
Observer-Based State Estimation for Recurrent Neural Networks: An Output-Predicting and LPV-Based Approach
Abstract
:1. Introduction
2. Problem Formulation
- (1)
- Lipschitz property: is -Lipschitz, i.e.,
- (2)
- Lipschitz property reformulated: for all , there exist functions and constants , such thatwith , where and .
3. Results
3.1. Single Observer
- Step 1: Fix the value of to constant and make an initial guess for .
- Step 2: Fix the value of , to some constants , and make an initial guess for the values of , .
- Step 3: Solve the LMI (12) for L with the fixed values , and ; if a feasible value of L cannot be computed, return to step 2 to reset the initial values of and ; if a feasible value of L can be computed, return to step 1 and increase the value of until L cannot be solved.
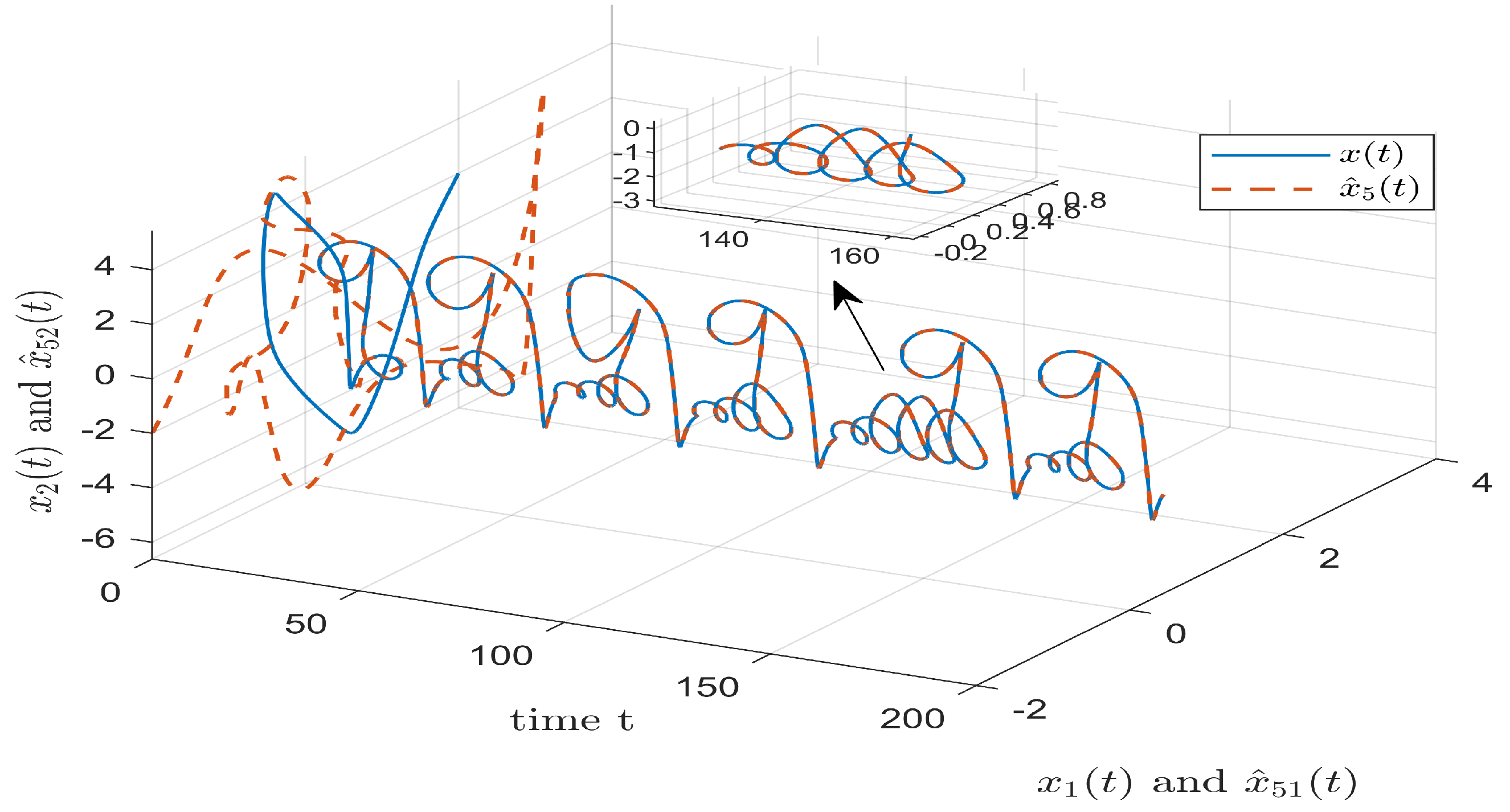
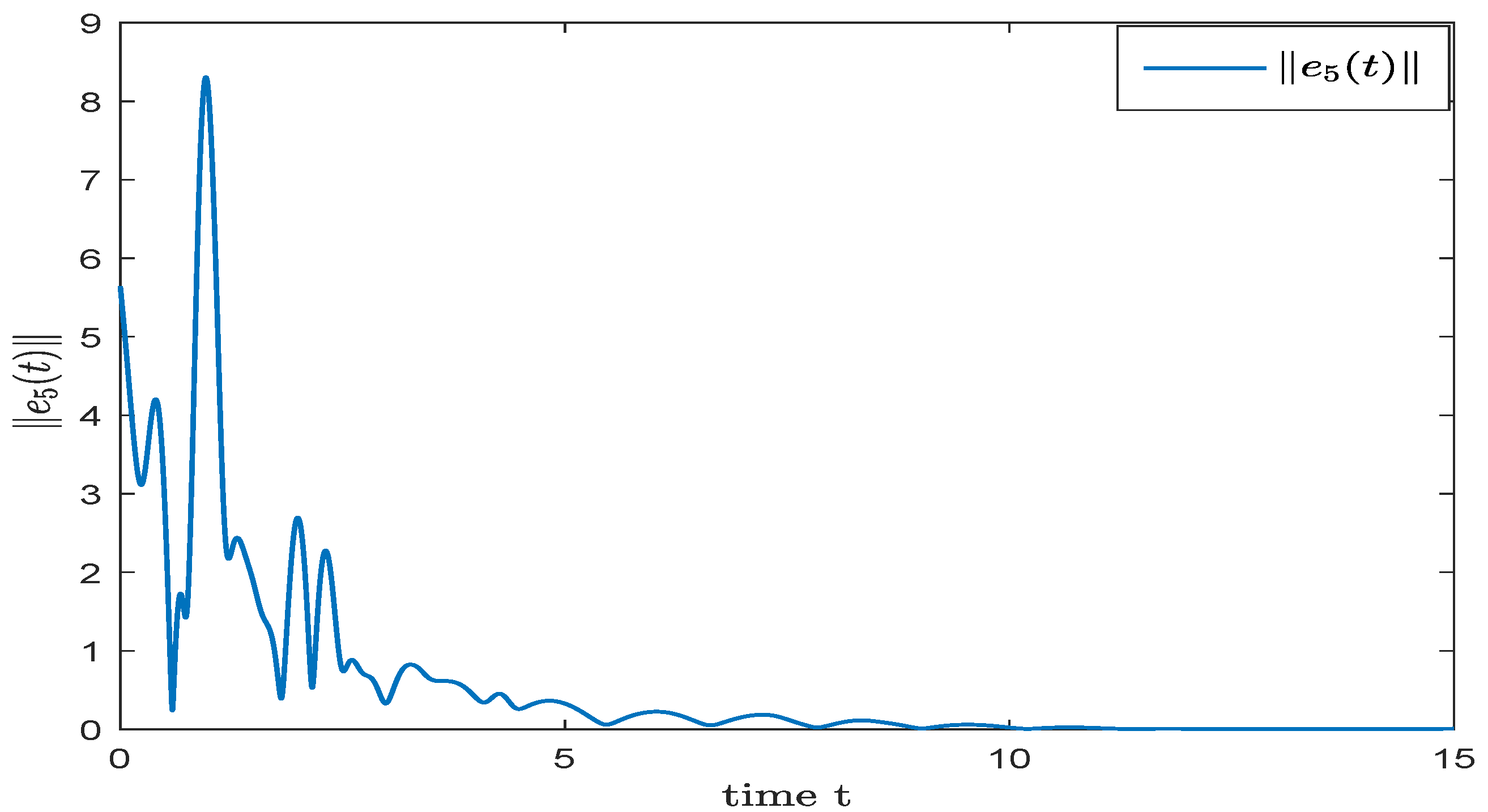
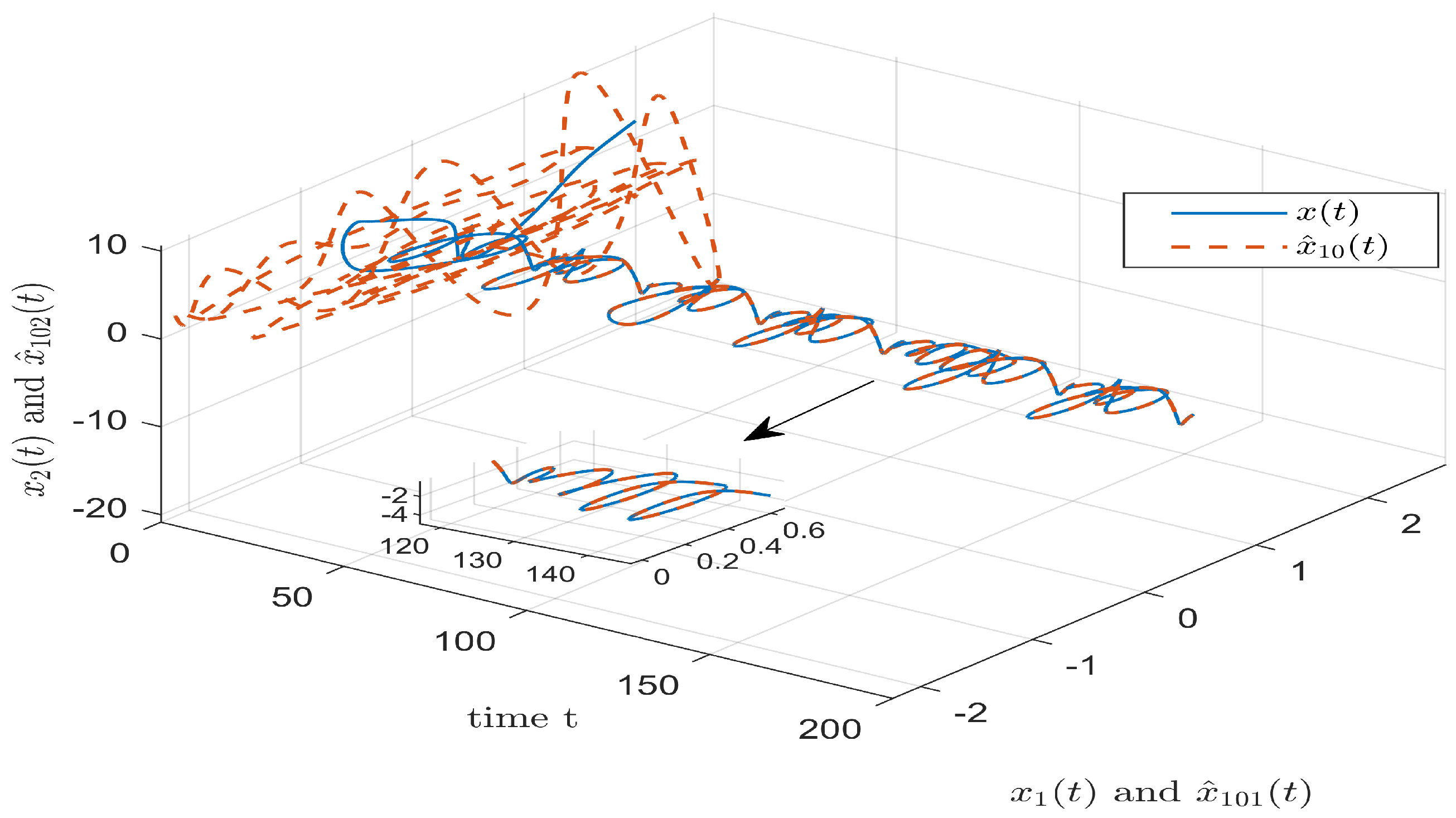
3.2. Cascade Predictor
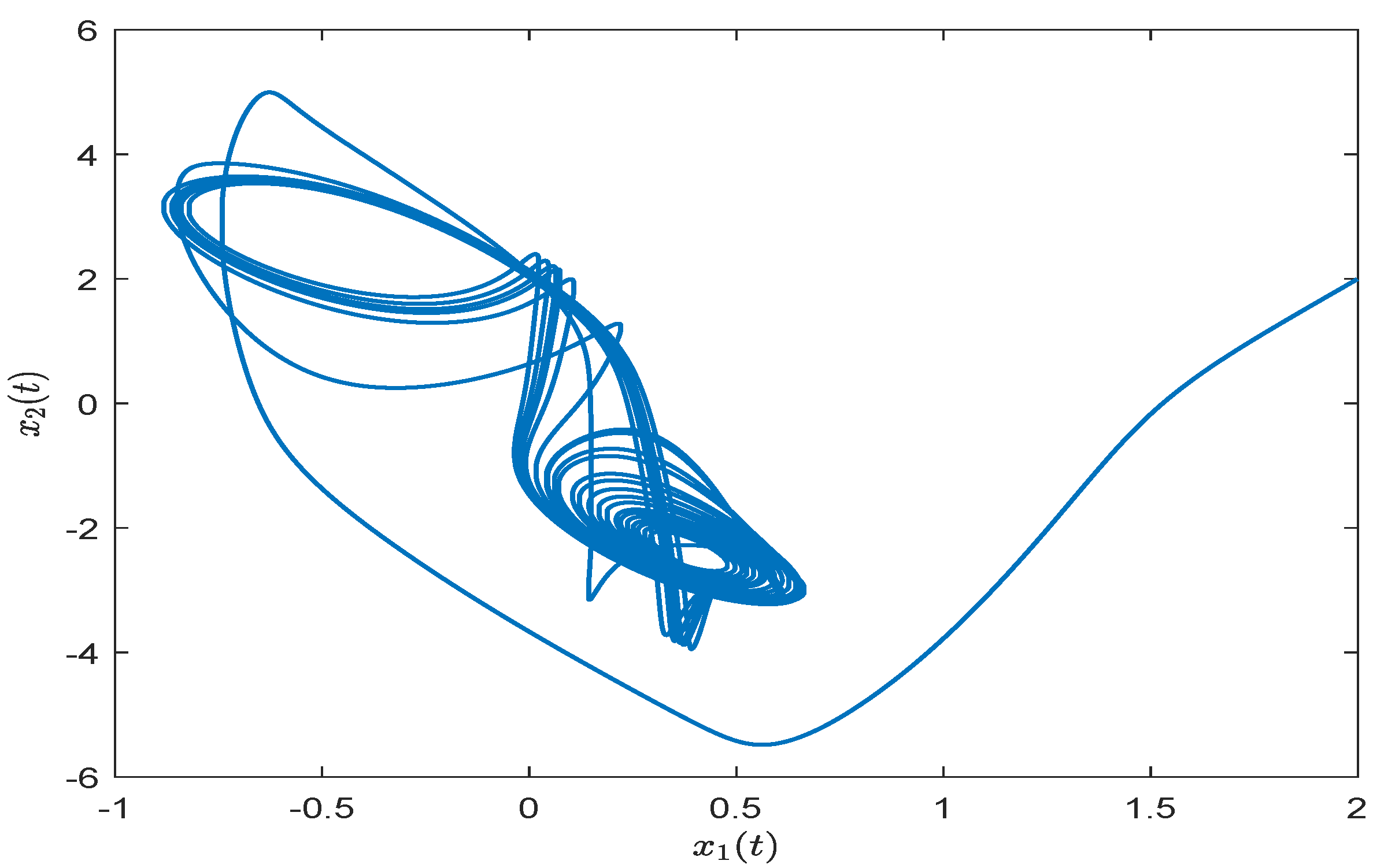
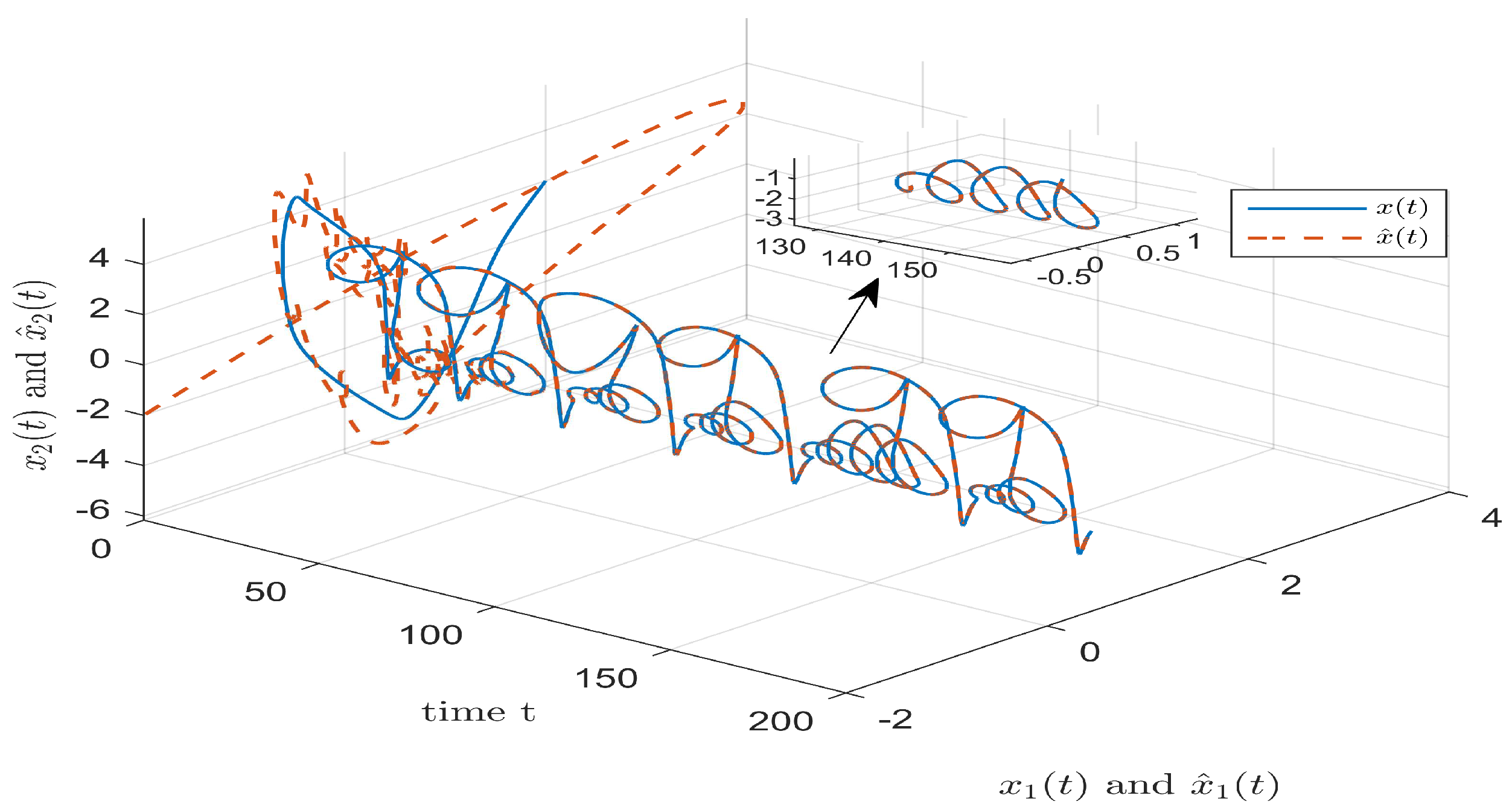
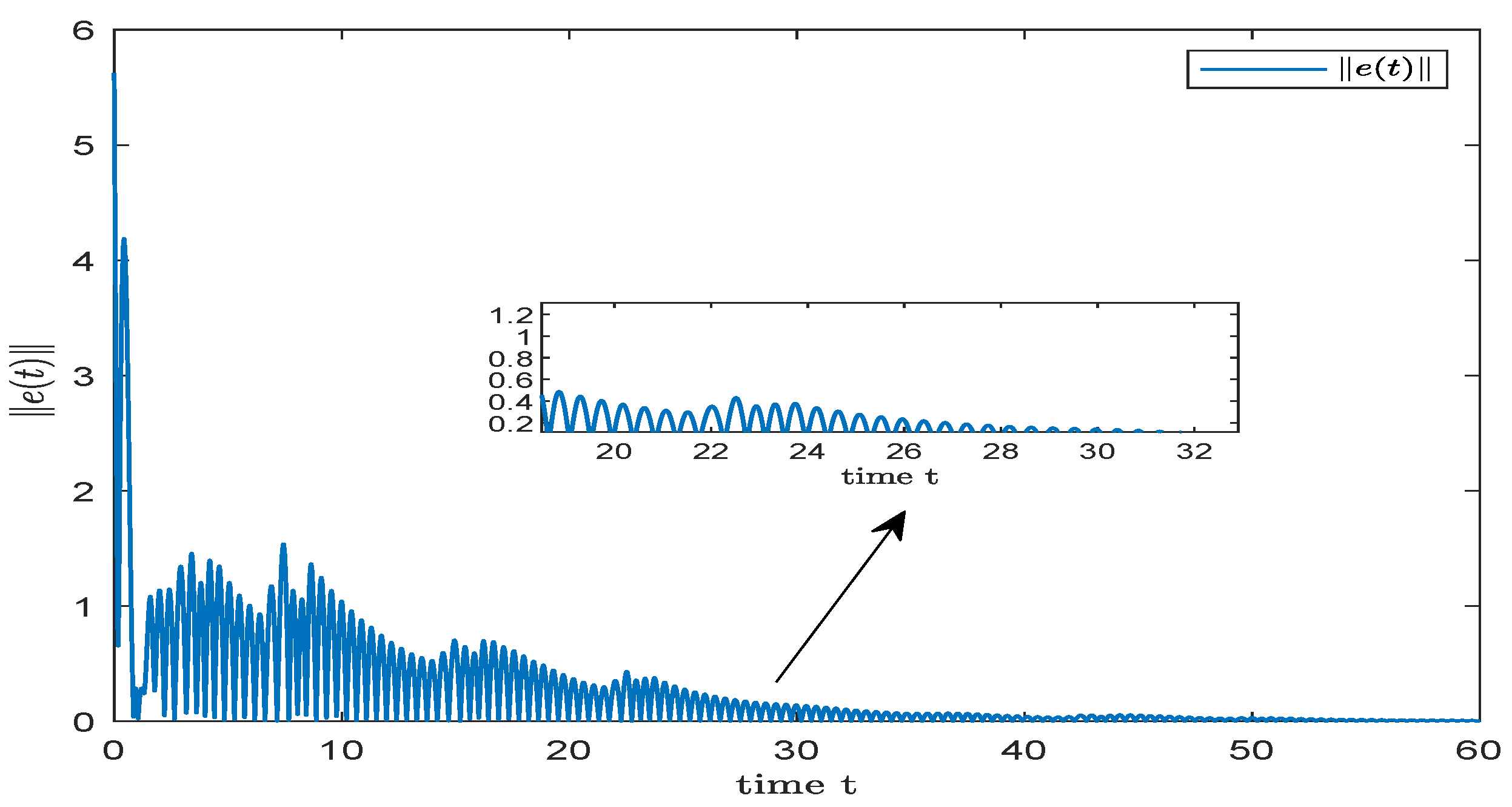
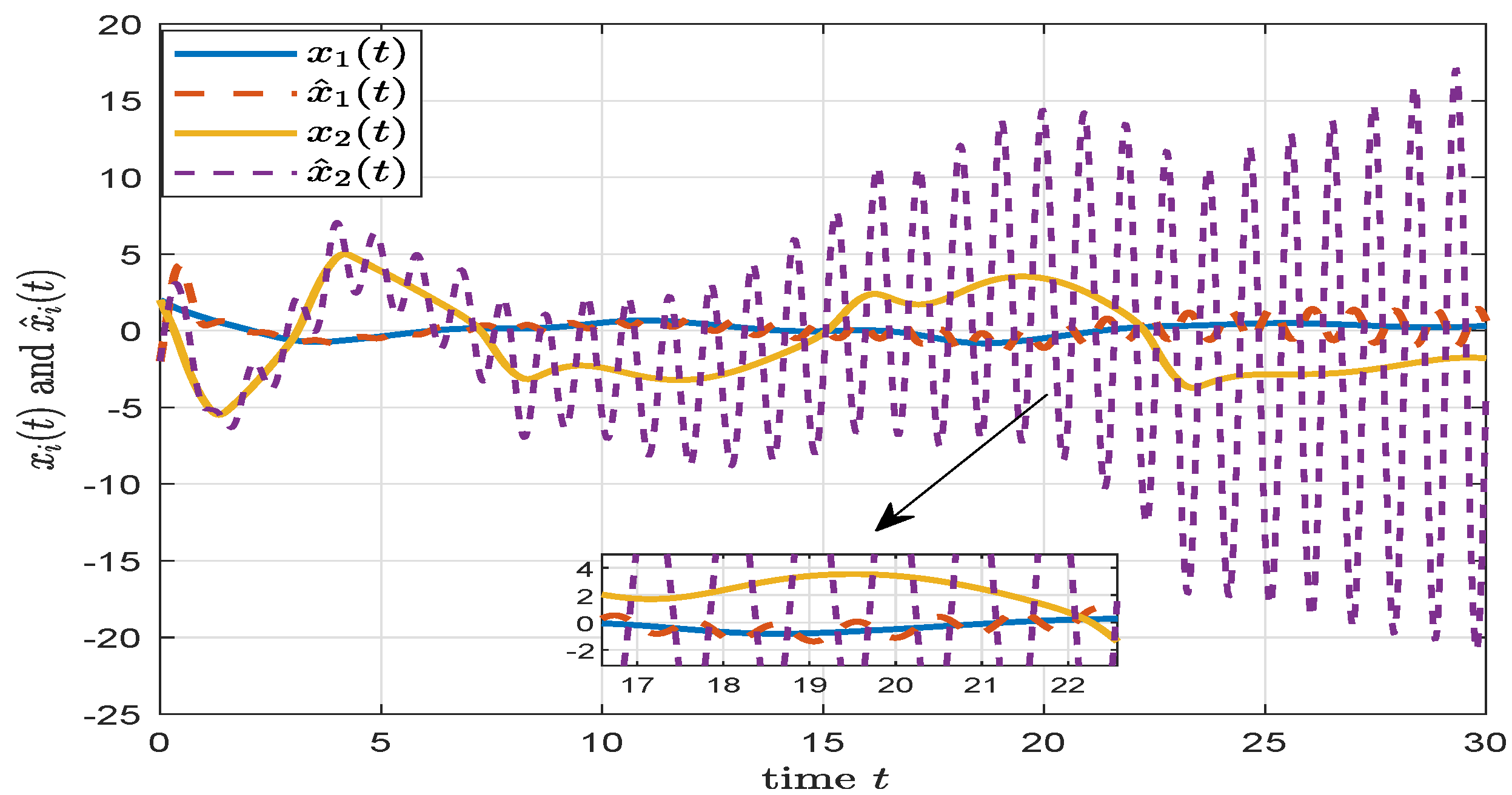
