



Intelligent Analysis of Construction Costs of Shield Tunneling in Complex Geological Conditions by Machine Learning Method
Abstract
:1. Introduction
2. Problem Description and Data Pre-Processing
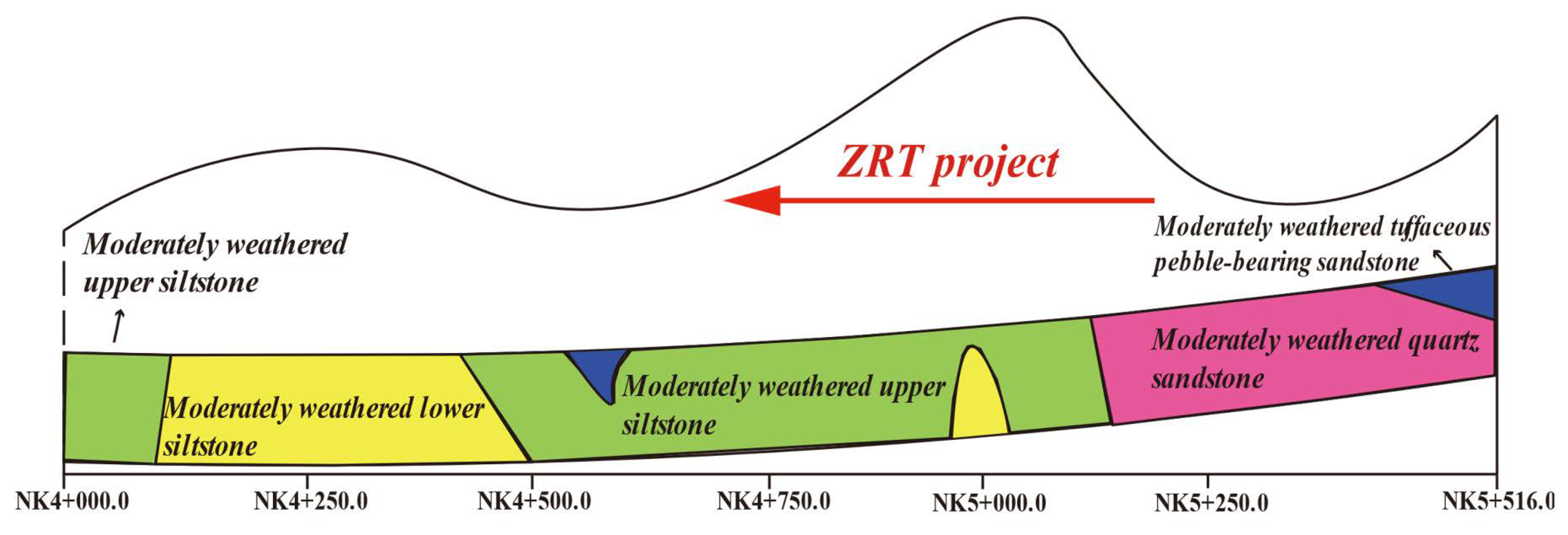
2.1. Background of the Project
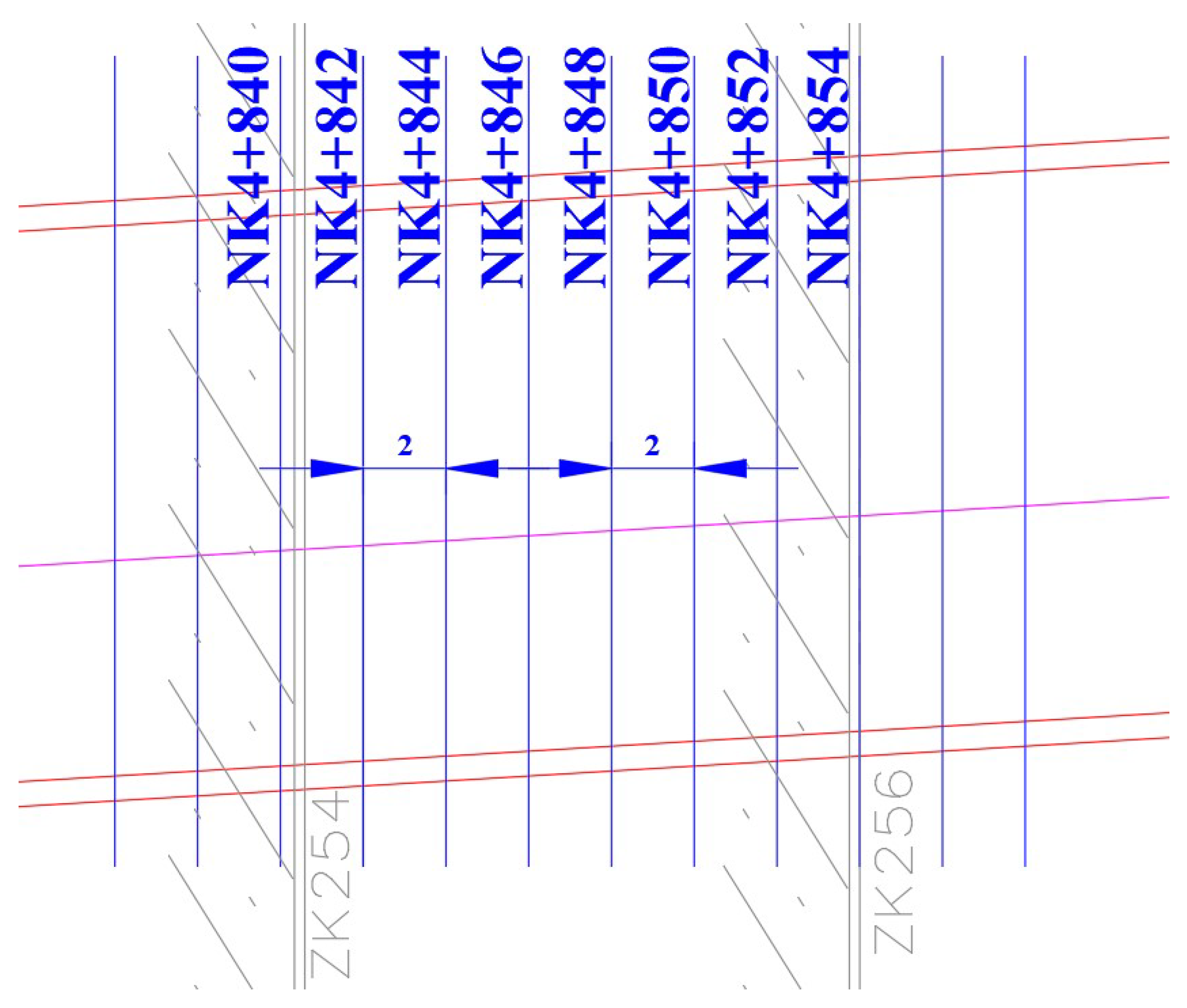
2.2. Collection of Geological Data and Tunneling Consumption
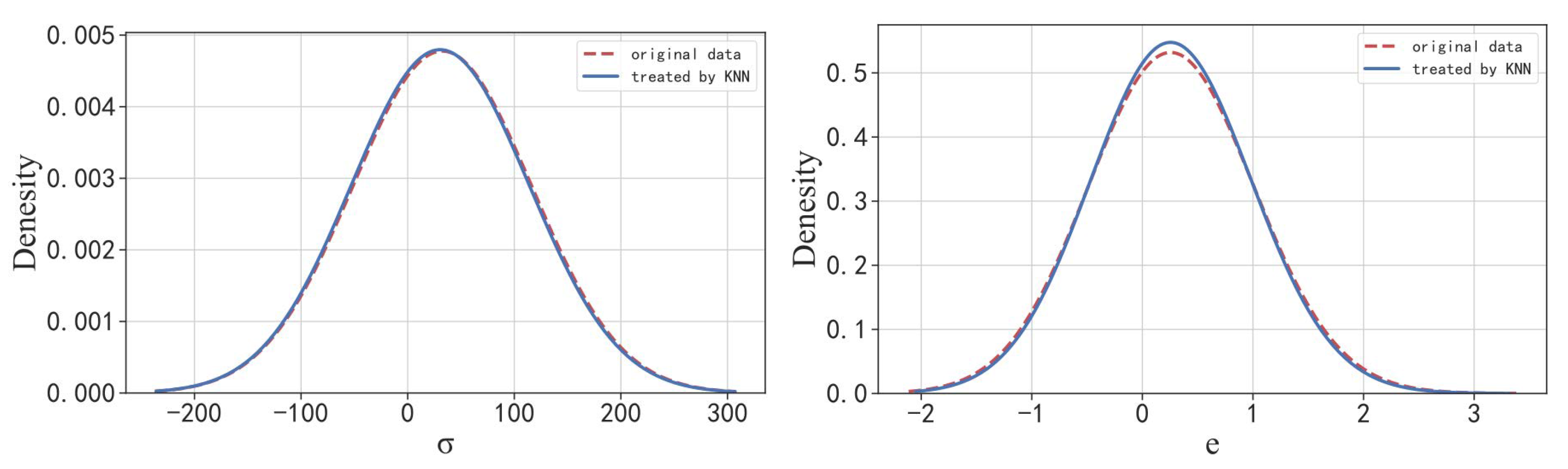
2.3. Pre-Processing of the Datasets
3. Methodology
3.1. Principle Technique of Random Forest
3.2. Application of the Random Forest-Based Method in Analysis of Tunneling Consumption in Complex Geological Conditions
4. Predictions of Construction Cost of Shield Tunneling in Complex Geological Conditions
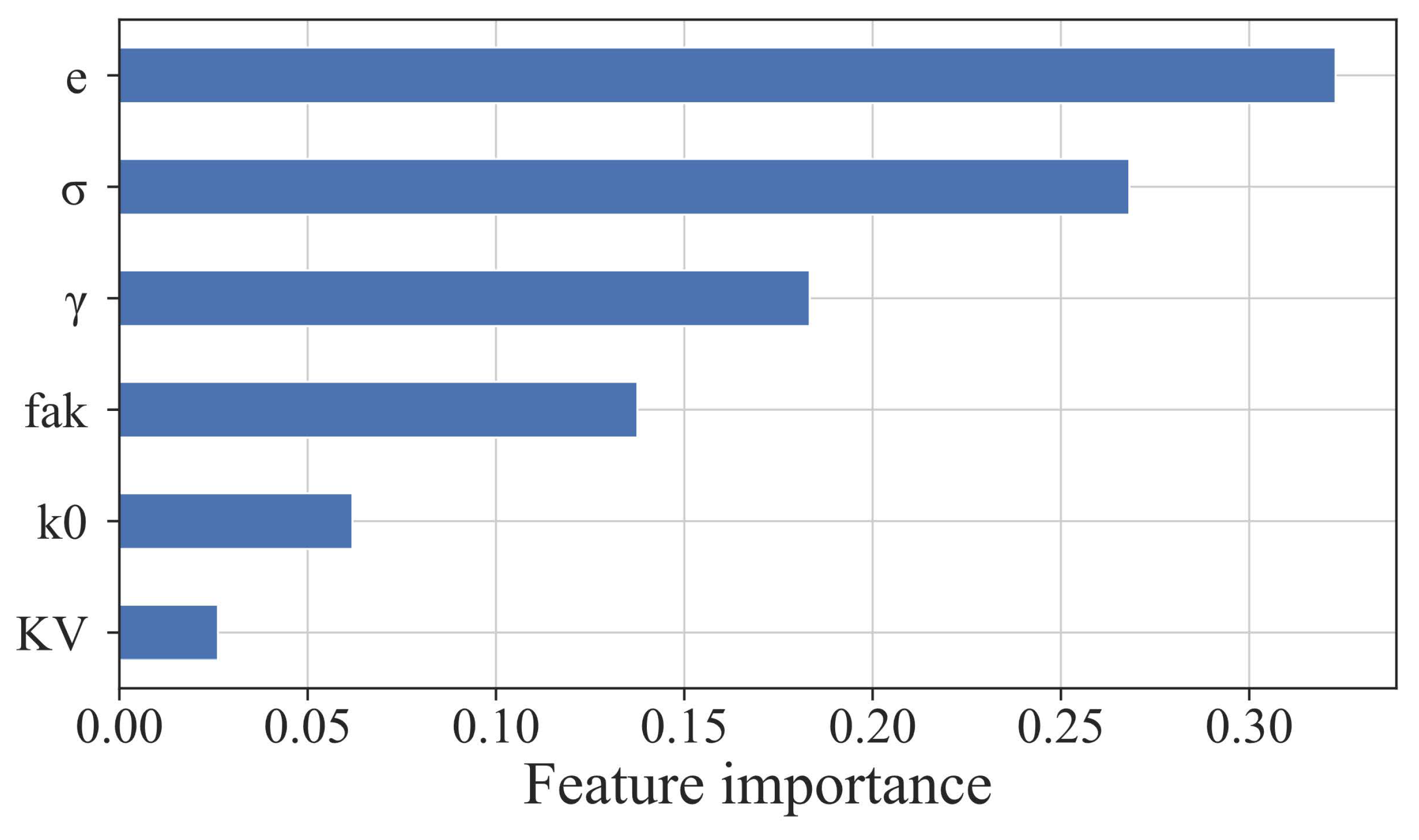
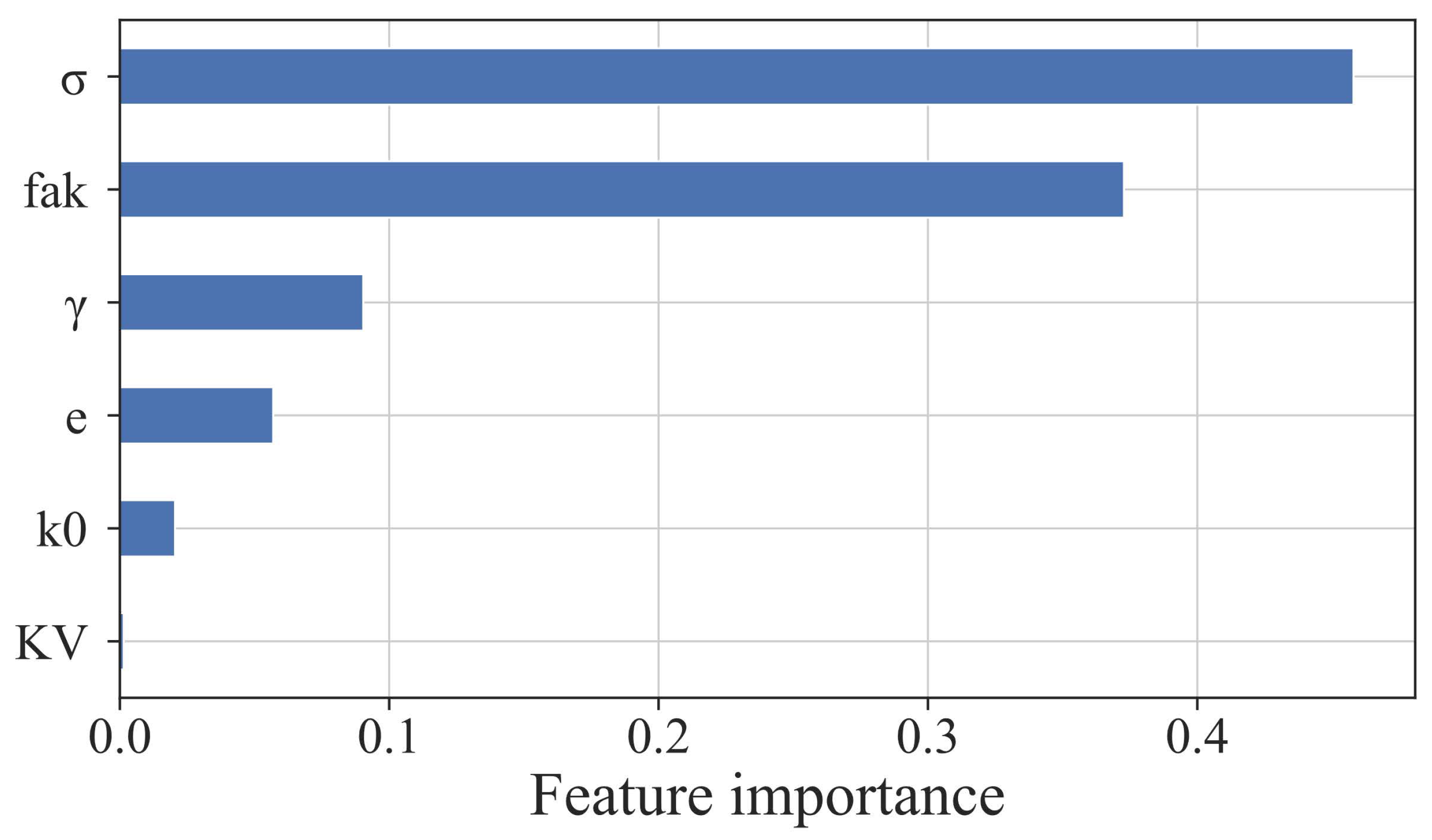
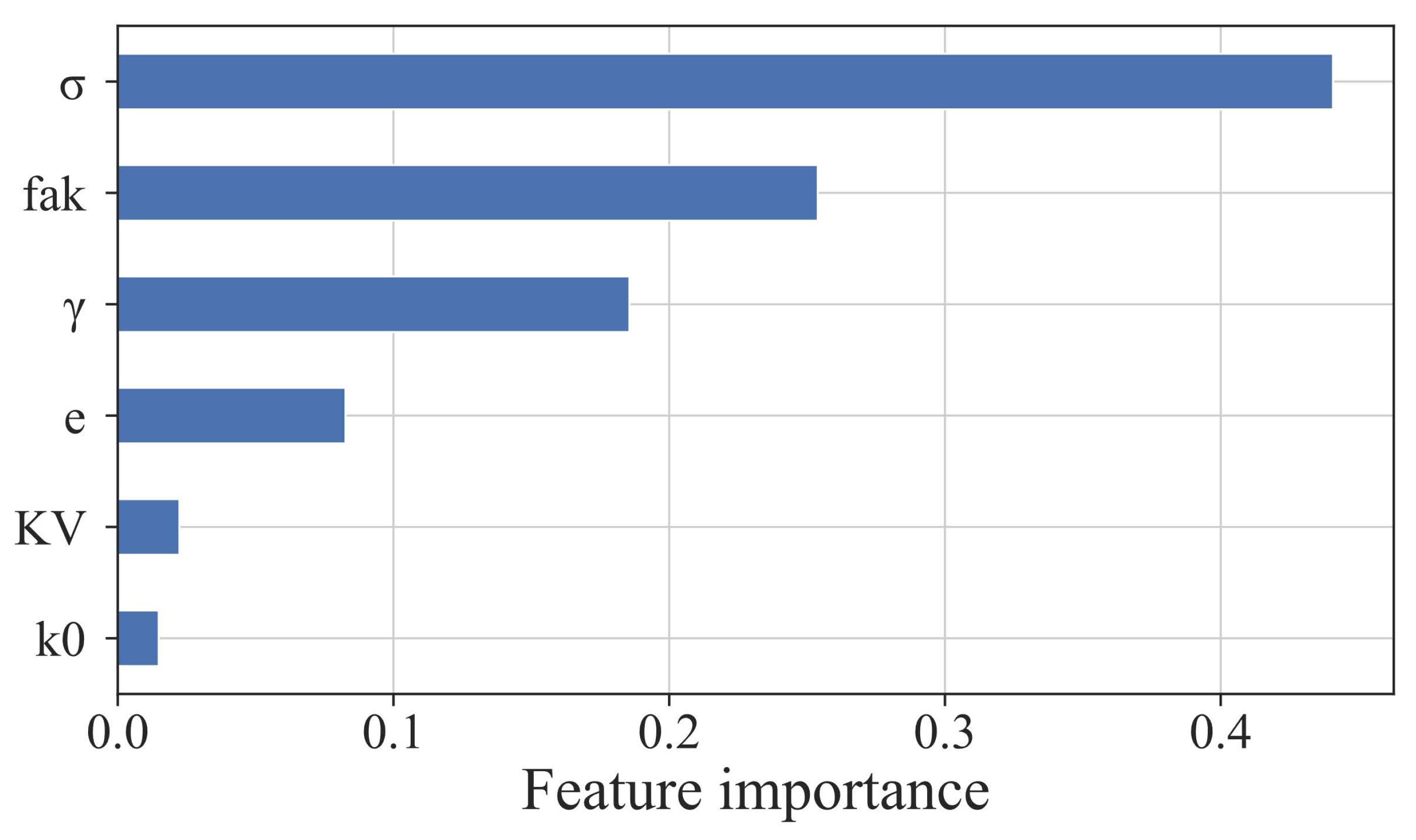
4.1. Feature Importance of Geotechnical Parameters for Consumption Factors
4.2. Quota of Budget for Shield Tunneling in Complex Geological Conditions Based on the Random Forest Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Demirkesen, S.; Ozorhon, B. Impact of integration management on construction project management performance. Int. J. Proj. Manag. 2017, 35, 1639–1654. [Google Scholar] [CrossRef]
- Kim, S.; Chang, S.; Castro-Lacouture, D. Dynamic modeling for analyzing impacts of skilled labor shortage on construction project management. J. Manag. Eng. 2020, 36, 04019035. [Google Scholar] [CrossRef]
- Kim, Y.; Bruland, A. A study on the establishment of Tunnel Contour Quality Index considering construction cost. Tunn. Undergr. Space Technol. 2015, 50, 218–225. [Google Scholar] [CrossRef]
- Huang, Z.; Zhang, D.; Pitilakis, K.; Tsinidis, G.; Huang, H.; Zhang, D.; Argyroudis, S. Resilience assessment of tunnels: Framework and application for tunnels in alluvial deposits exposed to seismic hazard. Soil Dyn. Earthq. Eng. 2022, 162, 107456. [Google Scholar] [CrossRef]
