
A Refined-Line-Based Method to Estimate Vanishing Points for Vision-Based Autonomous Vehicles


Abstract
:1. Introduction
- a method designed to effectively refine lines that satisfy structured shape and orientation;
- an algorithm developed to remove spurious VP candidates and obtain the VP by optimal estimation;
- an approach presented to estimate the VPs through refined-line strategy, which is robust to varying illumination and color.
2. Related Work
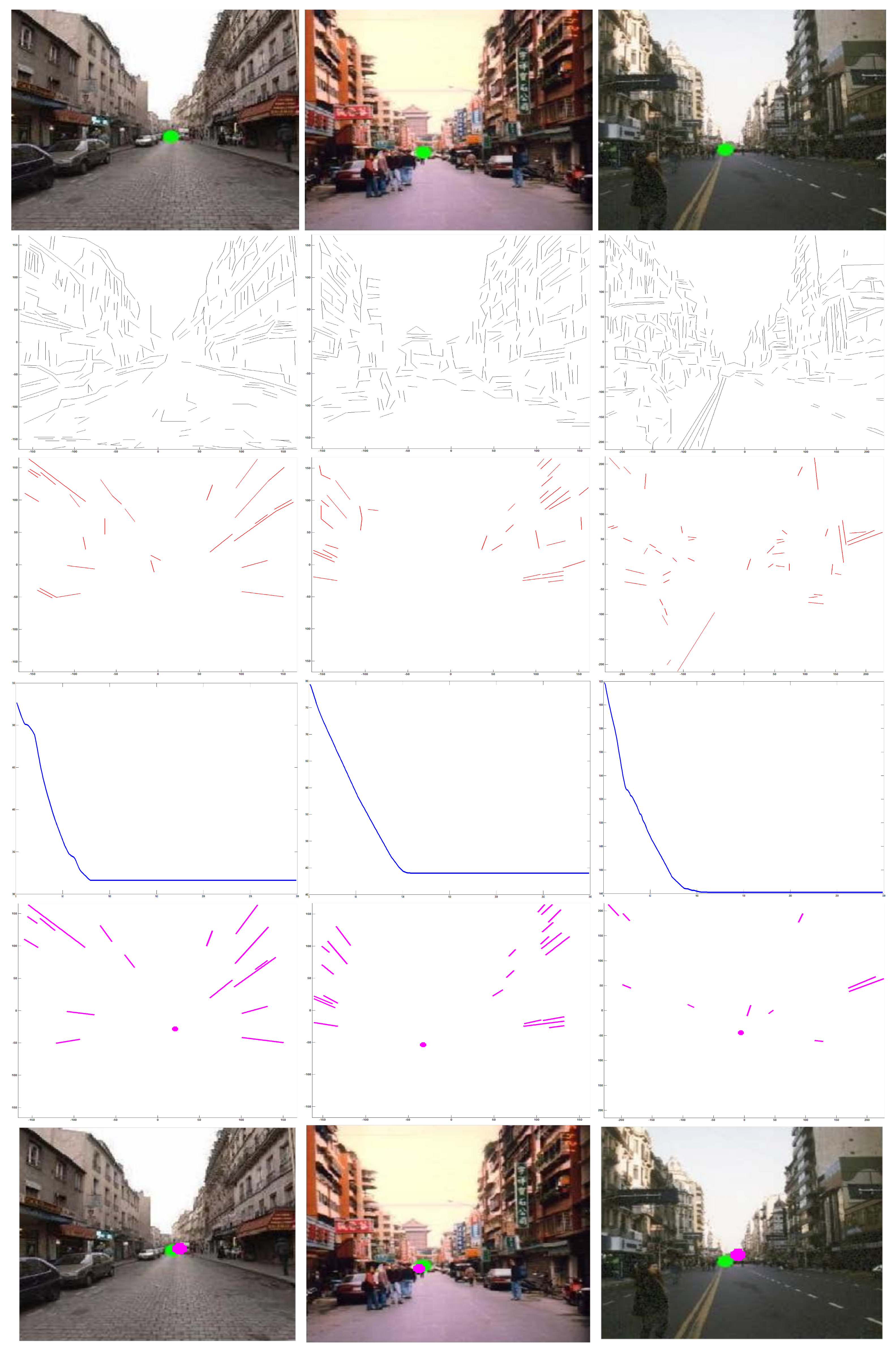
3. Vanishing Point Estimation
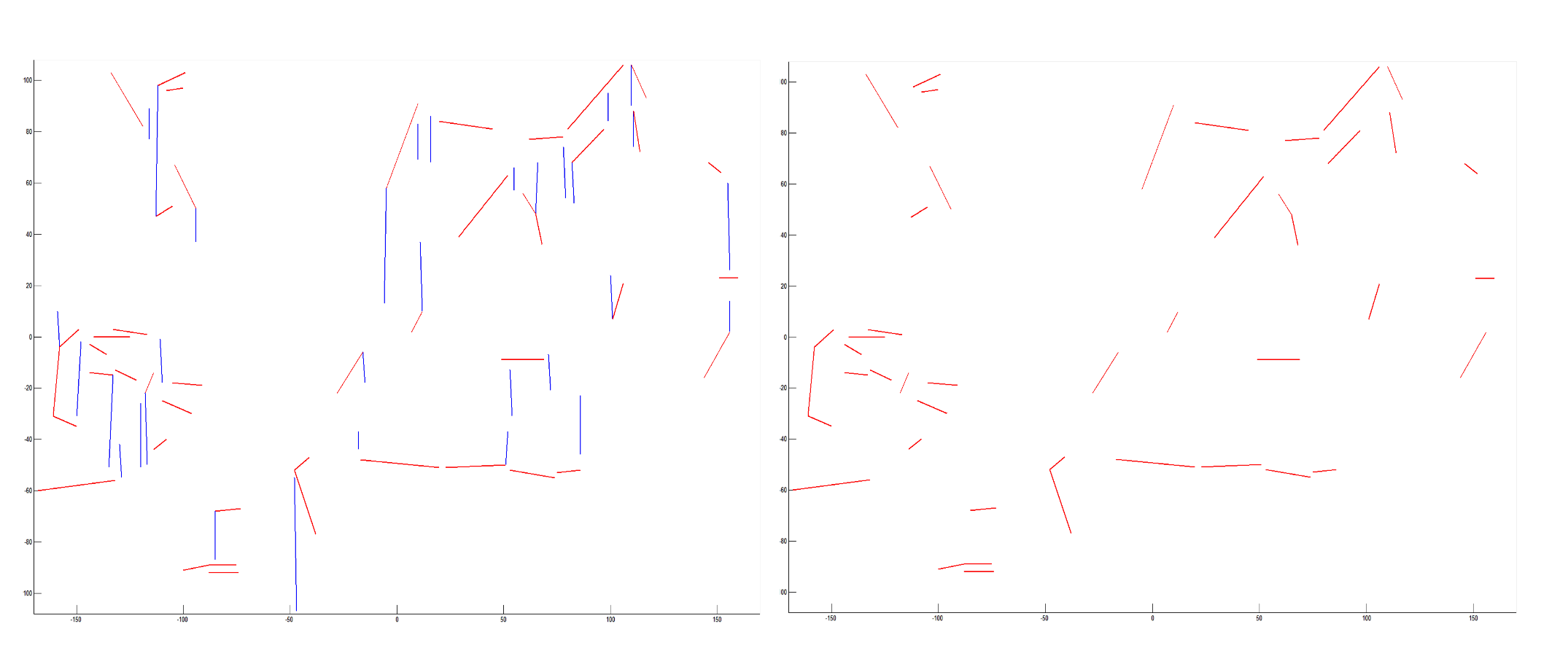
3.1. Preprocessing
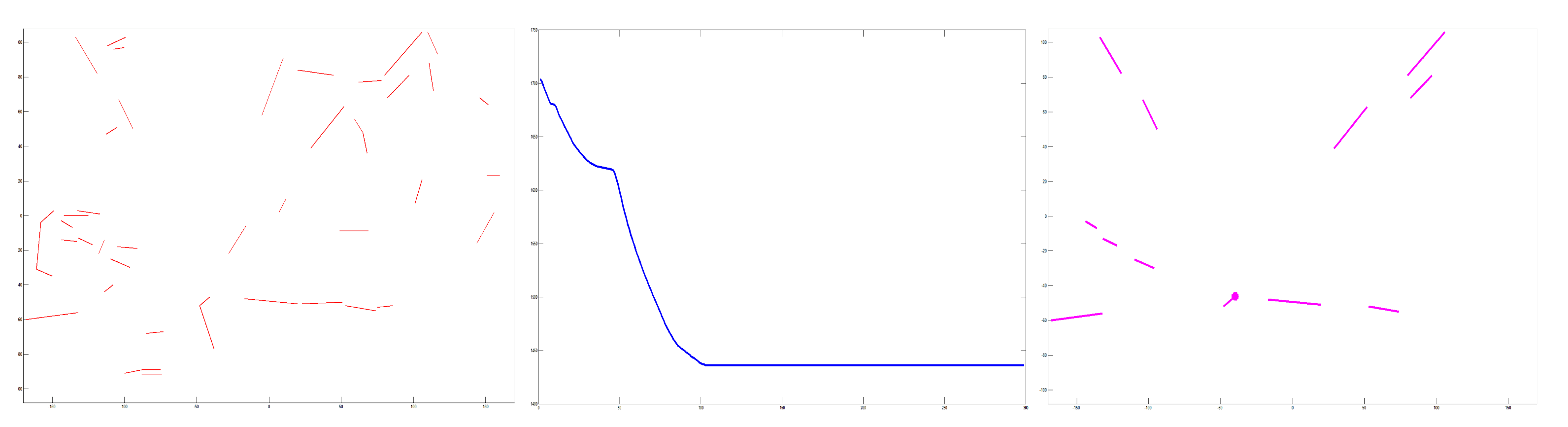
3.2. Refining Lines
| Algorithm 1 Extraction of |
Require: , a set of refined lines. , the number of extracted lines in . Ensure:. 1: for each do 2: do ; 3: for each do 4: do ; 5: do ; 6: do ; 7: ; 8: end for 9: end for 10: RANK ; 11: do from ; 12: return ; |
3.3. Optimal Estimation
| Algorithm 2 Optimization |
Require: H, swarm size D, dimension , the max generations Ensure: , optimal solution 1: for each particle do 2: for each dimension do 3: Initializing position 4: Initializing velocity 5: end for 6: end for 7: Initializing iteration 8: DO 9: for each particle do 10: Evaluating the fitness value though the function Equation (8) 11: if the fitness value is better than in history then 12: set current fitness value