
Macroeconomic Predictions Using Payments Data and Machine Learning

Abstract
:1. Introduction
2. Payments Systems Data
2.1. Adjustments to Payments Data
2.2. Payments Data for Macroeconomic Nowcasting
3. Methodology
3.1. Machine Learning Models for Nowcasting
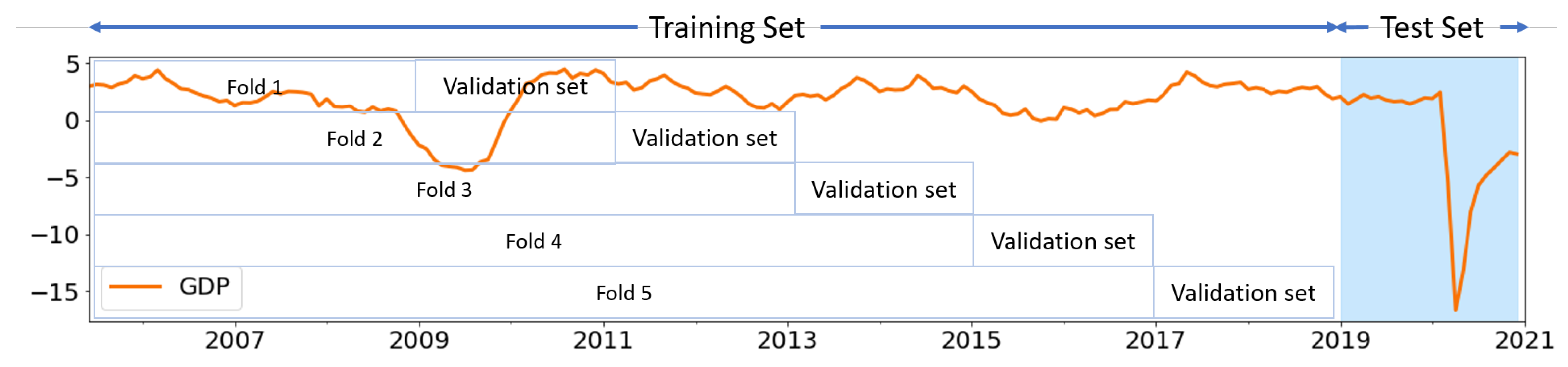
3.2. Machine Learning Model Cross-Validation
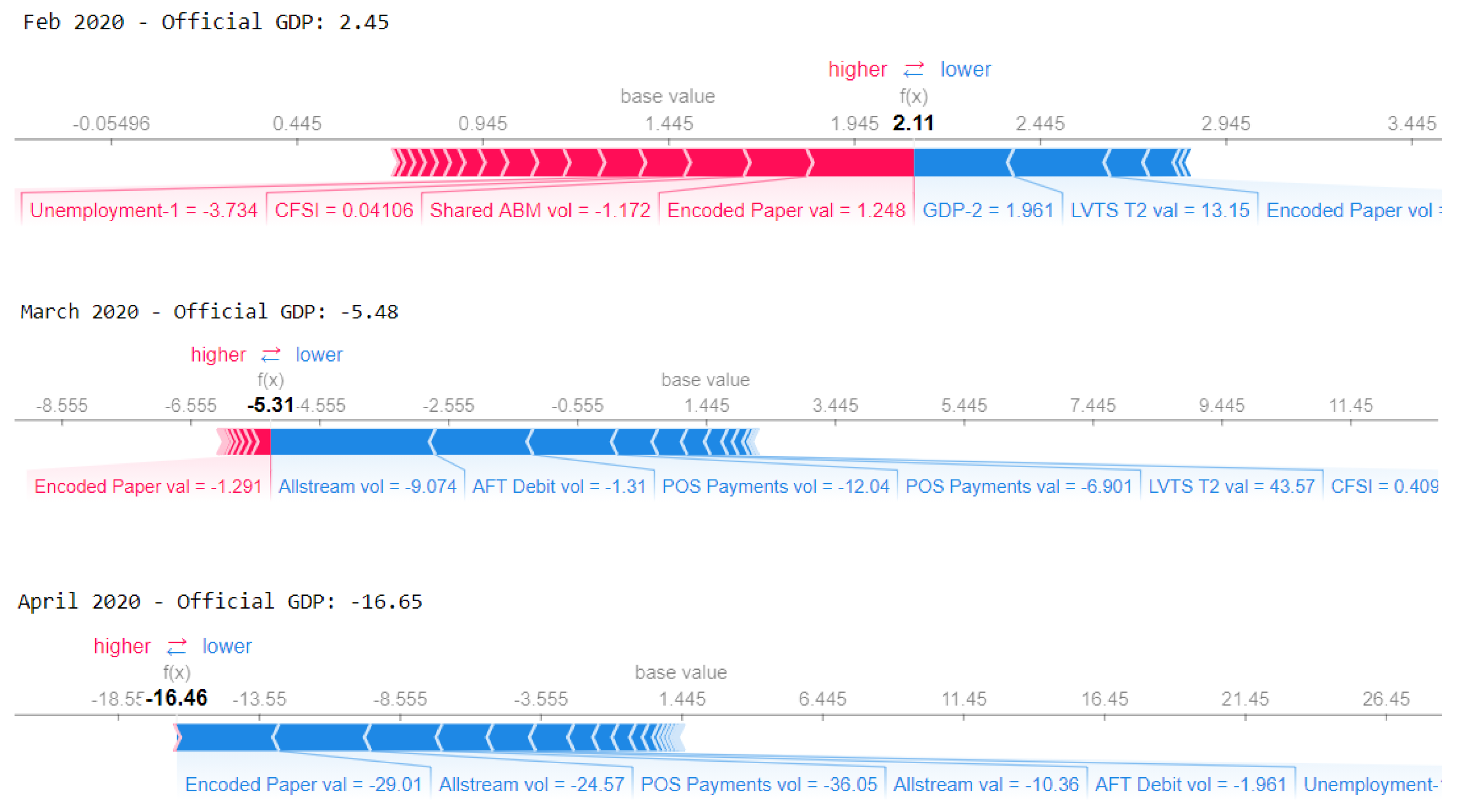
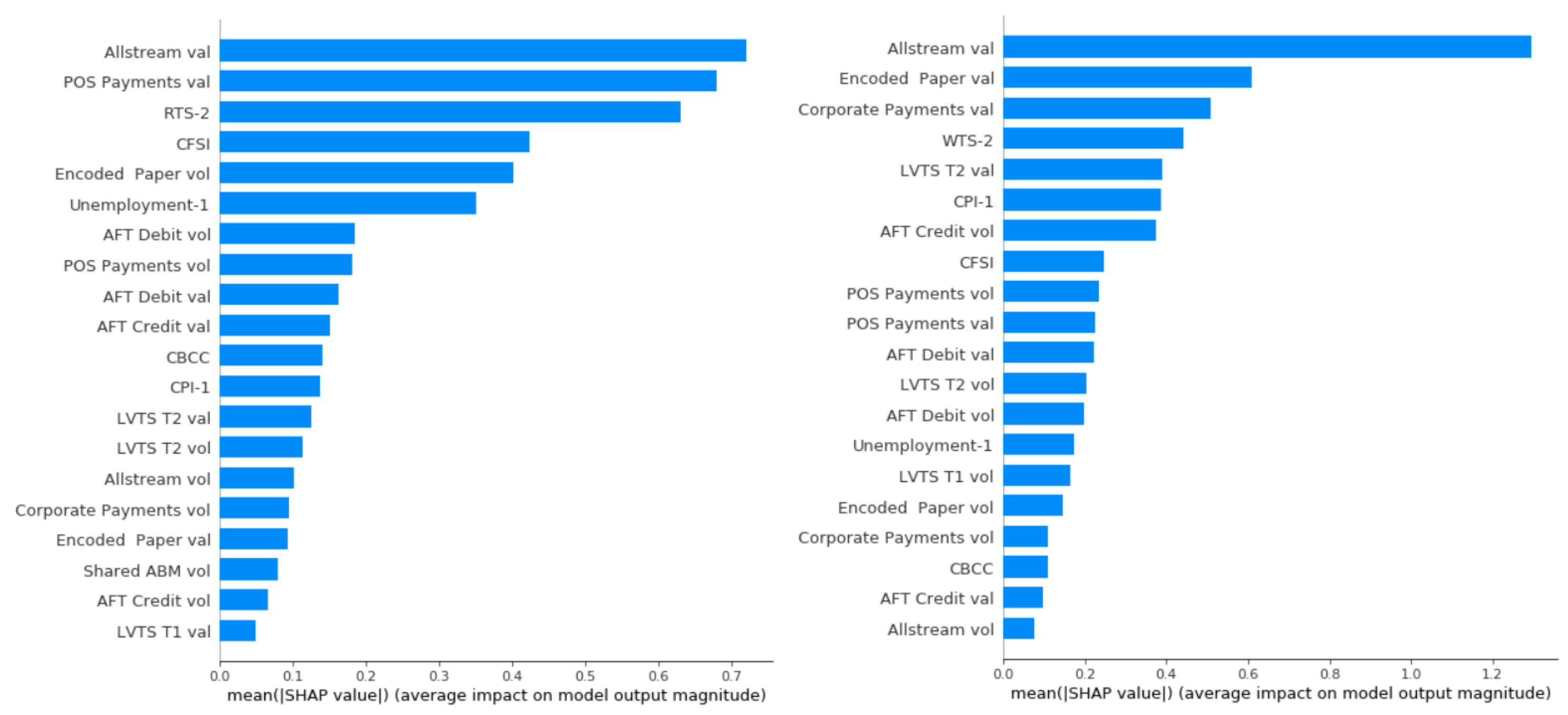
3.3. Machine Learning Model Interpretability
3.4. Case Specifications and Model Training
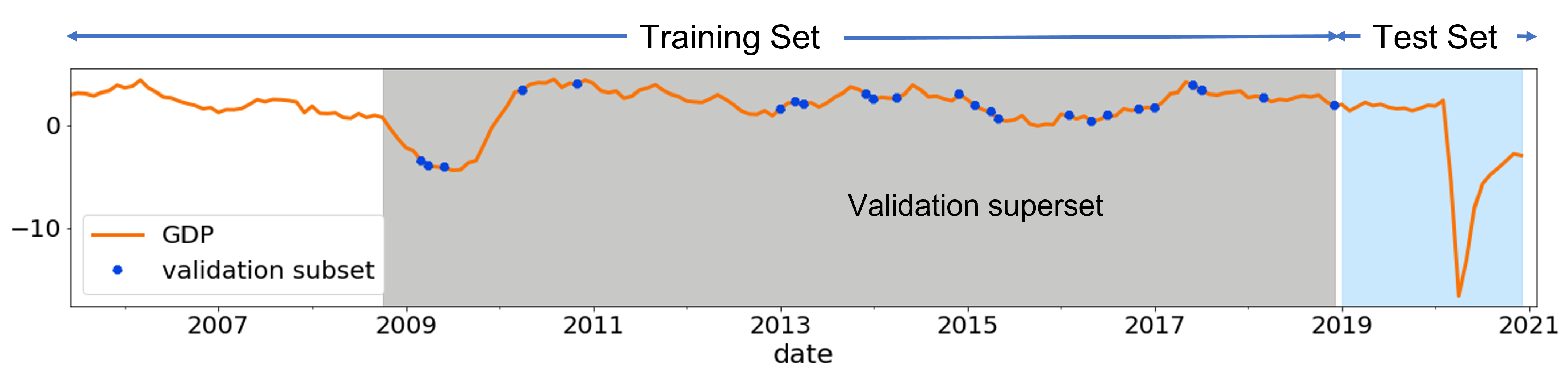
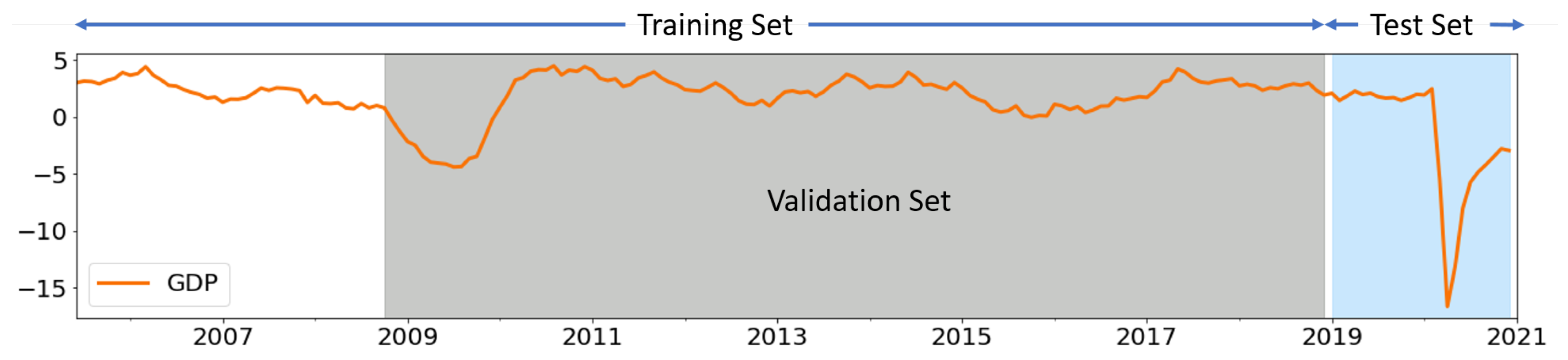
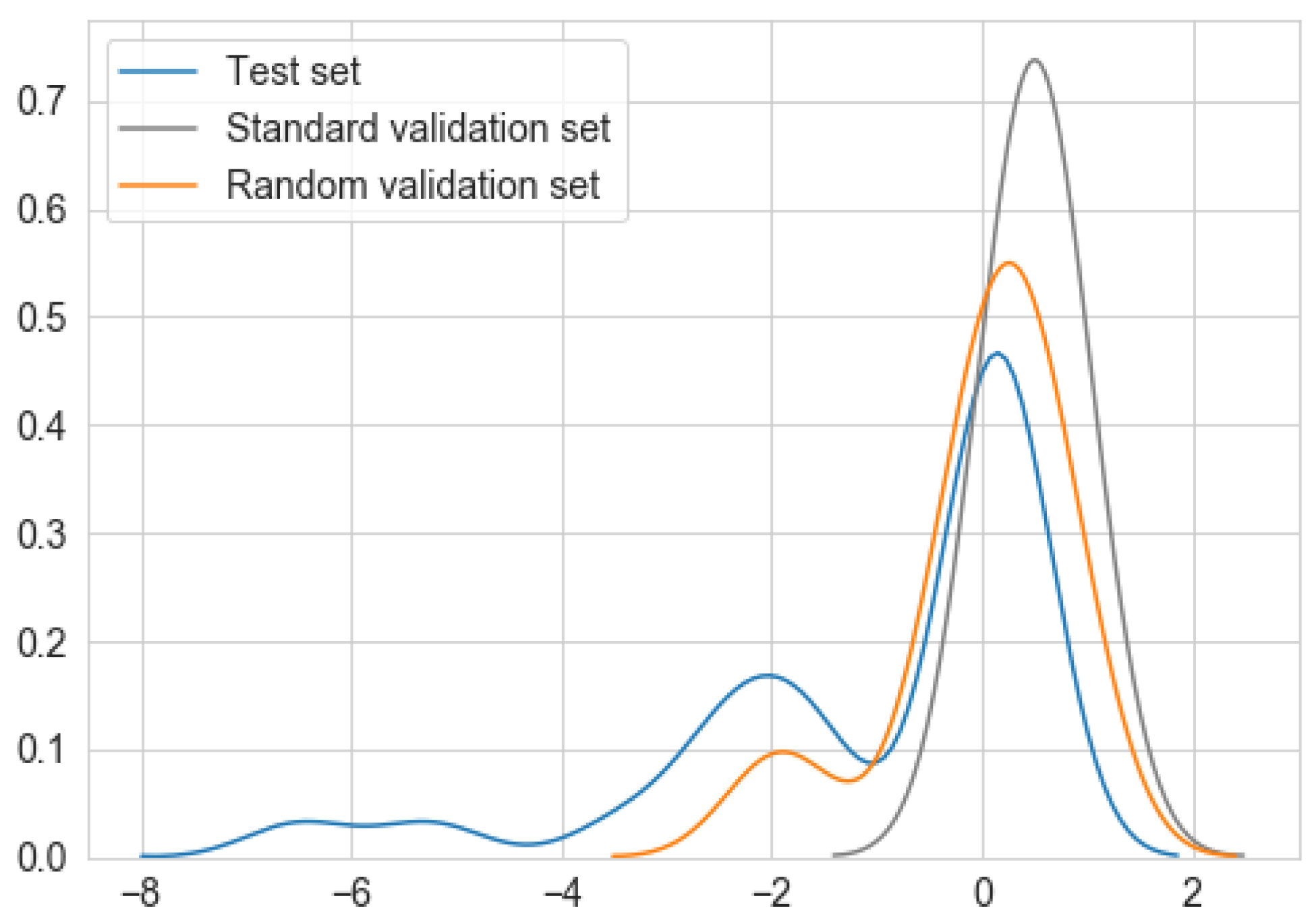
- From the training sample, we select two dates covering the wider range of training data as a validation superset (Figure 2) and randomly choose a set of n sample points as a validation set (where points, it is the same size as the test sample). (Note: we choose a start date just before the GFC period and an end date just before the test set, then select n random data points between these two dates as a validation