
A Distributed Optimization Accelerated Algorithm with Uncoordinated Time-Varying Step-Sizes in an Undirected Network


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- Based on the distributed optimization methods [19,26,35], we designed and discussed a faster distributed optimization accelerated algorithm, named UGNH (UG with Nesterov and Heavy-ball accelerated methods), which solves the distributed convex problems over an undirected network. In particular, the momentum with the Nesterov and Heavy-ball methods together improve the convergence rate, which can be seen in the numerical experiments.
- Compared to related algorithms, in our algorithm, not only the step-sizes but the coefficients of momentum terms (for convenience, we call them coefficients for short later) are uncoordinated, time-varying, and nonidentical, which are locally chosen for each agent. Through convergence analysis, the step-sizes and coefficients are more flexible than most existing methods. Meanwhile, if the local objective functions satisfy the conditions that are smooth and strongly convex, we can obtain an upper bound of step-sizes and coefficients. Under the upper bounds, the sequences generated by UGNH converge to the exact optimal solutions linearly.
- In contrast to related algorithms, the upper bounds of the largest step-sizes and coefficients of UGNH are more relaxed, which only depend on the parameters of objective functions and the topology of the network. Meanwhile, there can be zero step-sizes and coefficients (not all) among agents.
2. Preliminaries
2.1. Problem Formulation
2.2. Assumptions
- Non-negative:
- Symmetric:
- Doubly stochastic:
3. Algorithm Development
3.1. Related Algorithms
3.2. Distributed Accelerated Methods
3.3. The Proposed Algorithm
