1. Introduction
Safe and reliable flight is an important research topic in aircraft, and the process of approaching and landing is the phase with the highest accident rate during the flight of fixed-wing aircraft, so it is very important to guide the landing safely. traditional landing systems rely on landing systems with instruments, which are a proven landing solution, but the system requires expensive equipment and maintenance. For UAV (unmanned aerial vehicle) landing, typical ground-based landing systems include OPATS and SADA. With the continuous development of visual perception and positioning technologies, it has become possible to apply vision to guided landing systems in recent years. Vision sensors are resistant to interference and not easily detected compared to active sensors, such as radar and laser, so the application of vision sensors to guided landings has received a lot of attention [
1].
Vision-based landing systems for fixed-wing aircraft are composed of ground-based visual landing systems and space-based visual landing systems according to the implementation principle. Ground-based visual landing systems place vision sensors around the runway to determine the position of the UAV through multi-point observation to achieve landing. The scheme has sufficient computing resources, but it needs to rely on communication links, and its autonomy and applicability are somewhat limited. Space-based visual landing systems use the information provided by vision to achieve navigation and positioning, which further completes the vision-guided landing. The C2Land project is a typical example of this solution [
2].
The space-based visual landing system can be divided into image-based visual servoing (IBVS) and position-based visual servoing (PBVS). IBVS compares the image signal obtained from real-time measurements with a given image signal and uses the acquired image error for closed-loop control. However, PBVS uses the camera parameters to establish the relationship between the image signal and the aerial vehicle’s attitude and utilizes the attitude information in the closed-loop control. IBVS does not need to rely on the camera model, but the scheme is more scene-dependent. PBVS achieves the decoupling of vision problem and control problem, but the scheme requires an accurate camera model [
3].
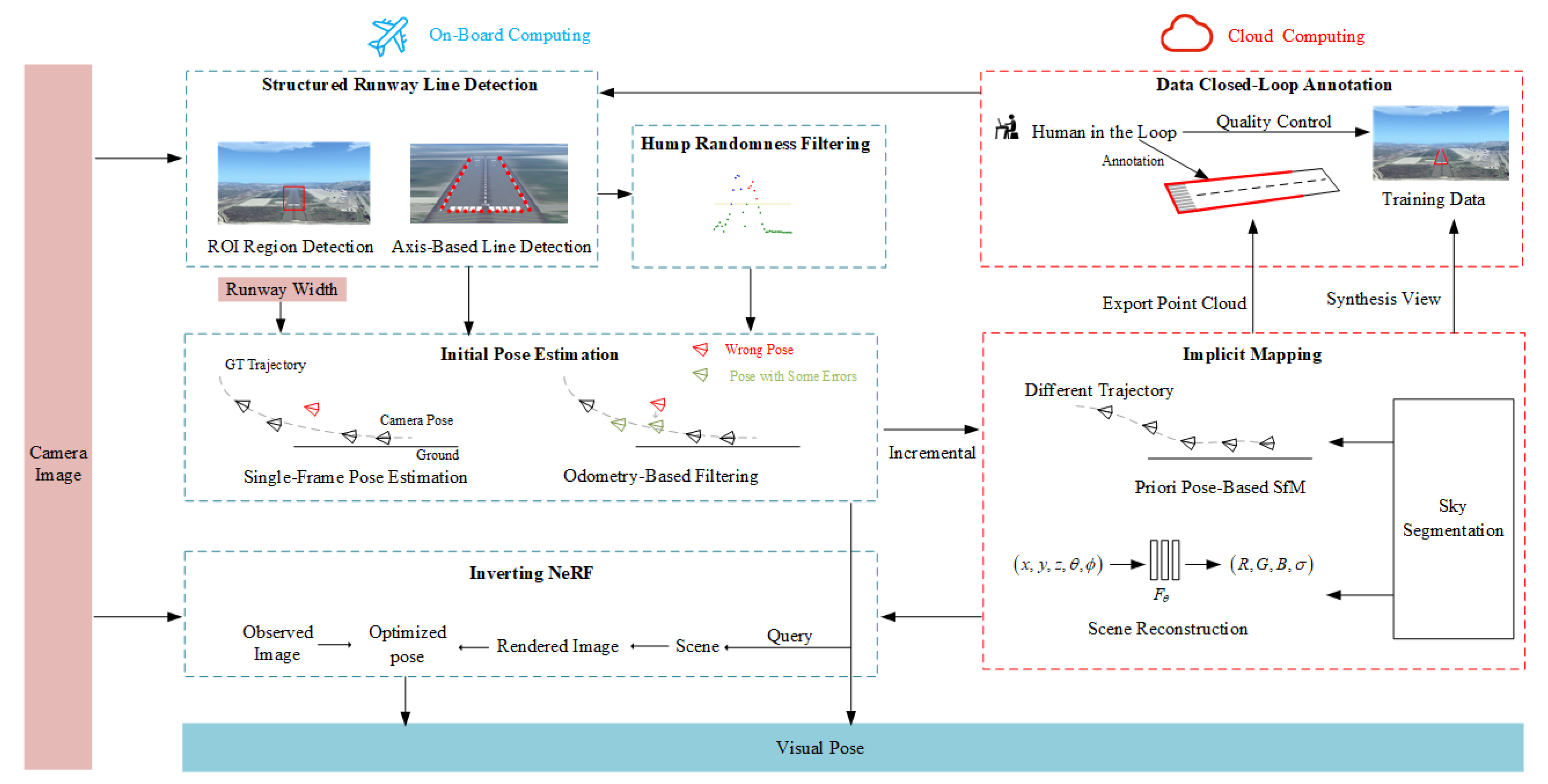
This paper proposes a solution to the pose-estimation problem in vision-only landing systems. We use the PBVS strategy to make the whole pose-estimation system robust and interpretable. To achieve higher accuracy, we propose a novel pose-estimation algorithm in a visual landing system, which is an implicit neural mapping solution (refer to
Figure 1). We use camera images as input and the pose estimation as output. The runway detection, initial pose estimation, and NeRF-inverting [
4] modules are computed on the on-board device (blue color in
Figure 1; implicit mapping and GT annotation modules are computed on the cloud device (red color in
Figure 1). The detection algorithm proposed in this paper is abbreviated as FMRLD (flexible multi-stage runway-line detection) in the experiment.
