

Applying Few-Shot Learning for In-the-Wild Camera-Trap Species Classification
 , , , and
, , , and
Abstract
:1. Introduction
- Environmental/Imagery challenges: Images obtained from camera traps may be very different from the generic images collected from the internet that are widely used when constructing benchmark datasets. These differences include images with much lower quality, incomplete objects, and smaller inter-class differences due to (1) different animals being captured with the same background, or (2) inherently similar appearances across species.
- Presence of distractors: Because our data processing pipeline starts with unlabeled raw videos, we have applied frame selection schemes and an off-the-shelf camera-trap animal detection model in order to produce the cropped images that are input to a classifier. Since we do not have a 100% accurate detector, we observe many cases of false detection—cases where a non-animal object is detected as an animal and, therefore, is considered for classification. Meanwhile, these “distractor” images are typically ignored when using benchmark datasets, and they are also not considered during typical FSL network design.
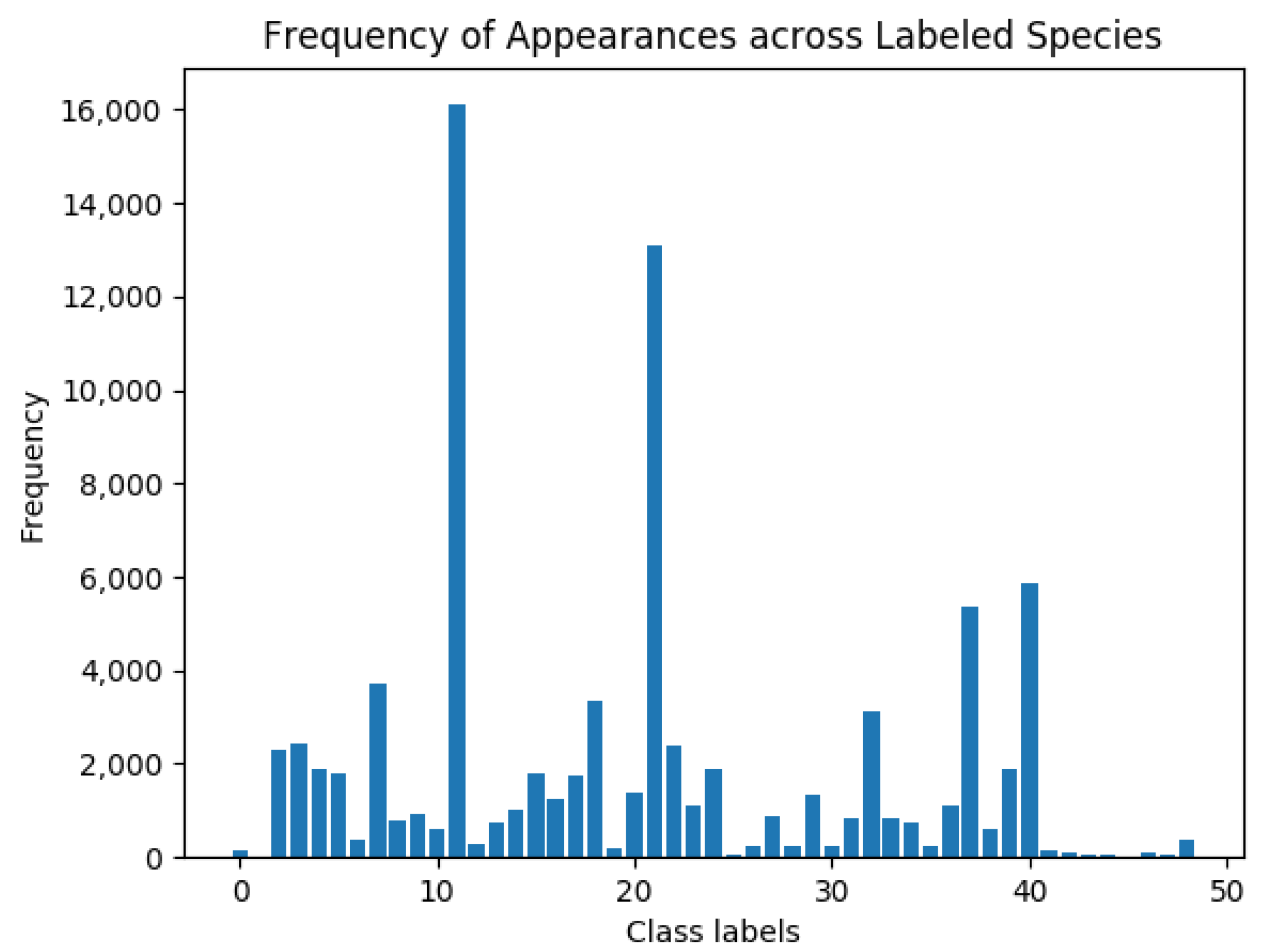
- Unbalanced class distribution: The distribution of animals in nature is inherently unbalanced, which causes some species to appear far more often than others; this has also not been considered in most FSL benchmark datasets.
- introducing additional evaluation protocols in the implementation settings to systematically quantify a network’s usefulness under the aforementioned challenges;
- conducting more comprehensive experiments with more FSL networks, and confirming our assumption that benchmark testing performance does not necessarily reflect real-world usefulness;
- performing additional experiments that explore the real-world impact, considering both factors involved in network design and factors not previously considered in benchmark testing.
2. Background
2.1. Species Classification for Camera-Trap Videos/Images
2.2. FSL Methods
2.3. FSL Benchmark Datasets and Evaluation Protocols
2.4. Applied FSL
3. Materials and Methods
3.1. Data Description
3.2. Challenges
3.2.1. Environmental/Imagery Challenges
3.2.2. Presence of Distractors
3.2.3. Unbalanced Class Distribution
3.3. Dataset Formation
3.3.1. Dataset 1: For a Benchmark-Style Evaluation
3.3.2. Dataset 2: For an Implementation-Style Evaluation
- False positive rate (FPR) is the number of distractor images that pass the decision rule divided by the total number of distractor images. The FPR measures a network’s effectiveness at eliminating distractor images.