as 13: end if 14: end for 15: Choose the particle having the best fitness value as the 16: for each particle i do 17: for each dimension d do 18: Calculating velocity equation ; 19: Updating particle position 20: end for 21: end for 22: t=t+1 23: WHILE maximum iterations or minimum error criteria are not attained 24: return the particle having the best fitness value |
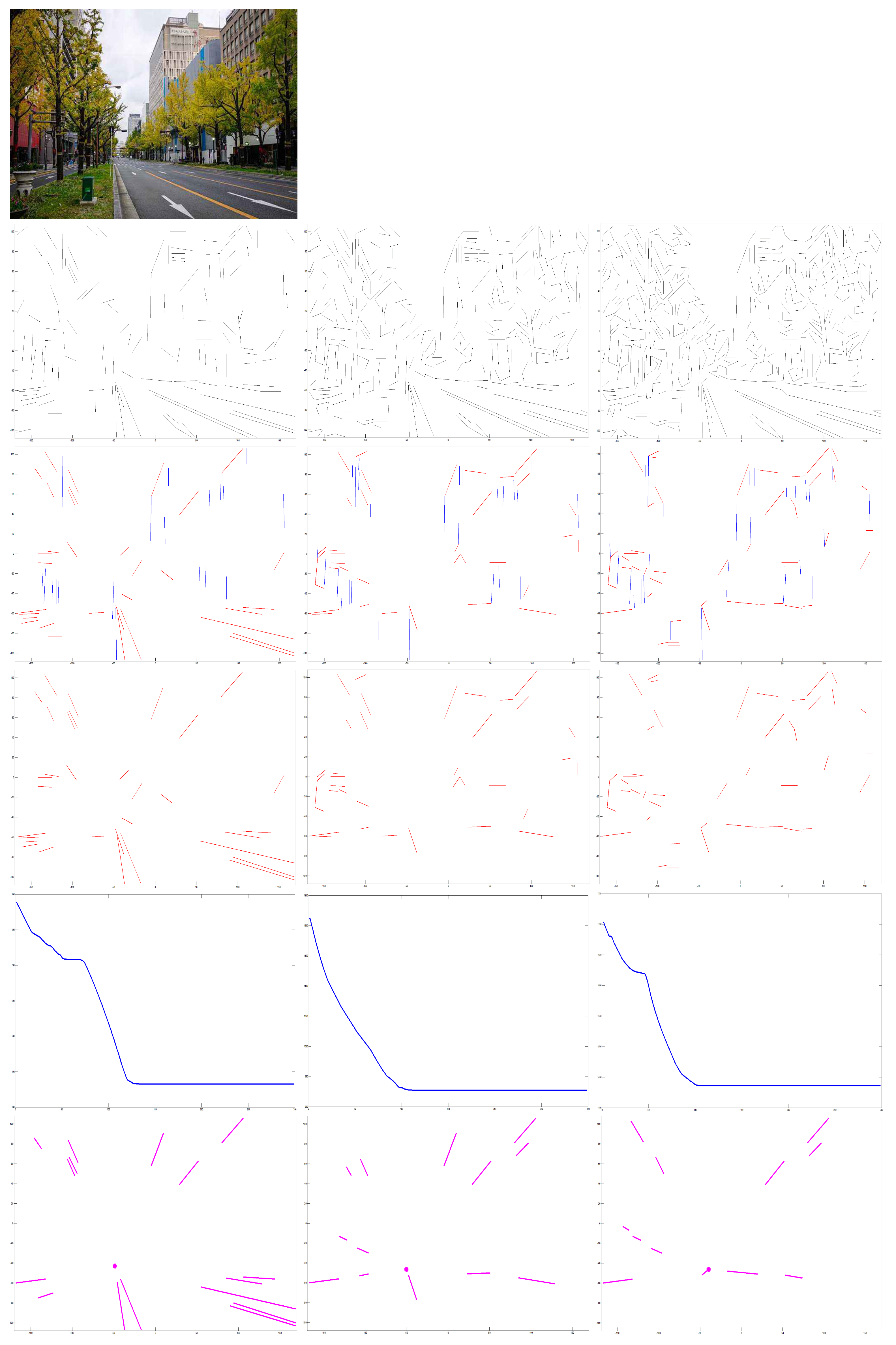
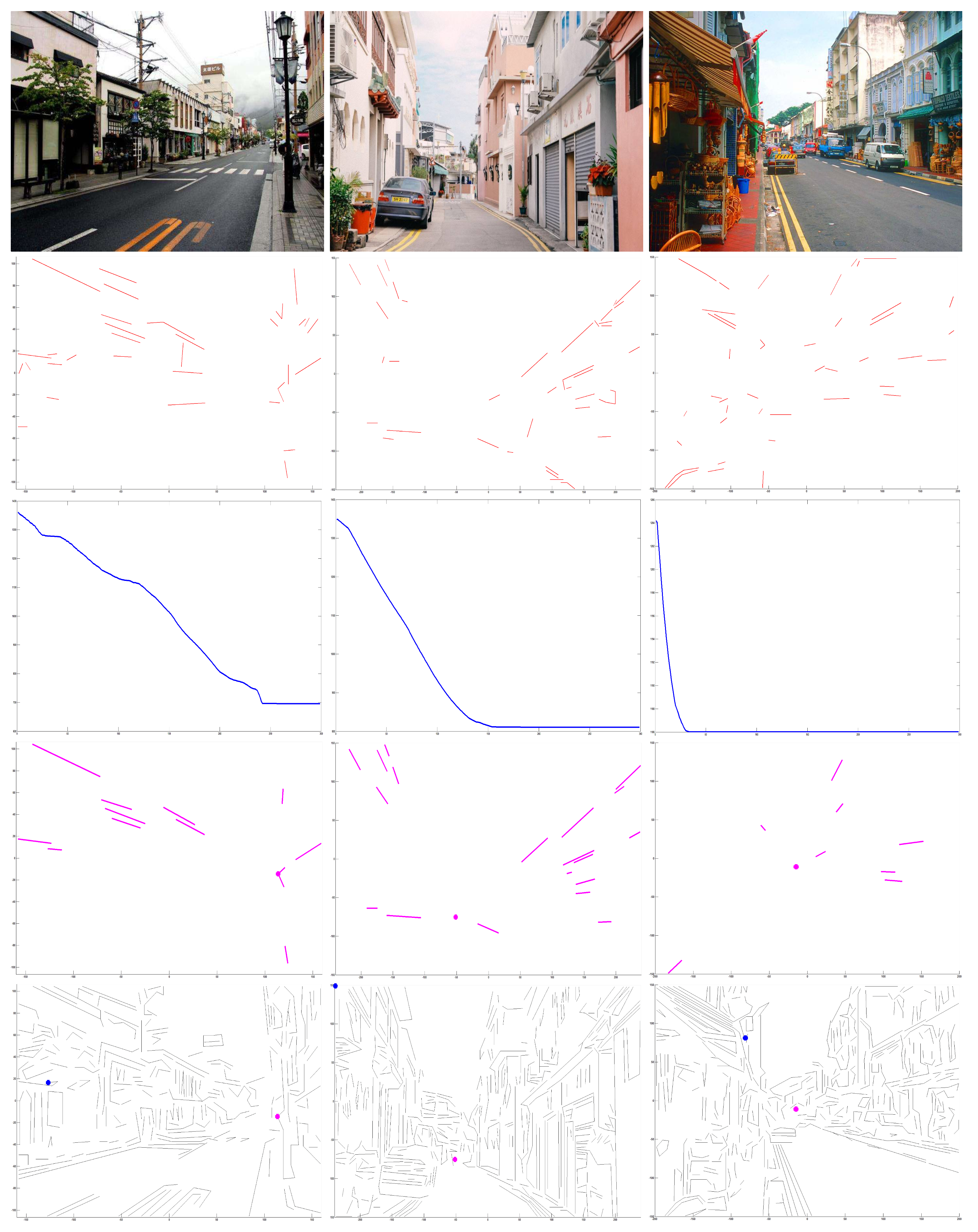
4. Experimental Results
4.1. Evaluation
4.2. Comparison
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Gibson, E.J.; Walk, R.D. The visual cliff. Sci. Am. 1960, 202, 64–71. [Google Scholar] [CrossRef] [PubMed]
- Koenderink, J.J.; Doorn, A.J.V.; Kappers, A.M. Pictorial surface attitude and local depth comparisons. Percept. Psychophys. 1996, 58, 163–173. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, H.W. Understanding of Indoor Scenes Based on Projection of Spatial Rectangles. Pattern Recognit. 2018, 81, 497–514. [Google Scholar]
- Wang, H.W.L. Visual Navigation Using Projection of Spatial Right-Angle In Indoor Environment. IEEE Trans. Image Process. (TIP) 2018, 27, 3164–3177. [Google Scholar]
- Wang, L.; Wei, H. Understanding of Curved Corridor Scenes Based on Projection of Spatial Right-Angles. IEEE Trans. Image Process. (TIP) 2020, 29, 9345–9359. [Google Scholar] [CrossRef] [PubMed]