Our proposed algorithm follows the basic paradigm of pose estimation. Firstly, we perform feature extraction on the runway lines. The extracted features are then used for initial pose estimation, which is further optimized to obtain accurate estimation results. In the feature extraction phase, we use deep learning-based runway line detection methods to enhance accuracy and robustness (
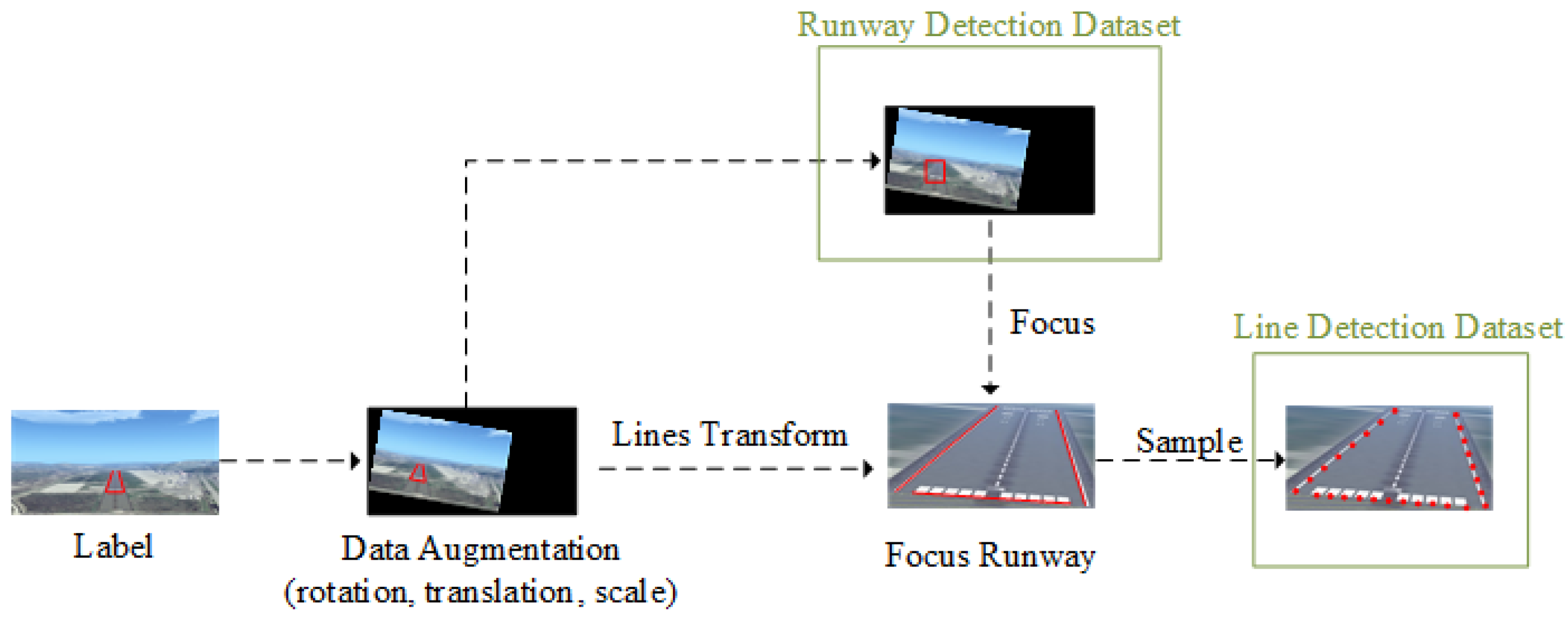
Section 3.1.1). These methods rely on high-quality datasets, so we utilize diverse data sources to construct datasets and perform data augmentation accordingly (
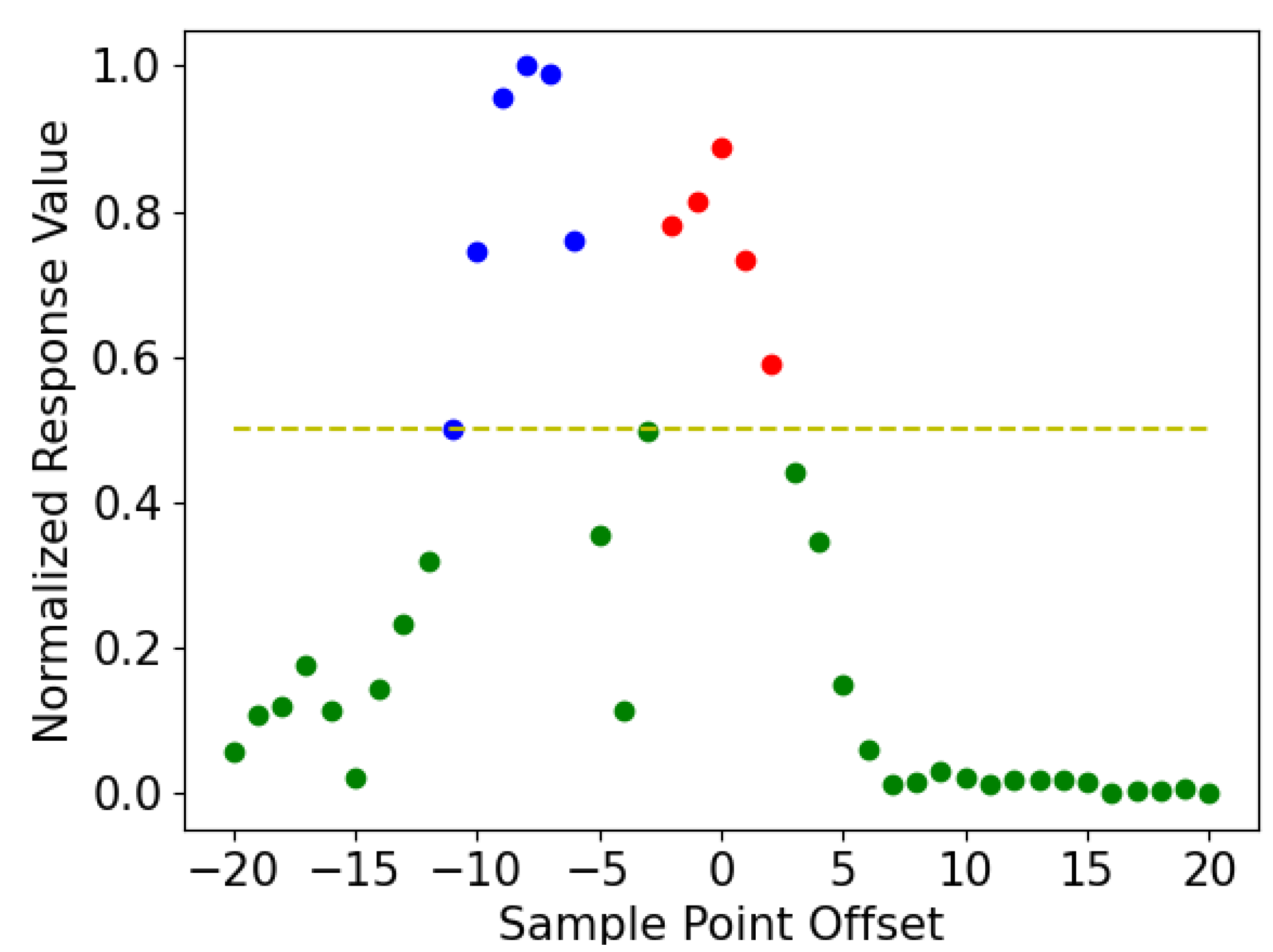
Section 3.3.1). Since the accuracy of runway line detection directly affects the initial pose, we propose hump randomness filtering to refine the detection results (
Section 3.1.2). During the initial pose estimation phase, we utilize the principle of multi-view geometry to estimate the pose. To ensure accuracy, we eliminate some incorrect estimation results (
Section 3.2.1). The pose optimization is divided into two parts: on-board and cloud-based. On the on-board computing platform, the pose optimization results are obtained through inverting NeRF (
Section 3.2.3). Meanwhile, on the cloud computing platform, the initial pose estimation results of the current trip are combined with the poses from historical trips for incremental pose optimization. The optimized results are then utilized for NeRF implicit mapping (
Section 3.2.2). To address the challenges of expensive and inefficient runway data annotation, we propose a data closed-loop annotation strategy that leverages mapping results to assist in the annotation process. Specifically, we export the explicit point cloud of NeRF and allow annotators to annotate directly on the 3D point cloud. This approach significantly enhances the efficiency of data reuse compared to traditional image annotation methods. As a result, the entire algorithm operates in a closed-loop data flow (
Section 3.3.2). The modules included in our proposed method are described below.
Runway detection: Accurate detection of runway lines is extremely important for navigation and positioning. Our structured runway line-detection and hump-randomness filtering modules provide consistent and reliable information on runway features. During the landing process, the visual features vary greatly among different runways, different weather conditions, and different landing phases, and these problems pose certain challenges to the accurate detection of runway lines. In this paper, our proposed coarse-to-fine accurate runway line-detection method fully considers the change in viewpoint during the landing of the aerial vehicle and the applicability of the algorithm to different scenarios. First, we use an object-detection algorithm to extract high-level semantic information about the runway, which ensures the uniform distribution of the runway in the image and facilitates the detection of subsequent runway lines. Then, we extract the left and right runway lines and the virtual start line in the focused image. We propose a column-anchor-based detection and parallel acceleration scheme for virtual start-line detection. Last, a runway line fine-tuning method based on clustering and optimization is proposed due to the randomness of detection arising from the width of the runway line. Our runway-detection module can provide good front-end detection information for pose estimation.
