1. Introduction
There has been growing demand for Unmanned Aerial Vehicles (UAVs), so called drones, with diverse capabilities in many fields such as agriculture, surveillance, logistics, military, and so on [
1]. The term of the drone is commonly known as remote (or autonomous) flying robots, but in fact, this term is also used to describe a variety of vehicles such as submarines or land-ropers. Focusing on drones as flying robots, commonly known as drones, we classified them into three types derived from the flying mechanisms [
2]: Multi-rotor drones, fixed-wing drones, and hybrid-wing drones. Multi-rotor drones have a set of rotary wings and are based on Vertical Take-Off and Land (VTOL) principle, and then they need to tilt for producing driving horizontal force. Fixed-wing drones can be imagined such as small airplanes, which have a higher potential of glide to fly fast than multi-rotor ones [
3]. Unlike multi-rotor drones, fixed-wing drones require a runway to take off and land due to their Horizontal Take-Off and Landing (HTOL) nature. As the other type of drones, hybrid-wing drones are utilized. They are called hybrid with regard to including fixed and rotary wings and can flexibly take advantage of either wing depending on the flight situation.
These drones are adopted depending on their usage. Especially for military usage, fixed-wing drones could be employed since the military has a runway long enough for such drones to be ready for taking off and landing [
4]; however, commercial use of drones such as logistics and smart city surveillance can hardly prepare the specialized runway so that multi-rotor drones have been commonly employed in the literature so far [
5].
In order to realize fully autonomous flight of drones, there must be an essential function that enables drones to perceive their surroundings and avoid collision with obstacles [
6]. There have been many works on obstacle avoidance for several decades and they have adopted depth perception methods through distance sensors such as ultrasonic sensors, LiDAR, Microsoft Kinect, or stereo cameras [
7,
8,
9,
10]. For instance, the authors employed high-performance sensors such as ultrasonic sensors and radars in the proposals [
11,
12,
13]. These methods achieved collision avoidance by acquiring the distance between the drone and the obstacle from the sensor and using an obstacle-free location as a waypoint. However, such sensors have a limitation of either range of distance or energy consumption due to battery capacity on drones and are not suitable for autonomous drones. On the other hand, several works employ LiDAR as a long-distance measurable sensor [
7,
8]. Although these methods have realized high-speed autonomous flight, the flight distance of a drone equipped with LiDAR is limited due to the high energy consumption caused by its weight. For example, the weight of HDL-64E is well-known as 12,700 g [
14]. Therefore, to make effective use of drones, it is necessary to estimate the long distance from light sensors. Instead of such sensors, a monocular camera as the depth sensor for obstacle recognition and avoidance has been an attractive solution for autonomous drones due to several advantages of the monocular camera, including ease of use, lightweight, small footprint, and low power consumption. Although in order to fly safely, vision-based methods require Deep Neural Networks (DNNs)-based algorithms with high power consumption, with the advancement of embedded systems technology, it is now possible to use small form-factor, low-power-consumption board computers (e.g., Jetson Nano and Jetson Xavier NX) that can be installed on drones for DNN-driven computations.
Most monocular depth estimation methods usually employ Convolutional Neural Networks (CNNs). In addition, high-accuracy depth estimation networks consist of large-scale CNN in many cases [
15,
16,
17,
18]. Several methods have achieved practical accuracy in long-depth estimation from a monocular camera using CNN. In the studies [
19,
20], the authors employed the two steps CNN to estimate depth accurately. In the first step, the network takes a monocular image and outputs a global rough depth map. The network refines the depth map locally from a monocular image and the global rough depth map in the second step, but the drawback of this network is low accuracy for the network size. To solve this problem, various efforts have been made to improve the accuracy of depth estimation.
One way to improve accuracy is to deepen and expand the network. In the work [
17], the authors employed Visual Geometry Group (VGG) to extract features from a monocular image for depth estimation. The architecture of VGG is characterized by its simple design and the use of multiple small convolutional filters, which led to its excellent performance on large-scale image classification benchmarks [
21] and the paper [
17] achieved higher accuracy than the works in [
19,
20]. These methods [
15,
16,
18,
22,
23] also used other deep CNNs (e.g., ResNet50 [
24] and DenseNet121 [
25]). In addition, the authors added the transformer techniques to the CNN depth estimator to refine the depth estimation map [
26,
27]. The deep CNN [
15,
16,
22] or transformer [
26,
27,
28] methods improve accuracy significantly. However, the inference time of these methods is too long for drones to fly safely, especially on a low or middle-grade Graphical Processing Unit (GPU), which can be loaded on drones. In order to utilize high accuracy and large-scale deep CNN-based methods, drones communicating with cloud servers have been recognized as an efficient solution in that the computation is conducted very quickly on a cloud server instead of on a drone itself. However, the latency between a drone and a cloud server usually takes up to a few seconds and it also jeopardized to security vulnerabilities, resulting in fatal systematical problems [
2,
29,
30,
31].
