
Knowledge-Enhanced Dual-Channel GCN for Aspect-Based Sentiment Analysis

Abstract
:1. Introduction
- Considering the deficiencies of the current ABSA methods, a dual-channel GCN based model is proposed, which processes both the syntax structure and the semantic information.
- The external knowledge is incorporated to enhance the semantics of the sentence, while the multi-head attention mechanism is taken to further filter the noise.
- Experiments on a variety of datasets indicate the effectiveness of the proposed method. Our model produces results considerably better than the baselines.
2. Related Work
2.1. Aspect-Based Sentiment Analysis
2.2. Graph Convolutional Networks
2.3. Commonsense Knowledge
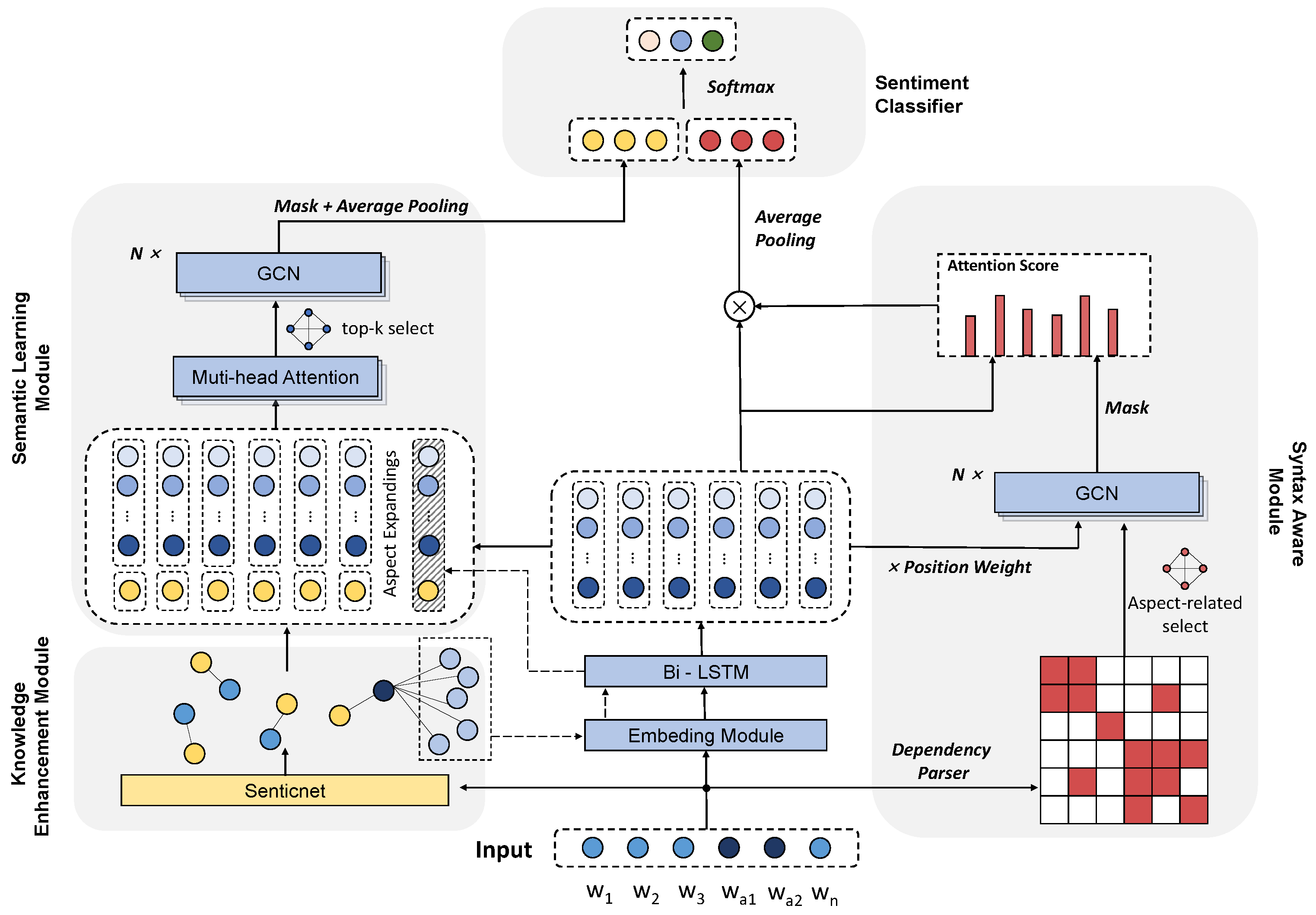
3. Methodology
3.1. Sentence Encoder
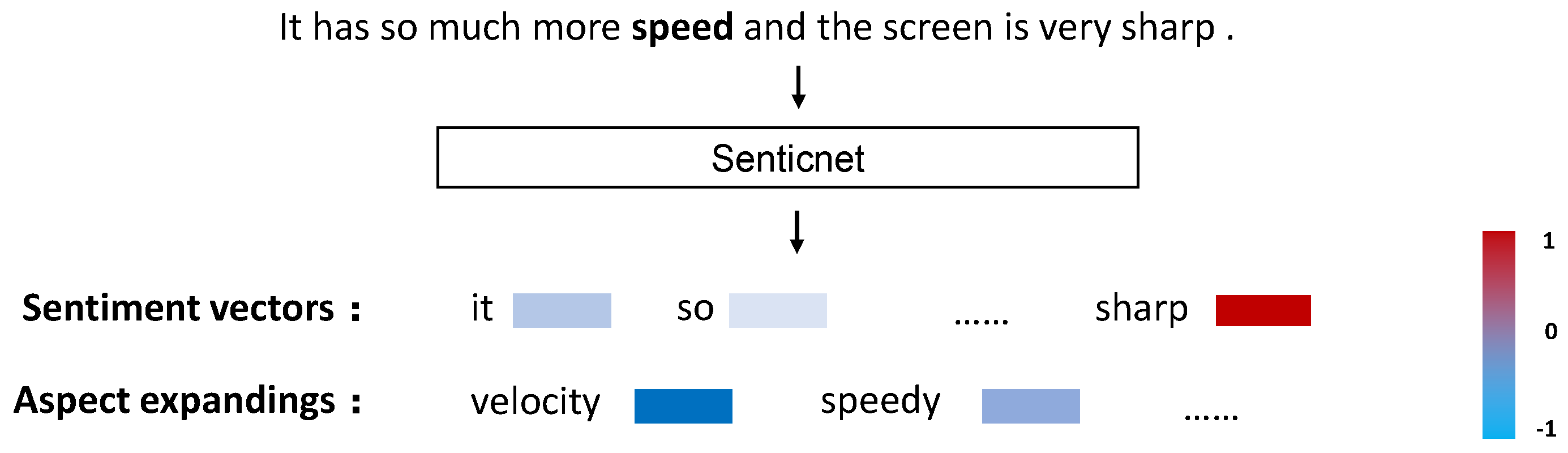
3.2. Knowledge Enhancement Module
3.3. Semantic Learning Module
3.4. Syntax Aware Module
3.5. Sentiment Classifier
3.6. Model Training
4. Experiment
4.1. Dataset
4.2. Implementation Details
4.3. Baseline
- CDT [8]: GCN is taken to deal with the syntax dependency tree, which aims to learn the sentence syntactic information. Specifically, it exploits a GCN to model the structure of a sentence through its dependency tree, where node (word) embeddings of the tree are initialized by means of a Bi-LSTM network.
- ASGCN [7]: On the task of ABSA, GCN is applied to learn the aspect-specific representation for the first time. Specifically, it starts with a LSTM layer to encode the sentence, and a multi-layered graph convolution structure is implemented on top of the LSTM output to obtain aspect-specific features.
- SK-GCN [14]: A syntax-based GCN and a knowledge-based GCN are designed to model the syntax dependency tree and knowledge graph, respectively. Specifically, it obtains the sentiment information from the SenticNet to enrich the representation of a sentence toward a given aspect.
- R-GAT [4]: It reshapes and prunes an ordinary dependency parse tree to obtain an aspect-oriented dependency tree structure rooted at a target aspect. Then, a relational graph attention network (R-GAT) is introduced to encode the new tree structure for sentiment prediction.
