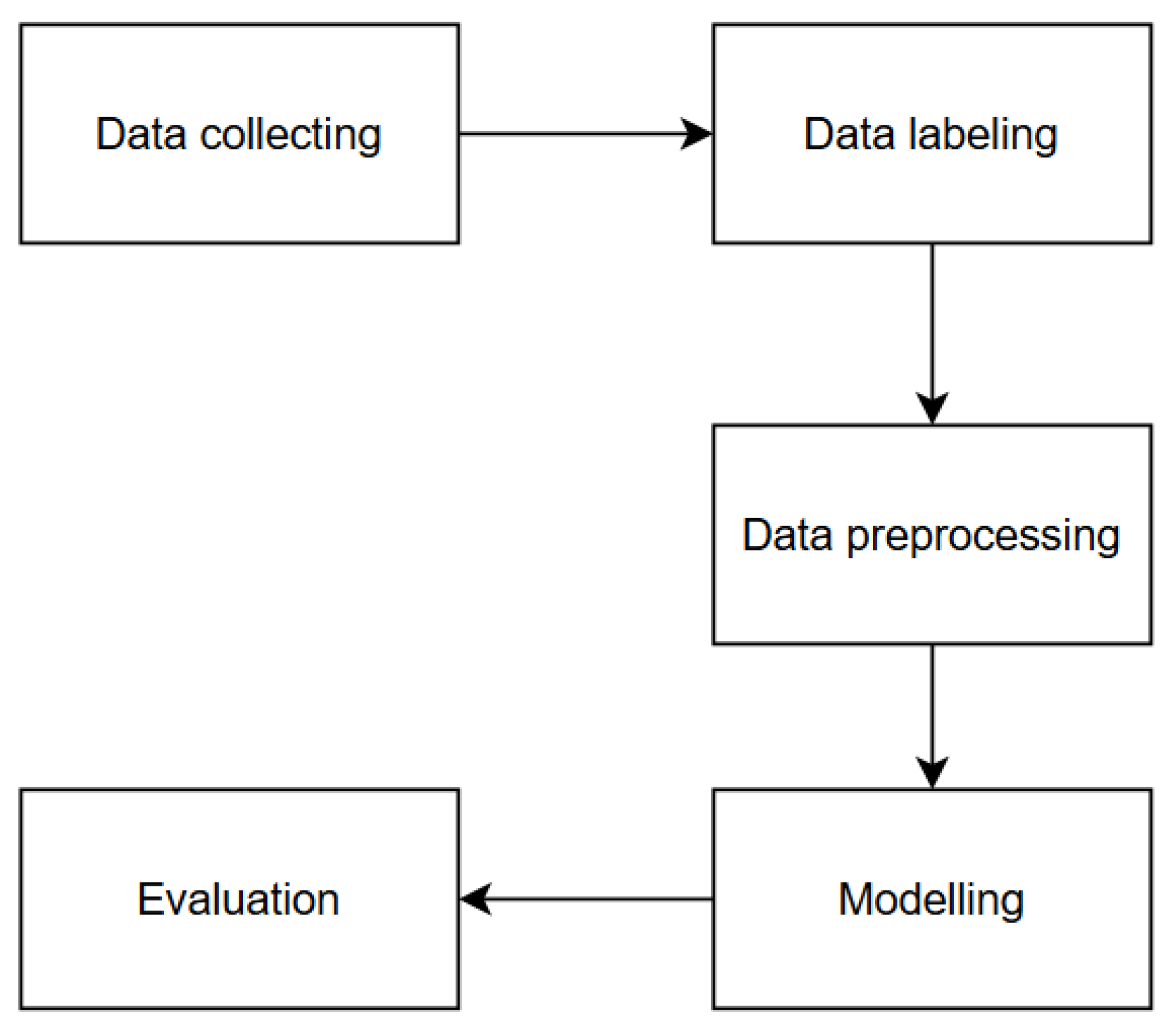
1. Introduction
The global increase in Coronavirus Disease 2019 (COVID-19) cases has continued worldwide, notably in Indonesia [
1]. As a result, the Indonesian government must undertake steps to limit the rising number of cases [
2]. To address the high number of confirmed positive cases, the government implemented a variety of programs to reduce the number of positive confirmed cases. One of the policy considerations raised by the administration concerned vacations [
3]. This strategy was implemented as an effort to avoid the formation of new clusters as a result of people taking extended vacations. To address this issue, the government issued Circulation No. 12 of 2021 concerning the Provisions for Domestic Travel During the 2019 Coronavirus Disease (COVID-19) Pandemic [
4] and Circular No. 13 of 2021 concerning the Elimination of Homecoming for Eid al-Fitr 1442 Hijri and Efforts to Control the Spread of Coronavirus Disease 2019 (COVID-19) During the Holy Month of Ramadan 1442 Hijri [
5]. The government was concerned that the number of positive COVID-19 cases might continue to grow, therefore the administration took measures designed to maintain a decline in positive cases by introducing this program.