set. This helps to include a few data points from the crisis period in each fold of the validation subset, at the same time avoiding use of a large cross-validation sample.)
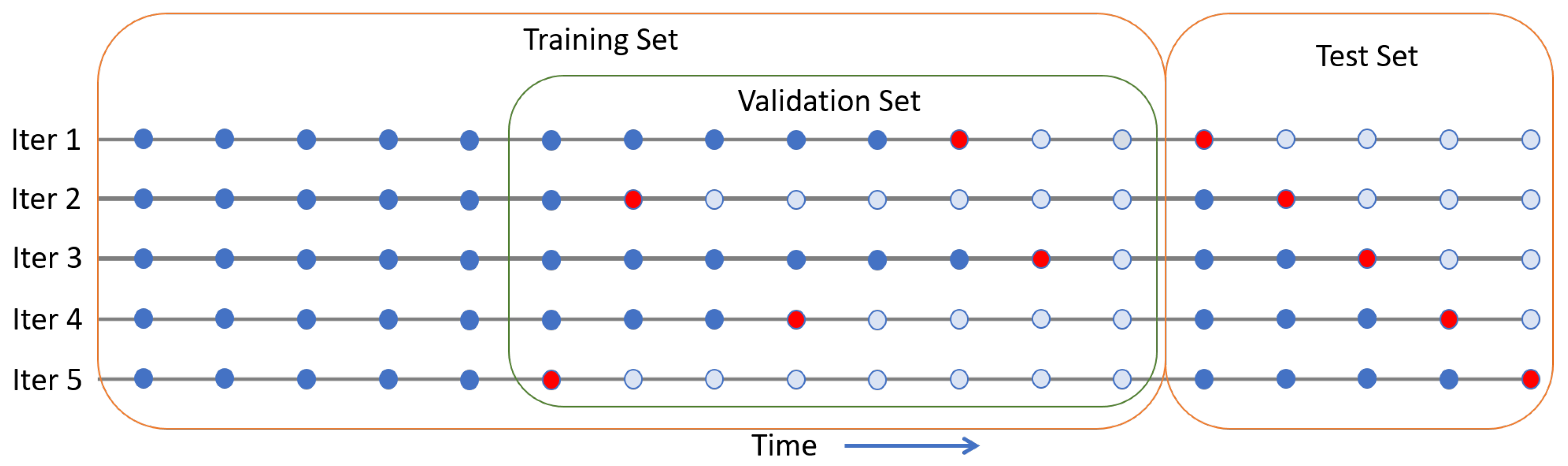
- Thereafter, for each sample date in the validation subset, we select all the sample points before that date for training and use the sample date for prediction (Figure 4).
- Next, for each model, we specify the grid for selected hyperparameters. Then, for each value of a specified parameter, we iterate over the validation subset and compute RMSE.
- Steps 2 and 3 are repeated k times for the same set of hyperparameters but with a different validation subset randomly sampled from the validation superset ( fold cross-validation).
- Next, we select the best set of model parameters, i.e., the parameters with the lowest average validation RMSE (averaged over k folds) as the final model.
- Finally, the chosen model is used for predictions on the test set by utilizing the standard expanding window approach over the training and test set (Figure 4).