- DualGCN [5]: Considering the complementarity of syntax structures and semantic correlations, a dual graph convolutional network is proposed to tackle both the syntactic information and semantic information.
- DMGCN [11]: A multi-channel GCN-based method is developed to exploit not only the syntax and the semantics, but also the correlated information from the generated graph.
- BERT [35]: The basic BERT model is established based on a bidirectional transformer. With the concatenation of sentence and the corresponding aspect, BERT can be applied to ABSA.
- TGCN+BERT [39]: The dependency type is identified with type-aware graph convolutional networks, while the relation is distinguished with attention mechanism. The pre-trained BERT is used for sentence encoding.
4.4. Experimental Results
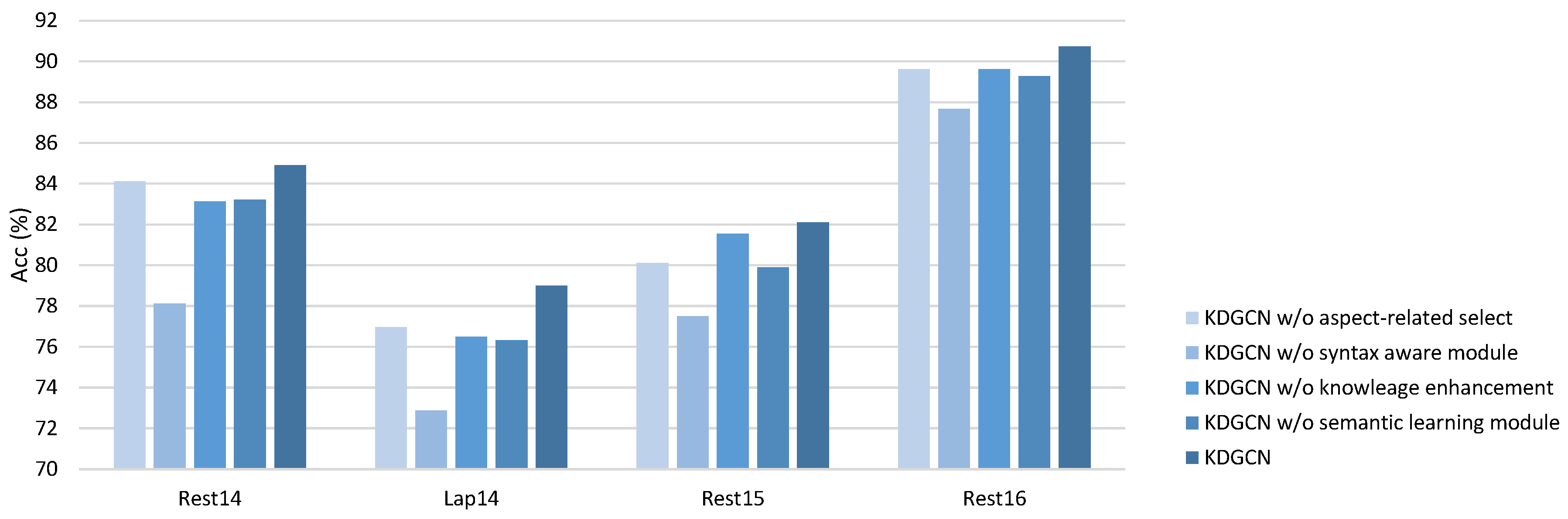
4.5. Ablation Study
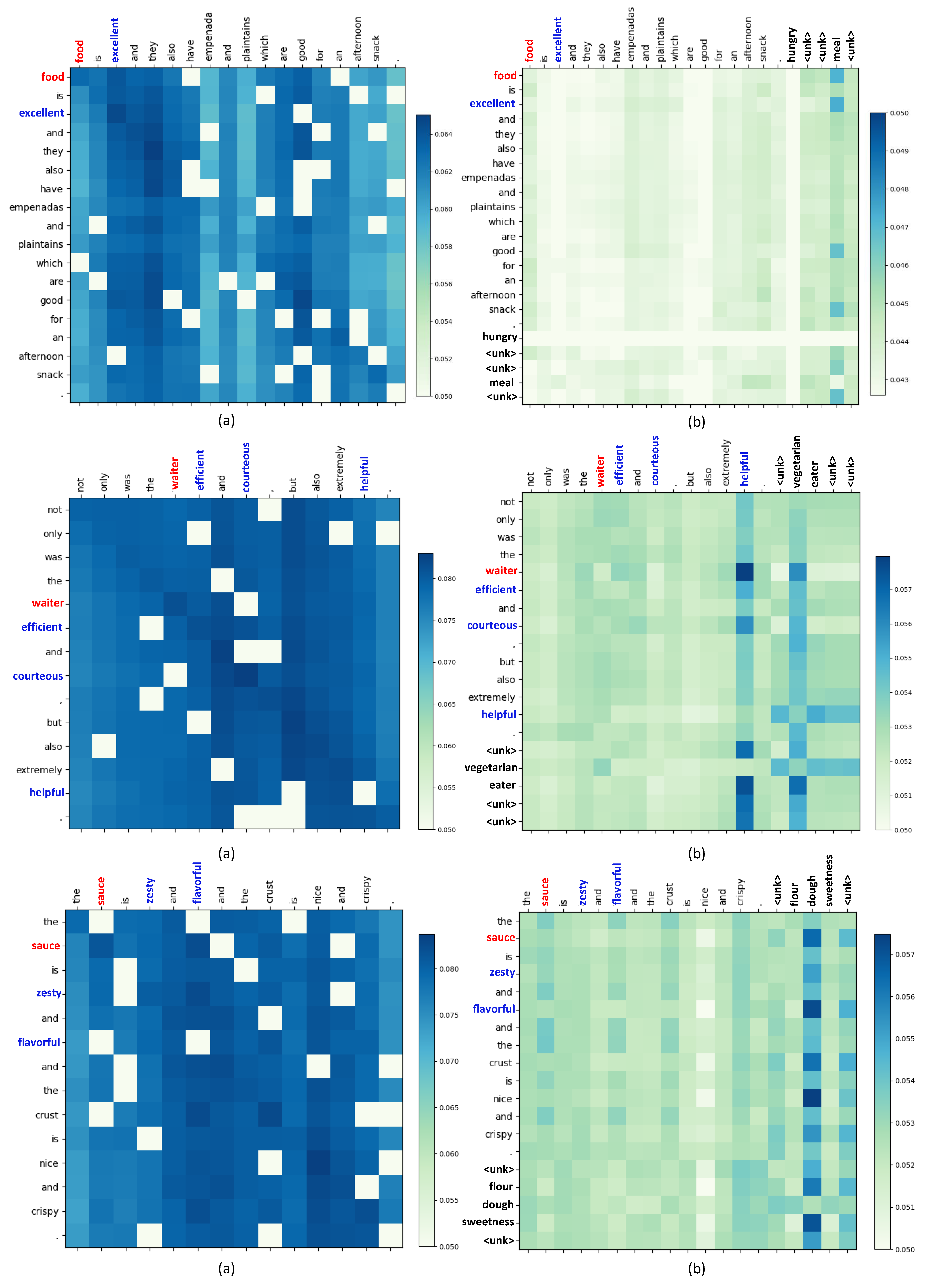
4.6. Attention Visualization
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Pontiki, M.; Galanis, D.; Papageorgiou, H.; Androutsopoulos, I.; Manandhar, S.; Al-Smadi, M.; Al-Ayyoub, M.; Zhao, Y.; Qin, B.; De Clercq, O.; et al. Semeval-2016 task 5: Aspect based sentiment analysis. In Proceedings of the 10th International Workshop on Semantic Evaluation, San Diego, CA, USA, 16–17 June 2016. [Google Scholar]
- Li, H.; Xue, Y.; Zhao, H.; Hu, X.; Peng, S. Co-attention networks for aspect-level sentiment analysis. In Proceedings of the CCF International Conference on Natural Language Processing and Chinese Computing, Guilin, China, 24–25 September 2019; Springer: Cham, Switzerland, 2019. [Google Scholar]
- Schouten, K.; Frasincar, F. Survey on aspect-level sentiment analysis. IEEE Trans. Knowl. Data Eng. 2015, 28, 813–830. [Google Scholar] [CrossRef]
- Wang, Y.; Huang, M.; Zhu, X.; Zhao, L. Attention-based LSTM for aspect-level sentiment classification. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016. [Google Scholar]
- Chen, P.; Sun, Z.; Bing, L.; Yang, W. Recurrent attention network on memory for aspect sentiment analysis. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 9–11 September 2017. [Google Scholar]
- Fan, F.; Feng, Y.; Zhao, D. Multi-grained attention network for aspect-level sentiment classification. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018. [Google Scholar]
- Zhang, C.; Li, Q.; Song, D. Aspect-based sentiment classification with aspect-specific graph convolutional networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 4567–4577. [Google Scholar]