- Masland, R. The fundamental plan of the retina. Nat. Neurosci. 2001, 4, 877–886. [Google Scholar] [CrossRef] [PubMed]
- Jonas, J.B.; Schneider, U.; Naumann, G.O. Count and density of human retinal photoreceptors. Graefe’s Arch. Clin. Exp. Ophthalmol. 1992, 230, 505–510. [Google Scholar] [CrossRef]
- Balasuriya, S.; Siebert, P. A biologically inspired computational vision frontend based on a self-organised pseudo-randomly tessellated artificial retina. In Proceedings of the IEEE Proceedings of the International Joint Conference on Neura Networks, Montreal, QC, Canada, 31 July–4 August 2005; pp. 3069–3074. [Google Scholar]
- Wei, H.; Li, J. Computational Model for Global Contour Precedence Based on Primary Visual Cortex Mechanisms. ACM Trans. Appl. Percept. (TAP) 2021, 18, 14:1–14:21. [Google Scholar] [CrossRef]
- Wang, H.W. A Visual Cortex-Inspired Imaging-Sensor Architecture and Its Application in Real-Time Processing. Sensors 2018, 18, 2116. [Google Scholar]
- Khaliluzzaman, M. Analytical justification of vanishing point problem in the case of stairways recognition. J. King Saud Univ.-Comput. Inf. Sci. 2021, 33, 161–182. [Google Scholar] [CrossRef]
- Jang, J.; Jo, Y.; Shin, M.; Paik, J. Camera Orientation Estimation Using Motion-Based Vanishing Point Detection for Advanced Driver-Assistance Systems. IEEE Trans. Intell. Transp. Syst. 2021, 22, 6286–6296. [Google Scholar] [CrossRef]
