
Triplet Contrastive Learning for Aspect Level Sentiment Classification

Abstract
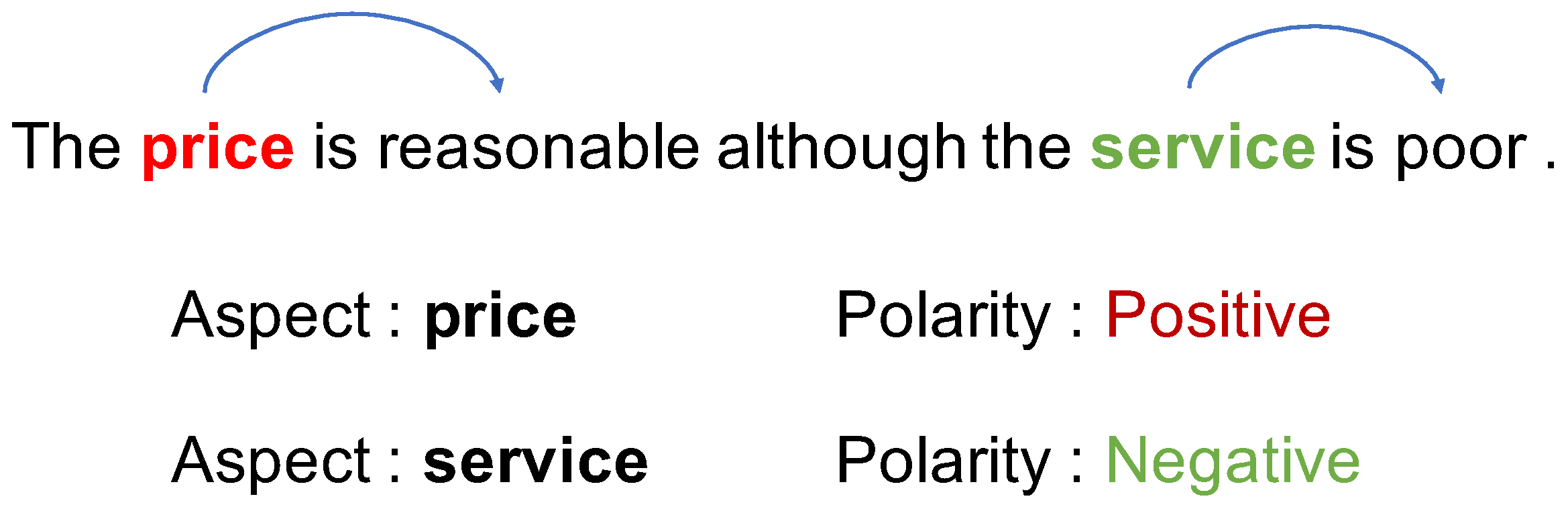
:1. Introduction
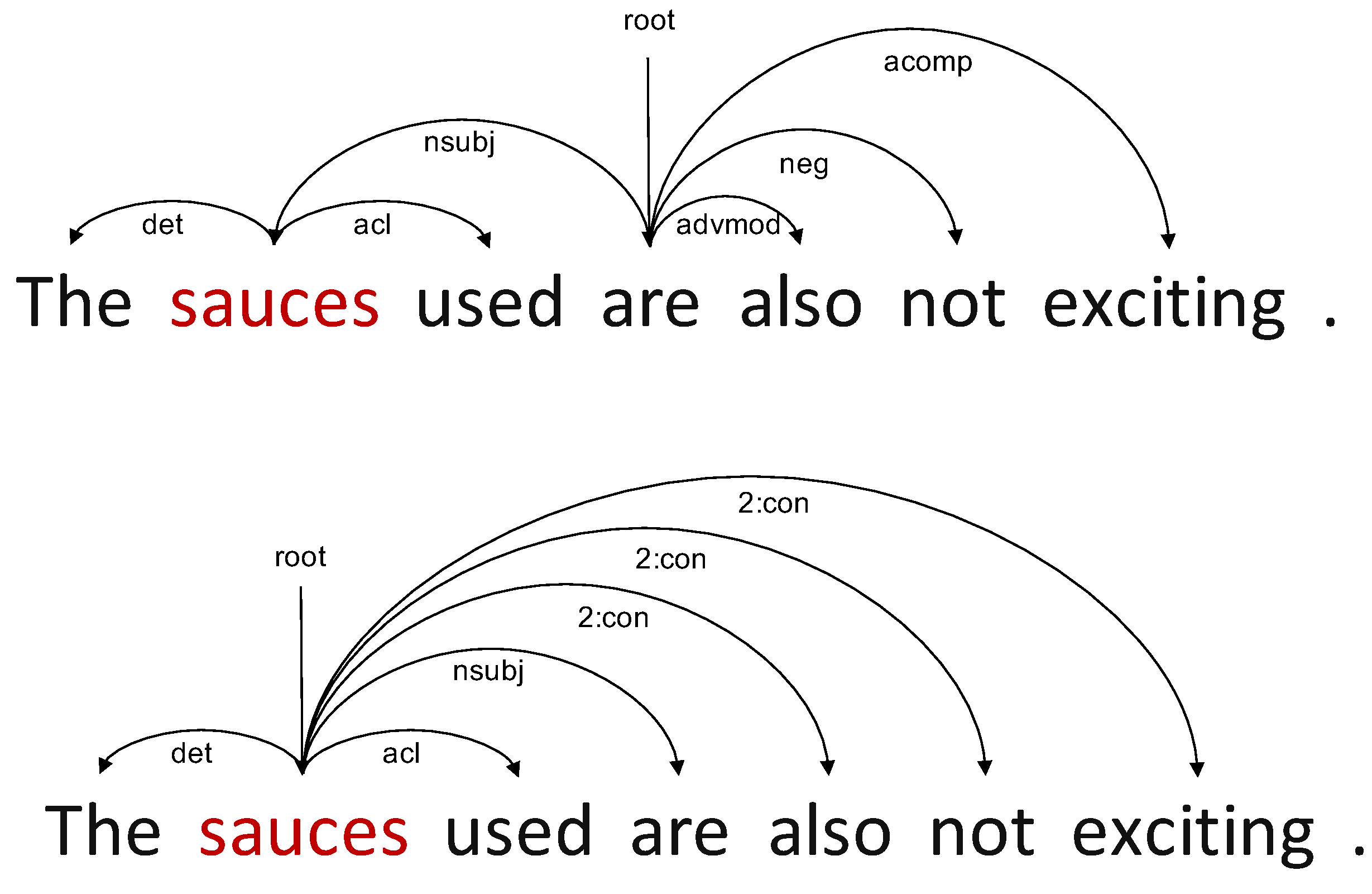
- The syntactic adjacency matrix of the dual-channel graph convolutional neural network is replaced with an aspect-oriented tree structure, which helps the model to better capture the information of opinion words related to aspect words.
- A syntactic contrastive learning scheme is designed to encourage the model to focus on keywords that are helpful for sentiment polarity classification, and to better learn features related to aspect words.
- Constructing the dual contrastive learning module can make the semantic features and syntactic features of sentences more fully interact and align.
- Experiments show that our method outperforms baseline models on three benchmark datasets.
2. Related Work
2.1. Aspect Level Sentiment Classification
2.2. Contrastive Learning
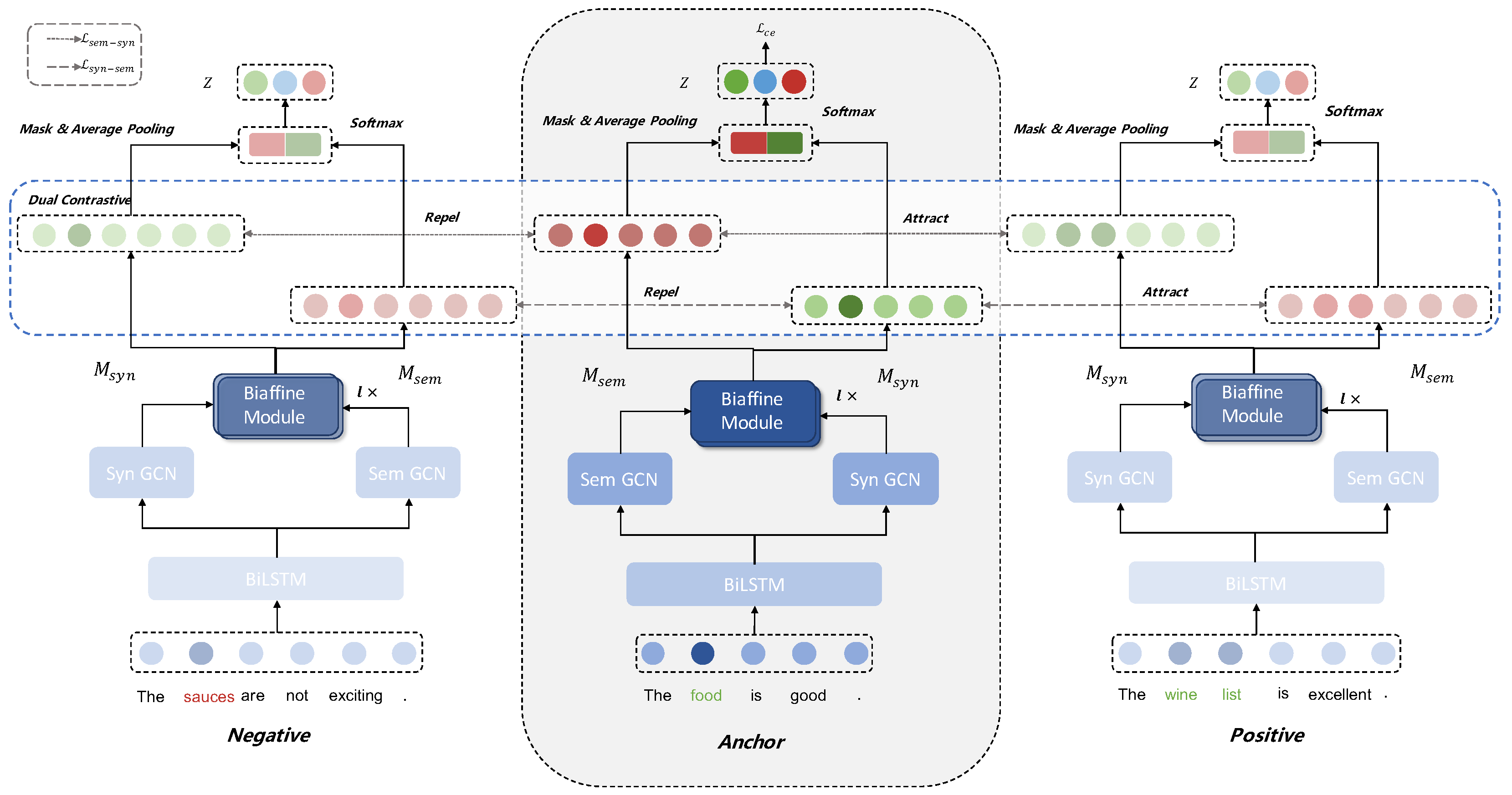
3. Proposed Method
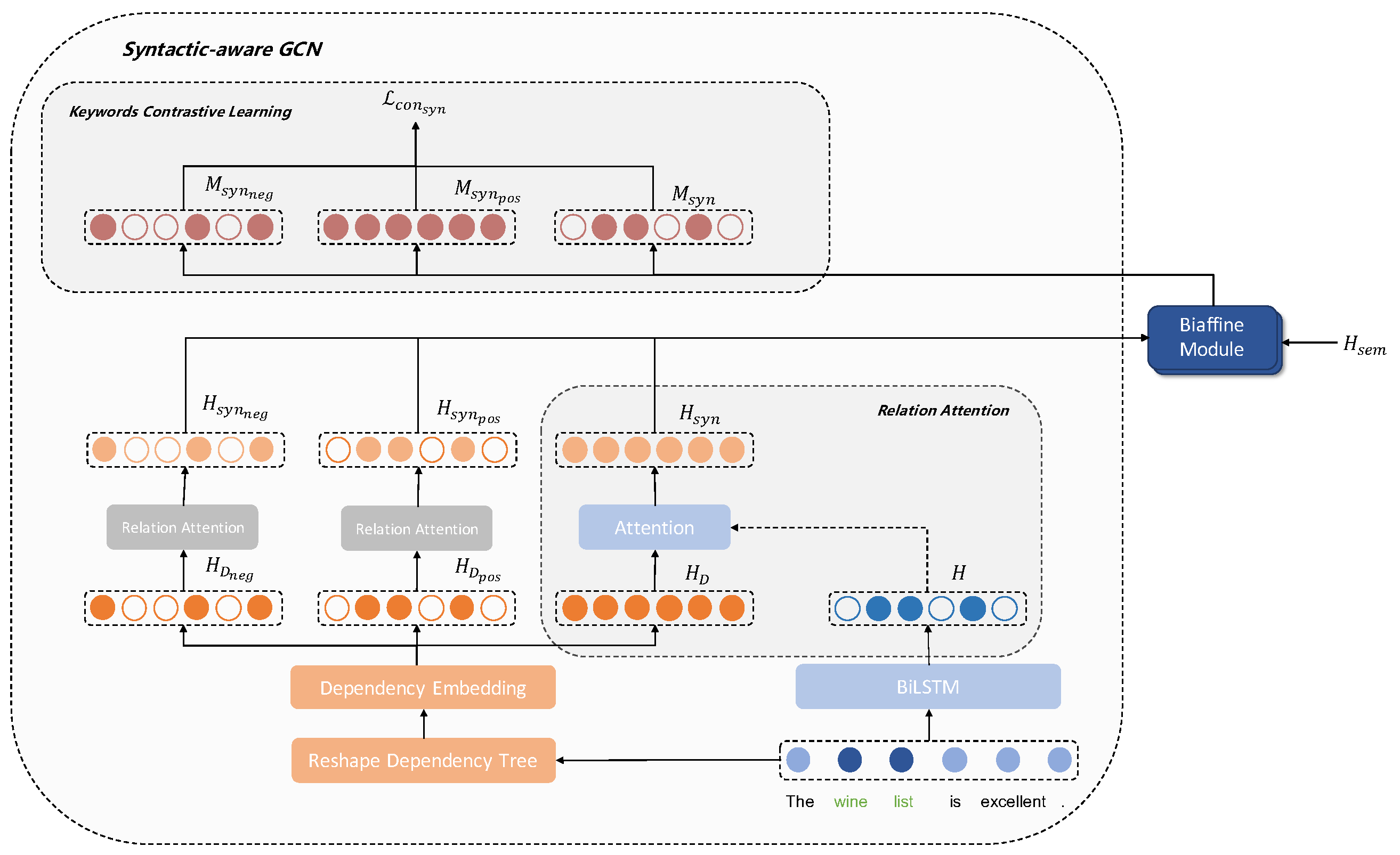
3.1. Syntactic-Aware GCN Module
3.1.1. Relational Graph Attention Module
| Algorithm 1 Aspect-Oriented Dependency Tree |
| Input: sentence , aspect , dependency tree T, and dependency relations R. Output: aspect-oriented dependency .
|
3.1.2. Syntactic Contrastive Learning Scheme
3.2. Semantic-Learning GCN Module
3.3. Biaffine Unit
3.4. Dual Contrastive Learning Scheme
3.5. Loss Function
4. Experiments
4.1. Datasets and Settings
4.2. Baselines
- (1)
