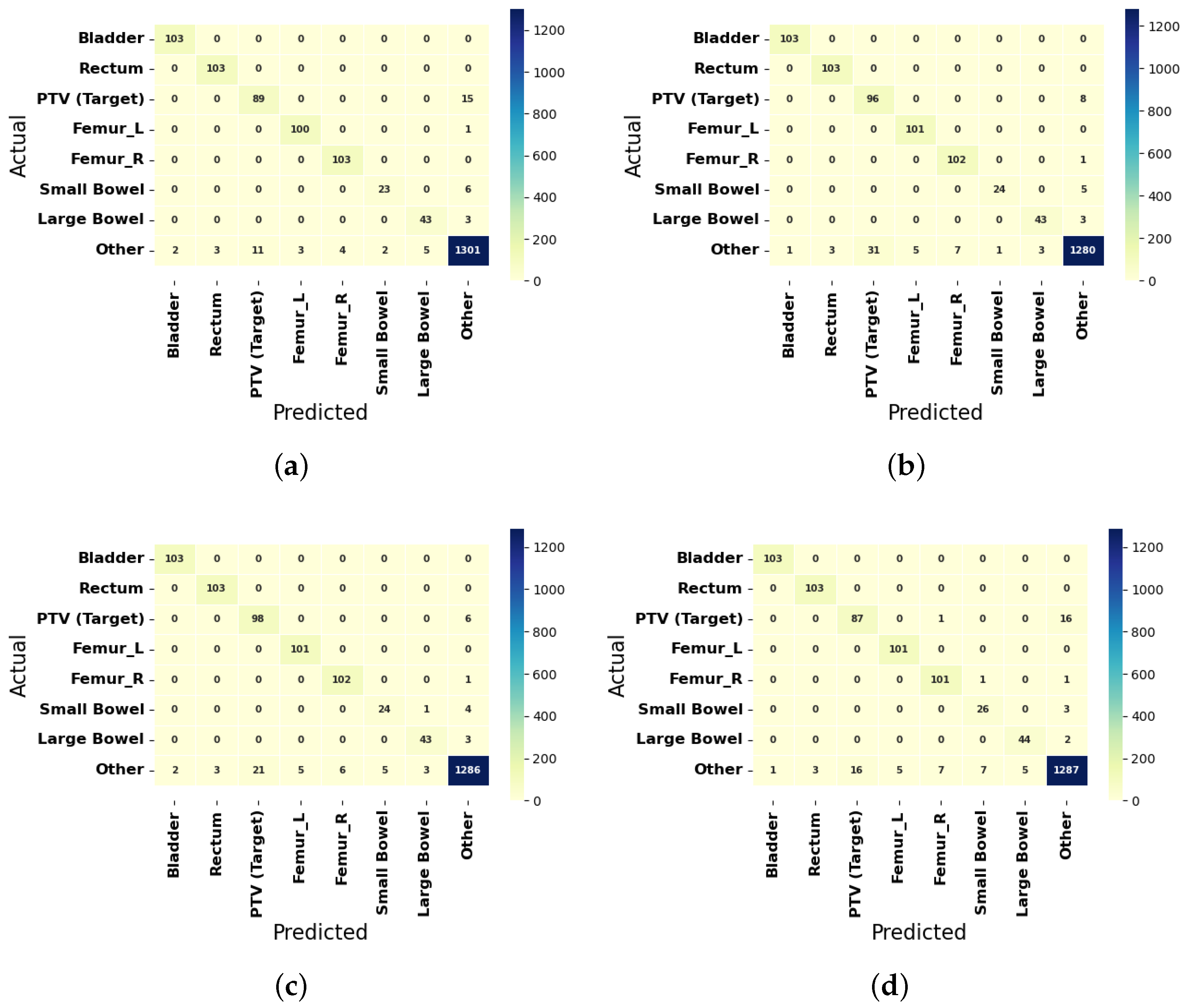
Figure 6.
