1. Introduction
Real-world application models take account of the facts concerning buildings and their details [
1,
2]. The energy system model is one such application that uses building-level information. Energy systems are undergoing extensive transformations in an effort to reduce carbon dioxide (CO
2) emissions. Consequently, renewable energy sources (RES) are being widely introduced into energy mixes. Evaluating the optimal integration of RES necessitates better enumeration of total energy consumption. Building energy consumption accounts for a significant proportion of the total energy consumed. Therefore, estimating energy consumption in buildings necessitates building-level information (e.g., building type, number of residents, living space, etc.). Unfortunately, detailed information with respect to buildings is not publicly available.
However, despite containing detailed building information, synthetic data on buildings, apartments, families, households, and populations are openly available [
3]. The synthetic data for Germany were produced from a survey conducted as part of the country’s 2011 census. Moreover, these data were aggregated for 100-m and one-kilometer grid cells. Each cell (100 m × 100 m) conveyed information about the buildings within it (i.e., the total number of each type, the identity of each cell, etc.). Nevertheless, data on the total number of buildings within the cells do not offer critical information regarding each of them. Therefore, building type classification of the building footprints is required.
Several studies have been conducted to date using a variety of classification approaches for building types. The classification of building types can be performed manually or automatically. As previously stated, surveying methods provide information about buildings (i.e., manually). However, this process requires a significant amount of time and human effort. Thus, automatic classification is the best method available at the moment. Advancements in remote sensing technology have enabled the extraction of physical features of buildings such as textures, geometries, size, and shape from remotely sensed images at low, medium, high, and very high resolution [
4]. Additionally, light detection and ranging (LiDAR) offers the building’s height information, which is missing from the image data [
5]. However, these building characteristics are retrieved through the use of machine learning or deep learning models. In addition to these features, the building footprints are gathered using edge-based geometric grouping or object-based classification [
6]. The labeling of buildings or the classification of building types were accomplished in [
5,
7,
8,
9,
10,
11,
12,
13,
14,
15,
16,
17] using the datasets produced from the aforementioned approaches using remote sensed images, google earth images [
18,
19] and LiDAR data. Ref. [
20] employs machine learning models to categorize buildings into single-family houses, multi-family houses, and non-residential buildings by utilizing LiDAR extracted data, including height and shape. Similarly, ref. [
5,
8,
13] classified buildings as low-rise [
5], multi-storey [
13], high-rise [
13], apartment [
5], residential [
8], non-buildings [
5], and various commercial buildings [
8]. Additionally, semantic labeling [
6,
12,
21] and ontology-based categorization [
7] were performed on the remote sensing data to identify building footprints as residential, non-residential, industrial, or factory. Here, several supervised machine learning techniques were used in these studies, including Random Forest [
5,
6,
8], Support Vector Machines (SVM) [
8], and deep learning methods [
12]. Apart from supervised machine learning techniques, ref. [
9,
15] used unsupervised machine learning techniques to cluster settlement types based on the spatial pattern of building footprints. However, because the experts’ high degree of semantics highlights a semantic gap in the remote sensed imaging data [
7], Point-of-Interest (POI) data (i.e., specific point location, e.g., hospital, office, restaurant, etc.), which is often user-generated data, was mapped to the remote sensed data to identify building types [
10,
11]. In this context, ref. [
10] used remote sensing imagery and point-of-interest data to increase the accuracy and completeness of classification tasks. In addition to the POI data, ref. [
14] identified residential and industrial buildings using nighttime light data and land cover data.
However, due to the complexity of image object extraction and classification in the remote sensing technique, several researchers are concentrating their research on classifying building types using geospatial vector data (i.e., points, lines, and polygons) [
22]. To categorize different types of buildings, ref. [
22,
23,
24,
25,
26,
27,
28,
29] included geospatial vector data gathered and maintained by national mapping agencies [
25], real estate cadasters [
23], government agencies [
22,
24], commercial data suppliers, and web mapping services [
4,
30,
31]. Additionally, ref. [
32] recommended using taxi and population density statistics to identify building functions. However, due to the scarcity of data from remote sensing, point-of-interest data, commercial geospatial vector data, and human activity data, the researchers are classifying buildings using data from web mapping services. The web mapping services include not only the footprints of buildings, but also point-of-information data such as addresses, building usage, building type, and building functionality, as well as other information about the buildings. In this context, several prior research [
4,
30,
33,
34,
35,
36,
37,
38] identified building types using web mapping services such as OpenStreetMap (OSM) [
39,
40], Google maps, Gaode Maps, and Baidu Maps [
4,
35]. For instance, ref. [
35] classified residential and numerous non-residential types using geographical data and POI data from Gaode and Baidu Maps. Additionally, ref. [
33] used OSM’s building footprints and POI data to identify residential and non-residential buildings suitable for pesticide spraying to aid with malaria prevention. This clearly implies that building type information is beneficial not just for energy, transportation, and marketing objectives, but also for the health sector in light of the current global crisis.
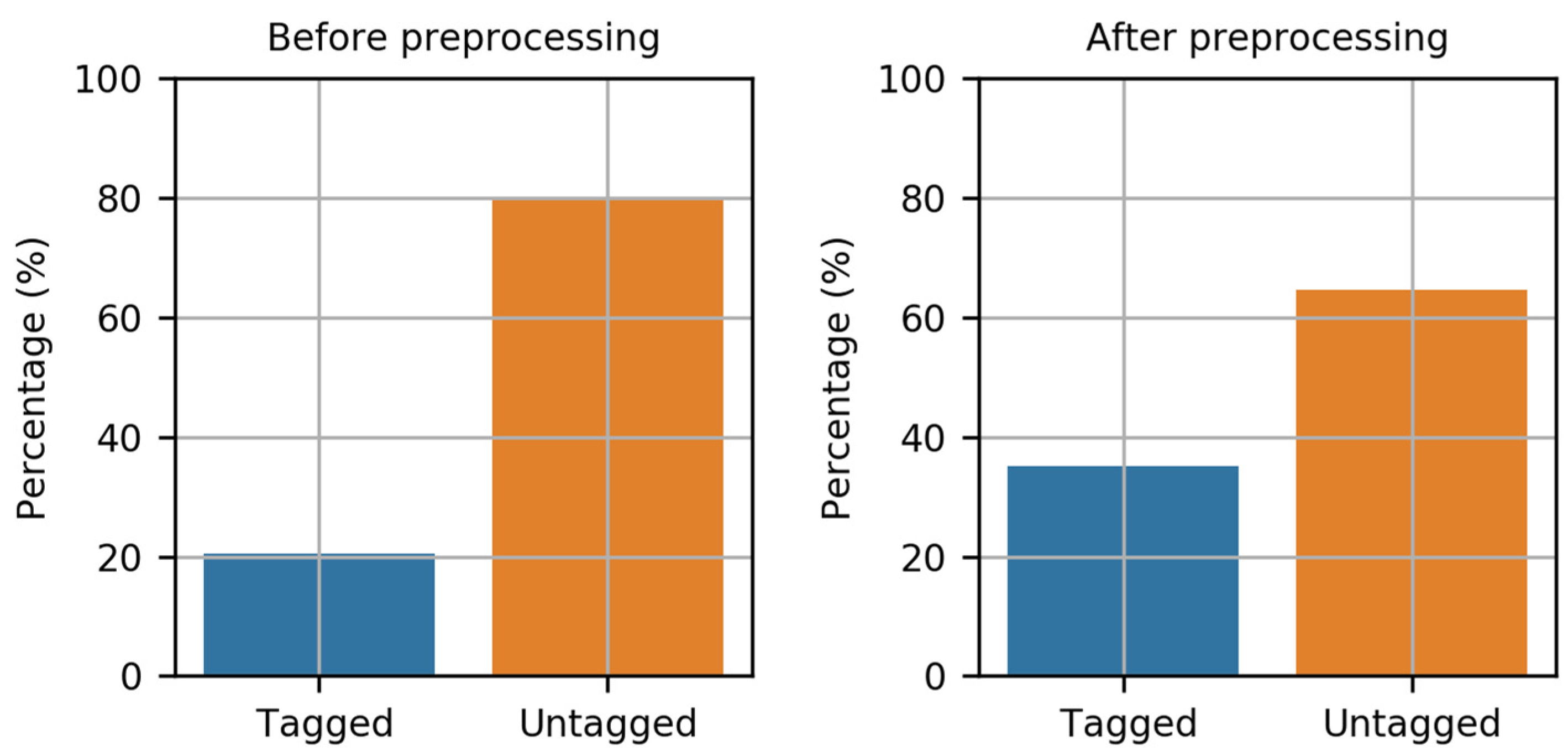
In summary, extracting building type information from remote sensing methods needs a significant amount of computational power when executing global or even country-level classification and object segmentation tasks. Additionally, managing and retrieving image data for such a large spatial coverage is implausible. Furthermore, acquiring geographic vector data and POI data from commercial and government agencies is always subject to constraints and limitations. Additionally, human activity data is always a source of concern when it comes to privacy. As a result, volunteer-generated open map data from OSM is now the best option for utilizing and classifying building types. The OSM dataset provides building footprints (instead of data acquired from images by remote sensing) and POI data (alternative to POI data from commercial data providers and government agencies). However, according to [
27], the incompleteness and discrepancies in OSM data are particularly noticeable. According to the results of the analysis of data collected from OSM, it has been discovered that the data is still incomplete, with several missing values; see
Section 3.
