
Prediction of Voice Fundamental Frequency and Intensity from Surface Electromyographic Signals of the Face and Neck

 ,
,
Abstract
:1. Introduction
2. Materials and Methods
2.1. Participants
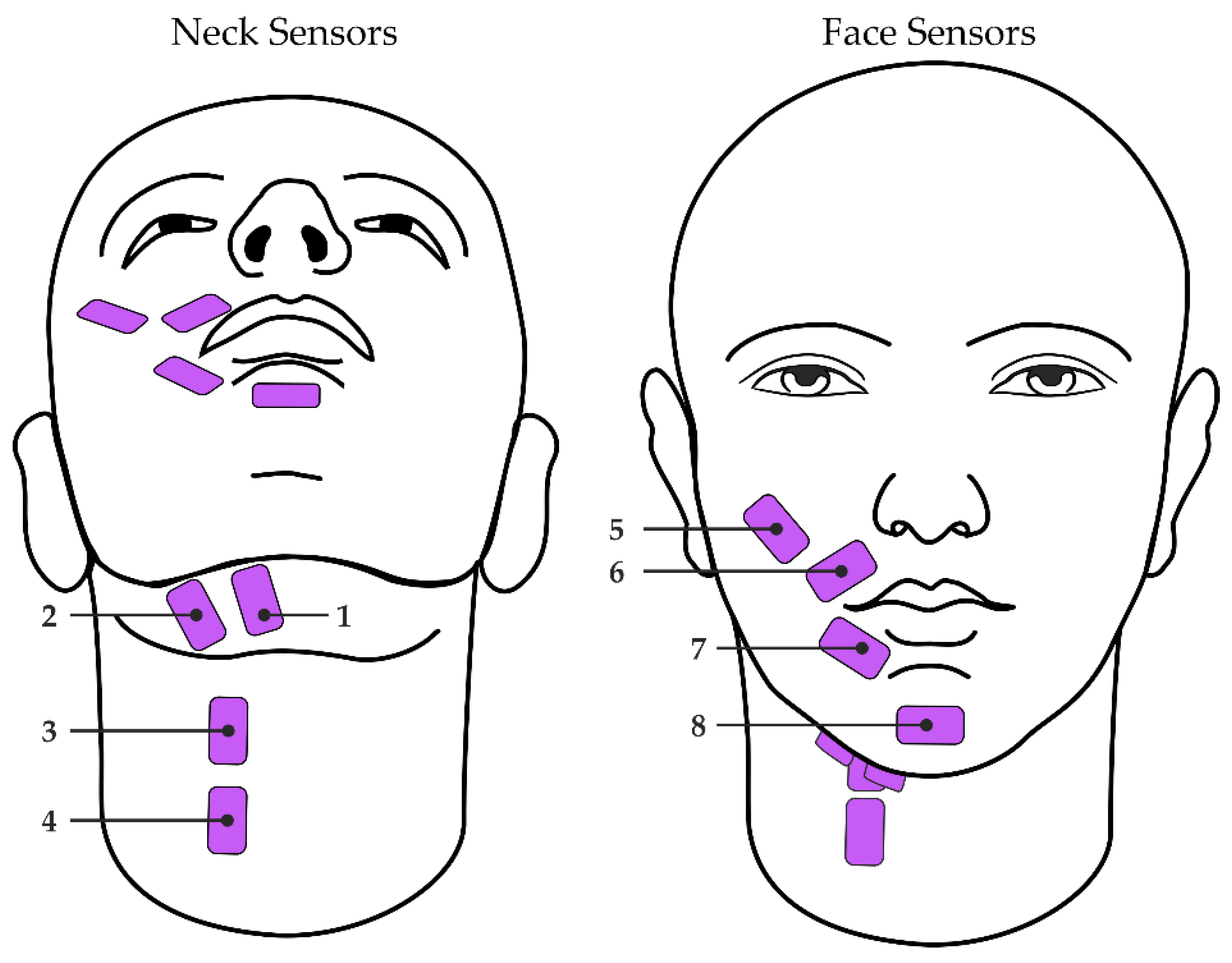
2.2. Experimental Protocol
- Tones—Sustained vowels /a/, /i/, /u/, and /ae/ produced for 3–5 s at a constant pitch and loudness (normative, high/low pitch, high/low loudness)
- Legatos—Continuous slide from one pitch to another for vowels /a/, /i/, /u/, or /ae/
- VCV Syllables—Vowel-consonant-vowel sequences (e.g., /afa/) where both vowels are equally stressed or only one vowel is stressed
- Phrases—Standard, short speech tokens uttered in a normal speaking voice
- Reading Passages—Standard passages uttered in a normal speaking voice
- Questions—Short segments of unstructured speech in response to a question
- Monologues—Long segments of unstructured speech in response to a prompt
2.3. Data Processing
2.3.1. Signal Alignment
2.3.2. Voice fo and Intensity Contour Extraction
2.3.3. Feature Extraction
2.3.4. Data Splitting
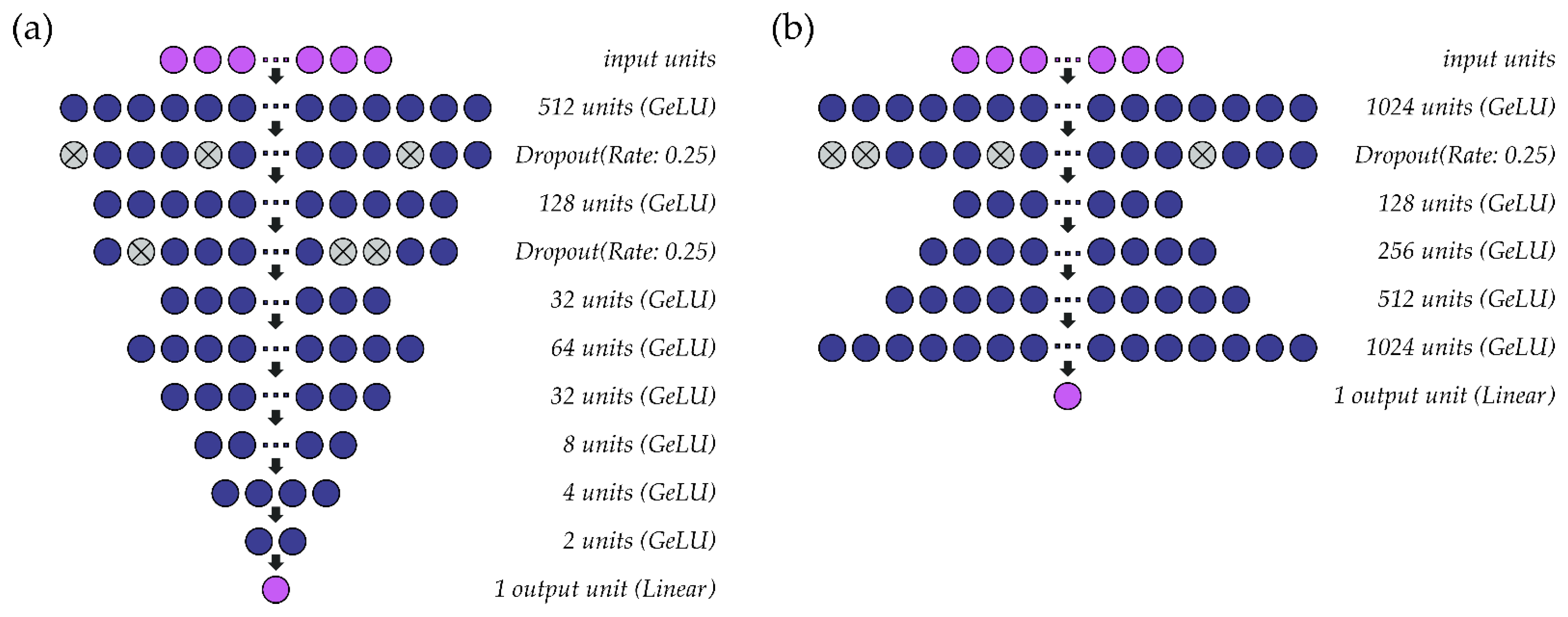
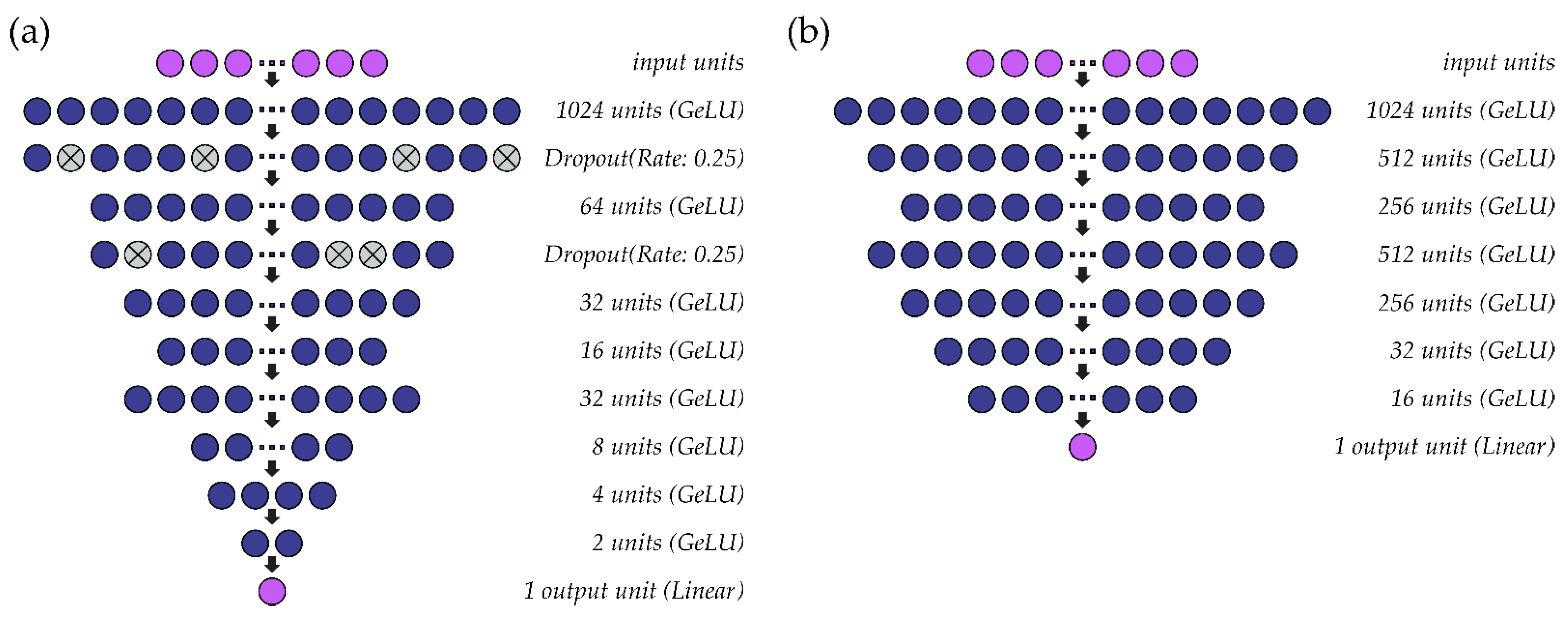
2.4. Model Development
2.5. Model Performance
3. Results
3.1. Single-Speaker Models
3.1.1. Training and Validation Set Performance
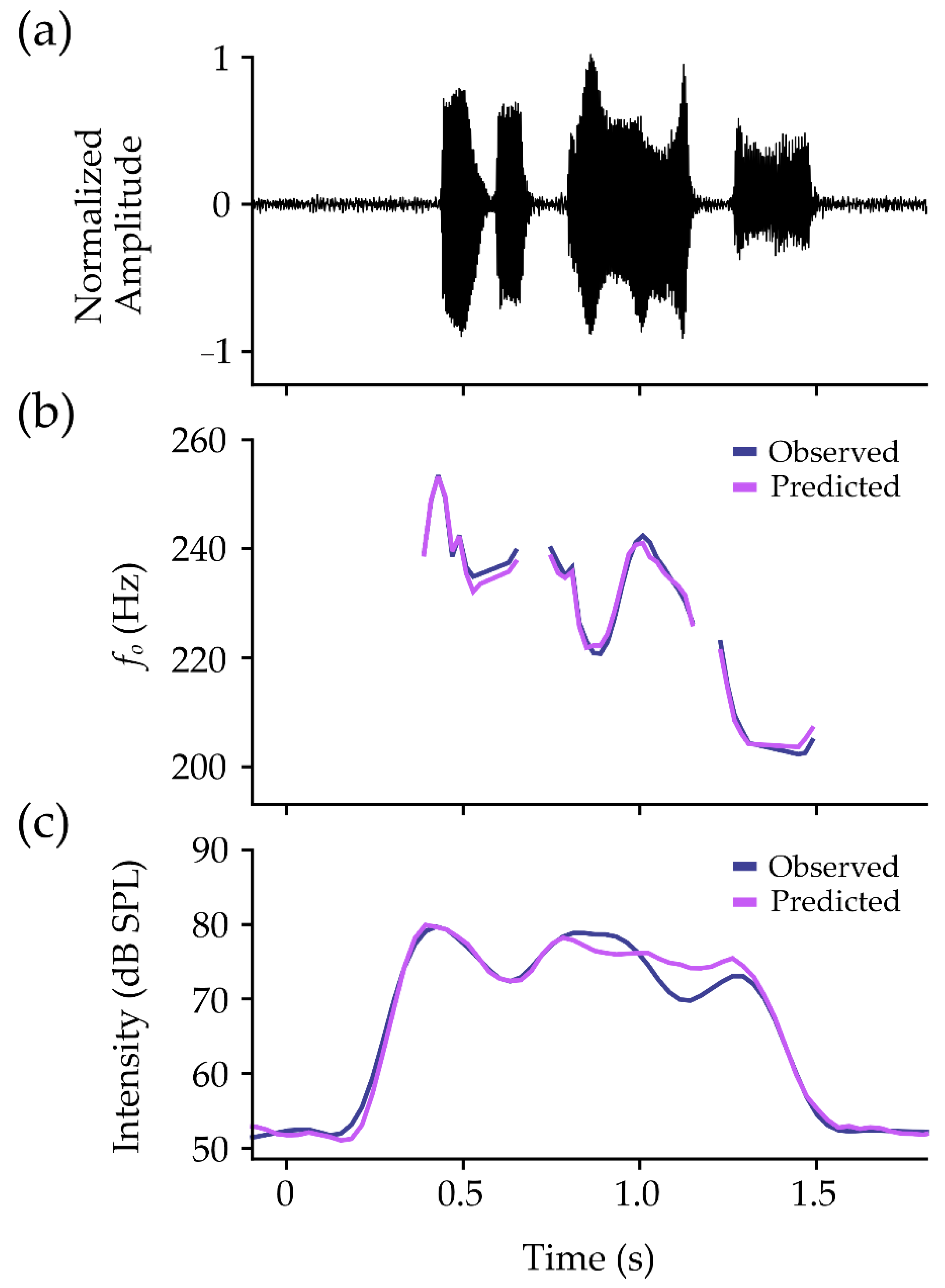
3.1.2. Test Set Performance
3.2. Multi-Speaker Models
4. Discussion
4.1. Single-Speaker vs. Multi-Speaker Models
4.2. Significance of Single-Speaker Model Performance
4.2.1. Comparisons to Model Performance in the Literature
4.2.2. Comparisons to Meaningful Changes in fo and Intensity
4.3. Physiological Interprations of Model Performance
4.4. Limitations and Future Directions
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Task | Description | Subtasks |
|---|---|---|
| Tones | Sustained vowels /a/, /i/, /u/, and /ae/ produced at a constant pitch and loudness, repeated three times for each variation | 1. Typical pitch and loudness |
| 2. High pitch | ||
| 3. Low pitch | ||
| 4. High intensity | ||
| 5. Low intensity | ||
| Legatos | Continuous slide from one pitch to another using the vowels /a/, /i/, /u/, and /ae/ | 1. Low pitch |
| 2. Mid pitch | ||
| 3. High pitch | ||
| VCV a Syllables | Bisyllabic productions repeated three times for each variation | 1. Equal stress |
| 2. Stress on first vowel | ||
| 3. Stress on second vowel | ||
| Phrases | Standard, short speech tokens that introduce various stress placements | 1. UNL Phrases |
| 2. RFF Phrases | ||
| Reading Passages | Standard reading passages that introduce various stress placements | 1. The Caterpillar Passage |
| 2. My Grandfather Passage | ||
| 3. Rainbow Passage | ||
| 4. Golf Passage | ||
| 5. Pronunciation Reading Passage | ||
| 6. Please Call Stella | ||
| 7. Comma Gets a Cure | ||
| 8. Frog and Toad | ||
| 9. Excerpt from Harry Potter and the Chamber of Secrets | ||
| 10. Excerpt from The Little Prince | ||
| 11. Excerpt from the Boston University Radio Speech Corpus | ||
| Questions | Short (<30 s) segment of unstructured, conversational speech | 1. If you could live in any decade, what would it be and why? |
| 2. What is your favorite time of day and why? | ||
| 3. If you were to make a movie about your life, what genre would you choose and why? | ||
| 4. How did you get here today? | ||
| 5. Do you have any vacation or travel plans? | ||
| 6. Tell me about how the weather has been recently. | ||
| 7. What did you do last weekend? | ||
| Monologues | Long (>60 s) segment of unstructured, conversational speech | 1. Tell me how to make a peanut butter and jelly sandwich. |
| 2. Tell me how you do your laundry. | ||
| 3. Tell me how you get ready for work. | ||
| 4. Tell me how you make your bed. |
Appendix B