| Algorithm 1 The update of the algorithm UGNH at each agent i |
|
|
|
|
4. Convergence Analysis
4.1. Supporting Lemmas
- (consensus)
- (optimality)
4.2. Main Results
5. Numerical Experiments
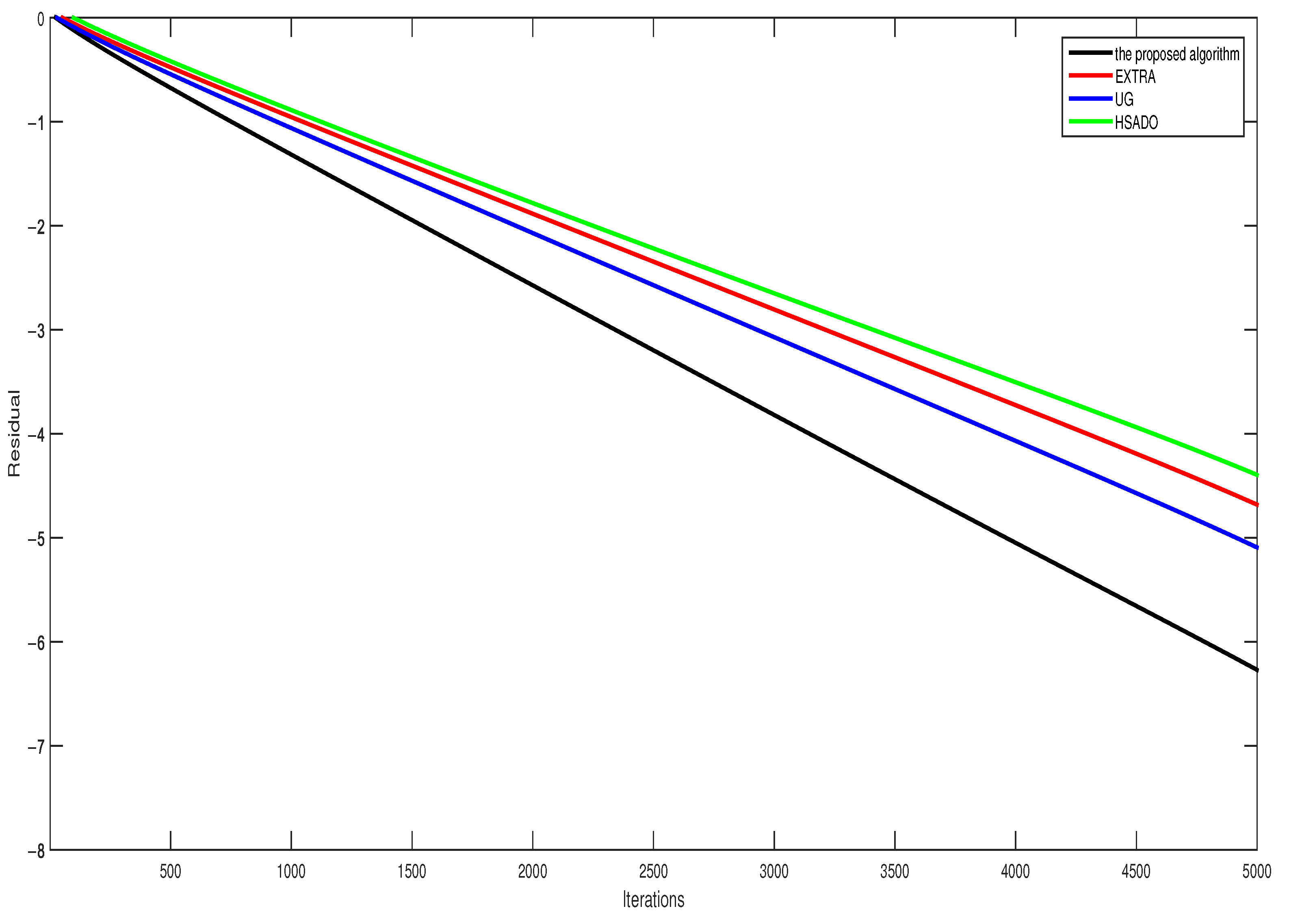
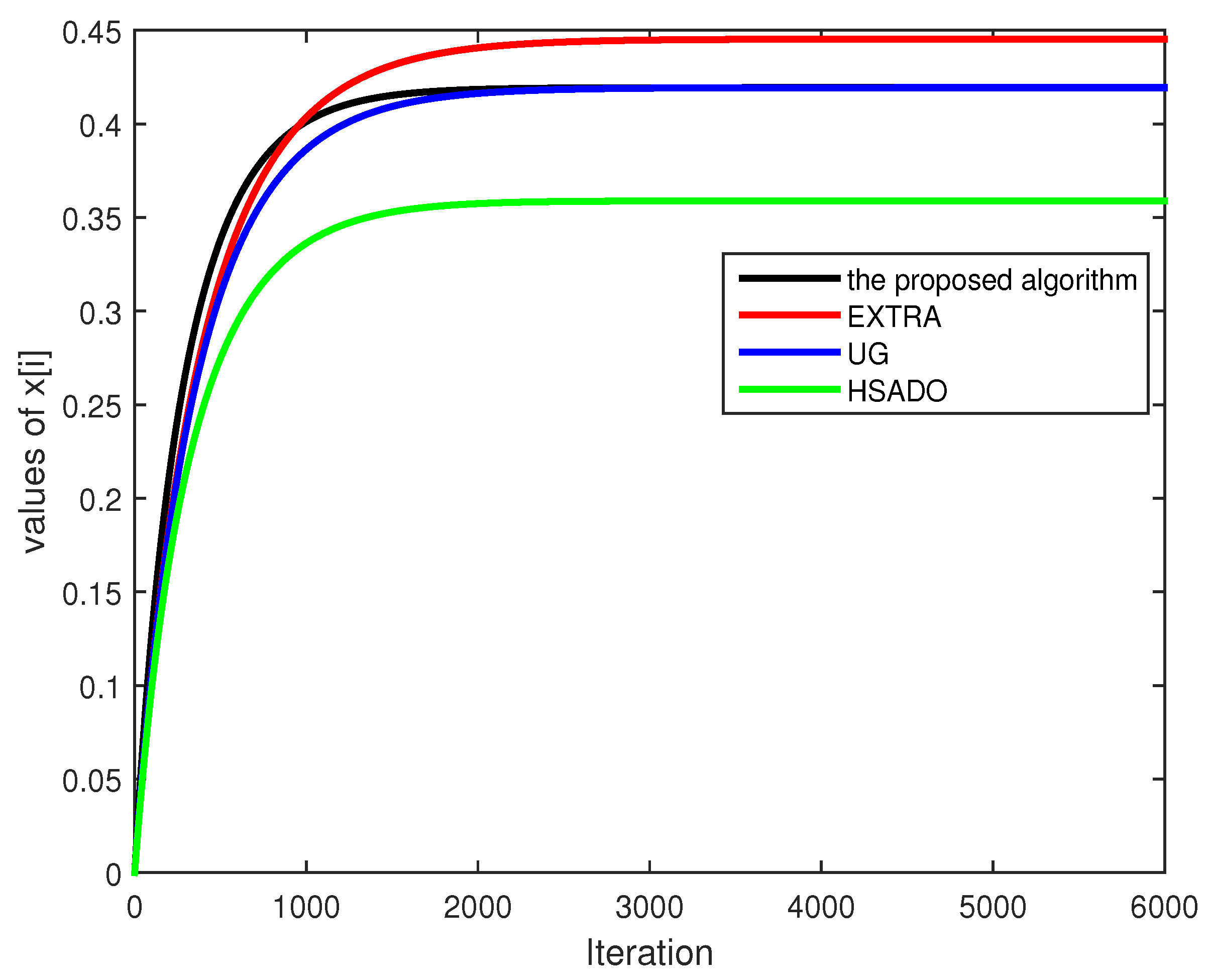
- Figure 1 indicates that the proposed algorithm UGNH promotes the convergence rate compared to the related algorithms in the real dataset; thus, UGNH is effective and superior. From Figure 2, the sequences generated by UGNH, EXTRA, UG, and HSADO can converge to the optimal solutions as expected. Avoiding confusion of the figure, only one dimension of each decision variable is exhibited.
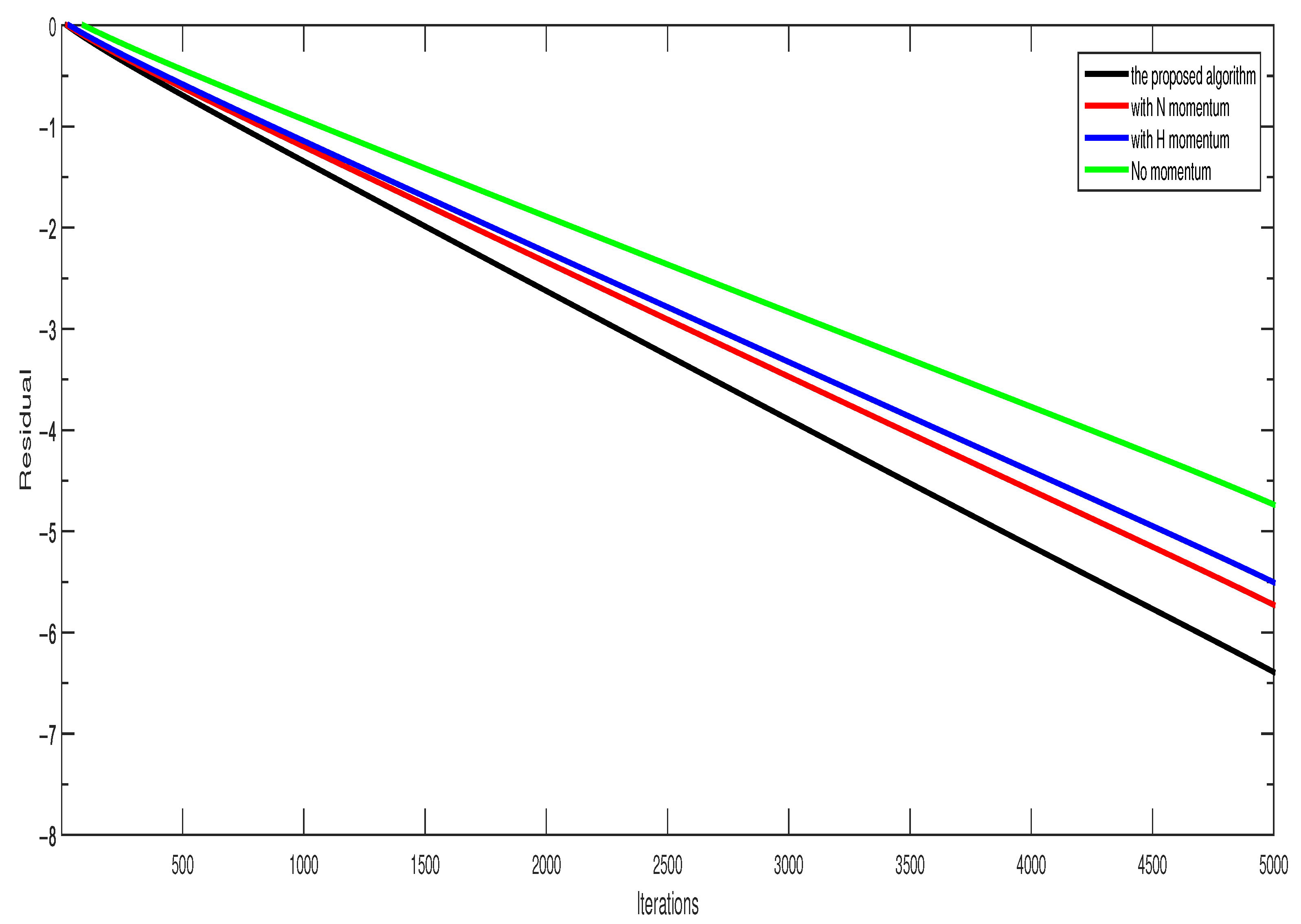
- Figure 3 means that UGNH with the Nesterov momentum and the Heavy-ball momentum improved the convergence rate compared to the algorithm with only one or no momentum.
