
Drone Based RGBT Tracking with Dual-Feature Aggregation Network
Abstract
:1. Introduction
- A lightweight network applied to a drone visible-infrared object tracking mission is porposed with Swin transformer as the backbone network.
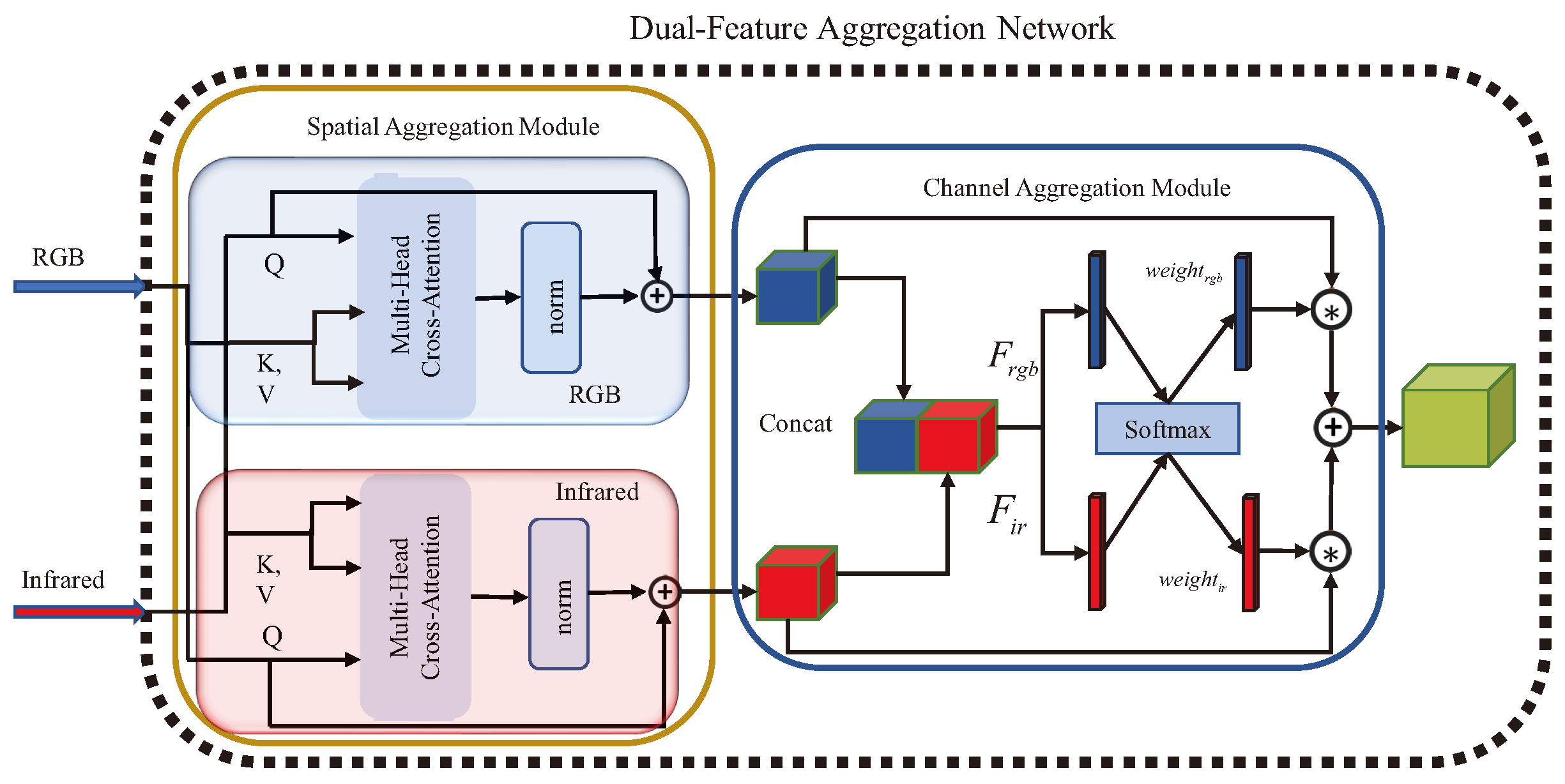
- A Dual-Feature aggregation module is integrated into this network, which aggregates visible-infrared image features from both spatial and channel dimensions using attention mechanisms. Ablation experiments are conducted to vefify the effectiveness of this module in fusing two modalities.
