
Using Social Media to Detect Fake News Information Related to Product Marketing: The FakeAds Corpus


Abstract
:1. Introduction
- To use Twitter as a social media resource to explore the use of fake and false news to promote products.
- To build annotated datasets for fake and real advertisements related to cosmetics, fashion, health and technology products.
- The corpus is freely available to stimulate the development of ML-based Text Mining (TM) systems for the automatic extraction and classifications of details, relating to fake news intended to mislead the consumer by promoting false products. The developed TM systems can ultimately be a useful data resource for the research community to further the study of social media credibility, in promoting products and circulating fake advertisements.
2. Related Work
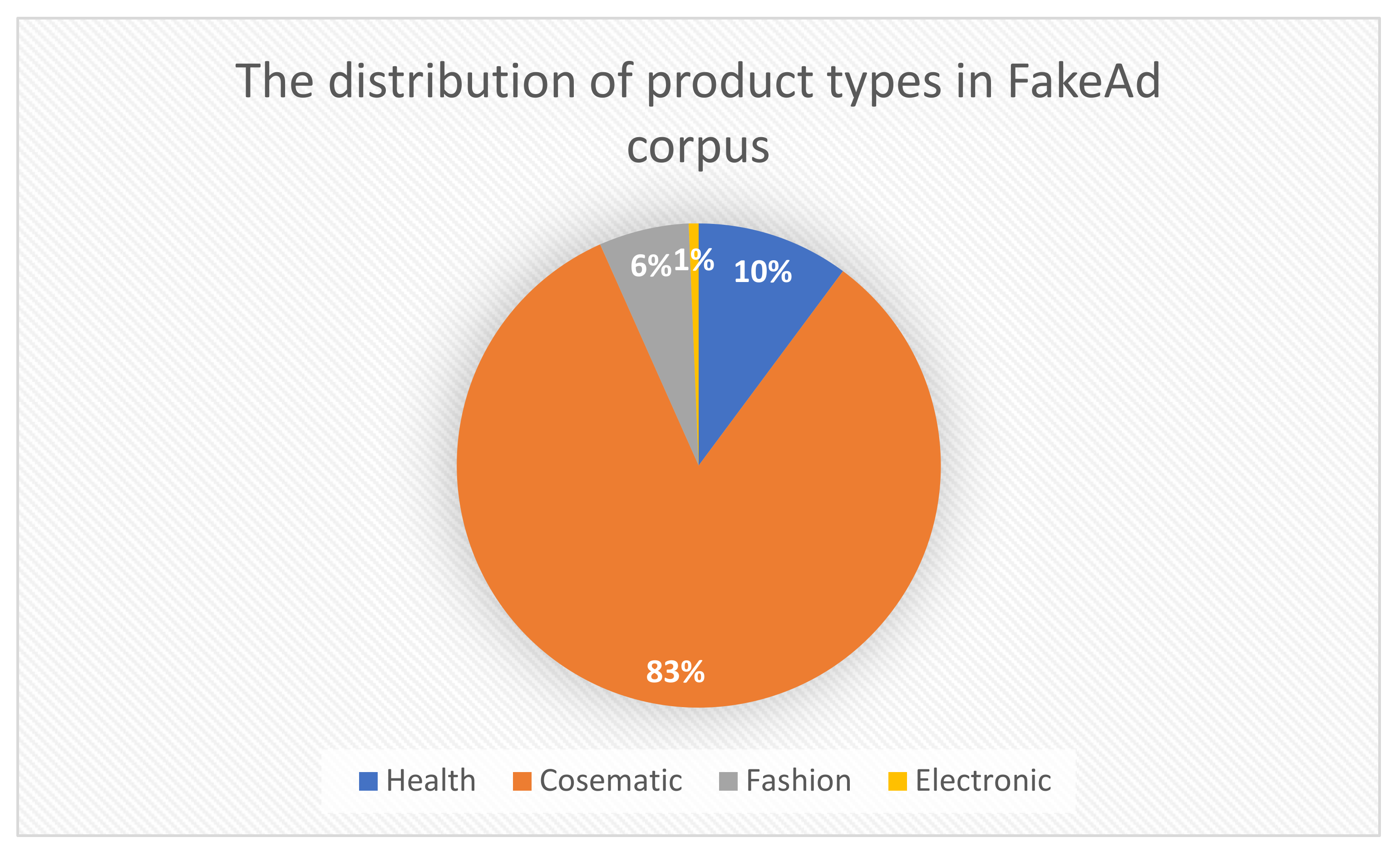
3. Results and Discussion
4. Materials and Methods
Corpus Construction
- At tweet level so that tweets were annotated as fake or real.