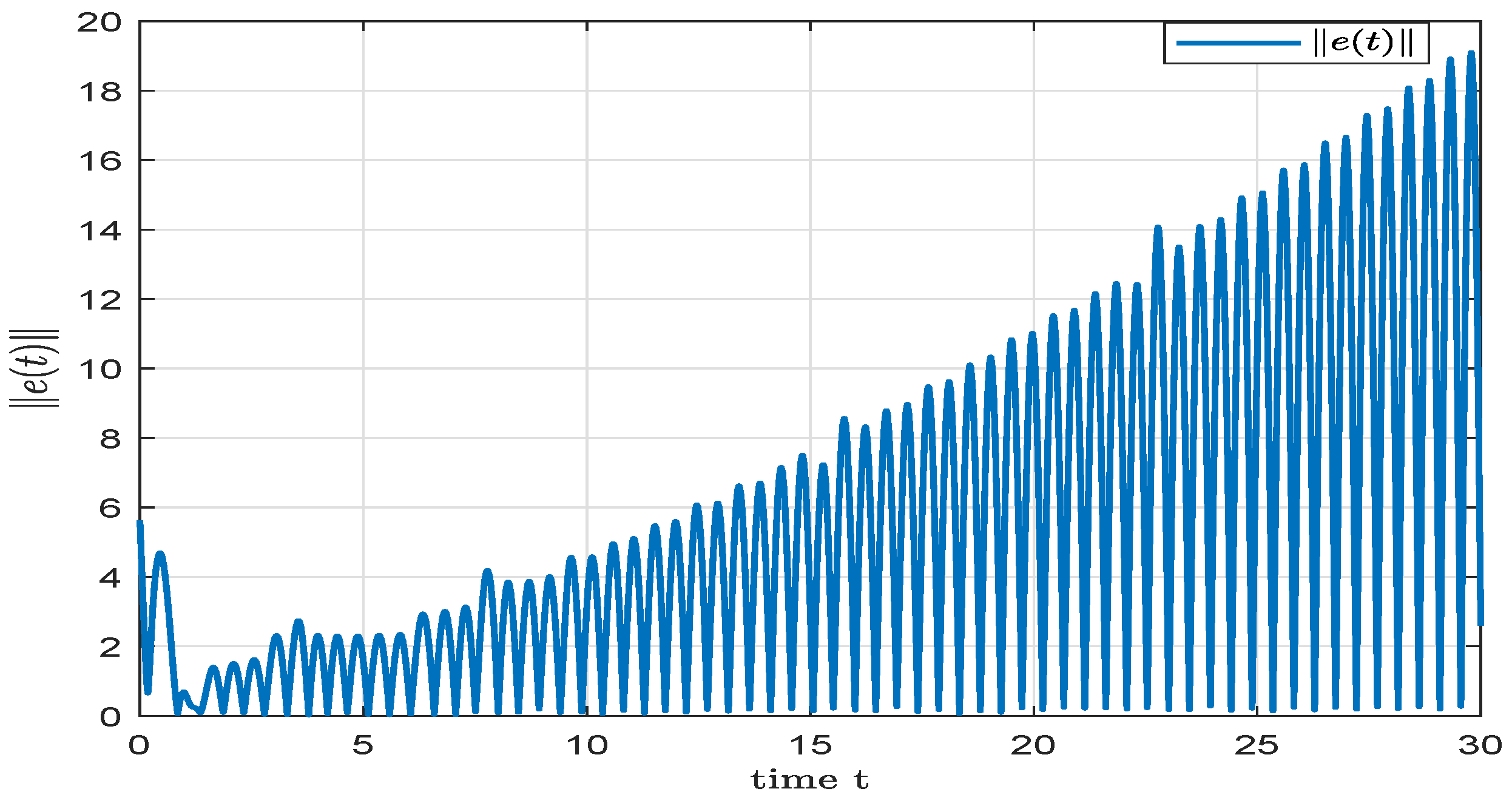
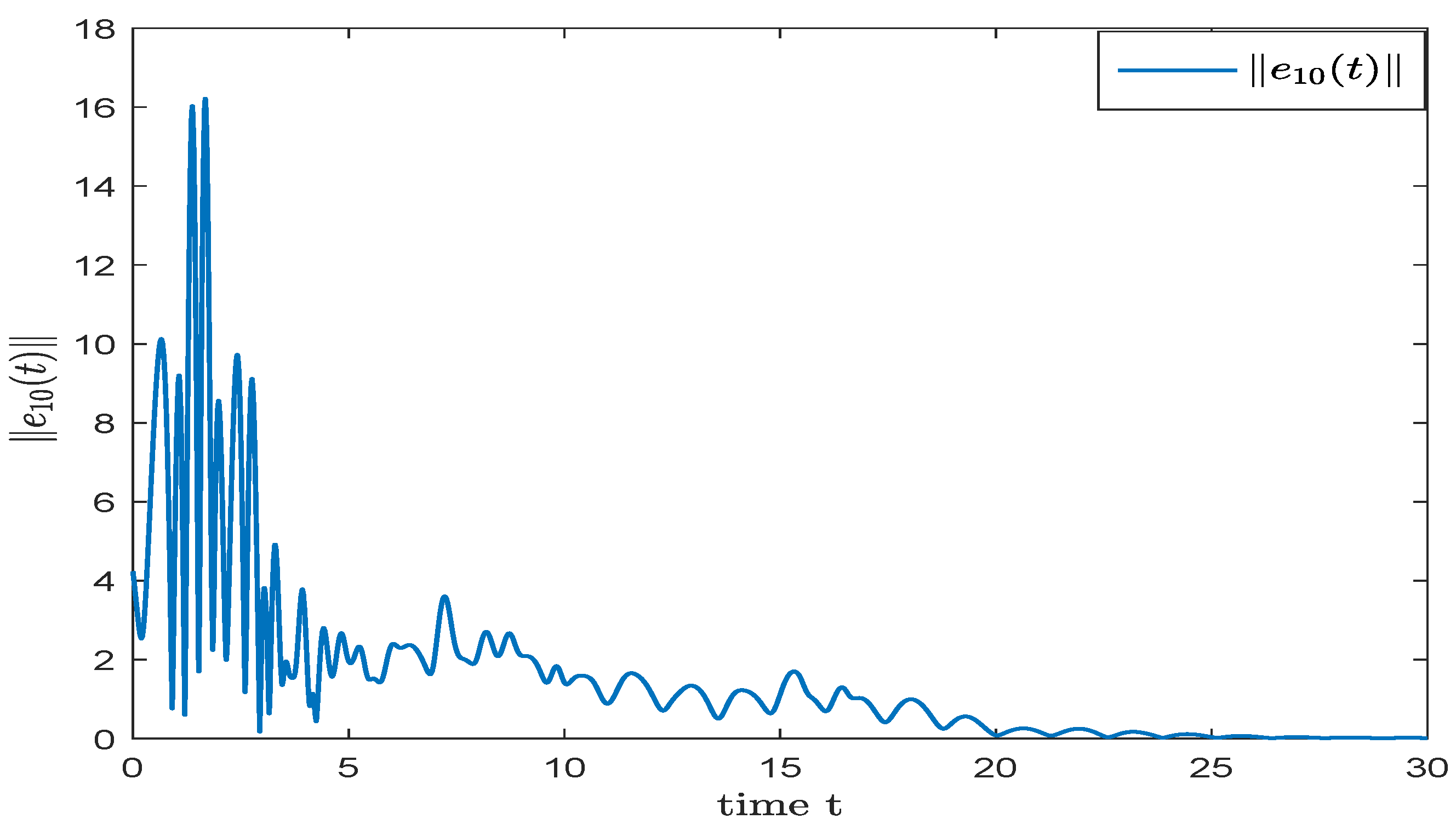
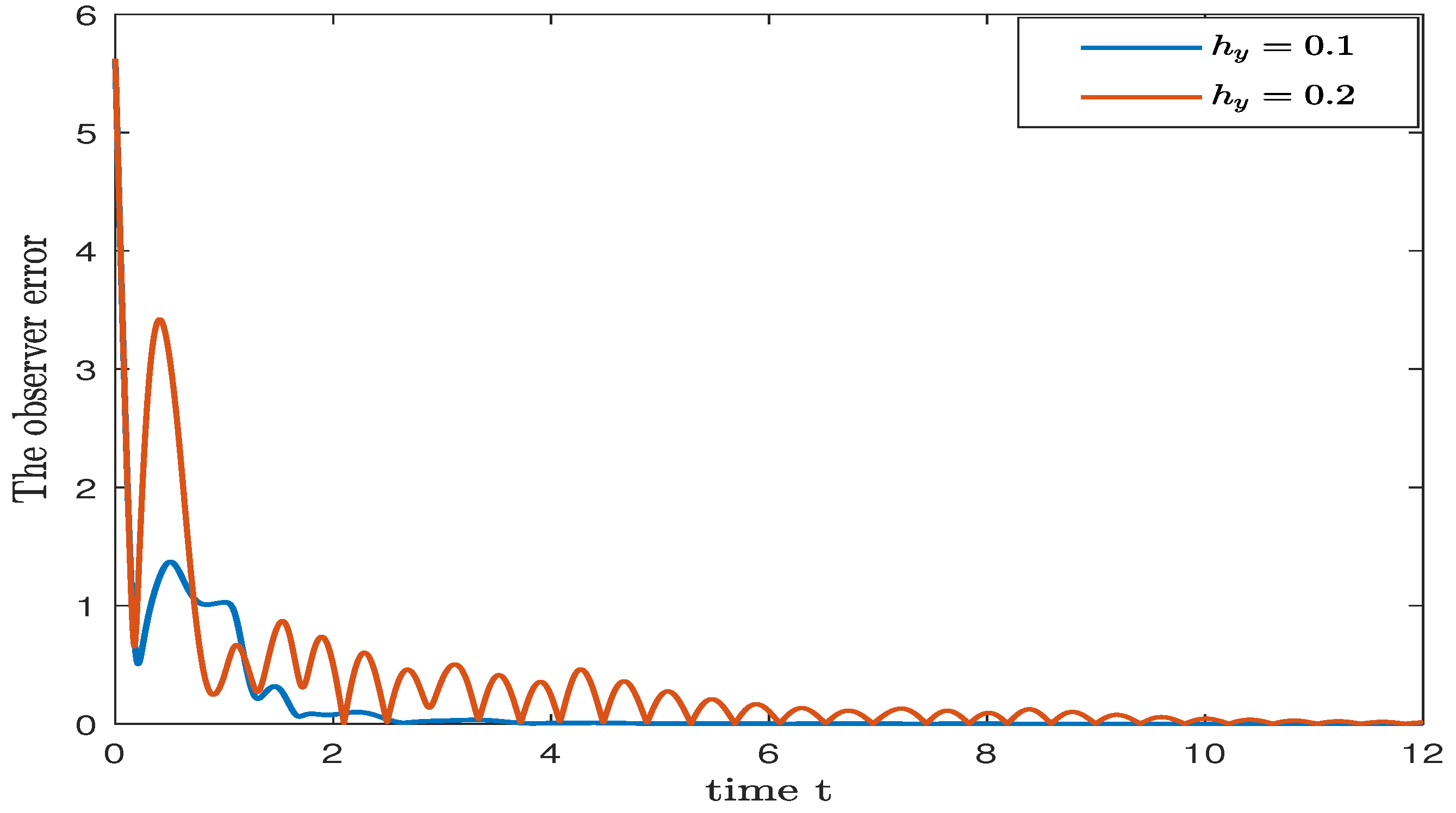
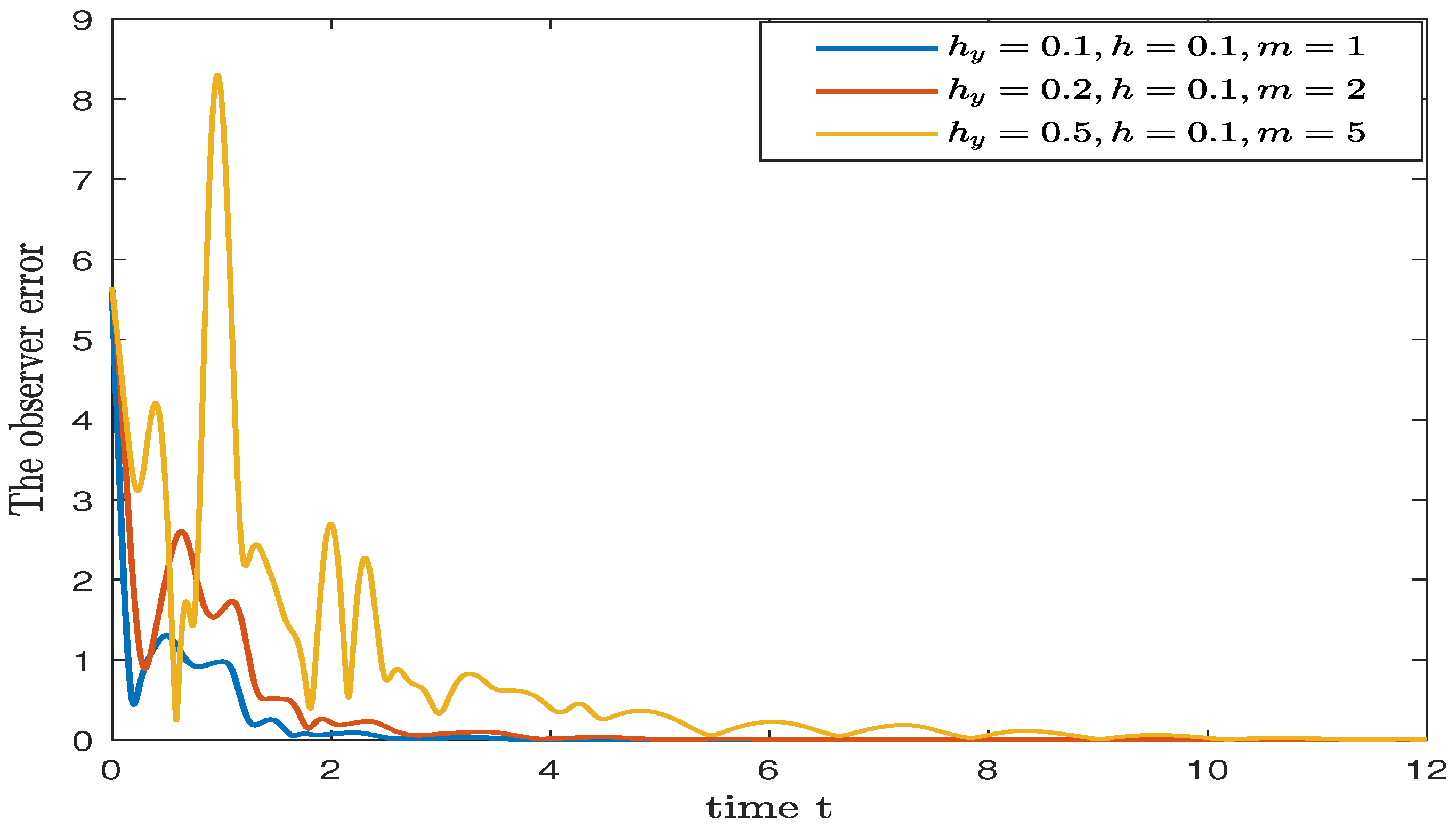
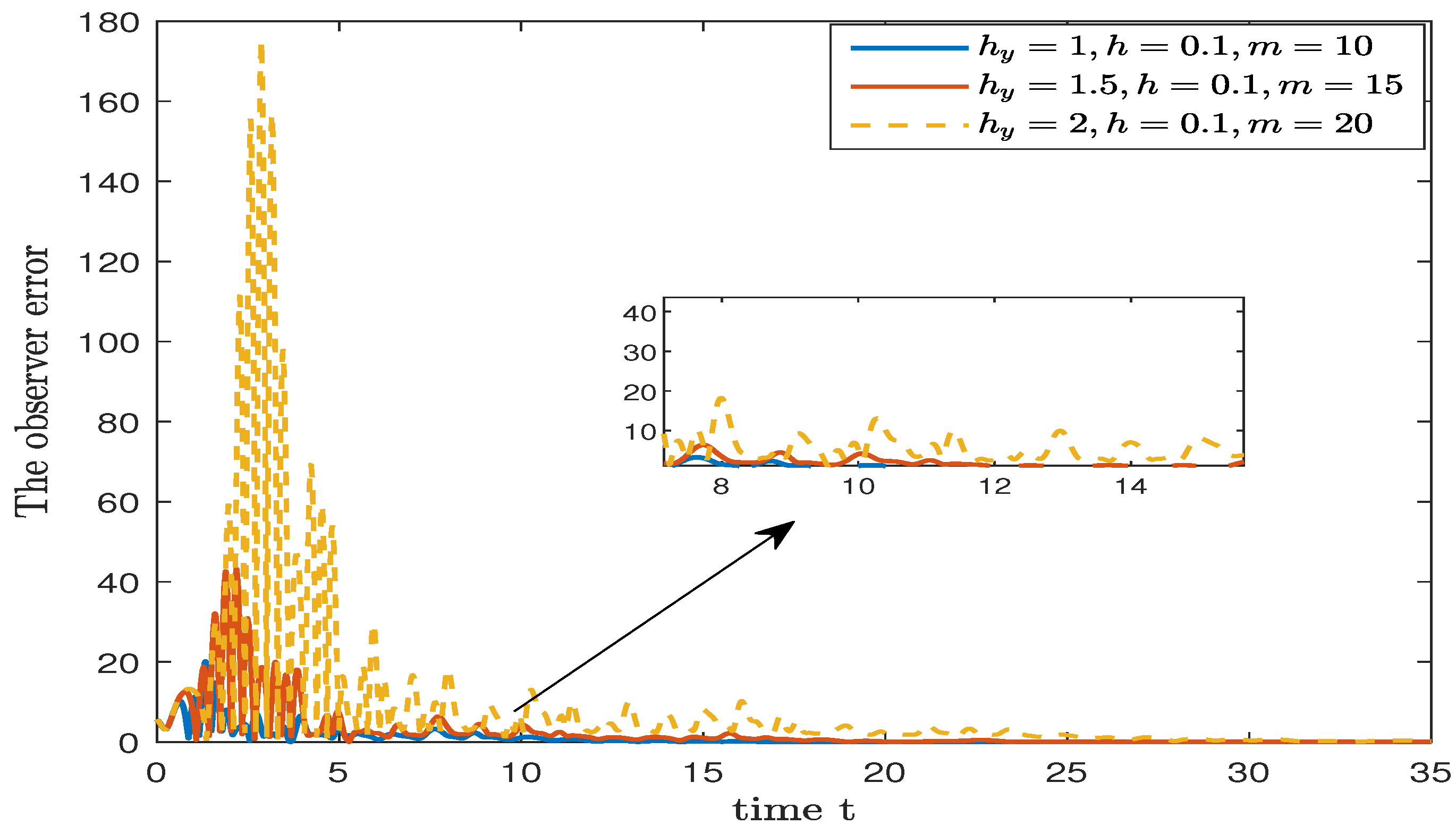
4. Numerical Simulation
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Chua, L.; Yang, L. Cellular neural networks: Application. IEEE Trans. Circuits Syst. 1998, 35, 1273–1290. [Google Scholar] [CrossRef]
- Cichocki, A.; Unbehauen, R. Neural Networks for Optimization and Signal Processing; Wiley: Chichester, UK, 1993. [Google Scholar]
- Joya, G.; Atencia, M.; Sandoval, F. Hopfield neural networks for optimization: Study of the different dynamics. Neurocomputing 2002, 43, 219–237. [Google Scholar] [CrossRef]
- Li, W.; Lee, T. Hopfield neural networks for affine invariant matching. IEEE Trans. Neural Netw. 2001, 12, 1400–1410. [Google Scholar] [CrossRef]
- Yong, S.; Scott, P.; Nasrabadi, N. Object recognition using multilayer Hopfield neural network. IEEE Trans. Image Process. 1997, 6, 357–372. