


TinyML Olive Fruit Variety Classification by Means of Convolutional Neural Networks on IoT Edge Devices

Abstract
:1. Introduction
2. Related Works
- Pioneering adoption of AI in Industry 4.0 and 5.0: We emphasize the adoption of ML for smart agriculture jointly with the development of industrial applications toward Industry 4.0 and Industry 5.0. We highlight the potential of AI in this domain by emphasizing the imperative need for low-cost, ML-enabled edge devices to universalize the benefits of smart agriculture across multiple farming scales.
- Dataset collection for Jordanian olive varieties: One of the major contributions of this paper is to collect and build a dataset for diverse olive fruits. We focus on the Jordanian varieties from northern Jordan as a special case of the Mediterranean region. The study also presents a framework for building the dataset, starting from capturing images, segmenting individual objects, and then moving toward data augmentation for the elimination of latent biases. This involved the collection of images for three distinct categories of olives, resulting in a dataset enriched with more than 16,500 individual fruits labeled across categories for good and bad qualities, for the sake of variety and quality classifications.
- CNN architecture implementation: The core framework of this paper presents the adoption of a sophisticated CNN model architecture that can solve the classification problem with minimal hardware resources via optimization for TinyML for edge devices.
- TinyML evaluation for edge deployment: To ensure that the adopted CNN model is suitable and feasible to run on ultra-low-cost edge devices, we present a practical implementation with inference results on the ESP32-S3 micro-controller unit (MCU). The results show the pipeline of how to tune the model hyperparameters while keeping a sensible accuracy with minimal performance degradation and memory footprints even after model compression and quantization.
- Assessing challenges and practical limitations: The final contribution of this paper is to provide technical and practical insights for deploying TinyML on edge devices for general-purpose classification or regression problems. We discussed the inference rate, image size effect, and memory footprints and how to deal with the trade-offs of these parameters.
3. Materials and Methods
3.1. Data Acquisition
3.2. Fruit Detection and Segmentation
- Original image: The image is loaded in its original form as shown in Figure 1a.
- Grayscale conversion: The RGB image is converted to grayscale to simplify further processing. This process can be represented mathematically as:where and are the red, green, and blue channels of the image, respectively. The result of this process is shown in Figure 1b.
- Binarization: The grayscale image is binarized using Otsu’s method, which determines an optimal threshold by minimizing the intra-class variance. Let T be the threshold, then the binarized image can be given as:The result of this process is shown in Figure 1c–f.
- Morphological processing: The binary image undergoes morphological operations to remove small artifacts. In our proposed methodology, we harness the principles of connected-component labeling to segment distinct entities within a 2D binary image. Adopting an 8-connectivity criterion ensures a comprehensive evaluation of objects, even if their neighboring pixels are diagonally juxtaposed. Post segmentation, morphological attributes, such as the area and the eccentricity of each object were meticulously calculated. Eccentricity, which is symbolic of an object’s deviation from a perfect circular form, was employed as the pivotal metric for subsequent morphological filtering. Once the filtering phase was complete, the refined binary representation, encapsulating only those entities that conformed to our eccentricity criteria, was visualized and cataloged for subsequent processing and analysis. The result of this process is shown in Figure 1d.
- Watershed process: This process aims at segmenting objects that are close to each other. By applying the watershed algorithm, boundaries of neighboring objects can be identified, especially when they touch or overlap. This ensures that each object, in this case, each olive fruit, is distinctly segmented from the rest. The outcome of this step facilitates the successive processes and increases the accuracy of object classification. The result of this process is shown in Figure 1e.
- Boundary smoothing: This stage focuses on preserving the actual shape of the detected objects. Using methods like Gaussian smoothing, the jagged edges or noise present in the object boundaries are smoothed out. This results in masks that more accurately represent the original shape of the object, thus leading to improved results in further analyses. The result of this process is shown in Figure 1e.
- Distance transform, voids filling, and boundary object removal: In the subsequent stage of our image analysis, a Euclidean distance transform was applied to the complement of the binary image. This operation transformed the segmented regions into a scalar representation of their distance from the closest non-object boundary. To further refine this transformation, small artifacts, potentially resulting from noise or minor discrepancies in the initial segmentation, were removed through an area-based opening operation with a predefined threshold. Ensuring this refinement, any existing internal voids within the segmented objects were addressed using a hole-filling technique, ensuring the coherence and solidity of each segmented region. By this transformation, we ensure robust clarity and precision for the fruit boundaries within the processed image. The result of this process and the numbering of the detected olives is shown in Figure 1f.