- At word level so that for each tweet, the product was classified into one of the following classes: cosmetics, health, fashion, and electronics.
5. Conclusions
6. Limitations and Future Works
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Meel, P.; Vishwakarma, D.K. Fake news, rumor, information pollution in social media and web: A contemporary survey of state-of-the-arts, challenges and opportunities. Expert Syst. Appl. 2020, 153, 112986. [Google Scholar] [CrossRef]
- Wang, W.; Chen, L.; Thirunarayan, K.; Sheth, A.P. Cursing in English on Twitter. In Proceedings of the 17th ACM Conference on Computer Supported Cooperative Work & Social Computing, Baltimore, MD, USA, 15–19 February 2014; Association for Computing Machinery: New York, NY, USA, 2014; pp. 415–425. [Google Scholar]
- Shu, K.; Sliva, A.; Wang, S.; Tang, J.; Liu, H. Fake news detection on social media: A data mining perspective. ACM SIGKDD Explor. Newsl. 2017, 19, 22–36. [Google Scholar] [CrossRef]
- Aslam, S. Twitter by the Numbers: Stats, Demographics & Fun Facts; Omnicore: San Francisco, CA, USA, 2018. [Google Scholar]
- Khan, T.; Michalas, A.; Akhunzada, A. Fake news outbreak 2021: Can we stop the viral spread? J. Netw. Comput. Appl. 2021, 190, 103112. [Google Scholar] [CrossRef]
- Aldwairi, M.; Alwahedi, A. Detecting fake news in social media networks. Procedia Comput. Sci. 2018, 141, 215–222. [Google Scholar] [CrossRef]
- Martin, N. How Social Media Has Changed How We Consume News. Forbes. Available online: https://www.forbes.com/sites/nicolemartin1/2018/11/30/how-social-media-has-changed-how-we-consume-news/?sh=40c30d723c3c (accessed on 20 February 2022).
- Wong, Q. Fake News Is Thriving Thanks to Social Media Users, Study Finds. CNET. Available online: https://www.cnet.com/tech/social-media/fake-news-more-likely-to-spread-on-social-media-study-finds/ (accessed on 20 February 2022).
- Nasir, J.A.; Khan, O.S.; Varlamis, I. Fake news detection: A hybrid CNN-RNN based deep learning approach. Int. J. Inf. Manag. Data Insights 2021, 1, 100007. [Google Scholar] [CrossRef]
- Aslam, N.; Ullah Khan, I.; Alotaibi, F.S.; Aldaej, L.A.; Aldubaikil, A.K. Fake detect: A deep learning ensemble model for fake news detection. Complexity 2021, 2021, 5557784. [Google Scholar] [CrossRef]
- Murayama, T.; Wakamiya, S.; Aramaki, E.; Kobayashi, R. Modeling the spread of fake news on Twitter. PLoS ONE 2021, 16, e0250419. [Google Scholar] [CrossRef]
- Carvalho, C.; Klagge, N.; Moench, E. The persistent effects of a false news shock. J. Empir. Financ. 2011, 18, 597–615. [Google Scholar] [CrossRef] [Green Version]
- Bovet, A.; Makse, H.A. Influence of fake news in Twitter during the 2016 US presidential election. Nat. Commun. 2019, 10, 7. [Google Scholar] [CrossRef]
- Shu, K.; Wang, S.; Liu, H. Exploiting Tri-Relationship for Fake News Detection. In Proceedings of the 12th ACM International Conference on Web Search and Data Mining (WSDM 2019), Ithaca, NY, USA, 20 December 2017; Cornell University: Ithaca, NY, USA, 2017. [Google Scholar]
- Klein, D.O.; Wueller, J.R. Fake news: A legal perspective. Australas. Polic. 2018, 10, 11. [Google Scholar]
- Roth, Y.; Pickles, N. Updating Our Approach to Misleading Information. Twitter Blog. Available online: https://blog.twitter.com/en_us/topics/product/2020/updating-our-approach-to-misleading-information (accessed on 20 February 2022).