- Sun, K.; Zhang, R.; Mensah, S.; Mao, Y.; Liu, X. Aspect-level sentiment analysis via convolution over dependency tree. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 5679–5688. [Google Scholar]
- Wang, K.; Shen, W.; Yang, Y.; Quan, X.; Wang, R. Relational graph attention network for aspect-based sentiment analysis. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 3229–3238. [Google Scholar]
- Li, R.; Chen, H.; Feng, F.; Ma, Z.; Wang, X.; Hovy, E. Dual graph convolutional networks for aspect-based sentiment analysis. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Virtual Event, 1–6 August 2021. [Google Scholar]
- Pang, S.; Xue, Y.; Yan, Z.; Huang, W.; Feng, J. Dynamic and multi-channel graph convolutional networks for aspect-based sentiment analysis. In Proceedings of the Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, Virtual, 1–6 August 2021. [Google Scholar]
- Dai, A.; Hu, X.; Nie, J.; Chen, J. Learning from word semantics to sentence syntax by graph convolutional networks for aspect-based sentiment analysis. Int. J. Data Sci. Anal. 2022, 14, 17–26. [Google Scholar] [CrossRef]
- Yang, P.; Li, L.; Luo, F.; Liu, T.; Sun, X. Enhancing topic-to-essay generation with external commonsense knowledge. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 2002–2012. [Google Scholar]
- Zhou, J.; Huang, J.X.; Hu, Q.V.; He, L. Sk-gcn: Modeling syntax and knowledge via graph convolutional network for aspect-level sentiment classification. Knowl.-Based Syst. 2020, 205, 106292. [Google Scholar] [CrossRef]
- Speer, R.; Chin, J.; Havasi, C. Conceptnet 5.5: An open multilingual graph ofgeneral knowledge. In Proceedings of the AAAI, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Cambria, E.; Poria, S.; Hazarika, D.; Kwok, K. SenticNet 5: Discovering conceptual primitives for sentiment analysis by means of context embeddings. In Proceedings of the AAAI, Edmonton, AB, Canada, 13–17 November 2018. [Google Scholar]
- Miller, G.A. WordNet: A lexical database for English. Commun. ACM 1995, 38, 39–41. [Google Scholar] [CrossRef]
- Jiang, L.; Yu, M.; Zhou, M.; Liu, X.; Zhao, T. Target-dependent twitter sentiment classification. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Portland, ON, USA, 19–24 June 2011. [Google Scholar]
