
Autonomous Human-Vehicle Leader-Follower Control Using Deep-Learning-Driven Gesture Recognition


Abstract
:1. Introduction
1.1. Leader-Follower Background
1.2. Gesture Recognition Background
1.3. Previous and Novel Work
2. Gesture Recognition
2.1. Neural Network Fundamentals
Convolutional Neural Networks
2.2. Gestures
2.3. Neural Network Development
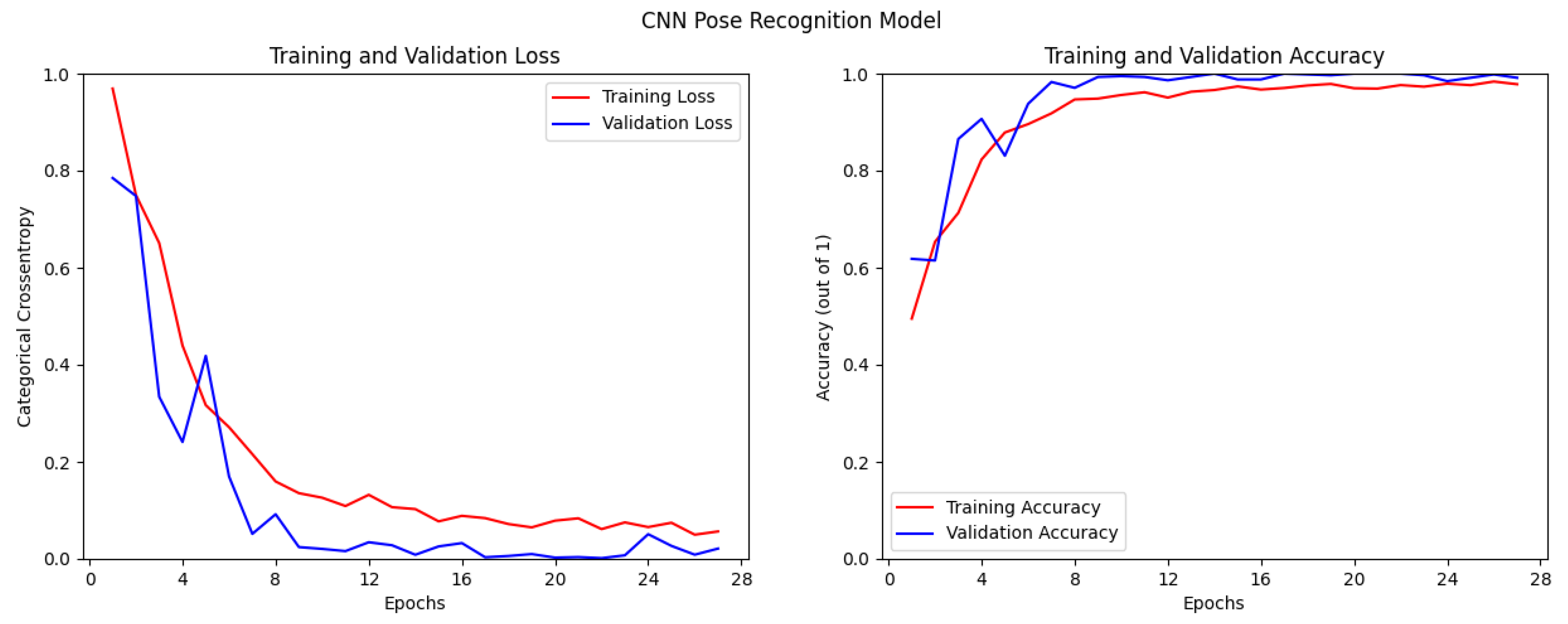
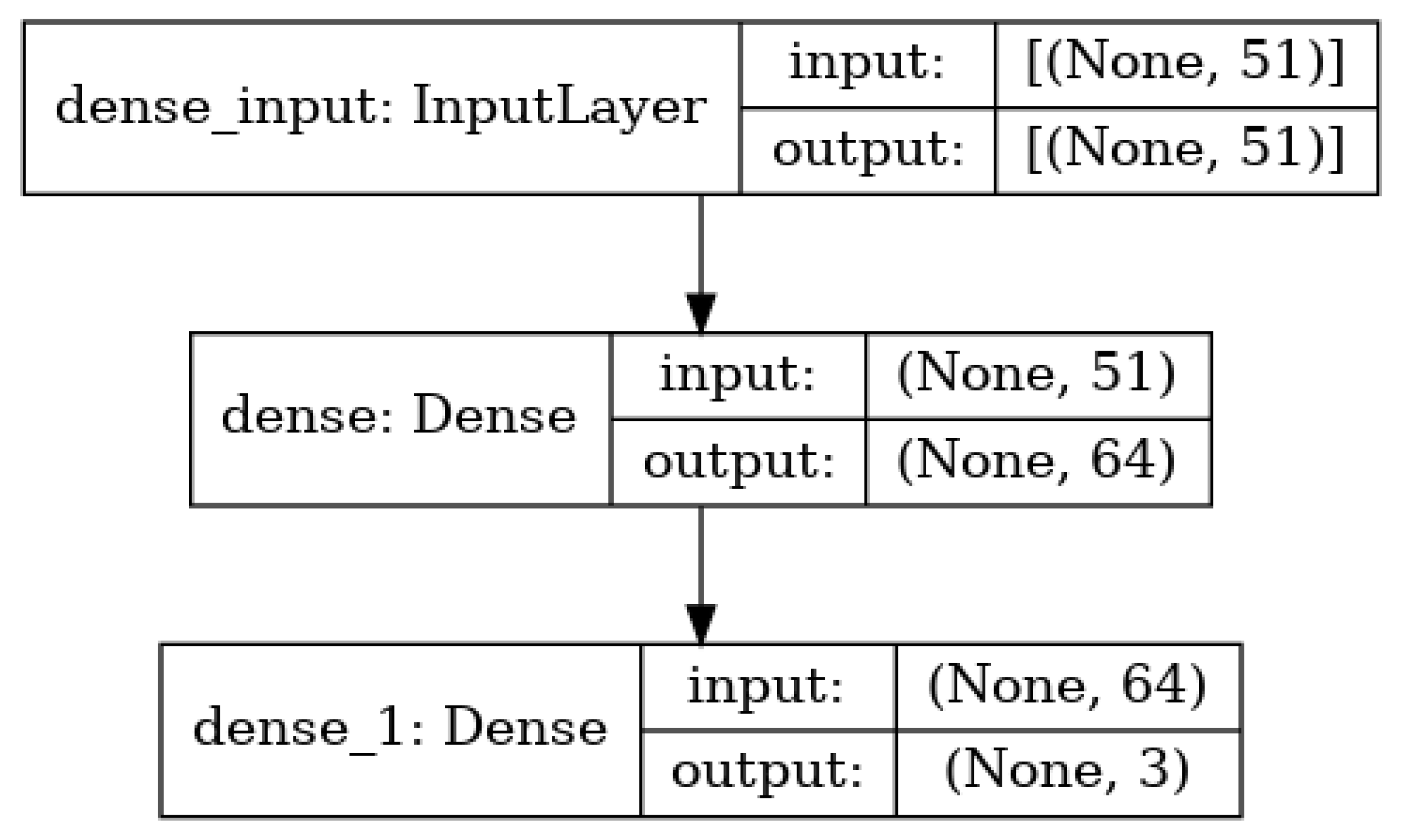
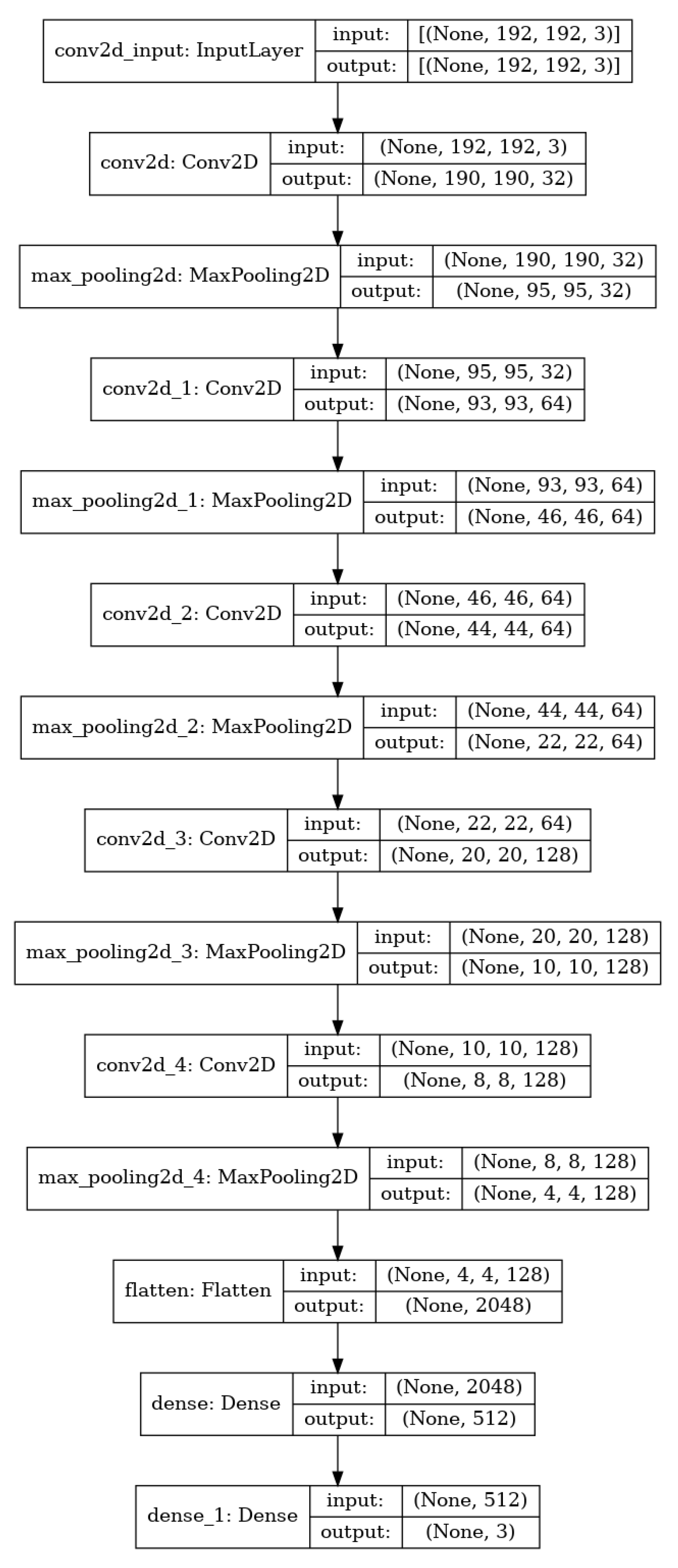
2.3.1. Building a Convolutional Neural Network
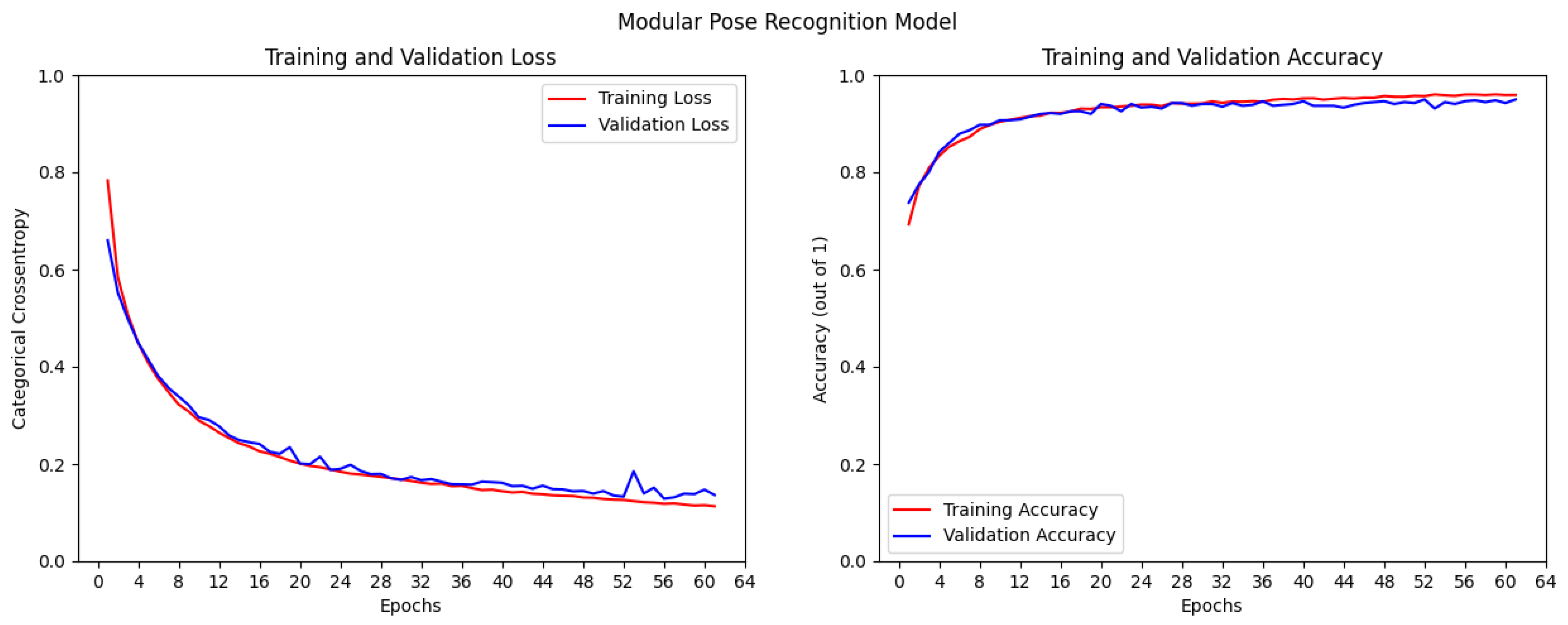
2.3.2. Modular Pipeline Design
3. Vehicle Implementation
3.1. ACTor 1 Overview
3.2. ROS Fundamentals
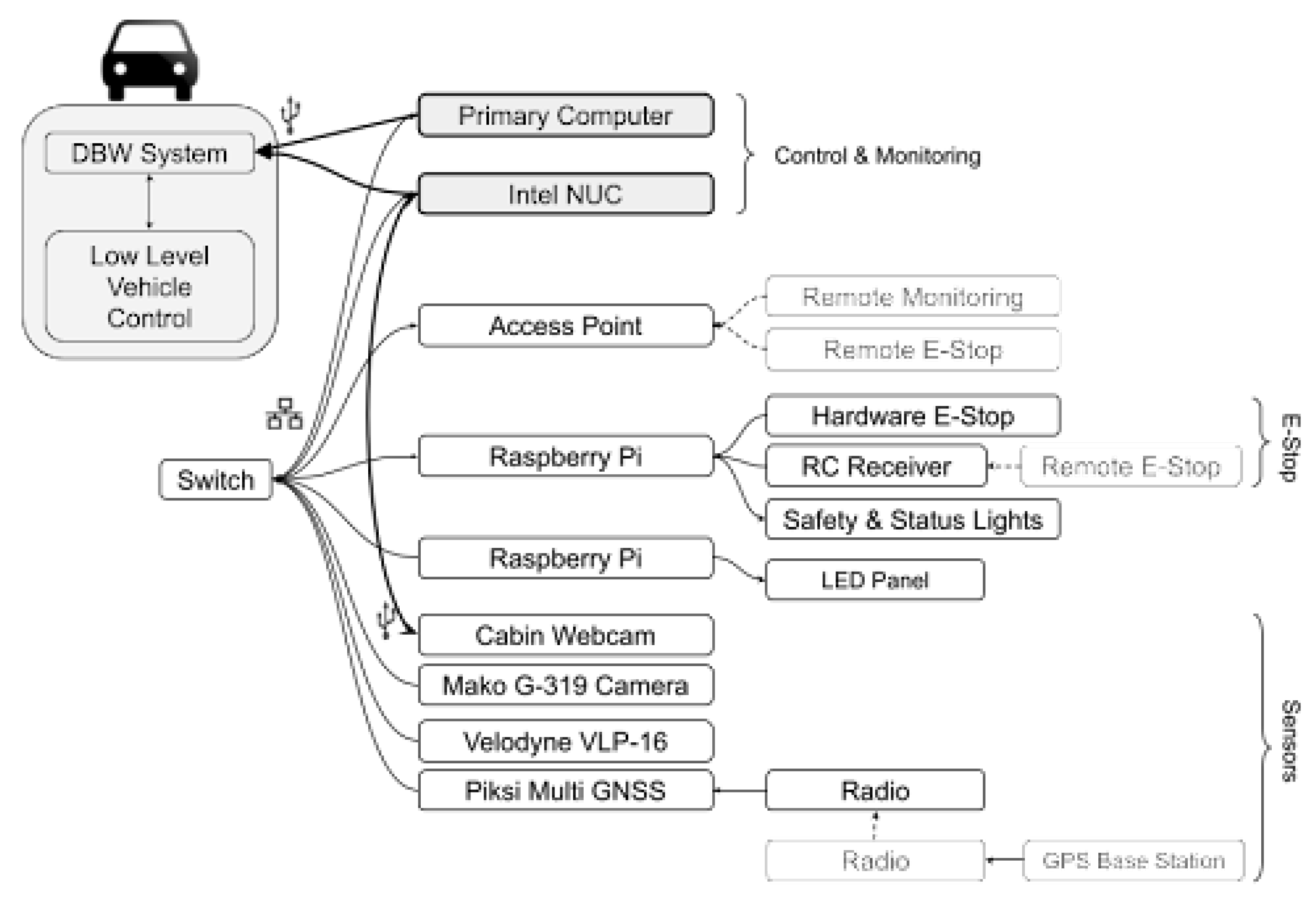
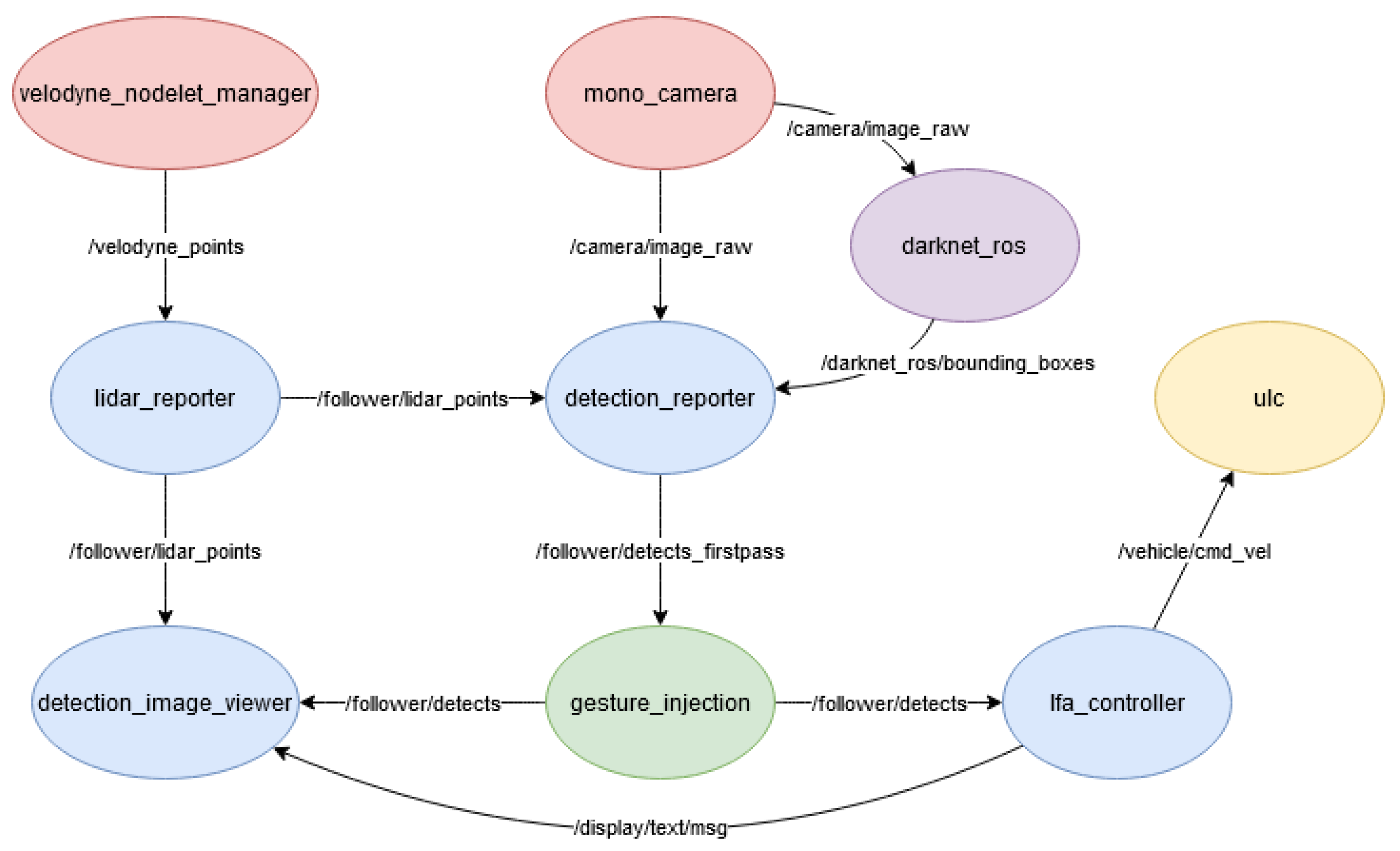
3.3. ROS Node Design
- Velodyne Nodelet Manager: This node provides an interface from our control unit to the LIDAR. It publishes the LIDAR sensor data for each point on the Velodyne Points topic;
- Mono Camera: This node provides an interface from our control unit to the camera. It publishes the camera frames on the Image Raw topic;
- LIDAR Reporter: This node receives raw input from the Velodyne Points topic, packages it into a convenient format, and publishes the reformatted data on the LIDAR Points topic;