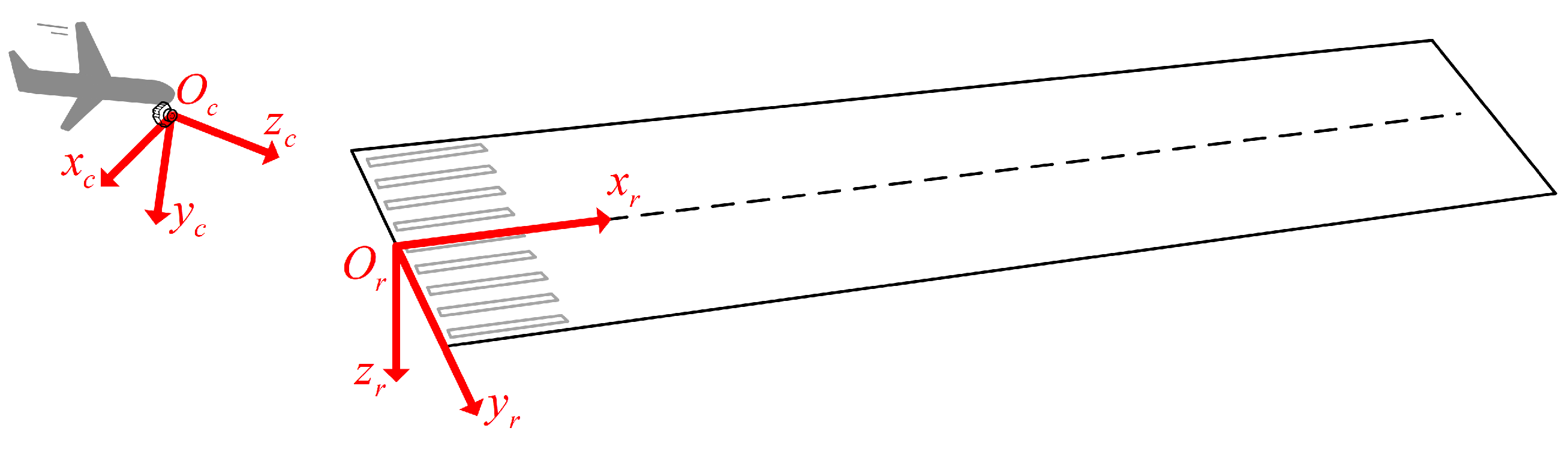
Initial pose estimation: The goal of our initial pose-estimation module is to estimate the UAV pose information with scales using a runway line feature. To obtain the scale, the module needs to input the runway width as a priori information. We use multi-view geometry, such as the vanishing point principle, to estimate the UAV’s initial pose. However, the pose is generated from a single image and does not guarantee the stability of the pose. We adopt the results of the visual odometry pose estimation as a reference to fix the instability in the initial pose estimation.
Incremental implicit mapping: The incremental implicit mapping module provides map information to the initial pose estimation and improves the accuracy of the pose estimation. It also provides high-quality point-cloud maps due to the differentiability and high fidelity of the neural radiance field (NeRF [
5]). Due to the limitations of NeRF [
5] in pose optimization in large scale scenes, we have split the implicit mapping module into two sub-modules: offline pose optimization and NeRF mapping. In the offline pose optimization sub-module, we have adopted the standard structure from the motion (SfM) process. However, we have two modifications. One is that we introduce a sky segmentation sub-module, which ensures that SfM does not extract feature points from the sky during the feature-extraction stage, preventing the problem of poor pose-estimation results due to feature mismatch. The other point is that we use the results of the initial pose estimation as prior information for triangulation and bundle adjustment, thus preventing the failure of pose estimation caused by local optima that SfM may fall into in large-scale scenes. In NeRF mapping, a submodule and a grid-based NeRF approach [
6] are adopted. We introduce appearance embedding to ensure robustness in different weather conditions. In addition, based on some characteristics of the runway itself, we introduce regularization losses (smoothness loss, sky loss, etc.) to improve the geometry of the NeRF mapping. Please refer to
Section 4 for more details.