- Kaliyar, R.K.; Goswami, A.; Narang, P. FakeBERT: Fake news detection in social media with a BERT-based deep learning approach. Multimed. Tools Appl. 2021, 80, 11765–11788. [Google Scholar] [CrossRef]
- Cresci, S.; Di Pietro, R.; Petrocchi, M.; Spognardi, A.; Tesconi, M. The Paradigm-Shift of Social Spambots: Evidence, Theories, and Tools for the Arms Race. In Proceedings of the 26th International Conference on World Wide Web Companion, Perth, Australia, 3–7 May 2017; International World Wide Web Conferences Steering Committee: Geneva, Switzerland, 2017; pp. 963–972. [Google Scholar]
- Gibert, D.; Mateu, C.; Planes, J. The rise of machine learning for detection and classification of malware: Research developments, trends and challenges. J. Netw. Comput. Appl. 2020, 153, 102526. [Google Scholar] [CrossRef]
- Bakhteev, O.; Ogaltsov, A.; Ostroukhov, P. Fake News Spreader Detection Using Neural Tweet Aggregation. In Proceedings of the CLEF 2020 Labs and Workshops, Notebook Papers, Thessaloniki, Greece, 22–25 September 2020; Cappellato, L., Eickhoff, C., Ferro, N., Névéol, A., Eds.; CEUR: Uzhhorod, Ukraine, 2020. [Google Scholar]
- Lee, K.; Caverlee, J.; Webb, S. Uncovering Social Spammers: Social Honeypots+ Machine Learning. In Proceedings of the 33rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Geneva, Switzerland, 13–19 July 2010; ACM: New York, NY, USA, 2010; pp. 435–442. [Google Scholar]
- Ghosh, S.; Korlam, G.; Ganguly, N. Spammers’ Networks within Online Social Networks: A Case-Study on Twitter. In Proceedings of the 20th International Conference Companion on World Wide Web, Hyderabad, India, 28 March–1 April 2011; ACM: New York, NY, USA, 2011; pp. 41–42. [Google Scholar]
- Wang, A.H. Don’t Follow Me: Spam Detection in Twitter. In Proceedings of the 2010 International Conference on Security and Cryptography (SECRYPT), Athens, Greece, 26–28 July 2010; IEEE: Piscataway, NJ, USA, 2010; pp. 1–10. [Google Scholar]
- Stringhini, G.; Kruegel, C.; Vigna, G. Detecting spammers on social networks. In Proceedings of the 26th Annual Computer Security Applications Conference, Austin, TX, USA, 6–10 December 2010; ACM: New York, NY, USA, 2010; pp. 1–9. [Google Scholar]
- Yardi, S.; Romero, D.; Schoenebeck, G. Detecting spam in a Twitter network. First Monday 2010, 15. [Google Scholar] [CrossRef]
- Rajdev, M.; Lee, K. Fake and spam messages: Detecting misinformation during natural disasters on social media. In Proceedings of the 2015 IEEE/WIC/ACM International Conference on Web Intelligence and Intelligent Agent Technology (WI-IAT), Singapore, 6–9 December 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 17–20. [Google Scholar]
- Potthast, M.; Köpsel, S.; Stein, B.; Hagen, M. Clickbait detection. In Advances in Information Retrieval; Springer International Publishing: Cham, Switzerland, 2016; pp. 810–817. [Google Scholar]
- Ott, M.; Cardie, C.; Hancock, J. Estimating the prevalence of deception in online review communities. In Proceedings of the 21st International Conference on World Wide Web, Lyon, France, 16–20 April 2012; ACM: New York, NY, USA, 2012; pp. 201–210. [Google Scholar]