Confusion Matrices of the best three predictions for the Prostate Cancer Patients by the F1-Scores are shown in (a) 3D VGG network and 1D CNN without undersampling, (b) 3D ResNet and 1D CNN with 3500 majority class samples, and (c) 3D VGG network and 1D CNN with 2500 majority class samples. Confusion Matrices of the best predictions of the architecture for the Prostate Cancer Patients by the F1-Scores are shown in (d) 3D CNN and 1D CNN with 1500 majority class samples.
Table 1.
Distribution of the Organ structure for the Prostate Cancer Patients.
| Standard Names | VHA Physician Given Name Counts | VCU Physician Given Name Counts | Total Physician Given Name Counts | Available Given Name Counts |
|---|
| Bladder | 609 | 50 | 659 | 519 |
| Rectum | 719 | 50 | 769 | 517 |
| PTV (Target) | 714 | 38 | 752 | 522 |
| Femur_L | 694 | 29 | 723 | 508 |
| Femur_R | 700 | 29 | 729 | 515 |
| SmallBowel | 250 | 49 | 299 | 145 |
| LargeBowel | 341 | 0 | 341 | 234 |
| ‘Other’ | 11,038 | 980 | 12,018 | 6763 |
| Prostate Total | 15,065 | 1225 | 16,290 | 9723 |
Table 2.
Distribution of the Physician Given Structure Names for the Prostate Cancer Patients.
| Structure Type | Standard Name | Patient 1 | Patient 2 | Patient 3 |
|---|
| OAR | LargeBowel | Colon_Sigmoid | - | - |
| OAR | Femur_R | Femur_Head_R | RtFemHead | Hip Right |
| OAR | Femur_L | Femur_Head_L | LtFemHead | Hip Left |
| OAR | Bladder | Bladder | bladder | Bladder |
| OAR | Rectum | Rectum | rectum | Rectum |
| OAR | SmallBowel | - | bowel | - |
| Target | PTV | PTV_7920 | PTV45Gy | PTV 2 |
| ‘Other’ | “Other” | z post rectum | ptv4cm | Rectum − PTV |
| ‘Other’ | “Other” | Body | nodalCTVfinal | Prostate + SV |
| ‘Other’ | “Other” | CTVp | NONPTVBlad | PTV 1 |
| ‘Other’ | “Other” | CouchInterior | CTVProsSV | Bladder − PTV |
| ‘Other’ | “Other” | PenileBulb | External | Seminal Vesicles |
| ‘Other’ | “Other” | Prostate | FinalISO | Seed Marker 1 |
| ‘Other’ | “Other” | z_rectuminptv | MarkedISO | Dose 104 [%] |
| ‘Other’ | “Other” | z_dosedec | CTVBst | Seed Marker 3 |
Table 3.
Performance of the CNN-based Models for the Prostate cancer patients during data selection.
| Data Modality | Method | Precision (in %) | Recall (in %) | F1-Score (in %) |
|---|
| struc+ image+ dose+ text | 3D CNN and 1D CNN | 91.93 | 92.93 | 92.42 |
| struc+ image+ dose+ text | 3D ResNet and 1D CNN | 92.72 | 93.74 | 93.2 |
| struc+ image+ dose+ text | 3D VGG and 1D CNN | 93.51 | 92.99 | 93.19 |
| masked image+ masked dose+ text | 3D CNN and 1D CNN | 93.65 | 93.29 | 93.4 |
| masked image+ masked dose+ text | 3D ResNet and 1D CNN | 91.05 | 94.83 | 92.76 |
| masked image+ masked dose+ text | 3D VGG and 1D CNN | 94.66 | 94.39 | 94.45 |
Table 4.
