
Enterprise Compensation System Statistical Modeling for Decision Support System Development


Abstract
:1. Introduction
2. Literature Sources Analysis and Purpose of Study Formulation
3. Purpose and Objectives of the Study
4. Materials and Methods of Research
- Define the place of CS statistical models in DSS architecture;
- Describe the main problems of developing CS models;
- Designate, compare, and choose one of the 3 main methods of developing CS models;
- Describe the scheme for the mathematical formalization of a CS;
- Represent the mathematical formalization of a piecework-bonus CS, which is used in obtaining the results;
- Describe model consistency.
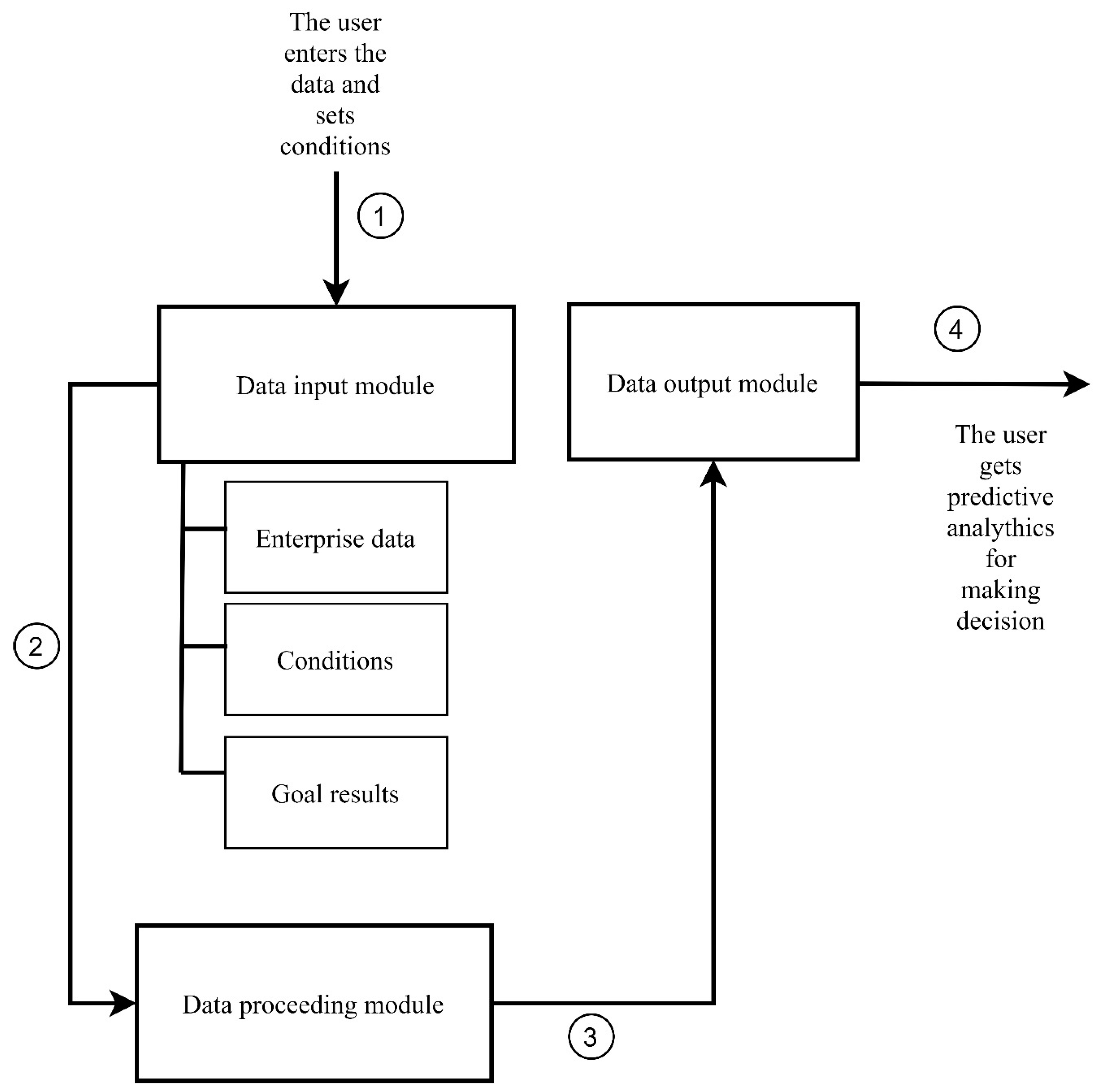
4.1. The Decision Support System for Compensation Plan Management Description
4.2. The Problem of Randomness and Variability CS
4.3. The Problem of the Randomness and Multivariance Nature of CS Solution
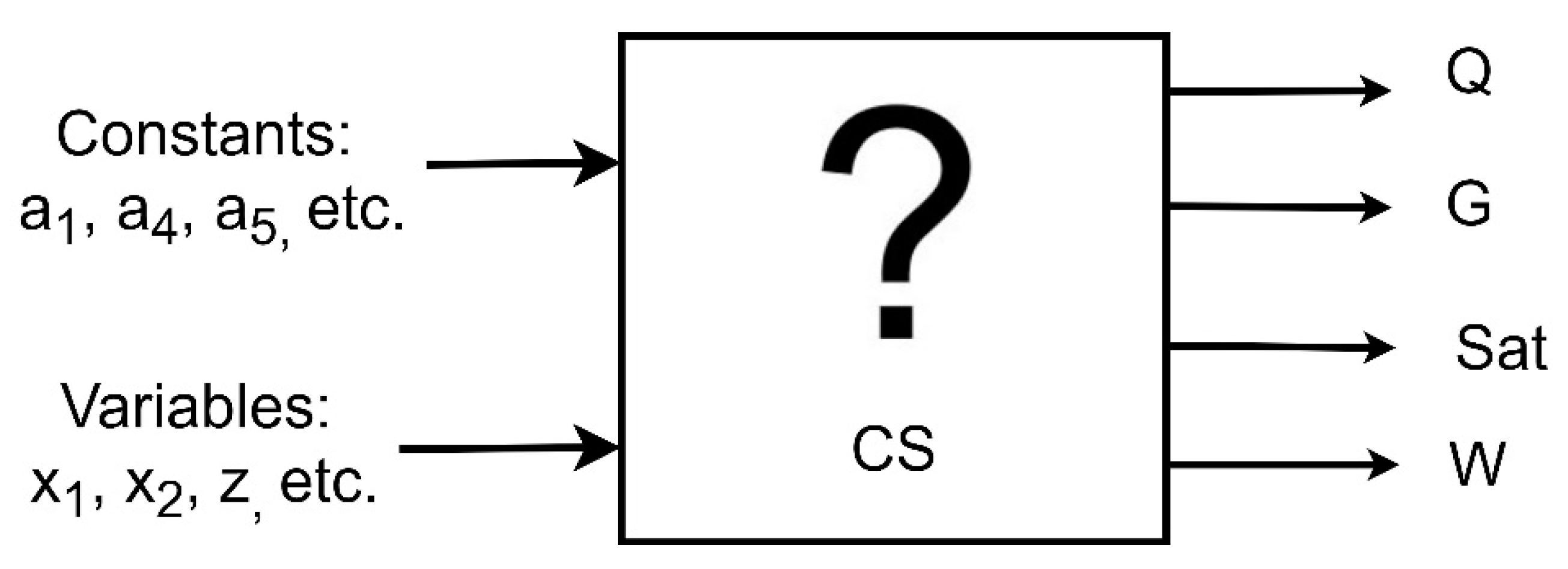