3.2.1. Dataset Augmentation
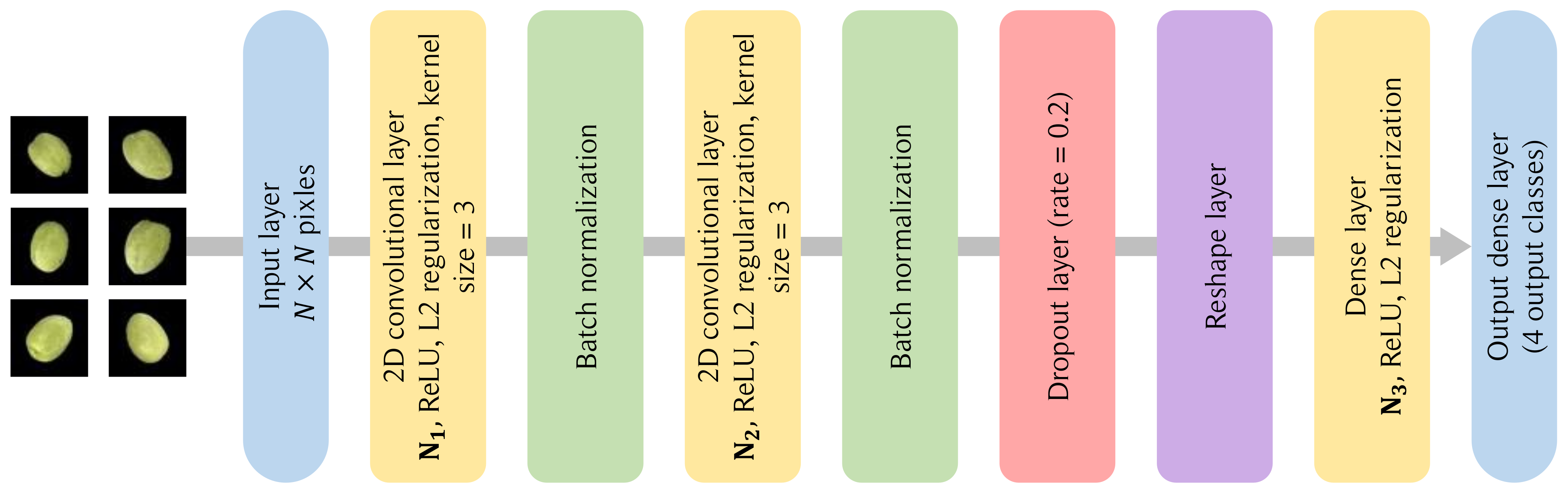
3.2.2. CNN Model Architecture
- Input layer: The model initiates with an input layer, denoted by the input_shape, which corresponds to the dimensions of our processed images.
- Conventional layer: The architecture incorporates two convolutional layers, each succeeded by a max-pooling layer. These convolutional layers employ filters of size , which are adept at detecting localized features in the image. The ReLU activation function introduces non-linearity, enabling the model to learn complex patterns. Regularization is achieved through regularization to prevent overfitting.
- Pooling layer: Subsequent to each convolutional layer, max-pooling layers of size are employed. These layers effectively down-sample the spatial dimensions while retaining the most salient features, thus enhancing computational efficiency and reducing the risk of overfitting.
- Dropout layer: After each pooling layer, dropout is applied with a rate specified by dropout_rate. Dropout is a regularization technique that randomly sets a fraction of input units to 0 at each update during training, which aids in preventing overfitting.
- Flatten layer: Post convolution and pooling, the matrix is flattened into a vector to prepare it for the fully connected layers.
- Dense layer: The flattened output is then passed through a dense layer, also known as a fully connected layer, with ReLU activation. Another regularization is applied here. The final dense layer uses a softmax activation to output the probability distribution over the classes, facilitating classification.
