1. Introduction
Alzheimer’s disease (AD) is a progressive neurodegenerative disorder associated with cognitive decline and is the most common form of dementia [
1]. In a social context of progressive aging in Western countries, and estimations of the population affected by AD being above tens of millions worldwide, expected to quadruple over the next coming decades, it becomes a serious and major public health concern due to its increasing prevalence, chronicity, caregiver burden, and the high personal and financial costs of care [
2]. Moreover, there are currently no treatments for AD that have been proven effective [
3], and consequently, there is an urgent need to develop new strategies for the management of this new pandemic [
1]. On the other hand, in recent years, several trials have demonstrated the efficacy of new treatments for AD in a well-selected subset of patients [
4]. In such a scenario, precise phenotyping for identifying such patients plays a crucial role. This points directly to the AD phenotyping problem that could provide robust mechanisms for the identification of potential patients who could take advantage of those new treatments. Recent advances in methodologies for data characterization have introduced the data-driven phenotyping of AD and related dementias [
4]. Such a computational approach is automated and non-biased, high-throughput, and can handle vast amounts of noisy healthcare data [
5,
6,
7]. Phenotyping has been widely used in genetic studies, but in recent years, the concept has been extended to wider sources of data [
8].
During the last decades, an increasing number of studies have confirmed epigenetic changes in AD, and although it is not clear whether these epigenetic changes are the cause or result of AD, they pave the way for new medical research worldwide [
9]. Consequently, a robust phenotyping mechanism must take into consideration the environmental effects on the patient during the process. At the same time, extensive evidence has been produced that indicates that the pathological signs of AD may be amyloid plaques and neurofibrillary tangles [
10], even if the underlying disease mechanism remains unknown. Imaging the brain for AD characterization has been applied extensively. The most employed technique for imaging the amyloid plaques is based on a combination of Positron Emission Tomography (PET) and Magnetic Resonance Imaging (MRI) [
10]. These point directly to the purpose of this work: to set up a methodological pipeline to obtain AD phenotypes using hyperparameter optimization for the different components involved in the pipelines for the PET imaging of amyloid-β (Aβ) plaques using Partial Volume Correction (PVC) and manifold learning.
Tracers such as [11C] PiB, [18F-AV45] Florbetapir, and [18F] AV-4517 are used to quantify in vivo fibrillar Aβ decomposition, one of the main indicators of AD pathology [
10]. The low spatial resolution of PET images reduces the indicator efficiency [
11]. This resolution ranges from 5 to 6 mm [
12] and it is quantified as Full Width at Half Maximum (FWHM). Due to this low resolution, the intensity of a particular voxel also reflects the tracer concentration of the surrounding area, not only the analyzed tissue area, complicating, even more, the quantification of Aβ plaque decomposition. In order to overcome the mentioned inconveniences of PET, due to low resolution and noise, the PET study must be merged with an MRI as a source of information that provides the anatomical information that is missed. Raw PET image-based quantification provides an inaccurate representation of Aβ deposition without adequate Partial Volume Correction (PVC), but there is no consensus regarding the correction processing pipeline to use [
13]. In addition to PET studies, MRI has also been extensively employed to assess AD. Even if MRI usage is limited by factors such as imaging hardware, scanning time, and costs, this imaging modality plays an important role in clinical and brain exploration [
14]. Previous works have discussed its role in cognitive impairment assessment from different approaches, such as using functional MRI, acquiring high-resolution MRI images clinically using super-resolution [
15], or how brain MRI to PET synthesis can improve AD diagnosis. In this paper, T1-weighted Magnetic Resonance Imaging (MRI—T1W) studies are employed to build a brain atlas for each patient.
At the same time, during the last decades, the scientific community has witnessed the emergence of artificial intelligence as an invaluable technique and tool to support research [
16]. Within this broad field, manifold learning has emerged as a disciple that permits one to reduce the magnitude of data. Manifold learning can be thought of as an attempt to generalize linear frameworks such as Principal Component Analysis (PCA) and Linear Discriminant Analysis (LDA) to be sensitive to non-linear structures in data [
17]. Many machine learning methods rely on the implicit assumption that data has some inherent structure. Manifold learning assumes that the observed data are found in a low-dimensional manifold embedded in a higher-dimensional space [
17]. This assumption states that the shape of the concerned data is relatively simple.
During the last years, a lot of epidemiological research [
18] has been suggesting that the simultaneous interactions of different lifestyle habits and environmental factors with Apolipoprotein E (APOE) alleles affect the risk of AD development. In the list of suggested epigenetic conditions repeated in the studies, the practice of physical exercise, nutritional habits, with a special focus on fat intake and ketogenic diets, coffee consumption, alcohol intake, education level, traumatic brain injury, cigarette smoking, and exposure to sunlight and pesticides have been gaining increasing attention. Even if the current level of evidence shows that younger APOE4 carriers in early stages would derive more benefit from preventive lifestyle interventions than older APOE4 noncarriers in later stages of dementia who may show the most pronounced effects, it is not robust. The current weak evidence or inconsistency could be caused by some confounding factors, such as sample sizes, the methodology used, and the demographic characteristics of the participants, including age and gender, potential related exposures, and comorbidities.
In this paper, a new methodology to identify AD phenotypes by selecting the best phenotyping pipeline (a combination of PVC techniques for feature selection on PET images and manifold learning for dimensionality reduction) under several epidemiological conditions, is presented.
Section 2 presents the required background for the work, namely PVC methods, the dataset, the manifold learning approaches, the k-means clustering algorithm, and the set of software packages.
Section 3 presents the proposed methodology. The results of applying the methodology to a cohort of patients derived from the OASIS-3 dataset are provided in
Section 4. The discussion and conclusion are provided in the final section.