- Lopez-Martinez, A.; Cuevas, F.J. Vanishing point detection using the teaching learning-based optimisation algorithm. IET Image Process. 2020, 14, 2487–2494. [Google Scholar] [CrossRef]
- Yoon, G.J.; Yoon, S.M. Optimized Clustering Scheme-Based Robust Vanishing Point Detection. IEEE Trans. Intell. Transp. Syst. 2020, 21, 199–208. [Google Scholar]
- Simon, G.; Tabbone, S. Generic Document Image Dewarping by Probabilistic Discretization of Vanishing Points. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 2344–2351. [Google Scholar]
- Garcia-Faura, A.; Fernandez-Martinez, F.; Kleinlein, R.; San-Segundo, R.; de Maria, F.D. A multi-threshold approach and a realistic error measure for vanishing point detection in natural landscapes. Eng. Appl. Artif. Intell. 2019, 85, 713–726. [Google Scholar] [CrossRef]
- Moon, Y.Y.; Geem, Z.W.; Han, G.T. Vanishing point detection for self-driving car using harmony search algorithm. Swarm Evol. Comput. 2018, 41, 111–119. [Google Scholar] [CrossRef]
- Lee, J.; Yoon, K. Joint Estimation of Camera Orientation and Vanishing Points from an Image Sequence in a Non-Manhattan World. Int. J. Comput. Vis. 2019, 127, 1426–1442. [Google Scholar] [CrossRef]