3.3. Performance Analysis
3.4. CNN with TinyML for Edge Devices
3.5. Validation and Continuous Learning
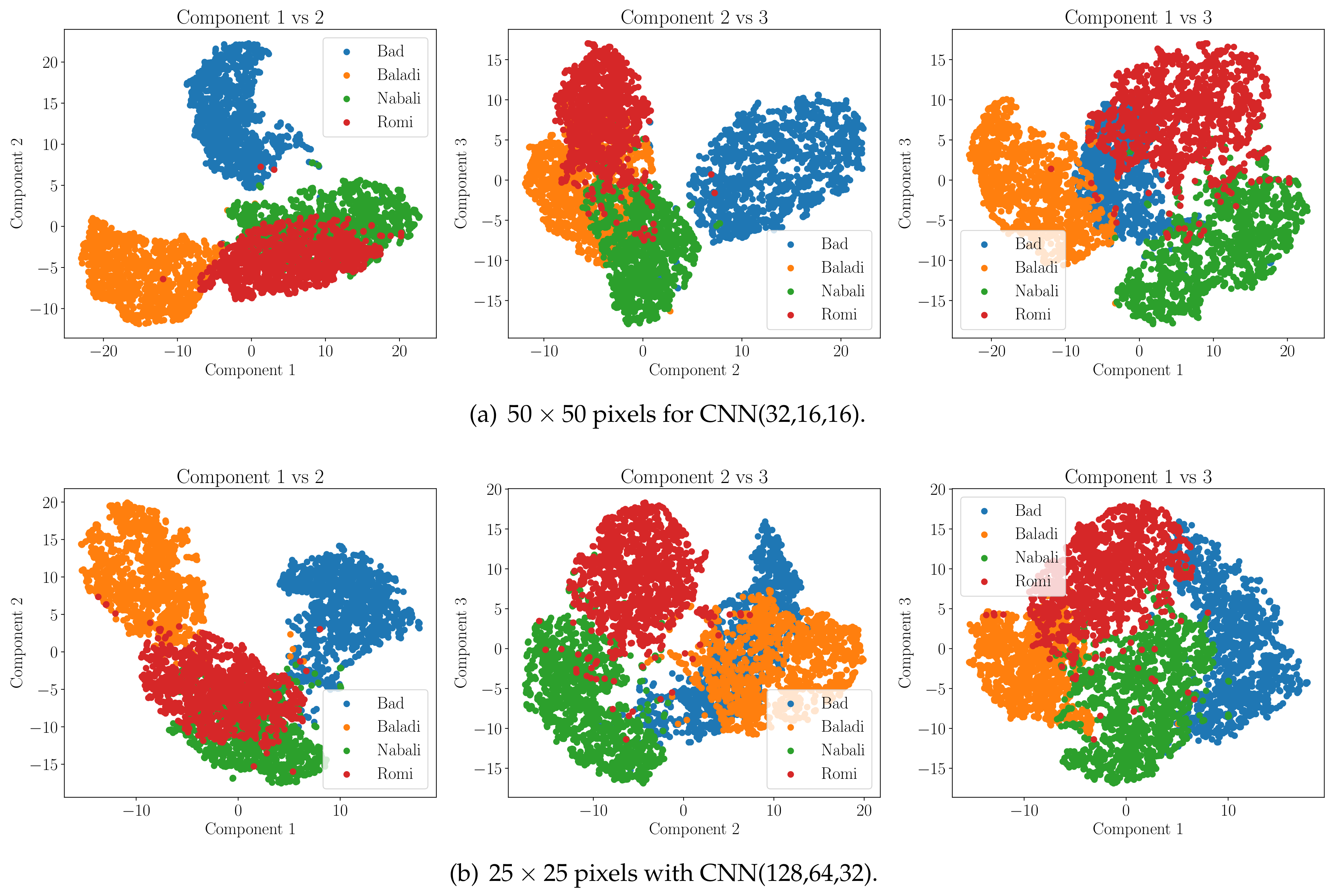
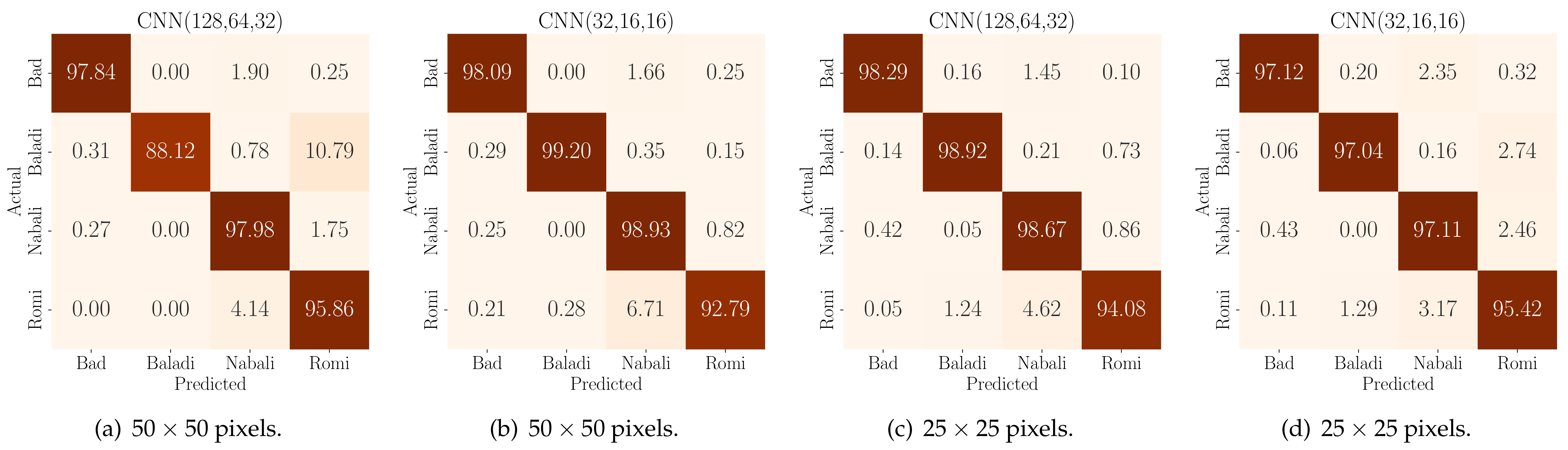
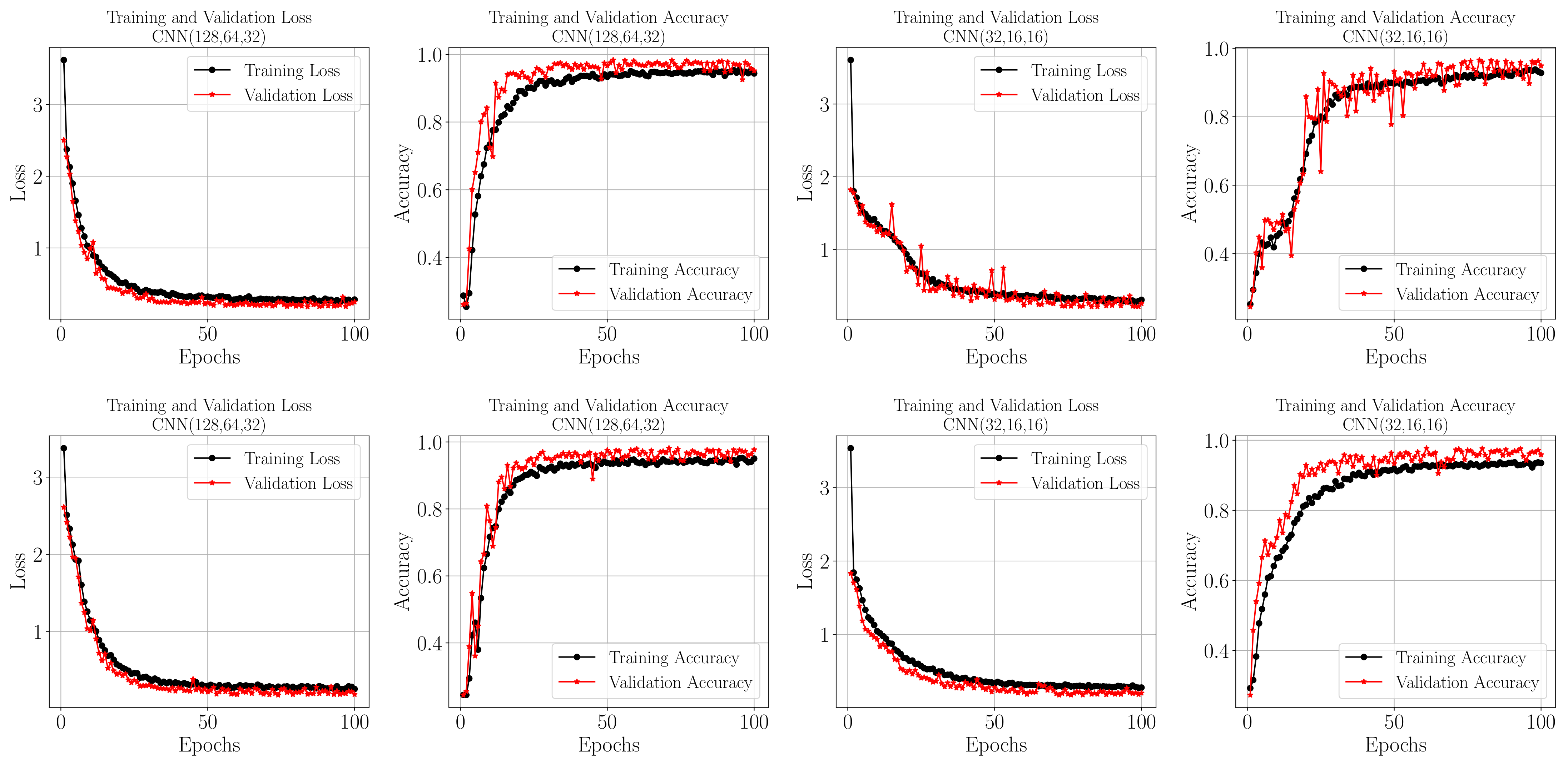
4. Results
5. Discussions
5.1. Comparative Performance Analysis with Previous Studies
5.2. Practical Implications for Edge Real-World Implementation
- Model selection for deployment: Opting for an architecture is a game of balance. For instance, while the CNN(128,64,32) for the image size showcases superior traditional test results, its large model size (332.3 kilobytes) and arena requirement (368.6 kilobytes) combined with a ‘Stack overflow’ issue make it unsuitable for deployment on the ESP32-S3. Instead, architectures like CNN(32,16,16) for both and image sizes, with their smaller footprint and no stack overflow issues, seem a more practical choice for edge deployment. These results emphasize the need to optimize the model hyperparameters and architectures to adapt to the available resources. Hence, based on the available edge resources, we need to optimize the input image resolution, the CNN model architecture, and the available memory of the edge device to ensure seamless integration while achieving the required olive fruit variety classification accuracy.