3. Method
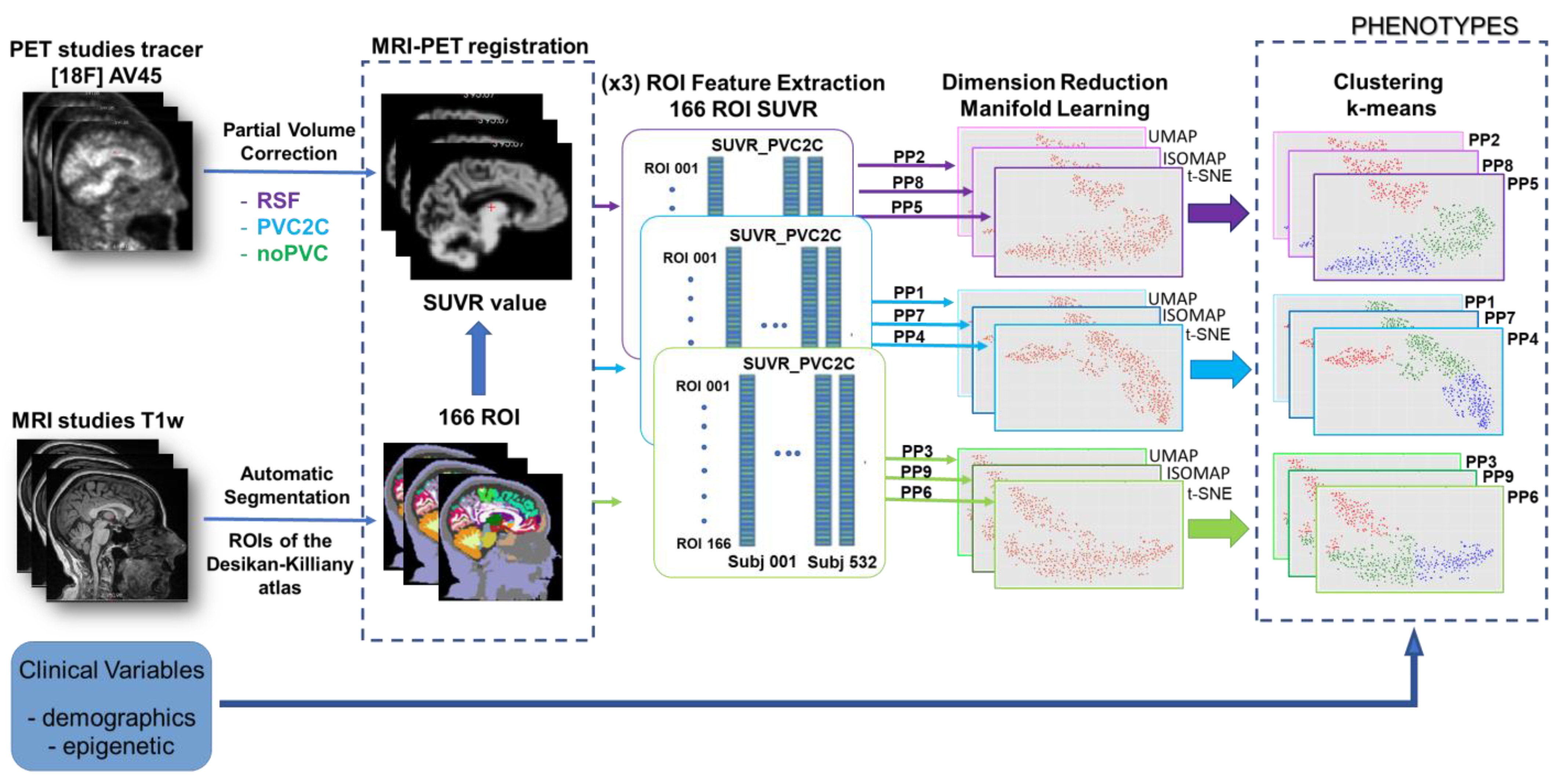
This paper presents a new methodology for the identification of AD phenotypes by analyzing the PET images of AD patients under epigenetic conditions. The method is based on the integration of two main parts, in a single phenotyping pipeline (PPi), and its optimization. Pipelines include a combination of several PVC approaches for extracting SUVR features from PET images and several manifold learning approaches for dimensionality reduction. The overall schema of the method is provided in
Figure 2, which presents those main blocks.
The first part deals with the obtention of different PET-corrected studies. In our case, we propose to use three different methods, namely RSF, PVC2C, and noPVC (not applying PVC), all described in
Section 2.2, and the extraction of regional features from the corrected images using the MRI-derived Desikan–Killiany atlas. This part is carefully described in
Section 3.1. After PVC, PET images are processed to extract the set of features (SUVR values for each Region of Interest (ROI)), producing information that will be provided to the next block of manifold learning in the second part of the pipeline. That part will produce a nonlinear reduction in dimensionality, using three different state-of-the-art methods, namely t-SNE, UMAP, and ISOMAP (all described above, in
Section 2.3). This process will be better described in
Section 3.2. Finally, all the results generated by the different phenotyping pipelines will be gathered on a common evaluation table by using the k-means algorithm, which permits us to merge the outputs in a unified way, and consequently compare the results from the mix of different combined approaches, providing the best set of clusters, identified as phenotypes.
To simplify the method explanation, PPi-s are named PP1 (combining PVC2C and UMAP), PP2 (combining RSF and UMAP), PP3 (combining noPVC and UMAP), PP4 (combining PVC2C and t-SNE), PP5 (combining RSF and t-SNE), PP6 (combining noPVC and t-SNE), PP7 (combining PVC2C and ISOMAP); PP8 (combining RSF and ISOMAP), and PP9 (combining noPVC and ISOMAP).
