
Early Prediction of DNN Activation Using Hierarchical Computations

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- A mathematical model that can accurately detect negative values based on the number of mantissa bits used a low precision MAC operation.
2. Literature Review
3. Background
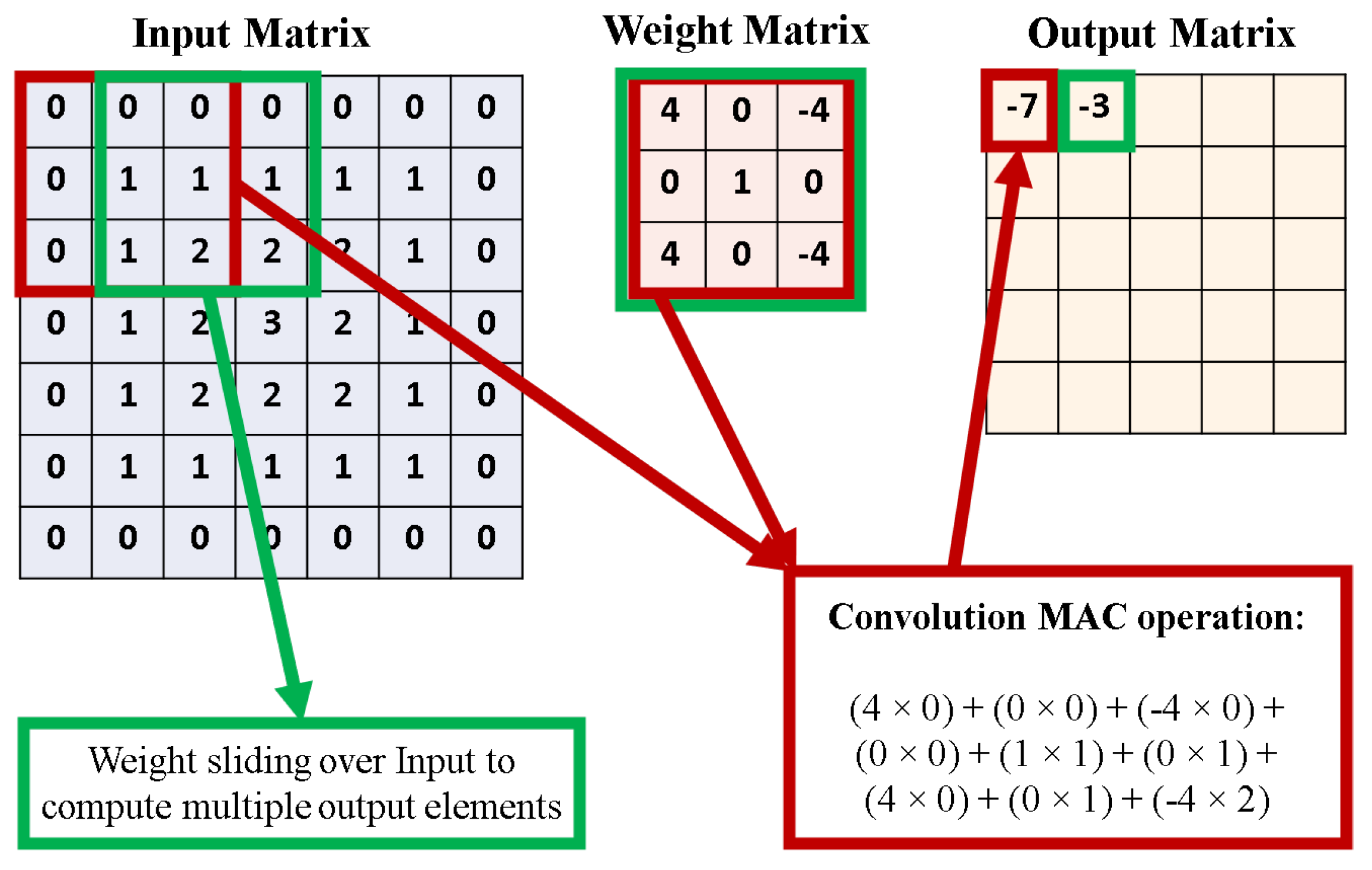
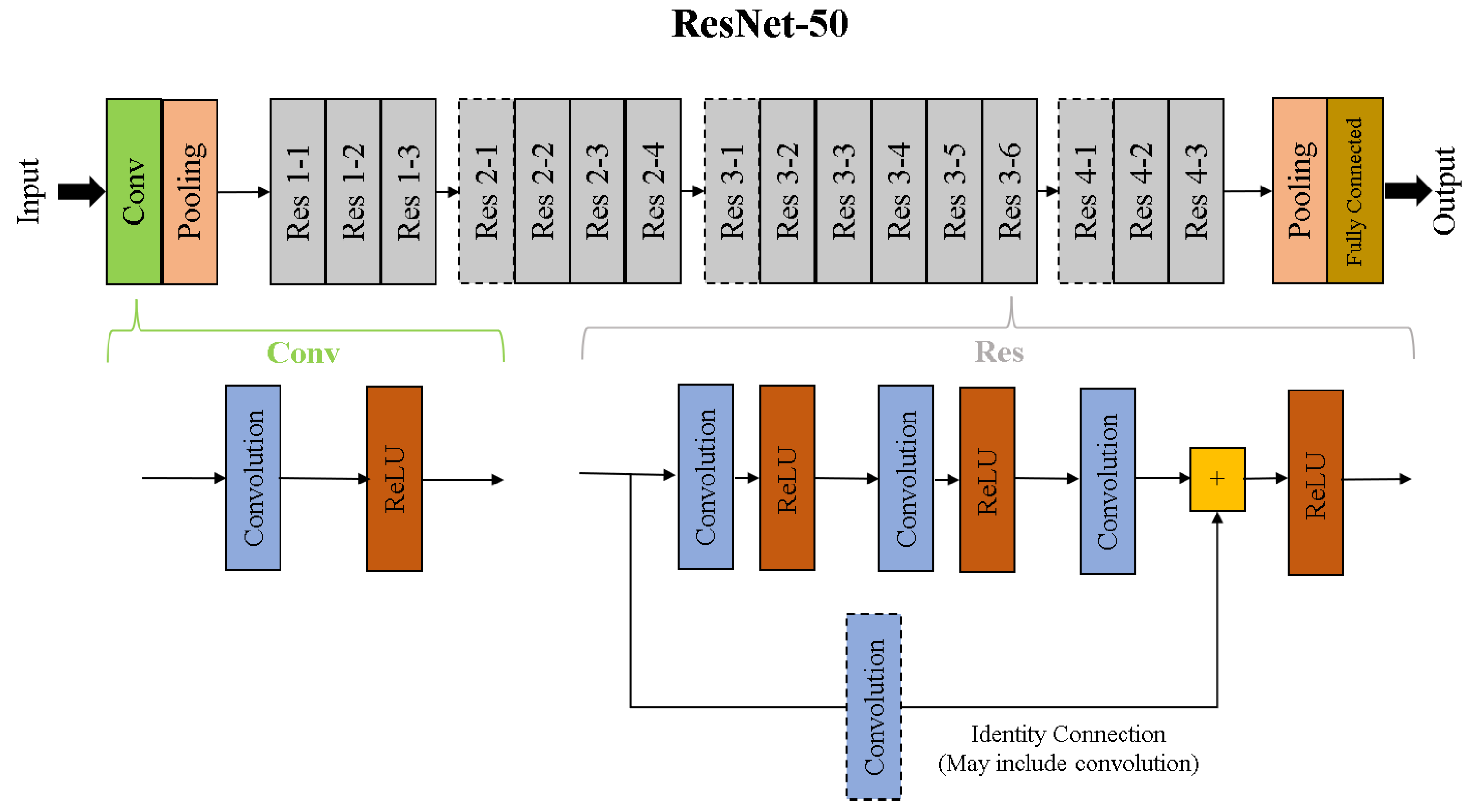
3.1. Convolutional Neural Networks
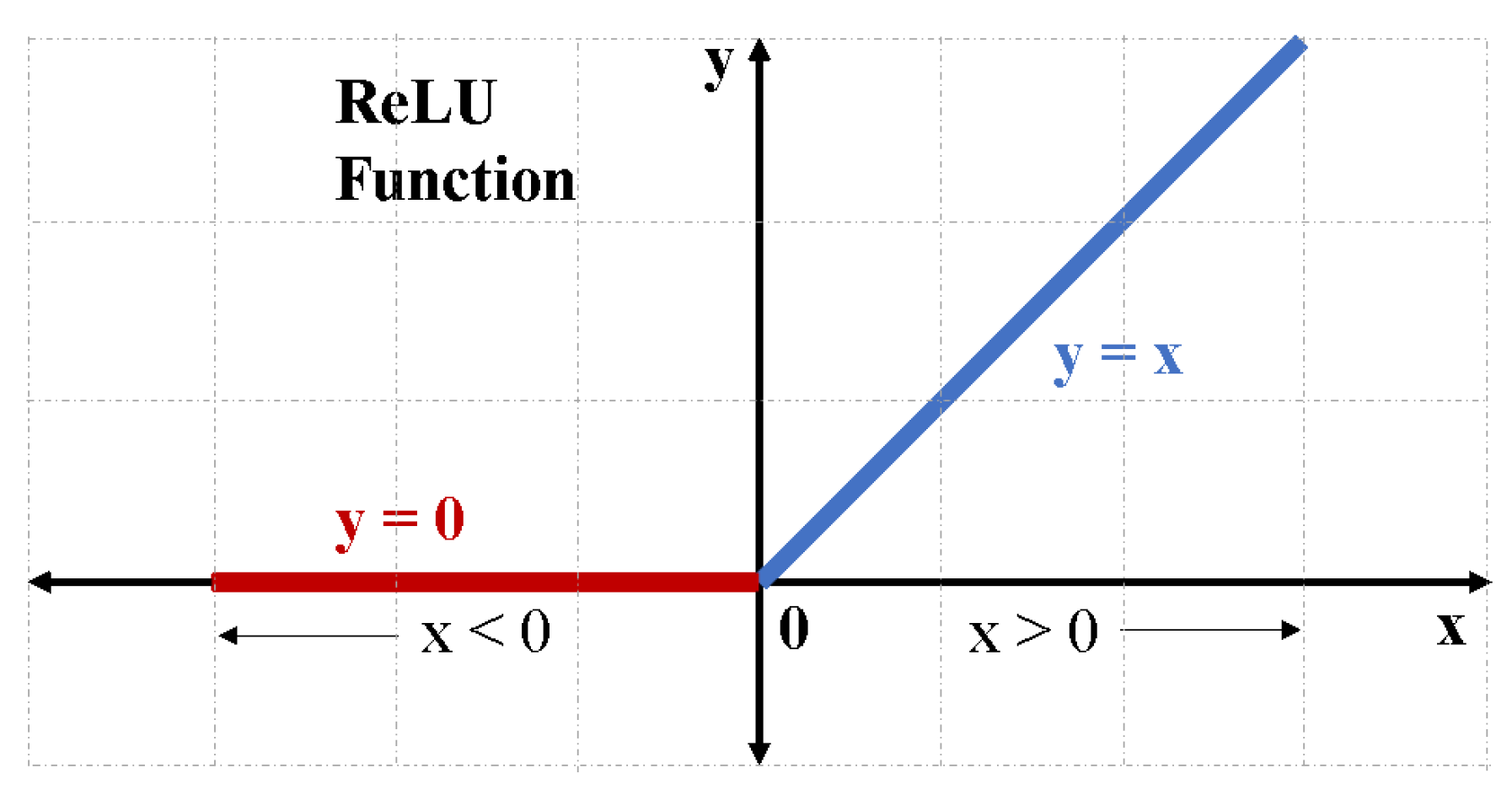
3.2. ReLU Activation Function