- ASGCN [6] The syntactical features are obtained using GCN via syntax dependency tree while the aspect-specific attention is applied to extract the features related to aspects.
- (2)
- CDT [30] The Bi-LSTM is taken to learn the sentence representations and the GCN encodes the syntactic information and capture the aspect-related syntactic features.
- (3)
- RGAT [12] The aspect-oriented dependency tree is constructed, based on which the relation graph attention network is developed to learn the dependencies between aspect and other words.
- (4)
- BiGCN [31] A global lexical graph and a concept hierarchy graph are constructed, which aims to integrate word pair co-occurrence and syntactic dependencies.
- (5)
- DualGCN [8] A dual-channel GCN method is proposed to extract both syntactic and semantic information, and then fuse the two categories of information.
- (6)
- BERT-SPC [27] The sentence-aspect pair is sent to BERT model with its token [CLS] used for sentiment classification.
- (7)
- T-GCN [20] A multilayer type-aware GCN is established to learn the relationship among words.
- (8)
- BERT4GCN [32] The intermediate layers of BERT is employed to augment GCN for ALSC.
- (9)
- DR-BERT [33] The Dynamic Re-weighting Adapter is proposed to encourage model to better understand aspect-aware sentiment through
4.3. Experimental Results and Analysis
4.4. Ablation Study
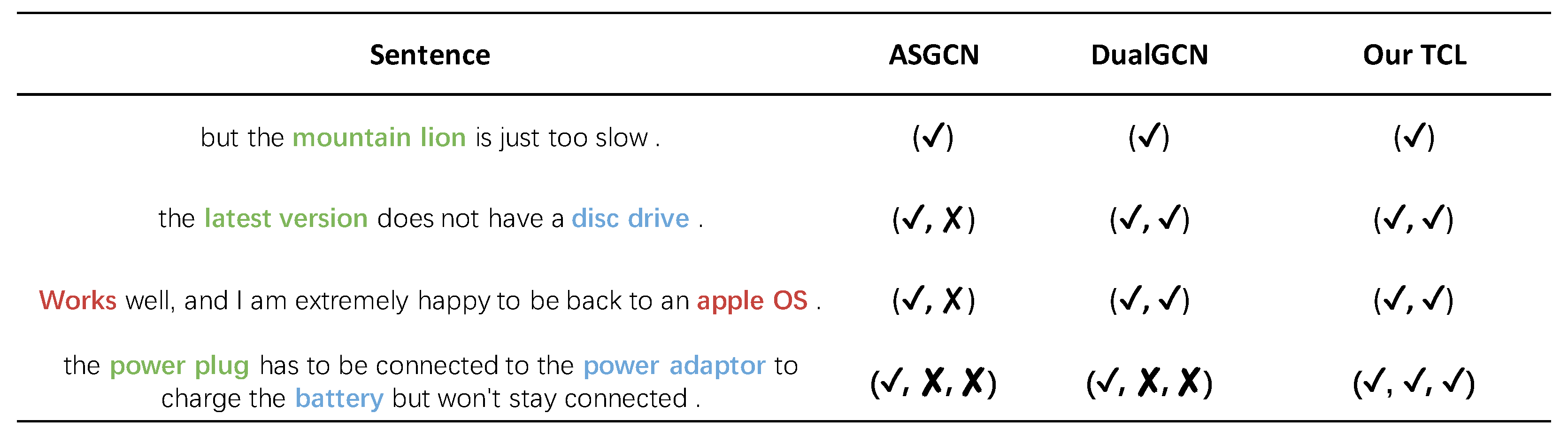
4.5. Case Study
4.6. Visualization
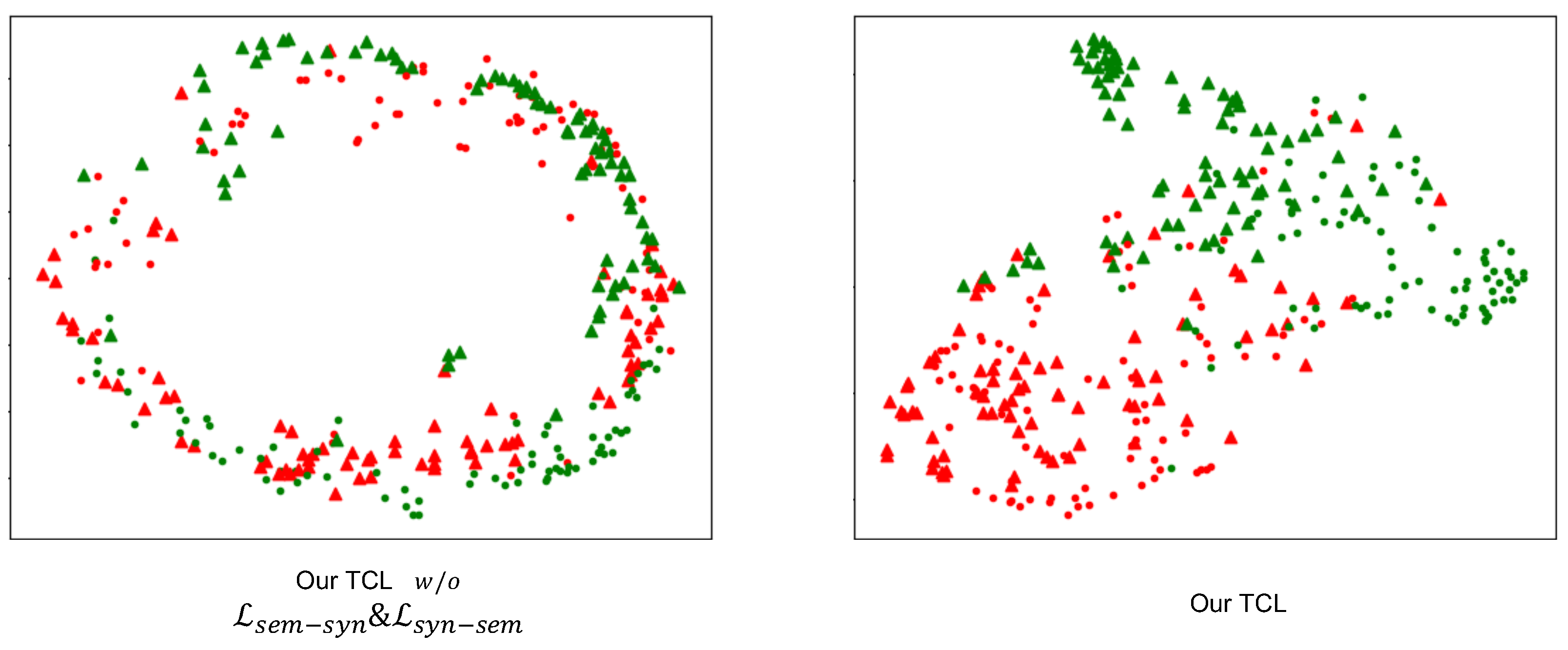
4.6.1. Comparison of Syntactic and Semantic Vectors
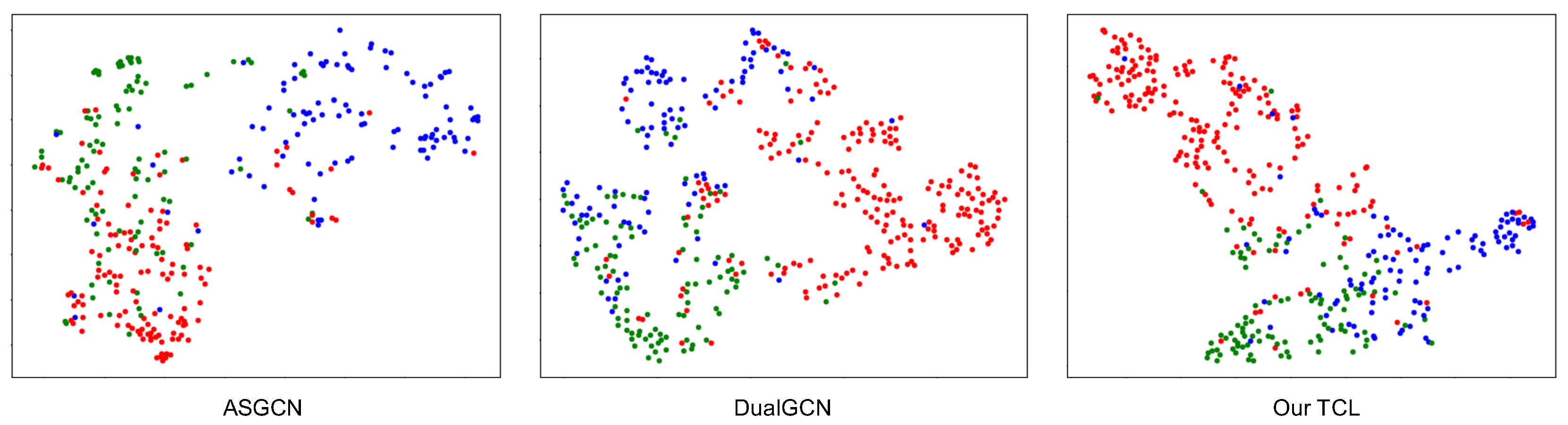