4. Results and Discussion
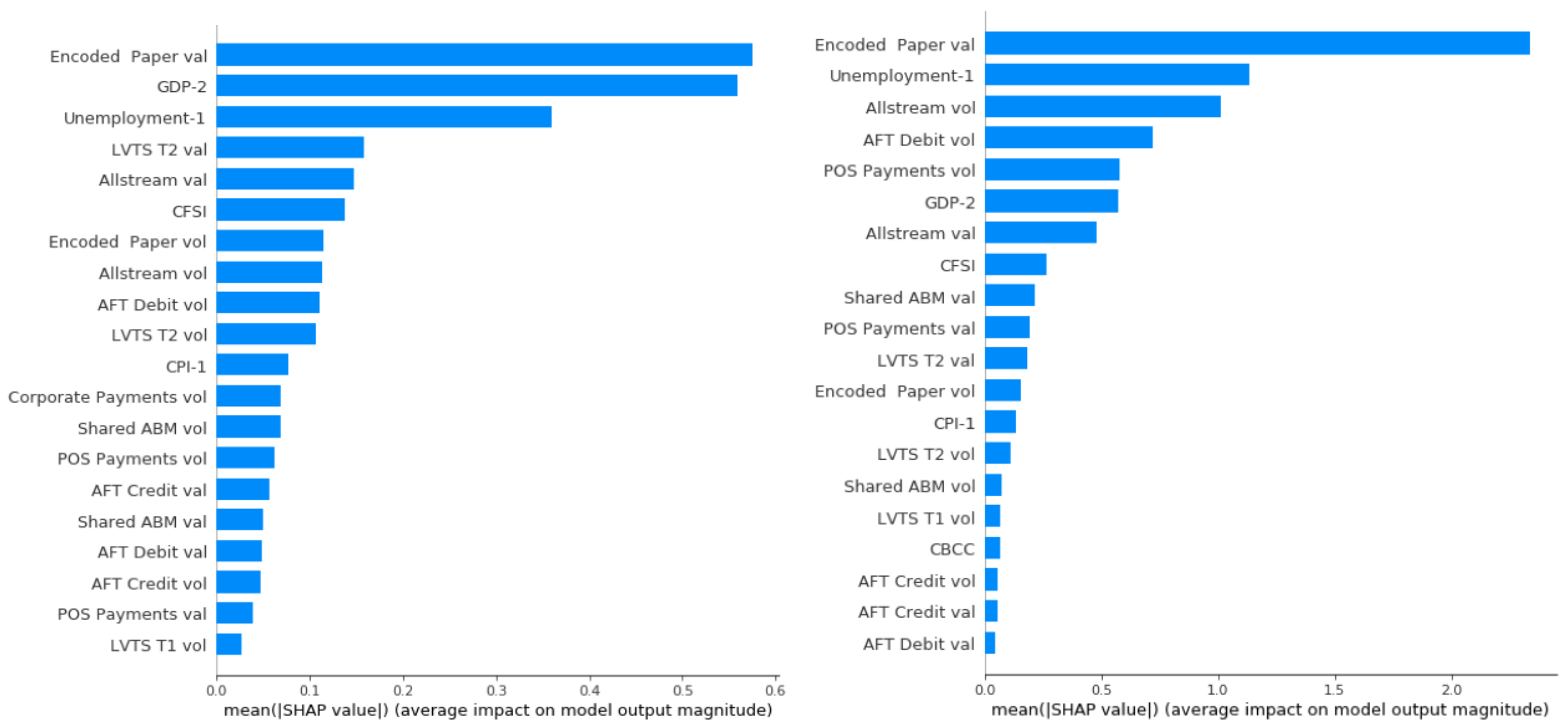
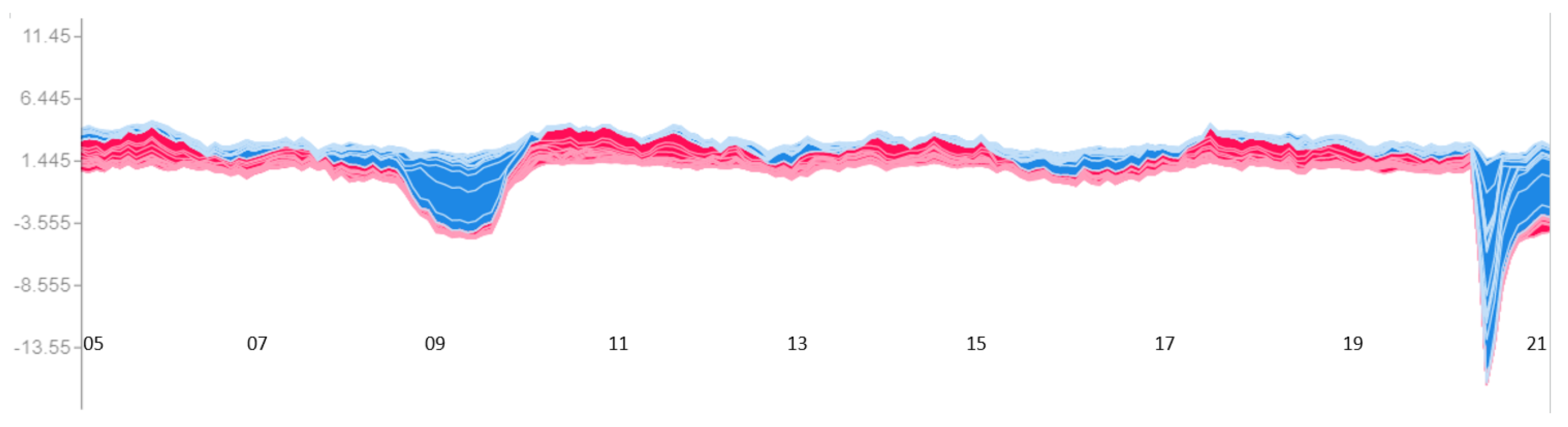
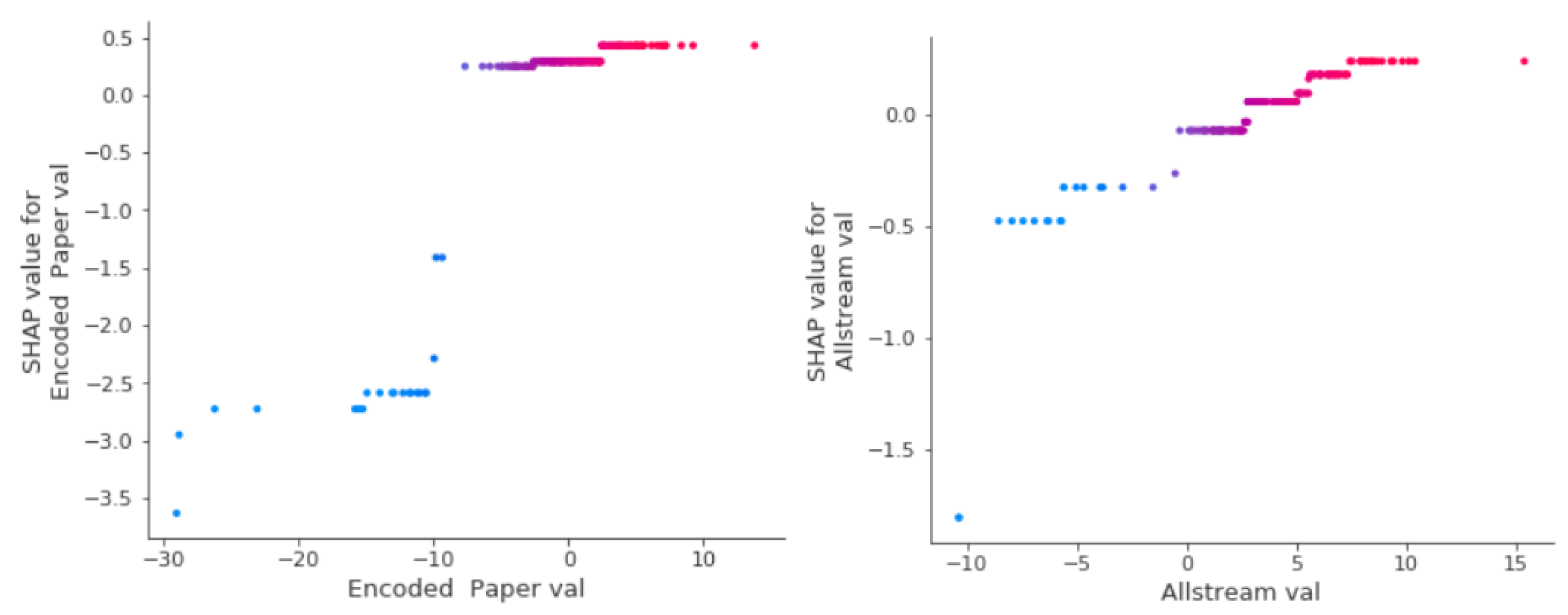
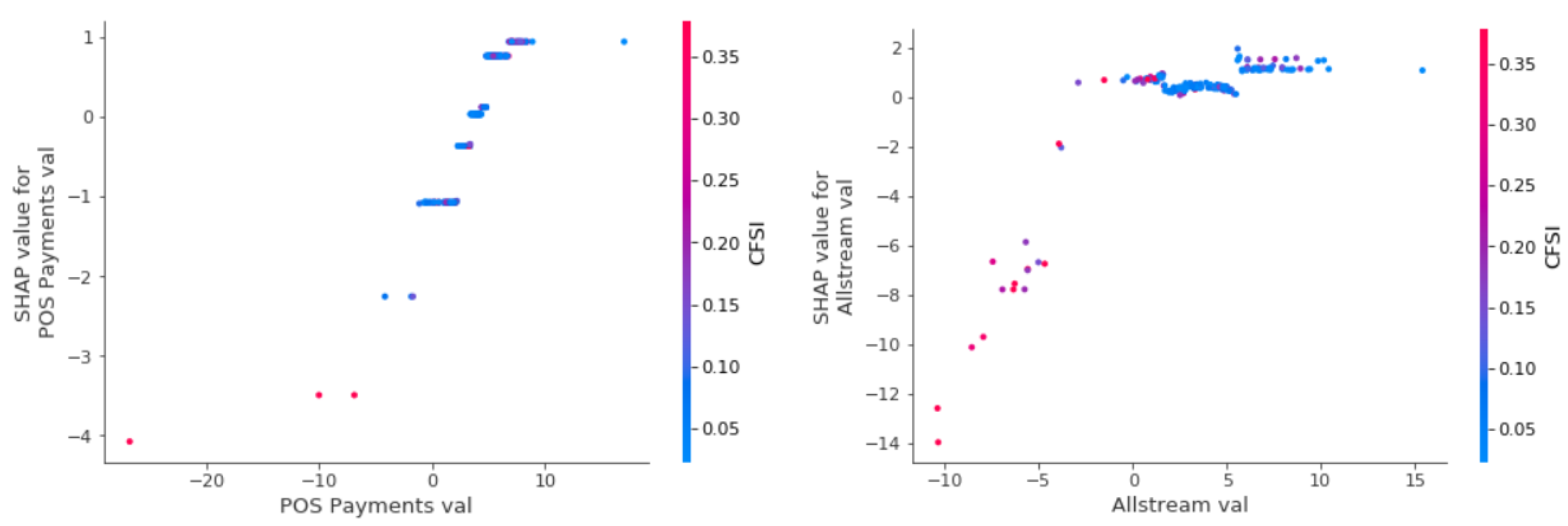
Model Interpretation and Payments Data Contribution
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Overview of ACSS and LVTS Payments Instruments
- A: ABM adjustments—processes POS payment items used to correct errors from shared ABM network stream N.