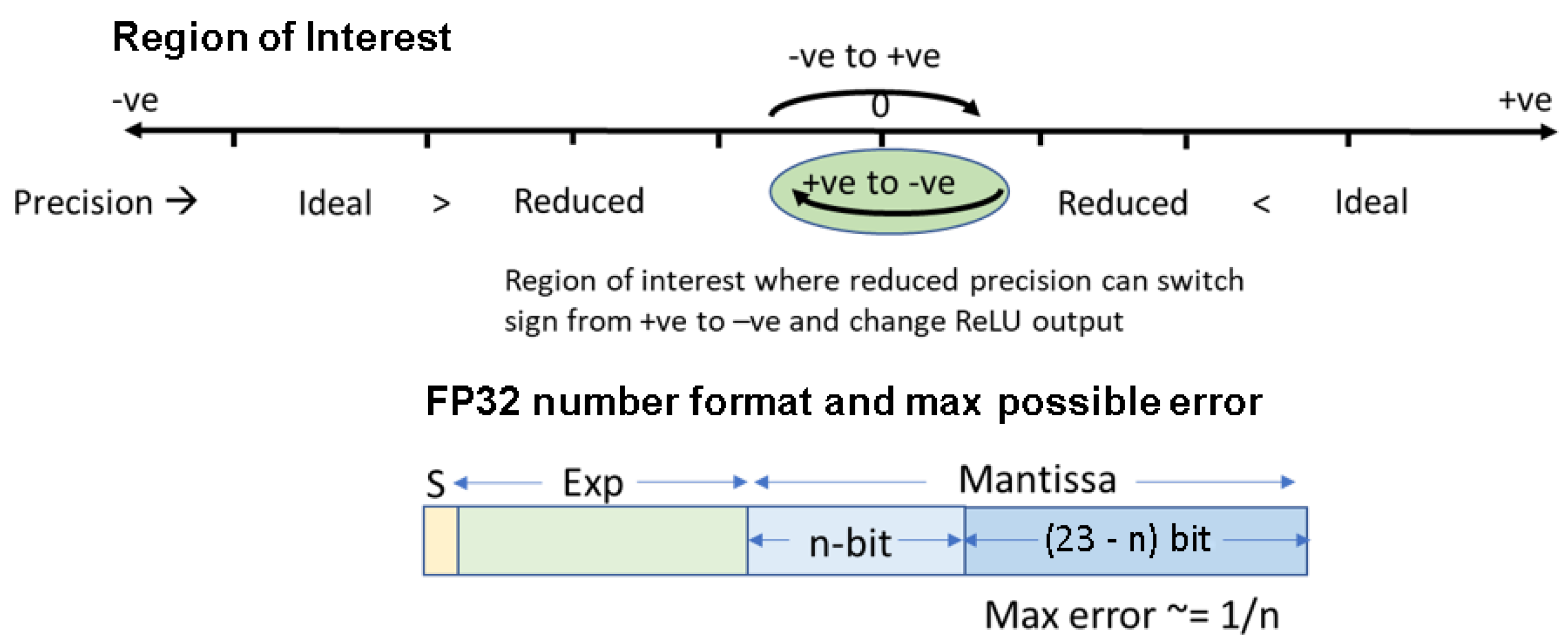
3.3. Floating Point Number Representation
4. Methodology
4.1. Dataset and Framework
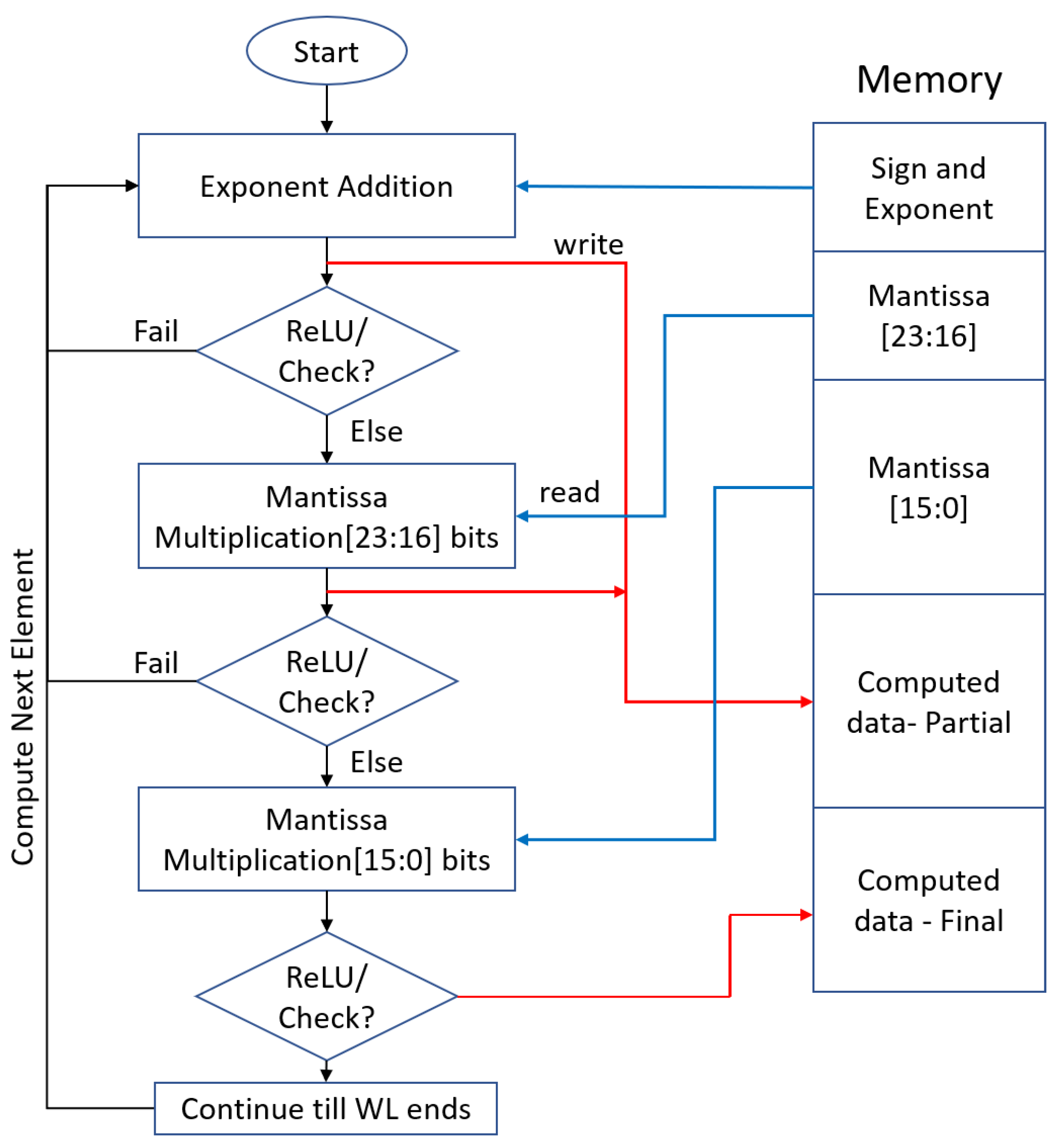
4.2. Proposed Hierarchical Computation
4.3. Mathematical Model
4.4. Early Negative Value Prediction
- 1.