Another way to improve the depth estimation method is to pre-process a monocular image and use lightweight CNN. For instance, the authors in [
32] employed semantic segmentation as a pre-processing to improve accuracy. This method [
32] identifies categories and calculates instance segmentation maps followed by dividing them into patches from categories and instance maps. In the next step, this method estimates the depth of each category and each instance. As a result, by category and instance-wise depth estimation, the computational cost for depth estimation is small, and the edges are sharper and more accurate than the other methods. However, the authors employed ResNet50 for segmentation, which increases the computational cost for pre-processing. Therefore, pre-processing for depth estimation on drones must process fast not to increase the total inference time of depth estimation.
The authors in [
33,
34] employed Pix2Pix [
35] for depth estimation and demonstrate that inference time is practical for autonomous flight. The authors [
34] concluded the estimation accuracy of this method [
33] is not enough for collision avoidance completely; therefore, the authors in [
34] employed optical flow as a pre-processing and improved accuracy. This method [
34] generates optical flow maps and replaces a part of monocular image pixels with the optical flow map pixels. However, this method [
34] does not utilize full optical flow information. The work in [
36] proposed a method that inputs two images into CNN and this method worked well to use all information in the image. The method [
36] employed ORB-SLAM presented in [
37], which is known as a Simultaneous Localization and Mapping (SLAM), as a pre-processing and generated a sparse depth map. SLAM is a technology that allows a device to create a map of its surroundings and determine its location within that map in real time without Global Positioning Systems (GPS). SLAM algorithms are computationally expensive, and real-time performance can be difficult to achieve on limited computational resources. In addition, the simplified depth map generated by the SLAM algorithm is a sparse depth map like a LiDAR cloud point map. However, due to the characteristics of CNNs, it is difficult to extract point cloud features from sparse depth maps. Stereo photogrammetry, Structure from Motion (SfM) photogrammetry and Multi-View Stereo (MVS) are also a process of creating 3D images from 2D images by using the stereogram principle, which involves the use of stereo imagery to derive 3D information about a scene. However, these methods need high-resolution cameras to create accurate 3D models. Furthermore, these methods can only obtain a 3D model if multiple images are acquired. Therefore, to use these methods for drone collision avoidance, it is necessary to pre-flight the flight route and create a 3D map in advance, which is not suitable for dynamic environments.
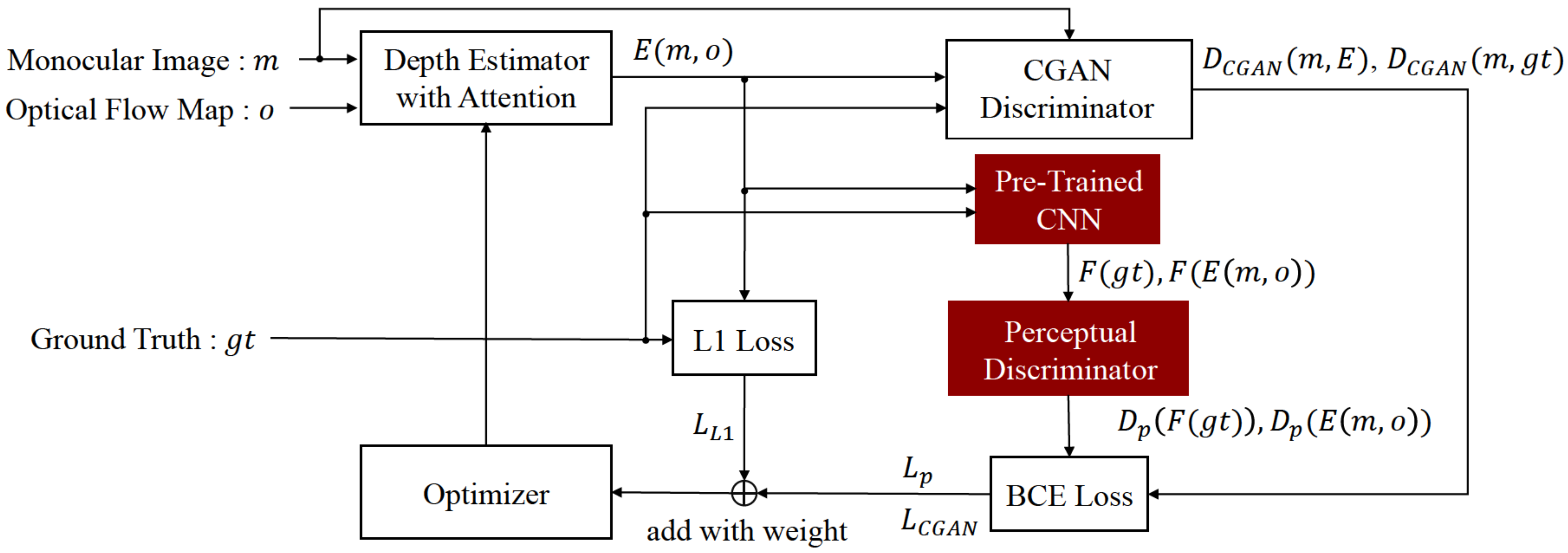
There exist some works that employ Conditional Generative Adversarial Networks (CGAN) [
38] to train CNN for depth estimation for its easy adaptation for many image-to-image problems [
33,
34,
39,
40]. CGAN improves the performance of the generator by feeding additional data to the generator and the discriminator. However, it is not enough to determine true/false with only one discriminator, and it is effective to determine true/false from other perspectives.
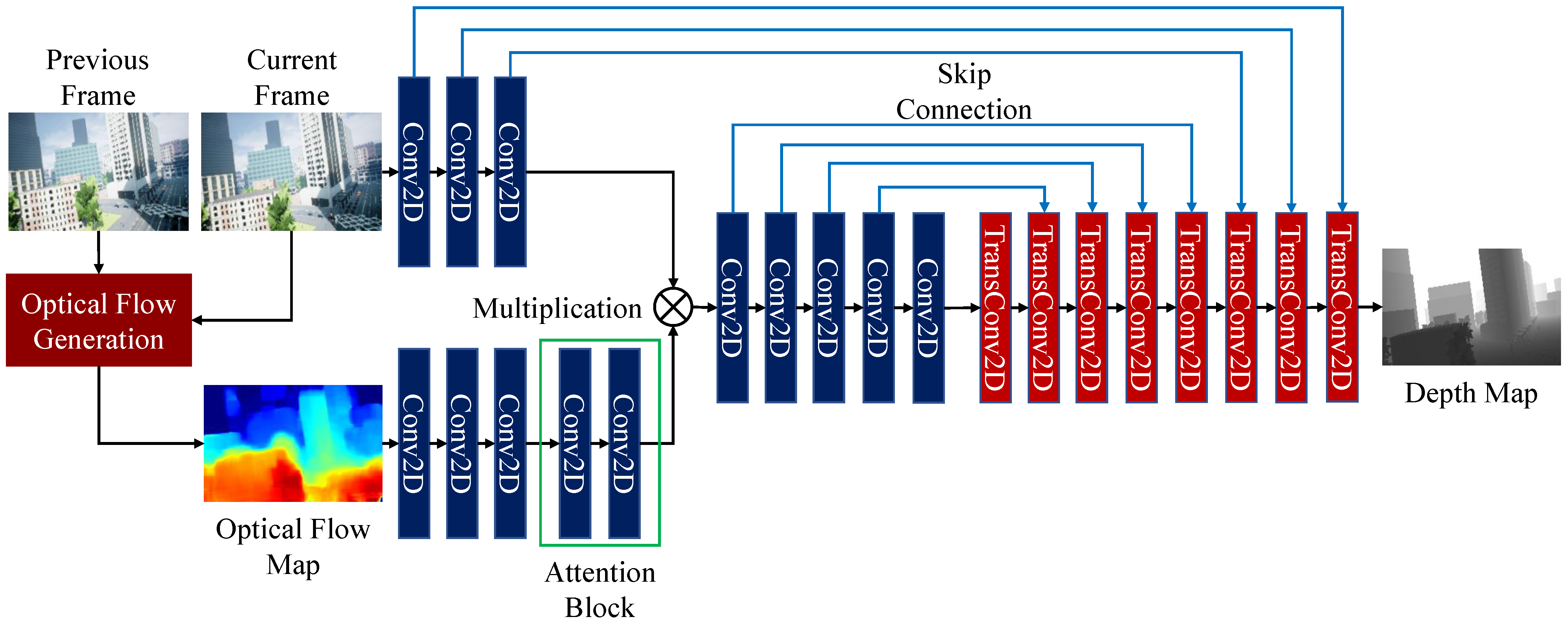
In this paper, we propose fast and effective pre-processing for depth estimation and CNN to utilize pre-processing information. To further enhance our proposal, we adopt a perceptual discriminator to improve the accuracy of depth estimation without increasing the complexity of the generator network.