- B: Canada Savings Bonds—part of government items. Comprises bonds (series 32 and up and premium bonds) issued by the Government of Canada. Start date: April 2012.
- C: AFT credit—processes direct deposit (DD) items such as payroll, account transfers, government social payments, business-to-consumer non-payroll payments, etc.
- D: AFT debit—pre-authorized debit (PAD) payments such as bills, mortgages, utility payments, membership dues, charitable donations, RRSP investments, etc.
- E: Encoded paper—paper bills of exchange that include cheques, inter-member debits, money orders, bank drafts, settlement vouchers, paper PAD, money orders, etc.
- F: Paper-based remittances—used for paper bill payments, that is, MICR-encoded with a CCIN for credit to a business. It is similar to electronic bill payments (stream Y).
- G: Receiver General warrants—part of government payments items. Processes paper items payable by the Receiver General for Canada. Start date: April 2012.
- H: Treasury bills and old-style bonds—part of government paper items. It processes certain Government of Canada paper payment items such as treasury bills, old-style Canada Savings Bonds, coupons, etc. Start date: April 2012.
- I: Regional image captured payment (ICP)—processes items entered into the ACSS/USBE on a regional basis. Start date: Oct 2015.
- J: Online payments—processes electronic payments initiated using a debit card through an open network to purchase goods and services. Start date: June 2005.
- K: Online payment refunds—processes credit payments used to credit a cardholder’s account in the case of refunds or returns of an online payment (stream J). Start date: June 2005.
- L: Large-value paper—similar to stream E with value cap. Starting in Jan 2014, this stream merged into encoded paper stream E.
- M: Government direct deposit—processes recurring social payments such as payroll, pension, child tax benefits, social security, and tax refunds. Start date: April 2012.
- N: Shared ABM network—POS debit payments used to withdraw cash from a card-activated device.
- O: ICP national—processes electronically imaged paper items that can be used to replace physical paper items such as cheques, bank drafts, etc.
- P: POS payments—processes payment items resulting from the POS purchase of goods or services using a debit card.
- Q: POS return—processes credit payments used to credit a cardholder’s account in the case of refunds or returns of a POS payment (stream P).
- S: ICP returns national—processes national image-captured payment returned items entered into the ACSS/USBE on a national basis. Start date: Oct 2015.
- U: Unqualified paper payments—processes paper-based bills of exchange that do not meet Canada payments association requirements for encoded paper classification.
- X: Electronic data interchanges (EDI) payment—processes exchange of corporate-to-corporate payments such as purchase orders, invoices, and shipping notices.
- Y: EDI remittances—processes remittances for electronic bill payments such as online bill and telephone bill payments.
- Z: Computer rejects—processes encoded paper items whose identification and tracking information cannot be verified through automated processes.
- Foreign exchange payments and payments related to the settlement of the Canadian-dollar leg of FX transactions undertaken in the continuous linked settlement (CLS) system.
- Payments related to Canadian-dollar-denominated securities in the CDSX operated by clearing and depository services (CDS).
- Payments related to the final settlement of the ACSS.
- Large-value Government of Canada transactions (federal receipts and disbursements) and transactions related to the settlement of the daily receiver.
- The Bank of Canada’s large-value payments and those of its clients, which include Government of Canada, other central banks, and certain international organizations.
Appendix B. Machine Learning Models
Appendix B.1. Elastic Net Regularization
Appendix B.2. Support Vector Regression
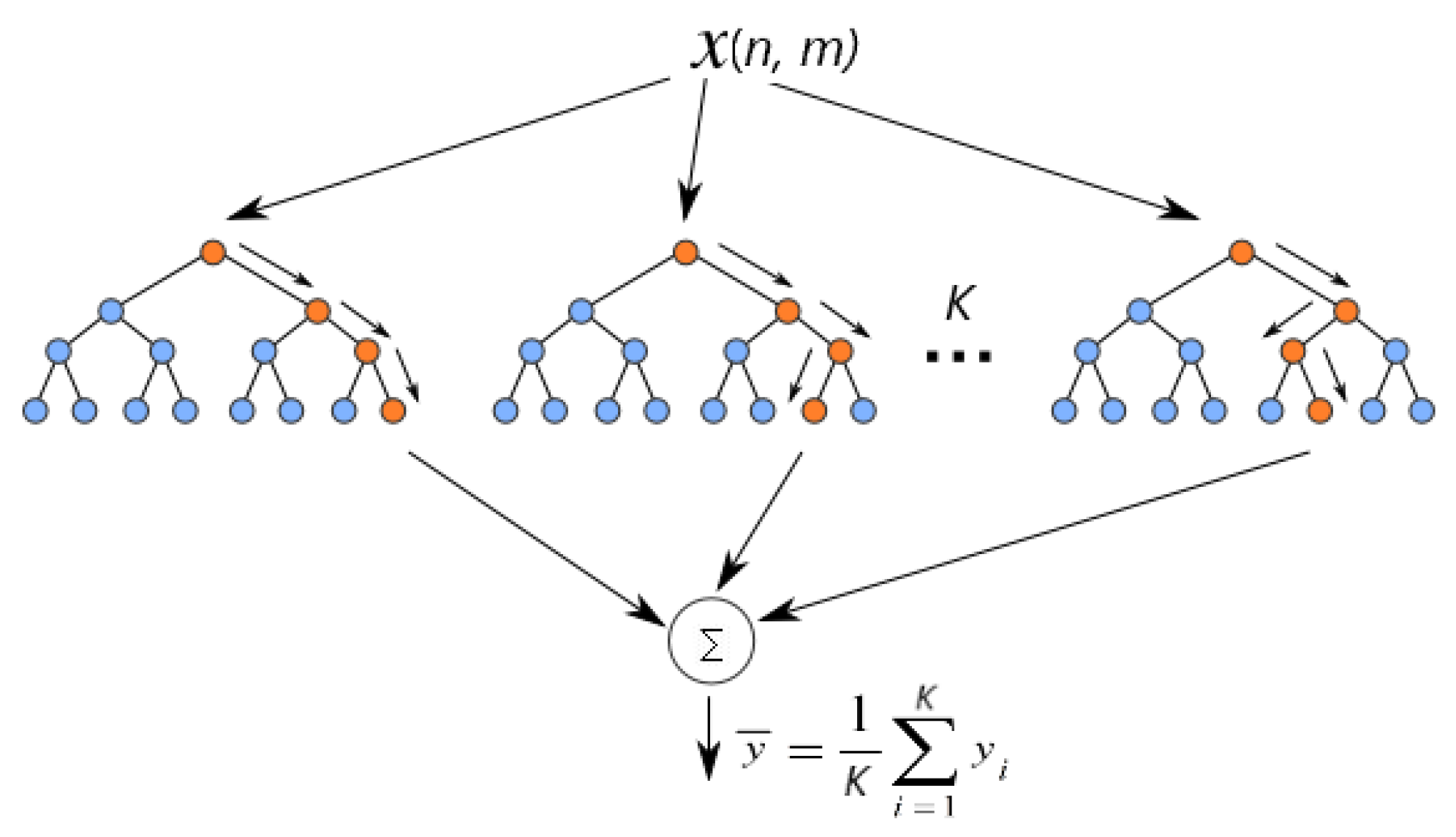
Appendix B.3. Random Forest

Appendix B.4. Gradient Boosting
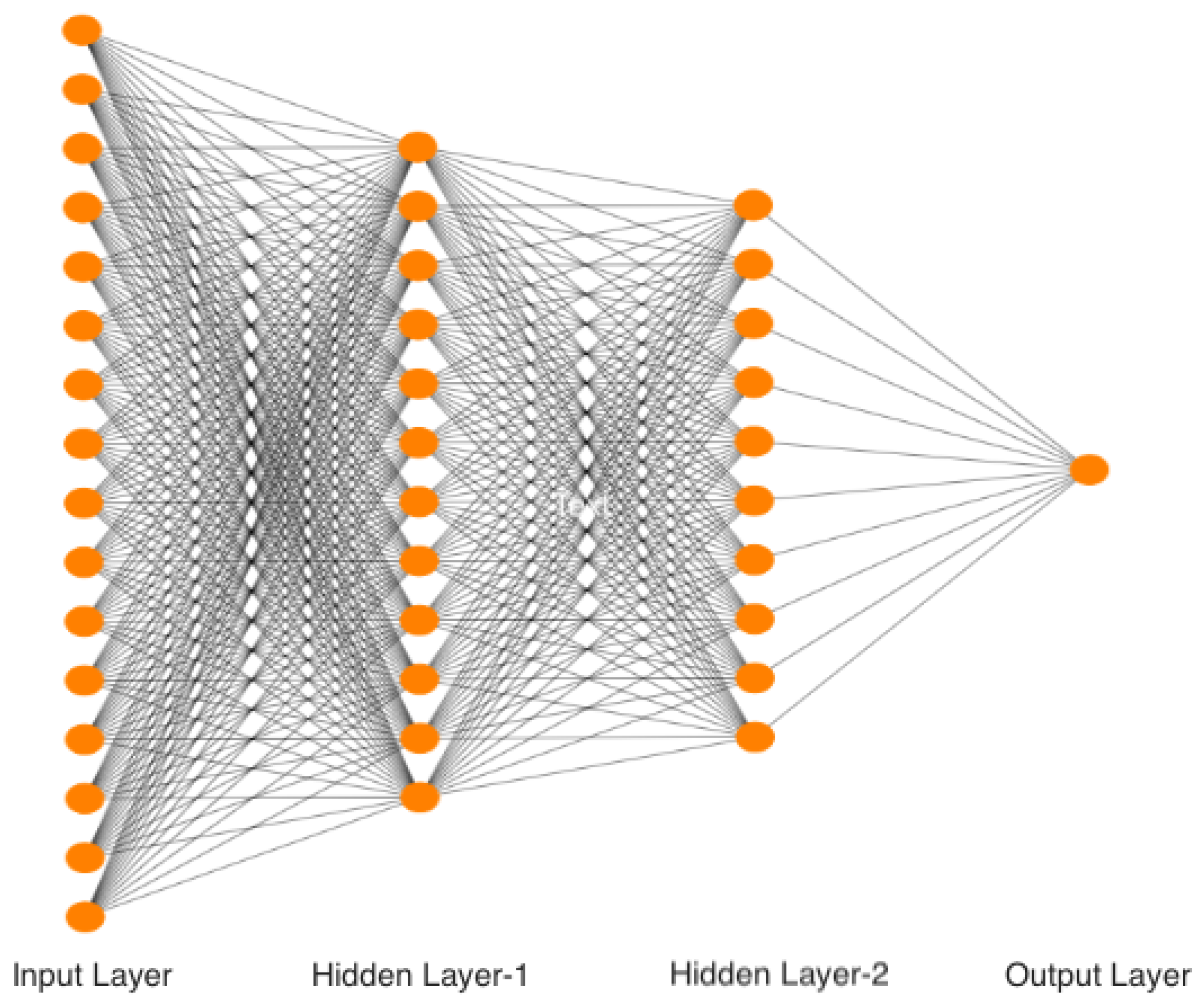
Appendix B.5. Feed-Forward Artificial Neural Network

Appendix B.6. ML Models Performance Caparison with DFM

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Target b | DFM c | ENT d | SVR d | RFR d | GBR d | ANN d | % Reduction e |
|---|---|---|---|---|---|---|---|
| GDP | 1.00 | 0.96 | 1.41 | 1.11 | 0.81 f | 0.82 | 19 |
| RTS | 1.00 | 0.89 | 1.27 | 1.07 | 0.85 | 1.02 | 15 |
| WTS | 1.00 | 0.96 | 1.14 | 0.82 | 0.69 | 0.51 | 31 |
| GDP | 1.00 | 0.87 | 1.62 | 1.14 | 0.82 | 0.85 | 18 |
| RTS | 1.00 | 0.87 | 1.36 | 1.15 | 0.90 | 0.97 | 11 |
| WTS | 1.00 | 0.89 | 1.19 | 0.91 | 0.81 | 0.70 | 19 |
- a In-sample training period, Mar 2005–Dec 2018, () and out-of-sample testing period, Jan 2019–Dec 2020, (). All RMSEs are normalized with respect to DFM. The performance gain using ML models for time horizon t are much smaller; however, the GBR model performed better compared to the other ML models.