- Mesároš, P.; Mandičák, T. Exploitation and benefits of BIM in construction project management. IOP Conf. Ser. Mater. Sci. Eng. 2017, 245, 062056. [Google Scholar] [CrossRef] [Green Version]
- Chmelina, K.; Rabensteiner, K.; Krusche, G. A tunnel information system for the management and utilization of geo-engineering data in urban tunnel projects. Geotech. Geol. Eng. 2013, 31, 845–859. [Google Scholar] [CrossRef]
- Li, J.; Jing, L.; Zheng, X.; Li, P.; Yang, C. Application and outlook of information and intelligence technology for safe and efficient TBM construction. Tunn. Undergr. Space Technol. 2019, 93, 103097. [Google Scholar] [CrossRef]
- Vargas, J.P.; Koppe, J.C.; Pérez, S.; Hurtado, J.P. Planning tunnel construction using Markov chain Monte Carlo (MCMC). Math. Probl. Eng. 2015, 797953. [Google Scholar] [CrossRef] [Green Version]
- Park, J.; Lee, K.H.; Park, J.; Choi, H.; Lee, I.M. Predicting anomalous zone ahead of tunnel face utilizing electrical resistivity: I. Algorithm and measuring system development. Tunn. Undergr. Space Technol. 2016, 60, 141–150. [Google Scholar] [CrossRef]
- Park, J.; Lee, K.H.; Kim, B.K.; Choi, H.; Lee, I.M. Predicting anomalous zone ahead of tunnel face utilizing electrical resistivity: II. Field tests. Tunn. Undergr. Space Technol. 2017, 68, 1–10. [Google Scholar] [CrossRef]
- Leu, S.S.; Joko, T.; Sutanto, A. Applied real-time Bayesian analysis in forecasting tunnel geological conditions. In Proceedings of the 2010 IEEE International Conference on Industrial Engineering and Engineering Management, Macao, China, 7–10 December 2010; pp. 1505–1508. [Google Scholar]
- Mahmoodzadeh, A.; Zare, S. Probabilistic prediction of expected ground condition and construction time and costs in road tunnels. J. Rock Mech. Geotech. Eng. 2016, 8, 734–745. [Google Scholar] [CrossRef]