- True positive rate (TPR) is the number of animal images that passes the decision rule and are correctly classified, divided by the total number of animal images. TPR measures a network’s effectiveness at admitting correct animal images. Due to the very low quality on some of the animal images, we do not expect all animal images to be classified. In other words, we do not expect the TPR to reach 100%.
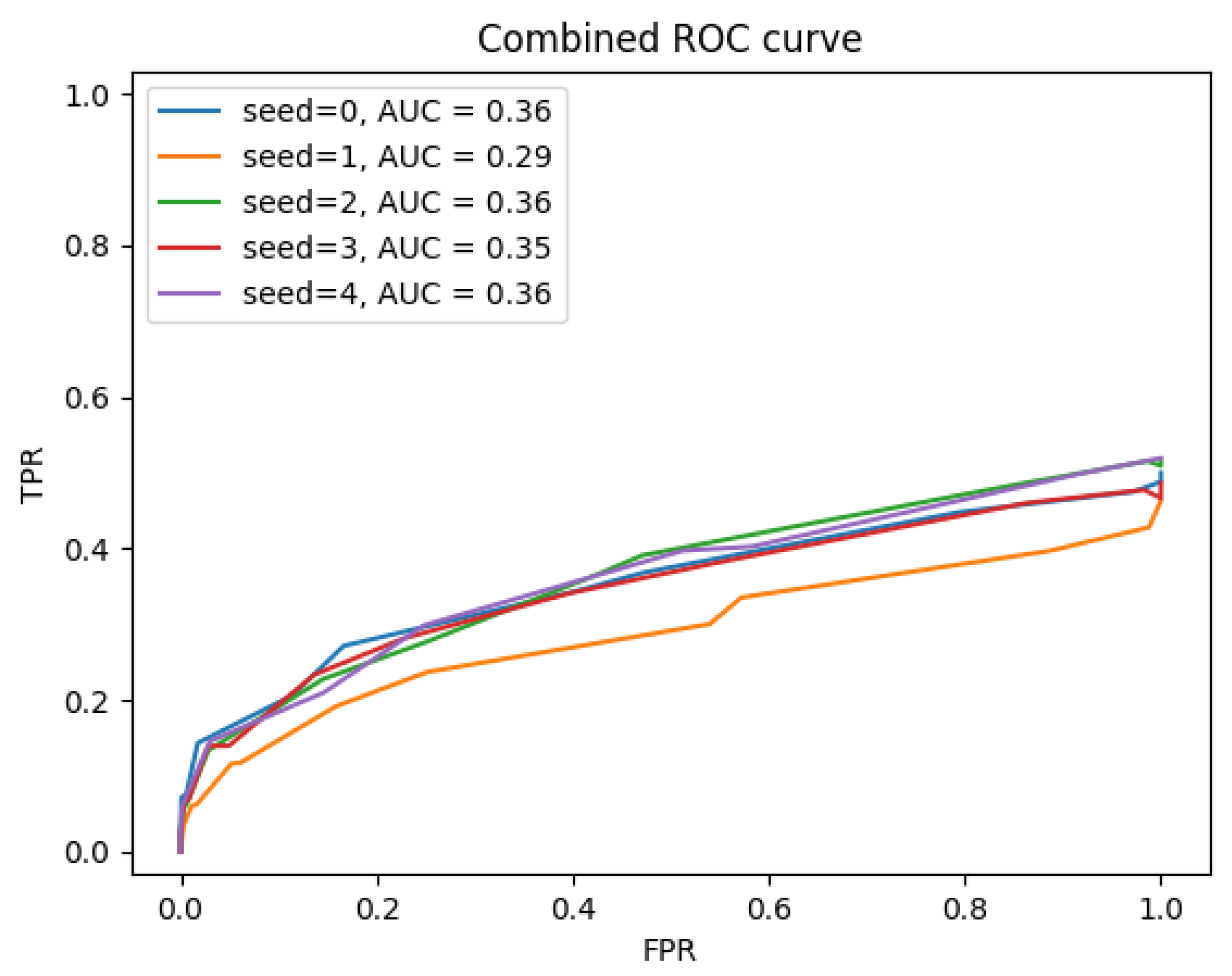
3.4. Network Training Settings
4. Results and Discussions
4.1. Overall Comparison of FSL Network Performance under Challenging Environments
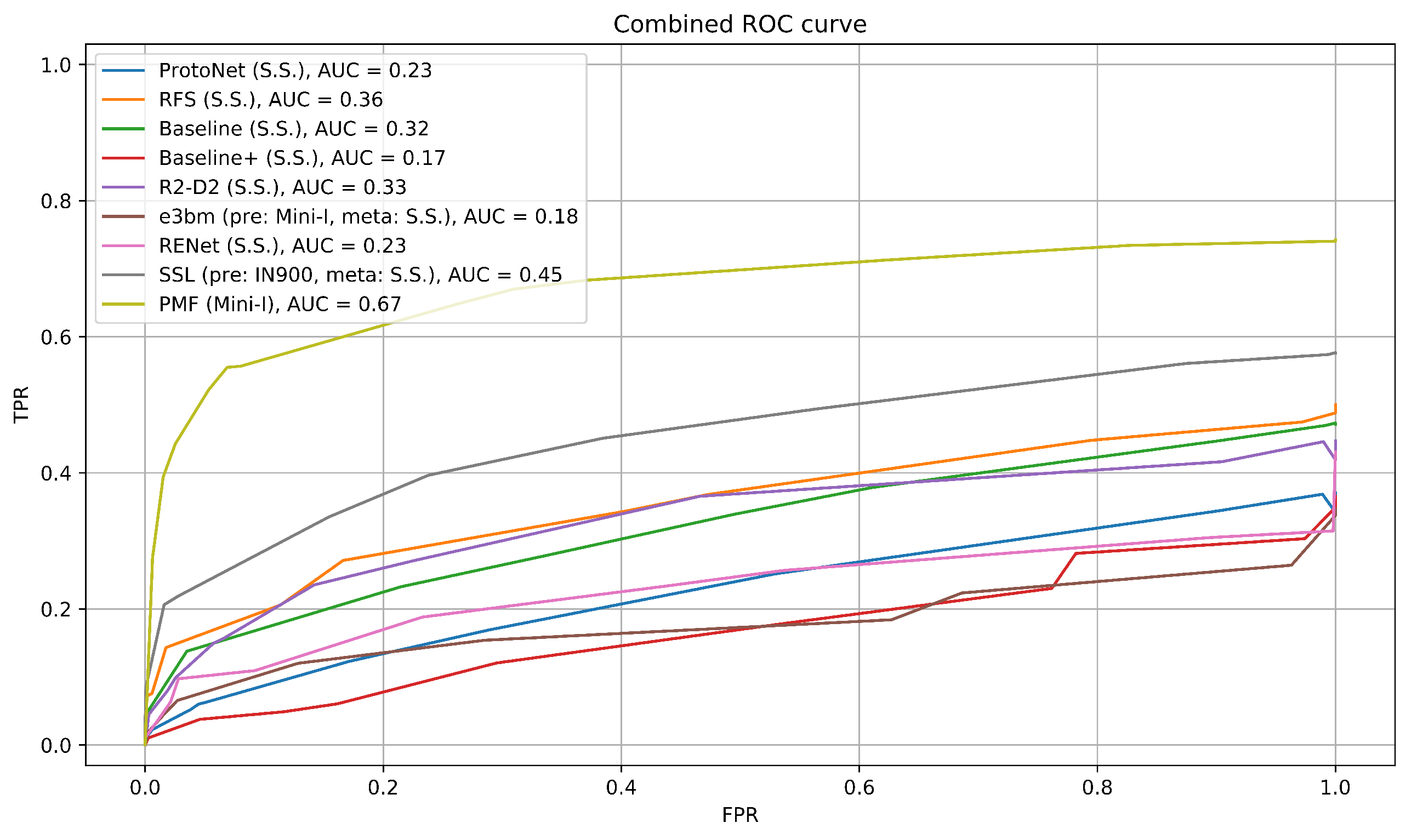
4.1.1. Results Part 1: Benchmark-Style Evaluation
4.1.2. Results Part 2: Implementation-Style Evaluation
4.1.3. Discussion: Performance Difference between Benchmark and Implementation Settings
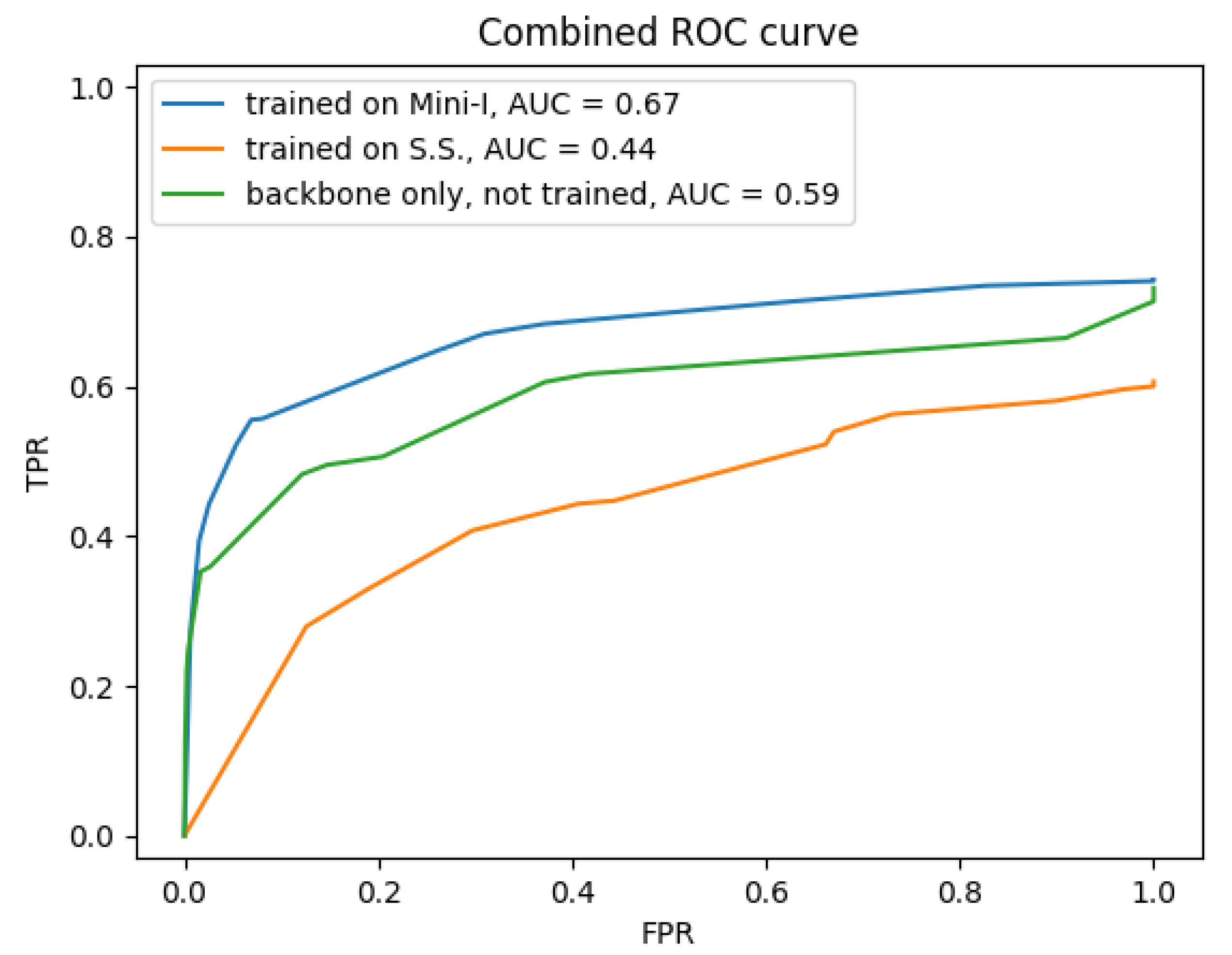
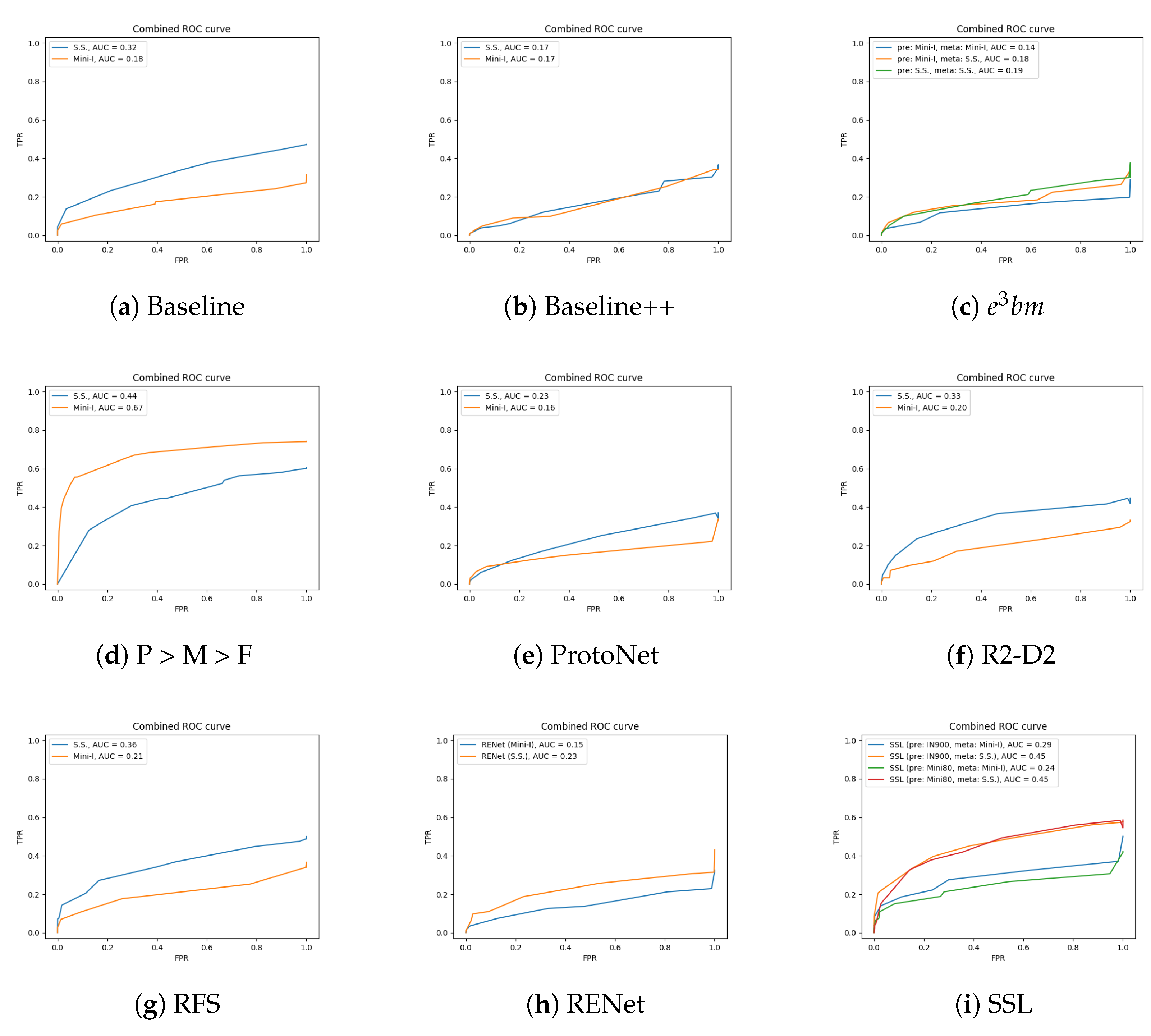
4.2. Benefit of Extra Training Data and an Effective Feature Extractor
4.3. A Deeper Look into FSL Classification in Implementation Settings
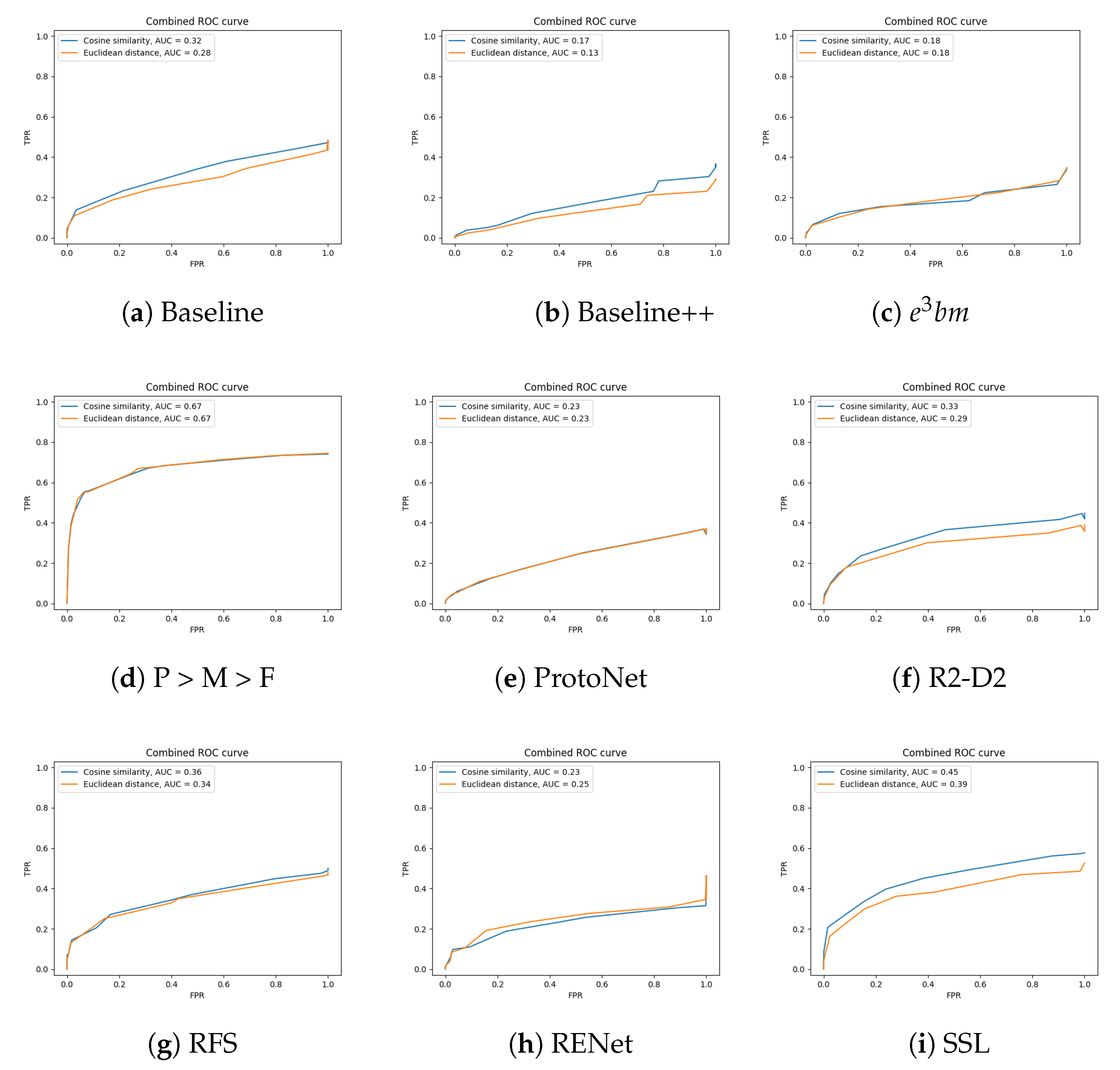
4.3.1. Distance Metrics
4.3.2. Additional Feature Transformation
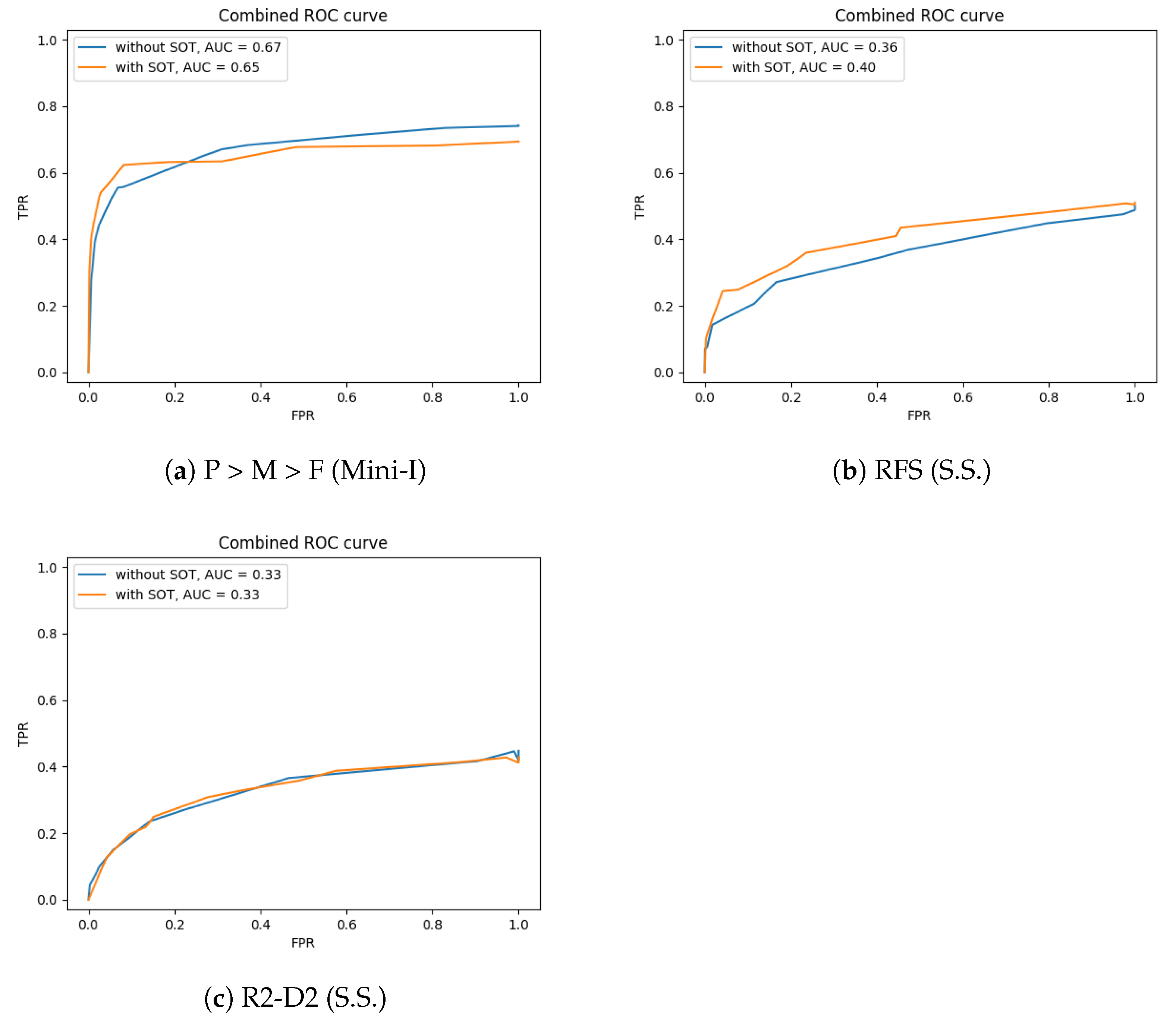
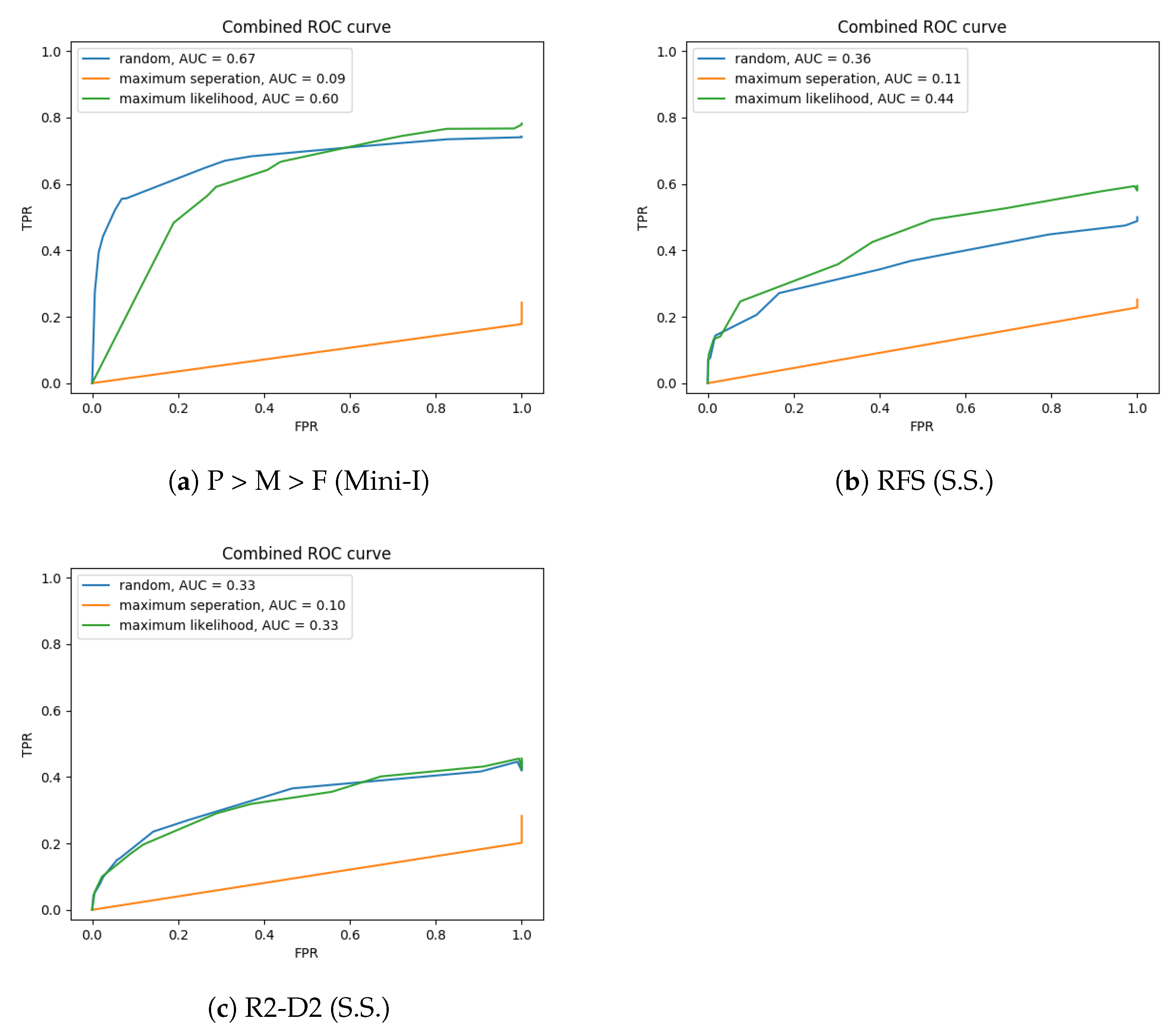
4.3.3. Support Data Selection
4.3.4. Ease of Implementation
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| FSL | Few-shot learning |
| KNN | K-nearest neighbor |
| CT | Camera trap |
| TPR | True positive rate (see Section 3.3.2 for detailed definition) |
| FPR | False positive rate |
| ROC | Receiver operating characteristic |
| MCA | Mean per-class accuracy |
| In figures and tables: | |
| S.S. | Snapshot Serengeti (dataset) |
| Mini-I | Mini-ImageNet (dataset) |
| Mini80 | Subset of ImageNet used for self-supervised pre-training in [36] |
| IN900 | ImageNet900, Subset of ImageNet used for self-supervised pre-training in [36] |
Appendix A. Additional Figures
Appendix A.1. Comparison between Training Datasets

Appendix A.2. Comparison between Distance Metrics

References