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.; Liu, L.; Shan, Q.; Zhang, H. Stability criteria for recurrent neural networks with time-varying delay based on secondary delay partitioning method. IEEE Trans. Neural Netw. Learn. Syst. 2015, 26, 2589–2595. [Google Scholar] [CrossRef] [PubMed]
- Zhang, C.; He, Y.; Jiang, L.; Wu, M. Delay-dependent stability criteria for generalized neural networks with two delay components. IEEE Trans. Neural Netw. Learn. Syst. 2014, 25, 1263–1276. [Google Scholar] [CrossRef]
- Zhang, X.; Han, Q. Global asymptotic stability analysis for delayed neural networks using a matrix-based quadratic convex approach. Neural Netw. 2014, 54, 57–69. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.; Zhang, H.; Jiang, B. LMI-based approach for global asymptotic stability analysis of recurrent neural networks with various delays and structures. IEEE Trans. Neural Netw. 2011, 22, 1032–1045. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.J.; Lee, S.M.; Kwon, O.M.; Park, J.H. New approach to stability criteria for generalized neural networks with interval time-varying delays. Neurocomputing 2015, 149, 1544–1551. [Google Scholar] [CrossRef]
- Wu, Z.; Shi, P.; Su, H.; Chu, J. Delay-dependent stability analysis for switched neural networks with time-varying delay. IEEE Trans. Syst. Man Cybern. Part B (Cybern.) 2011, 41, 1522–1530. [Google Scholar] [CrossRef]
- Zhu, Q.; Cao, J. Stability of Markovian jump neural networks with impulse control and time varying delays. Nonlinear Anal. Real World Appl. 2012, 13, 2259–2270. [Google Scholar] [CrossRef]
- Wang, Z.; Ho, D.W.C.; Liu, X. State estimation for delayed neural networks. IEEE Trans. Neural Netw. 2005, 16, 279–284. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.; Liu, R.; Liu, Y. State estimation for jumping recurrent neural networks with discrete and distributed delays. Neural Netw. 2009, 22, 41–48. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.; Wang, J.; Wu, Y. State estimation for recurrent neural networks with unknown delays: A robust analysis approach. Neurocomputing 2017, 227, 29–36. [Google Scholar] [CrossRef]
- Huang, H.; Feng, G.; Cao, J. Robust state estimation for uncertain neural networks with time-varying delay. IEEE Trans. Neural Netw. 2008, 19, 1329–1339. [Google Scholar] [CrossRef]