- Liu, Y.B.; Zeng, M.; Meng, Q.H. Unstructured Road Vanishing Point Detection Using Convolutional Neural Networks and Heatmap Regression. IEEE Trans. Instrum. Meas. 2021, 70, 1–8. [Google Scholar] [CrossRef]
- Lee, D.; Gupta, A.; Hebert, M.; Kanade, T. Estimating Spatial Layout of Rooms using Volumetric Reasoning about Objects and Surfaces. In Proceedings of the 23rd International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 6–9 December 2010; pp. 1288–1296. [Google Scholar]
- Wang, L.; Wei, H. Indoor scene understanding based on manhattan and non-manhattan projection of spatial right-angles. J. Vis. Commun. Image Represent. 2021, 80, 103307. [Google Scholar] [CrossRef]
- Pero, L.D.; Bowdish, J.; Fried, D.; Kermgard, B.; Hartley, E.; Barnard, K. Bayesian geometric modeling of indoor scenes. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 2719–2726. [Google Scholar]
- Wang, L.; Wei, H. Understanding of wheelchair ramp scenes for disabled people with visual impairments. Eng. Appl. Artif. Intell. 2020, 90, 103569. [Google Scholar] [CrossRef]
- Choi, H.S.; An, K.; Kang, M. Regression with residual neural network for vanishing point detection. Image Vis. Comput. 2019, 91, 103797. [Google Scholar] [CrossRef]
- Wang, L.; Wei, H. Avoiding non-Manhattan obstacles based on projection of spatial corners in indoor environment. IEEE/CAA J. Autom. Sin. 2020, 7, 1190–1200. [Google Scholar] [CrossRef]
