
Classification of Organic and Conventional Vegetables Using Machine Learning: A Case Study of Brinjal, Chili and Tomato

Abstract
:
1. Introduction
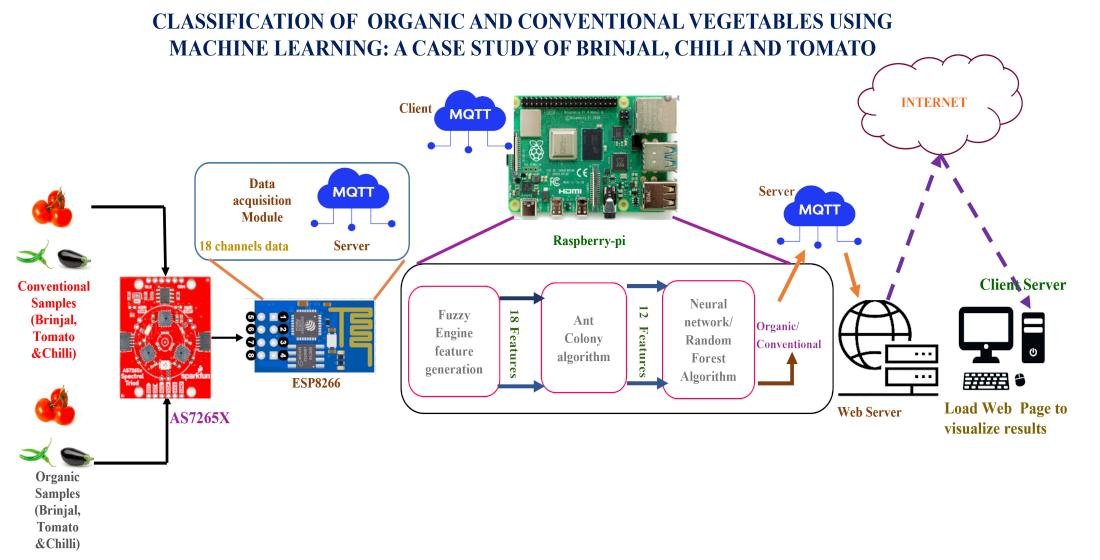
- Our proposed work includes the design and construction of a nondestructive, portable, rapid-analysis multispectral sensor system to discriminate between conventional and organic vegetable samples using random forest and neural network algorithms.
- A multispectral sensor system is designed with three bands of NIR, UV and visible to enable reliable detection.
- In practical use of the sensor system, the accuracy of detection is challenged by the influencing factors of the angle of placement of the sensor on the sample, the distance between the sensor and sample, the presence of ambient light, the size of the sample, variation in the color texture of the sample. Fuzzy-logic-based feature generation is employed to scope-up such variable factors.
- The ant colony algorithm is utilized for feature selection and parameter tuning to improve detection accuracy in the presence of variable factors and reduce the response time.
2. Materials and Methods
2.1. Multispectral Sensor System Model
2.1.1. Fuzzy Model for Feature Generation
2.1.2. Feature Selection Using Ant Colony Algorithm
2.1.3. Random Forest Algorithm
| Algorithm 1: Ensemble Random Forest algorithm |
| Input: best feature set from ant colony Sfd, parameters: Ts, NP, Rnp, Nd, Rnn, function ant_call () for ant colony, |
| Output: Optimal model |
| 1. Use optimal feature set and parameters from ACO algorithm as the input dataset |
| 2. Ensemble—RF (Sfd, Ts, NP, Rnp, Nd, Rnn) |
| 3. For n < −1 to NP do |
| a. (Train, test) ← random split (Sfd, Ts) |
| b. Split ← bootstrap (train, Rnp, Rnm) |
| c. Model ← Random Forest. Train (split, Nd) |
| d. Score ← evaluate (model, test) |
| e. Out[n] ← (model, score) |
| End for |
| ] = Call voter for optimal model selection] |
| g. Call ant_call ( ) function for parameter tuning and feature selection. |
| ) |
| h. If (the actual performance is less than the target performance), |
| then go to Step 1 |
| Else go to Step 4 |
| End if |
| 4. Return out |
2.1.4. Neural Network Architecture
2.2. Sample Preparation
3. Results and Discussion
3.1. Histogram Analysis of Photon Count Distribution–18 Channels
3.1.1. Histogram Analysis of Photon Count Distribution to Discriminate Organic and Conventional Vegetable–Red Color Tomato
3.1.2. Histogram Analysis of Photon Count Distribution to Discriminate Organic and Conventional Vegetable—Purple-Color Brinjal
3.1.3. Histogram Analysis of Photon Count Distribution to Discriminate Organic and Conventional Vegetable—Green-Color Chili
3.2. Individual Channel Responses
3.2.1. UV Channel Response for Brinjal
3.2.2. NIR-VIS Channel Response for Brinjal
3.3. ACO Results
3.4. Analysis of Neural Network Model
- The model proposed in [6] achieves an accuracy of 97.3% for organic and conventional yam discrimination. The cost of the experimented system model is expensive and not portable; therefore, mass spectroscopy is not applicable for real-time analysis. The system model is analyzed only with a single vegetable. The proposed work involves designing and constructing a nondestructive, less expensive, portable, rapid-analysis multispectral sensor system. It can discriminate between organic and conventional vegetables (tomato, green chili, brinjal) using fuzzy and ACO optimization algorithms for optimal feature selection. The optimal feature set is applied through random forest and neural network algorithms, achieving 100% classification accuracy.