4.4. Scheme of CS Mathematical Formalization
4.5. The Notation and Mathematical Formalization of a Piecework-Bonus CS
4.6. Model Consistency
5. Research Results
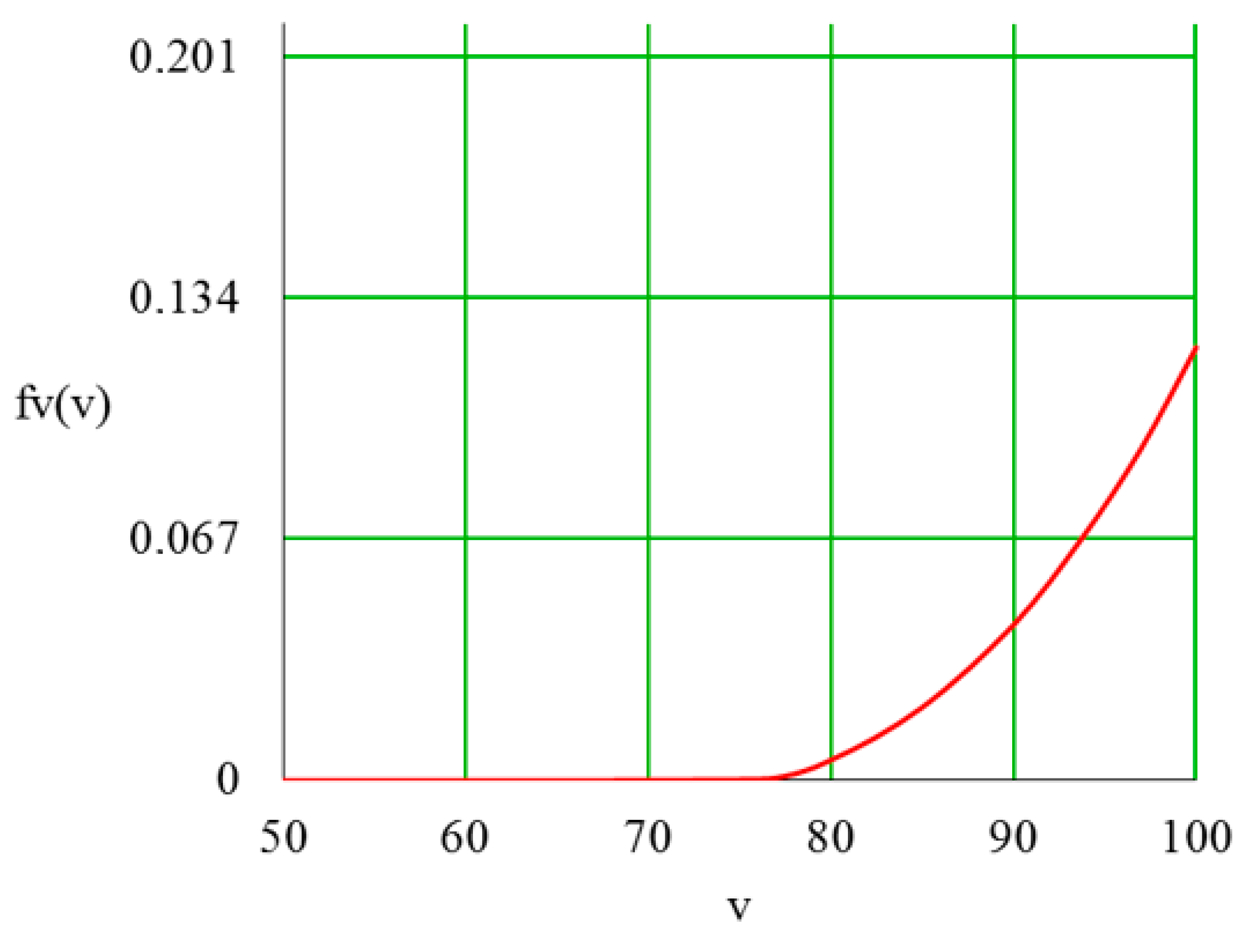
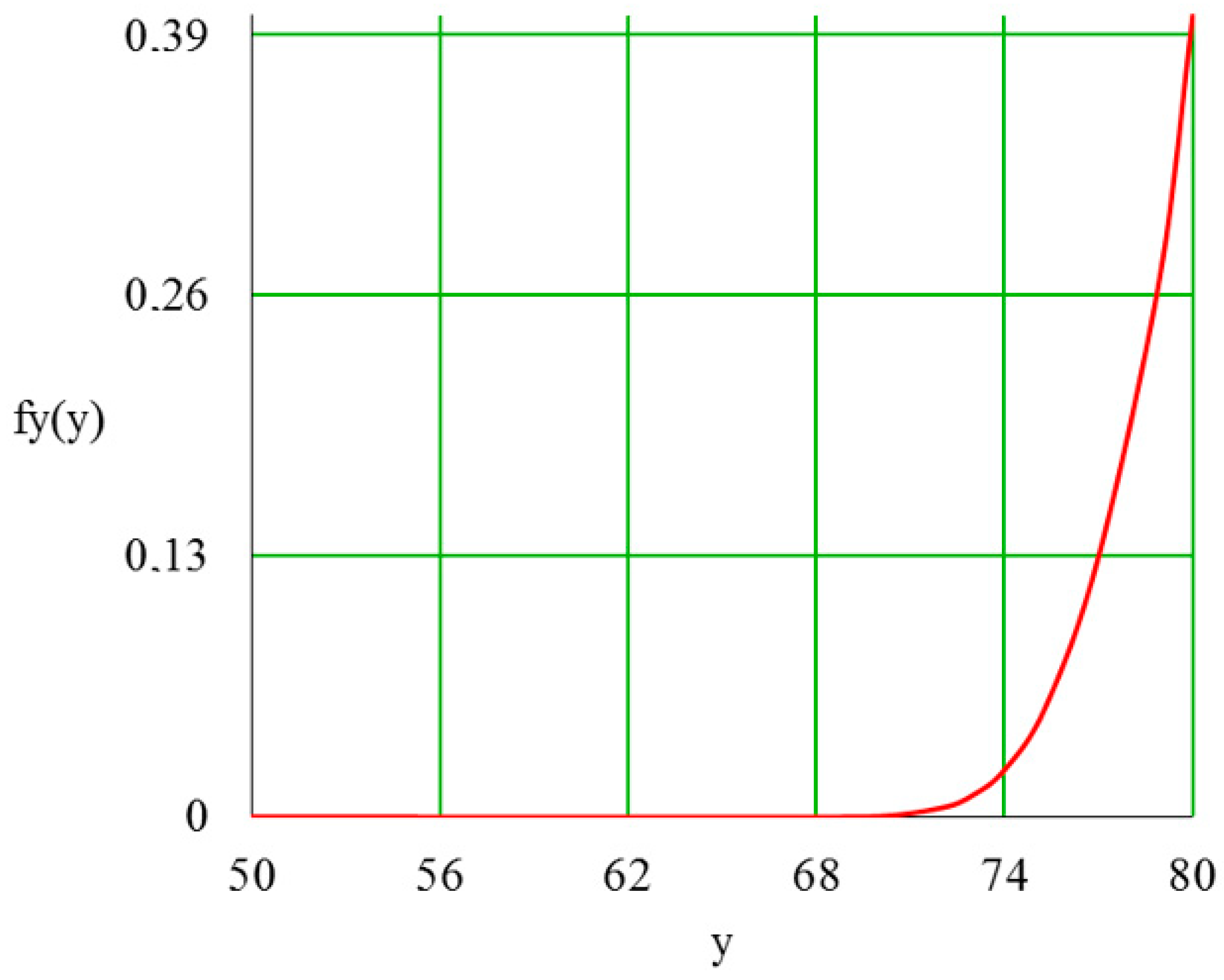
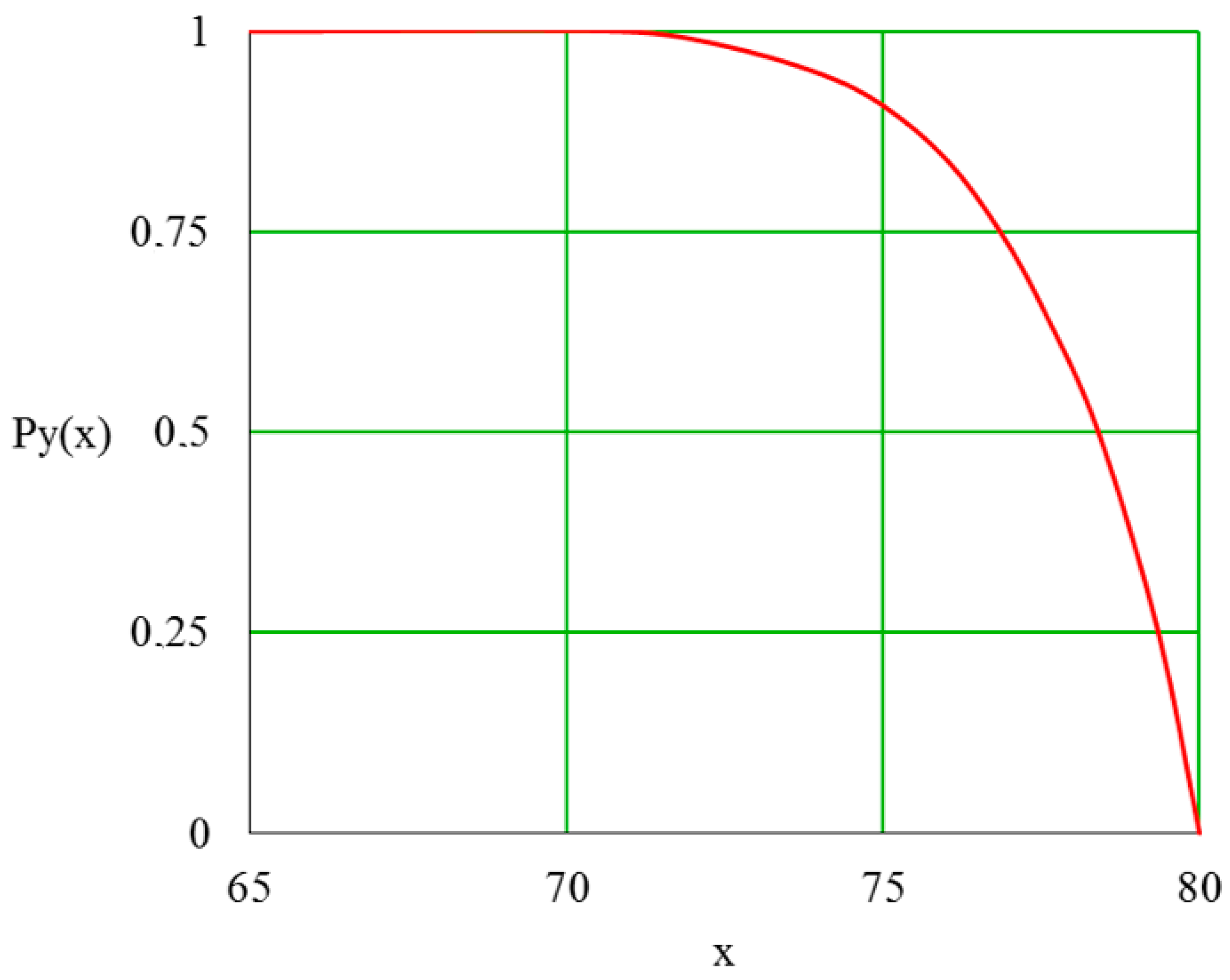
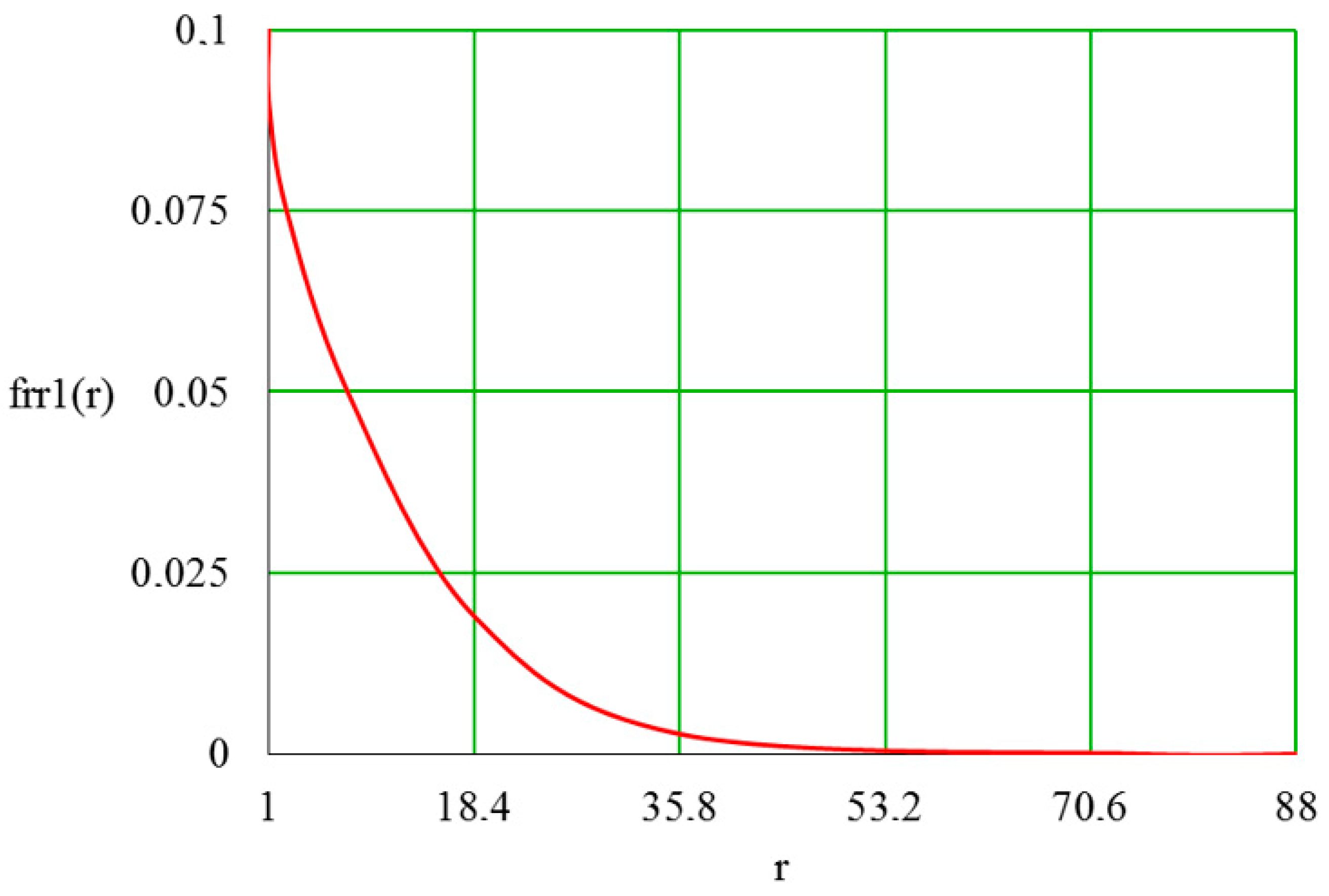
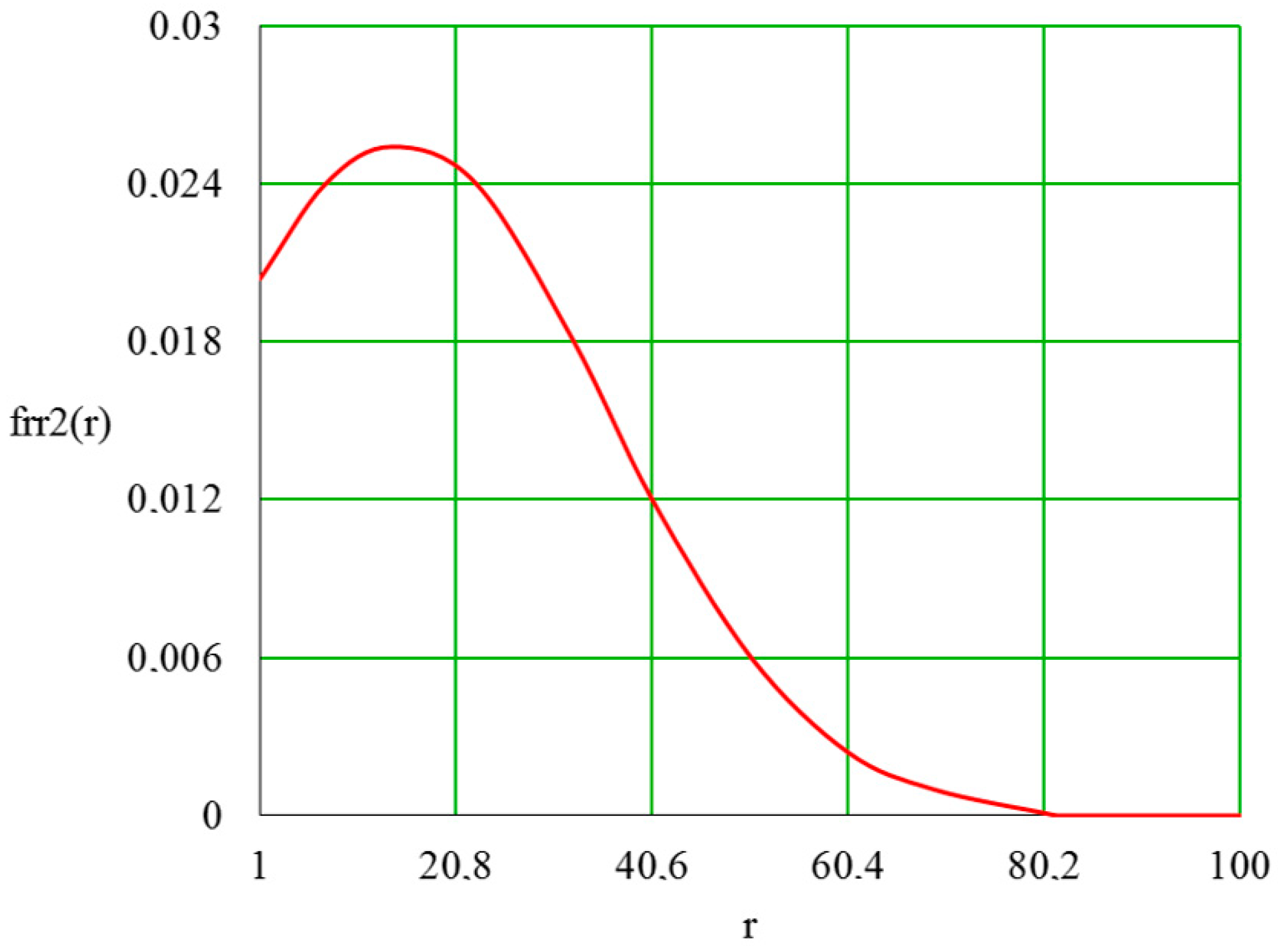
5.1. Output Distribution Density in a Piecework-Bonus CS
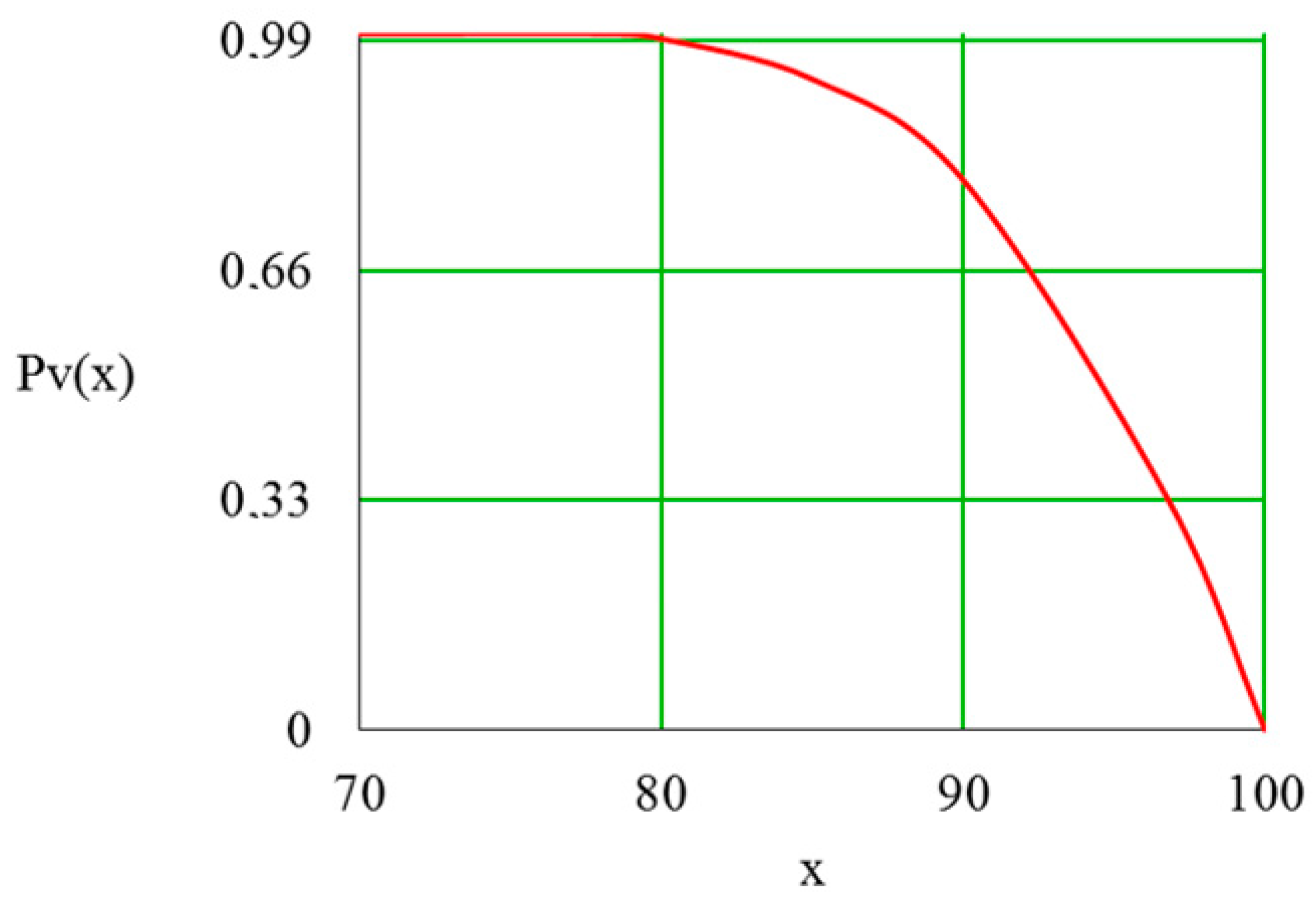
5.2. Quality Distribution Density in Piecework-Bonus CS
5.3. Distribution Density of a Wage Fund in a Piecework-Bonus CS
5.4. Distribution Density of Employee Satisfaction with Piecework-Bonus CS
5.5. Applying a Statistical Model to the Data Processing Module of the DSS
- The user specifies which indicator values they would like to obtain {Q, G, Sat, W};
- The user sets (in %) the level of risk they are prepared to accept in case MD in relation to the CS fail;
- The software processing module calculates statistical characteristics of CS parameters;
- The result for the MD is shown.
6. Conclusions
- It is possible to obtain and effectively apply algorithmic statistical models of CS in the CS DSS module.
- Analytical statistical models for CS are possible to obtain only with an even distribution of the initial CS data. However, even for this simple case, the resulting CS model seems to be more practical than the deterministic CS models.
- As a limitation, it must be mentioned that for more complex probability distributions of initial data (normal distribution, chi-square distribution, and others), the formulas for the probability densities of the resulting CS indicators become too complex and difficult to interpret.
- Further development of CS models is possible based on simulation modeling. The simulation modeling method allows the modeling of any process influenced by random factors. It is also a universal method for solving mathematical tasks.