- Wang, L.; Wei, H. Reconstruction for Indoor Scenes Based on an Interpretable Inference. IEEE Trans. Artif. Intell. 2021, 2, 251–259. [Google Scholar] [CrossRef]
- Khaliluzzaman, M.; Deb, K. Stairways detection based on approach evaluation and vertical vanishing point. Int. J. Comput. Vis. Robot. 2018, 8, 168–189. [Google Scholar] [CrossRef]
- Han, J.; Yang, Z.; Hu, G.; Zhang, T.; Song, J. Accurate and Robust Vanishing Point Detection Method in Unstructured Road Scenes. J. Intell. Robot. Syst. 2019, 94, 143–158. [Google Scholar] [CrossRef]
- Wang, E.; Sun, A.; Li, Y.; Hou, X.; Zhu, Y. Fast vanishing point detection method based on road border region estimation. IET Image Process. 2018, 12, 361–373. [Google Scholar] [CrossRef]
- Tarrit, K.; Molleda, J.; Atkinson, G.A.; Smith, M.L.; Wright, G.C.; Gaal, P. Vanishing point detection for visual surveillance systems in railway platform environments. Comput. Ind. 2018, 98, 153–164. [Google Scholar] [CrossRef]
- Wang, L.; Wei, H. Curved Alleyway Understanding Based on Monocular Vision in Street Scenes. IEEE Trans. Intell. Transp. Syst. 2021, 1–20. [Google Scholar] [CrossRef]
- Nagy, T.K.; Costa, E.C.M. Development of a lane keeping steering control by using camera vanishing point strategy. Multidimens. Syst. Signal Process. 2021, 32, 845–861. [Google Scholar] [CrossRef]