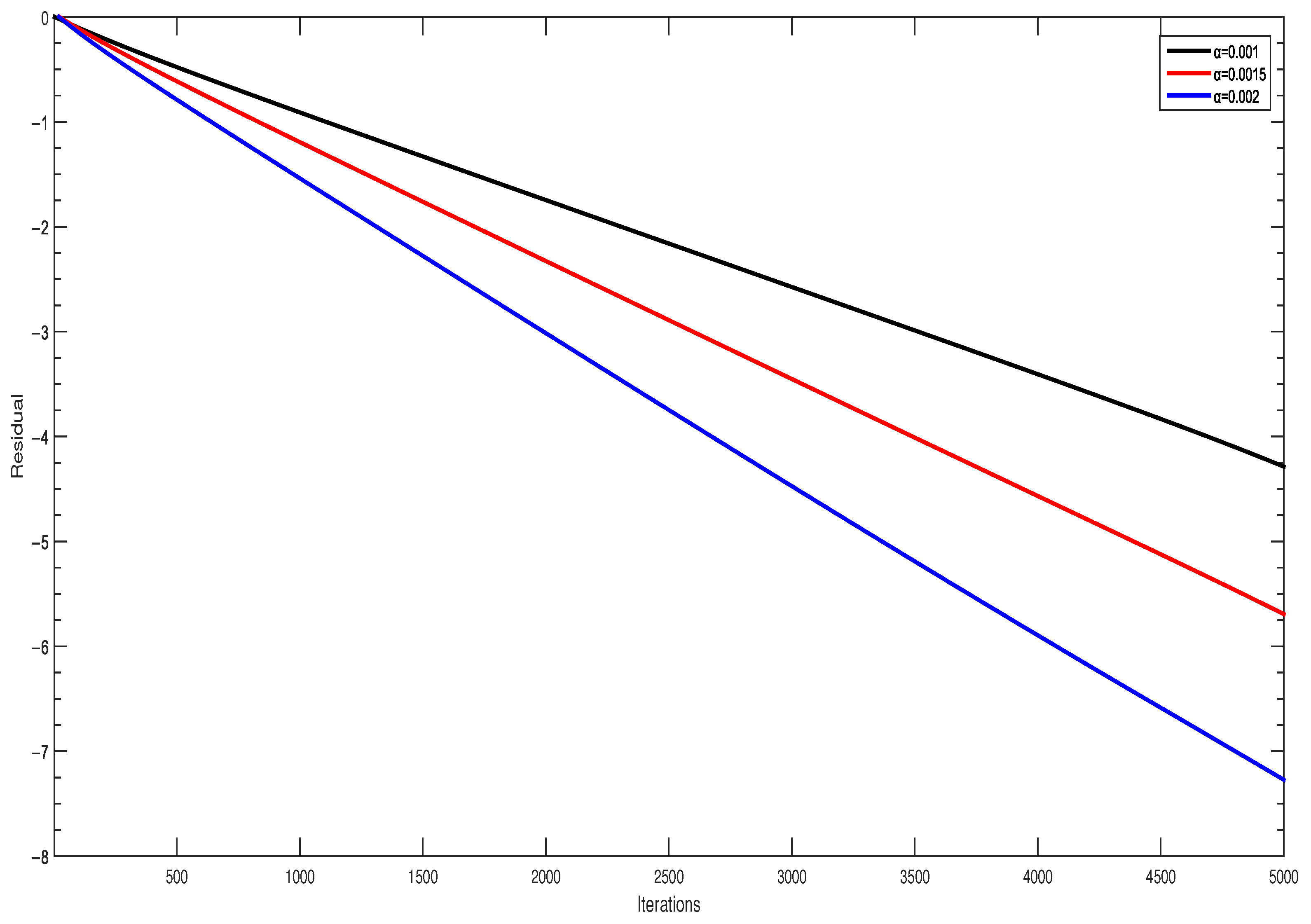
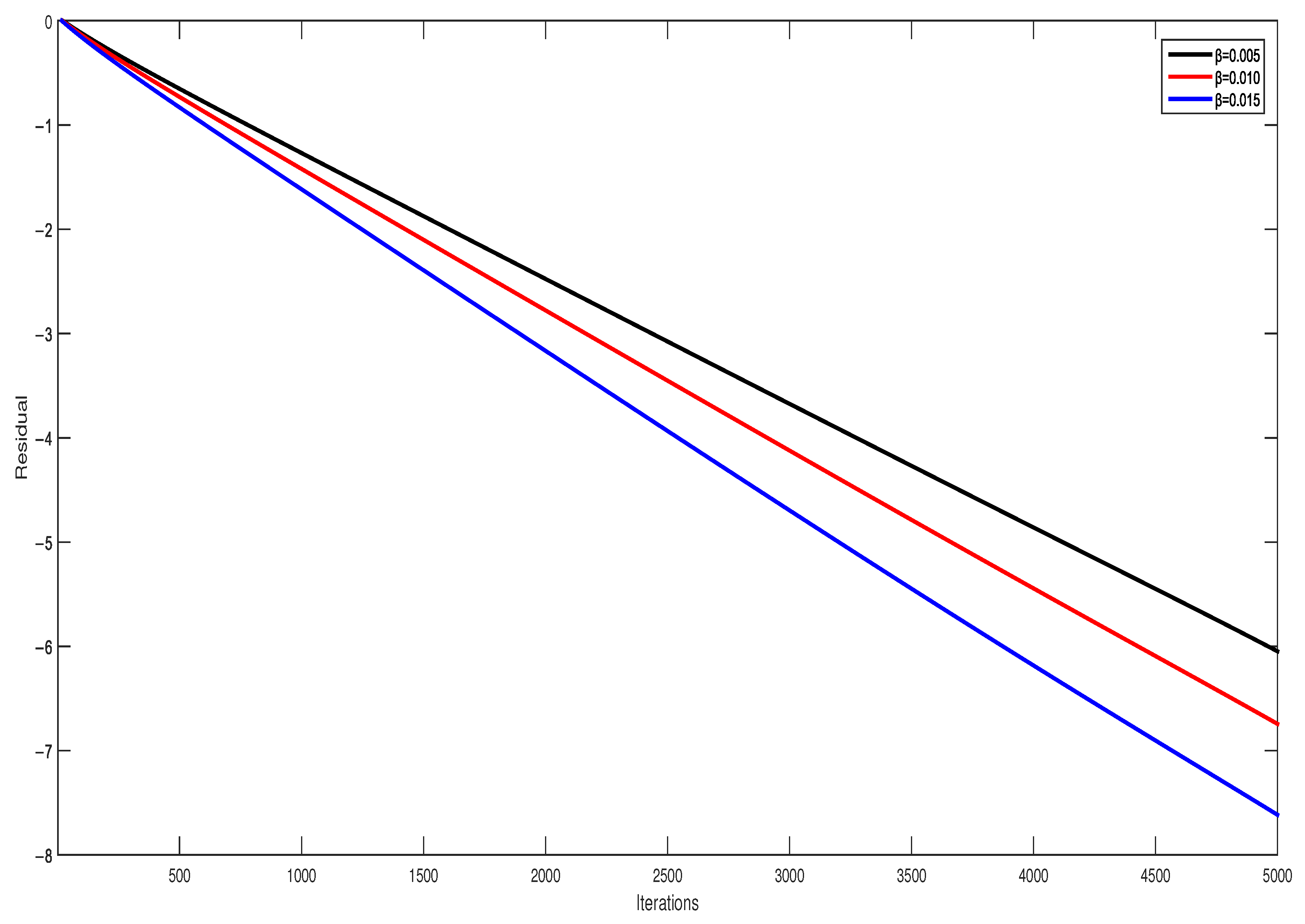
- In Figure 4, we can conclude that step-size is usually chosen very small; the larger step-size leads to a faster convergence rate if it is chosen under the upper bound. For the coefficient, a similar result can be obtained in Figure 5. Comparing the two figures, it can be concluded that small changes in step-size are more influential than that of the coefficient.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wang, H.; Liao, X.; Wang, Z.; Huang, T.; Chen, G. Distributed parameter estimation in unreliable sensor networks via broadcast gossip algorithms. Neural Netw. 2016, 73, 1–9. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dougherty, S.; Guay, M. An extremum-seeking controller for distributed optimization over sensor networks. IEEE Trans. Autom. Control 2016, 62, 928–933. [Google Scholar] [CrossRef]
- Rahmani, A.M.; Ali, S.; Yousefpoor, M.S.; Yousefpoor, E.; Naqvi, R.A.; Siddique, K.; Hosseinzadeh, M. An area coverage scheme based on fuzzy logic and shuffled frog-leaping algorithm (sfla) in heterogeneous wireless sensor networks. Mathematics 2021, 9, 2251. [Google Scholar] [CrossRef]
- Ren, W. Consensus based formation control strategies for multi-vehicle systems. In Proceedings of the 2006 American Control Conference, Philadelphia, PA, USA, 14–16 June 2006; p. 6. [Google Scholar]
- Yan, B.; Shi, P.; Lim, C.C.; Wu, C.; Shi, Z. Optimally distributed formation control with obstacle avoidance for mixed-order multi-agent systems under switching topologies. IET Control Theory Appl. 2018, 12, 1853–1863. [Google Scholar] [CrossRef]
- Cevher, V.; Becker, S.; Schmidt, M. Convex optimization for big data: Scalable, randomized, and parallel algorithms for big data analytics. IEEE Signal Processing Mag. 2014, 31, 32–43. [Google Scholar] [CrossRef]
- Zhang, Z.; Wang, W.; Pan, G. A Distributed Quantum-Behaved Particle Swarm Optimization Using Opposition-Based Learning on Spark for Large-Scale Optimization Problem. Mathematics 2020, 8, 1860. [Google Scholar] [CrossRef]