3.1. Obtention of Imaging Derived Features after PVC
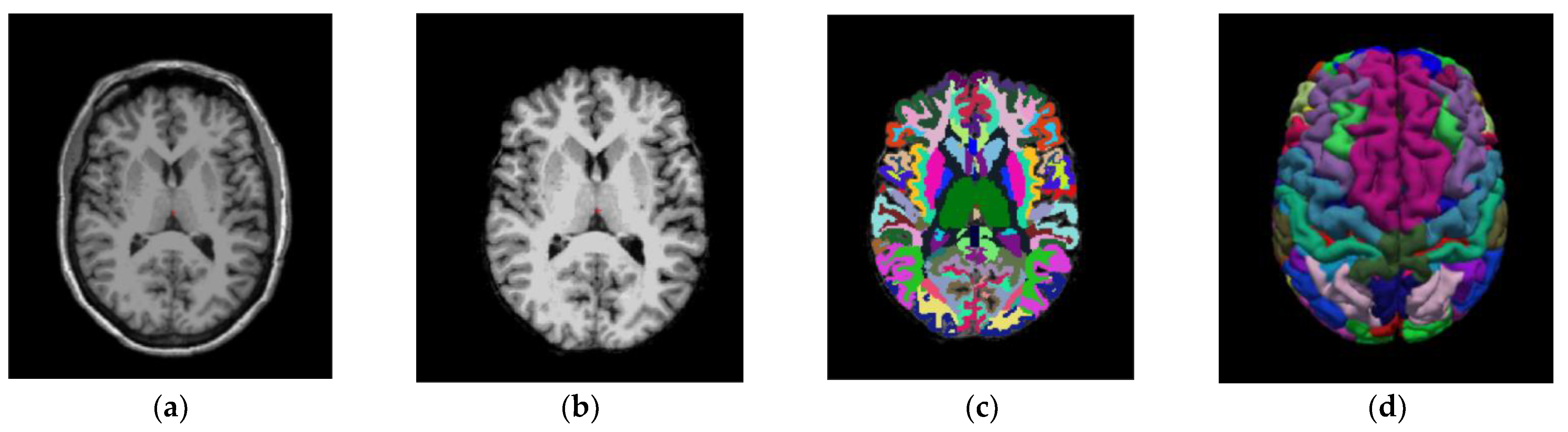
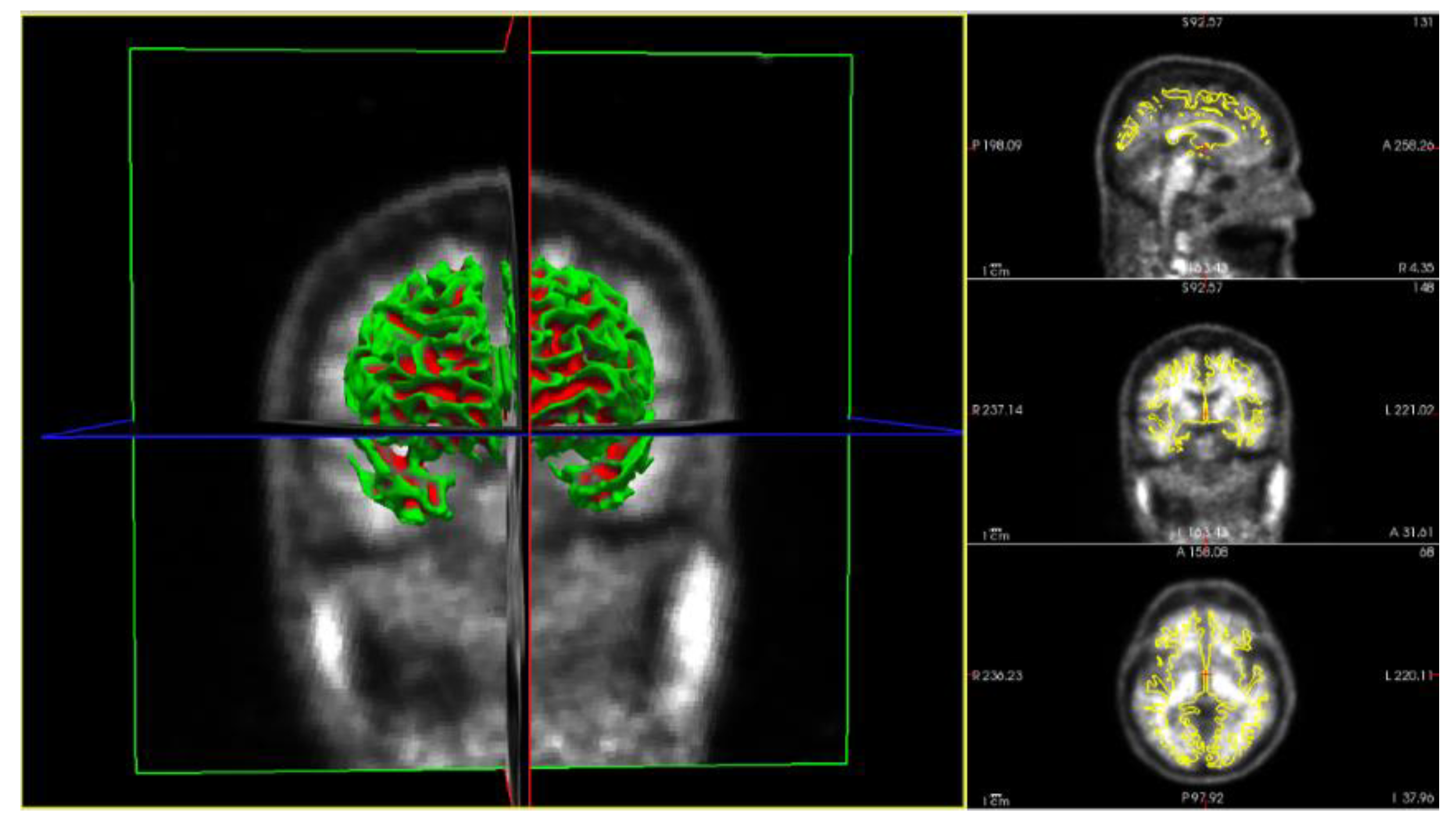
This part of the method deals with the obtention of the different SUVR values, obtained for all ROIs in the images by applying several PVC methods. The imaging pipeline has a double path, one for processing the PET studies and another for the MRI studies. The MRI path is devoted to obtaining the ROI to compute the SUVR values on the PET after PVC correction. For this purpose, the Desikan–Killiany atlas [
35] was employed,
Figure 3 shows the different stages of the MRI process [
32]. The atlas color labels [
35] are shown in
Figure 3c,d.
In the other imaging path, PET images are corrected to achieve a common spatial resolution of 8 mm to minimize inter-scanner differences [
36]. Even if the methodology is general and several methods could be considered, this work employs three of them. The first method is the PVC2C approach [
37,
38], which is the most widely represented in the amyloid imaging literature. The second method is based on the calculation of the RSF [
23,
39], which has also been widely applied in PET image analysis. The third approach is based on not applying PVC to the PET study, as in the literature there is no consensus regarding whether PVC is necessary or not for quantitative PET analysis [
10,
13].
Figure 4 shows the differences that PVC methods introduce in the PET image studies.
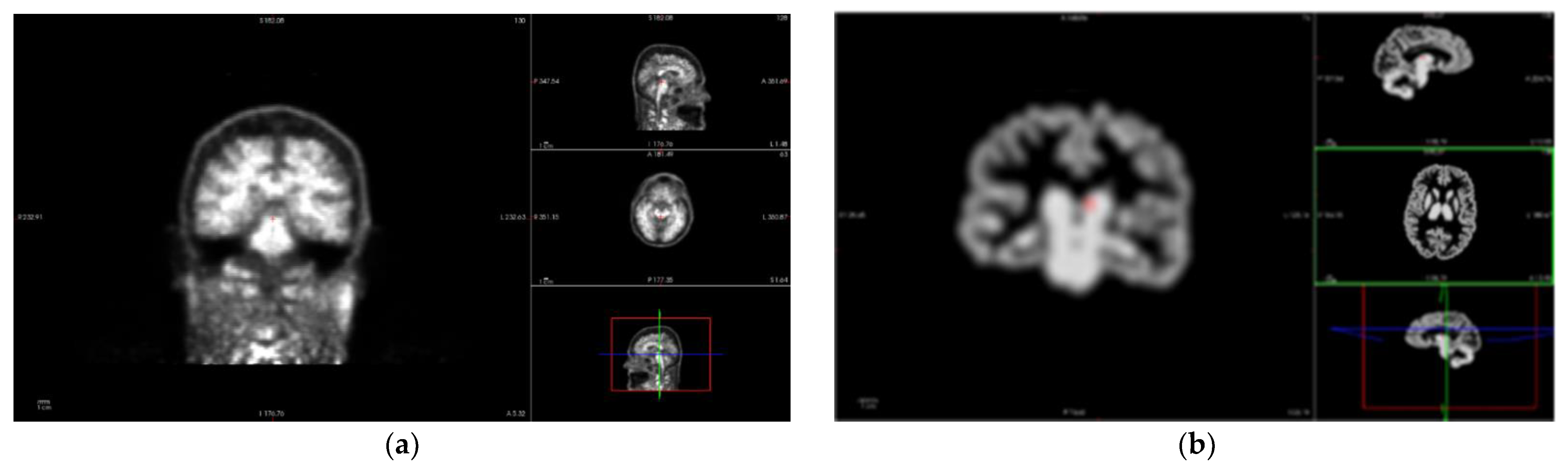
The vector–gradient algorithm [
40] is used for symmetrical PET-MR registration. This method consists of an average transformation for PET > MR, and the inverse of MR > PET was used as the final transformation matrix. The Freesurfer software provides regional PET segmentation using wmparc.mgz for the definition of the regions.