- Danescu-Niculescu-Mizil, C.; Kossinets, G.; Kleinberg, J.; Lee, L. How opinions are received by online communities: A case study on amazon.com helpfulness votes. In Proceedings of the 18th International Conference on World Wide Web, Geneva, Switzerland, 20–24 April 2009; ACM: New York, NY, USA, 2009; pp. 141–150. [Google Scholar]
- Feng, S.; Xing, L.; Gogar, A.; Choi, Y. Distributional footprints of deceptive product reviews. In Proceedings of the International AAAI Conference on Web and Social Media, Dublin, Ireland, 4–7 June 2012; pp. 98–105. [Google Scholar]
- Xie, S.; Wang, G.; Lin, S.; Yu, P.S. Review spam detection via temporal pattern discovery. In Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Beijing, China, 12–16 August 2012; ACM: New York, NY, USA, 2012; pp. 823–831. [Google Scholar]
- Jin, Z.; Cao, J.; Zhang, Y.; Luo, J. News verification by exploiting conflicting social viewpoints in microblogs. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; ACM: New York, NY, USA, 2016. [Google Scholar]
- Yang, S.; Shu, K.; Wang, S.; Gu, R.; Wu, F.; Liu, H. Unsupervised fake news detection on social media: A generative approach. In Proceedings of the AAAI Conference on Artificial Intelligence, Palo Alto, CA, USA, 8–12 October 2019; AAAI Press: Palo Alto, CA, USA, 2019; pp. 5644–5651. [Google Scholar]
- Potthast, M.; Kiesel, J.; Reinartz, K.; Bevendorff, J.; Stein, B. A stylometric inquiry into hyperpartisan and fake news. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Melbourne, Australia, 15–20 July 2018; Association for Computational Linguistics: Stroudsburg, PA, USA, 2017; pp. 231–240. [Google Scholar]
- Jin, Z.; Cao, J.; Zhang, Y.; Zhou, J.; Tian, Q. Novel visual and statistical image features for microblogs news verification. IEEE Trans. Multimed. 2016, 19, 598–608. [Google Scholar] [CrossRef]
- Gupta, A.; Lamba, H.; Kumaraguru, P.; Joshi, A. Faking sandy: Characterizing and identifying fake images on twitter during hurricane sandy. In Proceedings of the 22nd International Conference on World Wide Web, Rio de Janeiro, Rio de Janeiro, Brazil, 13–17 May 2013; ACM: New York, NY, USA, 2013; pp. 729–736. [Google Scholar]
- Castillo, C.; Mendoza, M.; Poblete, B. Information credibility on Twitter. In Proceedings of the 20th International Conference on World Wide Web, Hyderabad, India, 28 March–1 April 2011; ACM: New York, NY, USA, 2011; pp. 675–684. [Google Scholar]
- Minaee, S.; Kalchbrenner, N.; Cambria, E.; Nikzad, N.; Chenaghlu, M.; Gao, J. Deep learning–based text classification: A comprehensive review. ACM Comput. Surv. 2021, 54, 1–40. [Google Scholar] [CrossRef]
- Horne, B.; Adali, S. This just in: Fake news packs a lot in title, uses simpler, repetitive content in text body, more similar to satire than real news. In Proceedings of the Eleventh International AAAI Conference on Web and Social Media, Montreal, QC, Canada, 15–18 May 2017; Association for the Advancement of ArtificialIntelligence: Palo Alto, CA, USA, 2017; pp. 759–766. [Google Scholar]
- Mitra, T.; Gilbert, E. Credbank: A large-scale social media corpus with associated credibility annotations. In Proceedings of the Ninth International AAAI Conference on Web and Social Media, Oxford, UK, 26–29 May 2015; AAAI: Palo Alto, CA, USA, 2015; pp. 258–267. [Google Scholar]