- Detection Reporter: This node subscribes to the Bounding Boxes, LIDAR Points, and Image Raw topics and integrates their data to produce a coherent stream of information. It identifies the human detections reported by YOLO, superimposes their location in the image onto the 3D LIDAR point cloud to find their true location in three dimensions, identifies targets based on the given criteria, and attempts to keep track of the target from frame to frame. It publishes the consolidated information to the Detects Firstpass topic;
- Detection Image Viewer: This node subscribes to the LIDAR Points and Detects topics and to produce a visualization of the system’s state. For each detection in the image it draws the bounding box given by YOLO, draws the 17 pose points, and writes their distance from the vehicle’s LIDAR system, the gesture they are performing, and whether or not they are a pose target. It can also superimpose the LIDAR point cloud onto the image and report the current action being performed by the vehicle. This node is purely for monitoring and visualization;
- Gesture Injection: This node subscribes to the Detects Firstpass topic, implements our gesture recognition pipeline as described in Section 2.3.2 to identify each target’s gesture and the corresponding commands, then republishes the detection information with these new identifications to the Gesture Detects topic. This node serves as a convenient and effective way to splice in the gesture detection pipeline with minimal alterations to our existing code;
- LFA (Leader Follower Autonomy) Controller: This node subscribes to the Detects, Follower Start and Follower Stop topics and publishes to the Display Message, Display RGB, Enable Vehicle, and ULC command topics. This is the last node in our LFA pipeline, which takes the detection and gesture information generated by the prior nodes and determines the actual commands sent to the vehicle. Those commands are published on the Command Velocity topic;
- ULC (Universal Lat-Long Controller): This node provides an interface between our control unit and the drive-by-wire system. It takes the command from the Command Velocity topic and translates them into action by the vehicle.
4. Experiment and Results
5. Discussion
5.1. Summary
5.2. Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