- Li, K.; Liu, Q.; Yang, S.; Cao, J.; Lu, G. Cooperative optimization of dual multiagent system for optimal resource allocation. IEEE Trans. Syst. Man Cybern. Syst. 2018, 50, 4676–4687. [Google Scholar] [CrossRef]
- Jia, W.; Qin, S. Distributed Optimization Over Directed Graphs with Continuous-Time Algorithm. In Proceedings of the 2019 Chinese Control Conference (CCC), Guangzhou, China, 27–30 July 2019; pp. 1911–1916. [Google Scholar]
- Ahmed, E.M.; Rathinam, R.; Dayalan, S.; Fernandez, G.S.; Ali, Z.M.; Aleem, S.H.; Omar, A.I. A Comprehensive Analysis of Demand Response Pricing Strategies in a Smart Grid Environment Using Particle Swarm Optimization and the Strawberry Optimization Algorithm. Mathematics 2021, 9, 2338. [Google Scholar] [CrossRef]
- Zhang, Q.; Gong, Z.; Yang, Z.; Chen, Z. Distributed convex optimization for flocking of nonlinear multi-agent systems. Int. J. Control Autom. Syst. 2019, 17, 1177–1183. [Google Scholar] [CrossRef]
- Tang, X.; Li, M.; Wei, S.; Ding, B. Event-triggered Synchronous Distributed Model Predictive Control for Multi-agent Systems. Int. J. Control Autom. Syst. 2021, 19, 1273–1282. [Google Scholar] [CrossRef]
- Nedic, A.; Ozdaglar, A. Distributed subgradient methods for multi-agent optimization. IEEE Trans. Autom. Control 2009, 54, 48–61. [Google Scholar] [CrossRef]
- DeGroot, M.H. Reaching a consensus. J. Am. Stat. Assoc. 1974, 69, 118–121. [Google Scholar] [CrossRef]
- Ram, S.S.; Nedić, A.; Veeravalli, V.V. Distributed stochastic subgradient projection algorithms for convex optimization. J. Optim. Theory Appl. 2010, 147, 516–545. [Google Scholar]
- Nedic, A.; Ozdaglar, A.; Parrilo, P.A. Constrained consensus and optimization in multi-agent networks. IEEE Trans. Autom. Control 2010, 55, 922–938. [Google Scholar] [CrossRef]
- Duchi, J.C.; Agarwal, A.; Wainwright, M.J. Dual averaging for distributed optimization: Convergence analysis and network scaling. IEEE Trans. Autom. Control 2011, 57, 592–606. [Google Scholar] [CrossRef] [Green Version]