Inverting NeRF: Inverting NeRF aims to optimize the pose-estimation result based on the implicit map when a new initial pose arrives. We use the initial pose to query the NeRF map, and we can obtain a rendered image. Meanwhile, we can also obtain the camera image on that timestamp. Using the pose as an optimization variable, we optimize the pose by constructing a loss of the observed and rendered images.
GT annotation: The runway-detection network must be trained using annotated data, which is an extremely labor-intensive process. The GT annotation module reduces the annotation cost significantly by generating a 3D point-cloud map, annotating the runway in 3D space, and then projecting it into the 2D image. At the same time, due to the differentiable representation, NeRF can synthesize images with a novel view, thus providing true 3D data augmentation. The GT annotation module achieves a closed loop of data and enhances the iterative efficiency of the whole system.
Combining the above modules, we propose a complete algorithm for estimating the pose in a vision-only landing system. The proposed algorithm has been proven effective in simulation experiments.
The main contributions of our work are follows.
- (1)
A novel pose-estimation framework in a vision-only landing system is proposed, which introduces implicit mapping and ground-truth annotation modules to improve the pose-estimation accuracy and data-annotation efficiency.
- (2)
We build a runway-detection pipeline. The multi-stage detection framework proposed in this paper makes full use of the features of different stages, which can guarantee semantic features and positioning ability and therefore greatly improves the runway line detection accuracy.
- (3)
We present a NeRF-based mapping module in a visual landing system, whose high fidelity provides the possibility of reusing ground truth annotation, while its differentiability provides the basis for accurate pose estimation. Our NeRF-based mapping allows for the coding of different temporal styles, which is not possible with other mapping methods.
This paper is organized as follows: in
Section 2, we introduce related work, including runway detection algorithms and neural radiance fields; in
Section 3, we provide a detailed description of our algorithm, including implementation details of runway line detection, pose estimation, implicit mapping, and the data loop-closure module; in
Section 4, we validate our proposed algorithm through experiments on runway line detection, pose estimation, and lightweight network; in
Section 5, we discuss the advantages and disadvantages of our proposed algorithm, as well as future research directions; the conclusion is given in
Section 6.
2. Related Work
2.1. Runway Detection
Runway detection methods can be roughly divided into three categories: detection based on a priori information, detection based on templates, and detection based on features. Feature-based detection methods have become the dominant detection method in recent years.
A Priori information-based runway detection: In a priori information-based methods, runway detection is achieved using known runway models and the aircraft attitude, and the upper limit of landing is considered in terms of safety and reliability, with the vision system primarily used as an auxiliary navigation system. The authors of [
7] propose a model-based runway detection method that requires a known runway model (available through aeronautical information publication), the internal reference of the camera, and the rough pose provided by other sensors, and each line segment in the runway model can be mapped into the image using the above information. In [
8], a camera model is also mapped to the image first, but unlike [
7], the ROI given in this paper is the ROI of the smallest rectangle containing the left and right runway lines rather than the ROI of each segment of the runway model line. However, in tasks such as emergency landings, the initial attitude estimation is noisy and the sensor type is limited, and the model-based runway detection is less effective in this case.
Template-based runway detection: Template-based runway line detection uses the comparison of the query image and the template image to achieve detection. In [
9], LSD is used for line feature extraction, and chamfer matching is later used to achieve runway search, but due to the limitations of template matching itself, the template often cannot adapt to the large changes in view during the landing process. The authors of [
10] used a manually designed template to find the ROI and rotates the image in different directions after obtaining the binarized edge gradient map. Then, the sum of the pixel values in different columns is counted to find their peaks, and the peaks are clustered under different rotation angles. Finally, the clustering centers are mapped to straight lines in the original image to achieve runway line detection. Template-based detection methods are poorly generalized and often fail because they are more sensitive to runway geometry and light conditions.