4.6.2. Sentiment Classification Visualization
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Tang, D.; Qin, B.; Feng, X.; Liu, T. Effective LSTMs for target-dependent sentiment classification. arXiv 2015, arXiv:1512.01100. [Google Scholar]
- Ma, D.; Li, S.; Zhang, X.; Wang, H. Interactive attention networks for aspect-level sentiment classification. arXiv 2017, arXiv:1709.00893. [Google Scholar]
- Chen, P.; Sun, Z.; Bing, L.; Yang, W. Recurrent attention network on memory for aspect sentiment analysis. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 7–11 September 2017; pp. 452–461. [Google Scholar]
- Xu, G.; Zhang, Z.; Zhang, T.; Yu, S.; Meng, Y.; Chen, S. Aspect-level sentiment classification based on attention-BiLSTM model and transfer learning. Knowl.-Based Syst. 2022, 245, 108586. [Google Scholar] [CrossRef]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Zhang, C.; Li, Q.; Song, D. Aspect-based sentiment classification with aspect-specific graph convolutional networks. arXiv 2019, arXiv:1909.03477. [Google Scholar]
- Xu, K.; Zhao, H.; Liu, T. Aspect-specific heterogeneous graph convolutional network for aspect-based sentiment classification. IEEE Access 2020, 8, 139346–139355. [Google Scholar] [CrossRef]
- Li, R.; Chen, H.; Feng, F.; Ma, Z.; Wang, X.; Hovy, E. Dual graph convolutional networks for aspect-based sentiment analysis. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Bangkok, Thailand, 1–6 August 2021; pp. 6319–6329. [Google Scholar]