Undoubtedly, these policies attracted diverse viewpoints from the general populace. The numerous responses were generally categorized into three groups: agreeing (pro), disagreeing (contra), and indifferent. These comments were frequently disseminated in print media, online news channels, and social media. One such social media site is YouTube [
6], which features a comments area where varied views, ideas, opinions, and public opinion on government policies may be expressed. YouTube is the top social media platform in Indonesia, with most of the population having access to it. As a result, YouTube may be used as a source of information to gauge the public’s reaction to government efforts to fight the COVID-19 pandemic. To determine the public’s reaction to this policy, a sentiment analysis needs to be used in the YouTube video comment column. For the public impact worldwide, commercial choices, and policy formation, large-scale extractions of human emotions and reactions from social media networks are vital [
7].
Sentiment is a description of an emotion or an emotionally significant occurrence. It may additionally be described as an individual’s viewpoint (it is generally subjective). In contrast, sentiment analysis is a method for measuring opinions, emotions, and subjectivity in written texts [
8]. It is sometimes referred to as opinion mining, and a topic of research that employs natural language processing (NLP), text mining, computational linguistics, and a measurement to identify, release, evaluate, and explore emotional states and subjective data [
9]. The use of sentiment analysis is employed to evaluate the speaker’s disposition based on their emotional responses, which will indicate the emotional response of the speakers as they talk. It is possible to construct a system that detects and extracts text-based opinions using sentiment analysis. Currently, sentiment analysis may be used to investigate various social media opinions so as to determine an individual or group perspective on a certain topic. This evaluation is based on dialogue and evaluative discourse to examine attitudes and sentiments toward the associated brand [
10,
11]. In sentiment analysis, there are three key aspects to be considered, namely the topic, the polarity, and the opinion holder [
12]. The topic refers to the relevance to the issue being discussed. Polarity describes the value of the opinions expressed, and whether they are favorable, negative, or neutral. The person who conveys an opinion is the opinion holder. According to the above description, it is a technique used to extract information in the form of an individual’s opinion about a certain topic or event. Using sentiment analysis, the varied perspectives offered by each of these individuals will be interpreted and categorized. These categorization phases can be modified to match the aims of the research.
Machine learning is a subfield of artificial intelligence (AI) that allows machines to undertake human-like activities [
13]. The existence of machine learning supports many human activities. Among the applications of machine learning is sentiment analysis [
14,
15,
16]. Sentiment analysis is a science used to extract information in the form of an individual’s opinion on a topic or an incident [
17,
18,
19]. By using this kind of analysis, various public perspectives on a government’s policy may be determined. Sentiment analysis extracts the opinions expressed by the public via social media, which is information reflecting the perspective of the community on a particular policy. Undoubtedly, the government’s policy with regard to extended vacations during the COVID-19 pandemic would provoke a variety of responses among Indonesians. A portion of society agrees with and supports the government’s policy to reduce the spread of COVID-19 [
20]. On the other hand, there are individuals who oppose this program and there are also those who are uninterested in the topic. Using sentiment analysis to determine the public’s reaction to this government program is therefore of value.