References
- Consolini, L.; Morbidi, F.; Prattichizzo, D.; Tosques, M. Leader-follower formation control of nonholonomic mobile robots with input constraints. Automatica 2008, 44, 1343–1349. [Google Scholar] [CrossRef]
- Cheok, K.; Iyengar, K.; Oweis, S. Smooth Trajectory Planning for Autonomous Leader-Follower Robots. In Proceedings of the 34th International Conference on Computers and Their Applications, Honolulu, HA, USA, 18–20 March 2019; EPiC Series in, Computing. Lee, G., Jin, Y., Eds.; EasyChair: Manchester, UK, 2019; Volume 58, pp. 301–309. [Google Scholar] [CrossRef] [Green Version]
- Ramadan, A.; Hussein, A.; Shehata, O.; Garcia, F.; Tadjine, H.; Matthes, E. Dynamics Platooning Model and Protocols for Self-Driving Vehicles. In Proceedings of the 2019 IEEE Intelligent Vehicles Symposium, Paris, France, 9–12 June 2019; pp. 1974–1980. [Google Scholar] [CrossRef]
- Ng, T.C.; Guzman, J.; Adams, M. Autonomous vehicle-following systems: A virtual trailer link model. In Proceedings of the 2005 IEEE/RSJ International Conference on Intelligent Robots and Systems, Edmonton, AB, Canada, 2–6 August 2005; pp. 3057–3062. [Google Scholar] [CrossRef]