- Pang, S.; Xue, Y.; Yan, Z.; Huang, W.; Feng, J. Dynamic and multi-channel graph convolutional networks for aspect-based sentiment analysis. In Proceedings of the Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, Online, 1–6 August 2021; pp. 2627–2636. [Google Scholar]
- Wang, T.; Isola, P. Understanding contrastive representation learning through alignment and uniformity on the hypersphere. In Proceedings of the International Conference on Machine Learning. PMLR, Virtual, 13–18 July 2020; pp. 9929–9939. [Google Scholar]
- Chen, Q.; Zhang, R.; Zheng, Y.; Mao, Y. Dual Contrastive Learning: Text Classification via Label-Aware Data Augmentation. arXiv 2022, arXiv:2201.08702. [Google Scholar]
- Wang, K.; Shen, W.; Yang, Y.; Quan, X.; Wang, R. Relational graph attention network for aspect-based sentiment analysis. arXiv 2020, arXiv:2004.12362. [Google Scholar]
- Hu, J.; Li, Z.; Chen, Z.; Li, Z.; Wan, X.; Chang, T.H. Graph Enhanced Contrastive Learning for Radiology Findings Summarization. arXiv 2022, arXiv:2204.00203. [Google Scholar]
- Karamibekr, M.; Ghorbani, A.A. Sentiment analysis of social issues. In Proceedings of the 2012 international conference on social informatics, Alexandria, VA, USA, 14–16 December 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 215–221. [Google Scholar]
- Pylkkänen, L. The neural basis of combinatory syntax and semantics. Science 2019, 366, 62–66. [Google Scholar] [CrossRef]
- Shahi, T.; Sitaula, C.; Paudel, N. A Hybrid Feature Extraction Method for Nepali COVID-19-Related Tweets Classification. Comput. Intell. Neurosci. 2022, 2022, 5681574. [Google Scholar] [PubMed]