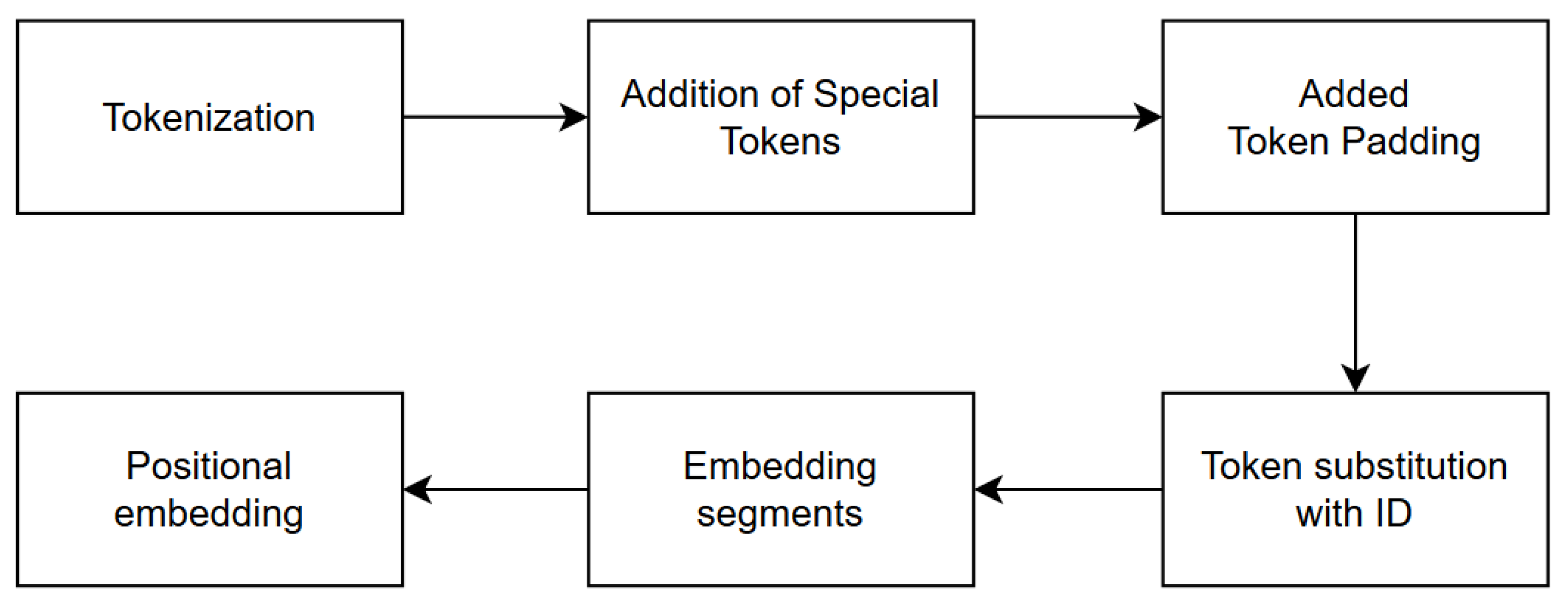
This study employs bidirectional encoder representations from transformers (BERT) to be used for sentiment analysis on this topic. It can educate robots to learn human speech patterns sentence-by-sentence, as opposed to the current method of learning word-by-word [
21]. Google released the algorithm for the first time in October 2019. BERT is an NLP technique that mixes machine and human language [
22]. BERT’s application includes two-way learning, which increases the model learning. It is more accurate than the conventional model [
23]. Consequently, the objective of this study is to automate the categorization of public sentiment toward government vacation policies during the COVID-19 pandemic. Considering that sentiment analysis has been developed to be used in English, this analysis is language dependent, so advances in processing technology in other languages cannot be applied directly to other languages. Therefore, this study also contributes to the methodology of sentiment analysis in Indonesian. It also provides a web-based application for sentiment analysis utilizing a trained BERT model. The anticipated significance of this study is that the government will be able to establish the policies taken during the COVID-19 outbreak when they are accepted by the people. Using sentiment analysis in this study will certainly make it easier to achieve this objective.