- Lee, J.; Sagong, M.; Cho, G.C.; Choo, S. Experimental estimation of the fallout size and reinforcement design of a tunnel under excavation. Tunn. Undergr. Space Technol. 2010, 25, 518–525. [Google Scholar] [CrossRef]
- Guan, Z.; Deng, T.; Jiang, Y.; Zhao, C.; Huang, H. Probabilistic estimation of ground condition and construction cost for mountain tunnels. Tunn. Undergr. Space Technol. 2014, 42, 175–183. [Google Scholar] [CrossRef]
- Zhang, Q.; Liu, Z.; Tan, J. Prediction of geological conditions for a tunnel boring machine using big operational data. Autom. Constr. 2019, 100, 73–83. [Google Scholar] [CrossRef]
- Carrière, S.D.; Chalikakis, K.; Sénéchal, G.; Danquigny, C.; Emblanch, C. Combining electrical resistivity tomography and ground penetrating radar to study geological structuring of karst unsaturated zone. J. Appl. Geophys. 2013, 94, 31–41. [Google Scholar] [CrossRef]
- Daraei, A.; H Sherwani, A.F.; Faraj, R.H.; Kalhor, Q.; Zare, S.; Mahmoodzadeh, A. Optimization of the outlet portal of Heybat Sultan twin tunnels based on the value engineering methodology. SN Appl. Sci. 2019, 1, 1–10. [Google Scholar] [CrossRef] [Green Version]
- Mahmoodzadeh, A.; Mohammadi, M.; Abdulhamid, S.N.; Nejati, H.R.; Noori, K.M.G.; Ibrahim, H.H.; Ali, H.F.H. Predicting construction time and cost of tunnels using Markov chain model considering opinions of experts. Tunn. Undergr. Space Technol. 2021, 116, 104109. [Google Scholar] [CrossRef]
- Shi, L.; Zhang, J.; Zhu, Q.; Sun, H. Prediction of mechanical behavior of rocks with strong strain-softening effects by a deep-learning approach. Comput. Geotech. 2022, 152, 105040. [Google Scholar] [CrossRef]
- Mahmoodzadeh, A.; Mohammadi, M.; Daraei, A.; Farid Hama Ali, H.; Ismail Abdullah, A.; Kameran Al-Salihi, N. Forecasting tunnel geology, construction time and costs using machine learning methods. Neural Comput. Appl. 2021, 33, 321–348. [Google Scholar] [CrossRef]