| ID | MAPE (%) | r | CCC | RMSE (ST) | MBE (ST) | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Train | Valid | Train | Valid | Train | Valid | Train | Valid | Train | Valid | |
| 1 | 1.36 (0.04) | 2.21 (0.71) | 0.98 (0.00) | 0.92 (0.06) | 0.97 (0.00) | 0.90 (0.08) | 0.29 (0.01) | 0.49 (0.16) | 0.23 (0.01) | 0.38 (0.13) |
| 2 | 1.27 (0.03) | 2.07 (0.43) | 0.98 (0.00) | 0.93 (0.04) | 0.97 (0.00) | 0.92 (0.04) | 0.28 (0.01) | 0.46 (0.10) | 0.22 (0.01) | 0.36 (0.07) |
| 3 | 1.60 (0.02) | 1.69 (0.08) | 0.98 (0.00) | 0.98 (0.00) | 0.98 (0.00) | 0.97 (0.00) | 0.34 (0.00) | 0.36 (0.02) | 0.28 (0.00) | 0.29 (0.01) |
| 4 | 1.79 (0.04) | 2.69 (0.75) | 0.97 (0.00) | 0.92 (0.06) | 0.97 (0.00) | 0.91 (0.06) | 0.38 (0.01) | 0.60 (0.18) | 0.31 (0.01) | 0.47 (0.13) |
| 5 | 1.66 (0.02) | 3.67 (2.63) | 0.97 (0.00) | 0.80 (0.29) | 0.97 (0.00) | 0.78 (0.32) | 0.36 (0.01) | 0.77 (0.51) | 0.29 (0.00) | 0.62 (0.43) |
| 6 | 1.79 (0.02) | 2.77 (0.80) | 0.97 (0.00) | 0.93 (0.06) | 0.97 (0.00) | 0.92 (0.06) | 0.39 (0.01) | 0.61 (0.20) | 0.31 (0.00) | 0.48 (0.14) |
| 7 | 1.63 (0.02) | 2.66 (0.84) | 0.98 (0.00) | 0.93 (0.06) | 0.98 (0.00) | 0.92 (0.06) | 0.35 (0.00) | 0.59 (0.20) | 0.28 (0.00) | 0.46 (0.15) |
| 8 | 1.13 (0.01) | 1.23 (0.09) | 0.98 (0.00) | 0.98 (0.00) | 0.98 (0.00) | 0.98 (0.00) | 0.25 (0.00) | 0.27 (0.02) | 0.19 (0.00) | 0.21 (0.02) |
| 9 | 1.80 (0.03) | 3.03 (1.18) | 0.97 (0.00) | 0.89 (0.11) | 0.97 (0.00) | 0.88 (0.13) | 0.38 (0.01) | 0.68 (0.29) | 0.31 (0.00) | 0.53 (0.21) |
| 10 | 1.78 (0.01) | 1.86 (0.02) | 0.97 (0.00) | 0.97 (0.00) | 0.97 (0.00) | 0.97 (0.00) | 0.38 (0.00) | 0.40 (0.00) | 0.31 (0.00) | 0.32 (0.00) |
| ID | MAPE (%) | r | CCC | RMSE (dB SPL) | MBE (dB SPL) | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Train | Valid | Train | Valid | Train | Valid | Train | Valid | Train | Valid | |
| 1 | 1.96 (0.31) | 3.88 (2.77) | 0.99 (0.00) | 0.90 (0.15) | 0.99 (0.00) | 0.89 (0.17) | 1.7 (0.25) | 3.94 (3.00) | 1.28 (0.21) | 2.60 (1.95) |
| 2 | 2.30 (1.01) | 3.80 (1.58) | 0.99 (0.00) | 0.95 (0.05) | 0.99 (0.01) | 0.94 (0.05) | 1.72 (0.67) | 3.33 (1.38) | 1.36 (0.59) | 2.28 (0.93) |
| 3 | 1.68 (0.36) | 3.44 (2.13) | 0.97 (0.01) | 0.81 (0.23) | 0.97 (0.01) | 0.81 (0.24) | 3.90 (0.88) | 9.30 (6.42) | 2.94 (0.62) | 5.96 (3.70) |
| 4 | 1.78 (0.81) | 2.39 (0.80) | 0.96 (0.03) | 0.93 (0.05) | 0.96 (0.04) | 0.92 (0.05) | 4.16 (1.85) | 5.91 (2.01) | 3.20 (1.41) | 4.31 (1.41) |
| 5 | 2.11 (0.16) | 4.27 (1.75) | 0.99 (0.00) | 0.92 (0.08) | 0.99 (0.00) | 0.91 (0.08) | 1.68 (0.09) | 4.21 (1.99) | 1.29 (0.09) | 2.67 (1.15) |
| 6 | 1.27 (0.16) | 2.07 (0.64) | 0.98 (0.01) | 0.93 (0.06) | 0.98 (0.01) | 0.92 (0.07) | 2.83 (0.35) | 5.06 (1.91) | 2.17 (0.27) | 3.54 (1.12) |
| 7 | 2.46 (0.09) | 4.65 (0.96) | 0.99 (0.00) | 0.94 (0.03) | 0.99 (0.00) | 0.94 (0.03) | 2.33 (0.09) | 5.87 (1.47) | 1.75 (0.08) | 3.41 (0.72) |
| 8 | 2.11 (0.12) | 3.55 (1.50) | 0.99 (0.00) | 0.95 (0.06) | 0.99 (0.00) | 0.94 (0.06) | 1.72 (0.08) | 3.25 (1.51) | 1.32 (0.07) | 2.21 (0.91) |
| 9 | 1.20 (0.21) | 1.83 (0.84) | 0.98 (0.01) | 0.91 (0.12) | 0.98 (0.01) | 0.91 (0.12) | 2.28 (0.46) | 4.39 (3.00) | 1.74 (0.30) | 2.62 (1.18) |
| 10 | 1.88 (0.05) | 3.18 (1.29) | 0.99 (0.00) | 0.96 (0.04) | 0.99 (0.00) | 0.96 (0.04) | 1.50 (0.03) | 2.88 (1.34) | 1.15 (0.03) | 1.93 (0.76) |
References
- Keszte, J.; Danker, H.; Dietz, A.; Meister, E.F.; Pabst, F.; Vogel, H.-J.; Meyer, A.; Singer, S. Mental disorders and psychosocial support during the first year after total laryngectomy: A prospective cohort study. Clin. Otolaryngol. 2013, 38, 494–501. [Google Scholar] [CrossRef] [PubMed]
- Terrell, J.E.; Fisher, S.G.; Wolf, G.T. Long-term Quality of Life After Treatment of Laryngeal Cancer. Arch. Otolaryngol. Head Neck Surg. 1998, 124, 964–971. [Google Scholar] [CrossRef] [Green Version]