- Huang, H.; Feng, G.; Cao, J. State estimation for static neural networks with time-varying delay. Neural Netw. 2010, 23, 1202–1207. [Google Scholar] [CrossRef]
- Ren, J.; Zhu, H.; Zhong, S.; Ding, Y.; Shi, K. State estimation for neural networks with multiple time delays. Neurocomputing 2015, 151, 501–510. [Google Scholar] [CrossRef]
- Liu, M.; Chen, H. H∞ state estimation for discrete-time delayed systems of the neural network type with multiple missing measurements. IEEE Trans. Neural Netw. Learn. Syst. 2015, 26, 2987–2998. [Google Scholar] [CrossRef]
- Guo, M.; Zhu, S.; Liu, X. Observer-based state estimation for memristive neural networks with time-varying delay. Knowl.-Based Syst. 2022, 246, 108707. [Google Scholar] [CrossRef]
- Beintema, G.I.; Schoukens, M.; Toth, R. Deep subspace encoders for nonlinear system identification. Automatica 2023, 156, 111210. [Google Scholar] [CrossRef]
- Germani, A.; Manes, C.; Pepe, P. A new approach to state observation of nonlinear systems with delayed output. IEEE Trans. Autom. Control 2002, 47, 96–101. [Google Scholar] [CrossRef]