3.5. System’s Response Time
3.6. Repeatability Analysis
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Annual Report 2020–2021, Department of Agriculture, Cooperation & Farmers Welfare. Available online: https://agricoop.nic.in/sites/default/files/Web%20copy%20of%20AR%20%28Eng%29_7.pdf (accessed on 31 March 2021).
- Bordeleau, G.; Myers-Smith, I.; Midak, M.; Szeremeta, A. Food Quality: A Comparison of Organic and Conventional Fruits and Vegetables. Ph.D. Thesis, Department of Ecological Agriculture, Kongelige Veterinoer-og Landbohøjskole, Frederiksberg, Denmark, 4 February 2002. [Google Scholar]
- Yordanov, N.D.; Novakova, E.; Lubenova, S. Consecutive estimation of nitrate and nitrite ions in vegetables and fruits by electron paramagnetic resonance spectrometry. Anal. Chim. Acta 2001, 437, 131–138. [Google Scholar] [CrossRef]
- Ponnusamy, V.; Coumaran, A.; Shunmugam, A.S.; Rajaram, K.; Senthilvelavan, S. Smart glass: Real-time leaf disease detection using YOLO transfer learning. In Proceedings of the 2020 International Conference on Communication and Signal Processing (ICCSP), Chennai, India, 28–30 July 2020; pp. 1150–1154. [Google Scholar] [CrossRef]
- Cui, F.; Yue, Y.; Zhang, Y.; Zhang, Z.; Zhou, H.S. Advancing biosensors with machine learning. ACS Sens. 2020, 5, 3346–3364. [Google Scholar] [CrossRef] [PubMed]
- Lombardi-Boccia, G.; Lucarini, M.; Lanzi, S.; Aguzzi, A.; Cappelloni, M. Nutrients and antioxidant molecules in yellow plums (Prunus domestica L.) from conventional and organic productions: A comparative study. J. Agric. Food Chem. 2004, 52, 90–94. [Google Scholar] [CrossRef] [PubMed]
- Lyu, C.; Yang, J.; Wang, T.; Kang, C.; Wang, S.; Wang, H.; Wan, X.; Zhou, L.; Zhang, W.; Huang, L.; et al. A field trials-based authentication study of conventionally and organically grown Chinese yams using light stable isotopes and multi-elemental analysis combined with machine learning algorithms. Food Chem. 2021, 343, 128506. [Google Scholar] [CrossRef] [PubMed]
- Shomaji, S.; Masna, N.; Ariando, D.; Paul, S.D.; Horace-Herron, K.; Forte, D.; Mandal, S.; Bhunia, S. Detecting Dye-Contaminated Vegetables Using Low-Field NMR Relaxometry. Foods 2021, 10, 2232. [Google Scholar] [CrossRef] [PubMed]
- Gupta, O.; Das, A.J.; Hellerstein, J.; Raskar, R. Machine learning approaches for large scale classification of produce. Sci. Rep. 2018, 8, 5226. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jiang, N.; Song, W.; Wang, H.; Guo, G.; Liu, Y. Differentiation between organic and Conventional apples using diffraction grating and image processing—A cost-effective approach. Sensors 2018, 18, 1667. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Song, W.; Wang, H.; Maguire, P.; Nibouche, O. Differentiation of organic and Conventional apples using near infrared reflectance spectroscopy—A pattern recognition approach. In Proceedings of the 2016 IEEE SENSORS, Orlando, FL, USA, 30 October–3 November 2016; pp. 1–3. [Google Scholar] [CrossRef]
- Hohmann, M.; Monakhova, Y.; Erich, S.; Christoph, N.; Wachter, H.; Holzgrabe, U. Differentiation of organically and conventionally grown tomatoes by chemometric analysis of combined data from proton nuclear magnetic resonance and mid-infrared spectroscopy and stable isotope analysis. J. Agric. Food Chem. 2015, 63, 9666–9675. [Google Scholar] [CrossRef] [PubMed]
- Amuah, C.L.; Teye, E.; Lamptey, F.P.; Nyandey, K.; Opoku-Ansah, J.; Adueming, P.O. Feasibility study of the use of handheld NIR spectrometer for simultaneous authentication and quantification of quality parameters in intact pineapple fruits. J. Spectrosc. 2019, 2019, 5975461. [Google Scholar] [CrossRef] [Green Version]
- Gąstoł, M.; Domagała-Świątkiewicz, I.; Krośniak, M. Organic versus conventional–a comparative study on quality and nutritional value of fruit and vegetable juices. Biol. Agric. Hortic. 2021, 27, 310–319. [Google Scholar] [CrossRef]
- Misal, R.M.; Deshmukh, R.R. Application of Near-Infrared Spectrometer in Agro-Food Analysis: A review. Int. J. Comput. Appl. 2016, 141, 0975–8887. Available online: https://www.researchgate.net/publication/303318955 (accessed on 15 May 2016).