- Bickford, J.M.; Coveney, J.; Baker, J.; Hersh, D. Self-expression and identity after total laryngectomy: Implications for support. Psycho-Oncology 2018, 27, 2638–2644. [Google Scholar] [CrossRef]
- Lúcio, G.D.S.; Perilo, T.V.D.C.; Vicente, L.C.C.; Friche, A.A.D.L. The impact of speech disorders quality of life: A questionnaire proposal. CoDAS 2013, 25, 610–613. [Google Scholar] [CrossRef] [PubMed]
- Garcia, S.M.; Weaver, K.; Moskowitz, G.B.; Darley, J.M. Crowded minds: The implicit bystander effect. J. Pers. Soc. Psychol. 2002, 83, 843–853. [Google Scholar] [CrossRef] [PubMed]
- Denby, B.; Schultz, T.; Honda, K.; Hueber, T.; Gilbert, J.; Brumberg, J. Silent speech interfaces. Speech Commun. 2009, 52, 270–287. [Google Scholar] [CrossRef] [Green Version]
- Fabre, D.; Hueber, T.; Girin, L.; Alameda-Pineda, X.; Badin, P. Automatic animation of an articulatory tongue model from ultrasound images of the vocal tract. Speech Commun. 2017, 93, 63–75. [Google Scholar] [CrossRef]
- Hueber, T.; Benaroya, E.-L.; Chollet, G.; Denby, B.; Dreyfus, G.; Stone, M. Development of a silent speech interface driven by ultrasound and optical images of the tongue and lips. Speech Commun. 2009, 52, 288–300. [Google Scholar] [CrossRef] [Green Version]
- Crevier-Buchman, L.; Gendrot, C.; Denby, B.; Pillot-Loiseau, C.; Roussel, P.; Colazo-Simon, A.; Dreyfus, G. Articulatory strategies for lip and tongue movements in silent versus vocalized speech. In Proceedings of the 17th International Congress of Phonetic Science, Hong Kong, China, 17–21 August 2011; pp. 1–4. [Google Scholar]
- Kimura, N.; Gemicioglu, T.; Womack, J.; Li, R.; Zhao, Y.; Bedri, A.; Su, Z.; Olwal, A.; Rekimoto, J.; Starner, T. SilentSpeller: Towards mobile, hands-free, silent speech text entry using electropalatography. In Proceedings of the CHI ‘22: Proceedings of the 2022 CHI Conference on Human Factors in Computing Systems, New Orleans, LA, USA, 29 April–5 May 2022; pp. 1–19. [Google Scholar] [CrossRef]
- Fagan, M.; Ell, S.; Gilbert, J.; Sarrazin, E.; Chapman, P. Development of a (silent) speech recognition system for patients following laryngectomy. Med. Eng. Phys. 2008, 30, 419–425. [Google Scholar] [CrossRef] [PubMed]
- Hirahara, T.; Otani, M.; Shimizu, S.; Toda, T.; Nakamura, K.; Nakajima, Y.; Shikano, K. Silent-speech enhancement using body-conducted vocal-tract resonance signals. Speech Commun. 2010, 52, 301–313. [Google Scholar] [CrossRef] [Green Version]
- Nakajima, Y.; Kashioka, H.; Shikano, K.; Campbell, N. Non-audible murmur recognition input interface using stethoscopic microphone attached to the skin. In Proceedings of the 2003 IEEE International Conference on Acoustics, Speech, and Signal Processing, Hong Kong, China, 6–10 April 2003; pp. 708–711. [Google Scholar] [CrossRef] [Green Version]
- Meltzner, G.S.; Heaton, J.T.; Deng, Y.; De Luca, G.; Roy, S.H.; Kline, J.C. Development of sEMG sensors and algorithms for silent speech recognition. J. Neural Eng. 2018, 15, 046031. [Google Scholar] [CrossRef]
- Meltzner, G.S.; Heaton, J.T.; Deng, Y.; De Luca, G.; Roy, S.H.; Kline, J.C. Silent Speech Recognition as an Alternative Communication Device for Persons With Laryngectomy. IEEE/ACM Trans. Audio Speech Lang. Process. 2017, 25, 2386–2398. [Google Scholar] [CrossRef]
- Maier-Hein, L.; Metze, F.; Schultz, T.; Waibel, A. Session independent non-audible speech recognition using surface electromyography. In Proceedings of the IEEE Workshop on Automatic Speech Recognition and Understanding, Cancun, Mexico, 27 November–1 December 2005; pp. 331–336. [Google Scholar] [CrossRef] [Green Version]
- Jou, S.-C.; Schultz, T.; Walliczek, M.; Kraft, F.; Waibel, A. Towards continuous speech recognition using surface electromyography. In Proceedings of the Ninth International Conference on Spoken Language Processing, Pittsburgh, PA, USA, 17–21 December 2006. [Google Scholar] [CrossRef]