- Jakovetić, D.; Xavier, J.; Moura, J.M. Fast distributed gradient methods. IEEE Trans. Autom. Control 2014, 59, 1131–1146. [Google Scholar] [CrossRef] [Green Version]
- Shi, W.; Ling, Q.; Wu, G.; Yin, W. Extra: An exact first-order algorithm for decentralized consensus optimization. SIAM J. Optim. 2015, 25, 944–966. [Google Scholar] [CrossRef]
- Shi, W.; Ling, Q.; Wu, G.; Yin, W. A proximal gradient algorithm for decentralized composite optimization. IEEE Trans. Signal Processing 2015, 63, 6013–6023. [Google Scholar] [CrossRef]
- Xi, C.; Khan, U.A. DEXTRA: A fast algorithm for optimization over directed graphs. IEEE Trans. Autom. Control 2017, 62, 4980–4993. [Google Scholar] [CrossRef]
- Zeng, J.; Yin, W. Extrapush for convex smooth decentralized optimization over directed networks. arXiv 2015, arXiv:1511.02942. [Google Scholar]
- Yuan, K.; Ying, B.; Zhao, X.; Sayed, A.H. Exact diffusion for distributed optimization and learning-Part I: Algorithm development. IEEE Trans. Signal Processing 2018, 67, 708–723. [Google Scholar] [CrossRef] [Green Version]
- Yuan, K.; Ying, B.; Zhao, X.; Sayed, A.H. Exact diffusion for distributed optimization and learning-Part II: Convergence analysis. IEEE Trans. Signal Processing 2018, 67, 724–739. [Google Scholar] [CrossRef] [Green Version]
- Jakovetić, D.; Moura, J.M.; Xavier, J. Linear convergence rate of a class of distributed augmented lagrangian algorithms. IEEE Trans. Autom. Control 2014, 60, 922–936. [Google Scholar] [CrossRef] [Green Version]
- Qu, G.; Li, N. Harnessing smoothness to accelerate distributed optimization. IEEE Trans. Control Netw. Syst. 2017, 5, 1245–1260. [Google Scholar] [CrossRef] [Green Version]
- Nedic, A.; Olshevsky, A.; Shi, W. Achieving geometric convergence for distributed optimization over time-varying graphs. SIAM J. Optim. 2017, 27, 2597–2633. [Google Scholar] [CrossRef]
- Jakovetic, D.; Krejic, N.; Malaspina, G. Linear Convergence Rate Analysis of a Class of Exact First-Order Distributed Methods for Time-Varying Directed Networks and Uncoordinated Step Sizes. arXiv 2007, arXiv:2007.08837 2020. [Google Scholar]