2. Related Works
As a means of connecting people and encouraging the exchange of ideas, information, and expertise, social media has created a number of online platforms. It is undeniable that social media platforms have more sway than ever before, and their prominence is on the rise [
11]. Since many people use their devices and spend so much time consuming content on social media sites, these platforms are sometimes referred to as the Big Data of the world; thus, social and statistical research have concluded that they have a significant impact on users’ habits. In terms of global use, YouTube, Facebook, Twitter, Instagram, and Reddit are among the top social media platforms. In spite of the vast amounts of information available on these sites, the material may have opposing impacts, including both good and negative psychological sway on users’ lives [
16]. It is possible that those who are addicted to social media use it to vent their frustrations and express their perspectives. Therefore, it is important to seek ways to convert these comments and postings into assets by utilizing sentiment analysis.
Studies on sentiment analysis have progressed significantly. This study has been conducted in a number of languages, including Arabic [
24], Malaysian [
25], Brazilian [
26], Persian [
27], German [
28], Portuguese [
29], Chinese [
30,
31], Urdu [
32], Bengali [
33], Vietnamese [
34], Indonesian [
35], and Lithuanian [
36]. This kind of research is language dependent, since the success of technology in one language cannot be applied straight to other languages. Each language has its own characteristics, such as word formation, sentence structure, and style of language use. This is a barrier for sentiment analysis research, as each language requires a unique approach. Research produced by Xu et al. presents a cross-lingual technique to accommodate diverse languages in this research [
37]. Their research advances not only language modeling but also the preprocessing techniques employed. Pradha et al. [
38] proposed a method for effectively processing text input and developing an algorithm for training Support Vector Machine (SVM), Deep Learning (DL), and Naive Bayes (NB) classifiers to categorize tweets. When computing the sentiment score, they designed a system that lends greater weight to hashtags and more recently cleansed content. They compared the success of Google Now and Amazon Alexa using Twitter data. According to the findings, the stemming method is the most efficient. de Oliveira et al. [
39], Sohrabi et al. [
40], Alam et al. [
41], and Resyanto et al. [
42] also conducted research pertaining to additional text preparation.
Many classification methods have also been extensively used to address the issues presented in this research. Several traditional machine learning techniques that have been implemented include Naive Bayes [
43,
44], Support Vector Machine (SVM) [
45], Decision Trees [
46], Random Forests [
47], and Regression [
48]. This investigation leads to the context of Big Data as the era of social media becomes more sophisticated. The created method is also in the deep learning stage of processing [
49,
50]. Long Short-Term Memory [
51], Convolutional Long Short-Term Memory [
52,
53,
54,
55], Bi-LSTM [
56], and BERT [
57,
58,
59] are some of the deep learning algorithms that have been developed.
4. Results and Discussion
At this stage of testing, four hyperparameters of the sentiment analysis model were assessed. This examination was divided into two sections: the preprocessing method and the BERT hyperparameter examination. This study determined which preprocessing strategy might be the most successful by administering several tests. Regarding the BERT hyperparameter, three factors were evaluated: the batch size, epoch, and learning rate.