To address the limitations mentioned above; this study developed a means of predicting the building type for each building extracted from the OSM data as accurately as possible. In order to perform this task effectively, several additional features have been added to the OSM data from various datasets. The most significant datasets bolstering the OSM data are Coordination of Information on the Environment (CORINE) [
41], the height of buildings in Berlin [
42], and 2011 census data for Germany [
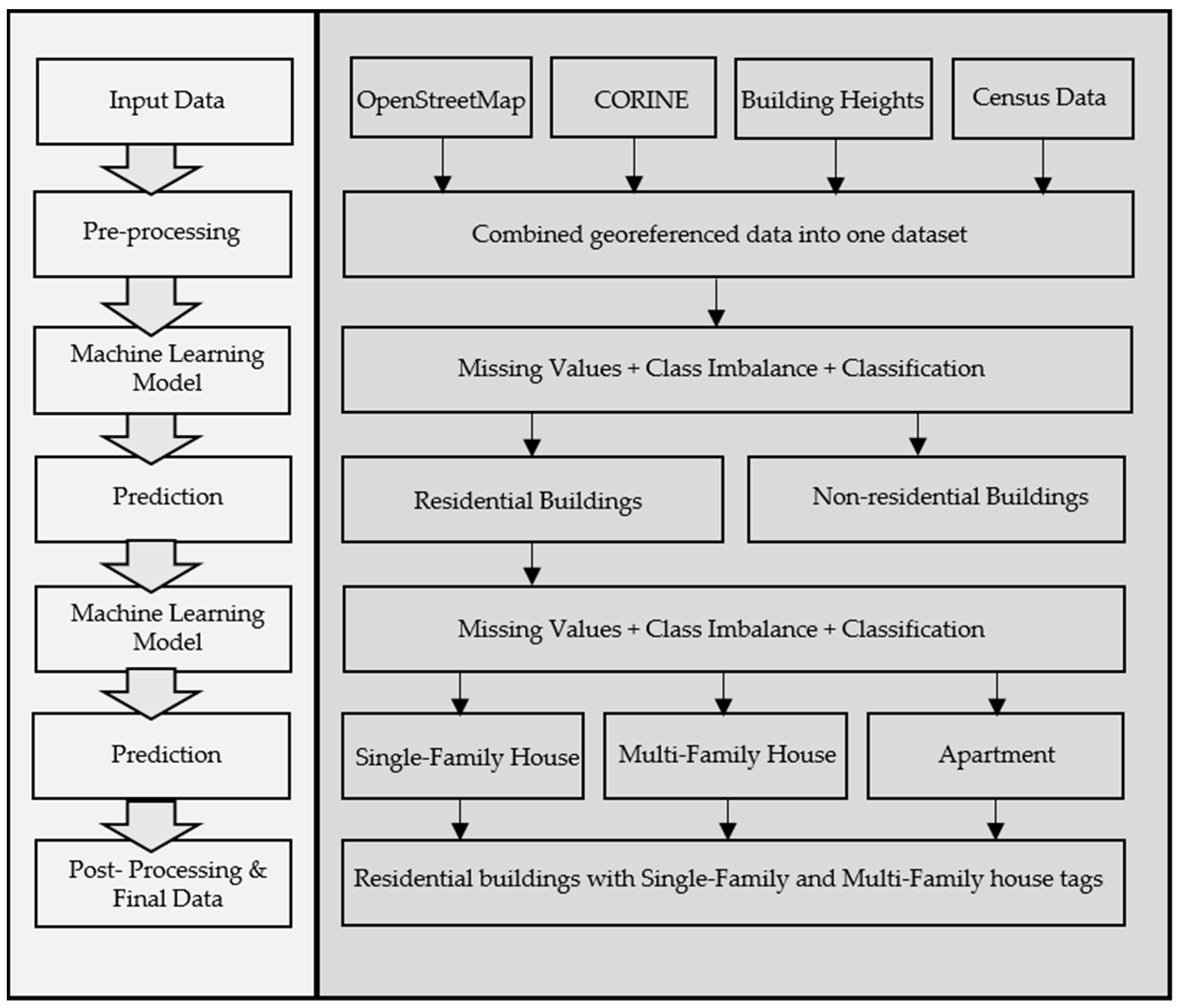
3]. The work conducted herein was motivated by a need for geo-referenced building location data and their labels, which could be used in several real-world applications. Moreover, the work conducted attempts to fill some of the gaps in the literature by classifying building types through the application of state-of-the-art machine learning algorithms to the incomplete dataset extracted from OSM. This study also addresses the challenges with respect to missing values and class imbalances in the datasets by pursuing the following objectives: (1) To extract building data with all of the corresponding features (e.g., geometry, area, address, tags, etc.); (2) to perform data analysis on the extracted data in order to quantify missing data; (3) to integrate additional features from the above-mentioned additional sources; and (4) to use sophisticated machine learning algorithms in order to classify building types with missing values and rectify class imbalances in the dataset.
The structure of the paper is as follows: the dataset is described in
Section 2.
Section 3 presents the data extraction, analysis, and preprocessing steps followed. This section also includes the application of a machine learning algorithm to the processed dataset. In addition, the results and validation of the tagged buildings are outlined.