Model performances for the Prostate cancer patients with varying data modalities.
| Masked Image | Masked Dose | Text | Method | Precision (in %) | Recall (in %) | F1-Score (in %) |
|---|
| ✓ | - | - | 3D CNN | 71.75 | 74.81 | 72.99 |
| ✓ | - | - | 3D ResNet | 73.94 | 74.24 | 73.92 |
| ✓ | - | - | 3D VGG | 76.19 | 74.46 | 74.82 |
| - | ✓ | - | 3D CNN | 74.18 | 70.79 | 72.17 |
| - | ✓ | - | 3D ResNet | 74.01 | 62.94 | 66.39 |
| - | ✓ | - | 3D VGG | 81.53 | 77.98 | 79.45 |
| ✓ | ✓ | - | 3D CNN | 93.6 | 91.52 | 91.93 |
| ✓ | ✓ | - | 3D ResNet | 94.23 | 93.65 | 93.82 |
| ✓ | ✓ | - | 3D VGG | 93.0 | 94.9 | 93.8 |
| - | - | ✓ | 1D CNN | 92.18 | 94.24 | 93.17 |
| ✓ | - | ✓ | 3D CNN and 1D CNN | 93.31 | 92.49 | 92.83 |
| ✓ | - | ✓ | 3D ResNet and 1D CNN | 91.33 | 95.18 | 93.15 |
| ✓ | - | ✓ | 3D VGG and 1D CNN | 92.24 | 91.35 | 91.71 |
| - | ✓ | ✓ | 3D CNN and 1D CNN | 91.86 | 93.66 | 92.61 |
| - | ✓ | ✓ | 3D ResNet and 1D CNN | 90.13 | 94.97 | 92.29 |
| - | ✓ | ✓ | 3D VGG and 1D CNN | 91.82 | 93.42 | 92.54 |
| ✓ | ✓ | ✓ | 3D CNN and 1D CNN | 93.65 | 93.29 | 93.4 |
| ✓ | ✓ | ✓ | 3D ResNet and 1D CNN | 91.05 | 94.83 | 92.76 |
| ✓ | ✓ | ✓ | 3D VGG and 1D CNN | 94.66 | 94.39 | 94.45 |
Table 5.
Model performances for the Prostate cancer patients with variation in the majority class samples.
| Total Samples from ‘Other’ Class | Method | Precision (in %) | Recall (in %) | F1-Score (in %) |
|---|
| 500 | 3D CNN and 1D CNN | 70.62 | 89.32 | 77.26 |
| 500 | 3D ResNet and 1D CNN | 76.47 | 87.21 | 80.98 |
| 500 | 3D VGG and 1D CNN | 71.71 | 83.61 | 76.33 |
| 1000 | 3D CNN and 1D CNN | 90.99 | 94.24 | 92.54 |
| 1000 | 3D ResNet and 1D CNN | 89.08 | 96.91 | 92.57 |
| 1000 | 3D VGG and 1D CNN | 89.82 | 95.16 | 92.25 |
| 1500 | 3D CNN and 1D CNN | 91.65 | 95.46 | 93.46 |
| 1500 | 3D ResNet and 1D CNN | 86.63 | 95.3 | 90.34 |
| 1500 | 3D VGG and 1D CNN | 88.79 | 96.35 | 92.05 |
| 2500 | 3D CNN and 1D CNN | 87.82 | 94.7 | 90.97 |
| 2500 | 3D ResNet and 1D CNN | 88.86 | 96.7 | 92.38 |
| 2500 | 3D VGG and 1D CNN | 92.56 | 95.76 | 94.09 |
| 3500 | 3D CNN and 1D CNN | 91.74 | 93.75 | 92.72 |
| 3500 | 3D ResNet and 1D CNN | 93.6 | 95.47 | 94.35 |
| 3500 | 3D VGG and 1D CNN | 92.48 | 95.36 | 93.83 |
| 4500 | 3D CNN and 1D CNN | 92.34 | 92.56 | 92.38 |
| 4500 | 3D ResNet and 1D CNN | 91.54 | 95.45 | 93.37 |
| 4500 | 3D VGG and 1D CNN | 91.42 | 92.95 | 92.12 |
| 5432 (No Sampling) | 3D CNN and 1D CNN | 93.65 | 93.29 | 93.4 |
| 5432 (No Sampling) | 3D ResNet and 1D CNN | 91.05 | 94.83 | 92.76 |
| 5432 (No Sampling) | 3D VGG and 1D CNN | 94.66 | 94.39 | 94.45 |
Table 6.