- There is potential for further CS research using a statistical models method. This includes defining the most significant distribution laws of CS model variables and then applying them to the presented algorithmic statistical model. These extensive results may be of great use in building DSSs and studying CSs.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Yabanci, O. From human resource management to intelligent human resource management: A conceptual perspective. Hum.-Intell. Syst. Integr. 2019, 1, 101–109. [Google Scholar] [CrossRef]
- Kraev, V.; Tikhonov, A. Risk Management in Human Resource Management. TEM J. 2019, 8, 1185–1190. [Google Scholar] [CrossRef]
- Turker, D. Social Responsibility and Human Resource Management. In Managing Social Responsibility. CSR, Sustainability, Ethics & Governance; Springer: Cham, Switzerland, 2018; pp. 131–144. [Google Scholar]
- Brink, W.; Kuang, X.; Majerczyk, M. The effects of minimum-wage increases on wage offers, wage premiums and employee effort under incomplete contracts. Account. Organ. Soc. 2021, 89, 101195. [Google Scholar] [CrossRef]
- Rajibul, A.M.; Kijima, Y. Can a Higher Wage Attract Better Quality Applicants without Deteriorating Public Service Motivation? Evidence from the Bangladesh Civil Service. Int. J. Public Adm. 2021, 44, 74–89. [Google Scholar] [CrossRef] [Green Version]
- Habel, J.; Alavi, S.; Linsenmayer, K. Variable Compensation and Salesperson Health. J. Mark. 2021, 85, 130–149. [Google Scholar] [CrossRef]
- Chung, C.; Sung Hoon, K.; Koangsung, C. Effects of wage-peak system on youth employment: Evidence from South Korea. Appl. Econ. 2021, 53, 4975–4984. [Google Scholar] [CrossRef]
- Morris, M.; Chen, H.; Heslin, M.J.; Krontiras, H. A Structured Compensation Plan Improves But Does Not Erase the Sex Pay Gap in Surgery. Ann. Surg. 2018, 268, 442–448. [Google Scholar] [CrossRef] [PubMed]
- Deelen, A. Flexible Wages or Flexible Workers? A Decomposition of Wage Bill Adjustment by Dutch Firms, 2006–2013. Economist 2021, 169, 179–209. [Google Scholar] [CrossRef]
- Bechter, B.; Braakmann, N.; Brandl, B. Variable Pay Systems and/or Collective Wage Bargaining? Complements or Substitutes? ILR Rev. 2021, 74, 443–469. [Google Scholar] [CrossRef] [Green Version]
- Yang, R.; Mai, Y.; Lee, C.-Y.; Teo, C.-P. Tractable Compensation Plan under Asymmetric Information. Prod. Oper. Manag. 2020, 29, 1212–1218. [Google Scholar] [CrossRef]
- Edmans, A.; Gabaix, X. Executive Compensation: A Modern Primer. J. Econ. Lit. 2016, 54, 1232–1287. [Google Scholar] [CrossRef] [Green Version]
- Zhou, B.; Li, Y.-M.; Sun, F.-C.; Zhou, Z.-G. Executive compensation incentives, risk level and corporate innovation. Emerg. Mark. Rev. 2021, 47, 100798. [Google Scholar] [CrossRef]
- Chung, K.; Boutaba, R.; Hariri, S. Knowledge based decision support system. Inf. Technol. Manag. 2016, 17, 1–3. [Google Scholar] [CrossRef] [Green Version]
- Jason, L.; Sukari, F.; Geoffrey, B. Biased self-assessments, feedback, and employees’ compensation plan choices. Account. Organ. Soc. 2016, 54, 45–59. [Google Scholar] [CrossRef]
- Pylkkänen, E. Modeling Wages and Hours of Work. In Proceedings of the 6th Nordic Seminar On Micro Simulation Models, Copenhagen, Denmark, 8–9 June 2000; pp. 1–47. [Google Scholar]
- Orlova, E. Innovation in Company Labor Productivity Management: Data Science Methods Application. Appl. Syst. Innov. 2021, 4, 68. [Google Scholar] [CrossRef]
- Bolgova, E.V. Modeling the behavior of the wage fund at various levels of staffing of the enterprise. Bull. Samara State Acad. Railw. 2014, 6, 60–64. [Google Scholar]
- Joseph, G.; Altonji, A.; Smith, A. Modeling earnings dynamics. Econometrica 2013, 81, 1395–1454. [Google Scholar] [CrossRef]
- Lupinos, E.A. Modeling the wage system. Omsk. Univ. Bull. Ser. Econ. 2011, 1, 122–126. [Google Scholar]
- Kustandi, C.; Reni, A.; Suharto, T.; Lestari, N. Providing Best Employee Rewards using Decision Support System Method. Int. J. Adv. Sci. Technol. 2020, 29, 6356–6363. [Google Scholar]
- Setiawan, N.; Rossanty, Y. Simple Additive Weighting as Decision Support System for Determining Employees Salary. Int. J. Eng. Technol. 2018, 7, 309–313. [Google Scholar]
- Irawan, Y. Decision Support System for Employee Bonus Determination with Web-Based Simple Additive Weighting (SAW). J. Appl. Eng. Technol. Sci. (JAETS) 2020, 2, 7–13. [Google Scholar] [CrossRef]
- Orlov, A.I. The development and approvement management decisions. Sci. J. KubSAU 2017, 130, 567–597. [Google Scholar]
- Vinogradova, E.Y. Topical issues of design and implementation of corporate management decision-making support systems at an enterprise. News Far East. Fed. Univ. Econ. Manag. 2018, 1, 102–111. [Google Scholar] [CrossRef]
- Bobrovnikova, A. Razvitie form i sistem oplaty truda v usloviyah rynochnoj ekonomiki Rossii. Territ. Nauk. 2017, 2, 175–178. (In Russian) [Google Scholar]
- Kochelorova, G. Sovershenstvovanie poryadka oplaty truda na predpriyatii. Soc.’no-Ekonomicheskij Gumanit. Zhurnal Krasnoyarskogo GAU 2018, 1, 28–41. (In Russian) [Google Scholar]