- Kehtarnavaz, N.; Griswold, N.; Lee, J. Visual control of an autonomous vehicle (BART)-the vehicle-following problem. IEEE Trans. Veh. Technol. 1991, 40, 654–662. [Google Scholar] [CrossRef]
- Simonsen, A.S.; Ruud, E.L.M. The Application of a Flexible Leader-Follower Control Algorithm to Different Mobile Autonomous Robots. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 24 October–24 January 2021; pp. 11561–11566. [Google Scholar] [CrossRef]
- Lakshmanan, S.; Yan, Y.; Baek, S.; Alghodhaifi, H. Modeling and simulation of leader-follower autonomous vehicles: Environment effects. In Unmanned Systems Technology XXI; Shoemaker, C.M., Nguyen, H.G., Muench, P.L., Eds.; International Society for Optics and Photonics, SPIE: Bellingham, WA, USA, 2019; Volume 11021, pp. 116–123. [Google Scholar]
- Solot, A.; Ferlini, A. Leader-Follower Formations on Real Terrestrial Robots. In Proceedings of the ACM SIGCOMM 2019 Workshop on Mobile AirGround Edge Computing, Systems, Networks, and Applications, Beijing, China, 19 August 2019; Association for Computing Machinery: New York, NY, USA, 2019. MAGESys’19. pp. 15–21. [Google Scholar] [CrossRef]