Section 4 provides the discussion concerning the method, application of the results, and the limitations. Finally,
Section 5 conveys the conclusions and user notes regarding data usage.
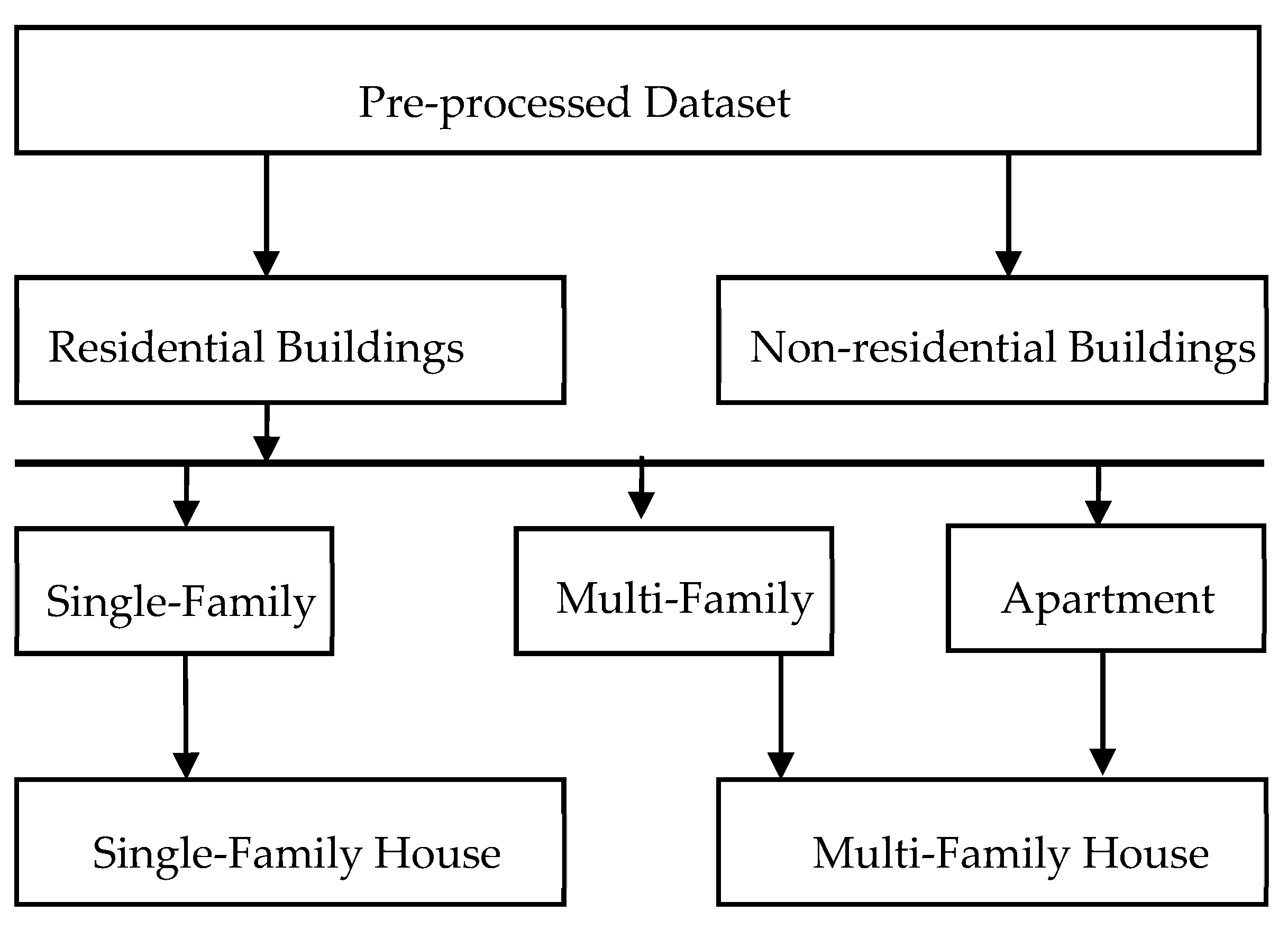
2. Data Description
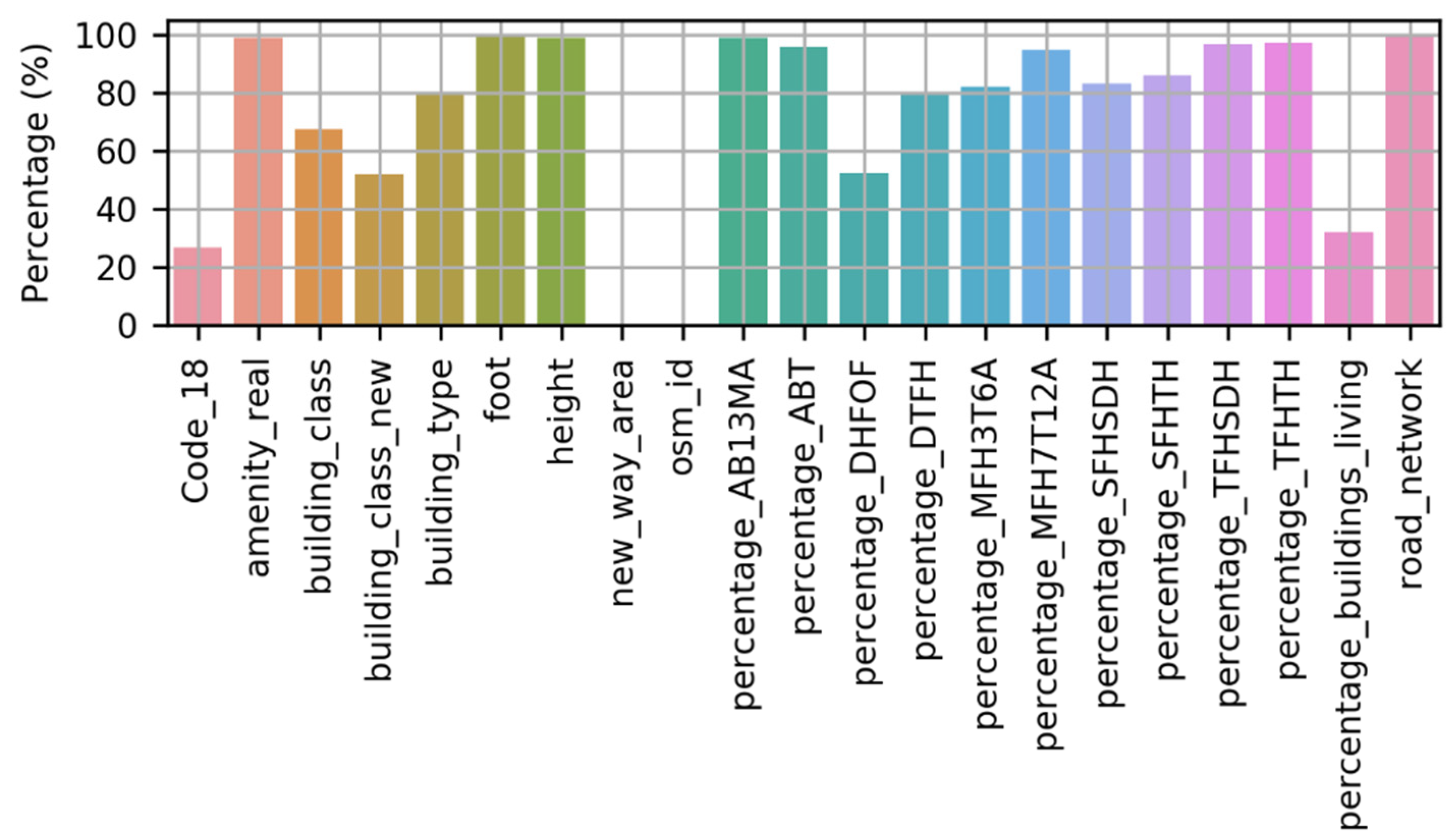
Prior to beginning the methods, this section describes the generated dataset with building types classified for Germany. The dataset was explicitly generated for Germany due to the requirement of building labels for developing geo-referenced synthetic electrical distribution grids in the country. However, the developed methodology can be applied to the generating of a dataset in any country. The dataset was provided in the GeoJSON file format. For the geographical features, the coordinate reference system used was the World Geodetic System 1984 (WGS 84) (EPSG:3857)—the original coordinate reference system of OSM data. The dataset comprises the attributes listed below.
The main features from the OSM data are as follows:
osm_id (numerical): unique identity for each building footprint (e.g., 208594362, 107204221, 208593145, etc.).
way_area (numerical): area of the building footprint in Mercator square meter obtained from original OSM data projection (e.g., 377, 2218.18, 493.99, 490.901, etc.).
amenity_real (categorical): facility of buildings tagged in OSM (e.g., office, shop, leisure, construction site, supermarket, grocery, etc.).
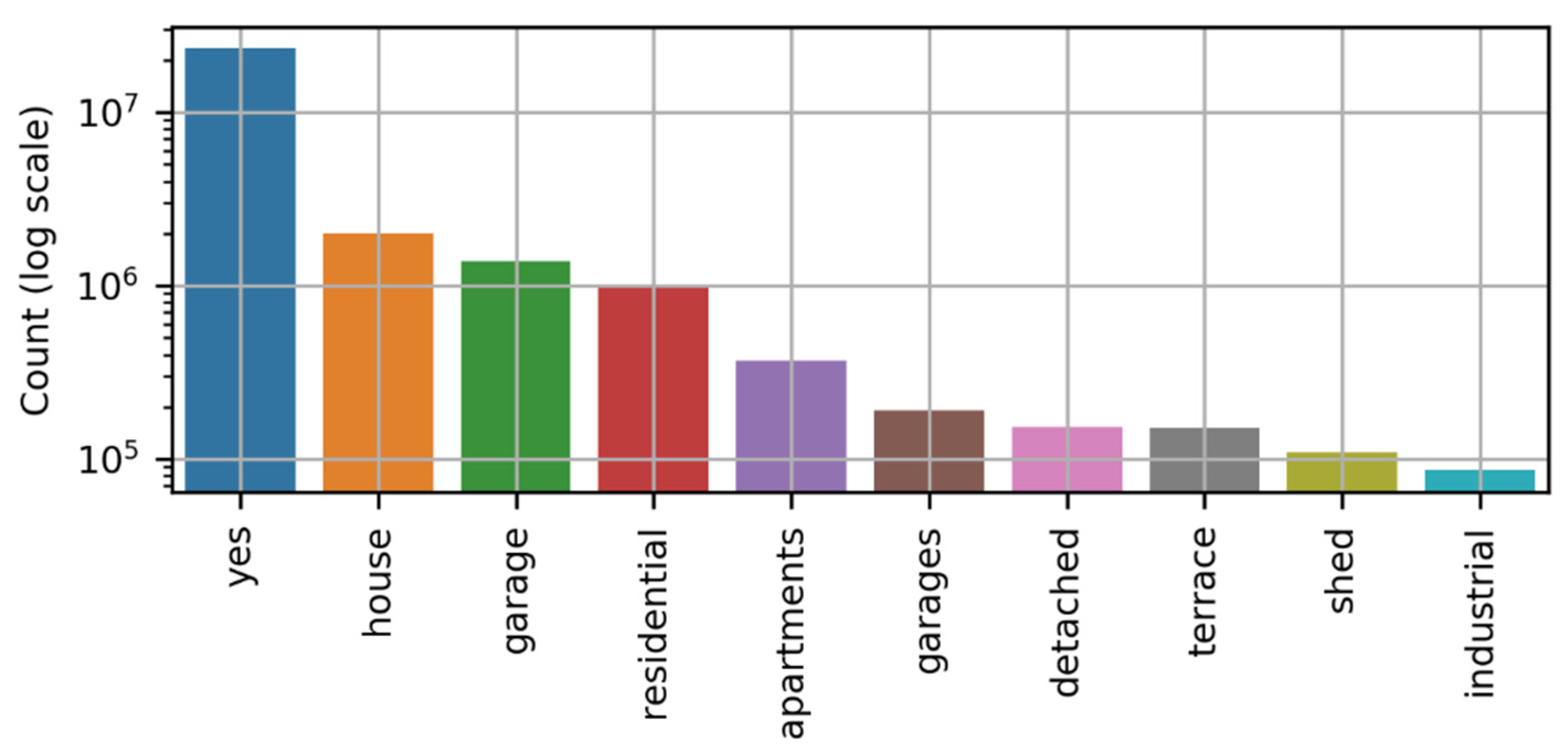
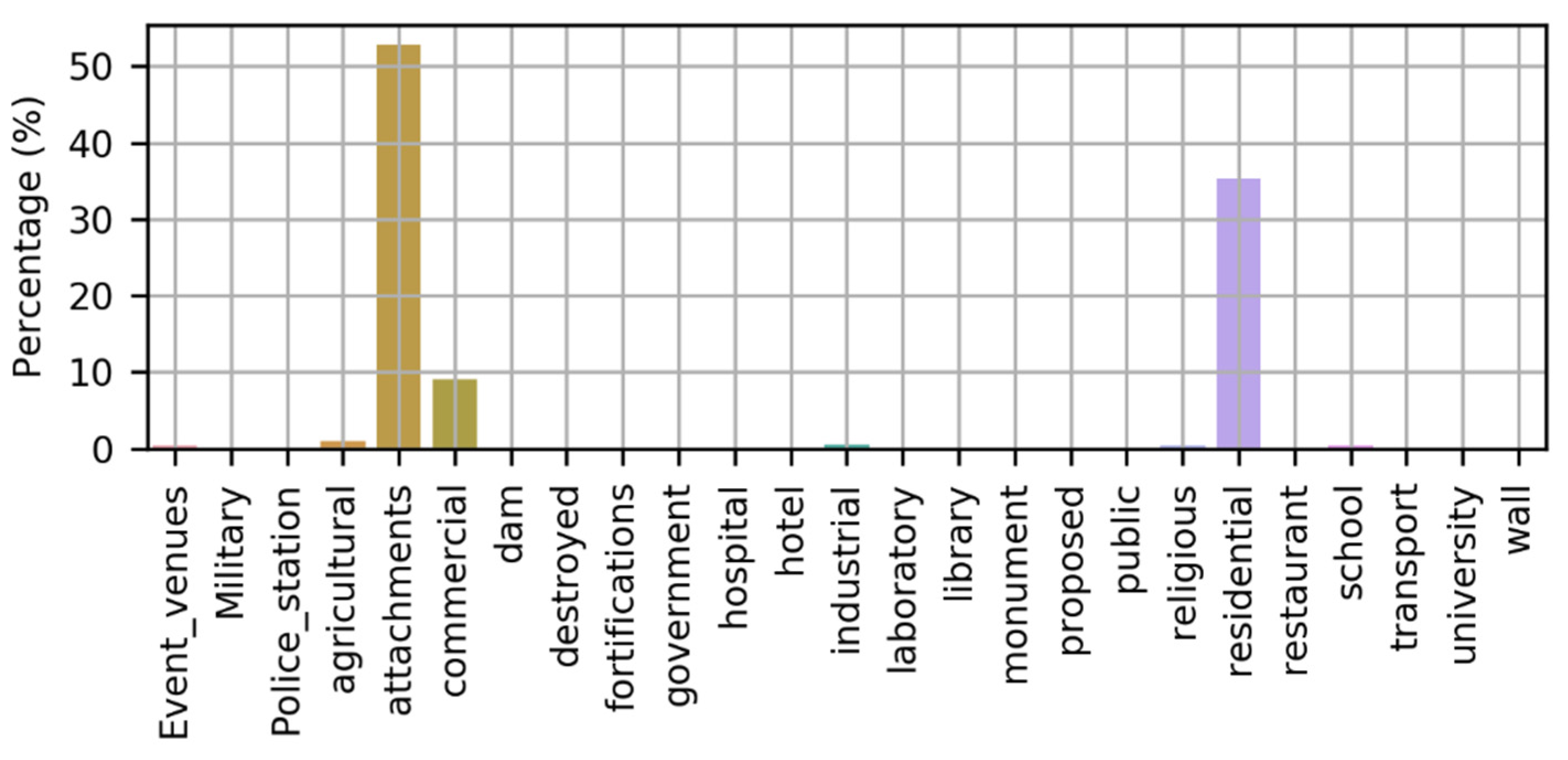
building_type (categorical): building tag originally tagged in OSM (e.g., yes, commercial, garage, terrace, office, train station, etc.).
area (numerical): area of the building footprint when projected on ETRS89 (i.e., EPSG:3035).
geometry (geometry): geometry for each building (EPSG:3857).