- Optimization techniques in TensorFlow Lite: TensorFlow Lite provides several optimization methods such as full integer quantization, which could further reduce the model size. For instance, the fact that ‘Model and input unsigned integers of 8 bits (uint8) quantization’ was employed and yielded good results implies that even higher quantization might be explored, leveraging TensorFlow Lite’s capabilities to achieve smaller models without significantly compromising accuracy. It is important to note that, given the nature of the RGB images of olives and their grayscale conversion, representing pixel intensity with numbers in the 0–255 range makes quantization using uint8 suitable for input to the CNN model without significantly degrading accuracy. However, quantizing the model’s weights contributes most prominently to the difference from representations using 32-bit floating points. Consequently, while the model’s memory footprint is reduced, the impact on accuracy is minimal.
- Memory management: The ‘Min Arena size’, which refers to the allocated memory for the tensors in the CNN model to run on the memory of the edge MCU (i.e., for this paper ESP32-S3), is a direct indication of the dynamic memory TensorFlow Lite needs to run the inference. Keeping the arena size minimal, as in the case of CNN(32,16,16) for a image size (22.33 kilobytes), ensures that the model runs efficiently without running out of memory, especially critical for devices with strict memory constraints.
- Real-time decision-making: The inference rate is paramount for real-time applications. As evident, simpler architectures with smaller image sizes, like CNN(32,16,16) for , can achieve rates as high as 55.56 Hz. This rapid processing allows for real-time decisions in an industrial setup, where olive fruits can be sorted or classified at high speeds. High real-time inference rates are typically sought after, but they become particularly beneficial in the classification of olive fruit quality as “good” or “bad”. To accurately assess the quality of an olive fruit, multiple views of the fruit are needed to ensure that defects are not concealed on its unseen sides. This demands rapid classification speeds. On the other hand, when classifying the variety of the olive, capturing just one side of the fruit is sufficient, as the primary determinant is its shape.
- Model simplification: To further reduce the model footprint on the ultra-low-cost MCUs, more model compression and size reduction techniques such as model pruning can be employed. Model pruning allows the model to skip some of the model weights that are relatively close to zero and thus remove the connection between the CNN nodes. This allows for less computational time and hence improves the real-time efficiency of the system. This could be useful, especially for architectures that currently experience stack overflow issues on the edge MCUs due to the inability to allocate the memory for the model tensors.
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Expert Market Research. Global Olive Market Size, Share, Growth, Forecast. Available online: https://www.expertmarketresearch.com/reports/olive-market (accessed on 24 September 2023).
- International Olive Council. The World of Olive Oil. Available online: https://www.internationaloliveoil.org/the-world-of-olive-oil/ (accessed on 24 September 2023).