- Ye, D. An Algorithm for Construction Project Cost Forecast Based on Particle Swarm Optimization-Guided BP Neural Network. Sci. Program. 2021, 2021, 4309495. [Google Scholar] [CrossRef]
- Lin, T.; Yi, T.; Zhang, C.; Liu, J. Intelligent prediction of the construction cost of substation projects using support vector machine optimized by particle swarm optimization. Math. Probl. Eng. 2019, 7631362. [Google Scholar] [CrossRef]
- Liu, J.B.; Ren, H.; Li, Z.M. Model on dynamic control of project costs based on GM (1, 1) for construction enterprises. In Fuzzy Information and Engineering Volume 2; Springer: Berlin/Heidelberg, Germany, 2009; pp. 1611–1620. [Google Scholar]
- Min, S.; Einstein, H.; Lee, J.; Kim, T. Application of decision aids for tunneling (DAT) to a drill & blast tunnel. KSCE J. Civ. Eng. 2003, 7, 619–628. [Google Scholar]
- Maruvanchery, V.; Zhe, S.; Robert, T.L.K. Early construction cost and time risk assessment and evaluation of large-scale underground cavern construction projects in Singapore. Undergr. Space 2020, 5, 53–70. [Google Scholar] [CrossRef]
- Shi, S.S.; Li, S.C.; Li, L.P.; Zhou, Z.Q.; Wang, J. Advance optimized classification and application of surrounding rock based on fuzzy analytic hierarchy process and Tunnel Seismic Prediction. Autom. Constr. 2014, 37, 217–222. [Google Scholar] [CrossRef]
- Belgiu, M.; Drăguţ, L. Random forest in remote sensing: A review of applications and future directions. ISPRS J. Photogramm. Remote Sens. 2016, 114, 24–31. [Google Scholar] [CrossRef]
- Feng, X.; Jimenez, R. Predicting tunnel squeezing with incomplete data using Bayesian networks. Eng. Geol. 2015, 195, 214–224. [Google Scholar] [CrossRef]
- Zhang, P.; Yin, Z.Y.; Jin, Y.F. Machine learning-based modelling of soil properties for geotechnical design: Review, tool development and comparison. Arch. Comput. Methods Eng. 2022, 29, 1229–1245. [Google Scholar] [CrossRef]