- Tran, N.T.; Fukuzawa, M. A portable spectrometric system for quantitative prediction of the soluble solids content of apples with a pre-calibrated multispectral sensor chipset. Sensors 2020, 20, 5883. [Google Scholar] [CrossRef] [PubMed]
- Salguero-Chaparro, L.; Gaitán-Jurado, A.J.; Ortiz-Somovilla, V.; Peña-Rodríguez, F. Feasibility of using NIR spectroscopy to detect herbicide residues in intact olives. Food Control 2013, 30, 504–509. [Google Scholar] [CrossRef]
- Sowmya, N.; Vijayakumar, P. Development of Spectroscopic Sensor System for an IoT Application of Adulteration Identification on Milk Using Machine Learning. IEEE Access 2021, 9, 53979–53995. [Google Scholar] [CrossRef]
- SparkFun Triad Spectroscopy Sensor-AS7265x. Available online: https://www.sparkfun.com/products/15050 (accessed on 9 November 2020).
- AS7265x Smart 18-Channel VIS to NIR Spectral_ ID 3-Sensor Chipset with Electronic Shutter-General Description. Available online: https://cdn.sparkfun.com/assets/c/2/9/0/a/AS7265x_Datasheet.pdf (accessed on 20 June 2020).
- Peng, H.; Ying, C.; Tan, S.; Hu, B.; Sun, Z. An improved feature selection algorithm based on ACO optimization. IEEE Access 2018, 6, 69203–69209. [Google Scholar] [CrossRef]
- Lin, W.; Wu, Z.; Lin, L.; Wen, A.; Li, J. An ensemble random forest algorithm for insurance big data analysis. IEEE Access 2017, 5, 16568–16575. [Google Scholar] [CrossRef]
- Natarajan, S.; Ponnusamy, V. A Review on the Organic and Conventional Fruits and Vegetable Detection Methods. In Proceedings of the 2021 Sixth International Conference on Wireless Communications, Signal Processing and Networking (WiSPNET), Chennai, India, 25–27 March 2021; pp. 1–5. [Google Scholar] [CrossRef]
- Red Soil Characteristics. Available online: https://www.vedantu.com/geography/red-soil (accessed on 26 January 2023).