- Kehtarnavaz, N.; Groswold, N.; Miller, K.; Lascoe, P. A transportable neural-network approach to autonomous vehicle following. IEEE Trans. Veh. Technol. 1998, 47, 694–702. [Google Scholar] [CrossRef]
- Tang, Q.; Cheng, Y.; Hu, X.; Chen, C.; Song, Y.; Qin, R. Evaluation Methodology of Leader-Follower Autonomous Vehicle System for Work Zone Maintenance. Transp. Res. Rec. 2021, 2675, 107–119. [Google Scholar] [CrossRef]
- Setiawan, S.; Yamaguchi, J.; Hyon, S.H.; Takanishi, A. Physical interaction between human and a bipedal humanoid robot-realization of human-follow walking. In Proceedings of the 1999 IEEE International Conference on Robotics and Automation (Cat. No.99CH36288C), Detroit, MI, USA, 10–15 May 1999; Volume 1, pp. 361–367. [Google Scholar] [CrossRef] [Green Version]
- Morioka, K.; Lee, J.H.; Hashimoto, H. Human-following mobile robot in a distributed intelligent sensor network. IEEE Trans. Ind. Electron. 2004, 51, 229–237. [Google Scholar] [CrossRef]
- More Info about Travelmate. 2021. Available online: https://travelmaterobotics.com/more-info-about-travelmate/ (accessed on 26 September 2021).
- Murakami, K.; Taguchi, H. Gesture recognition using recurrent neural networks. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, New Orleans, LA, USA, 27 April–2 May 1991; pp. 237–242. [Google Scholar]