Figure 5 shows the result of the analyzed region. This method generates two reports: regional measurements and SUVR images.
The output of this stage is an array of 166 SUVR values. This array of values can be obtained for each patient study and for each correction method. This huge amount of data requires an approach to reduce the dimensionality and make it affordable to manage.
3.2. Obtention of Manifold Derived Clusters
The second stage of the pipeline is devoted to reducing the dataset dimensions and merging it into the optimal set of clusters. It has two main parts. The first part of the process deals with dimension reduction using the manifold methods. Those methods, as explained above in
Section 2.3, use an implicit parameter (
D), which is the final dimension of the dataset in the manifold.
D has usually a very low value, and is much lower than the original dimension; in this work, the value of
D will be determined heuristically, selecting the lowest value that permits us to construct the pipelines while maximizing the silhouette coefficient. The whole dataset of images is processed using each pipeline. After reducing the dimensionality of data, in the second part of this stage, data will be clustered to identify the phenotypes using k-means. k-means uses an implicit variable of the number of clusters to be identified (
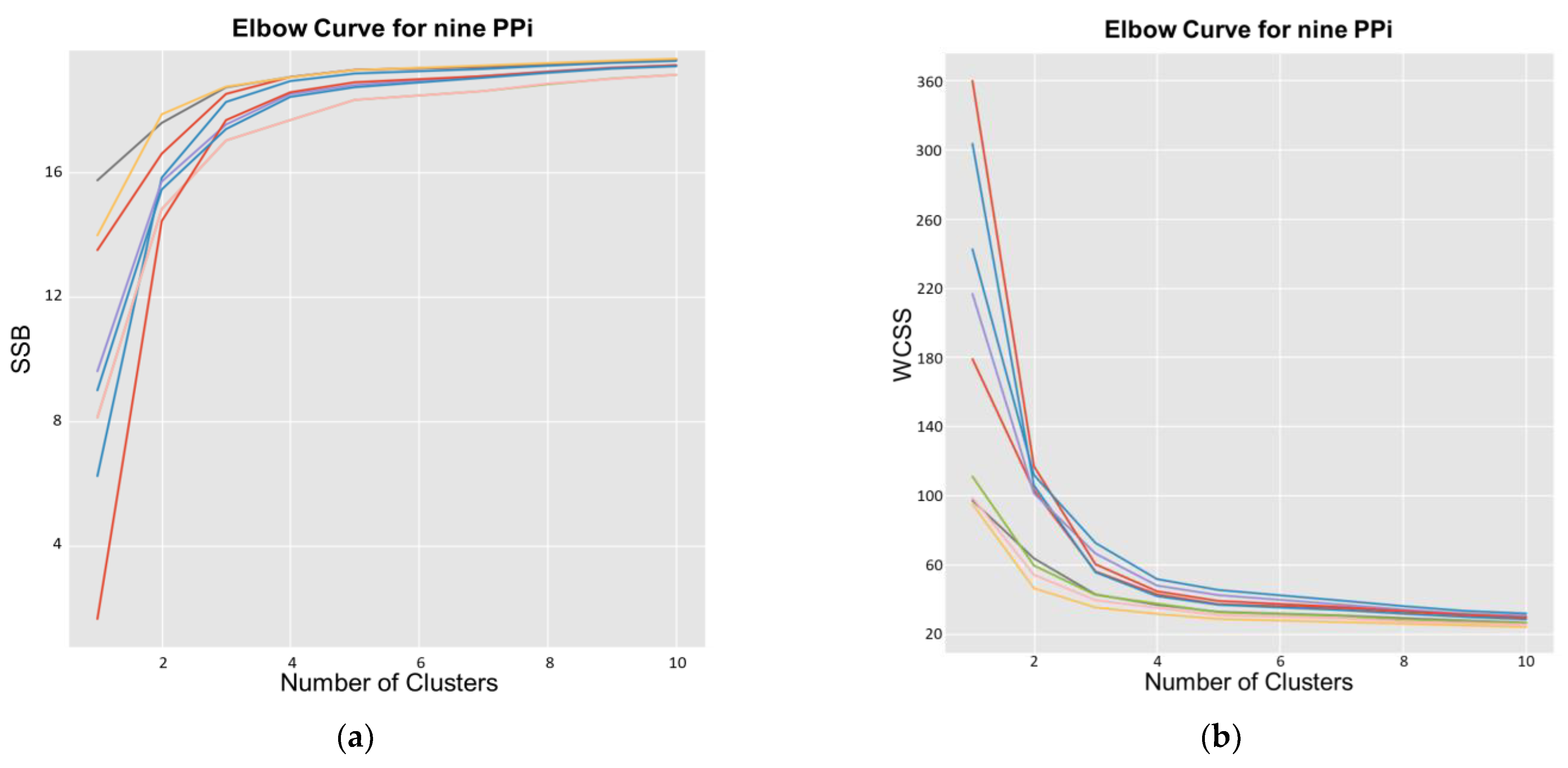
k in Equation (3)). After obtaining the clusters for each PPi, the metrics above-mentioned of the intra- and extra-cluster separability, as well as the p-values between clusters, are obtained. Data in this new format will permit us to identify the best number of clusters, using the elbow method and silhouette analysis. The elbow method [
41] is the most popular for finding the optimal number of clusters; this method uses
WCSS and
SSB scores, which account for the total variations within a cluster using Equations (4) and (5).
4. Results
In order to evaluate the results that produce each PPi on the Alzheimer’s level in PET studies under epigenetic conditions, several experiments have been conducted. To assess statistically the evaluation, the OASIS-3 dataset (described in
Section 2.1) was employed. A cohort of patients from OASIS-3 has been selected to fulfill the requirements of this work. A sub-dataset was extracted by selecting the cases with complete structural MRI—T1W, Aβ-PET scans, and clinical variables, which accounts for a total of 532 patients. The radiotracer injected for the PET image was the 18F-AV-45 for Aβ tracing. Statistics of the final cohort are provided in
Table 1. The difference between the total number of cases and the sum of determinations of the variables is due to the unknown determinations of some patients. Statistical values are obtained only for the known values and no imputation methods are employed.