- Li, F.-F.; Fergus, R.; Perona, P. One-shot learning of object categories. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 594–611. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Vinyals, O.; Blundell, C.; Lillicrap, T.; Kavukcuoglu, K.; Wierstra, D. Matching networks for one shot learning. In Proceedings of the 30th International Conference on Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- Wang, Y.; Yao, Q.; Kwok, J.T.; Ni, L.M. Generalizing from a few examples: A survey on few-shot learning. ACM Comput. Surv. 2020, 53, 1–34. [Google Scholar] [CrossRef]
- Chen, H.; Lindshield, S.M.; Reibman, A.R. Challenges and constraints when applying few shot learning to a real-world scenario: In-the-wild camera-trap species classification. Electron. Imaging 2023, 35, 280-1–280-6. [Google Scholar] [CrossRef]
- Lindshield, S.; Bogart, S.; Gueye, M.; Ndiaye, P.; Pruetz, J. Informing Protection Efforts for Critically Endangered Chimpanzees (Pan troglodytes verus) and Sympatric Mammals amidst Rapid Growth of Extractive Industries in Senegal. Folia Primatol. 2019, 90, 124–136. [Google Scholar] [CrossRef] [PubMed]
- Pruetz, J.; Bertolani, P.; Boyer Ontl, K.; Lindshield, S.; Shelley, M.; Wessling, E. New evidence on the tool-assisted hunting exhibited by chimpanzees (Pan troglodytes verus) in a savannah habitat at Fongoli, Sénégal. R. Soc. Open Sci. 2015, 2, 140507. [Google Scholar] [CrossRef] [Green Version]
- Norouzzadeh, M.S.; Nguyen, A.; Kosmala, M.; Swanson, A.; Palmer, M.S.; Packer, C.; Clune, J. Automatically identifying, counting, and describing wild animals in camera-trap images with deep learning. Proc. Natl. Acad. Sci. USA 2018, 115, E5716–E5725. [Google Scholar] [CrossRef] [Green Version]
- Pavlovs, I.; Aktas, K.; Avots, E.; Vecvanags, A.; Filipovs, J.; Brauns, A.; Done, G.; Jakovels, D.; Anbarjafari, G. Ungulate Detection and Species Classification from Camera Trap Images Using RetinaNet and Faster R-CNN. Entropy 2022, 24, 353. [Google Scholar] [CrossRef]