- Lu, L.; Meng, X.; Mao, Z.; Karniadakis, G.E. DeepXDE: A deep learning library for solving differential equations. SIAM Rev. 2021, 63, 208–228. [Google Scholar] [CrossRef]
- Ho, T.K. Random decision forests. In Proceedings of the 3rd International Conference on Document Analysis and Recognition, Montreal, QC, Canada, 14–16 August 1995; Volume 1, pp. 278–282. [Google Scholar]
- Ho, T.K. The random subspace method for constructing decision forests. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 832–844. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Strobl, C.; Boulesteix, A.L.; Augustin, T. Unbiased split selection for classification trees based on the Gini index. Comput. Stat. Data Anal. 2007, 52, 483–501. [Google Scholar] [CrossRef] [Green Version]
- Palomino, A.F.; Espino, P.S.; Reyes, C.B.; Rojas, J.A.J.; y Silva, F.R. Estimation of moisture in live fuels in the mediterranean: Linear regressions and random forests. J. Environ. Manag. 2022, 322, 116069. [Google Scholar] [CrossRef] [PubMed]
- Smith, P.F.; Ganesh, S.; Liu, P. A comparison of random forest regression and multiple linear regression for prediction in neuroscience. J. Neurosci. Methods 2013, 220, 85–91. [Google Scholar] [CrossRef] [PubMed]
- Piryonesi, S.M. The Application of Data Analytics to Asset Management: Deterioration and Climate Change Adaptation in Ontario Roads. Ph.D. Thesis, University of Toronto, Toronto, ON, Canada, 2019. [Google Scholar]
- Rajković, D.; Jeromela, A.M.; Pezo, L.; Lončar, B.; Grahovac, N.; Špika, A.K. Artificial neural network and random forest regression models for modelling fatty acid and tocopherol content in oil of winter rapeseed. J. Food Compos. Anal. 2023, 115, 105020. [Google Scholar] [CrossRef]
- Kang, K.; Ryu, H. Predicting types of occupational accidents at construction sites in Korea using random forest model. Saf. Sci. 2019, 120, 226–236. [Google Scholar] [CrossRef]