- Al Hiary, M.; Dhehibi, B.; Kassam, S. Market study and marketing strategy for olive and olive oil sector in the southern arid part of Jordan. J. Agric. Sci. Technol. 2019, 21, 1065–1077. [Google Scholar]
- Dong, L. Toward resilient agriculture value chains: Challenges and opportunities. Prod. Oper. Manag. 2021, 30, 666–675. [Google Scholar] [CrossRef]
- Xu, X.; Lu, Y.; Vogel-Heuser, B.; Wang, L. Industry 4.0 and Industry 5.0—Inception, conception and perception. J. Manuf. Syst. 2021, 61, 530–535. [Google Scholar] [CrossRef]
- Leng, J.; Sha, W.; Wang, B.; Zheng, P.; Zhuang, C.; Liu, Q.; Wuest, T.; Mourtzis, D.; Wang, L. Industry 5.0: Prospect and retrospect. J. Manuf. Syst. 2022, 65, 279–295. [Google Scholar] [CrossRef]
- Lee, J.; Davari, H.; Singh, J.; Pandhare, V. Industrial Artificial Intelligence for industry 4.0-based manufacturing systems. Manuf. Lett. 2018, 18, 20–23. [Google Scholar] [CrossRef]
- Ribeiro, J.; Lima, R.; Eckhardt, T.; Paiva, S. Robotic process automation and artificial intelligence in industry 4.0—A literature review. Procedia Comput. Sci. 2021, 181, 51–58. [Google Scholar] [CrossRef]
- Mhlanga, D. Artificial intelligence in the industry 4.0, and its impact on poverty, innovation, infrastructure development, and the sustainable development goals: Lessons from emerging economies? Sustainability 2021, 13, 5788. [Google Scholar] [CrossRef]
- Cioffi, R.; Travaglioni, M.; Piscitelli, G.; Petrillo, A.; De Felice, F. Artificial intelligence and machine learning applications in smart production: Progress, trends, and directions. Sustainability 2020, 12, 492. [Google Scholar] [CrossRef]
- Sharif, M.; Khan, M.A.; Iqbal, Z.; Azam, M.F.; Lali, M.I.U.; Javed, M.Y. Detection and classification of citrus diseases in agriculture based on optimized weighted segmentation and feature selection. Comput. Electron. Agric. 2018, 150, 220–234. [Google Scholar] [CrossRef]
- Tang, Z.; Yang, J.; Li, Z.; Qi, F. Grape disease image classification based on lightweight convolution neural networks and channelwise attention. Comput. Electron. Agric. 2020, 178, 105735. [Google Scholar] [CrossRef]
- Kamilaris, A.; Prenafeta-Boldú, F.X. A review of the use of convolutional neural networks in agriculture. J. Agric. Sci. 2018, 156, 312–322. [Google Scholar] [CrossRef]
- Horng, G.J.; Liu, M.X.; Chen, C.C. The smart image recognition mechanism for crop harvesting system in intelligent agriculture. IEEE Sensors J. 2019, 20, 2766–2781. [Google Scholar] [CrossRef]
- Zheng, Y.Y.; Kong, J.L.; Jin, X.B.; Wang, X.Y.; Su, T.L.; Zuo, M. CropDeep: The crop vision dataset for deep-learning-based classification and detection in precision agriculture. Sensors 2019, 19, 1058. [Google Scholar] [CrossRef] [PubMed]
- Paymode, A.S.; Malode, V.B. Transfer Learning for Multi-Crop Leaf Disease Image Classification using Convolutional Neural Network VGG. Artif. Intell. Agric. 2022, 6, 23–33. [Google Scholar] [CrossRef]
- Loddo, A.; Loddo, M.; Di Ruberto, C. A novel deep learning based approach for seed image classification and retrieval. Comput. Electron. Agric. 2021, 187, 106269. [Google Scholar] [CrossRef]
- Albanese, A.; Nardello, M.; Brunelli, D. Automated pest detection with DNN on the edge for precision agriculture. IEEE J. Emerg. Sel. Top. Circuits Syst. 2021, 11, 458–467. [Google Scholar] [CrossRef]
- Sujatha, R.; Chatterjee, J.M.; Jhanjhi, N.; Brohi, S.N. Performance of deep learning vs. machine learning in plant leaf disease detection. Microprocess. Microsyst. 2021, 80, 103615. [Google Scholar] [CrossRef]
- Sharma, A.; Jain, A.; Gupta, P.; Chowdary, V. Machine learning applications for precision agriculture: A comprehensive review. IEEE Access 2020, 9, 4843–4873. [Google Scholar] [CrossRef]
- Chlingaryan, A.; Sukkarieh, S.; Whelan, B. Machine learning approaches for crop yield prediction and nitrogen status estimation in precision agriculture: A review. Comput. Electron. Agric. 2018, 151, 61–69. [Google Scholar] [CrossRef]
- Coulibaly, S.; Kamsu-Foguem, B.; Kamissoko, D.; Traore, D. Deep neural networks with transfer learning in millet crop images. Comput. Ind. 2019, 108, 115–120. [Google Scholar] [CrossRef]
- Behera, S.K.; Rath, A.K.; Sethy, P.K. Maturity status classification of papaya fruits based on machine learning and transfer learning approach. Inf. Process. Agric. 2021, 8, 244–250. [Google Scholar] [CrossRef]
- Shahi, T.B.; Sitaula, C.; Neupane, A.; Guo, W. Fruit classification using attention-based MobileNetV2 for industrial applications. PLoS ONE 2022, 17, e0264586. [Google Scholar] [CrossRef] [PubMed]
- Altaheri, H.; Alsulaiman, M.; Muhammad, G. Date fruit classification for robotic harvesting in a natural environment using deep learning. IEEE Access 2019, 7, 117115–117133. [Google Scholar] [CrossRef]