- Ahmed-Ali, T.; Cherrier, E.; Lamnabhi-Lagarrigue, F. Cascade high gain predictors for a class of nonlinear systems. IEEE Trans. Autom. Control 2012, 57, 224–229. [Google Scholar] [CrossRef]
- Farza, M.; M’Saad, M.; Menard, T.; Fall, M.L.; Gehan, O.; Pigeon, E. Simple cascade observer for a class of nonlinear systems with long output delays. IEEE Trans. Autom. Control 2015, 60, 3338–3343. [Google Scholar] [CrossRef]
- Farza, M.; Hernandez-Gonzalez, O.; Menard, T.; Targui, B.; M’Saad, M.; Astorga-Zaragoza, C.M. Cascade observer design for a class of uncertain nonlinear systems with delayed outputs. Automatica 2018, 89, 125–134. [Google Scholar] [CrossRef]
- Zemouche, A.; Boutayeb, M. On LMI conditions to design observers for Lipschitz nonlinear systems. Automatica 2013, 49, 585–591. [Google Scholar] [CrossRef]
- Adil, A.; Hamaz, A.; N’Doye, I.; Zemouche, A.; Laleg-Kirati, T.M.; Bedouhene, F. On high-gain observer design for nonlinear systems with delayed output measurements. Automatica 2022, 141, 11281. [Google Scholar] [CrossRef]