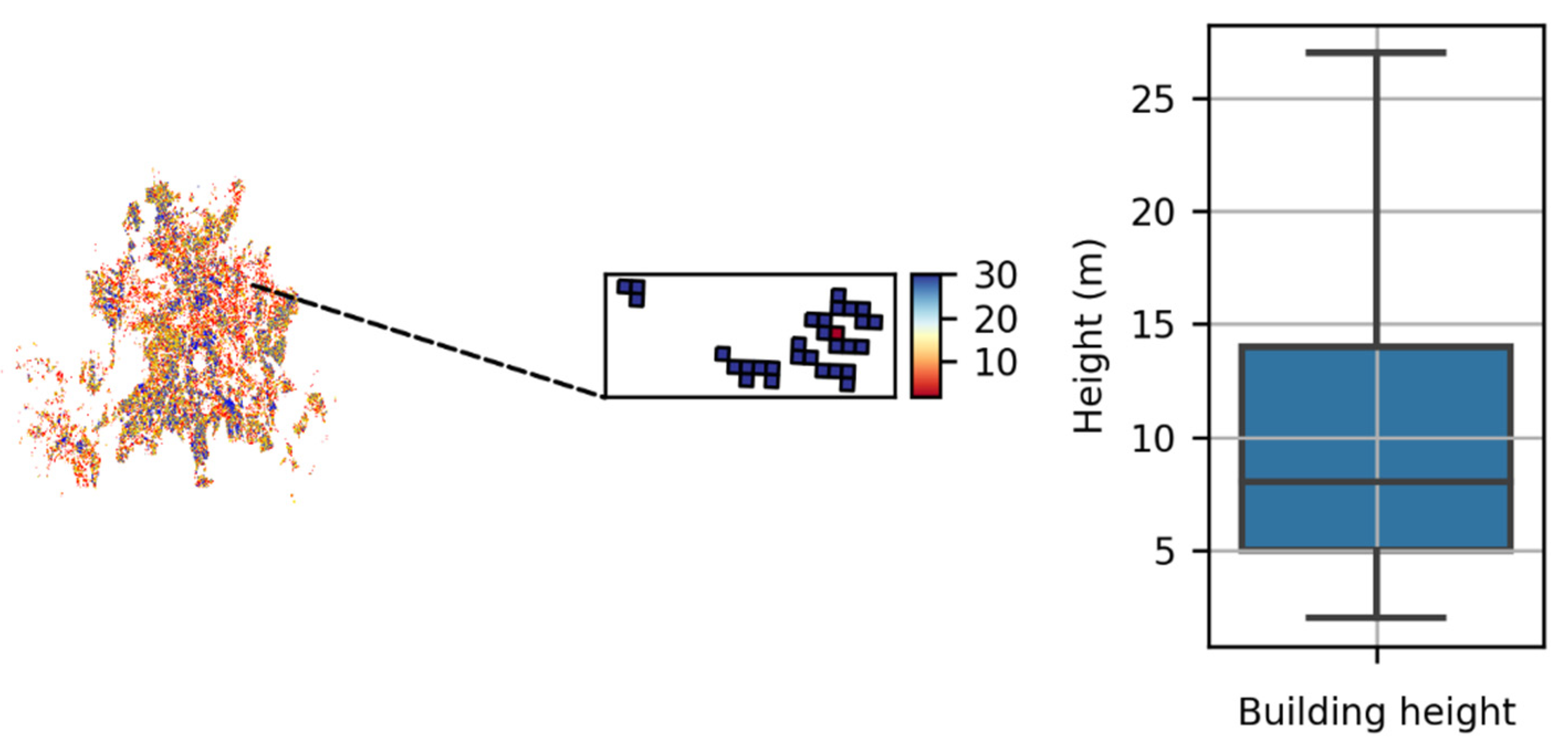
In addition, the height of each building was considered with respect to the heights dataset for Berlin public buildings.
height (numerical): height of each building in Berlin (e.g., 4, 5, 10, etc.).
Furthermore, in order to improve the model’s performance, additional features from the Corine dataset were considered:
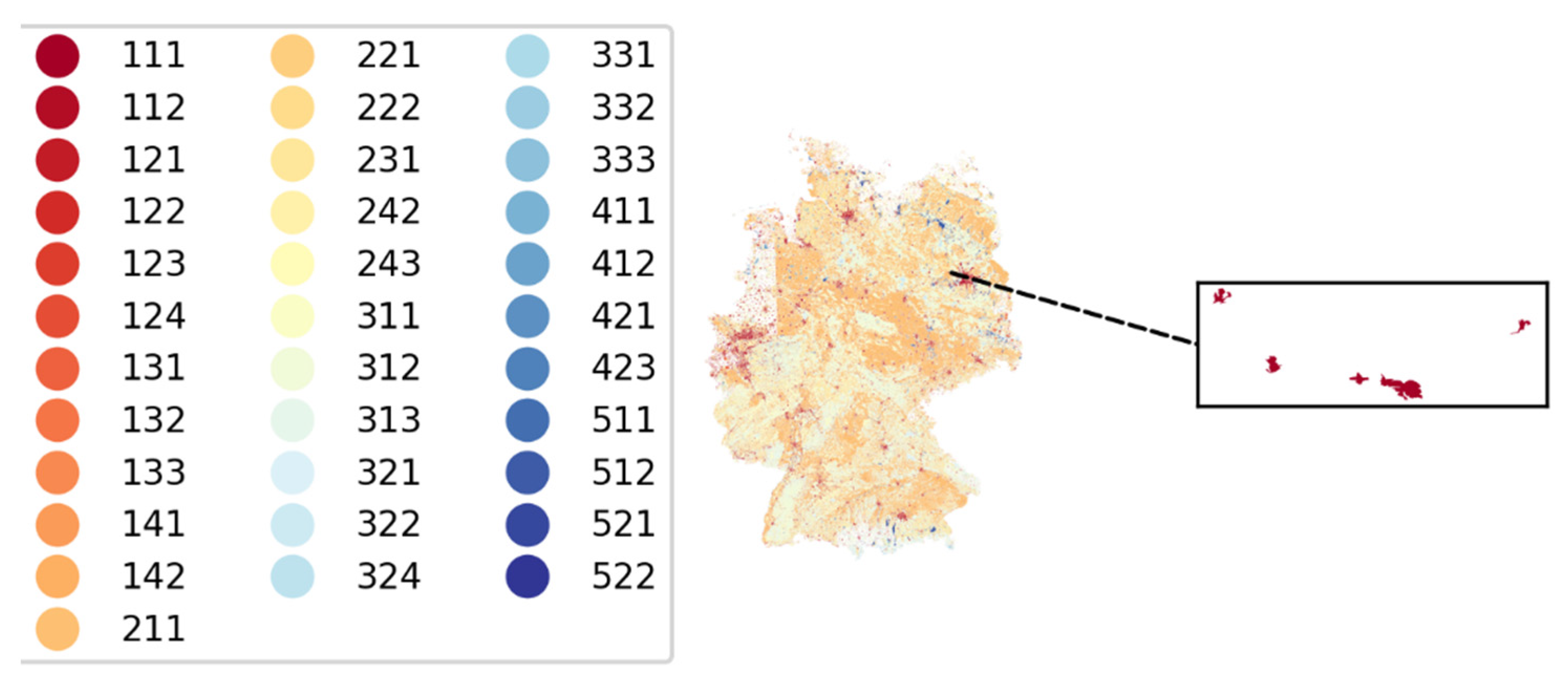
code 18 (numerical): this feature corresponds to the land cover type (e.g., 111: Continuous urban fabric, 112: Discontinuous urban fabric, 121: Industrial or commercial units, 141: Green urban areas, etc.)