- Vojtech, J.M.; Chan, M.D.; Shiwani, B.; Roy, S.H.; Heaton, J.T.; Meltzner, G.S.; Contessa, P.; De Luca, G.; Patel, R.; Kline, J.C. Surface Electromyography–Based Recognition, Synthesis, and Perception of Prosodic Subvocal Speech. J. Speech Lang. Hear. Res. 2021, 64, 2134–2153. [Google Scholar] [CrossRef]
- Brumberg, J.S.; Guenther, F.H.; Kennedy, P.R. An Auditory Output Brain–Computer Interface for Speech Communication. In Briefs in Electrical and Computer Engineering; Springer: Berlin/Heidelberg, Germany, 2013; pp. 7–14. [Google Scholar] [CrossRef]
- Porbadnigk, A.; Wester, M.; Calliess, J.; Schultz, T. EEG-based speech recognition impact of temporal effects. In Proceedings of the International Conference on Bio-Inspired Systems and Signal Processing, Porto, Portugal, 14–17 January 2009; pp. 376–381. [Google Scholar]
- Angrick, M.; Herff, C.; Mugler, E.; Tate, M.C.; Slutzky, M.W.; Krusienski, D.J.; Schultz, T. Speech synthesis from ECoG using densely connected 3D convolutional neural networks. J. Neural Eng. 2019, 16, 036019. [Google Scholar] [CrossRef] [PubMed]
- Herff, C.; Diener, L.; Angrick, M.; Mugler, E.; Tate, M.C.; Goldrick, M.A.; Krusienski, D.J.; Slutzky, M.W.; Schultz, T. Generating Natural, Intelligible Speech From Brain Activity in Motor, Premotor, and Inferior Frontal Cortices. Front. Neurosci. 2019, 13, 1267. [Google Scholar] [CrossRef]
- Gonzalez, J.A.; Cheah, L.A.; Gilbert, J.M.; Bai, J.; Ell, S.R.; Green, P.D.; Moore, R.K. A silent speech system based on permanent magnet articulography and direct synthesis. Comput. Speech Lang. 2016, 39, 67–87. [Google Scholar] [CrossRef] [Green Version]
- Lee, K.-S. EMG-Based Speech Recognition Using Hidden Markov Models With Global Control Variables. IEEE Trans. Biomed. Eng. 2008, 55, 930–940. [Google Scholar] [CrossRef] [PubMed]
- Diener, L.; Bredehöft, S.; Schultz, T. A comparison of EMG-to-Speech Conversion for Isolated and Continuous Speech. In ITG-Fachbericht 282: Speech Communication; ITG: Oldenburg, Germany, 2018; pp. 66–70. [Google Scholar]
- Johner, C.; Janke, M.; Wand, M.; Schultz, T. Inferring Prosody from Facial Cues for EMG-based Synthesis of Silent Speech. In Advances in Affective and Pleasurable Design; CRC: Boca Raton, FL, USA, 2013; pp. 634–643. [Google Scholar]
- Kohler, K.J. What is Emphasis and How is it Coded? In Proceedings of the Speech Prosody Dresden, Dresden, Germany, 2–5 May 2006; pp. 748–751. [Google Scholar]
- Nakamura, K.; Janke, M.; Wand, M.; Schultz, T. Estimation of fundamental frequency from surface electromyographic data: EMG-to-F0. In Proceedings of the International Conference on Acoustics, Speech and Signal Processing, Prague, Czech Republic, 22–27 May 2011; pp. 573–576. [Google Scholar] [CrossRef]
- Diener, L.; Umesh, T.; Schultz, T. Improving Fundamental Frequency Generation in EMG-To-Speech Conversion Using a Quantization Approach. In Proceedings of the 2019 IEEE Automatic Speech Recognition and Understanding Workshop, ASRU 2019—Proceedings, Singapore, 15–18 December 2019; pp. 682–689. [Google Scholar] [CrossRef]
- Gramming, P. Vocal loudness and frequency capabilities of the voice. J. Voice 1991, 5, 144–157. [Google Scholar] [CrossRef]
- Anderson, C. Transcribing Speech Sounds. In Essentials of Linguistics; McMaster University: Hamilton, ON, USA, 2018. [Google Scholar]
- Moore, R.E.; Estis, J.; Gordon-Hickey, S.; Watts, C. Pitch Discrimination and Pitch Matching Abilities with Vocal and Nonvocal Stimuli. J. Voice 2008, 22, 399–407. [Google Scholar] [CrossRef] [PubMed]
- Nikjeh, D.A.; Lister, J.J.; Frisch, S.A. The relationship between pitch discrimination and vocal production: Comparison of vocal and instrumental musicians. J. Acoust. Soc. Am. 2009, 125, 328–338. [Google Scholar] [CrossRef]