- Huang, H.; Huang, T.; Chen, X.; Qian, C. Exponential stabilization of delayed recurrent neural networks: A state estimation based approach. Neural Netw. 2013, 48, 153–157. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Z.; He, Y.; Zhang, C.; Wu, M. Exponential stabilization of neural networks with time-varying delay by periodically intermittent control. Neurocomputing 2016, 207, 469–475. [Google Scholar] [CrossRef]
- Huang, H.; Feng, G. Delay-dependent h∞ and generalized h2 filtering for delayed neural networks. IEEE Trans. Circuits Syst. Regul. Pap. 2009, 56, 846–857. [Google Scholar] [CrossRef]
- Gonzalez, A. Improved results on stability analysis of time-varying delay systems via delay partitioning method and Finsler’s lemma. J. Frankl. Inst. 2022, 359, 7632–7649. [Google Scholar] [CrossRef]
- Moon, Y.S.; Park, P.; Kwon, W.H.; Lee, Y.S. Delay-dependent robust stabilization of uncertain state-delayed systems. Int. J. Control 2001, 74, 1447–1455. [Google Scholar] [CrossRef]
- Gu, K.L.; Kharitonov, V.; Chen, J. Stability of Time-Delay Systems; Springer: Berlin, Germany, 2003. [Google Scholar]
- Body, S.; Ghaoui, L.E.; Feron, E.; Balakrishnan, V. Linear Matrix Inequalities in System and Control Theory; SIAM: Philadelphia, PA, USA, 1994. [Google Scholar]