- Hu, X.; Liu, Y.; Zhao, Z.; Liu, J.; Yang, X.; Sun, C.; Chen, S.; Li, B.; Zhou, C. Real-time detection of uneaten feed pellets in underwater images for aquaculture using an improved YOLO-V4 network. Comput. Electron. Agric. 2021, 185, 106135. [Google Scholar] [CrossRef]
- Yang, X.; Zhang, S.; Liu, J.; Gao, Q.; Dong, S.; Zhou, C. Deep learning for smart fish farming: Applications, opportunities and challenges. Rev. Aquac. 2021, 13, 66–90. [Google Scholar] [CrossRef]
- Ghahremani, M.; Williams, K.; Corke, F.M.; Tiddeman, B.; Liu, Y.; Doonan, J.H. Deep segmentation of point clouds of wheat. Front. Plant Sci. 2021, 12, 608732. [Google Scholar] [CrossRef] [PubMed]
- Ponce, J.M.; Aquino, A.; Andujar, J.M. Olive-fruit variety classification by means of image processing and convolutional neural networks. IEEE Access 2019, 7, 147629–147641. [Google Scholar] [CrossRef]
- Alshammari, H.; Gasmi, K.; Ben Ltaifa, I.; Krichen, M.; Ben Ammar, L.; Mahmood, M.A. Olive disease classification based on vision transformer and CNN models. Comput. Intell. Neurosci. 2022, 2022, 3998193. [Google Scholar] [CrossRef]
- Ghosh, S.; Das, N.; Das, I.; Maulik, U. Understanding deep learning techniques for image segmentation. ACM Comput. Surv. (CSUR) 2019, 52, 1–35. [Google Scholar] [CrossRef]
- Seo, H.; Badiei Khuzani, M.; Vasudevan, V.; Huang, C.; Ren, H.; Xiao, R.; Jia, X.; Xing, L. Machine learning techniques for biomedical image segmentation: An overview of technical aspects and introduction to state-of-art applications. Med Phys. 2020, 47, e148–e167. [Google Scholar] [CrossRef]
- Hesamian, M.H.; Jia, W.; He, X.; Kennedy, P. Deep learning techniques for medical image segmentation: Achievements and challenges. J. Digit. Imaging 2019, 32, 582–596. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Chen, Q.; Zheng, Z.; Hu, C.; Wang, D.; Liu, F. On-edge multi-task transfer learning: Model and practice with data-driven task allocation. IEEE Trans. Parallel Distrib. Syst. 2019, 31, 1357–1371. [Google Scholar] [CrossRef]
- Zaidi, S.A.; Hayajneh, A.M.; Hafeez, M.; Ahmed, Q. Unlocking Edge Intelligence through Tiny Machine Learning (TinyML). IEEE Access 2022, 10, 100867–100877. [Google Scholar] [CrossRef]
- Ponce, J.M.; Aquino, A.; Millan, B.; Andújar, J.M. Automatic counting and individual size and mass estimation of olive-fruits through computer vision techniques. IEEE Access 2019, 7, 59451–59465. [Google Scholar] [CrossRef]
- Nashat, A.A.; Hassan, N.H. Automatic segmentation and classification of olive fruits batches based on discrete wavelet transform and visual perceptual texture features. Int. J. Wavelets Multiresolution Inf. Process. 2018, 16, 1850003. [Google Scholar] [CrossRef]
- Hayajneh, A.M.; Aldalahmeh, S.A.; Alasali, F.; Al-Obiedollah, H.; Zaidi, S.A.; McLernon, D. Tiny machine learning on the edge: A framework for transfer learning empowered unmanned aerial vehicle assisted smart farming. IET Smart Cities 2023, 1–17. [Google Scholar] [CrossRef]
- Hassan, M.M.; Uddin, M.Z.; Mohamed, A.; Almogren, A. A robust human activity recognition system using smartphone sensors and deep learning. Future Gener. Comput. Syst. 2018, 81, 307–313. [Google Scholar] [CrossRef]
- Yang, Y.; Wang, H.; Jiang, R.; Guo, X.; Cheng, J.; Chen, Y. A review of IoT-enabled mobile healthcare: Technologies, challenges, and future trends. IEEE Internet Things J. 2022, 9, 9478–9502. [Google Scholar] [CrossRef]
- Antonini, M.; Pincheira, M.; Vecchio, M.; Antonelli, F. A TinyML approach to non-repudiable anomaly detection in extreme industrial environments. In Proceedings of the 2022 IEEE International Workshop on Metrology for Industry 4.0 & IoT (MetroInd4. 0&IoT), Trento, Italy, 7–9 June 2022; pp. 397–402. [Google Scholar]
- Vitolo, P.; Licciardo, G.D.; Amendola, A.C.; Di Benedetto, L.; Liguori, R.; Rubino, A.; Pau, D. Quantized ID-CNN for a low-power PDM-to-PCM conversion in TinyML KWS applications. In Proceedings of the 2022 IEEE 4th International Conference on Artificial Intelligence Circuits and Systems (AICAS), Incheon, Republic of Korea, 13–15 June 2022; pp. 154–157. [Google Scholar]
- Huang, H.; Lin, L.; Tong, R.; Hu, H.; Zhang, Q.; Iwamoto, Y.; Han, X.; Chen, Y.W.; Wu, J. Unet 3+: A full-scale connected unet for medical image segmentation. In Proceedings of the 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP 2020), Barcelona, Spain, 4–8 May 2020; pp. 1055–1059. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Jocher, G.; Chaurasia, A.; Qiu, J. YOLO by Ultralytics. 2023. Available online: https://github.com/ultralytics/ultralytics (accessed on 21 November 2023).