- b RTS—retail trade sales; WTS—wholesale trade sales. Note: we use the latest available values of targets for these exercises.
- c For DFM, we use payments data along with the predictors in the benchmark case. We use the DFM model with two factors and one lag in the VAR driving the dynamics of those factors. Idiosyncratic components are assumed to follow an AR(1) process.
- d We use elastic net (ENT), support vector regression (SVR), random forest regression (RFR), gradient boosting regression (GBR), and ANN. For these ML models, we select the model parameters and number of payment predictors based on target variables using the cross-validation procedure outlined in Section 3. Further details on these models are provided in Appendix B. Model selection and cross-validation procedures are detailed in Appendix C and Appendix D.
- e Percentage reduction in RMSE over DFM for the GBR model.
- f The models with out-of-sample prediction RMSE less than DFM (<1) are highlighted (bold) and the best model is also underlined
Appendix C. Model Parameter Selection and Cross-Validation
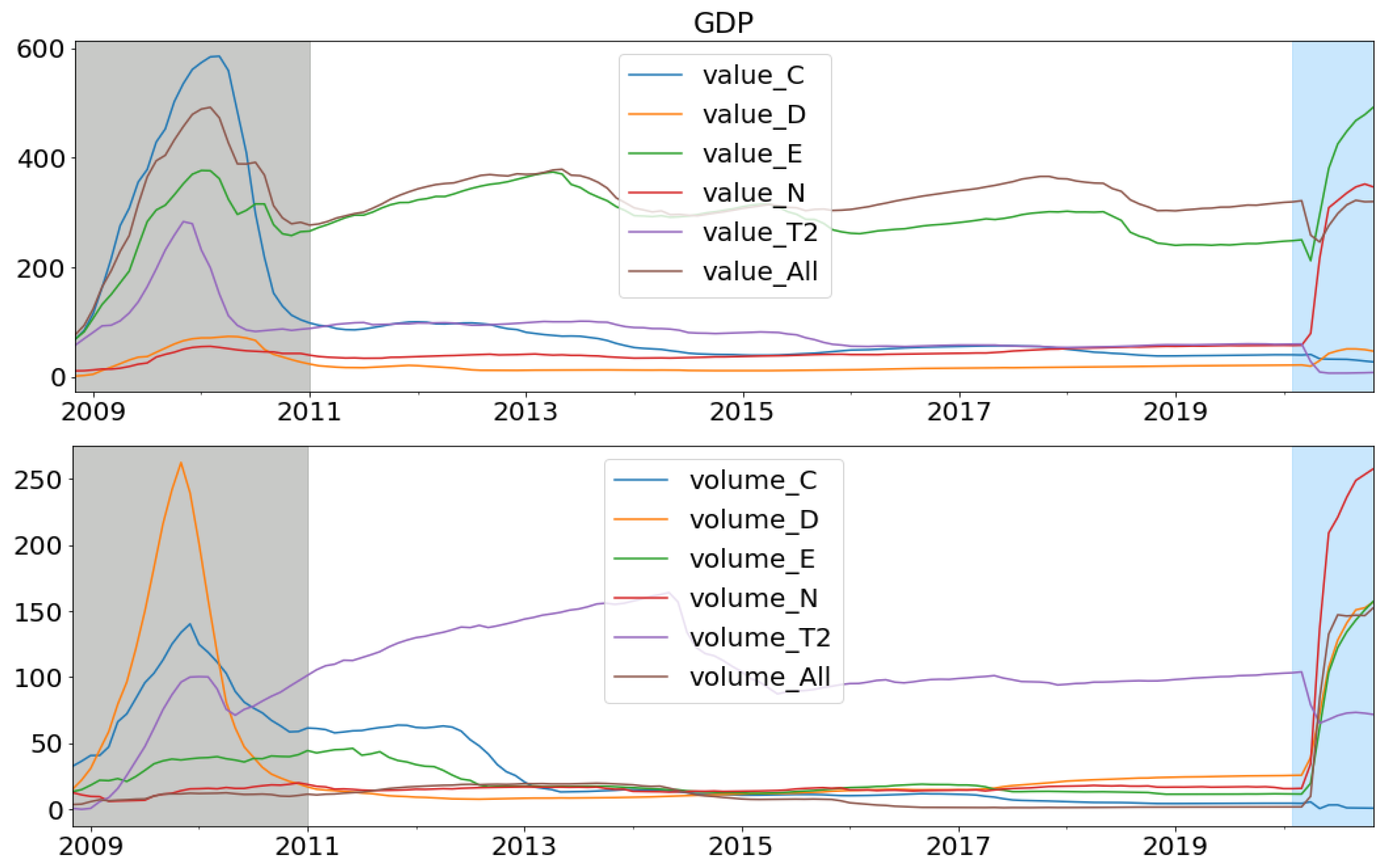
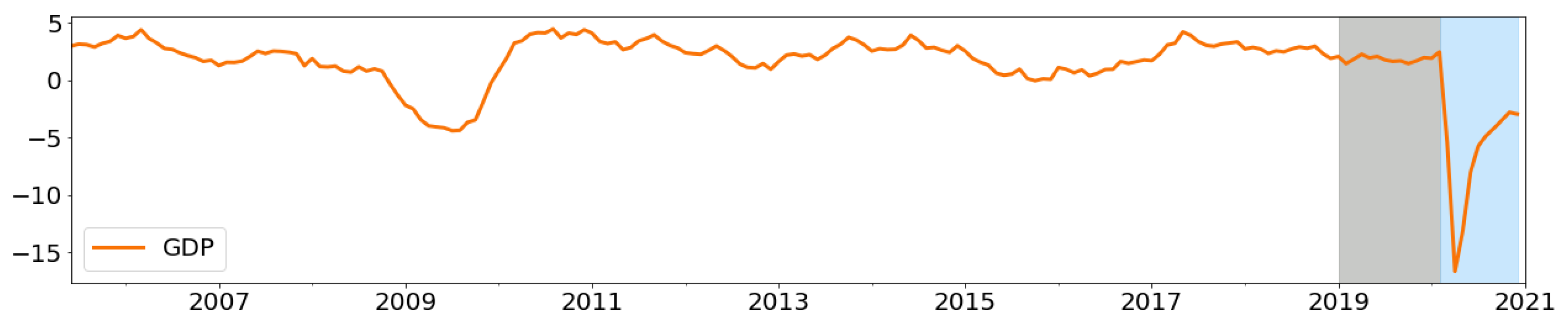
- Split the original dataset into a training set and test set (Figure A3). In our case, the training set is Mar 2005–Dec 2018, and the test set is Jan 2019–Dec 2020 (highlighted in blue).
- Specify the hyperparameters to tune and select the range for each parameter. See Appendix B for individual model parameters selected for tuning.
- Select two dates in the training set that define the validation superset (highlighted in gray in Figure A3). To include the global financial crisis, we chose those dates between Oct 2008 and Dec 2018.
- Next, for each fold in the cross-validation, we randomly sample 24 points (it is the same as the test set) from the validation superset as the validation subset (see Figure 2 for an example).
- Using the selected parameters grid and validation subset, we perform the following steps:(a) For each iteration in the expanding window over the validation subset, select a data point from that subset as the out-of-sample test point and use all the data points up to that point for training (see Figure 4, where red dots are test points and blue dots are training points).(b) Fit the model on the selected training sample.(c) Using the trained model, predict for the selected sample point in the validation subset.(d) Repeat steps a, b, and c for each point in the validation subset.(e) After finishing iterating the chosen validation subset, compute the validation RMSE.
- Repeat steps 4 and 5 k-times (typically k is between 5 and 10), each time using a new validation subset.
- Compute the average validation RMSE over the k-folds.
- Select the parameters for which the average validation RMSE is smallest.
- Use the tuned model to obtain the RMSE for the testing set by reusing the standard expanding window approach, as illustrated in Figure 4.