4.1. Hyperparameter Selection
The first set of experiments was conducted to identify the values of the hyperparameter that affects all pipelines (PPi), namely the final dimension of manifold (
D) and the number of clusters in k-means (
k). Concerning
D, several analyses have been conducted to heuristically identify the optimal value. Using the PP5 and
k = 3, the processing pipeline was applied for several
D values, computing the averaged silhouette coefficients. As for
D = 3, the average silhouette score is 0.3217. The result is worse than the average silhouette score of 0.563 obtained for
D = 2, and the purpose of this stage is to reduce as much as possible while keeping the information to solve the problem (high values of
D make data unmanageable). In the remainder of this work, pipelines were implemented considering
D = 2. Concerning the determination of
k, the nine PPi have been clustered using several values of
k (in the range of 1–20). This permits us to produce the value of
WCSS using Equation (4) and
SSB using Equation (5) for each possible value of
k (
elbow analysis).
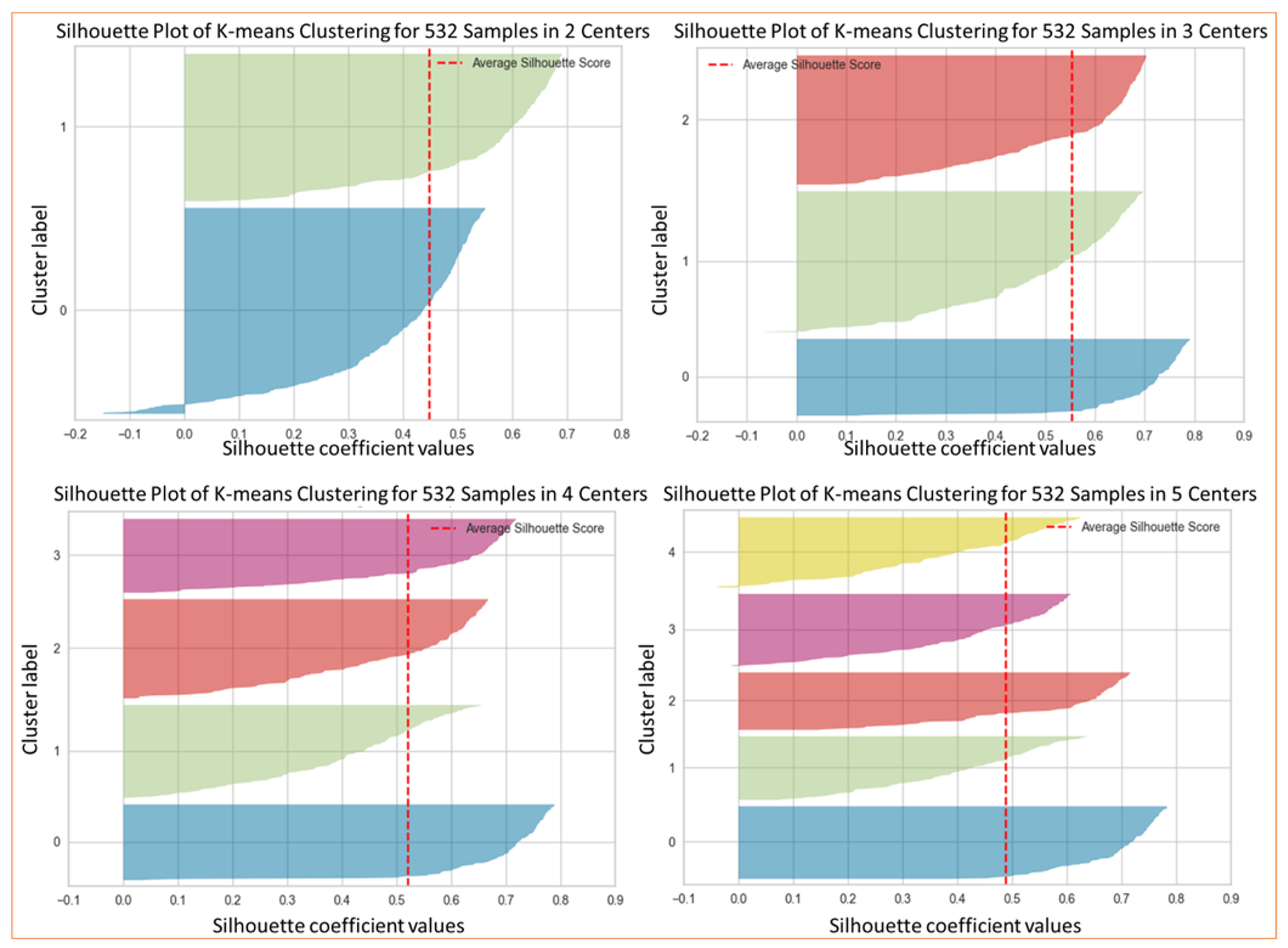
Figure 6 presents the results of applying the silhouette analysis of the data for
D = 2.
In this work, k-means was implemented using the classical Lloyd algorithm, using the following parameters: 10 as the number of times to run with different centroid seeds, 200 as the maximum number of iterations for a single run, and a value equal to 0.0001 for the relative tolerance with regards to the Frobenius norm of the difference in the cluster centers of two consecutive iterations to declare convergence.
Figure 7 presents the curves for such analysis, where it can be seen that
k = 3 is the optimal value of this parameter because the average silhouette score decreases as
k increases. Such a value is the largest when
k = 1.
To study the inter-cluster distances, we used silhouette analysis.
Figure 6 presents the results of such an analysis for PP5, showing how close each cluster is to its neighbors and allowing a visual evaluation of parameters such as the number of clusters. In
Figure 7, we can observe an elbow shape, where the graph has a sudden change to an asymptotic behavior on the X-axis. The k value in the elbow is the optimal
k value, i.e., the optimal number of clusters,
k = 3 in this case.
4.2. Aβ—PET Phenotypes Identification
The second set of experiments was conducted to evaluate the effects that each PPi produces on the emerging phenotypes. Using the image studies of those patients, as described above in
Section 3.1, the features derived from the nine PPi (RSF, PVC2C, and noPVC) have been applied to the whole set of 532 PET studies from 487 patients.