- Sitaula, C.; Basnet, A.; Mainali, A.; Shahi, T.B. Deep learning-based methods for sentiment analysis on Nepali covid-19-related tweets. Comput. Intell. Neurosci. 2021, 2021, 2158184. [Google Scholar] [CrossRef] [PubMed]
- Gou, J.; Yu, B.; Maybank, S.J.; Tao, D. Knowledge distillation: A survey. Int. J. Comput. Vis. 2021, 129, 1789–1819. [Google Scholar] [CrossRef]
- Yang, M.; Jiang, Q.; Shen, Y.; Wu, Q.; Zhao, Z.; Zhou, W. Hierarchical human-like strategy for aspect-level sentiment classification with sentiment linguistic knowledge and reinforcement learning. Neural Netw. 2019, 117, 240–248. [Google Scholar] [CrossRef]
- Tian, Y.; Chen, G.; Song, Y. Aspect-based sentiment analysis with type-aware graph convolutional networks and layer ensemble. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 6–11 June 2021; pp. 2910–2922. [Google Scholar]
- Yan, Z.; Pang, S.; Xue, Y. Semantic Enhanced Dual-Channel Graph Communication Network for Aspect-Based Sentiment Analysis. In Proceedings of the CCF International Conference on Natural Language Processing and Chinese Computing, Guilin, China, 24–25 September 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 531–543. [Google Scholar]
- Gao, T.; Yao, X.; Chen, D. Simcse: Simple contrastive learning of sentence embeddings. arXiv 2021, arXiv:2104.08821. [Google Scholar]
- Xu, P.; Chen, X.; Ma, X.; Huang, Z.; Xiang, B. Contrastive Document Representation Learning with Graph Attention Networks. arXiv 2021, arXiv:2110.10778. [Google Scholar]