- Fang, W.; Ding, Y.; Zhang, F.; Sheng, J. Gesture recognition based on CNN and DCGAN for calculation and text output. IEEE Access 2019, 7, 28230–28237. [Google Scholar] [CrossRef]
- Hu, Y.; Wong, Y.; Wei, W.; Du, Y.; Kankanhalli, M.; Geng, W. A novel attention-based hybrid CNN-RNN architecture for sEMG-based gesture recognition. PLoS ONE 2018, 13, e0206049. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jiang, D.; Li, G.; Sun, Y.; Kong, J.; Tao, B. Gesture recognition based on skeletonization algorithm and CNN with ASL database. Multimed. Tools Appl. 2019, 78, 29953–29970. [Google Scholar] [CrossRef]
- Wu, X.Y. A hand gesture recognition algorithm based on DC-CNN. Multimed. Tools Appl. 2020, 79, 9193–9205. [Google Scholar] [CrossRef]
- Schulte, J.; Dombecki, J.; Pleune, M.; DeRose, G.; Paul, N.; Chung, C. Developing Leader Follower Autonomy for Self-driving Vehicles Using Computer Vision and Deep Learning. Lawrence Technological University Eighth Annual Research Day, Poster Presentation 2021. Available online: http://qbx6.ltu.edu/chung/papers/LeaderFollower.pdf (accessed on 28 February 2022).