- Sokolova, A.; Duborkina, I. Sistema oplaty truda v kommercheskih organizaciyah. Serv. Ross. Rubezhom 2017, 11, 111–121. (In Russian) [Google Scholar]
- Filippova, T.; Zhabunin, A.; Ekova, V.; Shipunova, I. Ways to improve wages at the enterprise. Innov. Econ. Prospect. Dev. Improv. 2017, 1, 171–175. (In Russian) [Google Scholar]
- Slepcova, E.; Knyazeva, A. Optimization of wages in modern conditions. Econ. Bus. 2017, 1, 95–98. (In Russian) [Google Scholar]
- Borzhesh, A.; Lebedev, A. Methodological approach to assessing the effectiveness of management decision support systems in oil and gas corporations. Belgorod State Univ. Sci. Bull. 2018, 45, 239–250. [Google Scholar]
- Kitsios, F.; Kamariotou, M. Decision Support Systems and Business Strategy: A conceptual framework for Strategic Information Systems Planning. In Proceedings of the 6th IEEE International Conference on IT Convergence and Security (ICITCS2016), Prague, Czech Republic, 26 September 2016; pp. 149–153. [Google Scholar]
- Kaklauskas, A. Intelligent Decision Support Systems. In Biometric and Intelligent Decision Making Support; Springer: Cham, Switzerland, 2015; pp. 31–85. [Google Scholar]
- Demidovskij, A.; Babkin, E. Developing a distributed linguistic decision making system. Bus. Inform. 2019, 13, 18–32. [Google Scholar] [CrossRef] [Green Version]
- Aqell, M.; Nakshabandi, O.; Adeniyi, A. Decision Support Systems Classification in Industry. Period. Eng. Nat. Sci. 2019, 7, 774–785. [Google Scholar] [CrossRef] [Green Version]
- Rashidi, M.; Ghodrat, M.; Samali, B.; Mohammadi, M. Decision Support Systems. Manag. Inf. Syst. 2018, 2, 19–38. [Google Scholar]
- Sidorov, A.; Senchenko, P. Regional Digital Economy: Assessment of Development Levels. Mathematics 2020, 8, 2143. [Google Scholar] [CrossRef]
- Vinogradova, E. Questions of design corporate systems for support of acceptance of administrative decisions at the enterprise. Bull. Far East. Fed. Univ. Econ. Manag. 2018, 1, 102–111. [Google Scholar] [CrossRef]
- Karamyshev, A. Process-based management methodology analysis completely covering business processes of the enterprise. Bull. Belgorod State Technol. Univ. Named After. V. G. Shukhov 2017, 2, 214–217. [Google Scholar] [CrossRef]
- Osipov, V.; Gorina, A. Characteristic and directions of development of management accounting systems. [Harakteristika i napravleniya razvitiya sistem upravlencheskogo ucheta]. Vestn. Univ. 2019, 5, 40–47. [Google Scholar] [CrossRef]
- Shvedenko, V. Information support of interaction of process and functional management of enterprise activities. Izv. St.-Peterbg. Gos. Ekon. Univ. 2019, 6, 90–94. [Google Scholar]
- Borovkov, A.A. Applied Statistics; University Textbook; Lani: Saint-Petersburg, Russia, 2021; 704p. [Google Scholar]
- Davison, A.C. Statistical Models; Cambridge University Press: Cambridge, UK, 2008; 726p. [Google Scholar]
- Shilnikov, A.; Mitsel, A. Management of the compensation system based on statistical models and simulation. Vestn. Astrah. Gos. Tekhnicheskogo Univ. 2021, 3, 82–93. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value | Quantity |
|---|---|---|
| CS | Piecework bonus | 1 CS |
| Variables and constants | According to mathematical formalization (see Section 4.5). Value of each variable and constant varies in its own range. | 8 units |
| The distribution law | The values of variables and constants in the CS differ according to the enterprise. So, for researchers these are random. It is not possible to choose a distribution law; it is necessary to select from a number of known laws. As an example, 4 laws: even, lognormal, chi-square, and normal will be applied. | 4 Laws of distribution = 256 combinations |
| # | The Solution | The Essence |
|---|---|---|
| 1 | Based on statistical data | Probabilistic forecasts are based on statistics. Statistical data on the types and results of CSs in different enterprises are required. |
| 2 | Based on statistical models | Based on the analysis of statistical models, the probability density of a particular CS outcome is calculated. |
| 3 | Based on simulation modeling | Based on the CS simulation model, generated indicators are derived to be investigated and analyzed. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mitsel, A.; Shilnikov, A.; Senchenko, P.; Sidorov, A. Enterprise Compensation System Statistical Modeling for Decision Support System Development. Mathematics 2021, 9, 3126. https://doi.org/10.3390/math9233126
Mitsel A, Shilnikov A, Senchenko P, Sidorov A. Enterprise Compensation System Statistical Modeling for Decision Support System Development. Mathematics. 2021; 9(23):3126. https://doi.org/10.3390/math9233126
Chicago/Turabian StyleMitsel, Artur, Aleksandr Shilnikov, Pavel Senchenko, and Anatoly Sidorov. 2021. "Enterprise Compensation System Statistical Modeling for Decision Support System Development" Mathematics 9, no. 23: 3126. https://doi.org/10.3390/math9233126