- Zhang, Z.; He, Z.; Cao, G.; Cao, W. Animal Detection From Highly Cluttered Natural Scenes Using Spatiotemporal Object Region Proposals and Patch Verification. IEEE Trans. Multimed. 2016, 18, 2079–2092. [Google Scholar] [CrossRef]
- Singh, P.; Lindshield, S.M.; Zhu, F.; Reibman, A.R. Animal Localization in Camera-Trap Images with Complex Backgrounds. In Proceedings of the IEEE Southwest Symposium on Image Analysis and Interpretation (SSIAI), Albuquerque, NM, USA, 29–31 March 2020; pp. 66–69. [Google Scholar] [CrossRef]
- Karami, A.; Crawford, M.; Delp, E.J. Automatic Plant Counting and Location Based on a Few-Shot Learning Technique. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 5872–5886. [Google Scholar] [CrossRef]
- Tian, Z.; Lai, X.; Jiang, L.; Liu, S.; Shu, M.; Zhao, H.; Jia, J. Generalized Few-shot Semantic Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11553–11562. [Google Scholar] [CrossRef]
- Snell, J.; Swersky, K.; Zemel, R. Prototypical networks for few-shot learning. Adv. Neural Inf. Process. Syst. 2017, 30, 1–11. [Google Scholar]
- Tian, Y.; Wang, Y.; Krishnan, D.; Tenenbaum, J.B.; Isola, P. Rethinking few-shot image classification: A good embedding is all you need? In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; pp. 266–282. [Google Scholar] [CrossRef]
- Chen, W.Y.; Liu, Y.C.; Kira, Z.; Wang, Y.C.; Huang, J.B. A Closer Look at Few-shot Classification. In Proceedings of the International Conference on Learning Representations (ICLR), New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Finn, C.; Abbeel, P.; Levine, S. Model-agnostic meta-learning for fast adaptation of deep networks. In Proceedings of the International Conference on Machine Learning, Sydney, NSW, Australia, 6–11 August 2017; pp. 1126–1135. [Google Scholar]
- Liu, Y.; Schiele, B.; Sun, Q. An Ensemble of Epoch-wise Empirical Bayes for Few-shot Learning. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020. [Google Scholar] [CrossRef]