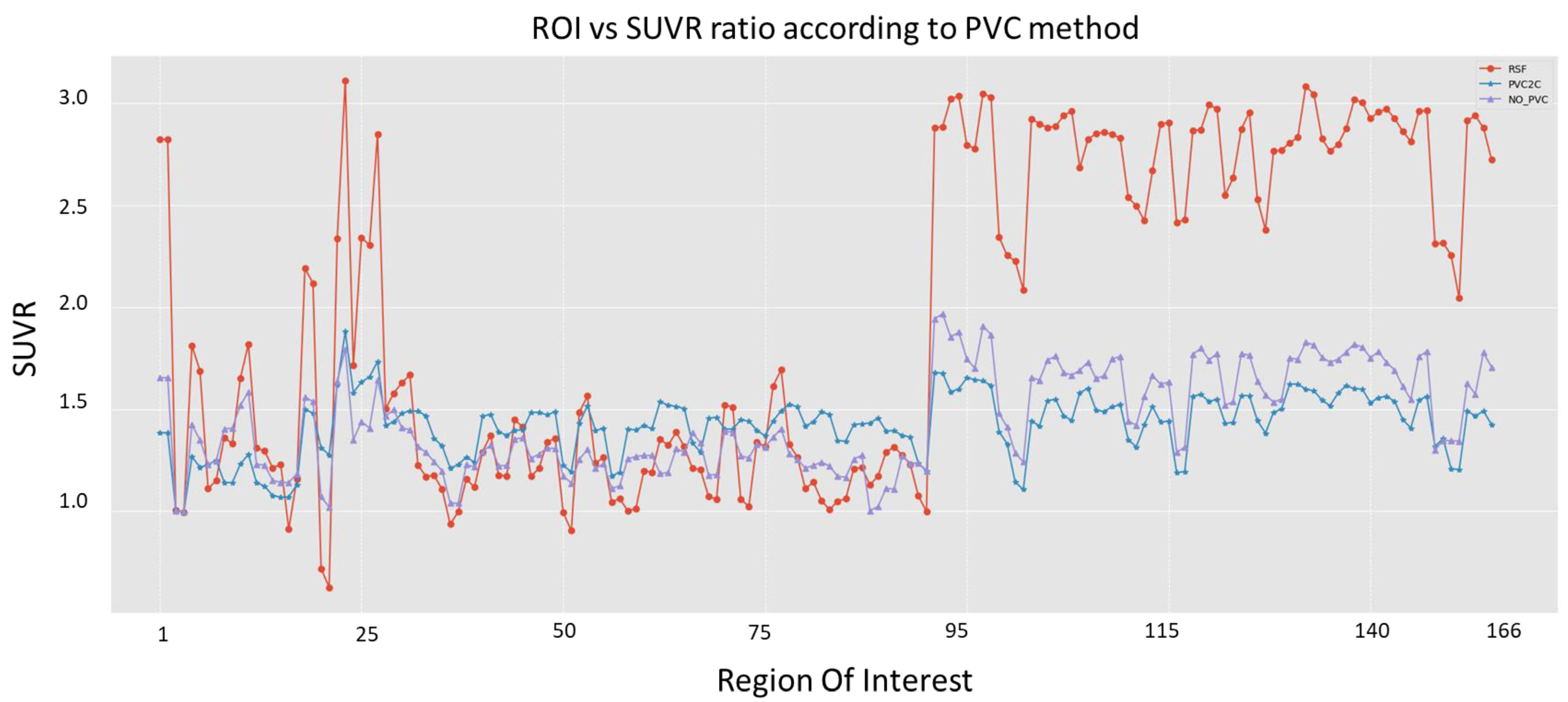
Figure 4 shows the output for the three approaches of PVC for one of the patients included in the study. In this work, we propose using 166 ROIs, as explained above. Different PVC methods provide different values of SUVR.
Figure 8 presents the results of applying the methods employed in this work, RSF (in red), PVC2C (in blue), and noPVC (in purple), to the dataset above described for the 166 ROIs. In this figure, it is clear that the approaches have different results for all the ROIs. Consequently, choosing a correction method will have consequences for the derived phenotypes.
The results of applying the PVC methods provide a triple matrix file, with 166 rows and 532 columns, for the SUVR values on the 166 regions of each patient. This high-dimensional set will enter the manifold learning block using the pipeline described in
Section 3.2, giving a result of the reduction in a two-dimensional (
k = 2) set of variables that will be grouped into three clusters using k-means (
k = 3), as explained in the previous section. After the dataset is processed using all pipelines (PPi), the next step is to identify the clusters in the data and consequently the phenotypes, named Phenotype1 (phen1), Phenotype2 (phen2) and Phenotype3 (phen3), using the methodology described in
Section 3.2. In this way, metrics based on mathematical measurements can be easily obtained. The metrics employed for measuring the clinical variables of the phenotypes in this work were p-values of the different clusters that emerged (phen1 vs. phen2, phen2 vs. phen3, and phen1 vs. phen3), as well as the inter- and intra-cluster variance, as explained in
Section 2.4, using Equations (4) and (5). All these data are provided in
Table 2 for the nine PPi.
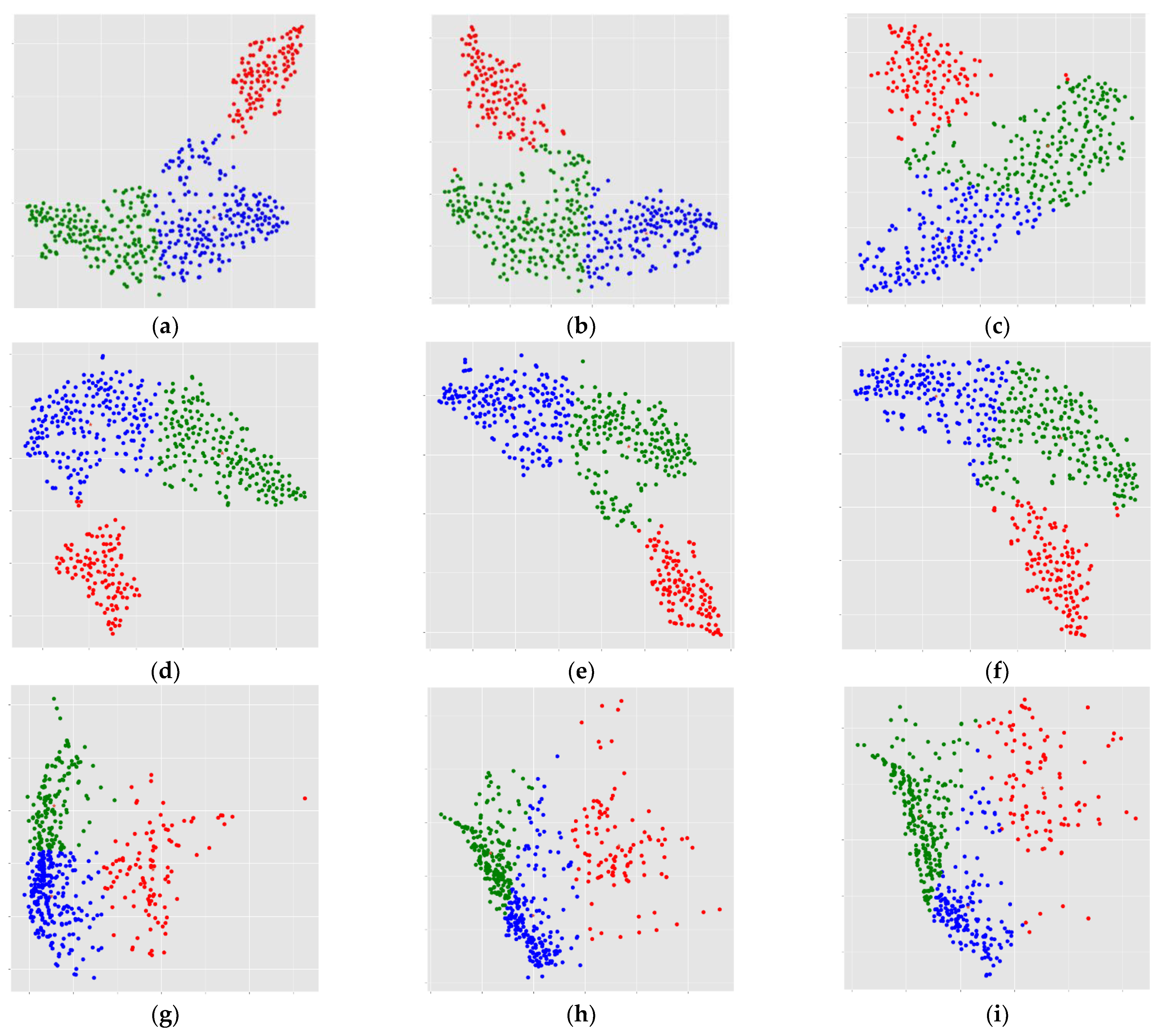
The results of this process are presented graphically in
Figure 9, which presents the emerging clusters (now understood as phenotypes) of several manifold methods applied to the three PVC methods. In those nine scatter plots (a to i), the abscissa is the first component of the manifold reduction, and the ordinate is the second component of the manifold decomposition. In those images, the axis is different for each pipeline, because the results take values on different ranges for each method. According to the clustering results and the optimized cluster number, three clusters were identified.