Moreover, a few other features from the most crucial dataset (the 2011 census) were integrated into the OSM buildings data. The dataset for Germany was accumulated across 100 m × 100 m grid cells, as follows:
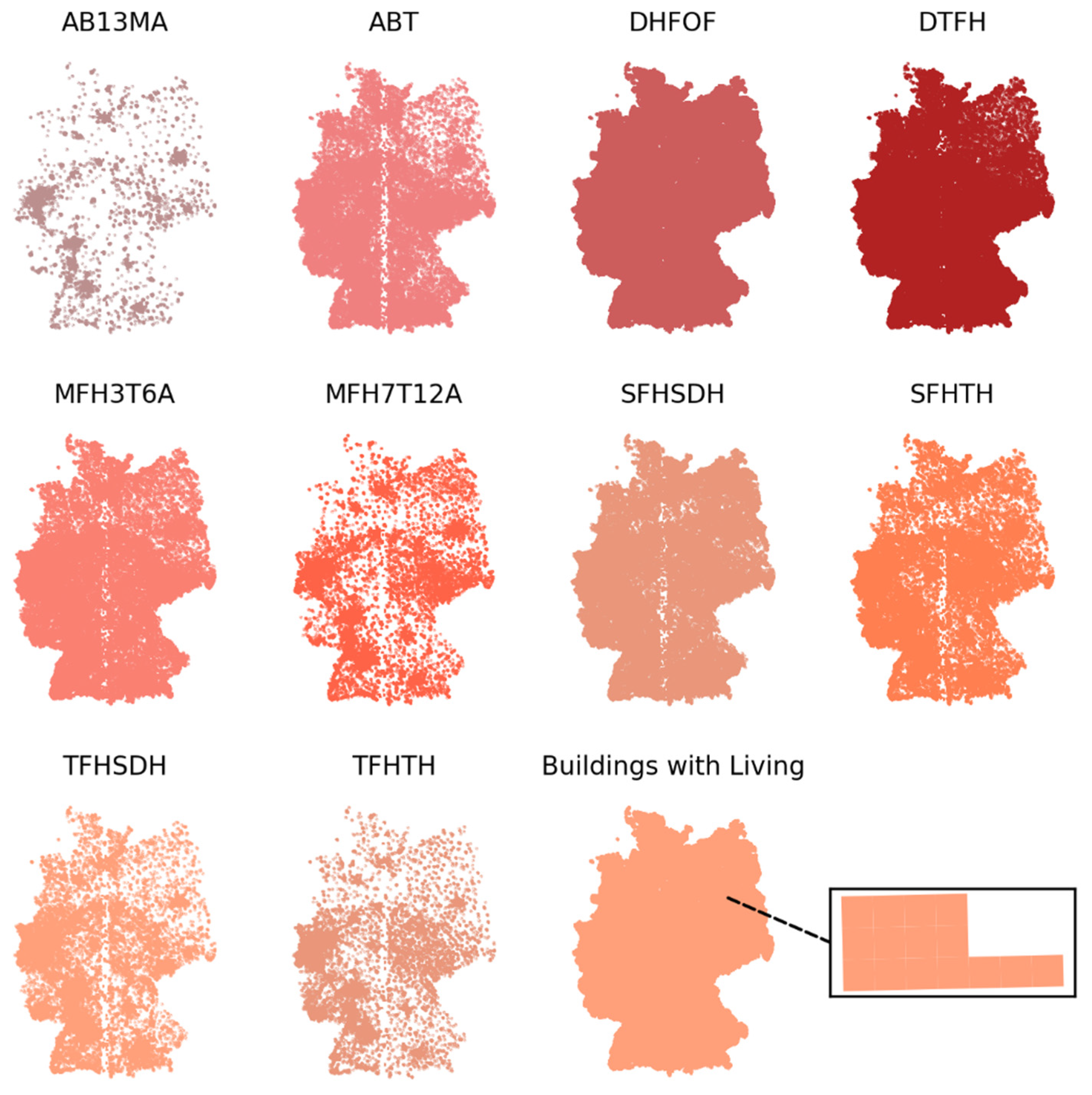
buildings_living_total (numerical): total number of buildings with living space within a 100 m × 100 m cell.
AB13MA_total (numerical): total number of apartment buildings, with 13 or more within a grid cell.
ABT_total (numerical): total number of other buildings within a grid cell.
DHFOF_total (numerical): total number of detached houses for single families within a grid cell.
DTFH_total (numerical): total number of detached two-family houses within a grid cell.
MFH3T6A_total (numerical): total number of multi-family houses within a grid cell (3–6 apartments).
MFH7T12A_total (numerical): total number of multi-family houses within a grid cell (7–12 apartments).
SFHSDH_total (numerical): total number of single-family houses within a grid cell (semi-detached house).
SFHTH_total (numerical): total number of single-family houses within a grid cell (terraced house).
TFHSDH_total (numerical): total number of two-family houses within a grid cell (semi-detached house).
TFHTH_total (numerical): total number of two-family houses within a grid cell (terraced house).
With the help of these 11 features from the census data, 11 other features were added to each building; see
Section 3. These features correspond to a percentage probability of buildings likely to correspond to the given type (i.e., building with living space, apartment, single-family house, multi-family house, and two-family house). These 11 features are percentage_buildings_living, percentage_AB13MA, percentage_ABT, percentage_DHFOF, percentage_DTFH, percentage_MFH3T6A, percentage_MFH7T12A, percentage_SFHSDH, percentage_SFHTH, percentage_DTFH, percentage_SFHTH, all of which constitute integers in percentages.
Finally, the essential characteristics result from the tags from OSM and machine the learning model’s output.
building_class (categorical): building type labels taken from OSM and labels generated by the machine learning model.
house_type (categorical): house type labels taken from OSM and labels generated by the machine learning model.
This dataset thus contains 29,497,772 buildings as rows and 32 features for each of the buildings as columns.
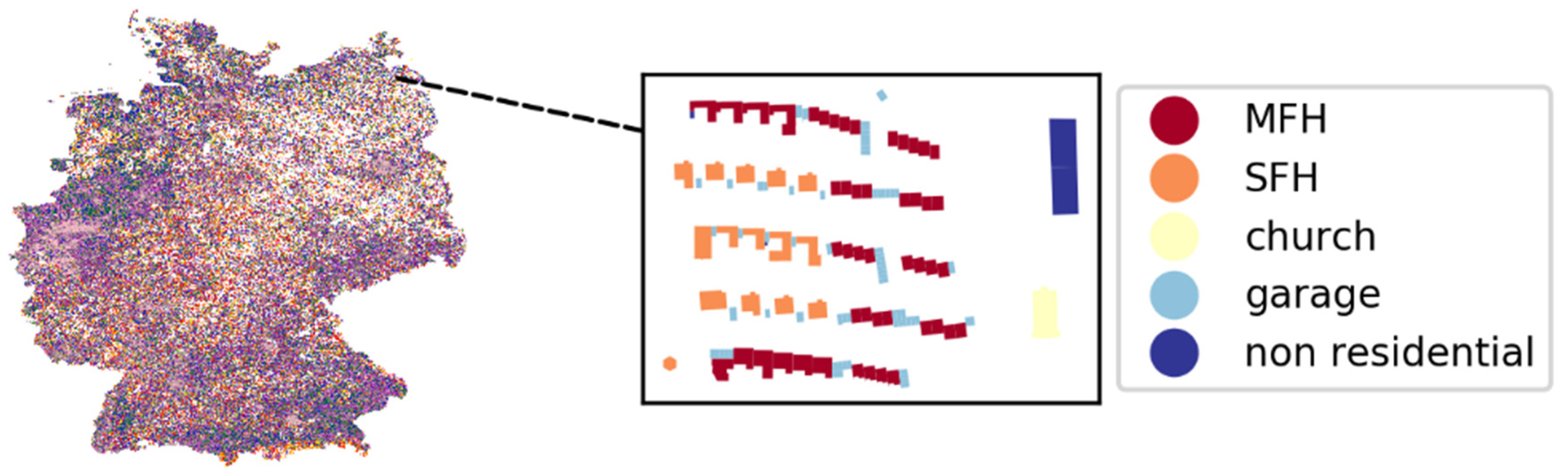
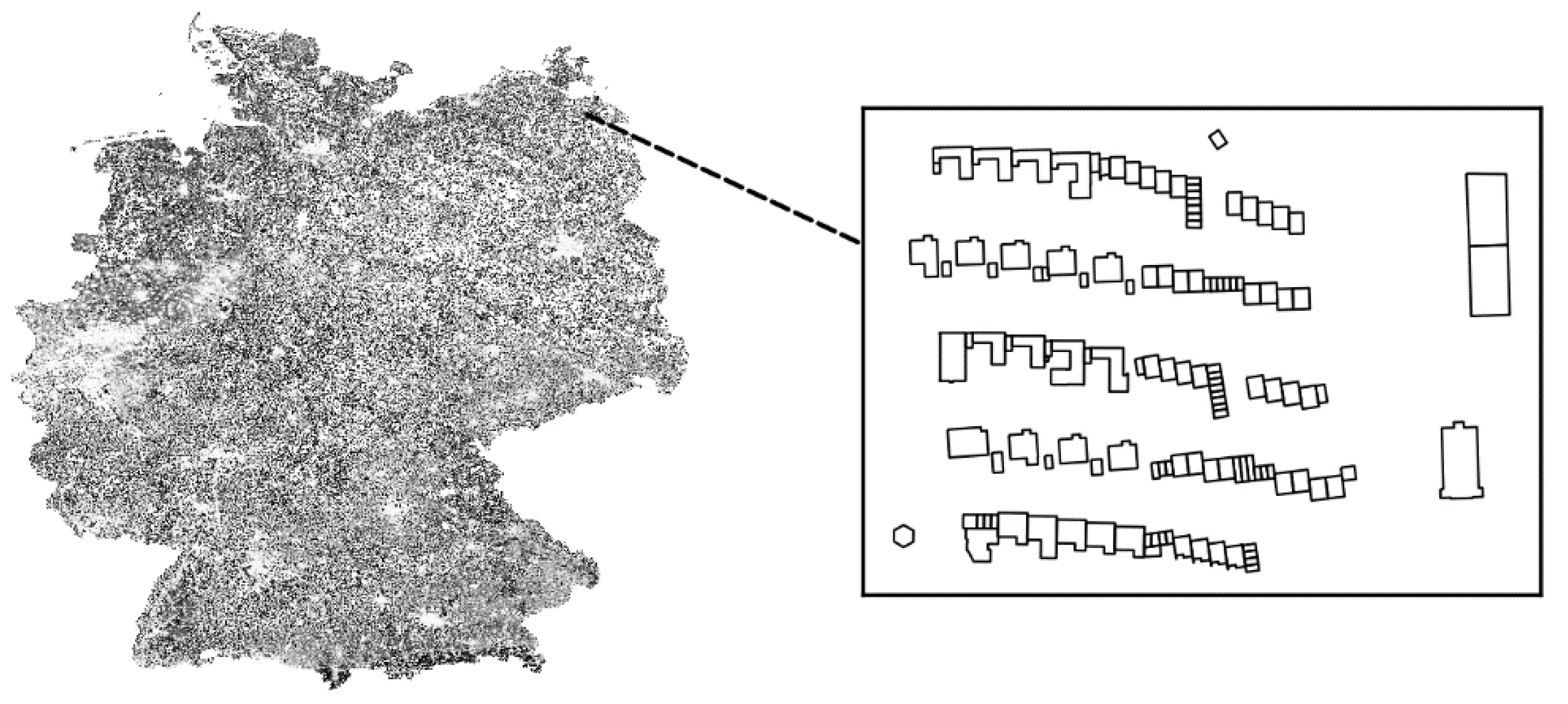
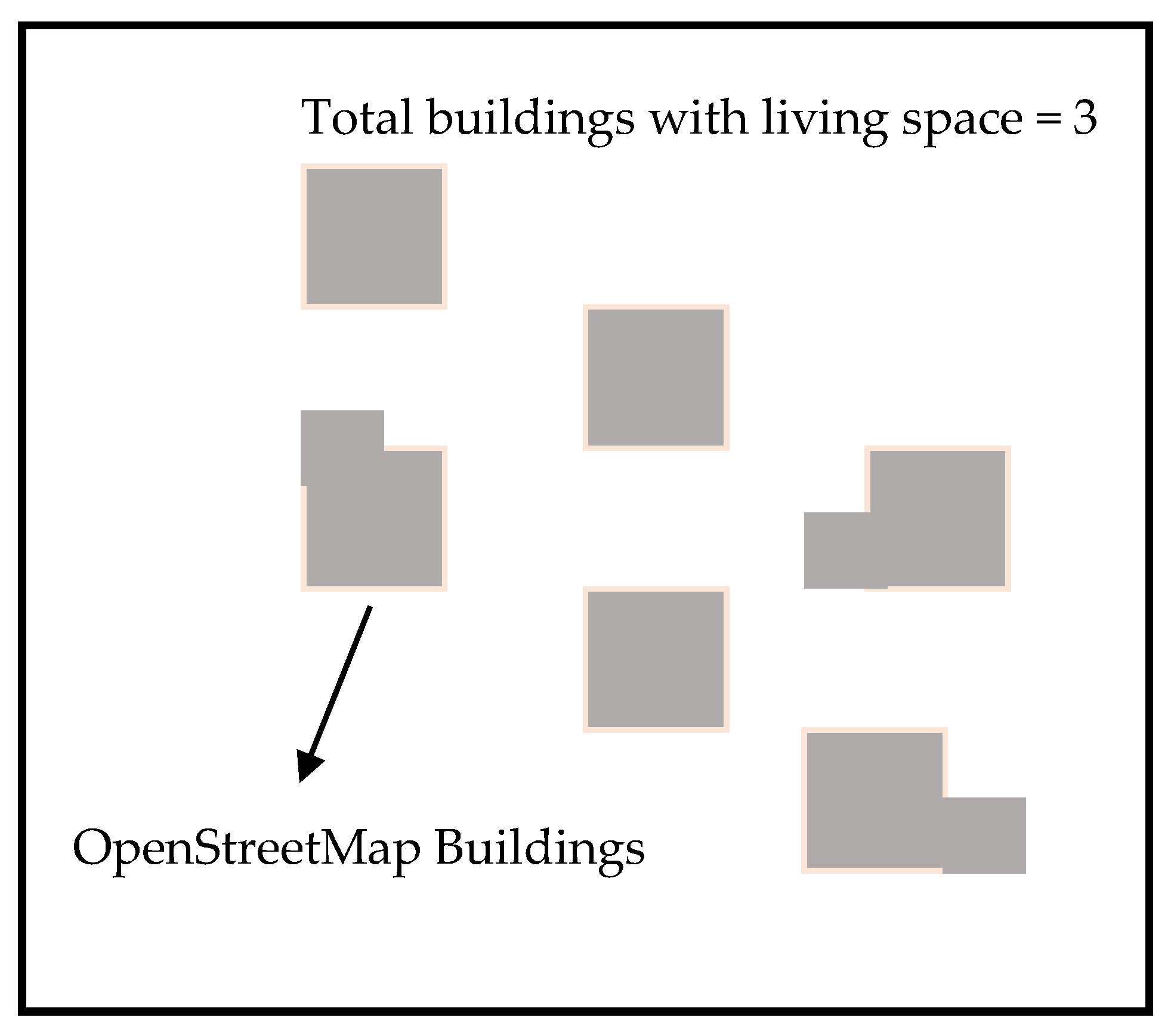
Figure 1 shows the building footprints and final labels for each unit (zoomed).
4. Discussion
Building type information serves as the foundation for a variety of models, including energy, mobility, disaster management, health care, and other applications that benefit humanity in a variety of ways. For example, in energy system models, forecasting the future energy required at the national level requires knowledge of the type of building and how it will be used. In the end, the introduction of environmentally friendly technologies is aided by this prognosis. Furthermore, this is not just in the energy systems, as ref. [