- Xiong, C.; Li, W.; Liu, Y.; Wang, M. Multi-Dimensional Edge Features Graph Neural Network on Few-Shot Image Classification. IEEE Signal Process. Lett. 2021, 28, 573–577. [Google Scholar] [CrossRef]
- Jiang, B.; Zhao, K.; Tang, J. RGTransformer: Region-Graph Transformer for Image Representation and Few-Shot Classification. IEEE Signal Process. Lett. 2022, 29, 792–796. [Google Scholar] [CrossRef]
- Lake, B.M.; Salakhutdinov, R.; Tenenbaum, J.B. Human-level concept learning through probabilistic program induction. Science 2015, 350, 1332–1338. [Google Scholar] [CrossRef] [Green Version]
- Sun, Q.; Liu, Y.; Chua, T.; Schiele, B. Meta-Transfer Learning for Few-Shot Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 403–412. [Google Scholar] [CrossRef] [Green Version]
- Bennequin, E.; Tami, M.; Toubhans, A.; Hudelot, C. Few-Shot Image Classification Benchmarks are Too Far From Reality: Build Back Better with Semantic Task Sampling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, New Orleans, LA, USA, 19–20 June 2022; pp. 4766–4775. [Google Scholar] [CrossRef]
- Ravi, S.; Larochelle, H. Optimization as a model for few-shot learning. In Proceedings of the International Conference on Learning Representations (ICLR), Toulon, France, 24–26 April 2017. [Google Scholar]
- Wah, C.; Branson, S.; Welinder, P.; Perona, P.; Belongie, S. Caltech-UCSD Birds 200; Technical Report CNS-TR-2011-001; California Institute of Technology: Pasadena, CA, USA, 2011. [Google Scholar]
- Nuthalapati, S.; Tunga, A. Multi-Domain Few-Shot Learning and Dataset for Agricultural Applications. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), Montreal, BC, Canada, 11–17 October 2021; pp. 1399–1408. [Google Scholar] [CrossRef]
- Zhang, A.; Li, S.; Cui, Y.; Yang, W.; Dong, R.; Hu, J. Limited Data Rolling Bearing Fault Diagnosis With Few-Shot Learning. IEEE Access 2019, 7, 110895–110904. [Google Scholar] [CrossRef]
- Yoo, T.K.; Choi, J.Y.; Kim, H.K. Feasibility study to improve deep learning in OCT diagnosis of rare retinal diseases with few-shot classification. Med. Biol. Eng. Comput. 2021, 59, 401–415. [Google Scholar] [CrossRef] [PubMed]