- Extensive experiments are conducted on the VTUAV dataset and drone hardware platform, the results showed that our tracker achieved good performance compared with other mainstream trackers.
2. Related Works
2.1. RGBT Tracking Algorithms
2.2. Transformer
2.3. UAV RGB-Infrared Tracking
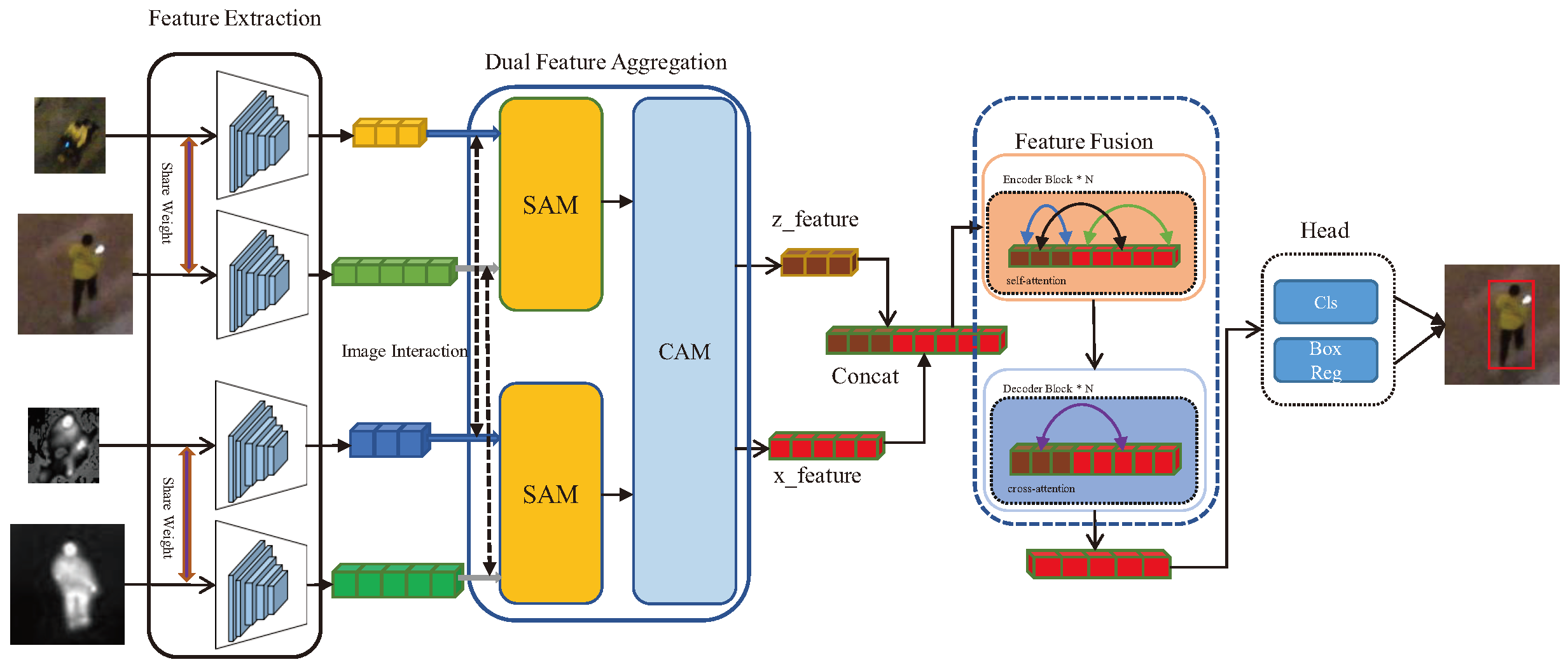
3. Material and Methods
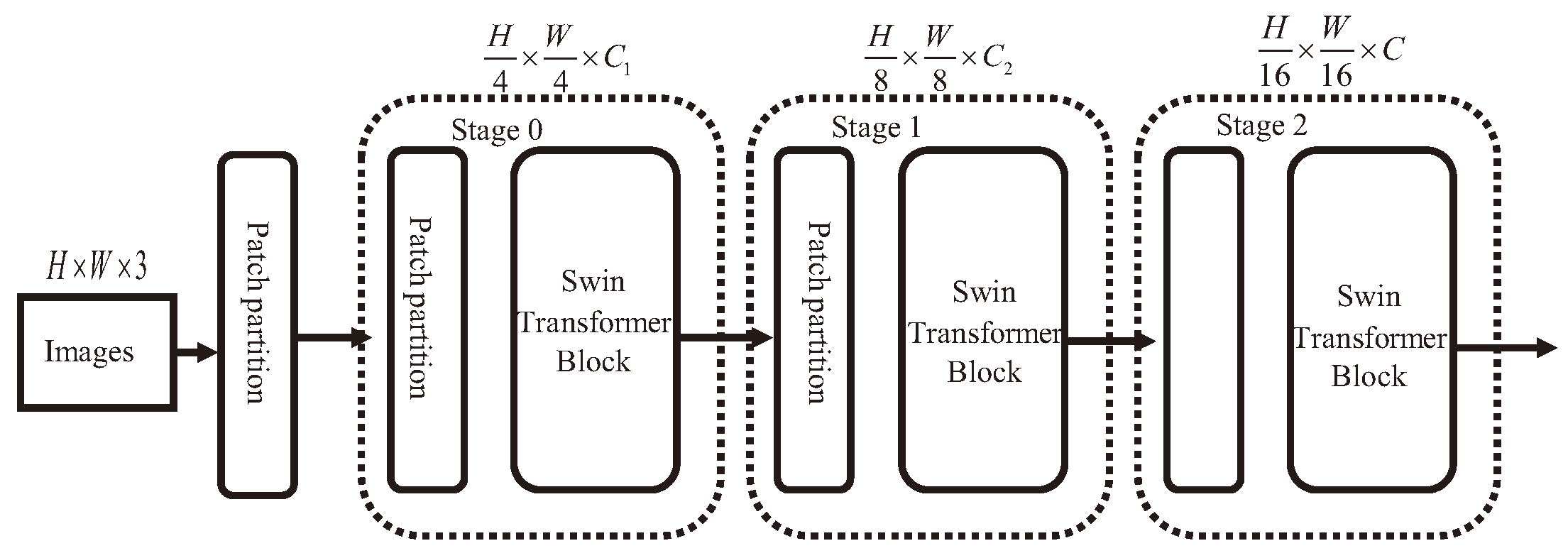
3.1. Feature Extraction Network
3.2. Dual-Feature Aggregation Network
3.3. Transformer-Based Feature Fusion Network
3.4. Head and Loss
4. Results
4.1. Implementation Details
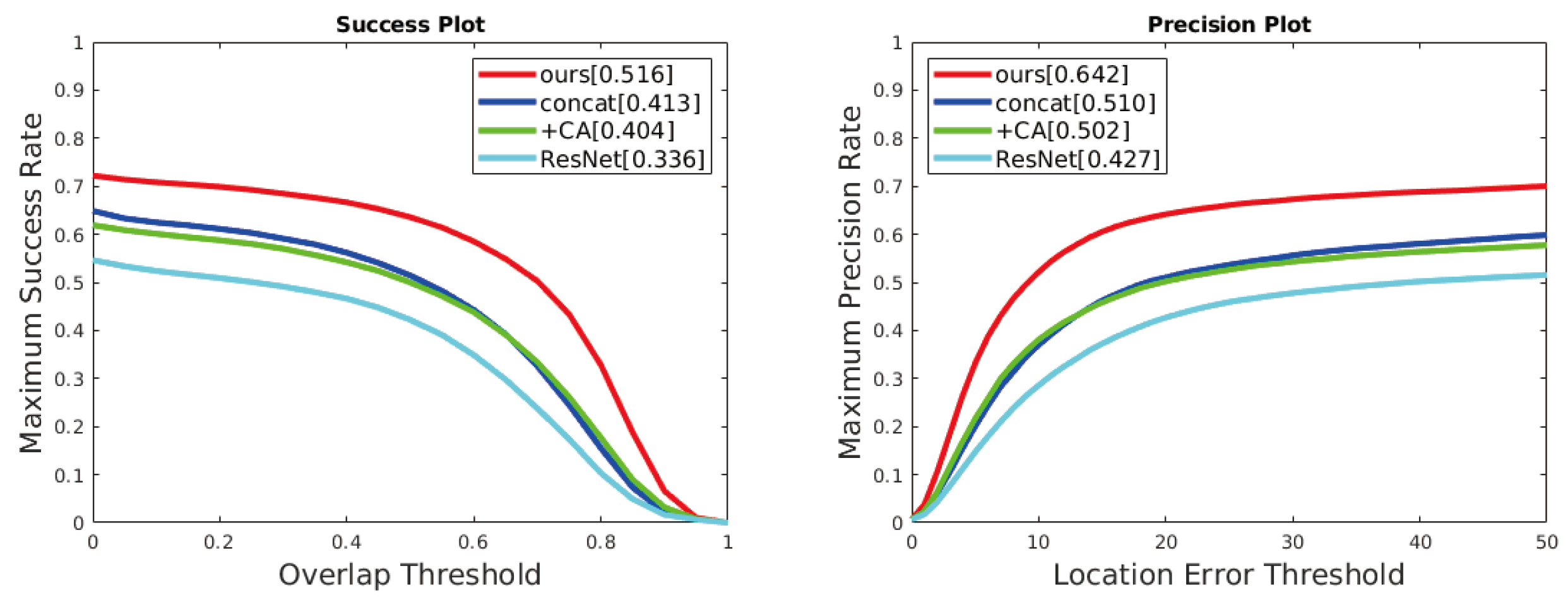
4.2. Ablation Experiment
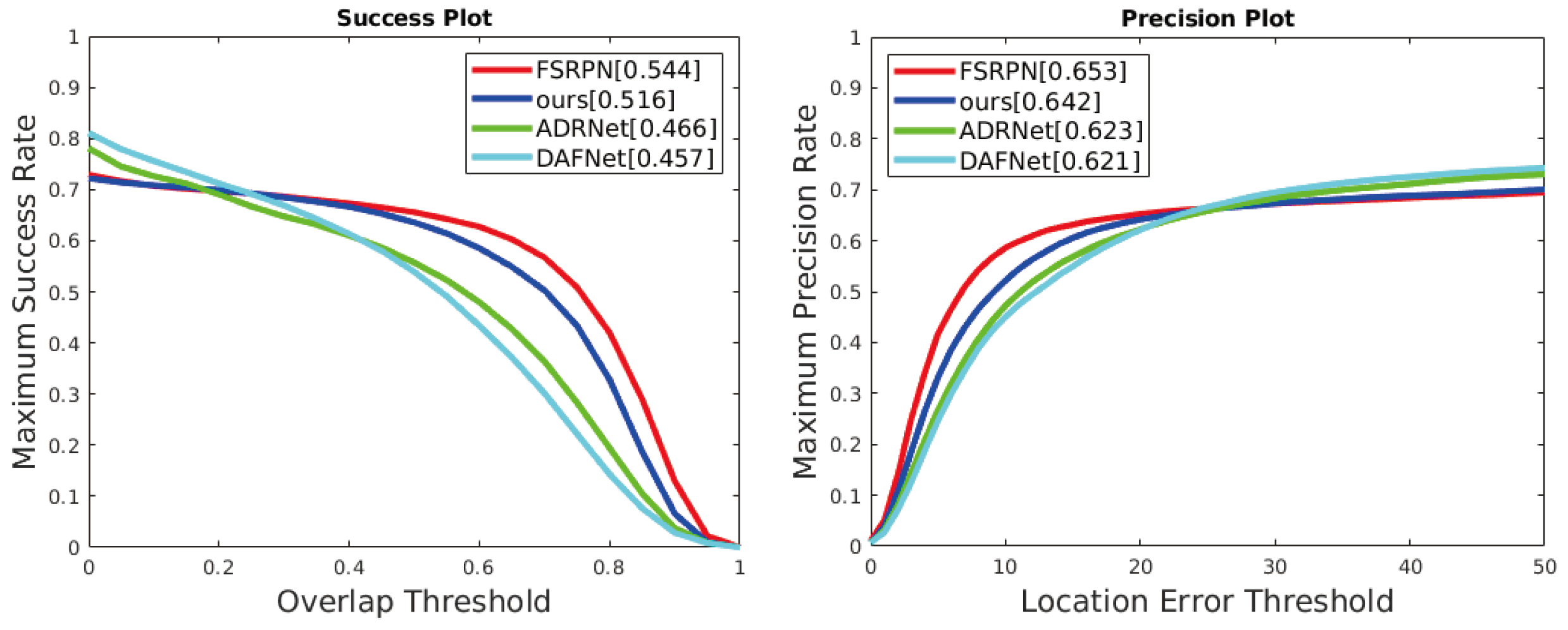
4.3. Contrastive Experiment
4.4. Drone Hardware Platforms
4.5. Visualization and Analysis
4.5.1. Algorithmic Effect of Drone Hardware Platform
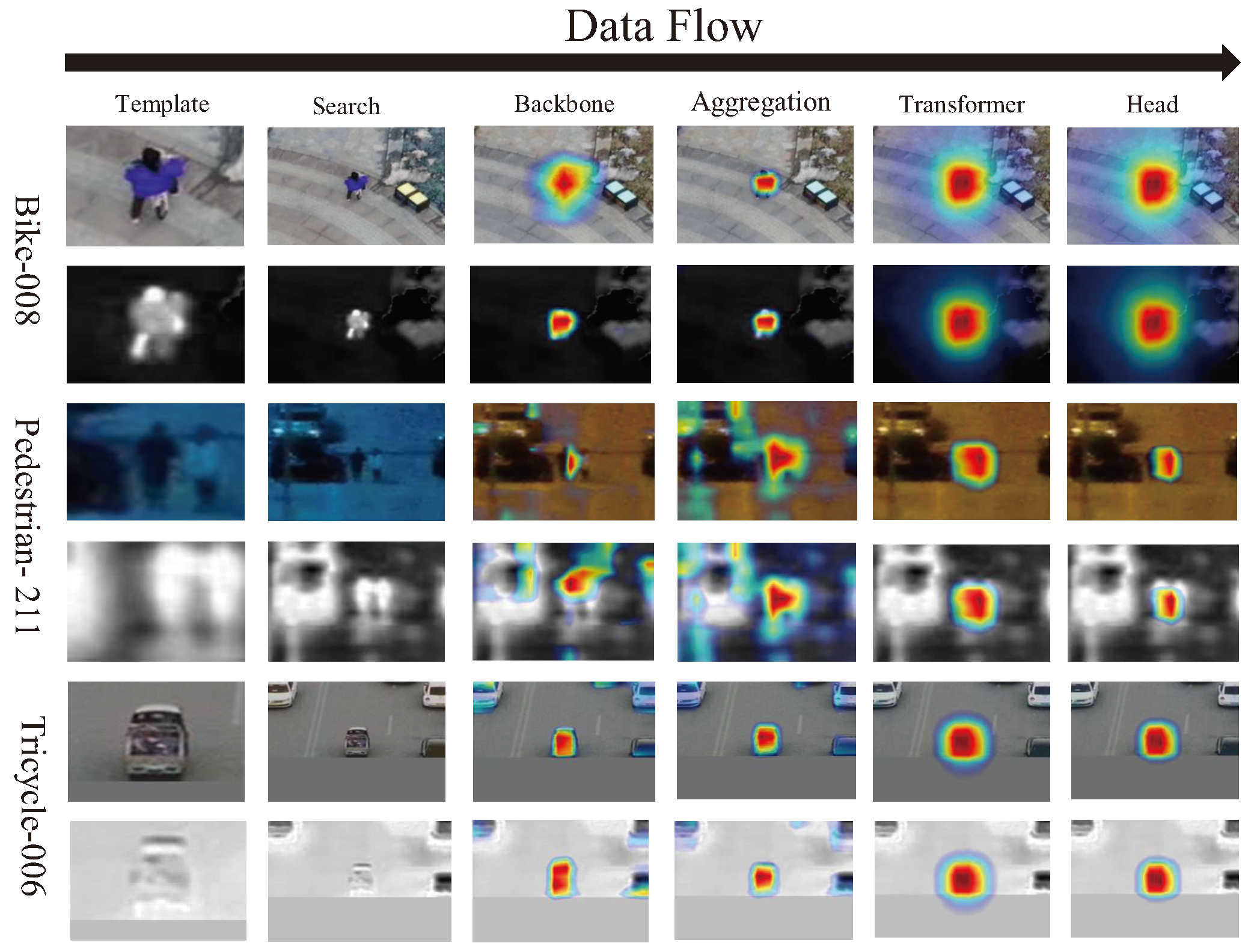
4.5.2. Heatmap
4.5.3. Typical Failure Cases
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhang, X.; Ye, P.; Leung, H.; Gong, K.; Xiao, G. Object Fusion Tracking Based on Visible and Infrared Images: A Comprehensive Review. Inf. Fusion 2020, 63, 166–187. [Google Scholar] [CrossRef]
- Huang, L.; Zhao, X.; Huang, K. GOT-10k: A Large High-Diversity Benchmark for Generic Object Tracking in the Wild. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 1562–1577. [Google Scholar] [CrossRef] [PubMed]