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Fruits/Vegetables | Spectroscopic Analysis and Methodology Applied | Maximum Accuracy |
|---|---|---|
| Olives [5] | NIR and PLS-DA | 85.9% |
| Fuji apple [9] | NIR and LSVM | 98% |
| Apple [10] | NIR and KNN, SVM, PLS-DA | 94% |
| Gala Apples [11] | NIR and PLS-DA | 96–98% |
| Tomato [12] | 1H NMR, MIR, IRMS and PCA, LDA, PLS-DA | 100% |
| Pineapple [13] | Digital Refractometer and KNN, PCA, LDA, PLSR, MSC-PCA-LDA | 100% |
| Input/Band | Input Crisp Value Range | Membership Function Value [a, b, c] |
|---|---|---|
| Channel [1–6] NIR band | Range (1–308–360) L, Range (361–395) M, Range (395–436) H, | [1, 308, 334], [361, 378, 395], [415.5, 436] |
| Range(1–105–130) L, Range (130–155) M, Range (155–224) H | [1, 105, 117.5], [130, 142.5, 155], [189.5, 224] | |
| Range (1–212–271) L, Range (271–380) M, Range (380–557) H | [1, 212, 241.5], [271, 325.5, 380], [468.5, 557] | |
| Range (1–45–50) L, Range (50–60) M, Range (60–148) H | [1, 45, 47.5], [50, 55, 60], [104, 148] | |
| Range (1–81–91) L, Range (91–107) M, Range (107–210) H | [1, 81, 86], [91, 99, 107], [158.5, 210] | |
| Range(1–103–150)L, Range (150–180) M, Range (180–210) H | [1, 103, 126.5], [150, 165, 180], [180, 195] | |
| Channel [9,11,13–16] Visible band | Range (1–31–33) L, Range (33–38) M, Range (38–103) H, | [1, 31, 32], [33, 35.5, 38], [70.5, 103] |
| Range (1–244–300) L, Range (300–329) M, Range (329–750) H | [1, 244, 272], [300, 314.5, 329], [539.5, 750] | |
| Range (1–680–840) L, Range (840–986) M, Range (986–1295) H | [1, 680, 760], [840, 913, 986], [1140.5, 1295] | |
| Range (1–31–400) L, Range (400–447) M, Range (447–825) H | [1, 31, 215.5], [400, 423.5, 447], [636, 825] | |
| Range (1–238–250) L, Range (250–284) M, Range (284–420) H | [1, 238, 244], [250, 267, 284], [352, 420] | |
| Range (1–97–112) L, Range (112–129) M, Range (129–192) H | [1, 97, 104.5], [112, 120.5, 129], [160.5, 192] | |
| Channel [7,8,10,12,17,18] UV band | Range (1–25–30) L, Range (30–33) M, Range (33–97) H | [1, 25, 27.5], [30, 31.5, 33], [65, 97] |
| Range (1–30–34) L, Range (34–37) M, Range (37–95) H | [1, 30, 32], [34, 35.5, 37], [66, 95] | |
| Range (1–58–63) L, Range (63–71) M, Range (71–120) H | [1, 58, 60.5], [63, 67, 71], [95.5, 120] | |
| Range (1–76–92) L, Range (92–103) M, Range (103–245) H | [1, 76, 84], [92, 97.5, 103], [174, 245] | |
| Range (1–230–259) L, Range (259–99) M, Range (299–495) H | [1, 230, 244.5], [259, 279, 299], [397, 495] | |
| Range (1–467–558) L, Range (558–679) M, Range (78–148) H | [1, 467, 512.5], [558, 618.5, 679], [348, 458] |
| Output Membership Function | Points [a, b, c] |
|---|---|
| Very Low | [1, 2, 2] |
| Low | [2, 4, 4] |
| Medium | [4, 6, 6] |
| High | [5, 8, 8] |
| Channel No | Minimum Count of Occurrence— Photon Count | Maximum Count of Occurrence— Photon Count | ||
|---|---|---|---|---|
| Conventional | Organic | Conventional | Organic | |
| 1 | 2-128 | 2-248 | 44-66 | 69-146 |
| 2 | 4-77 | 1-80 | 44-46 | 51-113 |
| 3 | 11-68 | 2-216 | 37-76 | 68-152 |
| 4 | 3-32 | 1-105 | 31-44 | 56-88 |
| 5 | 2-76 | 1-250 | 46-125 | 96-160 |
| 6 | 2-139 | 1-525 | 46-123 | 140-300 |
| 7 | 1-42 | 1-285 | 54-61 | 58-95 |
| 8 | 5-68 | 2-376 | 50-95 | 60-174 |
| 9 | 3-335 | 1-482 | 42-271 | 91-256 |
| 10 | 2-114 | 1-158 | 53-98 | 53-112 |
| 11 | 2-221 | 2-275 | 52-258 | 39-301 |
| 12 | 1-76 | 6-102 | 42-86 | 37-102 |
| 13 | 1-1820 | 1-2048 | 55-2300 | 62-4834 |
| 14 | 2-621 | 1-391 | 40-925 | 92-992 |