Appendix D. Feature Selection

Appendix E. The Shapley Values and SHAP for Model Interpretation
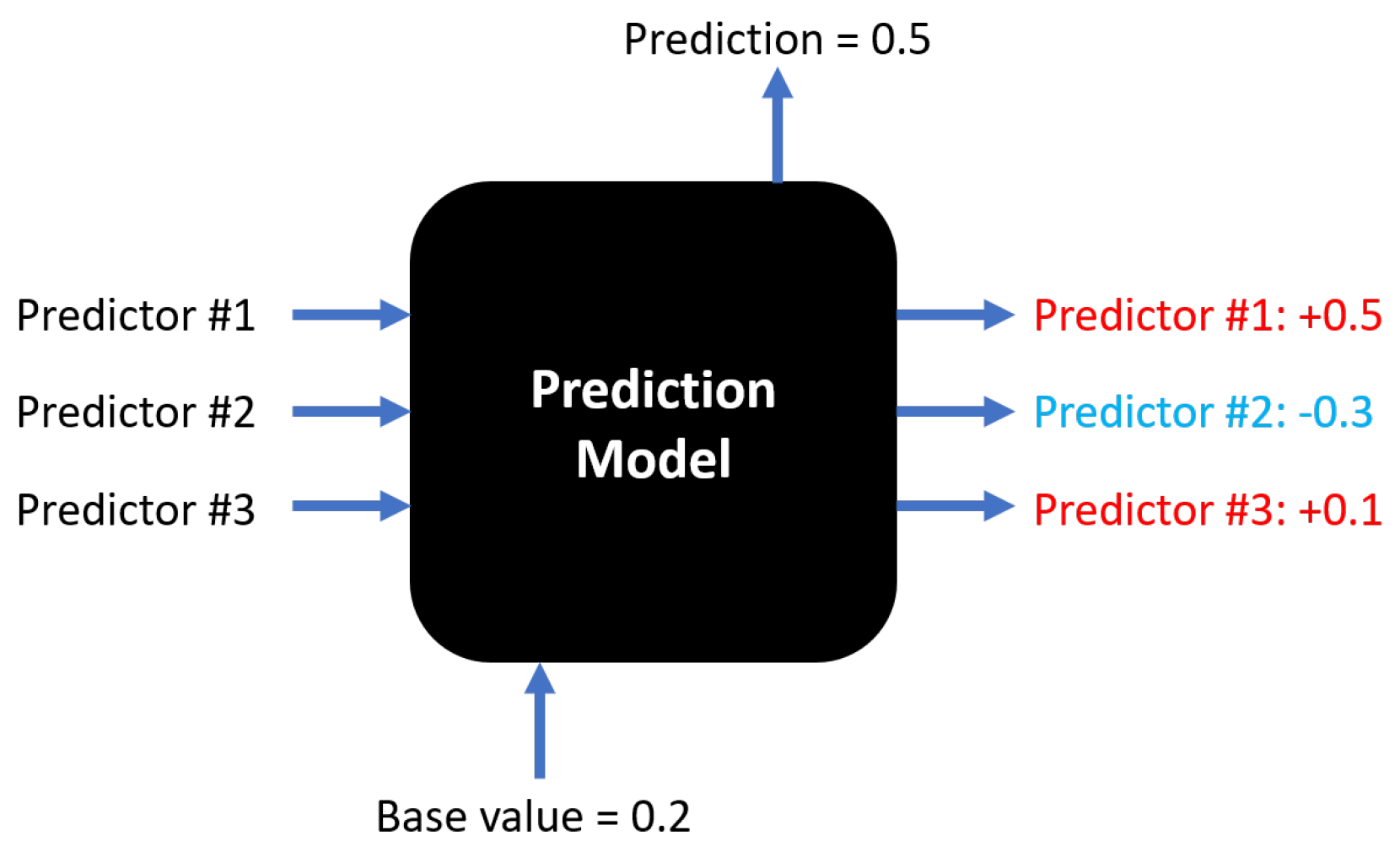
- Consider a nowcasting problem with three predictors (Figure A6) in a prediction model (it could be any model) to predict a target (for instance, monthly GDP growth).
- The average prediction of the model, that is, the base value is 0.2, and for the current instance (for example, month t), our model predicts GDP growth 0.5.
- By computing the Shapley values for all possible coalitions among three predictors, we can explain the difference between actual prediction (0.5) at current month t and the base value (0.2) in terms of each predictor’s contribution.
- In the current example, predictor 1 increases the growth rate by 0.5 percentage points, predictor 2 pushes it down by 0.3 points, and predictor 3 contributes +0.1 points. Thus, together these three predictors increase the prediction by +0.3 points from the average predictions of the entire sample of 0.2, leading to the final prediction of 0.5 growth.

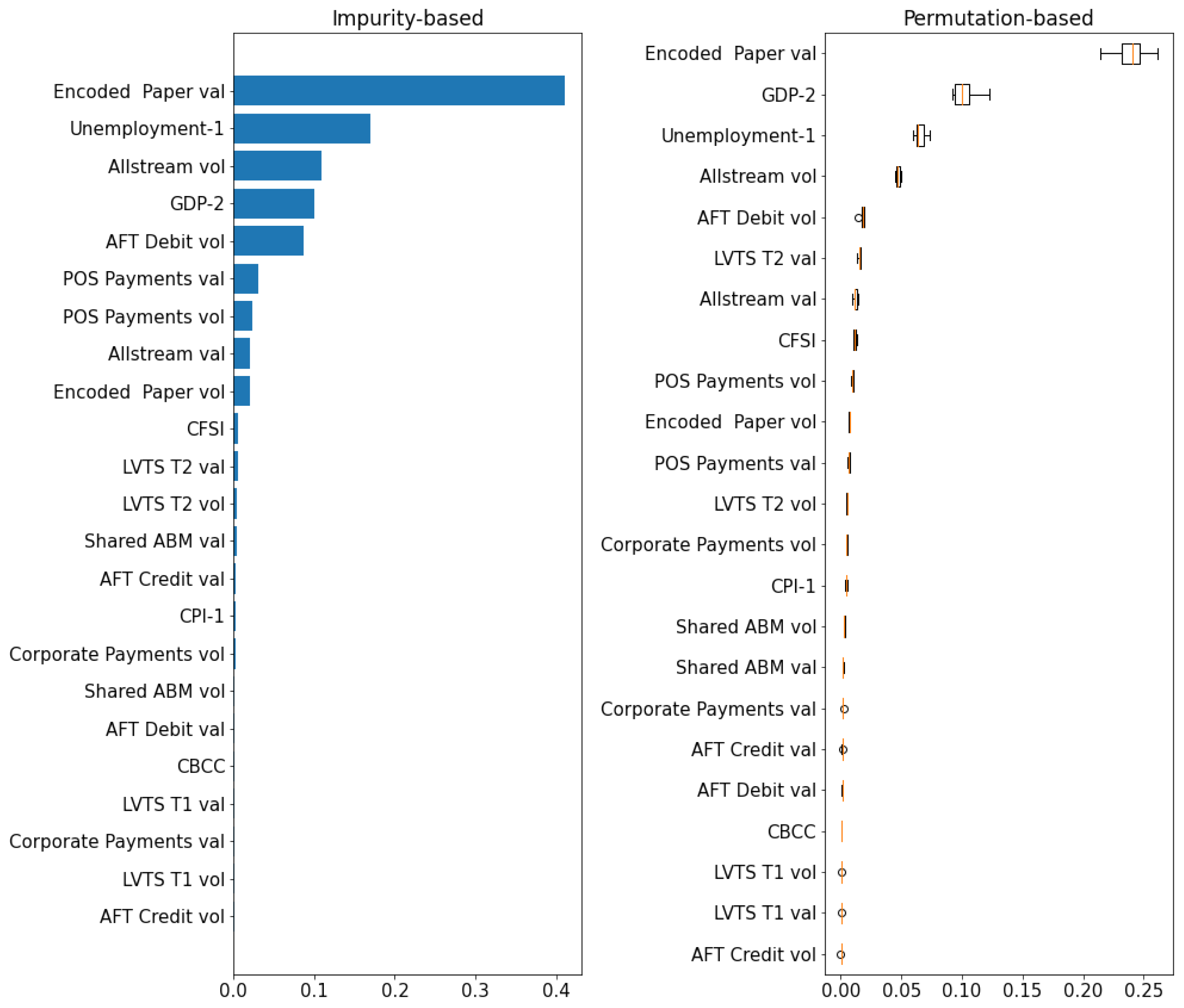
Global Feature Importance Comparison

Appendix F. Nowcasting Performance for Normal and COVID-19 Periods

| Targets | Pre-COVID-19 Test Set b | COVID-19 Test Set c |
|---|---|---|
| GDP | 16 | 34 |
| RTS | 14 | 35 |
| WTS | 27 | 37 |
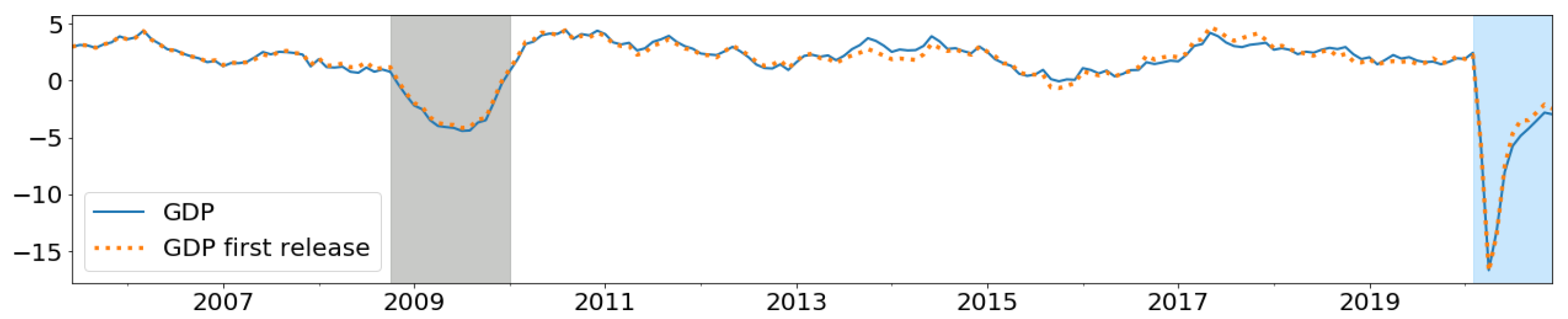
Appendix G. Nowcasting Performance for First and Latest Vintages
| Nowcasting Horizon b | Latest Vintages c | Real-Time Vintages d |
|---|---|---|
| t | 3.73 | 3.88 |
| 2.61 | 2.92 | |
| 2.66 | 2.68 |

References
- Giannone, D.; Reichlin, L.; Small, D. Nowcasting: The real-time informational content of macroeconomic data. J. Monet. Econ. 2008, 55, 665–676. [Google Scholar] [CrossRef]
- Angelini, E.; Camba-Mendez, G.; Giannone, D.; Reichlin, L.; Rünstler, G. Short-term forecasts of Euro area GDP growth. Econom. J. 2011, 14, C25–C44. [Google Scholar] [CrossRef]
- Spange, M. Can Crises be Predicted. Danmarks National Monetary Review. 2010. Available online: https://www.nationalbanken.dk/en/publications/Documents/2010/07/can%20crises_2q_2010.pdf (accessed on 6 October 2023).