Feature-based runway detection: Runway line detection based on image features is mainly achieved using visual images. Unlike remotely sensed runway detection [
11], the proportion of the runway in the image changes continuously in the landing scenario, and the left and right runway edges no longer have parallel characteristics. In [
12], the HSV color model and LSD algorithm were used to detect non-standard airfields, and the paper concluded that using the HSV color model could achieve better detection results than the RGB color model. In [
13], ROIs are formed by corner-point detection and clustering, and then a neural network is used to classify these ROIs to determine the location of runway edges. However, it is a challenge to choose the number of clusters effectively. The authors of [
14] use an end-to-end segmentation network for runway line detection and a self-attention module to enhance the segmentation, while a lightweight network is used to ensure real-time detection, but the paper does not give the impact of detection on subsequent tasks.
None of the above detection methods consider the effectiveness of detection under large viewpoint changes during landing, resulting in these methods only being effective when there is a small variation in perspective and therefore requiring different detection models to be set up for different landing stages (e.g., detection parameters need to be fine-tuned). Additionally, the detection of the starting line can enhance pose estimation performance; however, the above-mentioned methods often fail to detect the virtual start line as it often does not exist. Our proposed method overcomes these problems effectively and provides accurate and reliable runway line detection results.
2.2. Neural Radiance Field
NeRF is a recent breakthrough in the field of computer vision that allows for the generation of highly realistic 3D models of objects and scenes from 2D images. The method works by training a deep neural network to predict the radiance at any point in 3D space, given a set of images and corresponding camera poses. This allows for the creation of photorealistic renderings of objects and scenes from any viewpoint and even enables the synthesis of novel views that were not captured by the original images.
NeRF has been applied to a wide range of applications, including virtual reality, augmented reality, and robotics. It has also been used to generate 3D models of real-world objects and scenes, such as buildings, landscapes, and even human faces.
While NeRF has shown remarkable success in generating high-quality 3D models from a small number of images, it faces several challenges when applied to large-scale scenes.
Computation complexity: The continuity expression of NeRF and the weak assumption of spatial consistency result in slow convergence during training and while requiring large networks to compute the RGB and density of spatial sampling points, which also leads to the slow inference speed of the network. In large-scale scenes, a large number of points in the scene need to be calculated, so the computational requirements can become prohibitively large.
To address the challenge, several approaches have been proposed. It has been shown in recent research that grid-based representations can be used to speed up the training and inference of NeRF significantly. Plenoxels [
15] store density values and colors directly on a voxel grid, rather than relying on an MLP network. Instant-NGP [
6] greatly improves the training efficiency by utilizing hash encoding and multi-resolution mechanisms. F2NeRF [
16] delves deep into the mechanism of space warping to handle unbounded scenes and achieves fast free-viewpoint rendering by allocating limited resources to highlight the necessary details.
Few shot: The original NeRF method requires a 360-degree view of the target object, allowing the network to effectively learn the geometric properties of the scene due to the large amount of co-visible areas. However, in some scenes, the number of input views is limited or the view directions are relatively uniform, which may deceive the network and prevent it from learning the correct geometric information from the images. RegNeRF [
17] alleviates artifacts caused by the sparse input by adding regularizations on both geometry and appearance. DS-NeRF [
18] and Urban-NeRF [
19] improve the geometry of the scene by adding depth supervision.
During the visual landing process, the observation viewpoint is relatively uniform and falls into this category. To address these challenges, prior regularization constraints or depth supervision are often required to be added to the network.
Different resolutions: When there are multiple resolutions present in the input images, NeRF can exhibit blurring and aliasing. MipNeRF [
20] solves this problem effectively by using cone sampling. In the process of visual landing, there is a significant difference in resolution between the early and late stages of landing. Therefore, our paper adopts a MipNeRF-based approach to address this issue.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}