- Koch, G.; Zemel, R.; Salakhutdinov, R. Siamese neural networks for one-shot image recognition. In Proceedings of the ICML Deep Learning Workshop, Lille, France, 6–11 July 2015; Volume 2. [Google Scholar]
- Figueroa-Mata, G.; Mata-Montero, E. Using a Convolutional Siamese Network for Image-Based Plant Species Identification with Small Datasets. Biomimetics 2020, 5, 8. [Google Scholar] [CrossRef] [Green Version]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2242–2251. [Google Scholar] [CrossRef] [Green Version]
- Prabhu, V.; Kannan, A.; Ravuri, M.; Chablani, M.; Sontag, D.A.; Amatriain, X. Prototypical Clustering Networks for Dermatological Disease Diagnosis. arXiv 2018, arXiv:1811.03066. [Google Scholar]
- Wang, L.; Yang, X.; Tan, H.; Bai, X.; Zhou, F. Few-Shot Class-Incremental SAR Target Recognition Based on Hierarchical Embedding and Incremental Evolutionary Network. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5204111. [Google Scholar] [CrossRef]
- Zhong, Q.; Chen, L.; Qian, Y. Few-Shot Learning for Remote Sensing Image Retrieval with MAML. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Abu Dhabi, United Arab Emirates, 25–28 October 2020; pp. 2446–2450. [Google Scholar] [CrossRef]
- Bertinetto, L.; Henriques, J.F.; Torr, P.H.S.; Vedaldi, A. Meta-learning with differentiable closed-form solvers. In Proceedings of the International Conference on Learning Representations (ICLR), New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Kang, D.; Kwon, H.; Min, J.; Cho, M. Relational Embedding for Few-Shot Classification. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021. [Google Scholar]
- Chen, D.; Chen, Y.; Li, Y.; Mao, F.; He, Y.; Xue, H. Self-Supervised Learning for Few-Shot Image Classification. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 1745–1749. [Google Scholar] [CrossRef]
- Hu, S.X.; Li, D.; Stühmer, J.; Kim, M.; Hospedales, T.M. Pushing the Limits of Simple Pipelines for Few-Shot Learning: External Data and Fine-Tuning Make a Difference. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar] [CrossRef]