- Consider inputs and weights of convolution with reduced “n” mantissa bits
- 2.
- Compute , the sum of positive convolution terms, as per (22)
- 3.
- Obtain , the exponent value of , as per (22)
- 4.
- Compute = + , where is the sum of negative convolution terms
- 5.
- Obtain , the exponent value of , as per (20)
- 6.
- If > (− n), then assign the ReLU output as zero. The computation is complete.
- 7.
- If ReLU zero is not assigned, repeat steps 1–6 for higher values of “n”.
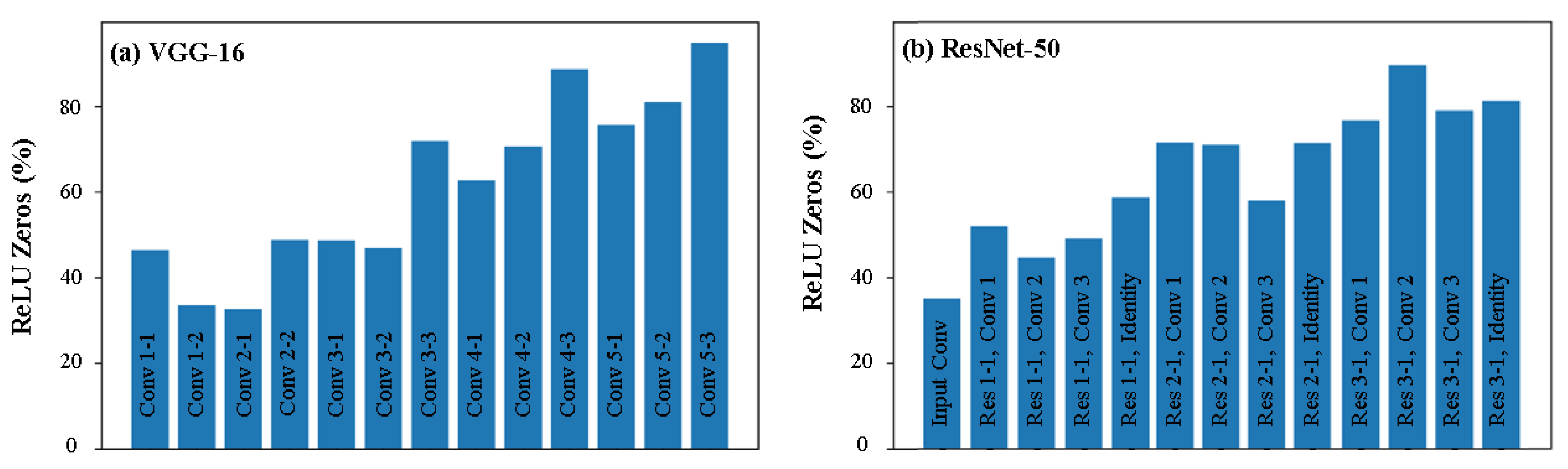
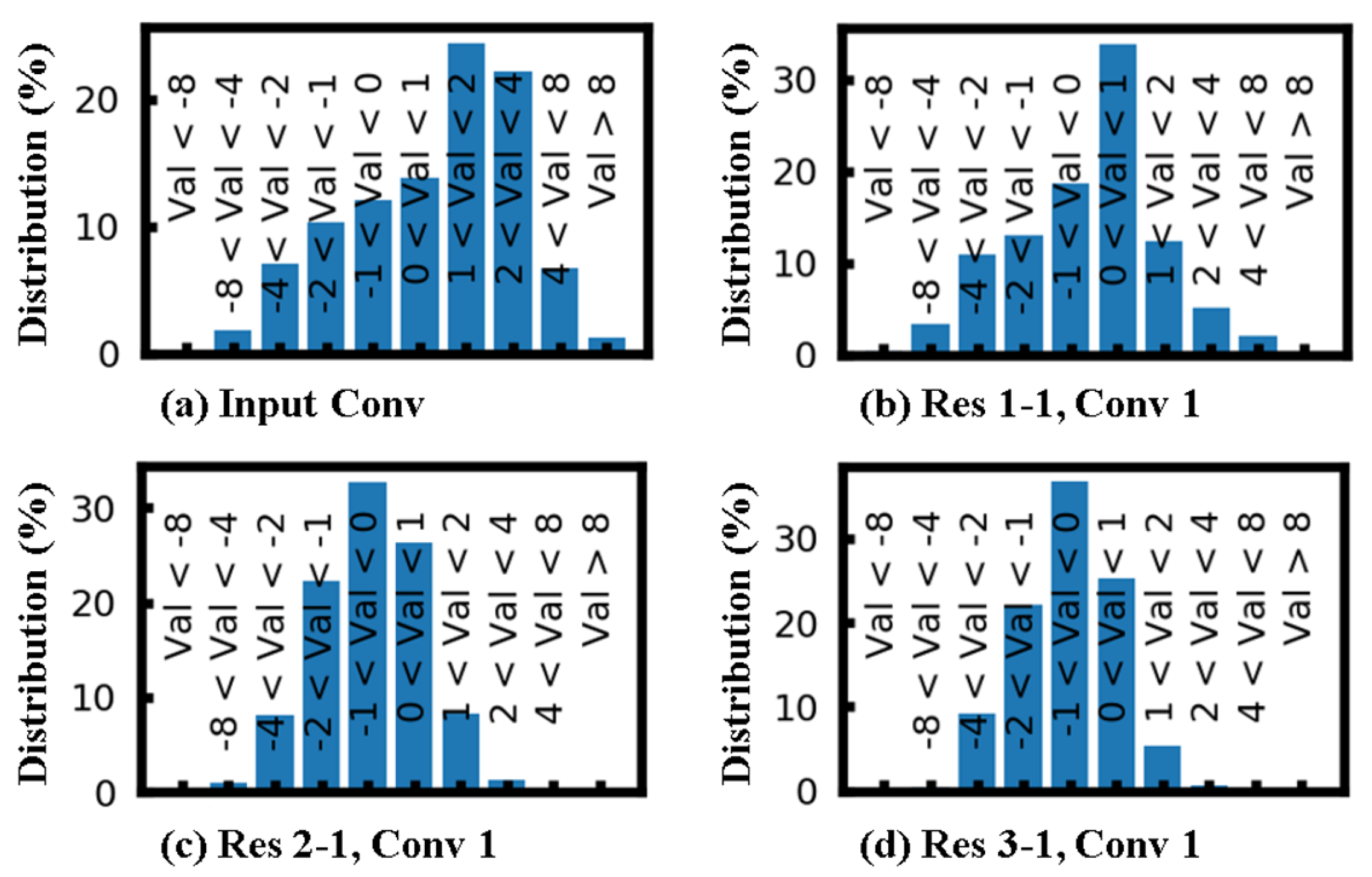
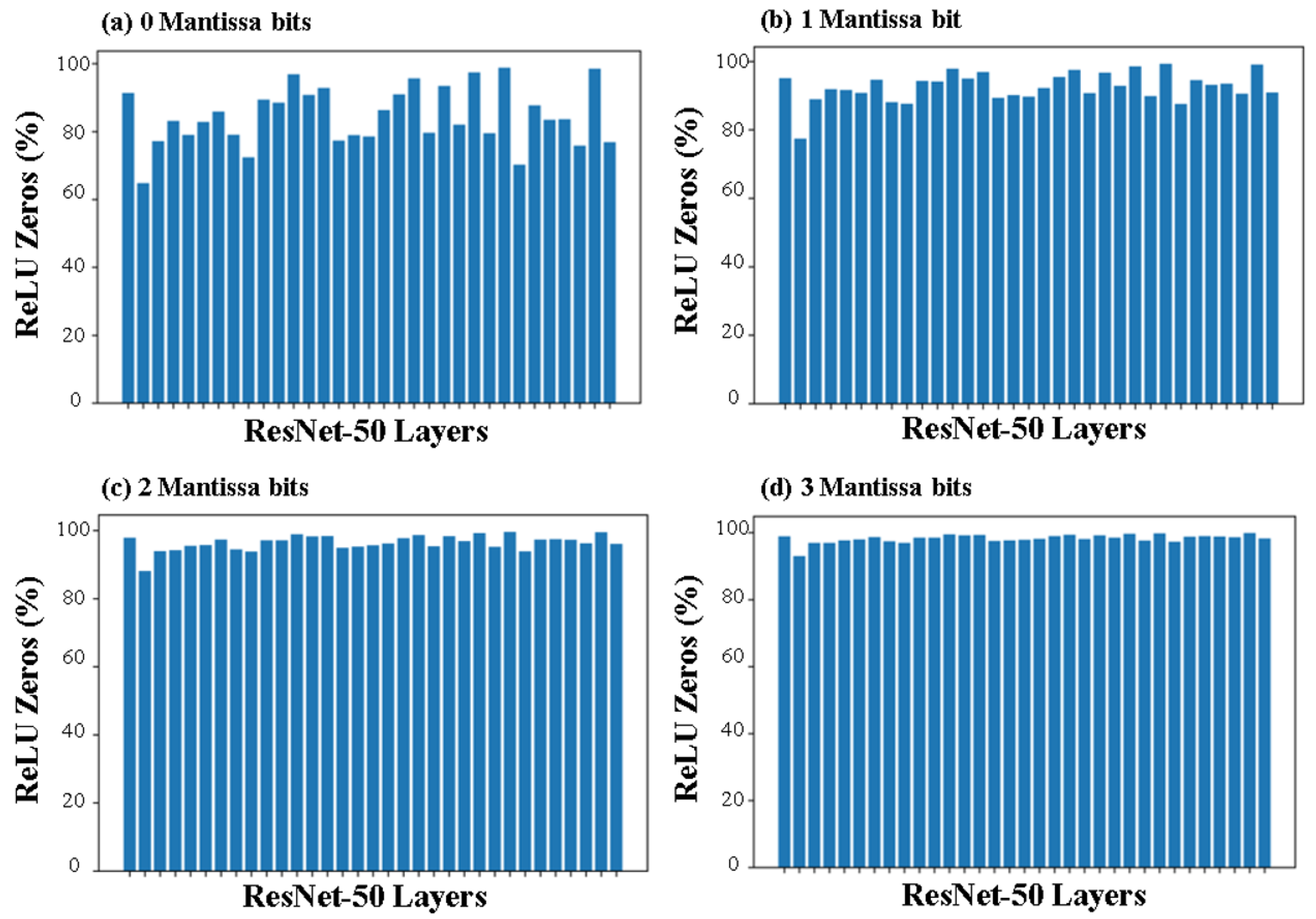
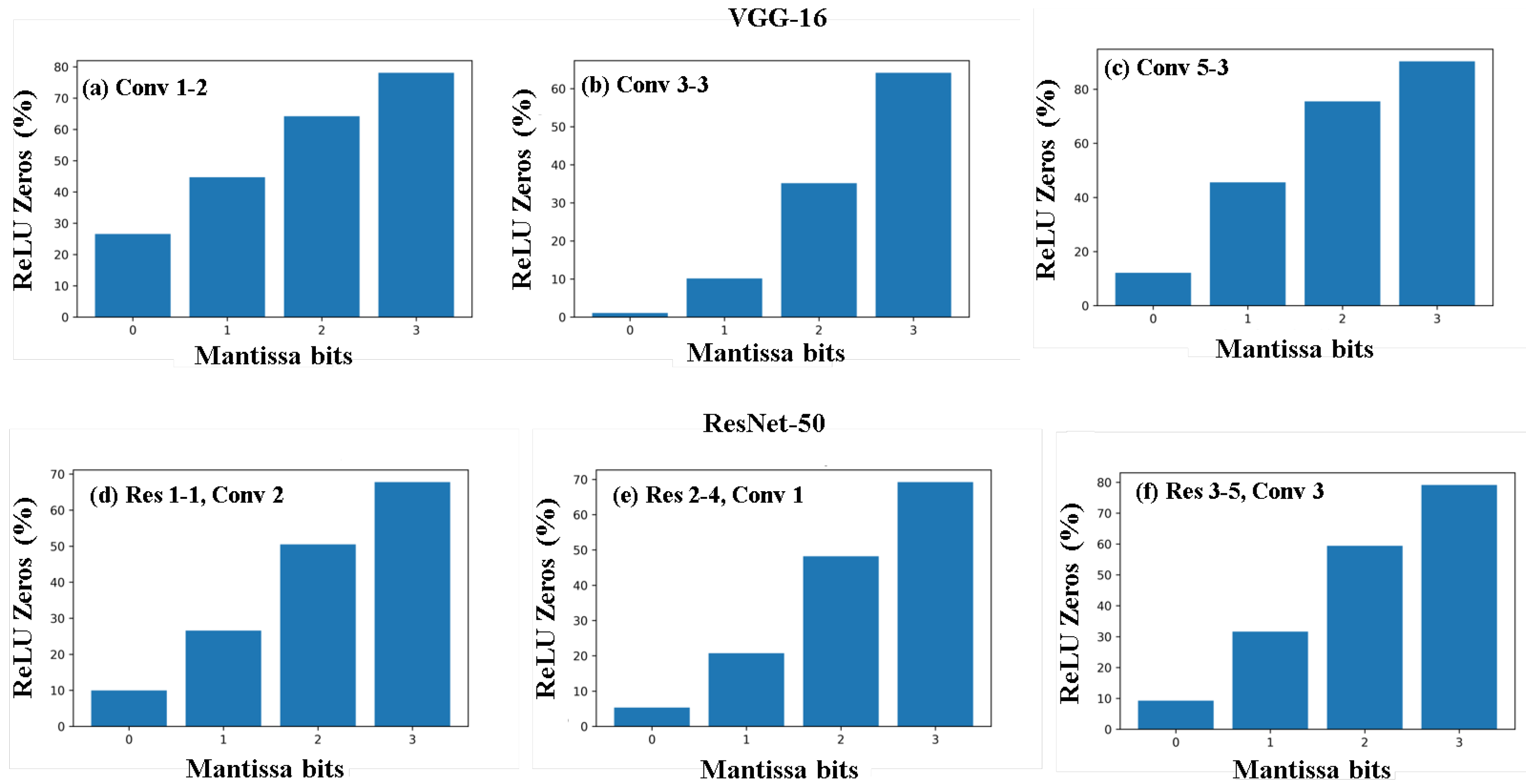
5. Results
6. Discussion
6.1. Generalization to Other DNNs
6.2. Implementation on GPU/Other Accelerators
6.3. Extension to Training
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| DNN | Deep Neural Network |
| ReLU | Rectified Linear Unit |
| VGG | Visual Geometry Group |
| ResNet | Residual Network |
| MAC | Multiply And Accumulate |
| GPU | Graphics Processing Unit |
| CNN | Convolutional Neural Network |
| IEEE | Institute of Electrical and Electronics Engineers |
| ILSVRC | ImageNet Large Scale Visual Recognition Challenge |
References
- Liu, W.; Wang, Z.; Liu, X.; Zeng, N.; Liu, Y.; Alsaadi, F.E. A survey of deep neural network architectures and their applications. Neurocomputing 2017, 234, 11–26. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, Y. Big data analysis by infinite deep neural networks. Jisuanji Yanjiu Yu Fazhan/Comput. Res. Dev. 2016, 53, 68–79. [Google Scholar] [CrossRef]
- Strubell, E.; Ganesh, A.; McCallum, A. Energy and Policy Considerations for Deep Learning in NLP. In Proceedings of the ACL 2019—57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 3645–3650. [Google Scholar]
- Harlap, A.; Narayanan, D.; Phanishayee, A.; Seshadri, V.; Devanur, N.; Ganger, G.; Gibbons, P. PipeDream: Fast and Efficient Pipeline Parallel DNN Training. arXiv 2018, arXiv:1806.03377. [Google Scholar]
- Deng, C.; Liao, S.; Xie, Y.; Parhi, K.K.; Qian, X.; Yuan, B. PERMDNN: Efficient Compressed DNN Architecture with Permuted Diagonal Matrices. In Proceedings of the 2018 51st Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), Fukuoka, Japan, 20–24 October 2018; pp. 189–202. [Google Scholar]
- Duggal, J.K.; El-Sharkawy, M. Shallow squeezenext: An efficient shallow DNN. In Proceedings of the 2019 IEEE International Conference on Vehicular Electronics and Safety (ICVES), Cairo, Egypt, 4–6 September 2019. [Google Scholar] [CrossRef]
- Wei, W.; Xu, L.; Jin, L.; Zhang, W.; Zhang, T. AI Matrix—Synthetic Benchmarks for DNN. arXiv 2018, arXiv:1812.00886. [Google Scholar]
- Hanif, M.A.; Javed, M.U.; Hafiz, R.; Rehman, S.; Shafique, M. Hardware–Software Approximations for Deep Neural Networks. In Approximate Circuits; Springer International Publishing: Cham, Switzerland, 2019; pp. 269–288. [Google Scholar] [CrossRef]