- Kiritchenko, S.; Zhu, X.; Cherry, C.; Mohammad, S. NRC-Canada-2014: Detecting aspects and sentiment in customer reviews. In Proceedings of the 8th International Workshop on Semantic Evaluation (SemEval 2014), Dublin, Ireland, 23–24 August 2014. [Google Scholar]
- Ding, X.; Zhang, Y.; Liu, T.; Duan, J. Deep learning for event-driven stock prediction. In Proceedings of the Twenty-Fourth International Joint Conference on Artificial Intelligence, Buenos Aires, Argentina, 25–31 July 2015. [Google Scholar]
- Tang, D.; Qin, B.; Feng, X.; Liu, T. Effective LSTMs for target-dependent sentiment classification. In Proceedings of the COLING 2016, the 26th International Conference on Computational Linguistics: Technical Papers, Osaka, Japan, 11–16 December 2016; pp. 3298–3307. [Google Scholar]
- Majumder, N.; Poria, S.; Gelbukh, A.; Akhtar, M.S.; Cambria, E.; Ekbal, A. IARM: Inter-aspect relation modeling with memory networks in aspect-based sentiment analysis. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 3402–3411. [Google Scholar]
- Tang, D.; Qin, B.; Liu, T. Aspect level sentiment classification with deep memory network. arXiv 2016, arXiv:1605.08900. [Google Scholar]
- Ma, D.; Li, S.; Zhang, X.; Wang, H. Interactive attention networks for aspect-level sentiment classification. arXiv 2017, arXiv:1709.00893. [Google Scholar]
- Huang, B.; Ou, Y.; Carley, K.M. Aspect level sentiment classification with attention-over-attention neural networks. In Proceedings of the International Conference on Social Computing, Behavioral-Cultural Modeling and Prediction and Behavior Representation in Modeling and Simulation, Stockholm, Sweden, 10–15 July 2018; Springer: Cham, Switzerland, 2018. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. In Proceedings of the ICLR, Toulon, France, 24–26 April 2017. [Google Scholar]
- Yao, L.; Mao, C.; Luo, Y. Graph convolutional networks for text classification. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 7370–7377. [Google Scholar]
- Huang, L.; Ma, D.; Li, S.; Zhang, X.; Wang, H. Text level graph neural network for text classification. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 3444–3450. [Google Scholar]
- Zhang, Y.; Qi, P.; Manning, C.D. Graph convolution over pruned dependency trees improves relation extraction. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 2205–2215. [Google Scholar]