- Murray, E.S.H.; Stepp, C.E. Relationships between vocal pitch perception and production: A developmental perspective. Sci. Rep. 2020, 10, 3912. [Google Scholar] [CrossRef] [Green Version]
- Hunter, E.J.; Titze, I.R. Variations in Intensity, Fundamental Frequency, and Voicing for Teachers in Occupational Versus Nonoccupational Settings. J. Speech Lang. Hear. Res. 2010, 53, 862–875. [Google Scholar] [CrossRef]
- Palmer, P.M.; Luschei, E.S.; Jaffe, D.; McCulloch, T.M. Contributions of Individual Muscles to the Submental Surface Electromyogram During Swallowing. J. Speech Lang. Hear. Res. 1999, 42, 1378–1391. [Google Scholar] [CrossRef] [PubMed]
- Ding, R.; Larson, C.R.; Logemann, J.A.; Rademaker, A.W. Surface Electromyographic and Electroglottographic Studies in Normal Subjects Under Two Swallow Conditions: Normal and During the Mendelsohn Manuever. Dysphagia 2002, 17, 1–12. [Google Scholar] [CrossRef] [PubMed]
- Eskes, M.; van Alphen, M.; Balm, A.J.M.; Smeele, L.E.; Brandsma, D.; van der Heijden, F. Predicting 3D lip shapes using facial surface EMG. PLoS ONE 2017, 12, e0175025. [Google Scholar] [CrossRef]
- Hermens, H.J.; Freriks, B.; Disselhorst-Klug, C.; Rau, G. Development of recommendations for SEMG sensors and sensor placement procedures. J. Electromyogr. Kinesiol. 2000, 10, 361–374. [Google Scholar] [CrossRef]
- Roy, S.H.; De Luca, G.; Cheng, M.S.; Johansson, A.; Gilmore, L.D.; De Luca, C.J. Electro-mechanical stability of surface EMG sensors. Med. Biol. Eng. Comput. 2007, 45, 447–457. [Google Scholar] [CrossRef] [PubMed]
- Patel, R.R.; Awan, S.N.; Barkmeier-Kraemer, J.; Courey, M.; Deliyski, D.; Eadie, T.; Paul, D.; Svec, J.G.; Hillman, R. Recommended Protocols for Instrumental Assessment of Voice: American Speech-Language-Hearing Association Expert Panel to Develop a Protocol for Instrumental Assessment of Vocal Function. Am. J. Speech Lang. Pathol. 2018, 27, 887–905. [Google Scholar] [CrossRef]
- Tralie, C.J.; Dempsey, E. Exact, Parallelizable Dynamic Time Warping Alignment with Linear Memory. In Proceedings of the 21st International Society for Music Information Retrieval Conference, Montréal, QC, Canada, 11–16 October 2020; pp. 462–469. [Google Scholar]
- Boersma, P.; Weenink, D. Praat: Doing Phonetics by Computer. 2013. Available online: http://www.praat.org (accessed on 19 August 2022).
- Jadoul, Y.; Thompson, B.; de Boer, B. Introducing Parselmouth: A Python interface to Praat. J. Phon. 2018, 71, 1–15. [Google Scholar] [CrossRef] [Green Version]
- Coleman, R.F.; Markham, I.W. Normal variations in habitual pitch. J. Voice 1991, 5, 173–177. [Google Scholar] [CrossRef]
- Baken, R.J. Clinical Measurement of Speech and Voice; College-Hill Press: Worthing, UK, 1987. [Google Scholar]
- Awan, S.N.; Mueller, P.B. Speaking fundamental frequency characteristics of centenarian females. Clin. Linguist. Phon. 1992, 6, 249–254. [Google Scholar] [CrossRef] [PubMed]
- Stepp, C.E.; Hillman, R.E.; Heaton, J.T. Modulation of Neck Intermuscular Beta Coherence During Voice and Speech Production. J. Speech Lang. Hear. Res. 2011, 54, 836–844. [Google Scholar] [CrossRef]
- Stepp, C.E.; Hillman, R.E.; Heaton, J.T. Use of Neck Strap Muscle Intermuscular Coherence as an Indicator of Vocal Hyperfunction. IEEE Trans. Neural Syst. Rehabil. Eng. 2010, 18, 329–335. [Google Scholar] [CrossRef] [PubMed]
- Phinyomark, A.; Phukpattaranont, P.; Limsakul, C. Feature reduction and selection for EMG signal classification. Expert Syst. Appl. 2012, 39, 7420–7431. [Google Scholar] [CrossRef]
- Malvuccio, C.; Kamavuako, E.N. The Effect of EMG Features on the Classification of Swallowing Events and the Estimation of Fluid Intake Volume. Sensors 2022, 22, 3380. [Google Scholar] [CrossRef]
- Joshi, D.; Bhatia, D. Cross-correlation evaluated muscle co-ordination for speech production. J. Med. Eng. Technol. 2013, 37, 520–525. [Google Scholar] [CrossRef]