- Shaar, S.; Hasanain, M.; Hamdan, B.; Ali, Z.S.; Haouari, F.; Nikolov, A.; Kutlu, M.; Kartal, Y.S.; Alam, F.; Da San Martino, G. Overview of the CLEF-2021 CheckThat! Lab task 1 on check-worthiness estimation in tweets and political debates. In Proceedings of the CLEF 2021—Conference and Labs of the Evaluation Forum, Bucharest, Romania, 21–24 September 2021; CEUR: Uzhhorod, Ukraine, 2021; pp. 369–392. [Google Scholar]
- Shahi, G.K.; Struß, J.M.; Mandl, T. Overview of the CLEF-2021 CheckThat! Lab: Task 3 on fake news detection. In Proceedings of the CLEF 2021—Conference and Labs of the Evaluation Forum, Bucharest, Romania, 21–24 September 2021; CEUR: Uzhhorod, Ukraine, 2021. [Google Scholar]
- Nakov, P.; Da San Martino, G.; Elsayed, T.; Barrón-Cedeño, A.; Míguez, R.; Shaar, S.; Alam, F.; Haouari, F.; Hasanain, M.; Babulkov, N.; et al. The CLEF-2021 CheckThat! Lab on detecting check-worthy claims, previously fact-checked claims, and fake news. In Proceedings of the ECIR: European Conference on Information Retrieval, Lucca, Italy, 28 March–1 April 2021; Springer International Publishing: Cham, Switzerland, 2021; pp. 639–649. [Google Scholar]
- Tacchini, E.; Ballarin, G.; Della Vedova, M.L.; Moret, S.; de Alfaro, L. Some Like It Hoax: Automated Fake News Detection in Social Networks, Technical Report UCSC-SOE-17-05; University of California: Santa Cruz, CA, USA, 2017. [Google Scholar]
- Tandoc, E.C., Jr.; Lim, Z.W.; Ling, R. Defining “fake news”: A typology of scholarly definitions. Digit. J. 2018, 6, 137–153. [Google Scholar] [CrossRef]
- Zubiaga, A.; Aker, A.; Bontcheva, K.; Liakata, M.; Procter, R. Detection and resolution of rumours in social media: A survey. ACM Comput. Surv. 2018, 51, 1–36. [Google Scholar] [CrossRef] [Green Version]
- Thompson, P.; Daikou, S.; Ueno, K.; Batista-Navarro, R.; Tsujii, J.; Ananiadou, S. Annotation and detection of drug effects in text for pharmacovigilance. J. Cheminform. 2018, 10, 37. [Google Scholar] [CrossRef]
- Hripcsak, G.; Rothschild, A.S. Agreement, the F-measure, and reliability in information retrieval. J. Am. Med. Inform. Assoc. 2005, 12, 296–298. [Google Scholar] [CrossRef]
- Thompson, P.; Iqbal, S.A.; McNaught, J.; Ananiadou, S. Construction of an annotated corpus to support biomedical information extraction. BMC Bioinform. 2009, 10, 349. [Google Scholar] [CrossRef] [Green Version]
- Brants, T. Inter-annotator agreement for a German newspaper corpus. In Proceedings of the Second International Conference on Language Resources and Evaluation (LREC’00), Athens, Greece, 31 May 2000; European Language Resources Association (ELRA): Paris, France, 2000. [Google Scholar]
- TweetScraper. Jonbakerfish/TweetScraper Is a Simple Crawler/Spider for Twitter Search without Using API. Available online: https://github.com/jonbakerfish/TweetScraper (accessed on 5 February 2022).
- Hashtagify. Search and Find the Best Twitter Hashtags-Free. Available online: https://hashtagify.me/hashtag/thebookofbobafett (accessed on 5 February 2022).