- Li, Z.; Xu, B.; Zhu, C.; Zhao, T. CLMLF: A Contrastive Learning and Multi-Layer Fusion Method for Multimodal Sentiment Detection. arXiv 2022, arXiv:2204.05515. [Google Scholar]
- Liang, B.; Luo, W.; Li, X.; Gui, L.; Yang, M.; Yu, X.; Xu, R. Enhancing aspect-based sentiment analysis with supervised contrastive learning. In Proceedings of the 30th ACM International Conference on Information & Knowledge Management, Online, 1–5 November 2021; pp. 3242–3247. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C. GloVe: Global Vectors for Word Representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; Association for Computational Linguistics: Doha, Qatar, 2014; pp. 1532–1543. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Pontiki, M.; Galanis, D.; Pavlopoulos, J.; Papageorgiou, H.; Androutsopoulos, I.; Manandhar, S. SemEval-2014 Task 4: Aspect Based Sentiment Analysis. In Proceedings of the 8th International Workshop on Semantic Evaluation (SemEval 2014), Dublin, Ireland, 23–24 August 2014; Association for Computational Linguistics: Dublin, Ireland, 2014; pp. 27–35. [Google Scholar] [CrossRef] [Green Version]
- Dong, L.; Wei, F.; Tan, C.; Tang, D.; Zhou, M.; Xu, K. Adaptive Recursive Neural Network for Target-dependent Twitter Sentiment Classification. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Baltimore, MD, USA, 22–27 June 2014; Association for Computational Linguistics: Baltimore, MD, USA, 2014; pp. 49–54. [Google Scholar] [CrossRef]
- Sun, K.; Zhang, R.; Mensah, S.; Mao, Y.; Liu, X. Aspect-level sentiment analysis via convolution over dependency tree. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 5679–5688. [Google Scholar]