33] employed building types to locate buildings where pesticide spraying was necessary, demonstrating that building level information is significant in the health sector. Therefore, information at the building level is essential for technological and economic advancements.
To identify building types, earlier research relied primarily on remote sensing data, geospatial vector data, and POI data from government agencies, mapping agencies, commercial POI data suppliers, and real estate cadasters, among others, despite data availability and computational complexity limitations. This study establishes the building type classification for the entire country by addressing the above limitations and resolving missing values and class imbalances in OpenStreetMap POI data and by mapping additional data to increase classification accuracy. Apart from OSM data with building footprint geometries and POI data, other data such as land cover data, census details, and building height data were also mapped to the building footprints in this study. However, the following are some of the advantages of the suggested classification methodology: To begin, the building footprints and POI data are derived directly from the same source of data, whereas in previous studies, the building footprints and POI data were derived from independent sources; as a result, mapping POI data to the building footprint is not always reliable. Second, the extra data from the census (manually surveyed) is mapped to the country’s existing dataset. Besides census data, land cover data with several classes has also been mapped in order to increase the accuracy of the classification. Third, the missing values and class imbalance concerns in the OSM data were handled by using implicit and explicit methods of classification algorithms that account for missing values and class imbalance issues. However, when trained on OSM labeled data, the explicit method outperforms the implicit methods.
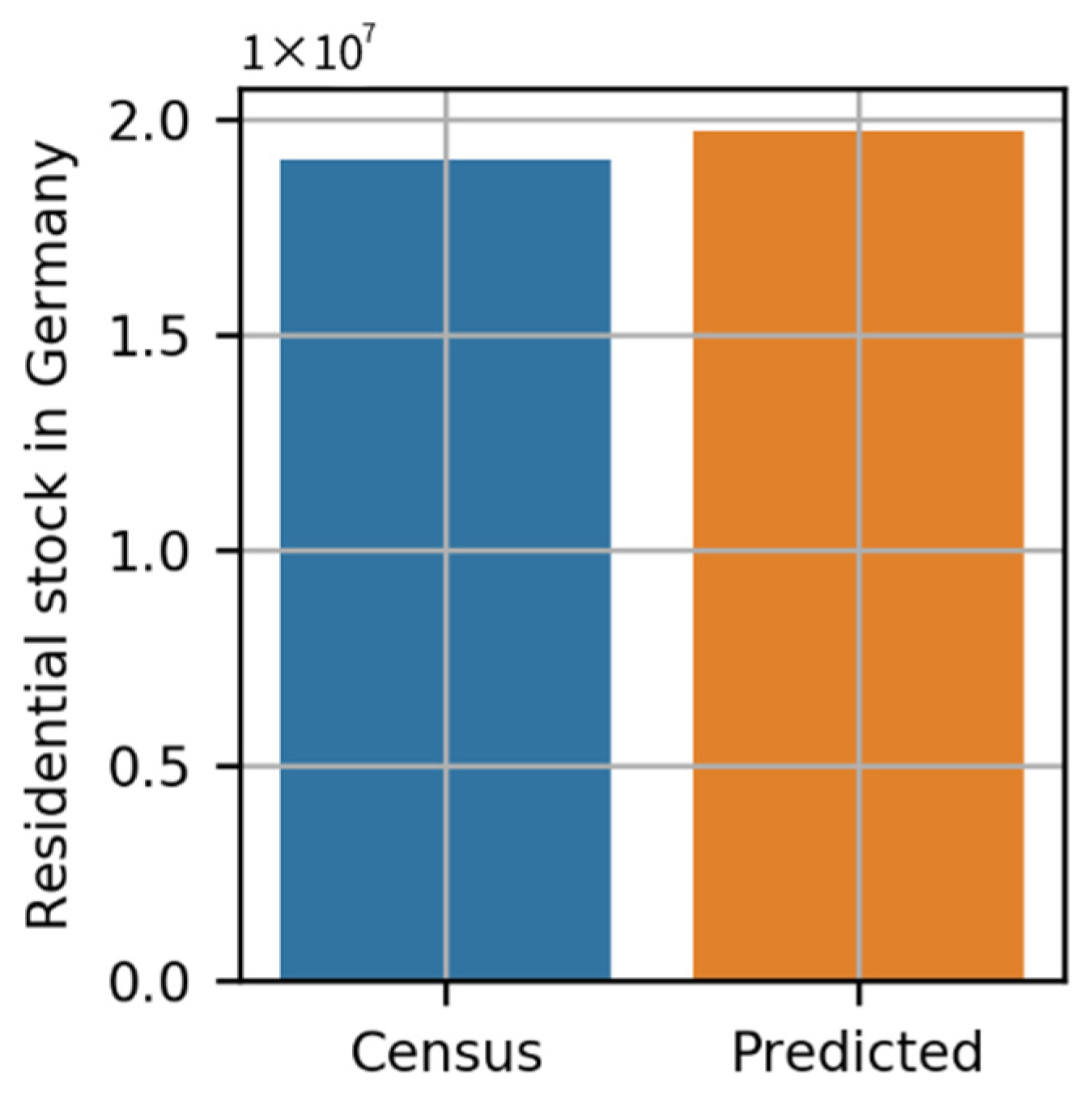
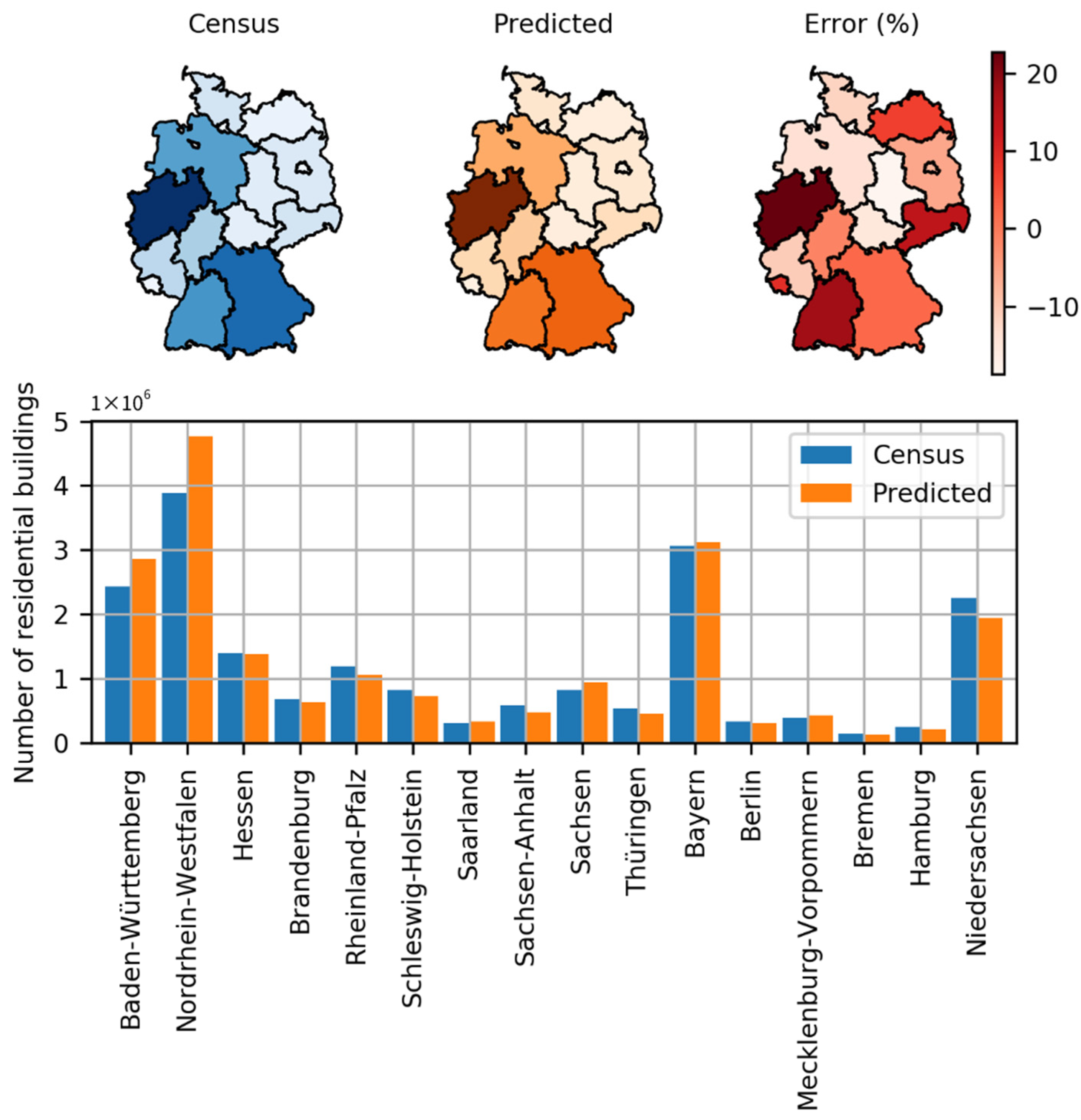
When deployed, the explicit method classified approximately 29 million building footprints into approximately 19 million buildings and the remainder as non-residential buildings, which comprised industrial, commercial, garage, and noncommercial-nonindustrial buildings. When compared to official statistics, the results indicate a percentage error of 3.64%. Furthermore, when compared to [
23], these results are encouraging, since ref. [
23] classifies polygons extracted from a real estate cadaster as residential buildings with a percentage error of 4.9% for Germany. Additionally, ref. [