- Agrawal, A.; Choi, J.; Gopalakrishnan, K.; Gupta, S.; Nair, R.; Oh, J.; Prener, D.A.; Shukla, S.; Srinivasan, V.; Sura, Z. Approximate computing: Challenges and opportunities. In Proceedings of the 2016 IEEE International Conference on Rebooting Computing (ICRC), San Diego, CA, USA, 17–19 October 2016. [Google Scholar] [CrossRef]
- Liu, B.; Wang, Z.; Guo, S.; Yu, H.; Gong, Y.; Yang, J.; Shi, L. An energy-efficient voice activity detector using deep neural networks and approximate computing. Microelectron. J. 2019, 87, 12–21. [Google Scholar] [CrossRef]
- Zhu, H.; Akrout, M.; Zheng, B.; Pelegris, A.; Jayarajan, A.; Phanishayee, A.; Schroeder, B.; Pekhimenko, G. Benchmarking and Analyzing Deep Neural Network Training. In Proceedings of the 2018 IEEE International Symposium on Workload Characterization (IISWC), Raleigh, NC, USA, 30 September–2 October 2018; pp. 88–100. [Google Scholar] [CrossRef]
- Nwankpa, C.; Ijomah, W.; Gachagan, A.; Marshall, S. Activation Functions: Comparison of trends in Practice and Research for Deep Learning. arXiv 2018, arXiv:1811.03378. [Google Scholar]
- Wang, Y.; Li, Y.; Song, Y.; Rong, X. The Influence of the Activation Function in a Convolution Neural Network Model of Facial Expression Recognition. Appl. Sci. 2020, 10, 1897. [Google Scholar] [CrossRef] [Green Version]
- Alom, M.Z.; Taha, T.M.; Yakopcic, C.; Westberg, S.; Sidike, P.; Nasrin, M.S.; Van Esesn, B.C.; Awwal, A.A.S.; Asari, V.K. The history began from alexnet: A comprehensive survey on deep learning approaches. arXiv 2018, arXiv:1803.01164. [Google Scholar]
- Shi, S.; Chu, X. Speeding up convolutional neural networks by exploiting the sparsity of rectifier units. arXiv 2017, arXiv:1704.07724. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Albericio, J.; Delmás, A.; Judd, P.; Sharify, S.; O’Leary, G.; Genov, R.; Moshovos, A. Bit-pragmatic deep neural network computing. In Proceedings of the 50th Annual IEEE/ACM International Symposium on Microarchitecture, Cambridge, MA, USA, 14–18 October 2017; pp. 382–394. [Google Scholar]
- Albericio, J.; Judd, P.; Hetherington, T.; Aamodt, T.; Jerger, N.E.; Moshovos, A. Cnvlutin: Ineffectual-neuron-free deep neural network computing. ACM SIGARCH Comput. Archit. News 2016, 44, 1–13. [Google Scholar] [CrossRef]
- Chen, T.; Du, Z.; Sun, N.; Wang, J.; Wu, C.; Chen, Y.; Temam, O. Diannao: A small-footprint high-throughput accelerator for ubiquitous machine-learning. ACM SIGARCH Comput. Archit. News 2014, 42, 269–284. [Google Scholar] [CrossRef]
- Judd, P.; Albericio, J.; Hetherington, T.; Aamodt, T.M.; Moshovos, A. Stripes: Bit-serial deep neural network computing. In Proceedings of the 2016 49th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), Taipei, Taiwan, 15–19 October 2016; pp. 1–12. [Google Scholar]
- Chen, Y.H.; Krishna, T.; Emer, J.S.; Sze, V. Eyeriss: An energy-efficient reconfigurable accelerator for deep convolutional neural networks. IEEE J. Solid-State Circuits 2016, 52, 127–138. [Google Scholar] [CrossRef] [Green Version]