- Fan, H.; Ling, H.; Lin, L.; Yang, F.; Liao, C. LaSOT: A High-Quality Benchmark for Large-Scale Single Object Tracking. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Liu, Q.; Li, X.; He, Z.; Fan, N.; Yuan, D.; Wang, H. Learning Deep Multi-Level Similarity for Thermal Infrared Object Tracking. IEEE Trans. Multimed. 2021, 23, 2114–2126. [Google Scholar] [CrossRef]
- Liu, Q.; Li, X.; He, Z.; Fan, N.; Liang, Y. Multi-Task Driven Feature Models for Thermal Infrared Tracking. arXiv 2019, arXiv:1911.11384. [Google Scholar] [CrossRef]
- Bertinetto, L.; Valmadre, J.; Henriques, J.F.; Vedaldi, A.; Torr, P.H.S. Fully-Convolutional Siamese Networks for Object Tracking. arXiv 2016, arXiv:1606.09549. [Google Scholar]
- Li, B.; Yan, J.; Wu, W.; Zhu, Z.; Hu, X. High Performance Visual Tracking with Siamese Region Proposal Network. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8971–8980. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Houlsby, N. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929v1. [Google Scholar]
- Chen, X.; Yan, B.; Zhu, J.; Wang, D.; Yang, X.; Lu, H. Transformer Tracking. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 2 November 2021; pp. 8122–8131. [Google Scholar]