- Abbaspour, S.; Lindén, M.; Gholamhosseini, H.; Naber, A.; Ortiz-Catalan, M. Evaluation of surface EMG-based recognition algorithms for decoding hand movements. Med. Biol. Eng. Comput. 2019, 58, 83–100. [Google Scholar] [CrossRef] [Green Version]
- Soon, M.W.; Anuar, M.I.H.; Abidin, M.H.Z.; Azaman, A.S.; Noor, N.M. Speech recognition using facial sEMG. In Proceedings of the 2017 IEEE International Conference on Signal and Image Processing Applications, ICSIPA, Sarawak, Malaysia, 12–14 September 2017; pp. 1–5. [Google Scholar] [CrossRef]
- Fraiwan, L.; Lweesy, K.; Al-Nemrawi, A.; Addabass, S.; Saifan, R. Voiceless Arabic vowels recognition using facial EMG. Med. Biol. Eng. Comput. 2011, 49, 811–818. [Google Scholar] [CrossRef]
- Srisuwan, N.; Phukpattaranont, P.; Limsakul, C. Three steps of Neuron Network classification for EMG-based Thai tones speech recognition. In Proceedings of the 2013 10th International Conference on Electrical Engineering/Electronics, Computer, Telecommunications and Information Technology, ECTI-CON, Krabi, Thailand, 15–17 May 2013; pp. 1–6. [Google Scholar] [CrossRef]
- Jong, N.S.; Phukpattaranont, P. A speech recognition system based on electromyography for the rehabilitation of dysarthric patients: A Thai syllable study. Biocybern. Biomed. Eng. 2018, 39, 234–245. [Google Scholar] [CrossRef]
- Phinyomark, A.; Limsakul, C.; Phukpattaranont, P. A novel feature extraction for robust EMG pattern recognition. J. Comput. 2020, 1, 71–80. [Google Scholar]
- Srisuwan, N.; Phukpattaranont, P.; Limsakul, C. Feature selection for Thai tone classification based on surface EMG. Procedia Eng. 2012, 32, 253–259. [Google Scholar] [CrossRef] [Green Version]
- Du, S.; Vuskovic, M. Temporal vs. spectral approach to feature extraction from prehensile EMG signals. In Proceedings of the 2004 IEEE International Conference on Information Reuse and Integration, Las Vegas, NV, USA, 8–10 November 2004; pp. 344–350. [Google Scholar] [CrossRef]
- Enders, H.; Maurer, C.; Baltich, J.; Nigg, B.M. Task-Oriented Control of Muscle Coordination during Cycling. Med. Sci. Sports Exerc. 2013, 45, 2298–2305. [Google Scholar] [CrossRef] [PubMed]
- Matrone, G.C.; Cipriani, C.; Secco, E.L.; Magenes, G.; Carrozza, M.C. Principal components analysis based control of a multi-dof underactuated prosthetic hand. J. Neuroeng. Rehabil. 2010, 7, 16. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Soechting, J.F.; Flanders, M. Sensorimotor control of contact force. Curr. Opin. Neurobiol. 2008, 18, 565–572. [Google Scholar] [CrossRef] [Green Version]
- Shorten, C.; Khoshgoftaar, T.M. A survey on Image Data Augmentation for Deep Learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef]
- Maharana, K.; Mondal, S.; Nemade, B. A review: Data pre-processing and data augmentation techniques. Glob. Transit. Proc. 2022, 3, 91–99. [Google Scholar] [CrossRef]
- Kuhn, M.; Johnson, K. Applied Predictive Modeling; Springer Science & Business Media: New York, NY, USA, 2013. [Google Scholar]
- De Armas, W.; Mamun, K.A.; Chau, T. Vocal frequency estimation and voicing state prediction with surface EMG pattern recognition. Speech Commun. 2014, 63–64, 15–26. [Google Scholar] [CrossRef]
- Ahmadi, F.; Araujo Ribeiro, M.; Halaki, M. Surface electromyography of neck strap muscles for estimating the intended pitch of a bionic voice source. In Proceedings of the IEEE 2014 Biomedical Circuits and Systems Conference, BioCAS 2014—Proceedings, Lausanne, Switzerland, 22–24 October 2014; pp. 37–40. [Google Scholar] [CrossRef]
- Janke, M.; Diener, L. EMG-to-Speech: Direct Generation of Speech From Facial Electromyographic Signals. IEEE/ACM Trans. Audio Speech Lang. Process. 2017, 25, 2375–2385. [Google Scholar] [CrossRef] [Green Version]