- Gao, M.; Pu, J.; Yang, X.; Horowitz, M.; Kozyrakis, C. Tetris: Scalable and efficient neural network acceleration with 3d memory. In Proceedings of the Twenty-Second International Conference on Architectural Support for Programming Languages and Operating Systems, Xi’an, China, 8–12 April 2017; pp. 751–764. [Google Scholar]
- Hua, W.; Zhou, Y.; De Sa, C.; Zhang, Z.; Suh, G.E. Boosting the performance of cnn accelerators with dynamic fine-grained channel gating. In Proceedings of the 52nd Annual IEEE/ACM International Symposium on Microarchitecture, Columbus, OH, USA, 12–16 October 2019; pp. 139–150. [Google Scholar]
- Chen, C.Y.; Choi, J.; Gopalakrishnan, K.; Srinivasan, V.; Venkataramani, S. Exploiting approximate computing for deep learning acceleration. In Proceedings of the 2018 Design, Automation & Test in Europe Conference & Exhibition (DATE), Dresden, Germany, 19–23 March 2018; pp. 821–826. [Google Scholar]
- Gupta, S.; Agrawal, A.; Gopalakrishnan, K.; Narayanan, P. Deep Learning with Limited Numerical Precision. In Proceedings of the 32nd International Conference on Machine Learning (ICML 2015), Lille, France, 6–11 July 2015; Volume 3, pp. 1737–1746. [Google Scholar]
- Judd, P.; Albericio, J.; Hetherington, T.; Aamodt, T.; Jerger, N.E.; Urtasun, R.; Moshovos, A. Reduced-Precision Strategies for Bounded Memory in Deep Neural Nets. arXiv 2015, arXiv:1511.05236. [Google Scholar]
- Shafique, M.; Hafiz, R.; Javed, M.U.; Abbas, S.; Sekanina, L.; Vasicek, Z.; Mrazek, V. Adaptive and Energy-Efficient Architectures for Machine Learning: Challenges, Opportunities, and Research Roadmap. In Proceedings of the 2017 IEEE Computer Society Annual Symposium on VLSI (ISVLSI), Bochum, Germany, 3–5 July 2017; pp. 627–632. [Google Scholar] [CrossRef]
- Sarwar, S.S.; Srinivasan, G.; Han, B.; Wijesinghe, P.; Jaiswal, A.; Panda, P.; Raghunathan, A.; Roy, K. Energy efficient neural computing: A study of cross-layer approximations. IEEE J. Emerg. Sel. Top. Circuits Syst. 2018, 8, 796–809. [Google Scholar] [CrossRef]
- Venkatesh, G.; Nurvitadhi, E.; Marr, D. Accelerating Deep Convolutional Networks using low-precision and sparsity. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 2861–2865. [Google Scholar]
- Liu, B.; Guo, S.; Qin, H.; Gong, Y.; Yang, J.; Ge, W.; Yang, J. An energy-efficient reconfigurable hybrid DNN architecture for speech recognition with approximate computing. In Proceedings of the 2018 IEEE 23rd International Conference on Digital Signal Processing (DSP), Shanghai, China, 19–21 November 2018; pp. 1–5. [Google Scholar]
- Ardakani, A.; Leduc-Primeau, F.; Onizawa, N.; Hanyu, T.; Gross, W.J. VLSI implementation of deep neural network using integral stochastic computing. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2017, 25, 2688–2699. [Google Scholar] [CrossRef] [Green Version]