- Tixier, A.J.P.; Hallowell, M.R.; Rajagopalan, B.; Bowman, D. Application of machine learning to construction injury prediction. Autom. Constr. 2016, 69, 102–114. [Google Scholar] [CrossRef] [Green Version]
- Wang, L.; Mao, Z.; Xuan, H.; Ma, T.; Hu, C.; Chen, J.; You, X. Status diagnosis and feature tracing of the natural gas pipeline weld based on improved random forest model. Int. J. Press. Vessel. Pip. 2022, 200, 104821. [Google Scholar] [CrossRef]
- Gu, Y.; Liu, D.; Arvin, R.; Khattak, A.J.; Han, L.D. Predicting intersection crash frequency using connected vehicle data: A framework for geographical random forest. Accid. Anal. Prev. 2023, 179, 106880. [Google Scholar] [CrossRef]
- Zermane, A.; Tohir, M.Z.M.; Zermane, H.; Baharudin, M.R.; Yusoff, H.M. Predicting fatal fall from heights accidents using random forest classification machine learning model. Saf. Sci. 2023, 159, 106023. [Google Scholar] [CrossRef]
- Mishra, N.B.; Crews, K.A. Mapping vegetation morphology types in a dry savanna ecosystem: Integrating hierarchical object-based image analysis with Random Forest. Int. J. Remote Sens. 2014, 35, 1175–1198. [Google Scholar] [CrossRef]
- Guan, H.; Li, J.; Chapman, M.; Deng, F.; Ji, Z.; Yang, X. Integration of orthoimagery and lidar data for object-based urban thematic mapping using random forests. Int. J. Remote Sens. 2013, 34, 5166–5186. [Google Scholar] [CrossRef]
- Peterson, L.E. K-nearest neighbor. Scholarpedia 2009, 4, 1883. [Google Scholar] [CrossRef]
- Santos, O.J., Jr.; Celestino, T.B. Artificial neural networks analysis of Sao Paulo subway tunnel settlement data. Tunn. Undergr. Space Technol. 2008, 23, 481–491. [Google Scholar] [CrossRef]
- Takoutsing, B.; Heuvelink, G.B. Comparing the prediction performance, uncertainty quantification and extrapolation potential of regression kriging and random forest while accounting for soil measurement errors. Geoderma 2022, 428, 116192. [Google Scholar] [CrossRef]