- Sun, K.; Zhang, R.; Mao, Y.; Mensah, S.; Liu, X. Relation extraction with convolutional network over learnable syntax-transport graph. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34. [Google Scholar]
- Gou, J.; Yu, B.; Maybank, S.J.; Tao, D. Knowledge distillation: A survey. Int. J. Comput. Vis. 2021, 129, 1789–1819. [Google Scholar] [CrossRef]
- Bastings, J.; Titov, I.; Aziz, W.; Marcheggiani, D.; Sima’an, K. Graph convolutional encoders for syntax-aware neural machine translation. In Proceedings of the EMNLP, Copenhagen, Denmark, 9–11 September 2017; pp. 1957–1967. [Google Scholar]
- Li, Y.; Pan, Q.; Yang, T.; Wang, S.; Tang, J.; Cambria, E. Learning word representations for sentiment analysis. Cogn. Comput. 2017, 9, 843–851. [Google Scholar] [CrossRef]
- Bengio, Y.; Ducharme, R.; Vincent, P.; Jauvin, C. A neural probabilistic language model. J. Mach. Learn. Res. 2003, 3, 1137–1155. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MI, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Suresh, M. Semeval-2014 task 4: Aspect based sentiment analysis. In Proceedings of the 8th International Workshop on Semantic Evaluation (SemEval 2014), Dublin, Ireland, 23–24 August 2014. [Google Scholar]
- Pontiki, M.; Galanis, D.; Papageorgiou, H.; Manandhar, S.; Androutsopoulos, I. Semeval-2015 task 12: Aspect based sentiment analysis. In Proceedings of the 9th International Workshop on Semantic Evaluation (SemEval 2015), Denver, CL, USA, 4–5 June 2015. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global vectors for word representation. In Proceedings of the 2014 Conferenceon Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Tian, Y.; Chen, G.; Song, Y. Aspect-based sentiment analysis with type-aware graph convolutional networks and layer ensemble. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Mexico City, Mexico, 6–11 June 2021. [Google Scholar]
- Liang, B.; Su, H.; Gui, L.; Cambria, E.; Xu, R. Aspect-based sentiment analysis via affective knowledge enhanced graph convolutional networks. Knowl.-Based Syst. 2022, 235, 107643. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Positive | Neutral | Negative | |||
|---|---|---|---|---|---|---|
| Train | Test | Train | Test | Train | Test | |
| Rest14 | 2164 | 728 | 637 | 196 | 807 | 196 |
| Lap14 | 994 | 341 | 464 | 169 | 870 | 128 |
| Rest15 | 1178 | 439 | 1c50 | 35 | 382 | 328 |
| Rest16 | 1620 | 597 | 88 | 38 | 709 | 190 |
| Models | Rest14 | Lap14 | Rest15 | Rest16 | ||||
|---|---|---|---|---|---|---|---|---|