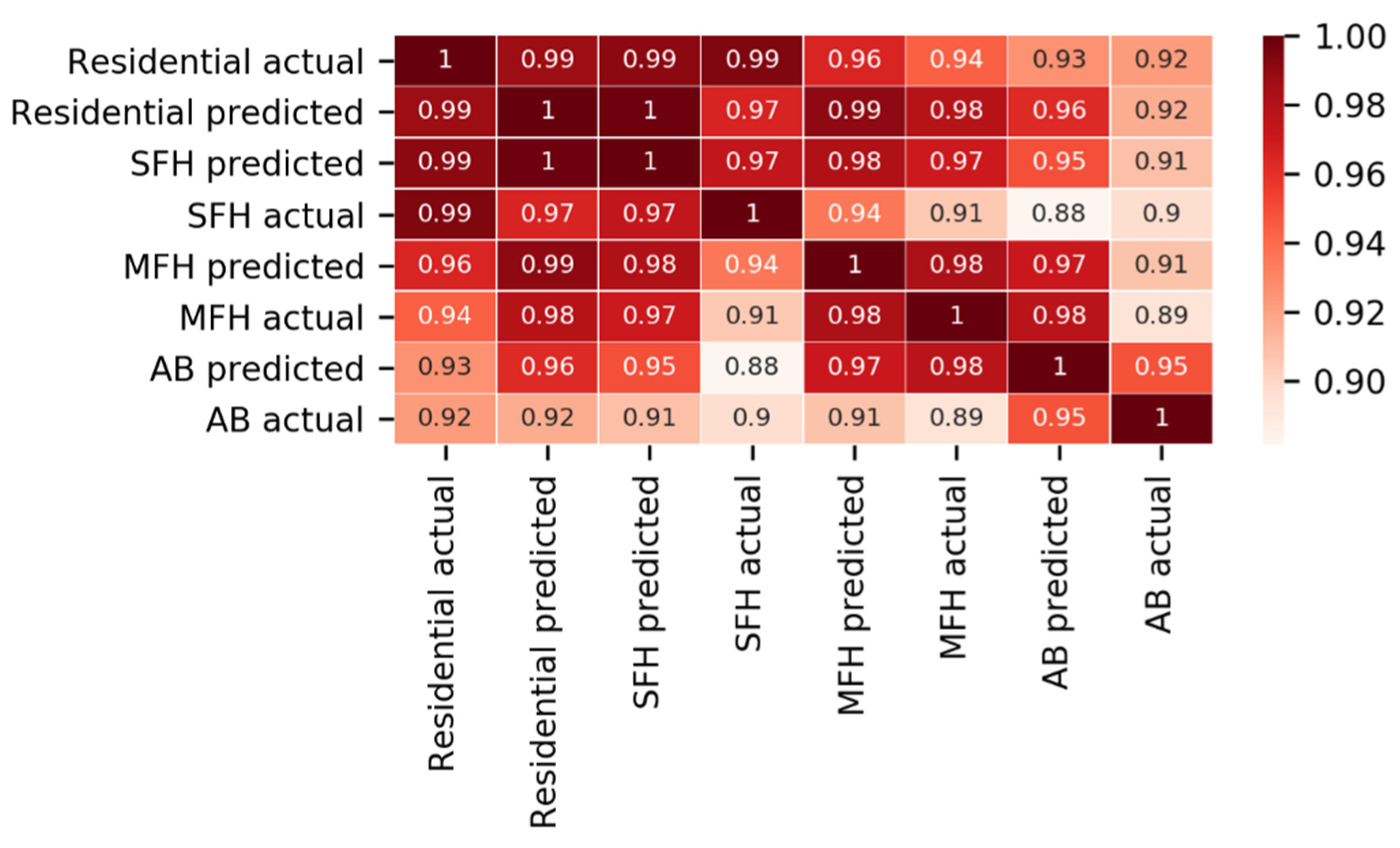
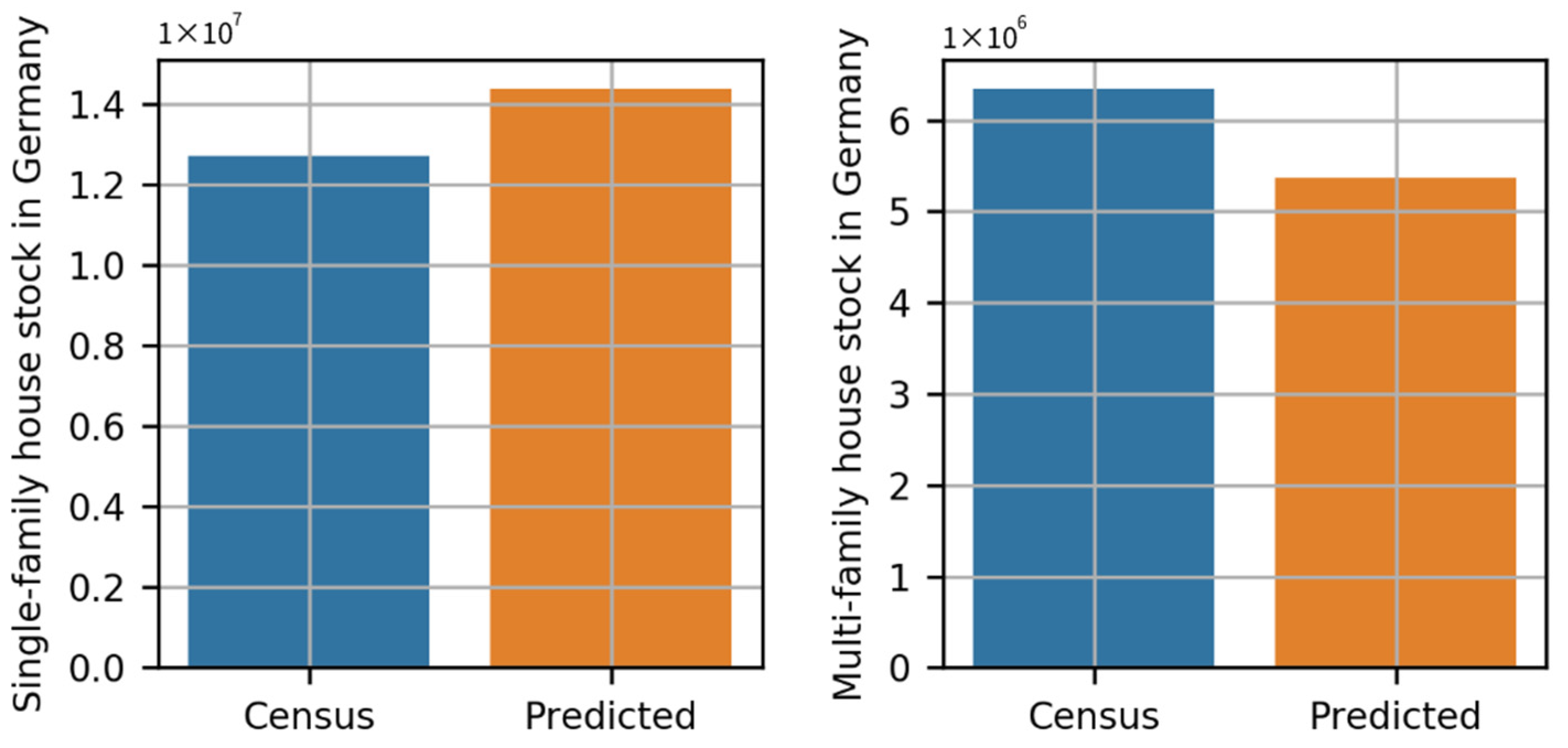
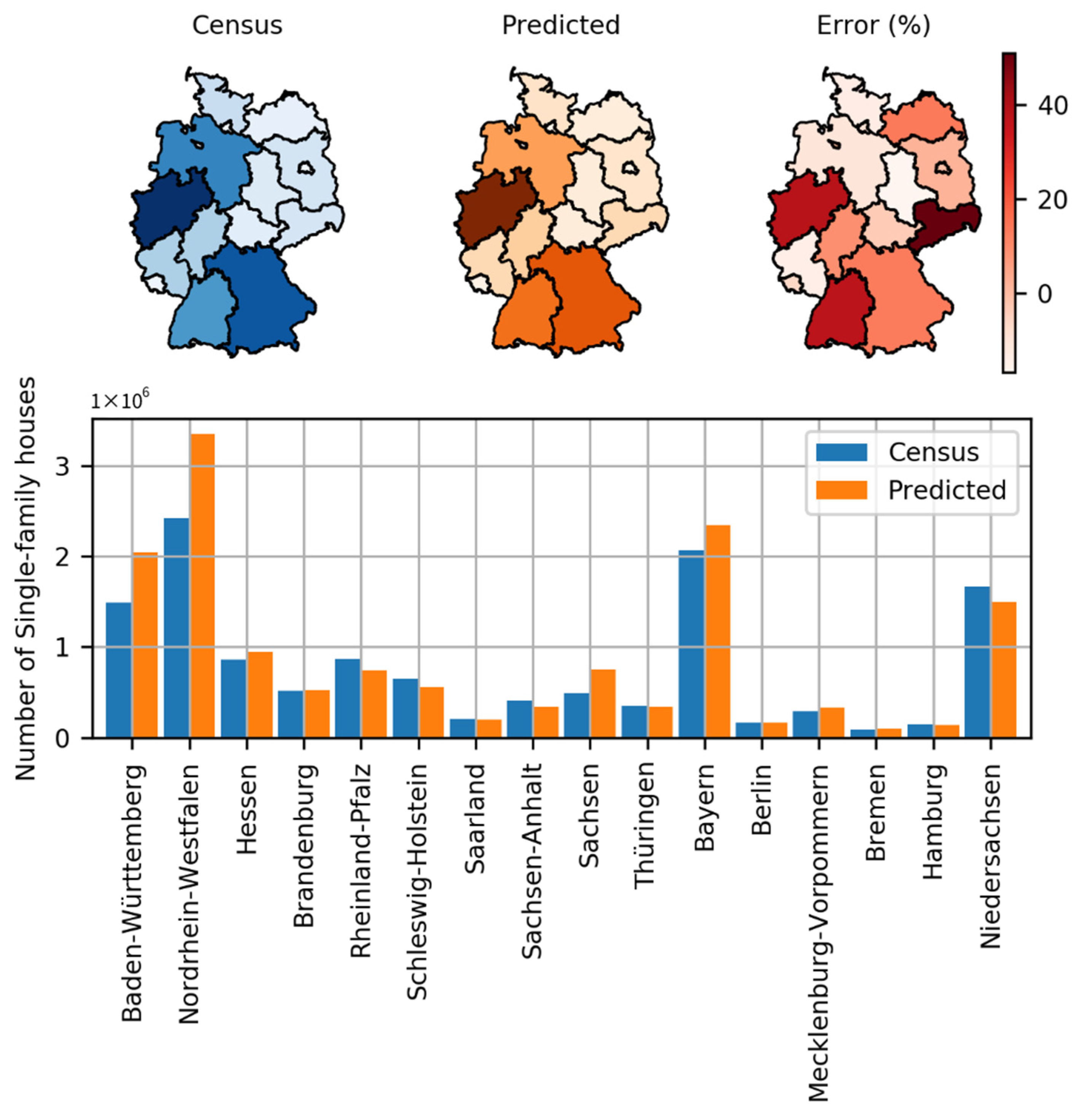
23] recommends using OSM data as supplemental data for classification. On the other hand, our study utilized OSM data and classified building types by addressing challenges with the OSM dataset (i.e., missing values and class imbalance). Furthermore, our analysis identified each residential building as a single-family house, a multi-family house, or an apartment building with a percentage error of 13.14% and −15.38%, respectively.
The collected results, however, are applied to the energy system model. Geo-referenced synthetic electrical distribution networks for Germany are estimated using data corresponding to residential buildings. Before the tagged residential building data for Germany was included in this model, the geo-referenced synthetic electrical low-voltage distribution networks developed had a percentage error of 33% when validated against the overall low-voltage network length for Germany [
53]. However, when classified residential buildings are included in the geo-referenced synthetic distribution network generator model, a percentage error of 0.89% is obtained. This improvement in the energy system model’s percentage error reflects the building type classification model’s accuracy. However, its accuracy varies depending on the model, as this model considers the entire nation, and any mismatch in one geographical location may be compensated for in another. As a consequence, it can be stated that the method employed delivered superior results and addressed the gap created by the complex image classification and POI data availability.
However, according to the findings of this study, the data mapping to the OSM data is still inadequate for the classification of non-residential buildings. The census data employed to achieve the precise classification concentrated exclusively on residential buildings and population. Additionally, the land cover data label the polygons to indicate if they are in an industrial or non-residential zone. Thus, additional data that assists in training the model that can focus on identifying the precise commercial and industrial buildings (i.e., offices, restaurants, supermarkets, glass industries, hospitals, schools, mini-supermarkets, shopping complex, etc.) provides additional classification of non-residential buildings. Moreover, this study covers a single nation owing to the requirement of developing a model capable of generating geo-referenced synthetic electrical distribution networks. Nevertheless, with certain adjustments, this methodology may be extended to other nations. The constraints may occur during the pre-processing stage due to ambiguity in the labels due to spelling errors and multilingual use. The manual decision