4.1. Preprocessing Data Analysis
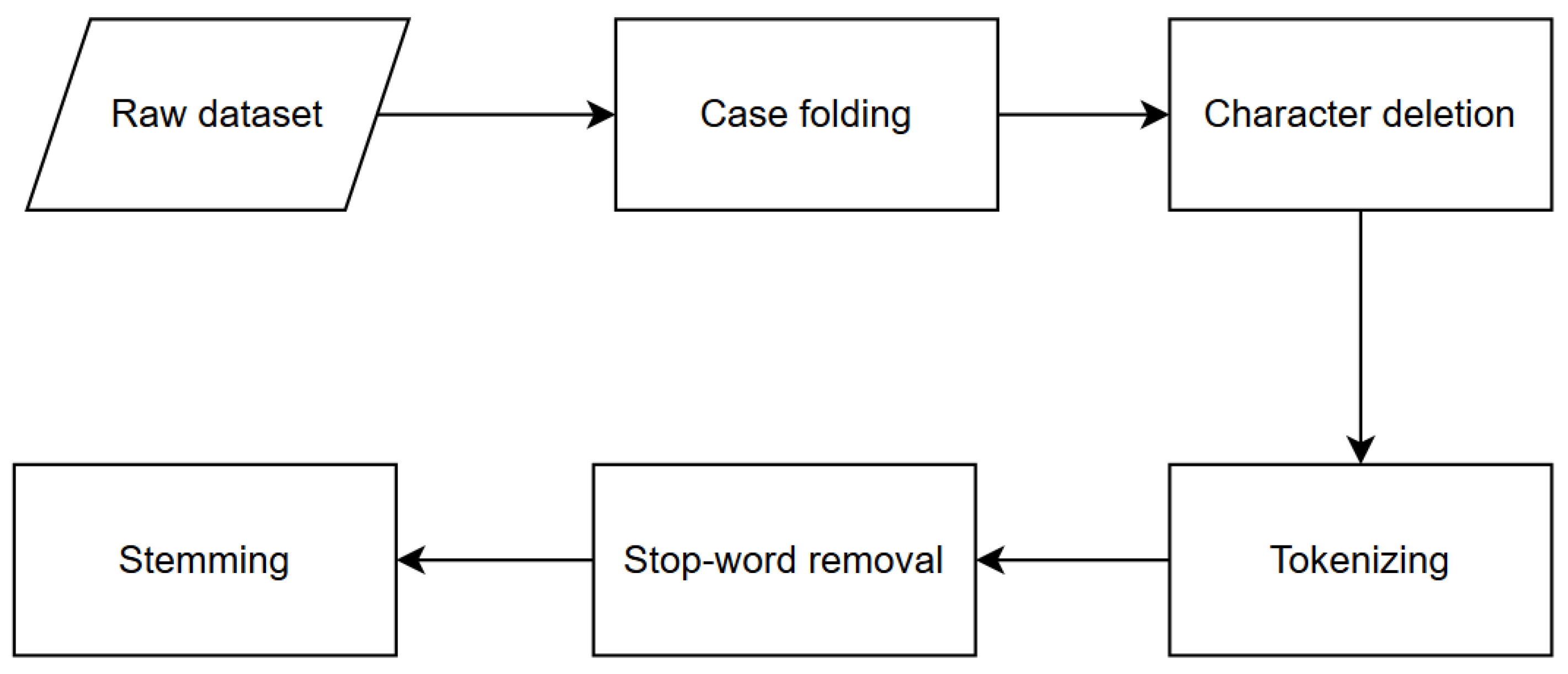
This study performed four distinct test combinations to identify the ideal preprocessing strategy. This number was derived by first employing the two stop-word lists used in the study, and then determining whether or not to utilize a stemming phase. Note that the amended version of the first list of stop words acts as the second list. The outcomes of the investigation that verified the preprocessing approach are presented in
Table 3. The greatest results were obtained when the second list of stop-words was used without stemming during preprocessing. It indicated that the BERT approach for sentiment analysis might be impacted by the inclusion or exclusion of certain phrases. When stemming was deactivated, both sets of results increased because the affix affected the BERT token. During the embedding process, the ID of the BERT token within the embedded word might be adjusted by stemming. In addition, there were infix words, repetition words, and words that melt upon meeting affixes that had not been adequately addressed in the employed technique, rendering stemming extremely hazardous when used on Indonesian words for this work.
4.2. Analysis of Batch Size
In this study, determining the ideal batch size required two distinct figures. It employed a predefined set of hyperparameter values, including a learning rate of 2e-5 and a set of three epochs. The information presented in
Table 4 suggests that 32 was the optimal number of batch sizes. Increasing the batch size would render the model more resilient. An epoch delivered a more even distribution of data. Therefore, 32 batch sizes were superior to 16 batch sizes.
4.3. Analysis of Learning Rate
Table 5 demonstrates that the best learning rate was 2e-5. Using a lesser learning value resulted in a superior and more stable model. Due to the progressive nature of weight-change methods, a smaller number would produce a more accurate amount of model adjustment. Consequently, the model training took more time.