The rest of this paper is organized as follows.
Section 2 describes a proposed method for depth estimation using optical flow attention and a perceptual discriminator. The experiments on the evaluation of error, accuracy, and collision rate are presented in
Section 3, and
Section 4 shows the results of these experiments.
Section 5 describes discussions about experimental results and issues of our proposed method.
Section 6 concludes this paper.
5. Discussion
In this section, we will discuss what makes high accuracy with a short inference time. We also discuss the technical issues that need to be addressed.
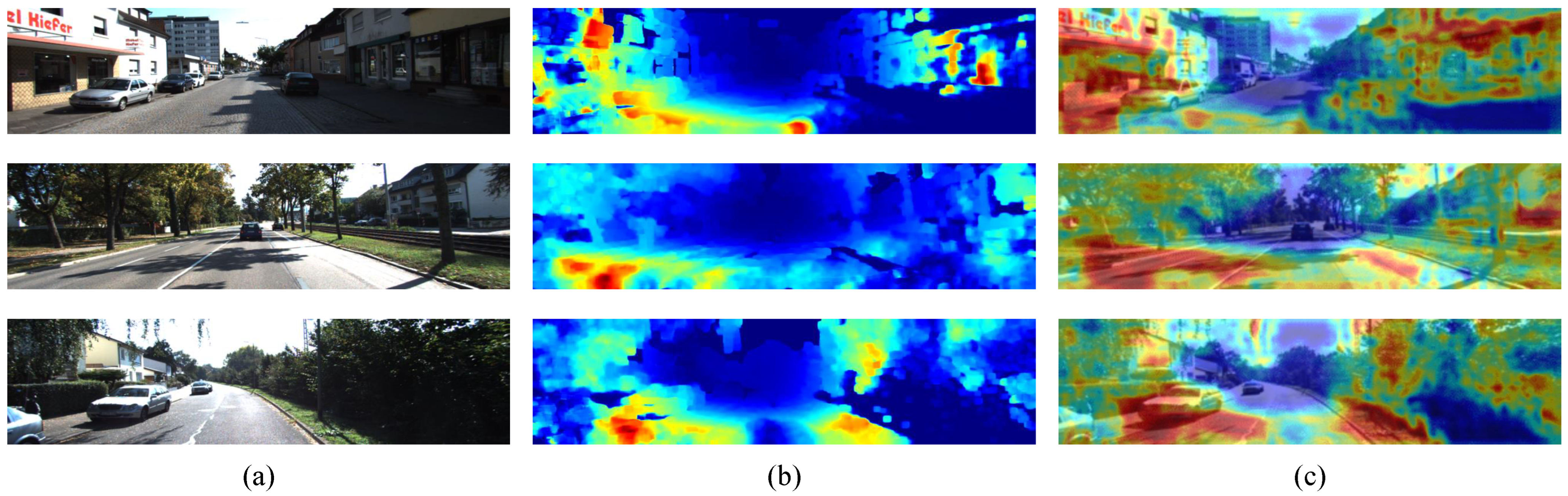
First of all, we show how optical flow attention actually works and how it contributes. The proposed method is superior to the other methods because of the optical flow attention as shown in
Table 1,
Table 2 and
Table 5.