- Yetisgen-Yildiz, M.; Solti, I.; Xia, F.; Halgrim, S. Preliminary experiments with Amazon’s mechanical turk for annotating medical named entities. In Proceedings of the NAACL HLT 2010 Workshop on Creating Speech and Language Data with Amazon’s, Los Angeles, CA, USA, 6 June 2010; Association for Computational Linguistics: Stroudsburg, PA, USA, 2010; pp. 180–183. [Google Scholar]
- Snow, R.; O’Connor, B.; Jurafsky, D.; Ng, A.Y. Cheap and fast–but is it good? Evaluating non-expert annotations for natural language tasks. In Proceedings of the 2008 Conference on Empirical Methods in Natural Language Processing, Honolulu, HI, USA, 25–27 October 2008; Association for Computational Linguistics: Stroudsburg, PA, USA, 2008; pp. 254–263. [Google Scholar]
- Eickhoff, C.; De Vries, A.P. Increasing cheat robustness of crowdsourcing tasks. Inf. Retr. 2013, 16, 121–137. [Google Scholar] [CrossRef] [Green Version]
- Gravano, A.; Levitan, R.; Willson, L.; Beòuš, Š.; Hirschberg, J.B.; Nenkova, A. Acoustic and prosodic correlates of social behavior. In Proceedings of the 12th Annual Conference of the International Speech Communication Association, Florence, Italy, 27–31 August 2011; Interspeech: Brno, Czech Republic, 2011; pp. 97–100. [Google Scholar]
- Gurajala, S.; White, J.S.; Hudson, B.; Voter, B.R.; Matthews, J.N. Profile characteristics of fake Twitter accounts. Big Data Soc. 2016, 3, 2053951716674236. [Google Scholar] [CrossRef] [Green Version]




{kind=link}
{kind=link}
{kind=link}
| Dataset | Size | Text Genre | Topic | Categories | Annotation Level |
|---|---|---|---|---|---|
| BuzzFeed [39] | 2283 | News articles | Presidential election, political biases: mainstream, left-leaning, and right-leaning. | Mostly true, mostly false, mixture of true and false, and no factual content | Sentence level |
| LIAR [3] | 12.8 K | Sentences collected from politifact | politics | false, barely true, half true, mostly true, and true | Sentence level |
| CREDBANK [40] | 60 M | Tweets | Real world events | -Certainly inaccurate -Probably inaccurate -Uncertain -Probably accurate -Certainly accurate | Sentence level |
| FaceBookHoax [44] | 15,500 | Facebook posts | Scientific news sources vs. conspiracy news sources | Hoax, no-hoax | Sentence level |
| CheckThat sub-task 1: check-worthiness estimation on Twitter CT–CWT–21 [41] | 1312 | Tweets | COVID-19 and politics | -Not worth fact checking -Worth fact checking | Sentence level |
| CheckThat sub-task 3: (CT-FAN-21) Multi-class fake news categorization of news articles [42] | 1254 | News articles | Health, climate, economy, crime, elections, and education | False, partially false, true, and other. | Sentence level |
| Dataset | Size | Text Genre | Topic | Categories/Labels | Annotation Level | # of Annotators | Agreement Measurement |
|---|---|---|---|---|---|---|---|
| FakeAds | 5000 | Tweets | Marketing and fake news | Binary classes: Fake Real Multi-classes: Health Cosmetics Fashion Electronic |
| 3 annotators for the binary annotation 2 annotators for the multi-class annotation | F-score (0.815) |
| CREDBANK | 60 M | Tweets | Real world vents |
| Sentence level | 1736 unique annotators from AMT | Intraclass correlations (ICC) (0.77) |
| CheckThat sub-task 1: check-worthiness estimation on Twitter | 1312 | Tweets | COVID-19 and politics |
| Sentence level | 3 annotators | Majority voting Averaged (0.597) |
| Entity Type | Description |
|---|---|
| Cosmetic | Is product mention related to skincare, body care or make-up, for example, lipsticks, creams etc. |
| Electronic | Is products that require electric currents or electromagnetic fields to work. Examples are electronic devices, phones, cameras, computers etc. |
| Health | Is product mention related to supplement(s) that promotes the wellbeing of individuals, e.g., vitamins, herbs, etc. |
| Fashion | Is product related to accessories such as clothing, shoes, bags jewelry, fragrances, etc. |
| Total Number of Annotations | Healh | Cosematics | Fashion | Electronics | |
|---|---|---|---|---|---|
| Real | 6159 | 300 | 5691 | 135 | 33 |
| Fake | 4807 | 200 | 4527 | 66 | 14 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alnazzawi, N.; Alsaedi, N.; Alharbi, F.; Alaswad, N. Using Social Media to Detect Fake News Information Related to Product Marketing: The FakeAds Corpus. Data 2022, 7, 44. https://doi.org/10.3390/data7040044
Alnazzawi N, Alsaedi N, Alharbi F, Alaswad N. Using Social Media to Detect Fake News Information Related to Product Marketing: The FakeAds Corpus. Data. 2022; 7(4):44. https://doi.org/10.3390/data7040044
Chicago/Turabian StyleAlnazzawi, Noha, Najlaa Alsaedi, Fahad Alharbi, and Najla Alaswad. 2022. "Using Social Media to Detect Fake News Information Related to Product Marketing: The FakeAds Corpus" Data 7, no. 4: 44. https://doi.org/10.3390/data7040044