- Lin, L.; Fan, H.; Xu, Y.; Ling, H. SwinTrack: A Simple and Strong Baseline for Transformer Tracking. arXiv 2021, arXiv:2112.00995v1. [Google Scholar]
- Zhang, P.; Zhao, J.; Wang, D.; Lu, H.; Ruan, X. Visible-Thermal UAV Tracking: A Large-Scale Benchmark and New Baseline. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 8876–8885. [Google Scholar]
- Luo, C.; Sun, B.; Yang, K.; Lu, T.; Yeh, W.C. Thermal infrared and visible sequences fusion tracking based on a hybrid tracking framework with adaptive weighting scheme. Infrared Phys. Technol. 2019, 99, 265–276. [Google Scholar] [CrossRef]
- Yun, X.; Sun, Y.; Yang, X.; Lu, N. Discriminative Fusion Correlation Learning for Visible and Infrared Tracking. Math. Probl. Eng. 2019, 2019, 2437521. [Google Scholar] [CrossRef]
- Zhang, P.; Wang, D.; Lu, H.; Yang, X. Learning Adaptive Attribute-Driven Representation for Real-Time RGB-T Tracking. Int. J. Comput. Vis. 2021, 129, 2714–2729. [Google Scholar] [CrossRef]
- Kristan, M.; Matas, J.; Leonardis, A.; Felsberg, M.; Pflugfelder, R.; Kämäräinen, J.K.; Zajc, L.C.; Drbohlav, O.; Lukezic, A.; Berg, A.; et al. The Seventh Visual Object Tracking VOT2019 Challenge Results. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seoul, Republic of Korea, 27–28 October 2019; pp. 2206–2241. [Google Scholar]