- Botelho, C.; Diener, L.; Küster, D.; Scheck, K.; Amiriparian, S.; Schuller, B.W.; Trancoso, I. Toward silent paralinguistics: Speech-to-EMG—Retrieving articulatory muscle activity from speech. In Proceedings of the Annual Conference of the International Speech Communication Association, INTERSPEECH, Brno, Czech Republic, 30 August–3 September 2020; pp. 354–358. [Google Scholar] [CrossRef]
- Choi, H.-S.; Ye, M.; Berke, G.S.; Kreiman, J. Function of the Thyroarytenoid Muscle in a Canine Laryngeal Model. Ann. Otol. Rhinol. Laryngol. 1993, 102, 769–776. [Google Scholar] [CrossRef]
- Chhetri, D.K.; Neubauer, J.; Sofer, E.; Berry, D.A. Influence and interactions of laryngeal adductors and cricothyroid muscles on fundamental frequency and glottal posture control. J. Acoust. Soc. Am. 2014, 135, 2052–2064. [Google Scholar] [CrossRef] [Green Version]
- Chhetri, D.K.; Neubauer, J. Differential roles for the thyroarytenoid and lateral cricoarytenoid muscles in phonation. Laryngoscope 2015, 125, 2772–2777. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lindestad, P.; Fritzell, B.; Persson, A. Quantitative Analysis of Laryngeal EMG in Normal Subjects. Acta Oto-Laryngol. 1991, 111, 1146–1152. [Google Scholar] [CrossRef]
- Vojtech, J.M.; Stepp, C.E. Electromyography. In Manual of Clinical Phonetics, 1st ed.; Ball, M., Ed.; Routledge: London, UK, 2021; pp. 248–263. [Google Scholar] [CrossRef]
- Ueda, N.; Ohyama, M.; Harvey, J.E.; Ogura, J.H. Influence of certain extrinsic laryngeal muscles on artificial voice production. Laryngoscope 1972, 82, 468–482. [Google Scholar] [CrossRef] [PubMed]
- Roubeau, B.; Chevrie-Muller, C.; Guily, J.L.S. Electromyographic Activity of Strap and Cricothyroid Muscles in Pitch Change. Acta Oto-Laryngol. 1997, 117, 459–464. [Google Scholar] [CrossRef]
- Hollien, H.; Moore, G.P. Measurements of the Vocal Folds during Changes in Pitch. J. Speech Hear. Res. 1960, 3, 157–165. [Google Scholar] [CrossRef]
- Collier, R. Physiological correlates of intonation patterns. J. Acoust. Soc. Am. 1975, 58, 249–255. [Google Scholar] [CrossRef]
- Andersen, K.F.; Sonninen, A. The Function of the Extrinsic Laryngeal Muscles at Different Pitch. Acta Oto-Laryngol. 1960, 51, 89–93. [Google Scholar] [CrossRef]
- Goldstein, E.; Heaton, J.; Kobler, J.; Stanley, G.; Hillman, R. Design and Implementation of a Hands-Free Electrolarynx Device Controlled by Neck Strap Muscle Electromyographic Activity. IEEE Trans. Biomed. Eng. 2004, 51, 325–332. [Google Scholar] [CrossRef]
- Wohlert, A.B.; Hammen, V.L. Lip Muscle Activity Related to Speech Rate and Loudness. J. Speech Lang. Hear. Res. 2000, 43, 1229–1239. [Google Scholar] [CrossRef]
- Zhu, M.; Wang, X.; Deng, H.; He, Y.; Zhang, H.; Liu, Z.; Chen, S.; Wang, M.; Li, G. Towards Evaluating Pitch-Related Phonation Function in Speech Communication Using High-Density Surface Electromyography. Front. Neurosci. 2022, 16, 941594. [Google Scholar] [CrossRef]
- Li, J.; Lavrukhin, V.; Ginsburg, B.; Leary, R.; Kuchaiev, O.; Cohen, J.M.; Gadde, R.T. Jasper: An End-to-End Convolutional Neural Acoustic Model. In Proceedings of the Annual Conference of the International Speech Communication Association, INTERSPEECH, Graz, Austria, 5–19 September 2019; pp. 71–75. [Google Scholar] [CrossRef]
- Post, M.; Kumar, G.; Lopez, A.; Karakos, D.; Callison-Burch, C.; Khudanpur, S. Improved speech-to-text translation with the Fisher and Callhome Spanish-English speech translation corpus—ACL Anthology. In Proceedings of the 10th International Workshop on Spoken Language Translation: Papers, Heidelberg, Germany, 5–6 December 2013. [Google Scholar]
- Rao, K.; Sak, H.; Prabhavalkar, R. Exploring Architectures, Data and Units For Streaming End-to-End Speech Recognition with RNN-Transducer. In Proceedings of the 2017 IEEE Automatic Speech Recognition and Understanding Workshop, ASRU 2017—Proceedings, Okinawa, Japan, 16–20 December 2017; pp. 193–199. [Google Scholar] [CrossRef]