- Khalil, H.K. Nonlinear Systems; Prentice-Hall: Englewood Cliffs, NJ, USA, 2002. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Predictor∖ | |||||||
|---|---|---|---|---|---|---|---|
| Convergence time | Simple observer | 1.6 | 8.5 | * | * | * | * |
| Cascade predictor | 1.8 (m = 1) | 3.6 (m = 2) | 9.1 (m = 5) | 16.3 (m = 10) | 27.4 (m = 15) | 31.5 (m = 20) | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, W.; Chen, J.; Huang, Z. Observer-Based State Estimation for Recurrent Neural Networks: An Output-Predicting and LPV-Based Approach. Math. Comput. Appl. 2023, 28, 104. https://doi.org/10.3390/mca28060104
Wang W, Chen J, Huang Z. Observer-Based State Estimation for Recurrent Neural Networks: An Output-Predicting and LPV-Based Approach. Mathematical and Computational Applications. 2023; 28(6):104. https://doi.org/10.3390/mca28060104
Chicago/Turabian StyleWang, Wanlin, Jinxiong Chen, and Zhenkun Huang. 2023. "Observer-Based State Estimation for Recurrent Neural Networks: An Output-Predicting and LPV-Based Approach" Mathematical and Computational Applications 28, no. 6: 104. https://doi.org/10.3390/mca28060104