- Swanson, A.; Kosmala, M.; Lintott, C.; Simpson, R.; Smith, A.; Packer, C. Snapshot Serengeti, high-frequency annotated camera trap images of 40 mammalian species in an African savanna. Sci. Data 2015, 2, 150026. [Google Scholar] [CrossRef] [Green Version]
- Caron, M.; Touvron, H.; Misra, I.; Jégou, H.; Mairal, J.; Bojanowski, P.; Joulin, A. Emerging properties in self-supervised vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 9650–9660. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Zagoruyko, S.; Komodakis, N. Wide residual networks. arXiv 2016, arXiv:1605.07146. [Google Scholar]
- Bachman, P.; Hjelm, R.D.; Buchwalter, W. Learning representations by maximizing mutual information across views. In Proceedings of the 33rd Conference on Neural Information Processing Systems (NeurIPS 2019), Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Shalam, D.; Korman, S. The Self-Optimal-Transport Feature Transform. arXiv 2022, arXiv:2204.03065. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Shipment | Videos | Images | Size (GB) | Cameras |
|---|---|---|---|---|
| 1 | 2998 | 106,283 | 187 | 48 |
| 2 | 25,606 | 10,433 | 1304 | 110 |
| 3 | 3489 | 2392 | 132 | 31 |
| 4 | 6894 | 1410 | 284 | 37 |
| 5 | 11,523 | 356 | 642 | 39 |
| 6 | 4759 | 1354 | 167 | 22 |
| Total | 55,269 | 122,228 | 2716 | 287 |
| Species | Images | Species | Images |
|---|---|---|---|
| Baboon | 1624 | Hartebeest | 21 |
| Buffalo | 566 | Oribi | 10 |
| Bushbuck | 46 | Patas monkey | 54 |
| Duiker | 212 | Roan antelope | 167 |
| Green monkey | 247 | Warthog | 245 |
| Guineafowl | 1831 | Distractors | 2586 |
| Species | Images | Species | Images |
|---|---|---|---|
| Baboon | 108 | Hartebeest | 25 |
| Buffalo | 74 | Oribi | 22 |
| Bushbuck | 126 | Patas monkey | 30 |
| Duiker | 53 | Roan antelope | 97 |
| Green monkey | 99 | Warthog | 83 |
| Guineafowl | 86 |
| Network | Train on Mini-I Test on Mini-I | Train on Mini-I Test on Senegal-B | Train on S.S. Test on Senegal-B |