- Hamilton, J.D. Calling recessions in real time. Int. J. Forecast. 2011, 27, 1006–1026. [Google Scholar] [CrossRef]
- Choi, H.; Varian, H. Predicting the present with Google Trends. Econ. Rec. 2012, 88, 2–9. [Google Scholar] [CrossRef]
- Buono, D.; Mazzi, G.L.; Kapetanios, G.; Marcellino, M.; Papailias, F. Big data types for macroeconomic nowcasting. Eurostat Rev. Natl. Acc. Macroecon. Indic. 2017, 1, 93–145. [Google Scholar]
- Bok, B.; Caratelli, D.; Giannone, D.; Sbordone, A.M.; Tambalotti, A. Macroeconomic nowcasting and forecasting with big data. Annu. Rev. Econ. 2018, 10, 615–643. [Google Scholar] [CrossRef]
- Kapetanios, G.; Papailias, F. Big Data & Macroeconomic Nowcasting: Methodological Review; Technical Report; Discussion Papers ESCoE DP-2018-12; Economic Statistics Centre of Excellence: London, UK, 2018.
- Galbraith, J.W.; Tkacz, G. Nowcasting with payments system data. Int. J. Forecast. 2018, 34, 366–376. [Google Scholar] [CrossRef]
- Koop, G.; Onorante, L. Macroeconomic Nowcasting Using Google Probabilities. In Topics in Identification, Limited Dependent Variables, Partial Observability, Experimentation, and Flexible Modeling: Part A; Emerald Publishing Limited: Bradford, UK, 2019; Volume 40, pp. 17–40. [Google Scholar]
- Foroni, C.; Marcellino, M.; Stevanovic, D. Forecasting the COVID-19 recession and recovery: Lessons from the financial crisis. Int. J. Forecast. 2022, 38, 596–612. [Google Scholar] [CrossRef]
- Babii, A.; Ghysels, E.; Striaukas, J. Machine learning time series regressions with an application to nowcasting. J. Bus. Econ. Stat. 2021, 40, 1094–1106. [Google Scholar] [CrossRef]
- Cimadomo, J.; Giannone, D.; Lenza, M.; Monti, F.; Sokol, A. Nowcasting with large Bayesian vector autoregressions. J. Econom. 2022, 231, 500–519. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer Science & Business Media: Dordrecht, The Netherlands, 2009. [Google Scholar]
- Ahmed, N.K.; Atiya, A.F.; Gayar, N.E.; El-Shishiny, H. An empirical comparison of machine learning models for time series forecasting. Econom. Rev. 2010, 29, 594–621. [Google Scholar] [CrossRef]
- Athey, S.; Imbens, G.W. Machine Learning Methods That Economists Should Know About. Annu. Rev. Econ. 2019, 11, 685–725. [Google Scholar] [CrossRef]
- Carlsen, M.; Storgaard, P.E. Dankort Payments as a Timely Indicator of Retail Sales in Denmark; Technical Report; Danmarks Nationalbank Working Papers 66; Danmarks Nationalbank: Copenhagen, Denmark, 2010; Available online: http://hdl.handle.net/10419/82313 (accessed on 6 October 2023).
- Barnett, W.; Chauvet, M.; Leiva-Leon, D.; Su, L. Nowcasting Nominal GDP with the Credit-Card Augmented Divisia Monetary Aggregates; Technical Report; The Johns Hopkins Institute for Applied Economics: Baltimore, MD, USA, 2016; Available online: https://ideas.repec.org/p/pra/mprapa/73246.html (accessed on 6 October 2023).
- Duarte, C.; Rodrigues, P.M.; Rua, A. A mixed frequency approach to the forecasting of private consumption with ATM/POS data. Int. J. Forecast. 2017, 33, 61–75. [Google Scholar] [CrossRef]
- Aprigliano, V.; Ardizzi, G.; Monteforte, L.; d’Italia, B. Using the payment system data to forecast the economic activity. Int. J. Cent. Bank. 2019, 15, 55–80. [Google Scholar]
- Galbraith, J.; Tkacz, G. Electronic Transactions as High-Frequency Indicators of Economic Activity; Technical Report; Bank of Canada: Ottawa, ON, Canada, 2007. [Google Scholar] [CrossRef]
- Paturi, P.; Chiron, C. Canadian Payments: Methods and Trends 2020; Technical Report; Payments Canada Report; Payments Canada: Ottawa, ON, Canada, 2020; Available online: https://www.payments.ca/sites/default/files/paymentscanada_canadianpaymentsmethodsandtrendsreport_2020.pdf (accessed on 6 October 2023).
- Chapman, J.T.; Desai, A. Using Payments Data to Nowcast Macroeconomic Variables During the Onset of COVID-19. J. Financ. Mark. Infrastructures 2020, 9, 1–29. [Google Scholar] [CrossRef]
- Chakraborty, C.; Joseph, A. Machine Learning at Central Banks; Technical Report; Bank of England Working Paper No. 674; Elsevier: Amsterdam, The Netherlands, 2017; Available online: https://ssrn.com/abstract=3031796 (accessed on 6 October 2023).
- Richardson, A.; van Florenstein Mulder, T.; Vehbi, T. Nowcasting GDP using machine-learning algorithms: A real-time assessment. Int. J. Forecast. 2021, 37, 941–948. [Google Scholar] [CrossRef]
- Maehashi, K.; Shintani, M. Macroeconomic forecasting using factor models and machine learning: An application to Japan. J. Jpn. Int. Econ. 2020, 58, 101104. [Google Scholar] [CrossRef]
- Yoon, J. Forecasting of real GDP growth using machine learning models: Gradient boosting and random forest approach. Comput. Econ. 2021, 57, 247–265. [Google Scholar] [CrossRef]
- Gogas, P.; Papadimitriou, T.; Sofianos, E. Forecasting unemployment in the Euro area with machine learning. J. Forecast. 2022, 41, 551–566. [Google Scholar] [CrossRef]
- Vrontos, S.D.; Galakis, J.; Vrontos, I.D. Modeling and predicting US recessions using machine learning techniques. Int. J. Forecast. 2021, 37, 647–671. [Google Scholar] [CrossRef]
- Coulombe, P.G.; Marcellino, M.; Stevanovic, D. Can machine learning catch the COVID-19 recession? Natl. Inst. Econ. Rev. 2021, 256, 71–109. [Google Scholar] [CrossRef]
- Liu, J.; Li, C.; Ouyang, P.; Liu, J.; Wu, C. Interpreting the prediction results of the tree-based gradient boosting models for financial distress prediction with an explainable machine learning approach. J. Forecast. 2022, 42, 1112–1137. [Google Scholar] [CrossRef]
- Mullainathan, S.; Spiess, J. Machine learning: An applied econometric approach. J. Econ. Perspect. 2017, 31, 87–106. [Google Scholar] [CrossRef]
- Athey, S. The impact of machine learning on economics. In Economics of Artificial Intelligence; University of Chicago Press: Chicago, IL, USA, 2017; Available online: http://www.nber.org/chapters/c14009 (accessed on 6 October 2023).
- Duprey, T. Canadian Financial Stress and Macroeconomic Conditions; Technical Report; Bank of Canada: Ottawa, ON, Canada, 2020. [Google Scholar] [CrossRef]
- Kwan, A.C.; Cotsomitis, J.A. The usefulness of consumer confidence in forecasting household spending in Canada: A national and regional analysis. Econ. Inq. 2006, 44, 185–197. [Google Scholar] [CrossRef]
- Athey, S.; Tibshirani, J.; Wager, S. Generalized random forests. Ann. Stat. 2019, 47, 1148–1178. [Google Scholar] [CrossRef]
- Buckmann, M.; Joseph, A.; Robertson, H. Opening the Black Box: Machine Learning Interpretability and Inference Tools with an Application to Economic Forecasting. In Data Science for Economics and Finance; Springer: Cham, Switzerland, 2021; pp. 43–63. [Google Scholar] [CrossRef]
- Bergmeir, C.; Benítez, J.M. On the use of cross-validation for time series predictor evaluation. Inf. Sci. 2012, 191, 192–213. [Google Scholar] [CrossRef]
- Bergmeir, C.; Hyndman, R.J.; Koo, B. A note on the validity of cross-validation for evaluating autoregressive time series prediction. Comput. Stat. Data Anal. 2018, 120, 70–83. [Google Scholar] [CrossRef]
- Chu, C.K.; Marron, J.S. Comparison of two bandwidth selectors with dependent errors. Ann. Stat. 1991, 19, 1906–1918. [Google Scholar] [CrossRef]
- Varian, H.R. Big data: New tricks for econometrics. J. Econ. Perspect. 2014, 28, 3–28. [Google Scholar] [CrossRef]
- Kuhn, M.; Johnson, K. Applied Predictive Modeling; Springer: Berlin/Heidelberg, Germany, 2013; Volume 26, Available online: https://vuquangnguyen2016.files.wordpress.com/2018/03/applied-predictive-modeling-max-kuhn-kjell-johnson_1518.pdf (accessed on 6 October 2023).
- Lundberg, S.M.; Lee, S.I. A Unified Approach to Interpreting Model Predictions. In Advances in Neural Information Processing Systems 30; Curran Associates, Inc.: Nice, France, 2017; pp. 4765–4774. Available online: https://arxiv.org/abs/1705.07874 (accessed on 6 October 2023).