4.4. Analysis of Epoch
This study employed four distinct values to estimate the optimal epoch. This analysis implied that three epochs were the ideal duration for this investigation, as shown in
Table 6. In the BERT framework, a low epoch value did not always result in mediocre model training. Due to the fact that the BERT model was a pre-train model, the training process was primarily focused on the stage of fine-tuning. Therefore, the BERT model might be trained with reduced epoch values.
4.5. Final Evaluation
Extensive testing demonstrated that the greatest results could be achieved with the second stop-word list without stemming, a batch size of 32, a learning rate of 2e-5, and a total of three epochs. When all conditions were optimal, the precision was 83.67%, the recall was 85%, and the f-score was 84.33%.
Table 7 depicts the resulted confusion matrix model. There were 284 pieces of negative news that were properly predicted to be negative, 25 pieces of negative news that were accurately predicted to be neutral, and seven pieces of negative news that were accurately predicted to be positive. Furthermore, there were 20 predictions for negative neutral data, 68 for neutral data, and 7 for positive neutral data. In the positive row, seven positive data were projected to be negative, four were predicted to be neutral, and the remaining 78 were predicted to be positive. The outcomes of our computations of precision, recall, and F-score based on the confusion matrix are displayed in
Table 8.
The obtained precision and recall percentages of negative sentiment were 91% and 90%, respectively. Consequently, when the F-score was computed from the two variables, a result of 91% for the negative sentiment was produced. The resulting precision value for the neutral sentiment, on the other hand, was 75%. It achieved a 77% recall rate for a neutral sentiment using this strategy. The sum of these two scores was 76%, showing an F-score of this opinion. The calculated precision for positive sentiment was 85%. Consequently, 88% of individuals recall having a positive view. This indicates that an F-score for optimism of 86% might be obtained using these two figures. The negative sentiment F-score was 91%, which was bigger than the neutral and positive sentiment F-scores. It can be concluded that predictive data models were more successful when dealing with negative sentiment when put into practice.
4.6. Comparison to Other Algorithms
Table 9 displays the results of comparing the BERT model to the naive Bayes, SVM, and LSTM. According to the study’s test data, the BERT algorithm produced the best model when compared to the other three algorithms. It demonstrates that, for the considered data set, the BERT algorithm surpassed its competitors in terms of sentiment analysis. The power of the BERT algorithm could not be separated from its two-way learning implementation, which enabled the extraction of a bigger number of context features.