- Zhang, M.; Qian, T. Convolution over hierarchical syntactic and lexical graphs for aspect level sentiment analysis. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Punta Cana, Dominican Republic, 8–12 November 2020; pp. 3540–3549. [Google Scholar]
- Xiao, Z.; Wu, J.; Chen, Q.; Deng, C. BERT4GCN: Using BERT Intermediate Layers to Augment GCN for Aspect-based Sentiment Classification. arXiv 2021, arXiv:2110.00171. [Google Scholar]
- Zhang, K.; Zhang, K.; Zhang, M.; Zhao, H.; Liu, Q.; Wu, W.; Chen, E. Incorporating Dynamic Semantics into Pre-Trained Language Model for Aspect-based Sentiment Analysis. arXiv 2022, arXiv:2203.16369. [Google Scholar]
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | #Pos. | #Neu. | #Neg. | Total | |
|---|---|---|---|---|---|
| Rest14 | Train | 2164 | 637 | 807 | 3608 |
| Test | 728 | 196 | 196 | 1120 | |
| Lap14 | Train | 994 | 464 | 870 | 2328 |
| Test | 341 | 169 | 128 | 638 | |
| Train | 1561 | 3127 | 1560 | 6248 | |
| Test | 173 | 346 | 173 | 692 | |
| Models | Rest14 | Lap14 | ||||
|---|---|---|---|---|---|---|
| Accuracy | Macro-F1 | Accuracy | Macro-F1 | Accuracy | Macro-F1 | |
| ASGCN [6] | 80.77 | 72.02 | 75.55 | 71.05 | 72.15 | 70.40 |
| CDT [30] | 82.30 | 74.02 | 77.19 | 72.99 | 74.66 | 73.66 |
| RGAT [12] | 83.30 | 76.08 | 77.42 | 73.76 | 75.57 | 73.82 |
| BiGCN [31] | 81.97 | 73.48 | 74.59 | 71.84 | 74.16 | 73.35 |
| DualGCN [8] | 84.27 | 78.08 | 78.48 | 74.74 | 75.92 | 74.29 |
| Our TCL | 84.27 | 77.04 | 79.27 | 76.05 | 76.81 | 75.53 |