- Niu, W.; Ma, X.; Lin, S.; Wang, S.; Qian, X.; Lin, X.; Wang, Y.; Ren, B. Patdnn: Achieving real-time dnn execution on mobile devices with pattern-based weight pruning. In Proceedings of the Twenty-Fifth International Conference on Architectural Support for Programming Languages and Operating Systems, Lausanne, Switzerland, 16–20 March 2020; pp. 907–922. [Google Scholar]
- Sarker, M.M.K.; Rashwan, H.; Akram, F.; Singh, V.K.; Banu, S.F.; Chowdhury, F.; Choudhury, K.; Chambon, S.; Radeva, P.; Puig, D.; et al. SLSNet: Skin lesion segmentation using a lightweight generative adversarial network. Expert Syst. Appl. 2021, 183, 115433. [Google Scholar] [CrossRef]
- Han, S.; Mao, H.; Dally, W.J. Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding. arXiv 2015, arXiv:1510.00149. [Google Scholar]
- Courbariaux, M.; Bengio, Y.; David, J.P. Training deep neural networks with low precision multiplications. arXiv 2014, arXiv:1412.7024. [Google Scholar]
- Louizos, C.; Reisser, M.; Blankevoort, T.; Gavves, E.; Welling, M. Relaxed quantization for discretized neural networks. arXiv 2018, arXiv:1810.01875. [Google Scholar]
- Chernikova, A.; Oprea, A.; Nita-Rotaru, C.; Kim, B. Are self-driving cars secure? Evasion attacks against deep neural networks for steering angle prediction. In Proceedings of the 2019 IEEE Security and Privacy Workshops (SPW), San Francisco, CA, USA, 19–23 May 2019; pp. 132–137. [Google Scholar]
- Pustokhina, I.V.; Pustokhin, D.A.; Gupta, D.; Khanna, A.; Shankar, K.; Nguyen, G.N. An effective training scheme for deep neural network in edge computing enabled Internet of medical things (IoMT) systems. IEEE Access 2020, 8, 107112–107123. [Google Scholar] [CrossRef]
- Sarker, M.M.K.; Makhlouf, Y.; Craig, S.G.; Humphries, M.P.; Loughrey, M.; James, J.A.; Salto-Tellez, M.; O’Reilly, P.; Maxwell, P. A Means of Assessing Deep Learning-Based Detection of ICOS Protein Expression in Colon Cancer. Cancers 2021, 13, 3825. [Google Scholar] [CrossRef]
- Li, Z.; Zhang, Y.; Wang, J.; Lai, J. A survey of FPGA design for AI era. J. Semicond. 2020, 41, 021402. [Google Scholar] [CrossRef]
- Dean, J. Machine learning for systems and systems for machine learning. In Proceedings of the 2017 Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Shomron, G.; Banner, R.; Shkolnik, M.; Weiser, U. Thanks for nothing: Predicting zero-valued activations with lightweight convolutional neural networks. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 234–250. [Google Scholar]
- Akhlaghi, V.; Yazdanbakhsh, A.; Samadi, K.; Gupta, R.K.; Esmaeilzadeh, H. Snapea: Predictive early activation for reducing computation in deep convolutional neural networks. In Proceedings of the 2018 ACM/IEEE 45th Annual International Symposium on Computer Architecture (ISCA), Los Angeles, CA, USA, 1–6 June 2018; pp. 662–673. [Google Scholar]
- Asadikouhanjani, M.; Ko, S.B. A novel architecture for early detection of negative output features in deep neural network accelerators. IEEE Trans. Circuits Syst. II Express Briefs 2020, 67, 3332–3336. [Google Scholar] [CrossRef]