Once the three clusters are identified for all PPi, the values of cognitive impairment were calculated by computing the mean value and the standard deviation of patients’ Mini-Mental State Examination (MMSE) included in each cluster, allowing the phenotype identification and characterization. The MMSE measures general cognitive status, ranging from 0 (severe impairment) to 30 (no impairment), based on a 30-point questionnaire that is used extensively in clinical and research settings [
19]. The results for each PPi are provided in
Table 2. Furthermore, this table also provides the p-value of the inter-phenotype comparisons, using the one-way analysis of variance (ANOVA) test, as well as the intra-cluster and inter-cluster measurements, using Equations (4) and (5).
In this way, the method permits us to identify the clearest phenotypes as the best-separated clusters. From those results, we can deduce that the best results are from line5, generated by PP5 (based on the t-SNE and RSF methods), providing values of
WCSS = 26.029 and
SSB = 19.341 and intra-cluster p-values of 0.012, 0.093, and 0.000, respectively, providing the total lowest values on average. More detailed results of pipeline five are provided in
Table 3.
Table 3 provides the statistical values using the clinical variables for the three phenotypes that have emerged in the previous step that identify PP5.
Analyzing the results in the table, considering gender, phen1 is well balanced, while in phen2 and phen3 the number of females is almost double that of men. Concerning age, the phenotypes are clearly separate: phen3 is the youngest at about 62.1 years old, phen1 is in the middle with a mean of 67.3 years, and phen2 is clearly different and the oldest group at 73.5 years; all values are means. Concerning cognitive impairment, the MMSE shows lower values correlated with age, moving from a nominal value of 29.3 in phen3, ranging to 28.280 in phen2, the oldest phenotype.
4.3. Epigenetic Analysis
In order to explore the way in which the proposed methodology can be employed to analyze how environmental conditions affect the emerging phenotypes, the above-identified phenotyping pipeline PP5 has been applied, repeating the analysis process with different environmental variables—such as the number of education years; TOBAC, measuring the binary smoking condition as cigarette smoking history with respect to the subject smoking more than 100 cigarettes in his/her life; DEPOTHR, measuring the occurrence of depression or other episodes during the previous 2 years; and alcohol abuse, as clinically significant impairment over a 12-month period manifesting in work, driving, legal, or social spheres—confronted with APOE. Results are provided in
Table 4.
Education year is presented as the mean and standard deviation; TOBAC is presented as a binary condition. DEPOTHR: Depression or other episodes prior to 2 years. APOE genotype—low risk: E2/E2, E2/E3, E3/E3; medium risk: E2/E4, E3/E4; high risk: E4/E4. Substance abuse: alcohol.
The figures in the table reveal that the environmental effect is very different on the phenotypes. Particularly, we can see that three phenotypes are characterized differently than in the previous subsection, which indicates that including epigenetic conditions in the analysis provides different results, as should be supposed. The level of education, in terms of the number of education years, is similar, with mean values ranging from 15.898 to 16.247, phen3 being the group with the highest level of education and lowest variability within the group. The smoking condition is very different, where in phen2 there is a higher proportion of smokers (more smokers than nonsmokers) at 58/38, and in phen1 and phen3 the proportion is 73/88 and 73/107, respectively. The psychiatric condition is affected differently; remarkably, phen3 is the group that has a smaller number of cases, 5 in 183, doubling the ratio with the other groups. Concerning alcohol consumption, the first remark is on the low value of cases; in this cohort study only a few cases are present—14 subjects in total—and, consequently, conclusions are difficult to extract.
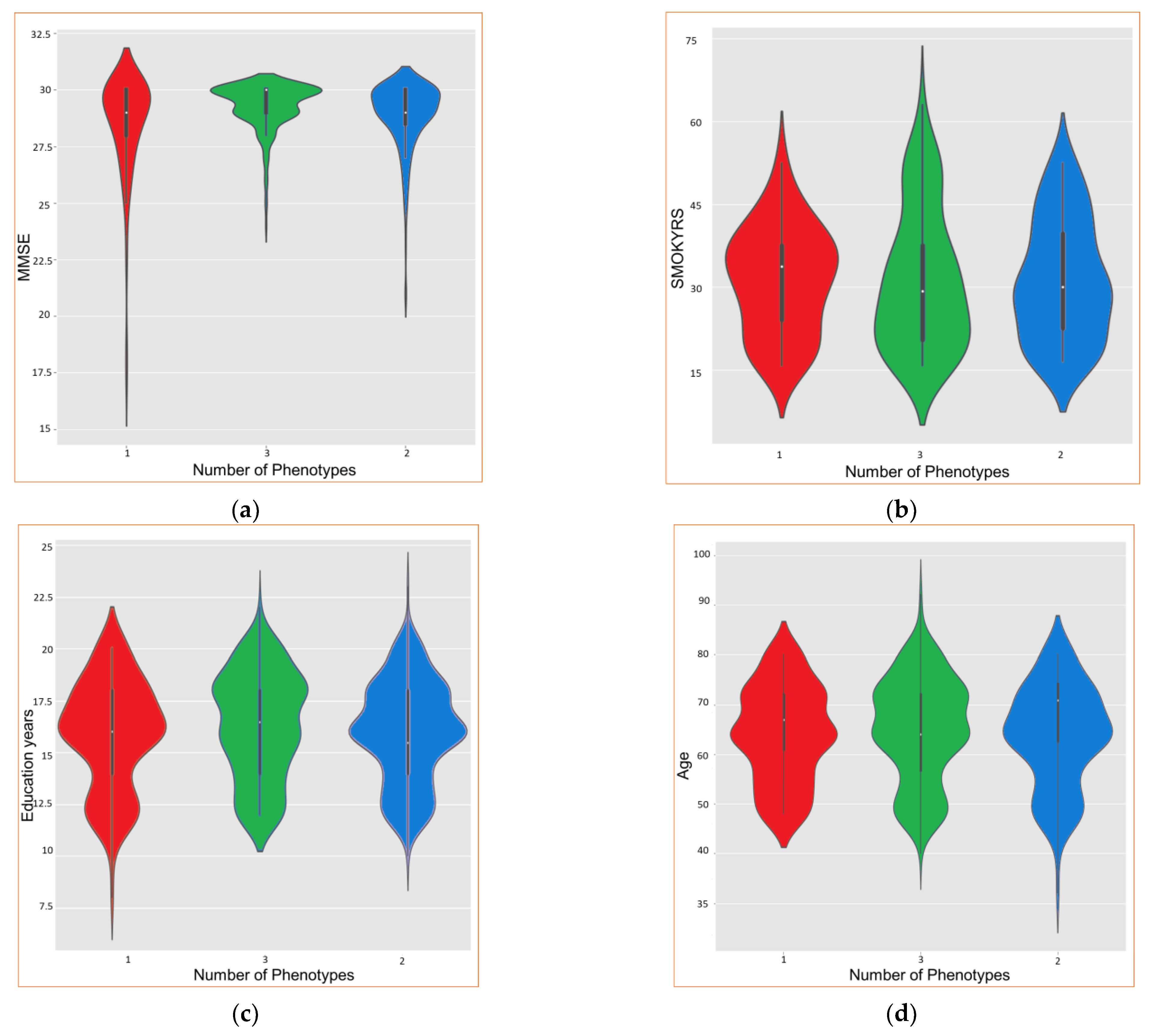
Upon obtaining the results, the “violin” plots can be employed to visually explore the different phenotypes. The results are presented in
Figure 10. It is important to remark that, in this study, except for numerical values, all results are categorical and do not permit us to extract useful insights. The results of this analysis allow us to identify the best choice for the set of combinations proposed in the methodology.