tree recognizes and updates the labels based on the data analysis conducted on the building labels. If the uncertainty is due to the language, a different approach would be necessary in this stage when applying this methodology to another nation. This is because OSM maps are entirely volunteer based, and if an individual contributor does not adhere to the process for labeling, the labels will be ambiguous. This limitation will prevent this methodology from being used in other countries; however, with some data analysis and adaptive labeling during the preprocessing stage, this limitation can be addressed.
5. Conclusions
The dataset was developed by classifying building types extracted from OSM data for Germany with the specific goal of generating geo-referenced synthetic electrical distribution networks and assessing synthetic energy profiles for the buildings. However, this dataset can be used in any other models that require building information.
Our approach consists of classifying building types with missing values and class imbalances in data extracted from OSM, from which the primary building data were drawn. This study also considered different datasets from various sources and added these to the primary dataset. Moreover, careful refining of the data, including hand label and data cleaning, was performed as part of the data-driven approach. This study employed two state-of-the-art implicit algorithms to classify missing values and class imbalances in one architecture and an explicit cascaded approach. The best performance model was used to classify building and house types in Germany.
The experiments conducted for this study showed the ability to predict building types in light of building footprints and some features corresponding to these. The results indicated a percentage error of 3.64% for the classification of residential buildings, 13.14% for single-family houses, and −15.38% for multi-family houses classification. In addition, this percentage error could be attributed to significant missing values and fewer features. Applying these results to the geo-referenced synthetic distribution model, the percentage error in the total network length was reduced from 33% to 0.89%.
However, given the limitations of non-residential building type prediction and the need to increase the accuracy of house type prediction (i.e., single-family house, multi-family house, and apartment building), some of these points should be considered in future work. First, more data should be collected to avoid misinterpretation of missing values in the dataset. Second, a significant number of additional features with building parameters would contribute to improving the model’s accuracy. Third, more fine-grained location-based data would help in the evaluation of inference data.


 ,
, 



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}