| 15 | 1-212 | 1-172 | 48-295 | 63-368 |
| 16 | 1-141 | 1-83 | 48-181 | 81-211 |
| 17 | 6-254 | 1-119 | 52-425 | 84-413 |
| 18 | 4-913 | 1-328 | 52-913 | 80-836 |
| Channel No | Minimum Count of Occurrence— Photon Count | Maximum Count of Occurrence—Photon Count | ||
|---|---|---|---|---|
| Conventional | Organic | Conventional | Organic | |
| 1 | 6-321 | 1-488 | 41-334 | 41-430 |
| 2 | 6-197 | 2-179 | 38- 184 | 41-122 |
| 3 | 9-390 | 7-342 | 32-308 | 58-256 |
| 4 | 4-147 | 3-61 | 32-97 | 50-50 |
| 5 | 1-210 | 2-105 | 43-149 | 53-84 |
| 6 | 3-181 | 1-113 | 39-154 | 52-151 |
| 7 | 6-57 | 1-34 | 59-70 | 91-31 |
| 8 | 5-95 | 4-38 | 46-81 | 51-35 |
| 9 | 5-89 | 1-40 | 39-95 | 52-34 |
| 10 | 2-95 | 3-70 | 40-105 | 59-64 |
| 11 | 1-750 | 1-261 | 33-505 | 59-296 |
| 12 | 3-235 | 4-101 | 29-152 | 68-93 |
| 13 | 2-1295 | 1-956 | 59-686 | 45-834 |
| 14 | 4-755 | 1-434 | 47-650 | 66-365 |
| 15 | 3-366 | 1-285 | 58-311 | 66-251 |
| 16 | 5-165 | 1-331 | 56-140 | 87-111 |
| 17 | 3-425 | 1-244 | 55-355 | 66-258 |
| 18 | 1-1022 | 1-659 | 47-835 | 74-552 |
| Channel No | Minimum Count of Occurrence— Photon Count | Maximum Count of Occurrence—Photon Count | ||
|---|---|---|---|---|
| Conventional | Organic | Conventional | Organic | |
| 1 | 2-1048 | 1-421 | 52-496 | 63-143 |
| 2 | 1-175 | 3-310 | 63-194 | 86-72 |
| 3 | 2-308 | 5-545 | 37-438 | 84-126 |
| 4 | 1-175 | 7-181 | 91-50 | 49-64 |
| 5 | 1-368 | 2-518 | 82-185 | 44-577 |
| 6 | 1-466 | 3-1805 | 1-466 | 50-1236 |
| 7 | 1-309 | 5-196 | 1-309 | 37-167 |
| 8 | 6-160 | 1-116 | 31-179 | 56-63 |
| 9 | 10-59 | 3-24 | 42-63 | 43-25 |
| 10 | 2-63 | 1-40 | 43-52 | 76-33 |
| 11 | 1-165 | 2-317 | 66-114 | 41-274 |
| 12 | 1-72 | 5-122 | 62-49 | 53-106 |
| 13 | 5-288 | 1-319 | 61-122 | 65-281 |
| 14 | 5-89 | 3-73 | 49-72 | 53-78 |
| 15 | 1-297 | 3-305 | 71-193 | 49-280 |
| 16 | 1-172 | 5-161 | 74-121 | 50-168 |
| 17 | 1-164 | 3-291 | 52-128 | 48-260 |
| 18 | 1-383 | 5-686 | 57-170 | 40-606 |
| Binary Classification | Before ACO RF/NN | After ACO RF/NN |
|---|---|---|
| Organic and conventional vegetable discrimination | 92/88 | 100/100 |
| Literature Work for Organic and Conventional Discrimination | Type of Spectroscopy Employed | Methodology Employed | Fruits/Vegetables Tested | Accuracy Achieved |
|---|---|---|---|---|
| Lyu, C., et al. [7] | Mass spectroscopy | Random forest classifier | Chinese yam | 97.3% |
| Proposed work with 18-channel raw data | Multispectral sensor system | Binary classification Neural network/random forest classifier | Green chili, tomato and brinjal | 89%/92% |
| Proposed work with fuzzy feature generation and ant colony optimization algorithm | Multispectral sensor system | Binary classification Neural network/random forest classifier | Green chili, tomato and brinjal | 100% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Natarajan, S.; Ponnusamy, V. Classification of Organic and Conventional Vegetables Using Machine Learning: A Case Study of Brinjal, Chili and Tomato. Foods 2023, 12, 1168. https://doi.org/10.3390/foods12061168
Natarajan S, Ponnusamy V. Classification of Organic and Conventional Vegetables Using Machine Learning: A Case Study of Brinjal, Chili and Tomato. Foods. 2023; 12(6):1168. https://doi.org/10.3390/foods12061168
Chicago/Turabian StyleNatarajan, Sowmya, and Vijayakumar Ponnusamy. 2023. "Classification of Organic and Conventional Vegetables Using Machine Learning: A Case Study of Brinjal, Chili and Tomato" Foods 12, no. 6: 1168. https://doi.org/10.3390/foods12061168