From
Figure 10, it is possible to conclude that phen2 presents higher values (mean) for age and years of smoking, while phen3 is the one with the lowest values for these parameters. Regarding the MMSE and the years of study, phen3 has higher values, while phen2 presents the lowest values. Phen1 presents intermediate values compared with phen2 and phen3. Therefore, phen3 could be associated with cognitively healthy people, phen1 with people with questionable dementia, and phen3 with mild or higher cognitive impairment.
5. Discussion and Conclusions
The objective of this study was to develop and validate a phenotyping method to test the hypothesis that there are identifiable AD phenotypes that are based on hidden patterns of the SUVR values of the PET studies of cognitive functions and epigenetic conditions. The presented phenotyping method uses pipelines of PVC and manifold methods. The proposed methodology uses both neuroradiological features from imaging and neuropsychological features from cognitive tests in an epigenetic environment. We compared the interpretability and discriminability of the phenotyping method. We compared the interpretability and discriminability of the phenotyping method using k-means.
Using this method, we derived three phenotypes. The method also identifies the hyperparameters (D and k) that play an important role in the results. This work presents the results of OASIS3 patients using nine PPis in a cross-validation matrix of three PVC methods and three manifold methods. The method could be easily extended to a larger number of PVC techniques and manifold methods without losing generality.
The results presented in this work show that PVC methods produce a different set of derived features (as shown in
Figure 8), and consequently, the selection of the method will play an important role in any other derived usage of the data. Once the features are extracted from the dataset, there are several manifold approaches that allow us to reduce the dimensionality of the data and consequently manage the information in a more suitable way. The proposed methodology allows us to determine which combination of components of the processing pipeline is the best for each approach to the epidemiologic analysis using a mathematical formulation based on intra- and extra-cluster variabilities (Equations (4) and (5)). The method involves several parameters, beyond the manifold algorithm, that must be selected as the number of the final dimension (
D) and the number of clusters to be identified in the cluster reassembling (
k). A procedure that permits us to identify those parameters was presented (elbow and silhouette analysis). The experiments conducted in this work permit us to identify those values for the dataset. Particularly
D = 2 and
k = 3 are the optimal parameters for analyzing PET images under epigenetic conditions.
The methodology proposed in this paper was employed to compare the methods PVC2C, RSF, and noPVC, and the output of the processed data was employed to feed the manifold pipeline to compare the effects of the manifold method on the aggregability of patients under different clusters. This allows us to measure the separability of the clusters using p-values between the outputs for each output variable involved in the analysis (in this work, the following variables have been employed: age, years of study, drinking, smoking, psychiatric events, and APOE), including epigenetic and non-epigenetic conditions. The proposed methodology allows us to identify the best set of phenotyping pipeline components involved in the analysis. Using the patients described in this work, the best results appear (PP5) using RSF as a PVC method and t-SNE as a manifold method, with an inter-phenotype separability (WCSS = 26.029), an extra-phenotype separability (SSB = 19.341), and a set of p-values of 0.012, 0.093, and 0.000 for phenotypes one and two, two and three, and one and three, respectively. The three phenotypes are mainly characterized considering gender: phen1 is well-balanced, while in phen2 and phen3 the number of females is almost double that of men. Concerning age, the phenotypes are clearly separate: phen3 is the youngest at about 62.1 years old, phen1 is in the middle with a mean of 67.3 years, and phen3 is clearly different and the oldest group at 73.5 years; all values are means. Concerning cognitive impairment, the values of MMSE, which shows lower values correlated with age, move from a nominal value of 29.3 in phen3 to 28.280 in phen2, the oldest phenotype.
Using this method, the derived phenotypes also characterize the epigenetic variables using violin plots to visualize the outcomes, and, consequently, how patients could decline in cognitively distinguishable ways. Phen2 could be associated with cognitively healthy people, phen1 with people with questionable dementia, and phen3 with mild or higher cognitive impairment.
The inclusion of other databases, either public (such as the Alzheimer’s Disease Neuroimaging Initiative, ADNI) or private (from any research group that could provide it), could be a way to provide more robust results and strengthen the validity of the proposed method. It is important to take into consideration the need for having simultaneously both types of imaging studies (PET and MRI) and the clinical variables employed in the studio. This is an additional analysis that lies out of the scope of this paper and is a clear new future work line. The methodology could also be extended by including longitudinal data on the pipelines, to permit the characterization of the longitudinal progression of AD by understanding the neurodegeneration patterns. Another future line of research to explore is to evaluate how the proposed methodology could be extended and made more general by including additional evaluation metrics in the analysis to further demonstrate the effectiveness of the method (including measures of accuracy, precision, recall, F1 score, mean squared error, or the coefficient of determination). Presenting a diverse range of evaluation metrics could provide a more comprehensive assessment of the method’s performance. The main issue to solve is that the above-mentioned metrics involved in measuring artificial intelligence classifiers are not eligible as they require a gold standard value in order to build the confusion matrix elements (TP, TN, FP, and FN). In this methodology, there is no a priori true phenotype. This, again, lies out of the scope of this paper.

 ,
, 










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}