| Speech Task | Recording Duration (s) |
|---|---|
| Tones | 351.7 (232.2–620.7) |
| Legatos | 132.1 (97.4–205.8) |
| VCV Syllables | 284.4 (174.6–464.0) |
| Phrases | 649.8 (523.5–790.9) |
| Reading Passages | 1041.1 (888.9–1209.0) |
| Questions | 241.6 (168.5–330.8) |
| Monologues | 274.8 (214.5–374.9) |
| Feature | Dimension per Channel | References | |
|---|---|---|---|
| 1 | Beta coherence | 8 | [50,51] |
| 2 | Central frequency variance | 1 | [52,53] |
| 3 | Coherence | 8 | [50,51] |
| 4 | Cross-correlation | 8 | [54] |
| 5 | Daubechies 2 wavelet coefficients, maximum (peak) | 4 | [55] |
| 6 | Daubechies 2 wavelet coefficients, mean | 4 | [55] |
| 7 | Daubechies 2 wavelet coefficients, variance | 4 | [55] |
| 8 | Maximum (peak) frequency | 1 | [52,55] |
| 9 | Mean absolute value | 1 | [56,57,58,59,60,61] |
| 10 | Mean frequency | 1 | [59,60] |
| 11 | Mean power density | 1 | [53,62] |
| 12 | Median frequency | 1 | [60,61] |
| 13 | Mel-frequency cepstral coefficients | 24 | [14,15,18] |
| 14 | Power density wavelength | 1 | [57] |
| 15 | Root mean square | 1 | [56,57,60,61] |
| 16 | Slope sign change | 1 | [57,60] |
| 17 | Spectral moments | 3 | [52,57,61,62] |
| 18 | Variance | 1 | [56,57,60,61] |
| 19 | Waveform length | 1 | [57,59,60,61] |
| 20 | Zero crossings | 1 | [17,57,59,60] |
| ID | fo | Intensity | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| MAPE (%) | r | CCC | RMSE (ST) | MBE (ST) | MAPE (%) | r | CCC | RMSE (dB SPL) | MBE (dB SPL) | |
| 1 | 1.75 | 0.96 | 0.95 | 0.38 | 0.05 | 2.21 | 0.98 | 0.98 | 2.06 | −0.27 |
| 2 | 1.82 | 0.95 | 0.94 | 0.40 | 0.09 | 2.44 | 0.98 | 0.98 | 2.23 | −0.03 |
| 3 | 2.49 | 0.94 | 0.94 | 0.55 | −0.02 | 1.60 | 0.97 | 0.97 | 4.17 | 0.88 |
| 4 | 2.33 | 0.95 | 0.94 | 0.51 | 0.03 | 1.46 | 0.98 | 0.98 | 3.53 | −0.69 |
| 5 | 2.36 | 0.94 | 0.94 | 0.52 | −0.04 | 3.40 | 0.96 | 0.95 | 3.35 | 0.85 |
| 6 | 2.26 | 0.96 | 0.95 | 0.50 | −0.01 | 1.36 | 0.97 | 0.97 | 3.33 | −0.35 |
| 7 | 2.25 | 0.96 | 0.96 | 0.49 | 0.00 | 4.60 | 0.94 | 0.94 | 6.17 | 2.04 |
| 8 | 3.79 | 0.79 | 0.74 | 0.86 | −0.16 | 2.75 | 0.98 | 0.98 | 2.41 | 0.10 |
| 9 | 2.41 | 0.95 | 0.94 | 0.53 | 0.07 | 1.54 | 0.97 | 0.97 | 3.11 | −1.00 |
| 10 | 4.03 | 0.83 | 0.80 | 0.90 | 0.12 | 2.50 | 0.98 | 0.98 | 2.17 | 0.52 |
| Dataset | MAPE (%) | r | CCC | RMSE (ST) | MBE (ST) |
|---|---|---|---|---|---|
| Training * | 8.15 (0.53) | 0.41 (0.04) | 0.17 (0.12) | 1.67 (0.12) | 1.42 (0.11) |
| Validation * | 8.16 (0.62) | 0.25 (0.10) | 0.10 (0.07) | 1.66 (0.11) | 1.42 (0.11) |
| Test | 7.95 | 0.36 | 0.25 | 1.65 | 0.13 |
| Dataset | MAPE (%) | r | CCC | RMSE (dB) | MBE (dB) |
|---|---|---|---|---|---|
| Training * | 12.67 (2.27) | 0.51 (0.10) | 0.44 (0.10) | 0.12 (0.03) | 0.10 (0.02) |
| Validation * | 13.18 (1.97) | 0.32 (0.10) | 0.24 (0.09) | 0.12 (0.01) | 0.10 (0.01) |
| Test | 12.36 | 0.56 | 0.48 | 0.11 | −0.02 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vojtech, J.M.; Mitchell, C.L.; Raiff, L.; Kline, J.C.; De Luca, G. Prediction of Voice Fundamental Frequency and Intensity from Surface Electromyographic Signals of the Face and Neck. Vibration 2022, 5, 692-710. https://doi.org/10.3390/vibration5040041
Vojtech JM, Mitchell CL, Raiff L, Kline JC, De Luca G. Prediction of Voice Fundamental Frequency and Intensity from Surface Electromyographic Signals of the Face and Neck. Vibration. 2022; 5(4):692-710. https://doi.org/10.3390/vibration5040041
Chicago/Turabian StyleVojtech, Jennifer M., Claire L. Mitchell, Laura Raiff, Joshua C. Kline, and Gianluca De Luca. 2022. "Prediction of Voice Fundamental Frequency and Intensity from Surface Electromyographic Signals of the Face and Neck" Vibration 5, no. 4: 692-710. https://doi.org/10.3390/vibration5040041