| Accuracy | Macro-F1 | Accuracy | Macro-F1 | Accuracy | Macro-F1 | Accuracy | Macro-F1 | |
| CDT [8] | 74.66 | 73.66 | 77.19 | 72.99 | - | - | 85.58 | 69.93 |
| ASGCN [7] | 80.77 | 72.02 | 75.55 | 71.05 | 79.89 | 61.89 | 88.99 | 67.48 |
| SK-GCN [14] | 80.36 | 70.43 | 73.20 | 69.18 | 80.12 | 60.70 | 85.17 | 68.08 |
| R-GAT [9] | 83.30 | 76.08 | 77.42 | 73.76 | 80.83 | 64.17 | 88.92 | 70.89 |
| DualGCN [10] | 84.27 | 78.08 | 78.48 | 74.74 | - | - | - | - |
| DMGCN [11] | 83.98 | 75.59 | 78.48 | 74.90 | - | - | - | - |
| Our KDGCN | 84.91 | 78.48 | 79.00 | 75.03 | 82.10 | 67.13 | 90.74 | 73.46 |
| BERT [35] | 85.62 | 78.28 | 77.58 | 72.38 | 83.48 | 66.18 | 90.10 | 74.16 |
| SK-GCN+BERT [14] | 83.48 | 75.19 | 79.00 | 75.57 | 83.20 | 66.78 | 87.19 | 72.02 |
| R-GAT+BERT [9] | 86.60 | 81.35 | 78.21 | 74.07 | 83.22 | 69.73 | 89.71 | 76.62 |
| DualGCN+BERT [10] | 87.13 | 81.16 | 81.80 | 78.10 | - | - | - | - |
| DMGCN+BERT [11] | 87.66 | 82.79 | 80.22 | 77.28 | - | - | - | - |
| TGCN+BERT [39] | 86.16 | 79.95 | 80.88 | 77.03 | 85.26 | 71.69 | 92.32 | 77.29 |
| Our KDGCN+BERT | 87.23 | 81.69 | 82.60 | 79.55 | 85.98 | 72.40 | 93.66 | 82.49 |
| Model | Rest14 | Lap14 | Rest15 | Rest16 | ||||
|---|---|---|---|---|---|---|---|---|
| Accuracy | Macro-F1 | Accuracy | Macro-F1 | Accuracy | Macro-F1 | Accuracy | Macro-F1 | |
| KDGCN aspect-related select | 84.11 | 77.02 | 76.96 | 73.14 | 80.10 | 66.48 | 89.61 | 70.94 |
| KDGCN syntax aware module | 78.13 | 68.34 | 72.88 | 68.13 | 77.49 | 52.19 | 87.66 | 66.74 |
| KDGCN knowleage enhancement | 83.13 | 76.01 | 76.49 | 72.38 | 81.55 | 58.71 | 89.61 | 72.01 |
| KDGCN semantic learning module | 83.22 | 75.35 | 76.33 | 73.27 | 79.89 | 60.87 | 89.28 | 71.96 |
| KDGCN | 84.91 | 78.48 | 79.00 | 75.03 | 82.10 | 67.13 | 90.74 | 73.46 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Z.; Ma, Z.; Cai, S.; Chen, J.; Xue, Y. Knowledge-Enhanced Dual-Channel GCN for Aspect-Based Sentiment Analysis. Mathematics 2022, 10, 4273. https://doi.org/10.3390/math10224273
Zhang Z, Ma Z, Cai S, Chen J, Xue Y. Knowledge-Enhanced Dual-Channel GCN for Aspect-Based Sentiment Analysis. Mathematics. 2022; 10(22):4273. https://doi.org/10.3390/math10224273
Chicago/Turabian StyleZhang, Zhengxuan, Zhihao Ma, Shaohua Cai, Jiehai Chen, and Yun Xue. 2022. "Knowledge-Enhanced Dual-Channel GCN for Aspect-Based Sentiment Analysis" Mathematics 10, no. 22: 4273. https://doi.org/10.3390/math10224273