- Nedić, A.; Olshevsky, A.; Shi, W.; Uribe, C.A. Geometrically convergent distributed optimization with uncoordinated step-sizes. In Proceedings of the 2017 American Control Conference (ACC), Seattle, WA, USA, 24–26 May 2017; pp. 3950–3955. [Google Scholar]
- Lu, Q.; Li, H.; Xia, D. Geometrical convergence rate for distributed optimization with time-varying directed graphs and uncoordinated step-sizes. Inf. Sci. 2018, 422, 516–530. [Google Scholar] [CrossRef] [Green Version]
- Qu, G.; Li, N. Accelerated distributed Nesterov gradient descent. IEEE Trans. Autom. Control 2019, 65, 2566–2581. [Google Scholar] [CrossRef] [Green Version]
- Xin, R.; Khan, U.A. Distributed heavy-ball: A generalization and acceleration of first-order methods with gradient tracking. IEEE Trans. Autom. Control 2019, 65, 2627–2633. [Google Scholar] [CrossRef] [Green Version]
- Mokhtari, A.; Ribeiro, A. DSA: Decentralized double stochastic averaging gradient algorithm. J. Mach. Learn. Res. 2016, 17, 2165–2199. [Google Scholar]
- Nedić, A.; Ozdaglar, A. Subgradient methods for saddle-point problems. J. Optim. Theory Appl. 2009, 142, 205–228. [Google Scholar] [CrossRef]
- Jakovetić, D. A unification and generalization of exact distributed first-order methods. IEEE Trans. Signal Inf. Processing Over Netw. 2018, 5, 31–46. [Google Scholar] [CrossRef] [Green Version]
- Xu, J.; Zhu, S.; Soh, Y.C.; Xie, L. Augmented distributed gradient methods for multi-agent optimization under uncoordinated constant stepsizes. In Proceedings of the 2015 54th IEEE Conference on Decision and Control (CDC), Osaka, Japan, 15–18 December 2015; pp. 2055–2060. [Google Scholar]
- Li, H.; Zheng, Z.; Lü, Q.; Wang, Z.; Gao, L.; Wu, G.C.; Ji, L.; Wang, H. Primal-Dual Fixed Point Algorithms Based on Adapted Metric for Distributed Optimization. IEEE Trans. Neural Netw. Learn. Syst. 2021, 2021, 1–15. [Google Scholar] [CrossRef]
- Liu, P.; Li, H.; Dai, X.; Han, Q. Distributed primal-dual optimisation method with uncoordinated time-varying step-sizes. Int. J. Syst. Sci. 2018, 49, 1256–1272. [Google Scholar] [CrossRef]