- Paul, N.; Pleune, M.; Chung, C.; Warrick, B.; Bleicher, S.; Faulkner, C. ACTor: A Practical, Modular, and Adaptable Autonomous Vehicle Research Platform. In Proceedings of the 2018 IEEE International Conference on Electro/Information Technology (EIT), Rochester, MI, USA, 3–5 May 2018; pp. 0411–0414. [Google Scholar] [CrossRef]
- DeRose, G.; Brefeld, T.; Dombecki, J.; Pleune, M.; Schulte, J.; Paul, N.; Chung, C. ACTor: IGVC Self-Drive Design Report. 2021. Available online: https://robofest.net/igvc/IGVC2021DesignReport_LTU.pdf (accessed on 28 February 2022).
- Stanford Artificial Intelligence Laboratory. Robotic Operating System. 2018. Available online: https://www.ros.org (accessed on 28 February 2022).
- OpenCV: Detection of ArUco Markers. 2021. Available online: https://docs.opencv.org/master/d5/dae/tutorial_aruco_detection.html (accessed on 28 February 2022).
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Peltarion. Categorical Crossentropy. Available online: https://peltarion.com/knowledge-center/documentation/modeling-view/build-an-ai-model/loss-functions/categorical-crossentropy (accessed on 21 December 2021).
- Chollet, F. Deep Learning with Python, 1st ed.; Apress: Berkeley, CA, USA, 2017; Manning. [Google Scholar]
- Dongare, A.; Kharde, R.; Kachare, A.D. Introduction to artificial neural network. Int. J. Eng. Innov. Technol. (IJEIT) 2012, 2, 189–194. [Google Scholar]
- Keras. 2015. Available online: https://keras.io (accessed on 28 February 2022).
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems. 2015. Software. Available online: tensorflow.org (accessed on 28 February 2022).
- Caliskan, A.; Bryson, J.; Narayanan, A. Semantics derived automatically from language corpora contain human-like biases. Science 2017, 356, 183–186. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Alphabet Inc. movenet/singlepose/lightning. 2021. Available online: https://tfhub.dev/google/movenet/singlepose/lightning/4 (accessed on 28 February 2022).
- O’Kane, J.M. A Gentle Introduction to ROS; CreateSpace Independent Publishing Platform: Scotts Valley, CA, USA, 2014; Available online: http://www.cse.sc.edu/~jokane/agitr/ (accessed on 28 February 2022).
- Redmon, J. Darknet: Open Source Neural Networks in C. 2013–2016. Available online: http://pjreddie.com/darknet/ (accessed on 28 February 2022).














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Gesture | Command |
|---|---|
| Hand on Heart | Begin Following |
| Palm out to the Side | Stop Following |
| Neither | No Change |
| Model | Test Loss | Test Accuracy |
|---|---|---|
| CNN | 5.2013 | 0.2684 |
| Modular | 0.4010 | 0.8500 |
| Trial | Start | Followed User | Stop | Others Around | Success |
|---|---|---|---|---|---|
| 1 | Y | Y | Y | N | Y |
| 2 | Y | Y | Y | N | Y |
| 3 | Y | Y | Y | N | Y |
| 4 | Y | Y | Y | 1 Person Behind User | Y |
| 5 | Y | Y | Y | 1 Person Behind User | Y |
| 6 | Y | Y | Y | N | Y |
| 7 | Y | Y | Y | Others in vicinity | Y |
| 8 | Y | Y | Y | 1 Person Behind User | Y |
| 9 | Y | Y | Y | 1 Person Behind User | Y |
| 10 | Y | Y | Y | N | Y |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Schulte, J.; Kocherovsky, M.; Paul, N.; Pleune, M.; Chung, C.-J. Autonomous Human-Vehicle Leader-Follower Control Using Deep-Learning-Driven Gesture Recognition. Vehicles 2022, 4, 243-258. https://doi.org/10.3390/vehicles4010016
Schulte J, Kocherovsky M, Paul N, Pleune M, Chung C-J. Autonomous Human-Vehicle Leader-Follower Control Using Deep-Learning-Driven Gesture Recognition. Vehicles. 2022; 4(1):243-258. https://doi.org/10.3390/vehicles4010016
Chicago/Turabian StyleSchulte, Joseph, Mark Kocherovsky, Nicholas Paul, Mitchell Pleune, and Chan-Jin Chung. 2022. "Autonomous Human-Vehicle Leader-Follower Control Using Deep-Learning-Driven Gesture Recognition" Vehicles 4, no. 1: 243-258. https://doi.org/10.3390/vehicles4010016