- Jingchao, P.; Haitao, Z.; Zhengwei, H.; Yi, Z.; Bofan, W. Siamese Infrared and Visible Light Fusion Network for RGB-T Tracking. arXiv 2021, arXiv:2103.07302v1. [Google Scholar]
- Wu, Y.; Blasch, E.; Chen, G.; Bai, L.; Ling, H. Multiple source data fusion via sparse representation for robust visual tracking. In Proceedings of the 2011 Proceedings of the 14th Conference on Information Fusion, Chicago, IL, USA, 5–8 July 2011. [Google Scholar]
- Zhu, Y.; Li, C.; Luo, B.; Tang, J. FANet: Quality-Aware Feature Aggregation Network for Robust RGB-T Tracking. arXiv 2018, arXiv:1811.09855. [Google Scholar]
- Li, C.; Wu, X.; Zhao, N.; Cao, X.; Tang, J. Fusing Two-Stream Convolutional Neural Networks for RGB-T Object Tracking. Neurocomputing 2017, 281, 78–85. [Google Scholar] [CrossRef]
- Liu, W.; Quijano, K.; Crawford, M.M. YOLOv5-Tassel: Detecting Tassels in RGB UAV Imagery with Improved YOLOv5 Based on Transfer Learning. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 8085–8094. [Google Scholar] [CrossRef]
- Li, C.; Xue, W.; Jia, Y.; Qu, Z.; Luo, B.; Tang, J. LasHeR: A Large-scale High-diversity Benchmark for RGBT Tracking. arXiv 2021, arXiv:2104.13202v2. [Google Scholar] [CrossRef] [PubMed]
- Li, C.; Cheng, H.; Hu, S.; Liu, X.; Tang, J.; Lin, L. Learning Collaborative Sparse Representation for Grayscale-Thermal Tracking. IEEE Trans. Image Process. 2016, 25, 5743–5756. [Google Scholar] [CrossRef]