| BERT-SPCBERT-SPC [27] | 86.15 | 80.29 | 81.01 | 76.69 | 75.18 | 74.01 |
| RGAT+BERT [12] | 86.60 | 81.35 | 78.21 | 74.07 | 76.15 | 74.88 |
| T-GCN [20] | 86.16 | 77.11 | 77.49 | 73.01 | 74.73 | 73.76 |
| DualGCN+BERT [8] | 87.13 | 81.16 | 81.80 | 78.10 | 77.40 | 76.02 |
| BERT4GCN [32] | 84.75 | 77.11 | 77.49 | 73.01 | 74.73 | 73.36 |
| DR-BERT [33] | 87.72 | 82.31 | 81.45 | 78.16 | 77.24 | 76.10 |
| Our TCL+BERT | 87.40 | 82.12 | 81.80 | 78.96 | 77.55 | 76.57 |
| Models | Rest14 | Lap14 | ||||
|---|---|---|---|---|---|---|
| Accuracy | Macro-F1 | Accuracy | Macro-F1 | Accuracy | Macro-F1 | |
| TCL | 82.31 | 74.14 | 77.69 | 74.11 | 75.18 | 73.59 |
| TCL | 82.30 | 74.73 | 78.01 | 74.72 | 75.33 | 74.01 |
| TCL | 81.94 | 74.17 | 77.53 | 74.57 | 74.00 | 72.76 |
| TCL | 83.02 | 74.96 | 78.32 | 74.75 | 75.48 | 74.27 |
| TCL | 84.27 | 77.04 | 79.27 | 76.05 | 76.81 | 75.53 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xiong, H.; Yan, Z.; Zhao, H.; Huang, Z.; Xue, Y. Triplet Contrastive Learning for Aspect Level Sentiment Classification. Mathematics 2022, 10, 4099. https://doi.org/10.3390/math10214099
Xiong H, Yan Z, Zhao H, Huang Z, Xue Y. Triplet Contrastive Learning for Aspect Level Sentiment Classification. Mathematics. 2022; 10(21):4099. https://doi.org/10.3390/math10214099
Chicago/Turabian StyleXiong, Haoliang, Zehao Yan, Hongya Zhao, Zhenhua Huang, and Yun Xue. 2022. "Triplet Contrastive Learning for Aspect Level Sentiment Classification" Mathematics 10, no. 21: 4099. https://doi.org/10.3390/math10214099