- Nesterov, Y. Introductory Lectures on Convex Optimization: A Basic Course; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2003; Volume 87. [Google Scholar]
- Rivet, A.; Souloumiac, A. Introduction to Optimization. Optimization Software, Publications Division; Citeseer: Washington, DC, USA, 1987. [Google Scholar]
- Xin, R.; Khan, U.A. A linear algorithm for optimization over directed graphs with geometric convergence. IEEE Control Syst. Lett. 2018, 2, 315–320. [Google Scholar] [CrossRef] [Green Version]
- Cheng, H.; Li, H.; Wang, Z. On the convergence of exact distributed generalisation and acceleration algorithm for convex optimisation. Int. J. Syst. Sci. 2020, 51, 1–17. [Google Scholar] [CrossRef]
- Lü, Q.; Liao, X.; Li, H.; Huang, T. A nesterov-like gradient tracking algorithm for distributed optimization over directed networks. IEEE Trans. Syst. Man Cybern. Syst. 2020, 51, 6258–6270. [Google Scholar] [CrossRef]
- Hestenes, M.R.; Stiefel, E. Methods of Conjugate Gradients for Solving Linear Systems; NBS: Washington, DC, USA, 1952; Volume 49. [Google Scholar]
- Dua, D.; Graff, C. UCI Machine Learning Repository. 2017. Available online: http://archive.ics.uci.edu/ml (accessed on 11 December 2021).





Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lü, Y.; Xiong, H.; Zhou, H.; Guan, X. A Distributed Optimization Accelerated Algorithm with Uncoordinated Time-Varying Step-Sizes in an Undirected Network. Mathematics 2022, 10, 357. https://doi.org/10.3390/math10030357
Lü Y, Xiong H, Zhou H, Guan X. A Distributed Optimization Accelerated Algorithm with Uncoordinated Time-Varying Step-Sizes in an Undirected Network. Mathematics. 2022; 10(3):357. https://doi.org/10.3390/math10030357
Chicago/Turabian StyleLü, Yunshan, Hailing Xiong, Hao Zhou, and Xin Guan. 2022. "A Distributed Optimization Accelerated Algorithm with Uncoordinated Time-Varying Step-Sizes in an Undirected Network" Mathematics 10, no. 3: 357. https://doi.org/10.3390/math10030357