- Li, C.; Liang, X.; Lu, Y.; Zhao, N.; Tang, J. RGB-T Object Tracking: Benchmark and Baseline. Pattern Recognit. 2019, 96, 106977. [Google Scholar] [CrossRef]
- Li, C.; Zhao, N.; Lu, Y.; Zhu, C.; Tang, J. Weighted Sparse Representation Regularized Graph Learning for RGB-T Object Tracking. In Proceedings of the Acm on Multimedia Conference, Bucharest, Romania, 6–9 June 2017; pp. 1856–1864. [Google Scholar] [CrossRef]
- Zhang, P.; Zhao, J.; Wang, D.; Lu, H.; Yang, X. Jointly Modeling Motion and Appearance Cues for Robust RGB-T Tracking. arXiv 2020, arXiv:2007.02041. [Google Scholar] [CrossRef] [PubMed]
- Wang, S.; Zhou, Y.; Yan, J.; Deng, Z. Fully Motion-Aware Network for Video Object Detection. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module; Springer: Cham, Switzerland, 2018. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized Intersection Over Union: A Metric and a Loss for Bounding Box Regression. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 658–666. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.a. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Gao, Y.; Li, C.; Zhu, Y.; Tang, J.; He, T.; Wang, F. Deep Adaptive Fusion Network for High Performance RGBT Tracking. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seoul, Republic of Korea, 27–28 October 2019; pp. 91–99. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| RGBT Tracker | Maximum Success Rate(MSR) | Maximum Precision Rate (MPR) | Parameter |