- Wang, H.W.D. V4 shape features for contour representation and object detection. Neural Netw. 2017, 97, 46–61. [Google Scholar]
- Arbelaez, P.; Maire, M.; Fowlkes, C. From contours to regions: An empirical evaluation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Miami, FL, USA, 20–25 June 2009; pp. 2294–2301. [Google Scholar]
- Wei, H.; Wang, L.; Wang, S.; Jiang, Y.; Li, J. A Signal-Processing Neural Model Based on Biological Retina. Electronics 2020, 9, 35. [Google Scholar] [CrossRef] [Green Version]
- Kennedy, J.; Eberhart, R. Particle swarm optimization. In Proceedings of the IEEE International Conference on Neural Networks, Perth, WA, Australia, 27 November–1 December 1995; pp. 1942–1948. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shen, S.; Wang, S.; Wang, L.; Wei, H. A Refined-Line-Based Method to Estimate Vanishing Points for Vision-Based Autonomous Vehicles. Vehicles 2022, 4, 314-325. https://doi.org/10.3390/vehicles4020019
Shen S, Wang S, Wang L, Wei H. A Refined-Line-Based Method to Estimate Vanishing Points for Vision-Based Autonomous Vehicles. Vehicles. 2022; 4(2):314-325. https://doi.org/10.3390/vehicles4020019
Chicago/Turabian StyleShen, Shengyao, Shanshan Wang, Luping Wang, and Hui Wei. 2022. "A Refined-Line-Based Method to Estimate Vanishing Points for Vision-Based Autonomous Vehicles" Vehicles 4, no. 2: 314-325. https://doi.org/10.3390/vehicles4020019