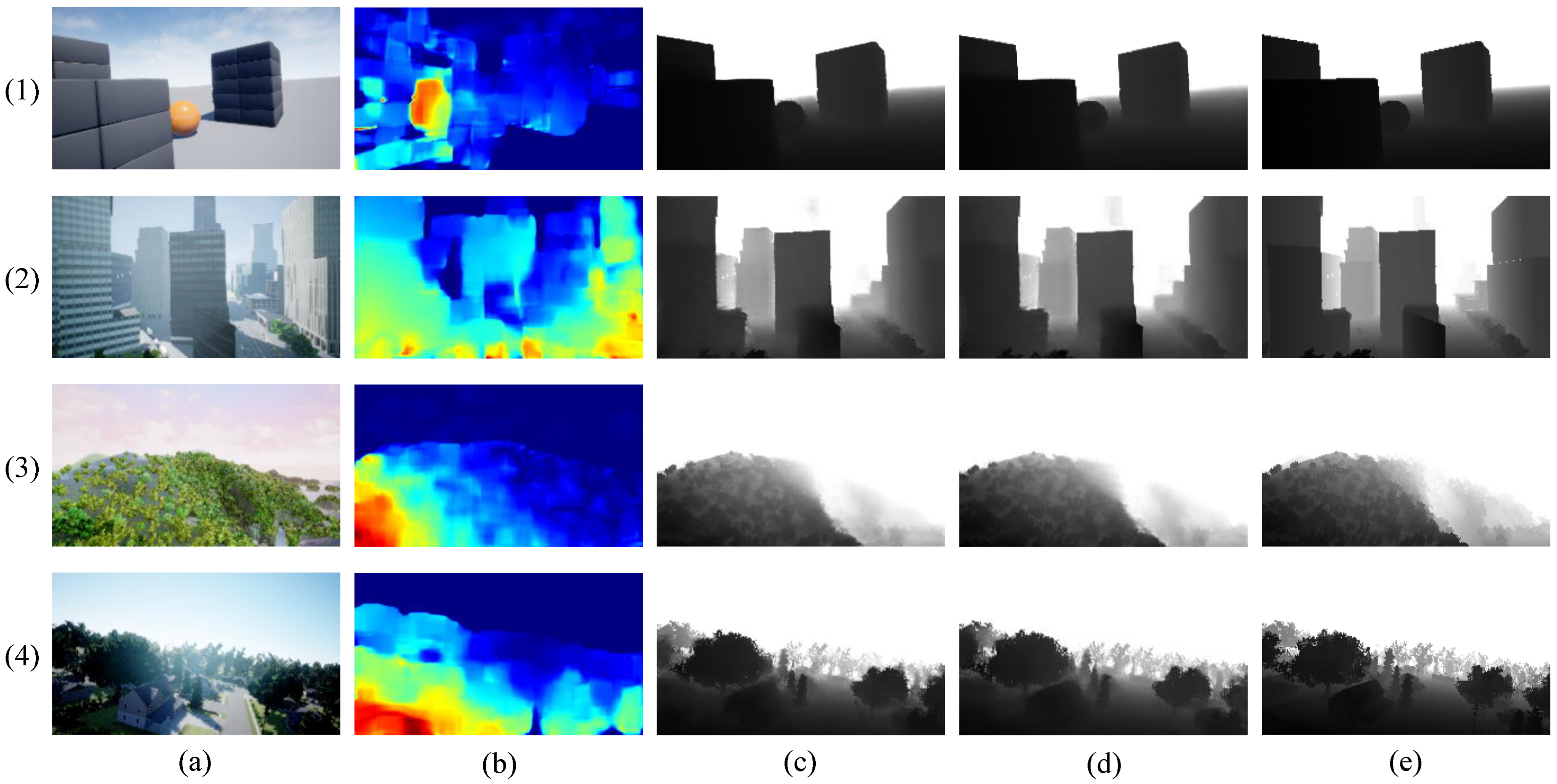
Figure 7 shows visualization of optical flow attention in KITTI dataset.
As shown in
Figure 7, the optical flow attention adds large attention to nearby objects. The optical flow attention can also add information to areas not represented by optical flow maps. The features of the monocular image enhanced by this attention are input to subsequent down-sampling, allowing more effective feature extraction than with monocular images. Therefore, the proposed method achieves high accuracy since the proposed method can utilize the optical flow information more than Shimada et al. method [
34] which takes only a part of optical flow pixels.
In addition, as shown in
Table 2, adding optical flow information by attention is possible to achieve the same accuracy as the Kuznietsov et al. method [
18], which is a high-performance CNN.
Figure 8 shows visual aspects using the KITTI dataset.
As shown in
Figure 8, the proposed method has clear edges and the results are comparable to the Kuznietsov method [
18]. On the other hand, the proposed method reflects the poles in the depth estimation results while the Kuznietsov method [
18] does not show them in the depth estimation results. As shown in
Figure 7c, the telephone poles have been highlighted by the optical flow attention with displacements detected in the previous and current frames. The shape of the car in side of a street is also clearer by the optical flow attention than in the Kuznietsov method, and these differences are reflected in the accuracy of the proposed method. Therefore, without deepening the CNN, the optical flow attention improves the accuracy of depth estimation with fast inference time.