4.7. Application Implementation
The web-based application that contains the sentiment analysis system was developed using the flask web framework in Python. Users can input hyperparameter values that will be used for training BERT models provided by the program. In addition to the confusion matrix and numbers for accuracy, precision, recall, and f-score displayed in
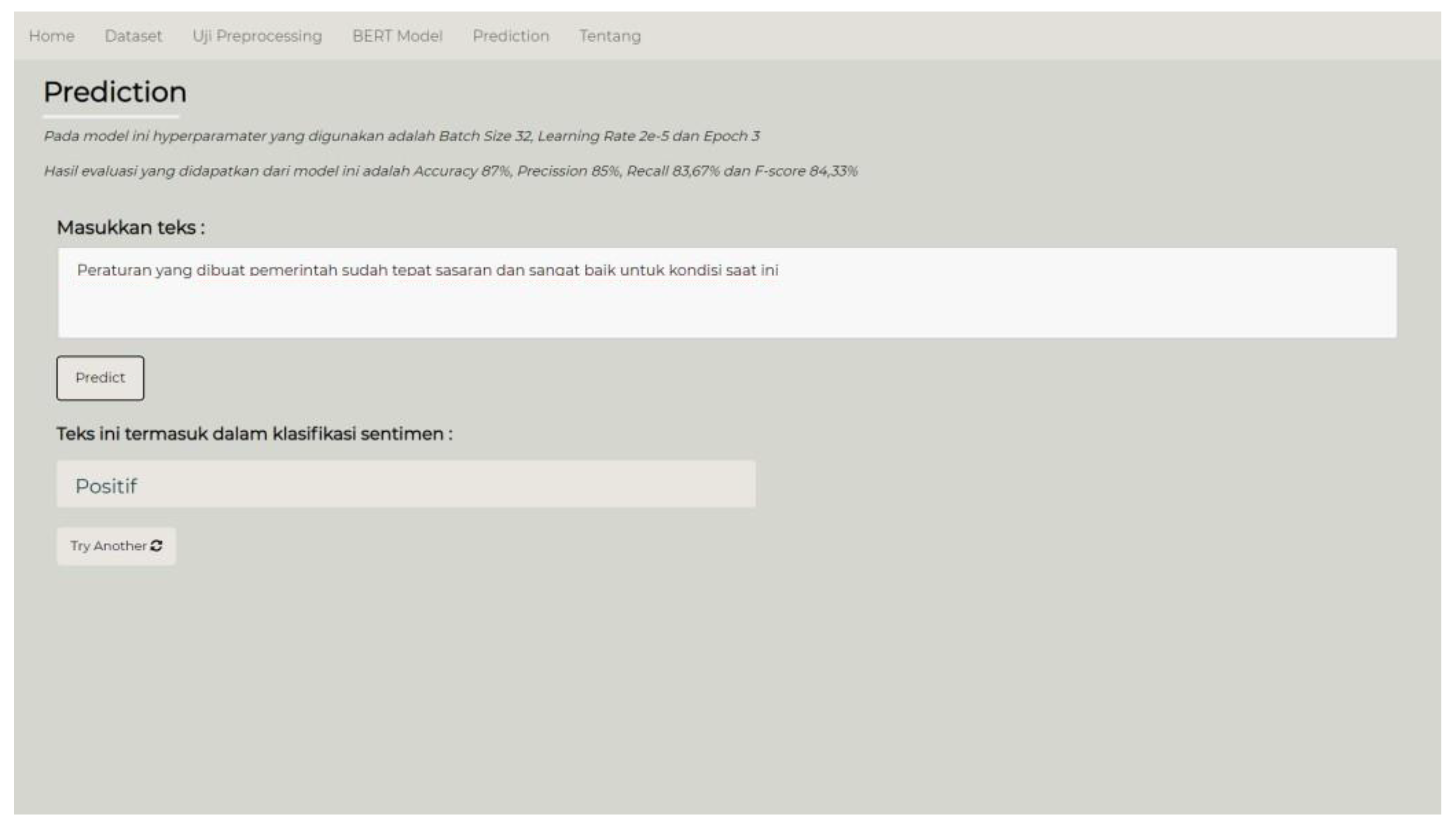
Figure 4, the viewer may examine the BERT model assessment results. In addition,
Figure 5 displays the interface for user prediction. Users can submit a sentiment statement and the program will predict its label and display the results to the user. The application uses the Indonesian language to make it easier for Indonesian people to use it.
5. Conclusions
Using the BERT approach, this study investigates the Indonesian people’s stance on the government policy on vacations during the COVID-19 pandemic. This study created a new dataset for this topic in which the information source was obtained from news outlet stories and the comment sections of YouTube videos. The method was designed to classify public sentiment as positive, neutral, or negative. It used an epoch size of 3, a learning rate of 2e-5, and a batch size of 32 for optimal results. Using Python and the Flask framework, an application for sentiment analysis was then constructed to apply the optimal BERT model. Based on the results of testing and applying the model, the obtained F-score was 84.33%. This study is expected to become one of the tools that can be used by the Indonesian people, especially the government, to see the extent of public acceptance of government policies that have been made, especially regarding vacations. This study demonstrates that the proposed strategy is effective due to its success in classifying emotions. In addition, however, the data acquired in this study can serve as the basis for sentiment analysis research in Indonesia. Sentiment analysis is based on language. The success of technology in a particular language cannot be immediately extended to other languages. Therefore, despite the rapid development of sentiment analysis in English, this cannot be directly applied to sentiment research in Indonesian. The existence of ground truth as a result of this research would enrich the Indonesian language’s collection of sentiments. Another thing that may be achieved is the correct method of processing Indonesian, which has its own distinct characteristics. However, the current ground truth has limits because it does not accept slang or regional languages, which frequently appear in YouTube comments. Therefore, sentiment analysis can be used as an effective tool when the input is supplied in formal language.


 ,
, 





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}