- Oquab, M.; Darcet, T.; Moutakanni, T.; Vo, H.; Szafraniec, M.; Khalidov, V.; Fernandez, P.; Haziza, D.; Massa, F.; El-Nouby, A.; et al. Dinov2: Learning robust visual features without supervision. arXiv 2023, arXiv:2304.07193. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Option | Value |
|---|---|
| Rotation | |
| Horizontal shift | −10 to 10 |
| Vertical shift | −10 to 10 |
| Scaling | 0.8 to 1.2 |
| Skewing | Vertical and horizontal |
| Flip | Vertical and horizontal |
| Option | Value |
|---|---|
| Optimizer | Adam |
| Learning rate | 0.01 |
| Maximum Epochs | 100 |
| Mini batch size | 32 |
| L2-regularization | 0.01 |
| Model Dropouts | 0.2 |
| Training Hardware resource | GPU RTX 3050TI |
| Edge inference unit | ESP32-S3 |
| Test Results | TinyML Inference Results (Model and Input uint8 Quantization) | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Image Size |
CNN Architecture | Recall | Precision | Accuracy | Recall | Precision | Accuracy | Inference Rate (Hz) | Model Size (kilobytes) |
Min Arena Size (kilobytes) |
Stack Overflow | ||
| CNN(128,64,32) | 0.9555 | 0.9525 | 0.9527 | 0.9525 | 0.9577 | 0.9549 | 0.9552 | 0.9549 | N/A | 332.3 | 368.6 | Yes | |
| CNN(64,32,16) | 0.9538 | 0.9487 | 0.9493 | 0.9487 | 0.9541 | 0.9488 | 0.9495 | 0.9488 | 5.93 | 87.7 | 184.3 | No | |
| CNN(32,16,16) | 0.9744 | 0.9739 | 0.9740 | 0.9739 | 0.9745 | 0.9741 | 0.9742 | 0.9741 | 12.34 | 41.3 | 92.3 | No | |
| CNN(128,64,32) | 0.9724 | 0.9720 | 0.9720 | 0.9721 | 0.9746 | 0.9743 | 0.9743 | 0.9743 | 12.04 | 117.2 | 94.4 | No | |
| CNN(64,32,16) | 0.9684 | 0.9681 | 0.9681 | 0.9681 | 0.9661 | 0.9657 | 0.9658 | 0.9657 | 27.03 | 33.92 | 44.23 | No | |
| CNN(32,16,16) | 0.9670 | 0.9669 | 0.9668 | 0.9668 | 0.9690 | 0.9685 | 0.9680 | 0.9680 | 55.56 | 14.45 | 22.33 | No | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hayajneh, A.M.; Batayneh, S.; Alzoubi, E.; Alwedyan, M. TinyML Olive Fruit Variety Classification by Means of Convolutional Neural Networks on IoT Edge Devices. AgriEngineering 2023, 5, 2266-2283. https://doi.org/10.3390/agriengineering5040139
Hayajneh AM, Batayneh S, Alzoubi E, Alwedyan M. TinyML Olive Fruit Variety Classification by Means of Convolutional Neural Networks on IoT Edge Devices. AgriEngineering. 2023; 5(4):2266-2283. https://doi.org/10.3390/agriengineering5040139
Chicago/Turabian StyleHayajneh, Ali M., Sahel Batayneh, Eyad Alzoubi, and Motasem Alwedyan. 2023. "TinyML Olive Fruit Variety Classification by Means of Convolutional Neural Networks on IoT Edge Devices" AgriEngineering 5, no. 4: 2266-2283. https://doi.org/10.3390/agriengineering5040139