|---|---|---|---|
| ProtoNet [13] | 74.19 | 62.16 | 60.97 |
| RFS [14] | 79.74 | 62.96 | 71.56 |
| Baseline [15] | 76.18 | 67.54 | 71.98 |
| Baseline++[15] | 66.36 | 54.39 | 56.49 |
| R2-D2 [34] | 74.35 | 63.93 | 67.63 |
| e3bm [17] (pre: Mini) | 80.60 | 67.01 | 68.59 |
| e3bm [17] (pre: S.S.) | - | - | 59.69 |
| RENet [35] | 82.23 | 69.81 | 66.62 |
| SSL [36] (pre: Mini80) | 81.21 | 66.69 | 71.81 |
| SSL [36] (pre: IN900) | 90.79 | 71.90 | 76.32 |
| P > M > F [37] | 97.30 | 92.10 | 92.10 |
| Network | Train on Mini-I Test on Senegal-I | Train on S.S. Test on Senegal-I |
|---|---|---|
| ProtoNet | 21.70 | 21.20 |
| RFS | 27.70 | 35.00 |
| Baseline | 27.20 | 35.80 |
| Baseline++ | 24.30 | 28.80 |
| R2-D2 | 22.30 | 31.10 |
| e3bm (pre: Mini-I) | 24.80 | 29.90 |
| e3bm (pre: S.S.) | 33.10 | |
| RENet | 27.00 | 37.80 |
| SSL (pre: Mini80) | 33.90 | 41.00 |
| SSL (pre: IN900) | 40.50 | 46.60 |
| P > M > F | 70.70 | 46.80 |
| Network | AUC Using Euclidean Distance | AUC Using Cosine Similarity |
|---|---|---|
| ProtoNet | 0.22 | 0.22 |
| RFS | 0.34 | 0.36 |
| Baseline | 0.29 | 0.32 |
| Baseline++ | 0.13 | 0.17 |
| R2-D2 | 0.27 | 0.32 |
| e3bm | 0.19 | 0.19 |
| RENet | 0.25 | 0.23 |
| SSL | 0.39 | 0.45 |
| P > M > F | 0.67 | 0.67 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, H.; Lindshield, S.; Ndiaye, P.I.; Ndiaye, Y.H.; Pruetz, J.D.; Reibman, A.R. Applying Few-Shot Learning for In-the-Wild Camera-Trap Species Classification. AI 2023, 4, 574-597. https://doi.org/10.3390/ai4030031
Chen H, Lindshield S, Ndiaye PI, Ndiaye YH, Pruetz JD, Reibman AR. Applying Few-Shot Learning for In-the-Wild Camera-Trap Species Classification. AI. 2023; 4(3):574-597. https://doi.org/10.3390/ai4030031
Chicago/Turabian StyleChen, Haoyu, Stacy Lindshield, Papa Ibnou Ndiaye, Yaya Hamady Ndiaye, Jill D. Pruetz, and Amy R. Reibman. 2023. "Applying Few-Shot Learning for In-the-Wild Camera-Trap Species Classification" AI 4, no. 3: 574-597. https://doi.org/10.3390/ai4030031