Model performances with 3D VGG nested ResNet and 3D VGG with Leaky ReLU activation for the Prostate cancer patients while varying the majority class samples.
| Total Samples from ‘Other’ Class | Method | Precision (in %) | Recall (in %) | F1-Score (in %) |
|---|
| 500 | 3D VGG with nested ResNet and 1D CNN | 86.75 | 96.37 | 90.62 |
| 500 | 3D VGG with LeakyReLU and 1D CNN | 85.57 | 96.28 | 89.74 |
| 1000 | 3D VGG with nested ResNet and 1D CNN | 87.37 | 95.49 | 90.92 |
| 1000 | 3D VGG with LeakyReLU and 1D CNN | 83.56 | 97.29 | 88.55 |
| 1500 | 3D VGG with nested ResNet and 1D CNN | 89.67 | 96.27 | 92.64 |
| 1500 | 3D VGG with LeakyReLU and 1D CNN | 91.66 | 95.4 | 93.44 |
| 2500 | 3D VGG with nested ResNet and 1D CNN | 90.8 | 93.38 | 92.02 |
| 2500 | 3D VGG with LeakyReLU and 1D CNN | 87.92 | 96.26 | 91.5 |
| 3500 | 3D VGG with nested ResNet and 1D CNN | 90.57 4 | 95.6 | 92.89 |
| 3500 | 3D VGG with LeakyReLU and 1D CNN | 88.56 | 94.75 | 91.44 |
| 4500 | 3D VGG with nested ResNet and 1D CNN | 90.97 | 93.33 | 92.11 |
| 4500 | 3D VGG with LeakyReLU and 1D CNN | 92.69 | 92.35 | 92.51 |
| 5432 (No Sampling) | 3D VGG with nested ResNet and 1D CNN | 92.19 | 94.71 | 93.36 |
| 5432 (No Sampling) | 3D VGG with LeakyReLU and 1D CNN | 91.95 | 94.29 | 93.04 |
Table 7.
Class-wise performances of the top three Models for the Prostate cancer patients.
| Class | VGG (with 5432 Majority Class Samples) | ResNet (3500 Majority Class Samples) | VGG (2500 Majority Class Samples) |
|---|
| Precision (in %) | Recall (in %) | F1-Score (in %) | Precision (in %) | Recall (in %) | F1-Score (in %) | Precision (in %) | Recall (in %) | F1-Score (in %) |
|---|
| Bladder | 98.1 | 100 | 99.04 | 99.04 | 100 | 99.52 | 98.1 | 100 | 99.04 |
| Rectum | 97.17 | 100 | 98.56 | 97.17 | 100 | 98.56 | 97.17 | 100 | 98.56 |
| PTV (Target) | 89.0 | 85.58 | 87.25 | 75.59 | 92.31 | 83.12 | 82.35 | 94.23 | 87.89 |
| Femur_L | 97.09 | 99.01 | 98.04 | 95.28 | 100 | 97.58 | 95.28 | 100 | 97.58 |
| Femur_R | 96.26 | 100 | 98.1 | 93.58 | 99.03 | 96.23 | 94.44 | 99.03 | 96.68 |
| Small Bowel | 92.0 | 79.31 | 85.19 | 96.0 | 82.76 | 88.89 | 82.76 | 82.76 | 82.76 |
| Large Bowel | 89.58 | 93.48 | 91.49 | 93.48 | 93.48 | 93.48 | 91.49 | 93.48 | 92.47 |
| ‘Other’ | 98.11 | 97.75 | 97.93 | 98.69 | 96.17 | 97.41 | 98.92 | 96.62 | 97.76 |
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).

 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}