- Carrasco, L.; Toquenaga, Y.; Mashiko, M. Extrapolation of random forest models shows scale adaptation in egret colony site selection against landscape complexity. Ecol. Complex. 2015, 24, 29–36. [Google Scholar] [CrossRef]
- Yang, L.; Meng, X.; Karniadakis, G.E. B-PINNs: Bayesian physics-informed neural networks for forward and inverse PDE problems with noisy data. J. Comput. Phys. 2021, 425, 109913. [Google Scholar] [CrossRef]
- Zhang, P.; Yin, Z.Y.; Jin, Y.F. Bayesian neural network-based uncertainty modelling: Application to soil compressibility and undrained shear strength prediction. Can. Geotech. J. 2022, 59, 546–557. [Google Scholar] [CrossRef]





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Geotechnical Parameters and Abbreviations | Soil 1 | Soil 2 | Soil 3 | Soil 4 | … | Rock 9 |
|---|---|---|---|---|---|---|
| Moisture content ( %) | 28.98 | 45.24 | 41.87 | 41.59 | … | - |
| Natural density ( kN/m) | 19.10 | 17.40 | 17.40 | 17.80 | … | 26.00 |
| Specific gravity () | 2.70 | 2.73 | 2.73 | 2.73 | … | - |
| Void ratio () | 0.80 | 1.30 | 1.15 | 1.23 | … | 0.032 |
| Saturability () | 95.66 | 95.25 | 96.12 | 92.47 | … | - |
| Liquid limit (WL) | - | 40.51 | 38.64 | 39.75 | … | - |
| Plastic limit (WP) | - | 24.34 | 23.94 | 23.97 | … | - |
| liquidity index (IL) | - | 16.17 | 14.70 | 15.77 | … | - |
| plasticity index (IP) | - | 1.32 | 1.20 | 0.97 | … | - |
| Bearing capacity (fak kPa) | 130 | 65 | 65 | 100 | … | 3500 |
| Modulus of compressibility ( MPa) | 7.0 | 2.3 | 2.4 | 4.0 | … | - |
| Lateral pressure coefficient ( MPa) | 0.40 | 0.58 | 0.58 | 0.54 | … | 0.25 |
| Horizontal permeability coefficient (KH cm/s) | … | |||||
| Vertical permeability coefficient (KV cm/s) | … | |||||
| Cohesion (c kPa) | 3.0 | 13.0 | 13.0 | 24.0 | … | 450 |