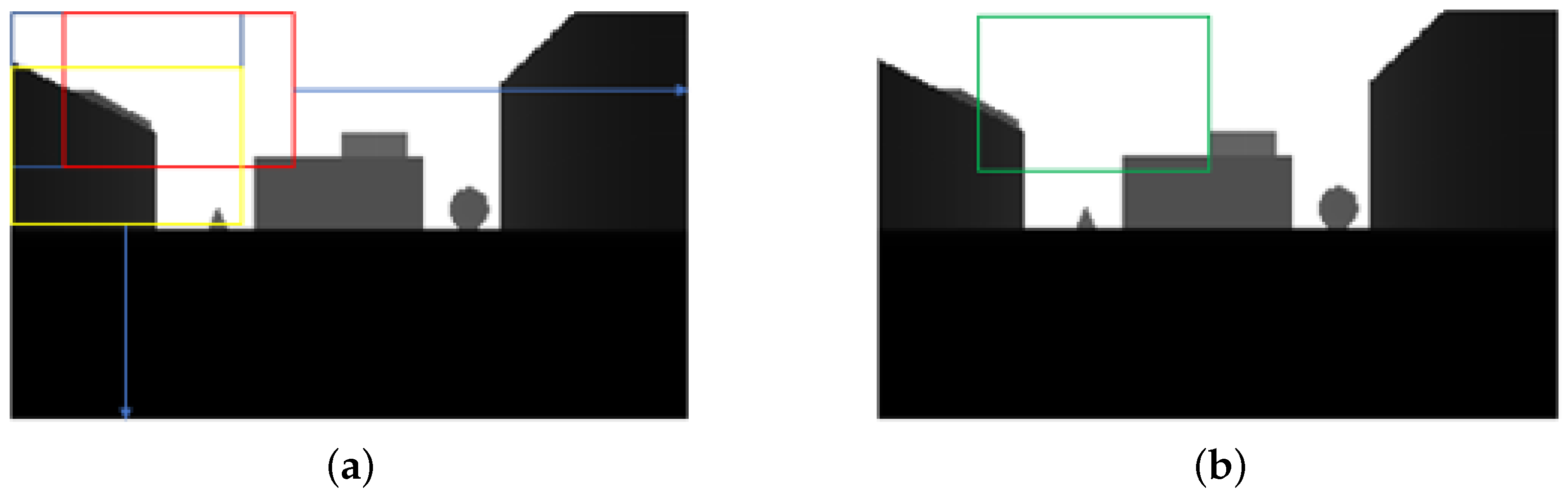
We describe the technical issues. Our proposed method employs an optical flow as a simplified depth. The simplified depth required by the optical flow requires the object to be moving between each frame. Therefore, optical flow acquired by a moving camera, such as a drone, can accurately calculate the simple depth outside the center of the image. On the other hand, in the central part of the image, there is very little or no movement between each frame of the moving camera and it does not show up in the optical flow. Objects moving at the same speed as the drone are similarly not represented in the optical flow.
Figure 9 shows an example that optical flow does not work.
As shown in
Figure 9, the bounding box shows a car location however in the optical flow map, there is no information in the bounding box. Therefore there is a necessity to develop a more effective simplified depth generation method.
6. Conclusions
In this paper, we propose a fast inference time and high-accuracy depth estimation method for autonomous drones. To achieve a highly accurate depth estimation of monocular images alone, it is generally necessary to use a deeper CNN to extract more features. However, this is not suitable for drones due to the long inference time. We propose optical flow attention that does not deepen the network but rather inputs optical flow as information that can aid in-depth estimation. In addition, we add perceptual discriminators and skip connections to make our fast estimator more effective than the conventional training method.
Experimental results demonstrate our proposed method is superior to the state-of-the-art in accuracy, error, and collision rate with fast processing time. Our proposed method is considered to be the most suitable method for the autonomous flight of drones. We also conduct an ablation study to confirm the contributions of our proposed method. The results of the ablation study demonstrate that the skip connection contributes to edge sharpness, the optical flow attention contributes to accuracy improvement, and the perceptual discriminator contributes to preventing the vanishment of detailed object estimation.
In future work, we will investigate more efficient information than optical flow. In addition, as shown in
Table 6, the collision rate in City Environment is too high to be feasible for real environments. Therefore, we will design more effective collision avoidance for depth estimation. There are also a number of challenges in the current technology of depth estimation for drones. These include, for example, reduced energy consumption, faster inference times, higher accuracy and fast and robust waypoint determination methods. Solving these problems is a future challenge for the field.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}