- Lundberg, S.M.; Erion, G.; Chen, H.; DeGrave, A.; Prutkin, J.M.; Nair, B.; Katz, R.; Himmelfarb, J.; Bansal, N.; Lee, S.I. From local explanations to global understanding with explainable AI for trees. Nat. Mach. Intell. 2020, 2, 2522–5839. [Google Scholar] [CrossRef]
- Shapley, L.S. A value for n-person games. Contrib. Theory Games 1953, 2, 307–317. [Google Scholar]
- Osborne, M.J.; Rubinstein, A. A Course in Game Theory; MIT Press: Cambridge, MA, USA, 1994; Available online: https://arielrubinstein.tau.ac.il/books/GT.pdf (accessed on 6 October 2023).
- Dahlhaus, T.; Welte, A. Payment Habits During COVID-19: Evidence from High-Frequency Transaction Data; Technical Report; Bank of Canada: Ottawa, ON, Canada, 2021. [Google Scholar] [CrossRef]
- Desai, A.; Lu, Z.; Rodrigo, H.; Sharples, J.; Tian, P.; Zhang, N. From LVTS to Lynx: Quantitative assessment of payment system transition in Canada. J. Paym. Strategy Syst. 2023, 17, 291–314. [Google Scholar]
- Arjani, N.; McVanel, D. A Primer on Canada’s Large Value Transfer System. 2006. Available online: https://www.bankofcanada.ca/wp-content/uploads/2010/05/lvts_neville.pdf (accessed on 6 October 2023).
- X13 Reference Manual. X-13ARIMA-SEATS Reference Manual, Version 1.1; Technical Report; Time Series Research Staff; Center for Statistical Research and Methodology, U.S. Census Bureau: Washington, DC, USA, 2017. Available online: https://www.census.gov/ts/x13as/docX13AS.pdf (accessed on 6 October 2023).
- Bank of Canada. Monetary Policy Report—April 2020; Technical Report; Bank of Canada: Ottawa, ON, Canada, 2020; Available online: https://www.bankofcanada.ca/wp-content/uploads/2020/04/mpr-2020-04-15.pdf (accessed on 6 October 2023).
- Stock, J.; Watson, M. Chapter 8—Dynamic Factor Models, Factor-Augmented Vector Autoregressions, and Structural Vector Autoregressions in Macroeconomics; Elsevier: Amsterdam, The Netherlands, 2016; Volume 2, pp. 415–525. [Google Scholar] [CrossRef]
- Chernis, T.; Sekkel, R. A dynamic factor model for nowcasting Canadian GDP growth. Empir. Econ. 2017, 53, 217–234. [Google Scholar] [CrossRef]
- Bańbura, M.; Modugno, M. Maximum likelihood estimation of factor models on datasets with arbitrary pattern of missing data. J. Appl. Econom. 2014, 29, 133–160. [Google Scholar] [CrossRef]
- Bańbura, M.; Giannone, D.; Reichlin, L. Nowcasting; Technical Report; ECB Working Paper No. 1275; Elsevier: Amsterdam, The Netherlands, 2010; Available online: https://ssrn.com/abstract=1717887 (accessed on 6 October 2023).
- Hindrayanto, I.; Koopman, S.J.; de Winter, J. Forecasting and nowcasting economic growth in the Euro area using factor models. Int. J. Forecast. 2016, 32, 1284–1305. [Google Scholar] [CrossRef]
- Bragoli, D. Now-casting the Japanese economy. Int. J. Forecast. 2017, 33, 390–402. [Google Scholar] [CrossRef]
- Coulombe, P.G.; Leroux, M.; Stevanovic, D.; Surprenant, S. How is machine learning useful for macroeconomic forecasting? arXiv 2020, arXiv:2008.12477. [Google Scholar] [CrossRef]
- Zou, H.; Hastie, T. Regularization and variable selection via the elastic net. J. R. Stat. Soc. Stat. Methodol. 2005, 67, 301–320. [Google Scholar] [CrossRef]
- Smola, A.J.; Schölkopf, B. A tutorial on support vector regression. Stat. Comput. 2004, 14, 199–222. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Bengio, Y. Learning deep architectures for AI. Found. Trends® Mach. Learn. 2009, 2, 1–127. [Google Scholar] [CrossRef]
- Friedman, J.; Hastie, T.; Tibshirani, R. The Elements of Statistical Learning; Springer Series in Statistics; Springer: New York, NY, USA, 2001; Volume 1. [Google Scholar] [CrossRef]
- Burges, C.J. A tutorial on support vector machines for pattern recognition. Data Min. Knowl. Discov. 1998, 2, 121–167. [Google Scholar] [CrossRef]
- Liaw, A.; Wiener, M. Classification and regression by Random Forest. R News 2002, 2, 18–22. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; Available online: https://www.deeplearningbook.org/ (accessed on 6 October 2023).
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.Y. Lightgbm: A highly efficient gradient boosting decision tree. In Proceedings of the Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2017; pp. 3146–3154. Available online: https://lightgbm.readthedocs.io/en/latest/ (accessed on 6 October 2023).
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Molnar, C. Interpretable Machine Learning; Lulu.com:Morrisville USA 2020. Available online: https://christophm.github.io/interpretable-ml-book/ (accessed on 6 October 2023).
- Alvarez-Melis, D.; Jaakkola, T.S. On the robustness of interpretability methods. arXiv 2018, arXiv:1806.08049. [Google Scholar]
- Slack, D.; Hilgard, S.; Jia, E.; Singh, S.; Lakkaraju, H. Fooling LIME and SHAP: Adversarial attacks on post hoc explanation methods. In Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society, New York, NY, USA, 7–8 February 2020; pp. 180–186. Available online: https://dl.acm.org/doi/pdf/10.1145/3375627.3375830 (accessed on 6 October 2023).
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Breiman, L. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef]










| Stream (ID) | Short Description |
|---|---|
| AFT credit (C) b | Government direct deposit (GDD): payrolls and account transfers |
| AFT debit (D) | Pre-authorized debit (PAD): automated bill and mortgage payments |
| Encoded paper (E) c | Paper bills of exchange: cheques, bank drafts, and paper PAD |
| Shared ABM (N) | Debit card payments to withdraw cash at shared ABM network |
| POS payments (P) d | Point-of-sale (POS) payments using debit card |
| Corporate payments (X) e | Exchange of corporate-to-corporate and bill payments |
| Allstream (All) f | The sum of all payment streams settled in the ACSS |
| LVTS-T1 (T1) g | Time-critical payments and payments to the Bank of Canada |
| LVTS-T2 (T2) h | Security settlement, foreign exchange, and other obligations |
- a The first six payment streams are representative of 20 payment instruments processed separately in the ACSS. There are a few additional payment instruments. However, they are not available for the entire period considered in this paper. Therefore, they are excluded from this study. The excluded streams are ICP regional image payments and ICP regional image payments return. Note: Excluded streams collectively account for only 0.001% of the total value settled in the system. For further details on individual ACSS streams, see Appendix A.
- b Stream C is the sum of AFT credit and Government direct deposit streams. We combine them because, starting in April 2012, Government direct deposit was separated from the AFT credit stream and processed independently.
- c Stream E is the sum of multiple streams settled separately in the ACSS. It combines encoded paper (E), largevalue encoded paper (L), image captured payments (O), Canada Savings Bonds (B), Receiver General warrants (G), and Treasury bills and bonds (H). It subtracts image-captured returns (S), unqualified (U), and computer rejects (Z) streams. We combine all of them because, over time, many of these streams were separated from the encoded paper stream and process similar types of payments.
- d The value and volume of stream P are obtained by summing online payments (J) and POS payments (P) streams and subtracting online returns (K) and POS refunds (Q) streams.
- e Stream X is the sum of paper remittances (F), EDI payments (X), and EDI remittances (Y). This stream is composed of all corporate-to-corporate payments and corporate bill payments and remittances.
- f Allstream is the sum of all payment streams processed in the ACSS.
- g We exclude payments from the Bank of Canada in stream T1.
- h The LVTS processes payment values equivalent to the annual GDP every five days, and the majority of the value and volume settled in the LVTS is processed in stream T2.
| Target b | Benchmark c | Main DFM d | Main ML e | RMSE Reduction (%) f |
|---|---|---|---|---|
| GDP | 4.58 | 3.95 | 3.70 | 19 |
| RTS | 7.88 | 7.40 | 7.38 | 7 |
| WTS | 6.34 | 5.81 | 5.74 | 10 |
| GDP | 3.97 | 2.98 | 2.43 * | 39 |
| RTS | 8.47 | 6.36 | 5.44 * | 36 |
| WTS | 7.17 | 6.18 | 4.28 * | 41 |
| GDP | 2.84 | 2.63 | 2.18 | 23 |
| RTS | 7.60 | 6.15 | 5.55 | 25 |
| WTS | 6.24 | 5.76 | 4.72 | 24 |
- a In-sample training period, Mar 2005–Dec 2018, and out-of-sample testing period, Jan 2019–Dec 2020.
- b GDP—gross domestic product; RTS—retail trade sales; WTS—wholesale trade sales. Note: we use the latest available values of these targets. We also perform similar exercises by using target variables at first release (real-time vintages). These results are presented in Appendix G.
- c As a benchmark, we use OLS with CPI, UNE, CFSI, CBCC, and the first available lagged target variable (i.e., the second lag at nowcasting horizon t).
- d For the main DFM case, we use payments data along with the predictors in the benchmark case. Similar to the model employed in [53], we use the DFM model with two factors and one lag in the VAR driving the dynamics of those factors. Idiosyncratic components are assumed to follow an AR(1) process. Note: including additional factors does not improve model performance.
- e We use GBR because it consistently performs better than other ML models (see Table A1 in Appendix B). We select model parameters using the cross-validation procedure outlined in Appendix C and Appendix D. For example, the selected model for GDP nowcasting at t + 1: learning_rate is 0.1, max_depth is 1, and n_estimators is 1000 (see Appendix B for further details).
- f Percentage reduction in RMSE over the benchmark model using ML on the main case. * denote statistical significance at the 10% level, for the Diebold–Mariano test using the benchmark.
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the Bank of Canada. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chapman, J.T.E.; Desai, A. Macroeconomic Predictions Using Payments Data and Machine Learning. Forecasting 2023, 5, 652-683. https://doi.org/10.3390/forecast5040036
Chapman JTE, Desai A. Macroeconomic Predictions Using Payments Data and Machine Learning. Forecasting. 2023; 5(4):652-683. https://doi.org/10.3390/forecast5040036
Chicago/Turabian StyleChapman, James T. E., and Ajit Desai. 2023. "Macroeconomic Predictions Using Payments Data and Machine Learning" Forecasting 5, no. 4: 652-683. https://doi.org/10.3390/forecast5040036