| Friction angle ( ) | 25 | 9.5 | 10 | 12 | … | 43 |
| Compressive strength ( MPa) | 5000 | 9.4021 | 0.9954 | … | 60.40 |
| Consumption Indicator | Components | Unit Price 1 | Index |
|---|---|---|---|
| Grease | Tail grease | 17.5 | |
| EP2 grease | 25.0 | ||
| Seal grease | 55.0 | ||
| Grouting | Grouting | 1.3–1.8 | |
| Labor | Labor | 135.0 | |
| Water & electricity | Water | 4.27 | |
| Electricity | 0.78 |
| Type | Compressive Strength (MPa) |
|---|---|
| Soil | ≤1 |
| Soft rock | ≤30 |
| Hard rock | ≥30 |
| Factor | Quota | Soil | Soft Rock | Hard Rock | |||
|---|---|---|---|---|---|---|---|
| Tail grease | 81.90 | 70.50 | 118% | 84.99 | 136% | 145.88 | 399% |
| EP2 grease | 14.18 | 14.16 | 70.79 | ||||
| Seal grease | 12.72 | 12.58 | 110.46 | ||||
| Grouting | 1.3–1.8 | 1.49 | 1.60 | 2.12 | |||
| Labor | 51.73 | 51.34 | 99% | 61.90 | 120% | 106.24 | 205% |
| Water | 78.93 | 176.74 | 223% | 227.92 | 289% | 334.65 | 424% |
| Electricity | 10,800 | 7449.25 | 69% | 9565 | 89% | 25,885 | 239% |
| Total cost | 72,153 | 68,039 | 94% | 72,996 | 101% | 99,719 | 138% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ye, X.; Ding, P.; Jin, D.; Zhou, C.; Li, Y.; Zhang, J. Intelligent Analysis of Construction Costs of Shield Tunneling in Complex Geological Conditions by Machine Learning Method. Mathematics 2023, 11, 1423. https://doi.org/10.3390/math11061423
Ye X, Ding P, Jin D, Zhou C, Li Y, Zhang J. Intelligent Analysis of Construction Costs of Shield Tunneling in Complex Geological Conditions by Machine Learning Method. Mathematics. 2023; 11(6):1423. https://doi.org/10.3390/math11061423
Chicago/Turabian StyleYe, Xiaomu, Pengfei Ding, Dawei Jin, Chuanyue Zhou, Yi Li, and Jin Zhang. 2023. "Intelligent Analysis of Construction Costs of Shield Tunneling in Complex Geological Conditions by Machine Learning Method" Mathematics 11, no. 6: 1423. https://doi.org/10.3390/math11061423