- Kim, C.; Shin, D.; Kim, B.; Park, J. Mosaic-CNN: A combined two-step zero prediction approach to trade off accuracy and computation energy in convolutional neural networks. IEEE J. Emerg. Sel. Top. Circuits Syst. 2018, 8, 770–781. [Google Scholar] [CrossRef]
- Chang, J.; Choi, Y.; Lee, T.; Cho, J. Reducing MAC operation in convolutional neural network with sign prediction. In Proceedings of the 2018 International Conference on Information and Communication Technology Convergence (ICTC), Jeju Island, Korea, 17–19 October 2018; pp. 177–182. [Google Scholar]
- Lin, Y.; Sakr, C.; Kim, Y.; Shanbhag, N. PredictiveNet: An energy-efficient convolutional neural network via zero prediction. In Proceedings of the 2017 IEEE International Symposium on Circuits and Systems (ISCAS), Baltimore, MD, USA, 28–31 May 2017; pp. 1–4. [Google Scholar]
- Song, M.; Zhao, J.; Hu, Y.; Zhang, J.; Li, T. Prediction based execution on deep neural networks. In Proceedings of the 2018 ACM/IEEE 45th Annual International Symposium on Computer Architecture (ISCA), Los Angeles, CA, USA, 1–6 June 2018; pp. 752–763. [Google Scholar]
- Sze, V.; Chen, Y.H.; Yang, T.J.; Emer, J.S. Efficient Processing of Deep Neural Networks: A Tutorial and Survey. Proc. IEEE 2017, 105, 2295–2329. [Google Scholar] [CrossRef] [Green Version]
- Agarap, A.F. Deep learning using rectified linear units (relu). arXiv 2018, arXiv:1803.08375. [Google Scholar]
- Kepner, J.; Gadepally, V.; Jananthan, H.; Milechin, L.; Samsi, S. Sparse deep neural network exact solutions. In Proceedings of the 2018 IEEE High Performance extreme Computing Conference (HPEC), Waltham, MA USA, 25–27 September 2018; pp. 1–8. [Google Scholar]
- Talathi, S.S.; Vartak, A. Improving performance of recurrent neural network with relu nonlinearity. arXiv 2015, arXiv:1511.03771. [Google Scholar]
- Kahan, W. IEEE standard 754 for binary floating-point arithmetic. Lect. Notes Status IEEE 1996, 754, 11. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2014, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Chollet, F. and others.; Keras. 2015. Available online: https://keras.io (accessed on 1 May 2021).
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems. Software. 2015. Available online: tensorflow.org (accessed on 1 May 2021).











Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Suresh, B.; Pillai, K.; Kalsi, G.S.; Abuhatzera, A.; Subramoney, S. Early Prediction of DNN Activation Using Hierarchical Computations. Mathematics 2021, 9, 3130. https://doi.org/10.3390/math9233130
Suresh B, Pillai K, Kalsi GS, Abuhatzera A, Subramoney S. Early Prediction of DNN Activation Using Hierarchical Computations. Mathematics. 2021; 9(23):3130. https://doi.org/10.3390/math9233130
Chicago/Turabian StyleSuresh, Bharathwaj, Kamlesh Pillai, Gurpreet Singh Kalsi, Avishaii Abuhatzera, and Sreenivas Subramoney. 2021. "Early Prediction of DNN Activation Using Hierarchical Computations" Mathematics 9, no. 23: 3130. https://doi.org/10.3390/math9233130