|---|---|---|---|
| Concat | 41.3 | 51.0 | 41.9 M |
| ResNet | 33.6 | 42.7 | 41.3 M |
| +CAM | 40.4 | 50.2 | 41.6 M |
| Ours | 51.6 | 64.2 | 47.9 M |
| RGBT Tracker | Maximum Success Rate(MSR) | Maximum Precision Rate (MPR) | FPS | Parameter |
|---|---|---|---|---|
| DAFNet | 45.7 | 62.1 | 21.0 | 68.5 M |
| ADRNet | 46.6 | 62.3 | 25.0 | 54.1 M |
| FSRPN | 54.4 | 65.3 | 30.3 | 53.9 M |
| Ours | 51.6 | 64.2 | 31.2 | 47.9 M |
| CPU | CPU Frequency | Display Memory | Computational Performance |
|---|---|---|---|
| Arm Cortex-A78AE | 2 GHz | 16 GB | 100TOPS |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gao, Z.; Li, D.; Wen, G.; Kuai, Y.; Chen, R. Drone Based RGBT Tracking with Dual-Feature Aggregation Network. Drones 2023, 7, 585. https://doi.org/10.3390/drones7090585
Gao Z, Li D, Wen G, Kuai Y, Chen R. Drone Based RGBT Tracking with Dual-Feature Aggregation Network. Drones. 2023; 7(9):585. https://doi.org/10.3390/drones7090585
Chicago/Turabian StyleGao, Zhinan, Dongdong Li, Gongjian Wen, Yangliu Kuai, and Rui Chen. 2023. "Drone Based RGBT Tracking with Dual-Feature Aggregation Network" Drones 7, no. 9: 585. https://doi.org/10.3390/drones7090585